LAFS: A Fast, Differentiable Approach to Feature Selection Using Learnable Attention
Hıncal Topçuoğlu, Atıf Evren, Elif Tuna, Erhan Ustaoğlu

TL;DR
LAFS is a fast and accurate feature selection method using neural attention to balance performance and efficiency in machine learning.
Contribution
LAFS introduces a differentiable, end-to-end framework for feature selection using learnable attention and a novel hybrid loss function.
Findings
LAFS identifies complex feature interactions and handles multicollinearity effectively.
LAFS achieves performance comparable to state-of-the-art methods like RFE-LGBM and FSA.
The hybrid loss function successfully encourages sparse and non-redundant feature selection.
Abstract
Feature selection is a critical preprocessing step for mitigating the curse of dimensionality in machine learning. Existing methods present a difficult trade-off: filter methods are fast but often suboptimal as they evaluate features in isolation, while wrapper methods are powerful but computationally prohibitive due to their iterative nature. In this paper, we propose LAFS (Learnable Attention for Feature Selection), a novel, end-to-end differentiable framework that achieves the performance of wrapper methods at the speed of simpler models. LAFS employs a neural attention mechanism to learn a context-aware importance score for all features simultaneously in a single forward pass. To encourage the selection of a sparse and non-redundant feature subset, we introduce a novel hybrid loss function that combines the standard classification objective with an information-theoretic entropic…
Click any figure to enlarge with its caption.
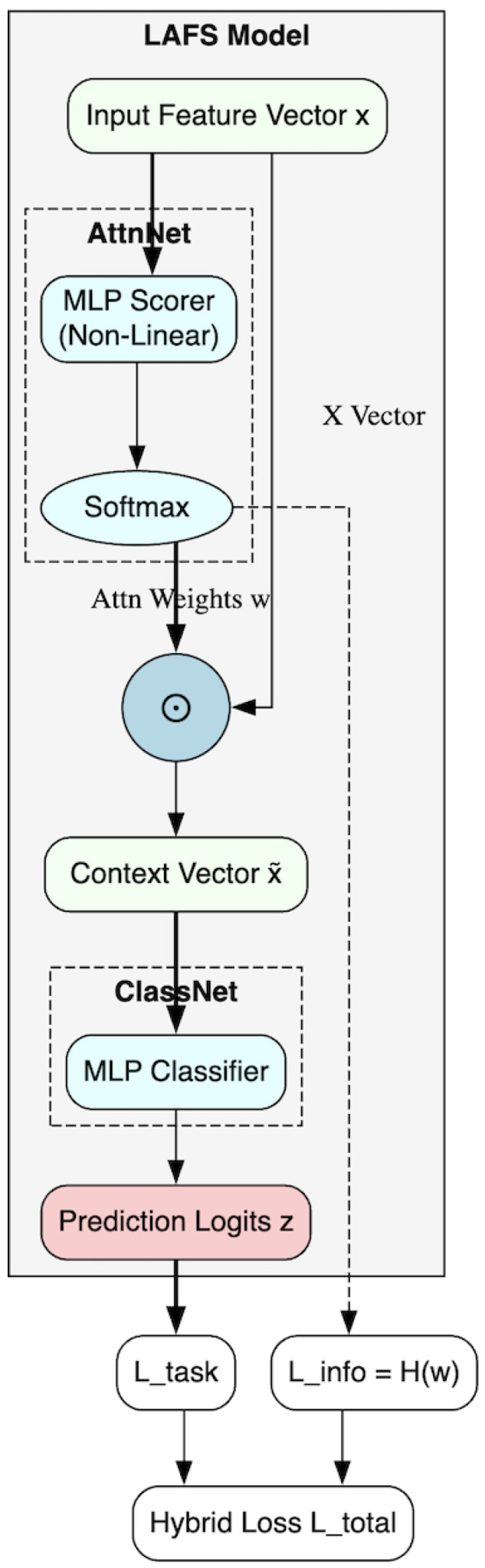 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFace and Expression Recognition · Stochastic Gradient Optimization Techniques · Advanced Neural Network Applications
1. Introduction
The rapid augmentation of high-dimensional data across scientific and industrial domains has made feature selection an indispensable component of the modern machine learning pipeline. In tasks ranging from genomic analysis to financial modeling, datasets can contain thousands or millions of features, encountering a phenomenon often termed the “curse of dimensionality” [1]. The presence of numerous irrelevant or redundant features can severely degrade the performance of predictive models, increase computational and storage costs, and hinder the interpretability of results [2]. Consequently, the development of algorithms that can efficiently and effectively identify a minimal, maximally informative subset of features remains a central challenge in machine learning research [3,4].
Existing feature selection methods can be broadly categorized into four families: filters, wrappers, embedded, and hybrid methods. The hybrid methods are combinations of these former three methods. Filter methods, such as those based on Mutual Information (MI) [5], are computationally efficient as they evaluate features based on their statistical properties, independent of any predictive model. On the other hand, wrapper and hybrid methods generally require a lot of computation time. However, this diversity is also their primary weakness; they assess features in isolation, rendering them “myopic” and often incapable of identifying feature subsets that are collectively powerful, especially in the presence of complex interactions [6].
For instance, wrapper methods, like Recursive Feature Elimination (RFE) [7,8], employ a predictive model to score and iteratively select feature subsets. This approach is powerful and often yields state-of-the-art results by directly optimizing for the performance of a specific classifier. This power, however, comes at a prohibitive computational cost, if it is used for specifying predictors. The iterative search, which involves training a model hundreds or thousands of times, becomes intractable for high-dimensional datasets. Embedded methods, such as L1 (Lasso) [9] regularization, integrate feature selection into the model training process itself. However, many embedded methods are inherently linear and may fail to capture non-linear feature dependencies.
We propose LAFS (Learnable Attention for Feature Selection), an end-to-end differentiable framework that learns to select features holistically. Instead of a greedy, sequential search, LAFS employs a neural attention mechanism [10] to assess all features in parallel and assign a context-aware importance score in a single forward pass. The core of our contribution is a hybrid, information-theoretic loss function designed to guide the learning process. By augmenting the standard task-based loss with an entropic regularizer on the attention distribution, we explicitly encourage the model to discover sparse and non-redundant feature subsets. Our work contributes to the growing body of research at the intersection of information theory and deep learning [11,12], demonstrating how classical information-theoretic principles can be leveraged to guide modern neural architectures.
Our contribution is threefold:
- A Novel Architecture: We propose LAFS, a fully differentiable attention-based model designed specifically for the task of feature selection.
- An Information-Theoretic Learning Objective: We introduce a hybrid loss function with an entropic regularizer that promotes the selection of minimal and non-redundant feature subsets.
- Comprehensive Empirical Validation: We demonstrate through a large-scale benchmark study across a diverse suite of datasets that our LAFS architecture matches the performance of the leading algorithms. Furthermore, on some datasets, including the highly multicollinear ones, it provides the real-world effectiveness of its entropic regularizer in handling feature redundancy.
2. Related Work
The challenge of feature selection has been a central theme in machine learning for decades, leading to a vast body of literature. Several comprehensive surveys are available that categorize the landscape of methods [13,14]. Our work, LAFS, positions itself at the intersection of classical feature selection principles and modern deep learning architectures.
2.1. Classical Feature Selection: Filters
Filter methods are computationally efficient and use statistical measures to rank features. Common criteria include Mutual Information (MI), the Chi-squared test [15], Fisher Score [16], and ReliefF [17], which estimates feature quality based on nearest-neighbor distances. Advanced filters like mRMR [18] go a step further by simultaneously maximizing feature relevance and minimizing inter-feature redundancy, a principle that shares a philosophical motivation with our entropic regularizer. However, these methods remain fundamentally limited by their inability to account for complex, multivariate feature interactions that a predictive model can capture.
2.2. Classical Feature Selection: Wrappers and Embedded Methods
Wrapper methods, such as Recursive Feature Elimination (RFE), directly optimize the feature subsets for modeling processes, often yielding superior performance. Their exhaustive, iterative nature, however, results in a combinatorial search that is computationally expensive for high-dimensional data. Some of the embedded methods offer a compromise by integrating the selection process into model training. An example, LASSO, which adds an L1 penalty to the loss function of a linear model, inducing sparsity in the feature coefficients.
Another notable embedded approach is “Feature Selection with Annealing (FSA)”, proposed by Barbu et al. [19]. This method integrates a deterministic annealing schedule into a constrained optimization framework. During training, the number of active features is gradually reduced from the total number of features, p, down to a target number, k. At each step, features with the smallest weights are pruned, effectively embedding a backward elimination process directly into the model’s training loop.
2.3. Hybrid Methods
To bridge the gap between the speed of filters and the power of wrappers, researchers have long explored hybrid methods. The typical approach involves a two-stage process: first, a fast filter method is used to pre-select a large subset of potentially relevant features, and second, a more computationally expensive wrapper or embedded method is applied to this reduced set. Early and influential examples include the work of Das [20], who proposed a boosting-based hybrid method.
A sophisticated example is the “Fuzzy Random Forest for feature selection (FRF-fs)” [21,22]. This algorithm employs a complex three-stage pipeline: (1) a Genetic Algorithm is used to find optimal fuzzy partitions for continuous features (a filter stage), (2) a Fuzzy Random Forest then ranks these features based on fuzzy information gain, and (3) a Sequential Forward Selection (SFS) wrapper is used to find the final subset. While powerful, these multi-stage approaches remain a sequence of not fully connected processes. Our LAFS framework can be viewed as a modern, differentiable reimagination of the hybrid concept, learning the “filtering” (via attention) and “wrapping” (via the classifier’s performance feedback) in a single, unified, end-to-end training process.
2.4. Attention and Transformers for Tabular Data
The unprecedented success of the Transformer architecture in natural language processing has inspired a new wave of research into its application for tabular data. TabNet [23] was a pioneering work in this area, utilizing a sequential attention mechanism to select features at each decision step. More recent works like the FT-Transformer [24] and SAINT [25] adapt the standard Transformer architecture for supervised learning. While these models are designed for high-accuracy classification, our LAFS model is explicitly architected as a feature selection tool, using its learned attention weights to output a final, reduced feature subset.
2.5. Information Theory in Deep Learning
Our work is grounded in the principles of information theory in deep learning. The Information Bottleneck (IB) principle [26] posits that an optimal model should learn a maximally compressed representation of the input that is still maximally informative about the target. This principle is widened through deep learning studies like variational information bottleneck [27]. Our entropic regularizer, , can be viewed through this lens; by minimizing the entropy of the attention distribution, we are effectively creating an information bottleneck that compresses the input features into a sparse, informative context vector. Recent work has also explored using deep learning models, such as Deep InfoMax (DIM) [28], which focuses on maximizing mutual information, and other methods like autoencoders with a concrete distribution to perform differentiable feature selection [29,30].
3. Methodology: The LAFS Algorithm
In this section, we formally define the architecture and learning objective of the LAFS framework. Our goal is to create a single, end-to-end differentiable model that learns a sparse and informative feature subset by combining a non-linear attention mechanism with an information-theoretic loss function.
3.1. Problem Formulation
Given a dataset , where each sample is a vector of d features and is the corresponding class label, the goal of feature selection is to identify a subset of feature indices with size , such that a model trained on the reduced feature vectors achieves optimal predictive performance.
3.2. Architecture
The LAFS model is composed of two primary sub-networks trained end-to-end: the Attention Scorer Network (AttnNet) and the Classifier Network (ClassNet). A schematic of the architecture is shown in Figure 1.
The input vector is processed by the AttnNet to produce attention weights . These weights are applied to via element-wise multiplication (⊙) to create a context vector , which is then fed to the ClassNet for prediction. Both the final logits and the attention weights are used in the hybrid loss function.
3.2.1. The Attention Scorer Network (AttnNet)
The AttnNet is responsible for learning a dynamic, sample-specific feature importance mask. To capture potentially complex and non-linear relationships between features, we implement the AttnNet as a Multi-Layer Perceptron (MLP).
Rationale: A simple linear layered model can only learn linear combinations of features. By using an MLP with a non-linear activation function (e.g., ReLU), the AttnNet can model higher-order feature interactions, allowing it to understand that the importance of one feature might depend on the value of another. This expressive power is crucial for rivaling the performance of non-linear wrapper methods like RFE-LGBM.
For an input sample , the MLP-based AttnNet first projects the input into a hidden representation and then outputs a vector of pre-softmax scores, or logits, . These scores are then normalized using the softmax function to produce a probability distribution over the features, which we term the attention vector :
Each component represents the learned importance of the j-th feature for the given input sample , with the property that .
Potential Downside and Regularization: The increased expressive power of an MLP comes with a higher number of parameters compared to a linear model, which can increase the risk of overfitting on datasets with very few training samples. This trade-off is managed through a combination of regularization techniques. Specifically, a Dropout [31] layer with a rate of p = 0.5 is applied within the AttnNet’s MLP to prevent co-adaptation of neurons. Furthermore, we employ L2 regularization (Weight Decay) with a factor of ** **, which is applied by the Adam optimizer [32] during the weight update step to penalize large weights. These techniques work in concert with our primary information-theoretic regularizer to ensure the model generalizes well.
3.2.2. The Classifier Network (ClassNet)
The attention vector is then used to re-weight the original feature vector , producing a “context vector” that emphasizes the features deemed important:
where ⊙ denotes element-wise multiplication. This context vector is then fed into the ClassNet, a standard multi-layer perceptron (MLP), to produce the final class prediction logits, .
3.3. Hybrid Information-Theoretic Loss Function
The key to guiding LAFS to learn a sparse and effective feature mask lies in our custom loss function. The training process is a multi-objective optimization problem that simultaneously aims for high accuracy and high sparsity. This is formalized by our hybrid loss function, where the total loss is a weighted sum of a task-performance term and an information-theoretic regularization term:
The task loss, , is the standard cross-entropy loss. It ensures the model learns to be accurate by maximizing the log-probability of the correct class.
The information-theoretic regularizer, , is the Shannon entropy of the attention vector . Minimizing this term encourages the model to produce low-entropy, “spiky” attention distributions, where a few features receive high weights and the rest receive near-zero weights, effectively promoting sparsity.
The hyperparameter is therefore the control parameter for the trade-off between these two competing objectives. The complete learning objective is to find the optimal model parameters that solve the following:
where is the softmax output of the ClassNet and is the softmax output of the AttnNet. This formulation explicitly instructs the optimizer to find a solution that balances the need for an accurate feature representation with the structural constraint of a sparse and decisive attention mask.
3.4. Feature Importance Extraction
After training the model end-to-end over the entire training dataset, a global feature importance vector is computed by averaging the sample-specific attention vectors for all samples in the training set:
The final feature subset S is obtained by selecting the k features with the highest global importance scores .
4. Experiments and Results
The first experiment is designed to test the algorithm’s ability to identify feature interactions. We generate a synthetic XOR dataset, which is a classic choice for benchmarking because it is linearly inseparable and forces feature selection methods to look for non-linear relationships or combinations of features. We also included a linearly separable dataset (SYNTH) experiment to test the performances of the methods where predictors are uniformly correlated.
As a second experiment, we conduct a comprehensive and a large-scale benchmark study for validating our method. This section details the experimental setup and presents the consolidated results across a diverse suite of datasets and feature sparsity levels.
4.1. Experiments on Synthetic XOR Dataset
To evaluate the algorithms’ ability to detect pure high-order interactions (where variables are individually useless but collectively predictive), we generated a 3-bit parity (XOR) dataset.
The data generation process for a sample x is defined as follows:
Feature Generation: We generate features from a standard normal distribution:
Interaction Definition: We designate the first three features ( ) as “relevant”.
Target Assignment: The target class y is determined by the sign of the product of these three features:
where is the indicator function. The objective is to identify exactly (VDR target = 3/3).
4.2. Experiment Setup and Simulation Parameters on XOR Datasets
Repetitions: Each experiment was repeated 50 times with independent simulations for each sample size n.
Evaluator: The performance of selected features was evaluated using an XGBoost classifier (max_depth = 10, n_estimators = 100), chosen for its ability to model the XOR interaction.
4.3. LAFS Algorithm Configuration for XOR Datasets
The LAFS algorithm uses a neural network to learn feature importance masks. Given the difficulty of the XOR problem (which requires learning a precise three-way interaction with no marginal signal), we tuned the hyperparameters for stability:
Epochs: 300 (Increased from default 50 to allow convergence on complex loss landscape).
Dropout: 0.05 (Low dropout prevents breaking the fragile three-way interaction signal during training).
4.4. Benchmark Results for XOR Dataset
Table 1, Table 2, Table 3, Table 4 and Table 5 summarize the performance of each feature selection algorithm across increasing sample sizes ( ).
4.4.1. Results for n = 100 Samples
At extremely low sample sizes, no algorithm can reliably distinguish the complex three-way XOR signal from random noise. All methods perform close to random guessing (F1-Score ≈ 0.5).
4.4.2. Results for n = 500 Samples
RFE-LGBM begins to detect the interaction signal significantly (VDR 2.12). LAFS also starts to learn (VDR 1.22), outperforming univariate filters like MI. Linear methods (FSA) and marginal filters (MI/mRMR) remain near random for n = 500.
4.4.3. Results for n = 1000 Samples
With sufficient data, RFE-LGBM achieves perfect detection (VDR 3.00) and near-perfect downstream accuracy. LAFS improves further (VDR 2.16), confirming its ability to model non-linear interactions, though it requires more samples than gradient boosting trees to converge fully.
4.4.4. Results for n = 2000 Samples
LAFS maintains solid detection (VDR∼2.18), proving it is superior to traditional filter methods for this problem class, though RFE-LGBM remains the most sample-efficient solver.
4.4.5. Results for n = 5000 Samples
For very large sample sizes, results are consistent with theoretical expectations: univariate methods (MI, mRMR) and linear methods (FSA) never solve the problem (F1-Score remains random ≈ 0.5). RFE-LGBM remains perfect.
4.5. Synthetic Linear Data Generation
The synthetic dataset is generated using a linear threshold model with correlated features. The generation process for and is defined in the following two steps:
4.5.1. Feature Generation: Uniform Correlation
To induce a uniform pairwise correlation between features, we construct the feature matrix X using a latent variable model. For each sample i and feature j, the following is calculated:
The common term introduces a covariance of 1 between any pair of features , resulting in a constant pairwise correlation of .
4.5.2. Target Generation: Linear Model
After generating the correlated feature matrix X, the target variable y is determined by a linear combination of these features. The coefficients (weights) are sampled from a continuous uniform distribution:
This process results in a linearly separable binary classification problem where all features are weakly relevant and uniformly correlated. Benchmark results of the methods for the linearly separable dataset (SYNTH) are given in Table 6.
4.6. Experiments with Benchmark Datasets
To ensure a robust and generalizable evaluation, we select a diverse suite of nine publicly available benchmark datasets, which are given in Table 7. These datasets are intentionally chosen from repositories such as PMLB and the original UCI archives to cover a wide range of characteristics, including “small p—small n”, “large p—small n”, and “large p—large n” scenarios.
Benchmark Algorithms: We compare our proposed architecture, LAFS, against five leading approaches that represent the primary families of feature selection: filter, wrapper, embedded, and hybrid methods.
MI (Mutual Information): A classic, fast filter method.mRMR (Minimum Redundancy Maximum Relevance): An advanced filter considering feature redundancy.RFE-LGBM (Recursive Feature Elimination with LightGBM): The state-of-the-art wrapper method.FSA (Feature Selection with Annealing): An embedded method using a deterministic annealing schedule.FRF-fs (Fuzzy Random Forest feature selection): A sophisticated three-stage hybrid method.
Evaluation Protocol: For each of the nine datasets, we perform a 5-fold cross-validation. Within each fold, every algorithm is tasked with selecting features based on three distinct “k” values. This multi-level evaluation provides a comprehensive view of each algorithm’s performance across a range of sparsity pressures.
The quality of each selected feature subset is evaluated by training a downstream XGBoost classifier on the training portion of the fold and measuring its F1-Score and AUC on the held-out validation portion. Tested algorithms with three different “k” values, and the corresponding F1-Scores and AUCs are listed in Table 8.
Our proposed method, LAFS, firmly establishes itself as a promising method when the number of features (p) is small or medium, achieving compatible results with leading algorithms, “RFE-LGBM” and “FSA”. However, when the number of features is larger, as in the “Arcene” and “Gisette” datasets, LAFS fails to meet the results of other methods that can be considered as a limitation.
4.7. Future Work
This research opens several promising avenues for future investigation, turning the limitations we discovered into new research questions.
Taming Complex Architectures: The failure of our Transformer-based models on tabular data is not an endpoint, but a challenge. Future work could focus on developing novel regularization techniques or self-supervised pre-training strategies specifically designed to control the high variance of self-attention mechanisms in low sample-to-feature ratio environments.Data-Efficient Meta-Learning: One may work on ‘LAFS-Meta‘-like architecture, which might be powerful on data-rich problems that can optimize parameters through the training process.Extension to Other Domains: The LAFS framework is inherently flexible. Extending the architecture to other domains is a natural next step. This includes adapting it for regression tasks by substituting the task loss with mean squared error and for survival analysis by incorporating a Cox proportional hazards loss, thereby broadening its applicability and impact.
5. Conclusions
This study aims to develop an innovative feature selection algorithm (LAFS), based on neural networks with an entropic loss function. LAFS is built upon a non-linear MLP-based attention mechanism specifically designed to model higher-order feature interactions. This capability is crucial for achieving high performance when the underlying data relationships are non-linear. Thus, LAFS offers a powerful, non-linear, and scalable solution alternative for feature selection.
LAFS is tested on synthetic and benchmark datasets against leading feature selection algorithms. The findings confirm that LAFS achieves its primary goal: A differentiable attention-based model designed specifically for the task of feature selection and the information-theoretic learning objective, which introduces a hybrid entropic loss function with a regularizer.
The results of synthetic and benchmark dataset experiments reveal that LAFS is a compatible feature selection algorithm. LAFS achieves the best or second-best performances with small and medium-sized feature datasets. However, our algorithm does not match the results of the leading algorithms, such as the RFE-LGBM wrapper and the embedded FSA, when the number of features is larger. Nevertheless, this can be improved by hyperparameter optimization.
Furthermore, our experiments provide a definitive, real-world validation of our core design principles. The consistent high performance of LAFS across a wide variety of datasets demonstrates the robustness of its MLP-based attention-gating mechanism, and it is capable of capture complex signals without being overwhelmed by noise. The success on datasets known for high multicollinearity (LSVT) also validates our information-theoretic entropic regularizer as an effective mechanism for achieving optimal feature selection.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bellman R. Adaptive Control Processes: A Guided Tour Princeton University Press Princeton, NJ, USA 1961
- 2Jain A. Zongker D. Feature selection: Evaluation, application, and small sample performance IEEE Trans. Pattern Anal. Mach. Intell.19971915315810.1109/34.574797 · doi ↗
- 3Guyon I. Elisseeff A. An introduction to variable and feature selection J. Mach. Learn. Res.2003311571182
- 4Guyon I. Gunn S. Nikravesh M. Zadeh L.A. Feature Extraction: Foundations and Applications Springer Berlin/Heidelberg, Germany 2008
- 5Cover T.M. Thomas J.A. Elements of Information Theory John Wiley & Sons Hoboken, NJ, USA 1991
- 6Chandrashekar G. Sahin F. A survey on feature selection methods Comput. Electr. Eng.201440162810.1016/j.compeleceng.2013.11.024 · doi ↗
- 7Guyon I. Weston J. Barnhill S. Vapnik V. Gene selection for cancer classification using support vector machines Mach. Learn.20024638942210.1023/A:1012487302797 · doi ↗
- 8Ke G. Meng Q. Finley T. Wang T. Chen W. Ma W. Ye Q. Liu T.Y. Lightgbm: A highly efficient gradient boosting decision tree Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017 Long Beach, CA, USA 4–9 December 2017 Volume 30