TaCD: Team-Aware Community Detection Based on Multi-View Modularity
Chengzhou Fu, Feiyi Tang, Lingzhi Hu, Chengzhe Yuan, Ronghua Lin

TL;DR
This paper introduces TaCD, a new community detection algorithm that considers team relationships in social networks to improve community discovery.
Contribution
The novel TaCD algorithm and the new SCHOLAT dataset with team information are introduced.
Findings
TaCD outperforms existing community detection algorithms on social networks with team information.
The SCHOLAT dataset is publicly available for testing community detection methods.
Using multi-view modularity with team and user views improves community detection accuracy.
Abstract
Community detection in social networks is one of the most important topics of network science. Researchers have developed numerous methods from various perspectives. However, the existing methods often overlook the team information encoded as a special type of user relation in the social network, which plays an important role in community formation and evolution. In this paper, we propose a novel community detection algorithm called Team-aware Community Detection (TaCD). Our model constructs a multi-view network by encoding the user interaction information as the user view and the team information as the team view. To measure the consistency across the two views, we use the Jaccard similarity to establish a cross-view coupling. Based on the constructed 2-view network, we use multi-view modularity to discover team-aware community structure, and solve the optimization problem using the…
Click any figure to enlarge with its caption.
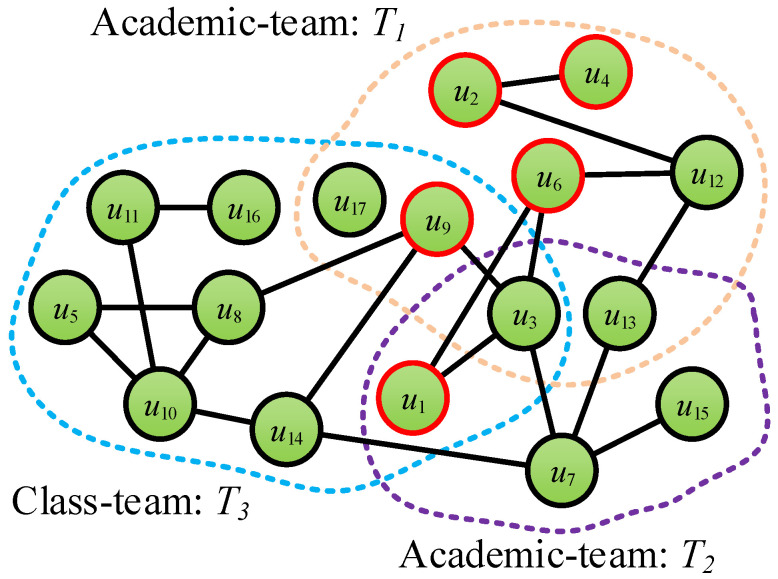 Figure 1
Figure 1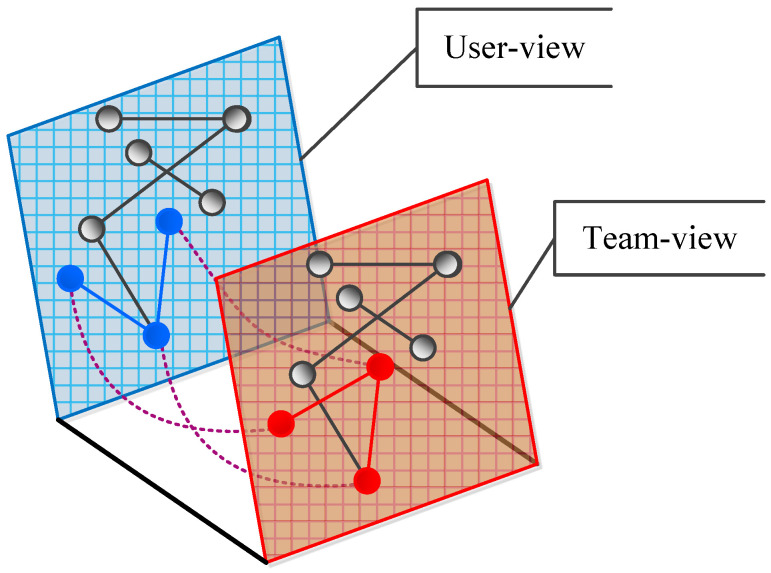 Figure 2
Figure 2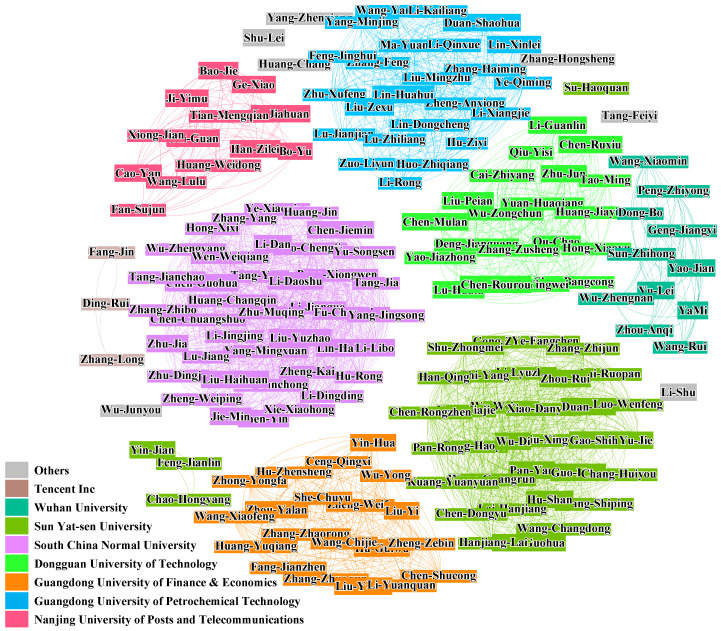 Figure 3
Figure 3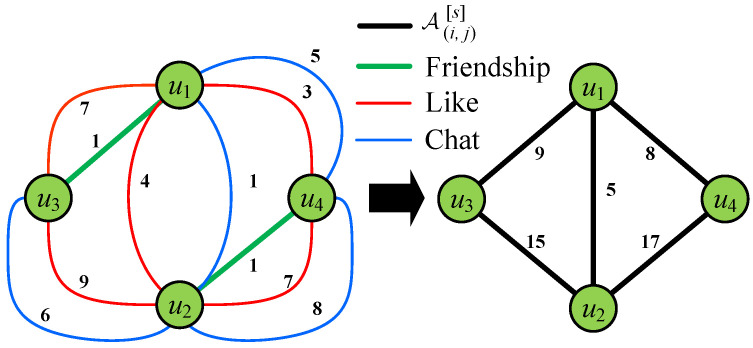 Figure 4
Figure 4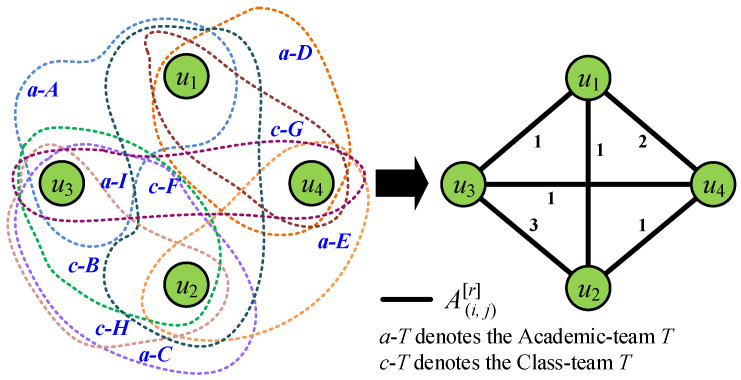 Figure 5
Figure 5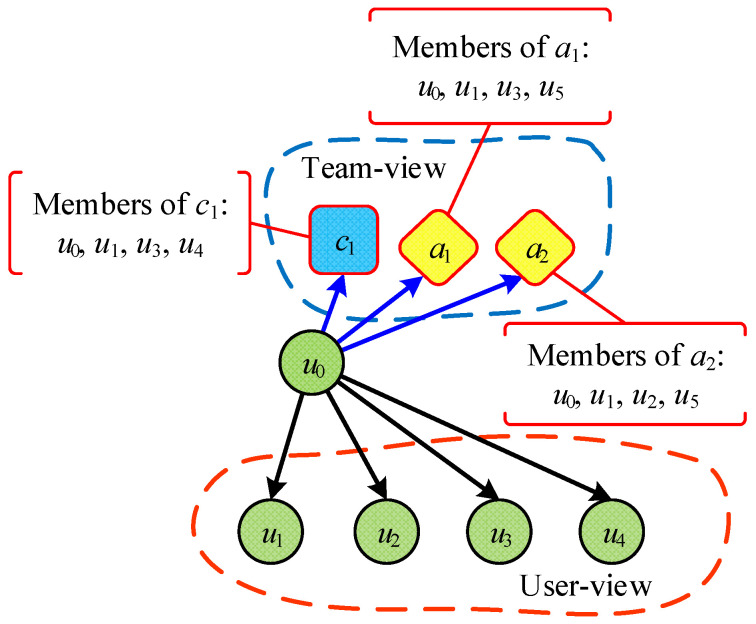 Figure 6
Figure 6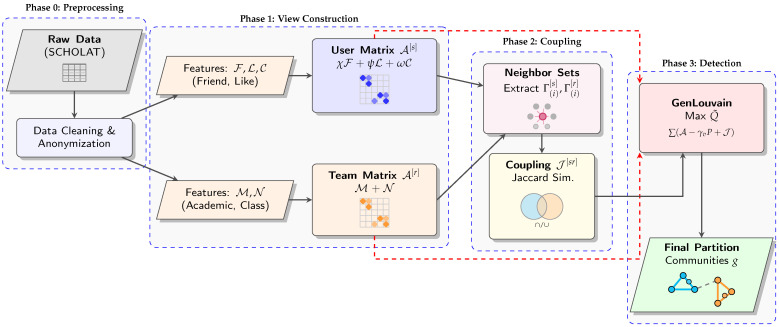 Figure 7
Figure 7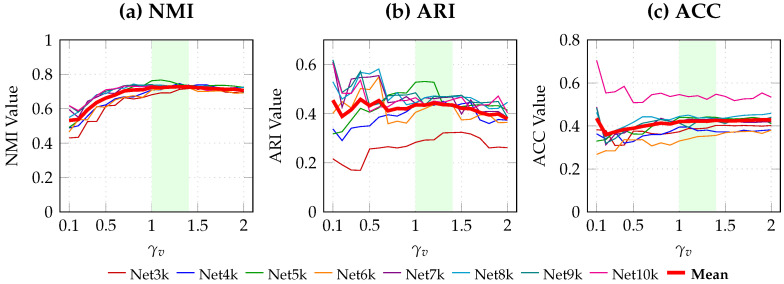 Figure 8
Figure 8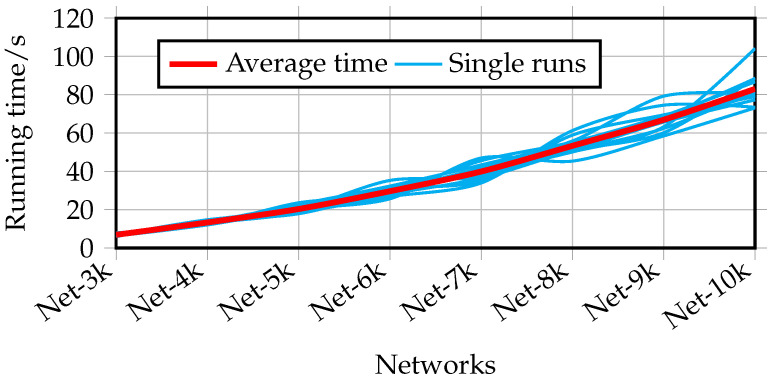 Figure 9
Figure 9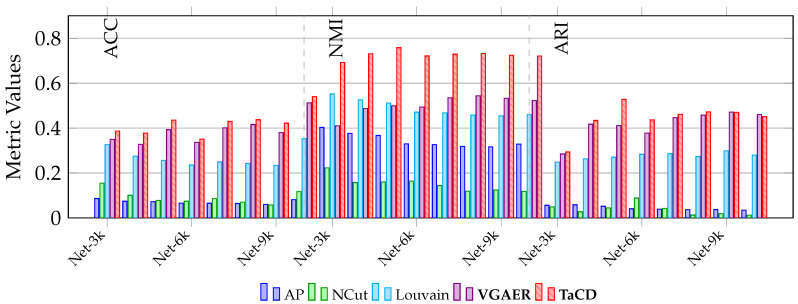 Figure 10
Figure 10 Figure 11
Figure 11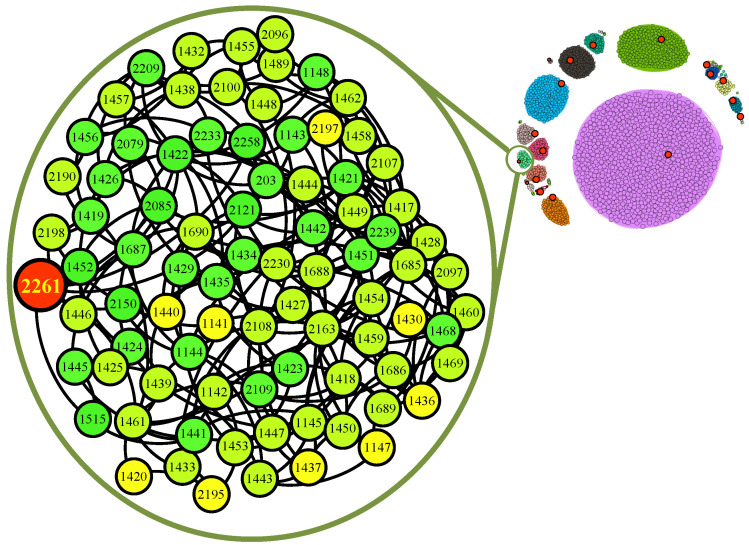 Figure 12
Figure 12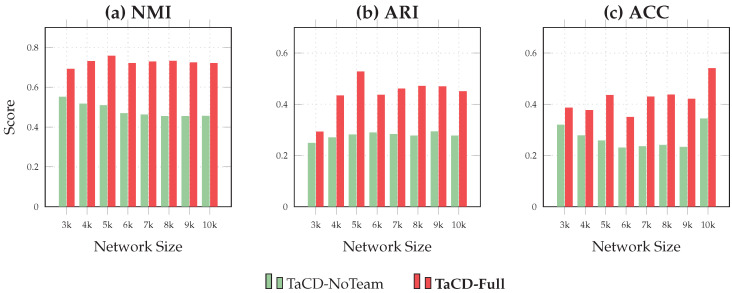 Figure 13
Figure 13- —Research Project of Guangdong Provincial Administration of Traditional Chinese Medicine
- —Teaching Quality Enhancement Project of Guangdong Pharmaceutical University
- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComplex Network Analysis Techniques · Advanced Graph Neural Networks · Mobile Crowdsensing and Crowdsourcing
1. Introduction
Community detection is to discover both hidden and defined communities from the distributed and disordered structure of the internet and complex social systems [1,2,3]. Identifying communities can provide information about how the network is organized. It allows us to focus on areas of the graph that have a degree of autonomy. It also helps to classify vertices according to their roles relative to their communities [4]. Community detection has various applications in different fields, which can be used to uncover potential relationships between users in the field of social software development [5,6]. It can also be used to detect the structure of protein–protein interaction in the field of biology [7,8,9]. Even for the real internet, community detection can also be used to discover related websites [10,11,12,13]. In the era of big data, it is critical to discover the meaningful community structure when dealing with numerous huge networks.
During the past few decades, more and more efforts have been made on community detection [14,15,16,17]. However, most of them only consider the user interaction or attribute information, but ignore the relationship with the teammates in the social network service platform. To demonstrate the importance of team information in community detection in social networks, we collect a dataset from SCHOLAT (SCHOLAT: https://www.scholat.com) [18] (a well-known academic social networking service platform in China). This dataset contains eight networks and will be made publicly available to all of the scholars for academic research usage. Different from the existing social network datasets, the social networks on the SCHOLAT dataset contain not only the user–user interaction information but also the team information. In SCHOLAT, the relationship between users is complex. There are many teams such as the Academic-team and Class-team which are created by users. As shown in Figure 1, there are three teams such as , , and . Some users are in the same team, but they may not have friendship (e.g., in the team : and , and , etc.). Similarly, the users have friendship, but they may not be in the same team (e.g., in the team and in the team / , etc.), and others may not be in the same team or have a friendship (e.g., in the team and in the team and , etc.).
Unlike traditional multi-layer networks that typically aggregate homogeneous relationships (e.g., merging Twitter and Facebook ties), TaCD introduces a heterogeneous coupling mechanism. It integrates the explicit “Affiliation Layer” (Team-view) with the implicit “Interaction Layer” (User-view). By measuring the structural consistency between these two distinct views, we can effectively filter out noise where team membership does not reflect actual social proximity.
Despite the aforementioned importance of team information, it is mostly ignored in the existing methods. To this end, in this paper, we propose a new community detection method called Team-aware Community Detection (TaCD). In particular, a new 2-view network is constructed from the original network with team information, which consists of the user view for encoding user–user interaction and the team view for encoding team information. For measuring the consistency across the two views, the Jaccard similarity is adopted, whereby a cross-view coupling is established. Based on the newly constructed 2-view network, multi-view modularity is adopted to discover team-aware community structure, and solve this optimization problem using the well-known Generalized Louvain approach. Another contribution of this paper is that a new SCHOLAT dataset consisting of several social networks with team information is collected and made publicly available as a testing dataset. Extensive experiments are conducted to confirm the superiority of the proposed TaCD method over the existing methods.
The method introduced in this work has the following novel contributions: constructing a new dataset that is more suitable for large-scale networks, supporting multi-layer networks, and solving the coupling calculation problems between layers. The rest of this paper is organized as follows. We briefly review the related work in Section 2, and introduce the SCHOLAT dataset and research background in Section 3. In Section 4, the newly proposed Team-aware Community Detection approach is described in detail. In Section 5, extensive experiments are conducted to validate the effectiveness of the proposed method. At last, we will draw the conclusions and describe the future work in Section 6.
2. Related Work
In this section, we will briefly review some related work on community detection. One major type of community detection methods relies on designing a quality function, by solving the optimization problem of which the community structure can be discovered. For example, the normalized cuts (NCut)-based method measures both the total dissimilarity between the different groups as well as the total similarity within the groups, where a real valued solution to the normalized cut minimization problem is provided by a generalized eigenvalue system [19]. The non-negative matrix factorization (NMF) is an effective approach for community detection that utilizes a Bayesian model to extract overlapping modules from a network [20]. Cluster Affiliation Model for Big Networks (BIGCLAM) is another overlapping community detection method that scales to large networks of millions of nodes and edges. The method builds on a novel observation that overlaps between communities are densely connected [15]. Communities from Edge Structure and Node Attributes (CESNA) is an accurate and scalable algorithm for detecting overlapping communities in networks with node attributes. CESNA statistically models the interaction between the network structure and the node attributes, which leads to more accurate community detection as well as improved robustness in the presence of noise in the network structure [11]. Recently, some efforts have been made in higher-order community detection. It has been shown that higher-order features captured by network motifs are crucial in many domains, such as biology and neuron-science, which can help to gain new insights into the network organization beyond the clustering at the level of individual nodes and edges [21]. Rosvall and Bergstrom use the simulated annealing optimization algorithm and the effective coding of random walks for community detection [22]. Raghavan et al. propose a Label Propagation Algorithm (LPA), which is based on the idea that the edge of the network often represents the propagation of information [23]. A label update rule is further proposed for further reducing computational overhead [24]. Ma et al. [25] propose a novel algorithm by joint multi-label learning and feature extraction (MLjFE), where temporal link prediction and feature extraction are integrated into an overall objective function. Mahmood and Small present a community detection algorithm based on the fact that each network community spans a different subspace in the geodesic space. For making the process of community detection more robust, they use sparse linear coding with norm constraint [26]. Jin proposes an approach to community detection termed Spectral Clustering On Ratios-of-Eigenvectors (SCORE), the main innovation of which is to use the entry-wise ratios between the first leading eigenvector and each of the other leading eigenvectors for clustering [27]. In fact, in community detection, new data are always generated continuously with subgraphs joining simultaneously in dynamic evolving networks. For addressing the above problem, Zhao et al. present a method to detect communities by handling subgraphs [28].
Recently, multi-view community detection has been widely studied, such as modularity-based methods [29,30] and information-theoretic methods [31]. Modularity evaluates the quality of a network partition, where a higher modularity value usually indicates a denser edge distribution within communities [32,33]. Furthermore, Delvenne et al. derive the multi-layer modularity by assessing the capability of the given community structure to capture a dynamic process in a multi-layer network [34]. Ma et al. propose a quantitative function (multi-layer modularity density), while considering the connection information among various layers [35] for community detection in multi-layer networks.
However, the algorithms described above ignore team information. The purpose of this paper is to enhance the performance of community detection by incorporating team information from the datasets. In particular, we use the multi-view method to detect team-aware communities as shown in Figure 2. For example, with the three blue nodes in User-view and three red nodes in Team-view, although they represent the same three nodes, they have different relationships in the two views.
Recent advancements have also explored dynamic and feature-based clustering. For instance, matrix factorization has been revisited for dynamic graph clustering [36], and joint learning frameworks have been proposed for large-scale temporal networks [37]. While effective, our approach differs by focusing specifically on leveraging static affiliation metadata as a structural view.
3. Dataset Description
In this section, we describe the SCHOLAT dataset from the following perspectives.
3.1. About SCHOLAT and Its Dataset
SCHOLAT is an academic social networking service website designed to promote exchanges and cooperation between researchers. The platform contains multiple features such as academic information management, literature search, academic network disk, teaching course management, and scholar exchange services.
Since its establishment, SCHOLAT has gained widespread recognition and has attracted a large number of scholars, teachers, and students to utilize its services. It serves as a scientific research platform for scholars, focusing on engineering applications, theoretical research, and academic exchange. SCHOLAT assists scientific researchers in building their own academic networks, helps students find suitable mentors, and provides up-to-date job opportunities for those seeking scientific research positions.
A given sample of real community relationship in SCHOLAT is shown in Figure 3, and a community summary is shown in at bottom left of the figure.
It is important to note that we cannot directly regard team as a community, because the concept of team is only relative to the users of SCHOLAT platform, but the underlying community is the collective division in real life.
For users, their relationship at the User-view and at the Team-view level are independent, but if we make good use of the relationship between the two levels in community detection, it can help us to have a better understanding of the relationship between users.
To this end, the motivation of this research can be addressed as it is necessary to consider team information on community detection. To tackle this issue, we propose a novel method for Team-aware Community Detection in social networks.
3.2. The Networks in Dataset
As shown in Table 1, we use the eight networks to do the experiments, namely, Net-3k, Net-4k, …, and Net-10k. The Nk notation (e.g., Net-3k) denotes a network with nodes (e.g., ). Specifically, the largest network consists of 10,000 nodes (with 5,713,566 edges and 218 communities). The work departments of users on the dataset mainly contain universities, academic organizations, and companies from China. In addition, these users are almost all registered with real names, and the quality of their information is also generally high. To protect the users’ privacy, we discretize their ids (If you use this dataset in your work, please cite this publication. You can download the dataset and related code from here (the password of the zip file is “Goodluck!”): https://www.scholat.com/research/tacd, accessed on 13 November 2025).
The SCHOLAT dataset includes the following files, which are
user_real_community.csv: the row number represents user id, and value in each cell is the real community id;link_friendship.csv: the link information of friendship as , using user follower/followee relations;matrix_common_team_count.csv: contains three columns such as , and the number of common teams;matrix_interact_times.csv: which contains interaction information, constructed via Equation (1) in Section 4.1;matrix_friendship.csv: the matrix of link_friendship.csv;matrix_jaccard.csv: which computed via Equation (4) in Section 4.2.
Example 1. In the net-3k with 3000 nodes and 689,480 edges, the user id range is from 1 to 3000. There are 157 communities in the real world, including Apple Inc., DIGITO Agency, Faimdata, Tai Fung Bank, Guangdong Pharmaceutical University, China University of Geosciences (Beijing) and South China Normal University et al. The users’ names are those such as Yong-Tang, Na-Tang, Xiao-Liu, Long-Zhang, Yuncheng-Jiang, and Li-Huang et al.
4. The Proposed TaCD Method
In TaCD, we propose a Generic Multi-view Interaction Framework designed to bridge heterogeneous social information. Unlike traditional multi-layer networks that aggregate homogeneous ties, our framework constructs a network consisting of two distinct logical views: an Interaction Layer (View s) representing implicit pairwise behaviors, and an Affiliation Layer (View r) representing explicit shared group memberships.
4.1. Constructing Matrices of the View Information
The conceptual structure is illustrated in Figure 2. For example, the three blue nodes in the User-view (Interaction Layer) and the three red nodes in the Team-view (Affiliation Layer) represent the same entities but exhibit different topological relationships. Our method exploits this complementary information.
The proposed framework is formalized by a set of adjacency matrices , specifically comprising the Interaction View and the Affiliation View . Here, is the adjacency matrix encoding the frequency of interactions between user pairs, and represents the matrix quantifying the extent of shared team affiliations. The detailed construction of these matrices is described as follows.
(1) Interaction Layer (View s): This layer encodes the intensity of pairwise user interactions. In a general social network, this is formalized as a weighted sum of various interaction types. Taking the SCHOLAT dataset as a specific case study, we instantiate this layer by mapping Friendship, Like, and Chat behaviors to the interaction weights:
We can compute the Friendship value of user i and j as
where is the Friendship value of user i and j are computed via Equation (2). The represents the number of times user i performs a ‘Like’ action on user j (or vice versa). The represents the frequency with which user i and j Chat with each other.
In our proposed generic framework, the weighting parameters , , and are tunable to reflect the varying importance of different interaction types across specific platforms. In the context of the SCHOLAT dataset, empirical observations suggest that explicit social ties imply stronger connections than casual interactions. Therefore, we set to emphasize the importance of friendship, while setting and for ‘Like’ and ‘Chat’ interactions, respectively.
Intuitively, the relationships among nodes are more important than other types of interaction, so it should have greater weight. Therefore, in this paper, we let and .
According to Equation (1), consider a scenario, where SCHOLAT users interact using the public interactions in view s as shown in Table 2 and Figure 4.
Example 2. The of user and in the interaction is computed as .
(2) Number of common teams (View r): This layer represents shared group memberships. quantifies explicit groups shared by users. Taking Academic-teams and Class-teams as specific instances in our case study, the affiliation matrix is defined as
where denotes the number of common Academic-teams and denotes the number of common Class-teams in SCHOLAT of user i and j. We now consider the second scenario, where SCHOLAT users denote common team-ship using the public team member information in view r as shown in Table 3 and Figure 5.
Example 3. The user and have the one common Academic-team a-C, and two Class-teams such as c-B and c-H, so of user and in view r is computed as .
4.2. Constructing a Matrix of Interaction Between Multi-View
The motivation for using Jaccard similarity is to act as a structural consistency filter. In social networks, a “team” relationship might exist without actual social interaction (noise). By computing the overlap of neighbors between the interaction view and the team view, we assign a high coupling strength only when the team structure aligns with the social structure. In this section, we use Jaccard similarity between view s and r to construct a matrix, which measures the cross-view clustering consistency. We need to define the data consistency for the two views as follows: (1) For the view s, let denote the friends of user i. (2) For the view r, let denote the teammates of user j, to this end, can be computed as
In this paper, we only measure the cross-view clustering consistency for each user, so we set in Equation (4). Given a user u, the Jaccard similarity between the view s and r for user u can be computed as
Example 4. We can use the number of the common friends to measure the similarity between the User-view and Team-view. According to Figure 6, we can find (1) tn the User-view: the friends of user are . (2) In the Team-view: the user has the team , , and (the nodes with red border, where a denotes Academic-team, and c denotes Class-team), while the other members are , , and . The friends of user are . In the end, we can compute the Jaccard similarity between view s and r of user as . The technical details for constructing matrix are as shown in Algorithm 1.
Algorithm 1 The Coupling Matrix Construction AlgorithmInput: n denotes the number of nodes, and the neighbor sets in the user-view and team-view for all .Output: The diagonal coupling matrix .
- 1:Initialize as an zero matrix.
- 2:for to n do
- 3: Compute ▹Using Equation (5)
- 4:
- 5: end for
- 6:return
4.3. The TaCD Method
There is currently no recognized community definition, which is only qualitatively considered to be a set of vertices with a “tight inside and loose outside” structure. In order to quantify the “tightness and looseness”, Newman and Girvan [32] propose the modularity , which is the most popular quality function for community detection. The modularity can be defined as
where represents the weight of the edge between node i and j. is the sum of the weights of the edges attached to vertex i. is the community to which vertex i is assigned, and is the Kronecker delta [38], e.g., if , otherwise . denotes the number of inner edges of an adjacent matrix [30].
Part of the algorithm efficiency results from the fact that the gain in modularity [2] obtained by moving an isolated node i into a given community C can easily be computed as
where
: the sum of the weights of the links inside C; : the sum of the weights of the links incident to nodes in C; : the sum of the weights of the links incident to node i; : the sum of the weights of the links from i to nodes in C; : the sum of the weights of all the links on the network.
The objective function of modularity can be computed using and as input. To solve this, the Generalized Louvain algorithm [39] can be used. For a more detailed explanation of its implementation, please refer to [40].
Using the steady-state probability distribution , where , we obtain the multi-view null model in terms of the probability of sampling node i in view s conditional on whether the multi-view structure allows one to step from to , accounting for view s and r steps separately [30] as
where each network view s is represented by an adjacency between node i and j, with view couplings that connect node j in view r to itself in view s.
In TaCD, we use the Jaccard similarity to compute the coupling of view s and view r, combining with Equation (4), our proposed method to compute the modularity as
where can be computed via Equation (4). denotes the matrix of view s. denotes the community label of node i in view s. is the Kronecker delta, which is the same as Equation (6). and [21]. The resolution associated with each view is dictated by . , where is the adjacency matrix for view s. represents the coupling between view s and r.
Where
: the degree (or weighted degree) of node i in view s. : the total weight of all edges present in view s. : the resolution parameter associated with view s, which regulates the granularity of the detected communities (higher values of yield smaller communities). : the coupling strength connecting node j between view s and view r. In our proposed method, this value is determined by the structural consistency (Jaccard similarity) between the views. : the community assignments of node i and node j, respectively. : denotes the set of interactions between view s and view r.
For clarity, Algorithm 2 summarizes the main procedure of the proposed method. The process flow of the dataset construction and TaCD algorithm is shown in Figure 7. Algorithm 2 The TaCD AlgorithmInput: n (the number of nodes), (Adjacency matrix for User-view), (Adjacency matrix for Team-view), for (Neighbor sets for both views), (Resolution parameter).Output: The community assignment vector .
- 1: ▹ Step 1: Compute the cross-view coupling
- 2:Compute the diagonal coupling matrix using Algorithm 1 with inputs and .
- 3: ▹ Step 2: Define the objective function
- 4:Define the multi-view modularity objective function using , , , and as defined in Equation (10).
- 5: ▹ Step 3: Optimize the objective function
- 6:Optimize using the Generalized Louvain algorithm [40] to find the final partition.
- 7: ▹ Step 4: Obtain the final community assignments
- 8:Let be the resulting community assignment vector, where is the community ID for node i.
- 9:return g
5. Experiments
5.1. Experimental Settings
In this set of experiments, we compare our approach with four existing state-of-the-art community detection techniques: AP (Affinity Propagation), NCut, Louvain, and VGAER. All experiments were conducted using a standard Personal Computer equipped with an Intel 3.4 GHz CPU and 16.0 GB RAM.
AP [41], which is a clustering algorithm based on “information transfer” between data points. AP algorithm does not need to determine the number of clusters before running the algorithm. The “examplars” searched by AP algorithm, e.g., clustering centroids, are the actual points on the dataset and represent each class;NCut [42], which is a clustering method based on segmentation. The normalized cuts criterion measures both the total dissimilarity between the different groups as well as the total similarity within the groups. We show that an efficient computational technique based on a generalized eigenvalue problem can be used to optimize this criterion;Louvain [2,43], which is an algorithm that optimizes modularity based on multi-level (round-robin heuristic). The modularity function is originally used to measure the quality of community detection algorithm results, and it is able to characterize the closeness of the communities found;VGAER [44], which is a novel unsupervised community detection method based on Variational Graph AutoEncoder (VGAE). Unlike traditional deep learning methods that typically reconstruct the adjacency matrix, VGAER reconstructs the modularity matrix to capture high-order community structures effectively. It represents the state-of-the-art in graph neural network-based unsupervised community detection.
5.2. Evaluation Measures
Since on each testing network, ground-truth labeling is provided for evaluating the clustering accuracy, we compare three widely used evaluation measures: ACC [45], NMI [46], and ARI [47].
Accuracy (ACC) shows what percentage of the samples you have predicted are correct [48]. Given the node , and is the assigned label of the node , is the real label of in the dataset. The ACC can be computed as
where is the Kronecker delta, which is the same as Equation (6). is the permutation mapping function that maps of node to the corresponding label in real community. n denotes the counts of nodes.Normalized Mutual Information (NMI) is used for measuring the clustering accuracy based on the underlying class labels [49].Given a network of size n, the clustering labels of c clusters, and actual class labels of classes, a confusion matrix is formed first, where entry . gives the number of points in cluster i and class j. The NMI can be computed from the confusion matrix [42] as
where and are the Shannon entropy of cluster labels p and , respectively, with and denoting the number of points in cluster i and class j. A high NMI indicates the clustering and real labels match well. If , . If and are completely different, .Apart from ACC and NMI, in the comparison results, we also use Adjusted Rand Index (ARI) to validate the algorithm. ARI has become one of the most successful cluster validation indices, and it is recommended as the index of choice for measuring agreement between two partitions in clustering analysis with different numbers of clusters. The ARI can be computed as
where a denotes the number of sample pairs in the same group of cluster and class ; b denotes the same cluster in the original partition , but the number of sample pairs in the cluster result that are not in the same group; c denotes not in the same cluster , but the number of sample pairs in the same in class ; d denotes the number of sample pairs in both cluster and class , which are not in the same group.
5.3. Parameter Analysis
In our proposed method, the resolution parameter plays a crucial role, with a range of 0 to 2. We conducted a sensitivity analysis for this parameter to determine the optimal value for our experiments.
As visually illustrated in Figure 8, the performance metrics (NMI, ARI, and ACC) across all eight networks exhibit a consistent trend. Crucially, a stable performance plateau is observed in the highlighted interval . The mean performance curves (represented by the thick red lines) demonstrate that the algorithm has robust to small parameter variations within this region. Within this robust interval, while yields a marginal peak in NMI, demonstrates highly competitive stability and achieves a slightly stronger balance in ARI scores.
Considering this balance between near-optimal NMI and strong ARI performance, we set as a robust and representative parameter to complete the community detection experiments with TaCD.
5.4. Complexity Analysis
The computational complexity of TaCD is determined by two main phases: the cross-view coupling construction (Algorithm 1) and the modularity optimization (Algorithm 2).
For the modularity optimization (Algorithm 2), we use the Generalized Louvain method. The complexity of the standard Louvain algorithm is known to be near-linear, often simplified to [43], where is the number of nodes and is the number of edges. In our multi-view model, the total number of nodes is n, and the total number of edges (intra-view plus inter-view couplings) is . Thus, the optimization step has a complexity of .
For the coupling construction (Algorithm 1), we compute the Jaccard similarity for all n nodes. This is sometimes mistakenly assumed to be an operation, which would involve computing a full similarity matrix. However, as shown in Algorithm 1, we only compute the n diagonal values ( ). The complexity of computing the Jaccard similarity for a single node i is proportional to the size of its neighbor lists, . Summing over all nodes, the total complexity for this phase is .
Therefore, the total complexity of TaCD is (Optimization). Letting be the total number of intra-view edges, the overall complexity simplifies to . This near-linear complexity is highly scalable. The experimental running times shown in Figure 9 confirm this gentle, near-linear growth as the network size increases.
5.5. Comparison Results
With the proposed method, we utilize both the interaction information matrix and the team information matrix as inputs, serving as two distinct views for the network. In contrast, existing methods typically rely solely on the interaction matrix. The community structures detected by each method are compared against the ground-truth communities in the SCHOLAT dataset.
For the stochastic methods (NCut, Louvain, VGAER, and TaCD), we conducted ten independent runs for each network and reported the mean results to ensure statistical reliability. The deterministic algorithm AP was run once. The comprehensive results are presented in Table 4, where the best results are highlighted in bold and the second-best results are underlined.
As presented in Table 4 and Figure 10, we conducted a comprehensive evaluation including the advanced deep learning-based method, VGAER [44].
In terms of Accuracy (ACC), the proposed TaCD method consistently outperforms all baselines. It achieves a peak ACC of on Net-10k, which is notably higher than the deep learning-based VGAER ( ) and significantly surpasses traditional methods like AP ( ). This indicates that integrating team affiliations effectively corrects misclassified nodes in boundary regions.
Regarding Normalized Mutual Information (NMI), TaCD demonstrates its most significant advantage. By establishing a structural coupling between the user view and the team view, TaCD achieves NMI scores consistently in the range of 0.69–0.75. In comparison, VGAER, despite being a powerful GNN-based reconstruction method, fluctuates between and . This validates that our multi-view modularity approach captures the global community structure more accurately than single-view reconstruction methods, which may struggle with the sparsity of social interaction data.
Interestingly, in the Adjusted Rand Index (ARI) metric, VGAER shows strong competitiveness, particularly on larger networks. As shown in Table 4, VGAER achieves ARI scores very close to TaCD, and even slightly surpasses TaCD on Net-9k ( vs. ) and Net-10k ( vs. ). This suggests that while TaCD is superior in global structure identification (NMI), VGAER is highly effective in pairwise classification decisions on large-scale graphs. Nevertheless, TaCD remains the best performing method overall, securing the highest scores across the vast majority of metrics and datasets.
5.6. Case Study and Visualization
The eight networks cluster results obtained by TaCD are shown in Figure 11, and the community information after processing with TaCD method is shown in Table 5. Next, we take a closer look at the experimental results. As Figure 12 shows, the big red node is the centroid of community, whose degree of edges is the highest. Through examples, what sets it apart from other community detection algorithms is that, TaCD is more sensitive to team information on the dataset networks and can fully utilize this information for more accurate community partitioning of nodes. Accurate segmentation can help us better develop recommendation algorithms on social networking platforms, thereby helping users create their social circles more quickly on the platform.
In addition, we find that among the eight clusters, there is a relatively large purple classification. By comparing the data in platform, we find that the classification is the greatest activity in SCHOLAT, while the name of largest class is South China Normal University, Guangzhou, China. In addition, the community is the birthplace of SCHOLAT.
5.7. Ablation Study
To verify that the performance gains are specifically driven by the team-aware modeling and not merely by parameter tuning or increased edge density, we conducted a comprehensive ablation study. We defined a baseline variant named TaCD-NoTeam, which utilizes only the Interaction Layer (User-view) by setting the cross-view coupling matrix to zero. We compared this baseline with the proposed TaCD-Full model, which fully integrates the Affiliation Layer (Team-view).
The comparative results across all eight networks (Net-3k to Net-10k) are visualized in Figure 13. In the figure, the green bars represent the performance of TaCD-NoTeam, while the red bars represent TaCD-Full. It is evident that the inclusion of team information yields a consistent and significant performance boost across all evaluation metrics (NMI, ARI, and ACC).
As illustrated in the figure, removing the team view results in a significant performance drop. This confirms that the explicit affiliation information contributes fundamentally to the detection accuracy.
6. Conclusions and Future Work
In this paper, we propose a novel method for community detection. The SCHOLAT dataset is combined with the characteristics of team attributes, and a multi-view approach is used to build a multi-layer community detection model based on team-aware named TaCD. The comparisons with other counterpart methods shows that the proposed method outperforms them. Furthermore, the dataset used for analysis is freely available to the research community to conduct further experiments on community detection. While our current implementation focuses on hard partitioning, which is essential for defining primary administrative units in organizations, we acknowledge that social communities often overlap. Future work will extend this multi-view framework to support overlapping community detection.
In the future, we plan to use more views beyond user-interactions view and team-relations view, and integrate more relationships to further enhance our method. For example, we can add time attributes, including interaction time, team creation time, and becoming friends time, which can form a new view. We can also apply the method to other datasets such as WebKB, SNAP_Pokec, DBLP, and so on, which consist of two or more types of relational data.
In addition, real networks always exhibit complex changes, and our methods are capable of conducting research on these dynamic networks. For example, our proposed multi-view approach can be used to solve community discovery problems in dynamic networks by treating networks before and after changes as different views.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ma H. Yang H. Zhou K. Zhang L. Zhang X. A local-to-global scheme-based multi-objective evolutionary algorithm for overlapping community detection on large-scale complex networks Neural Comput. Appl.2020335135514910.1007/s 00521-020-05311-w · doi ↗
- 2Kalyanaraman A. Halappanavar M. Chavarría-Miranda D. Lu H. Duraisamy K. Pande P.P. Fast Uncovering of Graph Communities on a Chip: Toward Scalable Community Detection on Multicore and Manycore Platforms Found. Trends Electron. Des. Autom.20161014524710.1561/1000000044 · doi ↗
- 3Yang Y. Sun Y. Wang Q. Liu F. Zhu L. Fast Power Grid Partition for Voltage Control with Balanced-Depth-Based Community Detection Algorithm IEEE Trans. Power Syst.2021371612162210.1109/TPWRS.2021.3107847 · doi ↗
- 4Truong H.B. Ivanovic M. Tran V.C. Community Detection Methods Based on Exploiting Attributes and Interactions on Social Networks: A Survey and Future Directions Vietnam J. Comput. Sci.20251211910.1142/S 2196888824300011 · doi ↗
- 5Tamburri D.A. Lago P. Van Vliet H. Uncovering latent social communities in software development IEEE Softw.201330293610.1109/MS.2012.170 · doi ↗
- 6Zhang W. Nie L. Jiang H. Chen Z. Liu J. Developer social networks in software engineering: Construction, analysis, and applications Sci. China Inf. Sci.20145712310.1007/s 11432-014-5221-6 · doi ↗
- 7Ozawa Y. Saito R. Fujimori S. Kashima H. Ishizaka M. Yanagawa H. Miyamoto-Sato E. Tomita M. Protein complex prediction via verifying and reconstructing the topology of domain-domain interactions BMC Bioinf.20101135010.1186/1471-2105-11-35020584269 PMC 2905371 · doi ↗ · pubmed ↗
- 8Ahn Y.-Y. Bagrow J.P. Lehmann S. Link communities reveal multiscale complexity in networks Nature 201046676110.1038/nature 0918220562860 · doi ↗ · pubmed ↗