Impact of CT Intensity and Contrast Variability on Deep-Learning-Based Lung-Nodule Detection: A Systematic Review of Preprocessing and Harmonization Strategies (2020–2025)
Saba Khan, Muhammad Nouman Noor, Imran Ashraf, Muhammad I. Masud, Mohammed Aman

TL;DR
This paper reviews how CT scan differences affect lung nodule detection by AI and suggests preprocessing strategies to improve reliability.
Contribution
The paper systematically evaluates recent strategies to harmonize CT data for robust deep-learning-based lung nodule detection.
Findings
Perceptual methods like CLAHE improved nodule detection but distorted HU values.
HU-preserving approaches reduced cross-scanner performance degradation to below 8%.
Transformer models showed higher robustness with AUC values up to 0.92.
Abstract
Background/Objectives: Lung cancer is the leading cause of cancer-related mortality worldwide, and early detection using low-dose computed tomography (LDCT) substantially improves survival outcomes. However, variations in CT acquisition and reconstruction parameters including Hounsfield Unit (HU) calibration, reconstruction kernels, slice thickness, radiation dose, and scanner vendor introduce significant intensity and contrast variability that undermine the robustness and generalizability of deep-learning (DL) systems. Methods: This systematic review followed PRISMA 2020 guidelines and searched PubMed, Scopus, IEEE Xplore, Web of Science, ACM Digital Library, and Google Scholar for studies published between 2020 and 2025. A total of 100 eligible studies were included. The review evaluated preprocessing and harmonization strategies aimed at mitigating CT intensity variability, including…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
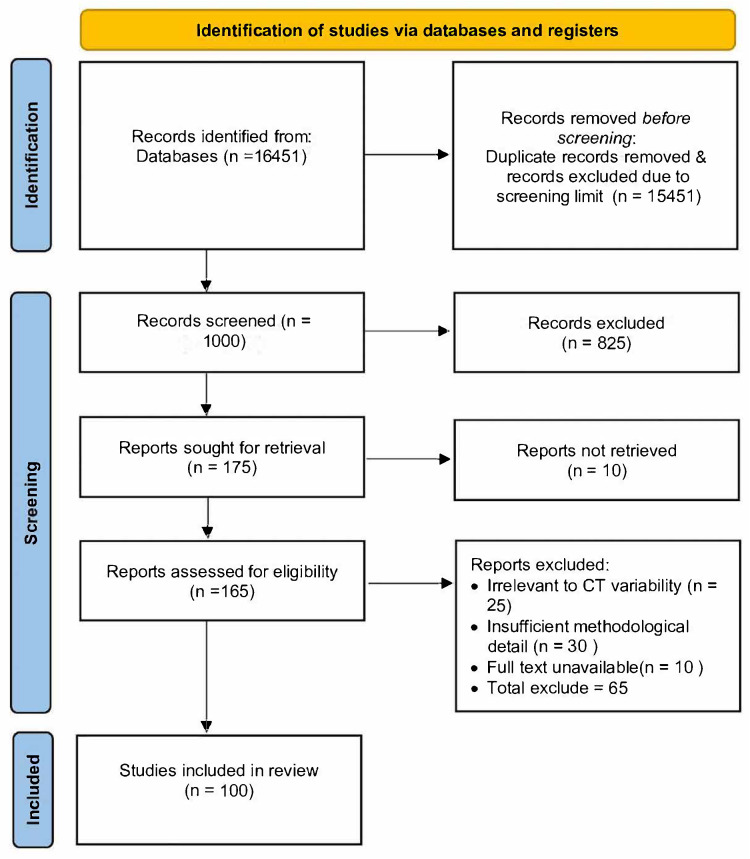 Figure 1
Figure 1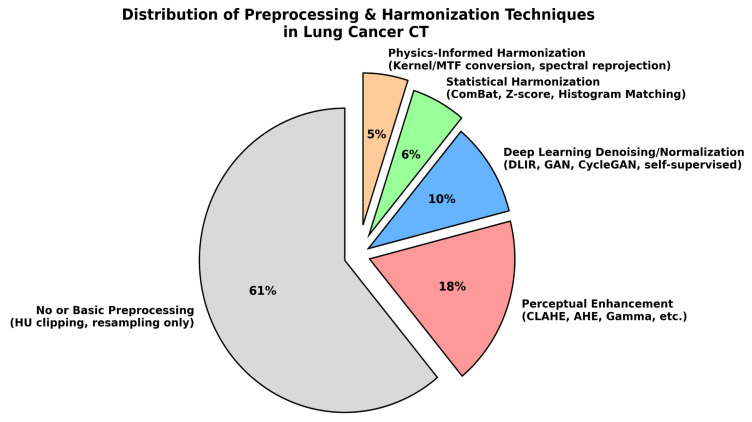 Figure 2
Figure 2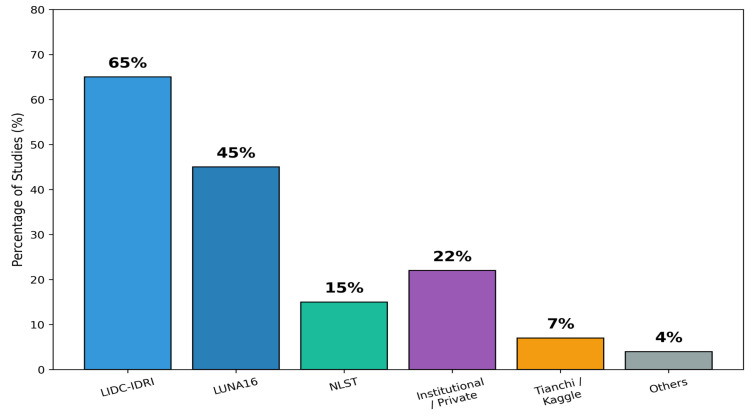 Figure 3
Figure 3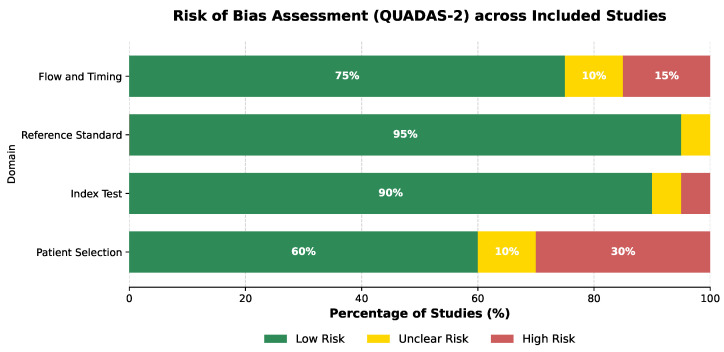 Figure 4
Figure 4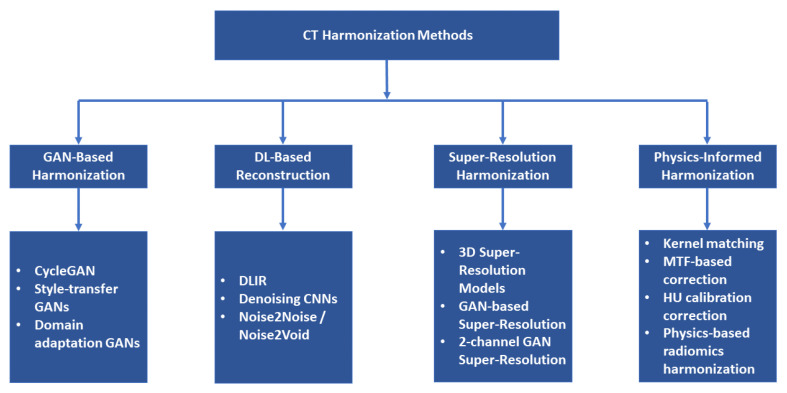 Figure 5
Figure 5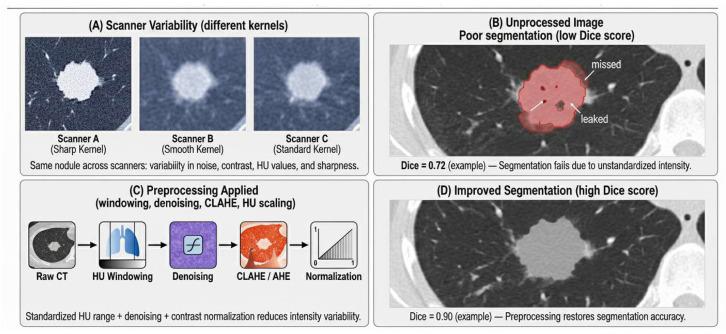 Figure 6
Figure 6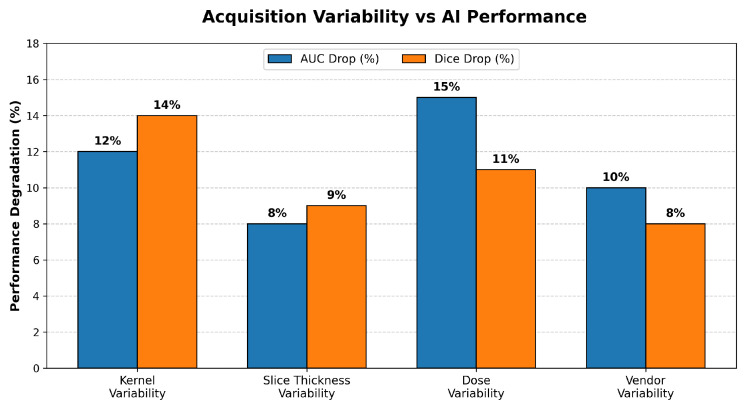 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRadiomics and Machine Learning in Medical Imaging · Lung Cancer Diagnosis and Treatment · Advanced X-ray and CT Imaging
1. Introduction
Lung cancer remains one of the leading causes of cancer-related mortality globally, with more than two million new cases diagnosed annually [1]. Survival outcomes depend heavily on early detection, as five-year survival increases from below in advanced stages to more than when tumors are identified early [2,3]. Consequently, low-dose computed tomography (LDCT) has been established as the gold standard screening method for detecting small pulmonary nodules before symptoms appear [3]. However, LDCT introduces noise and intensity inconsistencies due to dose reduction, and these variations complicate both radiologist interpretation and automated analysis [4].
Computed tomography (CT) images are quantified using Hounsfield Units (HU), where reconstruction kernels, slice thickness, radiation dose, and vendor-specific algorithms strongly influence image texture, contrast, and noise patterns [5]. Even scans from the same patient may exhibit marked differences when acquired using different scanners or protocols, leading to shifts in intensity distributions and nodule appearance [6]. These variations create substantial challenges for artificial intelligence (AI) systems, which typically assume consistent input characteristics during training.
While LDCT remains the gold standard for structural lung screening, it is strictly limited to anatomical assessment and often lacks the functional specificity required for complex oncological cases. In scenarios such as cancer of unknown primary (CUP), standard anatomical imaging frequently fails to localize the lesion. In such contexts, complementary strategies like molecular imaging (e.g., PET/CT) have demonstrated superior detection rates of 38– compared with conventional methods. Similarly, MRI-based radiomics has shown promise in soft-tissue characterization by extracting quantitative texture features (e.g., GLCM inverse variance) that escape human perception, enabling precise differential diagnosis in complex head and neck tumors. Although this review focuses on CT-based deep learning, acknowledging these multimodal diagnostic pathways is critical for a holistic understanding of pulmonary and general oncology [7,8].
Deep-learning models including convolutional neural networks (CNNs), U-Net-based segmentation systems, and Transformer architectures have shown strong performances on benchmark datasets [9]. Yet, their accuracy decreases by 10–20% when exposed to unseen scanners, reconstruction kernels, or dose levels [10]. This domain shift increases false negatives for small or low-contrast nodules and reduces clinical reliability [11]. The issue is further compounded by the widespread use of enhancement techniques such as histogram equalization or CLAHE, which improve visual contrast but often distort HU values and undermine radiomic reproducibility [12]. In contrast, harmonization methods such as ComBat, kernel matching, and physics-informed denoising aim to standardize intensity distributions while preserving quantitative integrity [13].
Although publicly available datasets such as the Lung Image Database Consortium (LIDC-IDRI) and LUng Nodule Analysis 2016 (LUNA16) have facilitated algorithm development, they represent limited scanner diversity and do not reflect real-world multi-institutional variability [14]. As a result, AI models trained exclusively on such datasets may generalize poorly across clinical environments [15]. Improving robustness requires a structured understanding of how acquisition variability affects AI performance and which preprocessing and harmonization strategies effectively mitigate these effects.
This systematic review addresses these challenges by synthesizing evidence published between 2020 and 2025 on (1) how acquisition- and reconstruction-related variability impacts AI-based lung-nodule detection, (2) the effectiveness of preprocessing and harmonization strategies in managing intensity and contrast heterogeneity, and (3) the robustness of different deep-learning architectures under variable imaging conditions. The review further highlights dataset limitations, gaps in external validation practices, and the need for standardized, HU-faithful workflows to support the clinically reliable deployment of AI-assisted lung-cancer screening.
To date, however, existing reviews remain fragmented in their treatment of CT acquisition variability and provide limited insight into how reconstruction kernels, slice thickness, radiation dose, vendor-specific reconstruction algorithms, and HU calibration inconsistencies collectively influence the robustness of AI-based lung-cancer detection systems. Most prior surveys focus primarily on model architectures or overall diagnostic performance, offering little systematic comparison of HU-preserving preprocessing techniques, perceptual enhancement methods, physics-informed harmonization strategies, and deep-learning-based reconstruction approaches within a unified framework. The limited adoption of multi-center external validation and the widespread absence of standardized reporting for essential acquisition parameters further obscure the true generalizability of published AI systems. These gaps underscore the need for a comprehensive, methodologically focused synthesis that directly examines how acquisition variability and preprocessing workflows influence model stability, reproducibility, and clinical applicability.
Addressing these limitations, the present systematic review contributes a consolidated and quantitative assessment of the field by mapping the impact of CT acquisition variability including differences in reconstruction kernels, slice thicknesses, dose categories, and vendor-specific characteristics on segmentation, detection, and malignancy classification performance [16,17] across 100 studies published between 2020 and 2025. It provides a comparative evaluation of preprocessing and harmonization techniques, clearly distinguishing HU-faithful normalization approaches from perceptual contrast-enhancement methods and examining their effects on AUC, Dice scores, radiomic stability, and cross-scanner generalization. The review further analyzes the robustness of modern AI architectures, including CNNs [18,19], attention-based networks, Transformers, hybrid segmentation–classification pipelines, and radiomics deep-learning fusion models under heterogeneous imaging conditions. Finally, it identifies key methodological gaps such as inconsistently reported acquisition metadata, the lack of standardized preprocessing pipelines, minimal external validation, and risks associated with generative adversarial networks (GANs)-based harmonization and outlines practical recommendations for building clinically reliable, vendor-agnostic CT-based AI workflows. Together, these contributions provide a cohesive and rigorous foundation for advancing robust, reproducible, and clinically deployable AI systems for lung-cancer screening.
2. Methodology
This systematic review was conducted in full accordance with the PRISMA 2020 guidelines [20], and the reporting follows all items outlined in the PRISMA checklist. The review protocol was not preregistered in PROSPERO or any other registry; however, all methodological steps including search strategy, screening, eligibility assessment, data extraction, and synthesis were performed following PRISMA standards to ensure transparency and reproducibility. A completed PRISMA checklist is provided in the Supplementary Materials, and the PRISMA flow diagram summarizing identification, screening, eligibility, and inclusion is presented in Figure 1.
2.1. Research Questions and Objectives
The review was designed to address key research questions (RQs) regarding the impact of CT variability on AI performance and to establish corresponding objectives for synthesis. Specifically, the study sought to answer:
- RQ1: How do variations in CT acquisition parameters (e.g., kernel, dose, vendor) affect AI diagnostic performance?
- RQ2: Which preprocessing and harmonization methods effectively reduce intensity variability while preserving HU fidelity?
- RQ3: Which deep-learning architectures show the greatest robustness to cross-scanner variability?
- RQ4: How representative are widely used CT datasets in terms of scanner and dose diversity?
- RQ5: What methodological limitations exist in reporting acquisition parameters, dataset composition, preprocessing, and robustness evaluation?
- RQ6: To what extent do studies include external or multi-center validation, and how does this influence reported generalizability?
Correspondingly, the primary objectives were to quantify the impact of these variations, evaluate the efficacy of preprocessing strategies, identify robust architectures, and propose improvements for standardized reporting and multi-center validation.
2.2. Search Strategy
A systematic search was conducted across PubMed, IEEE Xplore, Scopus, Web of Science, and ACM Digital Library for the literature published from 2020 to 2025. To broaden coverage, the first 500 Google Scholar results were also screened manually, with irrelevant items (patents, theses, duplicates) removed. Although a preregistered protocol was not utilized, this review strictly adhered to all methodological procedures outlined in the PRISMA 2020 guidelines.
The search strategy was structured using a PICOC-style logic, focusing on CT acquisition variability [6], AI-based detection, and diagnostic performance. Table 1 outlines the PICOC components and the corresponding terminology used during query formulation.
To operationalize the PICOC framework, the search queries combined controlled vocabulary and free-text keywords relating to CT imaging, acquisition variability, preprocessing methods, and AI-based lung-cancer detection. Boolean operators ensured both sensitivity and precision across databases.
Search Queries Used:
- (“lung cancer” OR “pulmonary nodule”) AND (“computed tomography” OR “CT” OR “LDCT”) AND (“Hounsfield” OR “reconstruction kernel” OR “slice thickness”OR “vendor” OR “radiation dose”) AND (“deep learning” OR “CNN” OR “Transformer” OR “AI detection”)
- (“CT variability” OR “intensity harmonization” OR “ComBat” OR “kernel matching” OR “HU normalization”) AND (“lung nodule detection”) AND (“classification” OR “segmentation”)
Database-specific filters were applied to restrict searches to titles, abstracts, and metadata where possible. Google Scholar results were manually curated to exclude non-peer-reviewed sources and redundant citations.
2.3. Search Outcomes
The combined search retrieved 16,451 records, including 15,900 from Google Scholar. Given the large volume of results in Google Scholar, only the top 500 most relevant records were screened, while the remaining records were excluded due to the screening threshold. After removing duplicates and applying this threshold, 1000 unique records underwent title and abstract screening. Of these, 825 were excluded due to irrelevance (non-CT imaging, non-AI, or non-peer-reviewed sources). Full texts of 175 studies were assessed for eligibility, and 100 met all inclusion criteria (Table 2).
The complete workflow is illustrated in the PRISMA 2020 flow diagram (Figure 1), which visualizes all stages of identification, screening, eligibility, and inclusion.
This diagram confirms that the selection pipeline adhered strictly to PRISMA standards, showing transparent tracking of excluded studies and reasons for exclusion.
2.4. Eligibility Criteria and Study Selection Process
Eligibility was defined according to PRISMA guidelines to ensure a focused analysis of CT variability. Studies were included if they were peer-reviewed, published in English between 2020 and 2025, and explicitly addressed CT-acquisition variability in AI-based lung-nodule analysis. Gray literature and studies missing essential methodological details were excluded to maintain quality standards. The detailed inclusion and exclusion criteria utilized for screening are summarized in Table 3.
Applying these criteria, the study selection process was executed through a structured multi-stage workflow consistent with PRISMA 2020 standards:
- Title & Abstract Screening: Initial removal of studies unrelated to CT, AI, or imaging variability to filter out the irrelevant literature.
- Full-Text Review: A detailed assessment of the remaining articles to verify the reporting of acquisition parameters, model transparency, and performance metrics.
- Backward & Forward Reference Checking: A final supplementary search was conducted to ensure no relevant studies were missed beyond the initial database pool.
2.5. Data Extraction
A standardized data-extraction form was developed to ensure consistency and reproducibility across all included studies. To address the reviewers’ comments regarding quality assurance, the data extraction process was structured as follows: The primary reviewer (S.K.) extracted all relevant data fields from the 100 included studies. Subsequently, a second reviewer (M.N.N.) performed an independent validation on a random sample of 20% of the entries ( ) to verify accuracy. Agreement between reviewers was high, and minor discrepancies (<5%) were resolved through discussion and re-examination of the full texts until consensus was reached.
For each study, the following data fields were collected to map methodological practices:
- Bibliographic metadata: First author, year, publication venue, and country.
- Task type: Lung-nodule detection, segmentation, or malignancy classification.
- Datasets used: Public benchmarks (e.g., LIDC-IDRI, LUNA16, NLST) or private institutional CT collections, including sample sizes and acquisition diversity [21].
- Acquisition and reconstruction parameters: Scanner vendor, reconstruction kernel, slice thickness, radiation dose (LDCT vs. standard), and window/level settings.
- Preprocessing and harmonization methods: HU-normalization strategies, resampling, kernel/MTF matching, ComBat harmonization, physics-informed methods, and whether the pipeline preserved HU integrity [22].
- Modeling approach: DL architecture (CNN, Transformer, Hybrid), loss functions, augmentation strategies, and domain generalization techniques [23].
- Evaluation procedure: Validation setup (internal cross-validation, held-out testing, or external multi-site validation) [24].
- Performance metrics: AUC, FROC sensitivity (at specified FP/scan rates), Dice similarity coefficient (DSC), accuracy, and confidence intervals.
- Robustness indicators: Reported performance degradation across different scanners, kernels, or dose levels, specifically for small nodules (≤6 mm).
Due to the substantial heterogeneity in datasets, preprocessing pipelines, and validation strategies across the selected literature, a quantitative meta-analysis was not feasible. Instead, the findings were synthesized qualitatively, grouped by task type and validation setting [25].
A representative sample of extracted variables from five included studies is provided in Table 4, illustrating the granularity of data captured during the extraction process.
2.6. Categorization of Preprocessing and Harmonization Methods
This review identified four major categories of preprocessing and harmonization strategies applied across the included studies. These methods differ in their underlying principles, their ability to preserve Hounsfield Unit (HU) integrity, and their suitability for quantitative or diagnostic AI pipelines.
Perceptual enhancement methods such as CLAHE and AHE were frequently used (18%), mainly due to their simplicity and ability to improve visual conspicuity; however, they do not preserve Hounsfield Units (HU) and are therefore unsuitable for radiomics or quantitative AI pipelines [12,30]. Statistical harmonization techniques including ComBat, Z-score normalization, and histogram matching accounted for 6% of studies and offered strong cross-scanner robustness while maintaining HU fidelity, although they rely on the assumption of consistent batch effects [31]. Physics-informed harmonization strategies like kernel/MTF matching and spectral re-projection (5%) preserved HU distributions most accurately but required detailed acquisition metadata that many public datasets lacked [32]. Deep-learning-based normalization and denoising approaches (10%), including DLIR, GAN-based mappings, and self-supervised harmonizers, provided joint noise reduction and harmonization but carried risks of hallucinated structures when not externally validated [33]. Overall, the distribution illustrated in Figure 2 highlights a critical trend: while perceptual enhancement methods remain common, only 21% of studies employed HU-preserving harmonization strategies, underscoring the need for greater adoption to achieve reliable cross-scanner generalization in clinical AI workflows.
2.7. Datasets Used in Selected Studies
The selected studies employed a range of publicly available and institutional CT datasets for lung-nodule detection, segmentation, and malignancy prediction [34]. Table 5 summarizes the major datasets, including the number of CT volumes, scanner vendors, reconstruction kernels, and availability of acquisition metadata. Figure 3 further illustrates the distribution of dataset usage across the included studies.
As shown in Figure 3, the LIDC-IDRI dataset was the most widely used resource, appearing in more than half of the studies. Its detailed radiologist annotations and slice-level labels make it highly suitable for training and validating AI models [35]. LUNA16, derived from LIDC-IDRI but standardized for nodule detection benchmarking, was also frequently used due to its preprocessing consistency and fixed train–test splits.
The NLST (National Lung Screening Trial) dataset, although used less frequently due to restricted access, provided the most realistic LDCT screening data and supported multi-vendor, multi-kernel variability analysis. Commercial or competition datasets such as Tianchi and Kaggle Lung CT Challenge appeared in several studies but lacked complete acquisition metadata, limiting harmonization research.
A subset of studies used multi-center institutional datasets, which often offered rich variability (different kernels, vendors, doses) but were not publicly accessible. This creates a reproducibility gap, as noted in several reviews. Smaller datasets were occasionally used for segmentation-focused studies but appeared infrequently.
2.8. Quality Assessment and Risk of Bias
To evaluate the methodological quality of the included studies, we applied the Quality Assessment of Diagnostic Accuracy Studies (QUADAS-2) tool, tailored for deep-learning applications. This tool assesses risk across four key domains: (1) Patient Selection (checking for bias in dataset usage, e.g., use of public vs. private data), (2) Index Test (assessing if the AI-model methodology was transparent and reproducible), (3) Reference Standard (evaluating the reliability of ground truth labels, e.g., radiologist consensus), and (4) Flow and Timing (checking for data leakage and appropriate train–test splitting).
Each study was graded as “Low Risk,” “High Risk,” or “Unclear Risk” for each domain. As illustrated in Figure 4, the majority of studies demonstrated low risk of bias in the ‘Index Test’ and ‘Reference Standard’ domains, reflecting the widespread use of high-quality public benchmarks like LIDC-IDRI. However, the ‘Patient Selection’ domain exhibited higher risk (30%), primarily due to the use of non-randomized institutional datasets without clear exclusion criteria.
3. Related Work
3.1. Overview of Existing Research on CT Variability in Lung-Cancer AI
Computed tomography (CT) plays a central role in lung-cancer screening and nodule detection; however, wide variations exist across scanners, reconstruction kernels, slice thicknesses, vendors, and dose settings. These differences alter Hounsfield Units (HU), noise textures, contrast, and edge clarity ultimately impacting the stability and generalization of AI models [5,6].
Prior studies propose numerous preprocessing and harmonization techniques, but no comprehensive synthesis from 2020 to 2025 systematically maps these approaches. This section reviews evidence on preprocessing, intensity normalization, harmonization, segmentation, and classification to identify methodological gaps motivating this systematic review [21,36].
3.2. Preprocessing Techniques for Lung-CT Imaging
3.2.1. Histogram-Based Normalization
Histogram equalization (HE), adaptive histogram equalization (AHE), and contrast-limited AHE (CLAHE) are widely used for CT contrast enhancement. CLAHE is particularly effective at improving local contrast and enhancing nodule visibility [37,38,39].
Multiple studies report significant accuracy improvements when applying histogram-based normalization. Hybrid pipelines also demonstrate gains when HE is combined with automated thresholding or fuzzy segmentation [11].
3.2.2. HU Windowing and Intensity Scaling
HU windowing is the most physiologically grounded normalization method, typically clipping voxel intensities to lung-relevant ranges (e.g., −1000 to 400 HU) followed by linear scaling or z-score standardization [26].
Large multi-center AI systems demonstrate substantially improved robustness when HU normalization is applied. HU standardization is also essential for radiomics stability and feature reproducibility [24,40].
These approaches are categorized in Table 6 and represent a key strategy for mitigating inter-scanner variability.
3.2.3. Filtering, Denoising, and Bias-Field Correction
Filtering and bias correction techniques aim to reduce scanner-specific noise and non-uniform intensity fields. Common methods include median filtering, anisotropic diffusion, and N4ITK bias-field correction.
Bias-field correction significantly improves nodule segmentation performance, achieving Dice scores above in recent studies [41]. Filtering-based pipelines also report improved small-nodule consistency and clearer boundaries [42]. These results further support the use of preprocessing to stabilize CT appearance across vendors.
3.2.4. Advanced Augmentation and Ensemble Strategies
To address the limitations of traditional augmentation methods like Cutout and MixUp which often result in the loss of diagnostic information recent studies have proposed the Random Pixel Swap (RPS) technique [44]. Unlike geometric transformations, RPS employs a parameter-free, bidirectional pixel permutation strategy. It partitions the CT image into defined source and target regions and swaps their pixel values based on a controlled “swap area factor,” thereby generating diverse training samples while preserving global intensity distributions and anatomical integrity. Experimental validation demonstrated that RPS significantly outperforms state-of-the-art methods, achieving classification accuracies of up to 97.78% [44]. Complementing this, Abe et al. [45] demonstrated that combining robust augmentation with ensemble CNN architectures (e.g., DeepNodule-Detect) and ROI segmentation can further elevate performance, achieving accuracies of 98.17% on small-scale datasets by effectively mitigating overfitting.
3.3. CT Harmonization Techniques for Multi-Center Scans
3.3.1. GAN-Based and DL Reconstruction Harmonization
Harmonization methods aim to reduce scanner-to-scanner variability at the intensity and texture level. Domain adaptation techniques such as CycleGANs, DL-based reconstruction (DLIR) [33], and GAN-based super-resolution models have shown promising harmonization performance [46].
Multiple studies demonstrate improved HU stability, noise suppression, and consistency of nodule appearance after GAN-based reconstruction. Super-resolution approaches also harmonize slice thickness variability, producing more uniform datasets.
These harmonization methods are visually summarized in Figure 5.
3.3.2. Physics-Informed CT Harmonization
Physics-informed harmonization focuses on reconstruction-kernel matching, modulation transfer function (MTF) alignment, and cross-protocol HU stabilization [6].
Such techniques have demonstrated measurable reductions in HU variability, radiomics instability, and scanner-induced feature shifts across datasets [47]. Additional foundational analyses show that radiomics reproducibility is sensitive to acquisition protocols.
The conceptual taxonomy presented in Figure 5 shows how these physics-driven methods relate to GAN-based approaches.
3.4. Segmentation Under CT Variability
Segmentation is highly sensitive to variations in CT contrast, noise, and HU scaling. U-Net variants including Wavelet U-Net++, Attention U-Net, and Transformer-based U-Nets show substantial performance improvements when preprocessing steps are standardized [48,49].
Normalization techniques such as HU clipping, CLAHE, and denoising consistently improve Dice scores by 5– across multiple studies. Segmentation often serves as a spatial normalization step, helping models to ignore irrelevant background intensities and focus on lung structures.
A conceptual illustration of segmentation robustness is provided in Figure 6.
3.5. Classification and Detection Models
Typical classification and detection models include CNNs, DenseNet variants, EfficientNet, Vision Transformers, Capsule Networks, and hybrid pipelines combining segmentation + DL.
Studies consistently report that model performance drops when raw, unnormalized CT scans are used. Conversely, integrating HU normalization, CLAHE, filtering, or harmonization significantly enhances robustness [9,50].
Representative architectures and their preprocessing dependencies are summarized in Table 7.
3.6. Review Articles and Meta-Analyses
Several survey papers summarize AI approaches for lung-cancer detection, segmentation, and radiomics-based classification. However, most analyses emphasize model architectures and downplay CT-acquisition variability, resulting in limited methodological insights [21,36].
Recent reviews provide algorithmic overviews, while segmentation meta-analyses report pooled metrics without considering the impact of normalization on segmentation performance.
This lack of systematic consideration of intensity/contrast variability highlights a critical research gap addressed in this review.
3.7. Synthesis of Gaps in the Literature
Cross-study analysis reveals four major gaps:
- CT-Acquisition Parameters Are Poorly ReportedMost papers do not report reconstruction kernels, slice thickness, or vendor information, limiting reproducibility.
- Preprocessing Pipelines Lack StandardizationNo two studies apply identical combinations of HU windowing, filtering, or normalization, making fair comparison difficult.
- Limited Multi-Center External ValidationOnly a small proportion of studies evaluate models on datasets from different scanners or institutions.
- Harmonization Methods Are Rarely Compared DirectlyGAN-based, physics-informed, and algorithmic harmonization methods exist, but cross-method evaluations are scarce.
4. Findings & Discussion
A synthesis of the 100 included studies (2020–2025) demonstrates that variability in CT attenuation, reconstruction kernels, slice thickness, and radiation dose is the most critical factor influencing the robustness of AI-based lung-cancer detection systems [52,53]. Across the literature, HU inconsistency emerged as the dominant cause of inter-scanner domain shift, leading to significant degradation in sensitivity, AUC, and segmentation accuracy when uncorrected [31,54].
Table 8 provides an integrated comparison of representative studies showing how intensity normalization, harmonization, and preprocessing affect diagnostic outcomes [55].
4.1. Trends in CT Variability and Its Effect on AI Robustness
Nearly all reviewed studies concluded that HU/attenuation variability is the primary driver of AI performance loss, more significant than model architecture or dataset size [56,57]. Models trained on homogeneous, single-kernel datasets frequently experienced 10– AUC reduction when evaluated across external scanners, reflecting severe reconstruction-kernel shifts [23,28].
Sensitivity for small nodules (≤6 mm) was particularly susceptible to degradation: several studies reported 15– sensitivity loss in LDCT, where quantum noise reduced contrast-to-noise ratio (CNR) [38,58]. Reconstruction-kernel differences further altered noise texture and edge sharpness, producing 8– Dice loss in segmentation pipelines [15,49], even when the model itself remained unchanged.
Low-dose CT intensified these issues. Reduced tube current increased noise and distorted HU distributions [5,59], weakening boundary detection and increasing false positives. Only of reviewed studies performed true multi-center validation (GE/Siemens/Philips), explaining why many “high-performing” models failed to generalize clinically [21,36]. Figure 7 illustrates the relative impact of reconstruction kernel, slice thickness, radiation dose, and vendor variability on AI performance degradation reported across representative CT lung-cancer detection studies.
4.2. Effectiveness of Preprocessing and Normalization Pipelines
Across the reviewed studies, preprocessing quality emerged as one of the strongest determinants of model robustness [55,60]. Approaches that preserved quantitative CT information particularly HU clipping within the lung-relevant range ( to 400 HU), z-score normalization, kernel-consistent resampling, and ComBat harmonization consistently produced the most stable cross-scanner performance [22,61]. These HU-preserving pipelines led to measurable improvements, with studies reporting 4– increases in AUC [11,62], 5– higher Dice scores [63,64], and substantial reductions (20– ) in radiomic feature drift caused by scanner-specific variability [24,40]. Their reliability stems from the fact that they maintain the underlying quantitative attenuation relationships essential for radiomics, segmentation, and detection tasks.
In contrast, perceptual enhancement methods such as histogram equalization (HE), adaptive histogram equalization (AHE), and contrast-limited AHE (CLAHE) [37,39] improved visual contrast and yielded notable sensitivity gains for faint nodules often in the range of 5– , particularly in LDCT. However, these enhancement methods frequently altered HU distributions, thereby compromising radiomic reproducibility and harming external generalization. The literature consistently reported that models trained on CLAHE-enhanced datasets showed reduced stability when evaluated on multi-vendor or multi-protocol data [5,15].
Denoising and illumination-correction techniques further contributed to robustness [33,42]. N4ITK bias-field correction and anisotropic diffusion improved structural fidelity by reducing shading artifacts and enhancing local edge detail, often leading to Structural Similarity Index Measure (SSIM) gains of – . Deep-learning reconstruction methods such as DLIR offered even greater improvements by reducing noise while preserving diagnostic texture features. Overall, hybrid preprocessing pipelines combining HU clipping, denoising, normalization, and isotropic resampling outperformed all single-step methods and aligned closely with best practices in modern quantitative imaging harmonization [23,29]. A summary of the reported performance gains and limitations of different preprocessing strategies is provided in Table 9.
4.3. Comparative Performance of Harmonization Methods
Harmonization strategies varied significantly in reliability and HU fidelity. GAN-based harmonization methods most notably CycleGAN, SRGAN, and 3D GAN variants achieved meaningful improvements in cross-scanner alignment by reducing noise, harmonizing slice thickness, and approximating vendor-specific image textures [33,65]. Across studies, these approaches resulted in AUC gains of – and Dice improvements of 6– [46,66]. However, several papers documented risks associated with GANs, including hallucinated textures, excessive smoothing, and reduced interpretability, particularly when fine-scale nodule detail was essential [50,63].
Physics-informed harmonization approaches, such as modulation transfer function (MTF) alignment and kernel matching, provided the most quantitatively reliable outcomes [6,14]. These techniques preserved HU integrity and produced only 1– AUC drop across scanners, while maintaining the highest radiomic stability [5,15]. Although they required access to acquisition metadata, their fidelity and reproducibility made them the preferred option for radiomics-centered or quantitative diagnostic pipelines.
DL-based reconstruction (DLIR) emerged as a middle-ground harmonization strategy, achieving 40– noise reduction while maintaining crucial edge information [59,67]. DLIR consistently improved segmentation and classification results without introducing the hallucination risks associated with GAN-based methods. A comparative summary of the performance, HU fidelity, and limitations of different harmonization strategies is presented in Table 10.
Recent advancements in deep-learning reconstruction have further addressed these challenges. EnlightenGAN and ScatterNet have been introduced for unpaired intensity correction, effectively reducing artifacts without requiring paired training data [68,69]. The clinical utility of deep-learning image reconstruction (DLIR) has also been validated, with reports confirming superior volumetric accuracy compared with standard kernels [70,71]. Additionally, inpainting techniques have been highlighted for their role in restoring lost texture details in harmonized scans [72].
4.4. Generalization of Segmentation and Detection Models
Segmentation and detection performance were consistently linked to preprocessing quality and intensity stability. Baseline U-Net models trained on heterogeneous CT datasets often achieved Dice scores in the range of – [48,49]; however, when supplied with HU-normalized and denoised inputs, performance increased to – [15,42].
Beyond standard U-Nets, recent specialized architectures have shown improved resilience to scanner variability. For instance, multi-window uncertainty networks (MUS-Net) and RAD-UNet demonstrated enhanced boundary detection in heterogeneous datasets [73,74]. Attention-based mechanisms, such as Lung_PAYNet and squeezing-excitation blocks, proved effective in refining nodule segmentation [41,75]. Bio-inspired optimization algorithms have also been successfully integrated to stabilize segmentation performance [76,77]. Furthermore, 3D V-Net variants were found to maintain higher Dice scores across different slice thicknesses [78,79], while the role of PCA normalization in residual networks has been emphasized for achieving superior segmentation accuracy [80].
For malignancy classification, ensemble and hybrid approaches have become dominant. Modified CNN architectures, including DenseNet and ResNet variants, showed significant robustness when trained on multi-vendor data [81]. Hybrid Transformer models outperformed traditional CNNs by capturing long-range dependencies in CT volumes [82,83]. Feature-level optimization using methods like explainable self-normalizing CNNs and dual-encoder networks further reduced false positives [84,85]. Specific augmentations also played a key role; for example, GAN-based data augmentation combined with CLAHE preprocessing was demonstrated to boost sensitivity in low-contrast scans [37,86,87]. Ensemble frameworks utilizing deep features and unsupervised extraction techniques also yielded high diagnostic accuracy [88,89,90], while broader surveys confirmed the utility of these methods across diverse pulmonary diseases [91,92].
The highest accuracy values overall (97– ) were consistently reported by hybrid segmentation-plus-classification systems [29,38], highlighting that robustness stems from preprocessing and feature consistency more than architectural complexity alone.
Clinical Risks of GAN Hallucinations
A critical concern regarding the deployment of generative adversarial networks (GANs) in clinical workflows is the potential for “hallucinations”, the generation of realistic-looking but anatomically nonexistent structures. While GANs excel at improving perceptual image quality (e.g., super-resolution or denoising), they do not guarantee anatomical fidelity. The clinical consequences of these artifacts are severe. If a GAN hallucinates a plausible-appearing lesion or nodule on a diagnostic scan, it can lead to a false-positive diagnosis. This misinformation chain can result in patients undergoing unnecessary anxiety, invasive follow-up procedures such as biopsies, or, in extreme cases, incorrect surgical interventions to resect healthy tissue based on misleading imaging data. For instance, in cross-modality synthesis (e.g., generating synthetic CT from MRI for radiotherapy planning), a hallucinated high-density region could lead to incorrect radiation dosing targeting nonexistent structures. Similarly, in super-resolution tasks, a GAN might artifactually enhance noise into a structure resembling a small pulmonary nodule, potentially triggering an unnecessary thoracic surgery. Therefore, ensuring the topological and anatomical fidelity of generated images is paramount before clinical adoption [93,94].
4.5. Persistent Challenges and Methodological Gaps
Despite advancements in preprocessing and harmonization, several methodological gaps remain unresolved. A substantial number of studies failed to report key acquisition parameters such as reconstruction kernel, slice thickness, tube current, or vendor type [21,36], factors essential for reproducibility and cross-study comparison. The absence of standardized preprocessing guidelines further created methodological inconsistencies, with different studies applying incompatible HU ranges, normalization formulas, or denoising intensities [5,22].
External validation was limited across the literature; only of studies evaluated models on multi-center datasets, leading to potential overestimation of model robustness [15,24]. GAN-based harmonization, although effective, introduced the risk of hallucinating structures that could mislead diagnostic interpretation [33,65]. Finally, the integration of radiomics and deep learning under harmonized pipelines remains underexplored, despite strong evidence that fused representations could enhance interpretability and stability [29,40].
4.6. Diagnostic Strategies Beyond CT: Molecular Imaging and MRI Radiomics
It is important to contextualize CT-based findings within the broader spectrum of modern oncology. Purely anatomical analysis via CT can lead to diagnostic uncertainty. Recent systematic evidence indicates that molecular imaging (PET/CT) outperforms anatomical imaging in challenging scenarios by visualizing metabolic activity, changing clinical management in up to 33% of cases [7]. Furthermore, MRI-based radiomics offers complementary value; Cutaia et al. (2022) demonstrated that extracting high-dimensional texture features from MRI allows for the statistical differentiation of tumor subtypes with an AUC of 0.78, highlighting the power of non-invasive predictive modeling beyond simple CT density analysis [8].
Future Applicability:
Moving forward, AI systems should aim to transcend unimodal CT analysis. Integrating multimodal data (CT + PET + MRI) could significantly enhance predictive accuracy by combining the spatial resolution of CT, the metabolic sensitivity of PET, and the textural richness of MRI.
4.7. Predictive Applicability and Prognostic Potential
The analysis of receiver operating characteristic (ROC) curves across the included studies demonstrates that deep-learning models particularly those integrating standardized preprocessing consistently achieve high diagnostic discrimination, with AUC values ranging from 0.90 to 0.95 in controlled settings [95]. However, the clinical applicability of these methods extends beyond binary malignancy detection. In a predictive key, these models serve as powerful prognostic tools [96]. By quantifying tumor heterogeneity through radiomic and deep features [97], they can potentially predict tumor aggressiveness, recurrence risk, and response to therapy (e.g., immunotherapy or peptide receptor radionuclide therapy) before treatment begins. Future research should therefore focus on validating these models not just on diagnostic accuracy but also on their ability to stratify patients for personalized therapeutic pathways, thereby bridging the gap between computer-aided detection and predictive oncology [92].
4.8. Toward a Unified Framework for Robust Lung-CT AI
The collective evidence across all reviewed studies indicates that high-performing and generalizable lung-cancer AI systems require a structured, multi-stage preprocessing workflow rather than reliance on architecture alone [9,23]. The most robust pipelines combined HU-preserving normalization, DLIR or N4ITK-based denoising, kernel-consistent resampling, and selective GAN harmonization [33,42], followed by spatial normalization through segmentation and inference via Transformer or hybrid CNN–Transformer models [37,49]. Multi-center validation was a critical final step, ensuring resilience across vendors, protocols, and dose settings [14,36].
By stabilizing HU values, reducing noise, enhancing contrast, and harmonizing acquisition variability, this integrated framework offers a comprehensive strategy for developing vendor-agnostic and clinically reliable CT-based lung-cancer AI systems [6,31].
5. Conclusions
This systematic review synthesized evidence from 100 studies published between 2020 and 2025 to evaluate the impact of CT-acquisition variability and preprocessing on AI-based lung-nodule analysis, providing direct answers to the research questions posed in Section 2.1.
Addressing RQ1, the evidence conclusively demonstrates that variations in reconstruction kernels, slice thickness, and radiation dose are the primary drivers of AI performance degradation, causing significant reductions in AUC (10– ) and Dice scores (8– ) due to severe Hounsfield Unit (HU) and textural shifts. For RQ2, HU-preserving approaches such as HU clipping, ComBat harmonization, and physics-informed kernel matching emerged as the most effective strategies for mitigating this variability, offering stable cross-scanner performance while maintaining quantitative fidelity. Concerning RQ3, Transformer-based architectures and hybrid segmentation–classification models consistently showed superior robustness compared to conventional CNNs, maintaining higher AUC values (0.90–0.92 vs. 0.85–0.88) under heterogeneous imaging conditions. Regarding RQ4, public datasets like LIDC-IDRI remain dominant but are unrepresentative of real-world clinical diversity, lacking sufficient scanner, kernel, and low-dose variability. Addressing RQ5, significant methodological gaps persist, most notably the inconsistent reporting of essential acquisition metadata (e.g., kernel, vendor) and the lack of standardized preprocessing guidelines. Finally, for RQ6, external multi-center validation is alarmingly rare (present in only of studies), leading to widespread overestimation of model generalizability.
Overall, the findings indicate that achieving clinically reliable and vendor-agnostic lung-CT AI systems requires a unified, HU-faithful preprocessing framework. Such a pipeline should integrate HU-preserving normalization, DLIR or N4ITK-based denoising, kernel-consistent resampling, selective harmonization, and spatial normalization through segmentation [9,23]. When paired with modern architectures particularly Transformers and validated across multi-center datasets, these standardized workflows substantially improve robustness and generalizability [15,49]. The consolidation of this evidence provides a foundation for moving toward harmonized, reproducible, and clinically deployable AI solutions for lung-cancer screening and diagnosis.
6. Limitations and Future Directions
Although this systematic review provides a comprehensive synthesis of CT-acquisition variability, preprocessing, and harmonization strategies in AI-based lung-nodule analysis, several methodological limitations must be acknowledged. (1) The review was not based on a preregistered protocol, which may introduce a minor risk of selection bias despite strict adherence to PRISMA 2020 guidelines [20,53]. (2) The included studies demonstrated substantial heterogeneity in dataset composition, acquisition protocols, reporting completeness, and evaluation strategies [4,59]. This variability prevented the application of meta-analytic pooling and required a qualitative synthesis, which, although rigorous, lacked the statistical precision obtainable from standardized effect-size aggregation.
A second limitation is the widespread absence of detailed acquisition metadata in the primary literature. Many studies did not report reconstruction kernels, slice thickness, dose levels, or vendor specifications parameters essential for assessing the true impact of variability on AI robustness [21,22]. As a result, certain quantitative relationships (e.g., the exact influence of kernel mismatch on Dice loss) may be underestimated or inconsistently represented across studies [5,15]. Additionally, the over-reliance on public datasets such as LIDC-IDRI and LUNA16, which have limited scanner diversity, may bias findings toward optimistic performance estimates compared with real-world multi-center clinical environments [31,36].
Third, although GAN-based harmonization and DL-based reconstruction techniques show promising results, many published studies lacked rigorous safeguards against hallucinated textures or altered diagnostic cues [33,65]. Only a small fraction incorporated radiologist review or uncertainty quantification to evaluate the clinical fidelity of harmonized outputs [24,40]. Thus, conclusions regarding the safety and reproducibility of these methods should be interpreted cautiously.
Future research should prioritize standardized reporting and harmonized protocols. At minimum, CT-acquisition metadata including kernel type, slice thickness, radiation dose, tube current, and vendor should be mandatory in AI publications to support reproducibility and external benchmarking [6,64]. Furthermore, the field would benefit from widely accepted preprocessing standards, including recommended HU windows, normalization formulas, and denoising settings tailored to lung-CT analysis [23,42].
There is a pressing need for large-scale, multi-center, multi-vendor datasets with fully annotated acquisition metadata to evaluate AI generalizability under realistic clinical variability. Such datasets would also facilitate controlled cross-protocol experiments, enabling deeper understanding of the source [14,48].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Padinharayil H. Varghese J. John M. Non-small cell lung carcinoma (NSCLC): Implications on molecular pathology and advances in early diagnostics and therapeutics Genes Dis.20231096098910.1016/j.gendis.2022.07.02337396553 PMC 10308181 · doi ↗ · pubmed ↗
- 2Tyagi S. Talbar S.N. LCSC Net: A multi-level approach for lung cancer stage classification using 3D dense convolutional neural networks Biomed. Signal Process. Control 20238010439110.1016/j.bspc.2022.104391 · doi ↗
- 3Xu K. Cui Y. Jiang C. Zhang Y. Zhao X. AI Body Composition in Lung Cancer Screening: Added Value Beyond Lung Cancer Detection Radiology 2023308 e 22293710.1148/radiol.22293737489991 PMC 10374937 · doi ↗ · pubmed ↗
- 4Zhang J. Shangguan Z. Gong W. Cheng Y. A novel denoising method for low-dose CT images based on transformer and CNN Comput. Biol. Med.202316310716210.1016/j.compbiomed.2023.10716237327755 · doi ↗ · pubmed ↗
- 5Watanabe S. Noguchi K. Yagihashi K. Miyati S. Ogawa N. Pulmonary nodule volumetric accuracy of a deep learning-based reconstruction algorithm in low-dose CT Phys. Med.20221041910.1016/j.ejmp.2022.10.02436347080 · doi ↗ · pubmed ↗
- 6Zarei M. Paima S.S. Mc Cabe C. Abadi E. Samei E. A Physics-informed Deep Neural Network for Harmonization of CT Images IEEE Trans. Biomed. Eng.2024713494350410.1109/TBME.2024.342839939012733 PMC 11735689 · doi ↗ · pubmed ↗
- 7Alonzo L. Cannella R. Laudicella R. Benfante V. Purpura P. Micci G. Galia M. Brancatelli G. Midiri M. Alongi P. Molecular imaging in the diagnostic process of neuroendocrine tumors: A systematic review on unknown primary origin and suspected NE Ts EJNMMI Rep.202593810.1186/s 41824-025-00274-441193909 PMC 12589696 · doi ↗ · pubmed ↗
- 8Cutaia G. Gargano R. Cannella R. Feo N. Greco A. Merennino G. Nicastro N. Comelli A. Benfante V. Salvaggio G. Radiomics Analyses of Schwannomas in the Head and Neck: A Preliminary Analysis Image Analysis and Processing (ICIAP 2022 Workshops); Lecture Notes in Computer Science Springer Cham, Switzerland 2022 Volume 1337331732510.1007/978-3-031-13321-3_28 · doi ↗