A Physical Framework for Algorithmic Entropy
Jeff Edmonds

TL;DR
This paper introduces a physical framework to better understand the relationship between entropy and algorithmic complexity, using intuitive models to explain abstract concepts.
Contribution
The paper explicitly identifies the complexity of a probability distribution with the physical complexity of a macrostate.
Findings
The 'Not Alone' principle is shown to naturally arise from the physical framework.
Algorithmic information imposes structural constraints on physical systems.
Apparent paradoxes in physics are resolved through the lens of this framework.
Abstract
This paper does not aim to prove new mathematical theorems or claim a fundamental unification of physics and information, but rather to provide a new pedagogical framework for interpreting foundational results in algorithmic information theory. Our focus is on understanding the profound connection between entropy and Kolmogorov complexity. We achieve this by applying these concepts to a physical model. Our work is centered on the distinction, first articulated by Boltzmann, between observable low-complexity macrostates and unobservable high-complexity microstates. We re-examine the known relationships linking complexity and probability, as detailed in works like Li and Vitányi’s An Introduction to Kolmogorov Complexity and Its Applications. Our contribution is to explicitly identify the abstract complexity of a probability distribution K(ρ) with the concrete physical complexity of a…
Click any figure to enlarge with its caption.
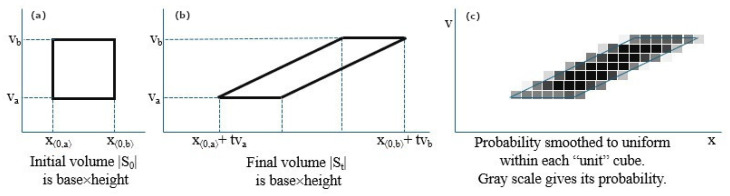 Figure 1
Figure 1- —Natural Sciences and Engineering Research Council of Canada (NSERC)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComputability, Logic, AI Algorithms · Statistical Mechanics and Entropy · Advanced Thermodynamics and Statistical Mechanics
1. Introduction
Boltzmann’s entropy was as important to the Industrial Age as Shannon’s is to the Information Age [1,2]. Both quantify uncertainty and the spread of information. Parallel to this, Kolmogorov complexity provides a measure of the information content of an individual object as the length of the shortest computer program required to describe it [3]. The deep interconnections between these frameworks are comprehensively detailed in landmark texts, most notably Li and Vitányi’s An Introduction to Kolmogorov Complexity and Its Applications [4].
The results in algorithmic information theory are often powerfully abstract and mathematically dense. This paper aims to provide a new pedagogical interpretation of these foundational results by explicitly applying them to the physical framework of thermodynamics. We emphasize that this implies a structural analogy to aid intuition, rather than a claim that continuous physical reality is identical to discrete algorithmic strings. Our central thesis revolves around the distinction, first articulated by Boltzmann, between observable low-complexity macrostates (like the temperature of a gas) and the unobservable high-complexity microstates (the precise configuration of all particles) that comprise them.
We must be clear about our contribution. The mathematical results we discuss—including the Levin–Chaitin bound [5,6] and the “Not Alone” principle (c.f. [4], (Thm. 2.1.3))—are known and foundational. The novelty of this paper lies not in proving new theorems but in synthesizing them into a single intuitive framework. Our central thesis is that the abstract complexity of a distribution can be identified with the concrete physical complexity of an observable macrostate . Though we say that a macrostate represents a collection of properties/constraints, we mean this only for intuition. Any attempt to map these properties to probabilities is well beyond the scope of this paper. In this framework, we explicitly identify the macrostate M with the code/program that generates its probability distribution . Thus, the complexity of the macrostate is effectively defined as the complexity of the distribution .
This physical framework allows us to re-derive and re-interpret these known results, demonstrating how they naturally emerge as structural constraints on physical systems. Our main application is exploring the “Not Alone” principle: we show how a microstate’s high complexity must be balanced by the size of the cluster it inhabits, where the cluster is defined by any simple computable property.
It is important to distinguish our approach from the seminal work of Zurek [7], who also integrated algorithmic randomness with physical entropy. While Zurek focused on the thermodynamic cost of measurement and the operation of heat engines, our work aims to provide a structural framework connecting the abstract properties of Kolmogorov complexity directly to the definition of macrostates and their cluster sizes.
While our framework highlights the deep structural connections between informational entropy and thermodynamic entropy, we acknowledge the ongoing debate regarding whether they are truly identical or merely analogous. Researchers such as Elitzur [8] and Meyer [9] have argued that information (or complexity) and thermodynamic “order” are distinct characteristics that should not be conflated. Elitzur posits that thermodynamic entropy measures the dispersal of energy, which is distinct from the informational content related to structure and complexity—a crystal, for example, has low entropy but low informational complexity, whereas a living organism has low entropy but high informational complexity. Meyer reinforces this by arguing that information is a measurable physical quantity distinct from thermodynamic entropy, essential for understanding biological organization. Our work takes the perspective that treating them as unified provides powerful pedagogical insights for statistical mechanics, but we respect the distinction emphasized in these works regarding biological and functional complexity.
Our contributions can be summarized as follows:
- (1) A Physical Framework: An intuitive model for pedagogical purposes that explicitly identifies the abstract complexity of a distribution with the concrete complexity of a physical macrostate .
- (2) A New Interpretation of the Not Alone Principle: We use this framework to show how the known “Not Alone” result (c.f. [4], (Thm. 2.1.3)) arises as a natural structural constraint linking a microstate’s high complexity to the size of the cluster defined by any of its simple properties.
- (3) A Unified View: We demonstrate how this physical interpretation connects to other foundational results including the Sandwich Theorem ( ) and the bounded variance of complexity in uniform distributions.
- (4) Macro- vs. Microstates in Physics: This section explores how macro-level concepts in physics are derived from the micro-level properties of particles. With this, we are able to resolve many of the field’s apparent paradoxes. This perspective reveals that the foundational laws of thermodynamics are not arbitrary but are the necessary statistical consequences of simple rules applied to a complex world, all governed by the universal logic of information.
**The paper is organized as follows: **Section 2 defines the key terms used in the theorems and illustrates each with intuition and concrete examples. Section 3 explores illustrative examples. Section 4 states the formal theorems and provides their proofs. Section 5 explores the connection to physics in more detail. Section 6 concludes. I end by acknowledging Paul Vitányi, Ming Li, and my AI collaborators.
2. Intuition About the Definitions and Results
In this section, we lay out the key concepts and intuitions that underlie the results of this paper, supported by concrete examples. Our goal is to offer an accessible and computationally grounded explanation of the connection between entropy and Kolmogorov complexity. Central to our perspective is the distinction between observable low-complexity macrostates and unobservable high-complexity microstates. We do not know to what extent this intuition was part of Levin’s original motivation for his Coding Theorem; however, we believe that the following explanation is an important contribution of this paper.
The Physical World: Boltzmann defined the macro- and microstates of a physical system like a gas [1].Microstate α is a finite binary string encoding a physical system’s complete unobservable high-complexity configuration
-
(e.g., it could encode the positions, velocities, and masses of all ≈ particles). Properties P(α) = p: Let P be any computable property of a microstate. For a given , let be the value of that property. The set is the cluster of all microstates sharing that property value (e.g., the temperature of the gas).Macrostate M represents the observable low-complexity collection of properties of the physical system (e.g., the temperature and pressure).Probability ρ(α) denotes the probability of the system being in microstate given that we know that it is in macrostate (e.g., in a system influenced by gravity, microstates representing molecules higher up have lower probabilities ).S_M_ is the set of microstates consistent with this macrostate, namely .Program for the macrostate is assumed to operate in two modes:
-
An approximation mode , which outputs an -approximation of the real-valued probability .
-
A decision mode , which returns to decide membership in . (It might be undecidable even with to know whether 0 because this probability might be arbitrarily small.)
-
As noted above, we explicitly identify the macrostate with the code/program that generates its probability distribution . Entropy : Boltzmann’s thermodynamics-motivated entropy [1] is defined to be the logarithm of the number of microstates consistent with the observed macrostate, namely (Physicists often use , where is Boltzmann’s constant. We use base-2 logarithms measuring entropy in bits, in line with Shannon and Kolmogorov).
(e.g., for a gas with particles in a room-sized of volume , , so ).
- Shannon [2] shifted the idea of entropy to informational uncertainty defining
measuring the expected number of bits of information needed to specify a randomly chosen microstate given that it is already known that . The intuition is that if all microstates had the same probability , their number would be , and the optimal code length for transmitting would be bits. Kolmogorov Complexity: Unlike entropy, which measures the information content of a distribution of objects, Kolmogorov Complexity measures the information content of a single object.Micro-Complexity K(α): The Kolmogorov Complexity of microstate is defined as the length of the shortest prefix-free program that outputs . Let be a fixed universal Turing machine. A program is a binary string such that . Prefix-Free: No valid program is a prefix of another. This allows programs to be concatenated and unambiguously separated.
-
This is assumed to be enormous. K(P) and K(M) denote the length of the shortest program that computes property and both the probability for macrostate and membership in .
-
For example, a very simple program computes the temperature of a gas from the velocity of each of its particles. K(p) denote the length of the shortest program that outputs the value . Note that some numbers like have short programs relative to their values.
-
For example, the number of gas particles could be represented by the size of its binary description or, even better, by bits. The latter program, for example, could just output the number 27, specifying . Macro-Complexity K(M, P, p) denotes the length of the shortest program that does all three.
-
This is assumed to be small. Results Presented: Though they have very different formulations the entropy of a macrostate and the Kolmogorov complexity of its microstates are closely related.
-
Levin’s Coding Theorem 1:
-
Sandwich Theorem 2:
-
Uniform Case Theorem 3:
-
-
The Not Alone Theorem 4:
-
See Section 4.1, Section 4.2, Section 4.3 and Section 4.4. Natural: In natural physical scenarios, we assume the micro-complexity is enormous while the total macro-complexity is small.c ≈ 1000, , and are assumed to be “constants”.Tight: This assumption is what makes the Sandwich Theorem , for example, tight.
3. Extreme Cases
The following examples illustrate the results in extreme regimes:
- Counting Strings of a Given Complexity, :
- The number of microstates with complexity is at most . This is because each such microstate requires a unique prefix-free program of length and there are at most such programs available.
- Random Strings: An -bit string is considered random if it is incompressible, i.e., . Most strings are random in this sense. The fraction of -bit strings that can be compressed by more than bits is at most because there are fewer than prefix-free programs of length less than .
- Strings with 49% Zeros: Let be the macrostate of all -bit strings containing exactly 49% zeros for some fixed value of . Then, by Stirling’s approximation,
where is the binary entropy function. Because a short program can check the 49%-zero condition, we know that is small. Given a particular such string , it is not clear how one would write a short program that outputs it. Levin’s Coding Theorem 1, however, gives such a program of length . This is only an upper bound, as some strings in may be highly compressible (e.g., a string of zeros followed by ones).
- All Microstates: Let be the macrostate of all microstates of length . The number of such strings is , so . Most such strings have complexity . The complexity of the macrostate itself is the size of the program that checks if has length . This is at most , as it only needs to encode the value . Here, Theorem 1 is tight in the natural extreme.
- Single-Element Macrostate: Let be the macrostate that accepts only one microstate . Then, . Any program to check membership in must effectively encode , so . In this case, Theorem 1 is tight in the unnatural extreme case. The inequality becomes
4. Theorems and Proofs
4.1. Levin’s Coding Theorem 1
Levin provides a foundational (though confusing) result in algorithmic information theory. It links the complexity of a string to its universal probability —the probability that a universal Turing machine with random input will output [6]. Moreover, Chaitin [5] shows that this universal probability multiplicatively dominates all other computable probabilities like our distribution . Together, the theorem states
where the constant depends only on the choice of the Universal Turing and also depends on the machine computing the distribution . The key thing is that they do not depend on the string . Diving into the proof, one can see that , where is precisely the length of the program needed to approximate the probabilities and is maybe 1000. This gives the revised statement:
Theorem 1(Levin’s Coding). For any distribution and microstate ,
- we have .
Qualitatively, this theorem establishes a “conservation of complexity” relative to probability. It states that an object cannot be both simple (low ) and improbable (low ) unless the distribution itself is complex. In physical terms, if a microstate is highly probable, it must have a relatively short description.
A quick proof sketch would go as follows: By definition, we give this bound on by giving a program that outputs described with bits. To bits of precision, our program is given the cumulative probability . With bits, it is given the program needed to approximate the probabilities . The remaining 1000 bits describe our program that enumerates through the strings computing this sum until the target is reached. What remains is to ensure that all the values are accurate enough so that this works. The more detailed proof is as follows.
Proof. The proof is by construction. We will describe a program that generates and its length will serve as the required upper bound on .
-
1. The Description of α: Our description of α consists of two parts which are fed to a fixed universal search program:
-
A Program for the Macrostate M: A program that for any given and a precision parameter computes its probability . The length of the shortest such program is by definition .
-
An Identifying Target : A binary string that uniquely identifies . This string represents a rational number defined as our “target” which is a multiple of . We define this precision as
This choice ensures that . The target is provided to the search program as a binary string of length bits.
- 2. The Search Algorithm: The Turing Machine is a fixed universal program (of length, say 1000 bits). It takes the program and the identifier as input. It then performs the following steps:
- It iterates through all microstates in lexicographical order.
- For each , it uses the provided program to compute an approximation of its probability. The required precision ensures that .
- It maintains a running sum of these approximate probabilities.
- The algorithm halts and outputs the current microstate at the exact moment this running sum surpasses the target value represented by . We claim this procedure outputs our intended microstate .
-
3. Correctness of the Search: We now prove that this search algorithm correctly and uniquely identifies .
-
Interval Width: The interval corresponding to our target microstate has width . We prove this is at least .
We know or else our theorem is trivially true.
-
Defining the Target : Imagine placing markers on the real number line at every integer multiple of . Because the interval for has a width greater than , it is guaranteed to contain at least one such marker. We define to be the value of one such marker. When the search algorithm’s running sum surpasses this value, it must have just finished adding and it correctly outputs .
-
Bounding |q_α_|: Recall is a binary string representing a rational number. The number of bits to the right of the decimal is at most its precision . The number of bits on the left is one because the value is less than 2, namely . The sum of probabilities is at most 1. The sum of the errors is bounded: .
-
4. Conclusion: The program that produces is the fixed search program with and hard-wired in. Hence, .
-
□
4.2. The Sandwich Theorem 2
We now explain and prove the Sandwich Theorem stating that the expected Kolmogorov complexity of a randomly chosen microstate is tightly “sandwiched” by the entropy of the macrostate.
Theorem 2(Sandwich Theorem). * * where .
In simple terms, this theorem confirms that the “typical” complexity of a microstate matches the entropy of its macrostate. This aligns with the physical intuition that for a gas in equilibrium, the complexity of a snapshot of the system is effectively determined by the volume of the phase space (entropy).
Proof. (Upper Bound) We move from the result at the micro level back to the macro level by taking the weighted sum of Levin’s Coding Theorem 1 with respect to giving
(Lower Bound) We compare the expected code lengths for two methods of assigning codewords to each microstate . The first method uses the shortest program for each microstate as its codeword. Recall that we required such programs to be prefix-free. By definition, the expected code length for this method is . The second method is Shannon’s code, which assigns to each microstate a codeword of the ideal length . By definition, its expected code length is . Because Shannon’s method provides the optimal expected code length [2], the expected length of the first code must be greater than or equal to the second. □
Kolmogorov-Based Conditional Entropy: Rearranging Theorems 1 and 2 gives the difference , which rings of conditional entropy. Hence, let us define it to be .
We denoted Shannon’s entropy of a macrostate by to emphasize it is a function of the macrostate’s distribution. Shannon himself might prefer the conditional entropy notation , viewing it as the expected bits needed to specify a randomly chosen given . He might express this as the difference between the information needed for and that for :
Conditional entropy is normally defined as . Here, we associate with and with . We assume learning determines , so . Our notation is an intuitive stand-in for the standard entropy .
Replacing with gives
Theorem 2 then becomes
This definition aligns with the standard AIT chain rule. Since the macrostate is computable from , . The symmetry of information states . Since , this yields , matching our definition.
4.3. The Uniform Case Theorem 3
The following are fun improvements when the distribution is uniform: the maximum and average complexities are close and the variance of complexity is tightly bounded by a small constant. This is in stark contrast to the non-uniform case. There exist “natural” macrostates with small and small average complexity , but infinite variance. For every , define and for every bit string , define . Then, and The first result is also key for our Not Alone Theorem 4.
Theorem 3(Uniform). Consider a uniform macrostate . *A: *
*B: *
Proof. (A) Levin’s Theorem 1 states . Replace with by applying the theorem to a microstate of maximum complexity. Because the distribution is uniform, must be finite. Because the distribution is uniform, . This gives the required . Theorem 2 states , which because uniform is the same as .(B) Partition based on their complexity relative to . Let be the set of microstates with complexity . Let be those with . For each integer , let be those with complexity exactly . Let denote this complexity value. From Theorem 3.A, we know and hence is empty. The contribution to the variance from the “middle” set is . This leaves . Note the total coefficient of is , which is equal to one. We can now consider the contribution. There are microstates with this complexity and Theorem 3.A gives that . Hence, the probability of encountering such a microstate is at most . The remaining variance is then bounded by , giving the result. □
4.4. The Not Alone Theorem 4
This section presents Theorem 2.1.3 in the book [4] in this light. We prove that observable low-complexity macrostates cannot contain lone unobservable high-complexity microstates because otherwise any program for would have to effectively “name” them, forcing . To avoid this, must be “hidden” in a large crowd of similar microstates all sharing a simple collective pattern, namely
By “similar”, we mean sharing the exact same value for any given low-complexity property . Namely, the cluster whose size we bound is defined to be where .
Theorem 4(Not Alone). If not empty, , where and are the average and max complexities over ,
and .
This result formalizes the intuition that “complex things cannot exist in isolation.” If a microstate is complex, it is not special; it is just one of many similar states. Structurally, this implies that high-complexity states form large, homogenous clusters (macrostates), while unique, isolated states must be simple enough to be described individually.
Example: For example, any microstate can be clustered with all those of the exactly same length , the same temperature, the same pressure, the same complexity , and the same probability simply by considering . Theorem 4 proves that this cluster has a size of at least . Note that this agrees with the first example in Section 3 that proves that the number of microstates with complexity is at most and, hence, this set is a constant fraction of these.
Here, is defined to be the time-bounded version of Kolmogorov Complexity that requires the program that outputs to halt within a specified time, e.g., steps. Unlike , the value is can be computed by a short program that simulates all -bit programs for the specified time limit . This means that the complexity of the property is small. And the set of microstates with unbounded time complexity is a super set of these.
What might be large is the complexity of outputting the value . The first value can be denoted . The next three are at most that. Hence, these values can be outputted by a program of size at most bits. The fifth value for natural macrostates, we will assume, is at least . Outputting it exactly would require too many bits. However, if you are happy with a two approximation of the probability, then bits does the trick. For a non-natural example, consider a macrostate with probability , where is the integer value of . To know the probability, a program must essentially know the entire string. Therefore, the complexity of the probability value is . The Not Alone Theorem bound correctly predicts that the cluster size is at most 1.
Empty Example: In the previous example, we chose some and then formed the cluster with similar properties. This construction ensures that the cluster contains at least itself. If, instead, we define the cluster based on some chosen property , then the cluster might be empty. In this case, the theorem is not broken because it only applies when is not empty. Alternatively, if property narrows the cluster to one microstate , then both and equal the complexity , hence the lower bound as needed.
Proof. Theorem 3.A applied to macrostate that is defined to be uniform over the cluster states . Simply exponentiating gives the result. □
As said, this result is the same as Theorem 2.1.3 in the book [4].
Theorem 5(Book Theorem 2.1.3 [4]). Let be recursively enumerable and let . Suppose is finite. Then, for some constant depending only on for all in , we have .
In our setting, , , , and .
5. Macro- vs. Microstates in Physics
This section explores how macro-level concepts in physics are derived from the micro-level properties of particles. With this, we are able to resolve some of the field’s apparent paradoxes. This perspective reveals that the foundational laws of thermodynamics are not arbitrary but are the necessary statistical consequences of simple rules applied to a complex world, all governed by the universal logic of information.
5.1. The Tension Between Discrete and Continuous Physics
We acknowledge a fundamental tension in applying algorithmic complexity (defined on discrete binary strings) to classical physics (defined on continuous variables). Our approach relies on discretization—converting continuous phase space into discrete cells. While this is a standard pedagogical tool, it has limitations. For instance, the “shape” of phase space regions (e.g., fractal strange attractors in chaotic systems) affects how entropy scales with precision in ways that simple box-counting may obscure.
Furthermore, we recognize that Quantum Mechanics offers a more rigorous interface between physics and information, where states are vectors in Hilbert space rather than discrete strings. However, our goal here is not to replace the quantum description but to provide a pedagogical bridge using the accessible language of classical statistical mechanics and algorithmic information theory.
5.2. The Precision of Phase Space Approximation
In physics, a microstate specifies the locations and momenta of all particles. With three position and three momentum real-valued coordinates per particle, is a point in space. This is called phase space. A macrostate carves out a subset of this space.
To make this discrete, let denote the set of infinitesimal cubes of volume that might be in, and let denote a set of corresponding unit-volume cubes. A probability distribution is defined using a probability density function , where is the probability of the microstate being within ’s infinitesimal cube.
Shannon’s entropy, which is the expected number of bits of information needed to specify a randomly chosen microstate , would be infinite if one had to specify which of the infinitesimal cubes is in. However, it is finite if we only need to name which unit-volume cube it is contained in (giving for a uniform distribution). We compute the continuous entropy (or differential entropy) as follows.
Choose a random according to the distribution . The probability of being in a specific unit cube is approximately (assuming is roughly constant within that cube). If all unit cubes had this same probability density, then the “number” of such cubes would be effectively , and the number of bits needed to specify ’s unit cube would be . This is the code length allocated to microstate . The expected number of bits needed is the continuous-case integral:
5.3. Scaling to N-Particle Systems (Algebra of Macrostates)
We apply these theorems to a system with particles by analyzing them one at a time. If we assume the particles are (mostly) independent, we can model the total macrostate as a cross product of individual macrostates: , where is the macrostate for the -th particle. This “Algebra of Macrostates” shows our theorems scale correctly.
Independent Cross Product: For , all key quantities (entropy , complexity , and average/max microstate complexity ) are additive (up to a small constant). The Not Alone Theorem’s bound remains consistent: the cluster size becomes multiplicative ( ), and since the terms in the exponent are all additive, the theorem correctly predicts this product.Dependent Cross Product: We can also define a dependent cross product , where is a simple, computable function (e.g., calculates a particle’s velocity from its position). Here, complexities increase only by the small . Both the cluster size and the theorem’s bound remain essentially unchanged.Example (The “Complex Property” Limit): This framework also handles the extreme case. Let be a function that gives a unique complex property . For example, outputs the integer (the value of ), and we define our property as .
- For any microstate, its cluster is a singleton ( ). The Not Alone Theorem correctly predicts this. Since knowing the property is the same as knowing itself, the complexity of the property is enormous: . The theorem’s bound becomes
This confirms that a microstate can be “alone” in its cluster, but only if the property defining that cluster is just as complex as the microstate itself (and thus not a “simple” macrostate property). Scaling of : We can address the scaling of for standard physical properties. If represents a global quantity like Total Energy in an -particle system, the value scales with . However, the number of bits required to describe this value is only . Since the microstate complexity scales linearly with (i.e., ≈ bits), the cost of describing the property (≈ bits) is negligible. Thus, even for extensive physical properties, the “constant” remains small relative to the system size, and the “Not Alone” bound remains non-trivial and physically meaningful.
5.4. Newtonian Determinism and Coarse-Graining
The Second Law of Thermodynamics states the entropy of a closed system can only increase over time. Let be the macrostate with all gas particles initially in a box of volume , and let be the macrostate at time , after they have dispersed into a room of volume . Boltzmann would argue that entropy increases by because the number of microstates increases.
First, let us be clear that the disorder that is measured by entropy does not arise because there are many particles doing the independent things but because there is uncertainty in what they are doing. Section 5.3 argues that instead of considering a system with particles, we can analyzing these one at a time. If we assume the particles are (mostly) independent, we can model the total macrostate as a cross product of individual macrostates: , where is the macrostate for the -th particle. This “Algebra of Macrostates” shows our theorems scale correctly.
An apparent paradox arises in a deterministic, reversible, closed physical system. Because the laws of physics are reversible, no information is gained or lost. The entropy should not change, in violation of the Second Law.
This is best explained by seeing that the Kolmogorov complexity of the microstate and hence the entropy does not change plus or minus a small constant . This is proved by describing a small program that outputs , where outputs , outputs , and encodes the laws of physics. Being reversible, gives the other direction. This requires you both know and can express these laws of physics.
Liouville’s fundamental Theorem takes this same paradox argument a step further. A microstate (describing the position and momentum of all particles) is a point in the continuous phase space. The macrostate is the “accessible subregion” of this phase space (e.g., all particles in the box with some energy). As time passes, this region evolves to . Even though the particles spread out to fill the larger room , Liouville’s Theorem proves the total volume of the accessible phase space does not change: . See Figure 1a,b.
How? Chaos stretches and folds the accessible region into a long, skinny, filament-like region that twists and turns throughout the entire phase space, but its total -dimensional volume remains unchanged. Because the differential entropy is directly related to this volume, it also does not change. .
The way this paradox is resolved and entropy is seen to increase is through coarse-graining. See Figure 1c. Any real measurement has limited precision. We cannot distinguish between points in and nearby points that are not in . We must “blur” our vision. This noise can be modeled as follows:
- Thermal Noise: Boltzmann’s “dust” being knocked around by particle collisions.
- Measurement Noise: Adding Gaussian noise to each value in the final microstate .
- Coarse-Graining: Making the probability distribution locally uniform within each “measurement cube” (e.g., ).
If the true accessible phase space is a long, skinny filament that twists through the entire room, any of these blurring effects will make it indistinguishable from a uniform distribution over the entire room. This larger, coarse-grained volume is what we perceive as the new, higher-entropy macrostate. This noise also helps restore the assumption of independence between particles, which is lost after they collide.
5.5. How Falling Particles Increase Entropy
Let denote the macrostate at time 0, representing a gas diffuse in a thin spherical shell of radius and area around the earth. Let represent the same gas after the particles have fallen under gravity to a smaller shell of radius and area . Being smaller, one might suspect that the volume of accessible phase space decreases, decreasing entropy, and breaking the Second Law of Thermodynamics that .
The paradox seems even worse if we focus on a single particle. Suppose the particle starts with a known velocity of zero, a known height , and a completely unknown location in the spherical shell. As the particle drops, its height and radial velocity remain known, but its location is only within the shrinking spherical shell. Hence, it takes fewer and fewer bits to communicate the missing location information, implying entropy is decreasing. Knowing such information precisely, however, is unnatural. Liouville’s Theorem requires an initial volume , which is zero unless every value has some at least infinitesimal uncertainty.
The resolution comes from Liouville’s Theorem, which states that the volume of the 6D phase space (position and momentum) is conserved. It is useful to first consider a simpler case: if gravity were a fixed, parallel acceleration , it would apply an additive change to each microstate’s velocity ( ) and position ( ). This merely shifts or shears the phase space volume , but does not change its volume. The force of gravity, however, is not a parallel force; it radiates towards the center. This radial force introduces a multiplicative scaling, which is resolved by the conservation of angular momentum. This is the same principle as a spinning ice skater: when they pull their arms in (decreasing ), they spin faster (increasing angular velocity).
Let us consider the particle’s phase space in polar coordinates. Let and denote the location (angle) and and denote the angular velocities in the two directions within the spherical shell.
Position Space Shrinks: When the radius shrinks (e.g., by a factor of 2), the area of the shell shrinks. The range of possible locations, and , also shrinks by this factor.Momentum Space Expands: By the conservation of angular momentum ( ), as shrinks by a factor of 2, the angular velocity must double by a multiplicative factor of 2. This causes the range of possible velocity variables, and , to grow by that same factor.
Suppose the initial volume of this 4D slice of phase space is , then after falling, the new volume is . As promised by Liouville’s Theorem, the multiplicative factors cancel perfectly. The accessible phase space volume does not change. Hence, the entropy does not either. The Second Law is not violated. The increase in entropy, which we observe in reality, only occurs after the fact due to coarse-graining the probability distribution. See Section 5.4.
5.6. Momentum, Energy, and Temperature from First Principles
Fundamental physical laws and definitions are linked to statistical realities. We can derive macro-level concepts like momentum, energy, pressure, and temperature from the simple, micro-level properties of particles.
Temperature vs. Particle Velocities: A key property of the microstate is the velocity and speed of each particle. The macro-parameter temperature is defined to be the average kinetic energy of these particles, namely scaled by the Boltzmann constant . When the particles of a gas are at equilibrium, the distribution for is according to the Maxwell–Boltzmann distribution. Formally, this is derived by finding the function that maximizes the system’s entropy (assuming entropy would otherwise increase). A strong physical intuition, however, comes from the Central Limit Theorem. Because it is the result of the “sum” of a vast number of random collisions, each component of the velocity is drawn independently from a Gaussian (normal) distribution:
A similar factor involving the potential energy of the state is added to the distribution on the height of a particle when there is a force of gravity making it exponentially unlikely for a particle to fly very far up.Momentum: Why is momentum defined as ? Because this is the quantity that is conserved in collisions. When two particles collide, Newton’s third law states they apply equal and opposite forces ( and ). Since , the two changes in momentum sum to zero. Therefore, the total momentum of the system remains a constant property of the macrostate.Angular Momentum: Kepler noted that a planet sweeps out equal areas in equal times. This is the conservation of angular momentum. It means that when a spinning ice skater pulls in their arms, they spin faster. Newton (and Richard Feynman) has a fantastic proof involving the area of triangles.Energy: It is reasonable to define potential energy to be as it should be linear in the force and distance the object has been pushed. Newton defines kinetic energy to be and not because this is the definition that allows for the conservation of energy. For a falling object (constant force ): The change in potential energy is . The change in kinetic energy is . Thus, , and the total energy is conserved. The total kinetic energy of the system is its internal thermal energy.Pressure P: Pressure is the force per unit area from particles hitting the container wall. This force is the rate of change of momentum ( ). Perhaps surprisingly, this depends on instead of on . The reason is because there are two complimentary effects:
- The frequency a particle hits a wall is proportional to its speed because the ones that are twice as fast reach the wall in half the time, and hence hit the wall with twice the frequency. Consider the sub-volume with area against the container and infinitesimal height . If the particles are always uniformly distributed, the expected number in it is . To avoid worrying about collisions between particles, assume this expected number is much less than one. If there is such a particle moving more or less in the right direction, then the time until collision with the container is and the “rate” of collisions per second is .
- The momentum transferred per hit is also proportional to . On collision, the perpendicular component of the momentum is transferred (times two because the particle bounces).
Concluding, the rate of momentum transfer is , as needed. This gives that the total force is proportional to . This is convenient because it directly links pressure to the average kinetic energy per unit volume. The exact relation is , where is the average kinetic energy of one particle. Recall . This gives the Ideal Gas Law .
6. Conclusions
This paper has provided an accessible and computationally grounded framework for understanding the deep connection between entropy and Kolmogorov complexity. Our central contribution is to show that this connection is not merely a mathematical abstraction but a direct consequence of the structural constraints governing how information is described.
Our constructive proof of a tighter Levin’s Coding Theorem reveals the explicit computational cost of specifying a microstate within a macrostate. This naturally leads to the “Not Alone” principle: a simple macrostate cannot contain an isolated complex microstate without its own description becoming complex. Together, these results demonstrate that the statistical properties of a system like its entropy are fundamentally constrained by the algorithmic properties of its individual constituents. They provide a clear intuitive mechanism for why high-complexity states must appear in organized “families” within low-complexity observable systems. We end by exploring concrete properties in physics, resolving a few apparent paradoxes, and revealing how these laws are the statistical consequences of simple rules.
Ultimately, our work reinforces the view that the laws of thermodynamics and information theory are two sides of the same coin both governed by the fundamental rules of computation and description.
Scope and Limitations
We acknowledge that this framework relies on the standard AIT assumption of a fixed optimal Universal Turing Machine, which introduces additive constants ( ) that are negligible only for sufficiently large systems. Furthermore, the mapping of continuous physical systems onto discrete strings requires coarse-graining, the specifics of which can influence the calculated complexity. This work is intended as an interpretive framework to build intuition, rather than a replacement for the rigorous formalisms of statistical mechanics or quantum information theory.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Boltzmann L. Weitere Studien über das Wärmegleichgewicht unter Gasmolekülen Sitzungsberichte der Kaiserlichen Akademie der Wissenschaften in Wien Wien, Austria 1872 Volume 66275370
- 2Shannon C.E. A mathematical theory of communication Bell Syst. Tech. J.19482737942410.1002/j.1538-7305.1948.tb 01338.x · doi ↗
- 3Kolmogorov A.N. Three approaches to the quantitative definition of information Probl. Inf. Transm.196511710.1080/00207166808803030 · doi ↗
- 4Li M. Vitányi P.M.B. An Introduction to Kolmogorov Complexity and Its Applications 4th ed.Springer Berlin, Germany 2019
- 5Chaitin G.J. A theory of program size formally identical to information theory J. ACM 19752232934010.1145/321892.321894 · doi ↗
- 6Levin L.A. Laws of information conservation (non-growth) and aspects of the foundation of probability theory Probl. Inf. Transm.197410206210
- 7Zurek W.H. Algorithmic randomness and physical entropy Phys. Rev. A 1989404731475110.1103/Phys Rev A.40.47319902721 · doi ↗ · pubmed ↗
- 8Elitzur A.C. Let there be life: Thermodynamic reflections on biogenesis and evolution J. Theor. Biol.199416842945910.1006/jtbi.1994.11238072301 · doi ↗ · pubmed ↗