DS-CKDSE: A Dual-Server Conjunctive Keyword Dynamic Searchable Encryption with Forward and Backward Security
Haiyan Sun, Yihua Liu, Yanhua Zhang, Chaoyang Li

TL;DR
This paper introduces a new encrypted search system that improves security and efficiency in cloud computing.
Contribution
A dual-server conjunctive keyword DSE scheme with forward and backward security is proposed.
Findings
The proposed DS-CKDSE scheme achieves adaptive security under a defined leakage function.
The system efficiently supports conjunctive keyword searches with high performance in updates and searches.
The dual-server architecture effectively mitigates KPRP leakage risks.
Abstract
Dynamic Searchable Encryption (DSE) is essential for enabling confidential search operations over encrypted data in cloud computing. However, all existing single-server DSE schemes are vulnerable to Keyword Pair Result Pattern (KPRP) leakage and fail to simultaneously achieve forward and backward security. To address these challenges, this paper proposes a conjunctive keyword DSE scheme based on a dual-server architecture (DS-CKDSE). By integrating a full binary tree with an Indistinguishable Bloom Filter (IBF), the proposed scheme adopts a secure index: The leaf nodes store the keywords and the associated file identifier, while the information of non-leaf nodes is encoded within the IBF. A random state update mechanism, a dual-state array for each keyword and the timestamp trapdoor designs jointly enable robust forward and backward security while supporting efficient conjunctive…
Click any figure to enlarge with its caption.
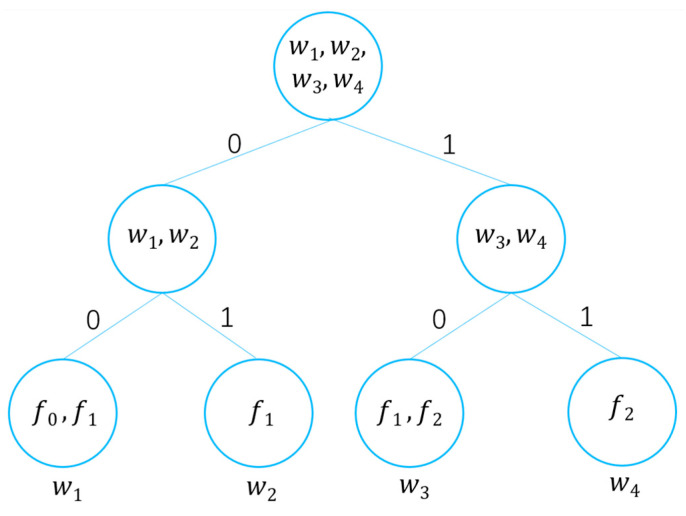 Figure 1
Figure 1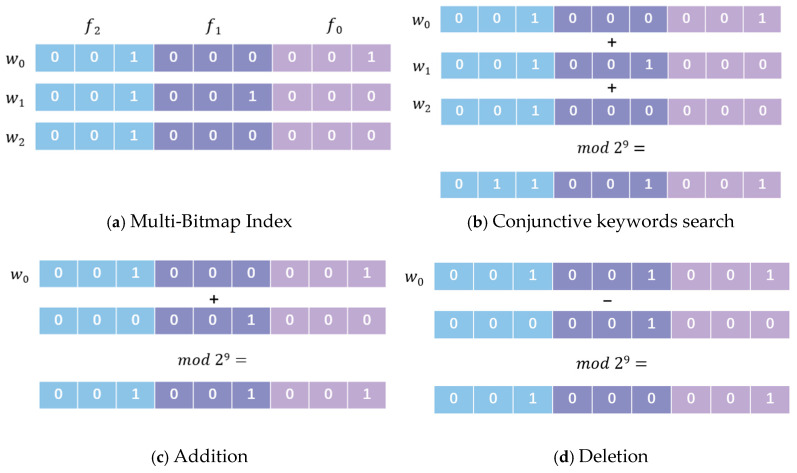 Figure 2
Figure 2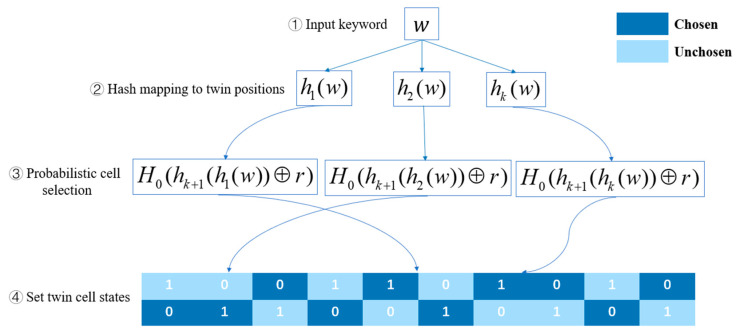 Figure 3
Figure 3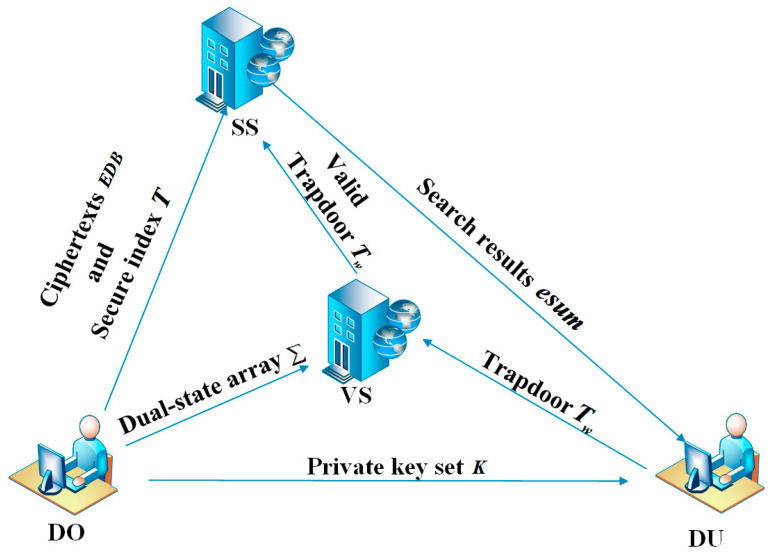 Figure 4
Figure 4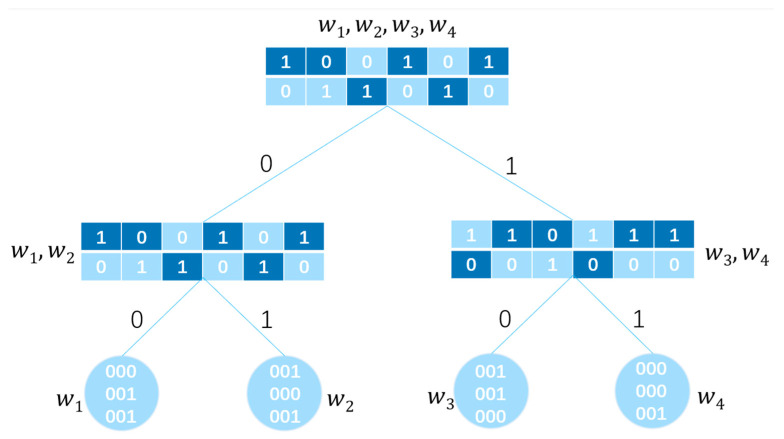 Figure 5
Figure 5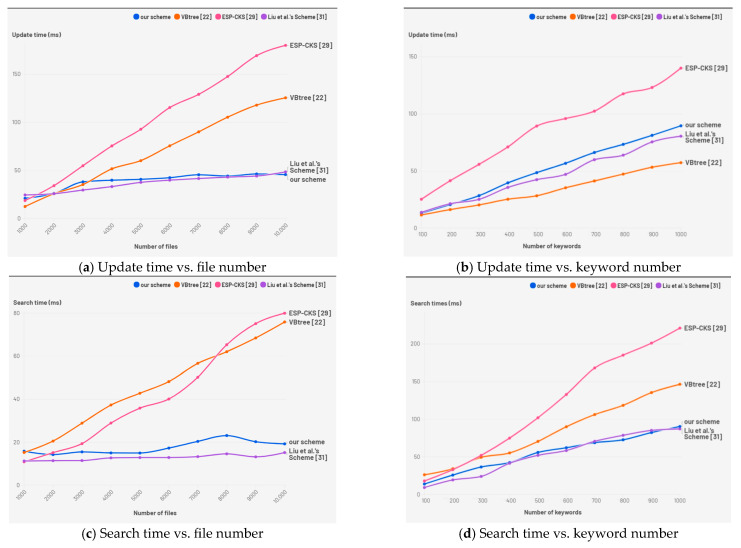 Figure 6
Figure 6- —Henan Province Key R&D Project
- —Science and Technology Research Project of Henan Province
- —CSC Visiting Fellow Scholarship
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCryptography and Data Security · Cloud Data Security Solutions · Chaos-based Image/Signal Encryption
1. Introduction
With the continuous development of cloud computing capabilities, both enterprises and individual users can offload local computational burdens and enjoy scalable, on-demand services provided by the cloud. However, while offering convenient and efficient storage, cloud service providers also raise serious data security concerns. When data is stored with cloud service providers that are not fully trustworthy, users risk losing authority and possession over their private data. Malicious cloud service providers may even attempt to steal or tamper with user data. To mitigate these risks, a growing number of users have opted to store their data in encrypted form, thereby enhancing confidentiality. However, the encryption process obscures the underlying data structure of the original plaintext, making efficient retrieval a major challenge.
In response to the aforementioned problem, Searchable Encryption (SE) emerged as a solution, enabling search functionality over encrypted data without revealing sensitive information. After Song [1] proposed the first SE scheme, a series of SE schemes were subsequently introduced. However, these schemes mainly focused on single keyword search, meaning that users could only use one keyword per search query. With the continuous growth in data volume and the increasing complexity of search requirements, single-keyword SE became inadequate for meeting complex query demands. To enable more precise data retrieval, the need for conjunctive keyword SE emerged.
Golle et al. [2] proposed the first SE scheme that supports conjunctive keyword search. However, the search complexity of this scheme increased linearly with the number of files, making it difficult to deploy in practical applications. Later, Cash et al. [3] proposed a sublinear SE scheme named Oblivious Cross-Tags (OXT). However, this scheme suffers from Keyword Pair Result Pattern (KPRP) leakage during the search phase. This means that for a conjunctive search query containing three keywords , the server can learn the encrypted file identifiers associated with each pair of query keywords , for which . To eliminate KPRP leakage, Lai et al. [4] subsequently proposed an efficient conjunctive keyword SE scheme based on OXT. However, all the aforementioned SE schemes lack support for dynamic updates, which are categorized as Static Searchable Encryption (SSE) for conjunctive keyword search.
In SSE schemes, if users need to add, delete, or modify data, they must reconstruct the entire index and ciphertext database. This imposes significant limitations on scalability and maintainability in real-world scenarios, rendering SSE unsuitable for practical situations that require frequent data updates. Due to the limitations of SSE in handling dynamic data updates, Dynamic Searchable Encryption (DSE) emerged. DSE supports dynamic operations, enabling it to adapt to scenarios with frequent data changes. Kamara et al. [5] introduced the first construction of a DSE scheme. This scheme allows data owners to encrypt and store their data, and subsequently perform searches and dynamic updates on the encrypted data. However, update operations introduce serious additional information leakage issues, and each update operation may decrease the system’s entropy, thereby leaking critical information to adversaries. For instance, a server might intentionally match previous search tokens with newly added file indexes to infer the keywords contained within the files or deduce query keywords from repeated search queries. To address these challenges, forward security [6] and backward security [7] were proposed as two core security properties to ensure data integrity and confidentiality: the former refers to the inability to link an updated file with previous search operations during an update, while the latter ensures that the results obtained during the user search phase do not include data that has already been deleted. Since then, a series of DSE schemes have emerged [8,9,10,11,12,13,14]. However, these schemes fail to simultaneously achieve forward security, backward security, and conjunctive keyword search. Currently, only the Oblivious Dynamic Cross-Tags (ODXT) scheme [15] supports conjunctive keyword search while guaranteeing both forward and backward privacy. Nevertheless, it remains vulnerable to KPRP leakage. Therefore, while ensuring forward and backward security, how to minimize information leakage during the search process—with the goal of eliminating KPRP leakage while still supporting efficient conjunctive keyword searches for data users—remains a significant topic for future research.
This paper proposes a dual-server scheme named DS-CKDSE, which supports conjunctive keyword search. The scheme is designed from an information-theoretic perspective to minimize information leakage, thereby achieving both forward and backward security and eliminating KPRP leakage. The main contributions of this work are as follows:
- A dual-server architecture is proposed, where one server is responsible for verifying the search trapdoor and the other for storing the encrypted secure index. This separation prevents the latter from accessing keyword states, thereby effectively preventing KPRP leakage.
- A privacy-preserving index is constructed based on a full binary tree, where the root node encompasses all keywords, non-leaf nodes store keyword sets, and leaf nodes hold individual keywords; this structure inherently supports efficient path-based retrieval. Each leaf node stores a single keyword and employs a multi-bitmap index to indicate which files contain it. During the conjunctive keyword search phase, the server can achieve efficient conjunctive keyword search without requiring file-by-file comparison or decryption. Non-leaf nodes use an Indistinguishable Bloom Filter (IBF) to store keyword data. By mapping keywords via hash functions, the IBF obscures their exact storage positions. This design effectively removes mutual information between the index’s structure and the actual keywords, thus preventing branch leakage as the tree is traversed.
- A dual-state array and a timestamp factor are introduced for each keyword to support secure update operations. The dual-state array records both the state and the update counters for each keyword during the processes of addition and deletion. The timestamp factor restricts the validity of the trapdoor. The combination of the dual-state array and the timestamp factor ensures both forward and backward security, thereby enhancing the overall security of dynamic data management.
2. Related Work
SE has emerged as a crucial mechanism for ensuring data confidentiality in the cloud and has received extensive attention in recent years. The concept of SE was first introduced by Song et al. [1] and later formalized by Curtmola et al. [16]. Depending on their functional characteristics and security goals, existing studies mainly focus on the following directions.
2.1. SSE Scheme for Conjunctive Keyword Search
In 2000, Song et al. [1] first proposed the concept of SE and designed an SSE scheme. In this SSE scheme, a file is divided into multiple keywords, and each keyword is encrypted using a symmetric key and a pseudo-random function (PRF) to generate a unique encryption key. This scheme ensures that the server learns nothing about the search keyword during the search process. However, the search efficiency is relatively low, as the server must traverse all keywords in every file. The search time scales linearly with the file size. Later, Goh [17] pioneered an SSE scheme based on a secure index. This scheme uses pseudo-random functions and Bloom filters to build a secure index for each file, where each keyword is mapped to fixed positions on the BF. During the search process, the server quickly determines whether a corresponding keyword exists using the BF to achieve high search efficiency, with a constant-time search per file. However, due to the inherent false positive rate of the BF, the search results may include some irrelevant files, thereby reducing the accuracy of the results. In 2006, Curtmola et al. [16] proposed an efficient SSE scheme in which the search computation cost is constant and independent of the number of keywords in all files. This scheme also supports multi-user search.
The above SSE schemes only support single keyword search, which is quite limited for complex query requirements. For example, users may need to perform conjunctive searches based on multiple keywords to improve the accuracy of the query. If only single keyword search is supported, the server may return a large number of irrelevant files, leading to unnecessary data transmission and downloads. As a result, SSE schemes supporting conjunctive keyword search emerged. In 2004, Golle et al. [2] were the first to propose two schemes for conjunctive keyword search over indirectly linked keywords. However, the search complexity of both schemes grows linearly with the number of files and involves numerous modular exponentiations and bilinear pairing operations, which renders them impractical for real-world applications. In 2014, Cash et al. [3] proposed an SSE scheme called OXT (Oblivious Cross-Tags). The scheme introduces a technique known as Cross-Tags, which constructs a specialized index structure that enables the server to efficiently process complex Boolean queries such as AND, OR, and NOT. The search time of this scheme depends on the number of files. Its key advantages include significantly enhanced search flexibility and scalability. However, this scheme leaks certain access patterns and incurs substantial computational overhead during the initial index construction phase. In 2018, Lai et al. [4] proposed an SSE scheme that supports conjunctive keyword search based on the OXT framework [3]. The scheme utilizes hidden vector encryption and BF to construct an encrypted index structure, enabling the server to efficiently process conjunctive keyword search over encrypted indexes. It offers high search efficiency and strong scalability when handling large-scale datasets. However, the use of encrypted index structure and cryptographic primitives leads to higher setup overhead and increased implementation complexity. The SSE scheme proposed by Zhang et al. [18] based on hardness assumptions supports conjunctive keyword search with integrity verification, which prevents semi-honest servers from returning incomplete ciphertexts in an attempt to reduce computation costs.
2.2. DSE Scheme for Conjunctive Keyword Search
Distinct from SSE, DSE not only enables ciphertext retrieval but also supports dynamic updates to the encrypted database.
Stefanov et al. [6] proposed a practical DSE scheme and were the first to formally define the concept of forward security. The scheme employs Oblivious RAM (ORAM) technology [19] and a specialized data structure called blind storage to construct a secure index. Through the ORAM mechanism, it effectively mitigates information leakage during search and update operations, ensuring that the server cannot obtain additional information beyond the search results. However, reliance on ORAM brings substantial computational and communication overhead, especially under frequent dynamic updates, thereby limiting its practicality in real-world applications. Later, Bost et al. [20] proposed a scheme that employs a PRF and an encrypted linked list structure to construct an encrypted index that supports efficient updates and satisfies forward security. This scheme also provided the first rigorous formal definition of forward security. By introducing trapdoor permutation functions as a foundation, the scheme redesigns the encryption process in the search phase, successfully optimizing the search time complexity to sublinear. However, the scheme cannot avoid the computational overhead caused by cryptographic primitives, and the maintenance cost of the index increases with the growth of the database. In 2017, Bost et al. [7] formally defined the notion of backward security and presented several efficient DSE schemes, one of which was called Janus. In Janus, the data index is encrypted using puncturable encryption, which allows the server to retrieve only the matching index entries that have not been deleted. However, puncturable encryption brings significant communication and computation overhead.
Later, Zuo et al. [21] proposed a DSE scheme designed to achieve both forward and backward security. This scheme leverages pseudo-random functions and homomorphic addition to construct the index, thereby achieving a stronger level of privacy. However, due to the use of homomorphic addition, the complexity of index updates is increased. Wu et al. [22] designed a tree-based data structure called VBTree, enabling a DSE scheme that supports conjunctive keyword search. By organizing index elements into a virtual binary tree, VBTree enables efficient conjunctive keyword search over encrypted data while mitigating privacy leakage risks associated with exposing traditional tree structures to the cloud. The core innovation of the scheme lies in its ability to support dynamic data updates in sublinear time without reconstructing the entire tree, thereby improving update efficiency. Subsequently, VBTree has been adopted as an effective data structure in many DSE schemes. However, VBTree only guarantees forward security and still leaks file access patterns, potentially exposing to the server the files that match a specific keyword. To address this, Wang et al. [23] optimized the VBTree structure based on the OXT framework, further reducing information leakage and improving the efficiency of conjunctive keyword search. Nevertheless, due to the use of public-key cryptographic primitives, the scheme still incurs relatively high computational overhead.
Lu et al. [24] proposed a verifiable DSE scheme that supports conjunctive keyword search and achieves both forward and backward security. The scheme constructs a forward index using a t-puncturable PRF and designs verification tags. During the search process, the scheme first narrows the search scope using an inverted index, then determines the final search result through the forward index, while verifying the correctness and completeness of the result using the verification tags. However, its drawback lies in the additional computational resources required to construct and maintain the encrypted index, resulting in high initial setup and update costs. In 2024, Jin et al. [25] proposed an improved bloom filter named Authenticator Bloom Filter (ABF) and applied it to a DSE scheme. The scheme supports forward and backward security, multi-user environments and dynamic updates. However, the ABF used in the scheme requires maintaining both a bit array and a counter, which brings additional storage and computation overhead. Later, the SDSSE-CQ scheme proposed by Zuo et al. [26] achieves forward and backward security in DSE by combining the OXT framework with aura technology. It is particularly well-suited for scenarios requiring efficient conjunctive queries. However, this scheme requires maintaining two instances of aura (“TSet” and “XSet”), which results in relatively high storage overhead.
3. Preliminaries
3.1. Notations
The main notations used in this paper are presented in Table 1.
3.2. Full Binary Tree
To support efficient tree traversal and secure search, this scheme adopts a full binary tree. In a binary tree of height , every non-leaf node has exactly two child nodes. The tree contains a total of nodes, among which are leaf nodes. In this scheme, the full binary tree serves solely as a logical structure, with node elements stored as key-value pairs in a hash table. The example of a full binary tree in this scheme is shown in Figure 1. As shown in Figure 1, the root node contains four keywords , non-leaf nodes store sets of keywords. Leaf nodes store a single keyword and its corresponding files, and paths are defined by binary encoding, for example, the path from the root node to keyword is ‘01’, the leaf node storing also stores the file containing the keyword . In this scheme, denotes a string concatenated with all tree branches beginning from the root node to the current node . refers to the node with . The full binary tree structure employs binary path encoding: The left branch is labeled ‘0’ and the right branch ‘1’. This encoding ensures that the path from the root to any node is uniquely represented as a binary string. The binary string can be computed from by tracing back to the root and recording the sequence of left/right moves.
3.3. Multi-Bitmap Index
To enhance the efficiency of conjunctive keyword search over encrypted database, this scheme adopts an extended bitmap index structure, called the multi-bitmap index. Unlike the traditional bitmap index [27], where each keyword is mapped to a simple binary vector, the multi-bitmap index utilizes a fixed-length bit group (e.g., bits) to represent the presence of files, which means each keyword corresponds to an -bit string that indicates which files contain the keyword. Assume that the system supports a maximum of files. Then each keyword is represented by a bit string of total length . If a file (where ) contains a particular keyword, the bit at position is set to 1, and the following bits, from position to , are set to 0. When users initiate a conjunctive keyword search, the server retrieves the multi-bitmap index for each queried keyword. After obtaining the relevant bit strings, the server performs a modular addition operation (mod ) across these bit strings and returns the resulting bit vector to the user. If the bits from position to in the resulting bit vector represent the binary representation of the total number of query keywords, it indicates that the file contains all the queried keywords; otherwise, the file is excluded from the final result set. If a user intends to add a file containing a specific keyword to the system, the modular addition operation (mod ) is performed on the multi-bitmap index of that keyword; similarly, if the user wishes to delete the file, the modular subtraction operation (mod ) is executed. An example is shown in Figure 2.
For instance, consider a database containing three files , , (i.e., ), where each file is represented using a 3-bit group (i.e., ). Each keyword will then be represented by a bit string with a total length of , i.e., 3·3 = 9. The corresponding file bits are mapped as follows: the positions {0, 1, 2} corresponds to file , {3, 4, 5} corresponds to , and {6, 7, 8} corresponds to . As shown in Figure 2a, for the keyword (contained in and ), if the file contain , its corresponding 3-bit segment is set to 001; otherwise it is set to 000. Consequently, the bit string corresponding to is 001000001. Similarly, the bit string corresponding to (contained in and ) is set to 001001000, whereas (contained in ) is set to 001000000. Figure 2b illustrates the execution of a conjunctive keyword query . The server first retrieves the multi-bitmap index 001000001, 001001000 and 001000000 corresponding to these keywords , , and , respectively. Then the server performs a modular addition operation (i.e., (001000001 + 001001000 + 001000000) mod = 011001001) and returns the result 011001001 to the user. Upon receiving the result vector 011001001, the user obtains the bits from position to is exactly 011 (the binary representation of the total number 3 of queried keywords), thus confirming that the file satisfies the query conditions. Figure 2c demonstrates the addition of file (containing , with bits 000001000) to the system (not containing , with bits 001000001), the required update bits can be obtained through modular addition operations (i.e., (000001000 + 001000001) mod = 001001001). Figure 2d illustrates the deletion of file (containing with bits 000001000) from the system (containing , with bits 001001001), the required update bits can be obtained through modular subtraction operations (i.e., (001001001 − 000001000) mod = 001000001).
3.4. Indistinguishable Bloom Filter
This paper utilizes an Indistinguishable Bloom Filter (IBF) [28] to store index elements. Unlike traditional BF, IBF introduces a twin-cell structure and additional hash functions to achieve indistinguishability. An IBF consists of an array of twins, each twin contains two 1-bit cells with opposite values (i.e., one bit is 0, the other is 1). It also includes hash functions , and a hash function . The functions are defined as , is defined as . To insert a keyword , the first hash functions map to twin positions in the IBF. Then, for each position, a randomized value is computed as , where . The hash function is then applied to this value to probabilistically select one of the two 1-bit cells in each twin through . The selected cell is set to 1, and the unselected cell is set to 0, ensuring that the cell selection process is probabilistic and indistinguishable. To verify whether a keyword exists in the IBF, the same hash computations are performed, and the bits at the selected positions are examined. The element is considered to be present in the IBF with high probability only if all corresponding bits are 1. Otherwise, if any bit is 0, the element is definitively absent.
Therefore, through its inherent randomized design, the IBF mechanism systematically eliminates the mutual information between the index structure and specific keywords. Figure 3 illustrates the structure of the IBF, where the deep blue cells represent the selected cells.
4. Problem Formulation
4.1. System Model
The DS-CKDSE system consists of four main entities as shown in Figure 4: a data owner (DO), a data user (DU), a verification server (VS) and a storage server (SS).
DO: Before uploading the files to SS, DO first extracts keywords from the files and initializes an empty dual-state array . These keywords are then encrypted to generate a secure index , and the files are encrypted to form a ciphertext. Finally, both the secure index and the ciphertext are uploaded to SS and the dual-state array is sent to VS.DU: An authorized DU aims to retrieve the collection of files that contain the queried keywords, without revealing them. To perform a conjunctive keyword search, DU constructs a search trapdoor for the queried keyword , and then submits the search trapdoor to VS for query processing.VS: After receiving the search trapdoor from DU, VS uses a pre-stored dual-state array to verify the validity of the trapdoor . If the trapdoor is invalid, VS returns ‘reject’ to DU. Otherwise, after confirming the validity of the trapdoor , VS sends it to SS.SS: SS is responsible for storing the encrypted database and the secure index , as well as for processing the valid trapdoors received from VS. Upon receiving a valid trapdoor , SS traverses the path-encoded binary tree structure to retrieve the matching encrypted file identifiers. These results are then returned to DU, who decrypts them to obtain the target file identifiers.
4.2. Algorithm Definition
- : This algorithm is executed by DO. Given a secure parameter and an initial database , it outputs the key set , the dual-state array , the secure index , the state index , and an encrypted database .
- : This is an interactive algorithm between DO and two servers, VS and SS. DO inputs a keyword , the dual-state array , a file identifier , along with the operation type (where “ ” denotes inserting a file into the system, “ ” denotes removing a file from the system), the secure index and the state index . After executing the algorithm, VS outputs the updated dual-state array and the updated state index , and SS outputs the updated secure index .
- : This is an interactive algorithm between DU and two servers, VS and SS. DU inputs a keyword , a timestamp , the current dual-state array and the encrypted database , then generates a search trapdoor , and transmits it to VS. Upon successful verification, VS sends the valid trapdoor to SS. SS then executes a query over the secure index and returns the corresponding encrypted results , which DU decrypts to obtain the identifiers of the matching files.
4.3. Security Definition
The security of a DSE scheme is defined by the ability of an adversary to distinguish between the real world and the ideal world . The real world corresponds to the original DSE scheme, where the adversary interacts with a challenger. The ideal world is a simulated environment that only includes the leakage information of the original scheme, where the adversary interacts with a simulator . The leakage function is defined as , where denotes the leakage permitted to the adversary during the setup phase, denotes the leakage permitted to the adversary during the update phase, and denotes the leakage permitted to the adversary during the search phase. The goal of the adversary is to determine whether it interacts with the real or the ideal world. Eventually, the adversary outputs a bit , where denotes that it interacts with the real world or denotes that it interacts with the ideal world.
:The adversary selects a database and submits it to the challenger. The challenger executes and returns the encrypted database and the key set to the adversary . Then the adversary adaptively issues a polynomial number of update and search queries. The challenger responds to each query by executing the real algorithms and returns the corresponding results to . At the end of the experiment, the adversary outputs a bit . :The adversary selects a database and sends it to the simulator . Given only the leakage function , the simulator generates a simulated encrypted database and sends it to the adversary . For each subsequent adaptive query issued by the adversary , the simulator responds using only the corresponding leakage function or , without access to the plaintext. Finally, the adversary outputs a bit .
Definition 1. We say that a DSE scheme with a leakage function is an -adaptively secure conjunctive keyword DSE scheme if for any probabilistic polynomial time (PPT) adversary , there exists a PPT simulator such that:
where is a negligible function in .
Informally, a dynamic DSE scheme is -adaptively secure with respect to a leakage function if the adversarial server provably learns no more information about other than that encapsulated by . The less information the leakage function reveals, the higher the residual entropy of the sensitive information from the adversary’s perspective, and thus the stronger the security guarantee.
4.4. Threat Model
In this scheme, DO and DU are assumed to be honest, meaning they do not leak secret keys or trapdoor information to unauthorized parties. An authorized DU is assumed to be non-malicious during the search phase. The system architecture includes two non-colluding servers: VS and SS, both modeled as honest-but-curious entities. Although VS and SS execute operations correctly, they may passively observe access patterns in an attempt to infer sensitive keyword information. Under the non-collusion assumption, VS and SS do not share their respective stored data.
4.5. Design Goals
The main design goals are as follows:
- Dynamic update support: The scheme should support frequent update operations, including file additions and deletions, while ensuring that each update maintains the security of the index structure.
- Forward security: After DO performs an addition operation, the scheme ensures that previously generated search trapdoors cannot be used to retrieve the newly added file.
- Backward security: After DO performs a deletion operation, the scheme guarantees that the deleted files cannot be retrieved by future search trapdoors.
- Search efficiency: While supporting conjunctive keyword search, this scheme aims to achieve sublinear search time complexity with respect to the total number of keywords.
- KPRP: The scheme must ensure that the server cannot infer whether any two keywords co-occur in the same file by observing trapdoors and query results.
5. Our Construction
In this section, we present the detailed construction of the DS-CKDSE scheme, which is defined as The scheme employs four hash functions , , , and , along with two pseudo-random functions and . The meanings of are shown in Table 1.
5.1. Setup Phase
In the setup phase, DO is responsible for generating the key set and building the secure index .
KeyGen: DO inputs the secure parameter and runs Algorithm 1 to generate a dual-state array , an empty IBF, a key set , where is used to encrypt keyword states, is used to encrypt keywords and is used to encrypt files. The dual-state array is maintained by DO, DU and VS, while SS is strictly prohibited from accessing keyword states and update counters, thereby enhancing security.
Algorithm 1: KeyGenInput: The secure parameter Output: The dual-state array , the , and the Key set 1. Initialize an empty map an IBF with element 0;2. which is used to encrypt keyword states; 3. which is used to encrypt keywords; 4. which is used to encrypt files; 5. return
Generate Trapdoor: DU inputs the keyword , the key set , and the dual-state array , then executes Algorithm 2 to generate a trapdoor .
Algorithm 2: Generate TrapdoorInput: The keyword , the Key set , the dual-state array Output: The trapdoor 1. Choose a PRF ;2. Choose a PRF ;3. Select ;4. Compute ;5. Get the current time ;6. Compute ;7. return
Build Secure Index: DO preprocesses the files by extracting keywords and forming keyword–file identifier pairs , where denotes the total number of keywords in the database, DO then inputs an IBF and keyword–file identifier pairs , and runs Algorithm 3 to generate a secure index . For each non-leaf node , the keywords in are mapped into the IBF using a total of hash functions: and . Each leaf node stores a keyword and the file identifiers that contain that keyword. During query execution, if the IBF does not contain the search keywords, the corresponding subtree can be skipped, thereby improving search efficiency. Each leaf node represents a keyword and stores the associated file identifiers in the form of multi-bitmap index.
Algorithm 3: Build Secure IndexInput: The , the keyword–file pairs , the dual-state array Output: The secure index 1. Initialize empty binary tree ;2. Initialize empty set ;3. Choose a PRF ;4. Choose a PRF ;5. Choose hash functions , , , ;6. for do7. for do8. ;9. while do10. Compute ;11. Select ;12. Get the current time ;13. Compute search trapdoor ;14. Let . Then compute ;15. ;16. ;17. ;18. ;19. end while20. ;21. end for22. end for23. for do24. ;25. ;26. end for27.
Figure 5 shows an example of a secure index. All keywords stored in the root node are encrypted using the IBF. Through a binary tree structure, the keyword sets in non-leaf nodes are progressively subdivided: and , ultimately reaching leaf nodes where they are refined into individual keywords. Leaf nodes store keywords and their corresponding files, with files represented using multi-bitmap index. For example, the keyword with path ‘01’ is stored as “001000001” for file and containing .
5.2. Update Phase
In the update phase, DO intends to add or delete a file associated with a keyword , while preserving forward and backward security.
As shown in Algorithm 4, during the update phase, DO inputs the keyword , the dual-state array and the file identifier . Depending on the type of operation , a new random -bit string is generated as the current keyword state, while the previous state is denoted as . Specifically, in the case of an addition operation “ ”, DO generates a new state , increments the addition counter and updates the dual-state array to , in the case of a deletion operation “ ”, DO generates a new state , increments the deletion counter and updates the dual-state array to This randomization mechanism ensures that the updated and historical search trapdoors are independent, effectively preventing information leakage, and ensuring both forward and backward security during updates.
Then, the keyword token is generated via . This token is used to compute the update trapdoor by . Based on the update trapdoor , the values and are further computed. Next, and are sent to VS, while and are sent to SS. SS updates the encrypted file identifier in the corresponding position of the secure index, VS updates the encrypted state information in the position of the state index. Finally returns the updated dual-state array , the updated state index and the updated secure index . Algorithm 4: UpdateInput: The keyword , dual-state array , file identifier , operation , , secure index , state index Output: Updated dual-state array , updated state index , updated secure index 1. ;2. ; 3. ; 4. ; 5. “ ” then6. ;7. ;8. ;9. ;10. end if11. “ ” then12. ;13. ;14. ;15. ;16. end if17. Compute encrypted keyword and token ;18. ;19. Computer update trapdoor ;20. ;21. ;22. ;23. ;24. do25. do26. do27. ;28. ;29. ;30. end for31. end for32. end for33. ;34. ;35.
5.3. Search Phase
The search phase relies on a dual-server architecture. Let be a conjunctive search query issued by DU. The search phase is described by Algorithm 5.
DU: When DU initiates a conjunctive keyword search over the encrypted database, Algorithm 2 is used to generate a time-restricted search trapdoor for each queried keyword. Then these trapdoors are aggregated into a set , which is sent to VS for verification.
VS: Upon receiving the trapdoors, VS checks the state of each keyword using the stored dual-state array and verifies whether the associated timestamp falls within the valid time window . If verification is successful, VS forwards the validated trapdoors to SS, which is responsible for index traversal.
SS: SS then traverses a full binary tree index, where each non-leaf node is equipped with an IBF that helps determine whether its subtree contains all queried keywords. The function ’ is used to check whether each keyword is present in a node. When the length of the path is , which means that the search has reached a leaf node, SS retrieves the encrypted file identifiers that match the conjunctive search. The set of encrypted file identifiers is then returned to DU.
DU: DU decrypts the file identifiers using the secret key to obtain the desired files. Algorithm 5: SearchInput: , the path, the time window Output: The set of file identifiers 1. DU: ;2. do 3. ; 4. Compute encrypted keyword and token ; 5. ;6. ;7. ;8. 9. end for10. to VS11. VS: do12. ;13. ;14. 15. then16. 17. end if18. to SS;19. end for20. SS: 21. for do22. then23. Return ‘not found’;24. end if25. then26. ;27. ; 28. else29. ;30. end if31. end for32. to DU;33. DU: do34. ;35. end for36.
6. Security Analysis
6.1. L-Adaptive Security
Theorem 1. We use the leakage function to represent the leakage information of the scheme. If and are secure pseudo-random functions, then our DS-CKDSE scheme is -adaptively secure against the leakage function defined as follows:
where the search pattern indicates that the keyword was searched in the -th query, and is the path from the root node to the updated node.
Proof of Theorem 1. We prove Theorem 1 via a sequence of games that transition from the real game to the ideal game . By constructing a sequence of games, we finally demonstrate that real game and ideal game are computationally indistinguishable, thus completing the proof of Theorem 1. Game ( ): This game is equivalent to the real game .Game : In , instead of pseudo-random functions and , we use truly random functions. In , the PRF is used to generate the encrypted keyword and the token . Compared to , uses a mapping table to store the encrypted keyword and the token . For each keyword , if the adversary queries a repeated keyword , returns the same random value recorded in ; Otherwise, it generates a new random bit string and records it.In , the PRF is used to generate as the update trapdoor. uses a mapping table to store the trapdoor value . When the search algorithm needs to generate , already exists in the mapping table . If it exists, return the corresponding value from ; Otherwise, generate a random bit string and record it.Since the PRF and a truly random function are computationally indistinguishable, the difference is negligible. Therefore, we have:
Game : Compared to , we replace the hash functions , , and with random oracles in . Some tables are established to record the random values generated. If the adversary queries the random oracle with an input undefined in the update or search operations, the oracle returns a uniformly random string and records this mapping in the corresponding table. Conversely, if the input already exists in the table, the random oracle directly returns the pre-recorded corresponding output. If the adversary successfully guesses the correct input value that has not yet been defined in an update or search query while querying the random oracle, a “Bad” event occurs.We now analyze the probability of the “Bad” event occurring. In the ideal random oracle model, since the output length of each hash function is bits, the probability of an adversary successfully guessing a specific valid input in a single random attempt is . Furthermore, the adversary does not know and , which may introduce a negligible advantage, denoted as . Assume that a PPT adversary makes at most queries to the random oracle, the probability of the “Bad” event happening is then bounded by: . Since both and are negligible functions in , the probability itself is also negligible.The adversary can only observe a discrepancy between the random oracle responses in and the real hash function behavior in if the “Bad” event occurs. Since that is negligible, the difference in the output distributions of the two games from the adversary’s perspective is negligible. Hence:
Game : The difference between and is the randomization of the IBF bit positions. For each keyword, the bit positions in the IBF are generated randomly, each cell is mapped by hash functions. Under the random oracle model, the encoded values of these cells are computationally indistinguishable from uniformly random strings, making it infeasible for the adversary to distinguish between real encoded bits and random bits. Thus, based on the indistinguishability between the IBF random strings and the random oracle simulation, we have:
Game : In this game, real trapdoors and state values are replaced with simulated values. Specifically, all instances of , , and are substituted with independent random strings. The timestamp verification logic in this game relies solely on the leakage function’s parameter . The simulator can directly determine the validity of a trapdoor based on the valid time window included in the leakage , without revealing any actual timestamp information. Therefore, we have:
Game : In this game, instead of using real file identifiers , the simulator generates random file identifiers for each file. The encrypted form is then set as: . Since the original is fully masked by the PRF and the resulting is computationally indistinguishable from a uniform random string, the adversary cannot distinguish this change. Therefore, we have the following:
Game ( ): In this game, the entire system output has been replaced with simulated data. All search trapdoors , dual-state array , and encrypted file identifiers are substituted with random strings generated by the simulator, which responds solely based on the leakage function . Since all values (keywords, states, and timestamps) are simulated consistently with the defined leakage, the adversary’s view is computationally indistinguishable from that in Game . Thus:
Summing the indistinguishability bounds over all game transitions, we obtain the overall security guarantee:
□
6.2. Forward and Backward Security
Theorem 2. Let be the leakage function defined in Theorem 1. An -adaptively secure DSSE scheme is forward security, if leakage function can be written in the following form:
Proof of Theorem 2. Forward security guarantees that previously generated trapdoors cannot be used to search over newly added files. Each keyword is associated with a dual-state array . For the file addition operation, DO generates a random string as the new state to replace the previous state. The updated trapdoor is computed as . The new state is independent of previous states, ensuring complete randomness and confidentiality, it is computationally infeasible for an adversary to link the new state to the old one. Therefore, the search trapdoors generated before the state update cannot match the newly added files, which ensures forward security. □
Theorem 3. An -adaptively secure DSSE scheme is backward security, if leakage functions and can be written in the following form:
Proof of Theorem 3. Backward security ensures that after a document containing a keyword is deleted, it cannot be retrieved by future searches, even if the adversary retains prior search trapdoors. This scheme ensures backward security through the following two mechanisms:
- Timestamp Constraint in Trapdoor Validation: Each search trapdoor incorporates a timestamp to limit its validity. During verification, VS checks the timestamp as: . This constraint ensures that a trapdoor is only valid within a limited time window , preventing old trapdoors from being reused to retrieve deleted files.
- Incorporation of Deletion States: The DS-CKDSE scheme utilizes a dual-state array explicitly tracks both addition and deletion states for each keyword. When a document containing is deleted, the data owner generates a new random deletion state , and increments the counter . Future trapdoors are constructed using only the active addition state , which is unaffected by the deleted state. This separation prevents the server from inferring the original contents of deleted files, ensuring that adversaries cannot recover deleted files through future queries. Therefore, the DS-CKDSE scheme guarantees forward and backward security. □
6.3. KPRP Privacy
To demonstrate that our proposed scheme effectively prevents KPRP leakage, we compare it with the ODXT scheme [15]. KPRP leakage refers to the ability of a semi-honest server to learn partial intersection results of individual keyword pairs during a conjunctive query, which may allow an adversary to infer the underlying query structure through repeated observation. In this scheme, VS only stores the dual-state array for each keyword and cannot access the secure index or encrypted database . SS only stores the secure index and the encrypted database , performing index-based retrieval but unable to obtain the dual-state array for each keyword. Even if one server is compromised, due to the separation between both servers, an attacker still cannot simultaneously acquire both keyword state information and index data. Consequently, the matching results of keyword pairs cannot be reconstructed, thereby effectively preventing KPRP leakage. We present a concrete example to demonstrate the privacy improvement. Consider a database that stores five encrypted files with associated keywords, as presented in Table 2.
Suppose the user issues a conjunctive query and the corresponding document set is , which represents the set of files containing the keyword within the database . The server then checks whether these files also contain and .
In ODXT, the server can learn partial intersections such as:
Thus, although the final intersection result is , the server gains additional information about intermediate keyword relations, leading to KPRP leakage.
In our scheme, the trapdoor structure incorporates randomized states and timestamp factor, which prevent the server from obtaining any intermediate keyword pair matches. The server learns only the final conjunctive query result without observing the result of or . Therefore, our DS-CKDSE scheme eliminates KPRP leakage.
7. Performance Analysis
In this section, we evaluate the performance of the DS-CKDSE scheme by comparing it with existing representative DSE schemes. As shown in Table 3, we have compared our scheme with existing ones in multiple aspects. The comparison includes dynamic update efficiency, search efficiency, forward and backward security, and KPRP privacy. As seen in Table 3, our scheme and ESP-CKS [29] are the only two that meet all security requirements; however, our scheme has the advantage of superior update and search efficiency. Specially, in terms of update efficiency, our scheme achieves logarithmic growth ( ) while ESP-CKS [29] only achieves linear growth ( ). In terms of search efficiency, our scheme achieves linearithmic growth ( ), while ESP-CKS [29] only achieves quadratic growth ( ). Compared to ODXT [15], although it exhibits better update efficiency, it fails to achieve KPRP privacy. Compared to VBTree [22], although it exhibits better search efficiency, it achieves this at the cost of backward security. The experiments were implemented in Java. The experimental platform was configured with an Intel^®^ CoreTM i5-13600kf processor (Manufacturer: Intel Corporation; Assembly Location: Wuhan, China), 16 GB of RAM, and the Windows 11 operating system. The Enron email dataset [30] was used as experimental data for testing.
Update efficiency: In terms of update efficiency, we compare our proposed scheme with other conjunctive keyword search schemes such as ESP-CKS [29] and VBtree [22]. Figure 6a illustrates how update time changes with an increasing number of files. The results demonstrate that the update time of DS-CKDSE increases relatively smoothly with the number of files, without significant growth. This is attributed to the multi-bitmap index, which supports batch processing of multiple files, thereby reducing redundant operations on individual files. As a result, DS-CKDSE achieves better update efficiency and more stable performance when handling a large volume of files. Figure 6b illustrates how the update time changes with an increasing number of search keywords. Experimental results indicate that the update time exhibits a linear relationship with the number of keywords. This is due to the height of the binary tree increases with the number of keywords. Therefore, to maintain high update performance, it is essential to reasonably control the number of keywords.
Search efficiency: In terms of search efficiency, the experimental results show that the search time of DS-CKDSE is independent of the number of files, as illustrated in Figure 6c. This is due to the fact that DS-CKDSE constructs the secure index based on a full binary tree, where the search process only depends on the keyword’s path and the search process does not require traversing all files. The search time increases linearly with the number of queried keywords, as shown in Figure 6d. The height of the secure index depends solely on the number of keywords. Compared with the VBTree scheme [22], DS-CKDSE achieves more consistent search performance when handling large file sets. This is due to the fact that the tree height is only affected by the number of keywords, rather than the total number of files.
8. Conclusions
The proposed DS-CKDSE scheme simultaneously achieves forward and backward security under a dual-server architecture. By integrating a full binary tree structure, an IBF, and a multi-bitmap index, DS-CKDSE enables privacy-preserving conjunctive keyword search. The dual-server architecture separates trapdoor verification from index storage, thereby preventing KPRP leakage. Additionally, the dual-state array and timestamp mechanism jointly ensure that the scheme achieves forward and backward security. This design effectively mitigates the leakage of information entropy during the system’s search and update processes. Through a sequence of games, we prove that the scheme is -adaptively secure under the defined leakage function . The experimental results show that the scheme maintains high efficiency in both update and search operations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Song D.X. Wagner D. Perrig A. Practical techniques for searches on encrypted data Proceedings of the 2000 IEEE Symposium on Security and Privacy (S&P)Oakland, CA, USA 14–17 May 20004455
- 2Golle P. Staddon J. Waters B. Secure conjunctive keyword search over encrypted data Proceedings of the International Conference on Applied Cryptography and Network Security (ACNS)Yellow Mountain, China 8–11 June 20043145
- 3Cash D. Jarecki S. Jutla C. Krawczyk H. Roşu M.-C. Steiner M. Highly-scalable searchable symmetric encryption with support for boolean queries Proceedings of the Annual Cryptology Conference (CRYPTO)Santa Barbara, CA, USA 18–22 August 2013353373
- 4Lai S.Q. Patranabis S. Sakzad A. Liu J.K. Mukhopadhyay D. Steinfeld R. Sun S.F. Liu D. Zuo C. Result pattern hiding searchable encryption for conjunctive queries Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS)Toronto, Canada 15–19 October 2018745762
- 5Kamara S. Papamanthou C. Parallel and dynamic searchable symmetric encryption Proceedings of the 17th International Conference on Financial Cryptography and Data Security (FC)Okinawa, Japan 1–5 April 2013258274
- 6Stefanov E. Papamanthou C. Shi E. Practical dynamic searchable encryption with small leakage Proceedings of the Network and Distributed System Security Symposium San Diego, CA, USA 23–26 February 2014
- 7Bost R. Minaud B. Ohrimenko O. Forward and backward private searchable encryption from constrained cryptographic primitives Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS)Dallas, TX, USA 30 October–3 November 201714651482
- 8Zhou Y. Li N. Tian Y. An D. Wang L. Public key encryption with keyword search in cloud: A survey Entropy 20202242110.3390/e 2204042133286195 PMC 7516898 · doi ↗ · pubmed ↗