Uncovering Neural Learning Dynamics Through Latent Mutual Information
Arianna Issitt, Alex Merino, Lamine Deen, Ryan T. White, Mackenzie J. Meni

TL;DR
This paper explores how neural networks process information during learning by tracking mutual information, revealing that label-relevant information concentrates in specific channels.
Contribution
The study introduces a new perspective on representation learning through selective concentration and decorrelation of information.
Findings
Label-relevant mutual information increases with network depth across different architectures.
High-MI channels are functionally important for accuracy, as confirmed by inference-time experiments.
A dependence-aware regularizer can improve training speed and accuracy by encouraging desired information patterns.
Abstract
We study how convolutional neural networks reorganize information during learning in natural image classification tasks by tracking mutual information (MI) between inputs, intermediate representations, and labels. Across VGG-16, ResNet-18, and ResNet-50, we find that label-relevant MI grows reliably with depth while input MI depends strongly on architecture and activation, indicating that “compression’’ is not a universal phenomenon. Within convolutional layers, label information becomes increasingly concentrated in a small subset of channels; inference-time knockouts, shuffles, and perturbations confirm that these high-MI channels are functionally necessary for accuracy. This behavior suggests a view of representation learning driven by selective concentration and decorrelation rather than global information reduction. Finally, we show that a simple dependence-aware regularizer based…
Click any figure to enlarge with its caption.
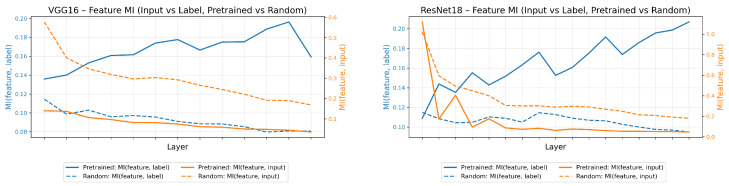 Figure 1
Figure 1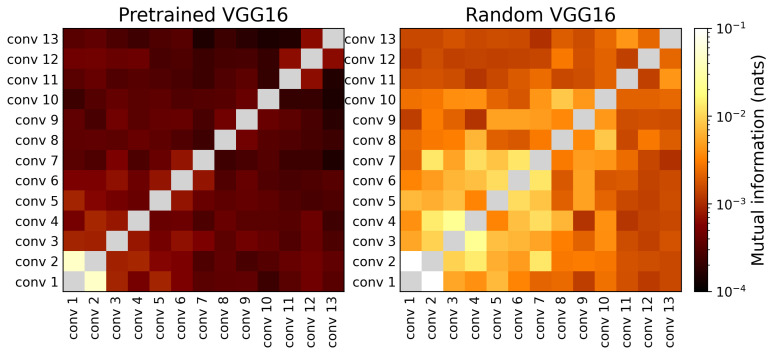 Figure 2
Figure 2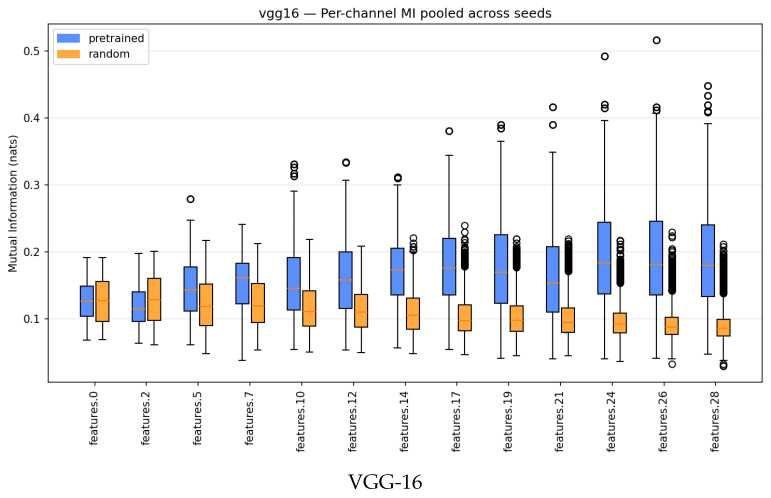 Figure 3
Figure 3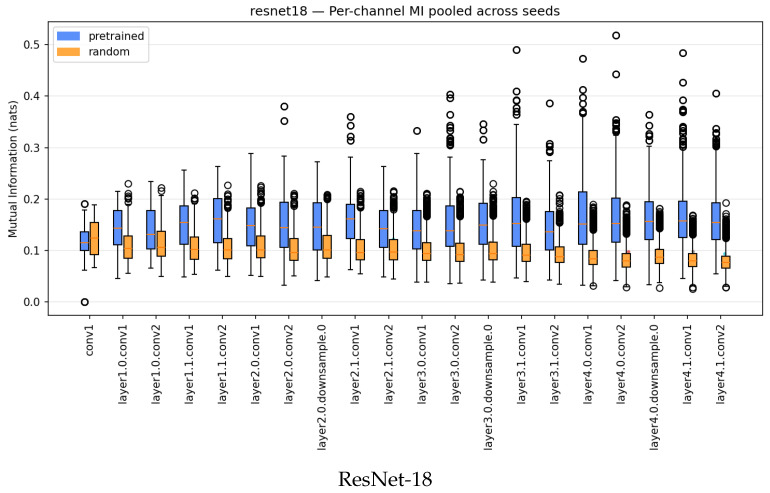 Figure 4
Figure 4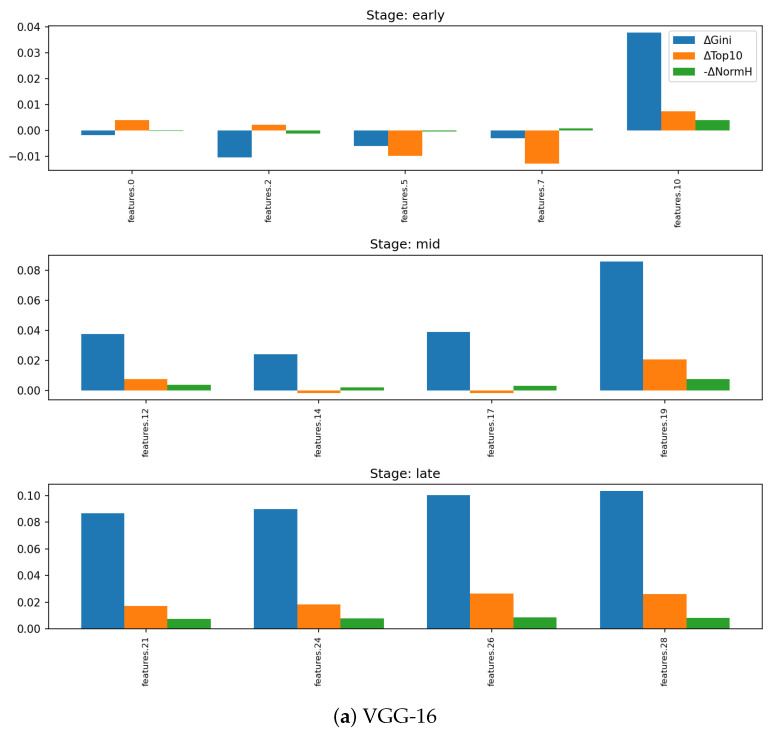 Figure 5
Figure 5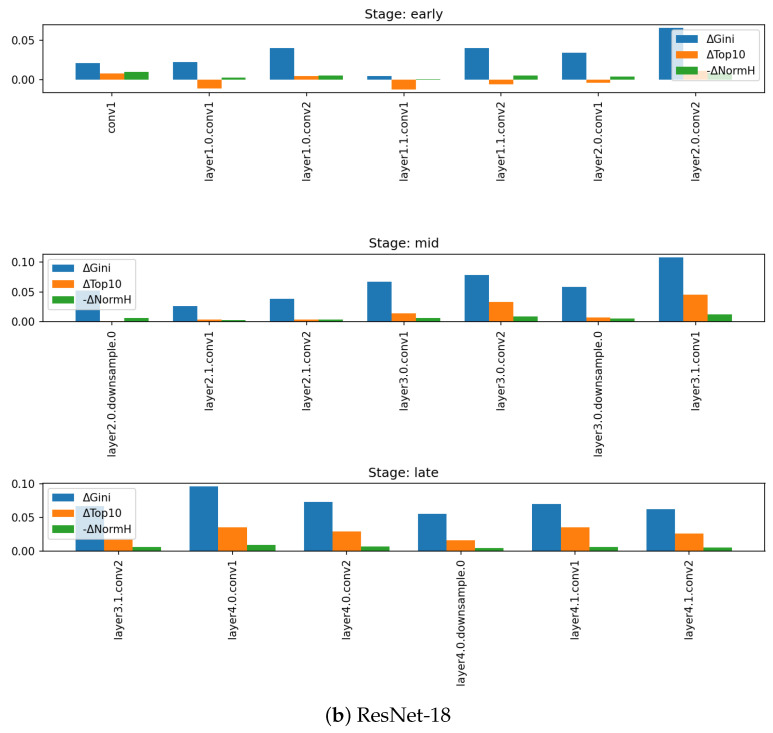 Figure 6
Figure 6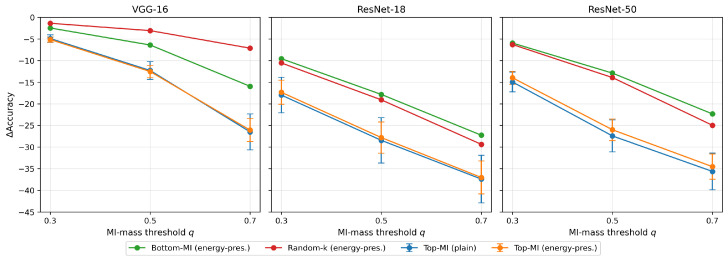 Figure 7
Figure 7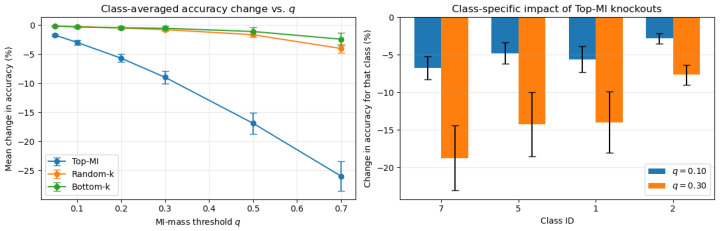 Figure 8
Figure 8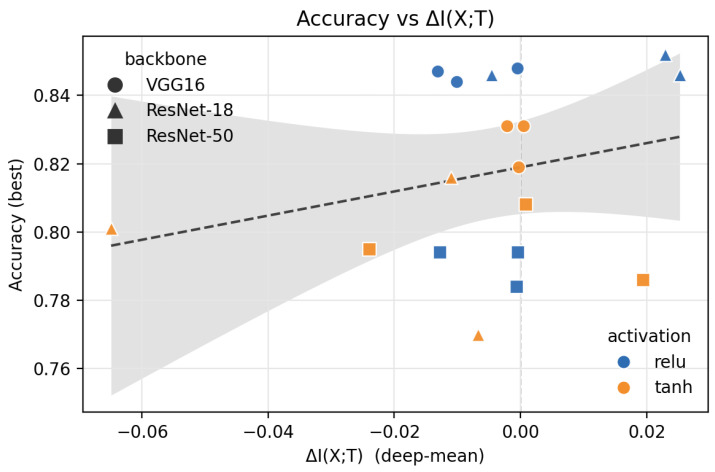 Figure 9
Figure 9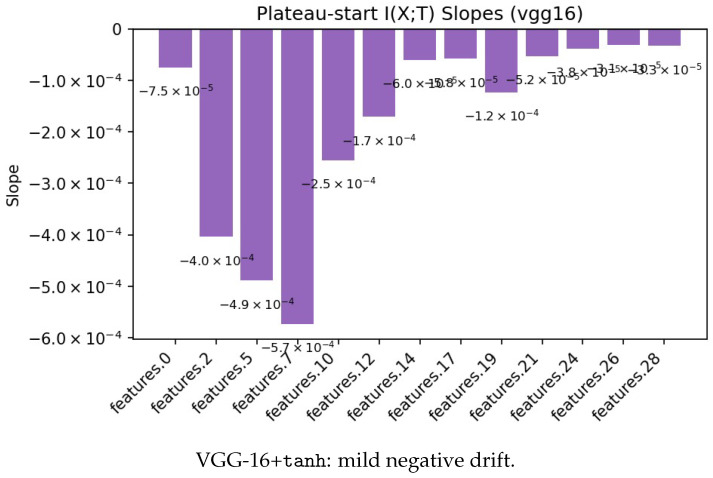 Figure 10
Figure 10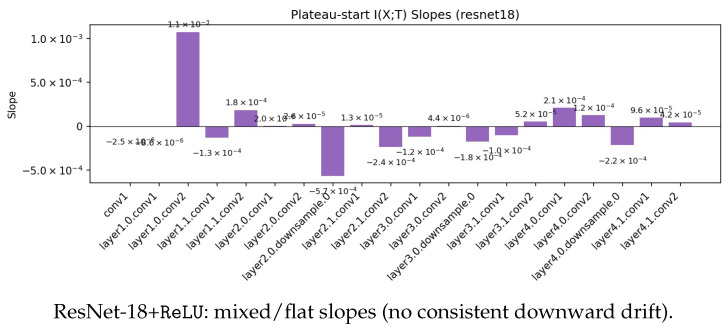 Figure 11
Figure 11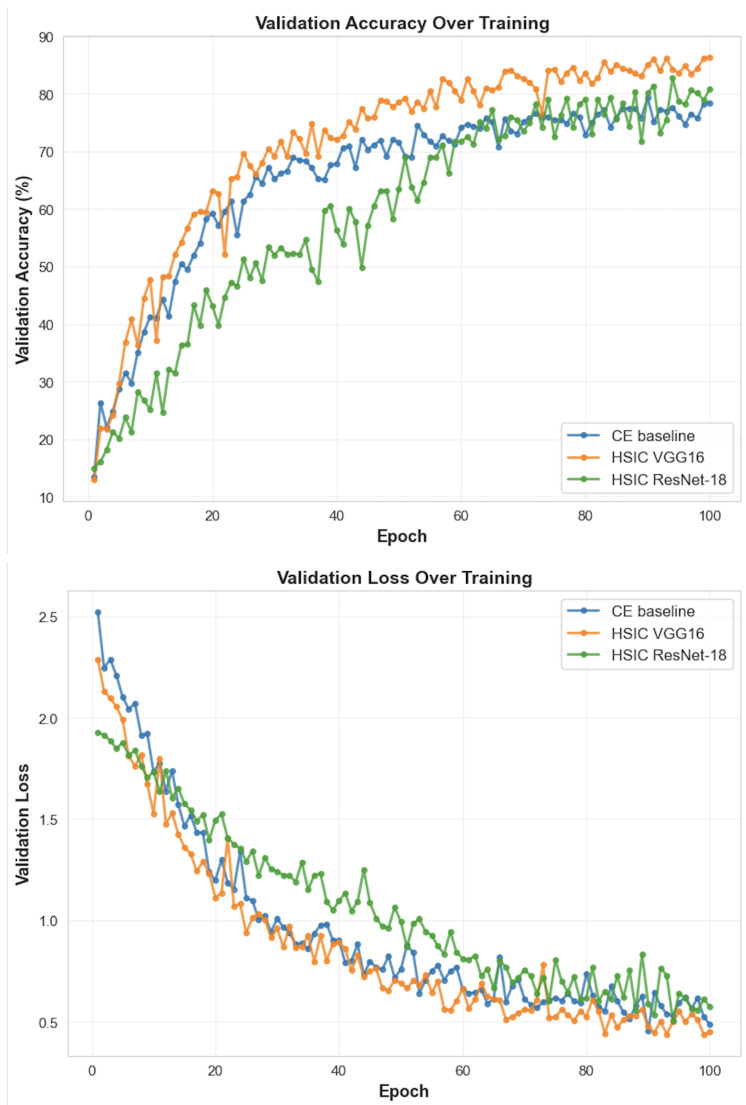 Figure 12
Figure 12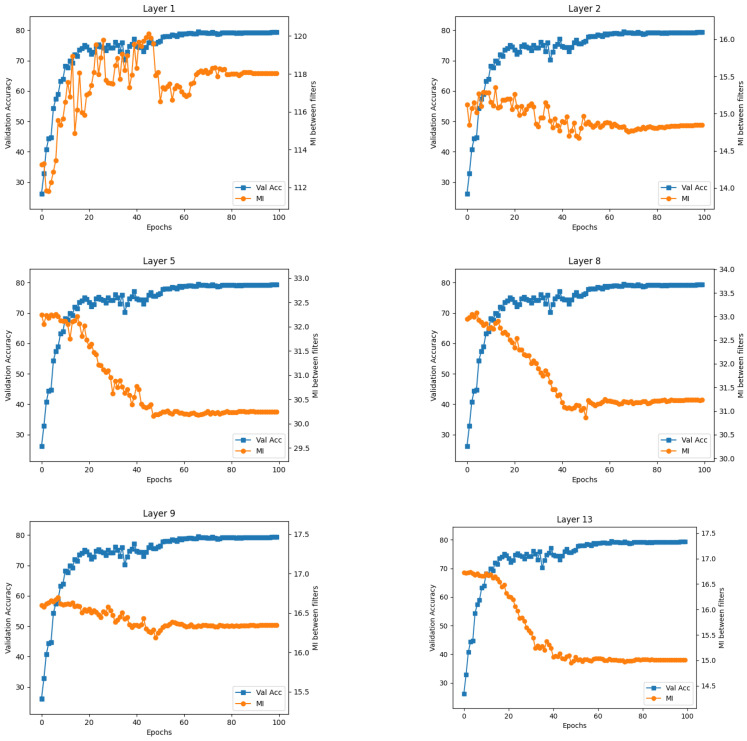 Figure 13
Figure 13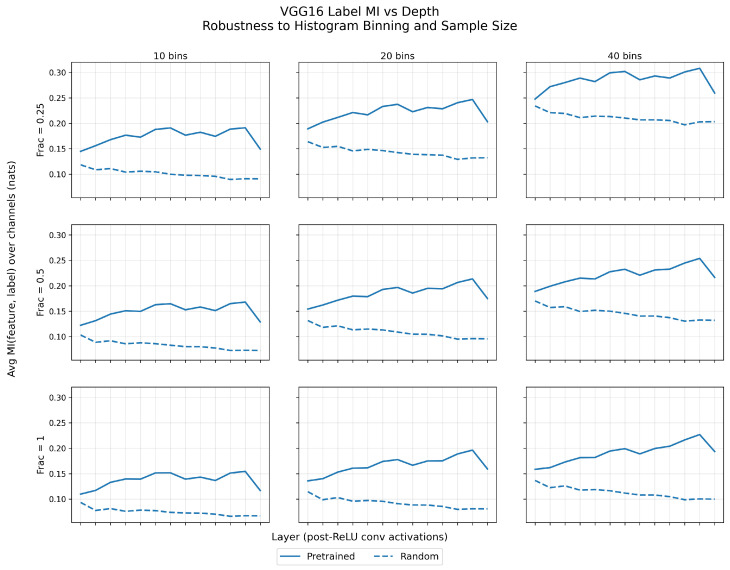 Figure 14
Figure 14- —U.S. Army Engineer Research and Development Center (ERDC)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Advanced Neural Network Applications · Generative Adversarial Networks and Image Synthesis
1. Introduction
Modern neural networks can achieve high accuracy while revealing little about how they organize information internally. This hidden structure governs what a model can transfer, how it fails under distribution shift, and whether we can reliably interpret or intervene in its behavior. As these systems move into sensitive and high-stakes applications, understanding how they encode and transform information becomes a practical requirement rather than a theoretical curiosity.
To make this internal organization explicit, we use mutual information (MI) to quantify how strongly each representation depends on the input and how much label-relevant structure it encodes. Measuring MI at both the layer and channel levels reveals how task-relevant information accumulates with depth and how networks reshape input variability as they learn, often concentrating discriminative signal into a small subset of channels.
We track these quantities over the entire training trajectory rather than at isolated checkpoints. This dynamic view shows when label-informative structure emerges, when it stabilizes, and why input-information “compression’’ appears only under specific architectural and activation choices rather than as a universal training phenomenon.
The contributions of this work are:
- Layer- and channel-level MI analysis. A unified MI framework for quantifying how input- and label-relevant information propagate through CNNs during training.
- Inference-time MI patterns across architectures. Consistent growth of label MI with feature depth and activation-dependent behavior of input MI across VGG-16, ResNet-18, and ResNet-50.
- Functional specialization of channels. We identify compact subsets of high-MI channels and demonstrate their necessity through knockouts, shuffles, and perturbations.
- Regularization aligned with MI structure. An HSIC-based regularizer reinforces these MI patterns, reducing redundancy and improving both accuracy and convergence speed.
These contributions show that MI exposes stable and functionally meaningful structure in CNN representations under the studied training setting—structure that is otherwise invisible through standard evaluation and that can be shaped through explicit regularization.
Accordingly, this work characterizes reproducible information-allocation patterns within a controlled and widely studied vision setting, rather than asserting dataset-independent laws.
2. Related Work
Mutual information (MI) quantifies statistical dependence between variables, and has been widely used to study how neural networks encode structure. For random variables X and Y with joint density f and marginals and ,
which is non-negative and vanishes only under independence. Within deep networks, MI provides a way to characterize the degree to which internal features retain input variability or capture label-relevant signal.
2.1. Estimating MI in Latent Spaces
High-dimensional MI is notoriously hard to estimate. Nearest-neighbor estimators such as KSG [1], variational methods such as MINE [2], and contrastive bounds such as InfoNCE [3] offer different tradeoffs in bias, variance, stability, and computational cost. Because these estimators often disagree in scale and occasionally in trend, many representation-focused studies emphasize comparative analyses within a single estimator family. Following this principle, we adopt a fixed histogram-based estimator and restrict attention to relative patterns across layers, channels, models, and training stages to emphasize changes in the representations themselves rather than differences in estimator behavior.
2.2. MI as a Learning Principle
Early information-theoretic formulations framed learning as maximizing retained information (InfoMax) [4,5], or conversely as trading off relevance and compression through the information bottleneck (IB) [6]. Empirical studies initially suggested a stereotyped “fitting then compression’’ pattern in during training [7]; however, subsequent work showed that this behavior is highly sensitive to activation functions, normalization layers, and choice of MI estimator [8]. More recent analyses have argued that compression is not a universal feature of training but emerges only in certain architectural or optimization regimes [9]. These debates highlight the need for measurement frameworks that emphasize internal consistency rather than absolute MI values.
2.3. Information-Guided Regularization
A parallel line of work uses information-theoretic criteria not only for analysis but as training signals that shape representation learning. Entropy-based regularizers have been shown to encourage desirable information flow patterns across layers, reduce redundancy, and improve convergence in dense and convolutional networks [10,11]. Such methods demonstrate that information structure can be steered during optimization rather than merely measured post hoc. Related ideas appear in mutual information-maximizing objectives such as InfoMax [4], MI-based feature selection [12], and dependence-promoting losses in representation learning [5]. Our approach aligns with this perspective; we analyze MI flow to identify characteristic patterns of specialization, then use HSIC, a stable and differentiable proxy for dependence, to gently bias training toward those structures.
While variational and contrastive MI estimators such as MINE and InfoNCE have become popular training time surrogates, they introduce additional instability due to critic parameterization, variance from negative sampling strategies, and scale inconsistency across batches. In contrast, HSIC provides a critic-free kernel-based dependence measure that is stable to estimate on mini-batches and differentiable without requiring density models or contrastive sampling. This makes HSIC a pragmatic regularizer in settings where MI objectives are desirable but direct MI estimation is computationally heavy or statistically volatile.
2.4. Representation Analysis Perspective
Prior analyses of neural representations emphasize that learned structure arises from interactions between architecture, data, and optimization rather than from universal information-theoretic laws. Here, we use MI as a diagnostic to quantify how information is distributed across layers and channels, allowing us to characterize the emergence of representational structure and channel-level specialization during training.
3. Methods
Our goal is to measure how CNNs redistribute input- and label-relevant information across depth during learning. We track the mutual information (MI) between inputs, intermediate activations, and labels across training epochs using a fixed histogram estimator applied uniformly across models and epochs. MI values are interpreted in relative terms within each model, enabling consistent comparisons of information flow and specialization over training.
3.1. Model Architectures
We study three standard CNN classifiers: VGG-16 [13], ResNet-18, and ResNet-50 [14]. For VGG-16, we retain the full convolutional backbone and replace the classifier head with two linear layers (4096 and 10 units) with a ReLU and 50% dropout on the first. ResNet-18 and ResNet-50 use their unmodified architectures.
MI is measured at well-defined activation sites. For VGG-16, we extract post-ReLU convolutional activations after every convolutional operation. For ResNets, each residual block provides two measurement points: (i) the output of the residual branch before skip-addition, and (ii) the post-addition output after the skip connection. These paired measurements allow us to separate changes introduced by the residual transformation from those due to residual aggregation.
3.2. Datasets and Training Setup
All experiments use the Imagenette2 dataset [15] with its standard training/validation split. Unless otherwise noted, training follows a consistent protocol: random resized crops and horizontal flips for augmentation, normalization matched to ImageNet statistics, and training from scratch using SGD with momentum 0.9, weight decay , and a batch size of 64. The initial learning rate is with ReduceLROnPlateau on validation accuracy (patience 10) and early stopping after 25 epochs without improvement. Each randomized experiment is averaged over five independent seeds.
Scope of Empirical Evaluation.
All experiments in this work are conducted on Imagenette2, a curated subset of ImageNet that preserves natural-image statistics while enabling dense information-theoretic measurements across training. Accordingly, our conclusions concern relative mutual information trends, channel-level specialization, and dependence structure in CNNs trained for natural image classification under ImageNet-like conditions. We do not claim universality across datasets or modalities, and treat generalization to larger datasets (e.g., full ImageNet) or other domains as an important direction for future research.
3.3. Histogram-Based MI Estimator
We estimate mutual information using a fixed histogram-based estimator applied to paired samples collected from the validation set. Each variable is discretized into B uniform bins, yielding empirical joint and marginal densities
from which the MI estimate is
Histogram-based estimators are known to degrade in high-dimensional settings due to exponential growth in bin counts and sample requirements, so we do not apply MI estimation directly to high-dimensional activation tensors; instead, activation tensors are reduced by global average pooling, providing a stable summary representation with low estimator variance while preserving relative trends across layers.
Because the estimator, binning strategy, and preprocessing are held fixed for all layers, channels, architectures, and training epochs, the resulting MI values serve as consistent relative comparisons of how information redistributes within a model over the course of training.
3.4. Representation-Level MI Measurement
Let be the activation tensor at layer ℓ and let denote channel c. For each checkpoint, we compute:
- and : dependence between layer or channel activations and class labels.
- and : retained dependence on the input.
- and : inter-layer and inter-channel dependence.
All quantities use the same fixed histogram estimator (bin size 20) for consistency across layers, checkpoints, and architectures, enabling relative comparisons of how information is reallocated throughout training. A robustness analysis with respect to histogram bin count and sample size is provided in Appendix F.
Next, we introduce a training objective to encourage ideal dependency patterns among features and labels.
3.5. Hilbert–Schmidt Independence Criterion (HSIC) and Training Objective
MI offers a principled way to study dependence between neural variables, but direct MI estimation is difficult to use as a training signal; estimators rely on computationally expensive density estimation, nearest neighbors, or learned critics that are sensitive to dimensionality and introduce bias. The Hilbert–Schmidt Independence Criterion (HSIC) [16,17] provides a related kernel-based dependence measure that avoids density estimation.
Given paired samples and kernels k and ℓ, the empirical estimate is
where K and L are the Gram matrices under k and ℓ, while and are their centered forms. HSIC equals zero only when X and Y are independent in the RKHS sense. As with MI, it captures both linear and nonlinear dependence; however, it is stable to estimate within a mini-batch and differentiable with respect to network parameters, making it suitable as a training loss.
Motivated by the representational patterns analyzed in later sections, we incorporate HSIC as a dependence-regularization term that encourages intermediate features to align more cleanly with class structure. During training, for each convolutional layer ℓ, we compute HSIC between the pooled activations and the mini-batch labels, using an RBF kernel for features and a delta kernel for labels. The total loss is
where controls the strength of dependence regularization. This formulation allows the architecture training to favor the types of effective representational structures identified in our analysis.
In practice, HSIC introduces two tunable components: the global scale controlling the overall strength of dependence regularization, and per-layer hyperparameters determining how strongly each layer is encouraged to align with labels. We choose small values ( , ) to avoid overwhelming the cross-entropy gradient; Section 4.3.2 evaluates the sensitivity of the method to these hyperparameters. Computationally, HSIC adds only two Gram matrix multiplications per layer per batch. Because Gram matrices use globally pooled activations, HSIC scales with channel count rather than spatial size, making the overhead modest even for large networks.
3.6. Experimental Design and Analysis Framework
Our experiments combine post hoc MI measurements, within-layer specialization metrics, and training time dynamics to form a unified view of how CNNs acquire and distribute label-relevant information.
Post Hoc Information Patterns across Layers and Architectures.
We first examine how trained models allocate information across layers by computing input-to-layer MI , layer-to-label MI , and inter-layer MI for VGG-16 and ResNet-18. Comparing trained CNNs with their randomly initialized counterparts isolates structure produced purely through optimization and reveals global tendencies toward feature disentanglement, compression, hierarchical label encoding, and architecture-dependent retention of input variability.
Channel-Level Specialization and Information Concentration.
To quantify how label information is distributed within a layer, we compute the per-channel label MI and form a probability distribution . Let denote the probability vector. the ascending sort of p, and its descending sort. We summarize within-layer structure using three standard concentration metrics: the Gini coefficient, Top- MI share, and normalized entropy:
Units.
MI is reported in nats throughout, consistent with our use of natural logarithms. By contrast, the normalized entropy is dimensionless since normalization by cancels the logarithmic information units.
We summarize within-layer structure using the Gini coefficient, which measures inequality in the MI distribution, the Top-k% MI share, which captures how much MI is concentrated in the most informative channels, and the normalized entropy, which quantifies the overall uniformity of MI across channels. These metrics quantify the extent to which training produces compact subsets of label-informative channels relative to random baselines.
Training Time Information Dynamics and Regularization Effects.
Representational structure develops gradually during learning; thus, we track each layer’s information trajectory over training. For each layer, we monitor across epochs to see when input structure is preserved, when it is discarded, and when label-relevant structure begins to dominate; for readability, we use the same notation to refer to the analogous layer–label and inter-layer quantities. These trajectories reveal when specialization emerges and whether it stabilizes or continues to drift. To test whether such dynamics can be shaped rather than simply observed, we introduce an HSIC-based regularizer and measure its effect on the timing and strength of label alignment, the concentration of information within channels, and overall accuracy. This allows us to evaluate whether promoting label dependence and reducing redundancy leads to more structured representations and faster convergence.
This methodology provides a unified approach to quantifying how CNNs encode, allocate, and refine information. By combining MI estimation, concentration metrics, and kernel-based dependence measures under a consistent validation protocol, we isolate representational changes arising from training rather than estimator or data artifacts.
4. Results
Our measurements reveal how CNNs rearrange information during learning: dependencies with inputs and labels shift predictably across depth, feature-label MI concentrates into small subsets of high-impact channels, and these structures emerge at distinct stages of training. These trends are consistent across architectures and can be strengthened through HSIC regularization, indicating that representation formation follows a selective, dependence-driven process.
4.1. Post Hoc MI Patterns Across Architectures
The experiments in this subsection will focus on patterns in MI we can measure post-training using only inference in different architectures.
Input-Layer and Layer–Label MI Structure.
Figure 1 shows how MI redistributes across depth in trained versus randomly initialized networks. For both VGG-16 and ResNet-18, the ImageNet-trained models exhibit a clear rise in layer-label MI as depth increases: later representations encode markedly stronger dependence on the class labels, whereas early layers remain weakly informative. By contrast, random networks show uniformly low label MI across all depths.
The orange curves highlight the complementary pattern for input-layer MI. In trained models, dependence on the raw input decreases with depth, reflecting a transition from low-level features to more abstract task-aligned representations. Random networks again lack structure, maintaining uniformly higher input MI because their layers remain entangled with the input signal.
Layer–Layer MI Structure.
Figure 2 visualizes the pairwise MI between intermediate VGG-16 representations. The ImageNet-trained network (left) shows a characteristic pattern: MI between distant layers is lower and MI decreases steadily with depth, indicating that successive transformations produce increasingly decorrelated feature spaces. The randomly initialized model (right) shows the opposite trend: significantly higher MI between many layers, reflecting redundant and entangled representations that have not yet specialized.
A notable exception in the trained network is the first convolutional pair: the MI for conv1–conv2 is roughly two orders of magnitude larger than for any other layer pair. These layers sit closest to the raw pixels and share highly overlapping receptive fields; thus, both effectively encode similar low-level statistics (edges, color blobs, local contrast) before later blocks reconfigure this front-end into more task-specific features. This pattern aligns with prior work using the PEEK [11] model visualization, where early convolutional filters appeared low-variance and visually unremarkable [18,19] yet were functionally critical and not safely prunable [20,21]. Entropy-based guidance results [10] showed that the first convolutional layers uniquely preserved most of the input entropy, unlike later layers.
These trends reveal that layers in well-trained CNNs carry strong label MI and weak input MI near the head, with weak layer–layer MI throughout. The model keeps what matters for classification, throws out what does not, and avoids redundant transformations. These patterns reveal a representation hierarchy that is selective, efficient, and structurally distinct from random baselines.
4.2. Channel-Level Specialization and MI Concentration
4.2.1. Channel-Level MI Concentration
We measure how label information is distributed across channels by computing the per-channel MI for each layer with filters and normalizing them across channels. We then assess the degree of MI concentration via the Gini coefficient (measuring inequality), Top- MI share (measuring share by highest-MI channels), and normalized entropy (measuring uniformity).
Across VGG-16 and ResNet-18, trained models show a clear shift toward more unequal MI distributions: Gini and Top-k% share rise consistently, especially in deeper layers, while normalized entropy decreases modestly. Random networks remain comparatively flat, with lower medians and tighter spreads across seeds. Figure 3 and Figure 4 show the emergence of heavier upper tails and larger positive training: random deltas in late layers, indicating that a small subset of channels becomes disproportionately label-informative.
These results highlight a robust pattern of within-layer specialization: training concentrates label information into a minority of channels while preserving overall diversity. This selective allocation provides a refined view of “compression” [6]; while layer-level MI may not contract strongly across layers with ReLU [8], the distribution of label dependence sharpens reliably.
4.2.2. Functional Necessity of High-MI Channels
Having established that label information concentrates into a small subset of channels, we next test whether these channels are functionally necessary for inference. For each trained model, we rank channels within each layer by label MI and perform knockout experiments that remove the top-MI channels until reaching cumulative MI-mass levels . These are compared against size-matched random and bottom-MI controls. All results are averaged over five seeds and shown in Figure 5.
We evaluate two variants: plain knockouts, which zero out the selected feature maps, and energy-preserving knockouts, which also rescale the remaining activations in the layer so that their norm matches the original pre-ablation magnitude. This controls for the possibility that accuracy drops might arise merely from reduced activation energy rather than from the removal of label-informative structure.
Top-MI knockouts consistently produce the largest accuracy drops across architectures and MI mass levels, showing that the channels carrying the most label information are also those most essential for prediction. Random and bottom-MI knockouts reduce accuracy far less, indicating that most channels contribute less to the decision. The energy-preserving variants, which restore the norm of the remaining activations, mirror the plain knockouts, confirming that the degradation is not an artifact of reduced feature magnitude. These results establish that high-MI channels encode task-critical structure rather than merely correlating with the labels.
A complementary analysis of residual blocks, including add-only MI concentration and skip-gain sweeps, is provided in Appendix A, where we show that skip connections primarily modulate how information is combined rather than which channels carry label-relevant signal.
Semantic and Architectural Localization.
We next test whether channel specialization aligns with semantic structure. For each class, we compute the class-conditional label MI and remove the smallest set of channels with cumulative MI mass that reaches a target level . Only predictions for that class are evaluated; performance on all other classes is left unchanged. Each targeted knockout is compared to size-matched random and low-MI controls (averaged over five seeds). Figure 6 shows a consistent pattern across all q: knocking out high-MI channels damages performance on the associated class far more than removing the same number of random or low-MI channels.
Across MI-mass levels, VGG-16 shows clear semantic dependence. At , and typically only 6–8 channels, class accuracy drops by roughly – while random and low-MI controls remain near – . At (about 14–16 channels), targeted drops roughly double, with controls still minimal. By , targeted effects become substantial; the most MI-dependent classes fall by 7– , while random controls at the same q remain around – . Full quantitative results, including per-class breakdowns and confidence intervals, are provided in Appendix B.
These findings show that high-MI channels form genuine class-specific support sets; each class depends on its own informative subset of “specialist” channels, and removing them selectively degrades that class while leaving others unaffected. Combined with the global knockout experiments, this demonstrates that MI ranking captures both overall importance and fine-grained semantic specialization in the network.
4.2.3. Robustness and Redundancy
We assess how stable and redundant these specialists channels are, i.e., whether they can be transplanted between models or replaced by redundant channels.
Cross-Model Specialist Transplants.
To test whether high-MI channels are reusable across networks, we transplant the top-MI out-channels from a trained donor model into a shape-matched recipient of the same backbone trained with a different seed. Across VGG-16, ResNet-18, and ResNet-50, every transplant reduces validation accuracy, with losses increasing monotonically with the MI mass level q. Size-matched random and low-MI controls show comparable degradation, indicating that high-MI channels are not transferable in isolation; rather, their function depends on the representational context in which they emerge rather than reflecting universally reusable “feature specialists”. Full backbone-wise tables and confidence intervals appear in Appendix C.
Redundancy and Minimal MI Cover Analyses.
We further compare a minimal MI cover set (the smallest non-overlapping subset of channels needed to reach a target MI-mass) with redundant MI-matched sets that achieve the same mass using overlapping channels. Redundant sets buffer perturbations well at small q, but become harmful once a large fraction of the most informative channels is removed. This flip in behavior indicates that early-layer features are highly overlapping, while later layers carry specialized non-interchangeable information. Complete results for all architectures and MI mass levels are provided in Appendix D.
4.3. Training Time Information Dynamics and Regularization Effects
4.3.1. Temporal Evolution of Information Flow
We analyze how and evolve during training to assess when label structure emerges and whether the classic “fitting then compression” behavior holds. For each run, we summarize the change in input information with a single : the difference between initialization and the best-accuracy checkpoint, averaged over the final third of layers (where estimator noise is minimal). Negative values indicate net “compression”, while positive values indicate “expansion”.
Figure 7 shows accuracy versus across VGG-16 and ResNet-18/50 using either ReLU or tanh activations (three seeds each). Points lie on both sides of zero with no downward trend; high performance does not require net compression, and many high-accuracy runs even expand input information. Activation choice matters more than accuracy; ReLU tilts toward expansion, while tanh produces a mix of compressive and expansive trajectories, consistent with prior findings that information plane behavior depends on activations rather than reflecting a universal training law [8].
To examine whether compression emerges after fitting, as sometimes suggested, we compute post-plateau slopes of using the data-driven plateau of as the reference point. Representative examples in Figure 8 show two patterns: a mild downward drift in a tanh/VGG run, and near-zero or mixed slopes in a ReLU/ResNet run. Across all models and seeds, slopes are near 0 nats per epoch, indicating that when post-plateau compression appears, it is weak and entirely activation- and architecture-dependent.
Additional exploratory analysis of weight-level MI (Appendix E) did not reveal consistent trends within the methodology herein and diverges to separate research path. It is included for completeness.
4.3.2. HSIC as Dependence-Based Regularization
We evaluate whether injecting a small HSIC term into the training objective improves optimization dynamics and final performance. HSIC serves as a differentiable proxy for mutual information, penalizing feature configurations that are statistically independent from the labels and rewarding those that express class-relevant structure. This makes it a natural counterpart to the representational patterns identified in our MI analysis.
We train two VGG-16 models on Imagenette2 with identical hyperparameters: one using standard cross-entropy (CE) and one augmenting CE with an HSIC regularizer applied to all convolutional layers (weights , scale ). HSIC is computed batch-wise on globally pooled activations using RBF kernels for features and a delta kernel for labels. The comparison focuses on validation accuracy and validation loss over 100 epochs.
Figure 9 shows a consistent pattern across runs. The HSIC-augmented VGG-16 model reaches a higher validation accuracy ( ) than the cross-entropy baseline ( ). HSIC-augmentation of ResNet-18 provided a tiny accuracy boost ( ) as well. The validation loss mirrors this trend: HSIC drives a faster early decrease and reaches a lower final value, suggesting a more directed optimization path. Importantly, neither accuracy curves nor loss curves show signs of increased overfitting; both models remain slightly underfitted, and their generalization gaps are nearly identical.
These results indicate that the HSIC term acts not merely as a regularizer but as a dependence-guided training signal. By rewarding activations that align with class structure, HSIC accelerates the formation of discriminative features and reduces representational drift during learning. This complements our earlier MI findings: the dependence structure revealed in the post hoc analysis translates into tangible training time benefits when optimized directly. In short, HSIC provides an actionable way to impose the representational geometry that MI analysis suggests is desirable.
We also quantify compute overhead. The HSIC model runs to slower per epoch than the CE baseline due to the additional Gram computations on pooled activations. This overhead remained consistent across tested batch size (64) and is minor relative to convolutional cost.
5. Conclusions
CNNs do not learn by uniformly compressing information. Instead, they form specialist channels consisting of a small subset of units that carry nearly all feature–label dependence, while the majority remain weakly informative or redundant. These specialists are functionally necessary, architecture-specific, and reproducible across runs, indicating that specialization is a structural property of learning rather than noise or estimator drift. These patterns arise consistently across architectures and training runs, and can be reinforced through a simple HSIC-based dependence regularizer that accelerates convergence and modestly improves accuracy.
Because Imagenette2 is drawn directly from ImageNet and preserves its natural-image statistics, supervision structure, and standard training pipelines, it provides a controlled proxy for ImageNet-scale vision tasks. While absolute mutual information values and optimization dynamics may shift with dataset scale, the qualitative patterns emphasized here (depthwise growth of label dependence, channel-level specialization, and dependence concentration) are tied to representational structure rather than dataset size. As such, Imagenette2 offers a practical setting for studying these mechanisms, even as direct validation on full ImageNet remains an important direction for future work.
More broadly, while the empirical results in this work are restricted to natural-image classification, the analysis framework itself is modality-agnostic. Whether similar MI dynamics and specialization patterns arise in other vision tasks or in non-visual domains such as language and audio remains an open question. Addressing this will require adaptation of MI estimation and representation analysis to domain-specific architectures and data structures, and is a focus of ongoing work.
Within this setting, these findings demonstrate that MI provides a stable and explanatory lens on representation formation and that the structures it reveals—specialization, sparsity, and dependence alignment—can be deliberately shaped during learning.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kraskov A. Stögbauer H. Grassberger P. Estimating mutual information Phys. Rev. E 20046906613810.1103/Phys Rev E.69.06613815244698 · doi ↗ · pubmed ↗
- 2Belghazi M.I. Baratin A. Rajeswar S. Ozair S. Bengio Y. Courville A. Hjelm R.D. MINE: Mutual Information Neural Estimationar Xiv 202110.48550/ar Xiv.1801.040621801.04062 · doi ↗
- 3van den Oord A. Li Y. Vinyals O. Representation Learning with Contrastive Predictive Codingar Xiv 20181807.03748
- 4Linsker R. An Application of the Principle of Maximum Information Preservation to Linear Systems Advances in Neural Information Processing Systems Touretzky D. Morgan-Kaufmann San Francisco, CA, USA 1988 Volume 1
- 5Hjelm R.D. Fedorov A. Lavoie-Marchildon S. Grewal K. Bachman P. Trischler A. Bengio Y. Learning deep representations by mutual information estimation and maximizationar Xiv 201910.48550/ar Xiv.1808.066701808.06670 · doi ↗
- 6Tishby N. Pereira F.C. Bialek W. The information bottleneck methodar Xiv 200010.48550/ar Xiv.physics/0004057 physics/0004057 · doi ↗
- 7Shwartz-Ziv R. Tishby N. Opening the Black Box of Deep Neural Networks via Informationar Xiv 201710.48550/ar Xiv.1703.008101703.00810 · doi ↗
- 8Saxe A.M. Bansal Y. Dapello J. Advani M. Kolchinsky A. Tracey B.D. Cox D.D. On the Information Bottleneck Theory of Deep Learning Proceedings of the International Conference on Learning Representations Vancouver, BC, Canada 30 April–3 May 2018