Concatenated Constrained Coding: A New Approach to Efficient Constant-Weight Codes
Kees Schouhamer Immink, Jos H. Weber, Tuan Thanh Nguyen, Kui Cai

TL;DR
This paper introduces a new method for designing efficient constrained codes by combining multiple low-complexity codes.
Contribution
The novelty is a concatenated constrained coding approach that enables efficient constant-weight codes with low complexity.
Findings
Concatenated constrained codes allow for long constrained codes not feasible with prior methods.
The approach is applied to constant-weight and low-weight code design with a focus on complexity-redundancy trade-offs.
Abstract
The design of low-complexity and efficient constrained codes has been a major research item for many years. This paper reports on a versatile method named concatenated constrained codes for designing efficient fixed-length constrained codes with small complexity. A concatenated constrained code comprises two (or more) cooperating constrained codes of low complexity enabling long constrained codes that are not practically feasible with prior art methods. We apply the concatenated coding approach to two case studies, namely the design of constant-weight and low-weight codes. In a binary constant-weight code, each codeword has the same number, w, of 1’s, where w is called the weight of a codeword. We specifically focus on the trading between coder complexity and redundancy.
Click any figure to enlarge with its caption.
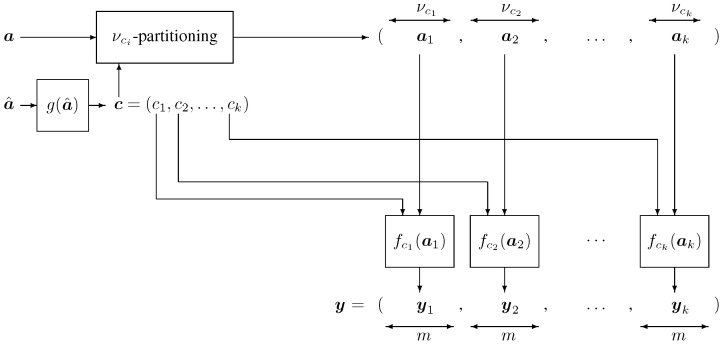 Figure 1
Figure 1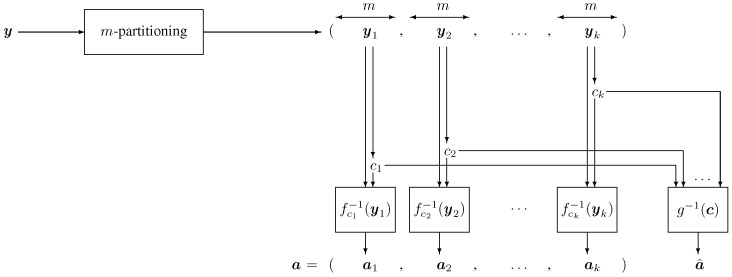 Figure 2
Figure 2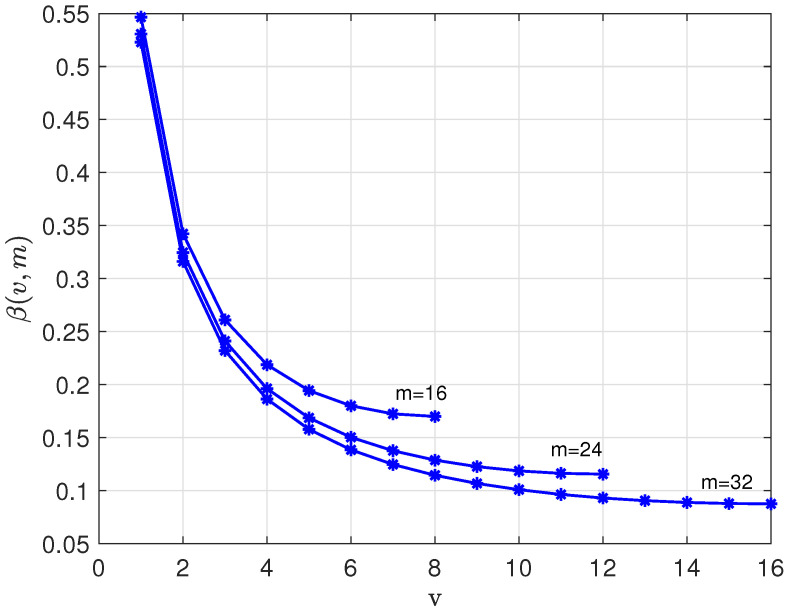 Figure 3
Figure 3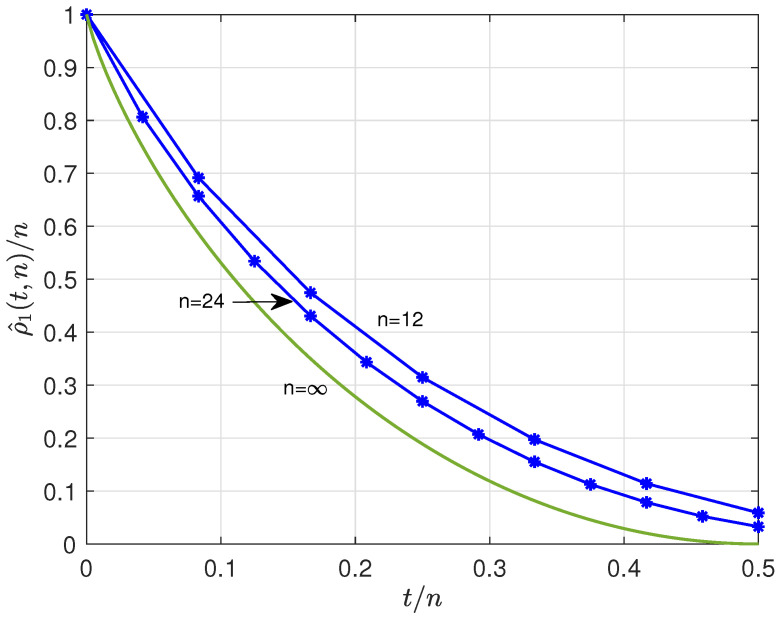 Figure 4
Figure 4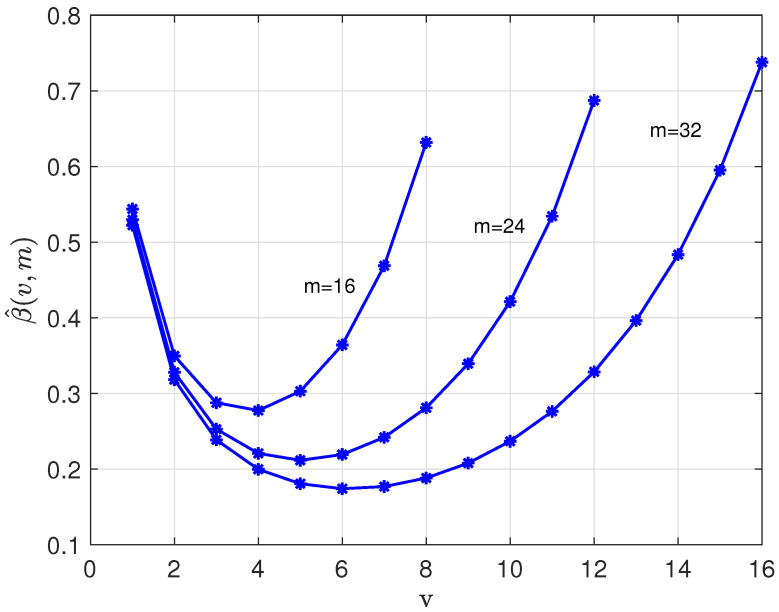 Figure 5
Figure 5- —Singapore Ministry of Education Academic Research Fund Tier 2
- —SUTD Kickstarter Initiative (SKI)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCellular Automata and Applications · graph theory and CDMA systems · Algorithms and Data Compression
1. Introduction
A constrained channel is not capable to transmit all possible signals, and only certain sequences may be allowed [1]. A constrained code implements these constraints by converting arbitrary source data into permitted signals [2,3,4]. Designing an invertible mapping from arbitrary, unconstrained source sequences into coded, constrained binary sequences is a fundamental challenge. In a conventional block code, the source data are segmented into small, manageable data blocks, which are then translated into sequences of permitted symbols. The resulting codewords satisfy the given constraints, allowing them to be freely cascaded without violating channel constraints. Naturally, larger block sizes enable more efficient encoding into permitted sequences. Numerous implementation strategies have been explored in the literature.
Implementations fall in three main categories: table look-up, replacement techniques, and arithmetic-based implementations. Table look-up is straightforward, but the size of the data blocks is limited by the maximum size of the tables used [5,6]. The replacement technique successively or iteratively removes forbidden subsequences in the source data to obtain a constrained sequence. Enumeration techniques [4,7,8,9,10,11,12] use integer arithmetic operations to translate source data into constrained codewords and vice versa. However, the required silicon area of the look-up table of integer coefficients does not scale linearly with the block size [13], and it may become unacceptably large with mounting word length, precluding their use in practical transmission or storage systems [5]. A second important consideration in enumerative encoding is error propagation, as a single bit error in the received codeword may corrupt an entire decoded word [14]. This necessitates the use of strong error correction codes, which in turn require additional redundancy.
Concatenated error correction codes [15] are widely used in data transmission and storage systems. Formed by combining two or more codes, typically referred to as the inner and outer codes, these constructions provide enhanced error performance while maintaining low decoder complexity. Inspired by this principle, we propose a concatenated constrained coding approach, in which two or more low-complexity constrained codes are combined to construct long constrained codes that are infeasible using conventional methods.
In the encoding device, the source data blocks are divided into two segments: a first segment and a second segment. The first segment of the source data is further partitioned into a plurality of small data subwords that are translated into an allowed codeword using several look-up tables whose sets of constrained output words are mutually disjoint. The second segment of source data is encoded using a second constrained code, which determines which look-up tables are applied during the first encoding stage. The final codeword, found by cascading the output words of the look-up tables, is transmitted. A decoder can uniquely restore the source data encoded by the first and second codes by observing the received codeword. We demonstrate that the concatenated constrained code enables the design of longer codewords with less redundancy than conventional methods, while avoiding the need for impractically large look-up tables.
We demonstrate the versatility of the concatenated constrained coding scheme through two case studies: designing long constant-weight and low-weight codes.
Paper structure: We introduce the fundamentals of concatenated constrained codes in Section 2. Section 3 reviews prior work on the properties of constant-weight codes, which sets a baseline for the new constructions. Section 4 presents new constructions of constant-weight codes using concatenated constrained codes. The construction of very long constant-weight codes is explored in Section 5, where we analyze the application of one concatenated constrained code layered on top of another. Applications to low-weight codes are covered in Section 6. Finally, Section 7 concludes the paper.
2. Concatenated Constrained Code, Basics
We describe an encoder that translates binary source data into n-bit binary codewords, denoted by y, which satisfy a given constraint . Let denote the set of n-bit codewords y that meet constraint . Since n is typically too large to permit direct generation of codewords via a single look-up table, the codeword y is divided into k equal-sized m-bit constrained subwords and and . The parameter m is chosen to be small enough to allow the use of look-up tables for mapping source data to the subwords .
2.1. Major Components Overview
We construct K, , distinct sets of m-bit subwords, denoted by , , each satisfying a specific constraint , . In practice, only distinct look-up tables are required as they can be re-used via multiplexing. Each set enables a bijective mapping of source bits into valid subwords, ensuring compatibility with .
To construct an n-bit codeword y, we concatenate k m-bit subwords , where each is selected from the corresponding subword set . The selection is guided by a control code , with . The goal is to ensure that the full codeword satisfies the overall constraint .
2.2. Basic Properties
The concatenated constrained coding scheme adheres to the following conditions:
- The sets , , must be pairwise disjoint.
- Each codeword y must encode a fixed number of source bits.
- Every codeword y must satisfy the global constraint .
We define two segments of source data:
- , .
- , .
The total number of encoded source bits, , is referred to as the throughput of the code.
The encoder generates the control word , , by applying a bijective mapping , where C is a constrained code. The ℓ-bit source data, a, are partitioned into k segments of bits, . Clearly, we demand and thus . The set of allowed vectors c is
This allows up to additional source bits to be encoded into the control vector c via the mapping . Consequently, the total number of source bits that can be represented in the n-bit codeword y is . Each of the k segments of the original source data, denoted , is mapped to an m-bit constrained subword using the mapping for . These subwords are then concatenated to form the complete codeword y, which is subsequently transmitted or stored. Importantly, the control vector c is not transmitted to the receiver. However, since the subword sets are pairwise disjoint, the decoder can uniquely identify which mapping was used for each . This ensures that both parts of the source data, a and , can be fully and uniquely reconstructed from the received codeword y.
Figure 1 and Figure 2 depict a block diagram of the encoder and decoder, respectively.
2.3. Complexity Issues
The encoder begins by mapping a segment of source bits into a control codeword c using the bijective function . It then proceeds to convert each of the k source subwords , each of length for , into corresponding m-bit constrained subwords via the mapping .
Assuming the k conversions can be implemented in a multiplexed fashion, the primary hardware requirements for encoding and decoding a concatenated constrained code are limited to the following:
- The K look-up tables for the sets , where .
- A look-up table for the mapping function that generates c.
Unlike traditional approaches that rely on a single large n-bit look-up table, the maximum codeword length n achievable with the proposed concatenated constrained coding scheme is governed by the product of the practical maximum sizes of the K look-up tables and the control codebook C. This significantly relaxes the constraints on memory size and look-up complexity.
A compelling example of this technique is the design of a binary constant-weight code, where each -bit codeword contains exactly 32 ones. This design is efficiently realizable using just three modest-sized look-up tables, highlighting the practicality of the concatenated constrained coding approach.
Example 1. We design an encoder that converts arbitrary source data into binary codewords, y, , of length n = 128, where each codeword has 32 1’s and 96 0’s. The maximum number of source bits that can be accommodated is , where denotes the truncation or floor function. Therefore, any code constructed for this setting must have a redundancy of at least 28 bits. Since n = 128 is too large to be handled by a single look-up table, we partition the codeword into subwords, each of length m = 8 bits. While other values for k and m are possible, the chosen values simplify manual calculations. In the prior art block code design of multiply constant-weight codes [16] or constant subblock-composition code [17], each subword contains exactly two 1’s, and the subwords can be freely cascaded with each other to form a codeword. Clearly, there are possible 8-bit subwords. Twelve excess subwords are deleted, so that each subword can convey four source bits, and hence, the 128-bit codewords can carry source bits, resulting in 64 bits of redundancy.
Using the concatenated constrained code construction, we define types of subword sets, namely the set of 8-bit words with a single 1, that is
and the set of 8-bit words with three 1’s, namely
We easily find that and , where denotes the cardinality of the set X. We delete excess subwords from (keeping 32 subwords). Consequently, we have and . Define the bijective mappings and . Each 128-bit codeword contains 32 ones by selecting eight subwords from and eight from . The subwords together convey source bits, matching the number of source bits in the prior art; so nothing is gained or lost so far. The k(=16)-bit word, c, whose elements determine whether to apply or , has equal numbers of 1’s and 0’s. The word, c, can therefore convey source bits. As a result, the total, combined, throughput is .
Alternatively, we may choose and , which requires larger look-up table for and . In this case, the traditional approach yields a throughput of bits. In contrast, the concatenated constrained code construction achieves a throughput of bits, that is, 90% of the maximum possible.
The above example shows that the new scheme leverages both subword composition and control-word combinatorics to improve data throughput beyond traditional designs.
In the next sections, we exploit the concatenated constrained code for the construction of efficient constant-weight and low-weight codes. We start with a review of the state of the art.
3. Constant-Weight Codes, Preliminaries, Redundancy, Prior Art
3.1. Introduction
In a binary constant-weight code, each codeword has the same number of 1’s. These codes, also known as ‘m-out-of-n’ [7], codes, have found applications across a wide range of devices and systems including data storage [2], code-division multiple-access (CDMA) systems for optical fibers [18], test pattern generation for circuit testing [19], identification coding [20], and VLSI design [21,22]. Traditionally, constant-weight codes have been employed in data transmission and data storage systems that suffer from low-frequency noise or are subject to low-frequency bandwidth constraints [2,23,24]. More recently, they have been proposed for use in DNA-based storage systems. Knuth’s celebrated implementation [25,26] generates ‘balanced’ codewords i.e., codewords of weight , n even, with a computational complexity that scales with n, and a redundancy that is approximately twice the theoretical minimum for large n.
A simple and efficient algorithm for producing a codeword with a prescribed imbalance is not available, and the development of such an algorithm remains an open research problem [22,27]. Designing low-complexity encoder/decoder architectures for very high-rate constant-weight codes is of significant practical and economic value. There is a clear demand for efficient constant-weight codes that avoid the need of exorbitantly large look-up tables while maintaining high performance.
3.2. Redundancy
Let , , be a binary word of length n. The Hamming weight of x, denoted by , is defined by . A constant-weight code, denoted by , defined by
comprises all binary words of length n and weight w, . The size of , denoted by , equals
where , , denotes the relative weight. In case we have a code with codewords with equal numbers of 1’s and 0’s, i.e., , n even, the code is said to be balanced. Note that without loss of generality we study the case as the case is simply found by inverting (flipping) the binary symbols of a codeword.
The capacity and maxentropic redundancy of constant-weight codes, denoted by and , are defined by
and
Using [28], we find the useful approximation
where Shannon’s entropy function, , is defined by
The maxentropic redundancy, , is applied as a yardstick to evaluate the performance of implemented codes.
3.3. Traditional Code Design Approach
In the prior art, see [29] and the references therein, a codeword, y, of length n is divided into k constrained subwords, , , of equal length m, where . The weight of each subword, , is prescribed and denoted by , , where . The weight distribution vector is denoted by . The redundancy, denoted by , equals, see (5),
Note that describes a lower bound to the redundancy of implemented codes as in practice the (sub)code sizes are truncated to the nearest power of two, see Example 1 for an illustration. We have opted not to truncate the code sizes in our computations, except in the worked design examples, in order to maintain analytical tractability. The efficiency of this construction, denoted by , is defined as [29]
It is shown in the Appendix A that a uniform, or flat, weight distribution minimizes the redundancy.
Numerical results for the efficiency of the prior art construction, , are presented in Table 1. Additional efficiency parameters, and , for the new constructions are introduced and discussed in Section 4.2 and Section 4.3, respectively.
In the next section, we apply the concatenated constrained code to the design of constant-weight codes.
4. Concatenated Constant-Weight Code
4.1. Concatenated Constrained Code
As in Section 3.3, the n-bit codeword y is partitioned into k subwords, , , of equal length m. We have , and . In the prior art, the subword weights, , are assumed to be fixed for the whole transmission. In this section, however, the weights of the subwords are controlled, ‘modulated’ in engineering terms, by a constrained codeword , which is taken from the predefined set . Note that and play the same role as c and C in Section 2.
The coding of y is carried out in two distinct steps. First, source data are mapped bijectively to the weight distribution vector via a look-up table. In the second step, the encoder uses the look-up tables corresponding to the constant-weight codes , , to convert the source data into the subwords . Since the mapping to , , is bijective, the decoder can uniquely determine the vector , and thereby recover the original source data from the received y.
Define the vector , , where represents the number of occurrences of the symbol j in . The vector u is commonly referred to as the histogram of . An allowed vector u must satisfy
The set is the set of k-vectors, , of fixed composition , that is, the number of 0’s, 1’s, ’s in is given by , respectively. The size of the constant composition code is
The number of source words that can be accommodated, denoted by , equals
Below we illustrate and analyze a design of two simple cases, where u contains or non-zero elements, which are denoted here by the binary and ternary case. We start with a description of the binary case, .
4.2. Binary Case, K=2
Let , so that and , and otherwise . We obtain from (10) that
There are manifold solutions to the above system of (positive) integer equations. An enticing option for k even is and , so that , and
denotes the set of allowed vectors .
The relationship between and c is a straightforward renumbering of their elements by
so that , and renaming and . The coding circuitry comprises two look-up tables, and , of width m, plus a (binary) look-up table for the balanced code, C, of width k. Note that Knuth’s algorithm can be used for mounting k, when the look-up table for c is uneconomically expensive.
We obtain from (14) that
so that, see (12),
Hence the redundancy, denoted by , is
Since
and
we obtain
so that
where
Figure 3 shows the coefficient versus v, , for , and 32.
The coefficient is an important parameter as it quantifies the additional redundancy per subword required for the concatenated coding system. Note in (21) that, with respect to the redundancy of the traditional code, , we have two additional terms in . On one hand we add redundancy, namely bit per subword, by deviating from the flat weight distribution, as discussed in Appendix A. On the other hand, we reduce redundancy, namely
bits per subword by encoding data in the second (binary) code C. Figure 3 shows that the loss, , is around 0.1–0.2 bits per subword over a wide range of the parameters v and m.
The efficiency of codes based on the binary concatenated constrained code is defined by
Table 1 presents numerical results for the code’s efficiency, . We observe a notable improvement in efficiency compared to that of the traditional scheme, , especially for larger values of k.
4.3. Ternary Case, K=3
For the ternary case, we define the values of by
and otherwise . Note that for we have the binary case, , as detailed in the previous subsection. Let denote the constant composition code based on u. Then
and the number of source words that can be accommodated, denoted by , equals
The overall redundancy, denoted by , is
For the special case , , we have
and
For , we obtain the Stirling approximation [30]
so that
Define the efficiency of this construction by
Table 1 shows numerical results for the code’s efficiency, . As in the binary case, we find c by renumbering the elements of according to , , so that . We then rename the sets as , and . It is assumed that a look-up table is used to map the source data into c. For larger values of k, where using a look-up table becomes impractical, we may resort to enumeration algorithms for multiset permutations [31] or Knuth-like algorithms [30,32], which can be employed instead. The next example elaborates Example 1 for .
Example 2. We choose, as in Example 1, , , , and . For the ternary case, , we obtain the following results from Example 1: , , and . From this, we can easily determine that the maximum throughput is attained for or .
4.4. Error Propagation Effects
Single bit errors in the received codeword can lead to an avalanche of errors during decoding. This phenomenon, called error propagation, is especially pronounced in long codes based on enumerative methods [14]. In this subsection, we examine the error propagation behavior of constant-weight codes constructed using concatenated constrained codes.
Let the received codeword be denoted by , which differs from the transmitted codeword, , in a single (unknown) position. Since y belongs to a constant-weight code, such an error is detectable.
For a constant-weight code constructed with parameter (binary case), as illustrated in Example 1, each subword belongs to the set , , and . Since the minimum Hamming distance between elements of this set is two, it is possible to identify the specific subword that was received in error. Assume that the subword with index j is in error, i.e., . By definition, we have , so the control vector c can be fully decoded by, see (15),
Thus, in the binary case, , all data can be recovered except for the unknown m-bit subword , which must be marked as an erasure. In the ternary case ( ), each belongs to the set , . Since the minimum Hamming distance between its elements is one, it is not always possible to identify the erroneous subword. As a result, the entire n-bit codeword must be flagged as an erasure. Note that for the ternary case we may choose the sets , and , so that it is also possible to identify the specific subword that was received in error.
5. Very Long Codes
In the previous sections, we demonstrate that concatenated constrained coding can efficiently produce longer constant-weight codewords compared to conventional state-of-the-art methods. However, the scalability of such codes is limited: the codeword length is, in practice, constrained by the maximum feasible size of the look-up tables, either the subword tables of width m, or the control code table C of width k.
To overcome these practical limitations, several strategies can be adopted:
- Use enumerative coding techniques to generate the subword sets and/or the control codebook C.
- Apply a second layer of concatenated constrained coding to generate entries within and/or C, effectively building a hierarchy of constrained encodings.
The next example illustrates the effectiveness of this method through numerical results for a constant-weight code of length .
Example 3. Consider the case where and ( ). The theoretical minimum redundancy for this constant-weight code is bits. Due to the large value of n, enumerative coding becomes impractical for this low-weight scenario, so we explore alternative coding strategies:
- We can cascade sixteen codewords of length and , see Example 2, with a total throughput of bit.
- We can, as illustrated in Example 1, select a concatenated constrained code with and . Since is too large for directly using a look-up table to generate the control word c, we alternatively consider applying enumerative coding for generating the balanced codeword c. Then, the redundancy is five bit, so that the scheme’s throughput is bit. We may apply Knuth’s algorithm to generate codeword c of length with an 8-bit redundancy, so that the throughput is bit.
- We may construct a long code by using multiple smaller concatenated constrained codes as building blocks. For example, an ( , ) code is constructed by first constructing two concatenated constrained codes with parameters of weights and , respectively, by using and instead of of the , code detailed in Example 2. Both codes have a throughput of 84 bit. On top of these codes, we define a concatenated constrained code with and , the combined throughput equals bit. The code’s implementation requires six small look-up tables.
While numerous other design options exist beyond those discussed above, the examples provided offer a representative insight into the key trade-offs involved.
6. Low-Weight Codes
Low-weight, or sometimes referred to as light-weight or bounded-weight, codes have found applications in efficiently synthesizing deoxyribonucleic acid (DNA) for massive data storage, where multiple DNA strands are synthesized in parallel [33]. Applications can also be found in memristor crossbar arrays for reducing the number of sneak-paths [34], and simultaneous energy and data transfer [17,35].
A low-weight code of length n and weight at most t, , denoted by , is defined by the union of the sets of words of weight ,
The redundancy, denoted by , equals
For asymptotically large n we obtain [28]
Figure 4 shows the normalized redundancy, , versus relative maximum weight, for , and ∞.
6.1. Code Design
The conventional construction of a low-weight block code follows a similar approach to that of constant-weight codes. The source data and codewords are partitioned into k manageable subwords, with look-up tables used to map the source data into these subwords. As assumed above let be the length of the low-weight codeword, where m is the length of each subword, and . The redundancy of a conventional code, denoted by , is
In the next subsection, we describe a simple low-weight code based on the concatenated constrained code format.
Binary Case, K=2
The source data are divided into two segments, namely and a. The first segment, , is translated into a binary constrained codeword, , where , of length k. The second segment, a, is translated into a series of k weight-constrained m-bit words, each taken from either the set or . For a concatenated constrained coding construction, the sets and must be disjoint. A convenient choice for these sets is
and
Let be a balanced word, k even, then the n-bit codeword found by cascading k m-bit subwords from , , has a weight less than or equal to t. The redundancy of the code, denoted by , equals
Define
then
Figure 5 shows the coefficient versus v, , for , and 32.
Define the efficiency parameters as and . Numerical results are presented in Table 2. It can be observed that the concatenated codes reduce the redundancy compared to the baseline by 6.5 percentage points for .
7. Conclusions
We have introduced a new class of constrained codes, referred to as concatenated constrained codes, which enable the construction of very long constrained codewords with significantly reduced complexity. Similar to traditional methods, the source data are divided into smaller blocks. In the first step, one segment of the source data is encoded using a set of small look-up tables, each corresponding to a disjoint set of valid output sequences. In the second step, another segment of the source data is encoded into a control codeword that determines which look-up table is used for each portion of the first segment.
This layered encoding structure enables the generation of longer codewords with lower redundancy compared to conventional approaches, while eliminating the need for massive look-up tables.
We demonstrated the effectiveness of this approach through two case studies focused on constructing binary constant-weight and light-weight codewords of length n, each containing exactly w ones, or not more than w ones, where . The concatenated constrained codes in these examples achieve lower redundancy than leading state-of-the-art solutions, while requiring only three or four compact look-up tables, highlighting both their efficiency and practicality.
We have shown that extremely long codewords can be constructed by applying a second layer of concatenated constrained coding on top of an initial concatenated constrained scheme, effectively generating elements within the sets and/or the codebook C.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Shannon C.E. A Mathematical Theory of Communication Bell Syst. Tech. J.19482737942310.1002/j.1538-7305.1948.tb 01338.x · doi ↗
- 2Immink K.A.S. Innovation in Constrained Codes IEEE Commun. Mag.202260202410.1109/MCOM.002.2200249 · doi ↗
- 3Marcus B.H. Siegel P.H. Wolf J.K. Finite-state Modulation Codes for Data Storage IEEE J. Sel. Areas Commun.19921053710.1109/49.124467 · doi ↗
- 4Ryabko B. A General Method for the Development of Constrained Codes IEEE Trans. Inf. Theory 2025713510351510.1109/TIT.2025.3552660 · doi ↗
- 5Modha D.S. Marcus B.H. Art of Constructing Low-complexity Encoders/decoders for Constrained Block Codes IEEE J. Sel. Areas Commun.20011958960110.1109/49.920168 · doi ↗
- 6Stockmeyer L. Modha D.S. Links Between Complexity Theory and Constrained Block Coding IEEE Trans. Inf. Theory 200248598810.1109/18.971739 · doi ↗
- 7Ramabadran T.V. A Coding Scheme for m-out-of-n Codes IEEE Trans. Commun.1990381156116310.1109/26.58748 · doi ↗
- 8Schulte P. Böcherer G. Constant Composition Distribution Matching IEEE Trans. Inf. Theory 20166243043410.1109/TIT.2015.2499181 · doi ↗