Federated Learning Under Evolving Distribution Shifts
Xuwei Tan, Tian Xie, Xue Zheng, Aylin Yener, Myungjin Lee, Ali Payani, Hugo Latapie, Xueru Zhang

TL;DR
This paper introduces new federated learning algorithms that handle changing data patterns over time, improving model performance in real-world scenarios.
Contribution
The paper proposes FedEvolve and FedEvp, novel algorithms that model evolving data distributions in federated learning.
Findings
FedEvolve and FedEvp outperform existing FL baselines in handling evolving data distributions.
The proposed methods show robustness to distribution shifts during testing.
Experiments on synthetic and real data validate the effectiveness of the algorithms.
Abstract
Federated learning (FL) is a distributed learning paradigm that facilitates training a global machine-learning model without collecting the raw data from distributed clients. Recent advances in FL have addressed several considerations that are likely to transpire in realistic settings, such as data distribution heterogeneity among clients. However, most of the existing works still consider clients’ data distributions to be static or conforming to a simple dynamic, e.g., in participation rates of clients. In real FL applications, client data distributions change over time, and the dynamics, i.e., the evolving pattern, can be highly non-trivial. Furthermore, evolution may take place from training to testing. In this paper, we address dynamics in client data distributions and aim to train FL systems from time-evolving clients that can generalize to future target data. Specifically, we…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1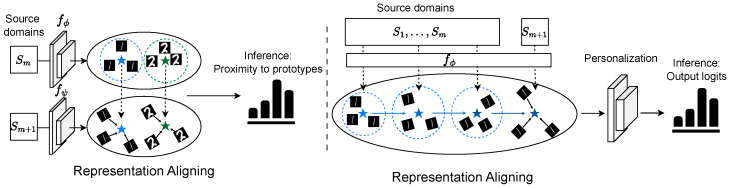 Figure 2
Figure 2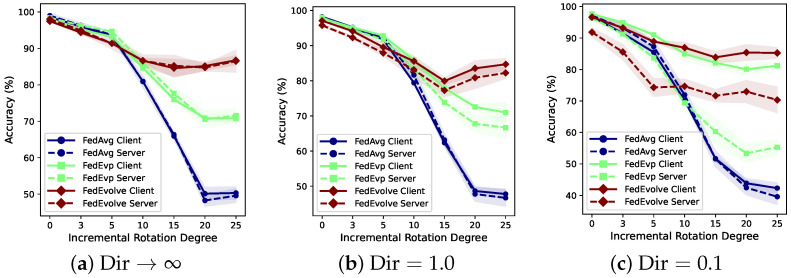 Figure 3
Figure 3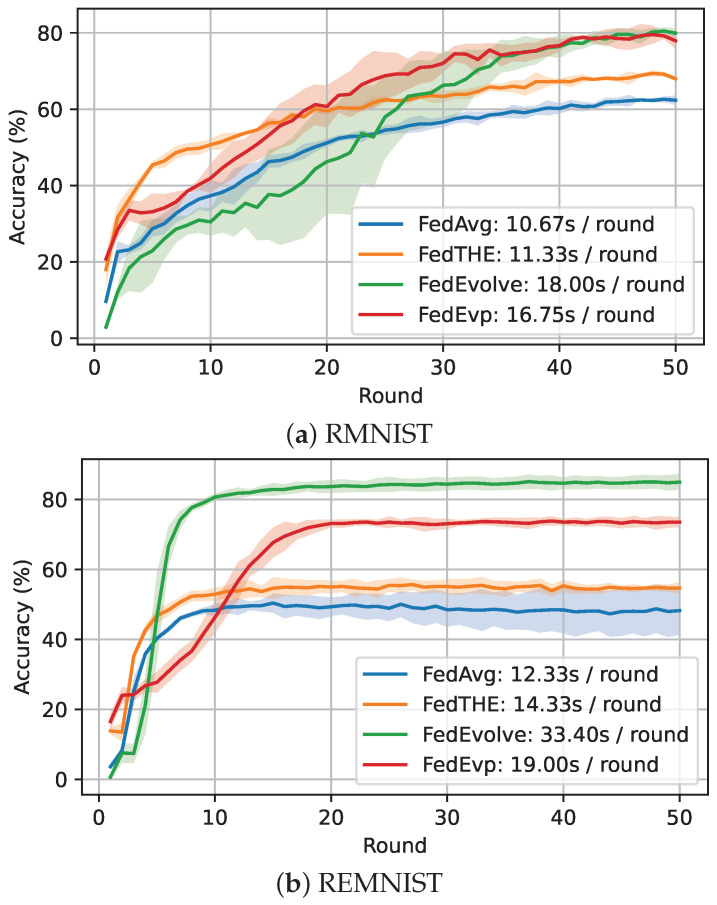 Figure 4
Figure 4- —Cisco Systems
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPrivacy-Preserving Technologies in Data · Domain Adaptation and Few-Shot Learning · Machine Learning in Healthcare
1. Introduction
Federated learning (FL) is a widely used distributed learning framework where multiple clients, using their local data, train machine-learning models collaboratively, orchestrated by a server [1,2,3]. A problem that has been extensively studied in FL literature is learning from heterogeneous clients, i.e., ensuring convergence of FL training and avoiding degradation of accuracy when clients’ data are not identically and independently distributed (non i.i.d.) [4,5,6].
Although a variety of approaches, such as robust FL [6] and personalized FL [7], have been proposed to tackle the issue of data heterogeneity, most of them still assume that the data distribution of each client is static and, in particular, remains fixed between training and testing. Some recent works [8,9] move one step further by proposing test-robust FL models when there exist distribution shifts between training and testing data. However, they only consider one-step shift between training and testing while the training data distribution is still assumed to be static. In practice, FL systems are trained and deployed in dynamic environments that may continually change over time, e.g., satellite data evolves due to spatial environmental changes and seasonal variations, clinical data evolve due to changes in disease prevalence and diverse across regions due to difference in hospital infrastructure, and human language exhibits temporal and regional changes, etc. Existing FL algorithms without considering such domain-level evolving distribution shifts may result in inaccurate models and show degradation under evolving shifts, especially when there is a large magnitude of the shift, as shown in Figure 3.
This work investigates FL under evolving distribution shifts and addresses two questions:
- How do domain-level time evolving distributions, with or without non-IID clients, affect FL system training and generalization?
- How can we exploit the evolving patterns from training data (source domains) and generalize our model on the unseen future distribution (target domain)?
We study these questions in a domain generalization setting: no target domain data are accessible during training. The goal is to continuously train an FL model from distributed, time-evolving data domains that can generalize well to the future target data domain. Figure 1 shows one motivating example.
Please note that although the problem of learning under evolving distribution shifts has been studied recently in the centralized setting (typically known as evolving domain generalization), e.g., see [11,12,13], it remains unclear how evolving distribution shifts can impact FL training and how to design FL algorithms when both evolving distribution shifts and data heterogeneity exist. The most relevant line of research to ours is continual federated learning (CFL) [14,15], which aims to train an FL system continuously from a set of distributed time series. However, the primary objective of these works is to stabilize the training process and tackle the issue of catastrophic forgetting (i.e., prevent forgetting the previously learned old knowledge as the model is updated on new data). In contrast, our work addresses evolving domain generalization, where the goal is ‘forward-looking’: we aim to extrapolate the evolving pattern to perform well on a future, unseen target domain. Standard CL methods are insufficient here because preserving past knowledge does not inherently guarantee the ability to predict future distributional shifts.
To answer the above two questions, we will examine the performance of existing FL methods on time-evolving data domains, including a wide range of methods such as traditional FL methods, personalized FL methods, test-time adaptation methods, domain generalization methods, and continual FL methods. We observe that existing methods cannot capture evolving patterns and fail to generalize to future data. We then propose FedEvolve, an FL algorithm that learns the evolving patterns of clients during the training process and can generalize to future test data.
Specifically, FedEvolve learns the evolving pattern of source domains through representation learning. It assumes there exists a mapping function for each client that captures the transition (“Transition” here refers to domain-level distribution shift across time steps and not an action-conditioned dynamical system) of any two consecutive domains. To learn such a transition, each client in FedEvolve learns two distinct representation mappings that map the inputs of domains in two consecutive time steps to a representation/latent space. By minimizing the distance between the distributions of these feature representations, FedEvolve captures the transition over two consecutive steps.
Although FedEvolve shows superior performance in learning from evolving distribution shifts in empirical experiments, the need for two distinct representation mappings brings double overhead during FL training. To reduce the computation cost and communication overhead, we further develop FedEvp as a more efficient and versatile version of FedEvolve by updating one representation mapping when evolving distribution shifts occur. Moreover, FedEvp better tackles heterogeneous data by incorporating the personalization strategy to partially personalize the model on each client’s local data.
We illustrate via extensive experiments that our algorithms significantly outperform current benchmarks of FL when the feature domain is evolving, on multiple datasets (Rotated MNIST/EMNIST, Circle, Portraits, Caltran) using different models (MLP, CNN, ResNet). Our main contributions are:
- We identify the evolving distribution shift in FL that the current robust FL, personalized FL, and test-robust FL frameworks have failed to consider.
- We propose FedEvolve to actively capture the evolving pattern from evolving source domains and generalize to unseen target domains.
- We propose a more efficient and versatile version of algorithm FedEvp that learns domain-invariant representation from evolving prototypes.
- We empirically study how FL systems are affected when both evolving shifts and local heterogeneity exist. Experiments on multiple datasets show the superior performance of our methods compared to previous benchmark models.
2. Related Work
We briefly review related previous works in this section.
Tackle client heterogeneity in FL. Many approaches have been proposed to tackle data heterogeneity issues in FL, and they can be roughly categorized into four classes. The first method is to add a regularization term. For example, Refs. [16,17] proposed to steer the local models towards a global model by adding a regularization term to guarantee convergence when the data distributions among different clients are non-IID. The second method is clustering [18,19,20]. By aggregating clients with similar distribution into the same cluster, the clients within the same cluster have lower statistical heterogeneity. Then, a cluster model that performs well for clients within this cluster can be found to reduce the performance degradation of statistical heterogeneity. The third method is to mix models or data. For example, Ref. [21] proposed a data-sharing mechanism where clients update models according to both the local train data and a small amount of globally shared data. Refs. [22,23] developed mixup data augmentation techniques to let local devices decode the samples collected from other clients. Ref. [24] finds a mixture of the local and global models according to a certain weight. The fourth method is robust FL. For instance, Refs. [6,25] obtain robust Federated learning models by finding the best model for worst-case performance. Notably, Ref. [6] only considers the affine transformation of data distributions, and [25] focuses on varying weight combinations over local clients. In addition, different personalization methods are applied to local clients, such as personalization [7,26,27,28], representation learning [8,27,29,30], and meta-learning [31].
FL with dynamic data distributions. While most previous works on statistical heterogeneity have considered static situations (i.e., the local heterogeneity stays constant during training), another line of literature focuses on FL in a dynamic environment where various distribution drifts occur. Some works aim to tackle drifts caused by time-varying participation rates of clients with local heterogeneity [32,33,34,35], while other works assume the global distributions are also evolving [14,15,36]. However, among all previous works, Refs. [8,9] are the only ones considering the distribution shift between training and testing, but they assume the training distribution is static.
Evolving domain generalization. Domain Generalization (DG) has been extensively studied to generalize ML algorithms to unseen domains where different methods, including data manipulation [37,38], representation learning [39,40], and domain adversarial learning [41,42]. To go one step further, a few works have considered the evolving patterns of the domains [11,12,13,43,44,45], but only [11,12,13] consider Evolving Domain Generalization (EDG) where the target domain is not accessible. Specifically, Ref. [11] developed an algorithm to learn embeddings of the previous domain and the current domain such that their representations are invariant. Ref. [12] developed a dynamic probabilistic framework to model the underlying latent variables across domains. Ref. [13] went beyond stationary dynamics to consider non-stationary evolving patterns across domains. Unlike these works that do not require access to the target domain during training, Ref. [46] considered the evolving domain adaptation problem, where the unlabeled data from a target domain is available, and the goal is to use domain discriminators to learn domain-invariant features and adapt the model to target data. Please note that domain adaptation differs from domain generalization, as domain generalization imposes stricter conditions by restricting access to the target domain during training, thereby making it a more challenging setting. However, all these previous works consider the centralized setting. Thus, there is a gap for EDG under distributed settings, and in particular for FL.
3. System Model
We consider a server–client federated learning (FL) system with K clients indexed by . Time evolves in discrete stages (“domains”) indexed by m. For each client k, data within domain m are drawn from a joint distribution over . We denote the local dataset in domain m by , where .
3.1. Client and Evolving Shifts
Clients are statistically heterogeneous: class marginals and feature distributions can differ across clients. Moreover, each client experiences evolving distributions over time, yielding a sequence of source domains during training, followed by an unseen target domain at test time.
3.2. Learning Model and Loss
Let denote the parameters of the global model (e.g., a neural network). For a labeled sample , let be a bounded per-example loss (e.g., cross-entropy). For client k in domain m, the expected loss is
3.3. Objective on the Future Target Domain
The goal is to learn a model on the distributed, time-evolving source data that generalizes to the subsequent target domain for each client. With nonnegative aggregation weights (e.g., proportional to client sample sizes) such that , we seek to find that minimizes the total loss at the target domain over K clients:
3.4. Communication Protocol
Training proceeds in synchronous rounds . In round t, the server selects a subset of clients and broadcasts the current parameters . Each client performs local optimization steps on its available source-domain data (potentially spanning multiple ), producing an update . The server aggregates updates (e.g., weighted averaging by local sample counts) to obtain . Clients may be partially participating; datasets can be unbalanced.
3.5. Assumptions (For Clarity)
- No target-domain samples are accessible during training (domain generalization, not adaptation).
- Label spaces are consistent across domains; per-client class coverage may be partial.
- The evolution can be arbitrary but is assumed to be learnable in representation space (exploited later in the methodology).
4. Methodology
To learn an FL model from time-evolving data that generalizes well to the future domain, we need to learn the evolving pattern of source domains during federated training. Motivated by [11,47], we assume there is an evolving pattern that captures the transition between every two consecutive domains and for each client. Instead of learning evolving patterns directly in the input space, we consider representation learning to learn the evolution in a representation space. Next, we introduce two algorithms FedEvolve and FedEvp, which align data representation from evolving domains and facilitate local personalization. Specifically, FedEvolve is designed to actively identify the evolving pattern between two consecutive domains, while FedEvp first learns an evolving invariant representation across all existing domains, then generalizes to the unknown evolving domain.
4.1. FedEvolve
Theoretical motivation. To actively capture the evolving patterns of source domains, FedEvolve learns two distinct learnable representation functions (Theoretically, we can also use one function f to demonstrate the evolving pattern directly in terms of the source domains. However, using two representation mappings brings empirical benefits and makes it easier for the model to learn the evolving patterns accurately in a latent representation space [47]). Given two consecutive domains and :
- is the estimated representation of subsequent domain using input .
- is the representation of input domain .
Since we define as the data distributions in input space, associated with each domain are the corresponding distributions in the representation space.
To measure the distance between two distributions, we adopt the Jensen-Shannon divergence . For each client k, define as the parameter pair that minimizes the average distance between representation distributions generated from consecutive local domains, i.e., . The following theorem characterizes an upper bound of the prediction error at the target domains .
Theorem 1 (Upper bound of error at target domains). Let be a classifier operated on a representation space, and denote as the expected losses of with respect to distributions , in the corresponding representation space. Suppose the loss function ℓ is bounded and define its range as . Then for any h, , and , the following holds
Proof. Denote as . From Lemma 1 in [11], we know that:
Next, for each , we have:
Moreover, since all the distributions have the same support (i.e., the representation space), we can apply the triangle inequality with respect to :
Plug these two equations into the first equation:
We sum from to and average to obtain get:
Substitute with and we obtain Theorem 1. □
The proof of Theorem 1 is motivated by [11]. Theorem 1 suggests that the prediction error at unseen target domains can be bounded. Specifically, Term 1 in the upper bound is the prediction error on estimated representations of the target domain (corresponding to minimizing the distance to the prototype of specific classes in Equation (5)). Term 2 measures the distance between representations generated from consecutive domains and it also indicates stationarity of evolving pattern of local source domains—for any given hypothesis classes of , it represents the extent to which we can use one pair to capture the evolution across domains (corresponding to aligning in Equations (4) and (5)). Term 3 measures the client heterogeneity in evolution patterns of the federated system (corresponding to the server aggregation in lines 23–24 of Algorithm 1). Term 4 represents whether the evolution pattern learned from source domains can be generalized to target domain , which is ensured if we have a consistent evolving pattern.
Theorem 1 provides insights for algorithm design: to learn an FL model with small prediction error on future target domains , we find such that the upper bound in Theorem 1 is minimized. Specifically, we aim to find a classification rule such that predictions on estimated representations are sufficiently accurate (reducing Term 1). Meanwhile, the parameter pair should be close to the optimal parameters of local clients on average (reducing Term 3), where should be learned from source domains such that representation is sufficiently close to estimated from previous domain (reducing JS-distance in Term 2). Following this idea, we design FedEvolve as detailed below.
*FedEvolve *algorithm. Because estimates the representation of a domain using the previous domain, we can use it to estimate unknown target domain from source domains for each client k. Let be the trainable neural network parameters of , respectively. To learn the evolving pattern, we aim to learn such that the estimated future domain representation is sufficiently accurate and close to the actual representation , i.e., we need to minimize the distance between and . While our theoretical framework relies on minimizing the JS divergence, directly optimizing this in high-dimensional feature spaces is computationally expensive and often unstable due to the difficulty of accurate density estimation. Inspired by [11], to align the two representations while capturing the class characteristics across evolving domains, we leverage prototypical learning [47] to directly align their representation prototypes. Instead of directly optimizing on representation functions, we maintain prototypes for each evolving domain to handle the representation shifts by learning the prototype differences. By aligning the class-conditional means (prototypes), we minimize the first-order statistical difference between distributions. This acts as a stabilizer and effectively bounds the divergence between the representation distributions, providing a robust objective for federated optimization. Algorithm 1 FedEvolve**Require:**Number of clients K; client participation ratio r; step size ; the number of local training updates ; communication rounds T; the number of source domains M; initial global parameter and global parameter for representation function f; distance metric d; local datasets and their known classes for .1:for do2: server samples clients as from all clients3: server sends , to 4: for each client in parallel do5: client k initialize , 6: for local training iterations do7: for do8: 9: 10: for do11: 12: 13: end for14: 15: for do16: 17: end for18: 19: end for20: end for21: client k sends local parameters to server22: end for23: 24: 25:end for26:Output and
Specifically, for each client k and domain , we let the average of representations for each class y learned by be the prototype , where is the local parameter learned on client k, i.e.,
where is a subset of data instances with label y, is the cardinality of this set. For the next domain , Instead of directly minimizing the JS-distance between representation distributions and , FedEvolve achieves this by aligning the representations from to prototypes computed from . Mathematically, we minimize the loss defined below:
where including all class labels in . d is a distance measure (e.g., Euclidean distance, cosine distance) that quantifies the difference between feature representation and the prototype of class y from the local dataset . In this paper, we employ Euclidean distance.
By minimizing (5) on all active clients, local models learn the evolving pattern by aligning representations of domain with prototypes from the former domain . After local updates, active clients send local parameters to the server and the server performs an average aggregation to update the global parameters . This aggregation rule is chosen to reduce Term 3 in Theorem 1 and the resulting aggregations encapsulate global information with diverse data contributions of all clients. Once consolidated, these models can be directly dispatched to the clients and facilitate continuous model generalizations to the evolving data distributions across the federated network.
After training on source domains, we can use the learned representation functions to predict the target domains . Specifically, we first compute the prototypes of on . Then, we apply to test samples in to generate representations and classify them based on proximity to prototypes. We present the pseudocode of FedEvolve in Algorithm 1.
4.2. FedEvp
Because the two distinct representation functions and in FedEvolve are usually large neural networks (e.g., ResNet [48] for complex image datasets), there is a non-negligible additional overhead to transmit extra parameters of the second representation function, rendering deployment challenges in environments with limited computational resources or network bandwidth. To address the potential overhead, we also present FedEvp, an efficient and streamlined strategy that achieves similar performance as FedEvolve.
Unlike the dual model mechanism of FedEvolve, FedEvp adopts a single-model strategy to reduce communication costs while simultaneously accelerating training. As shown in the right plot of Figure 2, FedEvp aims to learn the evolving-domain-invariant representation using a representation function by continuously aligning data to prototypes from previous domains. If we can develop a representation that is resilient to evolving distributional shifts, a single classifier could effectively serve all domains. To further address local heterogeneity, we also incorporate an efficient personalization step for the classifier.
To ensure a consistent learning process, FedEvp maintains evolving prototypes according to the classes of consecutive domains. In essence, the prototypes learned by FedEvp consolidate the global information from all previous domains to enable the learning of domain-invariant features. For each class y within client k, an evolving prototype is continually updated as (6),
where is set to zero, is the set of all instances in the current domain m that belongs to class y, and denotes the representation of instance under the client k’s local model parameters . Such an iterative update mechanism ensures that the prototype evolves as new domains are introduced, gradually incorporating information from each one. As a result, becomes a representative prototype of class y across all available training domains for client k.
We then align the data from domain to the prototypes to update parameter . We adopt the same loss function as FedEvolve given in (7),
where d is the same distance metric as in FedEvolve, and measures the distance between feature representation of instance x and the prototype of class y, is the set of classes in domain .
Indeed, the above idea of continuously aligning data to an evolving prototype also comes with theoretical support. Following [49], we construct another upper bound of prediction error at the target domain, as detailed in Lemma 1 below.
Lemma 1 (Upper bound of error at target domain ). Let be a classifier operated on a representation space, and denote as the expected loss of with respect to distribution . Suppose the loss function ℓ is upper bounded by C. Then the following holds for any and :
Lemma 1 provides an upper bound of prediction error at target domain . Please note that Term 2 in the upper bound is fully determined by domains and is out of our control. To attain a small error on target domain , Lemma 1 suggests that we may learn such that predictions on source domains are sufficiently accurate (reducing Term 1 which corresponds to the cross-entropy loss in Equation (8)). Meanwhile, we need to learn to minimize the maximum possible distance between representations generated from any two source domains (reducing Term 3 which corresponds to the online update of prototype on line 20 of Algorithm 2). As domains continuously evolve in a specific direction, a good representation function that minimizes the maximum JS-distance in Term 3 is to align data from the current domain to the average of all previous representations (i.e., evolving prototype in (6) is updated by averaging over all previous domains). Algorithm 2 FedEvp**Require:**Number of clients K; client participation ratio r; step size ; the number of local training updates ; communication rounds T; the number of source domains M; initial global parameter and global parameter w for representation function f; distance metric d; local datasets and their known classes for .1:for do2: server samples clients as from all clients3: server sends , w to 4: for each client in parallel do5: client k initialize , 6: for local training iterations do7: for do8: 9: end for10: for do11: 12: 13: for do14: 15: 16: end for17: if m ≥ 2 then18: 19: for do20: 21: end for22: 23: end if24: end for25: end for26: client k sends local parameters to server27: end for28: 29: 30:end for31:Server Output , w32:for each client k do33: Client Output , = personalize( , w, )34:end for
Besides minimizing to learn evolving-domain-invariant representation, we introduce a classifier operated in a representation space, where is parameter and is updated by minimizing empirical risk defined as:
where is the predicted outputs of the class y for instance , computed by the classifier . In our experiments, is the classical cross-entropy loss.
After local updates, FedEvp aggregates the local parameters of active clients at the server . These aggregated global models are then sent back to clients for future updates. As FedEvp relies on the classifier using evolving-domain-invariant features instead of directly using the difference between two consecutive domain representations, the prediction may be influenced by the client’s heterogeneity. To handle the issue raised by local heterogeneity, a personalization mechanism, akin to local finetuning, is further incorporated. Specifically, we personalize each client by updating both the classifier w and the last layer of the feature extractor for an additional epoch on the client’s local dataset. The pseudocode of FedEvp is given in Algorithm 2.
5. Experiments
To evaluate our methods, we consider classification tasks using various network architectures and report the average accuracy and standard deviation over three runs. The detailed implementation can be found in Appendix A. The Dirichlet distribution [50,51] is used to control the level of heterogeneity with parameter Dir . The smaller Dir implies that the clients are more heterogeneous. Heterogeneous clients may have access to different class labels. We report the average performance across clients and the performance on the server. Both are evaluated on the test domain after the last epoch. The federated training phase follows typical FL steps. In each communication round t, a subset of K clients join the system and the server distributes aggregated global model parameters to client . Upon receiving these parameters, each client k initializes its local parameters to those and performs local updates. We follow the same setting as [8] to use 20 clients in experiments. For datasets with a limited number of samples, we reduce the number of clients to 10. Details can be found in the dataset introduction in Appendix A.
5.1. Datasets and Networks
We evaluate FedEvolve and FedEvp on both synthetic data (Circle) and real data (Rotated MNIST, Rotated EMNIST, Portraits, and Caltran). All datasets either come with evolving patterns or are adapted to evolving environments. For all datasets, the last domain is viewed as the target domain. The feature extractor in the neural network is viewed as and , and the classifier is w mentioned in the previous section.
Circle [52]. These synthetic data have 30 evolving domains. A total of 30,000 instances within these domains are sampled from 30 two-dimensional Gaussian distributions, with the same variance but different means that are uniformly distributed on a half-circle. We use a 5-layer multilayer perception (MLP) with 3 layers serving as a representation function ( and in FedEvolve, in FedEvp) and the remaining 2 layers as a classifier ( in FedEvp).
Rotated MNIST [53] and Rotated EMNIST [54]. The Rotated MNIST is a variation of the MNIST data, where we rotate the original handwritten digit images to produce different domains. Specifically, we partition the data into 12 domains and rotate the images within each domain by an angle , beginning at and progressing in 15-degree increments up to . We also consider other increments spanning from to to simulate varying degrees of evolving shifts. EMNIST is a more challenging alternative to MNIST with more classes, including both handwritten digits and letters. We use the handwritten letters subset and split it into 12 domains by rotating images with a degree of . We design a model consisting of a 4-layer convolutional neural network (CNN) for representation layers, followed by two linear layers for classification.
Portraits [10]. It is a real dataset consisting of frontal-facing American high school yearbook photos over a century. This time-evolving dataset reflects the changes in fashion (e.g., high style and smile). We resize images to and split the dataset by every 12 years into 9 domains. We use WideResNet [55] as the representation function to train the gender classifier. Please note that the data are only intended to compare various methods.
Caltran [56]. This real surveillance dataset comprises images captured by a fixed traffic camera. We divide the dataset into 12 domains where the samples from every 2-h block form a domain (evolving shifts arising from changes in light intensity). ResNet18 [48] backbone is used as the representation function, and the last linear layer is used as the classifier.
5.2. Baselines
We compare FedEvolve and FedEvp with various existing FL methods. These baselines cover a broad range of methods, including regular FL methods, methods with personalization (PFL) or test-time adaptation (TTA) mechanisms, and methods designed for distribution shifts across domains or sequential tasks, e.g., domain generalization methods. Please note that this paper focuses on a domain generalization setting rather than domain adaptation. Therefore, domain adaptation methods are not included as baselines.
- FedAvg [1]: A FL method that learns the global model by averaging the client’s local model.
- GMA [57]: A FL method using a gradient masked averaging approach to aggregate local models.
- APFL [58]: A PFL method that leverages a weighted ensemble of personalized and global models.
- FedRep [29] and FedRoD [30]: PFL methods that use a decoupled feature extractor and classifier to enhance personalization in FL.
- Ditto [17]: A fairness-aware PFL method that has been shown to outperform other fairness FL methods.
- T3A [59]: A TTA method that is adapted to personalized FL by adding test-time adaptation to FedAvg with finetuning.
- FedTHE [8]: A TTA PFL method that tackles the data heterogeneity issue while learning test-time robust FL under distribution shifts.
- Flute [60]: Flute is a PFL method that facilitates the distillation of the subspace spanned by the global optimal representation from the misaligned local representations.
- FedSR [61]: A TTA FL method using the regular domain generalization method.
- CFL [36]: A continual federated learning method that learns from time-series data without forgetting old tasks.
- CFeD [62]: It uses distillation to learn from sequential tasks in continual federated learning to prevent catastrophic forgetting on learned domains.
5.3. Results
In Figure 3, we examine how the algorithm performance changes as the degree of evolving shifts varies. Table 1, Table 2 and Table 3 show the comparison with baselines, where we report both the averaged performance of clients’ local models and of the global model at the server. We also extend the experiments in Table 3 to the setting when clients are heterogeneous and present the results in Table 4 and Table 5. We bolded our methods’ results when they outperformed all baselines, and we also bolded baseline results when they achieved the best performance.
How do evolving distribution shifts and client heterogeneity affect federated learning performance? First, we examine the impact of distribution shifts and client heterogeneity on FL systems. Figure 3 presents the results on RMNIST data under clients with varying degrees of local heterogeneity ( ). Each sub-figure shows how performance changes as the extent of distribution shift changes from no distribution shift ( incremental angle) to high distribution shift ( incremental angle):
- In the absence of significant distribution shifts (e.g., rotation incremental angle , , or ), Figure 3a shows that, when there is no client heterogeneity, our methods have similar performance as the traditional FL methods. The learning task reduces to the standard FL task, and the classical FL methods maintain competitive performance. As clients become more heterogeneous, Figure 3b,c show that all methods experience performance degradation. Importantly, we observe a widening gap between client-side (personalized) and server-side (generalized) performance as heterogeneity increases. This is especially pronounced in Figure 3c where , highlighting the value of personalization under extreme heterogeneity. While FedEvolve’s server-side accuracy drops slightly below FedAvg, its client-side model retains competitive performance, and FedEvp shows consistently robust results across both views. This increasing gap indicates that personalized models benefit more from local adaptation when clients become highly non-iid, whereas server aggregation struggles to reconcile the diverging local objectives, as we also find in Table 4.
- When the rotation increments increase, FedAvg experiences a significant performance drop (e.g., nearly 12% decrease when the incremental angle increases for 5 degrees, see Figure 3a). Such impacts are more significant than the performance drop caused by client heterogeneity, indicating the challenge of evolving shifts. However, our methods are still robust against such shifts and significantly better than baselines. When both strong local heterogeneity and distribution shifts are present (Figure 3c), both the baselines and ours experience a performance drop, while ours exhibit a relatively slower decline. Additionally, the client-server performance gap grows under these settings, further validating the importance of personalization. Notably, the superior client-side performance of FedEvp under these compounded challenges further validates the effectiveness of the personalization mechanism of FedEvp.
Comparison with Baselines. We conduct extensive experiments on five datasets with different levels of client heterogeneity. Table 1 and Table 2 and the results of Circle data in Table 3 compare different methods in scenarios with strong evolving patterns. We observe that both FedEvolve and FedEvp outperform the baseline methods. In particular, FedEvolve attains the highest accuracy ( , , and on RMNIST, REMNIST, and Circle, respectively), demonstrating its capability to learn from the evolving pattern and effectively address the distribution shifts. This advantage also shows on other datasets (Portraits and Caltran) in Table 3 with less obvious evolving patterns.
For PFL or TTA baselines tuned on local source domains, without client heterogeneity (Dir ), the performance may deteriorate compared to classical FL, such as FedAvg. Specifically, methods such as FedAvgFT, APFL, and FedRep may experience a drop in client performance compared to the server on certain datasets. These methods, originally designed to tackle client heterogeneity without learning evolving patterns, suffer performance degradation; this further highlights the importance of considering evolving distribution shifts in FL systems. Nonetheless, when clients are heterogeneous (Dir is 1.0 or 0.1 in Table 1 and Table 2), their personalization or test-time adaptation can still be beneficial. Methods designed for addressing domain shifts or task shifts like FedSR, CFL, and CFeD tend to achieve better results than other baselines, indicating their capability to mitigate the influence of evolving distribution shifts. However, the gap between their performance and ours still emphasizes the need for a specific design to solve the problem.
Among all methods, our proposed FedEvolve and FedEvp show the best performance and are robust to both client heterogeneity and evolving shifts. FedEvp achieves comparable performance with FedEvolve but only uses half numbers of parameters as FedEvolve. Specifically, when , FedEvolve achieves accuracy of 83.86% and 87.67% on RMNIST and REMNIST, while FedEvp achieves similar accuracy of 83.15% and 87.01%. Thus, a careful design of personalization can prevent the unintended consequence of performance degradation.
How does the number of source domains influence generalization to the future target domain? Specifically, we conduct experiments under the same settings as shown in Table 6, while controlling for the number of source domains and test prediction performance for the target domain. Our methods are compared to FedAvg using reduced numbers of domains: 7 domains (rotation starting at and increasing to ), 10 domains (rotation starting at and increasing to ), and 12 domains (rotation starting at and increasing to ).
As the number of domains increases, FedAvg shows significant performance degradation across all heterogeneity settings. This indicates regular methods’ vulnerability to evolving distributional shifts. Both FedEvolve and FedEvp display robustness against increasing domain numbers and maintaining or improving performance. In particular, FedEvolve can fully learn the transition of two consecutive domains by incorporating more source domains. However, FedEvp remains less sensitive to domain transitions, performing consistently well across different settings. The robustness of our methods contrasts sharply with the performance drop observed in FedAvg, highlighting the importance of handling distribution variability in FL. In addition, we study the impact of the unexpected changing pattern on the target domain.
How robust are the methods to abrupt/unexpected target domain evolution? In previous experiments, we primarily focused on invariant changing patterns in image rotation experiments. Here, we examine whether our methods are robust against an unexpected pattern. In this experiment, we test the robustness of our methods against an unexpected pattern. Specifically, we simulate an unexpected domain by rotating images from the target domain by an additional and . To prevent confusion between numerals like 6 and 9 when rotated by , we set the incremental rotation degree as . Therefore, the images experience a rotation or a rotation instead of the expected . This experiment aims to evaluate whether our methods can handle abrupt or chaotic shifts from anticipated patterns where the ’smooth evolution’ assumption fails.
As shown in Table 7, all methods exhibit a significant performance drop when the test data distribution changes substantially; however, our methods still outperform the baseline, and the drop is less than that of the baseline. Notably, FedEvp demonstrates superior performance compared to FedEvolve when clients are heterogeneous. This difference arises because FedEvolve explicitly learns the distribution transition between consecutive domains, while FedEvp learns evolving-domain-invariant features. Consequently, when the distribution transition deviates from the learned pattern, the performance of FedEvolve is adversely affected, whereas FedEvp remains less influenced by the change.
Overhead Comparison. Table 8 compares transmission overhead. We use a CNN as an example to report the number of parameters and server–client transmission time in the MPI environment. Although FedEvolve has the higher transmission overhead, its cost-efficient version FedEvp has comparable overhead to the baselines. Here we also provide learning-curve plots and wall-clock time per round for FedEvolve and FedEvp in Figure 4.
Cost–benefit trade-off. As noted in Table 8, FedEvolve utilizes two distinct representation mappings ( ), resulting in approximately the parameter count (741,120 vs. 379,392) and transmission time (46.32 ms vs. 21.30 ms) compared to FedEvp and baselines like FedAvg. However, this additional cost yields substantial performance gains in complex shifting environments. For example, on the Rotated EMNIST dataset (Table 2, Dir ), FedEvolve achieves 83.58% accuracy compared to FedEvp’s 67.30%, which is a significant improvement. Similarly, on Rotated MNIST (Table 1), FedEvolve outperforms FedEvp by nearly 9% (84.75% vs. 75.99%). While FedEvp offers a lightweight alternative that matches baseline costs while providing robust performance, FedEvolve is the necessary choice for high-stakes applications (e.g., clinical diagnosis or autonomous surveillance) where maximizing generalization accuracy is paramount, and bandwidth is not the primary bottleneck. The “double overhead” of FedEvolve effectively purchases a 9–16% accuracy margin that simpler alignment methods cannot achieve. Otherwise, we recommend FedEvp for bandwidth-limited edge environments.
How much does personalization contribute to FedEvp? We also study the influence of personalization mechanisms of FedEvp on the performance in Table 9. The results show that personalizing part of the feature extractor and classifier can achieve the best results. We also notice that personalizing the classifier brings the most significant improvement, which means the classifier is most sensitive to the client heterogeneity with evolving distribution shifts.
Discussion. The empirical evidence suggests that conventional FL algorithms cannot simultaneously handle the evolving distributional shifts and client heterogeneity. In addition, evolving distributional shifts could be viewed as a specific form of data heterogeneity affecting client devices. Present personalization strategies, designed for data heterogeneity, fail in adapting models to unseen distributions. Simply tuning clients on known domains without considering shifts between training data and test data, these methods may inadvertently increase the model’s bias towards training data, resulting in performance that is sometimes inferior to that of non-personalized algorithms. While continual FL frameworks take account of dynamic distributional shifts during training, they primarily concentrate on preventing catastrophic forgetting of prior tasks or domains rather than adapting to new, unseen ones. This focus makes them inadequate for managing evolving distributional shifts effectively. However, when the distribution of a target domain is predictable based on existing data, our methods explicitly leverage and learn the pattern of distribution transitions, enabling the extrapolation of the model to the target domain. Therefore, our methods mitigate the performance drop and achieve the best results.
6. Conclusions
This paper studies FL under evolving distribution shifts. We explored the impacts of evolving shifts and client heterogeneity on FL systems and proposed two algorithms: FedEvolve that precisely captures the evolving patterns of two consecutive domains, and FedEvp that learns a domain-invariant representation for all domains with the aid of personalization. Extensive experiments show both algorithms have superior performance compared to SOTA methods.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mc Mahan B. Moore E. Ramage D. Hampson S. Arcas B.A.Y. Communication-efficient learning of deep networks from decentralized data Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) 2017 Fort Lauderdale, FL, USA 20–22 April 201712731282
- 2Yang Q. Liu Y. Chen T. Tong Y. Federated machine learning: Concept and applications ACM Trans. Intell. Syst. Technol.20191011910.1145/3298981 · doi ↗
- 3Zhang C. Xie Y. Bai H. Yu B. Li W. Gao Y. A survey on federated learning Knowl.-Based Syst.202121610677510.1016/j.knosys.2021.106775 · doi ↗
- 4Diao E. Ding J. Tarokh V. Hetero FL: Computation and Communication Efficient Federated Learning for Heterogeneous Clients Proceedings of the International Conference on Learning Representations Virtual Event, Austria 3–7 May 2021
- 5Achituve I. Shamsian A. Navon A. Chechik G. Fetaya E. Personalized Federated Learning with Gaussian Processes Adv. Neural Inf. Process. Syst.20213483928406
- 6Reisizadeh A. Farnia F. Pedarsani R. Jadbabaie A. Robust Federated Learning: The Case of Affine Distribution Shifts Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, Neur IPS 2020 Virtual 6–12 December 2020
- 7Wang K. Mathews R. Kiddon C. Eichner H. Beaufays F. Ramage D. Federated evaluation of on-device personalizationar Xiv 201910.48550/ar Xiv.1910.102521910.10252 · doi ↗
- 8Jiang L. Lin T. Test-Time Robust Personalization for Federated Learning Proceedings of the Eleventh International Conference on Learning Representations Kigali, Rwanda 1–5 May 2023