Robust Distributed High-Dimensional Regression: A Convoluted Rank Approach
Mingcong Wu

TL;DR
This paper introduces a robust regression method for high-dimensional data in distributed systems, effective even with noisy or outlier-prone data.
Contribution
A novel convoluted rank regression method with non-asymptotic error bounds for distributed settings and sparse regimes.
Findings
The proposed estimator achieves minimax-optimal convergence after logarithmic communication rounds.
Simulations show stable performance across various error distributions with accurate coefficient estimation.
The method supports fast optimization in high-dimensional and distributed environments.
Abstract
This paper investigates robust high-dimensional convoluted rank regression in distributed environments. We propose an estimation method suitable for sparse regimes, which remains effective under heavy-tailed errors and outliers, as it does not impose moment assumptions on the noise distribution. To facilitate scalable computation, we develop a local linear approximation algorithm, enabling fast and stable optimization in high-dimensional settings and across distributed systems. Our theoretical results provide non-asymptotic error bounds for both one-round and multi-round communication schemes, explicitly quantifying how estimation accuracy improves with additional communication rounds. Specifically, after a number of communication rounds (logarithmic in the number of machines), the proposed estimator achieves the minimax-optimal convergence rate, up to logarithmic factors. Extensive…
Click any figure to enlarge with its caption.
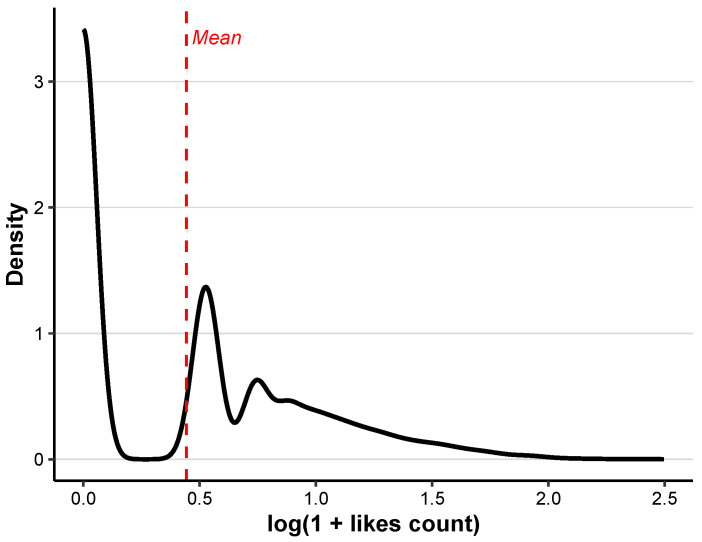 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSparse and Compressive Sensing Techniques · Stochastic Gradient Optimization Techniques · Distributed Sensor Networks and Detection Algorithms
1. Introduction
In the era of big data, the exponential growth in data volume and complexity has made traditional single-machine approaches insufficient for effective statistical modeling. To overcome this challenge, distributed algorithms break down data into manageable chunks and distribute them across multiple computing nodes for parallel processing. This approach greatly improves computational efficiency and scalability, proving essential for handling large-scale data analysis [1,2]. Distributed algorithms are widely used in various statistical learning tasks. For example, Wang et al. [3] studied distributed inference for the linear support vector machine (SVM) in the binary classification task and proposed a multi-round distributed linear-type estimator to achieve computational efficiency in conducting inference for the linear SVM. Chen et al. [4] established a new connection between quantile regression and ordinary linear regression and provided a distributed estimator that is both computationally and communicationally efficient. Chen and Peng [5] explored distributed statistical inference for a general class of statistics, including U-statistics and M-estimators, in the context of massive data. Additionally, concerns over privacy and regulatory compliance often result in data being stored across multiple institutions, where centralized aggregation is either impractical or prohibited. These challenges have further driven the development of distributed estimation methods that allow for statistical inference without requiring direct access to raw data [6].
A common class of distributed estimation methods follows the one-shot paradigm, where each machine independently computes a local estimator, and the final estimate is obtained through a single round of averaging [1,7,8]. While these methods are attractive due to their simplicity and low communication cost, they often require each machine to hold a sufficiently large number of samples to ensure accurate global estimation. When the local sample size is limited or the number of machines is large, their statistical performance can degrade significantly. To address the limitations of one-shot estimators under limited local sample sizes, Jordan et al. [2] proposed the Communication-Efficient Surrogate Likelihood (CSL) framework. For this approach, each machine computes the gradient of its local loss at a shared parameter value and sends it to a central node, which then constructs a surrogate loss function to approximate the global objective. The estimator is refined iteratively, leading to improved statistical accuracy with logarithmic communication rounds. Inspired by this, several works have extended the CSL method to high-dimensional settings, such as sparse linear models, generalized linear models, quantile regression and modal regression [9,10,11,12,13,14].
In the centralized setting, a substantial body of work has developed robust high-dimensional regression methods with strong theoretical guarantees in the presence of heavy-tailed errors and outliers. Among these methods, Wilcoxon rank regression (also referred to as rank regression) stands out. As introduced by Hettmansperger and McKean [15], the rank regression estimator achieves arbitrarily high relative efficiency under heavy-tailed error distributions while retaining at least 86.4% asymptotic relative efficiency under any symmetric error distribution with finite Fisher information. This combination of robustness and high estimation efficiency makes rank regression a powerful and attractive alternative to standard least squares. Consequently, rank regression has garnered increased attention in recent years. For instance, Wang et al. [16] proposed a tuning-free robust high-dimensional regression procedure based on a simulated tuning parameter, achieving near-oracle performance and strong robustness to heavy-tailed errors. Zhou et al. [17] developed sparse convoluted rank regression by smoothing the rank loss, establishing non-asymptotic properties and presenting an efficient algorithm for high-dimensional settings, in contrast to canonical rank regression. Cai et al. [18] explored statistical inference for high-dimensional convoluted rank regression, deriving estimation error bounds and constructing debiased estimators with valid simultaneous confidence intervals. Building on this line of work, we propose a distributed high-dimensional convoluted rank regression (DCR). Our main contributions are summarized as follows.
(Methodology). In the CSL framework, we propose a robust, communication-efficient, penalized estimator for high-dimensional linear regression. The proposed procedure does not impose moment assumptions on the error distribution and therefore remains applicable in the presence of heavy-tailed noise and outliers. It is tailored for sparse high-dimensional regimes and delivers accurate coefficient estimation, along with reliable support recovery. Compared with the distributed Huber regression approach proposed by Luo et al. [14], our method does not require the noise to have a finite second moment and avoids the need to tune the two key hyperparameters in the Huber loss. As a result, it is computationally more efficient and easier to implement in practice. Extensive simulation studies in Section 5 demonstrate that the method is stable across a wide range of error distributions and achieves strong empirical performance in both estimation and support recovery.(Algorithm). To solve the resulting optimization problem efficiently, we develop a local linear approximation-based algorithm. The algorithm converts the original objective into a sequence of tractable subproblems and can be implemented efficiently in distributed environments, leading to fast and stable computation in high dimensions.(Theory). We establish non-asymptotic theoretical guarantees for the proposed estimator under both one-round and multiple-round communication schemes. Specifically, we derive non-asymptotic error bounds characterizing how the accuracy improves as the number of communication rounds increases. After a sufficient number of communication rounds (logarithmic in the number of machines), the distributed estimator attains the minimax convergence rate (up to logarithmic factors).
The rest of the paper is organized as follows. Section 2 introduces the DCR estimator. Section 3 presents an optimization algorithm for the DCR estimator. Section 4 provides a comprehensive theoretical study of the DCR estimator. Numerical results, including simulation studies and real data analysis, are given in Section 5. All technical proofs are provided in Appendix A, Appendix B and Appendix C.
Notation. For a positive integer m, let . Denote by , , and the d-dimensional unit sphere, the indicator function, the identity vector and the identity matrix, respectively. For any matrix , let denote the spectral norm of matrix . Write . Specifically, if , we use and to denote, respectively, the -norm and -norm of the -dimensional vector . If is positive semi-definite and , for any vector , let . Define the ball and its translation for any and . For a countable set S, we use to denote its cardinality. For any two real numbers a and b, we write and . For two sequences of positive numbers and , we write or if there exist a positive constant c and a large enough integer such that for all . Write if and only if and hold simultaneously. We use to denote some generic positive constants, which may be different in different uses. Let be the Euclidean ball with radius r. Denote the zero-mean operator for any random matrix .
2. Distributed High-Dimensional Convoluted Rank Regression
Suppose that the sample of i.i.d. observations are generated from the following linear regression model,
where are one-dimensional responses, are random errors, are p-dimensional random vectors with mean zero and covariance matrix and is the unknown parameter of interest.
We begin by introducing the global convoluted rank regression, which forms the basis for our distributed extension. Given a sample of observations , the objective is to estimate the regression coefficient vector by minimizing a smoothed version of the canonical rank loss. Following the formulation in Zhou et al. [17], we define the convolution-based rank loss as
where is a kernel-smoothed convex loss function defined as
where with being the kernel function and being the bandwidth. We define the population parameter as
By Theorem 1 of Zhou et al. [17], we have for any . Thus, in high-dimensional settings ( ), we introduce the global penalized convoluted rank regression estimator for with entrywise regularizations as follows:
where is the j-th element of and is a penalty function with being a tuning parameter.
In the distributed setting, assume that the entire dataset is stored across m node machines: one central machine and local machines connected to the central machine. For , the j-th machine stores a subsample of observations, denoted by , where are disjoint index sets such that and . Without loss of generality, we assume that , so that . We refer to n as the local sample size.
Given bandwidth , we define the local convoluted rank loss as
Starting with an initial estimator for , we define the surrogate loss as
We allow the parametric dimension p to be much larger than the local sample size n. Denote by the true active set. Hence, is s-sparse with . At iteration for integer , the first machine solves the following minimization problem:
where is a tuning parameter. We choose to be the local penalized convoluted rank regression estimator such that
In the next section, we will propose an optimization algorithm for solving (3).
3. Optimization Algorithm
In this section, we focus on the iterations after the -th communication round. At the -th iteration, we use the local linear approximation (LLA) algorithm to update the estimate by solving (3) as follows:
where is the previous estimate in the k-th iteration. Specifically, in a coordinate-wise manner, we update the l-th coordinate by minimizing
where is defined in (3) and . We let
By Lemma 1 of Zhou et al. [17], we can construct a quadratic majorization function for :
Hence, we can update using the minimizer of :
For tuning parameter , we set for all . To select an appropriate value of , we propose a high-dimensional Bayesian information criterion (HBIC) in the distributed setting, which is defined as
where with being the j-th element of . Compared to cross-validation, selecting by minimizing the HBIC eliminates the need to split the data or repeatedly evaluate test error across multiple sub-datasets, thereby reducing computational cost while maintaining theoretical interpretability. Specifically, we compute the solution path over a decreasing grid , evaluating the HBIC for each and choosing the minimizer. In implementation, we first compute an initial penalty level similarly to Zhou et al. [17], using only the local data on the first machine to avoid extra communication, which is represented as follows:
We then form a decreasing geometric grid for . In our experiments, we set . We summarize this procedure in Algorithm 1, which is based on Algorithm 2. Algorithm 1 Estimation procedure for DCR
-
Require: (i) data batches , , stored on m local machines; (ii) initialization ; (iii) bandwidth h, regularization parameter , and communication times T.
-
1:for do
-
2: Compute local gradient and global gradient ;
-
3: Use Algorithm 2 to compute .
-
4:end for
-
Ensure: .
Algorithm 2 Local linear approximation (LLA) algorithm for solving (3)
-
Require: (i) local data ; (ii) initialization ; (iii) local gradient ; (iv) global gradient ; (v) bandwidth h and (vi) regularization parameter .
-
1:Initial .
-
2: repeat
-
3: for do
-
4: Compute , and for by (4), (5) and (6), respectively.
-
5: Compute
-
6: Let and set .
-
7: end for
-
8:until .
-
Ensure: .
4. Theoretical Results
In this section, we investigate the theoretical properties for the DCR estimator proposed in Section 2. Let and . Denote by the probability density function of conditional on and . To establish the theoretical guarantees, we need the following regularity assumptions.
Assumption **1.**There exist universal constants such that (i) * *; (ii) * *; and (iii) the eigenvalues of matrix Σ are bounded above by and below by .
Assumption **2.There exist universal constants such that (i) * for all and (ii) * .
Assumption 3. The kernel function satisfies that and for any , , and . There exist universal constants such that and .
Assumption **4.**Suppose that (i) *the penalty function satisfies and for all ; (ii) * is nondecreasing on the nonnegative real line; (iii) * is nonincreasing for *; (iv) * is differentiable for all and has a right derivative at with for universal constant *; and (v) there exists such that is convex.
Assumptions 1–3 are standard in high-dimensional convoluted rank regression, as discussed in, e.g., Zhou et al. [17]. Assumption 4 is standard in the literature on nonconvex penalized M-estimation and has been used in prior works such as Loh and Wainwright [19], Loh [20], Loh and Wainwright [21]. These assumptions ensure basic regularity properties (e.g., symmetry, monotonicity, local differentiability and a localized convexification) and are satisfied by a broad class of nonconvex penalties, including SCAD [22] and MCP [23].
Define the event for some , where is an -cone. Since we are interested in cases where the penalty may be nonconvex, we include the side condition for in (3) in order to guarantee the existence of local/global optima. Theorem 1 gives the convergence rate of the estimator after the first iteration under the norm , whose proof is given in Appendix A.
Theorem **1.**Let Assumptions 1–4 hold. Select , and . Restricted on the event , it holds with probability at least that and
provided that .
Remark 1. Theorem 1 illustrates that a single round of communication among machines can substantially improve the accuracy of the initial estimator , which is obtained from local computation based on only n samples. Specifically, is computed by solving a regularized surrogate problem (3) with , which incorporates both the local loss function and the global gradient , effectively integrating information from the entire dataset of size . The error bound on the right hand side of (7) demonstrates the gain from global information sharing: the first term reduces the estimation error related to limited local sample size n, while the second term decays with the total sample size N, enabling to reach the efficiency of a global estimator.
Theorem 2 gives the convergence rate of the estimator after the t-th iteration under the norm , whose proof is given in Appendix B.
Theorem 2. Let Assumptions 1–4 hold. Select , and . Then, it holds with probability at least that
provided that .
Remark 2. Theorem 2 highlights the effectiveness of multiple rounds of communication in distributed learning with penalized convoluted rank loss. On the right hand side of (8), the first term decays exponentially with the number of communication rounds t, while the second term matches the optimal rate of global convoluted rank regression with access to the full dataset of size N. Notably, when , the influence of the initial estimator , which only uses local data, is effectively eliminated. As a result, the final estimator achieves the same efficiency as one that directly solves the full-data problem, but without the need to collect all N samples on a single machine. This demonstrates that the proposed multi-round distributed procedure enables communication-efficient optimality, and only a logarithmic number of machines are needed to match the convergence rate of global learning.
5. Numerical Studies
5.1. Monte Carlo Examples
We consider three methods for comparison with our proposed method: (i) the global convoluted rank regression (Global CR) estimator [17] that uses all the available observations; (ii) the divide-and-conquer CR (DC-CR) estimator, which is based on averaging m local CR estimators; and (iii) the local convoluted rank regression (Local CR). A regularization parameter is included in all methods, and its value is selected by minimizing the corresponding HBIC. To measure the sparsity recovery performance, we calculated the F1 score:
where TP, FP and FN denote the numbers of true positives, false positives and false negatives, respectively. To measure estimation accuracy, we calculate the square root of the mean squared error (RMSE).
We generate data vectors from a heteroscedastic model , where , , and is independently generated from with . We consider that is independently generated from (1) standard normal distribution ; (2) t distribution ; (3) standard Cauchy distribution ; and (4) mixture normal distribution . We set , , and the number of communication rounds . In practice, we recommend an early-stopping strategy for T similar to that proposed by Zhang et al. [1]: communication iterations can be terminated when the gradient norm of the loss Function (2) drops below a predefined threshold.
We adopt the Epanechnikov kernel and construct the loss function as
In Algorithm 1, the bandwidth h is used only to smooth the rank loss. Importantly, this smoothing does not change the target parameter: by Theorem 1 of Zhou et al. [17], the population minimizer satisfies for any . Therefore, h mainly affects numerical smoothness and finite-sample constants rather than the estimator. Our theory only requires h to be of constant order, i.e., . In practice, we recommend a simple default choice of . For regularization, we employ the SCAD penalty, which is given by
for some . The default choice of parameter a is .
The simulation results, summarized in Table 1, show that the proposed DCR method achieves the best overall performance across all settings. It consistently yields the lowest RMSE and the highest F1 scores, indicating both accurate estimation and reliable support recovery. The DC-CR estimator, while comparable to DCR in terms of RMSE, suffers from significantly lower F1 scores, particularly under Cauchy and contaminated distributions, due to unstable variable selection. These results highlight the advantage of DCR in combining robustness, sparsity and distributed efficiency.
5.2. Real Data Example: LGBT Tweets
We illustrate our proposed method on a real-world dataset of tweets related to LGBTQ topics, collected using the keyword “LGBT” over the period from 21 August to 26 August 2022 (the dataset is publicly available at https://www.kaggle.com/datasets/vencerlanz09/lgbt-tweets (accessed on 20 April 2025)). The goal of this analysis is to identify linguistically salient words that have a significant impact on the like count of each tweet.
Each observation in our study represents a single post. Our initial sample consists of a total of tweets, each containing the keyword “LGBT”. For each post, we record the number of likes it received, denoted by , which serves as the outcome variable. The original like counts exhibit substantial variation, with most tweets receiving only a few likes and a small number garnering extremely high engagement. To address this scale disparity and stabilize the variance, we apply the transformation . As shown in Figure 1, the transformed variable retains a heavy-tailed distribution, indicating that the imbalance in user attention persists even after logarithmic scaling.
To construct the covariates, we preprocess the tweet text using Python 3.11.10 libraries, including spaCy for tokenization, lemmatization and part-of-speech filtering, and CountVectorizer for feature extraction. During preprocessing, we remove punctuation, stop words, auxiliary verbs, adverbs and informal abbreviations. After cleaning, we apply a binary bag-of-words encoding based on the 500 most frequently used informative words in the corpus. Specifically, the j-th coordinate of the covariate vector equals 1 if the j-th word in the vocabulary appears in the i-th tweet, and 0 otherwise. Posts that do not contain any of these 500 words are excluded from the analysis. After filtering, we retain a final sample of N = 31,644 observations. The data is randomly distributed across 100 machines, with an average of 316 data points per machine. The number of iterations is set to .
From Table 2, we observe that several keywords show strong positive associations with the number of likes, such as “character”, “queer” and “let”. These terms frequently appear in contexts emphasizing representation, identity affirmation or emotional solidarity (e.g., “queer character in media” and “let people love who they love”). Such expressions typically convey inclusive and positive sentiments, which tend to resonate with audiences and encourage affirmative responses in the form of likes.
In contrast, negatively weighted terms such as “groom”, “ban” and “loom” are often embedded in narratives involving controversy, fear or stigmatization. For instance, tweets referencing “ban LGBT education” or “danger looms” may attract attention but are less likely to elicit endorsement via likes, as users may refrain from visibly supporting content that is perceived as divisive or politically sensitive. Additionally, high-frequency yet semantically broad words such as “right” and “school” demonstrate weak or even negative associations with like counts. In particular, “school” frequently appears in tweets related to educational debates (e.g., “LGBT in schools” and “teaching gender identity”), which are often contentious. The polarizing nature of such discussions may lead users to engage cautiously or avoid expressing approval through likes.
Overall, the keywords selected by our proposed method highlight the crucial role of emotional valence and semantic framing in shaping engagement behavior. While positively framed language that conveys support, identity and collective belonging tends to promote user interaction, negatively charged or controversial expressions are less likely to generate positive engagement, despite their potential visibility.
6. Discussion
In this paper, we study high-dimensional linear regression in distributed settings and develop a DCR framework to mitigate the severe performance degradation of least-squares-based distributed procedures under heavy-tailed errors and outliers. Methodologically, the proposed approach integrates a convolution-smoothed rank loss into a communication-efficient surrogate-likelihood paradigm: at each communication round, a tractable surrogate objective is constructed by combining local empirical losses with a global gradient correction, and the central node solves a sparsity-regularized problem with nonconvex penalties (e.g., SCAD/MCP) to aggregate information without transferring raw data. To enable scalable computation, we further devise an optimization strategy based on the local linear approximation (LLA) method, reducing the nonconvex regularized estimation to a sequence of efficiently solvable subproblems. Additionally, an HBIC-based tuning procedure is provided to alleviate the computational burden of cross-validation in large-scale distributed regimes.
On the theoretical side, we establish non-asymptotic error bounds for both one-shot and multi-round communication schemes, explicitly characterizing how additional communication improves statistical accuracy. In particular, a single communication round already yields a substantial correction over purely local estimators, while the multi-round procedure exhibits a rapid contraction of the “local-sample-limitation” term in the error bound. When the number of communication rounds reaches a logarithmic order in the number of machines, the resulting estimator attains (up to logarithmic factors) the optimal convergence rate comparable to its centralized counterpart, thereby achieving communication-efficient statistical optimality.
Extensive experiments corroborate the robustness and effectiveness of the proposed method. Across a broad collection of noise distributions, DCR delivers stable performance in terms of estimation accuracy and support recovery. In a real-data application, DCR identifies interpretable keywords and yields effect estimates with coherent directions, illustrating its practical utility for large-scale high-dimensional problems with non-Gaussian noise.
Several directions merit further investigation. First, it would be valuable to extend the proposed framework to broader model classes (e.g., generalized linear or semiparametric models) and to formally analyze robustness and computational behavior under more complex data structures such as dependence, nonstationarity or distributional drift. Second, building on the current estimation theory, developing feasible distributed inference procedures along with a principled characterization of the trade-offs among inferential accuracy, communication cost and computation would substantially broaden the applicability of method. Third, for partially trusted distributed environments, integrating DCR with Byzantine-resilient aggregation or fault-tolerant mechanisms and establishing statistical consistency and worst-case error guarantees in the presence of adversarially corrupted worker messages would enhance both the security and reliability of the method in real-world deployments. We leave these considerations for future research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhang Y. Duchi J.C. Wainwright M.J. Communication-efficient algorithms for statistical optimization J. Mach. Learn. Res.20131433213363
- 2Jordan M.I. Lee J.D. Yang Y. Communication-efficient distributed statistical inference J. Am. Stat. Assoc.201911466868110.1080/01621459.2018.1429274 · doi ↗
- 3Wang X. Yang Z. Chen X. Liu W. Distributed inference for linear support vector machine J. Mach. Learn. Res.201920141
- 4Chen X. Liu W. Mao X. Yang Z. Distributed high-dimensional regression under a quantile loss function J. Mach. Learn. Res.202021143
- 5Chen S. Peng L. Distributive statistical inference for massive data Ann. Stat.2021492851286910.1214/21-AOS 2062 · doi ↗
- 6Duchi J.C. Jordan M.I. Wainwright M.J. Privacy aware learning J. ACM (JACM)20146115710.1145/2666468 · doi ↗
- 7Battey H. Fan J. Liu H. Lu J. Zhu Z. Distributed estimation and inference with statistical guarantees Biometrika 20181057795
- 8Lee J.D. Liu Q. Sun Y. Taylor J.E. Communication-efficient sparse regression J. Mach. Learn. Res.201718130