Geometric Learning of Canonical Parameterizations of 2D-Curves
Ioana Ciuclea, Giorgio Longari, Alice Barbora Tumpach

TL;DR
This paper introduces a geometric method to handle symmetries in datasets without data augmentation, using fiber bundle theory to improve classification.
Contribution
The novel contribution is a geometric framework using principal fiber bundles to mod out symmetries in data, enabling class separation without data augmentation.
Findings
A 2-parameter family of canonical curve parameterizations is introduced, including constant-speed parameterization.
The method effectively mod out symmetries like translation, rotation, scaling, and reparameterization in object contours.
The approach demonstrates improved class separation by optimizing the section of the fiber bundle.
Abstract
Most datasets encountered in computer vision and medical applications present symmetries that should be taken into account in classification tasks. A typical example is the symmetry by rotation and/or scaling in object detection. A common way to build neural networks that learn the symmetries is to use data augmentation. In order to avoid data augmentation and build more sustainable algorithms, we present an alternative method to mod out symmetries based on the notion of section of a principal fiber bundle. This framework allows to use simple metrics on the space of objects in order to measure dissimilarities between orbits of objects under the symmetry group. Moreover, the section used can be optimized to maximize separation of classes. We illustrate this methodology on a dataset of contours of objects for the groups of translations, rotations, scalings and reparameterizations. In…
Click any figure to enlarge with its caption.
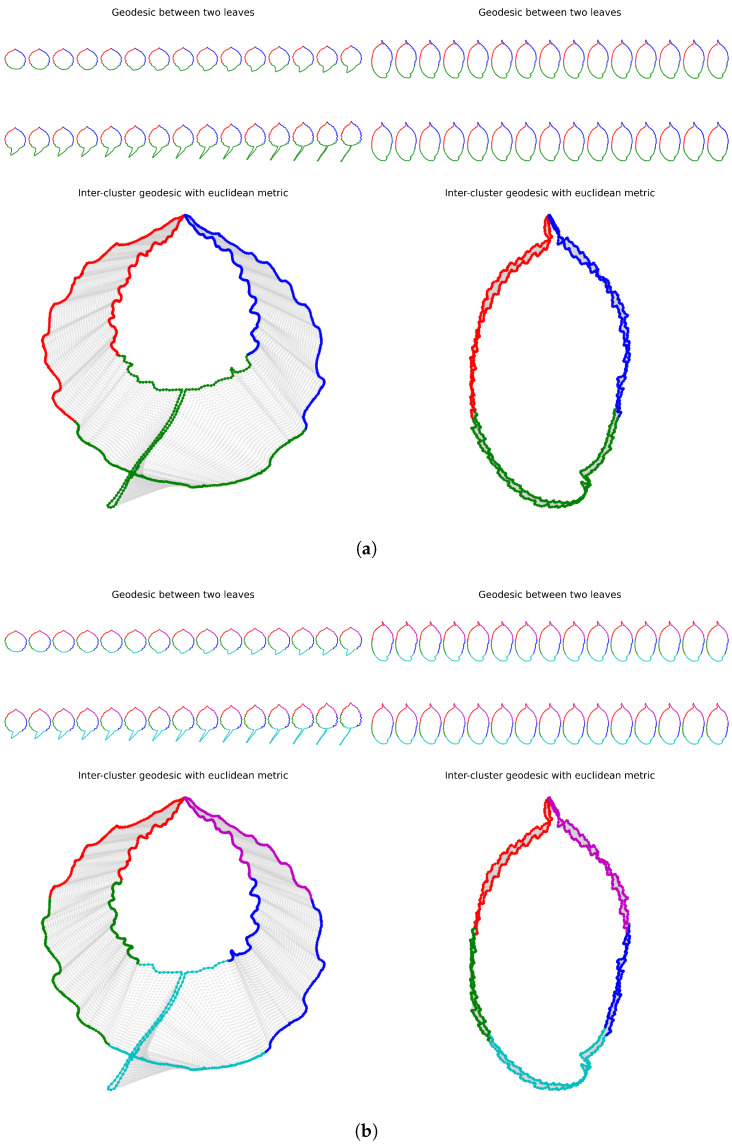 Figure 1
Figure 1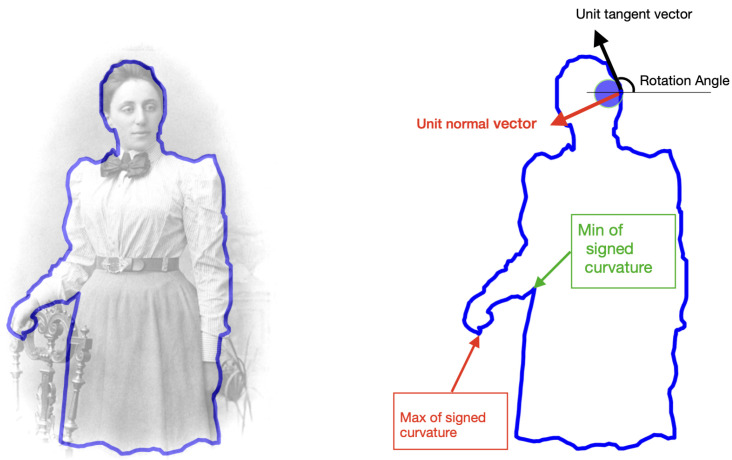 Figure 2
Figure 2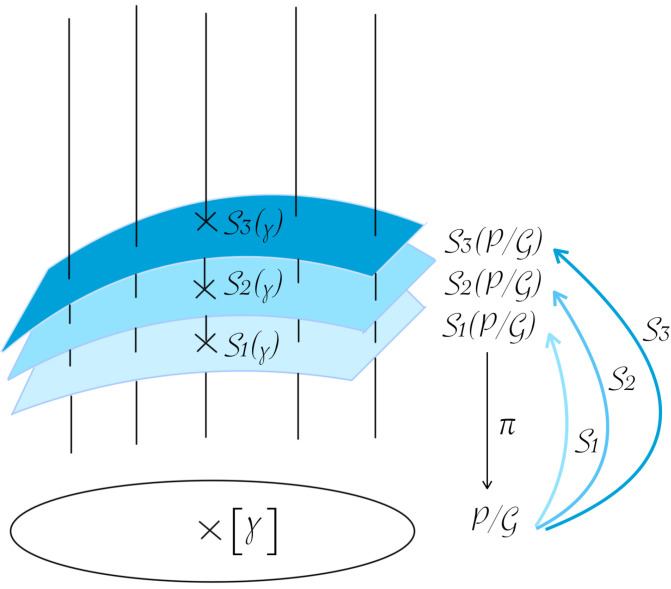 Figure 3
Figure 3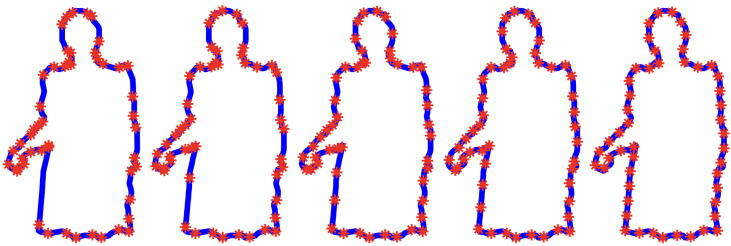 Figure 4
Figure 4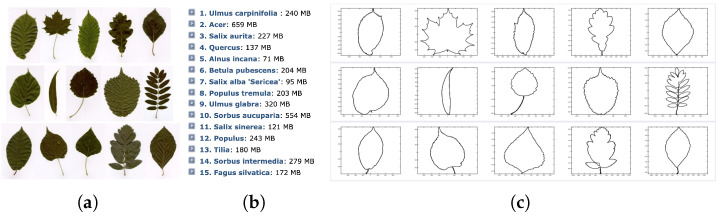 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7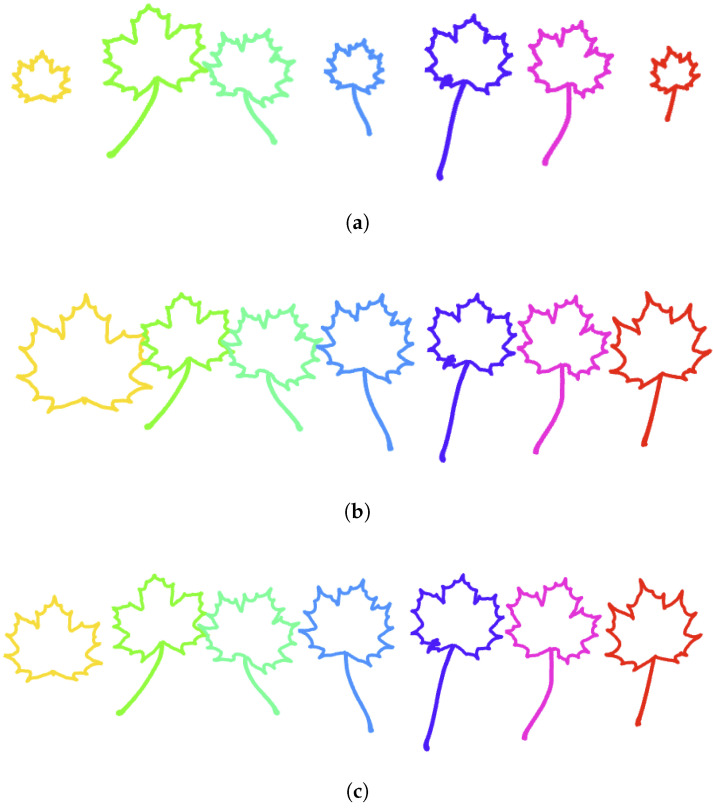 Figure 8
Figure 8 Figure 9
Figure 9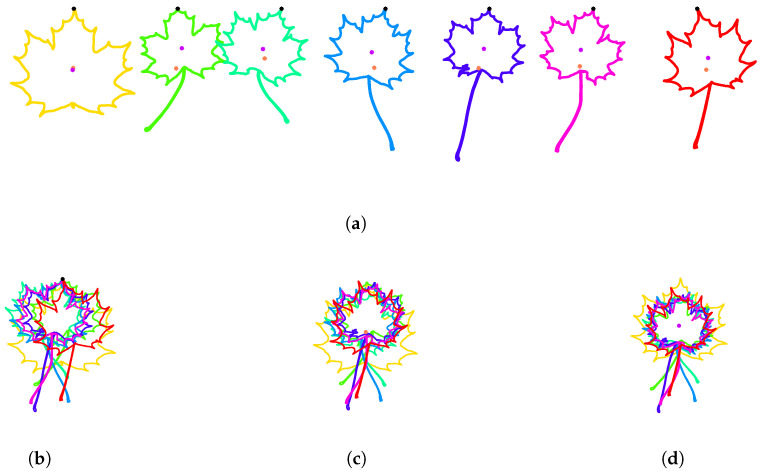 Figure 10
Figure 10 Figure 11
Figure 11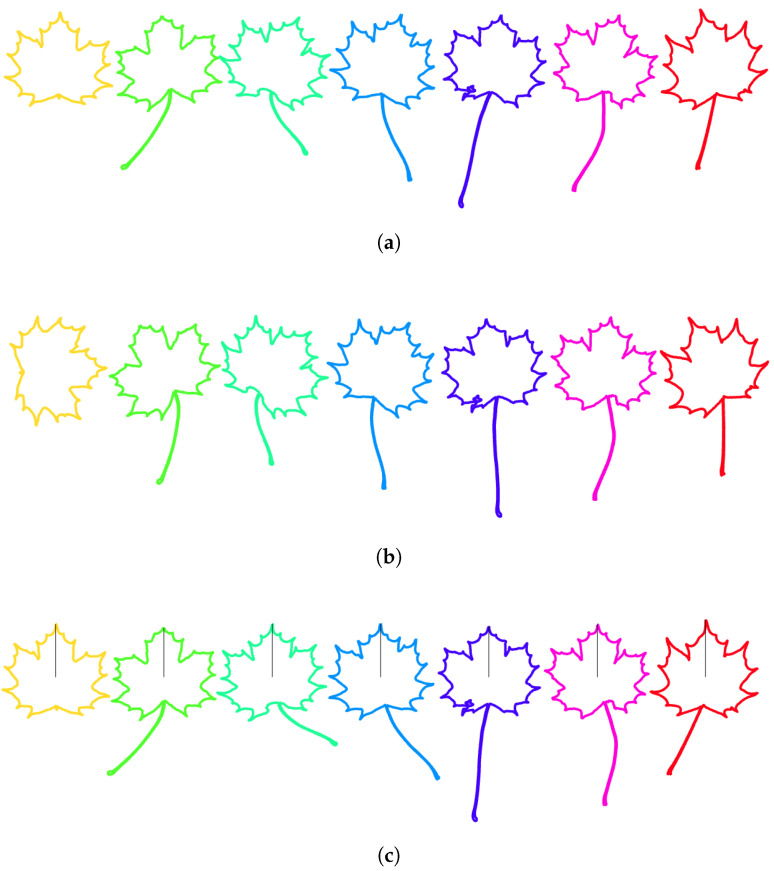 Figure 12
Figure 12 Figure 13
Figure 13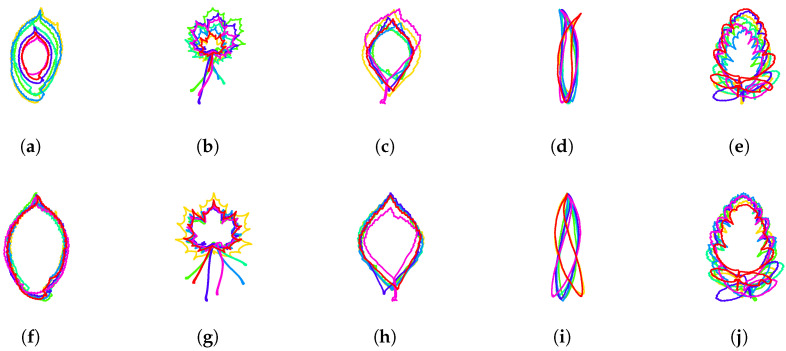 Figure 14
Figure 14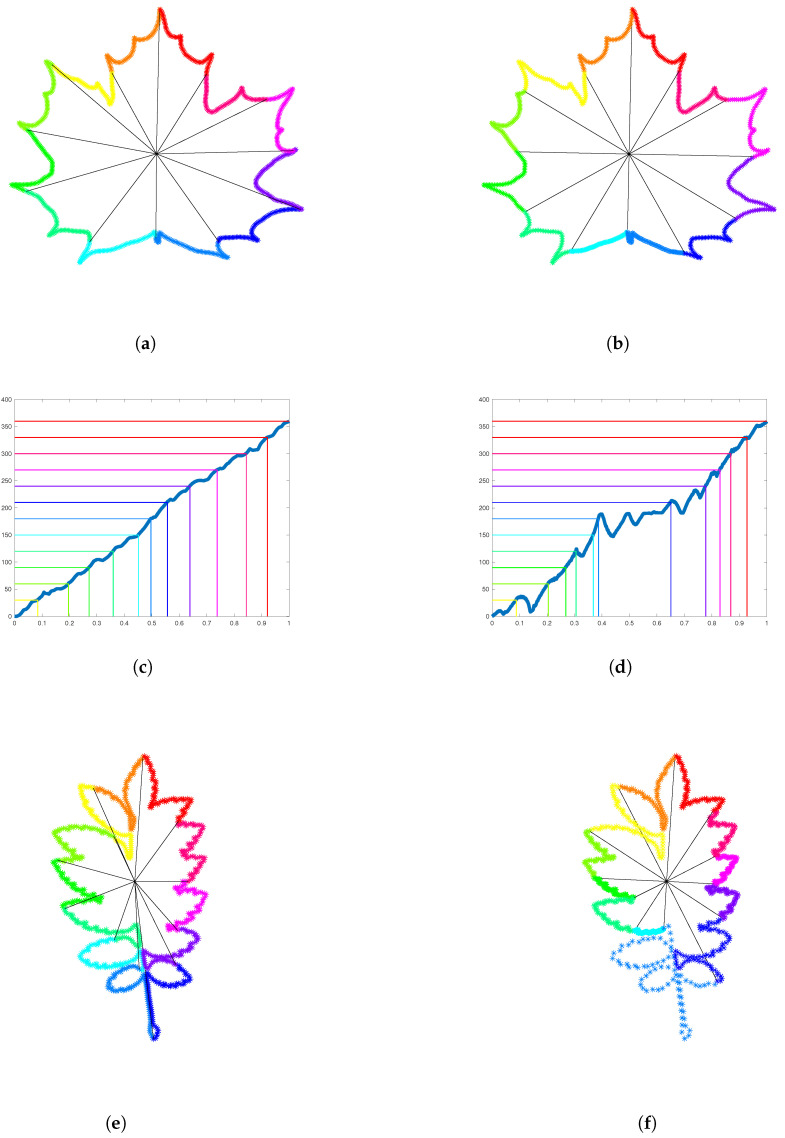 Figure 15
Figure 15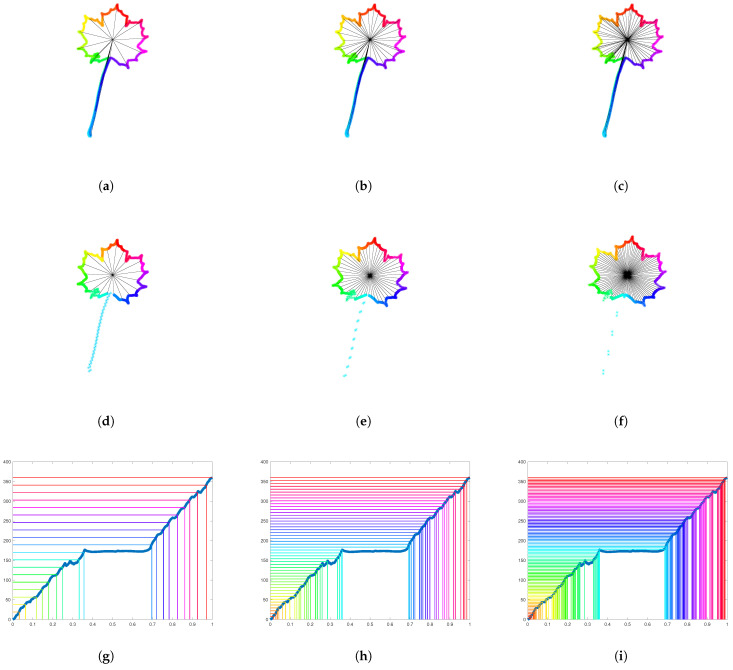 Figure 16
Figure 16 Figure 17
Figure 17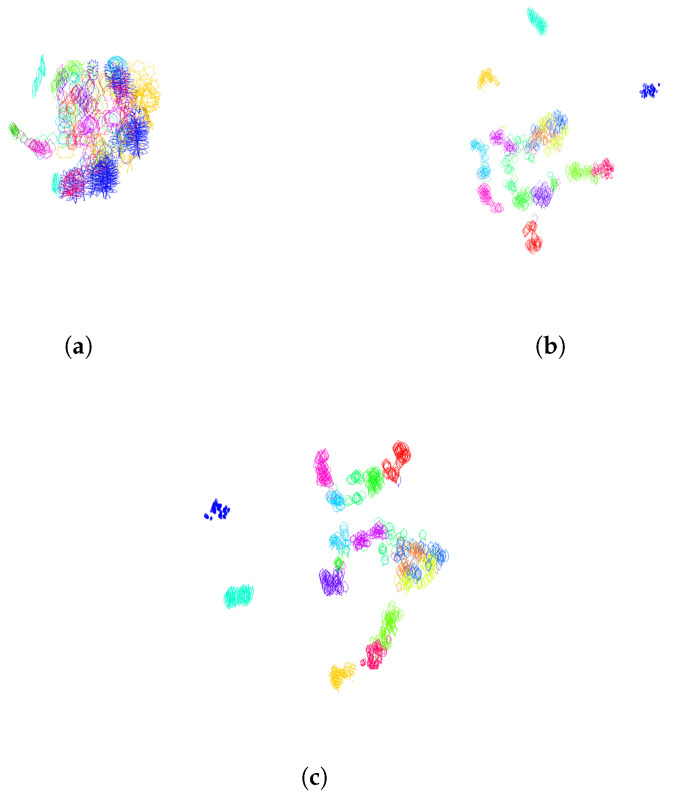 Figure 18
Figure 18 Figure 19
Figure 19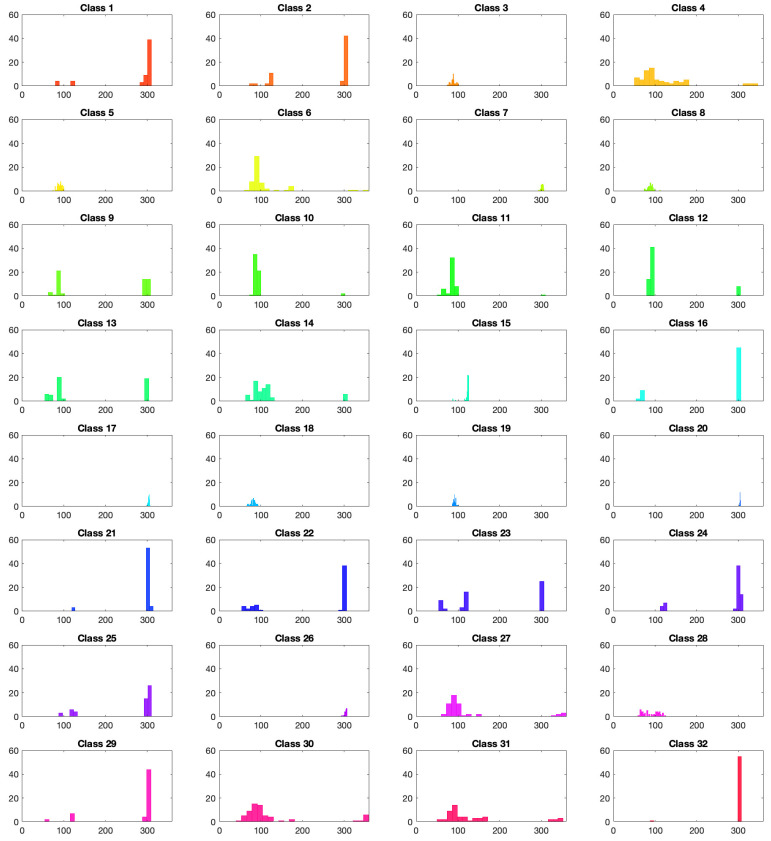 Figure 20
Figure 20- —Austrian Science Fund (FWF)
- —West University of Timişoara
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMedical Image Segmentation Techniques · Morphological variations and asymmetry · 3D Shape Modeling and Analysis
1. Extended Abstract
Our visual system is trained to identify objects that differ only by the action of a shape-preserving group, like the group of translations, rotations, and scalings. Consequently, these symmetries need to be taken into account in the design of algorithms for object detection and classification. A common way to build neural networks that learn the symmetries is to use data augmentation. This involves adding to the dataset new samples obtained by letting the symmetry group act on the original samples, for example, adding rotated images to the original images. In addition to the fact that data augmentation increases computational cost, it is also very memory-intensive. In this paper, we will consider, in particular, the symmetry group consisting of reparameterizations of contours in the plane, which is an infinite-dimensional Lie group.
In order to avoid data augmentation and build more sustainable algorithms, we present an alternative method to mod out symmetries based on the notion of section (also called cross-section) of a principal fiber bundle (see Section 2.2 and Section 2.3). Within this framework, a distinguished object is selected in each orbit under the symmetry group. This amounts to normalization or standardization of samples with respect to the action of the groups of translations, rotations, scalings, and reparameterizations.
One aim of the present paper is to investigate canonical parameterizations of curves, which allow one to mod out the action of the infinite-dimensional group of diffeomorphisms acting on curves by reparameterizations. A canonical parameterization can be understood as an automatic way to re-sample a curve according to some of its geometric features. An example of a canonical parameterization is provided by the arc-length parameterization, which consists of a unit speed travel along the shape drawn by the curve. In Section 3.2, we present a new 2-parameter family of canonical curve parameterizations, called curvature-weighted clock parameterizations, inspired by the small hand trajectory on a traditional clock, which moves at a constant angle every hour. These canonical parameterizations are very natural and may be a good choice in many applications, particularly in the presence of noise.
When the quotient space by the group action is unique, sections, when they exist, are numerous. In fact, for trivial fiber bundles like the fiber bundle of parameterized curves studied in the present paper, the space of sections is infinite-dimensional. Therefore, the present approach allows for a lot of flexibility and can be customized for particular applications. It also allows us to use a simple distance function on the total space of the fiber bundle in order to measure dissimilarities between orbits of objects under the symmetry group. Indeed, restricting a simple distance function, such as the distance, to the range of a chosen section, we obtain a distance function on the quotient space, which is easy to compute. An example of this construction of distance functions between curves irrespective of their parameterization is given in Section 2.7. They are straightforward to compute, and do not rely on any energy minimization algorithm. During training for a classification task, the section used to design the distance function measuring the dissimilarities between orbits can be optimized to maximize the separation of classes, solving a metric learning problem (see Section 2.8 and Section 3.3). Moreover, the optimal section gives rise to an optimal correspondence between points along any pair of contours in the dataset, solving a registration task. It therefore allows us to interpolate between contours, leading to optimal deformations between shapes (see Figure 1). Last but not least, our standardization procedure can be integrated into all classification algorithms for contours as a pre-processing step, allowing us to improve classification performance (see Section 4).
In Section 3, we illustrate this methodology with a dataset of leaves. More precisely, we optimize the Dunn index of clustering over a 2-parameter family of sections corresponding to the curvature-weighted clock parameterizations defined in Section 3.2. In Section 4.1, we show that this solution leads to good classification results for very low computational costs using classical machine learning algorithms. Indeed, with an optimization over only 2 parameters, our algorithm reaches 0.9602 accuracy (96.02% of correct classifications) with SVM for the dataset of Swedish leaves, whereas the state-of-the art model VGG-16 needs 138 million parameters to reach perfect accuracy (100% correct classifications) on the same dataset (see Section 4.1). We also show that taking into account all the shape-preserving groups boosts classification performance of all the classification algorithms that we considered, with even an increase of 25.71% of correct classifications for KNN on the Swedish leaf dataset (Section 4.1). Therefore, we argue that our method is a good pre-processing step that should be performed before any more complex feature extraction algorithm on contours.
The main contributions of this paper are the following:
- The idea of using sections of principal fiber bundles in order to mod out symmetries is explained in a comprehensive manner and illustrated in the context of plane curves for classical shape-preserving groups (Section 2.2).
- A 2-parameter family of canonical contour parameterizations is introduced, called curvature-weighted clock parameterizations (Section 3.2).
- For a labeled dataset of contours, the separation of classes is optimized based on cluster validity indices such as the Dunn index (Section 3.3).
- We demonstrate and quantify how taking into account symmetries affects clustering and classification results (Section 4.1).
- The proposed method not only allows us to measure distances between shapes in a parameterization-invariant manner, but also provides a registration and optimal deformation between shapes at a very low computational cost.
The code is available at the following link: https://github.com/GiLonga/Geometric-Learning (accessed on 13 November 2025). A tutorial notebook showcasing an application of the code to a specific dataset is available at the following link: https://github.com/ioanaciuclea/geometric-learning-notebook (accessed on 13 November 2025).
2. Mathematical Background and Method
2.1. Parameterized Versus Unparameterized 2D-Curves
In this section, we recall the distinction between parameterized and unparameterized -curves [1,2]. We will be mainly interested in the contours of objects, like the contours of objects depicted in Figure 2, which mathematically correspond to Jordan curves in the plane. More precisely, we will consider the following space of smooth embedded closed curves in the plane:
In what follows, the unit circle will be identified with via the map , . In particular, this identification distinguishes the point in .
The space has a natural structure of smooth Fréchet manifold [3]. Note that the parameterization of a contour with parameter space is not unique. In fact, the group , consisting of orientation-preserving diffeomorphisms of , is a Fréchet Lie group acting smoothly on by precomposition:
This action preserves the shapes of curves, and also the direction of travel along the curves. Moreover, two parameterized curves and in corresponding to the same oriented contour in the plane are necessarily related by a diffeomorphism : . Given a parameterized curve , one can consider its equivalence class modulo the action of :
also called the orbit of for the -action. The equivalence class is uniquely characterized by the range of , which is the shape drawn by in the plane, also called the unparameterized curve associated with , together with its orientation (the direction of travel). Consequently, the shape space of oriented contours in the plane is the quotient space of the manifold of smooth embeddings modulo the action of the Fréchet Lie group . It was proven in [3] that this quotient space admits a natural structure of smooth manifold and that the canonical projection
onto the quotient space defines a principal fiber bundle in the Fréchet category. This result was extended to freely immersed curves in [4], with some missing arguments in the proof, which were fully fixed in [5]. A visualization of a fiber bundle is given in Figure 3.
2.2. Sections of Fiber Bundles
In the present paper, we will be interested in choosing smoothly a preferred parameterization in each equivalence class defined by (2), where belongs to (some open subset of) the space of smooth embedded closed curves . This corresponds to the choice of a smooth section of the principal fiber bundle (see Figure 3). Let us recall the following definition.
Definition 1. A (global) smooth section of a fiber bundle is a smooth map such that .
Remark 1. It can be shown that the range of a smooth section of a principal fiber bundle is a smooth submanifold of . In particular, the manifold consisting of closed curves parameterized by arc length is a smooth manifold [6,7]. Using the parametrization with arc length of some particular curves, the authors of [8] were able to give the exact analytical solution of the linear static equation of curved Bernoulli–Euler beam.
The notion of section can be applied to different quotient spaces, in particular to the quotient space of the space of embedded closed curves modulo shape-preserving groups. We will see in Section 3 and Section 4.1 how the choice of a particular section can influence downstream analysis.
2.3. Canonical Parameterizations of 2D-Curves as Smooth Sections
An example of a smooth section for the fiber bundle is provided by the submanifold of curves parameterized proportional to arc-length. Let us recall how this particular parameterization is defined. Given a smooth parameterized curve in the plane , its length is defined as
where denotes the Euclidean norm in . The length is a geometric invariant of the curve, i.e., it does not depend on the parameterization. Given a starting point, which in our case will be the image of , there is a canonical way to reparameterize a curve by arc length, producing a unit speed curve. This procedure will change the parameter domain when the length of the curve is not equal to 1, and therefore may not belong to . However, there is a unique constantspeed reparameterization of with parameter domain , given as follows.
Proposition 1. Given a curve , consider the map ψ defined as
where . Then, is an orientation-preserving diffeomorphism, fixing . Moreover, the parameterized curve is the unique constant-speed reparameterization of γ with parameter space , which maps to and has the same orientation as γ.
Definition 2. We will denote by the subset of consisting of constant speed curves with parameter space . One has
The space of constant-speed parameterized curves with parameter space is just one example of space of canonically parameterized curves. The possible choices are infinite. In the present paper, we will use the following terminology:
Definition 3. Let be the infinite-dimensional manifold of parameterized closed embedded curves in defined in (1), and the Fréchet Lie group of orientation-preserving reparameterizations. A canonical parameterization will refer to the choice of a smooth section of the principal fiber bundle , which depends only on the geometric features of oriented contours. It can be understood as an automatic procedure to parameterize curves. It allows us to single out a distinguished parameterization of an oriented contour by associating with the parameterized curve . It also provides a (non-linear) projection , i.e., satisfying , given by
2.4. Examples of Curvature-Weighted Canonical Parameterizations
In Definition 2, the parameterization proportional to arc-length with parameter space is defined, and the corresponding submanifold is given in (6). In [9], we have introduced the parameterization proportional to curvature-length, as well as a variant called the parameterization proportional to curvarc-length. In fact, these particular procedures to automatically parameterize curves belong to a one-parameter family of canonical parameterizations, and we recall their construction below (see Equation (8)). This family provides an interpolation between the parameterization proportional to curvature-length ( ), the parameterization proportional to curvarc-length ( ), and converges to the parameterization proportional to arc-length when [9]. In order to have a picture in mind (see Figure 4) where the contour of Emmy Noether is sampled according to five different parameterizations from this family.
Equivalently, this one-parameter family of canonical parameterizations corresponds to a one-parameter family of sections , where (see Figure 4). These parameterizations are defined using the local differential invariant of curves given by the signed curvature . The signed curvature is the rate of turning angle of the moving frame attached to a parameterized curve. A visualization of this moving frame is illustrated in Figure 2.
More precisely, we introduce a one-parameter family of canonical reparameterizations of curves as follows. For a given , the corresponding reparameterization of a curve is given by , where depends on through the following equation involving the signed curvature of :
Note that the function is strictly increasing when , or when does not contain flat pieces. In these cases, is an orientation-preserving diffeomorphism of fixing . In the case and on some non-empty interval, the map defined by
is not injective and its graph presents horizontal portions. Consequently, is not a diffeomorphism, but it belongs to the semi-group of generalized reparametrizations [10]. In other words, is the limit of the diffeomorphisms when , and can be defined as the limit of in an appropriate topology.
Remark 2. In Equation (6) [9], another family of curvature-weighted parameterizations was introduced to assign a prescribed anatomical location to sample points on bone contours extracted from X-ray scans. It was used to measure the evolution of Rheumatoid Arthritis in a consistent way.
2.5. Different Ways to Define a Riemannian Metric on Unparameterized Curves
In ref. [7], the authors present three different methods for quantifying dissimilarities in quotient spaces based on Riemannian geometry. These methods consist of defining a Riemannian metric on the quotient space , which allows us to compute the length of paths in . The distance between two points and in (hence between two contours in the plane) is then defined as the infimum of the length of all paths connecting to . We recall, briefly, these three points of view.
2.5.1. Quotient Metric
The first method consists of endowing the space with a -invariant Riemannian metric. In this case, the Riemannian metric on descends to a Riemannian metric on the quotient space, called the quotient metric. A large body of literature is devoted to this method (see [1,2,11] and the references therein). For this method,
(i)Computing the distance between two points and relies on two optimization steps: First, the computation of the minimal path between and a element in the orbit of . Second, the optimization over the infinite-dimensional group of reparameterizations acting on .(ii)The Riemannian metric on is, in general, difficult to adjust to applications since the horizontal space may be difficult to compute.(iii)The added dimensions (infinitely many) that are going from to are dimensions that are irrelevant for the analysis of data living in the quotient space, but they need to be taken into account, particularly in the second optimization step.
A class of reparameterization-invariant Riemannian metrics on curves, called elastic metrics, was introduced in [12]. It corresponds to a 2-parameter family of Riemannian metrics penalizing bending as well as stretching. In [13], it was shown that, for a certain relation between the parameters, the resulting metric is flat on parameterized open curves. A similar method for simplifying the analysis of plane curves was introduced in [14]. These results have been generalized in [15], where the authors introduced another family of metrics, including the metrics from [12,14], which can be described using the restrictions of flat metrics to some cones. The flattening map has been significantly simplified in [16] and the previous cones interpreted as Regge cones. In [17], a precise algorithm for the matching problem of piecewise linear curves is implemented, giving a tool to compare contours in a meaningful way. For other parameter values, the transform introduced in [16] allows us to extend the precise algorithm of [17] to arbitrary parameter values . Approximations of these algorithms using neural networks were implemented in [18]. We believe that the results obtained do not justify the choice of these computationally intensive designs and are looking for more sustainable solutions.
2.5.2. Immersion Metric
The second method consists of identifying the quotient space with the range of a smooth section and endowing the submanifold with a Riemannian metric, such as those induced by a Riemannian metric on . In this case, the Riemannian metric on does not need to be -invariant. For this method,
(i)Computing the distance between two points and relies on one optimization step with constraint: it consists of minimizing the length of paths constrained to remain in the submanifold .(ii)The dimension of the space is preserved, since the quotient space and the range of the section s are diffeomorphic.(iii)The section s can be adapted to applications (we will see some optimization for sections s in the present paper).
Let us mention that, since the quotient space and the range of any section are diffeomorphic, any quotient metric on can be push-forward to the range of any section s. In [19], the authors have transported a particular family of quotient metrics, called elastic metrics, to the space of arc-length parameterized curves.
2.5.3. Gauge-Invariant Metric
The third method was introduced in [20] (see also [21]) and consists of defining a non-negative metric on (i.e., a non-negative symmetric bilinear form on the tangent bundle ), called a gauge-invariant metric, whose kernel coincides exactly with the direction of the fibers of the canonical projection , hence descending to a non-degenerate Riemannian metric on the quotient space. The idea behind this construction is that the vertical directions of the fiber bundle are irrelevant for the analysis of the data in the quotient space ; therefore, they should not interfere in the computation of distances in the quotient space. For this method,
(i)The dimensions irrelevant to the analysis of the quotient space do not play any role, since they do not contribute to the cost function.(ii)A reparameterization of curves can be performed on the fly without affecting the minimization algorithms.(iii)During a path-straightening algorithm for determining a geodesic in the quotient space, the paths can be lifted to and reparameterized with time-dependent reparameterizations without affecting downstream analysis, allowing for more robust algorithms to be designed and improving their convergence.
An example of application of this method to curves for action recognition is given in [22].
2.6. The Geodesic Distance Function Associated with a Riemannian Metric
Recall that the geodesic distance between two points in a Riemannian manifold is defined as the infimum of the lengths of curves connecting these two points. For a finite-dimensional manifold, this distance is non-degenerate and allows one to separate points. In other words, the geodesic distance between two points in a finite-dimensional Riemannian manifold is zero if and only if these two points coincide.
In an infinite-dimensional setting, the geodesic distance function associated with a Riemannian metric can be degenerate. The first example of this infinite-dimensional phenomenon was explicitly given in [23]. In this paper, the authors considered the reparameterization-invariant -Riemannian metric on the space of parameterized -curves, and the induced quotient metric on the space of unparameterized -curves. They proved that the quotient metric admits a vanishing geodesic distance function. In other words, the geodesic distance between any pair of curves is zero.
Clearly, when the distance function is degenerate, it cannot be used to measure the dissimilarities between pairs of points in the manifold. For this reason, as well as to avoid computationally costly optimization steps, we propose in this paper another strategy to measure the dissimilarity between contours in the plane.
2.7. Proposed Distance Between Oriented Contours
Recall that defined in (1) is the space of embedded closed -curves. As a space of smooth functions on the compact manifold with values in , it is contained in the Hilbert space of square-integrable functions on with values in , denoted by . Recall that the scalar product in is given by
where the dot denotes the scalar product on . The corresponding norm is given by
Since the scalar product (10) is not invariant by the group of reparameterizations , it cannot be used directly to measure the dissimilarity between oriented contours, since the result would depend on the way the contours are parameterized. However, if we fix the way contours are parameterized by choosing a canonical parameterization , then any oriented contour is associated with a unique function in , and we can measure the distance between and as
In other words, the -distance is restricted to the subset , which is in one-to-one correspondence with the quotient space consisting of oriented contours. The distance on the space of contours given by (12) is non-degenerate:
Proposition 2. For any section , and any oriented contours and in , one has
Proof of Proposition **2.**Suppose that . By definition (12), . Since is a Hilbert space, this implies that as elements in , and is thus almost everywhere. Since both and are smooth functions, one has for any . Consequently, . But by the Definition 1 of a section, . Hence, . The other implication is trivial. □
Proposition 3. For any smooth section , defined by ( 12 ) satisfies the triangular inequality.
Proof. Consider any smooth section , as well as the contours and in . One has
where we used the triangle inequality in . □
Remark 3. It follows from Proposition 2 and 3 that is indeed a distance function on the quotient space , i.e., it is non-negative, symmetric, non-degenerate, and satisfies the triangle inequality.
Remark 4. Propositions 2 and 3 can be generalized to any norm on the space of functions from to . The -norm was chosen since it is well suited for the datasets we are considering in Section 3 and Section 4.1. For instance, a leaf with peduncle and a leaf without peduncle belonging to the same class of leaves, see Section 3.1.4, are close in distance when induced by the -norm but distant if we use the -norm instead.
2.8. Metric Learning
Metric learning is a branch of Geometric Learning devoted to learning a distance function from a dataset. It emerged from the observation that the Euclidean distance of the ambient space in which the dataset is encoded may not be the best choice for measuring distances. Application-driven metric learning aims to design a distance function that measures similarities between sample points in a pertinent way for the application at hand.
In the present paper, we propose a metric learning algorithm based on an optimization over the section s. The distance defined in (12) clearly depends on the choice of section . Given a contour classification task, we can optimize the section s to obtain the best separation between classes on the training set. The quality of a clustering in a metric space can be measured using different validation indices (see Section 2.9), such as the Dunn index (Equation (16)). In Section 3.2, we present a 2-parameter family of sections that is used to define distance functions on contours using Equation (12). The optimization of the corresponding cluster validation indices is performed in Section 3.3 for the leaf dataset. The improvement of the classification performance is analyzed in Section 4.1.
In the finite-dimensional context, the field of supervised PAC (Probably Approximately Correct) learning provides theoretical guaranties that explain why and when supervised learning algorithms work. For PAC-Bayes guaranties to learning settings with non-compact, finite-dimensional symmetries, we refer the reader to the recent paper [24]. As far as we know, such a Bayesian approach has not been investigated for infinite-dimensional groups of symmetries.
2.9. Validation Indices of a Clustering
In order to quantify how the choice of different sections influences the distances between samples, we use two cluster validation indices, the Dunn index (Section 2.9.1) and the Davies Bouldin index (Section 2.9.2). A comparison of these two indices is made in Section 4.1. For a discussion and comparison of more general cluster validation techniques, we refer the reader to [25,26].
2.9.1. Dunn Index of a Clustering
In order to measure clustering efficiency in the algorithms we describe below, we use the Dunn index [27], which measures the ratio between the minimal interclass distance to the maximal intraclass distance. A high Dunn index characterizes dense and well-separated clusters, with a small variance between members of a cluster and different clusters sufficiently far apart, as compared to the within-cluster variance.
The Dunn index is computed as follows. For each class , (K being the number of classes), we compute the centroid of class as the mean of this class. In practice, the average of the positions of the points along the contours gives the average shape. The distance between classes is calculated as the distance between the centroid of class and the centroid and of class
where is defined in Equation (12) for a given section of the fiber bundle of parameterized contours (we will start with the section of arc-length parameterized contours, and optimize over a two-parameter family of sections in Section 3.3). The distance between classes is measured as the maximum distance between any pair of elements in class :
The Dunn index is defined as follows, with K being the number of classes:
2.9.2. Davies Bouldin Index of a Clustering
An alternative measure of clustering efficiency is the Davies Bouldin index [28] that measures the maximal ratio between the spread of two classes and the distance between their centroids. The Davies Bouldin index varies between 0 and , where a low index corresponds to a better classification. As with the Dunn index, for each class , (K being the number of classes), the centroid of class is computed as the mean of this class. Then, the mean distance of the elements of the class to their centroid is computed as
Finally, the Davies Bouldin index is defined as follows, with K being the number of classes:
Due to the averaging of the distances to a centroid over all elements of a class, the Davies Bouldin index is more stable than the Dunn index in the presence of outliers (see Section 4.2). On the other hand, the Dunn index can help detect outliers. By extracting from the dataset the pairs of samples from the same class maximizing the intraclass distance and the pair of samples from different classes that minimizes the interclass distance (see Section 3.3), one can spot some inconsistencies.
3. Illustration of the Methodology
3.1. Database and Pre-Processing Steps
3.1.1. Database
We used the Swedish leaves dataset from the Linköpling University, which can be freely downloaded from https://www.cvl.isy.liu.se/en/research/datasets/swedish-leaf/ (accessed on 8 September 2025).This dataset consists of pictures of leaves organized into 15 classes, with each class containing 75 leaves of the same variety. An element of each class is illustrated in Figure 5a, and the names of the corresponding varieties are listed in Figure 5b. In a preliminary step, we extract the contours of the leaves by transforming the pictures into black and white imprints, and then extract the boundaries of the resulting shapes with an appropriate algorithm (e.g., bwboundaries in Matlab). The resulting contours are illustrated in Figure 5c, and consist of an ordered set of points along the boundary of the leaves. This ordering gives us an initial parameterization of each contour.
We divide the resulting set of contours into a training set, containing 50 contours from each class, as well as a testing set containing the remaining contours. In particular, the training set and the testing set are disjointed.
3.1.2. Standardizing the Direction of Travel
The initial parameterizations of the contours obtained from the boundary extraction algorithm explained in Section 3.1.1 induce an orientation, leading to contours following clockwise or counterclockwise. As a first normalization step, we check if the contours are traveling counterclockwise, and flip the parameterization of those contours following clockwise. In order to automatically detect the orientation of a given contour, we compute the signed area enclosed by the contour. A positive signed area corresponds to a contour that traveled counterclockwise, and a negative area corresponds to a contour that traveled clockwise. The signed area can be computed using Stokes’ Theorem by integration along the contour of a leaf:
In practice, for the dataset of Swedisch leaves, we did not encounter any contour following clockwise. The Dunn index defined by Equation (16), calculated on the training set containing 50 leaves of each of the classes, is equal to when all contours have traveled counterclockwise. It decreases to when half of the contours chosen randomly have traveled clockwise, and the other half are traveled counterclockwise. To have a visual representation of the distance distribution of the leaves according to the distance function given by (12) with respect to the section s consisting of arc-length parameterized contours, we use the tsne algorithm. The resulting distribution of leaves in 2 dimensions with random direction of travel, as well as for contours that traveled counterclockwise, is given in Figure 6.
3.1.3. Standardizing the Starting Point of Parameterizations
Since the contour of a leaf is represented by an ordered set consisting of finitely many sample points along the contour, the starting point of this discretization induces variability that we need to take into account. In the continuous case, this amounts to standardizing the position of the starting point of the parameterization of contours. This corresponds to the normalization with respect to rotation in parameter space , i.e., with respect to the subgroup of rotations , where is the group of orientation-preserving reparameterizations.
For the dataset of leaves at hand, we detect automatically the point of each contour with the largest vertical component (which was unique for all contours) and reorder the sample points in such a way that this particular point becomes the starting point. In Figure 7, we illustrate the distance distribution using the tsne algorithm before and after normalization of the starting points. The starting points are showcased as black dots along the contours. The Dunn index increases from to after this normalization step.
3.1.4. Standardizing the Scale Variability
The dataset contains leaves of different sizes, as can be seen in Figure 8a on 7 samples of Acer leaves. In order to recognize the class of a leaf irrespective of its size, we need to eliminate the variability of the scale. We tested two normalization procedures:
- (a)Normalization of the length of contours: In this normalization method, we first compute the contour length of each leaf and then divide the initial parameterization by this length.
- (b)Normalization of the enclosed area: Each contour is a Jordan curve in the plane and encloses a domain in the plane that corresponds to the surface of the corresponding leaf. In this normalization step, we compute the area of each leaf using Equation (19) and renormalize the initial parameterization to have a unit area by dividing the parameterization by the square-root of (the absolute value of) the area.
As can be seen in Figure 8b,c, normalization to unit-length induces greater intraclass variability compared to normalization to unit-enclosed area. This is mainly due to the fact that, in the same class, leaves with peduncles as well as leaves without peduncles are present. Normalization by unit-length is heavily affected by the presence or absence of a peduncle. In contrast, the normalization to curves with unit-enclosed area is not affected by the presence or absence of peduncles, as peduncles barely contribute to the area.
Despite this fact, the Dunn index increases to after normalization by unit-length, and only to after normalization by unit area. This is due to the fact that the interclass distance increases more when normalization by the length is used, due to the characteristic boundary shape of different varieties of leaves. This can be seen in Figure 9. In the sequel, we therefore select the normalization by unit-length.
3.1.5. Standardizing the Position in Space
The shape of a leaf is invariant by translation in space. We have tested three normalization procedures that can be used to eliminate the variability in positions.
(a)Starting point at the origin: for this normalization method, we simply substract the coordinates of the first point visited by the initial parameterized contour, leading to a parameterized curve starting at .(b)Center of mass of the contour at the origin: in this normalization method, we compute the coordinates of the center of mass of the contour as the mean of the coordinated of points visited by the initial parameterization :
and then we substract the coordinates of this center of mass from the initial parameterization.(c)Center of gravity of the enclosed area at the origin: in this normalization method, we compute the coordinated of the center of gravity of the area enclosed by the contour (i.e., of the surface of the corresponding leaf) by using Stokes theorem:
and then we substract the coordinates of this center of gravity from the initial parameterization.
As can be seen in Figure 10a, on seven Acer leaves from the Swedish dataset, the positions of the first points (in black), the centers of mass of the contours (in orange), and the centers of gravity of the enclosed areas (in purple) are different. In this experiment, the initial parameterization is counterclockwise, the starting point of each parameterized curve coincides with the point of the contour with the largest vertical coordinate (see Section 3.1.3) and the scaling is by unit-length.
In Figure 10b, the contours of the Acer leaves are centered so that the first point of their parameterization coincides with the origin. The corresponding clustering of the training set after this normalization can be visualized in Figure 11a. The Dunn index decreased by this normalization process from (see Section 3.1.5) to .
In Figure 10c, the contours are centered so that the center of mass of the contours is at the origin. The corresponding clustering of the training set after this normalization can be visualized in Figure 11b. The Dunn index slightly decreases after this normalization process from to .
In Figure 10d, the contours are centered so that the center of gravity of the enclosed area is at the origin. One can see that the length of the peduncle influences the position of the center of mass of the contour, but not the position of the center of gravity of the enclosed area, leading to a better alignment of the contours. The corresponding clustering of the training set after this normalization can be visualized in Figure 11c. The Dunn index increases after this normalization process from to . Therefore, in what follows, the center of the enclosed area is used to center contours.
3.1.6. Standardizing the Orientation in Space
The leaves in the dataset we are considering have different orientations in space and need to be rotated in a consistent way to eliminate the orientation variability. We have tested two normalization procedures to align the orientations through the dataset.
(a)Axes of the approximating ellipse aligned: Each contour is rotated so that the ellipse that best approximates the contour has its minor axis along the horizontal axis, and its major axis vertically. We did not encounter contours with equal minor and major axes.(b)Segment that joins the tip of the leaf to the center of the enclosed area is placed vertically: Each contour is rotated so as to position the center of the enclosed area vertically below the highest point of the contour.
The first normalization method does not lead to good results because of the presence of leaves with a peduncle and leaves without a peduncle in the same class. As can be seen in Figure 12b on the example of Acer leaves, the alignment of the major and minor axis of the approximating ellipse leads to inconsistent orientation of the leaf without peduncle with respect to the other leaves. After this normalization procedure, the Dunn index decreases from to . The corresponding clustering can be visualized in Figure 13a.
The second normalization method gives better results (see Figure 12c), although the Dunn index decreases slightly from to . We will choose this second normalization method, in order to normalize the orientation variability and obtain consistent classification results. The corresponding clustering can be visualized in Figure 13b.
3.1.7. Resulting Normalization over Finite-Dimensional Shape-Preserving Groups
The resulting normalization over the finite-dimensional shape-preserving group consisting of scalings, translations, rotations in space and rotations in parameter space is illustrated for different classes of leaves in Figure 14. Let us summarize here the normalization steps that were selected:
- Counterclockwise travel along the curves (Section 3.1.2).
- Starting point at the tip of the leaves (Section 3.1.3).
- Unit-length curves (Section 3.1.4).
- Center of gravity of the enclosed area at the origin (Section 3.1.5).
- Segment joining the tip of the leaf to the center of gravity vertical (Section 3.1.6)
The remaining shape-preserving group is infinite-dimensional and consists of orientation-preserving reparameterizations fixing the starting (and ending) point. Mathematically, this group corresponds to the following subgroup of :
3.2. A New 2-Parameter Family of Canonical Parameterizations
3.2.1. Clock Parameterization of Jordan Curves
In this section, we introduce a new canonical parameterization of simple plane curves, called the clock parameterization. We will make use of the analogy with a traditional clock to explain how this parameterization is constructed. Suppose that we have points to place along the contour of the Acer leaf depicted in Figure 15a. If we place 720 points uniformly along the contour and cut the enclosed area as a pizza from its center of gravity to the points corresponding to a multiple of 60, then we obtain 12 pieces of different angles. This is illustrated in Figure 15a by a color change with every 60 points. In contrast, the clock parameterization automatically places each point numbered by a multiple of 60 in such a way that the corresponding angle is precisely 360/12 degrees, hence at the positions of the hours on a traditional clock (see Figure 15b). To place these 12 keypoints at the hours positions, we compute the angle between the vertical line and the segment connecting the center of gravity to a point traveling along the contour at constant speed. The graph of the angle function for the Acer leaf is illustrated in Figure 15c. It allows us to detect the constant speed parameter of the first point reaching an angle multiple of 360/12 degrees. In Figure 15c, the horizontal lines are spaced every 360/12 degrees and hit the angle function graph precisely at these constant speed parameters. Between two consecutive points that have these particular constant speed parameters, we distribute exactly 60 points uniformly along the portion of the curve between them. The resulting reparameterization of the Acer leaf is such that each colored portion of the curve describes the same angle with respect to the center of gravity and contains exactly the same number of points. In Figure 15d–f, the same procedure is applied to the more challenging shape of Sorbus leaf. Note the difference in the density of points on the light blue portion and on the dark blue portion of the curve. This is due to the structure of compound of Sorbus leaves, which are made up of multiple leaflets arranged along a central stalk.
In the previous procedure, the number of subdivisions of 360 was set to 12. For each choice of the number n of subdivisions, we obtain a different reparameterization procedure for Jordan curves. In Figure 16, we illustrate how the resulting parameterization of a curve depends on the number of subdivisions n. In this case, we distribute 1000 points along the contour of an Acer leaf, this time with a peduncle. The first row in Figure 16 corresponds to a parameterization with constant speed. From left to right, we use 20, 50, and 100 subdivisions to color the curve. The corresponding clock parameterizations are depicted in Figure 16d–f, respectively. The graph of the angle function with equally spaced horizontal lines is depicted in Figure 16g–i for 20, 50, and 100 subdivisions of 360 degrees. In contrast to the constant speed parameterization, for the clock parameterization, the density of points along the peduncle decreases with the number of subdivisions. Indeed, while the number of subdivisions increases, the angle formed by each colored piece of curve decreases. Since, on each colored piece of curve, we distribute the same number of points, the density of points on the piece containing the long peduncle decreases drastically.
Remark 5. The clock parameterization is well defined as long as the center of gravity is within the interior of the contour. In practice, this was generally the case, but we encountered some leaves with a center of gravity outside the interior. In these cases, the center of gravity was replaced by a reference point nearby but located inside the leaf. There are many possible automatic procedures for doing so:
After computing the closest point of the contour to the center of gravity, the reference point is initialized at the center of gravity and moved in the direction of this closest point until its index with respect to the contour increases from 0 to 1.
The reference point is initialized at the center of gravity and moved in the direction of the tip of the leaf until its index with respect to the contour increases from 0 to 1.
After computing the Delaunay triangulation for the contour and subsequently creating the Voronoi diagram, the leaf is translated so that the closest Voronoi vertex is at the origin.
After computing the closest point of the contour to the center of gravity, we consider triangles with one vertex at the closest point and two other vertices on the contour, and compute their centroids. We choose as a reference point a centroid near the center of gravity that has the property to be inside the shape, and we perform a translation so that this reference point is at the origin.
The first solution has the advantage of generalizing to datasets without distinguished point along the contour (which could take the role of the tip of the leaf), the second solution has the advantage of being compatible with the rotation alignment performed in Section 3.1.6. However, these two solutions are dependent on the step size of the displacement, which is an extra data-dependent parameter. In contrast, the last two translation procedures do not require learning an extra hyperparameter and are therefore preferred.
3.2.2. Curvature-Weighted Clock Parameterizations of Jordan Curves
In this section, we introduce a 2-parameter family of canonical parameterizations obtained by combining curvature-weighted parameterizations with parameter (see Section 2.4) and clock parameterizations with n subdivisions (Section 3.2.1). More precisely, each contour is first decomposed into n subdivisions forming n equal angles to the center of gravity. Secondly, each portion of the curve is reparameterized according to a curvature-weighted parameterization with parameter as in Section 2.4, Equation (8).
A sampling of a curve with N points according to the curvature-weighted clock parameterization with parameters goes as follows: the curve is subdivided into n portions forming equal angles at the center of gravity; points are distributed on each portion according to the curvature-weighted parameterization with parameter ; see Section 2.4 (for low parameter , the density of points decreases on flat parts of the contour and increases on curved parts, while for large parameter , the curvature-weighted parameterization tends to the constant speed parameterization).
In Figure 17, an Acer leaf (with peduncle) is resampled with 1000 points according to curvature-weighted clock parameterizations with different parameters . The first column corresponds to , the second to , and the third column to . At the same time, the first row corresponds to , the second row to , and the last row to . One can observe that the density of points along the peduncle decreases when decreases and/or the number of subdivisions increases.
3.3. Geometric Learning of Canonical Parameterizations
In this section, we consider the 2-parameter family of curvature-weighted clock parameterizations with parameters introduced in Section 3.2.2, as well as the corresponding sections of the fiber bundle consisting of embedded closed curves. The aim is to optimize clustering based on the distance between shapes defined in (12), which depends on the section chosen.
A table containing the Dunn index for various values of parameters (weighting the parameterization by curvature) and n (number of segments in the clock parameterization) is given in Table 1. The Dunn index values were averaged over a 30-fold cross-validation. For this experiment, we used the training set consisting of 15 classes of leaves with 50 leaves each. We can see in Table 1 that the largest Dunn index (corresponding to the best clustering for this metric) is obtained for subsections along the contours of the leaves, and , which corresponds to a curvature-weighted parameterization on each of the three portions of the curve. In Figure 1a, we visualize the pair of curves that maximizes the intraclass distance, as well as the pair of curves that minimizes the interclass distance. These two pairs of curves are responsible for the value of the Dunn index. We illustrate the segment in , which connects the leaves parameterized by the optimal parameterization ( , ). In the left picture of Figure 1a, we can see that the south portion of the contour of the leaf without peduncle deforms to create a peduncle. In comparison in the right picture of Figure 1a, two leaves from two different classes seem perfectly aligned. This illustrates the challenges of clustering or classifying this dataset of leaves, where very different shapes belong to the same class and similar shapes belong to different classes. Figure 18 illustrates a 2-dimensional representation of the distance distribution along the dataset using the tsne algorithm before any normalization and after normalization using the optimal parameterization for the Dunn index. One can see that the classes are significantly better clustered after normalization.
4. Classification Results
4.1. Testing on the Dataset of the Swedish Leaves
4.1.1. Clustering Evaluation Using Another Cluster Validation Index
Recall that the Swedish leaves dataset was divided into a training set, containing 50 contours from each class, and a testing set containing the remaining 25 contours per class. The standardization steps performed in Section 3.1 and Section 3.3 were necessary to define a distance between contours in the plane that is independent of their position and orientation in space, their scaling, and their parameterization (starting point, traveling direction, and velocity). The best standardization procedures were selected to optimize the clustering of the classes of the labeled training set. The quality of the clustering obtained can be measured by computing a cluster validity index, like the Dunn index or the Davies Bouldin index, as explained in Section 2.9, for the distance defined in (12). Table 1 and Table 2 contain, respectively, the values of the Dunn index and Davies Bouldin index, cross-validated over 30 partitions of the dataset into training set and testing set. As mentioned in Section 2.9.2, the averaging of the distances to a centroid over all elements of a class allows the Davies Bouldin index to be more stable than the Dunn index in the presence of outliers. We therefore select the Davies Bouldin index for classification task.
4.1.2. Improvement of the Classification Results After Normalization
In the present section, we illustrate how standardization procedures affect classification performance of samples from the testing set. We have used the following:
- Logistic Regression with -norm regularization;
- Random Forest with 400 trees;
- Support Vector Machine (SVM) with a non-linear Radial Basis Function (RBF) kernel;
- k-Nearest Neighbors (KNN) with nearest neighbors.
Complete parameter specifications are available in the code. The Support Vector Machine with an RBF kernel achieved the highest performance, with (the regularization parameter controlling the trade-off between margin size and classification error) and (the kernel coefficient that determines the influence radius of individual training samples). To assess classification performance, we used accuracy as an evaluation metric, defined as follows:
where is the true label of the i-th element in the testing set, and is the corresponding predicted label.
The results are displayed in Table 3. We see that all four classification algorithms perform significantly better after normalization, i.e., when a representative is chosen in each orbit of the shape-preserving groups in a consistent way. In particular, we observe an increase of 25,85% of correct classifications for the KNN algorithm between the first line of Table 3 (no normalization performed) and the last line (all finite and infinite-dimensional shape-preserving groups taken into account using optimized sections). This illustrates that including standardization of the representative of each orbits under shape-preserving groups in the pre-processing step improves classification results irrespective of the classification algorithms.
4.1.3. Comparison with State-of-the-Art Classification Results
Compared to the state-of-the art classification results displayed in Table 4 for classical machine learning algorithms (without Neural Networks) and in Table 5 for Neural Network-based algorithms, we observe that, with an optimization over only 2 parameters, our algorithm reaches 0.9602 accuracy (96.02% of correct classifications) with SVM on the dataset of Swedish leaves, whereas the state-of-the art model VGG-16 needs 138 million parameters to reach perfect accuracy (100% correct classifications) on the same dataset. This illustrates that algorithms using fewer but well-chosen parameters can compete with brute force algorithms using millions of parameters. We hope that this can motivate the investigation of more sustainable solutions for classifications tasks, as well as meaningful parameter optimization. Moreover, as shown in Section 4.1.2, our proposed method could be a beneficial pre-precessing step before applying fine-tuned algorithms since it leads to an optimal point-to-point correspondence across the dataset. Contrary to the other classification methods present in Table 4 and Table 5, the standardization procedure that we propose allows us to interpolate between elements in the dataset (as in Figure 1). It could be interesting to test whether the methods of [29,30] improve if we apply our standardization method as a pre-precessing step.
4.2. Testing on Flavia Dataset
To further assess the effectiveness of the proposed pipeline, we evaluated it on a second dataset. We use the Flavia dataset, which contains 1,907 leaf images belonging to 32 classes and is available at https://www.kaggle.com/datasets/gauravneupane/flavia-dataset (accessed on 13 November 2025). Figure 19 illustrates the different types of leaves present in this dataset. Achieving high classification accuracy on this dataset is more challenging due to the larger number of classes and the extremely similar shapes among many of them.
While applying our pipeline on the Flavia dataset, we were surprised to see that normalization of the orientation in space deteriorated the clustering drastically. After taking a closer look at the dataset, we discovered that the original Flavia dataset contains an alignment bias. Indeed, for some classes, all the leaves are oriented in a class-dependent direction in space. In Figure 20, the angle distribution of the leaves in each class is depicted. As we can see, for instance on classes 15, 19, and 32, the distribution is very concentrated around a mean orientation, and this mean orientation differs from class to class. This is probably due to the way the dataset was collected. Consequently, the orientation in space can be used to determine the belonging of a sample to a given class, which is unfortunate. In order to test our algorithm on an unbiased dataset, we applied random rotations to the samples of the dataset. The unbiased dataset is available at the following links: https://github.com/GiLonga/Geometric-Learning (accessed on 19 October 2025) and https://github.com/ioanaciuclea/geometric-learning-notebook (accessed on 19 October 2025).
Starting from the unbiased Flavia dataset, we can see in Table 6 that our normalization procedure improves the classification performance of all the algorithms tested. Since this dataset contains very similar shapes but with different scales, scale normalization was not performed because the scale contains valuable information in order to distinguish between classes. In order to optimize over the parameterization, we have used the Davies Bouldin index, which is more stable than the Dunn index in the presence of outliers. Table 7 contains the Davies Bouldin index for different values of the parameters, 30-fold cross-validated.
As a concluding remark, let us note that the optimal normalization procedure and the optimal parameters depend on the dataset and the selected cluster validity index. However, for a given dataset, the optimal parameterizations for various cluster validity indices seem to be close in the space of sections over the sample points. Indeed, as can be seen in Figure 1 for the Swedish leaves dataset, the optimal section for the Dunn index is different from the optimal section for the Davies Bouldin index (the former is associated with whereas the latter with ), but the corresponding contours parameterizations look very similar. This can be explained by the fact that the various cluster validity indices are linked to each other [25] and are continuous functions of the distances between samples, while these distances depend continuously on the section . From this perspective, it becomes clear that the standardization procedure improves classification performance, as the optimal distance function better reflects the intrinsic geometry of the dataset.
5. Discussion
In this paper, a supervised classification task is considered on contours in the plane. We have shown that classification performance is significantly improved when shape-preserving groups are taken into account and the dataset is appropriately normalized. In order to design classification algorithms that are independent of the action of shape-preserving groups and hence make sense on the quotient space, we propose to use customized sections of the corresponding fiber bundle for standardization or normalization along the dataset. This amounts to choosing a representant in each orbit of the shape-preserving group in a standardized way. We have introduced a distance on the manifold of contours in the plane based on a simple distance function and the choice of a section. We have presented multiple normalization procedures for the finite-dimensional groups of translations, rotations, and scalings, as well as for the infinite-dimensional group of reparameterizations (which act on the starting point and the velocity along the contours). In particular, for the latter group, we have introduced a new two-parameter family of canonical parameterizations of curves, called curvature-weighted clock parameterizations, that may be of interest for other applications. By optimizing a cluster validation index, like the Dunn or Davies Bouldin indices, of the resulting clustering in the training set, we are able to achieve high classification performance on the testing set, without the use of any neural network and by optimizing over only two parameters. This method can serve as a beneficial pre-processing step for more complex algorithms since it gives optimal point-to-point correspondances, solving a registration task. It can be easily generalized to curves in a Euclidean space of any dimension, and we will explore this in a future work. We hope that this work can serve as a guide for the design of more sustainable AI algorithms on manifolds of curves.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bauer M. Bruveris M. Michor P.W. Overview of the geometries of shape spaces and diffeomorphism groups J. Math. Imaging Vis.201450609710.1007/s 10851-013-0490-z · doi ↗
- 2Mennucci A.C.G. Metrics of Curves in Shape Optimization and Analysis Level Set and PDE Based Reconstruction Methods in Imaging Springer Lecture Notes in Mathematics Springer Berlin/Heidelberg, Germany 201320531910.1007/978-3-319-01712-9_4 · doi ↗
- 3Binz E. Fischer H.R. The manifold of embeddings of a closed manifold Differential Geometric Methods in Theoretical Physics, Proceedings of the International Conference Held at the Technical University of Clausthal, Clausthal-Zellerfeld, Germany, July 1978 Lecture Notes in Physics 139Springer Berlin/Heidelberg, Germany 1981
- 4Cervera V. MascaróF. Michor P.W. The action of the diffeomorphism group on the space of immersions Diff. Geom. Appl.1991139140110.1016/0926-2245(91)90015-2 · doi ↗
- 5Mennucci A.C.G. Neighborhoods and Manifolds of Immersed Curves Int. J. Math. Math. Sci.2021202110.1155/2021/6974292 · doi ↗
- 6Preston S.C. The geometry of whips Ann. Glob. Anal. Geom.20124128130510.1007/s 10455-011-9283-z · doi ↗
- 7Tumpach A.B. Preston S.C. Three methods to put a Riemannian metric on Shape Space Geometric Science of Information, Proceedings of the 6th International Conference, GSI 2023, St. Malo, France, 30 August–1 September 2023 Proceedings, Part I Springer Berlin/Heidelberg, Germany 202331110.1007/978-3-031-38271-0_1 · doi ↗
- 8MaksimovićS. BorkovićA. A New Class of Plane Curves with Arc Length Parametrization and Its Application to Linear Analysis of Curved Beams Mathematics 20219177810.3390/math 9151778 · doi ↗