MESPBO: Multi-Strategy-Enhanced Student Psychology-Based Optimization Algorithm for Global Optimization Problems and Feature Selection Problems
Guolin Zhai, Sai Li

TL;DR
This paper introduces MESPBO, an improved optimization algorithm that excels in solving global optimization and feature selection problems with better accuracy and efficiency.
Contribution
The novel contribution is the integration of three strategies to enhance SPBO, achieving superior performance in optimization and feature selection tasks.
Findings
MESPBO outperforms 11 metaheuristic algorithms on CEC2017 benchmarks across multiple dimensions.
MESPBO achieves 100% classification accuracy on several datasets while selecting minimal feature subsets.
Compared to SPBO, MESPBO improves fitness values by an average of 10% on seven datasets.
Abstract
Feature selection and continuous optimization are fundamental yet challenging tasks in machine learning and engineering design. To address premature convergence and insufficient population diversity in Student Psychology-Based Optimization (SPBO), this paper proposes a Multi-Strategy-Enhanced Student Psychology-Based Optimizer (MESPBO). The proposed method incorporates three complementary strategies: (i) a hybrid heuristic initialization scheme based on Latin Hypercube Sampling and Gaussian perturbation; (ii) an adaptive dual-learning position update mechanism to dynamically balance exploration and exploitation; (iii) a hybrid opposition-based reflective boundary control strategy to enhance search stability. Extensive experiments on the CEC2017 benchmark suite with 10, 30, and 50 dimensions demonstrate that MESPBO consistently outperforms 11 state-of-the-art metaheuristic algorithms.…
Click any figure to enlarge with its caption.
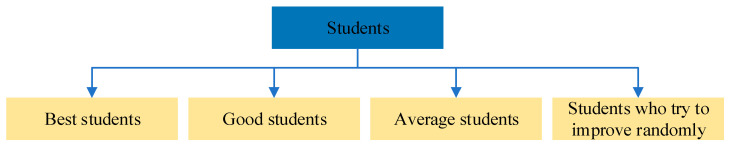 Figure 1
Figure 1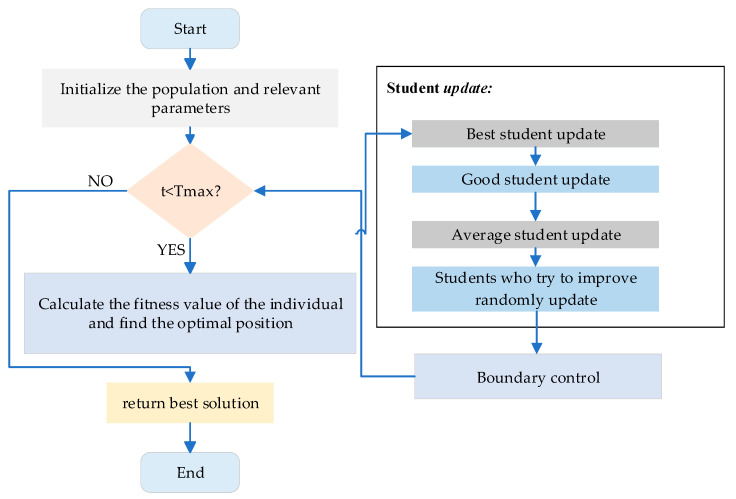 Figure 2
Figure 2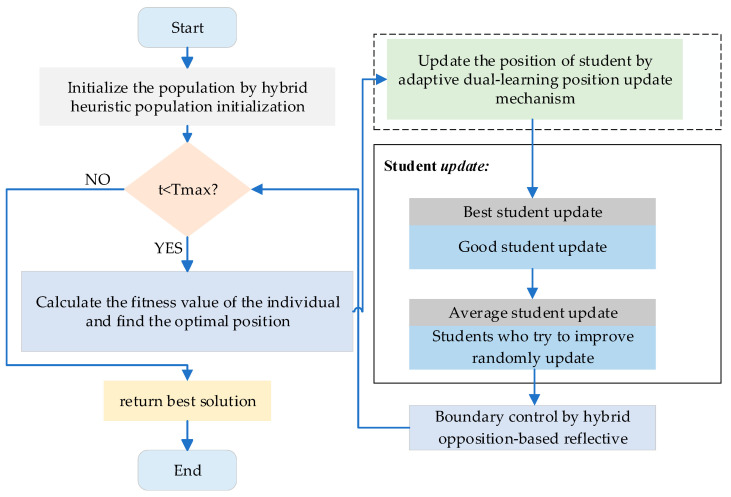 Figure 3
Figure 3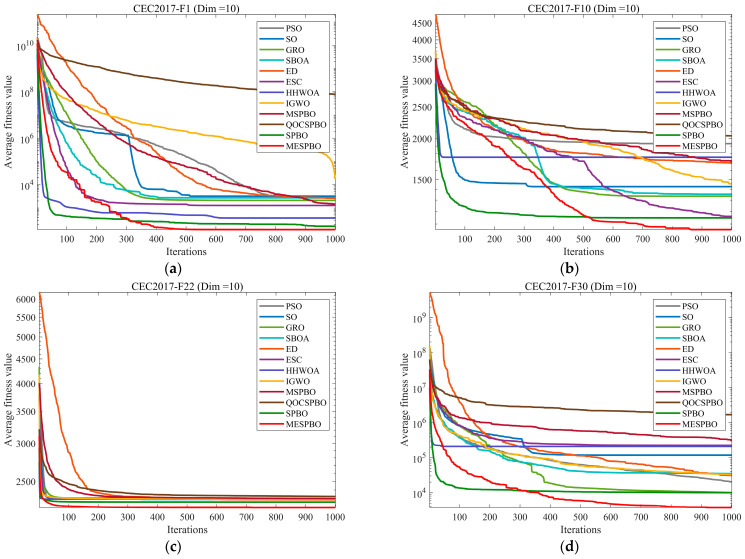 Figure 4
Figure 4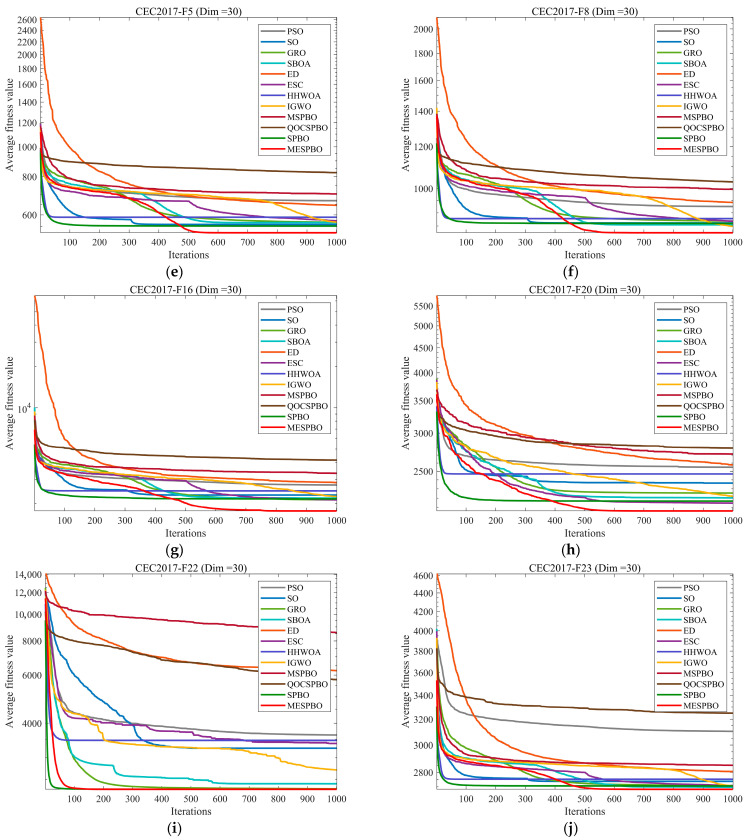 Figure 5
Figure 5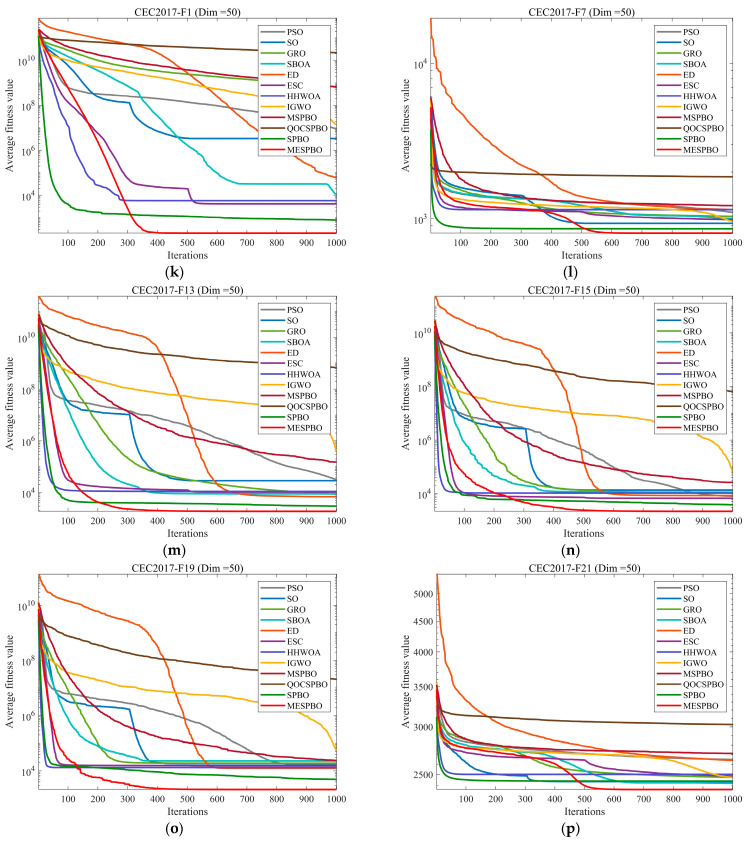 Figure 6
Figure 6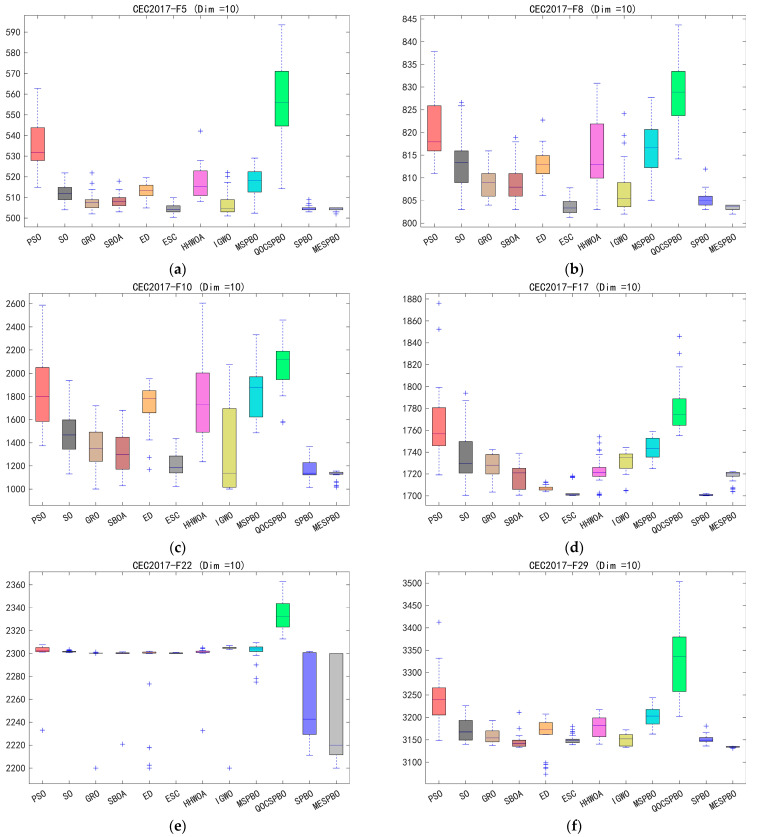 Figure 7
Figure 7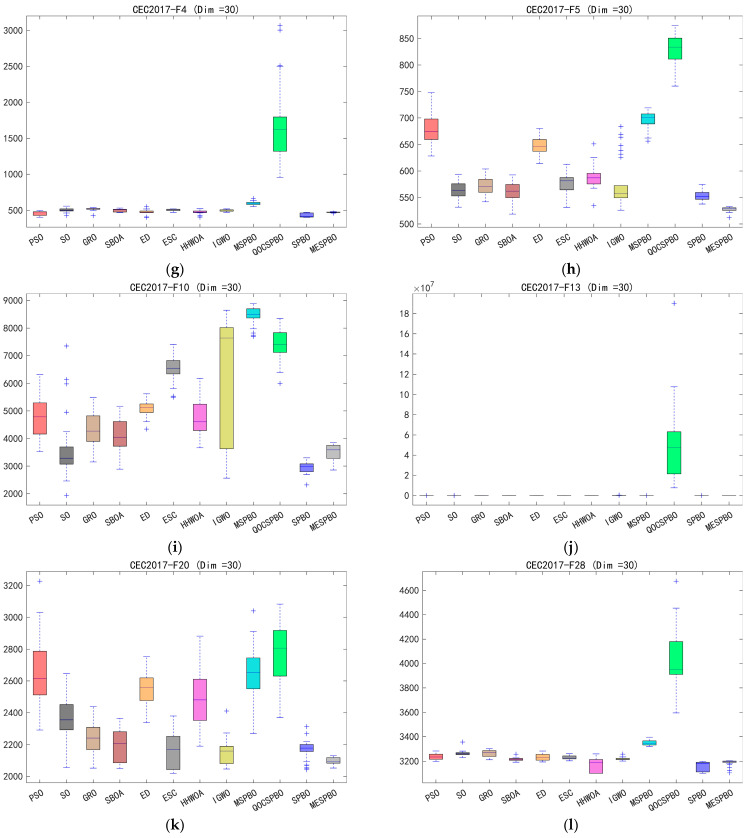 Figure 8
Figure 8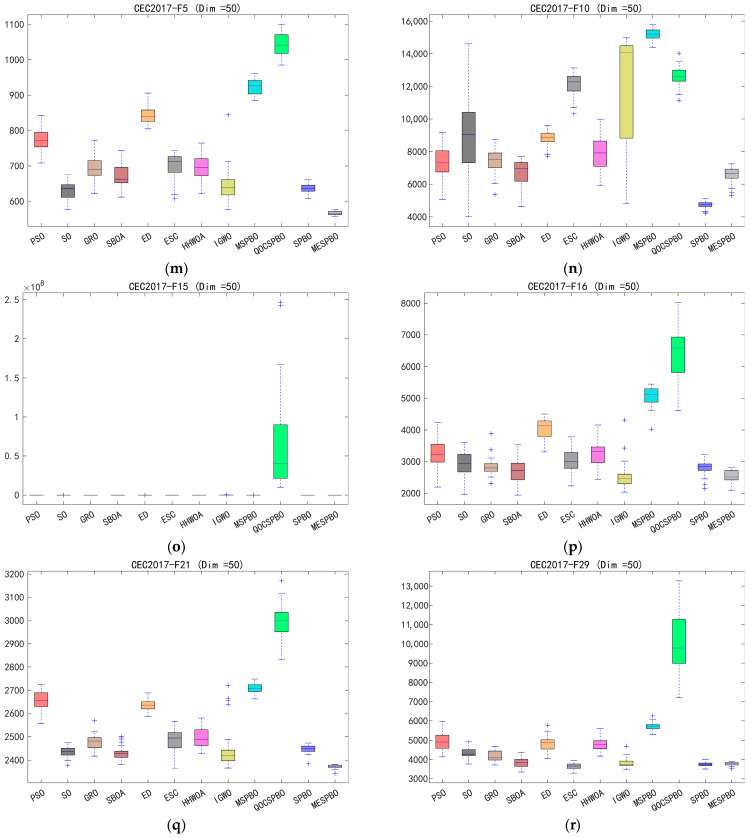 Figure 9
Figure 9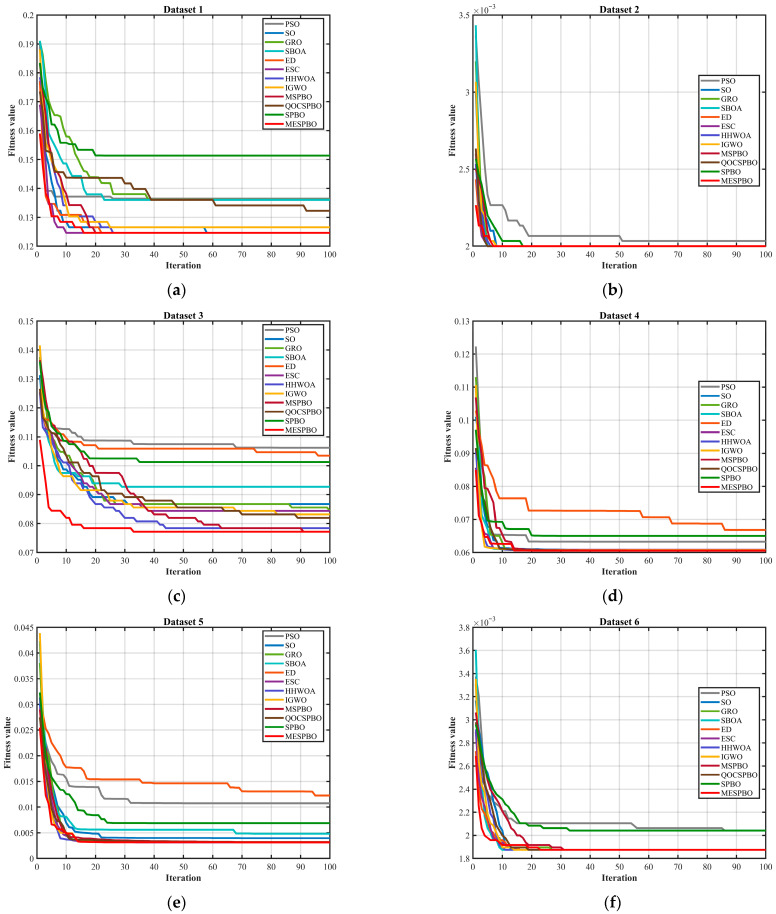 Figure 10
Figure 10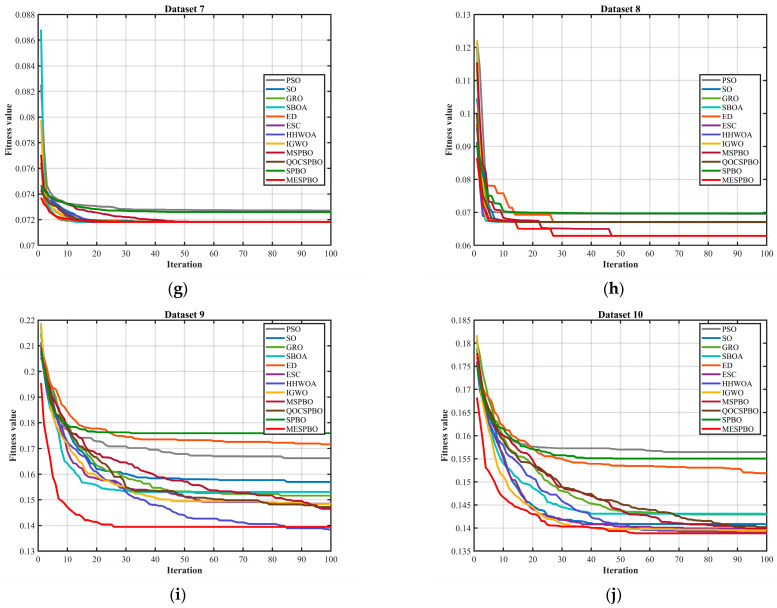 Figure 11
Figure 11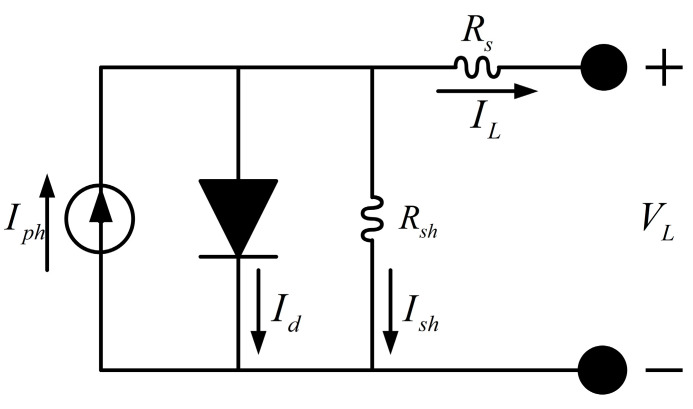 Figure 12
Figure 12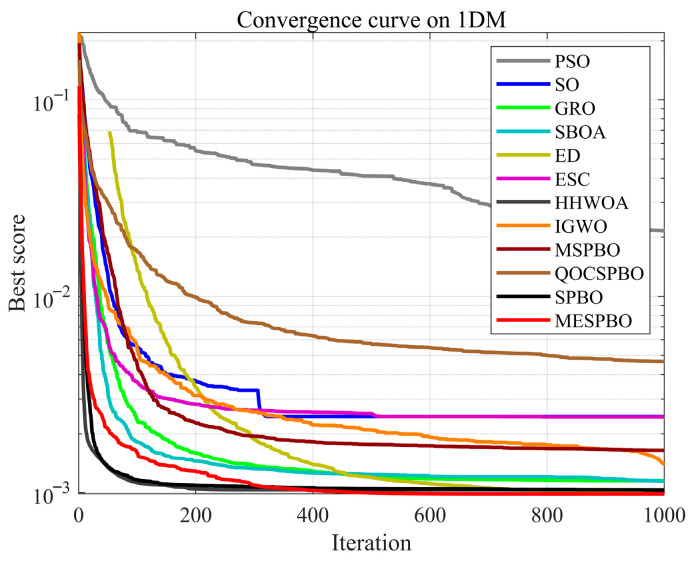 Figure 13
Figure 13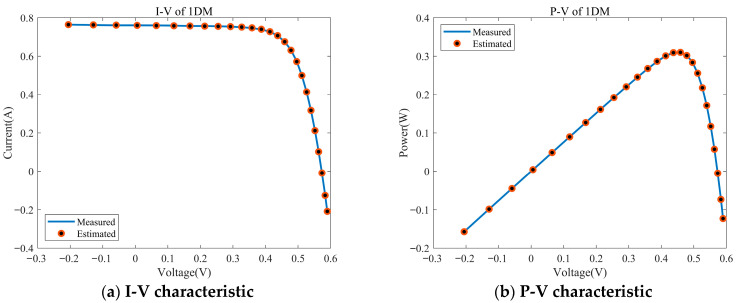 Figure 14
Figure 14- —Shandong Province Humanities and Social Sciences Collaborative Special Project
- —Natural Science Foundation of Zaozhuang University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetaheuristic Optimization Algorithms Research · Advanced Multi-Objective Optimization Algorithms · Machine Learning and Data Classification
1. Introduction
With the rapid integration of big data and artificial intelligence, machine learning has become an essential analytical tool across diverse fields, including medical diagnosis [1], financial risk assessment [2], image processing [3], and natural language understanding [4]. The effectiveness of these models, however, heavily depends on the quality and relevance of their input features. In real-world datasets, it is common for the feature space to contain redundant, irrelevant, or noisy attributes, which can obscure the intrinsic patterns of data. The presence of such redundant information not only amplifies computational complexity and prolongs training time but also triggers the curse of dimensionality, making optimization in high-dimensional spaces extremely challenging. More critically, it increases the likelihood of overfitting, where a model performs well on the training set but fails to generalize to unseen data [5]. To mitigate these issues, feature selection (FS) has emerged as a fundamental step in data preprocessing. The core objective of FS is to identify a compact subset of informative and discriminative features that preserves the essential characteristics of the original dataset while eliminating redundancy and noise. By reducing dimensionality, feature selection not only enhances learning efficiency and model interpretability but also improves classification accuracy and generalization capability [6]. Consequently, it has become an indispensable component of modern machine learning pipelines and plays a pivotal role in constructing efficient, reliable, and explainable intelligent systems.
Despite the significance of feature selection, identifying the optimal subset of features from high-dimensional data remains an NP-hard combinatorial optimization problem. Traditional methods—such as filter [7], wrapper [8], and embedded approaches [9]—often suffer from limited search capability or dependency on specific learning models, which restricts their generalization across diverse datasets. In particular, filter methods rely heavily on statistical correlations and may overlook complex nonlinear dependencies among features, while wrapper and embedded methods are computationally expensive and prone to overfitting when dealing with large-scale datasets.
In recent years, intelligent optimization algorithms inspired by nature and social behavior have garnered significant attention due to their powerful global search capabilities and flexibility in handling complex, nonlinear, and multimodal search spaces [10]. These algorithms, known as meta-heuristic algorithms, have been successfully applied in fields such as engineering design [11], machine learning, energy management [12], and feature selection [13]. For instance, Mozhdehi et al. proposed a novel Sacred Religion Algorithm based on an evolutionary socioeconomic approach inspired by religious societies [14]. This algorithm models interactions among followers, missionaries, and leaders, demonstrating outstanding performance across 23 standard benchmark functions and five practical optimization problems. Liu et al. proposed a novel graduate student evolutionary algorithm inspired by the daily behaviors of graduate students [15]. By simulating key processes such as identifying research directions and focusing on studies, the algorithm established a mathematical model for GSEA. It demonstrated favorable results on the CEC2017 and CEC2022 test sets. Furthermore, it exhibited the capability to solve real-world optimization problems in unmanned aerial vehicle and robot path planning tasks. Fu et al. simulated the search, pursuit, predation, and food storage behaviors of the Eurasian magpie to establish a mathematical model of RBMO [16]. This model demonstrated remarkable performance across the CEC2014 (Dim = 10, 30, 50, and 100), CEC2017 (Dim = 10, 30, 50, and 100) suites, drone path planning, and five engineering design problems.
Furthermore, as the no free lunch (NFL) theorem demonstrates, no single optimization algorithm performs exceptionally well across all problems. When averaged across all optimization problems, all algorithms exhibit identical performance. This implies that we should select algorithms based on the specific problems we need to solve. For instance, Tang et al. proposed a multi-strategy particle swarm optimization hybrid dandelion optimization algorithm to address the issues of slow optimization speed and susceptibility to local optima in the dandelion optimization algorithm. This approach was developed specifically for three engineering design problems of varying complexity that required resolution. Experimental results demonstrated that the algorithm achieved significant improvements in solving these three problems [17]. To address deployment challenges in wireless sensor networks, Bao et al. proposed a multi-strategy integrated group teaching optimization algorithm (MSIGTOA) employing strategies such as chaotic inverse learning. This approach achieved higher coverage while reducing node usage by at least 10%, thereby significantly lowering WSN deployment costs [18]. To address the issue of intraday operation optimization in microgrids, Lu et al. developed an Enhanced Sardine Optimization Algorithm (ESOA) incorporating composite adversarial learning. Through validation in microgrid dispatch applications, it demonstrated significant improvements over the standard Sardine Optimization Algorithm (SOA) [19].
Among various metaheuristics, the Student Psychology-Based Optimization (SPBO) algorithm, inspired by the learning behavior and psychology of students in a classroom, has recently shown promising performance in balancing exploration and exploitation [20]. SPBO models the process of students learning from top-performing peers and improving their knowledge based on collective interaction and self-learning. Despite its advantages, the original SPBO still suffers from limitations such as random initialization, fixed learning parameters, and inefficient boundary handling, which can hinder its convergence stability and search performance in complex optimization landscapes.
Many researchers have improved SPBO to better address the optimization problems they need to solve. For example, to address power system optimization problems, Balu et al. proposed a novel quasi-oppositional chaotic student psychological optimization algorithm [21]. In two radial distribution systems, considering different load models under three load levels, the algorithm achieves optimal location and size for distributed generation and parallel capacitors, yielding excellent results. To perform big data clustering, Shanmugam et al. proposed a robust and effective IoT routing technique based on SPBO [22]. By performing feature selection during the mapping stage, they effectively improved clustering performance in terms of energy, clustering accuracy, Jaccard coefficient, and Land coefficient. To address the economic dispatch problem, Basu et al. proposed an improved SPBO [23]. Experiments on economic dispatch problems involving valve point results, limited feasible area, ramp rate boundaries, and multi-pipe fueling demonstrate that the MSPBO is capable of providing better results.
To overcome these challenges, this paper proposes a Multi-Strategy-Enhanced Student Psychology-Based Optimization (MESPBO) algorithm. The proposed method integrates several improvement strategies to enhance the robustness, adaptability, and convergence efficiency of the original SPBO. Specifically, a hybrid heuristic population initialization mechanism based on Latin Hypercube Sampling (LHS) and Gaussian perturbation is introduced to improve the diversity and uniformity of the initial population. Furthermore, an adaptive dual-learning position update mechanism dynamically adjusts the learning intensity and direction of each individual according to iteration progress and population diversity, ensuring a smooth transition from exploration to exploitation. Additionally, a hybrid opposition-based reflective boundary control strategy is designed to prevent the loss of potentially valuable individuals and maintain population diversity near the boundaries.
To evaluate the effectiveness of MESPBO, extensive experiments are conducted on a set of well-known benchmark functions from the IEEE CEC2017 test suite, as well as on feature selection problems from real-world datasets. Comparative analyses with 11 state-of-the-art algorithms demonstrate that MESPBO achieves superior optimization accuracy, faster convergence speed, and better robustness across different problem categories. Moreover, the proposed algorithm shows strong generalization capability, making it suitable for both continuous global optimization and discrete feature selection tasks.
The main contributions of this work are summarized as follows:
- A hybrid heuristic initialization strategy combining LHS and Gaussian perturbation is proposed to ensure a well-distributed and diverse initial population.
- An adaptive dual-learning mechanism is developed to dynamically balance exploration and exploitation throughout the optimization process.
- Introduce hybrid oppositional reflection boundary control to enhance the stability and diversity of population evolution and improve the boundary control performance of the algorithm.
- Comprehensive experiments on benchmark and real-world datasets validate the superior performance and general applicability of MESPBO.
- The effectiveness of the MESPBO algorithm in solving practical problems was comprehensively analyzed by applying it to the practical application of photovoltaic model parameter extraction.
The remainder of this paper is organized as follows: Section 2 reviews the student psychology-based optimization algorithm. Section 3 presents the detailed formulation of the proposed MESPBO algorithm and its improvement strategies. Section 4 provides experimental settings and performance analysis on benchmark functions. Section 5 discusses the results and comparisons on feature selection tasks, and finally, Section 6 concludes the paper and outlines future research directions.
2. Student Psychology-Based Optimization Algorithm
Since the MESPBO proposed in this paper is an improvement upon SPBO, this section provides a brief introduction to SPBO. SPBO was conceived through research into student behavior across different schools and colleges, drawing inspiration from insights into student psychology. Bikash Das et al. categorize students into four groups: top performers, good students, average students, and those randomly attempting to improve. Each category exhibits distinct psychological activities, which are used to model the algorithm’s iterative update process. Specific details are as follows:
2.1. Best Student
Typically, the student who achieves the highest score on an exam is regarded as the top student. To maintain this position, the top student consistently strives to earn the highest grade in the class, necessitating greater effort. Consequently, the top student’s effort process can be modeled as shown in Equation (1).
where and represent the top student and the -th randomly selected student in a specific subject, respectively. denotes a random number between 0 and 1, while is a parameter randomly selected as either 1 or 2.
2.2. Good Student
If a student develops an interest in any subject, they will attempt to invest increasing effort into that subject to enhance their overall performance. Such students are defined as good students. The choices made by these students constitute a random process due to variations in student psychology. To achieve the highest scores on exams and become the best students, some students strive to exert effort comparable to or exceeding that of the top performers. The specific effort process of such students can be modeled by Equation (2).
where denotes the -th top student. Additionally, some students exert greater effort in their studies than their peers in the class and strive to emulate the efforts of the most accomplished students. The effort process of such students can be modeled by Equation (3).
where indicates the class’s average performance in a specific subject.
2.3. Average Student
Since the effort students exert depends on their interest in the subjects offered to them, if students are less interested in certain subjects, they will exert average effort in those subjects to improve their overall grades. Such students are defined as average students. Given the differing psychological profiles of students, their choices also constitute a random process, which can be modeled by Equation (4).
2.4. Students Who Try to Improve Randomly
In addition to the aforementioned three categories of students, some students attempt to improve their grades independently. They strive to enhance their overall exam performance by applying effort somewhat randomly across subjects. The efforts of this group of students can be specifically modeled as Equation (5).
where and represent the upper and lower bounds of the problems to be solved, respectively, and also denote the maximum and minimum scores achievable in the student subjects. The classification of students is shown in Figure 1. Algorithm 1 presents the pseudocode for the SPBO algorithm. Figure 2 presents the flowchart of the SPBO algorithm. Algorithm 1: the pseudo-code of the SPBO1: Begin2: Initialize the relevant parameters and the population3: ** while** 4: Evaluate the initial performance of the class5: check the category of the student6: *** Best students:***7: Modify performance by Equation (1)8: *** Good students:***9: Modify performance by Equations (2) and (3)10: *** Average students:11: Modify performance by Equation (4)12: *** Students who try to improve randomly:13: Modify performance by Equation (5)14: Check the boundary15: Update the students’ performance16: *** End while17: *** return best student18: end
3. Proposed MESPBO
Although the SPBO algorithm demonstrates good optimization capability inspired by student psychological behaviors, its search performance can still be limited by insufficient population diversity, static learning mechanisms, and inefficient boundary control. To overcome these drawbacks, the Multi-strategy-Enhanced Student Psychology-Based Optimization (MESPBO) introduces three major improvements, focusing on the population initialization, student position updating, and boundary control mechanisms.
3.1. Hybrid Heuristic Population Initialization
In the original SPBO, the initial population is generated randomly, which may lead to uneven distribution and weak exploration ability in the early stage. To enhance the population diversity and improve convergence performance, MESPBO introduces a hybrid heuristic initialization mechanism, which integrates Latin Hypercube Sampling (LHS) [24] and Gaussian perturbation [25].
3.1.1. Latin Hypercube Sampling (LHS)
For a -dimensional optimization problem, the initial population matrix is denoted by Equation (6).
where denotes the population size, while represents the problem’s dimensionality. The -th dimension is divided into equally spaced intervals, which can be expressed by Equation (7).
Then, one sample is randomly selected from each interval and permuted to ensure non-overlapping coverage, it can be expressed by Equation (8).
where and are the lower and upper bounds of the -th dimension, is a uniformly distributed random number in the -th interval, and is a random permutation function ensuring each interval is used once. This process guarantees that all samples are uniformly distributed in the search space.
3.1.2. Gaussian Perturbation
To prevent clustering and enhance local search diversity, Gaussian noise is applied to each generated solution. Specifically, it can be expressed as Equation (9).
where is a Gaussian perturbation with zero mean and variance , and it can be expressed as Equation (10).
where is a control parameter determining perturbation intensity. In summary, the final initial population can be expressed as Equation (11).
where .
In the initialization stage, each individual is first generated by Latin Hypercube Sampling to ensure global uniformity. Then, a Gaussian perturbation is applied to each dimension of the population to introduce local randomness, thereby enhancing population diversity and preventing premature clustering in specific regions.
This hybrid initialization mechanism combines the global uniformity of Latin Hypercube Sampling with the local stochasticity of Gaussian perturbation. It ensures a well-distributed and diverse initial population, which effectively improves global exploration and convergence stability.
3.2. Adaptive Dual-Learning Position Update Mechanism
In the original SPBO, each category of students updates their positions using fixed coefficients, resulting in a rigid exploration–exploitation balance that may not adapt to different optimization stages. To overcome this limitation, the proposed MESPBO introduces an adaptive dual-learning mechanism, where students dynamically adjust their learning intensity according to both iteration progress and population diversity [26].
Adaptive Learning Coefficients: At the beginning of the optimization, maintaining high population diversity is crucial for avoiding local optima; hence, a stronger global exploration component is adopted. As iterations proceed, the algorithm gradually shifts its focus toward local exploitation to refine the solutions around the best individuals. This transition is controlled by two time-varying learning coefficients and . The coefficients and decrease smoothly with the number of iterations, can be expressed as Equations (12) and (13)
where is the current iteration count; is the maximum iteration count; and control the exploration range; and control the exploitation range; and and are adaptation factors controlling the decay rate. The values of and are both set to 1.2, allowing the algorithm to explore better in the early stages and develop better in the later stages. dominates global exploration in the early stage, while gradually strengthens local exploitation in later iterations.
Dual-Learning Position Update Formula: The position of the student is updated according to both the best individual and the population mean, it can be expressed by Equation (14).
where and represent random numbers between 0 and 1, indicates the global optimum, and denotes the average value across the entire population.
The adaptive dual-learning strategy enables each student to dynamically balance between exploration and exploitation according to the optimization phase and population diversity. Early in the search, larger values promote exploration of the global search space. As the iteration progresses, smaller and larger values focus the search around promising regions, thus improving convergence accuracy and stability.
3.3. Hybrid Opposition-Based Reflective Boundary Control
Boundary handling is critical for preserving the stability and continuity of the population evolution. Instead of the common truncation or random re-initialization, MESPBO adopts a hybrid opposition-based and reflective boundary control [27]. When an individual component goes outside its feasible interval , it is remapped by either a reflective mapping or an opposition mapping. This hybrid strategy helps to keep infeasible individuals in the search process, reintroduce diverse candidate solutions, and reduce the likelihood of getting stuck in local optima.
Reflective mapping: When individuals in the algorithm exceed the bounds, reflective mapping can be used to reflect the out-of-bounds individuals back into the feasible domain, which can be specifically expressed as Equation (15).
Opposition mapping: The opposition mapping assigns outlier individuals to opposing positions within the interval to enhance the algorithm’s exploration capability, which can be calculated using Equation (16).
Additionally, to enhance the algorithm’s ability to escape local optima, we introduce small perturbations to opposing particles to increase diversity, which can be expressed as in Equation (17).
where restricts the value to .
Hybrid strategy: When individual crosses the boundary, it selects the opposition mapping with probability , otherwise it selects the reflection mapping. This can be expressed as Equation (18).
where and represent random disturbances following a uniform distribution.
To robustly handle out-of-bounds individuals, we propose a hybrid opposition-based reflective boundary control. When a decision variable exceeds its feasible range, it is remapped either by an opposition mapping or by a reflective mapping that mirrors the violation back into the feasible interval. The choice between opposition and reflection is governed by a probability . Small random perturbations are applied to the remapped values to avoid deterministic cycles, and the final result is clipped to This hybrid mechanism preserves search continuity, reintroduces potentially promising candidates, and enhances population diversity, thereby reducing the likelihood of premature convergence. To visually illustrate the algorithm’s execution process, Figure 3 presents the flowchart of the MESPBO algorithm.
3.4. Time Complexity Analysis
Time complexity analysis is essential for any heuristic algorithm, as it directly reflects the algorithm’s scalability and computational efficiency on large-scale problems. In this section, we analyze the time complexity of MESPBO, where the main computational overhead comes from the iterative loop and the update operations for all individual students in each iteration. Specifically, the algorithm needs to traverse all students in each iteration and execute an update strategy based on their category. Therefore, the overall time complexity of the algorithm can be expressed as , where is the population size and is the maximum number of iterations. The time complexity is the same as the original SPBO algorithm, without affecting the algorithm’s performance by orders of magnitude. In conclusion, the improvement to SPBO is acceptable in terms of time complexity.
4. Experimental Analysis of Global Optimization Problems
4.1. IEEE CEC2017 Benchmark Suite
To comprehensively evaluate the performance of the proposed MESPBO algorithm, the IEEE CEC2017 benchmark suite is employed as the standard test platform. The CEC2017 test set is a well-established and widely recognized benchmark collection designed by the IEEE Congress on Evolutionary Computation for assessing the performance of real-parameter optimization algorithms [28]. It consists of 30 continuous optimization functions, including unimodal, multimodal, hybrid, and composition functions, which progressively increase in complexity. These functions effectively represent different optimization challenges, such as local optima entrapment, high-dimensional nonlinearity, and strong variable interactions.
The diversity and difficulty of the CEC2017 test suite make it an authoritative benchmark for verifying the global search capability, convergence accuracy, robustness, and stability of intelligent optimization algorithms. Moreover, it provides a fair and unified testing environment that facilitates direct comparison with other state-of-the-art algorithms. Therefore, this paper adopts the CEC2017 benchmark suite to rigorously test the proposed MESPBO algorithm, ensuring that its performance evaluation is objective, comprehensive, and consistent with current research standards in the optimization community.
4.2. Comparison of Algorithms and Parameter Settings
In this section, the effectiveness of the proposed MESPBO algorithm is systematically examined on the widely recognized CEC2017 benchmark suite and benchmarked against multiple competitive optimization algorithms. The comparison algorithms include: Particle Swarm Optimization (PSO) [29], Snake Optimization (SO) [30], Gold Rush Optimizer (GRO) [31], Secretary Bird Optimization Algorithm (SBOA) [32], enterprise development optimization algorithm (ED) [33], Escape optimization algorithm (ESC) [34], hyper-heuristic whale optimization algorithm (HHWOA) [35], Improved Grey Wolf Optimizer (IGWO) [36], Modified Student Psychology-Based Optimization algorithm (MSPBO) [23], Quasi-oppositional chaotic student psychology-based optimization algorithm (QOCSPBO) [21], and Student Psychology-based optimization algorithm (SPBO) [20]. The algorithms parameters are listed in Table 1. All experiments were conducted in a Windows 11 environment using an AMD Ryzen 7 9700X octa-core processor (3.80 GHz) with 48 GB of memory and MATLAB 2024b software.
4.3. Experimental Results and Analysis of CEC2017 Test Suite
This section evaluates the performance of MESPBO using the CEC2017 benchmark suite. To comprehensively test its capabilities, experiments were conducted on CEC2017 functions with dimensions of 10, 30, and 50. To ensure fairness, the population size for all algorithms was set to 50, and the maximum number of iterations was set to 100. To mitigate the impact of algorithmic randomness on results, each algorithm was independently run 30 times. Table 2, Table 3 and Table 4 records the mean (Ave) and standard deviation (Std) from these 30 independent runs. For a more intuitive analysis of the experimental outcomes, Figure 4 presents the convergence curves of the algorithms. To comprehensively display the results from the 30 runs, Figure 5 shows the box plots of the algorithms.
The convergence curves on the CEC2017 benchmark under 10D, 30D, and 50D scenarios indicate that MESPBO achieves the best overall performance on most test functions. Specifically, MESPBO exhibits a markedly faster decrease in average fitness than PSO, SO, GRO, SBOA, ED, ESC, HHWOA, IGWO, MSPBO, QOCSPBO, and SPBO, while continuing to refine solutions in later iterations to reach lower final fitness values. Its trajectories are generally smoother with smaller fluctuations, demonstrating superior stability and robustness. As the dimensionality increases, many baseline and improved algorithms suffer from slower convergence or premature stagnation, whereas MESPBO maintains strong descending trends and attains higher-precision solutions, with particularly pronounced advantages on complex multimodal and high-dimensional problems. Overall, these results confirm that the proposed multi-strategy enhancements effectively improve population diversity and the exploration–exploitation balance, thereby significantly strengthening global optimization capability and high-dimensional adaptability.
As presented in Table 2, the proposed MESPBO algorithm exhibits outstanding performance on the 10-dimensional CEC2017 benchmark suite. It consistently achieves the best or near-best mean fitness values on the majority of test functions, demonstrating its powerful global optimization capability in low-dimensional search spaces. Moreover, MESPBO reports significantly smaller standard deviations compared with classical algorithms such as PSO, SO, GRO, and SBO, as well as more recent variants including HHWOA, IGWO, MSPBO, QOCSPBO, and SPBO. This evidences the algorithm’s high robustness and stability, ensuring reliable performance across independent runs. Table 3 presents the comparative results of all algorithms tested on the 30-dimensional CEC2017 benchmark suite. As the dimensionality increases, the complexity of the optimization task rises dramatically due to the enlarged search space and more rugged fitness landscapes. Despite these challenges, the proposed MESPBO algorithm maintains excellent optimization performance. MESPBO achieves the best or competitive mean fitness values across a majority of the 30-dimensional test functions, demonstrating that its strong global search capability extends naturally to more complex, higher-dimensional settings. Additionally, the algorithm continues to achieve notably smaller standard deviation values than all other competitors. This indicates that MESPBO remains highly stable and robust even under increased search difficulty. Table 4 reports the experimental results on the 50-dimensional CEC2017 benchmark set. As the dimensionality further increases, the optimization landscape becomes highly rugged and multimodal, greatly intensifying the difficulty of locating global optima. Nevertheless, the proposed MESPBO algorithm continues to deliver remarkable performance. Across the majority of 50-dimensional test functions, MESPBO achieves the lowest mean fitness values, clearly outperforming both traditional and state-of-the-art metaheuristic competitors. Its performance advantage is especially prominent on complex multimodal functions, where maintaining global search ability is crucial. Moreover, MESPBO consistently reports the smallest standard deviations, reaffirming its strong robustness and solution stability even under extremely high-dimensional and complex search scenarios.
Based on the boxplot results of the CEC2017 benchmark functions across 10, 30, and 50 dimensions, the proposed MESPBO algorithm demonstrates consistently superior performance. It exhibits the smallest box heights, short whiskers, and nearly no outliers for most test functions, indicating highly concentrated solution distributions and excellent stability across repeated runs. As the dimensionality increases from 10 to 50, most competing algorithms show noticeable degradation, reflected by significantly expanded box ranges and numerous outliers. In contrast, MESPBO maintains compact distributions and low median fitness values, highlighting its strong capability in handling high-dimensional optimization tasks. For F5, F8, F10, F17, F22, and F29 functions, MESPBO achieves the best or near-best median performance while presenting substantially lower variability than other methods. Overall, these results confirm that MESPBO consistently preserves robust and accurate optimization performance across different dimensional settings and stands out as the most competitive algorithm among all compared methods.
Across the CEC2017 benchmark tests with 10, 30, and 50 dimensions, the experimental results demonstrate that MESPBO consistently delivers superior optimization performance. In terms of mean performance, median values, and distribution stability, MESPBO significantly outperforms the competing algorithms. As the dimensionality increases, most algorithms exhibit larger fluctuations, unstable convergence behaviors, and numerous outliers. In contrast, MESPBO maintains a compact solution distribution, stable convergence, and reliable performance even in high-dimensional scenarios, reflecting its strong adaptability and robustness. Overall, MESPBO demonstrates clear advantages in global search ability, solution stability, and cross-dimensional scalability, making it the most competitive and effective algorithm among all the methods evaluated in this study.
4.4. Friedman Mean Rank Test
To further assess the statistical significance of performance differences among algorithms, we employed Friedman’s median rank test for evaluation. Friedman’s test is a nonparametric statistical test designed to detect performance variations across multiple algorithms on various benchmark functions [37]. Unlike parametric tests such as analysis of variance, it does not assume a normal distribution of data, making it particularly suitable for analyzing optimization results where performance values may not follow a Gaussian distribution.
In this test, each algorithm is assigned a ranking for each benchmark function based on its performance, with the best-performing algorithm receiving the lowest average ranking. The ranking of the algorithm across all test functions is then calculated, yielding the average ranking for each algorithm. A lower average ranking indicates better overall performance. Table 5 shows the rankings of each algorithm across various dimensions on the CEC2017 test set. represents the algorithm’s average ranking across 30 test functions, while indicates its final ranking.
As shown in Table 5, the Friedman mean-rank test results demonstrate that MESPBO consistently achieves the best overall performance on the CEC2017 benchmark suite across 10-, 30-, and 50-dimensional settings. Specifically, the mean ranks of MESPBO are 2.00, 1.67, and 1.67 for the three dimensionalities, respectively, which are significantly lower than those of the eleven competing algorithms. Moreover, MESPBO ranks first in total ranking across all dimensions, indicating that it maintains the top position on the majority of test functions. In contrast, traditional algorithms such as PSO and SO, as well as several enhanced variants including IGWO, MSPBO, and QOCSPBO, exhibit relatively high mean ranks and total ranks, reflecting their inferior performance on most test functions. Although algorithms like SPBO and SBOA show comparatively better rankings in some dimensions, their mean ranks remain noticeably higher than those of MESPBO, implying that they cannot compete with MESPBO in terms of overall optimization performance. Overall, the Friedman test results further validate the stability, superiority, and consistency of MESPBO across different dimensional settings. These findings confirm that MESPBO delivers the most competitive and reliable performance among all compared algorithms and is the strongest algorithm in terms of comprehensive optimization capability.
5. MESPBO for Feature Selection
In this section, the proposed MESPBO algorithm is applied to the feature selection task to further verify its effectiveness and practicality in real-world optimization scenarios. Feature selection plays a crucial role in machine learning and data mining, as it aims to identify the most informative subset of features that can improve classification accuracy while reducing computational cost and model complexity. However, due to the combinatorial and highly nonlinear nature of the search space, traditional deterministic methods often fail to achieve satisfactory results, especially when dealing with high-dimensional datasets.
To address these challenges, population-based metaheuristic algorithms have been widely adopted for feature selection because of their strong global search capability and flexibility. By leveraging its enhanced exploration–exploitation balance and the reinforcement mechanism introduced through RBMO, the proposed MESPBO algorithm is expected to effectively search for optimal feature subsets and achieve a good trade-off between feature reduction and classification performance. The subsequent experiments evaluate MESPBO against several state-of-the-art metaheuristic algorithms on multiple benchmark datasets to demonstrate its robustness, convergence efficiency, and feature selection quality.
5.1. The Proposed MESPBO-KNN
The feature selection (FS) problem refers to the process of selecting an optimal subset of features from an original, high-dimensional feature space to achieve certain optimization objectives [38]. These objectives typically include improving the predictive performance of learning models, enhancing generalization ability, and reducing computational cost and data redundancy. Formally, given an original feature set , the goal of FS is to identify a subset that maximizes model accuracy while minimizing the number of selected features.
The K-nearest neighbor (KNN) algorithm is a classic and widely used machine learning classifier that has been successfully applied in many fields [39], including medical image analysis [40], fault diagnosis [41], and natural language processing [42]. KNN performs classification by measuring the similarity between samples using the Euclidean distance. Its mathematical formula is shown in Equation (19).
For feature selection, the ultimate goal is to obtain the highest prediction accuracy by finding the minimum number of features. In this section, we propose a feature selection method called MESPBO-KNN by combining MESPBO with KNN. Assume that the dataset contains features: , where is a -dimensional feature vector, and is the response variable. Our goal is to select a subset of features from the original features to minimize our objective function, which is expressed as Equation (20)
where is a random number sampled from a uniform distribution; denotes the classification error rate, where is calculated by Equation (21); represents the number of selected features; and is the total number of features.
where represents the number of correctly classified positive samples, represents the number of correctly classified negative samples, indicates the count of false positive instances, and refers to positive samples misclassified as negative. The constraints of the optimization problem can be expressed as Equation (22)
where denotes the maximum number of features allowed to be selected. The decision variables are modeled as Equation (23)
where is a binary decision variable indicating whether feature is selected for sample : if , the feature is selected; otherwise, if , the feature is not selected.
5.2. Simulation Experiment Analysis
In this section, we use 10 public datasets to evaluate the performance of MESPBO-KNN. It is worth noting that we divide these datasets into three categories: small datasets, medium datasets, and large datasets. Each dataset is divided into training, testing, and validation subsets using cross-validation, and then classified using the KNN classifier. The detailed information of the datasets is shown in Table 6.
In addition, to verify the effectiveness and competitiveness of the proposed MESPBO-KNN algorithm, a series of comparative experiments were conducted against several state-of-the-art algorithms. For fair evaluation and to minimize randomness, the population size and maximum iteration count were fixed at 50 and 100, respectively, and each algorithm was independently run 30 times. The detailed results are presented in Table 7, Table 8 and Table 9. In order to judge the convergence speed of each algorithm, Figure 6 shows the convergence curves of each algorithm on 10 problems.
As illustrated in Figure 6a–j, the convergence curves on ten datasets clearly demonstrate the superiority of MESPBO in both convergence speed and final solution quality. For Datasets 1–6, MESPBO decreases the fitness value much faster than the competing algorithms, typically reaching the lowest or near-lowest level within the first 10–20 iterations, whereas most baselines still exhibit slow descending trends. For more challenging datasets such as Datasets 3, 5, 6, 9, and 10, many algorithms show premature stagnation or weak late-stage improvement, with their curves trapped at relatively high fitness plateaus. In contrast, MESPBO continues to reduce the fitness steadily and finally attains the lowest stable fitness among all methods, indicating stronger global optimization capability. Moreover, for Datasets 7 and 8 where the final performances of different algorithms are close, MESPBO still achieves the best or tied-best terminal fitness with the smallest fluctuation, reflecting excellent stability and consistency. Overall, these convergence results confirm that MESPBO consistently provides faster convergence and better final optimization outcomes across diverse datasets, outperforming PSO, SO, GRO, SBOA, ED, ESC, HHWOA, IGWO, MSPBO, QOCSPBO, and SPBO.
As shown in Table 7, MESPBO achieves superior optimization performance across the ten datasets, consistently obtaining the lowest or near-lowest average fitness values in almost all cases. Specifically, for Datasets 1, 3, 4, 5, 6, 7, 8, 9, and 10, MESPBO attains the best or tied-best mean performance among all algorithms, indicating its strong ability to adapt to various data characteristics and deliver high-quality solutions. In addition, MESPBO exhibits the smallest standard deviations across all datasets, with values significantly lower than those of other competing algorithms. This demonstrates excellent consistency over multiple runs and highlights the algorithm’s strong stability. In contrast, several enhanced algorithms such as HHWOA, MSPBO, and QOCSPBO occasionally produce comparable mean fitness on certain datasets but generally suffer from larger standard deviations, implying unstable convergence. Traditional methods like PSO, SO, and GRO show relatively higher average fitness values on many datasets, reflecting their tendency to be trapped in local optima and their limited overall performance. Overall, the statistical results in Table 7 further confirm the robustness, reliability, and comprehensive superiority of MESPBO. The algorithm not only delivers the best solution quality but also maintains remarkable stability across diverse datasets, making it the most balanced and effective optimization method among all competitors.
According to the accuracy comparison in Table 8, MESPBO achieves overall leading performance across the ten datasets. For Dataset 2, Dataset 4, Dataset 6, and Dataset 7, all algorithms obtain almost identical accuracies (100% for Datasets 4/6/7 and 97.1% for Dataset 2), indicating that these datasets are relatively easy and MESPBO maintains equally optimal performance. On more discriminative and challenging datasets, MESPBO shows clearer superiority: it attains the highest accuracies of 95.81%, 93.33%, 81.5%, and 81.5% on Datasets 5, 8, 9, and 10, respectively, outperforming all competitors; it also achieves the best or near-best result on Dataset 3 with 89.0%. Although MESPBO is slightly below the top accuracy on Dataset 1 (with a marginal gap of about 0.2%), its performance remains within the top tier. Overall, MESPBO delivers the best accuracies on most complex datasets while preserving optimal consistency on easier ones, demonstrating strong generalization ability and stable classification performance.
As reported in Table 9, MESPBO generally selects fewer or an equal number of features while maintaining competitive classification performance, demonstrating superior feature reduction capability. For Datasets 1–4, the average number of selected features is very close across all algorithms, and MESPBO achieves the same minimal level as the best competitors, indicating that it does not introduce redundant features on relatively simple datasets. On more challenging datasets (Datasets 5–8), MESPBO shows a clearer advantage by selecting notably fewer features; for instance, it chooses about 2.1 features on Dataset 5, which is lower than PSO, SO, GRO, and ESC (typically ranging from about 2.2 to 3.6). For high-dimensional feature datasets such as Dataset 9 and Dataset 10, MESPBO again yields the smallest or tied-smallest feature subset (around 5.7/6 features), significantly fewer than several competitors. Overall, these results confirm that MESPBO can obtain compact and effective feature subsets across diverse datasets, reducing model complexity while preserving search effectiveness, and thus provides a strong and stable feature selection performance.
Overall, the convergence curves and Table 7, Table 8 and Table 9 consistently show that MESPBO delivers the best comprehensive performance across the ten datasets. It achieves the lowest mean fitness values with the smallest standard deviations on most datasets, indicating superior solution quality and robustness. In terms of classification accuracy, MESPBO attains the best or near-best results on challenging datasets while matching the optimal performance on easier ones. Moreover, it generally selects the smallest or tied-smallest number of features, effectively reducing redundancy and model complexity without sacrificing accuracy. In summary, MESPBO demonstrates clear advantages in convergence efficiency, optimization reliability, accuracy, and feature reduction capability, confirming its effectiveness for feature selection and classification optimization tasks.
5.3. MESPBO for Photovoltaic Model Parameter Extraction
5.3.1. Single Diode Model (SDM)
The Single Diode Model (SDM) is one of the most classic and commonly used equivalent circuit models for photovoltaic (PV) devices and arrays. It accurately characterizes the nonlinear I-V/P-V characteristics of the cell with fewer parameters, achieving a good balance between accuracy and complexity. Therefore, it is widely used in engineering simulation, performance evaluation, and control design. Furthermore, SDM parameters have clear physical correspondences, reflecting the impact of factors such as temperature, irradiance aging, and shading on the internal mechanisms and external output of the device. This makes it an important tool for understanding PV degradation mechanisms, diagnosing faults, and conducting reliability analysis. Accurate SDM parameter identification is fundamental to many critical applications, such as maximum power point tracking (MPPT) algorithm design, inverter and grid-connected control, and PV system energy prediction and scheduling optimization. Inaccurate models or parameters will directly lead to power estimation errors, decreased control efficiency, and even system instability. In practical applications, PV systems often operate under dynamic environments (rapid temperature/irradiance changes, partial shading, and multi-peak characteristics). Researching high-precision and robust parameter extraction methods for single-diode (SDM) models helps improve the model’s generalization ability and real-time availability under complex conditions. Therefore, in this section, we investigate parameter extraction for single-diode models. The equivalent circuit of the single-diode model is shown in Figure 7.
The single-diode model comprises a current source that represents the photo-generated current induced by solar irradiation, a diode that characterizes the PN junction behavior of the semiconductor, a series resistance reflecting the ohmic losses of electrodes, interconnections, and materials, and a shunt resistance accounting for leakage paths through the semiconductor structure. The output current can be represented by Equation (24).
where , , and denote the photocurrent, the diode current, and the current through the shunt resistor, respectively. The diode and shunt currents can be expressed as follows:
where is the diode reverse saturation current, is the diode ideality factor, is the Boltzmann constant , is the electron charge , and ambient temperature in Kelvin.
Substituting Equations (25) and (26) into Equation (24) yields the output current–voltage relationship of the single-diode model:
Thus, the single-diode model is fully characterized by five parameters: .
The unknown parameters are obtained by casting their estimation as an optimization task, in which an objective function quantifies the mismatch between the measured experimental values and the model’s predicted outputs. The optimization procedure seeks to minimize this mismatch over a predefined search space, thereby yielding the best-fitting set of parameters. Commonly adopted error formulations for this purpose are listed below:
where set and . The total discrepancy between the experimental curve and the model prediction is assessed using the root mean square error (RMSE):
where is the total number of measured data points .
5.3.2. Experimental Parameter Setting and Simulation Analysis
In this section, the effectiveness of the proposed MESPBO algorithm in photovoltaic model parameter identification is thoroughly evaluated. We first provide a concise description of the experimental setup and related parameters. Subsequently, MESPBO is employed to estimate the unknown variables of the single-diode model (SDM). The detailed settings and procedures are presented as follows:
- (1)Experimental Parameter setting
Experimental measurements were obtained from a Photowatt-PWP 201 photovoltaic module comprising 36 polycrystalline silicon cells connected in series. At an operating temperature of 33 °C and a solar irradiance of 1000 W/m^2^, a total of 26 current–voltage (I–V) data points were recorded. These data were used to identify the unknown parameters of both the SDM and DDM for RTC France PV cells, and the resulting estimates were subsequently benchmarked against those produced by other state-of-the-art optimization methods.
All compared algorithms were coded in MATLAB 2024b and run on a personal computer equipped with a 2.5 GHz CPU, 16 GB RAM, and Windows 11. For each problem, every algorithm was executed independently 30 times, using a population size of 50 and a maximum of 1000 iterations. To emphasize performance differences and verify their statistical reliability, the Wilcoxon rank-sum test was adopted. The feasible ranges of the unknown parameters for each model are listed in Table 10, where and denote the lower and upper bounds, respectively.
As noted above, the root mean square error (RMSE) provides a simple and effective measure of the discrepancy between experimental observations and model simulations. A smaller RMSE indicates a tighter match between the calculated and measured data, thereby demonstrating the algorithm’s stronger ability to identify the unknown parameters of the photovoltaic system. In other words, the extracted diode model can more faithfully capture the real operating characteristics of solar cells and PV modules. Therefore, reducing this error is of vital importance.
Moreover, the absolute error (IAE) and relative error (RE) are adopted to evaluate the deviation at each measured voltage point, which are defined as follows:
(2)Experimental Analysis of SDM
In this subsection, we conducted experimental analysis using MESPBO and 11 other comparison algorithms. The experimental results are shown in Table 11, Meanwhile, Figure 8 shows its convergence curve. From the convergence curves on the 1DM model, all algorithms reduce the objective rapidly at the beginning, but their convergence rates and final precisions differ markedly. MESPBO achieves the steepest early decrease, driving the best score down to about the 10^−3^ level within the first tens of iterations, and stabilizes after roughly 200 iterations with the lowest final error among all competitors. This indicates both fast convergence and high solution accuracy. Algorithms such as SPBO, HHWOA, GRO, SBOA, and ED also keep improving toward the 10^−3^ range, but they converge more slowly or exhibit mid/late-stage plateaus, reflecting weaker exploitation or stability than MESPBO. In contrast, IGWO, MSPBO, ESC, and SO stagnate at higher error levels, suggesting premature convergence. PSO and QOCSPBO show the slowest convergence and the highest final errors, implying insufficient global exploration and fine local search for this parameter-identification task. Overall, MESPBO combines the fastest early descent with the best final precision and minimal stagnation, confirming that its multi-strategy enhancements significantly improve convergence speed, accuracy, and robustness on the 1DM PV model.
Figure 9 shows the I-V and P-V fitting results of MESPBO after parameter identification of the single diode model (1DM): the estimated curve (red circle) almost coincides with the measured curve (blue line) over the entire voltage range. The current plateau, inflection point/knee point position in the short-circuit region and the rapid drop segment near the open-circuit voltage are all aligned, indicating that the photocurrent, series and parallel resistance, diode parameters, etc., are accurately identified. The voltage position and peak height of the maximum power point in the corresponding P-V curve are also consistent with the measured values. The power drop trend after the peak is well matched, indicating that the algorithm can not only accurately fit the current–voltage characteristics, but also reliably predict the power output and MPP parameters, verifying the high accuracy and stability of MESPBO in 1DM parameter identification.
Table 12 reports the point-wise absolute errors of current and power obtained by MESPBO under the SDM. The overall pattern indicates highly accurate and stable fitting across the whole voltage range: the current errors (IAE_I) are mostly within the 10^−4^~10^−3^ order, showing only a slight increase in the knee/high-voltage sensitive region, while still remaining very small; the power errors (IAE_P) are even smaller, generally in the 10^−5^~10^−4^ range, with only minor fluctuations around the peak-power area and no systematic deviation. These results confirm that the SDM parameters identified by MESPBO can reconstruct the I–V and P–V characteristics with excellent global accuracy and robustness, achieving the smallest errors in the low-voltage region and maintaining low errors even near the knee point and MPP.
6. Summary and Limitations
In this paper, a novel metaheuristic algorithm called multi-strategy-enhanced student psychology-based optimization (MESPBO) was proposed to improve the optimization capability of the SPBO. By integrating three strategies—hybrid heuristic population initialization, adaptive dual-learning position update, and hybrid opposition-based reflective boundary control—MESPBO effectively enhances population diversity, improves convergence accuracy, and prevents premature stagnation. Extensive experiments conducted on the CEC2017 benchmark suite under 10-, 30-, and 50-dimensional scenarios demonstrated that MESPBO consistently outperforms eleven state-of-the-art optimization algorithms in terms of convergence speed, solution precision, and robustness. Furthermore, its successful application to feature selection tasks confirmed that MESPBO can efficiently reduce redundant features while maintaining or improving classification accuracy, thus proving its strong generalization ability and applicability in both continuous and combinatorial optimization domains.
Although MESPBO demonstrates strong performance and generalization ability across both benchmark optimization and feature selection tasks, several inherent limitations should be acknowledged. First, due to the integration of multiple enhancement strategies, the overall algorithmic structure becomes more complex than that of the original SPBO. This increased computational overhead may lead to relatively higher time consumption when handling extremely large populations or very high-dimensional optimization problems. Second, similar to most population-based metaheuristics, MESPBO still relies on stochastic search operators, which may introduce performance fluctuations across independent runs. Although robustness has been significantly improved, absolute consistency cannot be guaranteed. Third, the algorithm includes several hyperparameters related to learning mechanisms and boundary control, and while their default settings work well across various problems, their sensitivity on domain-specific tasks may still require careful tuning.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wang M. Chen H. Yang B. Zhao X. Hu L. Cai Z. Huang H. Tong C. Toward an Optimal Kernel Extreme Learning Machine Using a Chaotic Moth-Flame Optimization Strategy with Applications in Medical Diagnoses Neurocomputing 2017267698410.1016/j.neucom.2017.04.060 · doi ↗
- 2Zhang L. Wang L. An Ensemble Learning-Enhanced Smart Prediction Model for Financial Credit Risks J. Circuits Syst. Comput.202433710.1142/S 0218126624501299 · doi ↗
- 3Qiao Q. Image Processing Technology Based on Machine Learning IEEE Consum. Electron. Mag.202413909910.1109/MCE.2022.3150659 · doi ↗
- 4Pandey S. Basisth N. Sachan T. Kumari N. Pakray P. Quantum Machine Learning for Natural Language Processing Application Phys. A-Stat. Mech. ITS Appl.202362712912310.1016/j.physa.2023.129123 · doi ↗
- 5Cai J. Luo J. Wang S. Yang S. Feature Selection in Machine Learning: A New Perspective Neurocomputing 2018300707910.1016/j.neucom.2017.11.077 · doi ↗
- 6Barrera-García J. Cisternas-Caneo F. Crawford B. Sánchez M. Soto R. Feature Selection Problem and Metaheuristics: A Systematic Literature Review about Its Formulation, Evaluation and Applications Biomimetics 20249910.3390/biomimetics 9010009 PMC 1081381638248583 · doi ↗ · pubmed ↗
- 7Ming H. Heyong W. Filter Feature Selection Methods for Text Classification: A Review Multimed. Tools Appl.2024832053209110.1007/s 11042-023-15675-5 · doi ↗
- 8Jain R. Xu W. Artificial Intelligence Based Wrapper for High Dimensional Feature Selection BMC Bioinform.20232439210.1186/s 12859-023-05502-x PMC 1058589537853338 · doi ↗ · pubmed ↗