IHBOFS: A Biomimetics-Inspired Hybrid Breeding Optimization Algorithm for High-Dimensional Feature Selection
Chunli Xiang, Jing Zhou, Wen Zhou

TL;DR
This paper introduces IHBOFS, a new optimization algorithm inspired by biomimetics, which improves feature selection in high-dimensional data by combining adaptive strategies and enhancing exploration.
Contribution
The novel contribution is the integration of adaptive strategies and mechanisms like Good Point Set and Elite Opposition-Based Learning in a hybrid optimization framework for feature selection.
Findings
IHBOFS achieves an average classification accuracy of 92.57% on real-world datasets.
The algorithm outperforms nine metaheuristic methods in high-dimensional feature selection tasks.
Ablation studies on CEC2022 benchmarks confirm the effectiveness of the proposed strategies.
Abstract
With the explosive growth of data across various fields, effective data preprocessing has become increasingly critical. Evolutionary and swarm intelligence algorithms have shown considerable potential in feature selection. However, their performance often deteriorates in large-scale problems, due to premature convergence and limited exploration ability. To address these limitations, this paper proposes an algorithm named IHBOFS, a biomimetics-inspired optimization framework that integrates multiple adaptive strategies to enhance performance and stability. The introduction of the Good Point Set and Elite Opposition-Based Learning mechanisms provides the population with a well-distributed and diverse initialization. Furthermore, adaptive exploitation–exploration balancing strategies are designed for each subpopulation, effectively mitigating premature convergence. Extensive ablation…
Click any figure to enlarge with its caption.
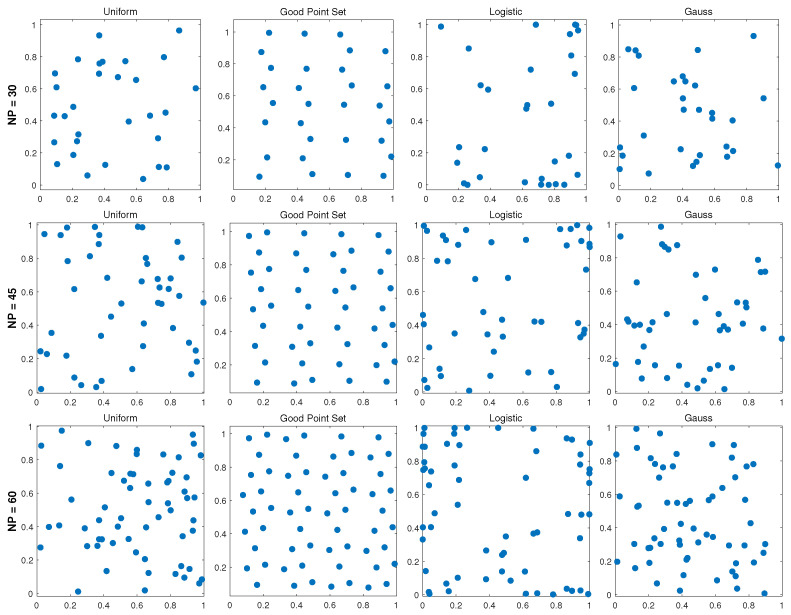 Figure 1
Figure 1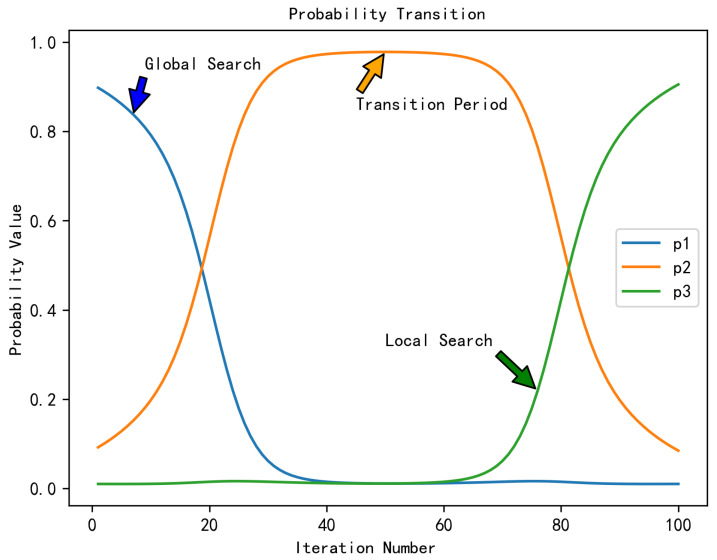 Figure 2
Figure 2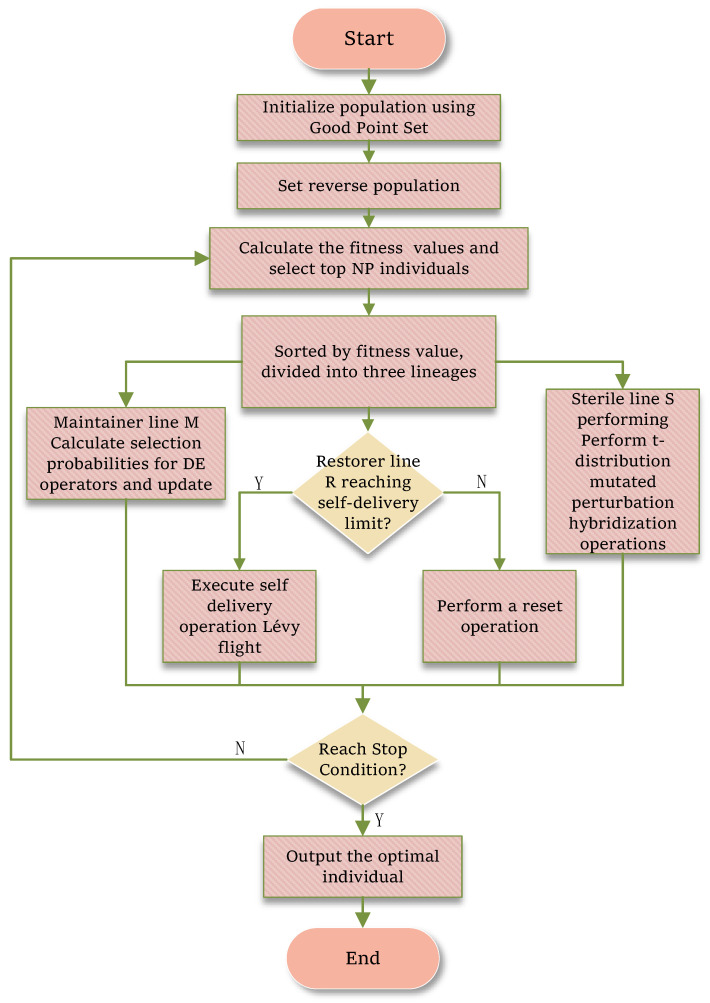 Figure 3
Figure 3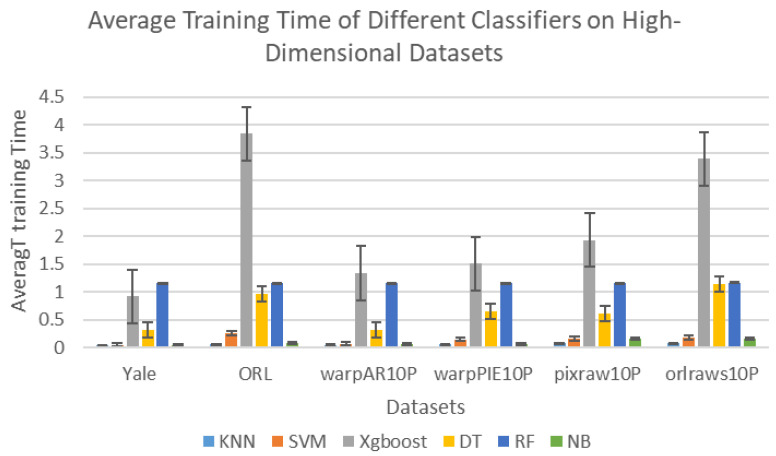 Figure 4
Figure 4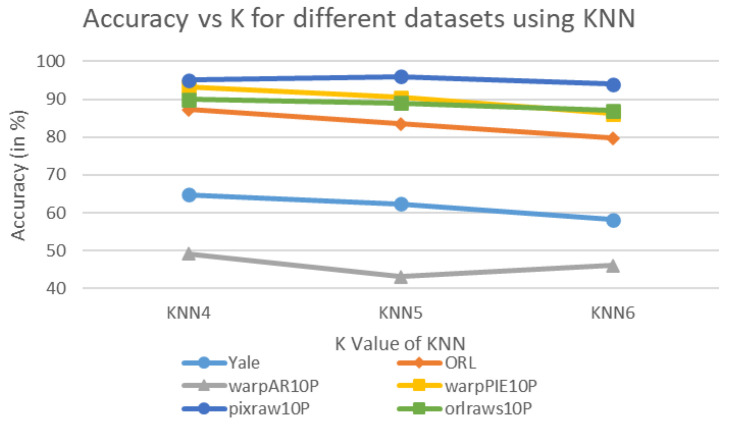 Figure 5
Figure 5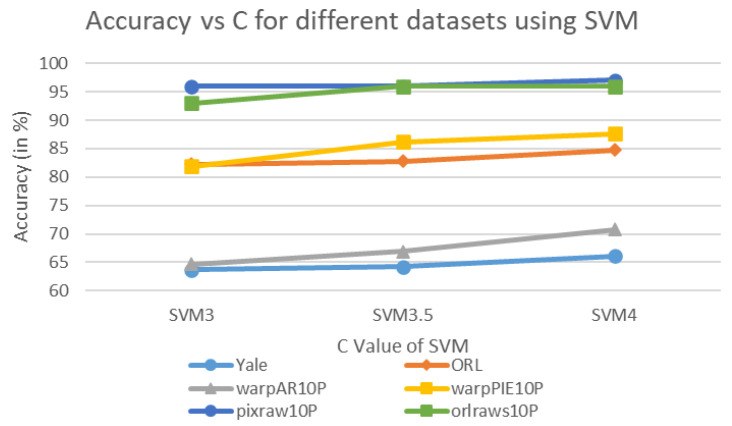 Figure 6
Figure 6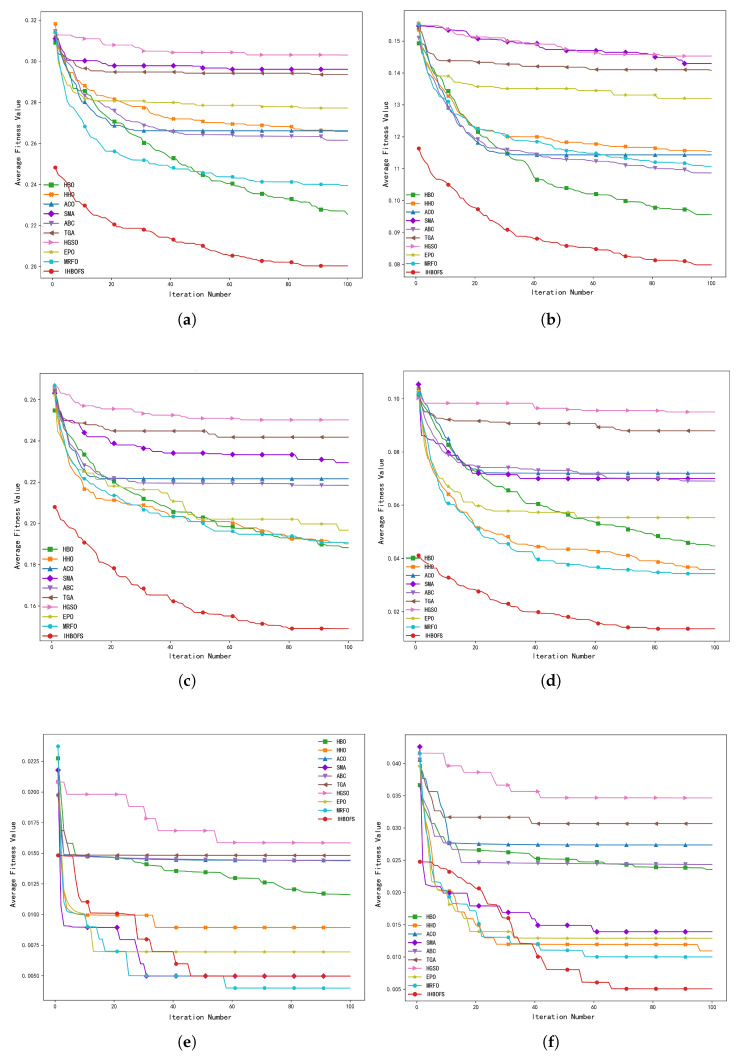 Figure 7
Figure 7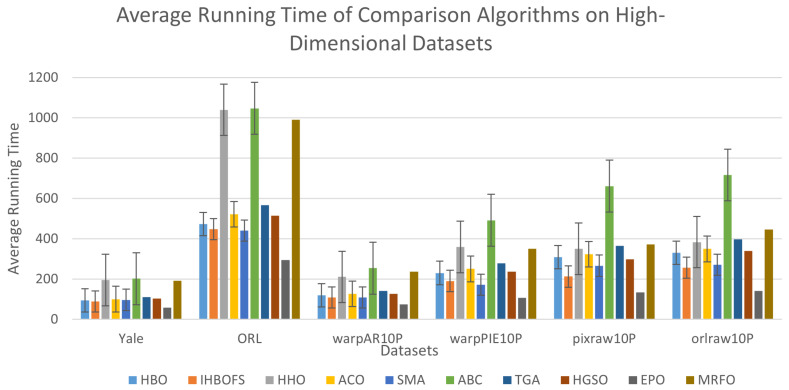 Figure 8
Figure 8- —National Natural Science Foundation of China
- —Key Research and Development Program of Hubei Province, China
- —Young and Middle-aged Scientific and Technological Innovation Team Plan in Higher Education Institutions in Hubei Province, China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetaheuristic Optimization Algorithms Research · Advanced Multi-Objective Optimization Algorithms · Machine Learning and Data Classification
1. Introduction
With the rapid expansion of dataset dimensions, high-dimensional data pose numerous challenges. In such spaces, data become sparse, making it difficult for models to learn effective patterns, which reduces the generalization capability [1]. When models contain excessive or redundant features, they tend to capture irrelevant patterns from the training samples, which in turn degrades their generalization ability on new data [2]. Moreover, as the dimensionality increases, the number of potential feature combinations grows exponentially, causing traditional search-based selection procedures to become computationally prohibitive [3]. Therefore, recent research has increasingly turned toward adaptive and scalable feature reduction techniques designed for complex high-dimensional datasets [4].
Feature selection (FS) serves as a fundamental procedure in the fields of machine learning and data analytics. Its objective is to extract the most informative subset of attributes from the full feature set, thereby enhancing model efficiency, reducing the computational burden, and improving the interpretability of learning outcomes [5]. Broadly, FS methods can be divided into three major categories: filter-based, wrapper-based, and embedded approaches. The filter-based category assesses feature importance without relying on any particular learning algorithm, often through statistical relevance measures such as correlation analysis, chi-square evaluation, or information gain [6]. Their low computational overhead makes them an effective choice for preprocessing extensive datasets [7]. In wrapper approaches, subsets of features are examined using a designated learning algorithm, training and assessing models to select the optimal subset, though incurring high computational cost [8], with popular approaches like recursive feature elimination (RFE) [9]. Embedded methods integrate FS within the model training procedure by tuning model parameters, allowing for an efficient and effective identification of relevant features [10], and are generally more computationally efficient, often yielding better model performance compared to wrapper methods [11].
Hybrid approaches integrate the advantages of both filter and wrapper techniques. Typically, a preliminary filter step is applied to limit the dimensionality, followed by a wrapper method to refine the optimal feature subset [12]. For example, a recent hybrid feature selection method combines ReliefF and fuzzy entropy with an enhanced equilibrium optimizer and achieves superior performance on medical datasets [13].
Despite the effectiveness of traditional and hybrid feature selection strategies, they often encounter limitations when applied to large-scale or highly complex datasets, particularly owing to the combinatorial complexity of feature subset selection. As the dimensionality of the data increases, exhaustive search becomes computationally infeasible, and heuristic-based methods may fall into local optima. To cope with this challenge, increasing attention has been devoted to evolutionary computation methods, which demonstrate remarkable global exploration ability and adaptability when tackling high-dimensional and nonlinear optimization tasks.
Evolutionary algorithms such as Grey Wolf Optimizer (GWO) [14], Genetic Algorithm (GA) [15], and Particle Swarm Optimization (PSO) [16] simulate natural evolution or swarm intelligence to explore high-quality solutions within challenging optimization landscapes. However, standard metaheuristics tend to converge slowly, with low efficiency in high-dimensional settings. As a result, researchers have considered various approaches to improve the algorithm in order to enhance the feature selection performance [17]. An improved Crayfish Optimization Algorithm (MCOA) was proposed to lead the exploration toward optimal results using an environmental update mechanism [18]. A self-adaptive weighted differential evolution algorithm (SaWDE) was proposed to tackle large-scale feature selection tasks and showed remarkable effectiveness across diverse high-dimensional datasets [19]. The Feature Weighting Particle Swarm Optimization method (FWPSO) effectively identifies biomarker genes within complex microarray data by integrating feature relevance assessment with optimized feature selection [20]. A hybrid Sine Cosine–Firehawk Algorithm (HSCFHA) was designed to perform feature selection by optimizing dataset variance [21]. In the past four years, other methods have been proposed, including VGS-MOEA [22], MTPSO [23], PSO-EMT [24], and DENCA [25].
Despite the effectiveness demonstrated by existing metaheuristic-based feature selection methods, their inherent random strategies, while ensuring global search capability, struggle to completely avoid local optima. Therefore, developing a computationally efficient high-dimensional feature selection method that exhibits good consistency and robustness remains a significant direction in current research. Ye et al. inspired by the theory of hybrid vigor and hybrid breeding mechanisms, proposed a hybrid breeding optimization algorithm [26]. HBO exhibits outstanding performance in exploration, search efficiency, and adaptability and has been employed to address various optimization challenges, including the 0–1 knapsack problem [27]. Despite its novel structure, standard HBO suffers from limited adaptability and may converge prematurely. To overcome these issues, several improved variants have been proposed. For instance, a Cooperative Hybrid Breeding Swarm Intelligence (CHBSI) algorithm was proposed to address the challenges of FS in high-dimensional spaces [28]. Furthermore, a Double-Stage Multimodal HBO (DSMHBO), integrating dynamic niching, neighborhood search, and elite mutation, was proposed to locate multiple optima effectively [29]. In the domain of network security, Ye et al. developed a Cooperative Co-evolution Improved HBO (CCIHBO) framework [30], effectively enhancing intrusion detection accuracy. These improvements significantly broaden the applicability and capability of the original HBO to handle intricate optimization problems involving high-dimensional search spaces.
The performance of HBO has already been validated on function optimization and engineering optimization problems. However, HBO and its improved variants face challenges such as low convergence accuracy and insufficient robustness in high-dimensional FS scenarios. Therefore, this paper focuses on HBO research, with the objective of thoroughly analyzing its potential and limitations in high-dimensional feature selection problems. We propose IHBOFS, which enhances the original HBO framework to better handle high-dimensional feature selection tasks.
The main findings highlighted in this work are as follows:
- An integrated multi-strategy improved hybrid breeding optimization algorithm is proposed, which effectively balances the exploration and exploitation capabilities.
- Ablation experiments are conducted on various types of benchmark functions to verify the effectiveness of the different enhancement strategies incorporated into the improved algorithm.
- The optimal combination of classifier and transfer function is identified based on experimental evaluations of the performance of different options.
- The performance of IHBOFS is evaluated against various metaheuristic-based FS methods on high-dimensional datasets to validate its effectiveness.
The structure of this paper is as follows: Section 2 provides a review of recent related studies, presenting the improvement strategies and their corresponding mathematical models. Section 3 introduces the proposed IHBOFS. Experimental findings and corresponding discussions are detailed in Section 4. Finally, Section 5 concludes the paper and outlines potential directions for future research.
2. Related Works
In recent years, numerous evolutionary algorithms have been proposed to address the challenges of high-dimensional feature selection, and attempts have been made to improve algorithm performance from various perspectives [31]. Table 1 summarizes the performance and limitations of several nascent hybrid algorithms tailored for feature selection tasks in various research fields. Among them, the HBO has shown strong potential due to its biological inspiration and excellent global search ability. As this work builds upon HBO as a baseline, this section first introduces the fundamental principles of the HBO and then presents recent improvements and related methods relevant to high-dimensional feature selection.
2.1. Hybrid Breeding Optimization Algorithm
To address the inefficiency of FS, Ye et al. [26] proposed the HBO, which exhibits strong exploratory capability and algorithm efficiency. During the initial stage, all individuals are sorted according to their fitness values, forming the population: , where n represents the population size. The maintainer line, which consists of individuals with the highest fitness values, is defined as . The sterile line is composed of individuals exhibiting the poorest fitness while the remaining individuals make up the restorer line .
Hybridization: The sterile individuals are updated during this step. The process of generating new individuals through hybridization is given by Equation (1),
where represents a new sterile-line individual generated in iteration t, and and represent individuals randomly drawn from the maintainer and sterile lines, respectively. While denotes a uniformly distributed random variable within , the subsequent parameters and share the same distribution and are utilized in later stages of the algorithm.
Selfing: In this step, the individuals in the restorer line integrate genetic information from other individuals to facilitate the evolution of the subpopulation towards an optimal solution. This process is formulated as Equation (2),
In this equation, refers to a newly generated individual obtained through self-fertilization between two restorer individuals i and j. The element represents the current best individual in iteration t, whereas represents another restorer individual randomly chosen from the population.
Renewal: If a restorer-line individual fails to update for a predefined number of consecutive iterations ( ), the algorithm resets it by randomly selecting new values from the search space. This mechanism is described as Equation (3),
where represents the restorer individual that has not been updated, and and are the maximum and minimum values of the search space.
2.2. Good Point Set
The Good Point Set (GPS) method, proposed by the Chinese mathematician Luogeng Hua, aims to generate a set of uniformly distributed points within the search space, which helps establish a balanced coverage of the search domain during initialization [41]. Its principle is as follows:
Suppose is the unit cube in the D-dimensional Euclidean space; then, is a Good Point Set, where and . The discrepancy is , and is a constant that only depends on r and ( is an arbitrarily small positive number), r is the good point, represents taking the fractional part, and n represents the number of points. In this paper, we take , where , and p is the smallest prime number satisfying . The initialization mapping is defined in Equation (4),
where and represent the lower and upper bounds of the d-th dimension in the search space, respectively. Figure 1 presents the two-dimensional initial population distributions generated by four different methods—logistic chaotic mapping, Good Point Set initialization, Gaussian perturbation, and uniform random initialization. As depicted, for relatively small population sizes, the Good Point Set-based initialization method significantly improves the uniformity of population distribution. It improves the coverage of the search space, reducing the sensitivity to the initial population distribution.
2.3. Elite Opposition-Based Learning (EOBL)
The core idea of EOBL is to exploit the symmetry of the problem space by mirroring each solution in the representation space. The principle is as follows:
Consider an elite individual , where , in a D-dimensional search space. Its opposite solution is defined as Equations (5) and (6):
where K is a dynamic coefficient taking values in [0, 1], and and denote the lower and upper bounds of the j-th dimension, respectively. When the computed opposite solution falls outside the search boundaries, it is adjusted according to a uniform distribution, as described in Equation (7).
The standard HBO mainly utilizes heterosis to update sterile lines and restorer lines, thereby achieving population evolution. However, the maintainer line lacks an effective update strategy, leading to underutilization. In addition, the original operators exhibit performance deficiencies in high-dimensional complex scenarios. With the aim of resolving these limitations, we designed four advanced strategies to optimize and improve the standard HBO.
3. The Proposed Method
A thorough explanation of the proposed method is provided in this section.
3.1. Integrated Multi-Strategy Improved HBO
The subsequent discussion offers a comprehensive introduction to the algorithm’s process and improvement measures.
3.1.1. Optimization of Initial Population Generation
Initial population generation is a crucial step in metaheuristic algorithms, directly affecting the search efficiency and accuracy. In the traditional HBO, random initialization is used. However, an excessively large population increases the computational burden, whereas a too-small population leads to uneven distribution, making it susceptible to becoming trapped in local optima, particularly for complex high-dimensional problems. Therefore, this paper introduces the GPS and EOBL to optimize the initial population generation. The GPS-initialized population is used to construct elite opposition solutions, from which the best individuals are selected as the final initial solution set.
3.1.2. Operations for the Maintainer Line
The sterile line holds significant potential. When guided in evolution by maintainer lines with currently high fitness values, there is a considerable probability of generating superior individuals. However, due to the low stability of the sterile line, strategy adjustments are required at different stages of the iteration process. Therefore, three refined variants of differential operators are introduced in this paper, each designed to operate at different stages of the search process. These operators, denoted as , , and , are mathematically defined in the following Equations (8)–(10).
where indicates the optimal solution obtained at iteration t, and refers to individuals randomly drawn from the maintainer line, with all indices being distinct. The updated value of the i-th maintainer line individual at iteration is represented by . The smoothing factor F controls the transition from a global to a local search, and the random coefficients and are independently generated within the interval [0, 1].
To allow different differential operators to be applied with varying probabilities during different phases of optimization, the following strategy is implemented: at the initial stage, the global differential operator is assigned a greater likelihood of selection, whereas during the the global-to-local search transition, the transition operator is preferred. At the later stage, the local differential operator is preferred to further refine the optimal solution. An adaptive algorithm is proposed to dynamically determine the selection probabilities corresponding to the three differential operators, while utilizing a roulette wheel selection algorithm for operator selection, as shown in Equations (11)–(17):
where and are parameters to constrain the lower and upper bounds before normalization. denotes the probability for selecting each differential operator after normalization. Here, t and T denote the current and maximum iteration counts, respectively. corresponds to the differential operator finally selected via the roulette wheel strategy.
As shown in Figure 2, the algorithm adjusts the selection probabilities of each operator as the iteration progresses.
3.1.3. Operations for the Hybridization Phase
To strengthen the hybridization process, a t-distribution mutation-based perturbation method is adopted. The modification of the HBO crossover phase is expressed in Equations (18)–(21):
The original random number r is replaced by a value selected through a random sampling strategy based on the t-distribution. denotes the Gamma function, while denotes the mutation scaling factor. This strategy enables broader exploration of the search space during the early iterations, while favoring more focused local search in the later stages.
3.1.4. Operations for the Selfing Phase
During the selfing phase, restorer individuals are updated. When an individual has reached the maximum selfing limit but fails to update the global optimal individual, this suggests that the algorithm has converged to a local optimum, thus requiring a reset.
This paper refines by allowing it to vary adaptively throughout the iterative process, as depicted in Equation (22).
During the algorithm’s initialization and global exploration, most individuals are highly likely to make productive moves within a short iteration cycle. Accordingly, the parameter is initialized with a comparatively high value. When an individual meets this criterion, this suggests premature convergence and triggers a reset. As the search advances, the chance of stagnation in local optima grows; so, a smaller is used to accelerate escape from such regions.
In addition, this paper also improves the selfing strategy for restorer individuals. The gene update formula for restorer individuals is replaced by Equations (23)–(25),
where serves as the step-length scaling coefficient, and is an adaptively varying factor that gradually decreases from 2 toward 0 in a nonlinear manner as the iteration proceeds. denotes a restorer individual randomly chosen from the population ( ), while is a uniformly distributed random variable within [0, 1]. The term Lévy(β) follows a Lévy flight distribution characterized by the parameter whose heavy-tailed nature allows the algorithm to perform frequent local movements interspersed with occasional long jumps, thereby improving both global exploration and local refinement capabilities [42]. The explicit mathematical form of this distribution is presented in Equation (26).
The flowchart of the IHBOFS is shown in Figure 3.
3.2. IHBOFS Method
The proposed feature selection method, based on IHBOFS, follows the workflow outlined below. Initially, the algorithm parameters are set, and the search space is defined according to the feature count in the dataset. Next, cross-validation is applied to partition the data. IHBOFS is then utilized on the training set to identify the optimal solution. Although HBO is designed for continuous space optimization, FS is inherently a discrete problem. Thus, a binary encoding technique is employed to adapt the original algorithm for continuous domains to a form that can address discrete challenges. To evaluate the performance of the selected feature subset, an SVM classifier is used, and a fitness function is calculated to assess the subset’s quality by balancing the classification accuracy and feature minimization.
3.2.1. Binary Encoding
Through experimental comparison among eight transfer functions, we selected the most suitable one for the current scenario, as shown in Equation (27):
The continuous values are mapped into the interval through the transfer function. Then, the transformed value is converted into a binary solution representation using Equation (28):
Here, “1” indicates that the corresponding feature is selected for classifier training, while “0” means the feature is not selected. denotes the transfer function, and rand is a random value within the range .
3.2.2. Fitness Function
The fitness function in feature selection must balance two conflicting objectives: classification performance and subset dimensionality. Relying solely on accuracy tends to produce oversized feature subsets, whereas minimizing the number of features alone often results in severe information loss and degraded predictive performance. To select as few features as possible while improving the accuracy, the fitness function designed in this paper is defined as follows:
where Fitness represents the fitness value, acc is the classification accuracy, and n and N represent the proportion of selected features to the total number of features, . The term ensures that maximizing the accuracy corresponds to minimizing the fitness value, which aligns with the minimization nature of evolutionary optimization. The ratio provides a scale-invariant measure of subset size, preventing bias toward datasets with different dimensionalities.
3.2.3. Complexity Analysis
With N as the population size, D as the dimension of the search space, and T as the iteration limit, the computational complexity for each operational stage is presented in Table 2.
Even though the time complexity for initializing the population in IHBOFS is roughly twice that of HBO, its effect on the overall time complexity remains minimal, as the population initialization occurs only once. IHBOFS incurs a moderate increase in time complexity, approximately one-third, due to the addition of a preservation sub-population update. However, this enhancement significantly improves the exploitation of high-quality individuals and enhances the population diversity. Notably, the time complexities of the population sorting and optimal solution updates remain consistent between IHBOFS and HBO. Therefore, the proposed improvement strategy maintains a relatively low additional computational cost while enhancing the algorithm’s search performance and population diversity, making it a relatively excellent improvement strategy.
4. Experiment Results and Discussion
The effectiveness of HBO has been demonstrated in function optimization and engineering problems. As a result, this paper concentrates on feature selection experiments, and three groups of experiments are organized:
- Ablation Study: this analysis aims to evaluate the role and significance of each component within the proposed IHBOFS, and experiments are conducted using different combinations of strategies on the CEC2022 test functions.
- Classifier and Transfer Function Selection: using high-dimensional real datasets from the Scikit feature selection repository, six classifiers (KNN, SVM, XGBoost, Decision Tree, Random Forest, Naive Bayes) are evaluated and selected based on performance; in addition, both standard HBO and IHBOFS are combined with eight different transfer functions to perform feature selection, in order to identify the best classifier and transfer function.
- Comparison with Other Algorithms: based on the selected SVM classifier and the S3 transfer function, IHBOFS is compared with various feature selection algorithms based on metaheuristics across multiple high-dimensional datasets.
All algorithms in the experiments are implemented in Python 3.8.20. Experiments are conducted on a computer equipped with an AMD Ryzen 7 5800H CPU @ 3.2 GHz and 32 GB RAM, using Windows 10 as the operating system.
4.1. Datasets
The CEC2022 benchmark suite includes 1 unimodal function (F1), 4 basic multimodal functions (F2–F5), 3 hybrid functions (F6–F8), and 4 composite functions (F9–F12), with a dimensionality of 20. A detailed description is provided in Appendix A.
The high-dimensional datasets are obtained from the standard Scikit feature selection database, as shown in Table 3. These datasets contain between 1024 and 10,304 features and 100 to 400 samples. All are multi-class classification problems, each presenting unique challenges. Their diversity provides a robust basis for evaluating IHBOFS’s ability to identify optimal feature subsets across various complex scenarios.
4.2. Experimental Settings
Table 4 presents the key parameter settings of HBO and its four improved strategy variants. For equitable evaluation and to confirm the contribution of each enhancement mechanism, each algorithm is independently executed 30 times on each test function at different dimensions. The maximum number of iterations is set to 1000 for all algorithms.
To ensure fairness in the number of fitness evaluations, the population size is set to 40 for IHBOFS and HBO_DE and to 60 for standard HBO and the other three improved algorithms. Five evaluation metrics are employed to comprehensively assess the algorithms’ performance: best fitness value (Best), worst fitness value (Worst), mean fitness value (Mean), standard deviation of fitness values (Std), and average execution time (Time).
To further assess the performance of IHBOFS, it is compared with several metaheuristic-based algorithms, including GA, Flower Pollination Algorithm (FPA) [43], Sparrow Search Algorithm (SSA) [44], Whale Optimization Algorithm (WOA) [45], the Rime-Ice Optimization Algorithm (RIME) [46], JAYA [47], GWO, and Harris Hawk Optimization (HHO) [48]. The parameter settings of these algorithms are listed in Table 5. All algorithms use a population size of 40 and a maximum of 1000 iterations. Each test function is run independently 30 times to minimize the impact of randomness. The parameter settings and evaluation metrics of HBO and IHBOFS are consistent with those used in the ablation study.
In the classifier evaluation and selection experiment, all classifiers are independently run 10 times on each dataset. A five-fold cross-validation and stratified sampling strategy is employed to reduce overfitting.
Properly designed transfer mechanisms can improve the interpretability and controllability of the feature selection process [49]. This study selects eight transfer functions (four S-shaped and four V-shaped), whose details are provided in Appendix B.
4.3. Comparison of Experimental Results and Analysis
Detailed experimental results and analyses are presented in the following subsections.
4.3.1. Ablation Study
Based on the results shown in Table 6, integrating all four improvement strategies into IHBOFS yields clear and consistent advantages over both the original HBO and all individually enhanced variants. IHBOFS achieves superior performance in terms of both the Best and Mean metrics, while further reducing the standard deviation, demonstrating significantly enhanced stability across multiple runs. Overall, the integrated strategy effectively leverages the complementary strengths of each individual enhancement, resulting in an optimized exploration process across the three populations and substantially improving the algorithm’s overall problem-solving performance and robustness.
4.3.2. Classifier Performance Evaluation and Selection
Ten independent runs were conducted for each classifier–dataset combination to ensure the statistical robustness of the validation findings. A five-fold cross-validation combined with stratified sampling was applied to mitigate overfitting risks. Table 7 summarizes the average classification accuracy and training time over 10 runs for several classifiers, including KNN, SVM, XGBoost, DT, RF, and NB.
As shown in Table 7, SVM exhibits strong overall performance with an average accuracy of 83.70%, ranking second only to RF, which attained 83.86%. Notably, SVM achieved exceptional accuracy on the pixraw10P and orlraws10P datasets, reaching 97.00% and 96.00% respectively, significantly outperforming other classifiers. This highlights the superior ability of SVM to handle high-dimensional data. In contrast, NB performs poorly on certain datasets such as pixraw10P, with an accuracy of only 22.00%, indicating that it may not be suitable for specific scenarios. Moreover, NB exhibits limited generalization across datasets, with its accuracy consistently lagging behind that of SVM and RF.
To provide a more intuitive comparison, Figure 4 presents the bar chart of training times for different classifiers. From the training time perspective, KNN is the fastest among all classifiers, significantly outperforming the others. SVM combines high accuracy with favorable training speed, averaging 0.145 s per run. This is 87.52% faster than RF (1.1617 s on average) and also substantially lower than XGBoost (2.155 s). This advantage is particularly important in real-time or resource-constrained environments.
In conclusion, SVM demonstrates dual strengths in classification accuracy and operational efficiency. Although RF offers a slight edge in accuracy, its longer training time may become a constraint in practical applications. Therefore, for high-dimensional classification tasks where both speed and accuracy are critical, KNN and SVM are generally more effective options. This study will further evaluate the classification performance of KNN and SVM under different parameter settings.
This study primarily focuses on the dimensionality reduction capability of evolutionary algorithms and their discriminative power across diverse categories. Given the complexity of parameter combinations across different classifiers, only key parameters significantly impacting classification performance are locally tuned. This approach emphasizes the search performance and efficiency of the evolutionary algorithm rather than the classifier itself.
Figure 5 and Figure 6 illustrate the classification accuracy of KNN and SVM under different parameter settings. Specifically, for KNN, the number of neighbors K is tested at values of 4, 5, and 6. For SVM, the penalty parameter C is evaluated at 3, 3.5, and 4. These parameters strongly influence the model’s performance and fitting behavior. In KNN, K determines the number of neighbors considered during classification, affecting the smoothness and generalization. For SVM, C controls the decision boundary margin and the tolerance to misclassifications, thereby determining the model complexity. As observed from Figure 5, as the value of K increases, KNN’s accuracy tends to decrease across most datasets. This suggests that a smaller K may provide more concentrated information and thus higher accuracy. On the other hand, SVM exhibits improved performance as C increases. Notably, SVM with (SVM4) shows superior accuracy on multiple datasets, especially on pixraw10P and orlraws10P, where it achieves 97.00% and 96.00%, respectively.
To prevent potential overfitting and to ensure generalization across datasets, this study adopts cross-validation and stratified sampling. Both strategies help reduce bias in the train–test split and provide a more reliable estimate of model performance. Moreover, since C in SVM determines the model complexity, a larger value may increase the risk of overfitting. However, the results in Table 7 show that using smaller C values does not improve the performance; instead, the accuracy decreases. Objectively, if the model were overfitting at , reducing the value of C (e.g., to 3 or 3.5) would simplify the model and alleviate overfitting, thereby improving the accuracy. However, the opposite trend is observed, indicating that the model is not overfitting at . Although larger C values may potentially yield higher accuracy, they also tend to enforce stricter fitting to the training samples, which could overshadow the feature-filtering capability of the metaheuristic algorithm. Therefore, excessively large C values are not further explored in this study.
With regard to the training time, the table shows that KNN and SVM demonstrate stable training times across different parameter settings. Overall, SVM4 exhibits a favorable trade-off, especially on complex and high-dimensional datasets. Its high accuracy and stability highlight strong modeling capability. Moreover, SVM shows better generalization than KNN across datasets. A reasonable training time further ensures its practicality. Based on these findings, SVM with is selected as the final classifier configuration for the subsequent experiments.
4.3.3. Transfer Function Experiments
To identify the most suitable transfer function for the algorithm, this subsection evaluates the performance of the multi-strategy improved IHBOFS in combination with the eight transfer functions introduced in Section 4.2. Feature selection experiments are conducted using the optimal classifier (SVM) selected in the previous subsection. Table 8 presents the classification accuracy of IHBOFS when combined with different transfer functions. In the table, Best denotes the highest accuracy among 10 independent runs, Worst denotes the lowest accuracy, while Mean and Std represent the average accuracy and standard deviation, respectively.
According to the results, the feature subsets obtained using S-shaped transfer functions significantly outperform those obtained using V-shaped functions. Among all transfer functions, S3 yields the best average classification performance when combined with IHBOFS, achieving the highest mean accuracy on five out of the tested datasets.
The combinations IHBOFS+S1, IHBOFS+S2, and IHBOFS+S3 all achieve the highest Best score on the last three high-dimensional datasets. Notably, S3 further enhances the lower-bound performance of IHBOFS, as evidenced by its superior Worst scores compared to other transfer functions. As a result, IHBOFS+S3 outperforms all other combinations in terms of overall average accuracy.
For the first three datasets, IHBOFS+S3 performs best across almost all accuracy metrics. Although IHBOFS+S3 does not achieve the highest average accuracy on the warpAR10P dataset (87.69% for IHBOFS+S4), the difference between the two is less than 1.79%. Overall, S3 produces feature subsets with better classification performance.
Table 9 records the number of features selected by IHBOFS with different transfer functions. Although V-shaped functions sometimes select fewer features on certain datasets, their classification accuracy is significantly inferior to that of S-shaped functions. Therefore, when classification performance is prioritized, V-shaped functions are not suitable as the final choice.
Moreover, the IHBOFS+S3 combination achieves the lowest standard deviation on three datasets, indicating enhanced stability. It also demonstrates the ability to select smaller feature subsets with higher classification accuracy, especially on the latter three high-dimensional datasets, outperforming other S-shaped functions.
4.3.4. Comparison with Other Algorithms and Result Analysis
In the previous sections, we compared the performance of different classifiers and transfer functions and selected SVM and the S3 transfer function as the final settings for the classification model. Based on this configuration, this section compares IHBOFS with various metaheuristic-based feature selection algorithms, including HHO, the Ant Colony Optimization Algorithm (ACO) [50], Slime Mould Algorithm (SMA) [51], Artificial Bee Colony Algorithm (ABC) [52], Tree Growth Algorithm (TGA) [53], Henry Gas Solubility Optimization Algorithm (HGSO) [54], Emperor Penguin Optimizer Algorithm (EPO) [55], Manta Ray Foraging Optimization Algorithm (MRFO) [56], and the standard HBO.
As shown in Table 10, IHBOFS achieves higher feature subset accuracy compared to all other algorithms. The only exception is the pixraw10P dataset, where IHBOFS ranks second to MRFO in terms of the mean classification accuracy. In all other datasets, IHBOFS outperforms the other algorithms across Best, Worst, and Mean metrics.
In particular, HGSO produces relatively weak feature subsets. On the Yale dataset, IHBOFS surpasses HGSO by 14.65% in mean classification accuracy and by 13.19% and 8.70% on warpAR10P and warpPIE10P, respectively. It is worth emphasizing that, while the original HBO performs better than most algorithms on the first four datasets, it fails to effectively search for optimal feature subsets on the two higher-dimensional datasets—an issue addressed by the improved IHBOFS.
In terms of the number of selected features and runtime, the EPO achieves the best performance. However, the EPO tends to prioritize selecting fewer features while compromising the classification performance. For instance, on the Yale dataset, the EPO’s Best and Mean scores are 73.33% and 72.06%, respectively—10.75% and 11.19% lower than IHBOFS.
Figure 7 presents the convergence curves of the average fitness values for all comparison algorithms. As shown, IHBOFS only ranks second to MRFO on the pixraw10P dataset. For all other datasets, IHBOFS achieves the smallest fitness values, significantly outperforming other algorithms. Moreover, IHBOFS exhibits better initial fitness values, thanks to the use of the Good Point Set and Elite Opposition-Based Learning strategies for population initialization, which helps generate higher-quality candidate solutions and accelerates convergence toward the global optimum.
Figure 8 visually compares the runtime of different algorithms. Although the EPO has the shortest runtime, IHBOFS—despite integrating multiple advanced strategies—does not exhibit performance degradation compared to HBO. Instead, it shows improvement, as IHBOFS selects fewer and higher-quality feature subsets, thus accelerating the search process. On higher-dimensional datasets, IHBOFS also demonstrates higher efficiency compared to other algorithms, confirming its suitability for high-dimensional feature selection tasks.
Table 11 shows the algorithm ranking obtained using the Friedman non-parametric statistical test based on mean accuracy. A lower rank indicates better performance. As shown, IHBOFS achieves the best average rank of 1.1667, followed by MRFO. TGA and HGSO rank lowest, indicating their inability to identify optimal feature subsets in this context. The computed p-value is significantly lower than the standard significance threshold (0.05), supporting the conclusion that performance differences among the algorithms are statistically significant.
5. Conclusions
In this paper, an adaptive improvement scheme for the Hybrid Breeding Optimization algorithm is proposed to address the problem of high-dimensional feature selection. The main contributions of this study are summarized as follows: First, the performance bottlenecks of HBO in high-dimensional and complex optimization tasks are analyzed, and IHBOFS is developed. IHBOFS incorporates several innovative strategies in a targeted manner, and these improvements comprehensively enhance the search ability and robustness of the algorithm at different evolutionary stages. Ablation experiments are conducted on 12 benchmark functions of different types and dimensions, and IHBOFS achieves the optimal average performance on 10 of these functions with significant reductions in the objective function values. In addition, IHBOFS exhibits zero or near-zero variance on several functions, reflecting extremely strong stability.
For high-dimensional feature selection tasks, a wrapper framework based on IHBOFS is designed in this paper, which maps continuous search spaces to discrete ones by means of multiple transfer functions. Combined with classifier selection and local fine-tuning strategies, this framework further improves the quality of the selected feature subsets and simultaneously enhances the classification performance. Extensive experimental validations show that IHBOFS achieves the highest mean classification accuracy on all six datasets, with the average accuracy improvement ranging from 2.54% to 3.49% compared with the original HBO, and its performance on each dataset outperforms other state-of-the-art metaheuristic algorithms. In terms of solution robustness, IHBOFS also has lower or comparable standard deviations to the comparison algorithms, indicating more stable search behavior. Furthermore, the improvements in IHBOFS lead to a maximum reduction of 98.8% and 94.0% in the size of the selected feature subsets while still maintaining extremely high accuracy. IHBOFS also demonstrates competitiveness in terms of the computational time.
Despite the promising results achieved above, several directions are worthy of further exploration. First, future research can incorporate the stability of feature subsets into the design of the fitness function to realize the collaborative optimization of classification accuracy, subset size, and stability. Second, considering the challenge of label scarcity in practical applications, future work can explore semi-supervised or unsupervised feature selection methods to better utilize unlabeled or partially labeled data, thereby improving the adaptability and practical application value of the algorithm.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Yang G. He J. Lan X. Li T. Fang W. A fast dual-module hybrid high-dimensional feature selection algorithm Inf. Sci.202468112118510.1016/j.ins.2024.121185 · doi ↗
- 2Asghar N. Khalil U. Ahmad B. Alshanbari H.M. Hamraz M. Ahmad B. Khan D.M. Improved nonparametric survival prediction using Cox PH, Random Survival Forest & Deep Hit Neural Network BMC Med. Inform. Decis. Mak.2024241203871500210.1186/s 12911-024-02525-z PMC 11531126 · doi ↗ · pubmed ↗
- 3Saraf T.O.Q. Fuad N. Taujuddin N.S.A.M. Framework of meta-heuristic variable length searching for feature selection in high-dimensional data Computers 202212710.3390/computers 12010007 · doi ↗
- 4Osama S. Shaban H. Ali A.A. Gene reduction and machine learning algorithms for cancer classification based on microarray gene expression data: A comprehensive review Expert Syst. Appl.202321311894610.1016/j.eswa.2022.118946 · doi ↗
- 5Hancer E. Xue B. Zhang M. A survey on feature selection approaches for clustering Artif. Intell. Rev.2020534519454510.1007/s 10462-019-09800-w · doi ↗
- 6Zandvakili A. Mansouri N. Javidi M.M. A new feature selection algorithm based on fuzzy-pathfinder optimization Neural Comput. Appl.202436175851761410.1007/s 00521-024-10043-2 · doi ↗
- 7Alsaeedi A.H. Al-Mahmood H.H.R. Alnaseri Z.F. Aziz M.R. Al-Shammary D. Ibaida A. Ahmed K. Fractal feature selection model for enhancing high-dimensional biological problems BMC Bioinform.2024251210.1186/s 12859-023-05619-z 38195379 PMC 10775438 · doi ↗ · pubmed ↗
- 8Nssibi M. Manita G. Korbaa O. Advances in nature-inspired metaheuristic optimization for feature selection problem: A comprehensive survey Comput. Sci. Rev.20234910055910.1016/j.cosrev.2023.100559 · doi ↗