Exploring the Impact of DNA Methylation on Gene Expression in CRC: A Computational Approach for Identifying Epigenetically Regulated Genes in Multi-Omic Datasets
Andrei Stefan Blindu, Silvia Berardelli, Federica De Paoli, Federico Manai, Rossella Tricarico, Susanna Zucca, Paolo Magni

TL;DR
This study uses computational methods to find genes affected by DNA methylation in colorectal cancer, aiming to improve patient classification and identify potential biomarkers.
Contribution
A promoter-centric, regression-based framework is proposed to identify epigenetically regulated genes in CRC using multi-omic data.
Findings
The framework identifies genes with methylation-expression associations enriched in CRC-related pathways.
The method is validated across multiple cancer types, showing robustness and generalizability.
Candidate genes are prioritized for biomarker discovery and epigenetic therapy studies.
Abstract
DNA methylation, a process that controls how genes are turned on or off, can become disrupted in colorectal cancer and contribute to tumor development. Some tumors show widespread methylation changes that may silence key genes involved in cell regulation. This study aims to systematically identify genes whose activity is influenced by DNA methylation by integrating large-scale molecular data from colorectal cancer patients. Different computational methods were compared to determine the most effective approach for detecting methylation-related changes in gene expression, and the results were validated in other cancer types. The findings establish a promoter-centric, regression-based framework that prioritizes candidate genes whose expression variability is strongly explained by promoter methylation across CIMP-stratified tumors, which could: (i) refine molecular subclassification of…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
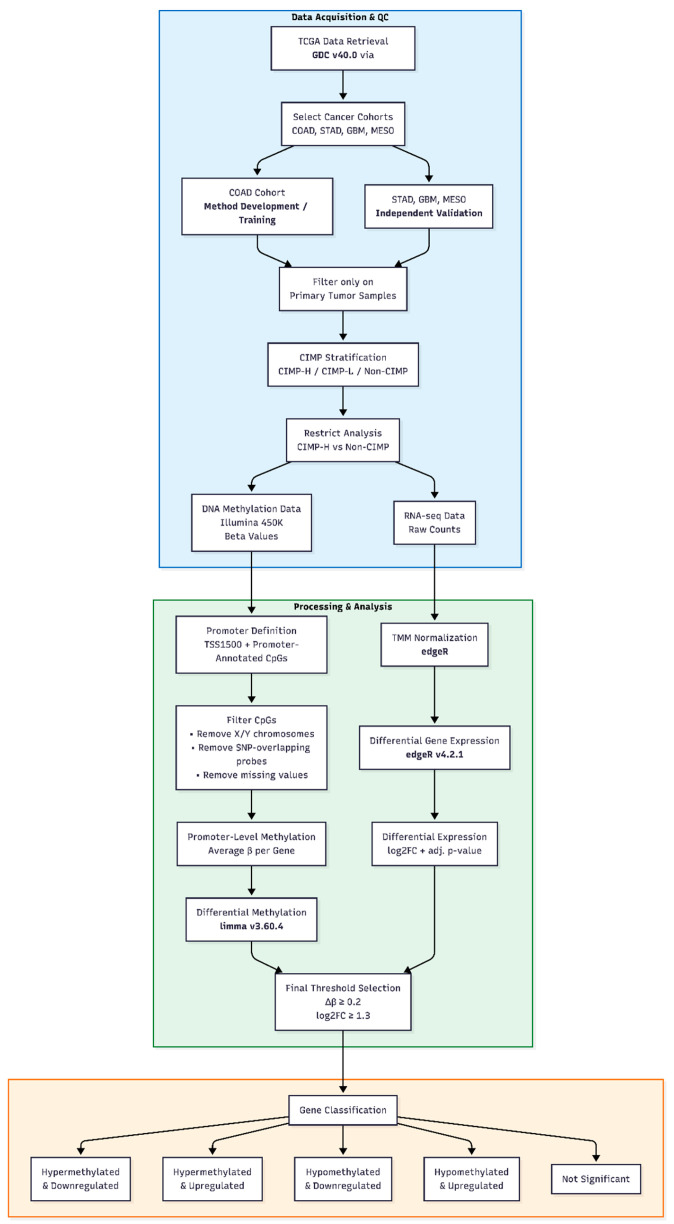 Figure 1
Figure 1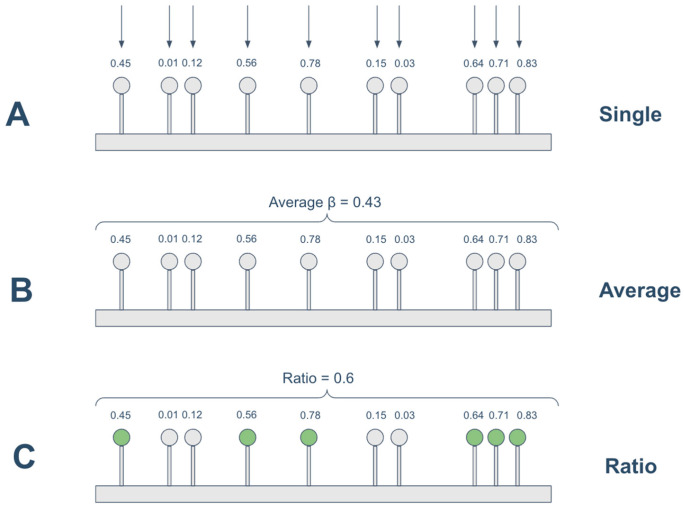 Figure 2
Figure 2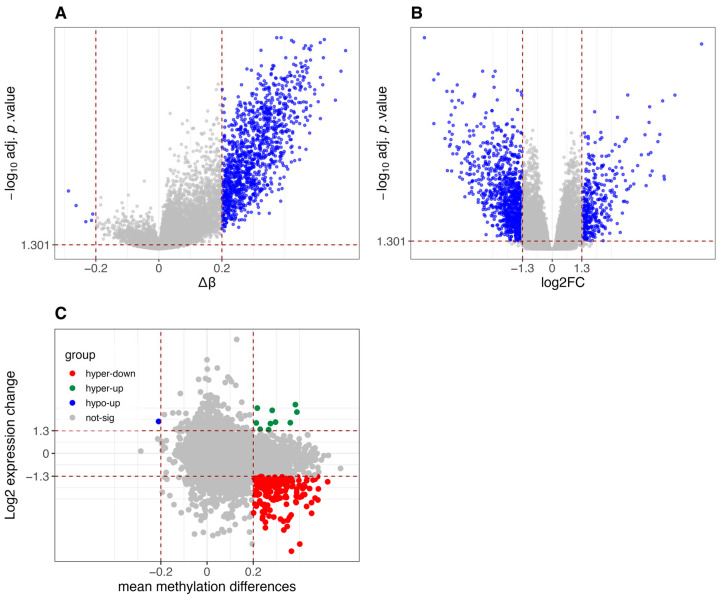 Figure 3
Figure 3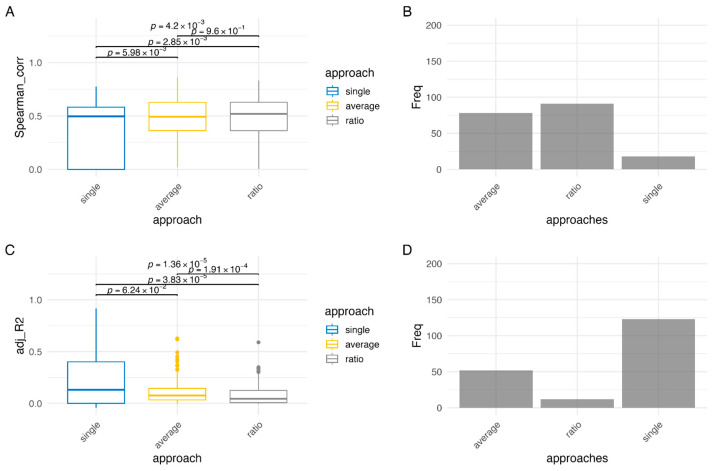 Figure 4
Figure 4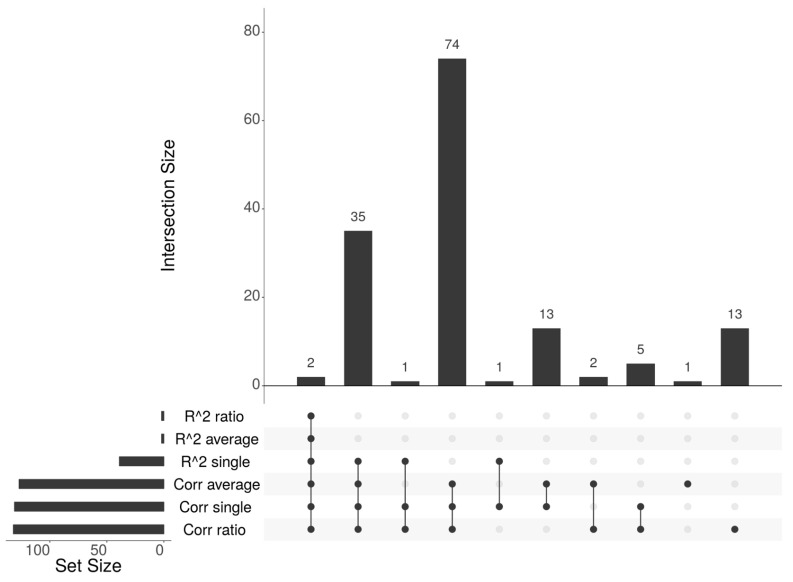 Figure 5
Figure 5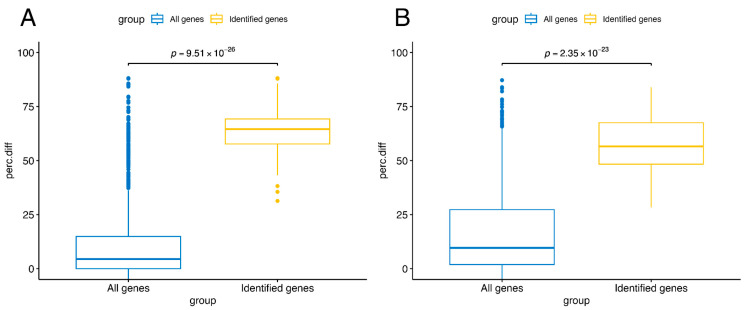 Figure 6
Figure 6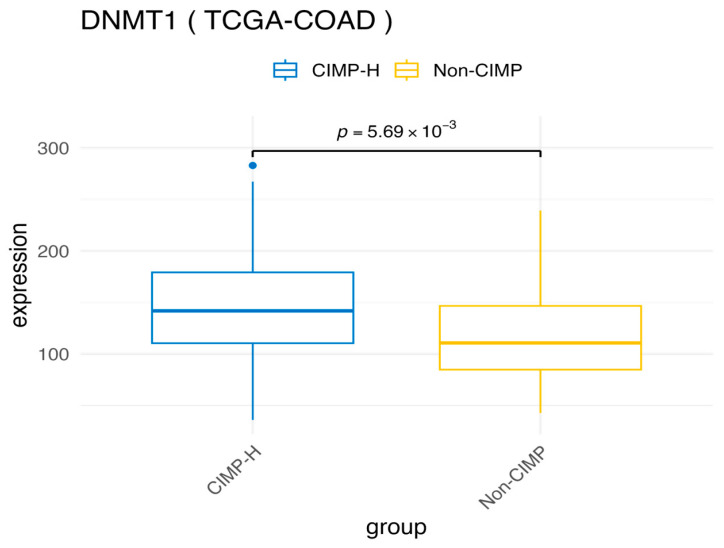 Figure 7
Figure 7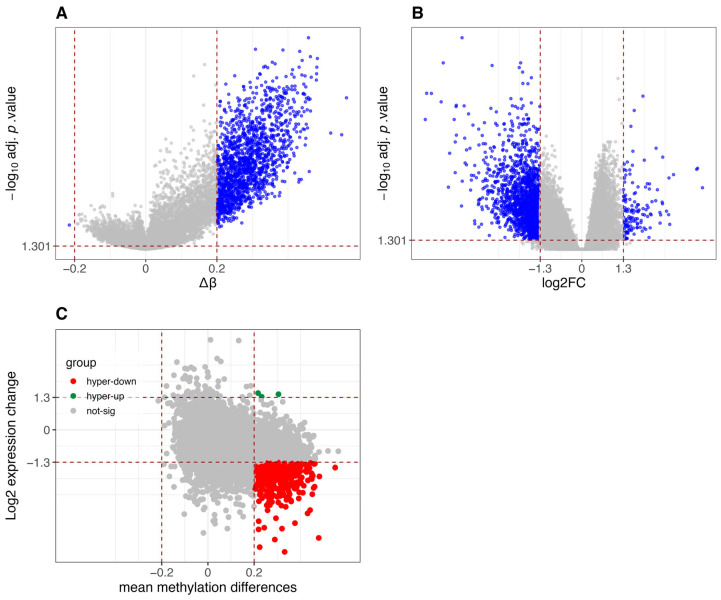 Figure 8
Figure 8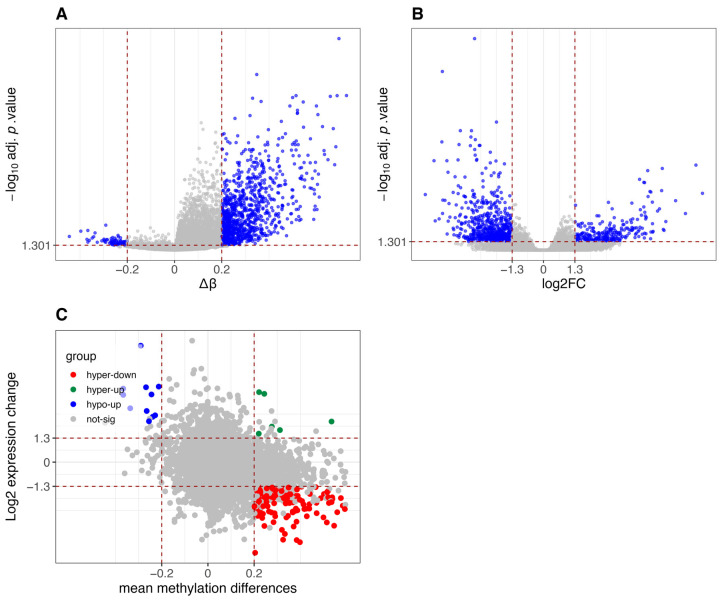 Figure 9
Figure 9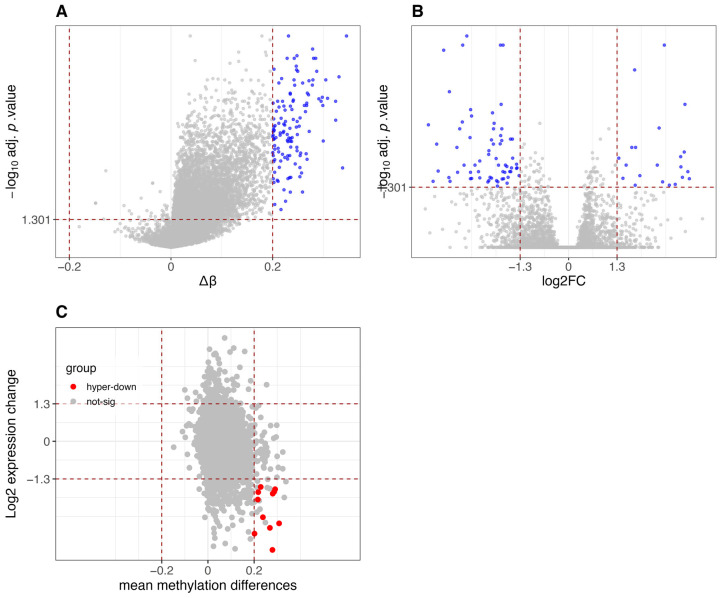 Figure 10
Figure 10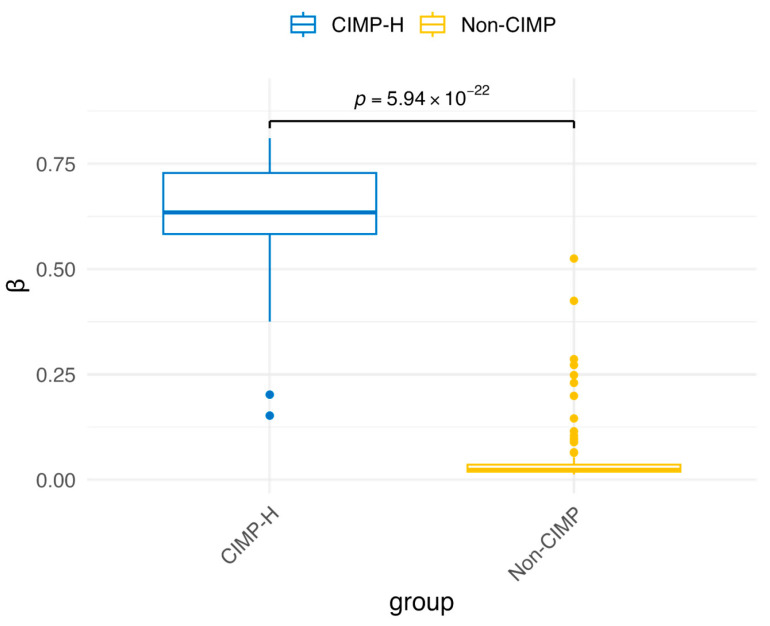 Figure 11
Figure 11- —PNRR-HPC
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEpigenetics and DNA Methylation · Ferroptosis and cancer prognosis · Kruppel-like factors research
1. Introduction
Analyzing gene expression is critical for elucidating complex biological processes and the mechanisms controlling gene activity under pathological conditions. The aim of this study is to develop, systematically compare, and validate computational strategies for identifying genes regulated by DNA methylation, with an emphasis on interpretability and cross-tumor robustness.
In cancer, key cellular pathways are frequently disrupted due to the abnormal regulation of critical genes, including the silencing of tumor suppressor genes or the activation of proto-oncogenes [1,2]. This alteration of gene expression can be driven by many biological mechanisms, with epigenetic regulations, such as DNA methylation, playing a crucial role [1,2]. DNA methylation is a modification that mainly occurs at cytosine residues in CpG dinucleotides when a methyl group (CH_3_) binds to the cytosine nucleotide. This process is tightly regulated by specific enzymes, including DNA methyltransferases (DNMTs), which catalyze de novo methylation (DNMT3A and DNMT3B) or maintain methylation patterns during DNA replication (DNMT1). Conversely, Ten-Eleven Translocation (TET) enzymes (TET1, TET2, and TET3) catalyze the oxidation of 5-methylcytosine, facilitating active DNA demethylation [3].
Aberrant promoter hypermethylation is generally associated with transcriptional silencing [1,2,4]. Consequently, changes in the methylation status of key genes can significantly impact disease development, progression, and prognosis.
Investigating the interplay between DNA methylation and gene expression is essential for uncovering novel epigenetic biomarkers and understanding tumor-specific regulatory mechanisms. In particular, a subset of tumors exhibit the CpG Island Methylator Phenotype (CIMP) [5], a molecular subtype characterized by widespread hypermethylation of CpG islands in gene promoter regions, leading to gene silencing. Cancer patients can be stratified into CIMP high (CIMP-H), CIMP low (CIMP-L) and Non-CIMP subtypes based on their level of CpG island methylation. Stratifying patients based on CIMP status delineates distinct molecular subtypes with characteristic methylation and genomic features, thereby informing tumor biology, therapeutic stratification, and prognostic assessment [6]. CIMP has been widely studied in Colorectal Cancer (CRC), where it defines distinct molecular subgroups associated with clinical outcomes and therapeutic response [6], and also in other malignancies, including gastrointestinal [7] and brain tumors [8]. In Colorectal Cancer, CIMP-positive tumors have been reported to exhibit distinct molecular features, including frequent BRAF mutations, microsatellite instability, and widespread promoter CpG island hypermethylation, which may contribute to their pathogenesis [6,9,10]. DNA methylation changes have also been explored as diagnostic and prognostic biomarkers in CRC, with reviews summarizing progress and clinical potential of methylation-based markers [11,12]. However, despite its biological and clinical relevance, the functional consequences of CIMP-related methylation changes and their impact on CRC progression and therapy resistance remain incompletely understood.
Integrative analysis of DNA methylation and transcriptomic data has become a widely adopted strategy for studying epigenetic regulation in cancer, supported by a growing body of statistical and computational methods for multi-omics data integration [13,14]. To elucidate the epigenetic mechanisms underlying CIMP and identify genes whose expression is regulated by methylation, computational approaches integrating multi-omics data are essential. Several tools have been developed for this purpose, including idiffomix [15], which applies joint mixture models to detect differential methylation and expression simultaneously; mixOmics (DIABLO) [16], which identifies predictive multi-omics signatures using supervised latent-variable models; MethylMix [17,18], which defines discrete methylation states to identify methylation-driven genes; ELMER [19], which links enhancer methylation to gene expression to reconstruct transcriptional regulatory networks; and MEAL [20], which provides region-level analyses of methylation–expression associations. These methods are generally model-based or network-oriented and often focus on predictive or latent representations of omics variation. In contrast, our approach adopts a transparent, promoter-centric framework that systematically tests biologically motivated thresholds and multiple promoter methylation summarization strategies through correlation- and regression-based analyses. This design prioritizes interpretability and cross-dataset robustness offering a simple means to evaluate methylation–expression relationships and identify candidate epigenetic biomarkers.
In this study, we investigated which computational strategy most robustly and interpretably identifies genes whose expression is regulated by promoter DNA methylation in CIMP-stratified colorectal cancer. We hypothesize that a promoter-centric regression framework, which models the combined effect of multiple CpG sites within gene promoters, provides a more biologically meaningful and transferable identification of epigenetically regulated genes. To this purpose, we developed and applied a computational strategy to identify genes whose expression is modulated by promoter methylation in a cohort of Colon Adenocarcinoma (COAD) patients from The Cancer Genome Atlas (TCGA) [21] identified according to CIMP status. We subsequently validated the best-performing method in other tumor types to assess its generalizability. By identifying novel epigenetic biomarkers, this approach enhances our understanding of CRC epigenetics and paves the way toward improved patient stratification and precision oncology.
2. Materials and Methods
2.1. Dataset Selection and CIMP-Based Stratification
This study was conducted using publicly available DNA methylation and gene expression data from The Cancer Genome Atlas (TCGA) [21]. Four cancer cohorts were analyzed: Colon Adenocarcinoma (COAD), Stomach Adenocarcinoma (STAD), Glioblastoma Multiforme (GBM), and Mesothelioma (MESO). These tumor types were selected because they have been reported to exhibit the CpG Island Methylator Phenotype (CIMP) [5]. The proposed method was developed and tested on the COAD dataset, which served as the primary cohort. The STAD, GBM, and MESO datasets were then used for validation to assess the method applicability across different tumor types.
The data has been retrieved from the v40.0 (29 March 2024) data release of NCI Genomic Data Commons (GDC), a data repository and computational platform for cancer researchers, through the TCGABiolinks R package (version 2.32.0) [22]. The DNA methylation data has been sequenced with the Infinium HumanMethylation450 BeadChip (Illumina Inc., San Diego, CA 92122 USA) [23], which covers about 450,000 CpG sites out of the approximately 28 millions in the human genome, and is provided in the form of beta values in range (0, 1), representing the methylation level of a CpG site. The transcriptome profiling data has been produced through RNA-seq and is provided in the form of raw counts, representing the expression levels of each gene.
This study exclusively considers primary tumor samples to ensure consistency across datasets. The patients have been stratified in three groups based on the CIMP status: CIMP-H, CIMP-L and Non-CIMP. The CIMP classification for the 4 datasets was obtained from the corresponding studies [24,25,26]. For the MESO dataset, the CIMP classification was not explicitly provided; however, a CIMP-index, a metric strongly correlated with CpG island methylation and computed at the CpG island level independently of gene-level annotations, was available. In the referenced study [27], the CIMP-index was calculated as the proportion of CpG islands per sample exhibiting a mean methylation beta value of at least 0.3, where island-level methylation was obtained by averaging beta values across all probes mapping to each CpG island. To achieve a balanced distribution of the three CIMP classes in our dataset, we classified samples with a CIMP-index of 0.5 or greater as CIMP-H, those with a CIMP-index of −0.5 or lower as Non-CIMP, and those with a CIMP-index between 0.5 and −0.5 as CIMP-L. Table 1 shows the number of primary tumor samples with both methylation and gene expression data, with the detail of CIMP groups stratification for the four datasets.
Analysis was restricted to CIMP-H and Non-CIMP groups due to their distinct methylation profiles, facilitating the identification of methylation-driven effects.
2.2. Data Preprocessing
Since our study focuses on the impact of promoter methylation on gene expression, we defined promoter regions as CpG sites included in the Illumina 450K manifest (Illumina Inc., San Diego, CA 92122 USA) that are located within 1500 base pairs upstream of a transcription start site (TSS1500). In addition, we included CpGs annotated as promoter-associated in the Illumina manifest. These annotations are based on genomic proximity to TSSs rather than direct experimental evidence of promoter activity, but they are likely to capture regions that influence transcription initiation. We note that this promoter definition may not capture all regulatory elements, such as distal enhancers or alternative promoters, and is limited by the coverage of the Illumina 450K array. To assess the robustness of our approach, the method was validated on independent cohorts (STAD, GBM, MESO), demonstrating consistent methylation-driven gene patterns across multiple tumor types.
To avoid confounding effects, CpGs located on sex chromosomes (X and Y) were excluded to mitigate sex-specific methylation biases, and CpGs overlapping common single nucleotide polymorphisms (SNPs) were removed, as these positions are prone to sequence variability that can affect probe binding. In addition, probes with missing values in at least one sample were excluded from the analysis to prevent bias and ensure the robustness of the statistical results.
The raw expression counts were normalized performing Trimmed Mean of M-values normalization (TMM) using the EdgeR [27] Bioconductor package (version 4.2.1) across all primary tumor samples, enabling accurate comparisons of gene expression between samples avoiding count biases caused by transcript length and sequencing depth.
Batch correction has not been applied since methylation and expression TCGA data are preprocessed and normalized to reduce technical variability.
2.3. Integrated Analysis of Differential Methylation and Gene Expression
An integrated differential methylation and differential gene expression analysis has been performed with the aim of identifying the genes that are both significantly differentially methylated and differentially expressed between the CIMP-H and Non-CIMP groups.
The differential methylation analysis was performed with the limma [28] package (version 3.60.4), while the differential gene expression analysis was conducted using EdgeR [27].
To investigate epigenetic regulation, it is essential to verify whether differentially methylated regions (DMRs) overlap with regulatory regions of differentially expressed (DE) genes. The methylation status of each gene promoter was approximated with the average beta value of the CpGs located within the relative region. For each gene, a promoter is considered differentially methylated based on both the Δβ (difference between beta values) or the log_2_ ratio and if the adjusted p-value is significant (lower than 0.05). In contrast, differential gene expression is determined solely based on the log_2_ fold changes and the adjusted p-value.
To select which genes exhibit a significant difference in either methylation or expression, between the two groups, several combinations of differential thresholds for the two omics were tested, as shown in Table A1. Thresholds used are based on those reported in other studies [29,30,31].
Finally, the selected thresholds were Δβ ≥ 0.2 for methylation and |log_2_FC| ≥ 1.3 for gene expression, as they represented a trade-off between retaining biologically relevant genes and excluding those with negligible methylation or expression differences between the two groups. The methylation threshold (Δβ ≥ 0.2) is widely accepted and used in previous studies [31,32]. The statistical significance of the differential expression threshold (|log_2_FC| ≥ 1.3) was validated through a sample size and power analysis, conducted with FPR = 0.05 and power = 0.9, using the RNASeqPower R package (version 1.44.0).
Based on these thresholds, the differentially methylated and expressed genes have been classified into five groups. Hypermethylated genes (Δβ ≥ 0.2) were either downregulated (log_2_FC ≤ −1.3) or upregulated (log_2_FC ≥ 1.3). Similarly, hypomethylated genes (Δβ ≤ −0.2) were downregulated (log_2_FC ≤ −1.3) or upregulated (log_2_FC ≥ 1.3). All other cases were considered not significant.
Figure 1 provides a schematic overview of the complete analytical workflow, from data retrieval and preprocessing to integrated differential methylation and gene expression analysis.
Publicly available TCGA DNA methylation (Illumina HumanMethylation450) and RNA-seq data were retrieved and primary tumor samples from COAD, STAD, GBM, and MESO cohorts were selected. Samples were stratified according to CIMP status, and the analysis was restricted to CIMP-H and Non-CIMP groups. DNA methylation data were filtered and summarized at the promoter level, while RNA-seq data were normalized using TMM. Differential methylation and differential gene expression analyses were performed independently and subsequently integrated. Final gene selection was based on predefined methylation (Δβ ≥ 0.2) and expression (|log_2_FC| ≥ 1.3) thresholds, leading to the classification of genes into five methylation–expression categories. The method was developed using the COAD cohort and validated on STAD, GBM, and MESO datasets.
2.4. Methylation-Expression Correlation: Spearman- and Regression-Based Approaches
Identifying the genes that are both differentially expressed and methylated is a necessary, but not sufficient, condition for determining epigenetically regulated genes. It is also crucial to assess the relationship between promoter methylation and gene expression.
To this end, various approaches have been developed, leveraging either Spearman correlation or linear regression to assess the relationship between promoter methylation and gene expression.
Spearman correlation was chosen to measure the monotonic relationship between methylation and gene expression. The Spearman-based methods involve computing, for each gene and for all available CIMP-H and Non-CIMP samples, the Spearman correlation between a methylation-based metric and the corresponding gene expression. Then, only genes with a correlation greater than 0.4 and an adjusted p-value below 0.05 were considered, as done in a similar study [30]. The Regression-based methods involve fitting, for each gene and for all CIMP-H and Non-CIMP samples, a linear regression model with one or more methylation-based features as predictors and the gene expression level as the response variable. These models are not intended for predictive purposes, but rather to assess how well promoter methylation explains gene expression variability within our data. To quantify this relationship, we evaluated both the adjusted R^2^ and the overall statistical significance of each model. The adjusted R^2^ metric was used to measure the proportion of variance in gene expression explained by promoter methylation, while the overall model p-value, derived from the F-statistic (using pf(summary(lm_fit)$fstatistic [1], ...) in R (version 4.4.1)), was used to assess whether the observed association was statistically significant. An adjusted R^2^ value greater than 0.5 was interpreted as indicating that methylation explains a substantial portion of the variability in gene expression, provided that the model p-value was also statistically significant (p < 0.05).
Both the Regression-based and Spearman-based models were tested under three different approaches for handling methylation on the promoter, as shown in Figure 2 and outlined below:
- •single: the unit methylation data is the beta value of each individual CpG site;
- •average: the promoter methylation status is calculated as the average of the beta values located on the promoter region;
- •ratio: the promoter methylation status was calculated as the ratio of methylated CpGs to the total number of CpGs in the promoter region. A CpG was considered methylated if its beta value was ≥0.3, following previous studies [26,33]. This threshold captures partially methylated CpGs that may influence transcription. More stringent cutoffs (e.g., β ≥ 0.5 or 0.7) could miss biologically relevant intermediate methylation, but future analyses may examine the impact of alternative thresholds.
Thus, for example, in the Spearman-single approach the beta value of each single CpG on the gene promoter is correlated with the expression of the gene, the correlations obtained are then averaged to have a single aggregated measure; while in the Spearman-average and Spearman-ratio, the expression of the gene is correlated with the average beta values of promoter CpGs and the ratio of methylated CpGs on the gene promoter, respectively.
Similarly, the Regression-single approach computes for each gene the adjusted R^2^ of a linear regression model having the gene expression as response variable and the beta values of all the CpGs on gene promoter as predictors; while the Regression-average and Regression-ratio consider as predictors the average beta value on gene promoter and the ratio of methylated CpGs on the promoter region, respectively.
Finally, for each method, the identified genes are ranked according to the corresponding score.
The different methods have been tested on the COAD dataset, and their results have been compared in terms of Spearman correlation coefficients or adjusted R^2^ scores to assess which methods are more effective at identifying high-scoring epigenetically regulated genes. For the three approaches within each of the two categories, the medians of the score distributions have been compared using a Kruskal-Wallis non-parametric test and we counted the number of genes for which each approach achieves the maximum score among the methods in the same category. Then, the overlapping between the list of genes identified with the different methods was considered and a qualitative evaluation was finally made based on the capability of the approaches to find relevant genes reported in other independent studies, such as MLH1 [34].
To determine the most suitable method, we prioritized the one that identified a large number of genes, with significant overlap with those detected by other methods, which can be interpreted as a form of validation, and that exhibited biological relevance.
The best method was selected and validated on the STAD, GBM, and MESO datasets.
It is important to note that the proposed analyses are designed as an unsupervised discovery framework rather than a supervised predictive model. No ground-truth labels are available that definitively define whether a gene is epigenetically regulated by promoter methylation across all samples. Consequently, classical performance metrics such as sensitivity, specificity, positive predictive value, and negative predictive value cannot be computed. Instead, methodological robustness was assessed through comparative analysis across multiple correlation- and regression-based strategies, evaluation of internal concordance among methods, and biological plausibility of the identified genes.
2.5. Validation Against Independent Studies
To assess the consistency of our results, the identified genes for COAD and STAD were compared with the results reported in another study [24] from which the CIMP classification was obtained. For each gene, the TCGA samples in which the gene is epigenetically silenced are reported in the study. To compare our results, the percentages of epigenetically silenced samples for each gene in the CIMP-H and Non-CIMP groups were calculated. The difference between the two percentages was then used as a metric to assess differential epigenetic silencing between the two groups. This difference can be considered as a consistency metric against an independent definition of epigenetic silencing. The validation against independent studies was not intended to estimate predictive performance, but rather to assess consistency with an external, independently derived definition of epigenetic silencing. This strategy provides an indirect assessment of biological relevance and robustness in the absence of a gold-standard reference set.
As a further step, the identified genes were searched in the literature to confirm their association with cancer epigenetic mechanisms.
2.6. Code Availability
The scripts used for the analysis are available at the Zenodo repository https://doi.org/10.5281/zenodo.17416495.
3. Results
The Results section is structured to guide the reader from global epigenetic differences associated with CIMP status to the identification and validation of candidate genes whose expression is associated with promoter DNA methylation. First, we characterize differential methylation and gene expression patterns between CIMP-H and Non-CIMP tumors across datasets (Section 3.1), providing an overview of the epigenetic context considered in this study. We then systematically compare alternative methylation–expression integration strategies and motivate the selection of a Regression-based approach (Section 3.2). Using this approach, we identify and prioritize, within each tumor type, genes showing consistent associations between promoter methylation and expression (Section 3.3). Finally, we compare the resulting gene sets with those reported in an independent study based on an orthogonal definition of epigenetic silencing (Section 3.4), providing external support for the consistency of the proposed framework.
3.1. Comparative Analysis of Differential Methylation and Gene Expression Between CIMP-H and Non-CIMP Groups
As expected, CIMP-H samples in the COAD dataset exhibit global hypermethylation compared to Non-CIMP samples (Figure 3A), a hallmark of the CIMP molecular subtype. This is further corroborated by the increased expression of DNMT1, the key enzyme responsible for maintaining DNA methylation [35], in CIMP-H samples compared to Non-CIMP, (Figure A1). Elevated DNMT1 levels in CIMP-H tumors have been previously reported in CRCs, further supporting its role in sustaining aberrant DNA methylation patterns in these tumors [29].
Figure 3B shows the differential gene expression between the two groups, with a high number of significantly downregulated genes (956) in CIMP-H compared to Non-CIMP, versus upregulated ones (394).
Figure 3C reveals that, when integrating differential methylation and gene expression, a substantial group of genes are hypermethylated and downregulated in CIMP-H patients. This result is consistent with expectations and supports the assumption that hypermethylation is one of the key factors playing a silencing role in the regulation of gene expression.
Similar results have been found for the differential analysis of the STAD, GBM and MESO datasets, as reported in Figure A2, Figure A3 and Figure A4, where CIMP-H samples show global hypermethylation compared to Non-CIMP samples and there is a substantial group of hypermethylated and downregulated genes.
3.2. Results of Methylation-Expression Correlation Methods and Method Selection
We applied the Spearman-based and the Regression-based methods with the three metrics for methylation (single, average, ratio) on the COAD dataset. When comparing the scores obtained from the Spearman-based methods, there is no significant difference between the average and ratio approaches, with a 0.96 p-value on the Kruskal-Wallis test (Figure 4A). Despite this, the ratio approach yields the highest Spearman correlation score for most genes (48.7%), although the effect size is minimal. Figure 4B shows the number of genes for which each of the three approaches yields the maximum Spearman-based score. These counts represent an intermediate comparison metric used to evaluate the relative performance of the Spearman-based methods; they are not the criteria for selecting the final list of epigenetically regulated genes. As expected, the single approach results in low correlation coefficients for many genes, as it is unlikely that the methylation status of one single CpG can significantly impact gene expression levels. Notably, the Spearman-single metric represents the average correlation of individual CpGs for each gene, which can dilute strong effects from a single CpG. All three methods have a median score around 0.5 which suggests, since there is a group of genes having a much lower score, that for a subset of genes there is a significant correlation between promoter methylation and gene expression.
The distributions of adjusted R^2^ scores for Regression-based methods, in Figure 4C, shows that the average and ratio approaches lead to low adjusted R^2^ scores for most genes, with mean adj-R^2^ = 0.1119 and SD = 0.1156 for the average approach and mean adj-R^2^ = 0.0868 and SD = 0.1116 for the ratio approach. The only two genes associated with a score higher than 0.5 in both approaches are PAX9 and TTC9B. On the other hand, the scores of the single approach, despite having a median (0.1322) that is not significantly higher than that of the average approach (0.0769), have an upper quartile with 39 genes exceeding 0.5 and 9 genes achieving scores above 0.8 (MLH1, CHFR, TMEM176B, ZNF350, ZNF570, ZNF530, ZNF347, ZNF461, ZNF470). Figure 4D confirms that the single approach yields the highest scores for more genes than the average or ratio approaches. The apparent discrepancy with the Spearman-single approach occurs because the Regression-single approach considers all CpGs on a gene’s promoter simultaneously as predictors, allowing the model to capture the combined effect of multiple CpGs or the strong effect of a single influential CpG, whereas the Spearman-single metric averages correlations across CpGs, potentially underestimating individual CpG contributions.
Notably, the MLH1 gene, whose hypermethylation is often associated with the CIMP subtype in colorectal cancer [34], has the highest adjusted R^2^ of 0.916.
There is a significant overlap between the list of genes identified by the different methods, as in all pairwise comparisons, the majority of genes in the smaller list are included in the larger one, as shown in the upSet plot in Figure 5. Specifically, the only two genes identified by the Regression-based average and ratio approaches (PAX9 and TTC9B), are confirmed by all other methods. Moreover, 37 of the genes identified by the Regression-based single approach (39) are identified also by all the Spearman-based methods, except for LARP6 that is not identified by the average approach and GAL that is not identified by average and ratio, while all 39 genes are identified by the Spearman-based single approach. Among the four methods able to identify a significant number of epigenetically regulated genes, the single Regression-based method has confirmed genes identified by different Spearman-based approaches. Additionally, this approach identified the MLH1 gene, known for its biological association with the CIMP subtype and its role in cancer progression due to its DNA repair function [34], as the highest scoring gene. To summarize, this method identified a significant number of genes (39), with 95% overlap with those detected by other methods, and included biologically relevant genes, such as MLH1. Therefore, it was selected for validation on the STAD, GBM, and MESO datasets.
3.3. Identified Epigenetically Regulated Genes
The selected method was used to identify the epigenetically regulated genes in the datasets under study. The top 10 genes identified as significantly epigenetically regulated on the COAD dataset are reported in Table 2, while in Table 3, Table 4 and Table 5 the genes identified on the STAD, GBM and MESO datasets, respectively, are reported. The full list of genes are reported in Appendix A Table A2, Table A3, Table A4 and Table A5.
There is no overlap between the genes identified in the gastrointestinal datasets and those in the GBM and MESO datasets. However, 11 genes overlap between the 39 genes identified in the COAD dataset and the 23 genes identified in the STAD dataset. Among the common genes, the most important is MLH1, as mentioned earlier. An enrichment analysis on the common identified genes using the “KEGG 2021 Human” and “WikiPathways 2024 Human” ontologies reveals that the VANGL2 gene is associated with the Wnt signaling pathway [36], whose dysregulation has been linked to uncontrolled cell growth and tumor development.
While our study does not uncover new molecular mechanisms of DNA methylation itself, it highlights candidate genes whose epigenetic regulation in CIMP tumors has been underexplored. These genes may contribute to tumor progression and represent valuable starting points for future functional investigations.
3.4. Validation Against Independent Studies
Figure 6 compares the distributions of the difference in the percentages of epigenetically silenced samples between the CIMP-H and Non-CIMP groups, calculated as described in the Methods section, in the overall gene population and in the genes identified by our approach. In the independent study [24], a gene is considered epigenetically silenced if more than half of its probes are epigenetically silenced; a probe is defined as epigenetically silenced if, in at least 1% of tumor samples, it has a beta value above 0.3 (classified as methylated) and the mean z-score of the methylated group is lower than −1.65 with an FDR-corrected p-value < 0.001. It can be observed that, for both COAD (Figure 6A) and STAD (Figure 6B), the genes identified by our approach exhibit a difference within the upper quartile of the overall gene population. This finding confirms that the identified genes are also reported as differentially epigenetically silenced in the results of this independent study.
As expected, MLH1 was identified as the top epigenetically regulated gene in both gastrointestinal datasets, COAD and STAD. MLH1 is a key player in DNA mismatch repair, and its promoter hypermethylation leads to transcriptional silencing, causing microsatellite instability (MSI). Our findings further support this link, as 69.8% of CIMP-H samples in COAD and 69.2% in STAD were classified as MSI-H, while the majority of Non-CIMP cases were microsatellite stable (MSS) (Table A6 and Table A7).
Another gene whose methylation is associated with CIMP in colorectal cancer is CDKN2A [37], a tumor suppressor. This gene was not identified in our study, since it is not differentially expressed in our data (log_2_FC = 0.09), although it is differentially methylated (Δβ = 0.26). Moreover, in the study [24] used for CIMP classification, its methylation status is evaluated solely based on the probe cg13601799. As shown in Figure A5, there is significant difference in methylation for this CpG site in our colon cancer data as well. Therefore, our findings align with the expected differential methylation of CDKN2A, but it was not identified in our study due to its lack of differential expression.
4. Discussion
Aberrant promoter DNA methylation modulates the expression of genes controlling processes such as DNA repair, cell-cycle regulation, and signaling pathways implicated in cancer progression. Therefore, computationally analyzing multiomic datasets to identify genes that are epigenetically regulated in a cohort of cancer patients has the potential to prioritize candidate diagnostic biomarkers and epigenetic therapeutic targets, providing a hypothesis-generating resource for downstream functional studies.
Our developed computational approach confirmed a significant correlation between promoter methylation and gene expression for a subset of genes. After testing different alternative approaches, which included Spearman correlation, linear regression, and various strategies for handling methylation data, the best model for capturing this correlation was the one based on the adjusted R^2^ coefficients, using the methylation beta values of its promoter CpGs as predictors. However, we note that correlation does not establish causality: promoter methylation–expression associations can arise from confounding factors such as copy-number variation, tumor purity, cell-type composition, co-methylated genomic domains, batch effects, and broader transcriptional programs. As a result, some candidates may represent false positives. Future extensions that incorporate partial correlations or multivariable models (e.g., controlling for CNV, purity, and mutation burden), replication across cohorts, and orthogonal functional evidence (e.g., chromatin accessibility or targeted perturbation) will be essential to strengthen causal inference.
In principle, the proposed method may be generalized on other cancer datasets to identify genes that are epigenetically regulated by DNA methylation between distinct subgroups, such as the CIMP-H and Non-CIMP subtypes. Moreover, cross-dataset comparison of the identified gene lists reveals tumor-type–specific epigenetic regulation and highlights shared versus context-dependent methylation–expression relationships. In particular, we noted a significant overlap between the genes identified in the COAD and STAD datasets, suggesting a similar epigenetic regulation profile between these two gastrointestinal tumors, while there is no overlap with the genes identified in the GBM and MESO datasets, suggesting that epigenetic regulation may affect different genes and pathways across different tumor types.
To assess the functional relevance of the identified genes in cancer, we investigated their known biological roles and associations with tumor progression. Given the exploratory and computational nature of the study, this interpretation is intended to contextualize the findings within established colorectal cancer biology rather than to infer novel mechanisms. Notably, a subset of genes identified in both the COAD and STAD datasets is functionally linked to key cancer-related processes, including DNA mismatch repair, mitotic checkpoint regulation, and Wnt signaling. These findings, detailed below, are consistent with previous studies and further reinforce the robustness of our analytical approach.
Among these, MLH1, a key player in the mismatch repair system, was epigenetically silenced in 14% of COAD and 19.7% of STAD samples. Similarly, CHFR, a tumor suppressor involved in the maintenance of the mitotic checkpoint, showed silencing frequencies of 32% in COAD and 29.3% in STAD. EPM2AIP1, which encodes for a protein interacting with the phosphatase laforin, although less characterized, was also found to be silenced in 9.9% of COAD and 14% of STAD samples [38], suggesting a potential, yet underexplored, role in gastrointestinal tumorigenesis.
We also identified genes related to the Wnt signaling pathway, including VANGL2 and FUZ. The latter has already been described in the literature for its prognostic value in various cancers, including STAD, where its overexpression correlates with poor overall survival [39]. This highlights FUZ as an epigenetically regulated gene that may affect tumor growth and malignancy through the Wnt signaling pathway. In addition, PCDHGC3, a member of the protocadherin gene cluster, was found hypermethylated in our dataset. Promoter hypermethylation of PCDHGC3 has been proposed as a potential biomarker for gastrointestinal neuroendocrine carcinomas and is frequently altered in COAD and STAD [40,41].
Additionally, many of the identified genes for the COAD and STAD datasets belong to the Zinc Finger (ZNF) family, whereas no ZNF genes were identified in the GBM and MESO datasets. The role of the Zinc Finger Proteins in the regulation of gastrointestinal tumors has been reported and explored in another study [42], although further research is needed to elucidate their specific involvement. Alterations in ZNF gene methylation have also been observed in Barrett’s esophagus, where they show predictive potential for progression to esophageal adenocarcinoma [43]. These observations suggest that the epigenetic deregulation of ZNF genes may contribute to gastrointestinal tumorigenesis and warrant further investigation.
In the TCGA-GBM dataset, several genes of potential biological and clinical relevance were also identified. For instance, VILL, which encodes for a member of the villin/gelsolin family, showed altered methylation in 1p/19q-deleted gliomas, and its upregulation has been associated with poor prognosis [44]. FBXO17, a gene involved in cell cycle regulation, has been correlated with unfavorable survival outcomes in high-grade gliomas [45,46]. Likewise, EMP3, which encodes a transmembrane epithelial protein and has been previously reported as a prognostic biomarker in glioblastoma, is linked to reduced proliferation and migration when silenced [47].
Other notable genes include KHNYN, a cofactor of the zinc finger ZAP protein, whose expression inversely correlates with overall survival; TUBA1C, which encodes the tubulin alpha 1c protein, associated with poor prognosis in low-grade gliomas; and ZDHHC12, a zinc finger protein associated with glioma growth and malignancy [48,49,50].
Although TSTD1 (thiosulfate sulfurtransferase-like domain containing 1) has not been directly studied in glioblastoma, it is of interest due to its epigenetic deregulation in other cancers. In particular, hypomethylation of TSTD1 has been associated with altered treatment response in breast cancer [51], suggesting a broader relevance in tumor biology.
Importantly, the primary contribution of this work is not the discovery of novel methylation mechanisms, but the systematic prioritization of genes whose promoter methylation correlates with expression in CIMP-stratified tumors. Many of these genes have been underexplored and may provide a foundation for future studies investigating their functional roles in tumor progression.
Altogether, these findings emphasize the biological plausibility of our approach and its capacity to identify functionally relevant genes across multiple tumor types. The enrichment of known cancer-related genes and pathways, especially in COAD and STAD, supports the validity of the computational pipeline and provides a valuable foundation for future experimental validation and functional studies.
Despite its promising results, the accuracy and significance of this exploratory analysis in identifying epigenetically regulated genes in cancer are mainly limited by the size of the datasets, the constraints of the technologies used to obtain the data, and the data-driven, unsupervised nature of the method proposed. The limited number of TCGA patients and the imbalance between CIMP-H and Non-CIMP cases may undermine the significance of the results. In particular, the results obtained on the GBM datasets are less robust compared to the others, since the GBM dataset is smaller and includes only 3 CIMP-H samples. A similar concern applies to MESO, where the number of CIMP-H cases is very low, further limiting statistical power. Accordingly, conclusions regarding CIMP-dependent methylation in GBM and MESO should be considered exploratory and interpreted with caution. Moreover, the methylation data available for the TCGA datasets were obtained using the HumanMethylation450 BeadChip, which covers a small fraction of the CpG sites in the human genome compared to other emerging technologies characterized by a higher coverage, such as the MethylationEPIC v2.0 array, or covering the whole genome, such as Whole Genome Bisulfite Sequencing (WGBS) and long-reads Oxford Nanopore sequencing (ONT). As a result, some relevant contributions to the overall epigenetic regulation may be missed. More significant results could be achieved by using larger, more balanced datasets and methylation data sequenced with techniques that provide better coverage than the 450 k.
A limitation of this study is that potential batch effects and covariates, such as sex, were not explicitly modeled in the differential and correlation analyses. Although TCGA data are preprocessed and normalized to reduce technical variability, unaccounted confounders could still contribute to noise in methylation or expression measurements. In particular, batch effects or biological covariates such as sex, age, tumor stage, tumor purity, and cell-type composition could inflate or attenuate the observed promoter methylation–expression associations for certain genes, potentially generating false positives or false negatives. Given that our focus was on significant differences between CIMP-H and Non-CIMP tumors, these effects are unlikely to alter the main findings, but future extensions should include covariate-adjusted models or batch correction methods to ensure robustness across larger and more heterogeneous cohorts.
A potential concern when introducing new computational approaches is the absence of classical performance metrics and explicit positive or negative controls. In our study, this limitation reflects the unsupervised nature of the problem: there is currently no comprehensive gold-standard set of genes that can be unambiguously labeled as epigenetically regulated or non-regulated by promoter methylation across tumor types. Well-characterized examples such as MLH1 represent only a small and biased subset and cannot serve as a complete reference for supervised evaluation. As a result, sensitivity, specificity, or predictive accuracy cannot be meaningfully estimated.
To address this, we adopted a multi-layered validation strategy based on internal concordance across methods, recovery of well-established biologically relevant genes, reproducibility across independent tumor cohorts, and consistency with an external study defining epigenetic silencing using independent criteria. Together, these analyses provide complementary evidence supporting the robustness and biological relevance of the identified genes, while avoiding overinterpretation of the method as a predictive classifier. Accordingly, the proposed framework should be interpreted as a hypothesis-generating tool for epigenetic discovery rather than a diagnostic or predictive model.
Moreover, a potential shortcoming of the selected Regression-based single method is that it involves the comparison of the R^2^ values of linear models having a different number of predictors, since the number of CpG sites on the promoter varies across genes. To address this, the adjusted R^2^ metric has been considered instead of the R^2^, in order to avoid bias towards larger models and ensure a higher degree of robustness in the method.
5. Conclusions
In this study, we presented a computational approach to identify genes epigenetically regulated by DNA methylation across different cancer types. By modeling the relationship between promoter methylation and gene expression using adjusted R^2^ metrics, we were able to effectively capture biologically meaningful associations and prioritize genes potentially involved in tumor progression. The method was first developed and tested on a COAD patient cohort stratified by CIMP status and subsequently validated on STAD, GBM, and MESO datasets, demonstrating its robustness and potential for generalization.
Our results highlight consistent patterns of epigenetic regulation within gastrointestinal tumors, including the silencing of MLH1, CHFR, and other genes linked to DNA repair, cell cycle control, and Wnt signaling. We also identified tumor-specific epigenetic signatures in GBM and MESO, further supporting the biological relevance of the findings.
Despite these promising results, limitations remain. These include the relatively small and imbalanced patient cohorts, particularly in the GBM dataset, potential unaccounted batch effects and the restricted CpG site coverage of the HumanMethylation450 array. The unsupervised nature of the method also constrains the ability to quantitatively compare alternative approaches. Nonetheless, the use of adjusted R^2^ mitigates model complexity bias and enhances methodological robustness.
The resulting ranked gene lists and validated analytical framework provide concrete resources for downstream functional studies and for the evaluation of methylation-based biomarkers in CIMP-associated cancers. Overall, our work underscores the value of computational frameworks in epigenetic research and demonstrates their potential to uncover novel biomarkers and therapeutic targets. Further development of the method is needed to address its limitations and take advantage of more comprehensive datasets and advanced sequencing technologies. Refining the method holds significant potential for deepening our understanding of epigenetic regulation and its clinical applications in cancer. Although not intended for immediate clinical deployment, this framework could have clinical relevance by refining patient stratification through identification of epigenetically distinct tumor subgroups, highlighting candidate methylation-based biomarkers (e.g., MLH1, CHFR, and ZNF genes) for diagnostic or prognostic purposes, and prioritizing genes for functional validation in epigenetic therapy studies, such as targeted demethylation or CRISPR/dCas9-mediated epigenetic editing.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Jones P.A. Baylin S.B. The Fundamental Role of Epigenetic Events in Cancer Nat. Rev. Genet.2002341542810.1038/nrg 81612042769 · doi ↗ · pubmed ↗
- 2Davalos V. Esteller M. Cancer Epigenetics in Clinical Practice CA Cancer J. Clin.20237337642410.3322/caac.2176536512337 · doi ↗ · pubmed ↗
- 3Liu R. Zhao E. Yu H. Yuan C. Abbas M.N. Cui H. Methylation across the Central Dogma in Health and Diseases: New Therapeutic Strategies Signal Transduct. Target. Ther.2023831010.1038/s 41392-023-01528-y 37620312 PMC 10449936 · doi ↗ · pubmed ↗
- 4Herman J.G. Baylin S.B. Gene Silencing in Cancer in Association with Promoter Hypermethylation N. Engl. J. Med.20033492042205410.1056/NEJ Mra 02307514627790 · doi ↗ · pubmed ↗
- 5Issa J.-P. Cp G Island Methylator Phenotype in Cancer Nat. Rev. Cancer 2004498899310.1038/nrc 150715573120 · doi ↗ · pubmed ↗
- 6Nazemalhosseini Mojarad E. Kuppen P.J. Aghdaei H.A. Zali M.R. The Cp G Island Methylator Phenotype (CIMP) in Colorectal Cancer Gastroenterol. Hepatol. Bed Bench 2013612012824834258 PMC 4017514 · pubmed ↗
- 7Toyota M. Ahuja N. Suzuki H. Itoh F. Ohe-Toyota M. Imai K. Baylin S.B. Issa J.P. Aberrant Methylation in Gastric Cancer Associated with the Cp G Island Methylator Phenotype Cancer Res.1999595438544210554013 · pubmed ↗
- 8Malta T.M. de Souza C.F. Sabedot T.S. Silva T.C. Mosella M.S. Kalkanis S.N. Snyder J. Castro A.V.B. Noushmehr H. Glioma Cp G Island Methylator Phenotype (G-CIMP): Biological and Clinical Implications Neuro-Oncology 20182060862010.1093/neuonc/nox 18329036500 PMC 5892155 · doi ↗ · pubmed ↗