Enhanced Educational Optimization Algorithm Based on Student Psychology for Global Optimization Problems and Real Problems
Wenyu Miao, Katherine Lin Shu, Xiao Yang

TL;DR
This paper introduces an improved optimization algorithm for UAV trajectory planning that outperforms existing methods in accuracy and stability.
Contribution
The novel ESPBO algorithm integrates time-adaptive scheduling, mentor pool guidance, and directional jump exploration for enhanced global optimization.
Findings
ESPBO outperforms seven other optimization algorithms in benchmark tests and UAV trajectory planning.
ESPBO achieves a 3D UAV path length of 199.8874 m with high stability in complex mountainous terrain.
Statistical tests confirm ESPBO's superior performance and robustness in global optimization tasks.
Abstract
To address the insufficient exploration ability, susceptibility to local optima, and limited convergence accuracy of the standard Student Psychology-Based Optimization (SPBO) algorithm in three-dimensional UAV trajectory planning, we propose an enhanced variant, Enhanced SPBO (ESPBO). ESPBO augments SPBO with three complementary strategies: (i) Time-Adaptive Scheduling, which uses normalized time (τ=t/T) to schedule global step-size shrinking, Gaussian fine-tuning, and Lévy flight intensity, enabling strong early exploration and fine late-stage exploitation; (ii) Mentor Pool Guidance, which selects a top-K mentor set and applies time-varying guidance weights to reduce misleading attraction and improve directional stability; and (iii) Directional Jump Exploration, which couples a differential vector with Lévy flights to strengthen basin-crossing while keeping the differential step…
Click any figure to enlarge with its caption.
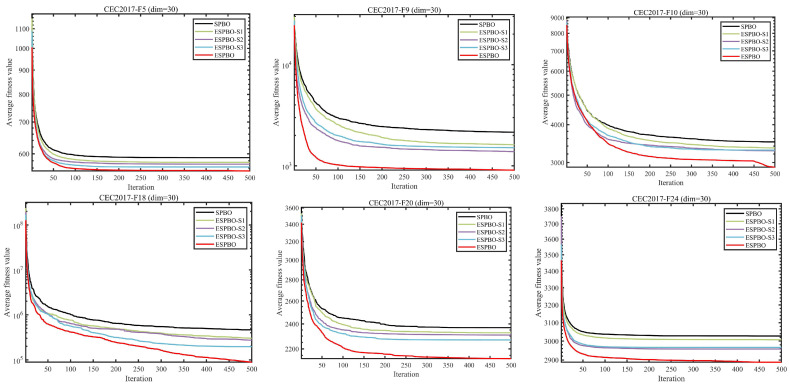 Figure 1
Figure 1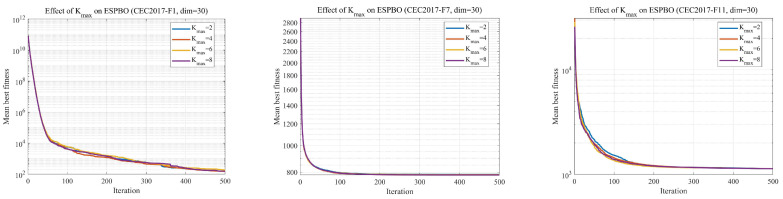 Figure 2
Figure 2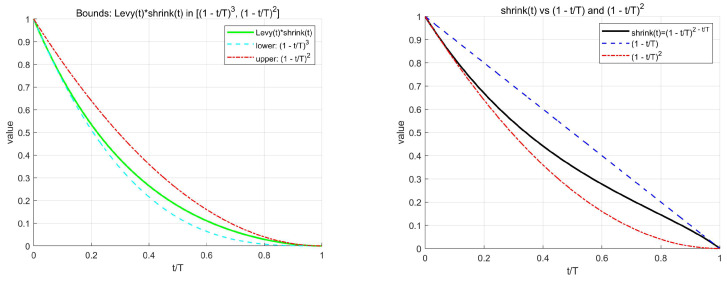 Figure 3
Figure 3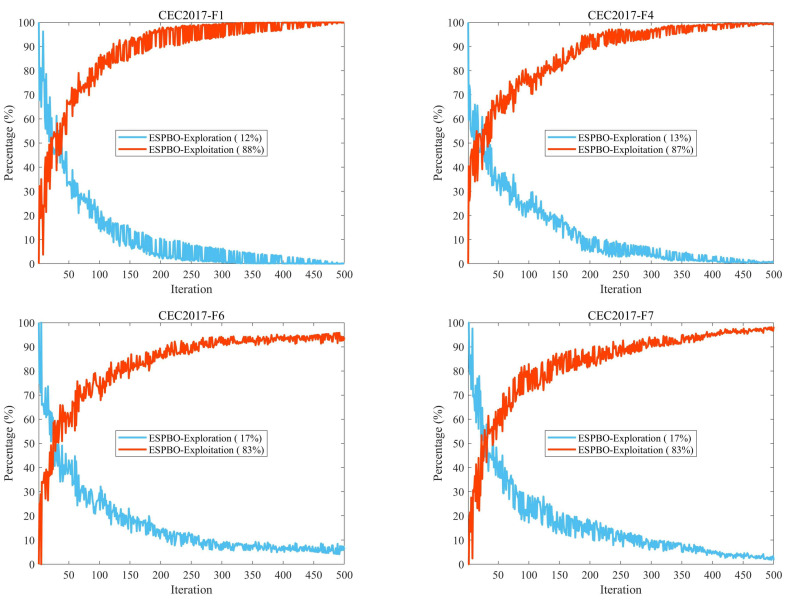 Figure 4
Figure 4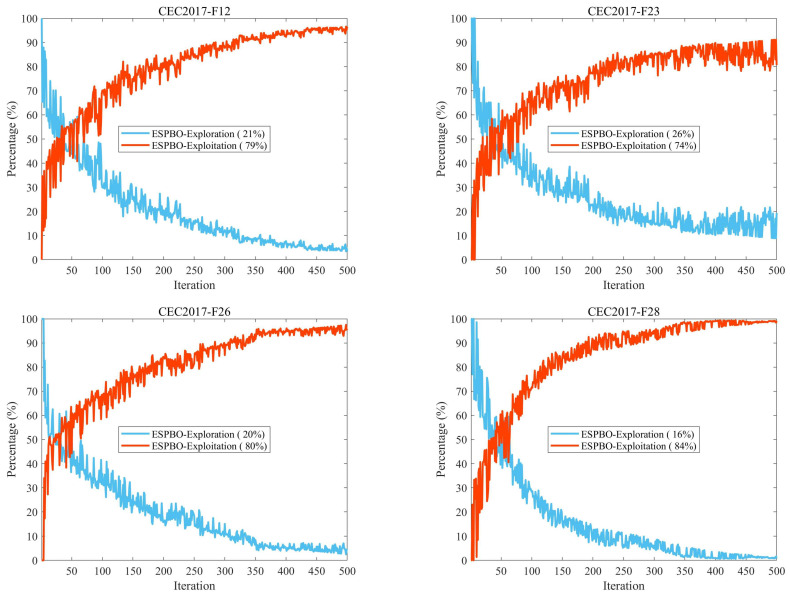 Figure 5
Figure 5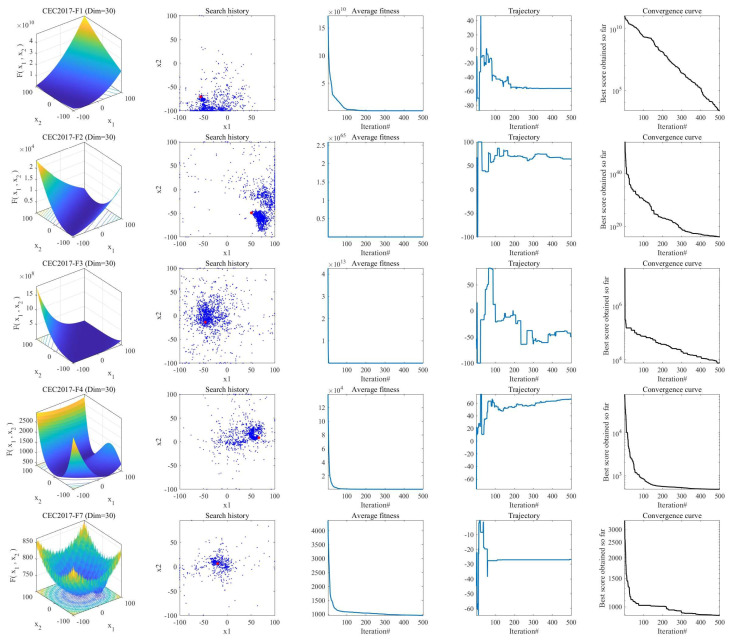 Figure 6
Figure 6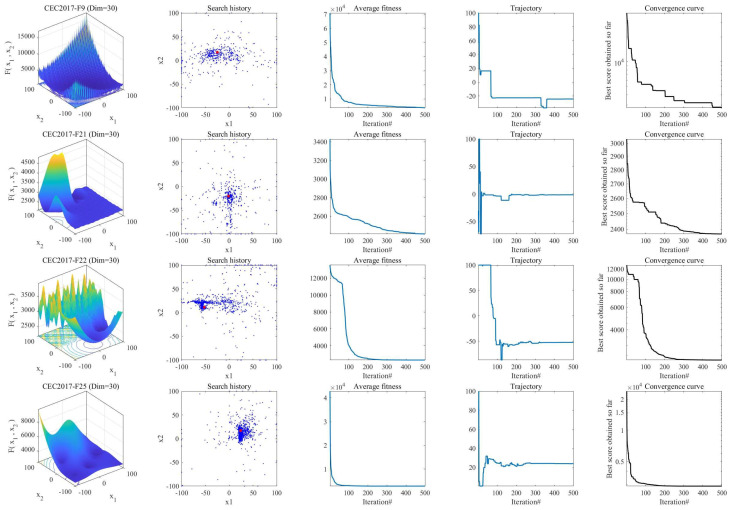 Figure 7
Figure 7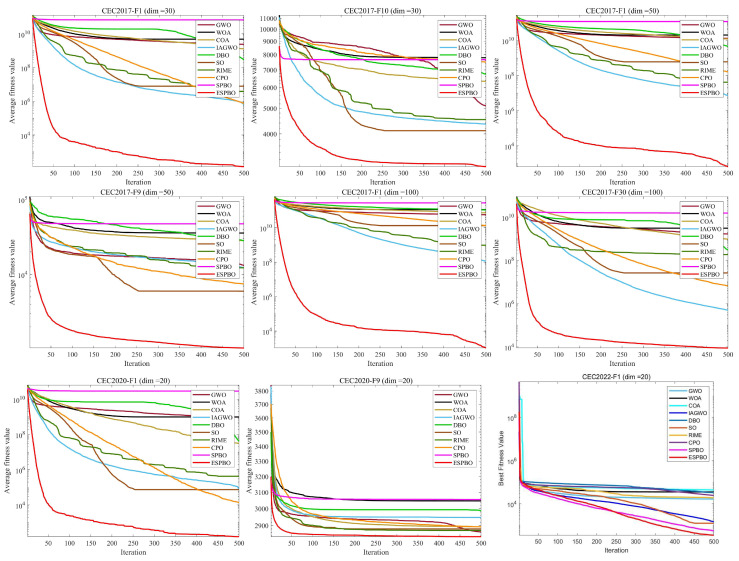 Figure 8
Figure 8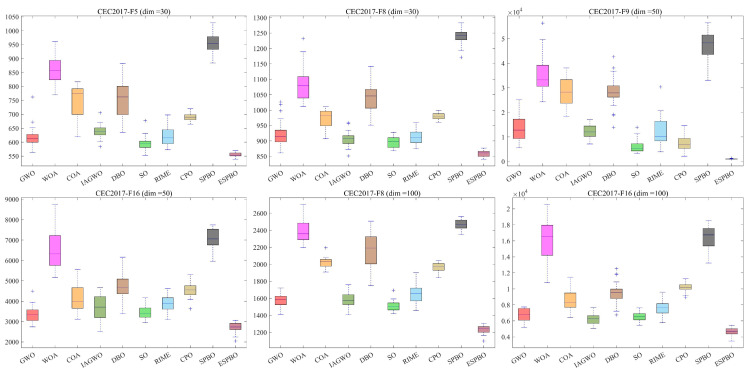 Figure 9
Figure 9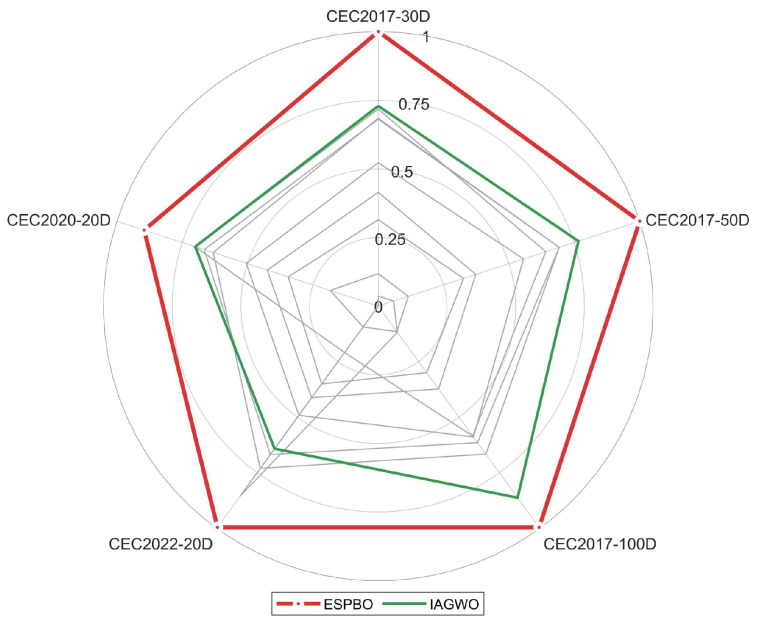 Figure 10
Figure 10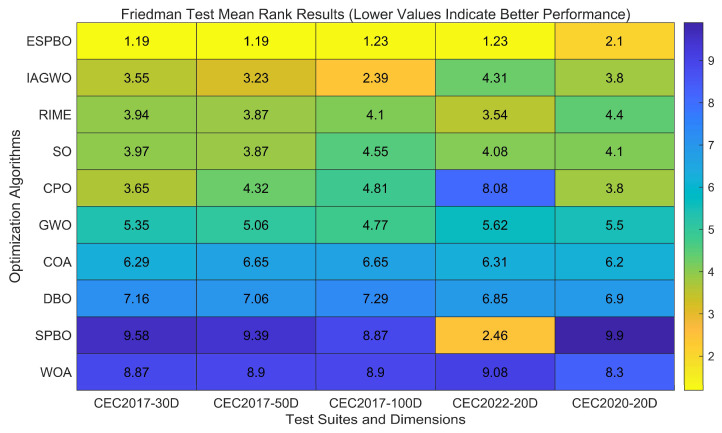 Figure 11
Figure 11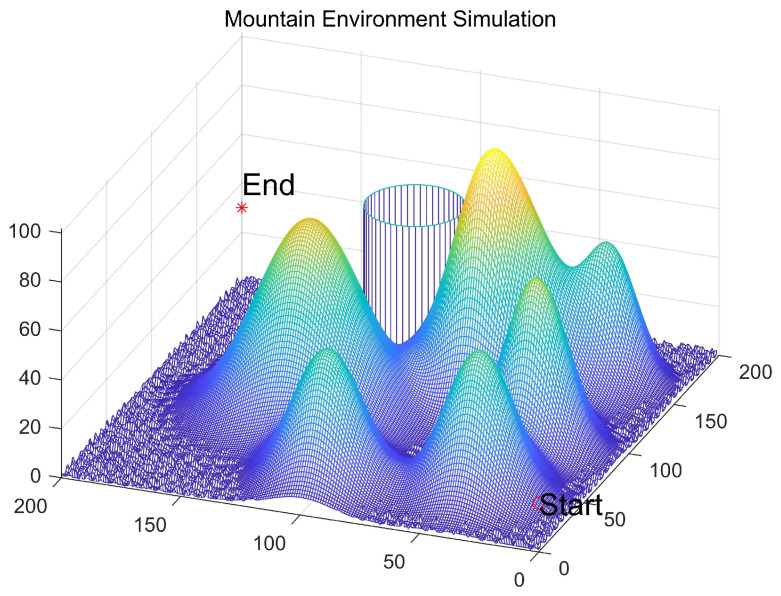 Figure 12
Figure 12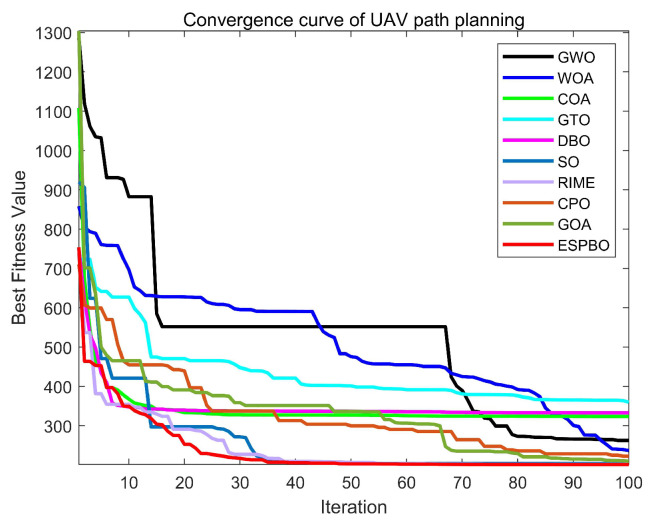 Figure 13
Figure 13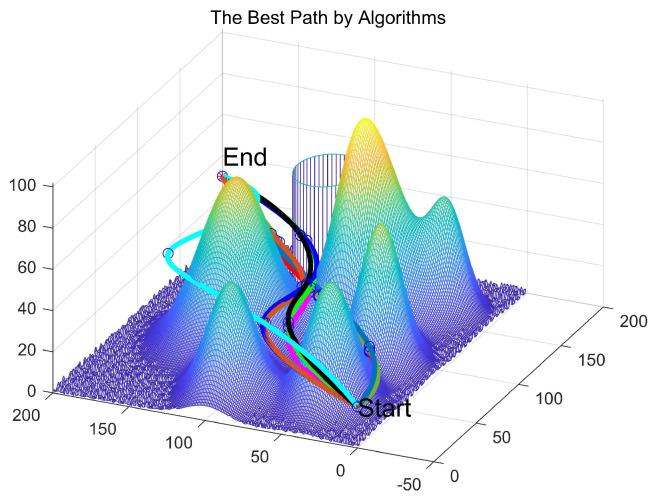 Figure 14
Figure 14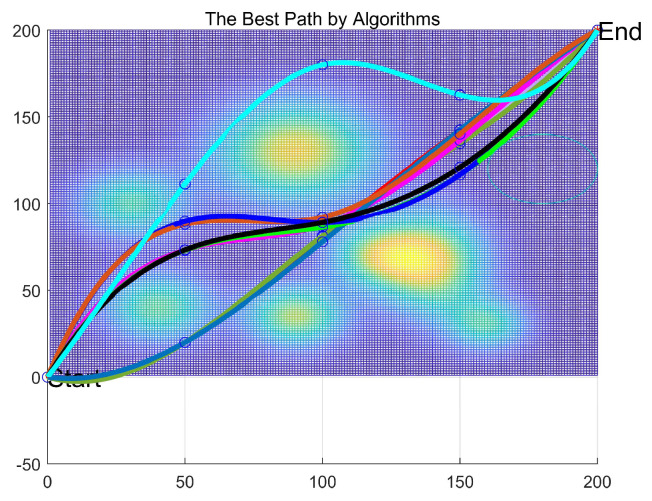 Figure 15
Figure 15Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotic Path Planning Algorithms · Spacecraft Dynamics and Control · UAV Applications and Optimization
1. Introduction
Path planning is a fundamental and crucial task in intelligent systems, especially in fields such as robotics, autonomous driving, and unmanned aerial vehicles (UAVs), where the effectiveness of path planning directly affects the performance and safety of the system [1]. The goal of path planning is to find an optimal or feasible path from the starting point to the target for robots, automated devices, or autonomous vehicles in complex, dynamic environments, avoiding obstacles and meeting specific constraints. With the continuous development of intelligent technologies, traditional rule-based path planning methods have gradually revealed their limitations in large-scale, complex environments [2]. To better address this issue, in recent years, path planning methods based on intelligent optimization algorithms have become a research hotspot.
Common path planning optimization methods include graph search methods, mathematical programming methods, and heuristic algorithms. Graph search methods, such as the A-star algorithm [3] and Dijkstra’s algorithm [4]. These methods are typically used for path planning in static environments, but their efficiency is relatively low in dynamic environments [5]. Mathematical programming methods solve complex mathematical models through optimization theory to obtain the optimal path. However, these methods typically require high computational costs and are difficult to handle real-time dynamic problems [6]. Therefore, intelligent optimization algorithms, especially those based on swarm intelligence and adaptive learning, have gradually become the mainstream choice for solving complex path planning problems. These algorithms, by simulating the intelligent behaviors of natural groups, such as ant foraging, bird flocking, and others, can effectively perform global optimization in more complex environments [7]. For example, the Ant Colony Optimization (ACO) algorithm [8] has long been used in classical combinatorial optimization problems, such as the Traveling Salesman Problem (TSP) [9] achieving significant results. This algorithm simulates the foraging process of ants, relying on the propagation and updating of pheromones to guide the search path, thereby continuously approaching the optimal solution. In path planning problems, ACO has also demonstrated strong potential, particularly in handling dynamic and uncertain environments, where it can adjust paths in real-time to avoid obstacles and quickly find feasible routes.
In addition to traditional swarm intelligence algorithms, many new optimization algorithms and strategies have been proposed in recent years to address path planning problems in complex dynamic environments [10]. Meanwhile, new nature-inspired optimizers explicitly target the convergence–diversity dilemma in high-dimensional search. For example, the Polar Fox Optimization (PFA) algorithm [11] models cooperative hunting behavior and alternates diversification and intensification phases to maintain population diversity while accelerating convergence; evaluated on expanded/shifted/rotated classical functions and the IEEE CEC2021 benchmark suite, PFA reports competitive performance and strong ability to escape local optima, which is directly relevant for large-scale, dynamic path planning. These advances are complemented by hybrid methodologies that combine global search with adaptive local refinement or algorithm selection to balance exploration and exploitation in large spaces—an idea already reflected in the IWOA, the Deep Q-learning-based scheduler, and the MF-DMOLSO discussed below. For example, the Improved Whale Optimization Algorithm (IWOA) [12] addresses obstacle avoidance and terrain constraints in UAV formation trajectory planning. By introducing a reverse learning mechanism to enhance the diversity of initial exploration, it improves search efficiency, particularly demonstrating better performance in dynamic and complex environments [13]. The algorithm dynamically adjusts the convergence factor and endpoint neighborhood perturbations, enabling it to quickly escape local optima and ensure better trajectory planning results. In addition, a swarm intelligence scheduling algorithm based on Deep Q-learning [14] has also been proposed in recent years, applied to multi-UAV formation trajectory planning. This algorithm uses Deep Q-learning for algorithm scheduling, selecting the most suitable optimization algorithm based on changes in the environment, thereby improving the real-time performance and adaptability of path planning. This method, by combining multiple optimization algorithms, not only improves the stability of the algorithm but also effectively handles dynamic changes in complex environments. The Multi-Objective Algorithm based on Lion Swarm Optimization (MF-DMOLSO) employs a hybrid strategy to solve multi-objective path planning problems, such as trajectory length, energy consumption, and other constrained objectives. This algorithm is particularly suitable for handling high-dimensional, dynamic path planning problems and has demonstrated excellent performance in robot and vehicle path planning. By incorporating multiple optimization strategies during the search process, MF-DMOLSO can better handle objective conflicts, improving planning accuracy and convergence speed [15]. Beyond the above, recent nature-inspired optimizers have focused explicitly on the convergence–diversity dilemma in high-dimensional search by hybridizing complementary operators and introducing adaptive controls. For example, the Crested Porcupine Optimizer (CPO) [16] maps four defensive behaviors (sight, sound, odor, physical attack) to exploration–exploitation phases and incorporates a cyclic population-reduction mechanism so that only “threatened” agents activate high-intensity updates, thereby improving both convergence rate and population diversity. In a related vein, the Adaptive Gazelle Optimization Algorithm (AGOA) [7] demonstrates a potent strategy for high-dimensional optimization. It effectively couples logistic-chaos initialization to ensure broad early coverage of the search space with adaptive Brownian motion and Lévy flights, which enable iterative step-size self-tuning. Furthermore, it incorporates a smoothed predator-effect schedule to effectively suppress late-stage oscillations. This synergistic combination of global diversification (via chaos and Lévy flights) and time-aware local refinement is a key factor contributing to its reported superior performance in both large-scale optimization accuracy and algorithmic robustness.
In Table 1, we have summarized the relevant work, covering the core operators/strategies of each method, the mechanisms for balancing exploration-development (alleviating the convergent–diversity dilemma) in high dimensions, typical benchmarks, and their applicability in unmanned aerial vehicle (UAV)/path planning.
Among the many swarm intelligence optimization algorithms, the Student Psychology-Based Optimization (SPBO) [17] is widely applied in path planning, function optimization, engineering design, and other fields [18,19] due to its simple theoretical foundation, minimal parameter settings, and ease of implementation. The core principle of this algorithm is to mimic the psychological behavior of students in the pursuit of academic achievements, constructing a self-improvement model based on changes in psychological states. Although the algorithm has achieved good results in handling some simple optimization tasks, its performance is significantly constrained when dealing with complex path planning and multi-modal optimization problems. Firstly, SPBO lacks an adaptive mechanism for updating step sizes and exploration strategies, leading to insufficient exploration in the early stages of the algorithm and an inability to effectively cover a broad solution space. In the later stages, a large step size can result in excessive adjustments, causing oscillations that affect the final convergence accuracy. Secondly, when the algorithm’s search process encounters a local optimum, it lacks sufficient guiding strategies, causing the individual update directions to become relatively random. As a result, the entire population is prone to getting trapped in specific regions, which impacts both the convergence speed and the effective discovery of the global optimum. Finally, the “random step size” strategy of the SPBO algorithm fails to effectively address multi-modal optimization problems. Particularly in high-dimensional solution spaces, the algorithm is often trapped by local extrema and lacks the ability to traverse different solution basins, thereby affecting the algorithm’s global search efficiency.
To address the shortcomings of the SPBO algorithm in complex path planning, this paper proposes an improved algorithm based on time-adaptive scheduling, mentor pool-guided updates, and directional jumps (ESPBO). By introducing a time-adaptive scheduling strategy, the step size and exploration intensity are dynamically adjusted, achieving an adaptive balance of “strong exploration in the early stages and strong exploitation in the later stages,” therefore refining both the convergence speed and the accuracy of the algorithm. Combined with the mentor pool-guided strategy, the top K individuals with the highest fitness in the population are selected as the “mentor pool,” providing diversified guidance information to enhance the search direction and avoid getting trapped in local optima. Additionally, through the directional jump exploration strategy, differential vectors and Lévy flights are used to enhance the ability to search across basins, helping the algorithm escape local extrema more quickly in multi-modal optimization problems, thereby improving global search efficiency. The proposed strategies improve the algorithm’s ability to adapt and optimize in changing environments.
The main contributions of this paper are as follows:
- (1)Proposal of the ESPBO algorithm: In response to the shortcomings of the standard SPBO, the ESPBO algorithm is developed by integrating three strategies: time-adaptive scheduling, mentor pool-guided search, and directional jump exploration, and the pseudocode is provided.
- (2)Numerical experiment verification: Based on the CEC2017/2020/2022 test sets, ESPBO is compared with algorithms such as GWO, RIME, and CPO. The optimization performance is validated through ablation experiments, convergence behavior analysis, and statistical tests.
- (3)Application to UAV 3D trajectory planning: ESPBO is applied to UAV trajectory planning in complex terrains. Its advantages are demonstrated through metrics such as best path length, mean trajectory length, and standard deviation.
The structure of the remaining sections in this paper is as follows: Section 2 introduces the origin, mathematical model, and search strategy of the standard Student Psychology-Based Optimization (SPBO), followed by a detailed explanation of the three enhancement strategies of the proposed Enhanced Student Psychology-Based Optimization (ESPBO). Section 3 runs experiments based on the CEC2017, CEC2020 and CEC2022 benchmark functions, with ablation experiments to analyze the individual contributions and synergistic effects of each enhancement strategy. Convergence behavior is analyzed using metrics such as convergence curves and search trajectories, and stability is verified through the Wilcoxon rank-sum test and the Friedman test to validate its optimization performance. Section 4 applies ESPBO to UAV 3D path planning, testing on complex terrains to demonstrate its advantages. Section 5 concludes the study, summarizes the advantages of ESPBO, and discusses potential future research directions.
2. Student Psychology-Based Optimization Algorithm and the Proposed Methodology
2.1. Student Psychology-Based Optimization Algorithm (SPBO)
This section primarily introduces the origin and mathematical model of the SPBO algorithm. SPBO optimizes the global objective by mimicking how students allocate their efforts across different subjects based on their interests and abilities. The core idea is that students adjust their investment in each subject according to their interests and capabilities, thereby improving their overall performance and ultimately achieving the optimal solution. The following section will provide a detailed explanation of its search strategy.
Let represent the individual , where is the dimensionality of the search space, and is the population size. represents the global best individual. The search strategy of SPBO is based on four types of students:
- Best Student: This is the student with the highest performance, who consistently strives to maintain their leading position. The position update formula for this student is:
where is the best student’s performance, is the performance of a randomly selected student, is a random value that can be either 1 or 2, and is a random number between 0 and 1.
- Excellent Student: This student follows the efforts of the best student and may exert more effort than the other students. The position update formula for this student is:
where is the performance of this student, and is the average performance of the class.
- Average Student: This student performs at an average level across all subjects, and their effort is typically based on the class’s average performance. The update formula is:
where is the average performance of the class.
- Randomly Improved Student: These students attempt to improve their performance through random adjustments. Their efforts are randomly adjusted within the range of subject scores. The update formula is:
where and are the minimum and maximum scores for the subject, respectively.
Drawbacks of SPBO and Motivation for ESPBO
While SPBO is simple and widely applicable, several limitations emerge in 3D UAV trajectory planning and multi-modal landscapes:
- Fixed Step and Update Intensity: In the absence of an adaptive step, early exploration is insufficient and late updates may oscillate, reducing convergence accuracy in complex terrains. This motivates a time-adaptive scheduling system that controls global step-size shrinking, Gaussian fine-tuning, and Lévy flight intensity via normalized time (see Equations (5)–(7)) to achieve “strong exploration early, fine exploitation late.”
- Vulnerability to Misleading Guidance: The Best/Excellent/Average/Random update rules are primarily based on and . If is stuck in a local basin, the population may converge prematurely, hindering progress. To stabilize the directionality, we introduce a mentor pool guidance system (top-K mentors with time-varying weights), where the new population, on average, follows a convex combination of (see Equation (8) and its expectation analysis). This ensures robustness to small weight perturbations and includes an anchor-stability condition for linear convergence in the later stages.
- Limited Basin-Crossing and Stability: The “random improvement step” lacks the ability to perform long jumps and can be easily trapped by local optima. To overcome this, we combine a differential vector with Lévy flights (Directional Jump Exploration). Additionally, to avoid step explosion when and have vastly different fitness values, we introduce an adaptive stability coefficient (Equation (9)) to bound the difference, scaling it with in the update (Equation (10)). Since , the differential contribution remains bounded, and boundary projection ensures feasibility.
These insights directly lead to the three components of ESPBO, as discussed in Section 2.2: Time-Adaptive Scheduling (Equations (5)–(7)), Mentor Pool Guidance (Equation (8) and its stability note), and Directional Jump Exploration (Equations (9) and (10)). Together, these strategies enhance early diversification, late-stage precision, and robustness, while maintaining the overall complexity, compatible with UAV path-planning constraints.
2.2. Proposed Enhanced Student Psychology-Based Optimization Algorithm (ESPBO)
2.2.1. Time-Adaptive Scheduling
In the traditional SPBO algorithm, the step size and update intensity are fixed, leading to insufficient exploration in the early stages, while in the later stages, the large step size can cause oscillations, reducing convergence accuracy. These issues are particularly prominent when dealing with complex path planning, as the algorithm is prone to getting trapped in local optima, which also affects the convergence speed. To address this, the ESPBO algorithm introduces the “time-adaptive scheduling” strategy, using normalized time ( , where is the current iteration and is the maximum number of iterations) to control the variation in step size and weight. This achieves the effect of “strong exploration in the early stages, strong exploitation in the later stages,” thereby ensuring fast convergence and precise optimization [20].
The time-adaptive scheduling strategy includes three key update channels:
- Global Step Size Shrinking: By gradually reducing the global step size, oscillations and excessive exploitation in the later stages are avoided. The formula is expressed as:
As the iterations progress, the step size gradually decreases, thereby enhancing local search in the later stages and reducing large jumps and oscillations.
- Gaussian Fine-Tuning Intensity: In the later stages, the step size rapidly decreases to facilitate fine search and capture of local optima. The formula is as follows:
This fine-tuning effectively reduces oscillations near the optimal solution, ensuring that the algorithm converges more stably.
- Lévy Flight Intensity: In the early stages, a strong long-distance jump capability is provided to enhance the ability to explore the solution space, while in the later stages, this capability is gradually reduced to avoid interfering with local convergence. The formula is as follows:
This strategy ensures that, in the early stages of optimization, the algorithm can broadly explore the solution space, while in the later stages, it focuses on fine search within local optimum regions [21].
Time-adaptive scheduling can effectively accelerate the convergence process in multi-modal complex functions and reduce oscillations, thereby improving the final convergence accuracy. Compared to the traditional SPBO algorithm, it offers significant advantages.
2.2.2. Mentor Pool Guidance
One issue faced by the standard SPBO algorithm is that if the current best individual gets trapped in a local optimum, the population may become misled and converge to a crowded area, slowing down the convergence speed. To address this issue, ESPBO introduces the “mentor pool guidance strategy,” which guides the search direction of other individuals by selecting the top K high-quality individuals from the population (mentor pool), thereby improving the efficiency and stability of the search.
Specifically, in each iteration, the top K individuals are selected based on fitness to form the “mentor set” . The update formula is given by:
where is the updated solution; is the current position of the individual in the dimension; is the solution in the dimension of the mentor set; is the value of the global best solution in the dimension; is the mean value of all individuals in the current population in the dimension; are random numbers between [0, 1]; is a random number drawn from the standard normal distribution; and are weights adjusted according to the time step, controlling the influence of the mentor guidance and the global best solution; is the Gaussian scaling factor adjusted according to the time step, controlling the amplitude of random perturbations.
Taking the conditional expectations of (given the current population and mentor pool) yields:
where , , and .
Thus, when (which satisfies the current time weight range), lies within the convex hull of , maintaining convexity in the expected sense. If there are small perturbations in the weight and , the margin becomes:
where represents a small perturbation introduced in the algorithm, typically a small value (e.g., ), used to test the robustness of the algorithm under slight variations, as long as , the property holds.
In addition, let (1) Anchor Stability: When entering the convergence stage, the mentor and global optimum satisfy:
Vanishing Variance of Interaction Terms: . Then, during the convergence stage:
Thus, the convergence is linear (because ). Since the interaction terms have zero mean and vanishing variance, they do not disrupt convergence.
This strategy effectively prevents the population from being misled, enhancing the search directionality and stability. By dynamically adjusting the weights of different guidance information, ESPBO can fully utilize diverse high-quality directions in the early stages and gradually focus on the region around the global optimum in the later stages, ensuring a stable and efficient search.
2.2.3. Directional Jump Exploration
The “random improvement step” strategy of the standard SPBO algorithm lacks the ability to cross basins and is prone to getting trapped in local extrema when encountering complex multi-modal functions. To address this issue, ESPBO introduces the “Directional Jump Exploration Strategy,” which enhances the ability to cross basins through differential vectors and Lévy flights, ensuring that the algorithm can jump into low-value basins in the early stages and increase the chances of finding the global optimum. In this strategy, the differential vector generates directional updates by selecting random individuals and
The adaptive stability coefficient is defined as:
where controls the decay strength and (e.g., ) ensures numerical stability. Because is normalized, is invariant to linear rescaling of the fitness function. When and have similar fitness (i.e., ), , and the original step is recovered. When their fitness differs significantly, decreases, thereby damping the difference vector and improving robustness under extreme pairings.
Subsequently, using the following equation:
where is the weight adjusted according to the time step, used to control the influence of the differential vector in the position update. and are random numbers in the range [0, 1]. is a one-dimensional -stable random variable, denoted ∼ , where is the characteristic exponent governing the heavy-tailed jump lengths, with . The tail obeys as ; smaller implies more frequent long jumps. is the scale parameter. Since the time factor in Equation (7) already modulates the jump magnitude, we set and use to provide the decaying scale over time. In all experiments we set . In Equation (10), is a scalar step-length multiplier with direction given by , serves as an attenuation factor, and boundary projection is applied to keep the solution feasible.
Since , the contribution of the differential term is bounded:
As increases, decreases monotonically, reducing the update magnitude and preventing instability when and have strongly different fitness.
This leapfrogging exploration effectively avoids local optima and increases the chances of global optimization. With this strategy, ESPBO can more quickly escape local optima and enter potential global optimum regions when handling complex multi-modal optimization problems.
By introducing these improvement strategies, ESPBO demonstrates stronger global search capabilities and higher convergence efficiency when handling complex multi-modal optimization problems. The time-adaptive scheduling ensures sufficient exploration in the early stages and fine optimization in the later stages. The mentor pool guidance prevents the population from being misled, enhancing the stability and directionality of the search, while the directional jump exploration strengthens the ability to cross basins, avoiding the problem of local optima. The combination of these three strategies significantly enhances the adaptability of ESPBO in dynamic environments, enabling it to better address complex constraints and uncertain environmental changes, thus achieving better optimization results.
2.2.4. Complexity Analysis
Let be the population size, the decision dimension, the iteration budget, the mentor-pool size, and the per-solution objective evaluation cost.
For baseline SPBO, each iteration updates solutions in arithmetic and evaluates objectives in . Therefore, the total complexity is .
For Time-Adaptive Scheduling, the scalars , , and are to compute and are reused across iterations. Their application is fused into the per-dimension updates, keeping the overall complexity at .
For Mentor Pool Guidance, building the mentor set of size costs with a size heap or expected with partial selection; computing costs ; updates remain . Therefore, the complexity for this step is per iteration.
For Directional Jump Exploration, forming the differential vector and applying , , , , and is per individual; uses stored fitness values, which is . Boundary projection is . Hence, the complexity for this step is per iteration.
Thus, the overall ESPBO complexity is per run. With partial selection, the complexity reduces to . For our UAV cost where , both SPBO and ESPBO have complexity.
The pseudocode of ESPBO is shown in Algorithm 1. Algorithm 1. SPBO Algorithm Pseudocode.1: Input N, dim, T, LB, UB, fobj2: Expand bounds to 1 × dim; if LB(d) > UB(d) swap; if LB(d) == UB(d) set UB(d) += 1 × 10^−12^3: X ← chaotic_init(N,dim,LB,UB); for i = 1…N: fit(i) = fobj(X(i,:)); [Best,idx] = min(fit); BestVec = X(idx,:)4: for t = 1…T5: τ = t/T; shrink = (1 − τ)^(2 − τ); g = (1 − τ)^τ; l = (1 − τ); p = 0.34×(1 − 0.5τ); wM = 0.9(1 − τ) + 0.1; wB = 0.8(1 − τ^2^); wD = 1.2(1 − τ)6: Mentors ← top ⌈0.15N⌉ by fit; par = X; par1 = X7: for d = 1…dim8: RB = g·randn(N,1); RL = l·levy(N, 1, 1.5); r1,r2 ← distinct indices per i9: for i = 1…N10: xi = par(i,d); mk = Mentors(randi, k).d11: if fit(i) == Best12: par1(i,d) = BestVec(d) + shrink·(RB(i)·(BestVec(d) − xi) + RL(i)·(mk − BestVec(d)))13: elseif rand < 0.514: par1(i,d) = xi + wM·rand·(mk − xi) + wB·rand·(BestVec(d) − xi) + RB(i)·randn·(xi − mean(X(:,d)))15: else16: diff = par(r1(i),d) − par(r2(i),d); par1(i,d) = xi + wD·rand·diff + RL(i)·rand·(BestVec(d) − xi)17: end18: end19: U = (rand(N,1) < p); if any(U): par1(U,d) += shrink·(randU(LB(d),UB(d),|U|) − par1(U,d))20: else: k = p * (1-rand) + rand; par1(:,d) += k·(par(randperm(N),d) − par(randperm(N),d))21: par1(:,d) = clip(par1(:,d),LB(d),UB(d))22: for i = 1…N23: Xcand = X(i,:); Xcand(d) = par1(i,d); fnew = fobj(Xcand); if fnew < fit(i): X(i,:) = Xcand; fit(i) = fnew24: end25: [Best,idx] = min(fit); BestVec = X(idx,:); par = X; par1 = X26: end27: K = max(1,round(0.05N)); worst = worst_indices(fit,K); rad = 0.1(1 − τ)·(UB − LB)28: for i ∈ worst: cand = clip(BestVec + rad·randn(1,dim),LB,UB); f = fobj(cand); if f < fit(i): X(i,:) = cand; fit(i) = f; if f < Best: Best = f; BestVec = cand29: Convergence_curve(t) = Best**30: end; return Best, BestVec, Convergence_curve
3. Numerical Experiments
3.1. Algorithm Parameter Settings
Benchmark test sets such as CEC2017 [22], CEC2020 [23] and CEC2022 [24] are widely adopted in the evolutionary computation community to provide a standardized and rigorous testbed for evaluating optimization algorithms [25]. These test sets consist of diverse function types (unimodal, multimodal, hybrid, and composition) that mimic real-world optimization challenges, including non-separability, ill-conditioning, and high-dimensional rugged landscapes [26]. By testing on these established benchmarks, researchers can objectively compare algorithm performance across a common platform, ensuring reproducibility and fairness [27]. The use of CEC suites also facilitates cross-study comparisons and meta-analyses, which are essential for advancing the field [28].
To assess the performance of ESPBO, we compare it with nine state-of-the-art algorithms on the CEC2017, CEC2020 and CEC2022 benchmark functions. These algorithms are classified into two groups: (1) traditional and widely recognized algorithms: GWO [29], WOA [30], SO [31]; (2) emerging and high-performance algorithms: COA [32], CPO [16], RIME [33], IAGWO [34] and DBO [35]. We first perform a comparative validation using the CEC-2017 test functions. The specific parameter settings for the comparison algorithms are shown in Table 2. All algorithms are independently run 30 times, and the experimental results will be presented in the subsequent sections. For each test function and its corresponding dimension, the best result will be highlighted in bold.
3.2. Ablation Experiment Analysis
To analyze the separate contributions and collaborative impact of the three enhancement strategies—Time-Adaptive Scheduling (S1), Mentor Pool Guidance (S2), and Directional Jump Exploration (S3)—we conducted ablation experiments on the CEC2017 benchmark suite (dimension ). Five variants of the algorithm were developed for comparison: SPBO (baseline), ESPBO S1 (containing only S1), ESPBO S2 (containing only S2), ESPBO S3 (containing only S3), and ESPBO, which incorporates all three strategies. The experimental results are shown in Figure 1.
Figure 1 presents a comparison of the iteration convergence curves of the standard SPBO algorithm and its variant strategies (ESPBO-S1, ESPBO-S2, ESPBO-S3) with ESPBO on the CEC2017 benchmark functions (dim = 30). From the convergence processes of typical functions such as CEC2017-F3, F9, and F11, it is apparent that the standard SPBO algorithm is prone to converging to local optima early on, attributed to a lack of sufficient exploration (as illustrated by the F3 function, the iterations begin to plateau shortly after starting and stagnate around the 1.2 × 10^5^ level), with slow convergence in the later stages. Although the single-strategy variants improve performance to some extent (e.g., ESPBO-S2 still shows a decreasing trend after 400 iterations in the F11 function compared to the standard SPBO), they still suffer from the defect of weak exploration ability in the early stages. In comparison, the ESPBO algorithm, which integrates three strategies, exhibits superior convergence performance across all benchmark functions. For function F3, its fitness value decreases rapidly with iterations and maintains a notable declining trend even after 500 iterations, significantly lower than other algorithms. On complex multimodal functions such as F9 and F11, ESPBO effectively avoids “positional oscillation” and sustains steady precision improvement in later iterations, validating the synergistic effects of its time-adaptive scheduling, mentor pool guidance, and directional jump mechanisms. This work establishes a performance foundation for future complex optimization tasks and trajectory planning applications.
3.3. Parameter Sensitivity Analysis
3.3.1. Parameter Sensitivity of k in the ESPBO Component
In the original SPBO algorithm, the parameter represents two discrete learning–effort levels of the best student (regular vs. reinforced learning).
ESPBO inherits this mechanism in its SPBO-based update component to preserve the behavioral consistency of the model.
To verify whether the fixed range affects the performance of ESPBO, we conducted a sensitivity study by generalizing the update rule to
and testing several values of .
The experimental results are shown in Table 3. The overall optimal values lie within a narrow range of 1136–1137.9, with no significant performance difference observed. Meanwhile, the standard deviation remains similar across all settings. These findings suggest that ESPBO exhibits good robustness to the choice of k, and enlarging the range does not lead to performance improvement.
Figure 2 summarizes the averaged convergence curves on three representative CEC2017 functions (F1, F7, and F11) from 30 independent runs. All curves almost overlap, and the final mean best fitness values remain in a very narrow range (e.g., 1136–1137.9 on F7).
No consistent improvement is observed when enlarging . On the contrary, larger occasionally leads to slightly higher variance.
These results indicate that ESPBO is highly insensitive to the choice of , and the main performance gain of ESPBO originates from its new exploration–exploitation mechanisms rather than this SPBO component. Therefore, the original SPBO setting is retained in the final version for both semantic consistency and numerical stability.
3.3.2. Mathematical Justification of the Decay Exponent
To analyze the mathematical justification of the decay exponent in Equation (5), we start by outlining the design criteria and then derive its properties and proofs. Through asymptotic expansion and scale balancing explanations, we further elucidate the behavior of this exponent.
Design Criteria
The decay exponent should satisfy the following design criteria (Desiderata):
- Boundary and Monotonicity: , , and should strictly decrease for ;
- Safe Holding: For any , ;
- Smoothness and Robustness: The function should be log-concave to ensure a “decreasing but not too fast” smooth decay;
- Scale Balancing: The exponent should match and , ensuring that the scale of fine-tuning and macro-jumps is controllable throughout the process, avoiding premature convergence or late oscillation.
- 2.Derivation and Properties of the Decay Exponent
To analyze the justification, we introduce the function , where is the normalized progress, and define . In the implementation, and .
- Boundary and Strict Monotonicity: According to Design Criterion 1, we have and , and strictly decreases for . By differentiating , we show that is decreasing throughout the interval and that the early drop is fast enough.
- Safe Holding: Design Criterion 2 proves that for any , . This ensures that the decay exponent is well-controlled throughout the process. The cumulative decay is bounded by , and the discrete sum also falls within the same order of magnitude.
- Log-Concavity: Design Criterion 3 proves that is log-concave. Specifically, as increases, the marginal decay per unit progress decreases, which helps to smooth the process during the later stages and suppress oscillations.
- Scale Balancing: Design Criterion 4 further analyzes the relationship between the decay exponent and and :
, showing that the fine-tuning scale is invariant over time;
, with the exponent lying between quadratic and cubic decay, ensuring the macro-jump scale varies strictly between these two bounds.
3.Asymptotic Behavior and Slope Analysis
At the endpoints, we perform asymptotic expansion:
As , the decay exponent expands as:
leading to , with , indicating sufficient early decay.
As , let , and we have , so , implying that the decay is linear during the termination phase, leading to smooth convergence without oscillation.
The above analysis satisfies the design criteria 1–4 and provides stronger analytical results: the combination of with and forms a provable “scale balancing” throughout the entire process. Furthermore, in the natural linear exponential family, we proved the uniqueness of this choice. These results provide principled and interpretable support for selecting in Equation (5): fast decay in the early stages, smooth refinement in the later stages, and no additional tuning parameters required. Figure 3 displays the functional trajectory of and its product with and , further verifying the theoretical results.
3.4. Exploration and Exploitation Behavior Analysis
In metaheuristic algorithm design, the balance between exploration and exploitation is a fundamental issue. The exploration phase aims to expand the search scope by scanning unknown regions to identify potential high-quality solutions, while the exploitation phase focuses on the intensive refinement of the neighborhood of known high-quality solutions to further improve their quality [36]. This dynamic balance directly determines algorithmic performance: adequate exploration helps maintain population diversity and prevents premature convergence, whereas effective exploitation accelerates local refinement and enhances convergence precision. Such a balance enables the algorithm to not only rapidly approach the global optimum but also adapt to problems of different complexity levels, thereby demonstrating stronger adaptability and robustness [37].
To quantitatively analyze this balance, this study employs Equations (11) and (12) to calculate the proportions of exploration and exploitation, respectively. Additionally, a dimensional diversity index , is introduced and computed using Equation (13), where denotes the position coordinate of the individual in the dimension, and records the highest diversity value observed throughout the iterative process. This metric serves to monitor the dynamic characteristics of population distribution throughout the search procedure [38].
The experimental setup is shown in Figure 4.
In Equation (13), a median-centered diversity measure is employed to enhance robustness against outliers. This choice is motivated by the fact that early-stage Lévy flights and occasional restarts may produce extreme individuals. With a mean-centered diversity, such outliers can significantly distort both the center of the population and the dispersion estimate, potentially triggering incorrect “increase exploration” actions. By contrast, the use of an L1 deviation around the median (dimension-wise , averaged across individuals) makes the diversity measure more robust. The median is insensitive to a small number of extreme values, ensuring that a few outliers do not dominate the scheduler’s decision-making process.
The robustness of this approach stems from the median’s 50% breakdown point. When the contamination of the data is below 50%, the median remains largely unaffected by outliers, preventing any spurious increase in the spread of the population. In contrast, the mean has a 0% breakdown point and can be heavily influenced by a single extreme value, amplifying both the shift in the center and the dispersion of the population.
For populations that are symmetric and unimodal, and without notable outliers, the diversity estimates based on the median and the mean are similar. Therefore, Equation (13) does not degrade the quality of estimation for clean data, making it a consistent and effective measure in practice.
3.5. Convergence Behavior Analysis
For evaluating the convergence performance of the ESPBO algorithm, this study systematically analyzes its convergence behavior through multiple sets of experiments, as illustrated in Figure 5. The two-dimensional morphologies of the test functions shown in the first column intuitively reveal the complexity and challenges of the problems to be solved. In the visualization of population distribution presented in the second column, ESPBO demonstrates exceptional spatial search capability: its search agents maintain extensive coverage of the solution space while rapidly focusing on potentially optimal regions, effectively overcoming the tendency of traditional algorithms to be confined to local optima. The average fitness evolution curves in the third column reveal the convergence dynamics of the algorithm. The maintained high fitness values during early iterations reflect sufficient global exploration, while the rapid decline and subsequent stabilization of fitness values demonstrate the algorithm’s capability for smooth transition from extensive search to refined exploitation.
Of particular note, the individual trajectories shown in the fourth column transition gradually from significant initial fluctuations to stable convergence. This phenomenon indicates that ESPBO successfully resolves the oscillation issue present in the original SPBO algorithm, achieving smooth convergence. From the convergence curves, it can be observed that ESPBO performs particularly well when dealing with multimodal functions. The algorithm not only consistently escapes local optima but also accurately locates the global optimum, which benefits from its well-designed balancing mechanism. Compared to the original SPBO, ESPBO effectively addresses the issues of insufficient early-stage exploration and excessive late-stage adjustment through its dynamic regulation strategy, thereby demonstrating more stable convergence performance and higher solution accuracy in complex optimization problems.
3.6. Experimental Results and Analysis of CEC2017 and CEC2022 Test Suite
This study conducts a comparative performance analysis of ESPBO and several benchmark algorithms based on the CEC 2017, CEC 2020 and CEC 2022 standard test suites. These test suites cover four typical categories of mathematical functions: unimodal, multimodal, hybrid, and composite functions. Among them, multimodal functions, characterized by numerous local optima, effectively evaluate an algorithm’s global exploration capability. In contrast, unimodal functions contain only one global optimum and are primarily used to assess an algorithm’s local exploitation efficiency. Hybrid and composite functions, with their more complex structural features, comprehensively test the robustness of optimization algorithms in avoiding premature convergence. To ensure the fairness of the comparative experiments and mitigate the effects of randomness, for all algorithms, the population size was consistently set to 30, with the maximum number of iterations fixed at 500, and each algorithm was executed independently 30 times. Experimental results are reported in terms of the average (Ave) and standard deviation (Std), with statistically superior values highlighted in bold. The experiments were conducted on a Windows 11 platform with an Intel i5-13400 processor and 16 GB of RAM, using MATLAB 2023a as the software environment. The convergence process and solution set distribution of the algorithms are visualized through the convergence curves in Figure 6 and the box plots in Figure 7, respectively, with detailed experimental results provided in Table 4, Table 5, Table 6, Table 7 and Table 8.
Based on systematic experimental analysis of the CEC 2017 (dimensions 30/50/100) and CEC 2020/2022 (dimension 20) benchmark suites presented in Table 4, Table 5, Table 6, Table 7 and Table 8, ESPBO demonstrates significantly superior optimization performance compared to other algorithms (including GWO [29], WOA [30], COA [32], IAGWO [34], DBO [35], SO [31], RIME [33], CPO [16], and standard SPBO [17]) across various problem types (unimodal, multimodal, hybrid, and composition functions). Particularly in high-dimensional test scenarios, the advantage of ESPBO becomes more pronounced.
Based on the CEC 2022 (dim = 20) test suite, for F1 (a unimodal function), the average fitness value of ESPBO (Ave = 3.474 × 10^2^) shows a significant reduction of 46.58% compared to the standard SPBO (Ave =6.502 × 10^2^). Furthermore, its standard deviation (Std = 3.336 × 10^1^) is considerably lower than that of the standard SPBO (Std = 2.805 × 10^2^), validating the effectiveness of the time-adaptive scheduling strategy in unimodal functions, which precisely guides the search process and maintains stability. For F9 (a composition function), the Ave value of ESPBO (2.481 × 10^3^) is very close to that of the standard SPBO (Ave = 2.481 × 10^3^), and its standard deviation (Std = 2.988 × 10^−4^) is nearly zero, indicating that ESPBO consistently produces high-quality solutions without significant influence from random initial conditions and achieves rapid convergence in complex multimodal functions.
In the F1 (unimodal function) test of CEC 2017 (dim = 30), the average value of ESPBO (Ave = 1.504 × 10^2^) is significantly lower than those of other comparative algorithms, such as GWO (Ave = 3.447 × 10^9^) and WOA (Ave = 4.990 × 10^9^). Moreover, its standard deviation (Std = 1.033 × 10^2^) is notably lower than most compared algorithms, demonstrating its efficiency and stability in unimodal optimization problems. This further validates the advantage of the directional jump exploration strategy in complex problems, effectively preventing premature convergence of the population and steadily exploiting the global optimum among multiple local optima. For F7 (multimodal function), the average value of ESPBO (Ave = 7.817 × 10^2^) is 73.44% lower than that of the standard SPBO (Ave = 2.944 × 10^3^), and its standard deviation (Std = 8.944 × 10^0^) is 95.50% lower than that of the standard SPBO (Std = 1.988 × 10^2^). These results indicate that the mentor pool guidance strategy effectively avoids local optima and successfully directs the search toward the global optimum. Based on the data in Table 8, we focus on two representative functions (F1 and F7) to analyze ESPBO’s performance and its advantages over other algorithms. In the F1 (unimodal function) test of CEC 2020 (dim = 20), ESPBO shows significant superiority in unimodal optimization problems. Its average fitness value (Ave = 1.625 × 10^2^) is the lowest among all algorithms, far lower than SPBO (Ave = 2.953 × 10^10^). This performance indicates that ESPBO outperforms other algorithms in unimodal problems, particularly in minimizing path length. Moreover, the standard deviation (Std = 8.840 × 10^1^) of ESPBO is considerably lower than SPBO (Std = 4.419 × 10^9^), indicating greater stability and consistency across multiple runs. This validates the effectiveness of ESPBO’s time-adaptive scheduling strategy, which guides the search process more precisely while maintaining stability in the solutions. For the multimodal function F7, ESPBO again demonstrates its strong optimization capability. The average fitness value (Ave = 4.811 × 10^4^) for ESPBO is approximately 99.99% lower than that of SPBO (Ave = 1.802 × 10^7^), showing that ESPBO excels at finding the global optimum solution. The standard deviation (Std = 9.351 × 10^4^) for ESPBO is also much lower than SPBO (Std = 1.271 × 10^7^), further confirming its high stability and superior solution quality in multimodal problems, effectively avoiding local optima. The iterative convergence curves in Figure 6 visually demonstrate the convergence advantage of ESPBO from a dynamic process perspective. For CEC2017-F10 (dim = 30), the convergence curve of ESPBO remains consistently lower than those of other algorithms, exhibiting a steeper descent trend. By the 300th iteration, the fitness value of ESPBO has stabilized close to the optimum, while algorithms such as the standard SPBO have already become trapped in local optima. This observation clearly reflects the high efficiency of the “global exploration in early stages—local convergence in later stages” dynamic mechanism. The boxplot analysis in Figure 7 reveals the stability advantage of ESPBO from a statistical distribution perspective. Across various test scenarios, the interquartile range of ESPBO remains consistently narrow, with stable box height significantly smaller than that of the standard SPBO. The absence of outliers demonstrates ESPBO’s ability to maintain high consistency across multiple independent runs while delivering high-quality solutions.
Integrating the detailed experimental data from Table 4 to Table 7 with the visualization results in Figure 6 and Figure 7, ESPBO—through the fusion of three core strategies (time-adaptive scheduling, mentor pool guidance, and directional jump exploration)—effectively addresses the challenges faced by standard SPBO in balancing exploration and exploitation, optimizing in high-dimensional spaces, and ensuring solution stability. Across varying dimensions and diverse types of optimization tasks, ESPBO achieves comprehensive improvement in solution precision, convergence speed, and robustness, thereby providing solid experimental support for its effectiveness in practical applications such as trajectory planning problems.
3.7. Statistical Test
In algorithm optimization research, statistical analysis serves as a critical methodology for establishing an objective evaluation framework to compare the performance of different methods [39]. This evidence-based paradigm effectively guides researchers in selecting optimal solutions for specific problems [40]. In this study, non-parametric statistical tests, including the Wilcoxon rank-sum test and Friedman test, are employed to validate the performance of the ESPBO algorithm, while the implementation procedures and result analysis of these tests are systematically elaborated.
3.7.1. Wilcoxon Rank-Sum Test
To comprehensively evaluate the overall performance of the proposed algorithm, this section introduces the Wilcoxon rank-sum test to conduct statistical analysis of the significance of differences between ESPBO and other comparative algorithms [41]. The test sets the significance level at 5%, with the null hypothesis H_0_ defined as follows: there is no statistically significant difference between the compared algorithms. If the resulting p-value is less than 0.05, the null hypothesis is rejected, indicating an essential difference in algorithm performance; conversely, if the p-value is greater than 0.05, the null hypothesis is accepted, suggesting comparable performance between algorithms. The notation “ ” in the table indicates that no distinguishable performance difference was observed between the algorithms.
Table 9 presents the aggregated Wilcoxon rank-sum test results (α = 0.05) across all 112 benchmark functions from the CEC2022 (20-dim), CEC2020 (20-dim), and CEC2017 (30-, 50-, and 100-dim) test suites. Following the conservative convention widely adopted in leading journals, bold values in the detailed p-value tables in Appendix A (Table A1, Table A2, Table A3, Table A4 and Table A5) highlight cases where p ≥ 0.05, indicating that ESPBO exhibits no statistically significant difference from the corresponding competitor. These cases are counted as “≈” in Table 9. Even with this strict criterion, ESPBO significantly outperforms the nine state-of-the-art competitors in 924 out of 1008 pairwise comparisons (91.7%) and is never significantly inferior to any competitor.
3.7.2. Friedman Mean Rank Test
To comprehensively rank the overall performance of the ESPBO algorithm, a statistical method capable of simultaneously comparing multiple related algorithms is required. The Friedman test fulfills this need precisely. As a rank-based non-parametric test, it does not rely on specific data distribution forms and is particularly suitable for evaluating the performance of multiple algorithms on the same set of benchmark functions. The test statistic [42] is determined by the following equation:
where represents the number of blocks, denotes the number of groups, indicates the sum of ranks for the group. When and are sufficiently large, the test statistic approximately follows a distribution with degrees of freedom.
Referring to the Friedman mean rank test results outlined in Table 10, the comprehensive performance of ESPBO on the CEC 2017, CEC 2020 and CEC 2022 test suites (including dimensions 30/50/100 and 20) was evaluated and ranked against other comparative algorithms (such as GWO [29], WOA [30], COA [32], IAGWO [34], DBO [35], SO [31], RIME [33], CPO [16], and SPBO [17]). The results are presented in terms of Mean Rank ( ) and Total Rank ( ). As a non-parametric statistical method, the Friedman test effectively mitigates the influence of non-normal data distribution or outliers, providing a more objective reflection of the global performance differences among the algorithms.
As evidenced by the data in the table, ESPBO achieved the best Mean Rank ( ) and Total Rank ( ) across all test scenarios, with statistically significant differences compared to other algorithms (the test statistic Q follows a χ^2^ distribution with degrees of freedom k − 1 = 9, p < 0.05). Specifically, on the CEC 2017 test set (dim = 30), the average rank of ESPBO ( = 1.29) was considerably lower than that of the second-ranked CPO ( = 3.65), and its final rank ( = 1) demonstrated a clear lead. Even in the high-dimensional scenario of CEC 2022 (dim = 20), the average rank of ESPBO only slightly increased to 1.31, still securing the top position, while the second-ranked SPBO had an average rank of 2.38, maintaining a substantial gap. This further highlights the advantage of ESPBO in high-dimensional spaces.
From the perspective of algorithm categories, traditional algorithms (such as GWO and WOA) exhibit average ranks concentrated in the range of 4.45–8.90, while ESPBO consistently maintains an average rank between 1.29 and 1.31. This demonstrates that ESPBO outperforms competing algorithms in overall performance, emphasizing the notable advantage of its three-strategy approach.
On the CEC2020 test set, ESPBO also demonstrated significant performance advantages, with an average ranking ( ) of 2.5 and a total ranking ( ) consistently ranking first. Although ESPBO’s average ranking on this test set is slightly higher than its performance in CEC2017 and CEC2022, it is still significantly better than other comparison algorithms. The average rankings of traditional algorithms such as GWO ( = 5.5, = 6) and WOA ( = 8.3, = 9) are still concentrated in the higher range, while the novel algorithms CPO ( = 3.7, = 2) and RIME ( = 3.8, = 3) in recent years perform better. However, there is still a certain gap compared with ESPBO. It is worth noting that SPBO had the highest average ranking in CEC2020 ( = 9.9, = 10), further highlighting the effectiveness of the ESPBO strategy.
The Friedman test results provide a comprehensive statistical comparison of the ten optimization algorithms across five benchmark scenarios with varying dimensions. As visually represented in the radar chart and heatmap, ESPBO consistently demonstrates superior performance, achieving the top ranking (Total Rank = 1) in all test suites. Figure 8 particularly highlights ESPBO’s dominant position, forming the outermost polygon that encompasses all other algorithms, indicating its comprehensive superiority across different problem types and dimensions. Figure 9 further reinforces these findings, with ESPBO showing the lowest (best) mean rank values consistently colored in the brightest shades. IAGWO emerges as the strongest competitor, securing second place in most scenarios, while traditional algorithms like WOA and SPBO generally occupy the lower performance tiers. The consistent excellence of ESPBO across diverse test conditions—from low-dimensional (20D) to high-dimensional (100D) problems—validates its robustness and adaptability, making it a highly reliable choice for complex optimization tasks including UAV trajectory planning.
Based on a comprehensive analysis of the Friedman test results in Table 10, ESPBO not only surpasses the comparison algorithms in quantitative performance metrics (such as Ave and Std) but also passes the global performance ranking test at the statistical level. Its rank distribution demonstrates “high stability and low volatility.” This advantage stems from the collaborative impact of its three core strategies: the mentor pool guidance strategy prevents the population from becoming trapped in local optima by directing the search toward promising regions, ensuring both efficiency and stability in global exploration; the time-adaptive scheduling enhances optimization capability in high-dimensional environments and improves the algorithm’s adaptability across different phases; meanwhile, the directional jump exploration strengthens global leap capability and local convergence precision, enabling rapid convergence on complex functions. Together, these strategies allow ESPBO to consistently maintain superior global performance across diverse benchmark suites and function types, providing robust statistical and visual support for its application in practical tasks such as UAV 3D trajectory planning.
4. Three-Dimensional UAV Path Planning
For unmanned systems, path planning is essential for mission accomplishment, particularly in UAVs, where the success of the mission heavily relies on the rationality of three-dimensional trajectory planning. Classic algorithms for path planning, such as the A-star algorithm [3], Dijkstra algorithm [4] and genetic algorithm [43], have achieved certain results in specific environments. However, their limitations become increasingly evident in complex scenarios, especially those involving intertwined factors such as mountainous terrain, high altitude, and no-fly zones [44]. Traditional methods often struggle to simultaneously satisfy multiple constraints, such as flight altitude, path length, and environmental obstacles. Consequently, they exhibit limited adaptability and efficiency when dealing with dynamic environmental changes or complex obstacles [45]. This study employs ESPBO for UAV path planning to validate its effectiveness.
In rugged mountainous environments, UAV flight paths face multiple complex challenges [46]. Factors such as steep mountains, abrupt weather shifts and no-fly zones [47] may pose threats to flight safety [48]. To ensure safe UAV operations, it is crucial to accurately avoid these obstacles and adverse conditions. This study addresses the UAV trajectory planning problem in mountainous terrain by incorporating topographical features, unpredictable meteorological conditions, and no-fly zones into the modeling framework, thereby forming a comprehensive path planning solution. The ground and obstacle models are illustrated in Figure 10:
In UAV operations, factors like flight altitude, distance, and maximum turning angle must be controlled to maintain both safety and operational efficiency. Taking into comprehensive consideration the UAV’s maneuverability, flight path length, flight altitude, and the scale of various threat sources, this study formulates the trajectory cost function as shown in Equation (17) and conducts performance evaluation accordingly.
To eliminate the influence of units and scales on the weighted scalarization, we first perform an ideal–nadir (utopia–nadir) normalization on the three metrics:
Here, represents metrics such as path length ( ), flight altitude ( ), and maximum turning angle ( ), with and being the ideal and nadir values of these metrics, respectively. The term ensures numerical stability.
Based on task preferences, we define a dimensionless priority vector , where , and map it to weights as follows:
The above formula is equivalent to “equal contribution calibration”: near the baseline solution, the marginal contributions of each metric to the objective function are roughly balanced. When there is no particular preference, can be set equally (restoring equal weighting). The resulting weights satisfy the non-negativity and summation constraints in Equation (16), and are insensitive to scale changes.
Optimality and Robustness:
Pareto Optimality: When and , the solution obtained by minimizing is Pareto optimal (if a dominating solution exists, it would reduce while maintaining or improving all other components, which would be contradictory).
Ranking Robustness (Weight Perturbation Bandwidth): Let be the current optimal solution and be the next best solution, with their normalized vectors . Under the baseline weights , we have:
If and , then , meaning the ranking remains unchanged.
The choice of baseline priority in the experiments is primarily to provide a stable reference for the task, ensuring that all optimization processes start from a unified standard, making the experimental results reliable and comparable. Using baseline priority effectively controls the adjustment of weights for each metric, ensuring flexibility across different task scenarios while maintaining the stability and robustness of the optimization process.
where the weights satisfy the constraint given in Equation (16), and
is the coupling–strength parameter. To eliminate the influence of physical units on the cost evaluation, the path length, flight altitude, and maximum turning angle are normalized as
where denote the reference scales of the task.
The coupling term adopts a second–order multiplicative form, defined as
where , represent the nonlinear interaction strengths between path length and flight altitude, path length and maximum turning angle, and flight altitude and maximum turning angle, respectively.
For example, when both the path is long and the ground height deviation is large, the term increases the overall cost, discouraging “high-altitude long-curve paths.” When the path is long while the curvature or second derivative is large, the term suppresses undesirable trade-offs such as “increasing path length to gain smoothness.” Similarly, when both the height variation and turning intensity are high, the term penalizes the compounded risk of “steep climb coupled with sharp turns.”
It is worth noting that when
Equation (17) degenerates to the , ensuring full consistency with the experimental results already presented in this work. When stronger coupling modeling is required by the task, a positive value of can be selected, and the relative magnitudes of can be adjusted according to the scenario. For instance, in environments with strict airspace or clearance safety constraints, the values of and may be increased accordingly.
- Trajectory Length Constraint: This constraint limits the maximum flight distance of the UAV, aiming to ensure that the mission range remains within permissible limits. By doing so, it effectively manages onboard resources, maintains necessary endurance, and guarantees successful mission completion. The specific form of the constraint is given by Equation (18).
- Maximum Turning Angle Constraint: This constraint defines the physical limit of the UAV’s steering maneuvers, directly determining the smoothness and feasibility of the trajectory. Its mathematical model is defined by Equation (19):
To address feasibility, let be the turn angle between consecutive segments with . Since cosine function is strictly decreasing on , we have if and only if , or equivalently, . Hence, each term in Equation (19) is strictly positive if and only if and non-positive otherwise; minimizing the overall cost therefore strongly discourages violations. In our implementation, is treated as a hard infeasibility (candidates are rejected or reprojected); equivalently, one can replace each term by the hinge with a sufficiently large weight. Both treatments guarantee that any minimizer satisfies , thus preventing infeasible turns while preserving the cosine smoothness inside the feasible region.
- Flight Altitude Constraint: The flight altitude is determined by safety requirements, mission specifications, and airspace regulations, all of which are critical to UAV operations. Its mathematical model is defined by Equation (20):
where represents the directional change angle between adjacent waypoints and , and denotes the system-defined maximum allowable rotation angle.
To assess the performance of ESPBO in UAV 3D path planning, this study designs multiple comparative experiments. The UAV parameters are configured as follows: maximum flight altitude of 50 m, cruising speed of 20 m/s, and maximum turning angle of 60°. The testing environment is constructed as a 200 × 200 × 100 m^3^ 3D airspace, with a start coordinate of (0, 0, 20) and a target coordinate of (200, 200, 30). Under identical experimental conditions, ESPBO is compared with nine mainstream intelligent algorithms, including GWO [29], WOA [30], COA [32], GTO [49], DBO [35], SO [31], RIME [33], CPO [16], and GOA [50]. The population size for all algorithms is set to 50, with a maximum of 100 generations. To mitigate the effects of randomness, each algorithm is independently executed for 30 repeated trials.
Table 11 presents the statistical analysis of the experimental results, where “Best” denotes the optimal path length achieved by each algorithm, “Ave” represents the average path length over 30 independent runs, and “Std” evaluates the stability of the algorithms. The convergence curve in Figure 11 provides a dynamic perspective to complement the static data in Table 11. ESPBO’s curve exhibits two ideal phases: rapid descent and stable convergence. Its steep decline during the early iterations (approximately the first 20) demonstrates a powerful global exploration capability, enabling it to quickly locate promising regions of the solution space. In the later stages, the curve smoothly converges to its final value without significant oscillation, reflecting an effective local exploitation and refinement capability that avoids overshooting. This efficient search behavior is the direct reason for its ability to find shorter paths.
In contrast, the curves of other algorithms, such as WOA and COA, either descend slowly or plateau prematurely at higher fitness values, indicating insufficient global exploration. The slight fluctuations at the end of some curves (e.g., GTO) correlate with their larger standard deviations, revealing solution instability.
The 3D path visualizations in Figure 12 and Figure 13 intuitively corroborate the above analysis from an engineering standpoint. The path planned by ESPBO (recommended to be highlighted in the figure) demonstrates high practical quality: it is not only the shortest in length but also smooth, coherent, with gentle turns, and adeptly conforms to the terrain. Such a path is highly compatible with the real-world kinematic constraints of UAV flight, promoting energy efficiency and stable navigation. Conversely, paths from other algorithms show clear shortcomings: WOA’s path is lengthy and meandering; paths from some others appear “jagged” with unnecessary steep climbs and descents, which are undesirable in practical operations. Consequently, ESPBO’s superiority is evident not only in quantitative metrics but also in the practicality and quality of the paths it generates.
The statistical data presented in Table 11 is crucial for evaluating the practical potential of the algorithms. ESPBO’s lead in the Best path length (199.8874 m) demonstrates its theoretical capability to find high-quality solutions. However, its performance in Average path length (205.8179 m) and Stability (Std: 5.3440) is of greater practical significance. A particularly noteworthy finding is that ESPBO’s average path length (205.8179 m) is significantly shorter than the best path lengths discovered by all other comparative algorithms (whose best paths range from 209.4727 m to 278.8787 m). This indicates that in the vast majority of practical deployments, ESPBO can consistently output paths superior to the best-found solutions of its competitors, providing a strong justification for its deployment in real-world systems requiring high reliability.
In contrast, the shortcomings of other algorithms are apparent. For instance, while the RIME algorithm shows acceptable stability (Std = 7.1473), its inferior best and average path lengths reveal a lack of optimization power. The WOA exhibits severe flaws; its large standard deviation (97.1586) and worst path length (736.6825 m) suggest a tendency to converge on entirely infeasible solutions, rendering its performance highly unreliable. Algorithms like GTO and DBO show significant performance fluctuations (Std of 65.6775 and 50.0317, respectively), indicating sensitivity to initial conditions or random seeds and a lack of consistency. In summary, ESPBO stands out as the only algorithm that achieves top-tier performance simultaneously in both solution quality and operational stability.
Based on the comprehensive analysis above, ESPBO demonstrates significant advantages in path planning precision, algorithmic stability, and convergence performance, significantly improving the performance and robustness of UAV path optimization, especially in intricate three-dimensional environments; the path optimization capability and stability exhibited by ESPBO underscore its substantial value in practical applications.
5. Summary
This paper addresses two core challenges in the current field of trajectory planning optimization: insufficient solution accuracy under complex constraints, and inadequate convergence stability under multidimensional coupled constraints. Based on the Student Psychology-Based Optimization (SPBO) algorithm, this study conducts in-depth research aimed at enhancing the performance of intelligent optimization methods in complex optimization tasks and trajectory planning through algorithmic innovation. First, the paper systematically analyzes the core limitations of the standard SPBO: its fixed step-size update rule leads to an imbalance between exploration and exploitation, its reliance solely on guidance from the global best individual tends to cause premature convergence of the population, and the random step-driven local search struggles to meet the demands of high-precision optimization. To address these issues, this paper proposes an enhanced Student Psychology-Based Optimization (ESPBO) algorithm, which integrates three key strategies: time-adaptive scheduling, mentor pool guidance, and directional jump exploration. The time-adaptive scheduling strategy dynamically adjusts step sizes and exploration intensity to achieve “strong exploration in early stages and strong exploitation in later stages,” ensuring effectiveness across different phases of the search process. This approach mitigates insufficient early-stage exploration and excessive late-stage adjustments, thereby improving convergence speed and precision. The mentor pool guidance strategy selects high-fitness individuals to form a “mentor pool,” providing diversified guidance to other individuals. This enhances the directionality and stability of the search, prevents the population from being misled during the optimization process, and ensures effective discovery of the global optimum. Lastly, the directional jump exploration strategy introduces differential vectors and Lévy long jumps to strengthen the algorithm’s ability to traverse across solution basins. This helps the algorithm escape local optima in complex multimodal optimization problems and accelerates the global search process. The combination of these three strategies significantly improves the optimization stability and solution accuracy of ESPBO under complex constraints.
To validate the optimization performance of ESPBO, this study designs multiple numerical experiments based on the CEC 2017 and CEC 2022 benchmark suites, comparing it with mainstream algorithms such as GWO, COA, IAGWO, WOA, RIME, DBO, SO, CPO, and the standard SPBO. Ablation studies are further conducted to analyze the individual contributions and synergistic effects of each enhancement strategy. The experimental results demonstrate that ESPBO achieves superior performance in terms of average fitness value, convergence speed, and stability. Across the CEC 2017 (dim = 30/50/100) and CEC 2022 (dim = 20) test suites, it consistently attains the top average rank. The Wilcoxon rank-sum test reveals statistically significant differences (p < 0.05) in performance compared to other algorithms on most functions, while the Friedman test further confirms its overall optimization capability as the best among all compared methods. On this basis, the present study applies the ESPBO algorithm to the three-dimensional trajectory planning problem for unmanned aerial vehicles (UAVs). Using a comprehensive objective function that optimizes total trajectory length, flight altitude, and path smoothness, tests were conducted in a 3D simulation environment incorporating complex mountainous terrain and no-fly zones. Key evaluation metrics included best path length, mean trajectory length, and standard deviation. Experimental results demonstrate that ESPBO achieves superior trajectory planning outcomes compared to other algorithms, consistently excelling in both path length and stability metrics. For instance, in a typical mountainous environment, the optimal path length planned by ESPBO reached 199.8874 m, significantly outperforming other high-performance algorithms. This verifies its effectiveness in balancing path quality and planning efficiency for trajectory planning in complex environments, thereby providing a reliable solution for autonomous UAV navigation.
6. Future Work
The promising results of the ESPBO algorithm open up several exciting avenues for future research, aimed at enhancing its theoretical foundation, algorithmic adaptability, and practical applicability.
A primary direction involves the development of intelligent, dynamic parameter control mechanisms to transition ESPBO towards a fully self-adaptive framework. Instead of relying on static empirical values, future work will explore encoding key parameters—such as the mentor pool size, the step-size decay factor, and the Lévy flight intensity—directly into the solution representation, allowing them to evolve concurrently with the positions. Beyond this evolutionary approach, leveraging reinforcement learning to guide real-time parameter adjustment based on the search state (e.g., population diversity and convergence entropy) presents a highly promising path to eliminate manual tuning and significantly boost robustness across diverse problems.
In terms of applications, extending ESPBO to complex multi-UAV cooperative planning in dynamic, uncertain environments is a critical next step. This necessitates designing distributed or decentralized versions of the algorithm where multiple populations, each representing a UAV’s trajectory, co-evolve while managing inter-agent constraints like collision avoidance and communication maintenance. Furthermore, the algorithm’s practicality must be tested under more realistic conditions, such as the presence of moving obstacles, sudden no-fly zones, and complex meteorological disturbances like wind fields. Developing a predictive or robust optimization variant of ESPBO that can handle such uncertainties is essential for bridging the gap between simulation and real-world deployment.
Finally, while the empirical performance of ESPBO is rigorously validated, a formal theoretical analysis of its convergence properties remains an open and compelling question. Establishing a mathematical foundation using probability theory or Markov chain models to prove global convergence guarantees and to analyze convergence rates would provide deeper insights into its search dynamics and further solidify its theoretical credibility. Exploring these interconnected directions—adaptive control, complex applications, and theoretical underpinnings—will comprehensively advance the algorithm’s capabilities and scope.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Tan C.S. Mohd-Mokhtar R. Arshad M.R. A Comprehensive Review of Coverage Path Planning in Robotics Using Classical and Heuristic Algorithms IEEE Access 2021911931011934210.1109/ACCESS.2021.3108177 · doi ↗
- 2Liu L. Wang X. Yang X. Liu H. Li J. Wang P. Path planning techniques for mobile robots: Review and prospect Expert Syst. Appl.202322712025410.1016/j.eswa.2023.120254 · doi ↗
- 3Xu B. Precise path planning and trajectory tracking based on improved A-star algorithm Meas. Control 2024571025103710.1177/00202940241228725 · doi ↗
- 4Deep B. Determination of least polluted route using Dijkstra’s algorithm Int. J. Environ. Sci. Technol.202320132891329810.1007/s 13762-022-04750-3 · doi ↗
- 5Zhang R. Xing Z. Chai S. Xia Y. Chai R. Learning-based trajectory planning for AG Vs in dynamic environment Expert Syst. Appl.202629812961610.1016/j.eswa.2025.129616 · doi ↗
- 6Cheng Q. Xu W. Liu Z. Hao X. Wang Y. Optimal Trajectory Planning of the Variable-Stiffness Flexible Manipulator Based on CADE Algorithm for Vibration Reduction Control Front. Bioeng. Biotechnol.2021976649510.3389/fbioe.2021.76649534692668 PMC 8531977 · doi ↗ · pubmed ↗
- 7Huang H. Fu Y. Liu D. Chen J. He L. Adaptive Gazelle optimization algorithm: A novel solution for complex optimization problems Clust. Comput.20252841910.1007/s 10586-024-05046-6 · doi ↗
- 8Dorigo M. Di Caro G. Ant colony optimization: A new meta-heuristic Proceedings of the 1999 Congress on Evolutionary Computation-CEC 99 (Cat. No. 99TH 8406)Washington, DC, USA 6–9 July 1999 Volume 21470147710.1109/CEC.1999.782657 · doi ↗