The Efficacy of Electronic Health Record-Based Artificial Intelligence Models for Early Detection of Pancreatic Cancer: A Systematic Review and Meta-Analysis
George G. Makiev, Igor V. Samoylenko, Valeria V. Nazarova, Zahra R. Magomedova, Alexey A. Tryakin, Tigran G. Gevorkyan

TL;DR
AI models using electronic health records can help detect pancreatic cancer early, but challenges like false positives and low accuracy in some cases remain.
Contribution
This study is the first systematic review and meta-analysis evaluating AI models for early pancreatic cancer detection using only structured EHR data.
Findings
AI models achieved a pooled AUC of 0.785, showing good overall discriminatory ability for pancreatic cancer prediction.
Neural networks outperformed other models in AUC, but had lower sensitivity and specificity compared to Light Gradient Boosting models.
Positive predictive values were consistently low (<1%), highlighting the difficulty of screening for a rare disease.
Abstract
Pancreatic cancer is often detected too late, leading to very low survival rates. Screening everyone is not practical due to the disease’s rarity and high costs. This study explores a new approach: using artificial intelligence (AI) to analyze patients’ existing electronic health records—like doctor’s visit notes and lab results—to identify those at high risk of pancreatic cancer long before symptoms appear. By systematically reviewing existing research, we aimed to determine how accurate these AI tools are. Our findings show they hold significant promise for early detection, which could allow doctors to monitor high-risk patients more closely and ultimately save lives by catching the cancer at a treatable stage. However, challenges such as the potential for false-positive results and the need for further validation in diverse clinical settings must be addressed before its widespread…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1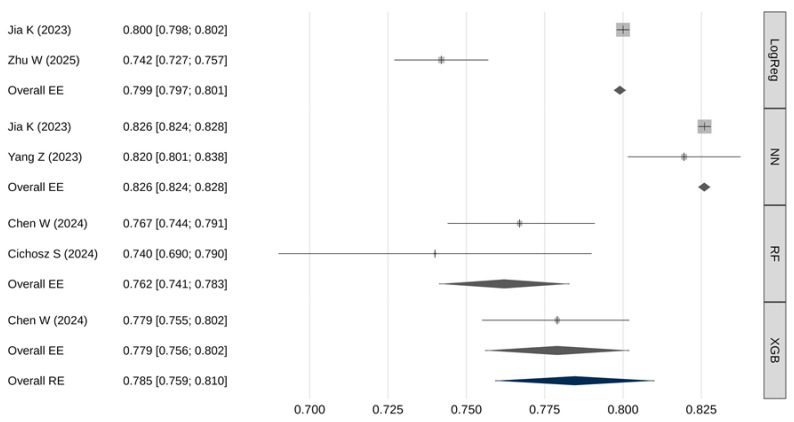 Figure 2
Figure 2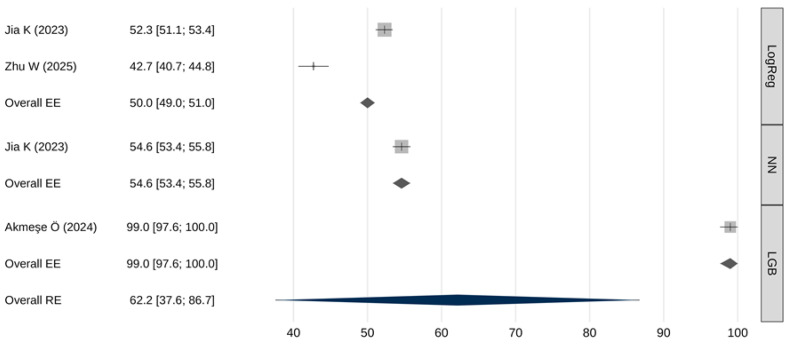 Figure 3
Figure 3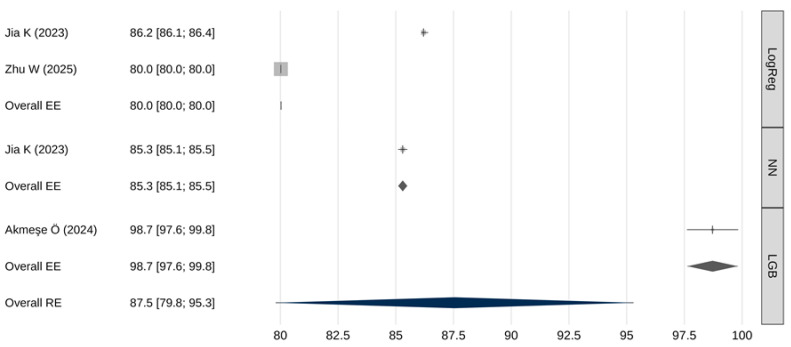 Figure 4
Figure 4| Reference | AI Type | AI Models | Outcome Measures | Population Characteristics | PC Cases ( | Total Sample ( | Model Performance Metrics |
|---|---|---|---|---|---|---|---|
| Chen, Q. et al. [ | ML | XGBoost | Diagnosis of PC; ability to distinguish early-stage PC patients from matched controls | Early-stage PC defined as surgically managed cases; controls matched by region and observation period | 3322 | 53,152 | Se = 60%, Sp = 89.8%, PPV = 0.07%, AUC = 0.84 (95% CI: 0.83–0.85) |
| Chen, W., Zhou, Y., Xie, F. et al. [ | ML | Random Forest | Detection of PC or PC-related death within 18 months | Adults aged 50–84 years with ≥1 clinical visit during 2008–2017; continuous enrollment ≥ 12 months prior to index date | 1792 | 1,801,931 | Se = 56.6%, Sp = 79.6%, PPV = 1.1%, C-index = 0.77 |
| Matchaba, S. et al. [ | ML | Ensemble Model | PC diagnosis predicted 1–2 years prior to clinical diagnosis | Patients with ≥3 healthcare interactions | 8438 | 18,987 | Se = 85.61%, Sp = 76.18%, PPV = 1.1%, AUC = 0.89 |
| Appelbaum, L. et al. [ | ML | Logistic Regression, Neural Network | PC diagnosis predicted 180, 270, and 365 days prior to clinical diagnosis | Patients with ≥6 months of observation prior to diagnosis (cases) or prior to last visit (controls) | 594 | 101,381 | AUROC = 0.71 (95% CI: 0.67–0.76), PPV = 0.93% |
| Park, J. et al. [ | DL | LogReg, NN, Random Masking, XGB, Black-box model | PC diagnosis predicted within 12 months | Patients with ≥1 documented risk factor (smoking, obesity, diabetes, chronic pancreatitis); exclusion of those undergoing treatment for chronic pancreatitis | 834 | 9057 | AUROC: LogReg 0.491; XGB 0.501; Black-box 0.644; NN (no masking) 0.649; NN + Random Masking 0.671 |
| Chen, W., Butler, R. et al. [ | ML | Random Forest | PC diagnosis or death from PC within 3 years after elevated HbA1c | Adults aged 50–84 years with ≥1 elevated HbA1c; exclusion of diabetes patients | 319 | 109,266 | Se = 60%, Sp = 80.3%, PPV = 2.5%, AUROC = 0.812 |
| Malhotra, A. et al. [ | ML | LogReg, RF | Binary classification: PC case vs. control with unrelated cancer | Patients aged 15–99 with primary PC; controls with other cancers | 1139 | 5695 | Se = 65%, Sp = 57%, AUC = 61%, PPV = 32.5% |
| Hsieh, M. et al. [ | ML | LogReg, NN | PC diagnosis among patients with type 2 diabetes | Adults > 20 years with newly diagnosed type 2 diabetes; exclusion of those with prior PC | 3092 | 1,358,634 | PPV: LogReg 0.995, NN 0.996; AUROC: LogReg 0.727, NN 0.605 |
| Muhammad, W. et al. [ | DL | Neural Network | Binary: PC diagnosis within 4 years of survey | General population; PC diagnosed < 4 years before survey | 898 | 800,114 | Se = 87.3%, Sp = 80.8%, AUROC = 0.86, NPV = 99.997%, PPV = 0.1% |
| Placido, D. et al. [ | DL | Transformer | Risk of PC at 3, 6, 12, 36, and 60 months | General population; archival EMRs | 26,403 | 8,123,446 | AUC = 0.879, PPV = 0.32% |
| Xiaodong, Li et al. [ | ML, DL | XGB + Deep NN | PC diagnosis within a 24-month prediction window | Adults ≥ 35 years seeking medical care | 4361 | 265,225 | Se = 54.35%, AUROC = 0.809, PPV = 67.62% |
| Zhao, D. et al. [ | ML | Weighted Bayesian Network Inference | Binary: PC vs. non-PC | Randomly selected controls plus symptomatic non-PC patients | 98 | 15,069 | Se = 84.7%, Sp = 85.2%, AUROC = 0.910 |
| Chen, W., Zhou, B., Jeon, C. et al. [ | ML | RF, XGB | Time-to-event: PC diagnosis or PC-related death within 18 months | Adults aged 50–84, ≥1 clinical visit, no prior PC | 1792 | 1,800,000 | RF: AUC 0.767; XGB: AUC 0.779; PPV ≈1% |
| Jia, K. et al. [ | ML | PrismNN, LogReg | PC risk prediction 6–18 months after index date | Adults > 40 with ≥16 records over 2 years | 35,387 | 1,535,468 | PrismNN: Se = 35.9%, Sp = 95.3%, AUROC = 0.826; LogReg: AUROC = 0.800 |
| Cichosz, S. et al. [ | ML | Random Forest | PC development within 3 years after diabetes onset | Adults > 50 with new-onset diabetes | 716 | 1432 | AUROC = 0.74; Se 21.4% at high specificity; NPV up to 99.8% |
| Shih-Min Chen et al. [ | ML | Linear Discriminant Analysis | PC diagnosis within 4 years post anti-diabetes therapy | Type 2 diabetes patients ≥ 40 years | 89 | 66,384 | Se 86.11%, Sp 84.03%, AUROC 0.907, PPV 0.02% |
| Zhichao Yang et al. [ | DL | NN, Transformer | Disease-/Outcome-agnostic prediction: all ICD oncology codes at next visit | General healthcare-seeking population; PC subgroup ≥ 45 years without other cancers | 4639 | 6,475,218 | AUROC = 0.82, PPV = 8.8% |
| Zhu, W. et al. [ | ML | Elastic-Net Regularized LogReg | PC diagnosis within 2.5–3 years | Adults with ≥3 years of continuous EMR data | 1932 | 53,741 | At 1st percentile threshold: Se = 6.78%, Sp = 99.01%, NPV = 99.93%, PPV = 0.65%, AUROC = 0.742 |
| Akmeşe, Ö. et al. [ | ML | LGBM, Bagging, CatBoost and others | Binary: PC vs. non-PC | PC-patients, non-cancerous (benign) pancreatic/hepatobiliary disease patients, healthy controls. In addition to clinical data, laboratory data were also used | 199 | 590 | LGBM (Best Model): accuracy = 98.8%, precision = 99%, recall = 99%, F1-Score = 0.99, Se = 99%, Sp = 98.7% |
| Study | Selection (/4) | Comparability (/2) | Outcome (/3) | Methodological Quality |
|---|---|---|---|---|
| Chen, Q. et al. [ | 4 | 0 | 2 | 6 (Fair) |
| Chen, W., Zhou, Y., Xie, F. et al. [ | 4 | 1 | 2 | 7 (Fair) |
| Matchaba, S. et al. [ | 4 | 0 | 2 | 6 (Fair) |
| Appelbaum, L. et al. [ | 4 | 1 | 2 | 7 (Fair) |
| Park, J. et al. [ | 4 | 2 | 3 | 9 (Good) |
| Chen, W., Butler, R. et al. [ | 4 | 2 | 3 | 9 (Good) |
| Malhotra, A. et al. [ | 4 | 2 | 3 | 9 (Good) |
| Hsieh, M. et al. [ | 4 | 2 | 3 | 9 (Good) |
| Muhammad, W. et al. [ | 4 | 2 | 2 | 8 (Good) |
| Placido, D. et al. [ | 4 | 2 | 2 | 8 (Good) |
| Xiaodong Li et al. [ | 3 | 0 | 2 | 5 (Poor) |
| Zhao, D. et al. [ | 4 | 2 | 3 | 9 (Good) |
| Chen, W., Zhou, B., Jeon, C. et al. [ | 4 | 2 | 2 | 8 (Good) |
| Jia, K. et al. [ | 4 | 2 | 2 | 8 (Good) |
| Cichosz, S. et al. [ | 4 | 1 | 3 | 8 (Good) |
| Shih-Min Chen et al. [ | 4 | 2 | 2 | 8 (Good) |
| Zhichao Yang et al. [ | 4 | 2 | 2 | 8 (Good) |
| Zhu, W. et al. [ | 3 | 1 | 3 | 7 (Fair) |
| Akmeşe, Ö. et al. [ | 3 | 0 | 2 | 5 (Poor) |
- —The Ministry of Economic Development of the Russian Federation
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPancreatic and Hepatic Oncology Research · Artificial Intelligence in Healthcare and Education · AI in cancer detection
1. Introduction
Despite advances in the diagnosis and treatment of malignant neoplasms, the prognosis for pancreatic cancer (PC) remains poor. The five-year survival rate persists at 3–15%, which is largely attributable to the fact that the disease is frequently diagnosed at advanced stages and current systemic treatments have limited effectiveness [1,2]. Although early detection of PC is crucial, the implementation of population-wide screening or early diagnostic programs faces several substantial obstacles [3]. Despite its high mortality, PC is a relatively rare disease. Its low prevalence, combined with the high cost and limited availability of specialized imaging modalities, makes screening of asymptomatic adults impractical [4].
To improve early detection of pancreatic cancer, researchers have increasingly turned to advanced computational approaches for risk assessment and stratification. In recent years, artificial intelligence (AI) has emerged as a powerful tool for the early detection of cancers and other diseases [5,6,7]. In several oncological fields, AI algorithms have demonstrated promising results, not only in improving screening efficacy but also in stratifying the risk of cancer development and progression, thereby identifying high-risk groups [8]. Furthermore, a number of AI-based diagnostic systems have been approved for the automated and non-invasive detection of diseases using medical data in clinical practice [9].
AI algorithms have been applied to the diagnosis of malignancies using clinical and molecular data, as well as via image analysis through radiomics-based techniques [10]. Of particular interest are AI models and algorithms constructed using textual, numerical, and binary variables extracted from electronic medical records (EMRs) [5,11]. This approach is relatively novel and highly feasible for implementation in real-world clinical practice. Unlike methods requiring specialized, non-routine tests or advanced imaging, EMR-based AI models can be seamlessly integrated into existing healthcare systems, offering a scalable and accessible tool for risk stratification and early detection. Nevertheless, the number of studies dedicated to this topic remains limited.
The objective of this study was to describe and comparatively evaluate different artificial intelligence approaches employed for the early diagnosis of pancreatic cancer using data derived from EMRs.
2. Methods
2.1. Search Strategy
We conducted a comprehensive literature search covering the last fifteen years (2010–2025) across four major online databases: PubMed, MedRxiv, BioRxiv, and Google Scholar. The primary search queries included the following terms: “application of artificial intelligence for pancreatic cancer screening based on database information,” “artificial intelligence and medical records data and pancreatic cancer and screening,” “(‘big data’ OR ‘machine learning’ OR ‘deep learning’ OR ‘artificial intelligence’ OR ‘AI’ OR ‘radiomics’) AND (‘cancer screening’ OR ‘tumor screening’ OR ‘neoplasm screening’ OR ‘oncology screening’ OR ‘early diagnosis’) AND (‘pancreatic cancer’),” “(artificial intelligence for pancreatic cancer screening); (artificial intelligence) AND (cancer screening); (((artificial intelligence) AND (screening)) AND (oncology)) AND (early diagnosis),” “AI-based early detection of pancreatic cancer,” “machine learning in pancreatic cancer screening,” “predictive analytics for pancreatic cancer.”
2.2. Inclusion and Exclusion Criteria
Studies were eligible for inclusion if they met the following criteria: utilization of EMR-derived data exclusively, without incorporating other data modalities (e.g., radiological imaging, molecular profiling); application of artificial intelligence methods as the primary analytical approach; availability of sufficient outcome data to enable performance assessment—specifically, AUC/AUROC metrics; a study objective focused on early detection of pancreatic cancer, which required inclusion of a population without pre-existing pancreatic cancer. Studies were excluded if they met any of the following criteria: published only as letters or abstracts; lacked quantitative performance metrics, used AI only for data extraction rather than prediction, included only patients with confirmed cancer, without a non-cancer comparison group. We followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines [12]. This study was registered in PROSPERO, registration number is CRD420261280741.
2.3. Data Extraction
Two researchers independently screened the literature. The following information was extracted from each eligible study: country of origin; data source, including the specific databases and repositories used; type and specific architecture of the AI models; validation methods employed; target outcomes and study design; study population characteristics; type of data inputs; number of patients with pancreatic cancer; total sample size. Performance metrics extracted included: sensitivity (Se), specificity (Sp), AUROC/C-index, NPV (negative predictive value), and PPV (positive predictive value). Additionally, bibliographies of relevant reviews, articles, and monographs were screened for supplemental references. Any discrepancies were resolved through discussion and consensus.
2.4. Statistical Analysis and Quality Appraisal
Descriptive and qualitative comparisons of the extracted data were used to summarize differences across AI approaches and methodological frameworks. Meta-analysis and data visualization were conducted using R version 4.5.1 (R Foundation for Statistical Computing), employing the metafor package (version 4.8-0). Random-effects models were applied to obtain pooled estimates of predictive performance and 95% prediction intervals. Fixed-effects models were used for meta-regression analyses and for obtaining pooled estimates within predefined algorithm categories. Heterogeneity across included studies was assessed using Cochran’s Q statistic and the I^2^ index. For meta-analyses including five or more studies, publication bias was evaluated using funnel plots and Egger’s regression test. Given the anticipated high heterogeneity in sensitivity and specificity estimates, we initially employed univariate random-effects meta-analysis. However, we acknowledge that bivariate models (such as HSROC (Hierarchical Summary Receiver Operating Characteristic)) are more appropriate for diagnostic accuracy meta-analyses and recommend their use in future studies when sufficient data are available.
The methodological quality of the studies included in the systematic review was assessed using the Newcastle–Ottawa Scale [13]. The authors evaluated each study by applying the Newcastle–Ottawa Scale criteria across three domains: selection of participants, comparability of groups, and outcome ascertainment. A point was awarded for each criterion that was fully met, while no points were given for unmet or partially met criteria. In accordance with the Agency for Healthcare Research and Quality guidelines, the overall quality of each study was then translated into a rating of “poor”, “fair”, or “good” based on the total score.
3. Results
3.1. Characteristics of the Included Studies
A total of 946 records were identified through database searches. The study selection process is depicted in Figure 1, and detailed characteristics of the studies included in the analysis are presented in Table 1. Nineteen studies met the predefined inclusion criteria. Most of the included studies were retrospective cohort analyses employing internal validation strategies, such as train–test split of the available datasets. Across all studies, the primary outcome measure was consistent—either the diagnosis of pancreatic cancer or the time to diagnosis (Table 1). All studies relied exclusively on EMR-derived data, which included clinical documentation related to healthcare encounters; in several cases, socio-demographic survey data were also incorporated.
For a clearer understanding of the role and future potential of AI in early cancer detection, it is important to distinguish between two related terms—machine learning (ML) and deep learning (DL). Machine learning refers to a broad class of algorithms capable of learning from data and improving their predictive performance over time. Deep learning, by contrast, is a specialized subset of ML that utilizes complex multilayer neural networks capable of capturing intricate nonlinear relationships [14]. For clarity, Table 1 lists ML and DL as separate AI categories, although DL is technically a subset of ML. Across the included studies, a variety of AI algorithms were used, including XGBoost (XGB), Random Forests (RFs), logistic regression (LogReg), ensemble models, neural networks (NNs), and Light Gradient Boosting (LGB).
3.2. Quality Assessment
The methodological quality of the included studies, assessed using the Newcastle–Ottawa Scale, was variable but generally acceptable for observational research (Table 2). The majority of the studies demonstrated an adequate design regarding participant selection and outcome assessment, receiving a rating of “good” or “fair” in terms of Methodological Quality. However, some heterogeneity was noted, particularly in the comparability of study groups and control for confounding factors.
3.3. Meta-Analytic Assessment of AUC
Not all studies provided adequate data for inclusion in the AUC meta-analysis. Table 3 and Figure 2 summarize the pooled AUC results. The overall pooled AUC using a random-effects model was 0.785 [95% CI: 0.759–0.810], with a 95% prediction interval ranging from 0.716 to 0.853. There was substantial heterogeneity across studies (I^2^ = 99.5%, Q(df) = 458.6, p < 0.001). No strong evidence of publication bias was identified (β = 0.82; [95% CI: 0.80–0.84]; p = 0.406).
Meta-regression demonstrated a statistically significant association between model type and AUC values (Q(3) = 398, p < 0.001). Pairwise comparisons using fixed-effects models showed (Table 4): neural networks had significantly higher AUROC values compared to logistic regression, RF, and XGB models (p < 0.001); logistic regression models had significantly higher AUROC than RF models (p < 0.001).
3.4. Meta-Analytic Assessment of Sensitivity
Table 5 and Figure 3 summarize the pooled sensitivity results. The overall pooled sensitivity (random effects) was 62.2% [95% CI: 37.6–86.7], with a 95% prediction interval from 7.2% to 100%. Extremely high heterogeneity was observed (I^2^ = 99.9%, Q(df) = 3636, p < 0.001). No significant publication bias was identified (β = 0.65; [95% CI: 2.43–3.73]; p = 0.981).
Meta-regression indicated that sensitivity differed significantly across AI model types (Q(2) = 3569, p < 0.001). Table 6 presents the results of pairwise comparisons of meta-analytic sensitivity estimates obtained using the fixed-effects models. LGB models demonstrated the highest sensitivity—statistically superior to both neural networks and logistic regression (p < 0.001), neural networks also demonstrated a slightly higher sensitivity compared to logistic regression (p < 0.001).
3.5. Meta-Analytic Assessment of Specificity
A meta-analysis of the specificity of AI models was also performed (Table 7 and Figure 4). The overall pooled specificity (random effects) was 87.5% [95% CI: 79.8–95.3], with a 95% prediction interval from 70.2% to 100%. Again, extremely high heterogeneity was present (I^2^ = 100%, Q(df) = 10,695, p < 0.001), and there was a trend toward publication bias (β = 0.8; [95% CI: 0.8–0.8;] p = 0.062).
The meta-analytic regression model revealed a statistically significant association between the type of predictive model and specificity estimates (Q(2) = 3913, p < 0.001). Table 8 presents the results of pairwise comparisons of meta-analytic specificity estimates obtained using fixed-effects models. LGB models demonstrated a statistically significantly higher specificity compared to both logistic regression models and neural network-based models (p < 0.001). Neural networks also showed a somewhat higher specificity than logistic regression (p < 0.001).
4. Discussion
This systematic review and meta-analysis demonstrate the substantial potential of artificial intelligence models trained on electronic medical record (EMR) data to address one of the most critical challenges in oncology—the early detection of pancreatic cancer (PC). The pooled AUC estimate of 0.785 [95% CI: 0.759–0.810] indicates overall good and clinically meaningful discriminatory performance of AI-based models. A notable finding of this review is the statistically significant difference in performance across AI model types. Neural network-based models consistently demonstrated the highest AUROC values, likely reflecting their ability to capture complex nonlinear relationships and temporal patterns within high-dimensional EMR data—patterns that may be undetectable by more traditional models such as logistic regression. However, while neural networks achieved the highest pooled AUC, caution is warranted in interpreting this result. Performance disparities could be influenced by study-specific factors—including sample size, feature engineering, temporal modeling, and validation design—rather than algorithmic advantage alone.
Performance comparisons across key metrics revealed additional important distinctions. In terms of sensitivity, LGB models markedly outperformed both neural networks and logistic regression (99% [97.6–100] vs. 54.6% [53.4–55.8] and 50% [49–51], respectively). Such high sensitivity makes LGB models particularly attractive for screening applications where failure to detect disease carries significant clinical risk. However, this exceptionally high sensitivity was reported in a single study, warranting cautious interpretation and the need for external validation. Similarly, LGB models demonstrated significantly higher specificity than neural networks or logistic regression (98.7% [97.6–99.8] vs. 85.3% [85.1–85.5] and 80% [80–80], respectively). Neural networks, meanwhile, exhibited intermediate—yet significantly superior—performance compared with logistic regression across both sensitivity and specificity metrics.
Despite encouraging results, the analysis revealed extremely high heterogeneity in sensitivity and specificity estimates between studies (I^2^ ≥ 99.9%). This could be explained by substantial differences in study design, variations in the studied populations, and the types of predictors used. Our meta-analysis is limited by the high methodological heterogeneity of the included works: they differed in design (case–control vs. cohort), outcomes (binary classification vs. time-to-event), time horizons (3–60 months), population composition (general population and at-risk cohorts), as well as classification thresholds defining sensitivity and specificity. Some studies used enriched cohorts or external data sources, which reduces comparability with models trained on ‘pure’ EMRs of the general population. Under such conditions, aggregating Se/Sp in univariate models may yield biased estimates; due to the high heterogeneity, the results for Se and Sp should be interpreted with caution. Therefore, in future analyses, once a larger number of studies on this topic become available, alternative approaches such as the bivariate HSROC model should be employed for a more accurate estimation.
Differences in prediction windows and outcome definitions are important sources of heterogeneity, but a stratified meta-analysis was not possible due to incomplete reporting. Few studies provided performance metrics for specific time horizons, and the number of comparable studies within each stratum was too low to allow robust subgroup analysis. This limitation underscores the need for standardized reporting of time-stratified results in future research on AI-based pancreatic cancer prediction.
The extremely low PPVs observed in most studies underscore a fundamental challenge in pancreatic cancer screening, driven by the disease’s low prevalence. Even a model with high specificity will generate a large number of false-positive results when applied to the general population, potentially leading to unnecessary diagnostic procedures. Consequently, an AI implementation strategy should focus not on universal screening, but on risk stratification and the identification of high-risk patient groups. Within these high-risk cohorts, more in-depth analyses using AI models should be conducted to define subgroups for targeted instrumental examination.
Our analysis highlights the critical need for AI methodologies that can effectively manage the inherent complexity, non-linearity, and temporal dynamics of longitudinal EHR-data. This imperative is echoed by contemporary methodological innovations in modeling other complex, chronic conditions. The DEPOT framework, for example, utilizes a graph-based AI approach specifically engineered to address the challenges of fragmented and heterogeneous EHR data [32]. By constructing an age-similarity graph and employing representation learning, DEPOT successfully identified distinct, high-risk progression trajectories for chronic kidney disease within a diabetic cohort. Importantly, this model’s ability to isolate a high-risk trajectory enriched with specific cancer phenotypes powerfully illustrates the principle of targeted risk stratification [33]. This aligns with our central conclusion that the early detection of pancreatic cancer will be most feasible and effective when AI models are applied to identify and monitor enriched high-risk subpopulations, rather than through untargeted general screening.
5. Conclusions
Artificial intelligence models trained on electronic medical record data represent a promising tool for improving the early detection of pancreatic cancer, demonstrating good discriminatory ability in certain studies. However, high heterogeneity, typically low positive predictive value, and the absence of further validation currently preclude their use as stand-alone screening tools. Their effective clinical implementation relies not on replacing clinicians, but on integrating AI systems as decision-support tools capable of identifying patients at elevated risk who may benefit from closer evaluation or targeted diagnostic testing.
Successful implementation of these technologies will require further prospective research, methodological standardization, and improved interpretability of AI models, as well as seamless integration into clinical workflows. By addressing these challenges, AI-driven risk stratification has the potential to transform the diagnostic landscape for pancreatic cancer and mitigate delays in detection—ultimately improving patient outcomes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bray F. Ferlay J. Soerjomataram I. Siegel R.L. Torre L.A. Jemal A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries CA Cancer J. Clin.20186839442410.3322/caac.2149230207593 · doi ↗ · pubmed ↗
- 2Arnold M. Rutherford M.J. Bardot A. Ferlay J. Andersson T.M. Myklebust T.Å. Tervonen H. Thursfield V. Ransom D. Shack L. Progress in cancer survival, mortality, and incidence in seven high-income countries 1995-2014 (ICBP SURVMARK-2): A population-based study Lancet Oncol.2019201493150510.1016/S 1470-2045(19)30456-531521509 PMC 6838671 · doi ↗ · pubmed ↗
- 3Strobel O. Neoptolemos J. Jäger D. Büchler M.W. Optimizing the outcomes of pancreatic cancer surgery Nat. Rev. Clin. Oncol.201916112610.1038/s 41571-018-0112-130341417 · doi ↗ · pubmed ↗
- 4Hart P.A. Chari S.T. Is Screening for Pancreatic Cancer in High-Risk Individuals One Step Closer or a Fool’s Errand?Clin. Gastroenterol. Hepatol.201917363810.1016/j.cgh.2018.09.02430268560 PMC 6557281 · doi ↗ · pubmed ↗
- 5Malhotra A. Rachet B. Bonaventure A. Pereira S.P. Woods L.M. Can we screen for pancreatic cancer? Identifying a sub-population of patients at high risk of subsequent diagnosis using machine learning techniques applied to primary care data P Lo S ONE 202116 e 025187610.1371/journal.pone.025187634077433 PMC 8171946 · doi ↗ · pubmed ↗
- 6Estiri H. Strasser Z.H. Klann J.G. Naseri P. Wagholikar K.B. Murphy S.N. Predicting COVID-19 mortality with electronic medical recordsnpj Digit. Med.202141510.1038/s 41746-021-00383-x 33542473 PMC 7862405 · doi ↗ · pubmed ↗
- 7Luchini C. Pea A. Scarpa A. Artificial intelligence in oncology: Current applications and future perspectives Br. J. Cancer 20221264910.1038/s 41416-021-01633-134837074 PMC 8727615 · doi ↗ · pubmed ↗
- 8Ramos-Casallas A. Cardona-Mendoza A. Perdomo-Lara S.J. Rico-Mendoza A. Porras-Ramírez A. Performance Evaluation of Machine Learning Models in Cervical Cancer Diagnosis: Systematic Review and Meta-Analysis Eur. J. Cancer 202522911576810.1016/j.ejca.2025.11576840957290 · doi ↗ · pubmed ↗