Chaos-Enhanced, Optimization-Based Interpretable Classification Model and Performance Evaluation in Food Drying
Cagri Kaymak, Bilal Alatas, Suna Yildirim, Ebru Akpinar, Gizem Gul Katircioglu, Murat Catalkaya, Orhan E. Akay, Mehmet Das

TL;DR
This study uses an advanced AI method to optimize and explain the drying process of Paşa pears, showing how temperature and air speed affect drying efficiency.
Contribution
The study introduces the first application of the oscillatory chaotic sunflower optimization algorithm (OCSFO) to generate interpretable rules for food drying without discretization.
Findings
Drying performance is significantly influenced by temperature and air velocity, with product mass decreasing from 450 g to 103 g.
The OCSFO algorithm achieved over 90% success in classifying drying performance into high, medium, and low categories.
Energy consumption and cabin temperature distribution play a supporting role in determining drying efficiency classes.
Abstract
Food drying is a widely used preservation technique; however, achieving high energy efficiency while maintaining product quality remains a significant challenge. This study aims to analyze comprehensive experimental data obtained during the hot-air drying process of the Paşa pear (regional pear) and the system’s autonomous control structure using an explainable artificial intelligence (XAI)-based method. The intelligent drying system, operating for approximately 17.5 h under two temperatures (50 °C and 65 °C) and two air speeds (0.63 m/s and 1.03 m/s), continuously adjusted the temperature and air speed using a PLC-based control mechanism; it ensured stable control throughout the process by monitoring parameters such as product weight, moisture, inlet–outlet temperatures, and air speed in real time. Experimental results showed that drying performance varied significantly with operating…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3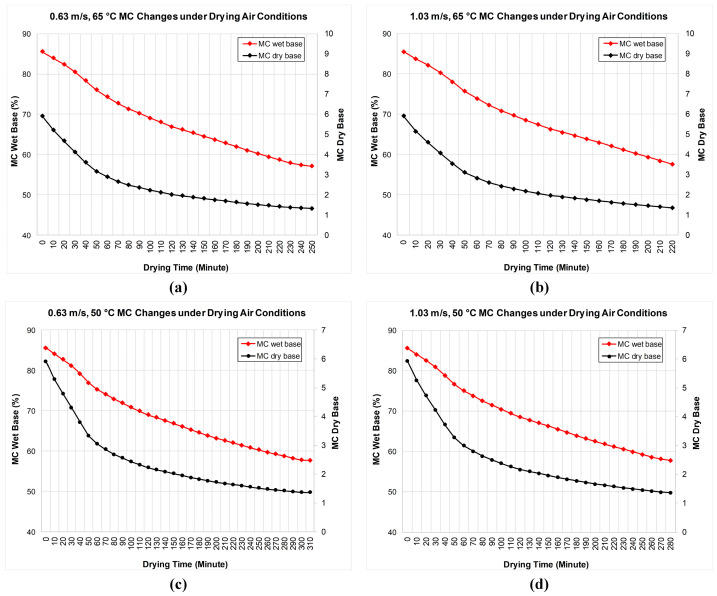 Figure 4
Figure 4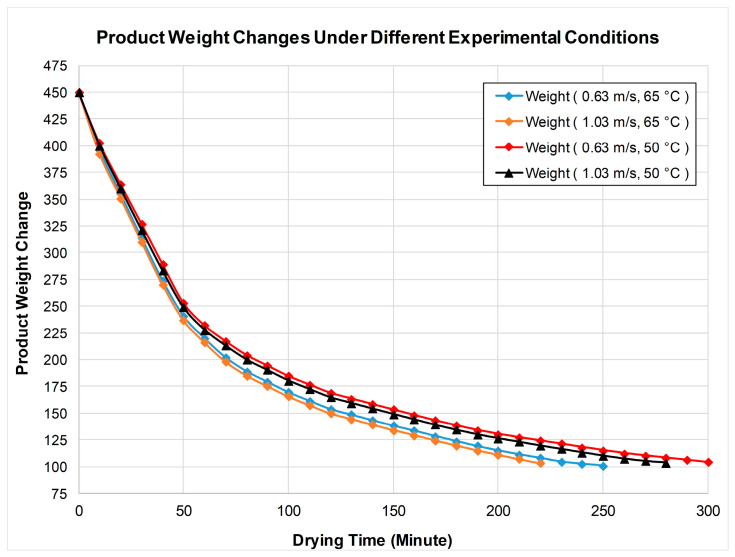 Figure 5
Figure 5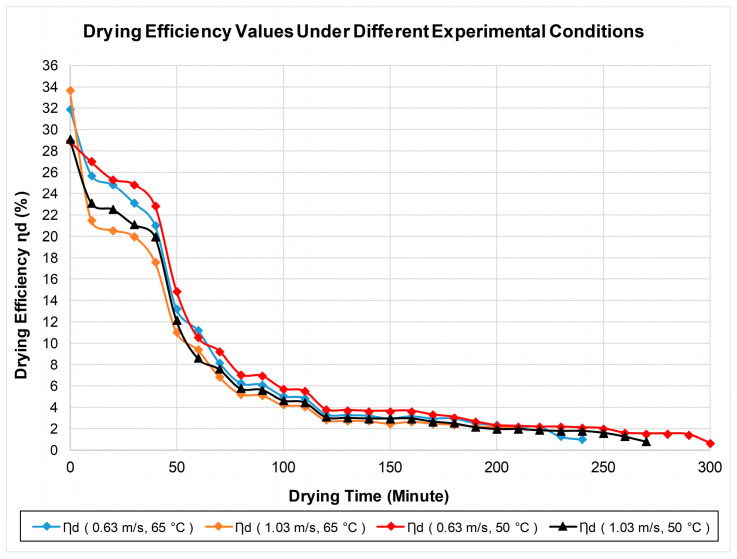 Figure 6
Figure 6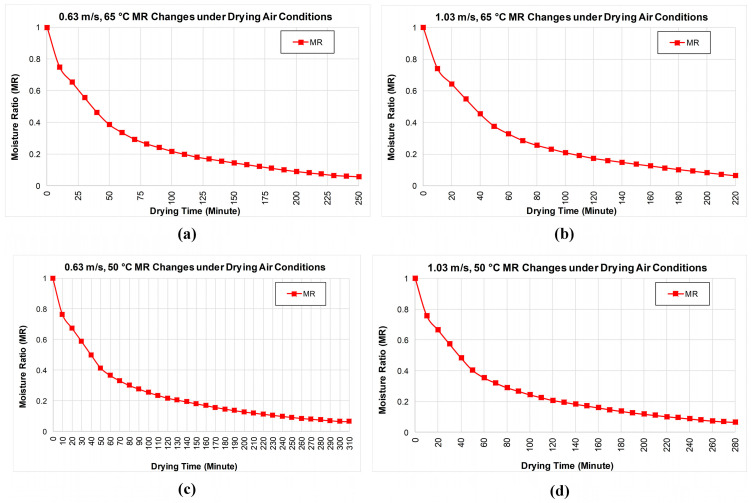 Figure 7
Figure 7- —Turkish Scientific and Technological Research Council (TÜBİTAK)
- —Firat University Scientific Research Projects Coordination (FUBAP)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFood Drying and Modeling · Microencapsulation and Drying Processes · Food Supply Chain Traceability
1. Introduction
It is well known that the development of societies is directly related to people’s balanced and healthy nutrition with quality foods. For society to meet its needs and maintain a healthy lifestyle, it must have easy access to healthy foods [1].
In recent years, food technology producers, motivated by a desire to access healthier food, have encouraged the cultivation of higher-quality products. The most common method used to meet the need for seasonal food consumption is food drying. The drying process involves heat and mass transfer, and drying agricultural products with solar energy is recognized as one of the oldest food preservation methods. Sunlight food drying causes a serious decline in food quality due to environmental factors. For this reason, performing the drying process with specially designed artificial dryers both shortens the drying time and enables the production of higher-quality, more hygienic products with a longer shelf life. Thanks to food-drying systems developed with technological advances, access to food available in almost every season has been made possible. In recent years, the food drying sector has made significant progress with artificial intelligence and control techniques.
Hosseinpour et al. [2] developed a fixed, unscaled image texture processing method to eliminate the effects of sample shrinkage on texture properties during the drying of shrimp. The images of texture properties were processed using an artificial neural network (ANN) to estimate the moisture content of shrimp. Janjai et al. [3] developed an innovative approach to evaluate the effectiveness of solar drying for Chinese cherries (lychees) in a parabolic greenhouse dryer using an ANN. They conducted ten trials with 100 kg of lychees to achieve higher performance. They used an ANN model to dry lychees and model their performance. To test the success of the ANN model, they evaluated seven standard datasets to train an ANN model with four inputs, one output, and two hidden layers. As a result, they found that their method had the capacity to predict the dryer’s operations after sufficient training. Guiné et al. [4] introduced an ANN modeling technique for the antioxidant activities and phenolic components of bananas for different drying methods. The bananas were air-dried at 50–70 °C and then cleaned and lyophilized, during which they were examined for antioxidant and phenolic content. The ANN modeling they applied in their study revealed that the number of phenolic compounds and antioxidant activity could be predicted with high accuracy using simple ANNs based on drying conditions, banana varieties, and specific types. Taheri-Garavand et al. [5] found that ANN successfully predicted drying parameters (moisture ratio, dry material, energy efficiency, and exergy efficiency) during the hot-air drying process of banana slices. Liu et al. [6] preferred the Bayesian extreme learning machine (BELM) method to analyze the color changes of mushroom slices throughout the drying process. In their research, they found that BELM predicted color changes in mushroom slices during drying more effectively than classical backpropagation neural networks. Nadian et al. [7] developed an intelligent fuzzy artificial vision control system that combines computer vision with fuzzy logic to manage process parameters in complex hot air and infrared drying processes, monitor color and volume changes during kiwi drying, and improve the quality of products obtained using a genetic algorithm (GA). This innovation reduced the time from 40 min to 24 min (40%) compared with the hot-air drying method alone. Chakravartula et al. [8] used a convective dryer equipped with a computer vision system and a load cell to continuously monitor unbleached or bleached carrot slices during the drying process. The setup of these systems enabled them to use the linear regression method to track product characteristics (weight, color, and size) and develop moisture prediction models related to shrinkage. The linear models based on the shrinkage examined yielded better results compared to more complex, specific thin-layer models.
All studies in the literature show that model results are mostly dependent on systems that operate as black boxes. In recent years, particularly in the fields of engineering and energy systems, the limitations of such black-box approaches have been highlighted, and it has been reported that interest in explainable artificial intelligence (XAI) methods, which aim to increase the understandability of decision mechanisms, has rapidly increased [9,10].
In recent years, optimization algorithms inspired by biomimetics have garnered significant attention in energy systems, process optimization, and intelligent control applications [11,12]. These methodologies, which replicate natural phenomena like swarm behavior, evolutionary adaptation, and plant intelligence, provide effective search capabilities for addressing difficult and nonlinear optimization challenges. Bio- and nature-inspired optimization algorithms have been effectively utilized in energy-efficient system design, renewable energy management, thermal system design, and control parameter tuning, where traditional deterministic methods often underperform [13,14,15].
Additionally, explainable artificial intelligence (XAI) has arisen as a pivotal research focus in engineering applications, seeking to address the shortcomings of opaque learning models by offering transparent and interpretable decision-making processes [16,17,18,19]. Recent studies have shown that combining bio-inspired optimization algorithms with interpretable models can markedly improve decision transparency, model dependability, and physical interpretability [11,12,13,14,20,21,22]. Notwithstanding these advancements, the amalgamation of plant intelligence-based optimization algorithms with XAI-driven quantitative rule mining for food drying systems remains predominantly unexamined. However, the model obtained in this study consists of explainable, understandable, transparent, and interpretable rules, and the effects of the relevant input parameters and their appropriate ranges on the output parameter are clearly visible. The sunflower optimization (SFO) algorithm is a nature-inspired optimization algorithm developed based on the sun-seeking behavior of sunflowers. The fundamental principle of the algorithm is based on iteratively moving towards the best solution, referred to as the “sun”. Although it is a relatively new method in the literature, it has produced successful results in various engineering problems. Qais et al. [23] used SFO for modeling and simulating photovoltaic modules and demonstrated that high accuracy could be achieved even with standard algorithm parameters. Gomes et al. [24] compared SFO with genetic algorithms and improved SFO variants in the damage detection problem of plate-like structures and reported that SFO-based approaches exhibited superior performance. Yuan et al. [25] proposed an improved SFO with a self-adaptive weighting mechanism for the parameter optimization of proton exchange membrane fuel cells (PEMFC). Hussein et al. [26] used SFO for optimizing PI controller parameters and compared the results with particle swarm optimization. Shaheen et al. [27] and Alshammari et al. [28] demonstrated that chaotic map-based SFO variants are more successful than classical optimization algorithms in the field of power systems. However, the vast majority of existing SFO-based studies focus on continuous optimization and black-box performance improvement problems; the potential of SFO in interpretable decision support systems, such as XAI and rule mining, has not yet been sufficiently addressed in the literature.
An artificial intelligence model that controls both the drying process and system energy and has explainable, interpretable features has not been used in food drying systems. In this study, an intelligent drying system capable of autonomously adjusting temperature and air speed for drying the “Paşa” pear, a variety specific to Elazig, was developed, and various drying scenarios were created. A total of four experiments, involving two different temperatures (50 °C and 65 °C) and two different air speeds (0.63 m/s and 1.03 m/s), lasted approximately 17.5 h in the designed system, and data were collected from the system at one-minute intervals. In the experiments, the product’s weight, surface temperature, inlet and outlet air temperature and humidity values, cabin internal temperature, and air speed were continuously measured, and energy consumption was analyzed. The experimental data were analyzed using explainable artificial intelligence (a hybrid method based on the sunflower optimization (SFO) algorithm), and the effects of drying parameters on energy consumption and drying efficiency were determined using transparent and interpretable rules. Thanks to these rules, optimal drying conditions were identified, and high-quality products were obtained with minimal energy consumption.
2. Materials and Methods
2.1. Experimental Drying System and Hardware Configuration
Figure 1a shows the three-dimensional design of the system designed for the experiments conducted and the numbering of its components, while Figure 1b shows the final state of the manufactured system.
The list of hardware components numbered in the three-dimensional design in Figure 1a is provided in Table 1.
When food samples are tested by drying, interface pages are created on the PLC’s HMI panel to enable the necessary calibrations and controls to be performed so that parameters such as temperature, humidity, weight, and air velocity can be successfully measured. This was implemented on the system as shown in Figure 2.
2.2. Experimental Procedure and Drying Scenarios
In the drying experiments conducted, the pear product was cut into oval pieces that were 10 mm thick. The fruit seeds were removed and placed on the drying tray. The tray had 0.5 mm holes, and its instantaneous weight was measured using load cells with a capacity of 10 kg on both sides. In the drying experiments, fresh air was supplied in a closed cycle, and when the humidity of the inlet and outlet air was equalized, fresh air was supplied again with the help of automatic open–close flaps. During the food-drying process, the system included 4 IR temperature sensors measuring the product surface temperature, 2 load cells measuring the product weight, air temperature, and humidity sensors at the drying compartment inlet and outlet, a cabin internal temperature sensor, and transmitter sensors measuring the drying air velocity. In the experiments conducted, air speeds of 0.63 m/s and 1.03 m/s were initially selected. Experiments were conducted at drying temperatures of 50 °C and 65 °C for each speed value. In line with the drying scenarios and quality constraints, a drying process with optimal energy use and high product quality was established. The initial and final states of the dried products are shown in Figure 3.
All sensor data were continuously recorded at 1-min intervals throughout the drying process. The raw data obtained were resampled at 10-min intervals to both represent the drying kinetics more consistently and to create a data structure suitable for explainable artificial intelligence (XAI)-based rule mining analyses. The resulting dataset preserved the temporal dynamics of the drying process while reducing measurement noise and enabling interpretable rule extraction.
2.3. Drying Kinetics and Energy Calculations
Mass transfer calculations for the product were performed in drying experiments. In the experiments, the product’s wet- and dry-basis moisture content, moisture ratio values, and drying efficiency values are calculated. The moisture content of food products is evaluated as the amount of water they contain. Percentage parameters are used to express the amount of water in food. Wet- and dry-basis definitions are used to determine moisture content. Equations (1) and (2) are used to calculate the moisture content ( ) of the food product on a wet basis ( ) and dry basis ( ).
In the equations, is the wet weight and is the dry weight. Dimensionless moisture ratio ( ) values were calculated using Equation (3).
Equation (3) presents the equilibrium relative humidity value of the dried product . The moisture content specified here represents the solid-matter-based reference moisture content determined by the Shimadzu MOC63u device (72.9 g water/g solid), not the environmental equilibrium moisture content. In Equation (4), is the dryer efficiency, and are the initial and final masses of the pear product (kg), is the latent heat of vaporization (kJ/kg), is the specific heat of water (kJ/kg. K), and are the dryer outlet temperature and ambient temperature (K), respectively, and is the total energy consumed by the heater and fan in the system.
2.4. Measurement Uncertainty Analysis
In the measurements performed, the equation provided by Holman et al. [29], expressed in Equation (5), was used for uncertainty analysis. In uncertainty analysis, also known as the partial differential method, it is expressed as the total error ratio ( ) in a measurement with independent variables.
In Equation (5), represents the dimension to be measured, represent the parameters affecting the measurement, and , , ,… represent the error rate related to the independent variable [30]. The uncertainty values calculated for the measurement parameters are presented in Table 2.
2.5. Input and Output Variables for Explainable AI (XAI) Modeling
In this study, the dataset used for the XAI-based rule mining model is structured with seven input variables and one output variable obtained from experimental measurements. The input variables represent the thermal, fluid, and energy-based dynamics of the drying process, while the output variable indicates the classified state of drying efficiency. The model’s output variable consists of high (H), medium (M), and low (L) classes defined according to drying efficiency values. The parameters used in the rules generated by explainable artificial intelligence methods for the pear product are given in Table 3.
** * Meaningfulness of Parameters and Literature Support * **
Output and input temperatures ( , ): Directly affect moisture removal rate. Temperatures outside the optimal range may cause crusting on the product surface or excessive energy consumption [2].
Air velocity ( ): High air velocities accelerate drying by increasing the moisture transfer coefficient. However, very high velocities can increase energy consumption [3].
Product weight ( ): Weight change is directly related to the decrease in moisture content. Mass loss reflects the degree of progress in the drying process [7].
Heat energy produced ( ): This is directly related to the energy expended in the drying cabinet for the product’s moisture loss. Energy efficiency increases within the optimal range [1].
Total energy consumption ( ): Efficiency is a directly effective parameter, as it is the ratio between the energy supplied to the system and the moisture removed [5].
2.6. Class Definition and Labeling for Drying Efficiency
This study regarded drying efficiency as a categorical output variable to facilitate explainable rule-based modeling. According to the computed drying efficiency values and quality–energy trade-off assessments, the drying process was categorized into three distinct performance levels: high (H), medium (M), and low (L) efficiency. This class-based format facilitates the derivation of clear and interpretable decision rules, explicitly demonstrating how varying operational parameter ranges affect drying performance. The implemented labeling technique guarantees an equitable depiction of efficiency levels while maintaining the physical significance of the drying process, thus enabling dependable explainable artificial intelligence (XAI) analysis.
In this study, drying efficiency was treated as a categorical output variable for explainable rule-based modelling. The drying efficiency values calculated from the experiments have been divided into three separate performance levels, taking into account both the numerical distribution and the energy–product quality balance: high (H), medium (M), and low (L). The high-efficiency class represents operating conditions in which maximum moisture removal per unit of energy is achieved while maintaining product quality. The medium-efficiency class denotes situations in which the system exhibits acceptable performance but is only partially deviating from optimal conditions. The low efficiency class covers operating conditions where moisture removal remains limited despite increased energy consumption, particularly in the final stages of drying. The threshold values for these classes have been determined based on drying efficiency ranges obtained from experimental data and are summarized in Table 4.
In this study, average drying efficiency was preferred over instantaneous drying efficiency as the classification target. Average drying efficiency is a stable performance indicator at the system level. It shows how much of the total energy input during the drying process is effectively used for moisture removal. Instantaneous drying efficiency values are highly sensitive to transient heating effects, sensor sensitivities, and short-term fluctuations, especially in the initial stages of drying. This sensitivity often makes it hard to obtain physically meaningful and generalizable rules from explainable artificial intelligence-based rule-extraction processes. In contrast, average drying efficiency is a more reliable and interpretable target for defining high (H), medium (M), and low (L) efficiency classes. It reflects the initial and final moisture conditions of the product, total energy consumption, and the energy–mass transfer balance of the entire drying process.
2.7. Sunflower Optimization (SFO) Algorithm
The study utilized the sunflower optimization (SFO) algorithm, a plant intelligence algorithm. There are two key reasons for choosing the SFO algorithm. First, plant intelligence-based approaches have not been previously studied for rule inference problems, to the best of our knowledge. Therefore, there is a need for a study in this field that can measure the performance of such algorithms. Second, the high performance of the SFO algorithm, which uses the internal loop principle, provides an advantage over other plant-based approaches. For these reasons, the SFO algorithm was selected to solve this problem.
At the core of the SFO algorithm lies the movement of sunflowers following sunlight [31]. In the SFO algorithm mechanism, individuals want to maintain their position if they are close to the sun and show greater orientation to approach the sun if they are far away. One of the important principles in the algorithm is the representation of sunflowers’ orientation towards the sun. The sun ( ), which is the current best solution in the population, serves as a reference for other sunflower individuals ( ). The orientation of the population containing individuals towards the sun is denoted by and is generally expressed as in Equation (6).
The algorithm’s progression toward the optimum is called the direction and is expressed by Equation (7). The convergence is based on two fundamental parameters. These are , the inertia coefficient, and , which represents the probability of convergence between the -th individual and the -th individual. As can be seen from the general expression, individuals closer to the sun will converge toward it in small steps, while those farther away will attempt to converge in larger steps.
In the classical SFO algorithm, in each iteration, some individuals far from the sun are removed from the search process according to the population removal rate ( ), and new individuals are generated to replace them. These new individuals join the population in each iteration, helping to find different exploration points. In addition, when determining the new positions of other individuals, it is necessary to pay attention to the maximum convergence value so as not to miss the global minimum individuals. This basic principle is provided by Equation (8). In this equation, and indicate the upper and lower limit values, while indicates the total number of individuals in the population. Equation (9) is used to calculate the value of the new individual. These basic steps and logical functions of the SFO algorithm can be seen in the pseudocode in Algorithm 1.
Algorithm 1. Sunflower Optimization (SFO) Algorithm pseudocode1. ← problem-defined upper and lower bounds2. ← maximum number of iterations3. ← population size 4. ← population removal rate (%)5. for i = 1 to 6. IndividualGeneratorFunction( )7. AddToPopulation( )8. end for9. CalculateObjectiveValue()10. ← FindSun()11. OrientTowardsSun()12. while(i < )13. for j = 1 to 14. CalculateIndividualVector()15. RemoveDistantIndividuals(%O, i)16. EvaluateNewIndividuals( )17. end for 18. CalculateObjectiveValue() 19. ← FindSun()20. End while21. DisplayBest()
In the SFO algorithm, the inverse square law of radiation applies, and one factor is the distance from the sun. In this law, there is an exponential (usually quadratic) inverse relationship between the radiation produced and the distance to the target. In other words, the distance of a sunflower (individual solution) from the best solution (the sun) will determine its presence within the population. This effect is denoted by and is generally expressed as in Equation (10). In this equation, is the power of the source and is the distance between the -th individual and the current best solution.
While the SFO algorithm has exhibited competitive efficacy in numerous optimization challenges, its direct utilization in explainable rule mining tasks may be hindered by restricted exploration capacity and premature convergence when addressing intricate and nonlinear parameter interactions. This paper introduces an improved variation, called the oscillating chaotic sunflower optimization (OCSFO) algorithm, to address these constraints and improve global search diversity and solution stability. OCSFO enhances the original SFO framework by incorporating oscillatory search dynamics and chaotic mapping processes to improve rule diversity, convergence robustness, and interpretability in XAI rule mining applications.
2.8. Oscillating Chaotic Sunflower Optimization (OCSFO) Algorithm
This section provides a detailed description of the oscillating chaotic sunflower optimization (OCSFO) [32] algorithm, emphasizing the improvements made to improve exploration diversity and convergence stability. In the classical SFO algorithm, rapid and excessive population growth is undesirable. For this reason, the algorithm executes an individual elimination mechanism within the population, which depends on an elimination coefficient (mortality rate). Excessive individual elimination is prevented by adding a certain proportion of new individuals to the population. A point that is often overlooked here is the possibility that the newly generated individuals may be similar to other individuals in the population. The OCSFO algorithm, which is a hybrid of chaotic search and sunflower optimization, uses a new oscillation-based individual generation to prevent this. Thus, the newly generated individual is positioned with limited randomness relative to the population optimum and the search space limits. A two-stage process is executed for this purpose. The first stage involves determining the position of the new individual solutions between the best solution and the search limits for a predefined ratio ( ). To do this, a Gaussian Distribution-based value is used, whose mean is the average distance between individuals. The mathematical expression for this stage is as shown in Equations (11) and (12). Here, the problem size , , mean value , location center , and variance are the determining parameters.
The second stage in generating the individual that will represent the new solution is to prevent the individuals produced from being similar to each other. Accordingly, the new individual position is then passed through a trigonometric auxiliary function presented in Equation (13). Accordingly, the random chaotic value ɳ and a predefined constant β cause the new position to oscillate relative to its previous value.
Unlike the classical SFO algorithm, the OCSFO algorithm uses chaotic map functions to add new individuals to the population. This ensures that all individuals, including the initial population, are generated chaotically. The performance of the OCSFO algorithm has been tested using different chaotic map functions known in the literature. The pseudocode of the algorithm is provided in Algorithm 2. Algorithm 2. Oscillating Chaotic Sunflower Optimization (OCSFO) Algorithm pseudocode1. ← define lower and upper bounds2. ← iteration number3. ← population value4. ← which chaotic function5. ← elimination rate (%)6. 7. )8. )9. end for10. FindObjectiveValues()11. ← FindBest()12. OptimizeSolutionsTowardsBest()13. )14. for j = 1 to …15. FindVectorForIndividual()16. )17. )18. end for19. FindObjectiveValues()20. ← FindBest()21. End while22. ReturnBestValue()where k represents the chaotic map function used. This function uses the parameters , , , and .
2.9. Hybrid Optimization-Based Quantitative Rule Mining Framework
This section presents a hybrid optimization-based quantitative rule mining framework, wherein the OCSFO algorithm is utilized to derive interpretable classification rules directly from numerical data without the need for discretization. It focuses on the applicability of the SFO algorithm, which has not been used in rule mining before, to rule mining. However, similar to other applications in the literature, the standard SFO algorithm is not directly applicable to rule inference systems, and it is thought that a version of the SFO algorithm adapted for this purpose, which is aimed at continuous optimization problems, is needed. For this adaptation, the representation forms of rule inference, individuals must be correctly determined.
There are many methods and algorithms used for classification rule mining [33,34]. Most of these classification algorithms and models are black-box-based approaches. However, understandable rules are quite important in explainable artificial intelligence data mining, which aims to arrive at correct rules as well as in datasets. Furthermore, mining interesting, understandable, and accurate classification rules in a dataset consisting of numerical features is more complex. Classification algorithms for quantitative data perform a type of discretization by performing a preprocessing step that can cause information loss. In this case, the dataset problem is changed in data mining. Therefore, the discovered classification rules belong to the model of the modified dataset. Changing the dataset is error-prone and also requires computational load. When the dataset is changed, the accuracy of the classification problem for which the solution is desired will also decrease. For this reason, it is more logical to adapt the classification method without changing the dataset [35]. Finding relevant intervals for quantitative features and combining mining for high-quality quantitative classification rules with multiple targets in a single step appear to be very meaningful in terms of speed and accuracy.
This study has adopted a different representation form for each solution in a population of n individuals in quantitative rule inference problems [35]. In this representation, a (number of attributes) dimensional solution contains three sub-datasets: , , and . holds binary data for each attribute of a solution. Whether a feature is added to the solution’s rule is determined by the value . In the initial population, is determined by the random generator function and a predefined threshold value “ ”. This operation is calculated using Equation (14).
represents the lower limits calculated for each property of the rule belonging to a solution, while indicates the upper limits of the attributes in the corresponding solution rule ( ϵ R). For attribute “ ” with a lower value and upper value in the search space, the condition “ ” always holds in each iteration. During iterations, each individual recalculates its own , and values. At the end of iterations, each attribute satisfying the condition is added to the “ ” solution rule [32]. Rule mining optimization was performed separately for each class in the dataset. This means that the main dataset (search space) is divided into subspaces for each class, and each optimization process takes place in the relevant subspace. The values of , and for a solution are checked for each data point in the relevant search space and used to calculate the fitness value of the objective function. For example, in a rule mining optimization process performed for a class “ ”, assume that a solution uses the 1st, 3rd, and 5th attributes in its own rule ( in iteration -th). In this case, the individual solution will be checked for the “ ” data ( ), according to Equation (15).
This calculation process is used to determine the suitability value of the objective. In the study, the “accuracy” value of the classification is taken as the objective function. To find the “accuracy” value of the solution, the condition in Equation (15) is checked individually for each data point belonging to the relevant “ ” class. As a result of these operations, true positive (TP), true negative (TN), false positive (FP), and false negative (FN) values are obtained. For this purpose, as shown in Table 5, the “if” part (antecedent) and the “then” part (consequent) of the relevant rule are evaluated separately. Then, the “accuracy” value used as the objective function is calculated as shown in Equation (16) based on the TP, TN, FP, and FN values of the relevant rule.
TP is the number of cases where both the left and right sides of the rule are correct, TN is the number of cases where both sides of the rule are incorrect, FP is the number of cases where the left side of the rule is correct and the right side is incorrect, and FN is the number of cases where the left side of the rule is incorrect and the right side is correct. The pseudocode given in Algorithm 3 shows the operation of the processes described above in the rule-inference-based SFO algorithm [32]. The algorithm operates in two stages. The first is the training stage. In this stage, the SFO algorithm adapted according to the suitability value for the training datasets is run. The rules obtained at the end of the algorithm iterations are retested on the test data. The same evaluation processes are performed on the test data this time. Algorithm 3. Adapted SFO Algorithm pseudocode1. Get the dataset2. Initialize the encoded population showing the individual classification rule set 3. ( )4. ← maximum number of iterations5. ← population size6. ← Population removal rate (%)7. for i = 1 to 8. IndividualGeneratorFunction( )9. AddToPopulation( )10. end for 11. SetDefaultValues(TP, TN, FP, FN) 12. CalculateObjectiveValue()13. ← FindSunRule()14. while(i < )15. DirectTowardsSun()16. for j = 1 to a. CalculateIndividualVector() b. RemoveDistantIndividuals(%O, i) c. EvaluateNewIndividuals( ) 17. end for18. SetDefaultValues(TP, TN, FP, FN)19. CalculateObjectiveValue()20. ← FindSunRule()21. End while22. TestRulesForTestData()23. ShowBestRule()
3. Results
This section delineates the experimental drying outcomes, the optimization efficacy of the OCSFO algorithm, and the elucidated categorization rules derived for drying efficiency. The physical drying characteristics of “Paşa” pears under various operational settings are presented. The optimization capacity of OCSFO and the resultant interpretable rules are then shown.
3.1. Experimental Drying Results
The moisture values calculated after the experiments are shown in Figure 4. Examining Figure 4a,b, it is observed that an increase in drying air velocity shortens the drying time. At the same temperature, the liquid inside the product evaporated more quickly from the product surface. Thus, the product dried approximately 30 min earlier. Under the specified drying conditions, the wet-basis moisture content of the pear product decreased from approximately 85% to 56%. The dry-basis moisture content decreased from approximately 5.9 to 1.32. When Figure 4c,d is examined, the drying time has decreases with increasing drying air velocity. In addition, the drying time also decreased with the decrease in temperature. At the same temperature, the liquid inside the product evaporated more quickly from the product surface. Reducing the drying temperature from 65 °C to 50 °C resulted in a longer drying duration and slower moisture removal kinetics, rather than an increase in the instantaneous liquid loss rate. With the increase in air velocity, the product dried approximately 30 min earlier, while with the decrease in temperature, the drying process took an average of 75 min longer.
The MR values presented here represent a dimensionless moisture content and should not be directly correlated with the weight change criterion ( ) used to experimentally terminate the drying process.
The time axis in each sub-graph represents the actual drying time under the relevant experimental conditions, and total drying times vary due to different air velocity and temperature values.
The product weight changes during the drying process under the four different experimental conditions are shown in Figure 5. The initial product weight was approximately 450 g, and the drying process continued until it reached 103 g. The experiments were terminated when the product weight change fell below 1 g. The fastest drying process occurred in the experiment conducted at an air speed of 1.03 m/s and an air temperature of 65 °C. However, the slowest drying process occurred in the drying experiment conducted at a speed of 0.63 m/s and a temperature of 50 °C.
Figure 6 shows the drying efficiency values for the pear product under four different drying conditions. Drying efficiency is calculated as the ratio of the energy required to remove liquid from the product to the total energy consumed by the system. The best average drying efficiency in this case is 8.57%, achieved at an air velocity of 0.63 m/s and an air temperature of 65 °C. Similarly, the average drying efficiency was 3.65% for the process with an air velocity of 0.63 m/s and an air temperature of 50 °C.
Figure 7 summarizes the moisture ratio (MR) decay for the four operating cases, showing a consistently faster drop at higher air velocity and temperature. Figure 7a (0.63 m/s, 65 °C) shows that the MR decreases from 1.00 at the start to approximately 0.39 after 50 min, 0.21 after 100 min, 0.14 after 150 min, and 0.06 after 250 min. Figure 7b (1.03 m/s, 65 °C) shows a more rapid reduction throughout the process, with MR falling to approximately 0.45 after 40 min, 0.33 after 60 min, 0.21 after 100 min, approximately 0.10 after 180 min, and approximately 0.06 after 220 min.
This indicates the shortest overall drying time among the cases. Figure 7c (0.63 m/s, 50 °C) shows a shift to longer times: MR is approximately 0.36 after 60 min, around 0.20 after 120 min, approximately 0.10 after 240 min, and reaches approximately 0.06 only after 310 min. Finally, Figure 7d (1.03 m/s at 50 °C) lies between the two 0.63 m/s cases and the 65 –1.03 m/s case. Here, MR is around 0.40 after 50 min, 0.25 after 100 min, 0.12 after 200 min, and 0.07 after 280 min. This shows that, while increasing the air velocity partly compensates for the lower temperature, it does not fully match the kinetics observed at 65 °C.
3.2. Performance Evaluation of the OCSFO Algorithm
In this section, the optimization performance of the OCSFO algorithm is evaluated through multifaceted analyses, including benchmark test functions and problem-specific performance metrics.
3.2.1. Performance on Benchmark Test Functions
To observe the performance of the OCSFO algorithm, the test functions listed in Table 6 were chosen. Two of the test functions used are constrained (Rosenbrock Cubic/Line and Disk). The problem sizes were selected as five for Sphere, three for Rastrigin, and two for the others. The internal and solution iteration counts were 20 and 5, respectively. The dusting rate was 0.05, and the elimination rate was 0.1. In the test results for the 20 independent experiments conducted, the minimum results in the iterations were first examined. In the evaluations, both classical and hybrid algorithms were evaluated together for each test function. The quality test functions used are presented in Table 7.
Comparative statistical evaluations of independent experiments are shown in Table 8.
The results presented in the table, when evaluated according to the relevant objective functions, show that while the methods generally yield good results for Camel, which has the lowest value of −1.03, chebyshevOCSFO, logisticOCSFO, sineOCSFO, and tentOCSFO are observed to be more successful. ClassicalSFO and circleOCSFO yielded poorer results in terms of performance when considering the standard deviation and mean values. The minimum value of the nonlinear function selected as the second test function is −0.28, and all methods studied yielded extremely successful results for this function. All methods used for all tests yielded results with almost the same success rate. In the Rastrigin function, it was observed that the best result was provided by logisticOCSFO. The logisticOCSFO was followed by the tentOCSFO and sineOCSFO algorithms. The logisticOCSFO was followed by the tentOCSFO and sineOCSFO algorithms. The true minimum value of the sphere function is 0, and sineOCSFO and tentOCSFO provided the closest values to this. ClassicOCSFO and circleOCSFO were other chaotic-based algorithms that approached this value. tentOCSFO stood out in terms of the results it provided for the mean and median values. Furthermore, classicOCSFO yielded better results than the chebyshevOCSFO and logisticOCSFO algorithms among chaotic-based SFOs. Another function with a true minimum value of 0 is the Rosenbrock Disk function. All methods were quite successful and performed well for this function. Based on the lowest and highest values, classicSFO and tentOCSFO were slightly less efficient than the others. Although the algorithms were successful in reaching the minimum value in Rosenbrock Cubic/Line, chebyshevOCSFO showed relatively low performance for the mean and median. When all these results are evaluated together, it is seen that chaoticSFO can produce more competitive results compared to classicalSFO. Among chaoticOCSFO, tentOCSFO stands out compared to other algorithms. Although it generally produces successful results, chebyshevOCSFO lags behind other chaoticOCSFO.
Based on the competitive optimization performance observed in benchmark tests, the following subsection evaluates the effectiveness of OCSFO in quantitative rule mining for drying efficiency classification.
3.2.2. Task-Specific Performance Evaluation of OCSFO
The flexibility of the algorithm used stems from the use of both chaotic and trigonometric approaches. The rules and metrics found by the proposed optimization algorithm according to the relevant classes are given in Table 9, Table 10 and Table 11. In this classification model, the data were determined as high (H), medium (M), and low (L) using the drying efficiency ranges in Table 4.
Furthermore, the consistency of accuracy values across various iterations suggests that the OCSFO algorithm delivers robust rule mining performance with minimal sensitivity to random initialization. The diminished accuracy values noted for the low-efficiency (L) class can be ascribed to the overlapping parameter ranges during the latter phases of drying, characterized by increased energy consumption and diminished moisture removal. The subsequent section examines the physical significance and interpretability of the extracted rules, despite the quantitative success of OCSFO in rule mining being demonstrated by these results.
3.3. Extracted Explainable Rules
In the study, the rules created using the oscillating chaotic sunflower optimization (OCSFO) classified drying efficiency as high (H), medium (M), and low (L). The fact that the accuracy rates of the obtained rules were above 90% indicates that the parameters are significantly related to drying efficiency.
High efficiency (H):
- Typically achieved under conditions such as an output temperature range of 37–49 °C;
- Product weight between 260–430 g;
- Heat energy ( ) produced varying between 3.5–10 W.
These rules indicate scenarios in which the product’s moisture is quickly removed and energy use is efficient. The literature also states that in hot-air dryers, moisture transfer accelerates within a certain temperature and air flow rate range, thus optimizing drying time and energy consumption [1,5].
Medium efficiency (M):
- Cabin interior temperature between 55–63 °C;
- Product weight should be around 260–310 g;
- Air velocity is at moderate values such as 0.69–0.76 m/s.
This situation indicates that the system is still functioning effectively during the drying process but is operating slightly outside optimal conditions. Similarly, Guiné et al. [4] have shown that efficiency decreases when drying temperatures deviate from optimal values.
Low efficiency (L):
- The output temperature must be within the range of 48–62 °C;
- Product weight decreasing to 100–300 g levels;
- The input temperature must remain between 29–40 °C.
In these scenarios, since the product is already largely dried, removing water has become more difficult, and the system’s energy consumption has increased while but efficiency has decreased. The literature also frequently reports that energy efficiency decreases and drying speed drops in the final stages of the drying process [6,8].
The resulting rules are consistent with general trends in the food drying literature. The parameters align meaningfully with both physical processes and findings reported in previous studies. Derived using explainable artificial intelligence, these rules go beyond black-box models, clearly showing researchers which parameter ranges yield high efficiency.
These rule-based interpretations demonstrate OCSFO’s ability to explain energy-efficient drying behaviors in a transparent and physically meaningful way.
4. Discussion
The derived explicable principles offer distinct insights into the correlation between operational factors and drying efficacy for “Paşa” pears. High drying efficiency is primarily linked to moderate to high air velocity and increased cabinet temperature ranges, aligning with the core principles of convective heat and mass transfer. Elevated air velocity facilitates moisture diffusion from the product surface, while increased drying temperatures augment the vapor pressure gradient, therefore expediting moisture removal during the first and intermediate phases of drying. Nonetheless, the regulations stipulate that excessive energy input during the final phases of drying does not inherently result in commensurate efficiency improvements. As moisture content declines, internal diffusion resistance prevails, resulting in declining returns from moisture extraction despite heightened energy expenditure. This pattern elucidates the diminished efficiency observed during the final drying phase and underscores the necessity of equilibrating thermal input and airflow to attain energy-efficient drying. The rule-based outcomes thus represent physically significant drying dynamics rather than merely data-driven correlations.
Most current research on food drying optimization depends on black-box machine learning techniques, such as artificial neural networks or deep learning frameworks, which attain great predictive accuracy but provide minimal interpretability. Although these models are proficient at prediction tasks, they offer less understanding of how certain operating parameters affect drying performance, thereby limiting their utility in practical decision-support systems. This paper presents a rule mining system driven by explainable artificial intelligence (XAI) that produces transparent, interpretable decision rules, clearly delineating parameter ranges linked to various efficiency levels. These rule-based explanations allow domain specialists to clearly comprehend the influence of air velocity, temperature, and energy-related variables on drying efficiency without necessitating supplementary post-hoc interpretation methods. In contrast to black-box methods, the suggested technique enhances knowledge extraction, process comprehension, and practical application, especially in industrial drying contexts where transparency and controllability are crucial.
The exceptional efficacy of the OCSFO algorithm in benchmark optimization assessments and task-specific rule mining is due to its improved balance between exploration and exploitation. By integrating oscillatory search behavior, OCSFO dynamically adjusts step sizes, facilitating efficient local refining around interesting solutions. The incorporation of chaotic mapping techniques enhances population variety and diminishes vulnerability to random initialization, thus alleviating premature convergence. These attributes are especially beneficial in quantitative rule-mining challenges, where intricate, nonlinear relationships among factors may result in fragmented or inefficient rule sets. The stability exhibited across numerous iterations indicates that OCSFO can reliably derive high-quality classification rules with robust generalization ability. The approach enhances optimization robustness and facilitates the creation of compact, diversified rule sets suitable for explainable artificial intelligence applications.
Despite the promising results obtained in this study, several limitations should be acknowledged. The experimental investigation focused solely on the “Paşa” pear, processed with a fixed slice thickness and a conventional hot-air drying setup. The extracted rules have clear physical meaning and internal consistency. However, these rules cannot be directly applied to other food materials, geometries, or drying technologies without further validation. The drying experiments also covered a limited range of air temperature and velocity, selected to maintain process stability and product quality. This limited scope may limit how widely the derived rules can be used across different industrial conditions. The proposed rule-based framework mainly relies on thermal, mass-related, and energy-based sensor data. It does not explicitly incorporate visual attributes linked to product quality, such as color changes, surface shrinkage, or texture. The OCSFO-based rule mining procedure was performed offline. Integrating it directly into a real-time adaptive control loop was beyond the scope of this study. Future research will extend this methodology to different food products and drying methods. The XAI framework will be enriched with image-based features and real-time, OCSFO-driven rules. These improvements aim to enable fully autonomous, energy-efficient drying systems.
5. Conclusions
This study involved the drying of “Paşa” pears, a regional agricultural product from Elazig, Turkiye, under various operational conditions utilizing an intelligent hot-air drying system. Experimental investigations were performed at two air velocity levels (0.63 m/s and 1.03 m/s) and two drying temperatures (50 °C and 65 °C) to assess drying behavior, energy efficiency, and process performance.
The most rapid drying process occurred at an air velocity of 1.03 m/s and a temperature of 65 °C, resulting in a reduction of product weight from roughly 450 g to 103 g. The slowest drying transpired at an air velocity of 0.63 m/s at a temperature of 50 °C. The optimal drying efficiency, from an energy efficiency standpoint, was achieved at an air velocity of 0.63 m/s at a temperature of 65 °C, yielding a value of 8.57%. Conversely, the minimal efficiency was noted at 3.65% with the same air velocity of 0.63 m/s but at a temperature of 50 °C. The results demonstrate that expedited drying does not inherently equate to enhanced energy efficiency, underscoring the significance of balanced operational conditions.
A quantitative rule mining framework based on explainable artificial intelligence (XAI) was utilized to facilitate transparent and interpretable analysis. In this context, the oscillating chaotic sunflower optimization (OCSFO) algorithm, an optimization algorithm inspired by plant intelligence, was employed for the first time in food drying applications to derive classification rules for high, medium, and low efficiency drying conditions. The suggested methodology effectively demonstrated distinct, physically significant correlations between drying factors and energy efficiency, with the derived classification rules attaining accuracy rates beyond 90%. The extracted rules indicated that drying temperature and air velocity are the primary determinants of drying efficiency, but energy consumption and inside cabinet temperature distribution serve a supplementary role in differentiating efficiency classes. Three typical rules were produced for each efficiency class, ensuring interpretability and robustness.
The findings indicate that the devised intelligent drying system, in conjunction with the suggested XAI-driven rule mining methodology, facilitates optimal energy consumption while maintaining product quality. To guarantee a physically significant and resilient classification, average drying efficiency was selected as the goal variable rather than instantaneous efficiency, offering a stable system-level performance metric appropriate for optimization-based rule extraction. This research develops a clear, data-informed decision-support framework for intelligent and energy-efficient food drying applications. Future endeavors will concentrate on augmenting the proposed methodology by including image processing techniques into the control framework and formulating adaptive real-time control strategies to further improve autonomous drying efficacy.
Future work will focus on developing XAI-based rule models for different food products (e.g., peppers) and integrating these rules with deep learning-based image processing to implement smart, energy-efficient control strategies for autonomous food drying systems.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ju H.Y. Vidyarthi S.K. Karim M.A. Yu X.L. Zhang W.P. Xiao H.W. Drying quality and energy consumption improvements in hot-air drying of papaya slices by step-down relative humidity based on heat and mass transfer characteristics and 3D simulation Dry. Technol.20234146047610.1080/07373937.2022.2099416 · doi ↗
- 2Hosseinpour S. Rafiee S. Aghbashlo M. Mohtasebi S.S. Computer vision system for in-line monitoring of visual texture kinetics during shrimp (Penaeus spp.) drying Dry. Technol.20153323825410.1080/07373937.2014.947513 · doi ↗
- 3Janjai S. Tohsing K. Lamlert N. Mundpookhier T. Chanalert W. Bala B.K. Experimental performance and artificial neural network modeling of solar drying of litchi in a parabolic greenhouse dryer J. Renew. Energy Smart Grid Technol.2018138395
- 4GuinéR.P.F. Barroca M.J. Gonçalves F.J. Alves M. Oliveira S. Mendes M. Artificial neural network modelling of the antioxidant activity and phenolic compounds of bananas submitted to different drying treatments Food Chem.201516845445910.1016/j.foodchem.2014.07.09425172734 · doi ↗ · pubmed ↗
- 5Taheri-Garavand A. Karimi F. Karimi M. Lotfi V. Khoobbakht G. Hybrid response surface methodology–artificial neural network optimization of drying process of banana slices in a forced convective dryer Food Sci. Technol. Int.20182427729110.1177/108201321774771229231074 · doi ↗ · pubmed ↗
- 6Liu Z.L. Nan F. Zheng X. Zielinska M. Duan X. Deng L.Z. Wang J. Wu W. Gao Z.J. Xiao H.W. Color prediction of mushroom slices during drying using Bayesian extreme learning machine Dry. Technol.2020381869188110.1080/07373937.2019.1675077 · doi ↗
- 7Nadian M.H. Abbaspour-Fard M.H. Sadrnia H. Golzarian M.R. Tabasizadeh M. Martynenko A. Improvement of kiwifruit drying using computer vision system and ALM clustering method Dry. Technol.20173570972310.1080/07373937.2016.1208665 · doi ↗
- 8Chakravartula S.S.N. Bandiera A. Nardella M. Bedini G. Ibba P. Massantini R. Moscetti R. Computer vision-based smart monitoring and control system for food drying: A study on carrot slices Comput. Electron. Agric.202320610765410.1016/j.compag.2023.107654 · doi ↗