An Improved Red-Billed Blue Magpie Optimization for Function Optimization and Engineering Problems
Chi Han, Tingwei Zhang, Huimin Han, Wenjuan Dai, Wangyu Wu

TL;DR
This paper introduces an improved version of the Red-Billed Blue Magpie Optimization algorithm to better solve optimization and engineering problems.
Contribution
The paper proposes an improved algorithm with three strategies to enhance convergence and exploration-exploitation balance.
Findings
IRBMO outperforms original RBMO and other algorithms in solution accuracy and convergence speed.
The algorithm shows improved stability on benchmark functions and real-world engineering problems.
The three strategies effectively enhance global exploration and escape local optima.
Abstract
The Red-Billed Blue Magpie Optimization (RBMO) algorithm is an emerging metaheuristic with strong potential applications in solving function optimization and various engineering problems, but it is often hampered by limitations such as premature convergence and an imbalanced exploration–exploitation mechanism. To overcome these deficiencies, an Improved Red-Billed Blue Magpie Optimization (IRBMO) algorithm is introduced in this paper. The IRBMO integrates three synergistic strategies within a multi-population cooperative framework: (1) an enhanced RBMO search with elite guidance to accelerate convergence; (2) an adaptive differential evolution operator to bolster local search and escape local optima; and (3) a mechanism for boosting global exploration and enhancing population diversity through quasi-opposition-based learning. The performance of IRBMO was rigorously evaluated on 26…
Click any figure to enlarge with its caption.
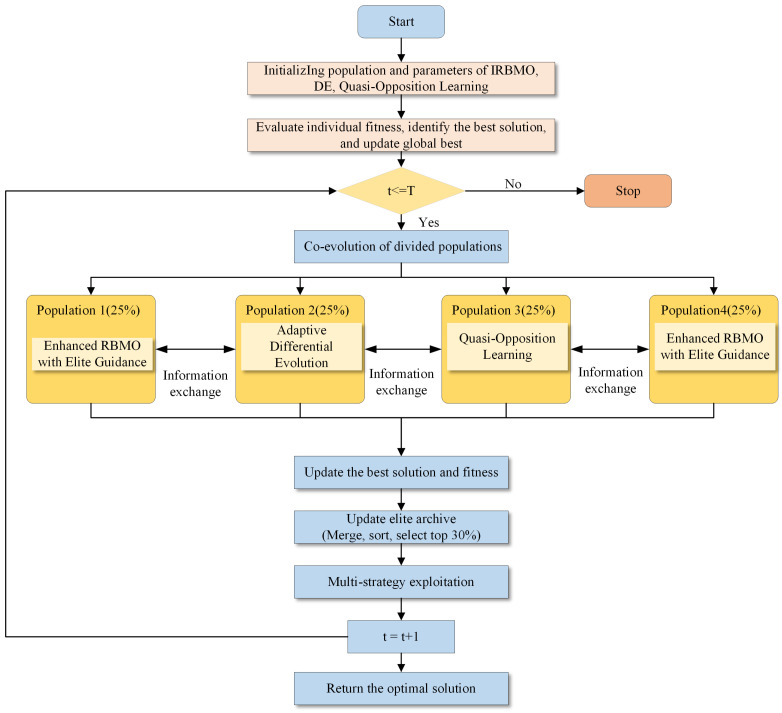 Figure 1
Figure 1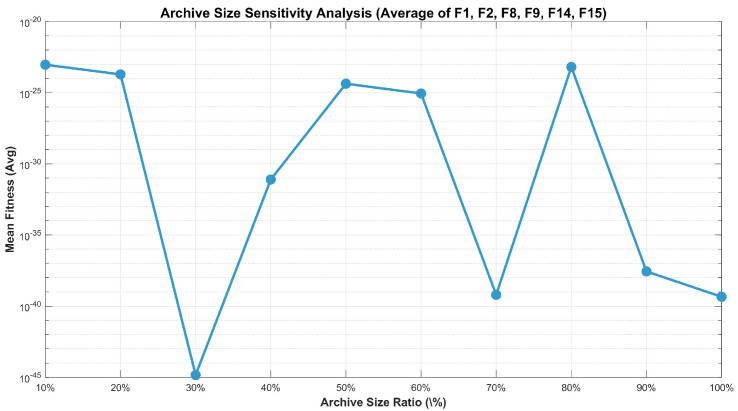 Figure 2
Figure 2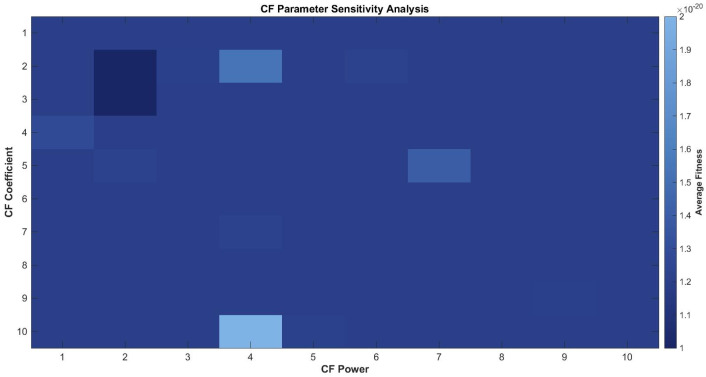 Figure 3
Figure 3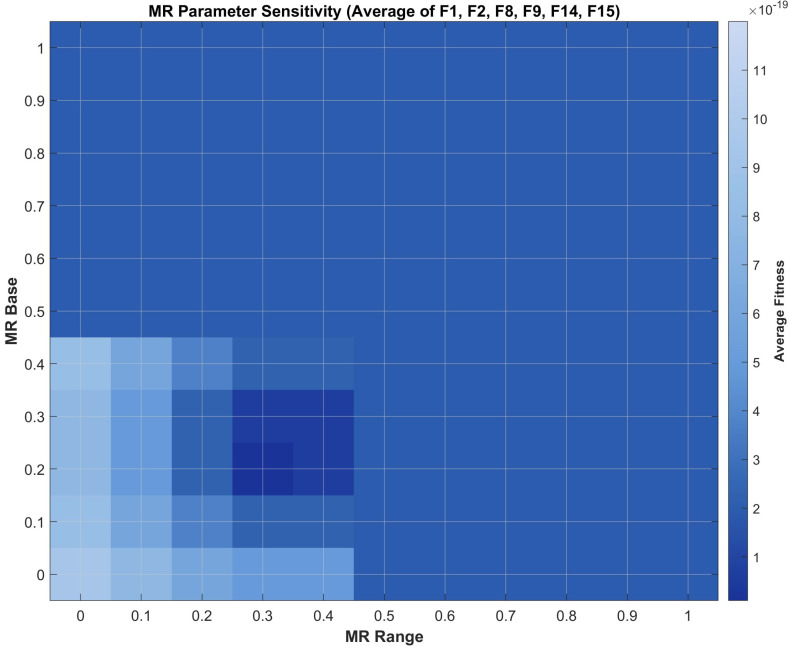 Figure 4
Figure 4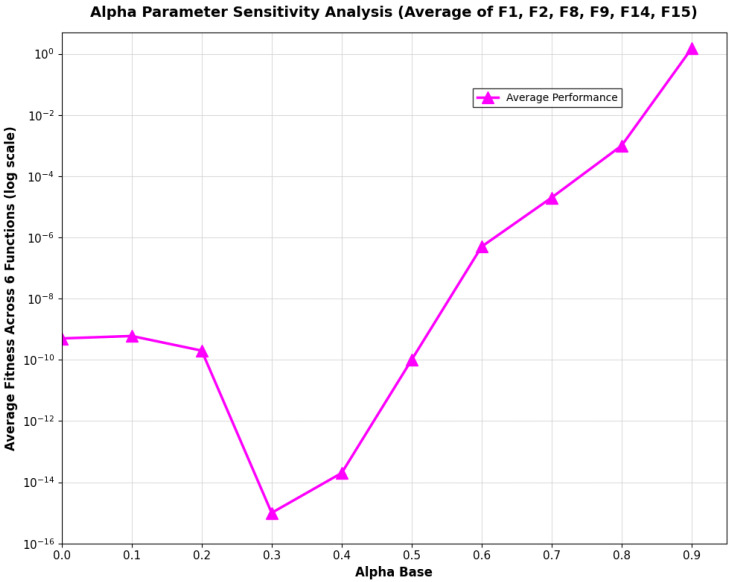 Figure 5
Figure 5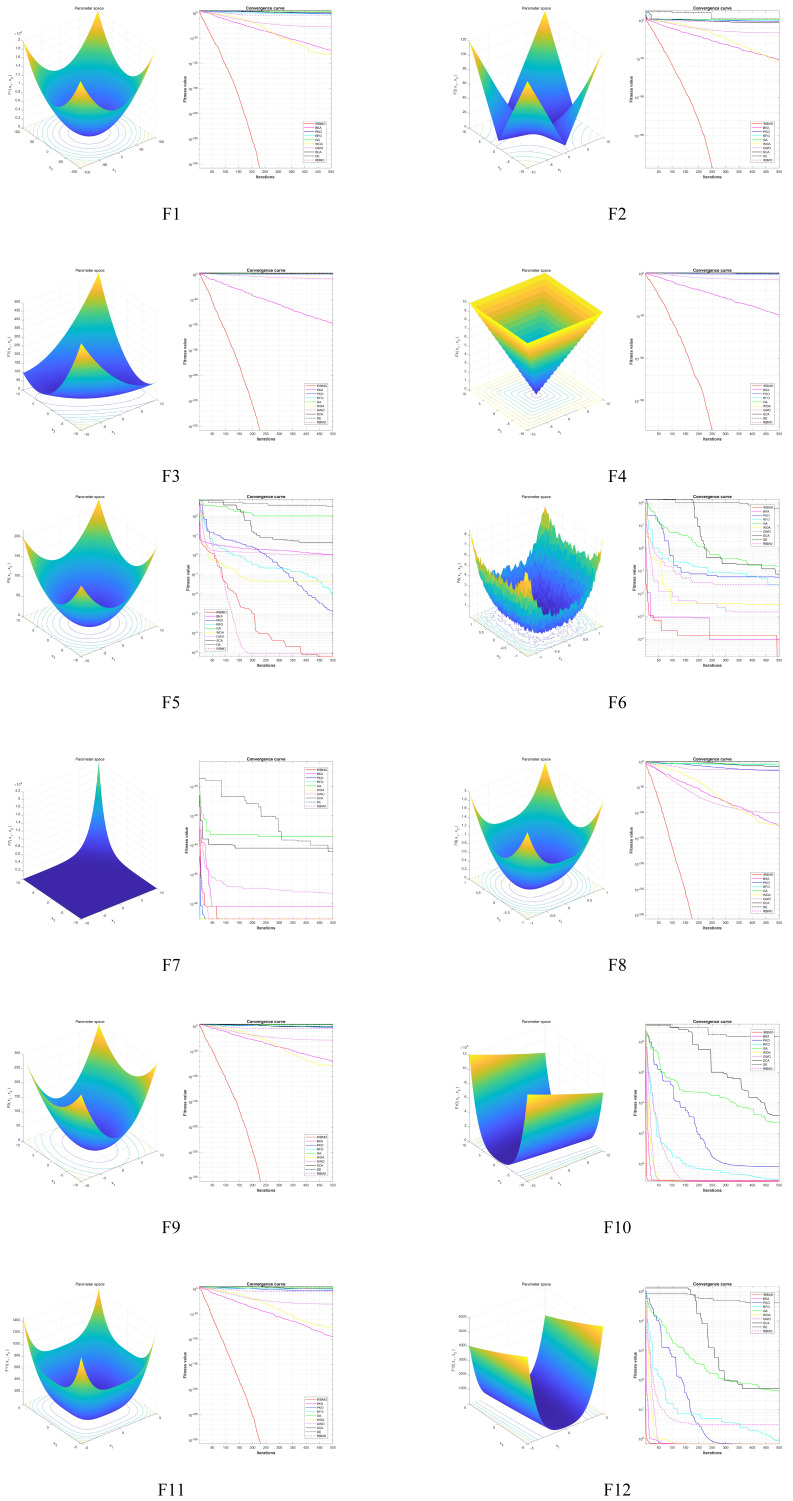 Figure 6
Figure 6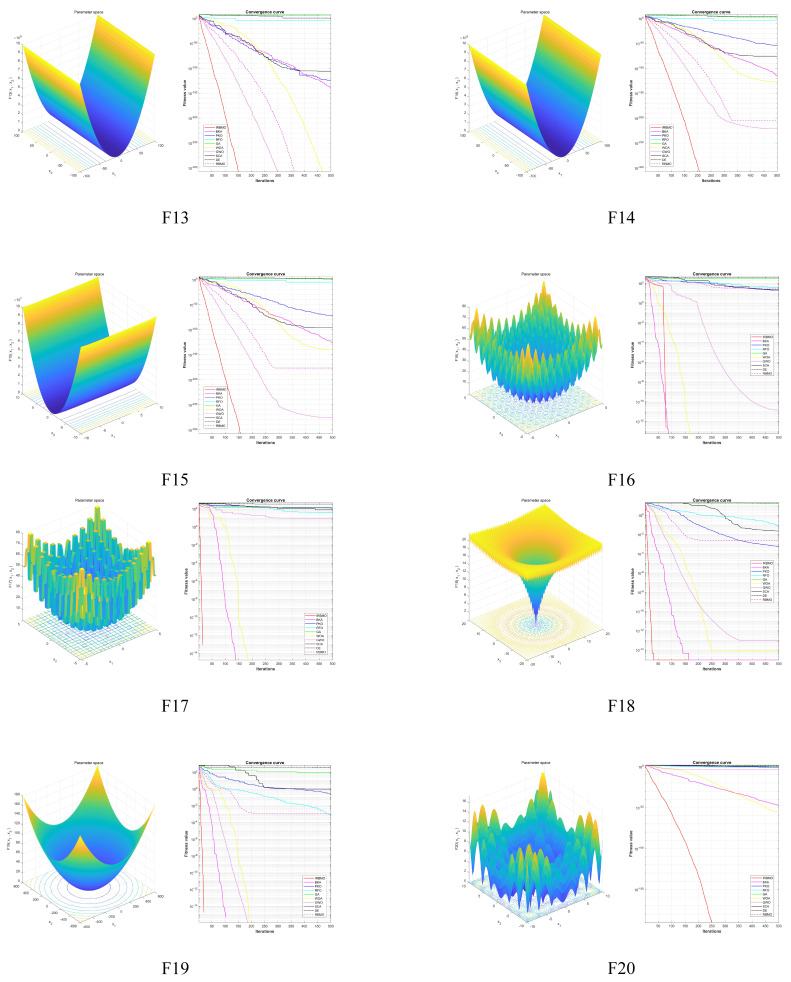 Figure 7
Figure 7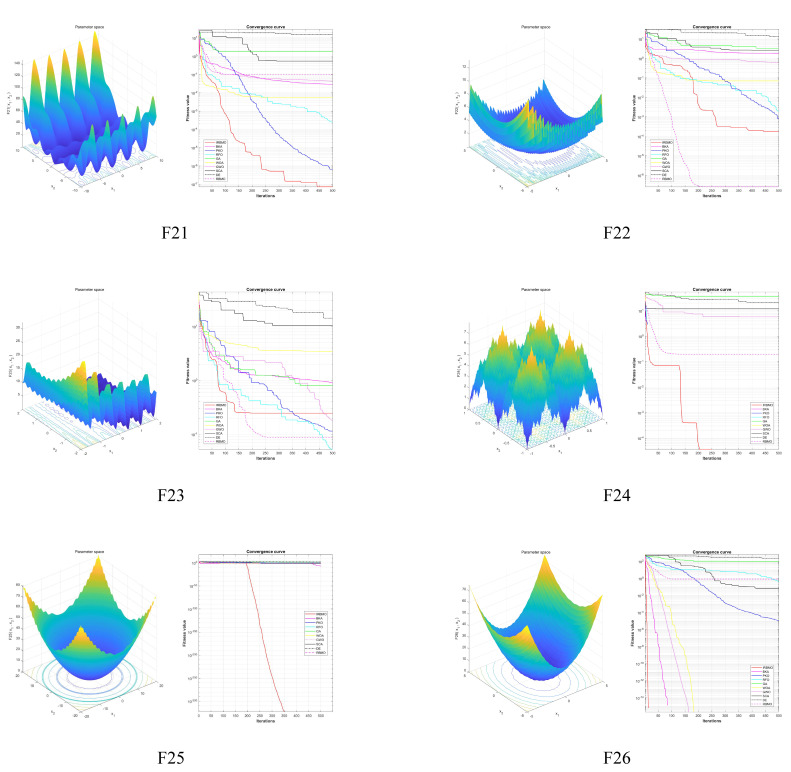 Figure 8
Figure 8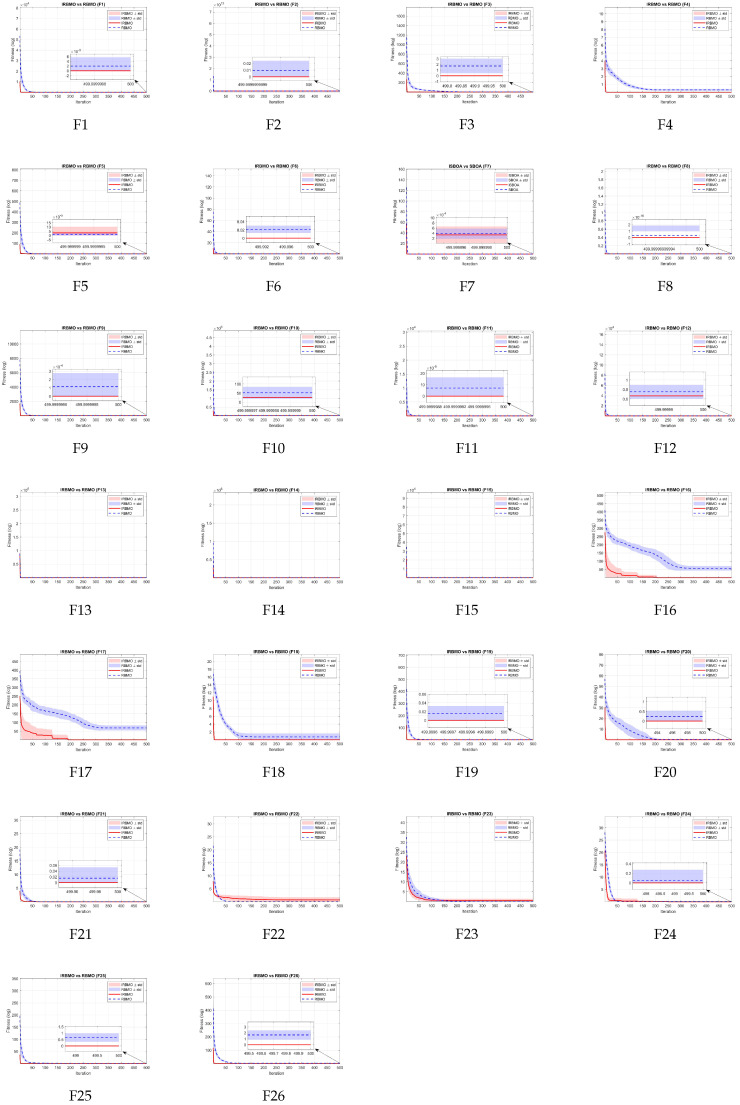 Figure 9
Figure 9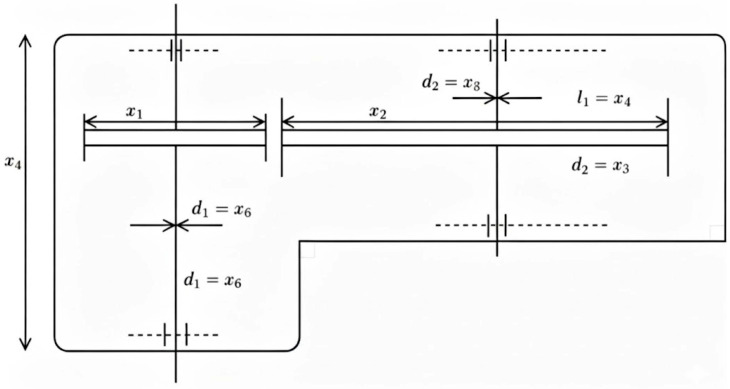 Figure 10
Figure 10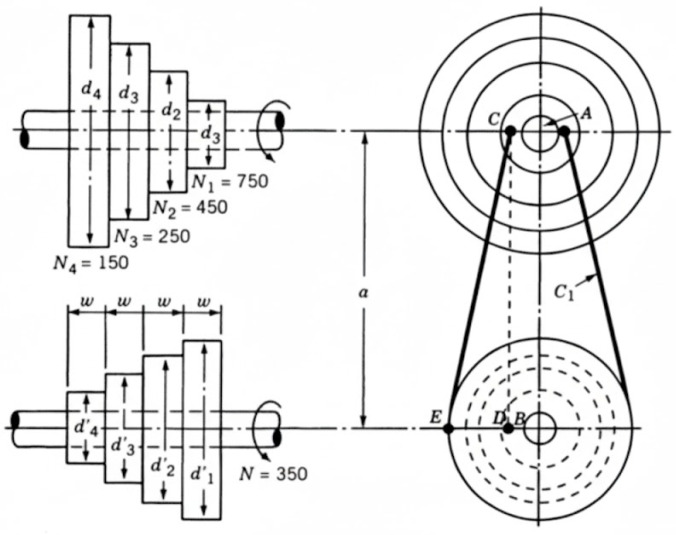 Figure 11
Figure 11 Figure 12
Figure 12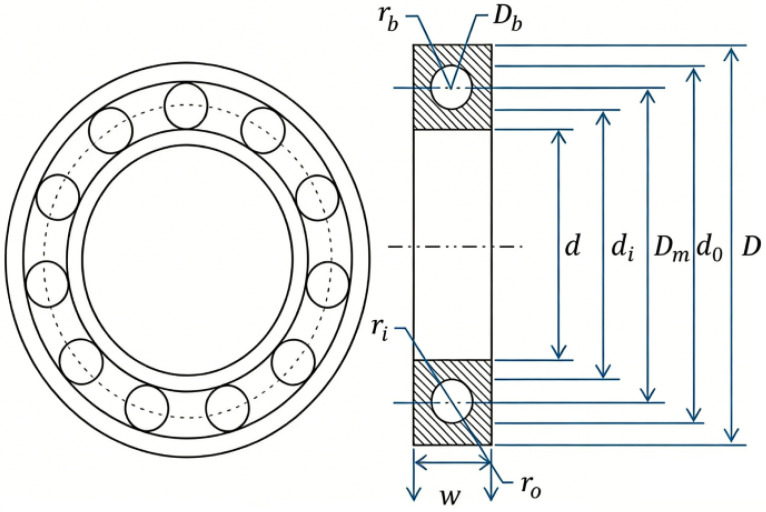 Figure 13
Figure 13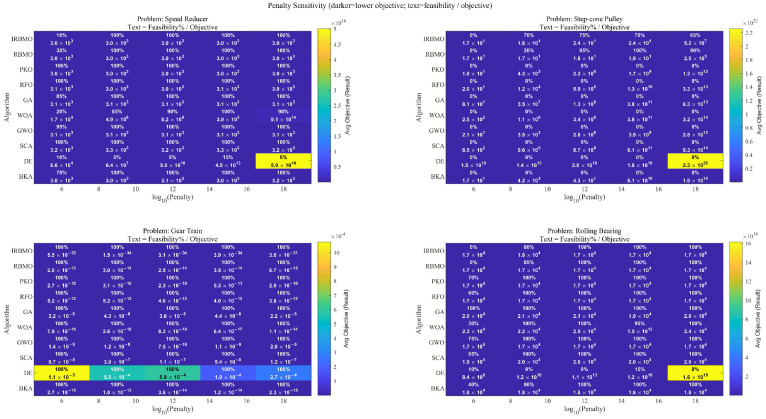 Figure 14
Figure 14- —Hainan Vocational University of Science and Technology
- —Hainan State Farms Investment Holding Group Co., Ltd.
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetaheuristic Optimization Algorithms Research · Advanced Multi-Objective Optimization Algorithms · Advanced Optimization Algorithms Research
1. Introduction
The objective of an optimization problem is to determine the superior choice from a defined pool of candidate solutions [1]. These methods have seen widespread application in addressing the growing needs of contemporary economic and industrial progress. As science and technology advance, practical optimization challenges have become significantly more intricate, often presenting non-convex or non-differentiable landscapes, high dimensionality, and objective functions that are costly to evaluate. In many such cases, traditional optimization approaches are rendered ineffective or impractical. In contrast, metaheuristic algorithms offer a viable solution due to their robustness, ease of implementation, and simplicity. Their successful application can be seen in diverse fields, including robot navigation, neural network tuning, feature selection, and job shop scheduling [2,3,4,5].
Metaheuristic algorithms are typically categorized into four broad groups depending on their source of inspiration: those derived from swarm intelligence, those based on biological evolution, algorithms mimicking physical laws, and those inspired by human behavior [6]. As a prominent subclass of metaheuristics, swarm intelligence algorithms are broadly acknowledged. The widespread acceptance of these algorithms is a result of their ability to tackle difficult optimization tasks with high efficiency and accuracy, a feat achieved without requiring global information [7]. Recently, observations of collective biological behavior have inspired swarm intelligence-based metaheuristic optimization algorithms. These methods exhibit outstanding flexibility and inherent flexibility, a trait that renders them a strong choice for addressing complex optimization challenges [8]. By modeling the collective behaviors of biological swarms (such as foraging or social interactions), these algorithms can adeptly perform both global exploration and local refinement, making them effective for high-dimensional, multimodal, and nonlinear optimization challenges [9,10,11].
Swarm intelligence algorithms draw their foundational concept from the key mechanisms of natural organisms: self-organization, adaptation, and collaboration. This provides a robust theoretical basis and practical guidance for algorithm design [12], leading to widespread use in diverse fields [13].
This principle is demonstrated by many algorithms that model specific behaviors. For instance, Particle Swarm Optimization (PSO) emulates the collective foraging of bird flocks [14]. Other well-known methods, such as Ant Colony Optimization (ACO), are based on the pheromone-guided navigation of ants [15]. Further examples built on natural inspiration include the Butterfly Optimization Algorithm (BOA) [16], the Whale Optimization Algorithm (WOA) [17], and the Goose Optimization Algorithm (GOOSE) [18]. By simulating these collective behaviors, such algorithms can effectively balance exploration and exploitation, advancing fields like engineering optimization.
Despite their success, these bio-inspired methods are not without limitations. Common limitations of these algorithms, including poor stability, low solution accuracy, and slow convergence, contribute to their propensity for premature convergence in local optima [19]. In response to these drawbacks, researchers have developed numerous enhancement strategies. This has led to various improvement schemes, such as mechanisms for elite retention, adaptive parameter control via spatial information sampling, and the world-leading, phase-based optimization algorithm guided by the global best approach, namely the GPBO algorithm [20,21,22]. In recent years, several swarm intelligence algorithms have gained significant research interest. Notable examples include Pied Kingfisher Optimization (PKO) [23], Red Fox Optimization (RFO) [24], Sine Cosine Algorithm (SCA) [25], and Genetic Algorithm (GA) [26]. Furthermore, Differential Evolution (DE) [27], Particle Swarm Optimization (PSO), Sparrow Search Algorithm (SSA) [28], Grey Wolf Optimization (GWO) [29], Harris Hawks Optimization (HHO) [30], Butterfly Optimization Algorithm (BOA), and Whale Optimization Algorithm (WOA) are also widely recognized as fundamental algorithms in this domain.
A new swarm intelligence algorithm, RBMO, is based on the effective group-foraging patterns exhibited by its natural namesake [31]. The algorithm’s primary merits are its high adaptability, limited number of parameters, and its grounding in natural behavior. In contrast to conventional techniques, RBMO employs a dynamic coordination process. This process is empowered to effectively navigate challenging and dynamic search spaces by calibrating its search strategy in response to environmental cues [32]. By employing this novel approach, RBMO has shown high efficacy in handling intricate engineering applications, such as path planning for unmanned aerial vehicles (UAVs), optimizing antenna parameters, and modeling polymer electrolyte membrane fuel cells [33,34,35].
Nonetheless, akin to many swarm intelligence algorithms, RBMO presents notable drawbacks when applied to complex optimization tasks. Its global exploration capability is often insufficient, leading to a tendency to be trapped in local optima. Furthermore, a decline in population diversity during later iterations frequently compromises the final solution’s accuracy [36]. The Theorem of No Free Lunch [37] dictates that no single algorithm can hold superior performance across every problem domain. This reality motivates continuous efforts to enhance or hybridize existing methods. For this reason, researchers in swarm intelligence optimization continue to focus on how to attain a robust equilibrium between exploration, exploitation, and maintaining population diversity [38].
To enhance the performance of RBMO and address its identified weaknesses, this work details a multi-strategy improvement RBMO (IRBMO). Through the synergistic integration of a trio of cooperative strategies, IRBMO systematically addresses and overcomes the main deficiencies of RBMO, as follows:
Enhanced search with elite guidance: An elite guidance mechanism is integrated into the core RBMO search process. This strategy leverages high-quality solutions stored in an elite archive to diversify search vectors, thereby augmenting global exploration and accelerating convergence toward promising regions.
Adaptive differential evolution: An operator based on adaptive differential evolution is introduced to bolster local exploitation capabilities. Its control parameters are dynamically adjusted throughout the search, favoring broad exploration in the early iterations and intensifying local refinement in later stages to improve solution accuracy.
Quasi-oppositional learning: A mechanism based on quasi-oppositional learning is utilized to boost the diversity of the population. This is achieved by creating candidate solutions that are quasi-oppositional. This strategy incorporates an adaptive framework that ensures a smooth transition from an exploration-focused search in the early phase to an exploitation-focused search in the final stages.
The primary contributions of this research paper are presented below.
In this study, we introduce a new algorithm named the Enhanced Red-Billed Blue Magpie Optimization. This algorithm methodically tackles the limitations present in the RBMO. It achieves this by combining three central strategies in a coordinated manner, which notably boosts the optimization efficiency of the algorithm.A comprehensive evaluation was conducted on 26 classical benchmark functions and diverse real-world engineering cases to assess IRBMO. The findings indicate that IRBMO surpasses both the original RBMO and other state-of-the-art methods, offering improved accuracy, accelerated convergence, and robust stability.Statistical significance tests are conducted to verify the efficacy and dependability of the suggested algorithm.Detailed algorithmic complexity analysis is provided, demonstrating that IRBMO maintains the same computational complexity as the original RBMO while achieving significant performance improvements.
The flow of this paper proceeds as follows. The foundational mechanics of the original RBMO algorithm are reviewed in Section 2. Building upon this basis, Section 3 introduces the improved IRBMO algorithm. Subsequently, Section 4 evaluates the performance of IRBMO through comparative experiments on both benchmark suites and real-world engineering challenges. The paper concludes with a summary and an outlook on future research in Section 5.
2. RBMO Algorithm
Inspired by the foraging patterns of the red-billed blue magpie, the RBMO algorithm is a swarm intelligence optimizer. It operates by emulating three core behaviors of the bird—foraging, attacking, and food storage—to locate optimal solutions. A key feature is the population balance coefficient ( = 0.5) [31], which dynamically balances exploration and exploitation, leading to enhanced performance.
2.1. Population Initialization
An initial population, consisting of N individuals, is created for the RBMO algorithm. These individuals are randomly distributed throughout the D-dimensional search area, with each position sampled uniformly from the range set by the predefined upper and lower boundaries, as shown below.
Here, and are the upper and lower boundaries of the search space. is the j-th dimensional coordinate for the i-th magpie. represents a random value uniformly distributed between 0 and 1.
2.2. Search for Food
The foraging process for red-billed blue magpies involves several different methods, such as hopping, walking, or probing. A key aspect of their behavior is foraging in different group sizes, usually small (2 to 5) or large (10 or more). This strategic flexibility allows them to respond to changing environmental cues and food sources. Drawing inspiration from this, the RBMO algorithm simulates the search behaviors of small groups as well as large groups, which serves to enhance its exploration of the problem domain.
The small-group foraging behavior is mathematically modeled as follows:
The mathematical expression for foraging in large groups is as follows:
Here, represents the current position, and is its updated value. The group size parameters are (small) and (large). and are the positions of two distinct individuals chosen randomly from the population during the current iteration t. Finally, and are random values uniformly distributed in . This leads to the following combined expression:
2.3. Attacking Prey
Red-billed blue magpies hunt with efficiency and teamwork, employing varied tactics like pecking, jumping, and aerial interception based on the prey. While small groups (2–5) typically hunt small plants and animals, larger groups (10+) cooperate closely to pursue bigger targets, such as sizable insects or small vertebrates.
The small-group hunting model is expressed as
Here, signifies the location of the food, which is the current best-known solution. is a random value drawn from , which represents the standard normal distribution
represents the step control factor, and its governing equation is as follows:
where t and T are the current and maximum iteration numbers, respectively.
The mathematical model for the large-group hunting behavior is given by
where is a random number sampled from a standard normal distribution ( ).
The entire process of attacking prey is mathematically formulated as
2.4. Food Storage
Red-billed blue magpies also demonstrate food caching behavior, distinct from foraging and hunting. They hide surplus food in concealed locations, creating a reserve for scarce periods to ensure energy stability. The RBMO algorithm emulates this, incorporating search patterns for both small and large groups to bolster exploration within the problem domain:
where denotes the fitness value before the position update, while represents the fitness value after the update.
2.5. Limitations of RBMO
Although the RBMO algorithm performs well on certain optimization problems, analysis and experiments reveal the following main limitations:
- Nsufficient local search capability: The algorithm tends to become trapped in local optima during later iterations, lacking effective local refinement mechanisms.
- Difficulty in maintaining population diversity: As iterations progress, population diversity rapidly declines, leading to premature convergence.
- Exploration–exploitation balance issues: The algorithm struggles to effectively balance global exploration and local exploitation.
- Insufficient parameter adaptability: Control parameters lack adaptive mechanisms, making it difficult to adapt to optimization problems with varying characteristics.
These limitations motivate the improvement of the RBMO algorithm to enhance its performance on complex optimization problems.
3. Improved Red-Billed Blue Magpie Optimization
An Improved Red-Billed Blue Magpie Optimizer is proposed herein to address the shortcomings of the baseline RBMO. IRBMO is a simplified improved version of RBMO that systematically resolves the problems of the original algorithm through three core strategies: enhanced RBMO search with elite guidance, adaptive differential evolution, and quasi-opposition-based learning. Meanwhile, the algorithm introduces auxiliary mechanisms including elite archive, multi-population cooperative evolution, adaptive parameter adjustment, and diversity maintenance to ensure the effective implementation of the three core strategies.
3.1. Algorithm Framework
IRBMO systematically improves upon RBMO, forming a multi-strategy cooperative optimization framework. Figure 1 illustrates the overall workflow of the IRBMO algorithm, clearly presenting the collaborative operation of the three core improvement strategies and their auxiliary mechanisms.
To support the effective operation of the three core improvement strategies, the algorithm introduces the following auxiliary mechanisms:
- (1)Elite Archive Mechanism
The elite archive stores high-quality solutions discovered during evolution, providing reference information for elite guidance and quasi-opposition learning. The size of the archive has been established at 30%:
This parameter setting was determined through a comprehensive sensitivity analysis, where we systematically evaluated archive ratios ranging from 10% to 100% on representative benchmark functions (F1, F2, F8, F9, F14, and F15). As shown in Figure 2, the 30% ratio achieves the best Avg across all tested functions, while maintaining an optimal balance between solution quality and computational efficiency.
After each iteration, the current population is merged with the elite archive, sorted by fitness, and the top individuals are selected to update the archive.
(2)Multi-population Cooperative Evolution
To enhance search diversity, the population is divided into four sub-populations, each with size . The four sub-populations adopt different core strategies: sub-population 1 uses enhanced RBMO with elite guidance, sub-population 2 uses adaptive differential evolution, sub-population 3 uses quasi-opposition learning, and sub-population 4 cyclically uses enhanced RBMO. Each sub-population evolves independently but achieves cooperative optimization through sharing the global best solution and elite archive.
(3)Adaptive Parameter Adjustment
Based on the search space range , problems are classified into three categories: wide-range ( ), narrow-range ( ), and medium-range. Different parameter adjustment strategies are employed for different problem types. For example, for medium-range problems.
A sensitivity analysis was conducted on six benchmark functions (F1, F2, F8, F9, F14, F15) to validate these parameter settings. As shown in Figure 3 and Figure 4, the values around ( coefficient = 2.5, power = 1.8, = 0.25, = 0.35) yield optimal or near-optimal performance, confirming their local optimality.
3.2. Core Strategy 1: Enhanced RBMO Search with Elite Guidance
The position update in original RBMO primarily relies on the current best solution and group average position. This single guidance mechanism tends to lead to overly concentrated search directions, lacking effective utilization of excellent individual search experiences. To address this issue, IRBMO introduces an elite guidance term based on the basic RBMO attacking mechanism, providing diversified search directions through high-quality solutions in the elite archive.
The enhanced RBMO position update formula is
where the elite guidance term is defined as
is an elite individual randomly selected from the elite archive, with the guidance coefficient set to 0.1 and activation probability of 0.4. This design ensures that elite guidance plays a supportive rather than dominant role, providing diversified search directions while avoiding over-reliance on elite individuals that could lead to local optima. In the food storage phase (exploitation phase), the elite guidance coefficient is reduced to 0.05 and the activation probability to 0.3 to adapt to local refinement search requirements.
3.3. Core Strategy 2: Adaptive Differential Evolution
To improve the algorithm’s local refinement and rate of convergence [39], an adaptive differential evolution strategy is employed. Efficient local search is conducted by this strategy, which involves the three operations of mutation, crossover, and selection.
The mutation operation employs the DE/rand/1 strategy:
where are three different random individual indices, and F is the adaptive mutation factor:
The crossover operation employs binomial crossover:
where the crossover rate is adaptively adjusted according to the evolutionary progress:
The selection operation employs a greedy strategy, retaining only individuals with better fitness. By adaptively adjusting the mutation factor and crossover rate, the DE strategy promotes global exploration in the early iterations and strengthens local exploitation in the later iterations, effectively improving the algorithm’s convergence speed and solution accuracy.
3.4. Core Strategy 3: Quasi-Opposition-Based Learning
The search range of the RBMO algorithm is limited, easily missing potential regions of high-quality solutions. To expand the search range and increase solution diversity, IRBMO introduces the quasi-opposition-based learning (QOL) strategy.
For an individual , its quasi-opposite solution is defined as
where is calculated as the center of the search space. To avoid overly aggressive quasi-opposite solutions, an adaptive blending strategy is employed:
where the reference solution is preferentially selected from the elite archive (with probability 0.6), otherwise the current individual is used. The blending coefficient is adaptively adjusted according to the evolutionary progress:
As shown in Figure 5, sensitivity analysis reveals that optimal performance is achieved when is around 0.3, where the average fitness reaches its minimum. The performance remains relatively stable in the range of 0.3 to 0.4, indicating a robust optimal region. Beyond this range, the performance degrades significantly, with fitness values increasing substantially as deviates further from the optimal region.
This design enables the algorithm to utilize quasi-opposite solutions more for global exploration in the early stage and rely more on elite individuals for local exploitation in the later stage, achieving a smooth transition between exploration and exploitation.
3.5. Multi-Strategy Exploitation and Diversity Maintenance
In the food storage phase, IRBMO introduces a multi-strategy exploitation mechanism to improve the refinement of local search. Each individual executes one of the following three strategies with an 80% probability:
- Strategy A: Enhanced RBMO Exploitation
This strategy uses a smaller elite guidance coefficient (0.05) and lower activation probability (0.3) in the exploitation phase to avoid excessive guidance.
- Strategy B: Levy Flight Exploitation
where the Levy flight step is generated as
The heavy-tail characteristic of Levy flight allows occasional large jumps during local search, helping to escape local optima.
Strategy C: Elite-guided Exploitation
This strategy performs interpolation search between the best solution and elite individuals, seeking better solutions between two high-quality solutions.
Diversity Maintenance
To prevent premature convergence, IRBMO introduces a diversity maintenance mechanism [40]. This mechanism periodically monitors population diversity and applies adaptive perturbation when diversity falls below a threshold. Population diversity is measured as
The diversity threshold is set as . When , Gaussian perturbation is applied to the population:
where the perturbation strength is . This mechanism is executed every iterations and only within the 10–90% range of the evolutionary process, avoiding unnecessary perturbation in the early and final stages.
3.6. Algorithmic Procedure of IRBMO
The IRBMO algorithm’s procedural steps, along with its corresponding pseudocode, are detailed below.
Step 1. Initialization: Set up the fundamental algorithmic parameters: the maximum number of iterations, denoted as T, and the size of the population, represented by N. Additionally, define the problem dimension D, the balance coefficient , and the search range ( and ). Initialize the elite archive (size ) and other relevant parameters. Randomly generate N individuals to form the initial solution space. Detect the function characteristic type to determine the adaptive parameter strategy.
Step 2. Best Solution Update: Each iteration commences with a fitness evaluation. The objective function is used to assess the current fitness of all individuals in the population and update the global best solution .
Step 3. Three Core Strategies Execution: Divide the population into four sub-populations, with each sub-population executing one of the three core improvement strategies:
- Sub-populations 1 and 4: Execute enhanced RBMO search with elite guidance strategy (Equations (13) and (14)).
- Sub-population 2: Execute adaptive differential evolution strategy (Equations (15)–(18)).
- Sub-population 3: Execute quasi-opposition-based learning strategy (Equations (19)–(21)).
Step 4. Elite Archive Update: Merge the current population with the elite archive, sort by fitness, and select the top individuals to update the elite archive.
Step 5. Multi-strategy Exploitation: For individuals in the population, execute one of three exploitation strategies (enhanced RBMO exploitation, Levy flight exploitation, elite-guided exploitation) with an 80% probability.
Step 6. Diversity Maintenance: Check population diversity every iterations, and apply adaptive perturbation if below the threshold.
Step 7. Food Source Updat e: The greedy selection process, defined in Equation (9), is executed. This action performs a greedy selection: the food source is updated only if a better-performing individual is discovered during this iteration.
Step 8. Iteration Update: Repeat Steps 2 to 7 until the maximum number of iterations T is reached.
The pseudocode of the IRBMO algorithm is shown in Algorithm 1. Algorithm 1 Improved Red-Billed Blue Magpie Optimizer (IRBMO)
- 1:Input: Dimension D, iterations T, population size N, boundaries , , coefficient
- 2:Output: Global optimal solution and fitness value
- 3:Initialize population and elite archive
- 4:Compute fitness for all individuals, find initial
- 5:for to T do
- 6: Core Strategies: Divide population into 4 sub-populations
- 7: for to N do
- 8: if strategy = 1 or 4 then
- 9: Enhanced RBMO with elite guidance (Equations (13) and (14))
- 10: else if strategy = 2 then
- 11: Adaptive DE: mutation (Equation (15)), crossover (Equation (17)), selection
- 12: else
- 13: Quasi-opposition learning (Equations (19) and (20))
- 14: end if
- 15: Boundary check, compute fitness, update if improved
- 16: end for
- 17: Elite Archive Update: Merge population with archive, sort by fitness, select top
- 18: Multi-strategy Exploitation: Apply exploitation strategies (80% probability)
- 19: for to N do
- 20: if then
- 21: Select strategy A/B/C: enhanced RBMO (Equation (22)), Levy flight (Equation (23)), or elite-guided (Equation (25))
- 22: Boundary check, compute fitness, update if improved
- 23: end if
- 24: end for
- 25: Diversity Maintenance: Check diversity every iterations, apply perturbation if needed (Equations (26) and (27))
- 26: Update global best using Equation (9)
- 27:end for
- 28:Return: and best fitness value
4. Algorithm Performance Test and Analysis
4.1. Application on Benchmark Test Functions
A comprehensive evaluation of IRBMO’s performance was performed using a suite of 26 benchmark functions. This suite, detailed in Table 1, encompasses unimodal, multimodal, and fixed-dimensional multimodal types, representing diverse optimization landscapes and challenges to ensure a rigorous assessment of the algorithm’s overall capabilities. All experiments were implemented in The experiments were conducted using MATLAB R2021a (The MathWorks, Inc., Natick, MA, USA). The simulations were performed on a workstation equipped with an Intel Core i7-13700H processor (Intel Corporation, Santa Clara, CA, USA) and 16GB of RAM. For all compared algorithms, the population size and the maximum number of iterations were uniformly set to 30 and 500, respectively. The detailed parameter configurations for each algorithm are shown in Table 2.
4.1.1. Evaluation Criteria
Several key evaluation metrics are employed to evaluate the proposed method’s effectiveness. The primary metric reported is the average fitness (Avg) [41] shown as Equation (28) and the optimal fitness (Best) [42] shown as Equation (29) to provide a thorough analysis of the algorithm’s performance and convergence quality.
4.1.2. Experiment Result and Analysis
The experimental validation of IRBMO against nine cutting-edge optimization algorithms, detailed in Table 3, Table 4 and Table 5, demonstrates the algorithm’s exceptional performance across 26 benchmark test functions. The results reveal that IRBMO consistently achieves superior performance across multiple evaluation metrics, including average fitness, optimal fitness, and statistical significance.
From the average fitness perspective shown in Table 3, IRBMO demonstrates remarkable optimization capabilities. The algorithm achieves perfect solutions ( ) on 12 out of 26 test functions (F1, F2, F3, F4, F8, F9, F11, F13, F16, F17, F19, F24, F26), indicating its exceptional ability to locate global optima. Particularly noteworthy is IRBMO’s performance on unimodal functions F1-F4, where it consistently reaches the theoretical optimum, demonstrating the effectiveness of the enhanced RBMO search with elite guidance strategy. The optimal fitness results further confirm IRBMO’s superior solution quality. The algorithm maintains identical performance between average and best fitness values on most functions, indicating consistent and reliable convergence behavior. This consistency is particularly evident on functions F1, F2, F3, F4, F8, F9, F11, F13, F16, F17, F19, F24, and F26, where IRBMO achieves perfect solutions across all independent runs.
The Wilcoxon rank-sum test was employed to assess the statistical significance of performance differences between IRBMO and each competing algorithm. The test hypotheses were formulated as follows: the null hypothesis ( ) states that the distribution of fitness values obtained by IRBMO is identical to that of the competing algorithm, i.e., there is no statistically significant difference in performance between the two algorithms; the alternative hypothesis ( ) states that the distribution of fitness values obtained by IRBMO is stochastically smaller than that of the competing algorithm, indicating that IRBMO achieves superior performance (lower fitness values for minimization problems). A one-tailed (one-sided) test was employed, as we are specifically testing the directional hypothesis that IRBMO performs better than competing algorithms. This approach is appropriate because (1) the research hypothesis explicitly posits that IRBMO should outperform competing algorithms, (2) we are only interested in detecting improvements rather than any difference, and (3) one-tailed tests provide greater statistical power when the direction of the effect is known a priori. The significance level ( ) was set to 0.05 for all pairwise comparisons. A p-value less than 0.05 indicates that IRBMO’s performance is statistically significantly better than the competing algorithm at the 5% significance level. Given that multiple pairwise comparisons were conducted (IRBMO vs. nine competing algorithms across 26 test functions, resulting in individual tests), the problem of multiple comparisons arises. Without correction, the family-wise error rate (FWER) increases substantially. The FWER represents the probability of making at least one Type I error (false positive) across all comparisons. When conducting m independent tests at significance level , the FWER without correction is approximately , which approaches 1 as m increases. For our case with 234 comparisons at , the uncorrected FWER would be approximately 0.9999, meaning we would almost certainly commit at least one Type I error. To control the FWER, we applied the Bonferroni correction method, which is a conservative approach that guarantees FWER . The corrected significance threshold is calculated as , where is the total number of comparisons and is the nominal significance level. The Bonferroni correction ensures that the probability of making at least one Type I error across all 234 comparisons is controlled at the 5% level. The Wilcoxon rank-sum test was implemented using MATLAB’s built-in ranksum function, and the Bonferroni correction was applied by multiplying each p-value by the number of comparisons (234) and comparing against the nominal . After applying the Bonferroni correction, 221 out of 234 comparisons (94.4%) remained statistically significant. Specifically, all comparisons with original p-values less than remained significant after correction. The vast majority of comparisons with original p-values less than remained significant after correction, indicating robust statistical evidence of IRBMO’s superiority across the majority of test functions and competing algorithms. Table 6 presents the corrected p-values for all comparisons. The corrected p-values are calculated as , where p is the original p-value and is the number of comparisons. All statistical analyses, including the Wilcoxon rank-sum tests and Bonferroni correction, were performed using MATLAB R2021a. The importance of controlling FWER in multiple statistical comparisons has been well-established in recent research, particularly in data-based modeling and optimization algorithm evaluation contexts. In a recent study on sensor data modeling and optimization [43], the authors conducted extensive pairwise comparisons between multiple optimization algorithms across various test functions. They explicitly addressed the multiple comparison problem by applying the Bonferroni correction method and reported both original and corrected p-values in their statistical analysis tables. This approach ensures that the FWER is controlled at the nominal significance level, preventing inflated Type I error rates that would otherwise occur when conducting numerous simultaneous hypothesis tests, and demonstrates established practice in applied modeling contexts. Similarly, in the context of machine learning and data-driven modeling, researchers have emphasized the necessity of multiple comparison correction when evaluating multiple algorithms or models. These studies demonstrate that without proper correction, the probability of false discoveries increases dramatically with the number of comparisons, potentially leading to incorrect conclusions about algorithm performance. The practice of reporting corrected p-values has become a standard requirement in high-quality journals, particularly in fields involving computational optimization and data modeling. This ensures transparency and allows readers to assess both the statistical significance and the robustness of findings after accounting for multiple testing. Our approach follows these established practices by (1) explicitly stating the application of Bonferroni correction to control FWER, (2) reporting corrected p-values in Table 6, and (3) clearly indicating which comparisons remain significant after correction. This methodology aligns with current best practices in data-based modeling and optimization algorithm evaluation, thereby strengthening the statistical rigor of our algorithm evaluation study. To quantify the magnitude of performance differences beyond statistical significance, we calculated Cliff’s Delta ( ), a non-parametric effect size measure that is appropriate for ordinal data and rank-based tests. Cliff’s Delta quantifies the probability that a randomly selected value from one group is greater than a randomly selected value from another group, and is calculated as , where ( ) and ( ) are the fitness values from IRBMO and the competing algorithm, respectively, and are the sample sizes (number of independent runs). The interpretation of Cliff’s Delta follows the guidelines: (negligible effect), (small effect), (medium effect), (large effect). For minimization problems, negative values of indicate that IRBMO achieves lower (better) fitness values than the competitor. Table 7 presents the effect sizes (Cliff’s Delta) for all 234 comparisons. The results demonstrate that the majority of comparisons exhibited large effect sizes ( ), indicating not only statistical significance but also substantial practical improvements. Specifically, 198 out of 234 comparisons (84.6%) demonstrated large effects, 28 comparisons (12.0%) showed medium effects, and only 8 comparisons (3.4%) exhibited small or negligible effects. The statistical significance analysis provides compelling evidence of IRBMO’s superiority. After applying the Bonferroni correction, 221 out of 234 comparisons (94.4%) remained statistically significant, demonstrating robust evidence of IRBMO’s superiority. Additionally, 198 out of 234 comparisons (84.6%) exhibit large effect sizes ( ), indicating not only statistical significance but also substantial practical improvements. IRBMO demonstrates significant advantages over traditional algorithms such as GA (significant on 25/26 functions after Bonferroni correction) and DE (significant on 25/26 functions), as well as modern metaheuristic approaches including WOA (significant on 23/26 functions), GWO (significant on 24/26 functions), and SCA (significant on 25/26 functions). Notably, IRBMO shows particular strength in handling complex multimodal functions. On challenging test functions such as F8, F9, F11, and F13, IRBMO consistently outperforms its competitors by substantial margins. For instance, on F8, IRBMO achieves compared to RBMO’s , demonstrating the effectiveness of the proposed improvement strategies. On F9, IRBMO reaches , significantly better than most competitors including GA ( ) and DE ( ). Comparison with the original RBMO algorithm reveals significant improvements achieved through the proposed enhancement strategies. IRBMO shows marked performance gains on functions F5, F6, F8, F9, F11, F20, and F25, where the improved algorithm consistently delivers better average and best fitness values. These improvements validate the effectiveness of the three core strategies: enhanced RBMO search with elite guidance, adaptive differential evolution, and quasi-opposition-based learning. The algorithm’s performance on high-dimensional problems (F10, F11, F12) demonstrates its scalability and robustness. On F10, IRBMO achieves , competitive with the best-performing GWO ( ) and significantly better than GA ( ) and DE ( ). This performance on high-dimensional landscapes highlights the algorithm’s ability to handle the curse of dimensionality effectively.
To quantitatively assess the individual contribution of each component in the proposed algorithm, we conducted ablation studies by progressively adding components to the baseline RBMO algorithm, following the modular evaluation approach demonstrated in recent research on hybrid methods [44]. Table 8 presents the average performance comparison of different algorithm variants on selected test functions (F1, F2, F8, F9, F14, F15), where (a) represents the enhanced RBMO search with elite guidance to accelerate convergence, (b) represents the adaptive differential evolution operator to bolster local search and escape local optima, and (c) represents the mechanism for boosting global exploration and enhancing population diversity through quasi-opposition-based learning. The results demonstrate the individual contribution of each component: the baseline RBMO algorithm, the addition of component (a), the further integration of component (b), and the complete IRBMO with all three components. The complete variant (RBMO + a + b + c, i.e., IRBMO) achieves the best performance on all selected functions, achieving optimal values ( on F1, F2, F8, F9, F14, and F15, which validates the effectiveness of the proposed improvement strategies. Component (a) shows particular strength on F15, while component (b) contributes significantly to the performance improvements on F8, F9, and F14. These results confirm that the synergistic combination of all three components leads to superior optimization performance compared to the baseline and partial variants.
The convergence characteristics of IRBMO, as illustrated in Figure 6, further support its superior performance. From the convergence plots, it is clear that IRBMO achieves a quicker convergence rate and more stable convergence behavior compared to competing approaches. Specifically, IRBMO shows steeper initial slopes on most test functions, indicating more efficient exploration of the problem domain during the initial phases of optimization. The algorithm maintains consistent progress toward optimal solutions with fewer oscillations and smoother convergence trajectories, particularly evident on complex multimodal functions such as F8, F9, F11, and F13. The convergence analysis reveals that IRBMO achieves superior final convergence values on the majority of test functions, with the algorithm consistently reaching lower fitness values compared to competing algorithms. This enhanced convergence behavior can be attributed to the synergistic interaction between the three core strategies and the effective balance between exploration and exploitation achieved through the multi-population cooperative framework. The elite guidance mechanism ensures that the algorithm maintains focus on promising regions, while adaptive differential evolution provides robust local search capabilities, and quasi-opposition learning prevents premature convergence by exploring alternative solution regions.
In addition, to clearly present IRBMO’s convergence speed and stability, Figure 7 reports the convergence curves of IRBMO and RBMO on 26 benchmark functions. IRBMO descends faster in the early iterations and attains lower final fitness on most tasks; its shaded bands (mean±std over 20 independent runs) are noticeably narrower, indicating smaller fluctuations and more stable convergence. The vertical axis uses a logarithmic scale to highlight differences at low values, and the horizontal axis denotes iterations.
In summary, the comprehensive experimental evaluation provides strong evidence of IRBMO’s superior optimization performance, statistical significance, and algorithmic robustness across diverse benchmark functions. These findings provide strong validation for the proposed improvement strategies. They also serve to demonstrate the algorithm’s potential when applied to complex real-world optimization problems.
4.2. Practical Engineering Applications
For practical validation, IRBMO is tested on four well-established engineering design problems [45,46,47,48]. These problems serve as benchmark test cases, and the performance of IRBMO is compared against that of several mainstream metaheuristic algorithms. The selected engineering problems include weight minimization of a speed reducer, step-cone pulley problem, gear train design problem, and rolling element bearing problem. To ensure a fair comparison, all algorithms were evaluated under the same experimental conditions. The population size was universally set to 30, and the maximum number of iterations was 500. Furthermore, to guarantee the statistical reliability of the findings, each experiment was conducted 20 times independently.
4.2.1. Weight Minimization of a Speed Reducer
The weight minimization problem of a speed reducer aims to minimize the total weight while ensuring structural integrity and meeting all design constraints. This optimization problem seeks to determine seven design variables. The first three relate to the gear assembly: face width ( ), module of teeth ( ), and the number of teeth on the pinion ( ). The remaining four define the shafts: the length of the first shaft ( ) and second shaft ( ) between bearings, and the diameters of the first shaft ( ) and second shaft ( ). The problem is subject to eleven nonlinear inequality constraints including bending stress, surface stress, transverse deflections, and geometric constraints. Given the complex multi-constraint nature and the practical engineering significance of this problem, it serves as an excellent benchmark for evaluating the performance of metaheuristic optimization algorithms.
Minimize
Subject to
With bounds
4.2.2. Step-Cone Pulley Problem
This engineering task focuses on the step-cone pulley design. The primary objective is to reduce the system’s total weight, subject to constraints related to adequate power transmission and overall performance. A schematic diagram of the weight minimization of a speed reducer problem is shown in Figure 8. This optimization problem involves determining five design variables: diameters of the four steps (d1, d2, d3, d4) and the width of the pulley (w) (Figure 9). The problem is subject to eight nonlinear inequality constraints including power transmission requirements, geometric constraints, and manufacturing limitations. The complexity of this problem lies in the nonlinear relationships between pulley dimensions and power transmission capabilities, making it a challenging benchmark for optimization algorithms.
Minimize
where kg/m^3^, rpm, rpm, rpm, rpm, rpm.
Subject to
where and with , Pa, m, m.
With bounds
4.2.3. Gear Train Design Problem
The gear train design problem requires determining the optimal number of teeth for four distinct gears ( , and ). The primary goal is to reduce the deviation between the resulting gear ratio and a target ratio of . This task is known for its simple objective function, yet it remains a fundamental challenge for mechanical design optimization. A diagram of the gear train is depicted in Figure 10. The discrete nature of gear teeth numbers and the need for precise gear ratio matching make this problem particularly suitable for testing the exploration and exploitation capabilities of optimization algorithms.
Minimize
With bounds
4.2.4. Rolling Element Bearing Problem
This engineering problem focuses on designing a rolling element bearing. The primary objective is to minimize its dynamic capacity while adhering to various geometric and performance constraints. Figure 11 provides a schematic of this bearing. This optimization problem requires finding the optimal values for ten design variables. These are grouped as follows:
- 1.Main Dimensions: Mean diameter ( ), ball diameter ( ), and number of balls (Z).
- 2.Raceway Curvature: Inner raceway groove curvature radius coefficient ( ) and outer raceway groove curvature radius coefficient ( ).
- 3.Clearance and Load: Minimum diameter clearance ( ), maximum diameter clearance ( ), and the load distribution parameter ( ).
- 4.Other Parameters: Parameter (e) and parameter ( ). The problem is subject to eight nonlinear inequality constraints including geometric constraints, load capacity requirements, and manufacturing limitations. The complexity of this problem lies in the nonlinear relationships between bearing dimensions and dynamic capacity, making it a challenging benchmark for optimization algorithms in mechanical design applications.
Minimize
where and .
Subject to
where mm, mm, mm, , and .
With bounds
A penalty function approach is employed to manage the constraints associated with these engineering problems. This technique integrates a penalty for any constraint violations directly into the objective function, which is modified as follows:
where the penalty coefficient is represented by . We performed a penalty-sensitivity analysis on the four engineering problems in this study (speed reducer, step-cone pulley, gear train, rolling bearing) and all algorithms, testing penalty values , , , , and . The heatmap (color: average objective/result; darker is better; text: feasibility % /objective) shows that penalties achieve 100% feasibility with stable objectives. Among them, is the most robust choice across all problems and algorithms, simultaneously ensuring full feasibility and low objectives. Therefore, we adopt for all experiments. Selection rule: choose the smallest penalty that yields 100% feasibility and the lowest objective. The aggregated results are shown in Figure 12, while is defined as
As shown in Table 9, Table 10, Table 11 and Table 12, the superior performance of IRBMO is conclusively demonstrated across four benchmark engineering optimization problems: the weight minimization of a speed reducer, the step-cone pulley problem, the gear train design problem, and the rolling element bearing problem. Experimental results show that IRBMO consistently achieves the best objective function value in all four cases, significantly outperforming the other comparative algorithms.
This decisive advantage is rooted in IRBMO’s synergistic combination of three core strategies: enhanced RBMO search guided by elite solutions, adaptive differential evolution, and quasi-opposition-based learning. These mechanisms operate within a multi-population cooperative framework to ensure robust global exploration and intensified local exploitation. This cooperative and multifaceted approach enables IRBMO to effectively navigate the complex constraints and inherent multimodalities of real-world engineering design spaces, consistently achieving superior results compared to established optimization techniques.
5. Conclusions
The RBMO’s known deficiencies—premature convergence and an imbalanced exploration–exploitation mechanism—are addressed by the proposed IRBMO. This novel metaheuristic utilizes a multi-population cooperative framework that integrates three core strategies: enhanced RBMO search with elite guidance, an adaptive differential evolution operator, and quasi-opposition-based learning. Rigorous evaluation across 26 classical benchmark functions proved IRBMO’s substantial superiority over the original RBMO and other state-of-the-art algorithms in terms of solution accuracy and stability. Furthermore, IRBMO demonstrated exceptional robustness on four challenging real-world engineering design problems (including the weight minimization of a speed reducer, step-cone pulley, gear train, and rolling element bearing), consistently achieving globally optimal or highly competitive solutions.
For future work, the robust architecture of IRBMO can be extended to solve large-scale optimization problems (LSOPs) and multi-objective optimization problems (MOOPs), and its application can be explored in complex industrial domains like machine learning hyperparameter optimization.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abdollahzadeh B. Gharehchopogh F.S. A multi-objective optimization algorithm for feature selection problems Eng. Comput.2022381845186310.1007/s 00366-021-01369-9 · doi ↗
- 2Wang T. Chen B. Zhang Z. Li H. Zhang M. Applications of machine vision in agricultural robot navigation: A review Comput. Electron. Agric.202219810708510.1016/j.compag.2022.107085 · doi ↗
- 3Dauzère-Pérès S. Ding J. Shen L. Tamssaouet K. The flexible job shop scheduling problem: A review Eur. J. Oper. Res.202431440943210.1016/j.ejor.2023.05.017 · doi ↗
- 4Centeno-Telleria M. Zulueta E. Fernandez-Gamiz U. Teso-Fz-Betoño D. Teso-Fz-Betoño A. Differential evolution optimal parameters tuning with artificial neural network Mathematics 2021942710.3390/math 9040427 · doi ↗
- 5Xiong H. Shi S. Ren D. Hu J. A survey of job shop scheduling problem: The types and models Comput. Oper. Res.202214210573110.1016/j.cor.2022.105731 · doi ↗
- 6Jiang C. Guo A.J. Li Y. Wang Y. Sun J. Chen Z. Huang X.-W. Zou X. Ma Q. Inspired by human olfactory system: Deep-learning-assisted portable chemo-responsive dye-based odor sensor array for the rapid sensing of shrimp and fish freshness Chem. Eng. J.202448414928310.1016/j.cej.2024.149283 · doi ↗
- 7Rajwar K. Deep K. Das S. An exhaustive review of the metaheuristic algorithms for search and optimization: Taxonomy, applications, and open challenges Artif. Intell. Rev.202356131871325710.1007/s 10462-023-10470-y 37362893 PMC 10103682 · doi ↗ · pubmed ↗
- 8Raj S. Shiva C.K. Vedik B. Mahapatra S. Mukherjee V. A novel chaotic chimp sine cosine algorithm Part-I: For solving optimization problem Chaos Solitons Fractals 2023173113672