Subclass-Aware Contrastive Semi-Supervised Learning for Inflammatory Bowel Disease Classification from Colonoscopy Images
Kechen Lin, Guangcong Ruan, Xiaoyang Zou, Yongjian Nian, Yanling Wei, Guoyan Zheng

TL;DR
This paper introduces a new semi-supervised learning method for classifying inflammatory bowel disease from colonoscopy images, achieving high accuracy with limited labeled data.
Contribution
The novel SACSSL method integrates subclass-aware contrastive learning to reduce confirmation bias and improve performance in semi-supervised IBD classification.
Findings
SACSSL achieves 93.2% accuracy and 80.1% F1-score on the Daping dataset with only 20% labeled data.
The method reaches 76.4% accuracy and 68.9% F1-score on the LIMUC dataset for UC severity grading.
Results show SACSSL outperforms existing methods in semi-supervised colonoscopy image classification.
Abstract
Inflammatory bowel disease (IBD) includes Crohn’s disease (CD) and ulcerative colitis (UC). The accurate classification of IBD from colonoscopy images is critical for diagnosis and treatment. However, the lack of labeled data poses a major challenge for developing deep learning-based IBD classification approaches. Recently, pseudo-labeling-based semi-supervised learning methods offer a promising solution in leveraging both labeled and unlabeled data to improve classification performance. Nevertheless, due to significant intra-class variability and the subtle inter-class differences in IBD colonoscopy images, pseudo-labels are often inaccurate, which results in confirmation bias and suboptimal performance. To address this challenge, a Subclass-Aware Contrastive Semi-Supervised Learning method, referred to as SACSSL, is proposed for accurate IBD classification by integrating a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
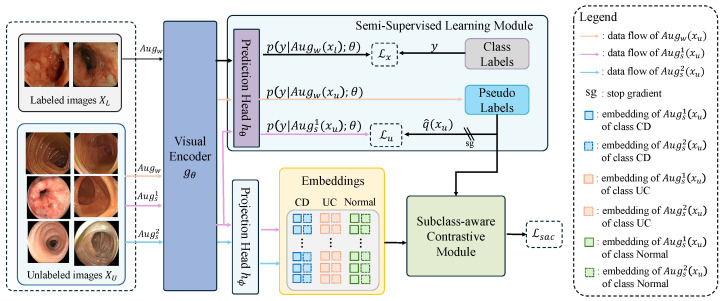 Figure 1
Figure 1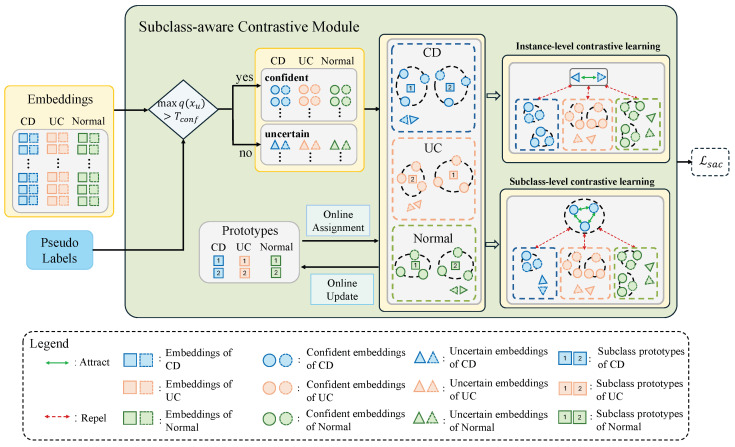 Figure 2
Figure 2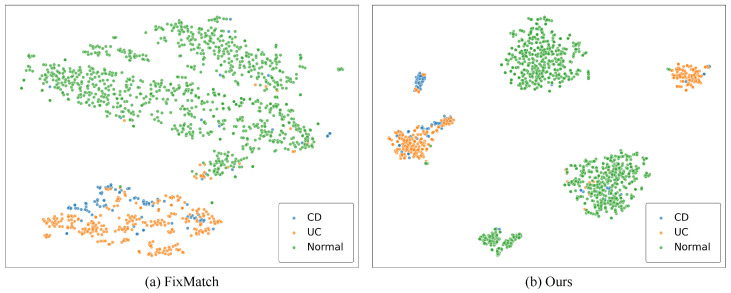 Figure 3
Figure 3- —Program of Chongqing Technology Innovation and Application Development Special Project
- —Natural Science Foundation of Chongqing, China
- —Chongqing Excellence Program for Innovation and Entrepreneurship Leadership Talent Project
- —National Nature Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAI in cancer detection · Inflammatory Bowel Disease · COVID-19 diagnosis using AI
1. Introduction
Inflammatory bowel disease (IBD), including Crohn’s disease (CD) and ulcerative colitis (UC) [1], has emerged as a global health concern in recent years [2]. Recent epidemiological studies have shown that IBD has evolved across different global regions with increasing incidence in newly industrialized countries [3]. The symptoms of IBD includes diarrhea, abdominal pain, and rectal bleeding, which can seriously affect patients’ quality of life [4,5]. The diagnosis of IBD relies on comprehensive evaluation using endoscopic, histological, clinical, and radiological criteria [6]. In practice, colonoscopy plays a vital role in the diagnosis, treatment, and follow-up monitoring of IBD [7,8]. However, since UC and CD have a similar appearance in colonoscopy, endoscopists may misinterpret the images due to limited experience or unconscious bias, resulting in misdiagnosis, missed diagnoses, and delayed treatment [9]. Therefore, it is necessary to improve the IBD classification accuracy to better distinguish between UC and CD in colonoscopy images, which would enhance patients’ quality of life and equip endoscopists with tools that increase both the accuracy and efficiency of clinical care [10].
With the rapid development of artificial intelligence, data-driven deep learning-based approaches have demonstrated impressive performance in computer-aided endoscopic tasks [11,12,13]. However, the lack of labeled data presents a major challenge for deep learning-based IBD classification. Semi-supervised learning, which leverages both labeled and unlabeled data, provides a promising solution to this problem [14,15]. Commonly adopted semi-supervised learning paradigms in endoscopic classification are pseudo-labeling [16] and consistency regularization [17]. In particular, pseudo-labeling-based methods [16] assign pseudo-labels to unlabeled data based on model predictions, which are then used for supervised training. Consistency regularization [17] assumes that different perturbed or augmented versions of the same input should yield consistent predictions. Building on these two paradigms, previous studies combine pseudo-labeling and consistency regularization techniques to achieve impressive performance [18,19,20,21]. However, high intra-class heterogeneity and low inter-class variance among IBD colonoscopy images may lead to inaccurate pseudo-labels. When the model overfits to these inaccurate pseudo-labels, performance degrades due to confirmation bias [22]. Recently, inspired by self-supervised learning approaches [23,24], Yang et al. [25] designed a class-aware contrastive module to learn more separated feature clusters at the class-level to improve model predictions. This method demonstrates promising performance on the semi-supervised classification of natural images. However, under the context of the IBD semi-supervised classification task, it overlooks intra-class heterogeneity. Forcing highly diverse samples within the same class to learn overly aligned representations may suppress fine-grained semantic information, leading to suboptimal classification performance.
To explicitly model intra-class heterogeneity, previous works [26,27] have attempted to decompose each class into multiple subclasses via clustering and then train classifiers with subclass-aware supervision. However, these methods require all samples to have class labels, thus failing to leverage abundant unlabeled data. Additionally, prototype-based learning has been widely adopted in clustering-based self-supervised learning approaches such as SwAV [28] and DeepCluster [29]. These methods learn representations by contrasting predicted cluster assignments of correlated views of the same image. To aggregate samples together while avoiding collapsed solutions, they employ simple clustering-based pseudo-labeling algorithms (e.g., K-means clustering [30] or the Sinkhorn–Knopp algorithm [31]) to generate assignments. Without access to labeled data, these self-supervised methods learn prototypes that do not encode explicit class information, resulting in suboptimal performance when directly applied to classification tasks.
To address these challenges, a Subclass-Aware Contrastive Semi-Supervised Learning (SACSSL) framework is proposed, which incorporates a carefully designed subclass-aware contrastive module into a pseudo-labeling-based semi-supervised learning paradigm (i.e., FixMatch [18]). The key innovation of the proposed subclass-aware contrastive module lies in explicitly exploiting abundant unlabeled samples to effectively capture intra-class heterogeneity. Instead of treating each class as a single compact cluster, multiple prototypes per class are introduced to automatically discover fine-grained subclasses in the embedding space. By associating unlabeled samples with different prototypes and enforcing subclass-aware contrastive objectives, the proposed module enhances intra-subclass compactness while preserving rich intra-class diversity, leading to more discriminative and semantically meaningful representations. Specifically, in the subclass-aware contrastive module, unlabeled data are partitioned into confident and uncertain sets based on the maximum probability of their pseudo-labels. Because confident samples with high prediction confidence are more likely to provide reliable supervision, while uncertain samples with low prediction confidence tend to introduce noise and thus require cautious handling, different contrastive objectives are designed to different subsets of unlabeled data to fully exploit their potential. Specifically, an instance-level contrastive loss is applied to encourage the separation of uncertain samples from all other samples in the embedding space to mitigate the confirmation bias in the semi-supervised training. To model the intra-class heterogeneity of IBD images, each class is represented by a set of prototypes in the embedding space. Confident samples are assigned to different prototypes within the same class to form fine-grained subclasses, which allows the supervised contrastive loss [32] to promote intra-subclass clustering among confident samples, effectively enhancing class separability while preserving fine-grained intra-class semantics. The main contributions of the proposed method can be summarized as follows:
- A novel subclass-aware contrastive semi-supervised learning framework for accurate colonoscopy image classification is introduced, which explicitly exploits abundant unlabeled samples to effectively capture intra-class heterogeneity.
- A novel subclass-aware contrastive module that adaptively handles unlabeled data with different contrastive objectives based on pseudo-label confidence is designed, aiming to suppress confirmation bias for uncertain samples and discover fine-grained subclasses for confident samples, thereby enhancing class separability while capturing intra-class variations.
- Comprehensive experiments are conducted on two colonoscopy image datasets, i.e., an in-house collected Daping dataset for IBD classification and a publicly available LIMUC dataset for UC severity grading. The experimental results demonstrate that the proposed method achieves superior classification performance compared to state-of-the-art semi-supervised learning methods on both datasets.
2. Related Works
2.1. Deep Learning-Based IBD Diagnosis Applications
A variety of deep learning-based approaches have been developed to assist the IBD diagnosis across different modalities. [12,13,33,34,35,36,37,38,39,40,41]. In colonoscopy, Ruan et al. [12] developed a deep learning model based on a deep convolutional neural network to distinguish between UC and CD using over 47,000 endoscopic images from a private dataset, achieving better classification performance compared to junior endoscopists. Similarly, Mauricio et al. [33] developed interpretable deep learning models to classify UC and CD with visualization modules that highlight disease-relevant regions, thereby enhancing clinical trust. In another study, Stidham et al. [34] evaluated the performance of Inception V3, a 159-layer CNN [35], on the task of endoscopic severity grading of UC, showing performance on par with experienced human reviewers. To address the class imbalance commonly observed in IBD-related classification tasks, recent works have proposed specialized techniques, such as high-frequency balancing and augmentation [38] or class distance weighted loss functions [39] to improve minority-class recognition.
Beyond colonoscopy, Klang et al. [36] employed EfficientNet-B5 [37] for detecting strictures from capsule endoscopy images in CD, showing robust generalization capability in multi-center datasets. Similarly, Malik et al. [40] achieved 99.45% accuracy in multi-class classification of UC, polyps, and dyed-lifted polyps from wireless capsule endoscopy (WCE) images using hybrid CNN-GRU architectures. Extending to panenteric capsule endoscopy, Brodersen et al. [41] demonstrated that AI-assisted PCE can effectively differentiate CD, UC, and cancer in a prospective multi-center study, significantly reducing image review time using the AXARO^®^ framework. More recently, Das et al. [42] developed a deep learning model for classifying IBD activity grades from histopathology whole slide images, achieving robust diagnostic performance that could assist pathologists in consistent IBD assessment.
However, these approaches heavily rely on large amount of expert-annotated data that is often difficult to acquire due to the time-consuming annotation process and expertise knowledge requirement.
2.2. Semi-Supervised Learning in Endoscopic Image Analysis
Semi-supervised learning has emerged as a promising paradigm by leveraging both labeled and unlabeled data to improve the IBD classification performance, thereby alleviating the heavy reliance on large amount of expert-annotated data. Previous studies have explored the application of semi-supervised learning in endoscopic image analysis [20,21,43,44,45], primarily employing two techniques: pseudo-labeling [16] and consistency regularization [17]. Guo et al. [43] proposed a semi-supervised learning framework with an Adaptive Aggregated Attention module for automatic wireless capsule endoscopy image classification, significantly outperforming supervised baselines. Muruganantham et al. [44] developed ACT-WISE, which employed a teacher–student framework to enforce consistency under perturbations of unlabeled wireless capsule endoscopy images, and integrated active learning for improving label efficiency. There exist other works that combine pseudo-labeling and consistency regularization techniques. Notably, FixMatch [18] integrated both techniques by applying weak and strong augmentations to each unlabeled image, where predictions from the weakly augmented image served as pseudo-labels for training on the strongly augmented image, which has shown impressive classification performance in natural image benchmarks. This has been extended by previous studies [20,21,45] to semi-supervised endoscopic image classification. For example, Huang et al. [20] proposed the class-specific distribution alignment strategy to improve the quality of pseudo-labels when training on highly imbalanced datasets and demonstrate its effectiveness in endoscopic image classification.
Beyond consistency regularization and pseudo-labeling, recent studies have explored incorporating auxiliary tasks into semi-supervised frameworks to enhance representation learning. These tasks can be employed either by self-supervised pretraining to provide better model initialization or incorporating auxiliary objectives into the semi-supervised framework to refine feature representations. For example, Wang et al. [46] proposed a semi-supervised framework that is first pretrained with self-supervised learning on a large unlabeled dataset and then fine-tuned on a limited labeled dataset, achieving promising performance on classifying colorectal neoplasia from narrow-band imaging colonoscopic images under low-label settings. Golhar et al. [47] proposed a novel semi-supervised method that combines an unsupervised jigsaw puzzle solving task with supervised learning, which has achieved promising results in classifying lesions from colonoscopy images. Yang et al. [25] incorporate a class-aware contrastive module into the pseudo-labeling-based semi-supervised framework. Specifically, they apply class-level clustering to in-distribution samples and instance discrimination contrastive loss to out-of-distribution samples, and they achieve impressive performance on natural image benchmarks.
3. Materials and Methods
In this work, we consider a semi-supervised IBD classification problem from colonoscopy images. Specifically, for a C-class classification problem, let the input image be and the ground truth label be , where H and W denote the height and width of the image, and 3 corresponds to the RGB channels. Let and be the labeled and unlabeled datasets, respectively, where and are the labeled images and the corresponding labels, and are the unlabeled images. and are the number of samples in the labeled dataset and the unlabeled dataset, respectively, where . We employ a visual encoder to obtain feature representation. We further attach a prediction head to the visual encoder to produce distribution over classes, i.e., . Moreover, we attach a projection head to the visual encoder to obtain low-dimensional features in embedding space for contrastive learning, i.e., , where z represents the projected representation of input image x. At each epoch, we first randomly shuffle the labeled dataset and the unlabeled dataset , and then split each dataset into a series of smaller data chunks. We sample one data chunk from the labeled dataset and one from the unlabeled dataset at each iteration. Let be a data batch which has B samples in total, containing labeled data and unlabeled data where and are the number of labeled samples and the unlabeled samples in the batch, respectively.
A schematic illustration of the proposed SACSSL is presented in Figure 1. The framework comprises a visual encoder , a prediction head and a projection head , which are integrated with a semi-supervised learning module and a novel subclass-aware contrastive module. Within the framework, we first apply a weak augmentation to all images and two strong augmentations and to the unlabeled images. All augmented images are then passed through the visual encoder to extract features, which are subsequently optimized by two complementary modules. In the semi-supervised learning module, ground-truth labels supervise the weakly augmented labeled samples, while pseudo-labels generated from weakly augmented unlabeled images serve as supervision targets for their first strongly augmented counterparts. Subsequently, embeddings from paired strongly augmented unlabeled images are extracted via the projection head and jointly processed by the subclass-aware contrastive module. In the subclass-aware contrastive module, confident and uncertain samples are identified based on pseudo-labels, and then tailored contrastive learning strategies are applied to each group to preserve fine-grained intra-class semantics while enhancing inter-class separability, as detailed in Section 3.2. These components are jointly optimized in an end-to-end manner with three objectives: a supervised loss , an unsupervised loss , and a subclass-aware contrastive loss . Details will be presented below. For a quick reference, we list common symbols used in this section in Table 1.
3.1. Semi-Supervised Learning Module
Following FixMatch [18], the semi-supervised learning module consists of two cross-entropy loss terms: a supervised loss applied to labeled data and an unsupervised loss applied to unlabeled data.
For each labeled sample (where , we are aiming at minimizing the cross-entropy loss between the model’s predicted distribution over classes on the weakly augmented view and the corresponding ground truth label . Accordingly, the supervised loss is defined as
where denotes the cross-entropy function.
For each unlabeled sample (where ), we generate a weak augmented view and a strong augmented view . The soft pseudo-label is derived by computing the model’s predicted distribution over classes on the weakly augmented view, i.e., . Subsequently, the hard pseudo-label is obtained by taking the class with the highest predicted probability, i.e., . To ensure quality of the pseudo-label, we retain only those samples whose highest predicted probability exceeds a threshold T for training. Formally, we define a binary indicator: , where is the indicator function that returns 1 if the condition holds and 0 otherwise. Finally, we aim to minimize the cross-entropy loss between the hard pseudo-label and the model’s predicted distribution over classes on the strongly augmented view, i.e., . Accordingly, the unsupervised loss is defined as
3.2. Subclass-Aware Contrastive Module
The limited visual difference between different classes and the significant appearance variability within the same class lead to inaccurate pseudo-labels, which post great challenges for accurate IBD classification. To meet these challenges, we introduce a subclass-aware contrastive module to regularize the low-dimensional feature embedding space. A schematic illustration of the proposed subclass-aware contrastive module is presented in Figure 2. In the subclass-aware contrastive module, confident and uncertain samples are first identified based on the pseudo-labels. To capture intra-class heterogeneity, each class is represented by a set of online-updated prototypes. Confident samples are then assigned to these prototypes to form subclasses, and distinct contrastive objectives are respectively applied to confident and uncertain samples in the embedding space. Specifically, uncertain samples are optimized with an instance-level contrastive loss to reduce the impact of inaccurate pseudo-labels. For confident samples, a subclass-level contrastive loss is designed to encourage subclass-level clustering, enabling the model to preserve fine-grained intra-class semantics and enhance inter-class separability. A step-by-step explanation of the details is presented below.
For each unlabeled sample , we generate a second strongly augmented view in addition to the first view . We then construct two data batches composed of the strong augmented views and the corresponding soft pseudo-labels, which are defined as and . Subsequently, these batches are merged into a multi-view batch , which contains samples. For notational simplicity, we denote the multi-view batch as , where represents a strongly augmented view and is its corresponding soft pseudo-label. Subsequently, all images in the multi-view batch are fed through the visual encoder and the projection head to produce the embedding set , where each embedding is -normalized. Next, let be the set of indices of all augmented samples within the multi-view batch. We partition I into confident and uncertain sets based on the confidence of the corresponding pseudo-label: , where is a scalar hyperparameter that determines whether a sample should be considered as a confident sample. This separation allows the model to employ the instance-level contrastive loss and the subclass-level contrastive loss anchored, respectively, at uncertain and confident samples. In the following, we describe the design of the instance-level and the subclass-level contrastive losses in detail.
3.2.1. Instance-Level Contrastive Loss
To mitigate the confirmation bias during training, we employ an instance-level contrastive loss on uncertain samples, following the formulation in SimCLR [23], where each image instance is treated as its own class. Specifically, taking an anchor embedding from the uncertain sample (where ) and another embedding (where ) for example, we regard the embedding pair to be positive only when is the embedding from the alternative augmented view of the same original image, which is denoted as . Otherwise, the embedding pair is considered to be negative. Subsequently, the instance-level contrastive loss is formulated as
where is a temperature parameter.
3.2.2. Prototype-Based Subclass-Level Contrastive Loss
To capture fine-grained intra-class semantics and improve inter-class separability, we propose a prototype-based subclass-level contrastive learning strategy. Confident samples are assigned to a set of class-specific prototypes, effectively forming subclasses. Inspired by [32], we designed a supervised contrastive loss to encourage samples within each subclass to cluster closely while remaining distinct from other subclasses. The details about the prototype-based subclass-level contrastive loss are presented below.
Online Prototype Assignment. For each class , we incorporate K subclass prototypes to represent this class, where each prototype is an -normalized vector in the embedding space. Let denote the indices of confident samples in the multi-view batch that are predicted as class c, i.e., , and let denote the number of samples in . We enumerate these indices as . The corresponding confident samples are collected as . Our objective is to assign the samples in to the K subclass prototypes of class c. We denote the sample-to-prototype mapping as where each represents the assignment probabilities of sample over the K prototypes.
Concretely, given the embedding matrix where each is the -normalized embedding of , is optimized by solving an optimal transport problem [48] that maximizes the cosine similarity between and the prototypes, i.e., with an entropy regularization term. The optimization objective is defined as
where is a parameter controls the smoothness of , while and denote all of the K-dimension and -dimension vectors, respectively. The unique assignment constraint, i.e., , ensures that each sample is assigned to one prototype. The equipartition constraint, i.e., , enforces each prototype is selected at least times on average in the multi-view batch, which prevents the trivial solution. The solution to this optimization problem is
where and are renormalization vectors, which can be updated by a few steps of the Sinkhorn–Knopp algorithm [31].
Prototype-based Subclass-level Contrastive Loss. With the assignment probability matrix , we online group the samples into K prototypes within class c. After processing all confident samples in the multi-view batch, each confident sample (where ) is assigned to -th prototype of class , where and .
Subsequently, taking an anchor embedding from a confident sample (where ) and an another embedding (where ) for example, we regard the embedding pair to be positive if one of the following conditions holds: (1) is the embedding from the alternative augmented view of the same original image, which is denoted as , or (2) corresponds to a different original image but is assigned to the same prototype as . Formally, we define the set of cross-image positive indices as . Otherwise, the embedding pair is considered to be negative. To weaken the bias of enforcing alignment between samples with potentially incorrect pseudo-labels, we introduce a confident weight for positive pairs from different images. Specifically, for a positive pair where , the confident weight is defined as .
We calculate contrastive loss anchored at as follows:
where denotes the temperature parameter.
The prototype-based subclass-level contrastive loss is defined by
where is the number of positive samples for the i-th sample in the multi-view batch.
Prototype Update. At the training stage, the prototypes are updated in an online manner using the embeddings assigned to them. Specifically, after each iteration, each prototype is updated based on the normalized center of its assigned embeddings, which can be formulated as
where represents the set of embeddings assigned to prototype in the multi-view batch, and is the momentum coefficient.
3.2.3. Subclass-Aware Contrastive Loss
The subclass-aware contrastive loss is defined as the average of losses anchored at the confident and the uncertain samples over the multi-view batch.
3.3. Overall Objective Function
The overall objective function of the proposed method is
where and are weighting parameters for the unsupervised loss and the subclass-aware contrastive loss , respectively.
4. Results
4.1. Experimental Setting
Study approval. This retrospective study was approved by the ethics committee of Daping Hospital affiliated with Army Military Medical University (No. 2018-137). A waiver of informed consent was granted by the same ethics committee. In addition, the clinical study registration number is ChiCTR2100043278. The study complies with the Declaration of Helsinki.
Datasets. We conduct comprehensive experiments on two colonoscopy image datasets: an in-house collected Daping dataset for IBD classification and a publicly available LIMUC dataset [49] for UC severity grading.
(1)Daping dataset: The Daping dataset comprises 17,161 colonoscopy images from 599 patients collected at the Department of Gastroenterology, Daping Hospital, Army Medical University, between January 2018 and November 2020. Following quality control, images were independently annotated by two experienced gastroenterologists with disagreements resolved by a third expert. Specifically, the Daping dataset consists of three categories, including 1093 CD images, 3379 UC images, and 12,689 normal mucosa images.(2)LIMUC dataset: The LIMUC dataset [49] consists of 11,276 colonoscopy images collected from 564 patients. The images are annotated by experienced gastroenterologists according to the Mayo Endoscopic Score (MES) and are distributed across four severity grades, including 6105 images with MES 0, 3052 images with MES 1, 1254 images with MES 2, and 865 images with MES 3.
We randomly split the dataset by patient into training and testing sets with a ratio of 8:2, ensuring that no images from the same patient appear in both sets. Within the training set, the labeled and unlabeled data are also split by patient to maintain patient-level separation. We adopt a default labeled-to-unlabeled data ratio of 2:8, meaning that 20% of the training samples are labeled while the remaining 80% are treated as unlabeled. The split is also performed at the patient level, ensuring that all images from a single patient are assigned exclusively to either the labeled or the unlabeled subset.
Implementation Details. The proposed framework is implemented in PyTorch 2.5.0, and all experiments are performed on one NVIDIA GeForce RTX 4090 GPU and an Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz. The network backbone is ViT-B/16-224 [50]. For experiments on the in-house collected Daping dataset, the visual encoder is initialized through self-supervised pretraining on the training set using i-JEPA [51]. For experiments on the publicly available LIMUC dataset [49], we initialize the visual encoder directly with ImageNet-pretrained weights [52] to facilitate reproducibility. It is worth noting that for fair comparison, all competing methods evaluated on the same dataset employ the identical visual encoder with the same initialization strategy. The weak augmentation includes random cropping and flipping. We adopt RandAugment [53] as the strong augmentation function . The training batch sizes for labeled and unlabeled data are 40 and 80, respectively. For the hyperparameters, we empirically set , , , , , , , and . The AdamW optimizer [54] is employed with a weight decay of . The learning rate is initialized to and linearly decreases to over 150 epochs. The model saved at the end of 150 epochs is used for testing.
Evaluation Metrics. We report the classification performance using four evaluation metrics: accuracy, specificity, sensitivity and F1-score. Accuracy is calculated as the proportion of correctly classified samples over the entire test set. In addition, sensitivity, specificity, and F1-score are computed for each class and then averaged across all classes. Specifically, for each class c, , , , and denote the true positives, true negatives, false positives, and false negatives, respectively. Then, the evaluation metrics are calculated by
4.2. Comparison with State-of-the-Art Semi-Supervised Learning Methods
To evaluate performance, we compared our method with five SOTA semi-supervised learning methods on both the Daping dataset and the LIMUC dataset [49]. The characteristics of each SOTA method are summarized as follows. (1) FixMatch [18], which combines pseudo-labeling with consistency regularization, and applies a fixed confidence threshold to ensure the quality of pseudo-labels; (2) FreeMatch [55], which extends FixMatch by adopting an adaptive thresholding strategy that dynamically adjusts the confidence threshold in a class-aware manner, achieving a better quality–quantity trade-off; (3) Class-aware Semi-supervised Contrastive Learning (CCSSL) [25], which integrates a class-aware contrastive module into the FixMatch framework. It separately handles in-distribution data with class-level clustering and out-of-distribution data with instance-level contrastive; (4) SoftMatch [56], which extends FixMatch by using a truncated Gaussian weighting function to assign confidence-based weights to unlabeled samples rather than using a fixed threshold to filter them; (5) Semantic-aware FixMatch (SA-FixMatch) [21], which replaces the standard random CutOut in FixMatch’s strong augmentation with a semantic-aware CutOut.
Moreover, to quantify the performance of different competing methods, we trained two additional models on the dataset. These two models had the same network architecture as our method. The first model, referred to as the upper bound, was trained on 100% labeled data in a fully supervised manner, while the second model, referred to as the baseline, was trained in a fully supervised manner on 20% labeled data without using any unlabeled data.
To assess the statistical significance of performance differences between models, we apply bootstrap resampling [57] to estimate the distribution of pairwise differences in F1-score, as the F1-score provides a more reliable overall metric than accuracy for imbalanced classification. A 95% confidence interval (CI) of the difference is then computed. Following established statistical interpretation [58,59], when a confidence interval (CI) includes zero, it means that the observed difference is not statistically significant at the 95% confidence level.
Results on the Daping Dataset. The quantitative comparison with the competing SOTA methods when using 20% labeled data for training is presented in Table 2. From this table, one can observe that our method achieves the best classification performance with an accuracy of , a sensitivity of and an F1-score of . Specifically, our method outperforms the second-best method (CCSSL [25]) by a margin of , and in terms of accuracy, sensitivity and F1-score, respectively. Moreover, the 95% CI of the F1-score difference is [0.003, 0.041], which does not include zero, indicating that the performance improvement of our method over CCSSL [25] is statistically significant at the 95% confidence level for the semi-supervised IBD classification task. The experimental results demonstrate the effectiveness of the proposed method in the semi-supervised IBD classification of colonoscopy images. Additionally, from Table 2, one can observe that our proposed SACSSL surpasses the baseline performance by a substantial margin of , , and in terms of accuracy, sensitivity, specificity and F1-score, respectively, and it is close to the upper-bound performance, with a small gap of , , and in terms of accuracy, sensitivity, specificity and F1-score, respectively. These results demonstrate the superior capability of our method in leveraging the unlabeled data for the semi-supervised IBD classification of colonoscopy images.
Results on the LIMUC Dataset. The quantitative comparison with the competing SOTA methods when using 20% labeled data for training is presented in Table 3. From this table, one can observe that our method achieves the highest accuracy (76.4%) and F1-score (68.9%) along with a sensitivity of 67.7% and a specificity of 91.0%. In comparison, CCSSL [25] attains a higher sensitivity of 68.9% and a specificity of 91.2% but with lower accuracy (75.9%) and F1-score (68.0%). The 95% CI of the F1-score difference between our method and CCSSL [25] is [−0.005, 0.026], indicating that the performance improvement is not statistically significant at the 95% confidence level. This outcome may be attributed to the inherent characteristics of the UC severity grading task, which consists of fine-grained categories with smaller inter-class differences and more constrained intra-class variation, naturally limiting the potential gains achievable by the subclass-aware contrastive module. Despite these constraints, our method still achieves the highest overall accuracy and F1-score. The experimental results demonstrate the effectiveness of the proposed method in semi-supervised UC severity grading, indicating its adaptability across different IBD-related colonoscopy image classification tasks.
4.3. Analytical Ablation Studies
We further conduct analytical ablation studies on the Daping dataset to investigate the effectiveness of different components of the proposed method. In particular, we conduct the following analytical ablation studies: (1) We first evaluate the classification performance of the proposed method using different percentages of labeled data; (2) We then investigate the effectiveness of each loss to the overall classification performance gain in the proposed method; (3) We further investigate the influence of the confidence threshold and the number of prototypes per class K in the subclass-aware contrastive module on the performance of the proposed method; (4) Additionally, we investigate the influence of the visual encoder backbone on the performance of the proposed method; (5) Finally, we conduct an analysis of learned features.
Evaluation under Different Percentages of Labeled Data. We conducted an ablation study to investigate the impact of the percentage of labeled data on the performance of the proposed method. We compared our method with the baseline model when 5%, 10%, 20% and 30% labeled data were used for training. In particular, the baseline model was trained in a supervised manner using only the labeled data, while our method was trained in a semi-supervised manner using both labeled and unlabeled data. The experimental results are presented in Table 4. As shown in this table, our method demonstrates consistent classification performance improvement under all proportions of labeled data compared to the baseline performance. Notably, when trained with only 5% labeled data, our method outperforms the baseline performance by a large margin of , , and in terms of accuracy, specificity and F1-score, respectively, demonstrating its effectiveness in leveraging unlabeled data under very limited labeled data. As the proportion of labeled data increases to 30%, our method outperforms the baseline performance by a margin of , , , and in terms of accuracy, sensitivity, specificity, and F1-score, respectively. These results demonstrate the superior capability of our method in leveraging the unlabeled data to improve classification performance.
Effectiveness of Different Losses. To validate the effectiveness of different losses used in our method, we conduct an ablation study by training the model with different combinations of losses using 20% labeled data: (1) ; (2) ; (3) ; (4) ; and (5) (where is a combination of and ). The experimental results are reported in Table 5. Compared to the baseline model trained with alone, the model trained with and improves the classification performance by a margin of 1.0% in terms of accuracy, while showing a performance drop by a margin of 3.1% and 1.1% in terms of sensitivity and F1-score, respectively, which could be potentially attributed to confirmation bias. In addition to and , incorporating further improves the accuracy, sensitivity, specificity and F1-score by a margin of 0.4%, 4.2%, 0.8% and 2.9%, respectively, which demonstrates the effectiveness of the instance-level contrastive loss when applied to uncertain samples. Similarly, incorporating in addition to and improves the classification performance by a margin of 0.5%, 2.0%, 0.5% and 1.5% in terms of accuracy, sensitivity, specificity and F1-score, respectively, demonstrating the effectiveness of the subclass-level contrastive loss when applied to confident samples. Finally, the model that incorporates all the losses results in the best classification performance, outperforming the second-best classification performance by a margin of 0.7%, 1.5%, 0.2%, and 2.8% in terms of accuracy, sensitivity, specificity, and F1-score, respectively, which demonstrates the two complementary components of our subclass-aware contrastive loss , composed of and , provide synergistic benefits for representation learning. These results demonstrate that the subclass-aware contrastive loss, derived from our proposed subclass-aware contrastive module, effectively enhances representation learning and improves the overall classification performance.
Influence of the Confidence Threshold . The confidence threshold determines the separation of confident and uncertain samples in our method. A low may include samples with incorrect pseudo-labels in the confident set, introducing noise to subclass-level contrastive learning, whereas a high may exclude correctly pseudo-labeled samples from the confident set, which weakens the effectiveness of subclass-level contrastive learning. To investigate the influence of the confidence threshold, we conduct an ablation study by setting to a value in . The experimental results are reported in Table 6. From this table, one can observe that the model achieves the best classification performance when is set to 0.9 with an accuracy of 93.2% and an F1-score of 80.1%. Therefore, we adopt in our study.
Influence of the Number of Prototypes per Class . The number of prototypes per class K controls the subclass granularity within each multi-view batch. Too few prototypes may fail to capture fine-grained intra-class variations in IBD colonoscopy images, while too many prototypes may push semantically similar samples away in the embedding space, reducing the effectiveness of contrastive learning. Here, we conduct an ablation study to investigate the performance of the proposed method when setting different K values, where K is in . The experimental results are reported in Table 7. From this table, the model achieves the best classification performance when K is set to 3 with an accuracy of 93.2% and an F1-score of 80.1%. Therefore, we adopt in our study.
Influence of the Visual Encoder Backbone. The choice of visual encoder backbone directly affects the quality of extracted visual features, which in turn influences classification performance. To evaluate this effect, we conduct an ablation study using three widely adopted models as the visual encoder backbone: two CNN-based models, ResNet50 [60] and EfficientNet-B5 [37], and a transformer-based model, ViT-B [50]. The experimental results are summarized in Table 8. From this table, one can observe that when using ViT-B [50] as the visual encoder, our method achieves the best classification performance, outperforming the best CNN-based backbone (ResNet-50 [60]) by a margin of 1.7%, 0.1%, 1.1%, and 2.5% in terms of accuracy, sensitivity, specificity, and F1-score, respectively. These results indicate that the transformer-based backbone consistently outperforms the CNN-based backbones in the semi-supervised colonoscopy image classification task. Accordingly, we adopt ViT-B as the visual encoder backbone in our study.
Analysis of the Learned Features. To validate the effectiveness of our method in representation learning, we use the t-SNE algorithm [61] to visualize the distributions of learned features extracted from the visual encoder by projecting the embedded features into a two-dimensional space. In Figure 3, we present a qualitative comparison of the t-SNE visualization on the Daping test set between FixMatch [18] and the proposed SACSSL. The t-SNE analysis is implemented in Python using the scikit-learn package [62] (version 1.5.1). Each point in Figure 3 represents the embedded feature from one colonoscopy image and is color-coded using the ground truth class label. From this figure, one can see that the classification boundary learned by FixMatch, especially between UC and CD, is unclear, such that it is difficult to correctly classify IBD from colonoscopy images. By incorporating our proposed subclass-aware contrastive module, SACSSL learns feature representations with clearer inter-class boundaries, while intra-class features are further partitioned into multiple compact clusters according to their semantic information. This explains why the proposed SACSSL achieves superior classification performance.
5. Discussion
The accurate classification of IBD from colonoscopy images is critical for timely diagnosis and effective treatment. Although deep learning-based approaches have achieved impressive performance in various medical image classification tasks, developing robust models for IBD diagnosis remains challenging due to the limited availability of annotated endoscopic data and the severe intra-class heterogeneity of colonoscopy images. Semi-supervised learning methods provide a promising alternative to this problem by leveraging both labeled and unlabeled data. In particular, the pseudo-labeling-based framework combined with consistency regularization [18,55,56] has proven to be an effective and simple approach. CCSSL [25] extended pseudo-labeling-based frameworks by refining learned features through class-aware contrastive learning that promotes intra-class clustering. Although this approach performs well on natural image tasks, it struggles to capture the substantial intra-class heterogeneity of colonoscopy images in IBD classification. However, prior approaches for modeling intra-class heterogeneity either rely on fully supervised subclass decomposition that cannot exploit unlabeled data or adopt class-agnostic prototype learning in a self-supervised manner, making it difficult to simultaneously leverage unlabeled data and capture fine-grained intra-class variations for IBD classification. To address these limitations, we propose SACSSL, which incorporates the proposed subclass-aware contrastive module into the FixMatch framework. This design enables us to refine learned features by applying an instance-level contrastive loss to distinguish uncertain samples and applying a subclass-level contrastive loss to confident samples to learn hierarchical clustered representations within each class. We evaluate our method on an in-house collected colonoscopy image dataset for IBD classification, which is referred to as the Daping dataset. The proposed method outperforms the SOTA methods, as presented in Table 2. As demonstrated in Table 4, our method achieves consistently improved performance compared to the baseline performance regardless of the percentage of labeled data, which demonstrates that our model can effectively leverage unlabeled data. Moreover, we further evaluate our method on the publicly available LIMUC dataset for UC severity grading, which is an IBD-related classification task. As shown in Table 3, our method outperforms other competing SOTA methods, demonstrating its effectiveness on UC severity grading as an additional colonoscopy image classification task.
The key to the superior performance of SACSSL lies in the carefully designed subclass-aware contrastive module. In particular, we leverage subclass prototypes to partition confident samples into subclasses and apply supervised contrastive loss to learn hierarchical, clustered representations within each class. Quantitative and qualitative results from our analytical ablation studies conducted on the Daping dataset demonstrate that SACSSL learns better-separated feature representations with the proposed subclass-aware contrastive module, as demonstrated by Figure 3 and Table 5.
The clinical implications of the proposed method merit further discussion. In clinical practice, large amounts of colonoscopy data are readily available, whereas obtaining expert annotations remains costly and time consuming. By effectively leveraging abundant unlabeled data available in clinical archives, the proposed framework alleviates the heavy reliance on expert annotations, which is one of the major barriers to the real-world deployment of deep learning models. Moreover, the improved inter-class separability and preserved intra-class diversity achieved through subclass-aware contrastive learning enhance the model’s capability to distinguish between UC and CD, which is a clinically important yet challenging task even for experienced endoscopists. Collectively, these advantages highlight the potential clinical impact of the proposed method in supporting large-scale, annotation-efficient colonoscopy image diagnosis.
In addition, several limitations of the current study, as well as potential directions for future research, deserve further discussion. First, although the proposed method achieves consistently superior performance on both the in-house Daping dataset and the publicly available LIMUC dataset, the current evaluation is still limited to single-center data. However, differences in patient populations, imaging devices, and acquisition protocols across institutions may introduce domain shifts, which could potentially lead to degraded performance on external datasets. Recent studies [63,64,65] have shown that semi-supervised domain adaptation techniques can effectively mitigate such discrepancies by leveraging labeled source data and unlabeled target domain data, which provides a promising direction for extending the proposed framework to multi-center scenarios. Second, the present work follows a closed-set semi-supervised learning setting, where all categories in the unlabeled data are assumed to be known. However, in real-world clinical environments, unlabeled data may inevitably contain unknown categories. Recent advances in open-set and universal semi-supervised learning [21,66] offer potential solutions by explicitly handling unknown samples during training. In future studies, integrating such strategies into the proposed framework could further enhance its robustness in practical scenarios. Third, the hyperparameters in this study were selected empirically. Although the current configuration already yields superior performance compared to other competing SOTA methods, more systematic hyperparameter optimization strategies, such as grid search, could be explored in future work to potentially achieve further performance gains.
6. Conclusions
In this paper, we propose a novel subclass-aware contrastive semi-supervised learning framework for accurate colonoscopy image classification, which is referred to as SACSSL. The proposed framework features a novel subclass-aware contrastive module, which explicitly captures intra-class heterogeneity by adaptively applying instance-level contrastive learning to uncertain samples and prototype-based subclass-level contrastive learning to confident samples, thereby enhancing inter-class separability while preserving fine-grained intra-class diversity and mitigating confirmation bias. Comprehensive experiments on both the in-house Daping dataset and the public LIMUC dataset demonstrate that SACSSL consistently outperforms existing semi-supervised learning methods in both IBD classification and UC severity grading. In addition, the t-SNE analysis further confirms that SACSSL is capable of learning clear classification boundaries while preserving fine-grained intra-class semantics, highlighting its effectiveness in IBD classification from colonoscopy images. In future work, we will focus on extending the proposed framework to semi-supervised domain adaptation, aiming to improve robustness across centers with different endoscopy systems and patient populations. Moreover, we will explore the universal semi-supervised learning method to explicitly handle non-IBD or atypical colonoscopic findings that commonly appear in large-scale unlabeled clinical data.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Baumgart D.C. Carding S.R. Inflammatory bowel disease: Cause and immunobiology Lancet 20073691627164010.1016/S 0140-6736(07)60750-817499605 · doi ↗ · pubmed ↗
- 2Ng S.C. Shi H.Y. Hamidi N. Underwood F.E. Tang W. Benchimol E.I. Panaccione R. Ghosh S. Wu J.C. Chan F.K. Worldwide incidence and prevalence of inflammatory bowel disease in the 21st century: A systematic review of population-based studies Lancet 20173902769277810.1016/S 0140-6736(17)32448-029050646 · doi ↗ · pubmed ↗
- 3Hracs L. Windsor J.W. Gorospe J. Cummings M. Coward S. Buie M.J. Quan J. Goddard Q. Caplan L. MarkovinovićA. Global evolution of inflammatory bowel disease across epidemiologic stages Nature 202564245846610.1038/s 41586-025-08940-040307548 PMC 12158780 · doi ↗ · pubmed ↗
- 4Harbord M. Eliakim R. Bettenworth D. Karmiris K. Katsanos K. Kopylov U. Kucharzik T. Molnár T. Raine T. Sebastian S. Third European evidence-based consensus on diagnosis and management of ulcerative colitis. Part 2: Current management J. Crohn’s Colitis 20171176978410.1093/ecco-jcc/jjx 00928513805 · doi ↗ · pubmed ↗
- 5Moran G.W. Gordon M. Sinopolou V. Radford S.J. Darie A.M. Vuyyuru S.K. Alrubaiy L. Arebi N. Blackwell J. Butler T.D. British Society of Gastroenterology guidelines on inflammatory bowel disease in adults: 2025 Gut 202574 s 1s 10110.1136/gutjnl-2024-33439540550582 · doi ↗ · pubmed ↗
- 6Miehlke S. Verhaegh B. Tontini G.E. Madisch A. Langner C. Münch A. Microscopic colitis: Pathophysiology and clinical management Lancet Gastroenterol. Hepatol.2019430531410.1016/S 2468-1253(19)30048-230860066 · doi ↗ · pubmed ↗
- 7Jung S.A. Differential diagnosis of inflammatory bowel disease: What is the role of colonoscopy?Clin. Endosc.20124525426210.5946/ce.2012.45.3.25422977813 PMC 3429747 · doi ↗ · pubmed ↗
- 8Spiceland C.M. Lodhia N. Endoscopy in inflammatory bowel disease: Role in diagnosis, management, and treatment World J. Gastroenterol.201824401410.3748/wjg.v 24.i 35.401430254405 PMC 6148432 · doi ↗ · pubmed ↗