Phylograd: fast column-specific calculation of substitution model gradients
Benjamin Lieser, Georgy Belousov, Johannes Söding

TL;DR
PhyloGrad is a fast tool for calculating gradients in phylogenetic tree models, enabling efficient exploration of site-specific substitution models.
Contribution
PhyloGrad introduces a highly efficient reverse-mode differentiation method for phylogenetic likelihoods, enabling faster and more memory-efficient model optimization.
Findings
PhyloGrad is 30-100 times faster than PyTorch for gradient calculations in phylogenetic models.
It uses 10-100 times less memory than automatic differentiation methods.
PhyloGrad is at least 10 times faster than IQ-TREE3 for fitting global substitution models.
Abstract
Most popular tools for reconstructing phylogenetic trees from multiple sequence alignments use a model of molecular evolution in which a single substitution matrix or a small set of fixed matrices are shared between all columns. Models with column-specific rate matrices can in principle be fit by automatic differentiation methods, but in practice the heavy computational burden associated with computing the gradients of the many matrix exponentials has hindered exploration of such models. Here, we present a highly efficient approach for reverse-mode differentiation of the log likelihood computed with Felsenstein’s algorithm under any time-reversible substitution model. PhyloGrad is implemented in Rust and has Python bindings to easily combine it with automatic differentiation tools. Depending on the tree size, PhyloGrad is 30-100 times faster than automatic differentiation in Pytorch…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
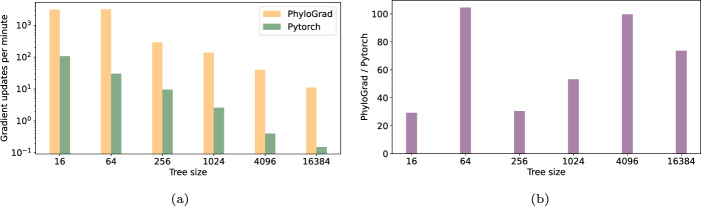 Figure 1
Figure 1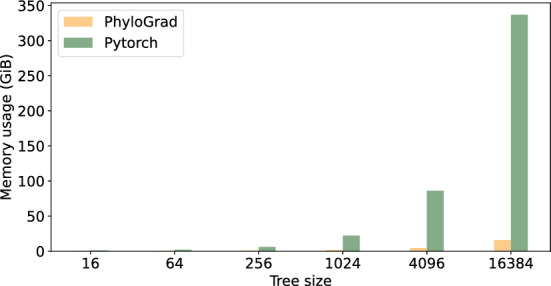 Figure 2
Figure 2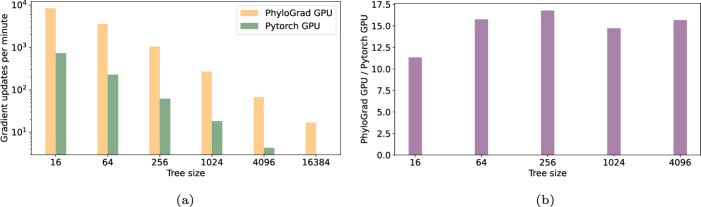 Figure 3
Figure 3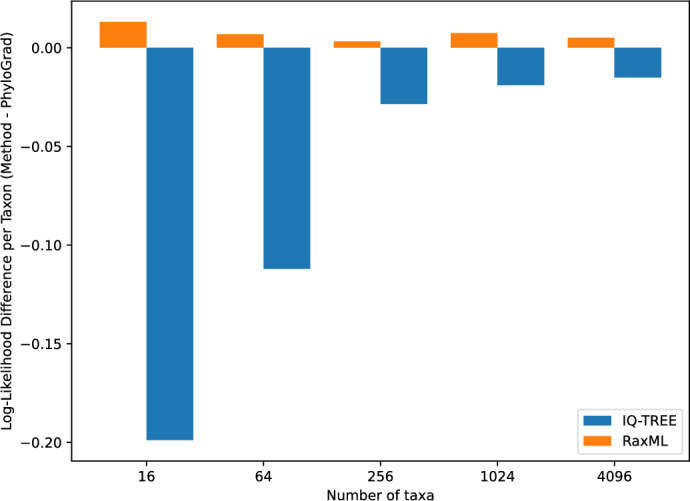 Figure 4
Figure 4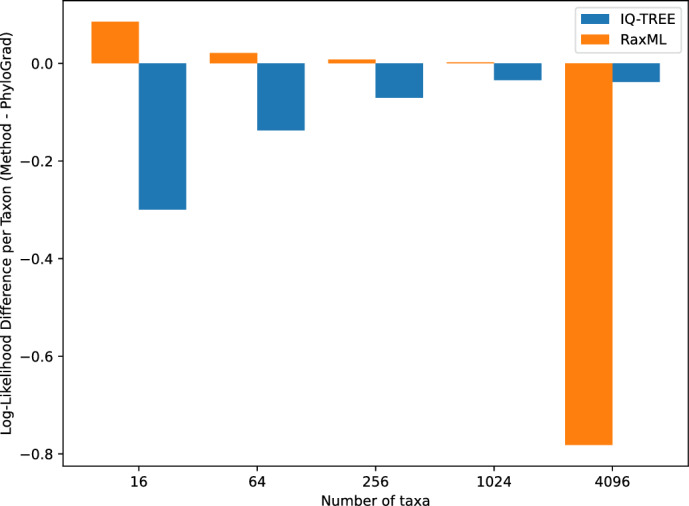 Figure 5
Figure 5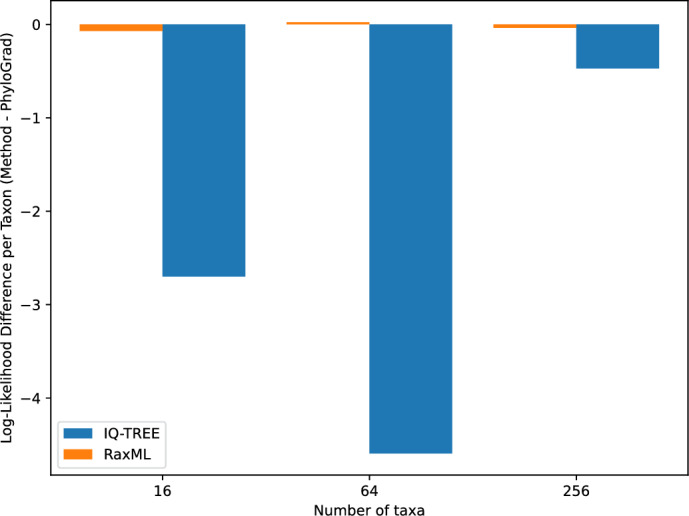 Figure 6
Figure 6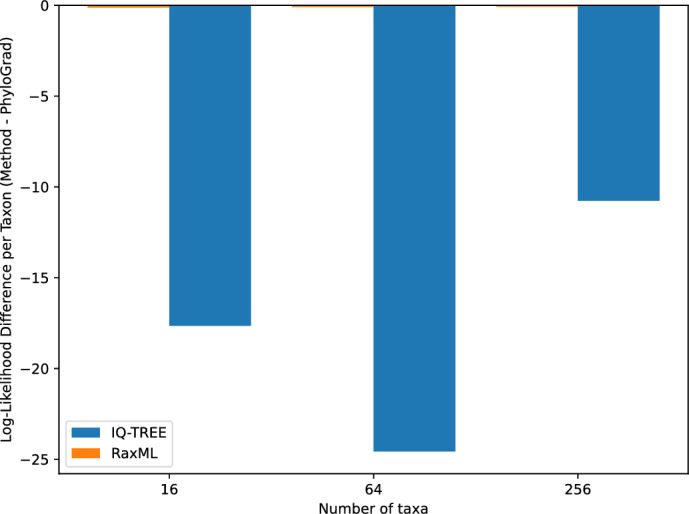 Figure 7
Figure 7 Figure 8
Figure 8- —Max Planck Institute for Multidisciplinary Sciences (2)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenomics and Phylogenetic Studies · Genome Rearrangement Algorithms · Evolution and Paleontology Studies
Background
The process of amino acid or nucleotide substitution in a Multiple Sequence Alignment (MSA) is commonly modeled by a continuous-time Markov chain (CTMC). A CTMC is specified by a rate matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q \in \mathbb {R}^{n \times n}$$\end{document} , where n is the number of different residues (amino acids or nucleotides), so typically 20 or 4. Given a phylogenetic tree of the sequences and the rate matrix, Felsenstein’s algorithm [1] can be used to calculate the likelihood of the MSA under this model.
Due to different selection pressures acting on different columns of the MSA, the process of residue substitution is different in each column. However, most of the models implemented in IQ-TREE3 [2] and RAxML [3] use a single parameter-less model like LG [4] or WAG [5], and add a rate model to account for differing overall mutation rates between columns. The models C10, C20, ..., C60 [6], inspired by CAT [7], are a popular choice to account for site-dependent selection pressures. They contain 10 to 60 amino acid profiles trained on a large amounts of MSAs. Except for the optional weights of mixture components, there are no free parameters.
For phylogenetic analysis on a larger alignment, it would be beneficial to fit more parameters. Even in the setting of Cxx models, the work of Baños et al. [8] points out that accuracy of these models can be improved by refitting the substitution matrices. In order to fit substitution matrices, an efficient way to compute their gradients is required. Currently the fitting on the input MSAs is discouraged because of the substantial runtimes involved.
Fast gradients also enable Bayesian estimates with Hamiltonian Monte Carlo (HMC). HMC sampling provides a substantial gain in efficiency over the common Metropolis-Hastings-based Markov Chain Monte Carlo, which currently is the most common approach for Bayesian tree estimation.
Our method PhyloGrad efficiently calculates the gradient of the log likelihood with respect to all elements of Q, including with respect to independent per-column substitution matrices, which is inaccessible with current phylogenetic software. This allows for very flexible and efficient methods of fitting these substitution matrices. It is easy to add regularization to prevent overfitting, and to use gradient-based optimization algorithms like LBFGS [9] or gradient decent.
First of all, we follow the reverse-mode differentiation approach, which has lower complexity than forward-mode differentiation for this task due to the possibly high number of model parameters. This idea builds on results of Ji et al. [10], who show how to compute the gradient with respect to branch lengths in linear instead of quadratic time with respect to the number of sequences.
The implementation of PhyloGrad is highly parallel and memory-efficient. We simplify the computation graph of Felsenstein’s algorithm, reducing the overhead of reverse-mode differentiation. All time critical computations are vectorized and optimized for memory locality.
In addition to these engineering improvements, a key step is optimizing the differentiation of the matrix exponential. The work of McGibbon and Pande [11] describes an approach to obtain an efficient and numerically stable solution for the forward-mode differential. We derive how to apply this approach also in the reverse-mode setting. Motivating and describing this computation is the main topic of the present article.
Implementation
From rate matrix to likelihood
In a CTMC model, the rate matrix Q, sometimes also called the generator matrix, specifies the infinitesimal rate of transition for each pair of residues. The transition probabilities over any specific time t can then be obtained from this matrix: namely, the probability of transitioning from residue a to residue b in time t is given by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(e^{Q t})_{a b}$$\end{document} . The rate matrix has non-negative off-diagonal entries, and each of its rows sums up to 0. In particular, the diagonal elements will be negative.
Felsenstein’s Algorithm [1] uses transition probabilities to calculate the log likelihood of observing the sequences of an MSA given a phylogentic tree. For each combination of a substitution matrix and an branch length in the tree we need to invoke one matrix exponential to get corresponding transition probabilities. When there are different rate matrices for different columns, one cannot reuse the transition probabilities and incurs a large computational cost.
Implementing this algorithm directly in Pytorch can calculate the desired gradients using automatic differentiation, but most of the time is spent in calculating the matrix exponential and its gradient.
Replacing the matrix exponential
The matrix exponential is a function from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^{n \times n} \rightarrow \mathbb {R}^{n \times n}$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ e^X:= \sum _{i = 0}^\infty \frac{X^i}{i!}$$\end{document} . Evaluating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$e^X$$\end{document} for an arbitrary input matrix X is quite expensive, as even the best available algorithms involve a significant number of matrix multiplications in this case [12]. We provide timings for random inputs in Appendix C.
If the matrix Q is diagonalized, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q = A \Lambda A^{-1}$$\end{document} with a diagonal matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Lambda = {{\,\textrm{diag}\,}}(\lambda _1,...,\lambda _n)$$\end{document} and an invertible matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A \in \mathbb {R}^{n \times n}$$\end{document} , we can calculate the matrix exponential \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ e^{Q t} = A e^{\Lambda t} A^{-1}$$\end{document} for time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t>0$$\end{document} using only n scalar \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\exp (\lambda _i t)$$\end{document} evaluations and two matrix multiplications. Notice that, although the computational cost of diagonalization is comparable to that of matrix exponentiation, we only have to compute it once for a given rate matrix Q and can then reuse it for different values of t. Because in Felsenstein’s algorithm we have as many different branch lengths t as we have branches in the phylogenic tree, diagonalization gives a significant speedup compared to the direct computations of each of the matrix exponentials.
Unfortunately, diagonalizing the matrix makes the gradient calculation numerically unstable, because the gradient of eigenvectors with respect to a matrix gets unstable when two eigenvalues get close to each other and is even undefined for repeated eigenvalues [13].
In the following we present a strategy to apply the diagonalization optimization and still get numerically stable gradients.
Forward- and reverse-mode differentiation
To better motivate our algorithm, we give here a short review on automatic differentiation.
Suppose our model is parameterized by a vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \in \mathbb {R}^{m}$$\end{document} . So instead of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q \in \mathbb {R}^{n \times n}$$\end{document} , we have a function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q(\theta )$$\end{document} . For the most general time-reversible model, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} would have \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m = n(n-1)/2$$\end{document} dimensions (see section about time symmetric parametrization).
For calculation of gradients, it seems natural to calculate the gradient with respect to each parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _u$$\end{document} of all the intermediate expressions in the algorithm and eventually the final log likelihood. This approach is called forward-mode differentiation, because the gradients are calculated in the same order as the values.
This turns out to be inefficient because you will have to calculate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{ \partial e^{Qt}}{\partial \theta _u}$$\end{document} for all the different times t. For each of the m parameters in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} , there are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n^2$$\end{document} partial derivatives, so \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n^2m$$\end{document} in total. Evaluating the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n^2$$\end{document} partial derivatives with respect to one parameter will take \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {O}(n^3)$$\end{document} operations. Overall, this will lead to a complexity of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {O}(n^3m)$$\end{document} , which will be \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {O}(n^5)$$\end{document} in the case of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m = n(n-1)/2$$\end{document} parameters.
Reverse-mode differentiation is a strategy for calculating gradients of any function. In case of scalar output, it will have the same complexity as evaluating the function. The idea is to first calculate the log likelihood L. Then you work back and calculate the derivative of L with respect to the intermediate expressions in the algorithm and eventually with respect to the parameters. So for example instead of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{ \partial e^{Qt}}{\partial \theta _u}$$\end{document} we calculate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\partial L}{\partial e^{Qt}}$$\end{document} . So we reduce the number of partial derivatives from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n^2m$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n^2$$\end{document} . The drawback is that we have to calculate the log likelihood L first and save the necessary information which is needed to perform the backward pass.
In general, forward-mode differentiation is more efficient if you have lower parameter dimension than output dimension, while reverse-mode differentiation is more efficient if you have higher parameter dimension than output dimension. This is always the case for a scalar function.
There are a lot of frameworks that automate this task, such as Pytorch, Tensorflow and Jax. The main problem is that it is not clear how to apply the diagonalization optimization to save the matrix exponential calculation, and a direct implementation leads to the above-discussed numerical instabilities. Moreover, automatic differentiation libraries typically incur some overhead compared to a well-designed manual implementation. The amount can vary a lot depending on the algorithm and framework. In our case with Pytorch we see an immensely higher memory consumption than in our manual implementation, see Fig. 2.
Numerically stable matrix exponential gradients
Reference [14] gives in Theorem 4.5 a useful formula for the case with a diagonalization \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q = A \Lambda A^{-1}$$\end{document} (see our proof in Appendix A):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{ \partial e^{Qt}}{\partial \theta _u} = A \left( A^{-1} \frac{ \partial Q}{\partial \theta _u} A \odot X(\Lambda , t) \right) A^{-1} \end{aligned}$$\end{document}with
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ X(\Lambda , t)_{i j} := {\left\{ \begin{array}{ll} t \exp (t \lambda _i) & \text {if } i = j \\ \frac{\exp (t \lambda _i) - \exp (t \lambda _j)}{\lambda _i - \lambda _j} & \text {if } j \ne i , \end{array}\right. } $$\end{document}and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\odot $$\end{document} denoting the element-wise multiplication (Hadamard product). The matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X(\Lambda , t)$$\end{document} can be computed in a numerically stable way even when the eigenvalues are close to each other or identical.
However, this formula is only applicable in the forward-mode differentiation setting, where we first calculate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{ \partial Q}{\partial \theta _u}$$\end{document} and then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{ \partial e^{Qt}}{\partial \theta _u}$$\end{document} . For reverse-mode differentiation we need to go from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{ \partial L}{\partial e^{Qt}}$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{ \partial L}{\partial Q}$$\end{document} .
Going from forward- to reverse-mode differentiation
Lets look at a simplified setting of calculating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L(\theta )$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \theta \rightarrow Q \rightarrow e^{Qt} \rightarrow L\Big ( e^{Q(\theta ) t}\Big ) \end{aligned}$$\end{document}Here t is constant, and we are interested in the gradient of the log likelihood function L with respect to the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} of matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q(\theta )$$\end{document} . To make things simpler we will think about Q as an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^{n^2}$$\end{document} vector by flattening it. The Jacobian Matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\partial e^{Qt}}{\partial Q}$$\end{document} has \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n^2 \times n^2$$\end{document} entries and represents a linear mapping from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^{n ^ 2}$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^{n ^ 2}$$\end{document} . By the chain rule we know that
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{ \partial e^{Qt}}{\partial \theta _u} = \frac{\partial e^{Qt}}{\partial Q} \, \frac{ \partial Q}{\partial \theta _u} \end{aligned}$$\end{document}and also
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{\partial L}{\partial Q} = \frac{\partial L }{\partial e^{Qt}} \, \frac{\partial e^{Qt}}{\partial Q} \end{aligned}$$\end{document}Equation 2 is a matrix–vector multiplication and Eq. 3 is a vector–matrix multiplication. So we can think about the Jacobian as a linear transformation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\partial e^{Qt}}{\partial Q}:\frac{ \partial Q}{\partial \theta _u} \mapsto \frac{ \partial e^{Qt}}{\partial \theta _u}$$\end{document} , and the transposed Jacobian as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left( \frac{\partial e^{Qt}}{\partial Q}\right) ^{\!\!\top }: \frac{\partial L }{\partial e^{Qt}} \mapsto \frac{\partial L}{\partial Q}$$\end{document} .
Equation 1 allows to evaluate Eq. 2 without computing all of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n^4$$\end{document} entries of the Jacobian. For reverse-mode differentiation, we need to evaluate Eq. 3 efficiently. So we need to find the corresponding expression for the transposed Jacobian.
We now consider the vector space of (non flattened) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n \times n$$\end{document} matrices. We define the standard scalar product \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\langle A, B \rangle := \sum _{i,j} A_{i j} B_{i j} = \sum _j (\sum _{i} (A^\top )_{ji} B_{i j}) ={{\,\textrm{Tr}\,}}(A^\top B)$$\end{document} . The Jacobian is a linear map from this space to itself.
In general for any linear map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F: \mathbb {R}^{n\times n} \rightarrow \mathbb {R}^{n\times n}$$\end{document} and any pair of matrices N, M we have \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\langle F(N),M \rangle = \langle N, F^\top (M) \rangle $$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F^\top $$\end{document} is the transposed map. The reverse is also true, that a map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F^\top $$\end{document} which has this property must the transposed map. We use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A^{-\top }$$\end{document} to denote the inverse of the transposed matrix.
Let’s take two arbitrary \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n \times n$$\end{document} matrices M and N:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\langle A (A^{-1} M A \odot X(\Lambda , t))A^{-1}, N \rangle = \nonumber \\ \text {(by def. of the scalar product)} =&{{\,\textrm{Tr}\,}}(A^{-\top } (A^{-1} M A \odot X(\Lambda , t))^\top A^\top N) \nonumber \\ \text {(by cyclic permutation in trace)} =&{{\,\textrm{Tr}\,}}((A^{-1} M A \odot X(\Lambda , t))^\top A^\top N A^{-\top }) \nonumber \\ \text {(by lemma in appendix B)}=&{{\,\textrm{Tr}\,}}( A^\top M^\top A^{-\top } (A^\top N A^{-\top } \odot X(\Lambda , t)) ) \nonumber \\ \text {(by cyclic permutation in trace)} =&{{\,\textrm{Tr}\,}}(M^\top A^{-\top } (A^\top N A^{-\top } \odot X(\Lambda , t)) A^\top ) \nonumber \\ \text {(by def. of the scalar product)} =&\langle M ,A^{-\top } (A^\top N A^{-\top } \odot X(\Lambda , t)) A^\top \rangle \end{aligned}$$\end{document}So, the linear map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N \rightarrow A^{-\top } (A^\top N A^{-\top } \odot X(\Lambda , t)) A^\top $$\end{document} is the transposed Jacobian and we can use it in the backward pass of reverse-mode differentiation.
After the diagonalization of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q = A \Lambda A^{-1}$$\end{document} , we can compute
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{\partial L}{\partial Q} = A^{-\top } \big (A^\top \frac{\partial L}{\partial e^{Qt}} A^{-\top } \odot X(\Lambda , t) \big ) A^\top \end{aligned}$$\end{document}with just four matrix multiplications for arbitrary t. In the Felstenstein algorithm we sum up all the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\partial L}{\partial Q}$$\end{document} contributions over all the branches, so we can factor out the two outermost matrix multiplications.
Parametrization for time-reversible models
The vast majority of phylogenetic models assume a condition called time reversibility. As shown in [11], this condition allows one to choose a convenient parametrization for the rate matrix, and ensures that it can be diagonalized, as summarized below.
For a vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} , we denote by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sqrt{\pi }$$\end{document} its component-wise square root, and by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\,\textrm{diag}\,}}(\pi )$$\end{document} the diagonal matrix whose entries are specified by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} .
A CTMC model is called time-reversible if there exists a distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} over its states such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _i q_{i j} = \pi _j q_{j i}$$\end{document} for all i, j, or, equivalently, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\,\textrm{diag}\,}}(\pi )Q = Q^\top {{\,\textrm{diag}\,}}(\pi )$$\end{document} . By transforming the expression into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\,\textrm{diag}\,}}(\sqrt{\pi }) Q {{\,\textrm{diag}\,}}(\sqrt{\pi })^{-1} = {{\,\textrm{diag}\,}}(\sqrt{\pi })^{-1} Q^\top {{\,\textrm{diag}\,}}(\sqrt{\pi })$$\end{document} , we see that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S:={{\,\textrm{diag}\,}}(\sqrt{\pi }) Q {{\,\textrm{diag}\,}}(\sqrt{\pi })^{-1}$$\end{document} is a symmetric matrix.
First of all, this implies that Q can be parametrized in terms of the symmetric matrix S and the vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} via \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q = {{\,\textrm{diag}\,}}(\sqrt{\pi })^{-1} S {{\,\textrm{diag}\,}}(\sqrt{\pi })$$\end{document} . By definition, Q must have non-negative off-diagonal elements, with diagonal entries chosen so that each row sums to 0. Thus only the upper triangular entries of S need to be explicitly specified in the parametrization.
In addition, recall that for an arbitrary matrix, a diagonalization may not exist, or it may be numerically unstable to compute. On the other hand, symmetric matrices are always diagonalizable in an efficient and numerically stable way, their eigenvectors are orthogonal and their eigenvalues are real numbers.
S is symmetric, and therefore has a diagonalization S =* B* Λ * B*^-1^ with * B*^-1^ = * B*^T^. Substituting back, we get \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q = {{\,\textrm{diag}\,}}(\sqrt{\pi })^{-1}B \Lambda B^{-1} {{\,\textrm{diag}\,}}(\sqrt{\pi })$$\end{document} . This gives a diagonalization for Q as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q = A \Lambda A^{-1}$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A:= {{\,\textrm{diag}\,}}(\sqrt{\pi })^{-1} B$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A^{-1} = B^{-1}{{\,\textrm{diag}\,}}(\sqrt{\pi }) = B^\top {{\,\textrm{diag}\,}}(\sqrt{\pi })$$\end{document} . These expressions are numerically stable as long as no entry of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sqrt{\pi }$$\end{document} is too small. The implementation treats every value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sqrt{\pi } < 10^{-10}$$\end{document} as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^{-10}$$\end{document} to avoid instabilities.
The optimization described in the previous two sections works whenever Q can be diagonalized, regardless of time-reversibility. Still, we assume that Q is time-reversible in PhyloGrad. It is a commonly satisfied condition, and it lets us provide a numerically stable parametrization for Q for the user’s convenience.
IQ-TREE and RaxML use the parametrization \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q = R {{\,\textrm{diag}\,}}(\pi )$$\end{document} , where R is a symmetric matrix. Parametrizing in terms of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sqrt{\pi }$$\end{document} instead of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} makes our approach slightly more numerically stable.
Code architecture
We have implemented reverse-mode differentiation for all parts of Felsenstein’s algorithm in the Rust programming language. We use our specialized method for the matrix exponential and standard approaches for all the other operations.
We provide Python bindings that take as input a phylogenetic tree and the residue profiles associated to its leaves (in particular, it can accept one-hot-encoded residue sequences, but more general profiles that account for sequencing ambiguity are also allowed). Given an equilibrium distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sqrt{\pi }$$\end{document} and an upper triangular matrix S, the package calculates the gradients of the log likelihood with respect to these two inputs.
The implementation parallelizes over multiple cores with the help of the Rust crate rayon, which is similar to OpenMP in the C/C++ world. As an alternative, we also provide a Jax implementation, which is able to also run on a GPU or TPU. On CPU, it is not as efficient as our Rust implementation.
Results
Comparison to IQ-TREE and RaxML
We want to compare the optimization of a global Q matrix between PhyloGrad and the IQ-TREE implementation provided by QMaker [15] and RaxML [3]. This case is computationally easier than the more general case of an independent rate matrix for each column. For better performance, PhyloGrad has an extra code path for the special case of a single, global matrix.
All three methods are gradient-based and are using LBFGS [16]. QMaker and RaxML use (one-sided) finite differences to obtain the gradients, which needs 209 Felsenstein evaluations for one gradient update (208 free parameters to optimize and 1 evaluation for the other term in the finite difference).
Our algorithm needs only one forward and one backward pass through the Felsenstein algorithm. Both passes are more complicated and therefore time-intensive. We calculate the partial likelihoods in log-space, which is simpler but slower than the optimized implementations in IQ-TREE and RaxML.
The trees are randomly generated and the alignments are simulated with IQ-TREE using the LG model. The results can be seen in Table 3 for single-threaded performance and Table 2 for multi-threaded performance.
We see that RaxML is considerably slower than IQ-TREE, but also produces better likelihoods, see Apendix D. We optimize until one LBFGS iteration does not improve likelihood by more than 0.0001%, which puts us close to the likelihood of RaxML and quite a bit ahead of IQ-TREE.
We can see a consistent speedup of a factor 10 while obtaining a better likelihood than IQ-TREE. In the multi-threaded run the difference is even larger.
We ran and compiled on a machine with two AMD EPYC 7742 64-Core Processors, making sure only one task was running on each machine at a time. The exact benchmark code can be found in the repository. Log files can be found in the logs.zip supplementary file. Table 1
If we define a partition for each column, we can make IQ-TREE and RaxML optimize a column-specific GTR model. Of course, this is extremely over-parametrized, but the gradients with respect to the full GTR model can be used to train very general but lower dimensional models, see for example our Pytorch benchmark. Table 2
IQ-TREE and RaxML now have to do a matrix diagonalization for each of the 209 Felsenstein passes per column. We only need to diagonalize once per column. There might also be considerable overhead in IQ-TREE and RaxML because they are not designed for single column partitions. Table 4
IQ-TREE does not seem to work properly in this setting and stops optimization prematurely. You can see this in the final likelihoods in the Appendix E. RaxML optimizes to very similar values than our method, but takes 100 to 1000 times as long. These extreme differences are probably due to poor optimization of this rather special use-case in RaxML.Table 1. Benchmarking of global GTR model of IQ-TREE and RaxML vs PhyloGrad with 1 threadTree sizeAlignment sizeIQ-TREE (s)RaxML (s)PhyloGrad (s)16509 / 13.0x22 / 32.5x0.68645029 / 9.6x91 / 30.1x3.042565076 / 7.8x409 / 42.0x9.73102450388 / 11.5x2669 / 79.1x33.764096502762 / 28.9x10094 / 105.8x95.441620016 / 9.0x55 / 31.9x1.7464200106 / 10.9x224 / 23.0x9.74256200297 / 9.6x1201 / 38.7x31.0310242001107 / 9.9x5304 / 47.2x112.4740962006002 / 14.0x12649 / 29.5x428.72Table 2Benchmarking of global GTR model of IQ-TREE and RaxML vs PhyloGrad with 32 threadsTree sizeAlignment sizeIQ-TREE (s)RaxML (s)PhyloGrad (s)16506 / 25.6x28 / 128.1x0.22645015 / 23.0x120 / 178.4x0.6725650126 / 74.4x542 / 319.1x1.70102450170 / 27.7x4518 / 737.0x6.134096501296 / 82.9x16779 / 1073.5x15.63162009 / 35.5x32 / 122.4x0.266420022 / 18.9x108 / 93.2x1.1625620074 / 22.2x686 / 204.8x3.351024200226 / 14.1x4536 / 281.9x16.0940962001356 / 25.2x10832 / 201.1x53.86Table 3Benchmarking of the per column GTR model of IQ-TREE and RaxML vs PhyloGrad with 1 thread. IQ-TREE stops optimizing very early, so these times are not representativeTree sizeAlignment sizeIQ-TREE (s)RaxML (s)PhyloGrad (s)16100.45 / 1.7x46.0 / 170x0.2764102.07 / 0.9x2145 / 887x2.4225610656.44 / 49.4x9931 / 747x13.3016504.28 / 2.7x392.9 / 246x1.60645015.75 / 1.3x16858 / 1350x12.49256503973.0 / 60.7x76325 / 1165x65.50Table 4Benchmarking of IQ-TREE and RaxML vs PhyloGrad with 5 threads. IQ-TREE does not run with 10 columns and 5 threadsTree sizeAlignment sizeIQ-TREE (s)RaxML (s)PhyloGrad (s)1610-15.6 / 194.4x0.086410-733.1 / 1078.1x0.6825610-3369.3 / 893.7x3.7716501.41 / 3.1x132.3 / 287.6x0.4664505.06 / 1.5x5486.0 / 1672.6x3.28256501246 / 69.1x25168.0 / 1394.3x18.05
Comparison to Pytorch
We also want to compare our implementation against another reverse differentiation approach. We could not find a already implemented software for our specific task of column-specific gradients, so we compare PhyloGrad to our own Pytorch implementation of Felsenstein’s algorithm. The Pytorch implementation has the same asymptotic time complexity, because it is also based on reverse-mode differentiation, but it does not take advantage of the matrix exponential optimization and has the potential overhead of automatic differentiation.
For benchmarking, we choose a simple model which has a shared S for all columns but a column specific \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} . This is similar to the Cxx models [6] but instead of predefined categories for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} we can learn a column specific \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} .
When there is not enough data to fit so many parameters without over-fitting, it is easy to parametrize \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} with something lower-dimensional and learn an embedding which is shared for all columns. We think that this flexibility will be key for advancing more flexible phylogenetic models in the future.
We generated 300 random columns with different numbers of taxa in the tree and gave the program 64 threads. CPU versions are executed on a machine with 2 AMD EPYC 7742 64-Core Processors and 1TiB memory. GPU versions are executed on a machine with 2 AMD EPYC 7513 32-Core Processors and a A100 80GB GPU.
We measure how many gradient updates we can do in 20 min and normalize to iterations per minute. Figure 1 shows the gradient updates per minutes for the Pytorch implementation and PhyloGrad. Depending on the tree size PhyloGrad is 30-100 times faster. Figure 3 shows the same but for GPU. Here we are 10-30 times faster.
Finally, we compare memory usage on CPU, where PhyloGrad is dramatically more memory-efficient.Fig. 1a Number of iterations per minute with 300 columns on 64 threads on CPU. b Relative speedup of PhyloGrad vs our Pytorch implementation of Felsenstein with 300 columns on 64 threads on CPUFig. 2Memory consumption on the CPU with 64 threads on 300 columnsFig. 3a Number of iterations per minute with 300 columns with 64 CPU threads on GPU. For the biggest tree size, Pytorch crashes because it needs more than 80GiB of memory. b Relative speedup of PhyloGrad vs our Pytorch implementation of Felsenstein with 300 columns with 64 CPU threads on GPU
Conclusion
Our algorithm and implementation is significantly faster than simple reverse-mode differentiation in Pytorch and the current IQ-TREE and RaxML version. It can be combined with automatic differentiation frameworks, allowing easy definition and efficient fitting of any time-reversible model. The considerable speed-up provided by PhyloGrad will enable the learning of evolutionary models with many more parameters than currently possible. We expect that PhyloGrad will thereby facilitate the development of more realistic and accurate phylogenetic tree reconstruction and ancestral sequence reconstruction methods.
A preprint [17] by Ji et al., published shortly before the submission of this paper, also offers fast gradients of the phylogenetic model likelihood. The article deals with the optimization of branch-specific parameters, while our focus is on column-specific ones, so the implementations cannot directly be compared. Their approach is based on [10] and therefore can leverage already well implemented Felsenstein implementations. Our current implementation uses the logsumexp function for numerical stability which could be improved. On the other hand, in the algorithm of Ji et al. one has to re-evaluate the equation (11) from [17], for every parameter that requires gradients, so it can probably be improved using the ideas from this article. A combination of both ideas will probably yield the best results for phylogenetic gradients in the column and the branch specific case.
Availability and requirements
Project name: PhyloGrad
Project home page: https://github.com/soedinglab/phylo_grad
Operating system: Platform independent, tested on Linux
Programming language: Rust and Python
Other requirements: Python 3.7 or newer, Rust compiler to compile from source
License: MIT or Apache2
Any restrictions to use by non-academics: No
Supplementary Information
Supplementary file 1 (zip 4800 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ji X, Redelings B, Su S, Bao H, Deng W-M, Hong SL, Baele G, Lemey P, Suchard MA. Detecting evolutionary change-points with branch-specific substitution models and shrinkage priors. ar Xiv preprint ar Xiv:2507.08386 2025.