Integrating curation into scientific publishing to train AI models
Jorge Abreu-Vicente, Hannah Sonntag, Thomas Eidens, Cassie S Mitchell, Thomas Lemberger

TL;DR
This paper introduces a new dataset called SourceData-NLP, created by integrating data curation into the scientific publishing process to improve AI training for biomedical research.
Contribution
The novel integration of curation into publishing enables comprehensive annotation of experimental roles and methodologies alongside bioentity recognition.
Findings
SourceData-NLP contains over 620,000 annotated biomedical entities from 3,223 articles.
The dataset supports AI training for tasks like named-entity recognition and figure caption segmentation.
A new context-dependent semantic task was introduced to assess entity roles in experiments.
Abstract
High-throughput extraction and structured labeling of data from academic articles are crucial for enabling downstream machine learning applications and secondary analyses. Current approaches lack integration with the publishing process and comprehensive annotation of experimental roles and methodologies alongside bioentity recognition. We embedded multimodal data curation into the academic publishing process to annotate segmented figure panels and captions, combining natural language processing with authors’ feedback to increase annotation accuracy. The resulting dataset, SourceData-NLP, comprises over 620 000 annotated biomedical entities, curated from 18 689 figures in 3223 articles in molecular and cell biology. Annotations include eight classes of bioentities (small molecules, gene products, subcellular components, cell lines, cell types, tissues, organisms, and diseases), plus…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
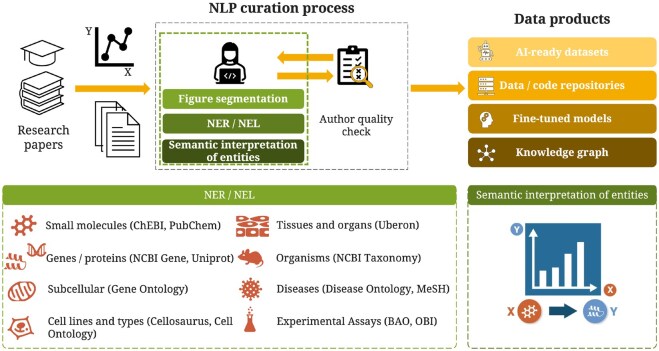 Figure 1
Figure 1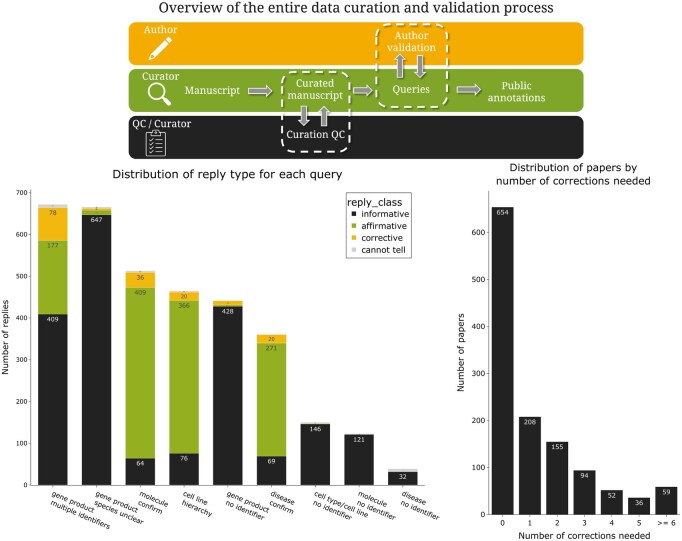 Figure 2
Figure 2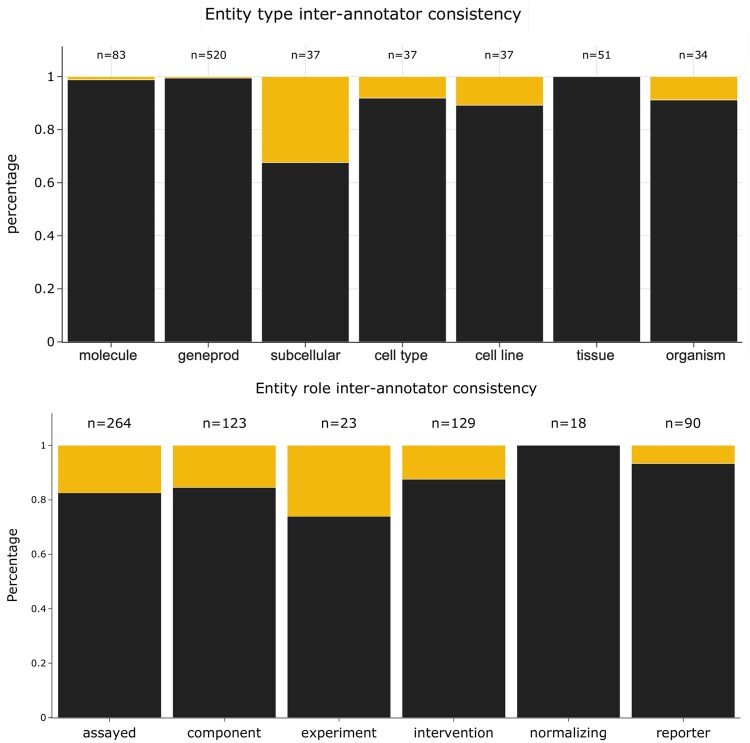 Figure 3
Figure 3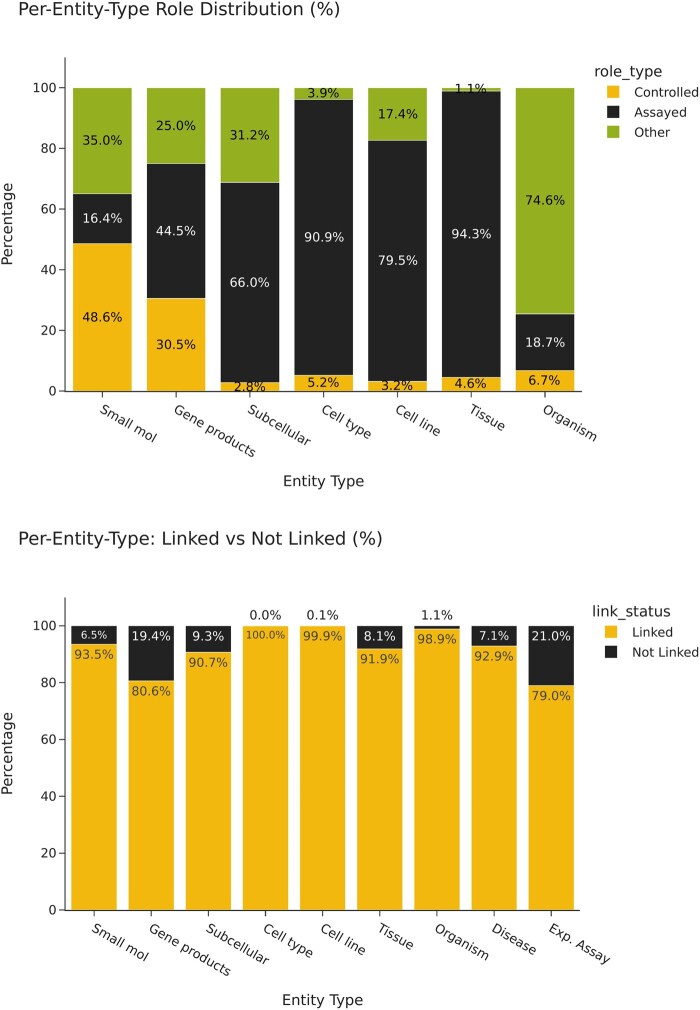 Figure 4
Figure 4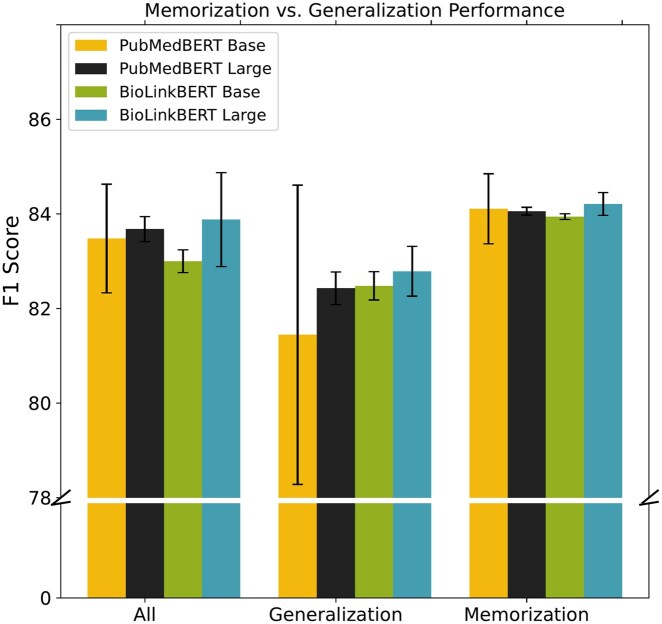 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBiomedical Text Mining and Ontologies · Cell Image Analysis Techniques · Artificial Intelligence in Healthcare and Education