Evaluating the efficacy of large language models in cardio-oncology patient education: a comparative analysis of accuracy, readability, and prompt engineering strategies
Zhao Wang, Lin Liang, Hao Xu, Yuhui Huang, Chen He, Weiran Xu, Haojie Zhu

TL;DR
This study compares how well large language models perform in providing accurate and easy-to-understand information for cardio-oncology patient education.
Contribution
The study introduces a comparative evaluation of LLMs in cardio-oncology education, including the impact of prompt engineering on response quality.
Findings
63.3% of LLM responses were rated as correct, with no significant differences in accuracy between models.
Prompting reduced readability complexity but compromised comprehensiveness and helpfulness, especially for DouBao.
Tailored fine-tuning and specialized frameworks are needed to optimize LLMs for this domain.
Abstract
The integration of large language models (LLMs) into cardio-oncology patient education holds promise for addressing the critical gap in accessible, accurate, and patient-friendly information. However, the performance of publicly available LLMs in this specialized domain remains underexplored. This study evaluates the performance of three LLMs (ChatGPT-4, Kimi, DouBao) act as assistants for physicians in cardio-oncology patient education and examines the impact of prompt engineering on response quality. Twenty standardized questions spanning cardio-oncology topics were posed twice to three LLMs (ChatGPT-4, Kimi, DouBao): once without prompts and once with a directive to simplify language, generating 240 responses. These responses were evaluated by four cardio-oncology specialists for accuracy, comprehensiveness, helpfulness, and practicality. Readability and complexity were assessed…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
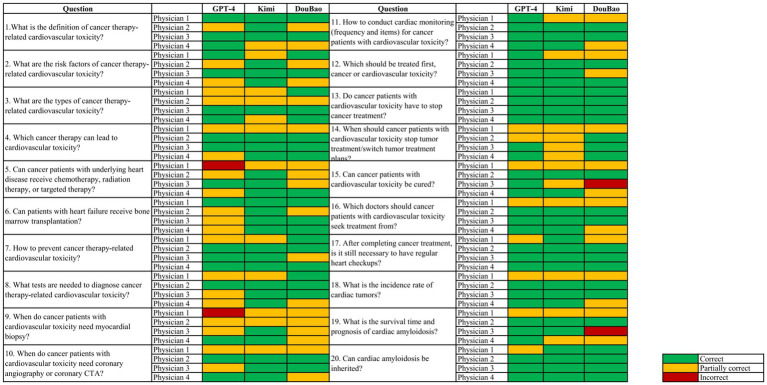 Figure 1
Figure 1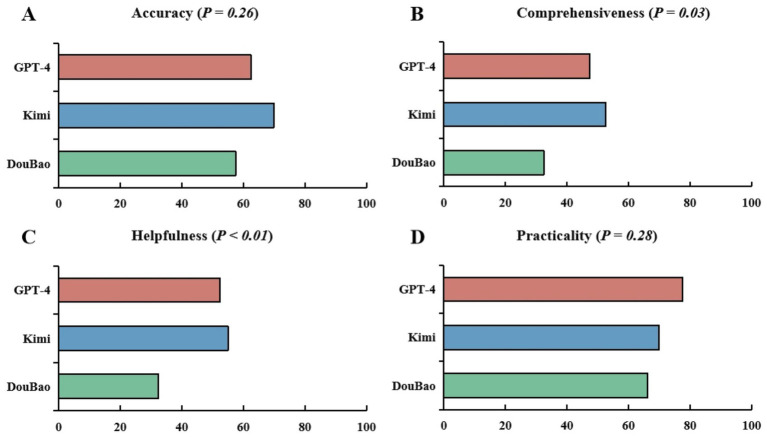 Figure 2
Figure 2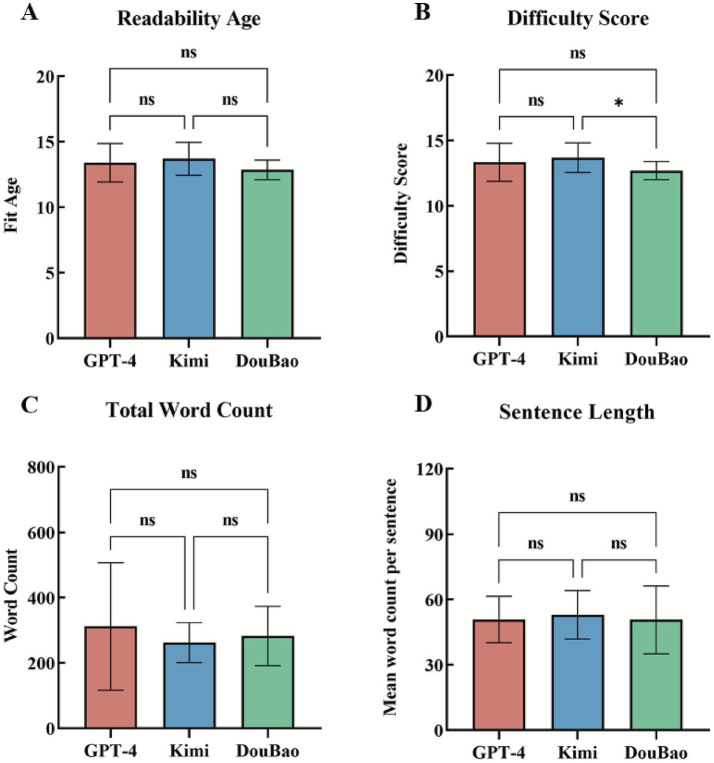 Figure 3
Figure 3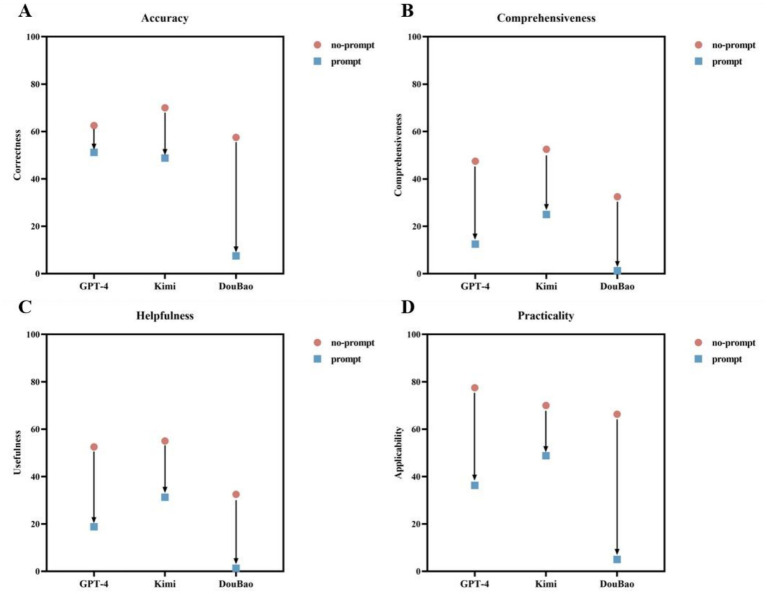 Figure 4
Figure 4 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Text Readability and Simplification · Topic Modeling