Reliability of Large Language Model Generated Clinical Reasoning in Assisted Reproductive Technology: Blinded Comparative Evaluation Study
Dou Liu, Ying Long, Sophia Zuoqiu, Di Liu, Kang Li, Yiting Lin, Hanyi Liu, Rong Yin, Tian Tang

TL;DR
This study evaluates how reliable large language models are at generating clinical reasoning in reproductive medicine and finds that high-quality examples significantly improve their performance.
Contribution
The study introduces a 'dual principles' framework for generating trustworthy clinical reasoning using strategic prompt design.
Findings
The selective few-shot strategy significantly outperformed other methods in logical clarity, key information use, and clinical accuracy.
Low-quality examples in the random few-shot strategy were as ineffective as no examples at all.
Human experts, not AI evaluators, were able to detect differences in the quality of generated clinical reasoning.
Abstract
High-quality clinical chains-of-thought (CoTs) are essential for explainable medical artificial intelligence (AI); yet, their development is limited by data scarcity. Large language models can generate medical CoTs, but their clinical reliability is unclear. We evaluated the clinical reliability of large language model–generated CoTs in reproductive medicine and examined prompting strategies to improve their quality. In a blinded comparative study at a clinical center, senior clinicians in assisted reproductive technology evaluated CoTs generated via 3 distinct strategies: zero-shot, random few-shot (using random shallow examples), and selective few-shot (using diverse, high-quality examples). Expert ratings were then compared with evaluations from a state-of-the-art AI model (GPT-4o). The selective few-shot strategy significantly outperformed other strategies across logical clarity,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
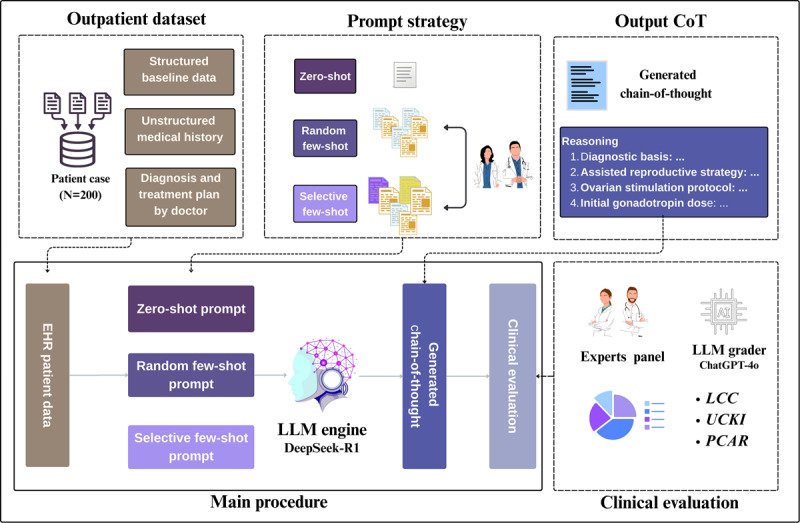 Figure 1
Figure 1 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Healthcare · Explainable Artificial Intelligence (XAI) · Topic Modeling