Confidence Interval Construction for Causally Generalized Estimates With Target Sample Summary Information
Yi Chen, Guanhua Chen, Menggang Yu

TL;DR
This paper introduces a new method to build confidence intervals for causal estimates when only summary data from a target population is available.
Contribution
A resampling-based perturbation method is proposed for constructing confidence intervals using only summary-level target data.
Findings
The method effectively constructs confidence intervals for the target ATE with only summary-level data.
Simulation and real data experiments validate the approach's performance under covariate shift.
The method improves statistical inference when individual-level data is not accessible.
Abstract
Generalizing causal findings, such as the average treatment effect (ATE), from a source to a target population is a critical topic in biomedical research. Differences in the distributions of treatment effect modifiers between these populations, known as covariate shift, can lead to varying ATEs. Chen et al. [1] introduced a weighting method to estimate the target ATE using only summary‐level information from a target sample while accounting for the possible covariate shifts. However, the asymptotic variance of the estimate was shown to depend on individual‐level data from the target sample, hindering statistical inference. In this article, we propose a resampling‐based perturbation method for confidence interval construction for the estimated target ATE, utilizing additional summary‐level information. We demonstrate the effectiveness of our approach through simulation and real data…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
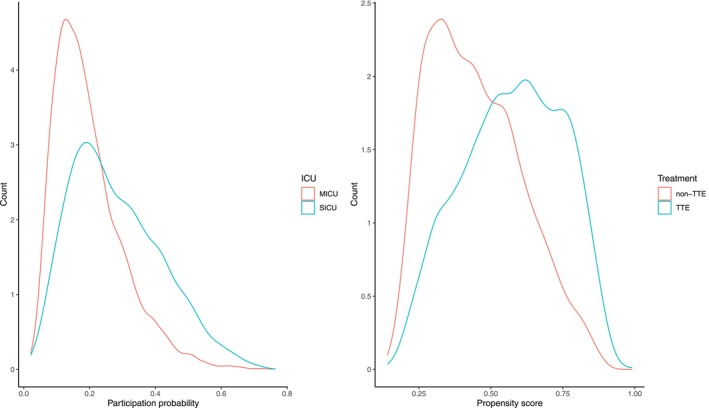 FIGURE 1
FIGURE 1| Settings | Consistency Condition | Empirical coverage of | Average (95% CI) | ||
|---|---|---|---|---|---|
| Linear | T1+M2 | (b) | −0.140 | 95.2% | −0.131 (−0.422, 0.159) |
| T1+M3 | (b) | −0.138 | 95.6% | −0.152 (−0.534, 0.220) | |
| T2+M1 | No | −0.042 | 76% | −0.242 (−0.561, −0.076) | |
| Nonlinear | T1+M1 | (a) | −0.179 | 95.5% | −0.180 (−0.570, 0.206) |
| T3+M1 | No | −1.525 | 94.2% | −1.496 (−1.843, −1.164) | |
| T1+M3 | No | −0.179 | 93.2% | −0.188 (−0.538, 0.157) | |
| Settings | Consistency Condition | Covariate correlation | Empirical coverage of | Average (95% CI) | ||
|---|---|---|---|---|---|---|
| Linear | T1+M2 | (b) | −0.126 | 0.1 | 94.8% | −0.122 (−0.410, 0.164) |
| −0.097 | 0.3 | 94.5% | −0.096 (−0.382, 0.190) | |||
| T2+M1 | No | −0.054 | 0.1 | 76.8% | −0.249 (−0.566, 0.066) | |
| −0.079 | 0.3 | 79.8% | −0.251 (−0.560, 0.055) | |||
| Nonlinear | T1+M1 | (a) | −0.166 | 0.1 | 94% | −0.175 (−0.437, −0.083) |
| −0.140 | 0.3 | 94.6% | −0.144 (−0.391, 0.100) | |||
| T1+M3 | No | −0.169 | 0.1 | 94% | −0.176 (−0.518, 0.164) | |
| −0.143 | 0.3 | 94.6% | −0.139 (−0.467, 0.186) | |||
| Settings | Consistency Condition | Methods | % Infeasible | Empirical coverage | Average (95% CI) | ||
|---|---|---|---|---|---|---|---|
| Linear | T1+M2 | (b) | −0.652 | RPM‐CI | 26.0% | 87.3% | −0.660 (−1.335, 0.125) |
| RPM‐AB | 0% | 92.6% | −0.624 (−1.414, 1.174) | ||||
| T2+M1 | No | 0.800 | RPM‐CI | 26.9% | 60.9% | −0.017 (−1.029, 1.075) | |
| RPM‐AB | 0% | 90.2% | 0.005 (−0.958, 1.890) | ||||
| Nonlinear | T1+M1 | (a) | 0.038 | RPM‐CI | 5.6% | 95.2% | 0.034 (−0.702, 0.767) |
| RPM‐AB | 0% | 94.6% | 0.030 (−0.806, 0.808) | ||||
| T2+M2 | No | 0.539 | RPM‐CI | 4.9% | 70.4% | 1.083 (0.256, 2.036) | |
| RPM‐AB | 0% | 74.2% | 1.095 (0.223, 2.212) | ||||
| SICU () | MICU () | SMD | TTE () | non‐TTE () | SMD | |
|---|---|---|---|---|---|---|
| Age | 64.79 (16.28) | 66.59 (17.02) | −0.111 | 65.74 (16.55) | 66.69 (17.21) | −0.057 |
| Weight | 80.75 (25.18) | 81.00 (25.71) | −0.010 | 83.28 (27.08) | 78.49 (23.69) | 0.177 |
| Female | 674 (49%) | 2459 (49%) | 0.004 | 1558 (48%) | 1575 (51%) | −0.061 |
| Body Temperature | 36.83 (1.97) | 36.78 (1.40) | 0.023 | 36.85 (1.89) | 36.74 (1.06) | 0.057 |
| Mean Arterial Pressure | 83.78 (19.82) | 78.83 (19.42) | 0.250 | 79.97 (19.87) | 79.80 (19.33) | 0.009 |
| Heart Rate | 90.62 (20.26) | 94.90 (20.90) | −0.212 | 94.95 (21.73) | 92.96 (19.81) | 0.092 |
| Platelet | 5.23 (0.62) | 5.13 (0.72) | 0.160 | 5.13 (0.71) | 5.18 (0.69) | −0.068 |
| Partial Pressure of Oxygen | 4.90 (0.63) | 4.60 (0.62) | 0.480 | 4.66 (0.63) | 4.68 (0.64) | −0.028 |
| Lactate | 1.10 (0.43) | 1.10 (0.44) | 0.016 | 1.10 (0.43) | 1.10 (0.44) | −0.009 |
| Blood Urea Nitrogen | 3.10 (0.67) | 3.35 (0.71) | −0.365 | 3.36 (0.70) | 3.22 (0.71) | 0.195 |
| SAPS | 19.75 (5.30) | 20.34 (5.72) | −0.111 | 20.76 (5.44) | 19.63 (5.79) | 0.208 |
| SOFA | 5.14 (3.60) | 6.02 (3.76) | −0.244 | 6.33 (3.79) | 5.30 (3.62) | 0.271 |
| Elixhauser Score | 8.17 (7.60) | 9.62 (7.57) | −0.191 | 10.07 (7.67) | 8.51 (7.45) | 0.204 |
| CHF | 306 (22%) | 1561 (31%) | −0.211 | 1304 (40%) | 563 (18%) | 0.445 |
| AFib | 370 (27%) | 1308 (26%) | 0.021 | 1056 (32%) | 622 (20%) | 0.263 |
| RF | 700 (51%) | 2782 (56%) | −0.087 | 2127 (65%) | 1355 (44%) | 0.451 |
| Malignancy tumor | 258 (19%) | 1253 (25%) | −0.157 | 729 (22%) | 782 (25%) | −0.069 |
- —Patient‐Centered Outcomes Research Institute10.13039/100006093
- —National Science Foundation10.13039/100000001
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Causal Inference Techniques · Bayesian Modeling and Causal Inference · Statistical Methods and Inference
Introduction
1
Causal inference plays a pivotal role in population health research, providing essential tools for understanding and shaping effective health interventions. One of its popular research questions is how to generalize causal findings from a study population to a target population [1, 2, 3]. For example, we may want to generalize findings about the effectiveness of a treatment from a properly conducted randomized clinical trial (RCT) to its target population. We usually refer to this type of problem as generalizability [4, 5], transportability [6, 7], or data fusion [8, 9, 10]. There are some differences between these terminologies, and more detailed explanations are found in article by Colnet et al. [3].
For much of this article, for demonstration purposes, we focus on generalizing the average treatment effect (ATE), although similar considerations can be given to other causal estimands such as the Average Treatment effect on the Treated (ATT) or Average Treatment effect on the Overlap population (ATO) [3]. Our method mainly deals with causal generalization from a source to a target population when individual treatment effects are heterogenenous. Specifically, the individual treatment effects may depend on certain covariates, known as effect modifiers. In addition, the distributions of the effect modifiers can differ between the two populations [11].
Much of the existing literature take a data fusion or integrated data analysis approach to this problem [3, 8, 9, 10, 12]. Such approaches typically require individual data from both populations. However, there can be settings when comprehensive data at the individual level may not be consistently accessible within a target sample, owing to various practical considerations such as restricted data sharing, storage constraints, and privacy apprehensions [2]. On the contrary, obtaining summary‐level information from the target sample is comparatively more feasible. This type of information can be readily gathered from diverse sources such as healthcare databases, census data, and published literature.
To deal with the challenges posed by lack of individual data from the target population, Dong et al. [13] adapted the entropy balancing weights approach [14, 15] for generalizing ATE estimation from an RCT to a given target population. Josey et al. [16] then extended the approach to the setting when the source sample is from observational studies. In particular, they proposed a two‐step procedure to adjust for covariate shift and confounding separately. By showing that the weights produced by the two‐step procedure can be consolidated into a one‐step procedure, Chen et al. [1] developed a more intuitive strategy that may further mitigate bias under mild conditions, which rely solely on summary‐level information from the target sample and individual‐level covariates from the source sample. Recently, Chattopadhyay et al. [17] proposed a very similar strategy.
The purpose of this article is to provide a practical solution to a key limitation with these methods: how to construct confidence intervals (CIs) for the resulting causally generalizable estimates. Chen et al. [1] showed that the asymptotic variance of their estimator depends on individual‐level data in the target sample. Similarly, the asymptotic variance of the estimator from Chattopadhyay et al. [17] also depends on the individual‐level data in the target sample. This article addresses this limitation by proposing a method to construct CIs for the proposed estimator from Chen et al. [1] using resampling‐based perturbation, without requiring individual‐level data from the target sample.
This article is organized as follows: in Section 2, we present general notations and assumptions for our method. In Section 3, we present two methods to do the resampling‐based perturbation for CI construction. In Sections 4 and 5, we evaluate the proposed methods using simulation studies and a real data application using cross‐validation. In Section 6, we conclude the article with a discussion.
Notation and Framework
2
Suppose we have individual‐level data in a representative sample of our source population 𝒮, denoted as {(Xi;Ai;Yi):i∈𝒮} with ns subjects. We denote Xi∈𝒳⊂ℝp as the pre‐treatment covariates which include confounders and treatment effect modifiers. The treatment indicator is denoted as Ai∈{0,1}, and Yi is the outcome we are interested in. For a representative sample of our target population 𝒯, the sample size is nt but we do not observe the individual‐level data. Instead, we only have the information for the first moments based on a set of linearly independent covariate functions hk:𝒳→ℝ;k=1,…,Kh from the target sample as follows.
Each hk is usually defined on one or two covariates, instead of on the full covariate vector. For continuous covariates, if hk is defined as an identity function, then h‾k,𝒯 represents the mean of this component. If hk is defined as a polynomial function of degree 2, h‾k,𝒯 corresponds to the second moment, or variance, of this component. For discrete covariates, hk could be defined as an indicator function to count the number of subjects in a particular category.
Here, we formulate the causal problem using the potential outcome framework [18, 19]. For each subject, we define a “full” random vector (Xi,Si,Ai,Yi(0),Yi(1)), where Si is a population indicator in source or target such that Si=1 for i∈𝒮 and Si=0 for i∈𝒯. The total sample size is n=ns+nt and each subject assumed to be i.i.d. from a joint distribution of (X,S,A,Y(0),Y(1)). Moreover, 𝒮0 is used to denote the subjects in the source control group, and mathematically, 𝒮0={i:Si=1;Ai=0}; 𝒮1 is defined for the source treated group similarly. According to Rosenbaum and Rubin [19], we use the propensity score π(x)=ℙ(A=1|X=x,S=1) to determine the treatment assignment mechanism. The main estimand in this article, ATE of the target population, is
The following 3 standard assumptions are used which enable identification of causal effects within the source population.
Assumption 1 (Stable Unit Treatment Value Assumption or SUTVA) There is no interference between different subjects and no hidden variation of treatments.
Assumption 2 (No unmeasured confounders of treatment assignment) In the source population, (Y(0),Y(1)) are conditionally independent of A given X: (Y(0),Y(1))╨A|X,S=1.
Assumption 3 (Positivity of treatment assignment) The propensity score of the source population is bounded away from 0 and 1: for some c>0, c≤π(X)≤1−c almost surely.
To extend the generalizability of the causal estimates to the target population, a key quantity is the participation probability between source and target defined as ρ(x)=ℙ(S=1|X=x). We further adopt two additional assumptions from Rudolph and van der Laan [6] and Dahabreh et al. [20].
Assumption 4 (Mean exchangeability across populations) The conditional mean of the potential outcomes given the covariates are equal between the two populations: 𝔼{Y(a)|X,S=1}=𝔼{Y(a)|X,S=0} almost surely for a∈{0,1}.
Assumption 5 (Positivity of participation probability) The participation probability is bounded away from 0: ρ(X)>c almost surely for some c>0.
We further denote the conditional mean and variance of the potential outcomes in the source population as μa(x)=𝔼{Y(a)|X=x,S=1} and σa(x)=Var{Y(a)|X=x,S=1}. Under Assumption 4, we have μa(x)=𝔼{Y(a)|X=x,S=0}=𝔼{Y(a)|X=x}. The conditional average treatment effect (CATE) function is denoted as τ(x)≡μ1(x)−μ0(x).
Method
3
Gap in the Existing Work
3.1
Given Assumptions 1, 2, 3, 4, 5, we can estimate τ∗ in terms of the observable from the source sample data by a difference of weighted outcomes as follows:
The weights {wi:i∈𝒮} take the following form Chen et al. [1] and in appendix, we also provide the identification proof:
Directly estimation of wi is usually computationally unstable. Without the individual data it is also infeasible. Therefore, Chen et al. [1] proposed a method for estimation of the weights as follows, based on entropy balancing weighting framework [14].
In particular, functions {hk:X→ℝ;k=1,…,Kh} are used to address covariate shift between source and target samples, while functions {gk:X→ℝ;k=1,…,Kg} are employed to further correct for imbalances between the treatment and control groups within the source sample. From the theorem below, we can see that ideally the hk functions should be chosen so that the linear span formed by them can at least cover treatment modifiers, even all outcome related variables if possible. The gk functions should be chosen to complement hk to determine the treatment assignment mechanism.
The weight normalization constraint at the last line of Equation (3) can be absorbed to the first two constraints by introducing h0(x)≡1. Denote H=(h0,h1,…,hKh) and G=(g1,…,gKg). The following theorem is adopted directly from Chen et al. [1] which originally listed 3 conditions under any of which could lead to consistency of the resulting weighting estimator for τ∗. Here we only list two of them as the other one was not as intuitive.
Theorem 1 Suppose ŵ *is the solution of Equation *(3). If either Condition (a) or (b) below holds, τ^ŵ is a consistent estimator of τ∗: Condition (a). μa(x)∈ Span {H(x)}, a=0,1. Condition (b). log{π(x)/(1−π(x))}∈ Span {H(x),G(x)} and τ(x)∈ Span ({H(x)}).
Chen et al. [1] further derived the asymptotic variance for τ^w. However, estimation of the asymptotic variance directly from their formula requires individual covariate values in the target sample. We intend to overcome this limitation by introducing a resampling‐based perturbation method for CI construction that do not require such information from the target sample.
Resampling‐Based Perturbation for Confidence Interval Construction
3.2
Parzen et al. [21] introduced a straightforward resampling method for inference based on pivotal estimating functions within a semiparametric model framework. The authors demonstrated that for a broad class of estimating functions meeting two mild convergence conditions, a valid asymptotic CI could be constructed using the resampling method on the pivotal estimating functions. Hu and Kalbfleisch [22] further broadened the idea by using bootstrapped general estimating functions for statistical inference. In particular, when the estimating functions are sums of independent terms, we can resample or bootstrap these terms to obtain an empirical distribution of the estimating functions. Solving the corresponding bootstrapped estimation equations then leads to valid statistical inference for the resulting estimators. Here, we extend this idea to our setting.
Since Equation (3) has constraints, we work with its dual problem which is unconstrained for our purpose. In particular, we have the following characterization of the weights from Equation (3).
where (λ^1,λ^0,γ^)∈ℝKh+1×ℝKh+1×ℝKg is the solution to the dual problem:
Here H‾𝒯=(h‾0,𝒯,…,h‾Kh,𝒯) with h‾0,𝒯=1.
Equation (4) leads to the following first order condition to solve for (λ^1,λ^0,γ^):
Therefore, if we can use bootstrap to capture the variance of the estimating equations in Equation (5), we can back‐propagate the estimation error to the estimated weights, enabling us to construct a CI for the estimator τ^w in Equation (2). The classic bootstrap [23] can be applied to the elements in the source population {H(Xi),G(Xi)} to generate bootstrapped versions {H(Xi)(b),G(Xi)(b)} for b=1,…,B. However, for the summary level information H‾𝒯, we resort to parametric bootstrap [24]. Because H‾𝒯 are sample averages, we assume that H‾𝒯∼N(μH‾,∑H‾) asymptotically. Therefore, when ∑H‾ is available from the target sample, we can draw H‾𝒯(b) from the multivariate normal distribution with mean H‾𝒯 and variance‐covariance matrix ∑H‾. It is more common that only the diagonal elements of ∑H‾ is available, especially if the summary information is from published literature. Then we propose to estimate the correlation matrix corresponding to ∑H‾ using the individual data from the source population.
We formalize the above proposed resampling‐based perturbation method to construct the confidence interval (RPM‐CI) in Algorithm 1. For a particular data set, in step 1, we estimate the correlation of target moments R^H‾𝒯=corr(H(Xi)),i∈𝒮 using the source data and estimate the corresponding target ATE τ^w. In step 2, for each bth over B iteration, we first sample the source population with replacement as {(Xi(b);Ai(b);Yi(b)):i∈𝒮}. Then we use multivariate normal distribution to perturb the target sample mean H‾𝒯 and generate target data perturbed means H‾𝒯(b)∼𝒩(H‾𝒯,var(H‾𝒯)1/2R^H‾𝒯var(H‾𝒯)1/2) assuming var(H‾𝒯) is available from the target sample. Next, we use the simulated {(Xi(b);Ai(b);Yi(b)):i∈𝒮} and H‾𝒯(b) to estimate weights {ŵi(b):i∈S} and its corresponding τ^w(b) for b=1,…,B using Equation (3) and (2). Finally, we construct the CI for our estimator τ^w based on 2.5 and 97.5 percentiles of τ^w(b),b=1,…,B.
ALGORITHM 1Resampling‐based perturbation method for CI construction (RPM‐CI).
Resampling‐Based Perturbation Method With Approximate Balancing
3.3
In practice, the exact balancing approach may not always produce a feasible solution due to finite sample. Therefore, Wang and Zubizarreta [25] advocated a more flexible approach for covariate balancing weight construction for causal inference. The approach can be extended in a straight‐forward fashion to our causal generalization setting as follows.
Therefore, the exact balancing constraints is relaxed in Equation (6) by introducing δ1,δ1′∈ℝKh and δ2∈ℝKg. The weight normalization constraint at the last line of Equation (6) again can be absorbed to the first two constraints by introducing an extra element h‾0,𝒯=1 and setting the corresponding relaxation δ1,0,δ1,0′≡0. This flexibility trades bias for variance and offers two key advantages: it enables us to incorporate a broader set of covariate functions, and it helps overcome computational challenges when exact balancing is infeasible during the construction of CIs with the resampling‐based perturbation.
Naturally, a practical consideration when using approximate balancing is how to determine the appropriate degree of approximate balance. Chattopadhyay et al. [17] advocated using a constant factor (i.e., 0.1 times) of each covariate's standard deviation. Instead of the standard deviation, we advocate the following strategy based on the dual problem of Equation (6).
In particular, the dual of Equation (6) takes the following form:
where λ˜0,λ˜1,γ˜ minimize
Compared with the dual form (4) for the exact balancing, Equation (7) contains three additional L1 regularization terms for the dual parameters: |λ1|⊤δ1+|λ0|⊤δ1′+|γ|⊤δ2. Thus, we propose to use the Adaptive LASSO [26] to determine the degree of approximate balancing. In particular, assume that we have estimates (λ^1,λ^0,γ^) from Equation (4) based on the exact balancing problem. Then for resampling‐based perturbations that have no exact balancing solution or are infeasible for (3), we use fractions of (λ^1,λ^0,γ^) for (δ1,δ1′,δ2). The details are listed in Algorithm 2.
When there is no exact balancing solution for the original exact balancing problem τ^w, we advocate using Chattopadhyay et al. [17] idea of allowing imbalances to be up to a constant factor (i.e., 0.1 times) each covariate's standard deviation until we get a solution and then follow Algorithm 2 for CI construction.
ALGORITHM 2Resampling‐based perturbation with approximate balancing (RPM‐AB).
Evaluation With Simulated Settings
4
In this section, we conduct simulation studies to evaluate the performance of the proposed methods in finite sample settings. For each simulation set‐up, we could estimate τ∗ using Equation (1). Then, for each m over a total of M simulations, we estimate τ^w(m) and its corresponding 95% CI using methods we proposed in Algorithm 1, or Algorithm 2 if exact balancing is infeasible. The performance is measured in terms of bias of E(τ^w(m)) and the empirical coverage of τ∗ within the 95% CI constructed by the proposed methods.
Exact Balancing and Algorithm 1 Evaluation
4.1
We first examine exact balancing CI construction method in Algorithm 1 with simulation settings that always had feasible solutions for Equation (3) and the corresponding resampling‐based perturbations. We set the total sample size n=ns+nt=800 with the bootstrap iteration B=1000 and M=500 simulated data sets. In our simulations, due to random sampling, the source sample size ns varies between 350 and 450 observations. We generate 5 covariates X=(X1,…,X5) from a uniform distribution U(−2,2). We consider the case when the covariates are independent of each other and the case when correlation among them are 0.1 and 0.3.
In the target sample, we only have summary‐level information of X1,X2, and X3. We set H(x)=(1,x1,x2,x3) and G(x)=(x4,x5). We consider balancing on the first moments of all covariates.
In light of Theorem 1, we consider scenarios when one of the conditions for consistency hold and also when none of them holds.
Therefore, for the propensity score model, we first assume a scenario when the treatment assignment is related to H linearly with logit{π(x)}=0.7x2+0.5x3. In this case, all the confounders are included in H, and it is enough that we only balance on H to account for confounding. We also assume a scenario when the propensity score is related to H and G nonlinearly with logit{π(x)}=0.35x2−0.4max(x3,x4)−0.7x5.
For the outcome model, we assume it has the form of Yi=m(Xi)+(Ai−0.5)τ(Xi)+ϵi with ϵi∼i.i.dN(0,1). We assume the CATE function comes from the following settings:
- (T1) τ(x)=x1−0.6x2−0.4x3.
- (T2) τ(x)=x1−0.6x2−0.4x3+0.8x4−0.3x5.
- (T3) τ(x)=x1−0.5exp(x2−0.8x3)
We assume the main effect m(x) comes from the following settings:
- (M1) m(x)=0.5x1+0.3x2+0.3x3.
- (M2) m(x)=0.5x1+0.3x2+0.3x3−0.4x4−0.7x5.
- (M3) m(x)=0.5x1+0.8x22+0.2exp(0.5x3−x4−1)−0.7x5.
When the propensity score lies within the linear span of H and the CATE function follows (T1), τ(x) is linearly related to H and satisfies the consistency Condition (b) in Theorem 1, regardless of the main effect settings. However, this condition does not hold under (T2) or (T3) because (T2) depends on both H and G, while (T3) is nonlinearly related to H. When the propensity score is not within the linear span of H, but the outcome satisfies (T1) and (M1), μa(x) remains linear in H, thereby meeting Condition (a). Outside these scenarios, neither Condition (a) nor Condition (b) holds, which may introduce bias in the estimator τ^w.
For covariate shift, similar to the propensity score model, we also consider a linear setting when the participation probability is logit{ρ(x)}=0.4x1+0.3x2−0.2x4. That is, there is shift in the distribution of (X1,X2,X4). We also consider a nonlinear setup when the participation probability is logit{ρ(x)}=0.3x1+0.5x2·x4−0.2x4.
The performance of our method is summarized in Table 1 for independent covariates and Table 2 for correlated covariates. For bias evaluation, we see that the bias of average τ^w for our method is ignorable under linear and nonlinear settings when the consistency conditions are met. In terms of the CI construction, when the consistency conditions are met, we find that under both linear and nonlinear settings, the constructed CI by Algorithm 1 can cover around 95% of the time. Even when the consistency conditions are not fully met, our method maintains approximately 95% coverage as long as the estimator is not severely biased. However, when the estimator exhibits significant bias, the constructed confidence interval (CI) results in lower coverage of τ∗.
Approximate Balancing and Algorithm 2 Evaluation
4.2
Now we consider settings that Algorithm 2 needs to be invoked due to infeasibility of perturbed Equation (4), in particular in smaller sample size settings with noisy covariates. We set the total sample size n=ns+nt=400 with bootstrap iteration B=800, and generate covariates X=(X1,…,X5) from uniform distribution U(−2,6). The rest of the settings are the same as in the previous subsection.
The performance of our methods is summarized in Table 3. We also report the percent of non‐feasible solutions over M×B iterations for exact balancing. In terms of bias evaluation, for exact balancing, even though some simulations may not admit solutions, the bias of τ^w is small when the consistency conditions are met. When we use approximate balancing for target ATE estimation simulation cases with no exact balancing solution, the bias is larger as it trades bias for variance. In terms of the CI construction, when most of the perturbations admit an exact balancing solution, our findings about the CI coverage are consistent with what we observe in Table 1 and Table 2. Especially, when the consistency conditions are satisfied, we find that both exact and approximate balancing CI could cover τ∗ around 95% times. However, regardless of the consistency conditions, if we could not admit enough feasible solutions during the CI construction process, we would get poor CI coverage for exact balancing. The CI constructed by the approximate balancing method is wider and thus could help in this situation with a better coverage.
Evaluation With a Real Data Setting
5
In this section, we illustrate the proposed method by evaluating and generalizing the causal effect of transthoracic echocardiography (TTE) on 28‐day survival, using data from the MIMIC‐III database [27]. The study population includes 6361 ICU patients, of whom 51.3% underwent TTE either during or within 24 h before ICU admission. Following Chen et al. [1], we restrict the dataset to the first ICU admission and exclude patients from coronary and cardiac surgical units. Our goal is to estimate the effect of TTE in surgical ICU (SICU) patients and generalize it to medical ICU (MICU) patients with sepsis incorporating uncertainty through CI construction and evaluation. In appendix, we also provide a cross‐validation based evaluation using the same data base.
TTE is a fundamental, noninvasive modality for hemodynamic assessment in critically ill patients, providing timely information to guide fluid management, vasoactive therapy, and diagnosis of cardiac dysfunction. Early use of TTE, either during or within 24 h before ICU admission, has the potential to guide timely diagnostic and therapeutic decisions, which may directly influence short‐term outcomes such as 28‐day survival [28]. However, its prognostic impact may vary by ICU setting. SICU and MICU populations are different in terms of the patients' physiological status, and clinical management. Compared with SICU patients, MICU patients are typically older, have more physiologic derangements and comorbidity burden, whereas SICU patients more often present with acute postoperative derangements [29]. These systematic differences in patient characteristics, underlying causes of hemodynamic instability, and therapeutic priorities suggest that the survival benefit of early TTE may not be uniform across ICU settings. This underscores the need to account for population heterogeneity when evaluating and generalizing treatment effects across SICU and MICU subgroups.
The dataset we used encompasses demographic details, such as age, gender, and weight, along with severity at admission measured by the Simplified Acute Physiology Score (SAPS), Sequential Organ Failure Assessment (SOFA) score, and Elixhauser comorbidity score. Additionally, it includes comorbidity indicators (denoted as cmbi), including congestive heart failure (CHF), atrial fibrillation (AFib), respiratory failure (RF), and malignant tumor. Vital signs like mean arterial pressure, heart rate, and temperature, as well as laboratory results, are also part of the dataset. To address right‐skewed distributions of lab results, a log transformation is applied, and standardization is employed for continuous variables. Missing values are addressed through imputation using the missForest method, which is a flexible non‐parametric missing value imputation approach with no assumptions needed [30].
Table 4 summarizes baseline characteristics for both ICU types and compares TTE and non‐TTE groups with their Standardized Mean Difference (SMD). Of the 6361 patients, 1364 were admitted to the SICU (with 669 receiving TTE) and 4997 to the MICU (with 2593 receiving TTE). Compared to MICU patients, SICU patients were slightly younger and had higher mean arterial pressure and partial pressure of oxygen values, but lower heart rates and lower severity scores at admission (including SOFA and Elixhauser comorbidity scores). SICU patients were also less likely to have a history of CHF or malignant tumor. When comparing patients who received TTE to those who did not, TTE recipients had larger body weight and higher rates of comorbidities including CHF, RF, and AFib. They also presented with higher severity at admission including SOFA and SAPS.
To conservatively account for potential covariate shift between source (SICU) and target (MICU), we select all variables except weight, RF and AFib for Kh, which we assume are collected for both SICU and MICU. We select weight, RF and AFib as the additional confounder set Kg that further correct for imbalances between TTE and non‐TTE groups within the SICU sample, as they are important confounders but not significantly different between SICU and MICU from Table 4. Since individual level data of receiving TTE and ICU type were fully observed, Figure 1 visualizes the estimated participation score (ρ^(X)) and propensity scores (π^(X)) to verify sufficient overlap between SICU and MICU and between TTE and non‐TTE samples. Both scores were estimated using logistic regression models accounting for all baseline covariates. This diagnostic assessment confirms the validity of the positivity assumptions (Assumptions 3 and 5), demonstrating adequate overlap for causal generalization.
Density plots for the estimated participation probability (left panel), and the estimated propensity score (right panel).
Using entropy balancing, the estimated ATE of TTE for SICU patients is 0.029 (95% CI: [−0.014, 0.072]), while the ATE for MICU patients is 0.063 (95% CI: [0.040, 0.087]). Applying causal generalization to transport the effect from SICU to MICU, we utilize only summary level information (mean and variance) from MICU patients. The causally generalized ATE estimate is 0.053 (95% CI: [−0.007, 0.108]). Although this generalized estimate does not reach statistical significance, it shows an increased effect relative to the original SICU estimate and is directionally consistent with the MICU ATE. The slightly wider confidence interval may reflect the larger variability introduced by the relatively smaller SICU sample size or by higher‐order moment differences in covariate distributions between SICU and MICU populations. Collectively, these patterns suggest the presence of covariate shift, indicating that ICU‐specific factors may influence the magnitude of TTE's effect on 28‐day survival. These findings highlight the importance of considering population heterogeneity when generalizing treatment effects across ICU types.
Discussion and Conclusion
6
We have developed a resampling‐based perturbation method for CI construction to make inference about generalizing ATE estimation to a target population. It is an important step to complement the work of Chen et al. [1] to quantify the uncertainty associated with the estimated treatment effect for the target population. Although we require slightly more information from a target sample than Chen et al. [1] did, our requirement is minimum as we only need the variance of the summary statistics H‾𝒯. Note that for binary and discrete variables, such variance is not needed as we can directly use H‾𝒯 to estimate its variance. When the target sample's individual data is available but cannot be shared due to privacy reasons, then requesting this further information is relatively straightforward.
To achieve an unbiased causal generalization, exact balancing is essential, as it ensures that covariates are equally balanced between populations. For the CI construction using the resampling‐based perturbation method, exact balancing should be prioritized because it directly aligns with the goal of unbiased causal generalization by precisely matching covariate distributions. However, when a feasible solution for exact balancing is unattainable due to sample size limitations or high‐dimensional covariates, approximate balancing can be a practical alternative. Although it may introduce a small bias, approximate balancing provides a close solution that maintains the integrity of the analysis by minimizing discrepancies in covariate distributions. Therefore, we recommend approximate balancing only as a secondary option, to be used when exact balancing solutions are not feasible.
Funding
This work was supported by the Patient‐Centered Outcomes Research Institute (Grant No. ME‐2024C1‐37433) and the National Science Foundation (Grant No. DMS‐2515263).
Conflicts of Interest
The authors declare no conflicts of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1R. Chen , G. Chen , and M. Yu , “Entropy Balancing for Causal Generalization With Target Sample Summary Information,” Biometrics 79, no. 4 (2023): 3179–3190, 10.1111/biom.13825.36645231 · doi ↗ · pubmed ↗
- 2I. Degtiar and S. Rose , “A Review of Generalizability and Transportability,” Annual Review of Statistics and Its Application 10, no. 1 (2023): 501–524, 10.1146/annurev-statistics-042522-103837. · doi ↗
- 3B. Colnet , I. Mayer , G. Chen , et al., “Causal Inference Methods for Combining Randomized Trials and Observational Studies: A Review,” Statistical Science 39, no. 1 (2024): 165–191, 10.1214/23-STS 889.41059256 PMC 12499922 · doi ↗ · pubmed ↗
- 4S. R. Cole and E. A. Stuart , “Generalizing Evidence From Randomized Clinical Trials to Target Populations: The ACTG 320 Trial,” American Journal of Epidemiology 172, no. 1 (2010): 107–115, 10.1093/aje/kwq 084.20547574 PMC 2915476 · doi ↗ · pubmed ↗
- 5C. O'Muircheartaigh and L. V. Hedges , “Generalizing From Unrepresentative Experiments: A Stratified Propensity Score Approach,” Journal of the Royal Statistical Society Series C: Applied Statistics 63, no. 2 (2013): 195–210, 10.1111/rssc.12037. · doi ↗
- 6K. E. Rudolph and d M J. Laan , “Robust Estimation of Encouragement‐Design Intervention Effects Transported Across Sites,” Journal of the Royal Statistical Society Series B 79, no. 5 (2017): 1509–1525.10.1111/rssb.12213 PMC 578486029375249 · doi ↗ · pubmed ↗
- 7J. Pearl and E. Bareinboim , “Transportability of Causal and Statistical Relations: A Formal Approach,” in 2011 IEEE 11th International Conference on Data Mining Workshops (IEEE, 2011), 540–547.
- 8E. Bareinboim and J. Pearl , “Causal Inference and the Data‐Fusion Problem,” Proceedings of the National Academy of Sciences of the United States of America 113, no. 27 (2016): 7345–7352.27382148 10.1073/pnas.1510507113 PMC 4941504 · doi ↗ · pubmed ↗