Multi‐Model Ensembles in Infectious Disease and Public Health: Methods, Interpretation, and Implementation in R
Li Shandross, Emily Howerton, Lucie Contamin, Harry Hochheiser, Anna Krystalli, Nicholas G. Reich, Evan L. Ray, Alvaro J. Castro Rivadeneira, Lucie Contamin, Sebastian Funk, Aaron Gerding, Hugo Gruson, Harry Hochheiser, Emily Howerton, Melissa Kerr, Anna Krystalli, Sara L. Loo

TL;DR
This paper introduces a framework for combining multiple models to improve infectious disease forecasting and provides a practical tutorial using real data.
Contribution
The paper introduces the hubEnsembles package, a flexible and accessible framework for multi-model ensembling in public health.
Findings
Multi-model ensembles improve the accuracy and reliability of infectious disease outbreak forecasts.
The hubEnsembles package offers a practical implementation for ensembling predictions in public health applications.
A case study using FluSight data demonstrates the effectiveness of the proposed methods.
Abstract
Combining predictions from multiple models into an ensemble is a widely used practice across many fields with demonstrated performance benefits. Popularized through domains such as weather forecasting and climate modeling, multi‐model ensembles are becoming increasingly common in public health and biological applications. For example, multi‐model outbreak forecasting provides more accurate and reliable information about the timing and burden of infectious disease outbreaks to public health officials and medical practitioners. Yet, understanding and interpreting multi‐model ensemble results can be difficult, as there are a diversity of methods proposed in the literature with no clear consensus on which is best. Moreover, a lack of standard, easy‐to‐use software implementations impedes the generation of multi‐model ensembles in practice. To address these challenges, we provide an…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
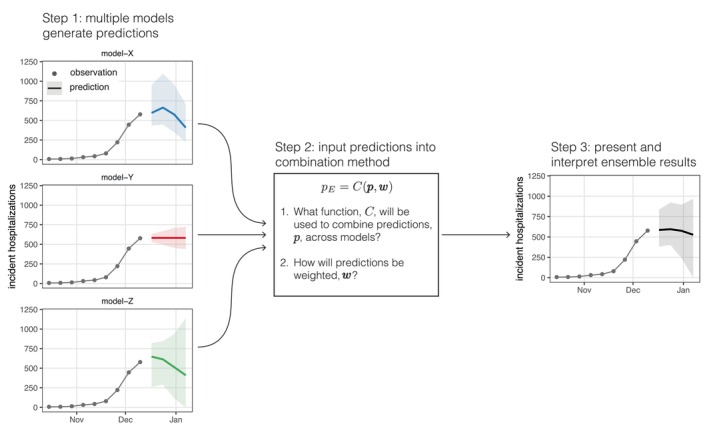 FIGURE 1
FIGURE 1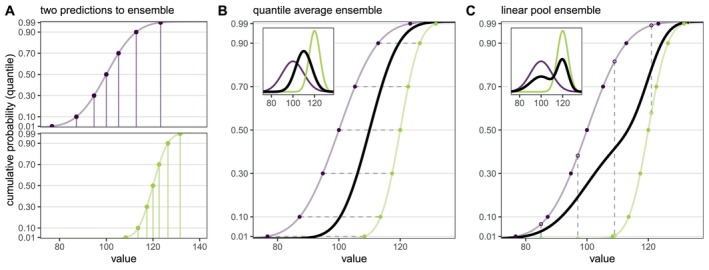 FIGURE 2
FIGURE 2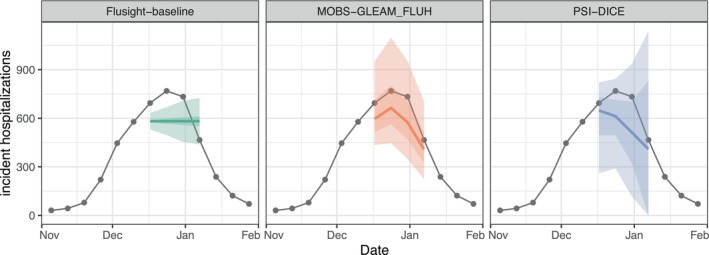 FIGURE 3
FIGURE 3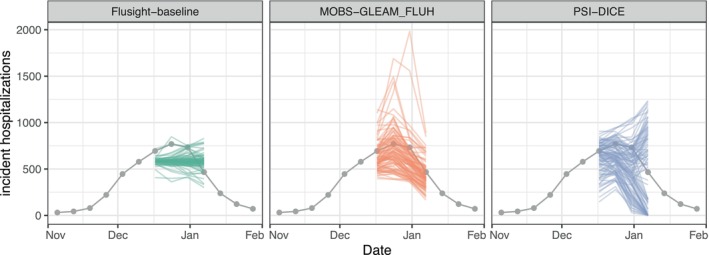 FIGURE 4
FIGURE 4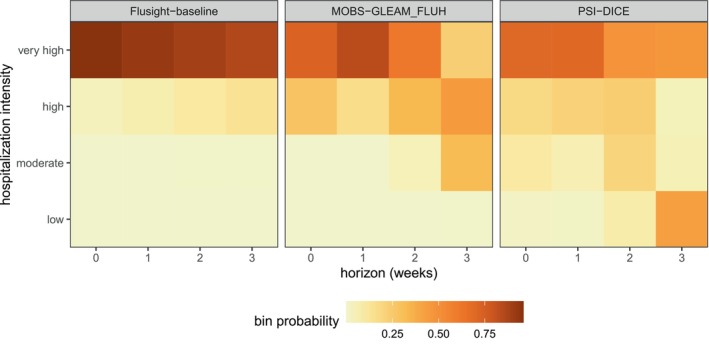 FIGURE 5
FIGURE 5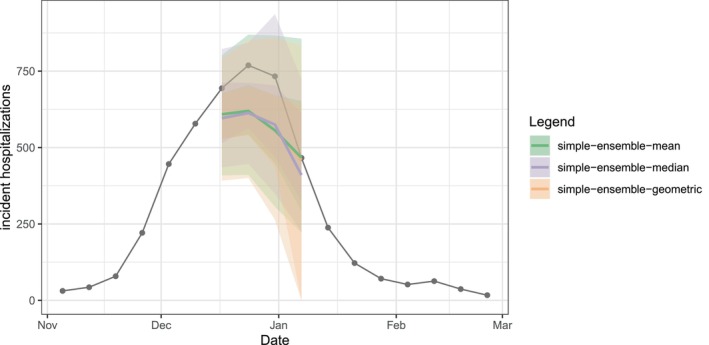 FIGURE 6
FIGURE 6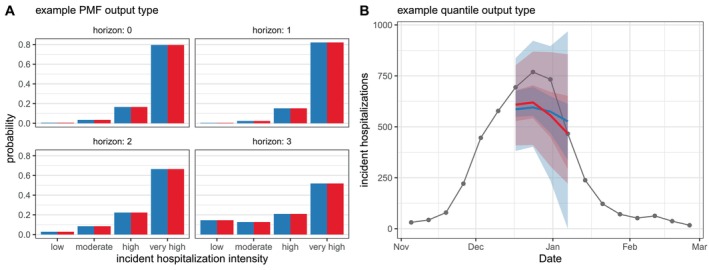 FIGURE 7
FIGURE 7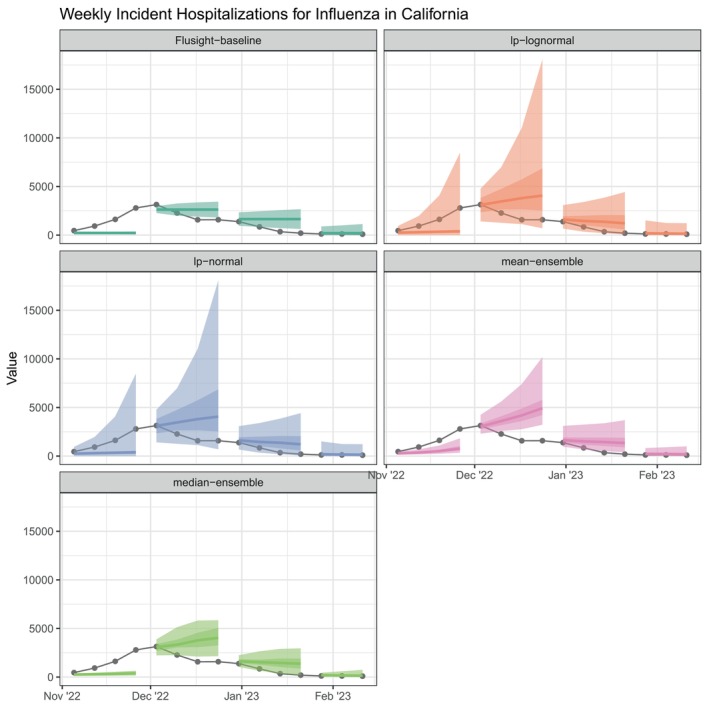 FIGURE 8
FIGURE 8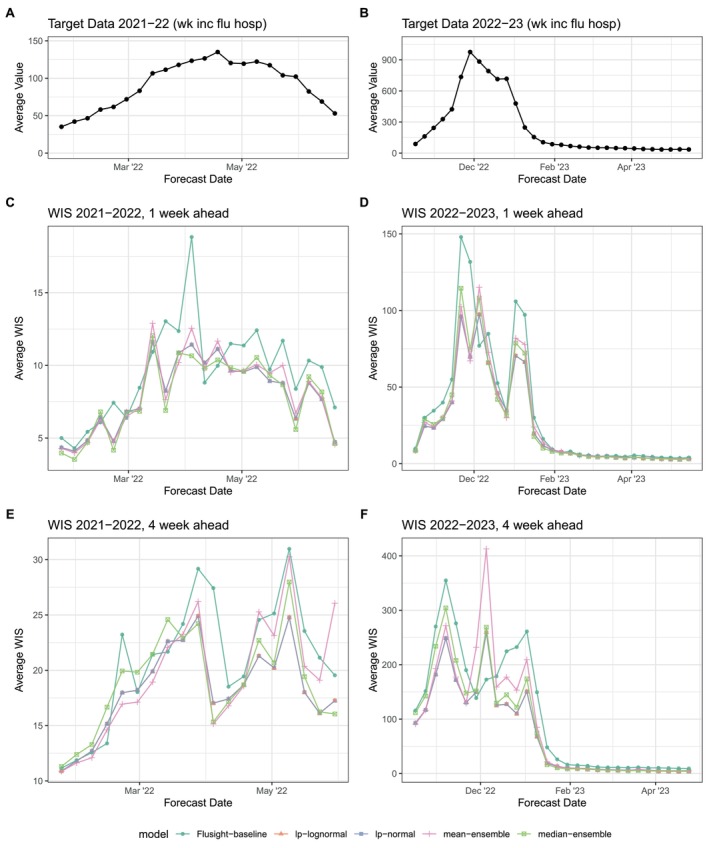 FIGURE 9
FIGURE 9| Model_id | Loc | ref_date | h | Target | Output_type | otid | Value |
|---|---|---|---|---|---|---|---|
| team1‐mod | MA | 2022‐12‐17 | 0 | wk flu hosp | quantile | 0.25 | 514 |
| team1‐mod | MA | 2022‐12‐17 | 0 | wk flu hosp | quantile | 0.5 | 596 |
| team1‐mod | MA | 2022‐12‐17 | 0 | wk flu hosp | quantile | 0.75 | 713 |
| team1‐mod | MA | 2022‐12‐17 | 1 | wk flu hosp | quantile | 0.25 | 563 |
| team1‐mod | MA | 2022‐12‐17 | 1 | wk flu hosp | quantile | 0.5 | 664 |
| team1‐mod | MA | 2022‐12‐17 | 1 | wk flu hosp | quantile | 0.75 | 803 |
| team1‐mod | MA | 2022‐12‐17 | 2 | wk flu hosp | quantile | 0.25 | 469 |
| team1‐mod | MA | 2022‐12‐17 | 2 | wk flu hosp | quantile | 0.5 | 575 |
| team1‐mod | MA | 2022‐12‐17 | 2 | wk flu hosp | quantile | 0.75 | 705 |
| team1‐mod | MA | 2022‐12‐17 | 3 | wk flu hosp | quantile | 0.25 | 324 |
| team1‐mod | MA | 2022‐12‐17 | 3 | wk flu hosp | quantile | 0.5 | 408 |
| team1‐mod | MA | 2022‐12‐17 | 3 | wk flu hosp | quantile | 0.75 | 512 |
|
|
|
|
|---|---|---|
|
| NA (not used for mean predictions) | Numeric: The mean of the predictive distribution |
|
| NA (not used for median predictions) | Numeric: The median of the predictive distribution |
|
| Numeric between 0.0 and 1.0: A quantile level | Numeric: The quantile of the predictive distribution at the quantile level specified by the |
|
| String or numeric naming a possible value of the target variable | Numeric between 0.0 and 1.0: The cumulative probability of the predictive distribution at the value of the outcome variable specified by the |
|
| String naming a possible category of a discrete outcome variable | Numeric between 0.0 and 1.0: The probability mass of the predictive distribution when evaluated at a specified level of a categorical outcome variable |
|
| Integer or string identifying the sample | Numeric: A single sample value from the predictive distribution |
|
|
|
|
|---|---|---|
|
| Mean of individual model means | Mean of individual model means |
|
| Mean of individual model medians | NA |
|
| Mean of individual model target variable values at each quantile level, | Quantiles of the distribution are obtained by computing the mean of estimated individual model cumulative probabilities at each target variable value, |
|
| Mean of individual model cumulative probabilities at each target variable value, | Mean of individual model cumulative probabilities at each target variable value, |
|
| Mean of individual model bin or category probabilities at each target variable value, | Mean of individual model bin or category probabilities at each target variable value, |
|
| NA | Samples of the distribution are obtained by stratified draw from individual models' samples |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| Flusight‐baseline | wk inc flu hosp | 1 | mean | NA | 582.07 |
| Flusight‐baseline | wk inc flu hosp | 1 | median | NA | 582.00 |
| Flusight‐baseline | wk inc flu hosp | 1 | quantile | 0.05 | 496.00 |
| Flusight‐baseline | wk inc flu hosp | 1 | quantile | 0.25 | 566.00 |
| Flusight‐baseline | wk inc flu hosp | 1 | quantile | 0.75 | 598.00 |
| Flusight‐baseline | wk inc flu hosp | 1 | quantile | 0.95 | 668.00 |
| Flusight‐baseline | wk inc flu hosp | 1 | sample | 2101 | 606.00 |
| Flusight‐baseline | wk inc flu hosp | 1 | sample | 2102 | 576.00 |
| Flusight‐baseline | wk inc flu hosp | 1 | sample | 2103 | 578.00 |
| MOBS‐GLEAM_FLUH | wk inc flu hosp | 1 | mean | NA | 704.73 |
| MOBS‐GLEAM_FLUH | wk inc flu hosp | 1 | median | NA | 664.00 |
| MOBS‐GLEAM_FLUH | wk inc flu hosp | 1 | quantile | 0.05 | 446.00 |
|
|
|
|
|
|---|---|---|---|
| 2022‐11‐05 | wk inc flu hosp | 25 | 31.000 |
| 2022‐11‐12 | wk inc flu hosp | 25 | 43.000 |
| 2022‐11‐19 | wk inc flu hosp | 25 | 79.000 |
| 2022‐11‐26 | wk inc flu hosp | 25 | 221.000 |
| 2022‐12‐03 | wk inc flu hosp | 25 | 446.000 |
| 2022‐12‐10 | wk inc flu hosp | 25 | 578.000 |
| 2022‐12‐17 | wk inc flu hosp | 25 | 694.000 |
| 2022‐12‐24 | wk inc flu hosp | 25 | 769.000 |
| 2022‐12‐31 | wk inc flu hosp | 25 | 733.000 |
| 2023‐01‐07 | wk inc flu hosp | 25 | 466.000 |
| 2023‐01‐14 | wk inc flu hosp | 25 | 238.000 |
| 2023‐01‐21 | wk inc flu hosp | 25 | 122.000 |
| 2023‐01‐28 | wk inc flu hosp | 25 | 71.000 |
| 2022‐11‐05 | wk flu hosp rate | 25 | 0.444 |
| 2022‐11‐12 | wk flu hosp rate | 25 | 0.616 |
| 2022‐11‐19 | wk flu hosp rate | 25 | 1.132 |
| 2022‐11‐26 | wk flu hosp rate | 25 | 3.167 |
| 2022‐12‐03 | wk flu hosp rate | 25 | 6.391 |
| 2022‐12‐10 | wk flu hosp rate | 25 | 8.282 |
| 2022‐12‐17 | wk flu hosp rate | 25 | 9.945 |
| 2022‐12‐24 | wk flu hosp rate | 25 | 11.019 |
| 2022‐12‐31 | wk flu hosp rate | 25 | 10.503 |
| 2023‐01‐07 | wk flu hosp rate | 25 | 6.677 |
| 2023‐01‐14 | wk flu hosp rate | 25 | 3.410 |
| 2023‐01‐21 | wk flu hosp rate | 25 | 1.748 |
| 2023‐01‐28 | wk flu hosp rate | 25 | 1.017 |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| Flusight‐baseline | wk flu hosp rate category | 1 | pmf | low | 0.000 |
| Flusight‐baseline | wk flu hosp rate category | 1 | pmf | moderate | 0.003 |
| Flusight‐baseline | wk flu hosp rate category | 1 | pmf | high | 0.073 |
| Flusight‐baseline | wk flu hosp rate category | 1 | pmf | very high | 0.924 |
| MOBS‐GLEAM_FLUH | wk flu hosp rate category | 1 | pmf | low | 0.000 |
| MOBS‐GLEAM_FLUH | wk flu hosp rate category | 1 | pmf | moderate | 0.002 |
| MOBS‐GLEAM_FLUH | wk flu hosp rate category | 1 | pmf | high | 0.163 |
| MOBS‐GLEAM_FLUH | wk flu hosp rate category | 1 | pmf | very high | 0.835 |
| PSI‐DICE | wk flu hosp rate category | 1 | pmf | low | 0.013 |
| PSI‐DICE | wk flu hosp rate category | 1 | pmf | moderate | 0.065 |
| PSI‐DICE | wk flu hosp rate category | 1 | pmf | high | 0.218 |
| PSI‐DICE | wk flu hosp rate category | 1 | pmf | very high | 0.704 |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| simple‐ensemble‐mean | wk flu hosp rate category | 1 | pmf | high | 0.15 |
| simple‐ensemble‐mean | wk flu hosp rate category | 1 | pmf | low | 0.00 |
| simple‐ensemble‐mean | wk flu hosp rate category | 1 | pmf | moderate | 0.02 |
| simple‐ensemble‐mean | wk flu hosp rate category | 1 | pmf | very high | 0.82 |
| simple‐ensemble‐mean | wk inc flu hosp | 1 | mean | NA | 627.09 |
| simple‐ensemble‐mean | wk inc flu hosp | 1 | median | NA | 619.67 |
| simple‐ensemble‐mean | wk inc flu hosp | 1 | quantile | 0.25 | 541.67 |
| simple‐ensemble‐mean | wk inc flu hosp | 1 | quantile | 0.75 | 704.33 |
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
| UMass‐trends_ensemble | 1 wk ahead inc flu hosp | quantile | 12 | NA | NA | NA | 0.025 | NA |
| UMass‐trends_ensemble | 1 wk ahead inc flu hosp | quantile | 17 | NA | NA | NA | 0.100 | NA |
| UMass‐trends_ensemble | 1 wk ahead inc flu hosp | quantile | 25 | NA | NA | NA | 0.250 | NA |
| UMass‐trends_ensemble | 1 wk ahead inc flu hosp | quantile | 46 | NA | NA | NA | 0.750 | NA |
| UMass‐trends_ensemble | 1 wk ahead inc flu hosp | quantile | 56 | NA | NA | NA | 0.900 | NA |
| UMass‐trends_ensemble | 1 wk ahead inc flu hosp | quantile | 68 | NA | NA | NA | 0.975 | NA |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| UMass‐trends_ensemble | wk ahead inc flu hosp | 1 | quantile | 0.025 | 12 |
| UMass‐trends_ensemble | wk ahead inc flu hosp | 1 | quantile | 0.100 | 17 |
| UMass‐trends_ensemble | wk ahead inc flu hosp | 1 | quantile | 0.250 | 25 |
| UMass‐trends_ensemble | wk ahead inc flu hosp | 1 | quantile | 0.750 | 46 |
| UMass‐trends_ensemble | wk ahead inc flu hosp | 1 | quantile | 0.900 | 56 |
| UMass‐trends_ensemble | wk ahead inc flu hosp | 1 | quantile | 0.975 | 68 |
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
| CMU‐TimeSeries | 31.866 | 0.677 | 47.325 | 0.827 | 0.403 | 0.850 |
| MOBS‐GLEAM_FLUH | 33.371 | 0.709 | 45.256 | 0.791 | 0.332 | 0.699 |
| PSI‐DICE | 34.338 | 0.729 | 46.227 | 0.808 | 0.390 | 0.781 |
| lp‐normal | 34.393 | 0.730 | 52.359 | 0.915 | 0.574 | 0.960 |
| lp‐lognormal | 34.394 | 0.730 | 52.360 | 0.915 | 0.574 | 0.960 |
| Median‐ensemble | 37.672 | 0.800 | 52.053 | 0.909 | 0.478 | 0.811 |
| UMass‐trends_ensemble | 38.554 | 0.819 | 57.212 | 0.999 | 0.666 | 0.917 |
| Mean‐ensemble | 39.480 | 0.838 | 54.615 | 0.954 | 0.461 | 0.779 |
| SGroup‐RandomForest | 39.694 | 0.843 | 56.338 | 0.984 | 0.463 | 0.871 |
| CU‐ensemble | 41.972 | 0.891 | 52.318 | 0.914 | 0.423 | 0.703 |
| GT‐FluFNP | 42.045 | 0.893 | 51.992 | 0.908 | 0.426 | 0.698 |
| SigSci‐TSENS | 45.865 | 0.974 | 58.231 | 1.017 | 0.485 | 0.726 |
| Flusight‐baseline | 47.095 | 1.000 | 57.244 | 1.000 | 0.499 | 0.776 |
| UVAFluX‐ensemble | 57.242 | 1.215 | 68.383 | 1.195 | 0.208 | 0.448 |
| SigSci‐CREG | 60.227 | 1.279 | 67.644 | 1.182 | 0.298 | 0.545 |
- —National Institutes of General Medical Sciences
- —US Centers for Disease Control and Prevention10.13039/100000030
- —National Science Foundation10.13039/100000001
- —Eberly College of Science Barbara McClintock Science Achievement Graduate Scholarship in Biology at the Pennsylvania State University
- —National Institutes of General Medical Sciences
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCOVID-19 epidemiological studies · Data-Driven Disease Surveillance · Zoonotic diseases and public health
Introduction
1
Predictions of future outcomes are essential to planning and decision making, yet generating reliable predictions of the future is challenging. One method for overcoming this challenge is combining predictions across multiple, independent models. These combination methods (also called aggregation or ensembling) have been repeatedly shown to produce predictions that are more accurate [1, 2] and more consistent [3] than individual models. Because of the clear performance benefits, multi‐model ensembles are a widely used statistical tool across fields, including weather forecasting [4], climate modeling [5], and economics [6]. In the last decade, the number of multi‐model ensemble predictions generated and used in real time for public health planning and response has grown rapidly.
In particular, predicting infectious disease outbreaks and anticipating the effects of potential interventions has demonstrated utility for public health officials and medical practitioners. Underlying these predictions are mathematical models that use historical disease incidence data, including cases, hospitalizations, and deaths, to make probabilistic predictions of incidence in the future [7, 8, 9, 10, 11]. Given the performance benefits of multi‐model ensembles, it is becoming increasingly common to convene multiple modeling teams into a collaborative “hub” [12], where each team generates independent predictions that are aggregated to collectively produce an ensemble. For example, this approach has been used to make real‐time, multi‐model predictions for seasonal influenza [10, 13], dengue [14], West Nile virus [15], and more recently SARS‐CoV‐2 [16, 17, 18].
Generating multi‐model ensembles or interpreting the resulting predictions depends on understanding the underlying statistical methodology. There are many proposed methods for generating ensembles, and these methods differ in at least one of two ways: (1) the function used to combine or “average” predictions, and (2) how predictions are weighted when performing the combination. A few methodological papers have discussed theory of multi‐model ensembles and tested various ensembling methods in public health applications specifically [19, 20, 21, 22, 23, 24, 25], yet there is no consensus on which method should be favored. There are software packages that support various aspects of multi‐model ensembling [26, 27, 28, 29]. However, these packages only support a subset of methods and prediction types, illustrating the need for standard, easy‐to‐use implementations of common methods.
Here, we provide an introduction to the statistical foundations of multi‐model ensembles in applied probabilistic forecasting (Section 2). In addition, to improve accessibility, reproducibility, and interoperability, we have developed a comprehensive R package hubEnsembles that implements these methods (Section 3). The hubEnsembles package provides a flexible framework for generating ensemble predictions from multiple models across a range of common methods and prediction types, including both discrete and continuous outcomes. It is situated within the broader “hubverse” collection of open‐source software and data tools to facilitate the development and management of collaborative modeling exercises [30]. These two factors together, a simple implementation framework across methods and integration with hubverse data standards and tools, make hubEnsembles accessible and easy to use.
Finally, we present a basic demonstration of multi‐model ensemble generation and interpretation (Section 4), and a more in‐depth analysis using real influenza forecasts (Section 5). The case studies demonstrate the utility of hubEnsembles to support a range of prediction types, and together motivate a discussion and comparison of the various methods (Section 6). While the case studies focus on infectious disease applications, the software and tools presented are general and could be used for applications in other areas of biomedical and public health research, or other domains. By reviewing multi‐model ensemble methodology and synthesizing these methods into an easy‐to use implementation, this tutorial provides guidance on understanding, interpreting, and implementing multi‐model ensembles.
How to Generate a Multi‐Model Ensemble
2
In this section, we provide an overview of the process to generate a multi‐model ensemble, including an outline of key statistical concepts in probabilistic forecasting, and an overview of the classes of methods that are typically used for generating a multi‐model ensemble. See Box 1 for a glossary of key terms and definitions.
Key Statistical Concepts in Forecasting
2.1
Generating an ensemble requires multiple predictions to be combined, and a combination method for calculating the ensemble from these predictions (Figure 1). These predictions will often be produced by different statistical or mathematical models, and the output from these models (referred to as “model output” from here on) will vary based on the setting. For example, some public health questions, such as short‐term resource allocation, may depend on a forecast of public health outcomes weeks into the future, whereas longer‐term decisions about vaccination schedules may require projections months into the future across multiple possible scenarios. Some intervention decisions, such as quarantine and isolation policy, may depend on estimates of key biological parameters such as the generation interval for an infectious pathogen. Throughout, we will use the general term “prediction” to encapsulate all such outcomes that could be modeled, encompassing short‐term forecasts, scenario projections, and parameter estimates. Predictions can also capture varying degrees of uncertainty in the outcome. A point prediction gives a single estimate of an outcome while a probabilistic prediction provides an estimated probability distribution over a set of outcomes. In either case, the basic steps required to generate an ensemble are the same.
Overview of process to generate a multi‐model ensemble. Predictions, pi are generated from N independent models (step 1). Then those predictions, p={pi|i∈1,…,N}, are combined with some function, C, and set of weights, w={wi|i∈1,…,N}. This figure illustrates example probabilistic forecasts for incident influenza hospitalizations, where the median (line) and 90% prediction interval are shown. In this case, the ensemble is constructed using the linear pool method (FLOP(x)).
Mathematical Definitions and Properties of Ensemble Methods
2.2
Here, we use N to denote the total number of individual predictions that the ensemble will combine. For example, if predictions are produced by different models, N is the total number of models that have provided predictions. Individual predictions will be indexed by the subscript i. Optionally, one can calculate an ensemble that uses a weight wi for each prediction; we define the set of model‐specific weights as w={wi|i∈1,…,N}. Informally, predictions with a larger weight have a greater influence on the ensemble prediction, though the details of this depend on the ensemble method (described further below).
Then, for a set of N point predictions, p={pi|i∈1,…,N}, each from a distinct model i, an ensemble of these predictions is
using any function C and any set of model‐specific weights w. For example, an arithmetic average of predictions yields pE=∑i=1Npiwi, where the weights are non‐negative and sum to 1. If wi=1/N for all i, all predictions will be equally weighted. More complex functions for aggregation are also possible, such as a (weighted) median or geometric mean.
For probabilistic predictions, there are two commonly used classes of methods to average or ensemble multiple predictions: quantile averaging (also called a Vincent average [31]) and probability averaging (also called a distributional mixture or linear opinion pool [32]) [33]. To define these two classes of methods, let F(x) be a cumulative density function (CDF) defined over values x of the target variable for the prediction, and F−1(θ) be the corresponding quantile function defined over quantile levels θ∈[0,1]. Throughout this article, we may refer to x as either a “value of the target variable” or a “quantile” depending on the context, and similarly we may refer to θ as either a “quantile level” or a “(cumulative) probability”. Additionally, we will use f(x) to denote a probability mass function (PMF) for a prediction of a discrete variable or a discretization (such as binned values) of a continuous variable.
The quantile average combines a set of quantile functions, 𝒬={Fi−1(θ)|i∈1,…,N}, with a given set of weights, w, as
This computes the average value of predictions across different models for each fixed quantile level θ. For a normal distribution or any distribution with a location and scale parameter, the resulting quantile average will be the same type of distribution, with location and scale parameters that are the average of the location and scale parameters from the individual distributions (Figure 2, panel B). In other words, this method interprets the predictive probability distributions that are being combined as uncertain estimates of a single true distribution. It is also possible to use other combination functions, such as a weighted median, to combine quantile predictions.
(Panel A) Example predictions from two distributions (N(100,10) in purple and N(120,5) in green) shown as cumulative distribution functions (CDFs). To ease submission to a hub, the prediction can be summarized at a fixed number of points along the distribution. Here, the solid points show model output for seven fixed quantile levels (θ = 0.01, 0.1, 0.3, 0.5, 0.7, 0.9, and 0.99). The y‐axis ticks show each of the fixed quantile levels. The associated values for each fixed quantile level are shown with vertical lines. (Panel B) Quantile average ensemble, which is calculated by averaging values for each fixed quantile level (represented by horizontal dashed gray lines). The distributions and corresponding model outputs from panel A are re‐plotted and the black line shows the resulting quantile average ensemble. Inset shows corresponding probability density functions (PDFs). (Panel C) Linear pool ensemble, which is calculated by averaging cumulative probabilities for each fixed value (represented by vertical dashed gray lines). The distributions and corresponding model outputs from panel A are re‐plotted. To calculate the linear pool in this case, where model outputs are not defined for the same values (i.e., vertical lines in Panel A do not line up), the model outputs are used to interpolate the full CDF for each distribution from which predicted cumulative probabilities can be extracted for fixed values (shown with open circles). The black line shows the resulting linear pool average ensemble. Inset shows corresponding PDFs.
The probability average or linear opinion pool (LOP, or simply linear pool) is calculated by averaging probabilities across predictions for a fixed value of the target variable, x. In other words, for a set of CDFs ℱ={Fi(x)|i∈1,…,N} and weights w, the linear pool is calculated as
For a set of PMF values, {fi(x)|i∈1,…,N}, the linear pool can be equivalently calculated as fLOP(x)=∑i=1Nwifi(x). Statistically this amounts to a mixture of the probability distributions, and the resulting probability distribution can be interpreted as one where the constituent probability distributions represent alternative predictions of the future, each of which has a probability wi of being the true one. If individual samples (trajectories) from the predictive distributions are collected, the LOP is equivalent to collecting samples across all models and pooling them into a single distribution. For a visual depiction of these equations, see Figure 2 below.
The different averaging methods for probabilistic predictions yield different properties of the resulting ensemble distribution. For example, the variance of the linear pool is σLOP2=∑i=1Nwiσi2+∑i=1Nwi(μi−μLOP)2, where μi is the mean and σi2 is the variance of individual prediction i, and although there is no closed‐form variance for the quantile average, the variance of the quantile average will always be less than or equal to that of the linear pool [33]. Both methods generate distributions with the same mean, μQ=μLOP=∑i=1Nwiμi, which is the mean of individual model means [33]. The linear pool method preserves variation between individual models, whereas the quantile average cancels away this variation under the assumption it constitutes sampling error [24].
Applications in Public Health and Infectious Disease Outbreaks
2.3
Multi‐model ensembles have become the gold standard for forecasting and prediction efforts that support public health in real time [12, 34, 35, 36]. One prominent domain is forecasting key characteristics of infectious disease outbreaks, including weekly disease incidence or healthcare demand over future weeks, disease burden for the entire season, and timing and magnitude of the outbreak peak [14, 15, 16, 23, 37]. Projections of disease outcomes under multiple possible future scenarios have also been used to estimate intervention effectiveness to inform policy [38, 39, 40], and it has been proposed to use short‐term forecasts of disease incidence to inform vaccine efficacy trials [41]. Standard guidelines for reporting of prediction efforts in outbreak and public health settings have also been established [42].
Across a variety of pathogens and outbreak settings, multi‐model ensembles have been shown to produce forecasts that are as good or better than the individual models that compose the ensemble [10, 13, 14, 16, 17, 18, 19, 23]. Notably, the ensemble does not always outperform the best model, but typically offers improved consistency and robustness over individual models [16, 17, 20, 43]. However, in one instance, a baseline historical average of West Nile Virus cases in the US outperformed most model predictions, including the ensemble [15].
Examinations of ensemble methodology in infectious disease contexts suggest there is not one method that universally performs best. In short‐term forecasting settings, a simple linear pool average of component predictions tends to produce prediction intervals that are too wide (i.e., suggesting outcomes are more uncertain than in reality); beta‐transformation [44] and dynamic weighting [45] have been suggested to mitigate this problem. A median quantile average has been shown to provide similar performance to a weighted mean in short‐term forecasting challenges, while also offering robustness to changes in performance across individuals models [25], and was thus used as the primary ensemble for short‐term forecasts of COVID‐19 [16, 17]. For longer‐term predictions of COVID‐19, a trimmed LOP ensemble performed best, as models tended to be more overconfident in this setting [18]. The number of models submitting real‐time predictions has varied dramatically (from as few as four models for longer‐term predictions of COVID‐19 [18] to more than 40 for short‐term forecasts of COVID‐19 [16]). Research including applications across influenza and COVID‐19 suggests that at least 3 models are needed, with diminishing returns for every model that is added [46].
The growing body of literature on multi‐model ensembles in public health domains emphasizes the utility of these approaches to inform response in real time. Future research on optimizing ensemble performance for different targets and time horizons will further improve utility. Moreover, expanding the use of these methods to other pathogens and countries will enable further methodological development.
BOX 1Keywords and definitions: Concepts in statistical forecasting.
- Ensemble: the combination of outputs from multiple models into a single, aggregate prediction
- Forecast: a specific quantified prediction of an observable event or trend that has yet to be observed, conditional on data that has been observed up to a specified time.
- Horizon: time frame over which predictions are generated (e.g., 4 weeks ahead)
- Linear opinion pool: method for ensembling probabilistic predictions, which treats constituent probability distributions as alternative predictions of the future. Also called probability average.
- Scenario projection: estimates of future observations of future trends conditional on specific assumptions about a given scenario. Scenarios describe possible future conditions in terms of model parameters that might be varied, such as transmissibility, vaccine adoption, vaccine efficacy, the emergence of a new variant, etc.
- Prediction: estimate of current or future outcomes, typically generated from a model. Here, used to encapsulate a range of outcomes that could be modeled, encompassing short‐term forecasts, scenario projections, and parameter estimates.
- Point prediction: a prediction represented by one single estimate, which generally represents a typical or common future outcome (e.g., a mean or median)
- Probabilistic prediction: a prediction that quantifies a probability distribution over future outcomes. This enables quantification of most likely outcomes and the risk of extreme events.
- Model weighting: a set of real numbers that defines the relative contribution of each constituent prediction in the ensemble (e.g., equal weighting or performance‐based weighting).
- Quantile average: method for ensembling probabilistic predictions, which treats constituent probability distributions as uncertain estimates of a single true distribution. Also called Vincent average.
- Quantile level/cumulative probability: the y value in a cumulative distribution function, representing the cumulative probability of a future value (e.g., 50% cumulative probability
- Value of the target variable/quantile: the x value in a cumulative distribution function, or the future values over which the probability distribution is defined (e.g., incident hospitalizations)
How to Implement Ensemble Calculations
3
The methods described in Section 2 are implemented via the hubEnsembles package in a flexible, easy‐to‐use framework. Importantly, hubEnsembles is situated within the broader hubverse software infrastructure, which provides data standards and conventions for representing and working with model predictions [30], including for example, collecting and manipulating predictions (hubUtils) as well as visualization (hubVis). In 2024–2025, the hubverse supported over a dozen collaborative modeling hubs used by public health agencies across the globe. We begin with a short overview of hubverse concepts and conventions that support the process of combining model predictions, supplemented by example predictions provided by the hubverse in hubExamples, then explain the implementation of the two primary ensembling functions included in the package, simple_ensemble() and linear_pool(). Box 2 provides a glossary of key hubverse terms and definitions for reference.
Terminology and Data Standards in the Hubverse
3.1
In the hubverse, predictions are always represented in a standardized tabular format called “model output”, codified by the model_out_tbl S3 class in hubUtils (a package of basic utility functions). Each row represents a single, unique prediction while the columns provide information about what is being predicted, its scope, and value. A single model output object can store and organize many predictions while remaining easy to parse at a glance, which is particularly useful when collecting predictions from multiple models to combine into an ensemble. Any tabular predictions can be transformed into model output using the as_model_out_tbl() function from hubUtils (see Section 5 for an example).
The model_out_tbl class is defined by four standard types of columns: (i) the model ID, which denotes which model has produced the prediction; (ii) the task IDs (also referred to as “task ID variables” or “task ID columns”), which provide details about what is being predicted; (iii) the model output representation, which specify the type of prediction and other identifying information; and (iv) the value of the prediction itself. While most of these columns are always required and have standardized column names, the task ID variables may vary according to the needs of the modeling hub or modeling task [30].
Table 1 provides an example of model output that stores short‐term forecasts of weekly influenza hospitalizations for different US states and territories. By reading across the table, we can see that these are quantile predictions (output_type) of the quartiles (output type ID: otid) from a single model (model_id of “team1‐mod”) for four distinct forecast horizons. Here, details about the prediction related to modeling task are represented by the task ID variables loc (location abbreviation), ref_date (reference date: the “starting point” of the forecasts), h (horizon: how many weeks into the future, relative to the ref_date), and target (what is being predicted).
As mentioned previously, task ID variables are not fixed in name, number, or composition to incorporate flexibility in the model_out_tbl class. Different modeling efforts may use different sets of task ID columns with different values to define their prediction goals, or may simply choose distinct names to represent the same concept. For example, the date task column was named ref_date above but could easily be called origin_date or forecast_date instead. Some standard examples of task ID variables are available on the hubverse documentation website [30].
The “model output representation” columns output_type and output_type_id contain metadata about how the predictions are conveyed. The hubverse data standards require that these columns are included in a model_out_tbl. The output_type column defines how a prediction is represented and may be “mean” or “median” for point predictions, or one of “quantile”, “cdf”, “pmf”, or “sample” for probabilistic predictions. The output_type_id provides additional identifying information for prediction and is specific to the particular output_type (see Table 2). The last column, value, always contains the numeric value of the prediction, regardless of output type. Requirements for the values of the output_type_id and value columns associated with each valid output type are summarized in Table 2.
In addition to these six output types mentioned above, other types of predictions not explicitly defined in the hubverse may be represented within model output. For example, trajectories may be encoded using the “sample” output type while predictions of binary events can be captured using the “pmf” output type.
All output types can summarize predictions from univariate marginal distributions, for example, for a single location and time point. The sample output type—which represents randomly drawn values from a probabilistic predictive distribution—is unique in that it can additionally represent predictions from joint predictive distributions. This means that samples may encode dependence across combinations of multiple values for task ID variables, for example across multiple locations and/or time points. One common example is a trajectory that represents a single model run across all time points, and in such cases collecting predictions as samples can offer benefits [47]. In this case, rows of sample predictions with the same index (specified by the output_type_id) from a particular model may be assumed to correspond to a single sample from a joint distribution.
For quantile predictions, the output_type_id is a numeric value between 0 and 1 specifying the cumulative probability associated with the quantile prediction. In the notation we defined in Section 2, the output_type_id corresponds to θ and the value is the quantile prediction F−1(θ). For CDF or PMF predictions, the output_type_id is the target variable value x at which the cumulative distribution function or probability mass function for the predictive distribution should be evaluated, and the value column contains the predicted F(x) or f(x), respectively.
The hubverse also provides standards for target data (i.e., observed data corresponding to each prediction target), which can be stored in one of two formats: target time series or oracle output. The two tabular representations differ in terms of columns and purposes. Target time series data is a more traditional representation of the observed “truth” in a time series format with minimal columns; this format usually serves as calibration data for generating forecasts or might be used for visualization of predictions. Oracle output, on the other hand, represents prediction that an “oracle model” would have made had it known the observed values in advance. This format resembles model output data and is suited for evaluating forecasts. Some examples of target data are given in Section 4.
Ensemble Functions in hubEnsembles
3.2
The hubEnsembles package contains two functions that perform ensemble calculations: simple_ensemble(), which applies some function to each model prediction, and linear_pool(), which computes an ensemble using the linear opinion pool method. In the following sections, we outline the implementation details for each function and how these implementations correspond to the statistical ensembling methods described in Section 2. A short description of the calculation performed by each function is summarized by output type in Table 3.
BOX 2Keywords and definitions: Terminology from the hubverse.
- Modeling Task: a definition of the goals of a modeling effort, possibly including conditions, assumptions, and targets (collectively known as task ID variables). Some tasks may be fixed across rounds, such as for forecast hubs that regularly solicit predictions for a set time horizon in the near‐term future. Other tasks may be more variable; for example, those in scenario hubs that model hypothetical futures with different assumptions for different modeling rounds.
- Compound modeling task: a single, modeled unit with a multivariate outcome of interest, such as an epidemic trajectory across multiple weeks
- Model output: a dataset containing predictions of modeling tasks in tabular format generated in response to some modeling task for a specific round. A model might result from a single team's response to the task or from an ensemble of results representing the outcomes of multiple efforts.
- Output type: a classification of model output that is supported by the hubverse (i.e., the types of predictions that can be processed). See Table 2 for definitions of each.
- Round: a time period for which a set of specific model outputs is solicited. Rounds define the “cadence” of submission for a modeling hub. For example, some hubs might accept daily submissions, where each day is considered a different round. Other hubs might have one round every month, with a submission period that may be open for multiple days.
- Task ID variables: a collection of conditions, assumptions, and potentially targets that are used to parameterize a model task. These represent columns in the model output. A more detailed explanation of task ID variables can be found in the documentation.
- Target: an outcome of interest for a modeling hub (e.g., “incident case counts”). Targets typically (and sometimes implicitly) refer to a value of an observable variable in a given window of time, a given location, and possibly other stratifications (such as age group).
Simple Ensemble
3.2.1
The simple_ensemble() function directly computes an ensemble from component model outputs by combining them via an aggregation function (C) within each unique combination of task ID variables, output types, and output type IDs. This function can be used to summarize predictions of output types mean, median, quantile, CDF, and PMF. Samples must be converted to a different output type (e.g., summarized into a CDF) in order to be ensembled using this function, as there is no meaningful equivalent for individual predictive draws. The mechanics of the ensemble calculations are the same for each of the output types, though the resulting statistical ensembling method differs for different output types (Table 3).
By default, simple_ensemble() uses the mean for the aggregation function C and equal weights for all models. For point predictions with a mean or median output type, the resulting ensemble prediction is an equally weighted average of the individual models' predictions. For probabilistic predictions in a quantile format, by default simple_ensemble() calculates an equally weighted average of individual model target variable values at each quantile level, which is equivalent to a quantile average. For model outputs in a CDF or PMF format, by default simple_ensemble() computes an equally weighted average of individual model (cumulative or bin) probabilities at each target variable value, which is equivalent to the linear pool method.
Any aggregation function C may be specified by the user. For example, a median ensemble may also be created by specifying median as the aggregation function, or a custom function may be passed to the agg_fun argument to create other ensemble types. Similarly, model weights can be specified to create a weighted ensemble.
Linear Pool
3.2.2
The linear_pool() function implements the linear opinion pool (LOP) method for ensembling predictions. This function can be used to combine predictions with output types mean, quantile, CDF, PMF, and sample. Since the LOP is an average of probabilities, it does not support ensembles of medians. Unlike simple_ensemble(), this function handles its computation differently based on the output type. For the CDF, PMF, and mean output types, the linear pool method is equivalent to calling simple_ensemble() with a mean aggregation function (see Table 3), since simple_ensemble() produces a linear pool prediction (an average of individual model cumulative or bin probabilities).
Linear Pool of samples
3.2.2.1
For the sample output type, the LOP method collects a stratified draw of the individual models' predictions and pools them into a single ensemble distribution. By default, all samples are used to create this ensemble. Additionally, only equally‐weighted linear pools of samples are supported by the hubEnsembles package during this time. Samples may also be converted to another common output type such as quantiles or bin probabilities (as the main scientific interest often concerns a summary of samples), and other ensemble methods may then be utilized for that output type.
When requesting a subsetted ensemble of samples, it becomes important to distinguish between marginal and joint predictive distributions so that the dependence structure can be passed to linear_pool(). We introduce the concepts of the compound task ID set and derived task ID variables here, as they help identify the underpinnings the dependence structure of the ensembled predictive distributions.
As stated in the previous section, the sample output type is unique in that it can represent predictions from both marginal distributions and joint distributions. Hence, samples can encode dependence across combinations of multiple values for task ID variables, for example, across multiple locations and/or time points. In this case, sample predictions with the same index (output type ID) from a given model may be assumed to correspond to a single trajectory.
The compound task id set consists of independent task id variables that, together, identify a “compound modeling task” corresponding to a single, modeled unit with a multivariate outcome of interest. Samples summarizing a marginal distribution will generally have a compound task ID set composed of all the task ID variables (except for derived task IDs). Conversely, samples summarizing a joint distribution will have a compound task ID set only containing task ID variables for which the joint distribution does not capture dependencies. For example, if a joint distribution is estimated across multiple forecast horizons separately for each location (i.e., horizon‐based trajectories), the task ID “location” would be included in the compound task ID set but “horizon” would not.
Derived task IDs are another subgroup of task ID variables that must be specified in a call to linear_pool() for a subsetted sample ensemble; their values are derived from a combination of the values from other task ID variables (which may or may not be part of the compound task ID set). A common example of a derived task ID variable is the target date for a prediction, which is a deterministic function of the reference date of the prediction and the prediction horizon. Generally, the derived task IDs won't be included in the compound task ID set because they are not needed to identify a single modeled unit for an outcome of interest, unless all of the task ID variables their values depend on are already a part of the compound task ID set.
Not all model outputs will contain derived task IDs, in which case the argument may be set to NULL (the default value). However, it is important to provide the linear_pool() function with any derived task IDs when calculating an ensemble of (subsetted) samples, as they are used to check that the provided compound task ID set is compatible with the input predictions and the resulting LOP is valid.
Linear Pool of quantiles
3.2.2.2
For the quantile output type, calculation of LOP requires a few extra steps. This is because LOP averages cumulative probabilities at each value of the target variable, but the predictions are given as quantiles (on the scale of the target variable) for fixed quantile levels. The value for these quantile predictions will generally differ between models; hence, we are typically not provided cumulative probabilities at the same values of the target variable for all component predictions. This lack of alignment between cumulative probabilities for the same target variable values impedes computation of LOP from quantile predictions and is illustrated in panel A of Figure 2.
Given that LOP cannot be directly calculated from quantile predictions, we must first obtain an estimate of the CDF for each component distribution from the provided quantiles, combine the CDFs, then calculate the quantiles using the ensemble's CDF. We perform this calculation in three main steps, assisted by the distfromq package [48] for the first two:
- Interpolate and extrapolate from the provided quantiles for each component model to obtain an estimate of the CDF of that particular distribution.
- Draw samples from each component model distribution. To reduce Monte Carlo variability, we use quasi‐random samples corresponding to quantiles of the estimated distribution [49].
- Pool the samples from all component models and extract the desired quantiles.
For step 1, functionality in the distfromq package uses a monotonic cubic spline for interpolation on the interior of the provided quantiles. The user may choose one of several distributions to perform extrapolation of the CDF tails. These include normal, lognormal, and Cauchy distributions, with “normal” set as the default. A location‐scale parameterization is used, with separate location and scale parameters chosen in the lower and upper tails so as to match the two most extreme quantiles. The sampling process described in steps 2 and 3 approximates the linear pool calculation described in Section 2.
A Simple Demonstration of Multi‐Model Ensembles
4
In this section, we provide a simple example to illustrate how to compute a multi‐model ensemble and compare the methods supported by the functions of hubEnsembles. In doing so, we use a number of other packages available through the hubverse, including to access example data and to visualize outputs. See the Data Availability Statement for details about implementation and required package versions.
Example Data: A Forecast Hub
4.1
The first step in generating a multi‐model ensemble is to gather the predictions we wish to combine. In this example, we use some short‐term forecasts already formatted as model output data from the hubExamples package. These model outputs are from a larger example modeling hub, created using a modified subset of predictions from the FluSight Forecasting challenge (discussed in further detail in Section 5). In addition to toy model output data, the example hub also includes observed data in the form of target time series data and oracle output.
The model output is stored in a data object named forecast_outputs and contains mean, median, quantile, and sample forecasts of future incident influenza hospitalizations, as well as CDF and PMF forecasts of hospitalization intensity. Each prediction is described by five task ID variables: the location for which the forecast was made (location), the date on which the forecast was made (reference_date), the number of steps ahead (horizon), the date of the forecast prediction (target_end_date, a combination of the date the forecast was made and the forecast horizon), and the forecast target (target). We begin by examining the predictions for weekly incident influenza hospitalizations, displaying a subset of each output type in Table 4.
While the hubExamples package provides both formats of target data, we focus on the target time series data (Table 5) which is convenient for making forecasts and plotting. The forecast_target_ts data object provides observed values for weekly incident influenza hospitalizations and weekly rate change of influenza hospitalizations in a given week for a particular location using columns observation, target_end_date, location, and target. The forecast‐specific task ID variables reference_date and horizon are not relevant for this time series representation of the target data, and are thus not included as columns.
We can plot the quantile and median forecasts and the target time series data (Figure 3) shown above using the plot_step_ahead_model_output() function from hubVis, another package in the hubverse suite for visualizing model outputs. We subset the model output data and the target data to the target, location, and time horizons we are interested in. LISTING
One example set of quantile forecasts for weekly incident influenza hospitalizations in Massachusetts from each of three models (panels). Forecasts are represented by a median (line), 50% and 90% prediction intervals (ribbons). Gray points represent observed incident hospitalizations.
Some hubs request modeling teams submit samples instead of, or in addition to, predicted distributions (Figure 4). Samples can be useful for capturing additional correlations across targets that are difficult to represent when predictions are summarized using quantile or CDF output types. In this example, separate probabilistic predictions of incident influenza hospitalizations in each week cannot capture the shape of possible epidemic trajectories, but multivariate samples for the trajectory of disease incidence across weeks can. We filter to the sample output type and plot. These samples are representative draws from the distributions plotted in Figure 3.
One example set of sample forecasts for weekly incident influenza hospitalizations in Massachusetts from each of three models (panels). Each sample is represented by a single line. Gray points represent observed incident hospitalizations.
Next, we examine the PMF forecasts for hospitalization intensity in the example model output data. For this target, teams forecasted the probability that hospitalization intensity will be “low”, “moderate”, “high”, or “very high”. These four categories are determined by thresholds for weekly hospital admissions per 100,000 population. In other words, “low” hospitalization intensity in a given week means few incident influenza hospitalizations per 100,000 population are predicted, whereas “very high” hospitalization intensity means many hospitalizations per 100,000 population are predicted. These forecasts are made for the same task ID variables as the quantile forecasts of incident hospitalizations except for the target, which is “wk flu hosp rate category” for these categorical predictions.
We show a representative example of the hospitalization intensity category forecasts in Table 6. Because these forecasts are PMF output type, the output_type_id column specifies the bin of hospitalization intensity and the value column provides the forecasted probability of hospitalization incidence being in that category. Values sum to 1 across bins. For the MOBS‐GLEAM_FLUH and PSI‐DICE models, incidence is forecasted to decrease over the horizon (Figure 3), and correspondingly, there is lower probability of “high” and “very high” hospitalization intensity for later horizons (Figure 5).
One example PMF forecast of incident influenza hospitalization intensity is shown for each of three models (panels). Each cell shows the forecasted probability of a given hospitalization intensity bin (low, moderate, high, and very high) for each forecast horizon (0–3 weeks ahead). Darker colors indicate higher forecasted probability.
Creating Ensembles With simple_ensemble()
4.2
Using the default options for simple_ensemble(), we can generate an equally weighted mean ensemble for each unique combination of values for the task ID variables, the output_type and the output_type_id. Recall that this function corresponds to different statistical ensemble methods for different output types: for the quantile output type in our example data, the resulting ensemble is a quantile average, while for the CDF and PMF output types, the ensemble is a linear pool (Table 3). LISTING
The resulting model output has the same structure as the original model output data (Table 7), with columns for model ID, task ID variables, output type, output type ID, and value. We also use model_id = “simple‐ensemble‐mean” to change the name of this ensemble in the resulting model output; if not specified, the default is “hub‐ensemble”.
Changing the Aggregation Function
4.2.1
We can change the function that is used to aggregate model outputs. For example, we may want to calculate a median of the component models' submitted values for each quantile. We do so by specifying agg_fun = median. LISTING
Custom functions can also be passed into the agg_fun argument. We illustrate this by defining a custom function to compute the ensemble prediction as a geometric mean of the component model predictions. Any custom function to be used must have an argument x for the vector of numeric values to summarize, and if relevant, an argument w of numeric weights. LISTING
As expected, the mean, median, and geometric mean each give us slightly different resulting ensembles. The median point estimates, 50% prediction intervals, and 90% prediction intervals in Figure 6 demonstrate this.
Three different ensembles for weekly incident influenza hospitalizations in Massachusetts. Each ensemble combines individual predictions from the example hub (Figure 3) using a different method: arithmetic mean, geometric mean, or median. All methods correspond to variations of the quantile average approach. Ensembles are represented by a median (line), 50% and 90% prediction intervals (ribbons). Geometric mean ensemble and simple mean ensemble generate similar estimates in this case.
Weighting Model Contributions
4.2.2
We can weight the contributions of each model in the ensemble using the weights argument of simple_ensemble(). This argument takes a data.frame that should include a model_id column containing each unique model ID and a weight column. In the following example, we include the baseline model in the ensemble, but give it less weight than the other forecasts. LISTING
Creating Ensembles With linear_pool()
4.3
We can also generate a linear pool ensemble, or distributional mixture, using the linear_pool() function; this function can be applied to predictions with an output_type of mean, quantile, sample, CDF, or PMF. Our example hub includes the median output type, so we exclude it from the calculation. LISTING
As described above, for quantile model outputs, the linear_pool function approximates the full probability distribution for each component prediction using the value‐quantile pairs provided by that model, and then obtains quasi‐random samples from that distributional estimate. The number of samples drawn from the distribution of each component model defaults to 1e4, but this can be changed using the n_samples argument.
In Figure 7, we compare ensemble results generated by simple_ensemble() and linear_pool() for model outputs of output types PMF and quantile. As expected, the results from the two functions are equivalent for the PMF output type: for this output type, the simple_ensemble() method averages the predicted probability of each category across the component models, which is the definition of the linear pool ensemble method. This is not the case for the quantile output type, because the simple_ensemble() is computing a quantile average.
Comparison of results from linear_pool() (blue) and simple_ensemble() (red). (Panel A) Ensemble predictions of Massachusetts incident influenza hospitalization intensity (classified as low, moderate, high, or very high), which provide an example of PMF output type. (Panel B) Ensemble predictions of weekly incident influenza hospitalizations in Massachusetts, which provide an example of quantile output type. Note, for quantile output type, simple_ensemble() corresponds to a quantile average. Ensembles combine individual models from the example hub, and are represented by a median (line), 50% and 90% prediction intervals (ribbons) (Figure 3).
Weighting Model Contributions
4.3.1
Like with simple_ensemble(), we can change the default function settings. For example, weights that determine a model's contribution to the resulting ensemble may be provided. (Note that we must exclude the sample output type here because it cannot yet be combined into weighted ensembles.) LISTING
Changing the Parametric Family Used for Extrapolation Into Distribution Tails
4.3.2
When requesting a linear pool of quantiles, we may also change the distribution that distfromq uses to approximate the tails of component models' predictive distributions to either log normal or Cauchy using the tail_dist argument (the default is normal) [48]. This choice usually does not have a large impact on the resulting ensemble distribution, though, and can only be seen in its outer edges. (For more details and other function options, see the documentation in the distfromq package at https://reichlab.io/distfromq/.) LISTING
Requesting a Subset of Input Sample Predictions to be Ensembled
4.3.3
Recall that for the sample output type, linear_pool() simply collects and pools the input sample predictions into a single distribution. By default, the resulting ensemble model output contains all provided sample predictions so that the total number of samples for the ensemble is equal to the sum of the number of samples from all individual models. LISTING
To change this behavior, the user may instead specify a number of sample predictions for the ensemble to return using the n_output_samples argument. Then, a random subset of predictions from individual models will be selected to construct a LOP of samples so that all component models are represented equally. This random selection of samples is stratified by model to ensure approximately the same number of samples from each individual model is included in the ensemble.
The compound task ID set and any derived task IDs must also be specified to ensure the function returns a valid ensemble. For example, one compound task we are predicting for in the model output is the number of weekly incident influenza hospitalizations (“target”) in Massachusetts (“location”) starting on December 5, 2022 (“reference_date”). Here, “horizon” is not part of the compound task ID set, indicating that sample predictions made at each horizon depend on those for the other horizons within every compound task for the sample output type. Each sample can therefore be interpreted as a trajectory giving a possible path of hospitalizations over time. These three task id variables (“reference_date”, “location”, and “target”) make up the compound task ID set that is specified in the call to linear_pool(). The remaining task ID variable “target_end_date” is a derived task ID since its value is a function of “reference_date” and “horizon”. LISTING
Example: In‐Depth Analysis of Forecast Data
5
To further demonstrate the differences between the two ensemble functions and the utility of the hubEnsembles package, we provide a more complex example that walks through the full process of generating multi‐model ensembles. This case study gathers real forecasts collected by a modeling hub to create four equally‐weighted ensembles, then evaluates their performance to determine the best approach for the application.
The predictions we use to create the ensemble models are sourced from two seasons of the FluSight forecasting challenge. Since 2013, the US Centers for Disease Control and Prevention (CDC) has been soliciting short‐term forecasts of seasonal influenza from modeling teams through this collaborative challenge [50]. Using simple_ensemble() and linear_pool(), we build four equally‐weighted, multi‐model ensembles to predict weekly influenza hospitalizations: a quantile (arithmetic) mean, a quantile median, a linear pool with normal tails, and a linear pool with lognormal tails. Then, we compare the resulting ensembles' performance through plotting and scoring their forecasts.
Only a select portion of the code used in this analysis is shown for brevity, but all the functions and scripts used to generate the case study results can be found in the associated GitHub repository (https://github.com/hubverse‐org/hubEnsemblesManuscript). In particular, the figures and tables supporting this analysis can be reproduced using data from .rds files stored in the analysis/data/raw‐data directory and scripts in the inst directory of the repository.
Data and Methods
5.1
We collect the predictions used to generate the four ensembles by querying them from Zoltar [51], a repository designed to archive forecasts created by the Reich Lab at UMass Amherst. For this analysis we only consider FluSight forecasts in a quantile format from the 2021–2022 and 2022–2023 influenza seasons. These quantile forecasts are stored in two data objects, split by season, called flu_forecasts‐zoltar_21‐22.rds and flu_forecasts‐zoltar_22‐23.rds, which are then joined together into a single data frame. A subset is shown below in Table 8. LISTING
Although these forecasts are in a tabular format, they are not model_out_tbl objects and thus cannot yet be fed into either of the hubEnsembles functions. Thus, we must use the as_model_out_tbl() 1 function from hubUtils to transform the raw forecasts so that they conform to hubverse standards. Below, we specify the appropriate column mappings in the call with task ID variables of forecast_date (when the forecast was made), location, horizon, and target. LISTING
To ensure the quantile mean and median ensemble had consistent component forecast make‐up at every quantile level, we only included predictions (defined by a unique combination of task ID variables) that contained all 23 quantiles specified by FluSight (θ∈{.010,0.025,.050,.100,…,.900,.950,.990}). This requirement required no further action on our part, since it was consistent with FluSight submission guidelines. However, we did remove the baseline and median ensemble models generated by the FluSight hub from the component forecasts, a choice motivated by the desire to match the composition of models in the official FluSight ensemble. (Note, though, that the component models included in our ensembles did not always exactly match those included in the FluSight‐ensemble for every forecast week as a result of slightly different inclusion criteria.)
With these inclusion criteria, the final data set of component forecasts consists of predictions from 25 modeling teams and 42 distinct models, 53 forecast dates (one per week), 54 US locations, 4 horizons, 1 target, and 23 quantiles. In the 2021–2022 season, 25 models made predictions for 22 weeks spanning from late January 2022 to late June 2022, and in the 2022–2023 season, there were 31 models making predictions for 31 weeks spanning mid‐October 2022 to mid‐May 2023. Fourteen of the 42 total models made forecasts for both seasons. Locations consist of the 50 US states, Washington DC, Puerto Rico, the Virgin Islands, and the entire US; horizons 1 to 4 weeks ahead, quantiles the 23 described above, and target week ahead incident influenza hospitalization. The values for the forecasts are always non‐negative. In Table 9, we provide an example of these predictions, showing select quantiles from a single model, forecast date, horizon, and location.
Next, we can combine the predictions into a single model_out_tbl object used to generate forecasts for each ensemble method. Then, we call the appropriate function in hubEnsembles to generate predictions for each equally‐weighted ensemble, storing the results in four separate objects of model output data. LISTING
We then evaluate the performance of the ensembles using scoring metrics that measure the accuracy and calibration of their forecasts. We chose several common metrics in forecast evaluation, including mean absolute error (MAE), weighted interval score (WIS) [52], 50% prediction interval (PI) coverage, and 95% PI coverage. MAE measures the average absolute error of a set of point forecasts; smaller values of MAE indicate better forecast accuracy. WIS is a generalization of MAE for probabilistic forecasts and is an alternative to other common proper scoring rules which cannot be evaluated directly for quantile forecasts [52]. WIS is made up of three component penalties: (1) for over‐prediction, (2) for under‐prediction, and (3) for the spread of each interval (where an interval is defined by a symmetric set of two quantiles). This metric is a weighted sum of these penalties across all prediction intervals provided. A lower WIS value indicates a more accurate forecast [52]. PI coverage provides information about whether a forecast has accurately characterized its uncertainty about future observations. The 50% PI coverage rate measures the proportion of the time that 50% prediction intervals at that nominal level included the observed value; the 95% PI coverage rate is defined similarly. Achieving approximately nominal (50% or 95%) coverage indicates a well‐calibrated forecast.
We also use relative versions of WIS and MAE (rWIS and rMAE, respectively) to understand how the ensemble performance compares to that of the FluSight baseline model. These metrics are calculated as
where model m is any given model being compared against the baseline. For both of these metrics, a value less than one indicates better performance compared to the baseline while a value greater than one indicates worse performance. Because the baseline model is designed to represent a naive prediction, relative scores less than one indicate the model is outperforming a simple prediction that could be made in the absence of a model. By definition, the FluSight baseline itself will always have a value of one for both of these metrics.
Each unique prediction from an ensemble model is scored against target data in the oracle output format using the score_model_out() function from the hubEvals package, made for scoring hubverse model outputs with commonly used evaluation metrics including those mentioned above. We use median forecasts taken from the 0.5 quantile for the MAE evaluation. Example code scoring the ensembles' forecasts can be seen below. We attach forecasts from the baseline model in order to calculate the relative metrics. LISTING
Performance Results Across Ensembles
5.2
The four ensembles rank in the top half in terms of accuracy when compared to the individual component models that made predictions for influenza hospitalizations (Table 10). The ranking of the models differs slightly among the four scoring metrics; the two linear opinion pools perform better than the other ensembles in terms of WIS and 95% prediction interval coverage while the quantile median has slightly better MAE and the best 50% coverage across ensembles. The quantile mean displayed the worst values for every metric out of the ensembles, particularly for MAE.
Plots of the ensemble models' forecasts can aid our understanding about the origin of these accuracy differences (Figure 8). For example, the linear opinion pools consistently have some of the widest prediction intervals, and consequently the highest coverage rates. The wider intervals provided by the LOP ensembles yield the best 95% prediction interval coverage, however, this also leads to 50% interval coverage that nearly always exceeded the nominal level. Moreover, the linear pools demonstrate the strongest WIS performance at both 1st and 4th week ahead horizons during the 2022–2023 season (see Figure 9); this season was especially difficult to forecast due to its unusual timing and large peak. The wider prediction intervals prove useful in this uncertain context when other models are overconfident in their forecasts.
One to four week ahead forecasts plotted against target data for California. Each panel shows the baseline and four ensembles being evaluated. All plots show the various models' forecasts summarized by the median (line) and 50% and 95% prediction intervals (darker and lighter ribbon, respectively), as compared to observed influenza hospitalizations (gray points and line). For simplicity, only predictions from select four‐week periods during the 2022–2023 influenza season are shown.
Weighted interval score (WIS) averaged across all locations. Average target data across all locations for 2021–2022 (A) and 2022–2023 (B) seasons for reference. For each season, average WIS is shown for 1‐week (C,D) and 4‐week ahead (E‐F) forecasts. Results are plotted for each ensemble model (colors) across the entire season. Lower values indicate better performance.
Although the LOP ensembles provide the best scores for WIS and 95% PI coverage, they are not always the top ensemble model. The quantile median ensemble tends to have slightly better median (point) forecasts and mid‐width intervals, including the best MAE and 50% interval coverage of all of the ensembles. While the quantile median ensemble is generally well calibrated for most of the predictions evaluated, it fails to appropriately capture uncertainty during the large peak of the 2022–2023 season which resulted in WIS values higher than that of the linear opinion pools (Figure 9). The quantile mean's interval widths vary throughout both seasons. Although it usually has narrower intervals than the linear pools, the quantile mean ensemble's median forecasts have a larger error margin compared to the other ensembles, especially at longer horizons. This pattern is demonstrated for the 4‐week ahead forecast in California following the 2022–2023 season peak on December 5, 2022 (Figure 8). Here, the quantile mean predicted a continued increase in hospitalizations, at a steeper slope than the other ensemble methods.
All of the ensemble variations outperform the baseline model in this analysis. The linear pool ensembles improve WIS by 27% over baseline, the quantile median by 20% and the quantile mean by 16%. Such improvements come mostly from the ensembles providing better calibrated prediction intervals, as improvements in point estimate accuracy improve over baseline by at most 9% (as measured by rMAE). While the best model (CMU‐TimeSeries) improves WIS more (by 33%), ensembles are typically more robust than individual models, and thus some decrease in overall performance may be accepted in order to avoid extreme misses.
Linear pool ensemble methods are known to generate wider, more conservative, prediction intervals than quantile averaging methods. In this context, where influenza dynamics were perturbed by the COVID‐19 pandemic interventions, the wider prediction intervals were suitable when making predictions for an influenza season with an unusually large peak. However, such wide intervals will likely be detrimental in other short‐term forecasting contexts, including, for example, during the milder season without any periods of rapid change (where the median and mean quantile ensembles demonstrated more robust performance). Expanding this evaluation to include other influenza seasons will be important to characterize the robustness of these conclusions and test how much the unusual timing and magnitude of the analyzed seasons affected forecast performance.
The choice of an appropriate ensemble aggregation method will depend on the forecast target, the goal of forecasting, and the behavior of the individual models contributing to an ensemble. One case may call for prioritizing high coverage rates while another may prioritize accurate point forecasts. The simple_ensemble() and linear_pool() functions and the ability to specify component model weights and an aggregation function for simple_ensemble() allow users to implement a variety of ensemble methods.
Summary and Discussion
6
Ensembles of independent models are a powerful tool to generate more accurate and more reliable predictions of future outcomes than those from a single model alone. Here, we have provided an overview of multi‐model ensemble methodology with the goal of improving use of ensemble results in public health and biomedical research settings, as well as other domains that use probabilistic forecasting. Moreover, we have demonstrated how to utilize hubEnsembles, a simple and flexible framework to combine individual model predictions into an ensemble.
Multi‐model ensembles are becoming the gold standard for prediction exercises in the public health domain. Collaborative modeling hubs can serve as a centralized entity to guide and elicit predictions from multiple independent models, as well as to generate and communicate ensemble results [12, 36]. Given the increasing popularity of multi‐model ensembles and collaborative hubs, there is a clear need for generalized data standards and software infrastructure to support these hubs. By addressing this need, the hubverse suite of tools can reduce duplicative efforts across existing hubs, support other communities engaged in collaborative efforts, and enable the adoption of multi‐model approaches in new domains.
When generating and interpreting an ensemble prediction, it is important to understand the methods underlying the ensemble, as methodological choices can have meaningful effects on the resulting ensemble and its performance. Although there may not be a universal “best” method, matching the properties of a given ensemble method with the features of the component models will likely yield best results [24]. Our case study on seasonal influenza forecasts in the US demonstrates this point. The two linear opinion pools with different distributional tails performed best for many of the metrics we evaluated—weighted interval score, mean absolute error, and prediction interval coverage—particularly when outlying component forecasts were important. Yet, the quantile averaging methods outperformed the linear pools during periods of greater stability and less variation. All ensembles showed clear improvement over the baseline model, demonstrating the accuracy gains from ensemble models that motivate the use of a “hub‐based” approach to prediction for infectious diseases, public health, and in other fields.
Conflicts of Interest
N.G.R. reports consulting income from Google Research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1R. T. Clemen , “Combining Forecasts: A Review and Annotated Bibliography,” International Journal of Forecasting 5, no. 4 (1989): 559–583, 10.1016/0169-2070(89)90012-5. · doi ↗
- 2A. Timmermann , “Chapter 4 Forecast Combinations,” in Handbook of Economic Forecasting, vol. 1 (Elsevier, 2006), 135–196, 10.1016/S 1574-0706(05)01004-9. · doi ↗
- 3M. Hibon and T. Evgeniou , “To Combine or Not to Combine: Selecting Among Forecasts and Their Combinations,” International Journal of Forecasting 21, no. 1 (2005): 15–24, 10.1016/j.ijforecast.2004.05.002. · doi ↗
- 4R. B. Alley , K. A. Emanuel , and F. Zhang , “Advances in Weather Prediction,” Science 363, no. 6425 (2019): 342–344, 10.1126/science.aav 7274.30679358 · doi ↗ · pubmed ↗
- 5C. Tebaldi and R. Knutti , “The Use of the Multi‐Model Ensemble in Probabilistic Climate Projections,” Philosophical Transactions. Series A, Mathematical, Physical, and Engineering Sciences 365, no. 1857 (2007): 2053–2075, 10.1098/rsta.2007.2076.17569654 · doi ↗ · pubmed ↗
- 6K. A. Aastveit , J. Mitchell , F. Ravazzolo , and H. K. van Dijk , The Evolution of Forecast Density Combinations in Economics, Tinbergen Institute Discussion Paper, No. TI 2018‐069/III (Tinbergen Institute, 2018).
- 7J. Shaman and S. Kandula , “Improved Discrimination of Influenza Forecast Accuracy Using Consecutive Predictions,” PLOS Currents (2015), 10.1371/currents.outbreaks.8a 6a 3df 285af 7ca 973fab 4b 22e 10911 e.PMC 460884126512336 · doi ↗ · pubmed ↗
- 8L. Held , S. Meyer , and J. Bracher , “Probabilistic Forecasting in Infectious Disease Epidemiology: The 13th Armitage Lecture,” Statistics in Medicine 36, no. 22 (2017): 3443–3460, 10.1002/sim.7363.28656694 · doi ↗ · pubmed ↗