Diagnostic performance of large language models on the NEJM image challenge: a comparative study with human evaluators and the impact of prompt engineering
Yuchen Zhou, Weiping Wang, Peng Wang, Ke Hu

TL;DR
This study compares the diagnostic accuracy of large language models and human evaluators on a medical image challenge, finding that the best model outperformed all human participants.
Contribution
The study demonstrates that a leading multimodal LLM achieves higher diagnostic accuracy than medical students and physicians on a standardized image challenge.
Findings
OpenAI o4-mini-high achieved 94% accuracy, surpassing human participants.
Most model errors were due to diagnostic logic lapses, not input processing.
Prompt engineering corrected over half of the model's initial errors.
Abstract
Multimodal large language models (LLMs) that can interpret clinical text and images are emerging as potential decision-support tools, yet their accuracy on standardized cases and how it compares with human performance across different difficulty levels remains largely unclear. This study aimed to rigorously evaluate the performance of four leading LLMs on the 200-item New England Journal of Medicine (NEJM) Image Challenge. We assessed OpenAI o4-mini-high, Claude 4 Opus, Gemini 2.5 Pro, and Qwen 3, and benchmarked the top model against three medical students (Years 5–7) and an internal-medicine attending physician under identical test conditions. Additionally, we characterized the dominant error types for OpenAI o4-mini-high and tested prompt engineering strategies for potential correction. Our results suggest that OpenAI o4-mini-high achieved the highest overall accuracy of 94%. Its…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
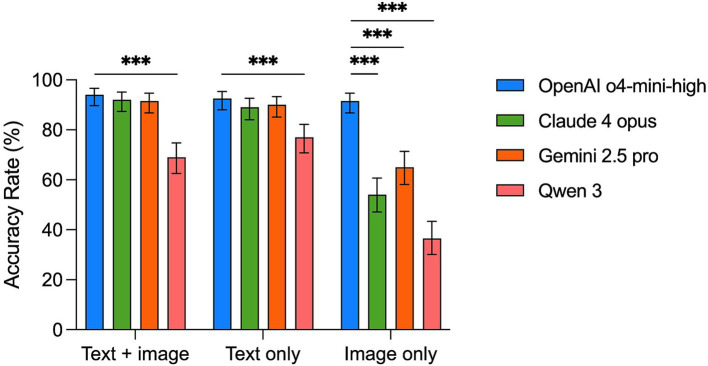 Figure 1
Figure 1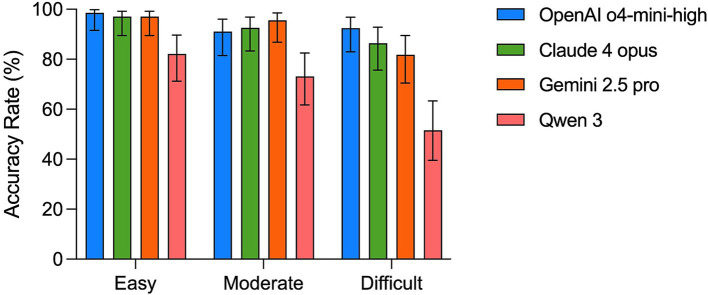 Figure 2
Figure 2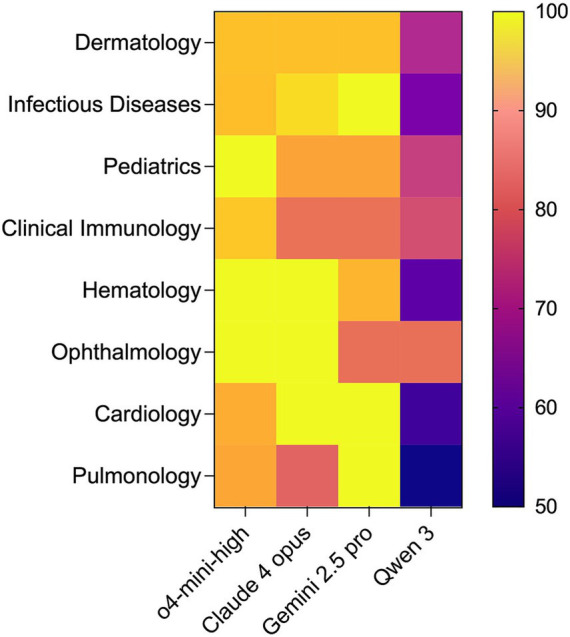 Figure 3
Figure 3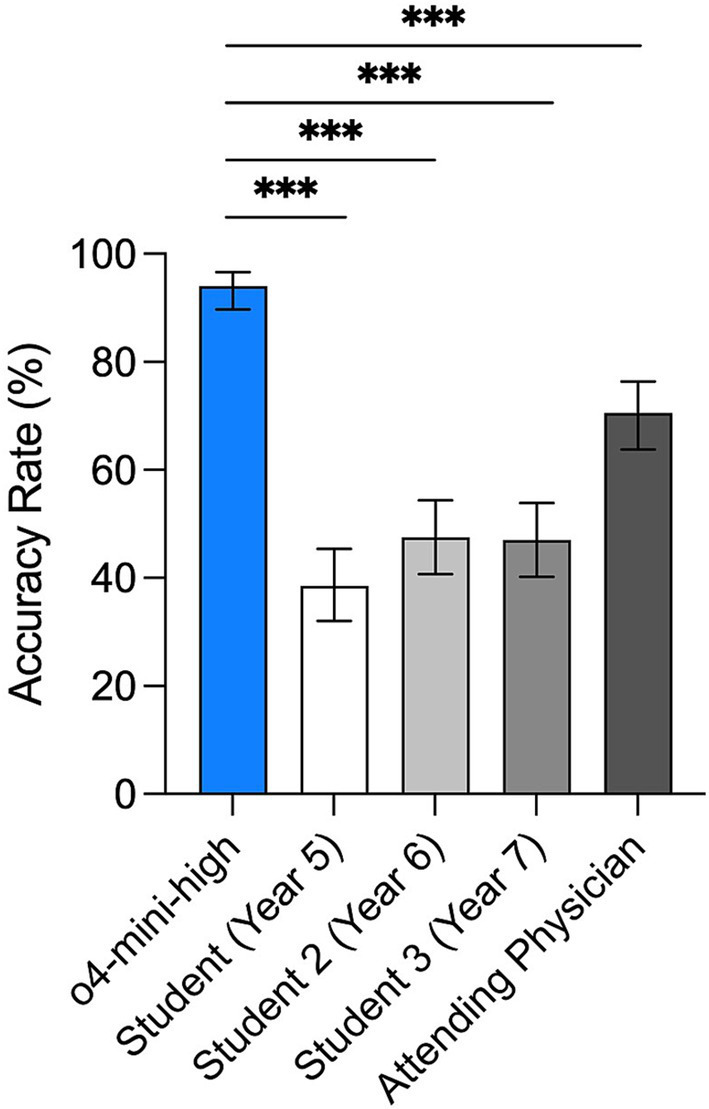 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · COVID-19 diagnosis using AI · Topic Modeling