Lord’s Paradox and two network meta-analysis models
Yu-Kang Tu, James S. Hodges

TL;DR
This paper explains how two network meta-analysis models differ by comparing them to a classic statistical paradox, highlighting when they might give conflicting results.
Contribution
The paper draws a novel analogy between network meta-analysis models and Lord’s Paradox to clarify their differing assumptions and outcomes.
Findings
The CBM and BM differ in assumptions about baseline treatment outcomes and treatment contrasts.
The analogy to Lord’s Paradox explains how different modeling choices can lead to conflicting results in NMA.
Discrepancies between the models may indicate violations of the transitivity assumption.
Abstract
The contrast-based model (CBM) is the most popular network meta-analysis (NMA) method, although alternative approaches, e.g., the baseline model (BM), have been proposed but seldom used. This article aims to illuminate the difference between the CBM and BM and explores when they produce different results. These models differ in key assumptions: The CBM assumes treatment contrasts are exchangeable across trials and models the reference (baseline) treatment’s outcome levels as fixed effects, while the BM further assumes that the baseline treatment’s outcome levels are exchangeable across trials and treats them as random effects. We show algebraically and graphically that the difference between the CBM and BM is analogous to the difference between the two analyses in a statistical conundrum called Lord’s Paradox, in which the t-test and analysis of covariance (ANCOVA) yield conflicting…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
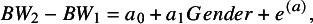 Figure 1
Figure 1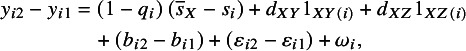 Figure 2
Figure 2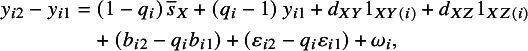 Figure 3
Figure 3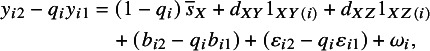 Figure 4
Figure 4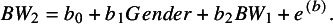 Figure 5
Figure 5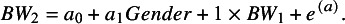 Figure 6
Figure 6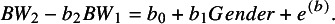 Figure 7
Figure 7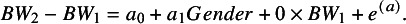 Figure 8
Figure 8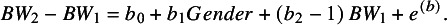 Figure 9
Figure 9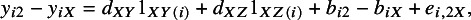 Figure 10
Figure 10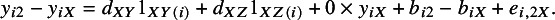 Figure 11
Figure 11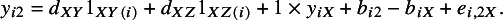 Figure 12
Figure 12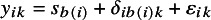 Figure 13
Figure 13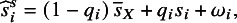 Figure 14
Figure 14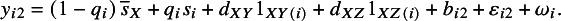 Figure 15
Figure 15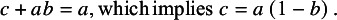 Figure 16
Figure 16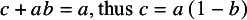 Figure 17
Figure 17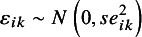 Figure 18
Figure 18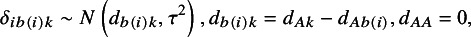 Figure 19
Figure 19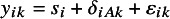 Figure 20
Figure 20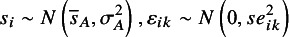 Figure 21
Figure 21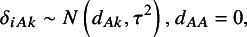 Figure 22
Figure 22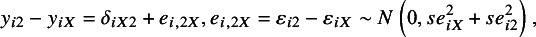 Figure 23
Figure 23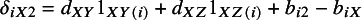 Figure 24
Figure 24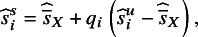 Figure 25
Figure 25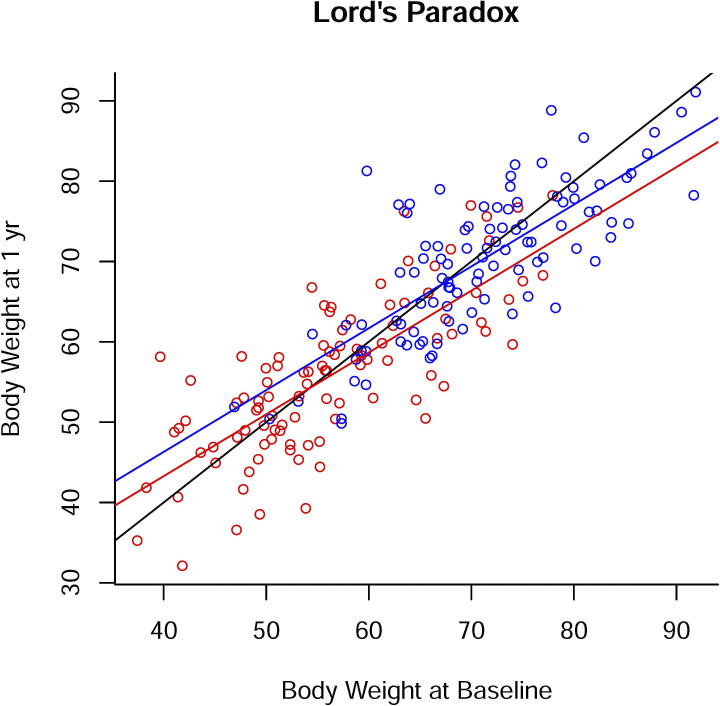 Figure 1
Figure 1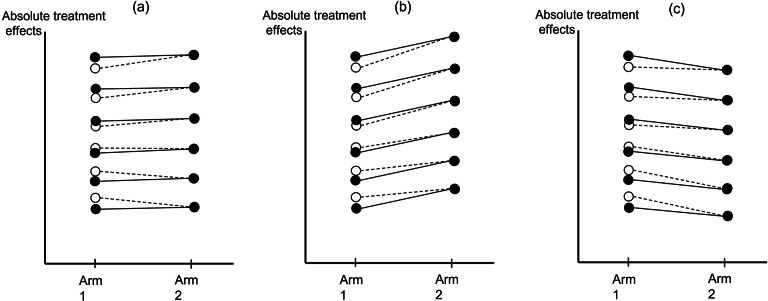 Figure 2
Figure 2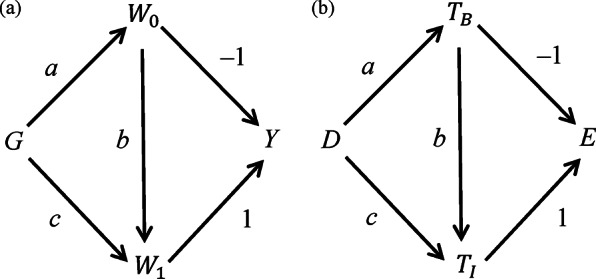 Figure 3
Figure 3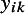 Figure 29
Figure 29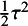 Figure 30
Figure 30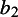 Figure 31
Figure 31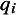 Figure 32
Figure 32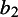 Figure 33
Figure 33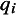 Figure 34
Figure 34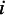 Figure 35
Figure 35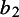 Figure 36
Figure 36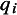 Figure 37
Figure 37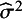 Figure 38
Figure 38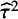 Figure 39
Figure 39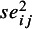 Figure 40
Figure 40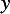 Figure 41
Figure 41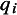 Figure 42
Figure 42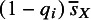 Figure 43
Figure 43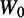 Figure 44
Figure 44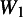 Figure 45
Figure 45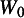 Figure 46
Figure 46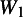 Figure 47
Figure 47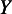 Figure 48
Figure 48 Figure 49
Figure 49 Figure 50
Figure 50- —National Science and Technology Councilhttps://doi.org/10.13039/501100020950
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMeta-analysis and systematic reviews
Highlights
What is already known?
The CBM for NMA assumes treatment contrasts are exchangeable across the included studies, while the BM further assumes the baseline (or reference) treatment’s outcome level is also exchangeable across trials. A recent study showed that these two models may yield different results when the baseline risks vary across different designs of studies that compared different sets of treatments.
What is new?
We show that a key distinction between these two NMA models is similar to Lord’s Paradox, a statistical conundrum about whether a t-test or ANCOVA should be used to compare two groups according to a change in the outcome. We show that the CBM uses the observed treatment contrasts as the outcome in the analysis, while the BM uses adjusted treatment contrasts as the outcome. Alternatively, the CBM estimates the unconditional differences between one treatment and the baseline treatment, while the BM estimates the conditional difference by adjusting for the baseline effects.
Potential impact for RSM readers
The two NMA models make different assumptions about the relationship between treatment contrasts and the reference treatment effects. These differences in statistical assumptions reflect different perspectives on how the data were generated and how treatments impact patients. Therefore, choosing the appropriate model should depend on evaluating the validity of these assumptions in real-world scenarios.
Introduction
1
Network meta-analysis (NMA) combines direct and indirect evidence to compare the benefits and harms of multiple treatments.1 ^–^ 3 Several approaches have been proposed to estimate relative effects between treatments; differences in their model specifications reflect different assumptions about how treatments should be compared.4 ^,^ 5 The contrast-based model (CBM), also called the Lu and Ades model, uses the difference in outcome between a pair of treatments in a given study, i.e., a treatment contrast, as the unit of analysis, assuming that a given treatment contrast is exchangeable across studies.6 ^,^ 7 The baseline model (BM) further assumes that the reference treatment’s outcome levels are exchangeable across studies.1 ^,^ 5 Although these two models are closely related, there has been debate as to which should be preferred.4 ^–^ 6 ^,^ 8 ^,^ 9
White et al.1 ^,^ 5 discussed when the CBM and BMs yield different results. We aim to illuminate a key difference between these two models and to show that this difference is analogous to Lord’s Paradox, a conundrum about whether a t-test or analysis of covariance (ANCOVA) should be used to compare two groups according to a change in an outcome.10 ^,^ 11
Our article is organized as follows. First, we give a brief overview of the CBM and BM and their assumptions. We then describe Lord’s Paradox and how the paradox occurs, after which we discuss how the assumptions of the two NMA models are related to Lord’s Paradox, using directed acyclic graphs (DAGs) to illustrate the relation. Finally, we discuss how Lord’s Paradox can illuminate the differences between the two NMA models.
NMA models and their statistical assumptions
2
Both NMA models were initially described within the Bayesian statistical framework.1 ^,^ 4 ^,^ 12 For simplicity, we use the frequentist framework.
Contrast-based model
2.1
The CBM assumes a given treatment contrast is exchangeable across studies, as standard pairwise meta-analysis does. The CBM can be written as
where is treatment k’s response in study i with standard error ; is treatment k’s trial-specific effect relative to trial i’s baseline treatment ; is the average of the contrast between k and ; , a variance, describes heterogeneity between trials in this contrast, and is the difference between the average of treatment k and a reference treatment A. The heterogeneity is usually assumed identical for all treatment contrasts, so their covariances are . For binary data, is usually the log odds or log risk, so and are the log odds ratio or log risk ratio between two treatments. For continuous data, is the outcome or change in outcome from the start of observation, so and are the mean difference in the outcome between two treatment groups. For either type of data, is a fixed-effect parameter specific to study i, often interpreted as a study effect, while is a random effect following a normal distribution, implying that it is exchangeable across studies.
Baseline model
2.2
The BM differs from the CBM in that the reference treatment’s level is modeled as a random effect with a separate draw from a normal distribution for each study. If we designate treatment A as the reference treatment, regardless of whether it was included in every study, we can write the BM (in arm-based form) as12
where is the (possibly hypothetical) true response for treatment A in study i, and and are the mean and variance across studies of this true response; is assumed identical for all treatment contrasts, so their covariances are . The random effects and are assumed independent. (Model-2 is equivalent to Model 3 in the article by White et al. therein called the CBM with random study intercepts.)5 Different specifications of this model have been published. As specified in Model 2, the analysis results do not depend on the choice of reference treatment; as specified in White et al.5, the results do depend on the choice of reference treatment. The Supplementary Material gives more details. Other parameters are as in the CBM. Thus, the baseline and CBMs differ in that is a draw from a random effect in the former but a fixed effect in the latter.
Statistical assumptions of these NMA models
2.3
The study effect in the CBM, a fixed effect, is the response of study i’s control group to the baseline treatment; the baseline treatment response is specific to each study and is not assumed exchangeable across studies. Rather, the difference in responses between two treatment groups—the treatment contrast or relative effect—is exchangeable.
This assumption that treatment contrasts are exchangeable further implies no association between study i’s baseline effect and study i’s relative effect . Suppose all studies include the reference treatment A. The assumption is that if A has a large or small absolute effect in study i, this has no relation to the relative effect between A and the other treatments in study i. Even if the included studies come from different populations with different distributions of treatment effect modifiers, such as age, the relative treatment effects between A and other treatments in different studies remain similar by assumption, although the absolute effect of A may vary from study to study with differences in age.
The BM assumes baseline treatment A’s effect is exchangeable across studies, a random effect with a normal distribution. When a study’s patients are randomly assigned to A and other treatments, that study’s other treatments are thus randomly sampled from the same population, so the BM implicitly assumes all treatment effects are exchangeable across studies.5 We revisit this later when we discuss the selection of a baseline treatment.
Lord’s Paradox
3
We may gain insight into the differences between the CBM and BM from the literature about Lord’s Paradox.10 ^,^ 11 This literature is vast13 ^–^ 16; we do not provide a comprehensive review.
In FM Lord’s original article, a university studied the effect on students’ body weight of the diet provided in the university dining halls. The study also asked whether males and females differed in the effects of the diet. Each student’s weight was measured upon their arrival in September and again the following June. Two statisticians analyzed the data independently.
A numerical example
3.1
For our demonstration, we simulated body weights of 100 female and 100 male students. Table 1 summarizes the simulated data.Table 1. Summary statistics for the hypothetical body weight data with 100 male and 100 female studentsGenderFemalesMales N 100100bw156.21 (9.50)70.90 (9.13)bw255.75 (9.61)70.08 (9.10)cw−0.46 (6.60)−0.83 (6.17) Note: bw1, body weight measured at baseline; bw2, body weight measured at follow-up; cw, change in weight.
The first statistician calculates the mean weights of female students at the beginning and end of the year (56.20 kg and 55.75 kg, respectively) and finds the change (−0.46 kg) very small. The mean weights of male students at the beginning (70.90 kg) and end of the year (70.08 kg) are also similar, and the change (−0.83 kg) is also small. She compares weight change between females and males using a t-test, obtains a p-value of 0.68, and concludes that females and males did not differ in weight change. This t-test can be written as a linear regression model:
where and are body weights measured at baseline and follow-up, respectively, and Gender is a dummy variable with females coded 0 and males 1. The estimate of is −0.46 kg, the mean weight change in females, and is −0.37 kg, suggesting no difference between sexes in mean weight change.
The second statistician notices that males are larger than females at baseline on average (70.9 kg vs 56.2 kg), so she uses ANCOVA to adjust for the baseline difference in body weight. The ANCOVA model can also be written as a linear regression:
The estimate of is 12.49 kg, the estimated mean body weight at the end of the year for females whose baseline body weight is zero, so has no practical meaning. The estimate of is 3.02 kg, the estimated difference in follow-up body weight between females and males with the same baseline body weight. The estimate of is 0.77, the estimated difference in follow-up body weight between students of a given gender whose baseline body weights differ by 1 kg. Because is statistically significant, the second statistician concludes that, on average, males gain 3 kg more than females. The horizontal and vertical axes of Figure 1’s scatterplot are the baseline and follow-up body weights, respectively. Red and blue circles represent females and males. Red and blue lines are fitted parallel regression lines for females and males, respectively, both with slope . Their intercepts differ by .Figure 1. Scatterplot of the hypothetical data with 100 male (blue circles) and 100 female (red circles) students. The blue and red solid lines are the fitted regression lines for male and female students, respectively. The black solid line has an intercept of zero and a slope of 1.
How does Lord’s Paradox happen?
3.2
When the difference between males and females in mean body weight change is small, the regression coefficient in Equation (1) will be close to 0. However, in Equation (2) equals 0 only under very special conditions.
Equation (1) can be rearranged as
The t-test is thus a linear regression in which is regressed on and with s coefficient constrained to , represented by Figure 1’s black line. When is close to 0 as in our example, the fitted black lines for males and females are indistinguishable. Comparing Equations (3) and (2), we see that Lord’s Paradox arises when is substantially less than 1 in Equation (2), in which case the two statisticians will give different conclusions.
We can rearrange Equation (2) as
Comparing Equations (1) and (4), Lord’s Paradox can be interpreted as follows: The first statistician regresses the observed weight change on , while the second regresses the adjusted weight change on . If , as in our example, then . Because both males and females have tiny observed weight changes, for both genders, so the two genders show a negligible difference in weight change. Thus, the first statistician finds no difference in weight change between females and males. In contrast, males have greater than females, so males have greater adjusted weight change. In our example, the average adjusted weight changes for males and females are and , respectively, so the difference is about 3 kg, as the ANCOVA estimates.
An alternative formulation of Lord’s Paradox
3.3
Alternatively, we can consider the difference between the first and second statisticians as arising from their differing assumptions about the relationship between change score and baseline body weight. The first statistician assumes no relationship between weight change and baseline body weight, because Equation (1) can be expressed as
The coefficient for is 0, so Equation (1) assumes weight change is not related to baseline body weight. Thus, although males have greater body weight than females, on average, that plays no role in comparing their weight changes.
The second statistician assumes there is a relationship between weight change and baseline weight, as seen when Equation (2) is reexpressed as
The two statisticians reach the same conclusion if . Because of random errors in weight measurements and natural variation in body weight within each student, is likely to be rather less than 1.14 ^,^ 17 This is what FM Lord tried to demonstrate in his short article.10
The relation between NMA models and Lord’s Paradox
4
We use an NMA with treatments X, Y, and Z to show how Lord’s Paradox illuminates the differences between the two NMA models. Following White et al.1 ^,^ 5, our NMA includes only trials comparing two treatments, one of which is treatment X. Thus, this NMA includes only two types of trials, also called designs in the NMA literature18: one comparing X with Y (design XY) and the other comparing X with Z (design XZ). X is each trial’s baseline treatment and also the network’s reference treatment, so it is treatment “A” in Model-1 (the CB model) and Model-2 (the BM) above. We wish to know whether Z’s effect differs from Y’s.
The CBM for this NMA can be expressed (in contrast-based form) as a regression model:
where group 2 is either Y or Z; group 1 is always X so the subscript “1” has been replaced by X. Model 1’s trial-specific effect of treatment k relative to trial i’s baseline treatment , , can be expressed as
where and are as in Model 1; 1 when study i has design XY and 0 when study i has design XZ; when study i has design XZ and 0 when study i has design XY; and captures heterogeneity. The CBM is then
where the subscript 2 for represents each study’s second treatment group, Y or Z. We can add to Equation (7), so it becomes clear that the CBM assumes no relationship between the treatment contrast and the baseline treatment:
Equation (8) can be further rearranged by moving to the right side, yielding:
The CBM can thus be viewed as regressing the test treatment level on the reference treatment level, with the regression coefficient fixed at 1. In all these ways, the CBM’s analysis is like the first statistician’s analysis in Lord’s Paradox.
Now consider the BM for this NMA, Model 2. Suppose we have an estimate for . Such an estimate using Model 2, a mixed linear model, will be shrunk (hence the superscript) toward , an estimate of , the mean of s distribution, so can be written
where is the shrinkage factor and is the unshrunk estimate of from a CBM fit, where the baseline treatment is a fixed effect. Each study and arm has its own sampling-error variance (usually treated as known), so is a complex function of the heterogeneity and reference-group random-effect variance but it is easy to show that as i.e., as the BM tends toward the CBM, .
Now and , where and have mean zero because the respective estimates are unbiased. Therefore,
where has mean 0. If we replace the hypothetical true response for treatment for study i, , in Model 2 with its estimate, , then
where the sum of the last three terms has a mean of zero.
Now , so
where the second line of Equation (10) has a mean of zero.
Equation (10) can be rewritten in ways that are analogous to Equations (4) and (6). First, recall that . Gather these items from Equation (10)’s right side to give
where Equation (11)’s second line has mean zero. Equation (11) and Equation (6) have the same form: The BM implicitly assumes the study-specific treatment contrast and baseline effect are associated, while the CBM assumes they are independent.
Finally, we can move to the left-hand side of Equation (11), giving
where the second line of Equation (12) has mean zero. Equation (12) and Equation (4) have the same form: The BM, in effect, has as its dependent variable an adjusted difference between the non-reference and reference treatments, where the adjustment depends on the shrinkage induced by the random effect used to model the reference treatment.
We make two comments about the BM. First, the shrinkage factor has the same role that has in Lord’s Paradox in Equations (4) and (6), but and differ in other ways: is the same for all students in Lord’s example, while takes different values for different studies , and is estimated by fitting the regression in Equation (4), while the depend on the data indirectly through the study sample sizes, the estimates and , and the . The will be close to zero only for very small studies. Second, is present in Equations (11) and (12) but has no analog in Equations (4) and (6). From Equation (11), biases in the BM’s estimates of treatment effects are a function of these terms.
NMA models and the two statisticians in Lord’s Paradox
4.1
Comparing Equations (5) and (8) and Equations (6) and (12), the CBM is the first statistician, while the BM is the second statistician. Each student has two measurements of body weight, as each trial has two treatments. Each student’s weight change corresponds to the treatment contrast in each trial. Males and females correspond to designs XZ and XY, respectively. The two statisticians’ approaches yield different results when males have larger baseline body weight; the two approaches to NMA may yield different results when the effects of baseline (and reference) treatment X differ between the two trial designs.
Graphical comparisons of NMA models
5
Figure 2 graphically explains the difference between the two models’ results in different scenarios. In terms of the preceding development for the BM, Figure 2 connects most directly to Equation (10). In Figure 2, two filled circles connected with a solid line represent a trial comparing two treatments, Arms 1 and 2. The horizontal axis is the treatment arms, and the vertical axis is the absolute treatment effects. In Figure 2a, the two arms in each of the six trials have the same outcome levels. In Figures 2b and 2c, the two arms have different outcome levels, but the difference between the two arms is identical in all trials. The open circles are the BM’s shrunken estimates for Arm 1, which are “shrunk” toward Arm 1’s average level.Figure 2. Line plots for comparing contrast-based and baseline models. The two filled circles connected with a solid line represent a trial comparing two treatments, Arms 1 and 2. The open circles are the shrunken estimates of Arm 1 given by the baseline model; these open circles are “shrunk” closer to the average effect of Arm 1. The horizontal axis is the treatment arms, and the vertical axis is the absolute treatment effects. In (a), the two arms in each of the six trials have the same treatment effects. In (b), Arm 2 is better than Arm 1, and in (c), Arm 1 is better than Arm 2. The difference between the two arms is identical in every trial.
Suppose we include two types of trials in the analysis: design XY and design XZ. X is Arm 1, each study’s baseline treatment, and the network’s reference treatment, and we aim to know whether Z differs from Y. In the CBM, the difference between the two arms’ outcomes in each trial is the difference between the values of each trial’s two filled circles. In the BM, however, the difference in treatment levels is the difference between the open circle on the left and the solid circle on the right, connected by the dashed line. Because X’s level is modeled as a random effect, for trials with above-average levels of X, their estimated levels of X are shrunk downward, and for trials with below-average X, their estimated X are shrunk upward.
When designs XY and XZ have the same distribution of X, e.g., each design includes all six trials in Figure 2, Y and Z do not differ using the CBM or BM. But if the top three trials have design XZ and the bottom three trials have design XY, the two models give different results. In Figure 2a, the CBM finds no difference between Z and Y, but the BM finds Z is better than Y (because Z is better than X in design XZ, and X is better than Y in design XY). In Figure 2b, the CBM finds that both Z and Y are better than X, and Z and Y do not differ. The BM, however, finds that both Z and Y are better than X, but Z is also better than Y. In Figure 2c, the CBM finds that X is better than Z and Y, and again Z and Y do not differ. The BM now finds that X is slightly better than Z but much better than Y, so Z is better than Y.
Directed acyclic graphs for Lord’s Paradox and NMA models
6
Figure 3a is a DAG for Lord’s Paradox, slightly modified from Pearl’s DAG.19 Each node represents a variable in the model; an arrow’s direction describes the relation between the two nodes. In Figure 3a, node G, gender, is a cause of baseline body weight ( ) and final weight ( ), while is a cause of and weight gain ( ), and is a cause of . The letter or number associated with an arrow denotes the strength of the path represented by the arrow and can be interpreted as a regression coefficient. For example, because on average, weight does not change for either males or females, the effect of on is equal to its effect on , which can be written as
Statistician 1 considers the total effect of on , the sum of three paths from to , , , and , so the total effect is . Statistician 2, however, considers the conditional effect of on by blocking paths through ; this conditional effect is . The two statisticians have the same result if or , i.e., (respectively) males and females do not differ in baseline body weight, or the regression of final weight on baseline weight has a coefficient of 1.Figure 3 Directed acyclic graphs for (a) Lord’s Paradox: represents gender; and denote the baseline body weight and final weight, respectively; is the weight gain and (b) NMA models: represents study design (XY vs XZ); and denote the effects of baseline treatment and the intervention treatment (Y or Z); is the difference in the effects between and .
Figure 3b shows an analogous DAG for NMA. Node represents design (XY vs XZ), which influences the effects of both the baseline treatment ( ) and the intervention treatment Y or Z ( ). is a cause of and of the difference in the effects of and ( ), and is a cause of . Suppose the average relative treatment effect (difference between treatments) is the same in designs XY and XZ, so the effects of Y and Z relative to X do not differ, on average. Then the effect of on and are the same, which implies
The CBM considers the total effect of on , the sum of three paths from to : , , and , so the total effect is . The BM estimates the conditional effect of on by blocking paths through ; this conditional effect is . The two models give the same result if or , i.e., (respectively) X has the same effect in designs XY and XZ, or the regression of the intervention treatment (Y or Z) on the baseline treatment (X) has a coefficient of 1.
Figure 3a shows that the t-test and ANCOVA give the same result if either the average baseline body weights are identical or the coefficient for regressing final body weight on baseline body weight is 1. In his 1967 article, FM Lord was more concerned about the latter, as this coefficient tended to be less than 1 because of natural fluctuations in body weights and measurement errors, causing imperfect correlation between two body weight measurements. In a NMA, even if the differences in the average treatment effects between X and Y and between X and Z are the same, the correlations (across studies) between treatment effects are unlikely to be 1, so the CBM and BM give different results.
Discussion
7
Comparing the two NMA models
7.1
When the baseline effects have similar distributions in the different trial designs, the contrast-based and BMs yield similar results. This is analogous to using the t-test or ANCOVA to analyze change scores from a randomized trial: both tests yield the same results because the treatment groups have similar baseline values.20 The key question, therefore, is which model is more appropriate when trial designs have different baseline effects.
Variation between trials in the effect modifiers of individual patients can lead to differences in baseline effects. Including study-level effect modifiers in the analysis may reduce unexplained variation between trials, but caution is still necessary. Moreover, some effect modifiers may be unknown or unavailable. Also, trials with similarly distributed effect modifiers may still have different baseline effects. If the baseline and CBM show substantially different results, this suggests that baseline effects are heterogeneous across trial designs. Caution is therefore needed in interpreting results from either model, as this heterogeneity may reflect an imbalance in the distribution of some effect modifiers, resulting in violation of the transitivity assumption. We may need to reassess the eligibility of individual trials against the prespecified criteria in the systematic review’s protocol.
Figure 3’s DAGs offer another perspective on the differences between the two models. The BM estimates the adjusted difference between Y and Z in the treatment effects conditional on the effect of X, while the CBM estimates the total, unadjusted difference. Whether the adjusted or unadjusted difference is more clinically meaningful is likely to be context specific. For instance, suppose the effect modifiers are distributed similarly in trials of different designs, while the effects of X are on average slightly higher in design XZ than in design XY. The BM may give a more precise estimate for the difference between Y and Z by adjusting for the heterogeneity in X’s effect. In contrast, if patients’ characteristics differ substantially in designs XZ and XY, neither of these two models can provide a definitive answer about the difference between Y and Z.
Different formulations of NMA models and selection of the baseline treatment
7.2
In our discussion of the two NMA models, the treatment X was included in every trial, so it was the natural candidate for both the baseline and reference treatment. However, it is rare for a treatment to be included in all trials, so our single-level formulation of the BM in Equations (10)–(12), with treatment contrasts as the unit of analysis, is not applicable to most NMAs. Nevertheless, we used this formulation to show the similarity between these NMA models and Lord’s Paradox. A more practical formulation of these NMA models uses treatment arms as the unit of analysis, in which case any treatment can be the reference or baseline treatment (if Model 2’s specification is used; see the Supplementary Material).
In a previous study, Shi and Tu6 used structural equation modeling to show that the CBM is a BM with the variance of the random study effects approaching infinity. This implies that results from the BM are not affected by the selection of reference treatment. There are, in fact, two versions of the BM that differ in their specification of random effects.5 ^,^ 6 The choice of a reference treatment affects the results in one specification but not the other. The Supplementary Material gives a more thorough technical discussion of the BM’s two specifications and of how the choice of the reference treatment affects their results differently.
Finally, although we used a specific NMA to demonstrate the analogy between Lord’s Paradox and the two NMA models, the conclusions and implications of this analogy extend beyond the specific NMA. For instance, we showed that the CBM uses observed treatment contrasts as outcomes, while the BM uses adjusted treatment contrasts. Thus, if the baseline treatment’s effect varies substantially across different designs of trials, these two models may yield different results. We refer readers to our previous article on bias propagation in NMA for simulations and a complex example in which results from these models can differ greatly.21
Conclusion
8
This article used Lord’s Paradox to provide a framework for comparing the CBM and BMs for NMA. These two models make different assumptions about the relationships between baseline and relative treatment effects. When they yield substantially different results, we need to be cautious in interpreting either model’s results.
Supporting information
Tu and Hodges supplementary materialTu and Hodges supplementary material
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Dias S , Sutton AJ , Ades AE , Welton NJ . Evidence synthesis for decision making 2: a generalized linear modeling framework for pairwise and network meta-analysis of randomized controlled trials. Med Decis Mak. 2013;33(5):607–617. 10.1177/0272989 x 12458724.PMC 370420323104435 · doi ↗ · pubmed ↗
- 2Lu G , Ades AE . Combination of direct and indirect evidence in mixed treatment comparisons. Stat Med. 2004;23(20):3105–3124. 10.1002/sim.1875.15449338 · doi ↗ · pubmed ↗
- 3Salanti G . Indirect and mixed-treatment comparison, network, or multiple-treatments meta-analysis: many names, many benefits, many concerns for the next generation evidence synthesis tool. Res Synth Methods. 2012;3(2):80–97. 10.1002/jrsm.1037.26062083 · doi ↗ · pubmed ↗
- 4Hong H , Chu HT , Zhang J , Carlin BP . A Bayesian missing data framework for generalized multiple outcome mixed treatment comparisons. Res Synth Methods. 2016;7(1):6–22. 10.1002/jrsm.1153.26536149 PMC 4779385 · doi ↗ · pubmed ↗
- 5White IR , Turner RM , Karahalios A , Salanti G . A comparison of arm-based and contrast-based models for network meta-analysis. Stat Med. 2019;38(27):5197–5213. 10.1002/sim.8360.31583750 PMC 6899819 · doi ↗ · pubmed ↗
- 6Shih M-C , Tu Y-K . Evaluating network meta-analysis and inconsistency using arm-parameterized model in structural equation modeling. Res Synth Methods. 2019;10(2):240–254. 10.1002/jrsm.1344.30834677 · doi ↗ · pubmed ↗
- 7Tu Y-K . Use of generalized linear mixed models for network meta-analysis. Med Decis Mak. 2014;34(7):911–918. 10.1177/0272989 x 14545789.25260872 · doi ↗ · pubmed ↗
- 8Hong H , Chu H , Zhang J , Carlin BP . Rejoinder to the discussion of “a Bayesian missing data framework for generalized multiple outcome mixed treatment comparisons,” by S. Dias and A. E. Ades. Res Synth Methods. 2016;7(1):29–33. 10.1002/jrsm.1186.26461816 PMC 4779393 · doi ↗ · pubmed ↗