Dynamic context–based updating of object representations in the visual cortex
Giacomo Aldegheri, Surya Gayet, Marius V. Peelen

TL;DR
The visual cortex updates object representations using predictable changes in the surrounding scene, even when objects are partially visible or occluded.
Contribution
This study demonstrates that the visual cortex uses contextual geometric information to dynamically update object representations in natural vision.
Findings
Visual cortex representations are enhanced when objects rotate congruently with the surrounding scene.
Object orientation can be decoded from visual cortex activity even when the object is fully occluded.
Abstract
Objects in real-world scenes are often poorly or partially visible, for example because they are occluded or appear in the periphery. An additional challenge of real-world vision is that it is dynamic, causing the appearance of objects (e.g., their size and orientation) to change as we move. Notably, however, these changes are predictable from the three-dimensional structure of the surrounding scene. In two functional magnetic resonance imaging studies, we find that the visual cortex dynamically updates object representations using this predictive contextual information. First, visual cortical representations of objects were enhanced when they rotated congruently (versus incongruently) with the surrounding scene. Second, the inferred orientation of the object could be decoded from visual cortex activity even when the object was fully occluded. These findings indicate that predictive…
Click any figure to enlarge with its caption.
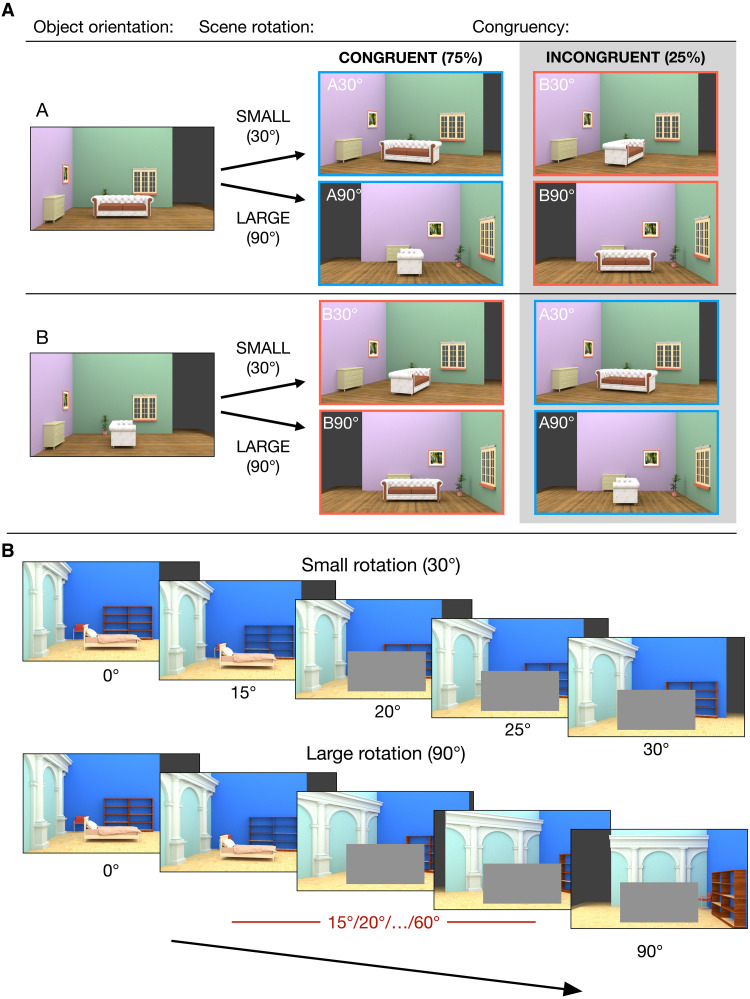 Fig. 1
Fig. 1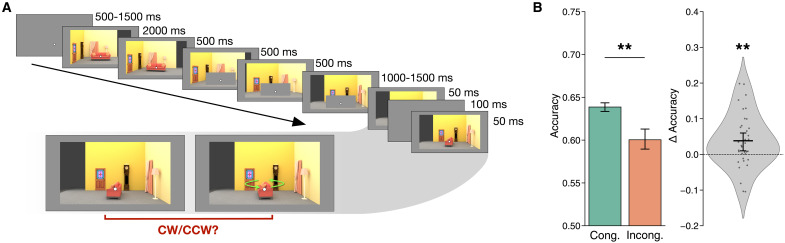 Fig. 2
Fig. 2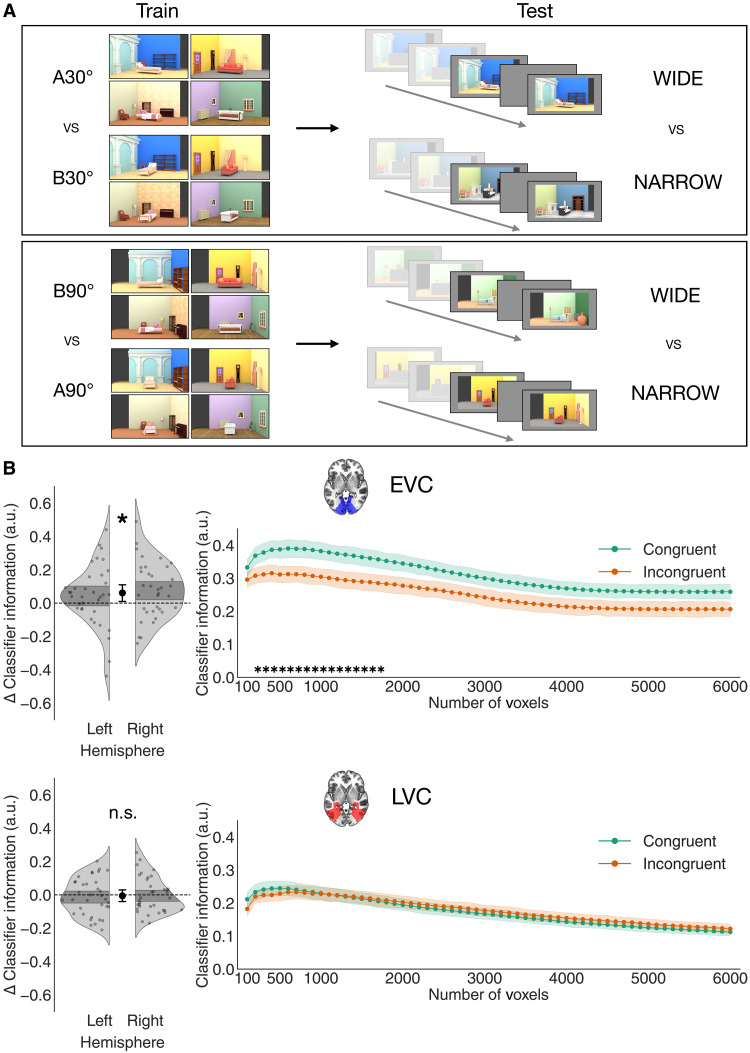 Fig. 3
Fig. 3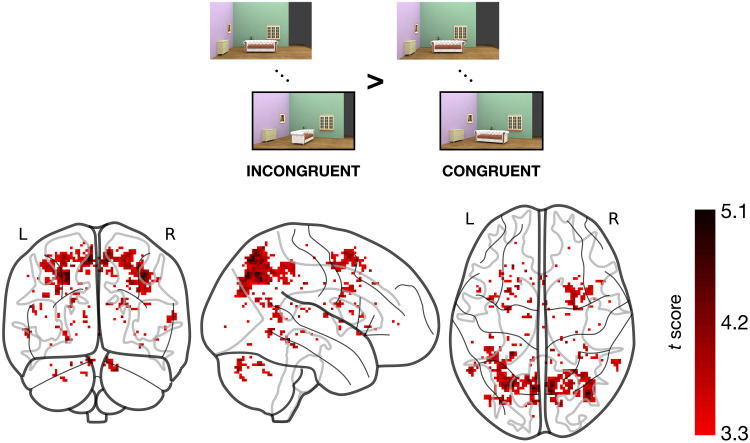 Fig. 4
Fig. 4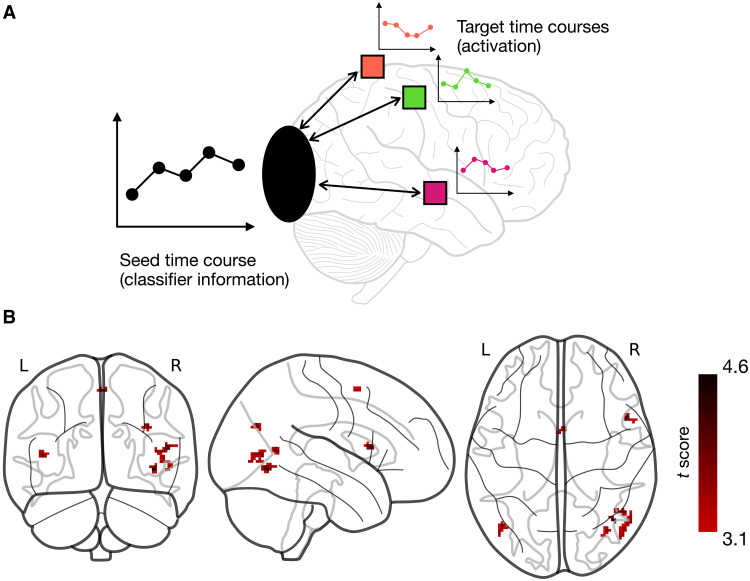 Fig. 5
Fig. 5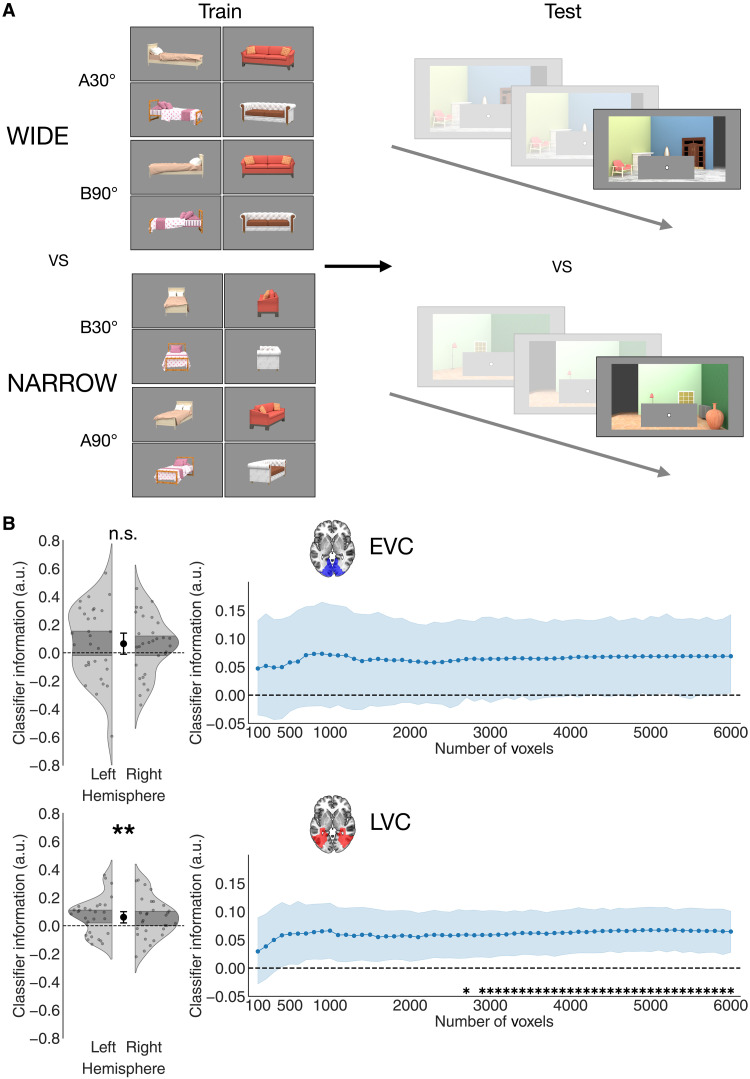 Fig. 6
Fig. 6- —http://dx.doi.org/10.13039/100010663H2020 European Research Council
- —http://dx.doi.org/10.13039/501100003246Nederlandse Organisatie voor Wetenschappelijk Onderzoek
- —Dutch Research Council (NWO Talent Programme 2023)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFace Recognition and Perception · Visual perception and processing mechanisms · Memory and Neural Mechanisms
INTRODUCTION
Real-world vision is inherently inferential (1–3). For example, when part of a scene is occluded, we use contextual information to infer the occluded parts (4). Recent research has shown that such perceptual inferences activate regions of the visual cortex that are also activated during stimulus-driven perception. For example, neuroimaging studies in humans (5–7), and electrophysiological recordings in nonhuman primates (8) and rodents (9), revealed that patterns of neural activity in the early visual cortex (EVC) contained information about occluded parts of scenes. Similarly, neuroimaging studies showed that scene context modulated late visual cortex (LVC) representations of degraded and poorly visible objects, such that these representations became more similar to the representations of fully visible objects (10, 11). These studies show that perceptual inferences based on (static) scene context do not only affect higher-level decisional stages (12) but also modulate and activate visual cortex representations, thereby shaping our perceptual experience (13, 14).
Perceptual inferences in the real world, however, are not only based on static context. As we move, our view of a scene—and the objects within that scene—changes. These changes depend on geometric constraints such as the way a three-dimensional (3D) rotation results in a 2D image change on the retina. Inanimate objects (e.g., a bed) usually remain stable relative to the scene background (e.g., a room). This allows for predicting the appearance of objects from new viewpoints based solely on viewing the scene background. In a recent behavioral study, we found that temporarily occluded objects placed in scenes were automatically mentally rotated together with the changing viewpoint of the surrounding scene (15). Specifically, participants performed better on a challenging change discrimination task on the visual object, when the object reappeared in an orientation that was consistent with the (now rotated) background scene. Because the amount of scene rotation was unpredictable in that study, the new viewpoint of the object could only be inferred from the new viewpoint of the scene and not through continuous mental rotation of the object alone. This finding provides evidence that predictions of 3D object rotations can occur automatically, as a product of contextual information [in a subsequent study, we found this to occur for translation as well as rotation (16)]. To our knowledge, it is unknown whether such dynamic context predictions modulate and/or activate visual cortex activity in the way that static context predictions do. Are visual object representations (i.e., predictions about the 2D appearance of an object) dynamically updated to account for changes in scene viewpoint? If so, this would entail that changes in the 3D scene context are used to generate predictions about the (novel) appearance of an object within that scene, potentially supporting object perception in dynamic, 3D, real-world environments.
Here, we used functional magnetic resonance imaging (fMRI) to address this question. In Experiment 1, we tested for modulatory effects of dynamic context predictions in the visual cortex. Specifically, we hypothesized that visual cortex representations are enhanced when objects reappear in a viewpoint that is congruent rather than incongruent with the (new) scene viewpoint. Note that we adopt an operational definition of “object representations,” referring specifically to the proximal shape of an object’s projection on the retina—“wide” versus “narrow”—as decoded via multivariate pattern analysis (MVPA). In Experiment 2, we went one step further and tested whether dynamic context predictions of object appearance not only modulate but also directly activate the visual cortex. That is, we tested whether information about the new object orientation (derived from the scene viewpoint) would be present in the visual cortex, even when the object itself is still occluded and thus fully invisible. If so, this would provide an important generalization of studies investigating static context predictions (5, 6, 8) or predictions involving highly simplified stimuli (17, 18) to the complexity of real-world environments.
In both fMRI studies, we focused on two regions of interest (ROIs) within the visual cortex: EVC (Brodmann areas 17 and 18), given its known role in the completion of partially visible scenes (5, 6, 8), and LVC (Brodmann areas 19 and 37), which has been implicated in context-driven inference of object properties (10, 11, 19). In Experiment 1, we decoded, from activity patterns in these two ROIs, the proximal (i.e., 2D) shape of objects that, after an occlusion period, reappeared oriented congruently or incongruently with the rotation of the surrounding scene (Fig. 1A). Critically, the initial viewpoint and amount of rotation were chosen such that objects could reappear either in a “wide” or “narrow” projection on the 2D image plane (e.g., a bed viewed from the side versus the tail end). We found that representations of congruent objects, relative to incongruent objects, were enhanced in the EVC, as demonstrated by better discriminability of multivariate activity patterns (i.e., “wide” versus “narrow” decoding). This enhancement was accompanied by an overall lower activation at the whole-brain level, in line with effects of other forms of expectations in the visual cortex (20, 21). In Experiment 2, we directly decoded the proximal shape of these same objects, but now during the period of occlusion (while no object was visible on the screen), to determine whether object representations were updated coherently with the rotation of the scene context. Here, we found that proximal object shape could be reliably decoded in the LVC, providing evidence for purely top-down–driven activity reflecting the predicted object orientation, solely derived from the new scene viewpoint.
Experimental design of Experiment 1.(A) Outline of the experimental design. The stimuli were images of rooms containing a central object, which could be shown at one of two possible orthogonal orientations (labeled A and B) relative to the room. The room could undergo two different total amounts of rotation: small (30°) and large (90°). After the room’s rotation, the object could be either in a congruent view (with the same orientation relative to the room as at the beginning of the trial) or in an incongruent view (with the other possible orientation B if the initial orientation was A or vice versa). (B) Examples of the full rotation sequence for a small and large rotation. The rotation was shown in discrete steps, and the object was fully occluded after the first two rotation steps until the whole rotation was complete. The intermediate scene orientations (including the last visible object orientation and the occluded orientations) were fixed (15°-20°-25°) for the 30° rotation trials and randomly sampled from the set {15°, 20°, 25°, 30°, …, 55°, 60°} for the 90° rotation trials, always shown in increasing order.
Together, these results indicate that scene completion in the human visual cortex generalizes to the prediction of object appearance across viewpoint changes in 3D scenes, providing a potential mechanism for efficiently processing partially visible scenes in dynamic real-world environments.
RESULTS
Experimental design
In both fMRI experiments, participants viewed realistic indoor scenes (rooms) featuring a central object (a bed or couch) oriented in one of two possible angles relative to the scene (Fig. 1A). On each trial, the scene would start rotating around the vertical axis in discrete snapshots, causing a change in scene viewpoint (Fig. 1B). During the first two snapshots the object was fully visible, so that participants could learn how the object was positioned within the room. During the subsequent three snapshots the object was occluded, so that participants would only see the rotating room. In the last snapshot, which occurred on every trial of Experiment 1, the occluder was removed, so that the object became visible again (Fig. 2A). Critically, the object reappeared in an orientation that was either congruent or incongruent with its original positioning within the room (Fig. 1A). The total amount of rotation (from initial to final viewpoint) was either 30° or 90°, with each rotation amount occurring on half of the trials within each condition. The amount of rotation on a given trial remained unknown before the object was occluded. Therefore, the new orientation of the object could only be inferred from the new orientation of the room. The exact same stimuli (initial and final viewpoints) were used for trials with congruently and incongruently rotated objects. Thus, whether an object was rotated congruently or incongruently could only be inferred through dynamic updating of the object orientation, based on the changing viewpoint on the scene.
*Trial sequence and behavioral results of Experiment 1.(A) Temporal outline of a trial. After the rotation was complete, the occluder would disappear, revealing the object in either the congruent or incongruent view. The object would be briefly flashed (50 ms) twice, in two slightly different orientations. Participants had to determine whether the second orientation was clockwise or counterclockwise relative to the first. This task was fully orthogonal to the congruency of the object’s orientation, thus allowing us to test whether participants would automatically predict the orientation of the object from the (current) viewpoint on the surrounding scene. (B) Mean (and SEM) accuracy on the behavioral task for congruent and incongruent trials (left) and distribution of differences in accuracy (congruent minus incongruent) across participants. Participants were more accurate when the object’s final view was congruent. *P < 0.01.
Another key aspect of the design is that the two initial object orientations and the two scene rotation angles were chosen to result in two categorically distinct proximal object shapes in the final snapshot: either a wide or a narrow shape (i.e., the object evoked a wide or narrow projection on the 2D image plane). This was done to maximize the power of the multivariate decoding analyses, discriminating between patterns of activity evoked by wide versus narrow shapes.
Enhanced representations of congruently rotated objects in the EVC
In Experiment 1 (N = 35), the occluder was removed during the final scene viewpoint, so that the object reappeared. On 75% of trials, the object reappeared in an orientation that was congruent with the rotation of the surrounding scene, whereas on the remaining 25% it was incongruent (Fig. 1A). The same physical stimuli counted as congruent or incongruent depending only on the trial context, avoiding any stimulus-related confounds. We compared participants’ performance in an orthogonal perceptual task (see Materials and Methods and Fig. 2), as well as blood oxygenation level dependent (BOLD) activity patterns in our two ROIs, evoked by congruent and incongruent reappearing objects.
Behaviorally, participants were more accurate on congruent than incongruent trials [mean accuracy: 0.64 versus 0.60, t34 = 2.99, P = 0.005, d = 0.67, confidence interval (CI) = [0.01, 0.06]; Fig. 2B]. This indicates that the rotation of the scene influenced participants’ perceptual processing of the objects.
To examine the information about congruent and incongruent objects in the visual cortex, we trained linear classifiers to distinguish the object’s proximal shape (wide versus narrow projection) from BOLD activation patterns. These classifiers were trained on separate training runs, in which all possible final object and scene orientation combinations were shown without the preceding rotation sequence (Fig. 3A). The purpose of these training runs was to estimate benchmark visual cortical responses to wide versus narrow object orientations, regardless of their contextual (in)congruency. Overall, the proximal shape of the objects could be decoded reliably above chance in both the EVC (mean classifier information 0.28, t34 = 13.85, P < 0.001, d = 2.39, CI = [0.24, 0.32]) and LVC (mean classifier information 0.11, t34 = 11.86, P < 0.001, d = 2.00, CI = [0.14, 0.20]). Thus, information about the object’s appearance was present throughout the visual cortex. Decoding accuracy was significantly higher in the EVC than LVC (t34 = 7.11, P < 0.001, d = 1.02, CI = [0.08, 0.14]), likely due to the stronger sensitivity of earlier visual areas to changes in an object’s appearance, such as across viewpoints (22).
*Results of Experiment 1.(A) Cross-decoding scheme used in Experiment 1. Linear classifiers were trained to distinguish wide and narrow object views from cortical responses obtained in separate training runs. The stimuli in these runs were the final views shown in the main task runs but presented without any preceding rotation sequence. To ensure that decoding was driven by the object’s proximal shape and not by covarying features such as the overall orientation of the scene, separate classifiers were trained to distinguish wide and narrow views with different background orientations (30° and 90°). These were then tested on the (wide versus narrow) object views shown at the end of rotation sequences in the main task runs. Classifier information was then averaged across backgrounds and compared between congruent and incongruent trials. (B) Multivariate decoding results of Experiment 1: As the number of voxels to be selected in each ROI (based on the functional localizer) was arbitrary, we varied this number between 100 and 6000 in steps of 100 voxels, creating 60 sub-ROIs with an increasingly liberal inclusion criterion. Classifier information was then averaged across sub-ROIs, and the difference between congruent and incongruent was computed for each participant and each hemisphere. This difference is shown on the left side: Classifier information was significantly higher for congruent than incongruent object views in the EVC, indicating that more information about the proximal object shape was present in this ROI. On the other hand, this difference was not found in the LVC. The right side shows that these results were consistent across numbers of included voxels, averaged across participants and hemispheres (shaded regions denote SEM across participants). Asterisks denote significance of the difference between congruent and incongruent classifier information after applying TFCE (see Materials and Methods for details). P < 0.05. n.s., not significant; a.u., arbitrary units.
Turning to our central analysis, we found that the shape of congruent objects could be cross-decoded better than the shape of incongruent objects in the EVC, and this was consistent across a large range of voxel inclusion thresholds (Fig. 3B, congruent versus incongruent means across voxel numbers: 0.31 versus 0.25, t34 = 2.38, P = 0.023, d = 0.44, CI = [0.01, 0.11]). This result was consistent in both directions of decoding (classifiers trained on training runs and tested on main task runs or vice versa; fig. S7) and when using classification accuracy instead of classifier information (fig. S4). It was also consistent when only including the subset of trials in which the last visible object orientation was perfectly matched across small and large scene rotations (fig. S2). This indicates that the enhancement of object representations was driven by the scene context and not by differences in the visible object orientations before occlusion (see Materials and Methods for more details on this control analysis). On the other hand, no difference in cross-decoding performance between congruent and incongruent objects was found in the LVC (Fig. 3B, congruent versus incongruent means across voxel numbers: 0.17 versus 0.18, t34 = −0.37, P = 0.71, d = 0.06, CI = [−0.04, 0.03]). To confirm that the difference between congruent and incongruent cross-decoding was stronger in the EVC, we ran a within-subject analysis of variance (ANOVA) with congruency (congruent and incongruent) and ROI (EVC and LVC) as factors. This analysis revealed a significant interaction between congruency and ROI (F1,34 = 12.18, P = 0.0014, η^2^p = 0.26). Congruency with the scene’s rotation, then, enhances the information present in the visual cortex about the object’s proximal shape, and this effect appears to be specific to early stages of visual processing.
Incongruent objects elicited a larger univariate response
We next investigated whether the observed enhancement in multivariate decoding was accompanied by an overall higher univariate response. If participants were actively anticipating the appearance of an object that matched their scene-driven expectations, it is possible that attention to congruent objects would lead to a larger univariate response (23–25) . For example, a larger response would be expected if participants were actively maintaining the congruent object in working memory (25) or if attention was captured by the congruent object (23, 24, 26). A higher signal-to-noise ratio under conditions with overall higher response amplitudes could then underlie the better multivariate decoding under the congruent condition. Alternatively, the enhancement of object information in the EVC could have occurred in the absence of a higher univariate response or even with a lower response. This would be more consistent with expectations resulting in a more efficient neural code (20, 21).
In the EVC, which showed enhanced decoding for congruent object information, we did not observe any difference in univariate response, independently of the number of voxels included in the analysis (fig. S3): congruent versus incongruent means across voxel numbers −1.98 versus −1.90, t34 = −1.05, P = 0.302, d = 0.04, CI = [−0.22, 0.07]. The mean activation on congruent trials was numerically lower. This result indicates that the enhanced multivariate decoding we observed in the EVC does not result from an overall larger univariate response.
We next ran a whole-brain univariate contrast to determine whether any clusters in the brain display a significantly higher response to either congruent or incongruent objects. There were no clusters responding more to congruent than incongruent objects. Conversely, several clusters responded more to incongruent than congruent objects (Fig. 4 and table S1). The most prominent clusters were found in the precuneus, angular gyrus, and inferior parietal lobe, areas associated with attentional reorienting and cognitive control. Together, these results indicate that the congruency of objects with the rotation of the scene evoked an overall smaller, not larger, univariate response. This finding is consistent with the idea of congruent object representations being represented more efficiently in the visual cortex (20, 21). Moreover, it reinforces the conclusion of our recent behavioral work (15) that scene-driven object predictions are generated automatically rather than as a product of active and voluntary mental operations.
Results of the univariate contrast between incongruent and congruent trials.Several clusters responded more strongly to incongruent trials, whereas none responded more to congruent ones. This result suggests that incongruently oriented objects elicited a “surprise” response.
Multivariate enhancement covaried with activation in the higher-level visual cortex
The contextual enhancement observed in the EVC required the integration of information across large regions of the visual field. Moreover, it was based on high-level scene information. For these reasons, it most likely involved computations occurring in higher-level visual or associative areas. The previously reported enhanced decoding of degraded objects embedded in scenes, for example, is driven by feedback from scene-selective cortex (10, 14, 27). To reveal which brain regions were involved in the enhancement we observed, we ran an information-activation coupling analysis (28). This analysis determines whether the univariate activation of particular voxels covaries, across time points after stimulus onset, with the accuracy of multivariate decoding in a seed region, in our case, the EVC. In particular, we tested whether this coupling was stronger under the congruent than the incongruent condition (see Materials and Methods for details). Locations in the brain that are more strongly coupled with the decoding accuracy in the seed region on congruent than incongruent trials are likely to be involved in the enhancement of congruent object representations.
We contrasted the coupling for congruent and incongruent conditions across the whole brain as we did not have strong prior hypotheses about which regions might be the source of dynamic scene-driven predictions. This analysis revealed several clusters showing greater coupling for congruent than incongruent objects (Fig. 5 and table S2). We used the Neurosynth platform (29) to search for the terms most strongly associated with the peak coordinates of these clusters, based on meta-analysis maps. This search (see table S3) revealed that two of the clusters were associated with visual motion and motion-sensitive area V5/MT (most associated terms: “visual motion,” “v5,” “motion,” and “mt”) as well as with object processing (“fusiform,” “objects,” and “object”). Other clusters were most strongly associated with the inferior frontal gyrus and premotor cortex (“inferior frontal,” “premotor,” “imitation,” and “handed”), as well as with parietal cortex and spatial cognition (“spatial,” “parietal occipital,” “visuo,” and “navigation”). These results suggest that the object predictions we observed involved the interaction between the EVC and higher-level visual areas related to motion and object processing, as well as the inferior frontal gyrus, premotor and parietal cortices, which were previously implicated in coordinate transformations and mental rotation (30, 31).
Information-activation coupling analysis.(A) Illustration of the information-activation coupling analysis. Given a seed time course of multivariate classifier information in an ROI (in our case, the EVC) after stimulus onset, and a target time course of univariate activation for each voxel in the brain, the per-voxel correlation with the seed time course is computed across the whole brain. These correlations are then compared between the congruent and incongruent conditions to reveal voxels that are more strongly coupled with multivariate information in the EVC under the congruent condition. (B) Results of the one-sided univariate contrast between the correlation maps for congruent and incongruent trials. Several clusters were found that were significantly more coupled on congruent than incongruent trials, corresponding to the higher-level visual cortex, parietal, premotor, and inferior frontal cortex (see text for details).
Scene rotation updated object representations in the absence of visual input
Experiment 1 showed that scene-driven predictions about occluded objects enhance visual cortical object representations. This may indicate that a representation of the predicted object shape is preactivated in the visual cortex, based on changes in scene viewpoint. Alternatively, it may reflect a reactive signal that distinguishes “congruent” from “incongruent” scenes (i.e., devoid of any visual content) and modulates visual cortex activity. Previous works have found that expectations based on environmental regularities, beyond modulating visually evoked activity, can also drive the inference of occluded parts of visual scenes (5, 6, 8) and elicit visual predictions in the absence of sensory input (17, 18). In Experiment 2 (N = 30), we therefore set out to directly investigate whether changes in scene viewpoint preemptively evoke a visual representation of the predicted object while the object was fully invisible (i.e., during occlusion).
The experimental design was largely consistent with that of Experiment 1, except that in Experiment 2, the central object remained occluded until the end of the trial. This made it possible to directly examine the internal representation of the object. Moreover, in this experiment, participants did not have to actively perform a visual discrimination task on the object, providing a strong test for the automaticity of scene-driven object updating. To ensure that they still paid attention to the stimulus sequence, the object reappeared on 12.5% of trials. When the object did reappear, it was always oriented congruently. At the end of each run, participants had to report the number of reappearances within the run. The data from these catch trials were excluded from all subsequent analyses.
As in Experiment 1, we trained linear classifiers on separate runs to discriminate the proximal shape of objects (wide or narrow; Fig. 6A). In this case, the classifiers were trained on BOLD responses to visually presented objects without any background and tested on BOLD responses to scenes with occluded objects, thus cross-decoding from visually evoked to purely top-down responses. We analyzed the same ROIs as in Experiment 1, the EVC and LVC, again testing for robustness across varying numbers of included voxels.
*Results of Experiment 2.(A) Multivariate cross-decoding scheme used in Experiment 2. Linear classifiers were trained to distinguish wide and narrow object views from BOLD activity in training runs. In these runs, objects were shown without any background. Object views were grouped in the “wide” and “narrow” categories based on their proximal shape, independently of their orientation relative to the scene and the viewer. Thus, the “wide” category included both A30° and B90°, and the “narrow” category included both B30° and A90°. The classifiers thus trained were then tested on the final period of trials in the main task runs, in which the scene had completed its rotation, and the object was still occluded. The goal was to determine whether an expectation of the occluded object’s rotated view was present in the visual cortex despite the object not being visible. (B) Results of the multivariate decoding analysis of Experiment 2. Varying the number of voxels included in the analysis, we found that the expected proximal object shape could be reliably decoded above chance in the visual cortex. In particular, classifier information was positive regardless of the number of included voxels in the LVC, although the difference between the LVC and EVC was not significant, indicating that information about object shape was present throughout the visual cortex (see text for details). Left: Distribution of classifier information, averaged across voxel numbers, for each participant and hemisphere. Right: Classifier information, averaged across hemispheres, for each number of included voxels. Shaded regions indicate SEM across participants, and asterisks indicate significance after TFCE. *P < 0.05; *P < 0.01.
We found that the object’s proximal shape could be decoded above chance in the visual cortex, consistently across a wide range of voxel numbers (Fig. 6B). In the LVC, decoding was reliably above chance (mean classifier information across sub-ROIs: 0.061 ± 0.002 SEM, t29 = 2.96, P = 0.006, d = 0.54, CI = [0.02, 0.1]). This result was consistent without any participant exclusions, despite noisier data (fig. S6), when using classification accuracy instead of classifier information as a measure of decoding (fig. S4) and across both decoding directions (fig. S7). On the other hand, decoding was not significantly above chance in the EVC: mean classifier information across sub-ROIs was 0.064 ± 0.004 SEM, t29 = 1.72, P = 0.095, d = 0.31, CI = [−0.01, 0.14]. However, a paired t test comparing classifier information across the two ROIs revealed no significant difference between them (t29 = 0.12, P = 0.902, d = 0.02, CI = [−0.06, 0.07]), suggesting that information about the occluded object’s orientation was not strongly confined to any specific region. This result shows that viewpoint changes in a scene can elicit expectations of object appearance in the visual cortex, even when the objects are fully invisible.
DISCUSSION
Vision in complex real-world environments often requires inferring the properties of temporarily invisible objects (32). The ability of the human visual cortex to predict incomplete visual scenes has been studied extensively (5, 6, 33), but it is still an open question how this ability can generalize to predictions based on complex regularities of the environment, such as its 3D geometry. Here, in two neuroimaging studies, we show that activity patterns in the visual cortex reflect predictions of the appearance of an occluded object across viewpoint changes in a 3D scene.
In Experiment 1, we found that the proximal shape of objects (a wide versus narrow projection on the 2D image plane) in a rotating scene was decoded better when the objects emerged from occlusion in an orientation that was congruent with the new scene viewpoint, compared to incongruent objects. This multivariate enhancement was accompanied by an overall reduced amount of (i.e., univariate) brain activation, consistent with an effect of expectation on visual representations (20, 21). In Experiment 2, we found that these predictions of object appearance from scene viewpoint could elicit visual representations in the absence of visual input. We found that the proximal shape of the rotated object (i.e., a wide versus narrow projection) could be decoded from visual cortex activity, even when the object remained fully occluded. These results show that temporarily invisible objects can evoke a visual representation, as informed by the surrounding (visible) scene context. To do so, the visual cortex capitalizes on the predictable way in which objects in the real world rotate coherently with the surrounding scene. Such seamless integration of visible and invisible information can be extremely useful in tracking objects across periods of invisibility, as is often required in daily life (32).
Across our two experiments, as well as in previous behavioral studies (15, 16), we found multiple converging lines of evidence suggesting that scene-driven predictions occur automatically: (i) They can affect behavioral performance in an orthogonal task [Experiment 1 and previous behavioral studies (15, 16)] and can be reliably decoded in the absence of any explicit task (Experiment 2). Thus, they do not seem to be driven by task requirements. (ii) In Experiment 1, we found that incongruent objects elicited a larger univariate response than congruent ones. If participants were actively maintaining an attentional template of the predicted object, we would expect objects matching this template to be boosted, evoking a higher response (23–26). (iii) In two previous behavioral studies (15, 16) with large participant samples (N = 152 and 151), we found that the effect of scene-driven expectations on task accuracy was entirely uncorrelated with participants’ responses in a questionnaire assessing their behavioral strategy. This provides further evidence that these expectations were not driven by an explicit, voluntary strategy. Relatedly, the effect of scene-driven expectations was more likely to be driven by real-world structural regularities rather than by short-term regularities extracted during the experiment. Although, in Experiment 1, congruent object orientations were shown on a majority of trials, thus conflating their real-world congruency with their short-term frequency, in previous behavioral studies (15, 16), we found that short-term frequency was not necessary for congruency effects on task performance. Even when the congruent object view was shown on a minority of trials, participants’ predictions still followed real-world (i.e., scene-congruent) expectations. Moreover, in Experiment 2, in which the congruent object orientation was only shown on a small minority of trials (remaining under occlusion on most trials), the predicted orientation could still be decoded above chance, providing further evidence for the automatic and long-term nature of these scene-driven expectations. Overall, the automaticity of these effects and their dependence on real-world regularities, rather than short-term contingencies, supports their potential relevance to real-world predictive vision.
In Experiment 1, the modulatory effect of scene-object congruency on orientation decoding was specific to the EVC, suggesting that expectations modulated relatively low-level visual representations. Possible features driving this effect include the differences in retinal size, stimulated area, or edge orientations between wide and narrow views of the objects. The present experiment was not designed to distinguish between the roles of various low-level features; however, this question remains open for future investigation. Conversely, in Experiment 2, orientation decoding of the occluded object was significant only in the LVC. This discrepancy across experiments may reflect that purely top-down generated object predictions are represented relatively more coarsely, providing a “scaffold” to modulate more fine-grained, stimulus-evoked responses in the EVC through feedback projections. This interpretation is in line with the results of the coupling analysis of Experiment 1, showing that univariate activity in the occipitotemporal cortex (in the proximity of motion-selective and object-selective regions) was more strongly coupled with congruent than incongruent orientation decoding in the EVC. This dissociation has been observed in previous studies as well: The EVC has been implicated in a wide variety of cognitive, but visually based, processes, including mental imagery (34), working memory (35), mental rotation (36, 37), tracking of occluded objects (38), and intuitive physics (39, 40). All these cognitive operations share a fundamentally spatial nature: They require maintaining or manipulating visual information at a specific location in (retinotopic) space. On the other hand, very similar processes that are less spatially specific seem to involve the LVC instead. For example, mental imagery only involves the EVC when the location and scale of the stimulus to be imagined is clearly specified, and it involves the LVC otherwise (34). Similarly, the scene-driven modulation of a visible object’s perceived size in the Ponzo illusion (41, 42) occurs in the EVC (43, 44), whereas the size of an object’s search template, a top-down signal without a specific position in the scene, is observed in the LVC (19). Consistently with these prior findings, in our study, the difference in tasks between Experiments 1 and 2 potentially also contributed to the discrepancy in the involved processing regions. The task of Experiment 1 involved a precise perceptual comparison of two subtly different stimuli, which likely requires the fine-grained spatial resolution of the EVC. Experiment 2, on the other hand, featured a much less visually precise task (detecting the reappearance of an object from occlusion), which may not require the fine-grained precision or retinotopic organization typical of the EVC.
The present work focuses on investigating the content of expectations based on scene context: a prediction of the object’s proximal shape. Future work should investigate the format of the representations that make these expectations possible. One possibility is that the scene is represented as a structural description in allocentric 3D coordinates (45–47) and then translated back to retinotopic coordinates, leading to the egocentric 2D shape predictions we observed in our study. This kind of explicit coordinate transformation has been proposed to underlie spatial navigation and mental imagery (48, 49). Alternatively, predictions might be represented exclusively in terms of egocentric views, with no involvement of explicit 3D descriptions. Human behavior in spatial navigation tasks, for example, is consistent with scene representations in terms of 2D views (50–52). Moreover, recent works have shown that objects’ proximal shape is represented explicitly in several tasks that involve the 3D structure, such as mental rotation (53, 54) or searching for objects at different depths in a scene (19, 55). Future studies could shed light on the representations underlying scene-driven predictions, for example, by investigating how these predictions are affected by 3D features (such as the angle of rotation) and 2D features (such as egocentric motion patterns), as done in a recent work on mental rotation (53).
Regardless of whether the representations that participants relied on in our study are based on egocentric views or the 3D structure, our results suggest that humans can represent scene-object relations in a sufficiently rich manner to support predictions across changes in viewpoint. This extends a long line of empirical and theoretical work investigating how the internal representation of objects reflects their properties in the external world (56–58). This includes the ability to mentally rotate objects (59) or to simulate their physical dynamics (60). It is possible that these internal representations also incorporate models of how objects interact with their context, including (but not limited to) how objects rotate concurrently with the surrounding scene. One way to efficiently process these kinds of spatial relations in complex scenes is to represent them in a hierarchical manner, linking scenes to the objects they contain and linking objects to their parts. These kinds of hierarchical representations are extensively used in computer graphics and game engines (61, 62), and artificial intelligence research has addressed the problem of how they can be extracted from unstructured visual input (63–68). Some evidence exists that humans process scenes hierarchically (69–71), suggesting that a similar representation might underlie the present results. Alternatively, the link between scenes and objects might be represented in a “flat,” nonhierarchical manner, similar to relations between objects (72) or social interactions between agents (73). To adjudicate between these two alternatives, future studies could test whether the effect of scene rotation on object representations are asymmetric—scenes can rotate objects, but not vice versa, arguing for hierarchical representations, or symmetric, arguing for flat representations.
In conclusion, the current findings show that the visual cortex generates visual predictions derived from the 3D structure of scenes. These findings suggest that previously reported mechanisms for perceptual predictions (e.g., of partially occluded 2D images) generalize to structured and dynamic real-world environments.
MATERIALS AND METHODS
Participants
Participants were recruited through the Radboud University participant pool (SONA systems) and received a monetary reimbursement for their participation. They provided informed consent before the experimental session. The study was conducted in accordance with the institutional guidelines of the local ethical committee (CMO region Arnhem-Nijmegen, The Netherlands, protocol CMO2014/288). For both studies, we aimed to collect a predetermined sample size of 34 to achieve 80% power for detecting a medium-sized (d > 0.5) within-subject effect using a two-tailed one-sample or paired t test. In Experiment 1, a total of 35 participants took part in the study (21 females, mean age = 24.1, SD = 4.4). In Experiment 2, a total of 34 participants took part, of which 4 were excluded due to not paying sufficient attention to the stimulus sequences, as measured through our simple task of counting object reappearances. Specifically, at the end of each main task run, participants were asked to report how many times the object had reappeared after the occlusion period. The Pearson’s correlation, across runs, between the true and reported number of object reappearances was used as a measure of each participant’s accuracy. Specifically, participants were excluded when their average correlation was more than two interquartile ranges away from the first quartile. The final sample size was then 30 participants (16 females, mean age = 25.2, SD = 8.5). These participants’ responses were positively correlated with the true values (mean r = 0.89, minimum = 0.39), with a majority (25/30) having correlations higher than 0.80, as shown in fig. S5.
Apparatus
Participants viewed the stimuli through a mirror mounted on the head coil of the scanner. In Experiment 1, stimuli were presented on a 32-inch BOLDscreen monitor (Cambridge Research) with a resolution of 1920 by 1080 px and 120-Hz refresh rate. The total viewing distance (eyes from mirror + mirror from screen) was 1206 mm. In Experiment 2, stimuli were presented on an EIKI LC-XL100 projector with a resolution of 1024 by 768 px and 60-Hz refresh rate, back-projected onto a projection screen (Macada DAP diffuse KBA) attached to the back of the scanner bore. The total viewing distance was 1440 mm. In both experiments, stimuli were presented using Psychtoolbox (74) in MATLAB R2017b. Participants provided responses on a HHSC-2x4-C button box.
Stimuli
In both experiments, the stimuli for the main task and classifier training runs were 20 different indoor scenes (fig. S1) modeled in Blender 2.80 and rendered using the Cycles rendering engine for realistic lighting. The scenes all had the same layout (floor, two walls at a right angle, and a main object in the center) but contained various additional objects, adjacent to the walls, and different textures on the walls and floors to increase their perceptual variability. The central object was a couch for half of the scenes and a bed for the other half. The retinal size of the central objects was approximately the same across scenes. For each scene, a range of viewpoints was rendered, by rotating the entire scene around the vertical axis (out of the image plane) between 0° and 90°, in steps of 5°. A subset of these viewpoints was presented on each trial: The trial always started with the 0° viewpoint and ended either with 30° or 90°. The three intermediate viewpoints were chosen in the following way: For 30° rotation trials, a fixed sequence (15°, 20°, and 25°) of intermediate viewpoints was shown. For 90° rotation trials, three intermediate viewpoints were randomly sampled (without replacement) from the set {15°, 20°, 25°, …, 55°, 60°}, and shown in increasing order. The object was occluded after the first intermediate viewpoint. In Experiment 1, this meant that the last visible object viewpoint could differ between 30° and 90° rotation trials. This did not substantially affect the results because consistent findings were obtained when using a subselection of trials in which the last visible object viewpoint was perfectly matched between rotation conditions (fig. S2). Moreover, in Experiment 2, the last visible object viewpoint was fixed at 10° for both rotation conditions, thus avoiding any potential influence of the last visible object orientation on the decoding of the expected object orientations.
In all scenes, the two walls were oriented such that the scene was fully visible from all the viewpoints. The scenes were presented at the center of the screen with a size of 20.53 by 11.64 degrees of visual angle (dva), surrounded by a gray background. The occluder was a gray rectangle (same color as the background), which had the height and width of the largest possible view of the object in that particular scene (average size: 5.50 dva by 2.86 dva) plus a margin (horizontal: 1.08 dva; vertical: 0.43 dva) to ensure the object was fully covered and its shadow was not visible, which would have provided a cue to its orientation. The fixation dot (radius: 0.1 dva, shown at the center of the central object, 3.24 dva below the center of the screen) was always visible on top of the images.
In Experiment 1, the stimuli for the classifier training runs were the final views of the objects shown in the Main Task runs, with the scene background (Fig. 3A). In Experiment 2, they were the same objects but without the scene background (Fig. 6A). The size of the stimuli was the same as in the Main Task runs.
General procedure
In Experiment 1, before the fMRI scanning session, participants performed a short practice session (40 trials, around 10-min duration) to familiarize themselves with the main task of the experiment. During this session, they received feedback on every trial, and they saw their overall accuracy at the end of the session as well. After the practice, they were also instructed about the other tasks they would have to perform in the scanner (one-back task in the Classifier training and Functional Localizer runs). During the 5-min anatomical scan, they practiced the main task again, also with trial-by-trial feedback. In total, participants were in the scanner for 12 functional runs (~75 min). Each functional run began and ended with 15 s of fixation.
In Experiment 2, given the less challenging task, there was no practice session. Before entering the scanner, participants were instructed about the main task they were going to perform and were shown example stimuli. They were also told that, on some runs, they would have to detect repeated images (one-back task in the Classifier training and Functional Localizer runs). During the 5-min anatomical scan, they practiced the main task, receiving feedback. Participants were in the scanner for a total of 13 functional runs (~70 min). One participant included in the final sample (and one excluded participant) only completed seven main task runs instead of eight.
Procedure: Main task runs
In Experiment 1, participants completed seven runs of the main task, each consisting of 48 trials (336 trials in total). Within each run, 36 trials (75%) featured the congruent object orientation at the end of the stimulus sequence and the remaining 12 (25%) the incongruent orientation. We chose to present congruent orientations on a majority of trials because our previous behavioral work (15) revealed that the behavioral accuracy difference between conditions was highest with this design (although the effect remained present even when the incongruent trials outnumbered the congruent trials). By choosing the design in which the effect was strongest, we maximized the power for uncovering the neural correlates of this behavioral effect. Both congruent and incongruent trials were equally divided among the four possible initial orientation/amount of rotation combinations (A30°, A90°, B30°, and B90°).
Crucially, the behavioral task that participants had to perform was fully orthogonal to the congruency manipulation: They did not have to explicitly judge whether the object remained in the same orientation relative to the beginning of the trial or to explicitly predict its upcoming view after the occlusion period. Participants were told that their task pertains exclusively to the final viewpoint but were nonetheless instructed to remain attentive during the whole stimulus sequence. Each trial (Fig. 2A) began with a fixation dot for 500 ms, followed by the initial view of the scene for 2000 ms. The scene then started rotating, in three intermediate views, each shown for 500 ms. The object was fully occluded starting from the second of these intermediate views. The final view of the scene, with the object still occluded, was displayed for a randomly jittered time between 1500 and 2000 ms. The object then reappeared and was briefly flashed twice (with the scene background always present) for 50 ms each, with a 100-ms interstimulus interval in between. We refer to these two brief presentations of the object as the probes. On a given trial, the second probe was rotated clockwise or counterclockwise, with equal probability, relative to the first, and the participants’ task was to indicate “clockwise” or “counterclockwise” using the index or middle finger of their right hand, respectively. Participants had a maximum of 1500 ms to respond, after which the experiment would skip to the next trial and the current trial would be counted as missed. The duration of the initial fixation period for the following trial was adjusted to compensate for the participants’ response time on the current trial to ensure that the overall duration of each run was constant. The first probe’s orientation was randomly sampled from a normal distribution centered around the congruent or incongruent orientation (depending on the current trial’s condition), with an SD of 1°, to add a small amount of jitter and then rounded to the nearest integer. The second probe was rotated, clockwise or counterclockwise, relative to the first by an angle that was titrated using a 2-down, 1-up staircase, to keep the task difficulty constant across participants. To ensure that the visual stimuli in congruent and incongruent trials did not differ, and thus avoid any stimulus-related confounds, a single staircase was used across both Congruency conditions, allowing for accuracy differences between conditions. Unlike in the practice session, participants did not receive feedback on every trial to avoid any possible effects on the fMRI response of differing feedback between congruent and incongruent conditions. Instead, their overall accuracy within a run was displayed at the end of the run.
In Experiment 2, participants completed eight runs of the main task (40 trials each) for a total of 320 trials. The stimulus sequence and durations were the same as in Experiment 1. The main difference was that, on a majority of trials, the central object was not shown again after the occlusion period. It was shown only on 40/320 trials (12.5%), randomly spread across the eight runs (between 2 and 10 per run). On these trials, the occluder disappeared, revealing the object in the final orientation (there was no congruency manipulation in this experiment) for 200 ms. To encourage participants to pay attention to the stimulus sequence, at the end of each run, they were asked to report on how many trials the object reappeared. An adjustable number (initially set to 0) was shown on screen, and participants could increase it using their middle finger or decrease it using their index finger. To confirm their estimate, they used their ring finger. They were then shown both their estimate and the correct number as feedback.
Procedure: Classifier training runs
The purpose of the classifier training runs was to estimate benchmark response patterns to the central objects used in our main task, without the context of the whole rotation sequence. In both experiments, participants completed three training runs.
In Experiment 1, the images displayed in the training runs were the final frames of the sequences shown in the main task. They were presented in mini-blocks corresponding to the four possible object orientation/scene rotation combinations (A30°, A90°, B30°, and B90°; see Fig. 3A). Each mini-block consisted of 18 images (different scene exemplars, all in the same orientation/rotation combination), with each image presented for 350 ms and followed by a 400-ms blank interval (each mini-block lasted 13.5 s in total). After a series of four mini-blocks (54 s), a longer blank interval was shown for 6.75 s. The participants’ task was to press any button whenever the exact same image was repeated twice in a row (one-back task). Each run included 20 mini-blocks (divided into five blocks).
In Experiment 2, the objects in the training runs were shown without any scene background (Fig. 6A). Aside from the absence of a background, the position and size of the stimuli were the same as in the main task runs. Different object exemplars were grouped in mini-blocks by their proximal shape, such that a given mini-block contained exclusively wide or exclusively narrow objects, including different initial orientation and rotation combinations (wide mini-blocks included A30° and B90°, and narrow mini-blocks included B30° and A90°). Each mini-block consisted of nine images (6.75 s in total), each image being shown for 350 ms and followed by a 400-ms blank interval. After a series of eight mini-blocks (54 s), a longer blank interval was shown for 6.75 s. Participants performed the same one-back task as in Experiment 1.
Procedure: Functional localizer runs
In both experiments, participants completed two runs of a functional localizer scan used for ROI voxel selection. The stimuli used in the functional localizer runs in both experiments were the same as those in a well-established functional localization study (75). They included images from four stimulus categories (objects, scrambled objects, faces, and scenes) shown in separate mini-blocks, each lasting 15 s and comprising 20 unique images. Each image was shown for 450 ms and followed by a 300-ms blank. Each localizer run included 16 mini-blocks (divided into four blocks, each containing all four stimulus categories in varying order). Participants performed the same one-back task as in the classifier training runs. Stimuli were shown with a size of 12 dva by 12 dva, against a uniform gray background.
Acquisition and preprocessing of fMRI data
In Experiment 1, fMRI data were collected on a 3T MAGNETOM Skyra MR scanner (Siemens AG, Healthcare Sector, Erlangen, Germany) using a 32-channel head coil. Functional data were acquired using a T2*-weighted gradient echo planar imaging (EPI) sequence, with a 6× multiband acceleration factor [repetition time (TR) 1 s, echo time (TE) 35.2 ms, flip angle 60°, 2-mm isotropic voxels, 66 slices]. For the main task runs, 404 images were acquired per run, and 333 and 318 images were acquired for the classifier training and functional localizer runs, respectively.
In Experiment 2, fMRI data were collected on a 3T MAGNETOM PrismaFit MR scanner (Siemens AG, Healthcare Sector, Erlangen, Germany) using a 32-channel head coil. Functional data were acquired using a T2*-weighted gradient echo EPI sequence, with a 6× multiband acceleration factor (TR 1 s, TE 34 ms, flip angle 60°, 2-mm isotropic voxels, 66 slices). For the main task runs, 315 images per run were acquired, and 333 and 318 images were acquired for the classifier training and functional localizer runs, respectively.
In both experiments, at the start of the scanning session, a high-resolution T1-weighted anatomical scan was acquired using a Magnetization Prepared Rapid Gradient Echo (MPRAGE) sequence [TR 2.3 s, TE 3.03 ms, flip angle 8°, 1-mm isotropic voxels, 192 sagittal slices, field of view (FOV) 256 mm]. The data were preprocessed using SPM12 (76) functions through the Nipype 1.11.0 (77) interface in Python. The functional volumes were field map–corrected, spatially realigned, coregistered with the anatomical image, normalized to MNI 152 space using the template provided in SPM, and smoothed with a FWHM (full width at half maximum) Gaussian filter of 3 mm.
General linear model estimation
The responses evoked by each of the stimulus types relevant to our analyses were modeled using general linear models (GLMs) in SPM12 (76), through the Nipype 1.11.0 (77) interface. In both experiments and in all GLM analyses, time series were convolved with the canonical hemodynamic response function (HRF) provided in SPM12.
In Experiment 1, in the main task, the onsets of the final object views were modeled as impulse functions as they were very rapid visual events. We included regressors for each combination of object orientation and final scene rotation (A30°, A90°, B30°, and B90°), separately for the congruent and incongruent trials. Because the congruent condition included three times as many trials as the incongruent condition, estimating beta weights using all trials would have led to a higher signal-to-noise ratio and consequently a spuriously higher decoding accuracy. To correct this imbalance, we randomly split the 36 congruent trials within each run into three subsets of 12 trials each (thereby matching the number of incongruent trials). The random splits were determined using a specified seed (different for each subject and run) for reproducibility. Each of the splits was modeled as a separate condition in the GLM, and all subsequent analyses were performed separately on each split and then averaged. In the classifier training runs, individual mini-blocks were modeled as boxcars. As in the main task runs, we included regressors for each object orientation/scene rotation combination, yielding one beta weight map per condition, per mini-block, per run. For the univariate analysis, we modeled the onsets of the final object views as impulse functions. We only included regressors for the two congruency conditions, congruent and incongruent, obtaining two beta weight maps per run.
In Experiment 2, in both the main task and classifier training runs, we only included regressors for the two proximal object shapes (wide and narrow), rather than the four separate orientation/rotation combinations. The reason for this was that the objects in the training runs were presented without any background, removing the need to match images by background in the GLM and MVPA analyses (Fig. 6A, also see the section “Multivariate pattern analysis”). In the training run mini-blocks, objects were also grouped by their proximal shape regardless of the specific orientation-rotation combination. In the main task runs, the entire period from the onset of the final scene view to its offset was modeled as a boxcar as we assumed a prediction of the object in its updated orientation would be present throughout this period. Trials in which the object reappeared after the occlusion period were excluded from the analysis. We estimated one beta weight map per run per condition (wide and narrow). In the classifier training runs, each mini-block was modeled as a boxcar. We estimated one beta weight map per mini-block, per run, per condition.
In the functional localizer runs of both experiments, mini-blocks belonging to the four stimulus categories (objects, scrambled objects, faces, and scenes) were modeled as boxcars, yielding one beta weight map per condition per run.
All GLMs included six motion parameters and one run-based regressor as nuisance regressors. As participants were performing a one-back task in the classifier training and localizer runs, these runs included an additional nuisance regressor synchronized to participants’ button presses (modeled as impulse functions).
ROI definition
To select voxels for inclusion in our visual cortex ROIs (in both experiments), we used subject-level t-contrast maps estimated using data from the functional localizers, contrasting stimuli (both objects and scrambled objects) against the fixation baseline. These maps were intersected with an anatomical mask corresponding to Brodmann areas 17 and 18 [corresponding to areas V1 and V2 (78)] for the EVC and Brodmann areas 19 and 37 for the LVC (79). BA19 includes the lateral occipital gyrus and the superior occipital gyrus, whereas BA37 corresponds to the occipitotemporal cortex and includes the posterior fusiform gyrus and the posterior inferior temporal gyrus. The LVC ROI includes high-level visual regions such as the object-selective LO (lateral occipital) and pFs (posterior fusiform gyrus), as well as the motion-selective hMT+. Each participant’s map, in each hemisphere, was then thresholded to only include the top N most responsive voxels in the stimulus versus baseline contrast, as measured by the t-statistic. The number of selected voxels (N) ranged from 100 to 6000 in steps of 100, creating 60 sub-ROIs per each ROI and hemisphere, with an increasingly liberal voxel inclusion criterion.
Multivariate pattern analysis
Our cross-decoding analysis consisted of training linear classifiers on benchmark responses (beta weights) to objects devoid of any context (sequence), obtained from the classifier training runs, and testing them on responses to objects appearing at the end of the rotation sequence in Experiment 1 (Fig. 3A) and on responses to scenes with fully occluded objects in Experiment 2 (Fig. 6A).
In Experiment 1, to decode the stimulus feature of interest—proximal object shape (wide versus narrow), we separately trained classifiers to discriminate between the A and B object orientations embedded in scenes rotated by 30° or 90° (Fig. 3A), which corresponds to discriminating conditions A30° and B30° and A90° and B90°, in such a way as to classify the object’s shape against a matched background. The accuracies of classifiers trained on the two backgrounds were then averaged. The three splits of congruent trials (see the section “General linear model estimation”) were also decoded separately, and accuracy was then averaged across them. The labels of the beta weights corresponding to incongruent trials in the main task runs corresponded to the object orientation that was actually presented on the screen, not the one expected given the context, as our goal was to assess how the same visual stimuli are processed differently depending on the context.
In Experiment 2, as objects were displayed without any background in the classifier training runs, we did not need to implement the background-matched decoding. In addition, different views that resulted in the same proximal shape were grouped together in the same mini-blocks of the classifier training runs (e.g., A30° and B90° were grouped together as wide). Classifiers were trained to discriminate between wide and narrow objects, and tested on responses to the final views of the scene in the main task runs, where the object was occluded. As the object only reappeared on a small minority of trials, which were excluded from further analyses, these response patterns solely reflected participants’ expectations about the proximal shape of the occluded object.
Besides training on the classifier training runs and testing on main task runs, decoding was also done in the opposite direction (training on main task runs and testing on classifier training runs) and decoding performance was averaged across directions. This was done because factors unrelated to the task or stimulus, such as different signal-to-noise ratios, can lead to asymmetries between cross-decoding directions (80). Although our results were consistent in the two decoding directions, they showed different noise levels (fig. S7). For all analyses reported in the main text, we thus averaged across directions to obtain a more robust estimate of the stimulus-related information present in multivariate activation patterns. The training and testing datasets were z-scored before decoding.
MVPA was conducted using linear support vector machines (SVMs) implemented in Scikit-learn (81). As a measure of decoding performance, and thus information content in a given brain region, we used the continuous distance from the SVM’s hyperplane (i.e., distance to boundary) rather than discrete classification accuracy. Continuous measures of the distance between brain activation patterns have been found to be more reliable than discrete ones, likely due to the lossy compression inherent in binary classification outcomes (82). Specifically, we used the following continuous measure of decoding performance (which we call classifier information)
where d_i_’s are the z-scored (across test samples) distances from the hyperplane, l_i_’s are the true labels (either −1 or 1) for each sample, and n is the number of samples in the test set. Intuitively, this measure corresponds to the average match between each distance from bound and the corresponding ground-truth label, i.e., the degree to which the distance is positive when the target is positive, and negative when the target is negative. This measure is greater than zero when classification is above chance. The purpose of z-scoring the distances is to remove potential differences between SVMs trained and tested on different data, such as different hemispheres or decoding directions. If the signal-to-noise ratio is higher when training on main task runs, for example, distances under this condition will be higher overall, leading to a disproportionate contribution of this condition when averaging across conditions. Similarly, averaging distances across test samples, rather than summing them, allows us to directly compare classification performance under different conditions, which might have different numbers of samples, and average across them. Specifically, it is necessary for averaging across decoding directions. Classifier information was computed for each sub-ROI within the EVC and LVC, in each hemisphere, and each subject. It is important to note that this measure is closely linked to classification accuracy, and all our results were consistent, albeit noisier, when using classification accuracy instead of classifier information (fig. S4).
Significance testing
To statistically test differences under classifier information between conditions (Experiment 1) and absolute amounts of classifier information (Experiment 2), we used two approaches. (i) To avoid making assumptions regarding the appropriate numbers of voxels to include in the analysis for each ROI, we averaged classifier information across numbers of included voxels (sub-ROIs) for each subject and ROI. In Experiment 1, this summary measure was compared between the congruent and incongruent conditions with a two-sided paired-samples t test. In Experiment 2, it was compared against zero with a two-sided one-sample t test. These statistical tests, as well as the test on behavioral accuracy differences in Experiment 1, were run using Pingouin (83). (ii) To assess the robustness of (differences in) classifier information across numbers of selected voxels, we used threshold-free cluster enhancement (TFCE) (84). TFCE boosts the magnitude of a statistic based on its extent across neighboring samples (in this case, sub-ROIs with similar numbers of voxels), reflecting the assumption that any signal in the data should be smooth across consecutive datapoints. This measure is then compared with a null distribution generated by randomly shifting the signs of each participant’s 1D map (classifier information across sub-ROIs). This null distribution has the same variance and autocorrelation as the original signal. The shuffling procedure was performed 10,000 times. A z-score then expresses how likely each observed TFCE values is, given the TFCE values in the 10,000 permuted (null) datasets, thus implicitly correcting for multiple comparisons. TFCE was computed using the MNE toolbox (85).
Univariate analysis
In Experiment 1, we used a univariate analysis to estimate differences in the overall response elicited by congruent and incongruent trials. This was done within the main visual ROIs, as well as across the whole brain. For the within-ROI analysis in the visual cortex, we used the same sub-ROIs as in the multivariate analysis, to directly compare the amount of information with the level of activation in the same voxels. We averaged the beta weights across voxels within each sub-ROI (number of selected voxels), separately in the EVC and LVC, resulting in one mean beta per condition (congruent and incongruent) and participant for each sub-ROI. The averages across sub-ROIs under the congruent and incongruent conditions were then compared using a two-sided paired t test. For the whole-brain analysis, we ran a second-level contrast (one sample two-sided t test against zero across participants) with α = 0.001 (False-Positive Rate corrected) and a cluster threshold of 10 voxels, using the threshold_stats_img function in Nilearn (86).
Information-activation coupling analysis
The goal of the information-activation coupling analysis was to reveal regions of the brain in which univariate activation was more strongly correlated with the presence of multivariate information in the EVC in congruent than incongruent trials. To compute the average time courses of each voxel in the brain for each condition of interest, we used GLMs with a finite impulse response (FIR) basis function (87). We thus obtained, for each condition and run, the BOLD response for 10 time bins (one second each) after stimulus onset (final object appearance). To extract multivariate decoding time series, the BOLD activation patterns of the EVC in each time bin were fed to an SVM classifier trained to distinguish wide versus narrow mini-blocks in the training runs. The decoding procedure was the same as in the main multivariate analysis of Experiment 1. This yielded a classifier information score for each time bin for the congruent and incongruent conditions. We computed the Pearson’s correlation of these multivariate decoding time series with the time-resolved activation (averaged across runs) in each voxel of the brain for congruent and incongruent conditions. This resulted in two whole-brain maps of correlations for each subject for the congruent and incongruent conditions. To assess robustness to voxel inclusion (for the multivariate decoding in the EVC), the whole analysis was repeated for different numbers of included voxels (based on activation in the stimulus versus baseline contrast, across both hemispheres): 500, 600, 700, 800, 900, and 1000 voxels. The resulting whole-brain maps were averaged. The maps for the congruent and incongruent conditions were then compared using a paired-samples t test to find voxels that were significantly more correlated with multivariate classification under the congruent than the incongruent condition. As we were exclusively interested in clusters that showed more coupling for congruent than incongruent trials, we ran a one-sided test. Apart from this, we used the same Nilearn function and parameters as in the univariate analysis of Experiment 1 (see the section “Univariate analysis”).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1H. Von Helmholtz, Handbuch Der Physiologischen Optik (Voss, 1867).
- 2D. C. Knill, W. Richards, Perception as Bayesian Inference (Cambridge Univ. Press, 1996).
- 3F. P. De Lange, M. Heilbron, P. Kok, How do expectations shape perception? Trends Cogn. Sci. 22, 764–779 (2018).30122170 10.1016/j.tics.2018.06.002 · doi ↗ · pubmed ↗
- 4D. Kersten, P. Mamassian, A. Yuille, Object perception as Bayesian inference. Annu. Rev. Psychol. 55, 271–304 (2004).14744217 10.1146/annurev.psych.55.090902.142005 · doi ↗ · pubmed ↗
- 5F. W. Smith, L. Muckli, Nonstimulated early visual areas carry information about surrounding context. Proc. Natl. Acad. Sci. U.S.A. 107, 20099–20103 (2010).21041652 10.1073/pnas.1000233107 PMC 2993348 · doi ↗ · pubmed ↗
- 6A. T. Morgan, L. S. Petro, L. Muckli, Scene representations conveyed by cortical feedback to early visual cortex can be described by line drawings. J. Neurosci. 39, 9410–9423 (2019).31611306 10.1523/JNEUROSCI.0852-19.2019 PMC 6867807 · doi ↗ · pubmed ↗
- 7J. Ortiz-Tudela, J. Bergmann, M. Bennett, I. Ehrlich, L. Muckli, Y. L. Shing, Concurrent contextual and time-distant mnemonic information co-exist as feedback in the human visual cortex. Neuroimage 265, 119778 (2023).36462731 10.1016/j.neuroimage.2022.119778 PMC 9878579 · doi ↗ · pubmed ↗
- 8P. Papale, F. Wang, A. T. Morgan, X. Chen, A. Gilhuis, L. S. Petro, L. Muckli, P. R. Roelfsema, M. W. Self, The representation of occluded image regions in area V 1 of monkeys and humans. Curr. Biol. 33, 3865–3871.e 3 (2023).37643620 10.1016/j.cub.2023.08.010 · doi ↗ · pubmed ↗