Machine learning-enabled systematic review on coded healthcare data in heart failure research
Asgher Champsi, Karin T Slater, Simrat Gill, Tomasz Dyszynski, Megan Schröder, Kiliana Suzart-Woischnik, Benoit Tyl, Guillaume Allée, Alfonso Sartorius, R Thomas Lumbers, Folkert W Asselbergs, Diederick E Grobbee, Georgios Gkoutos, Dipak Kotecha

TL;DR
This study uses machine learning to analyze how often heart failure research uses coded healthcare data and finds that reporting is often not transparent enough.
Contribution
A machine learning model was developed to automate the identification of heart failure studies using coded healthcare data.
Findings
21.2% of heart failure studies used coded healthcare data, but only 47.5% described dataset construction clearly.
The NLP model achieved high accuracy (AUC 0.97, F1 0.96) in identifying studies using coded data.
No correlation was found between coded data reporting and publication year or citation count.
Abstract
Coded healthcare data are now commonly used in clinical research. This study aimed to assess the transparency of reporting within heart failure studies and employ machine learning to facilitate larger-scale evaluation. A systematic search of EMBASE and MEDLINE (2015–2020) identified 4279 heart failure studies with accessible Extensible Markup Language published in the top 25 journals by impact factor. Manual extraction in a random sample of 170 studies by independent human reviewers characterized 40 studies (23.5%) that used coded healthcare data, with 34 of these (85%) reporting doing so and only 19 (47.5%) providing clear descriptions of dataset construction and linkage. Another 420 studies underwent manual annotation to further train a Natural Language Processing (NLP) model designed for this study to automate and upscale review. The NLP model processed 3689 studies with a high…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
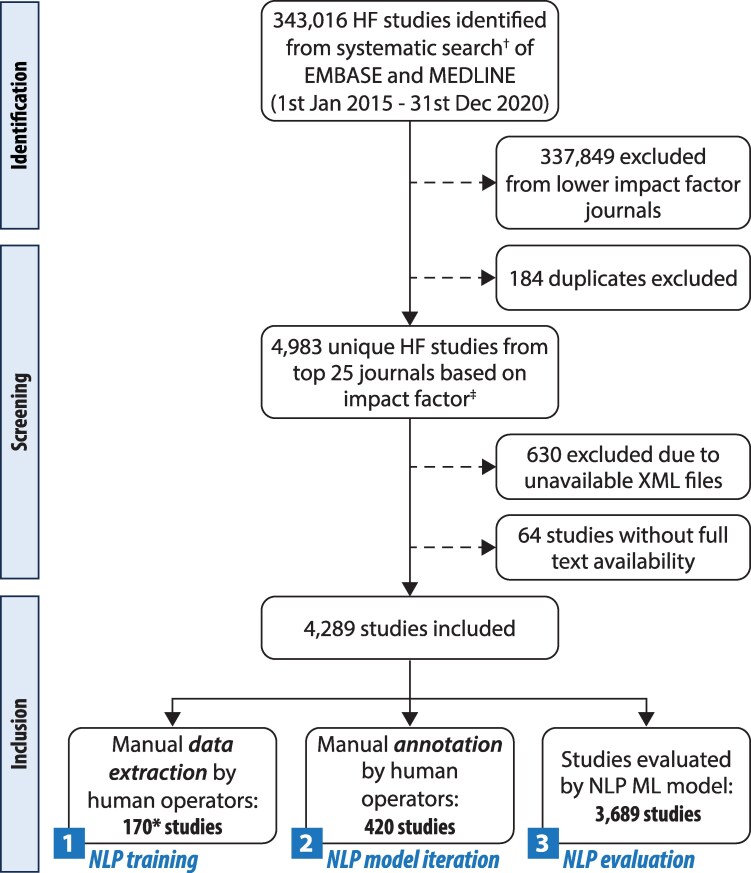 Figure 1
Figure 1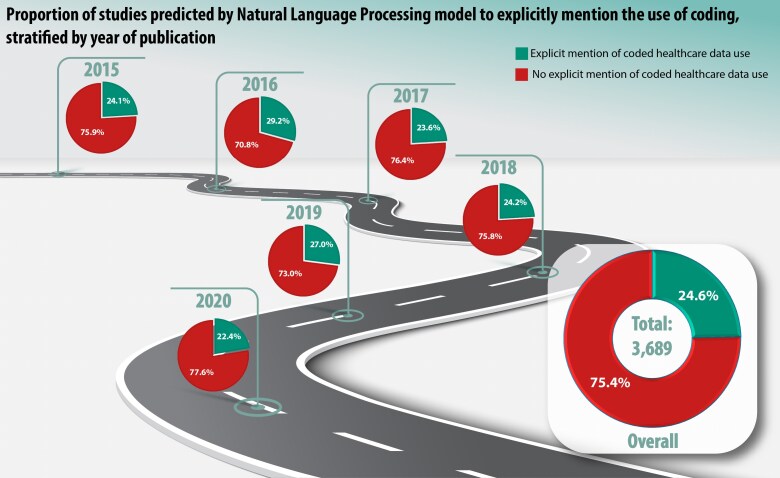 Figure 2
Figure 2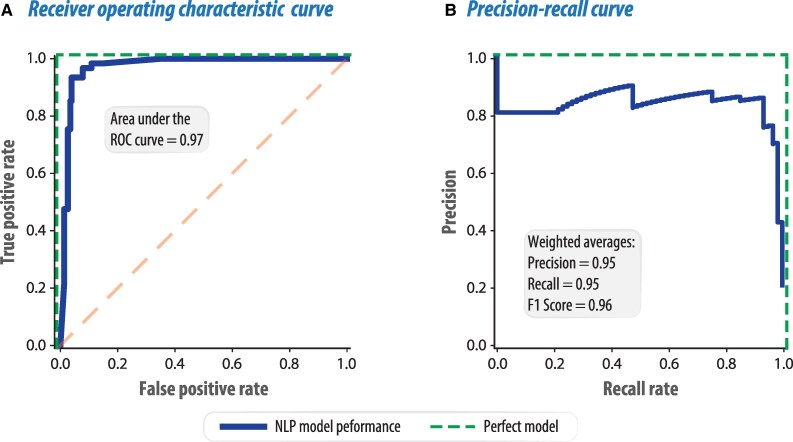 Figure 3
Figure 3| Characteristics of studies (total | Number of studies (%) |
|---|---|
|
| |
| Observational | 118 (69.4%) |
| Randomized controlled trial | 33 (19.4%) |
| Genetic association study | 4 (2.4%) |
| Validation study of disease definition | 2 (1.2%) |
| Other | 13 (7.6%) |
|
| |
| Multiple Regions | 25 (14.7%) |
| Asia-Pacific/Middle East/Africa | 26 (15.3%) |
| Europe | 74 (43.5%) |
| North America | 36 (21.2%) |
| Not specified | 9 (5.3%) |
|
| |
| Administrative/claims | 18 (10.6%) |
| Electronic healthcare records | 13 (7.6%) |
| Registry | 40 (23.5%) |
| Clinical study | 89 (52.4%) |
| Health surveys | 1 (0.6%) |
| Other | 9 (5.3%) |
|
| |
| Reduced ejection fraction | 31 (18.2%) |
| Mid-range ejection fraction | 1 (0.6%) |
| Preserved ejection fraction | 7 (4.1%) |
| All/any/not specified | 131 (77.1%) |
| Studies using coded healthcare data (total | Number of studies (%) |
|---|---|
|
| |
| Primary care/community | 13 (32.5%) |
| Secondary care/hospital | 15 (37.5%) |
| Both primary and secondary care | 12 (30.0%) |
|
| |
| <100 | 1 (2.5%) |
| 100–1000 | 6 (15.0%) |
| >1000–10 000 | 15 (37.5%) |
| >10 000 | 18 (45.0%) |
|
| |
| Explicit mention of coded healthcare data use | 34 (85.0%) |
| Clear description of dataset construction and data sources linkage | 19 (47.5%) |
| Pre-specification and/or publication of relevant code lists | 18 (45.0%) |
|
| |
| Define diseases or comorbidities | 11 (27.5%) |
| Define outcomes | 11 (27.5%) |
| Define both diseases/comorbidities or outcomes | 16 (40.0%) |
| Unspecified | 2 (5.0%) |
|
| |
| ICD-9 | 18 (45.0%) |
| ICD-10 | 18 (45.0%) |
| ICD (version 8 or below, or ICD unspecified) | 2 (5.0%) |
| Other (Read codes, SNOMED CT, region specific codes) | 2 (5.0%) |
| Unspecified | 9 (22.5%) |
|
| |
| Use of coding to define heart failure | 30 (75.0%) |
| Validation of coded heart failure definition | 11 (36.7%) |
| Inclusion of LVEF or NTProBNP in heart failure definition | 4 (10.0%) |
| Pre-adjudication | Post-adjudication by a third human | |||
|---|---|---|---|---|
| Group | Inter-reviewer | NLP-to-human agreement | Reviewer-adjudicator | NLP-to-human agreement |
| 1 | 0.83 | 0.78 | 0.92 | 0.85 |
| 2 | 0.50 | 0.72 | 0.75 | 0.95 |
| 3 | 0.93 | 0.83 | 0.97 | 0.87 |
| 4 | 0.89 | 0.84 | 0.95 | 0.84 |
| 5 | 0.87 | 0.78 | 0.94 | 0.84 |
| 6 | 0.72 | 0.74 | 0.86 | 0.87 |
| Average | 0.79 | 0.78 | 0.90 | 0.87 |
- —BigData@Heart
- —Innovative Medicines Initiative 2 Joint Undertaking
- —European Union’s Horizon 2020 research and innovation programme
- —European Federation of Pharmaceutical Industries and Associations10.13039/100013322
- —Bayer10.13039/100015340
- —Copyright Clearance Center
- —Wiley Publishers
- —National Institute for Health and Care Research10.13039/501100000272
- —NIHR Birmingham Biomedical Research Centre10.13039/501100018952
- —MRC Health Data Research UK10.13039/501100023699
- —NHS Data for R&D Subnational Secure Data Environment programme
- —British Heart Foundation10.13039/501100000274
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare
Background
The use of large-scale data from routine clinical care has the potential to expand our understanding of disease and develop more effective prevention and treatment strategies. Health data science has undergone rapid development in recent years and electronic healthcare record (EHR) systems are now in widespread use, enabling clinical episodes to be summarized using standardized, coded data elements. Although historically this practice primarily supported administrative and billing purposes, contemporary literature underscores its increasing utility for clinical research.^1^ Structured labels facilitate large-scale population studies and real-world evidence generation, although limitations must be recognized such as incomplete data, coding inaccuracies, and variability across institutions and regions. In addition, there is a clear lack of transparency about how EHR data are used and how medical conditions and outcomes are defined in clinical research, undermining the value of scientific findings and limiting external validation. Addressing these issues was the rationale for the global CODE-EHR multi-stakeholder framework on research using health data.^2^
Using heart failure as an exemplar, the purpose of this study was to evaluate transparency in the reporting of coded healthcare data. We conducted a systematic search and manually curated a sample of studies to evaluate reporting practices. The extracted findings were then used to train a machine learning algorithm using Natural Language Processing (NLP). We hypothesized that reporting of the use of healthcare data in research studies was suboptimal, and NLP would enable automated and scalable analysis across a volume of journal articles too large for manual review to address the transparency of reporting.
Methods
This programme of work was initiated under the European Union (EU) Innovative Medicines Initiative BigData@Heart, involving collaboration between academic and industry partners. This systematic review has been reported in accordance with PRISMA recommendations, and the protocol was prospectively published on the EU Open Research Repository.^3^ As many of the included studies used EHR data, the CODE-EHR framework^2^ was applied, with this study meeting all five of the minimum standards, and two out of five domains meeting preferred criteria; see Supplementary material online, Table S1.
Search strategy and eligibility criteria
EMBASE and MEDLINE databases were systematically searched, spanning the period from 1st January 2015 to 31st December 2020. A broad search description for heart failure was used to identify relevant studies published in the top 25 journals based on impact factor rating from the Clarivate Analytics 2019 categories of ‘Cardiac & Cardiovascular Systems’ or ‘Medicine, General & Internal’; see Supplementary material online, Table S2 for search criteria and Supplementary material online, Table S3 for the full list of journals. Studies were included if full text was available and Extensible Markup Language (XML) data could be extracted for the purposes of NLP. Reviews, case reports, basic science research, animal studies, and non-English articles were excluded.
Data extraction
Manual data extraction was performed on 180 studies that were randomly selected using a computer-generated random number sequence. Each study was independently assessed by two reviewers using a standardized data extraction form, with ten studies excluded as they did not involve human participants. Both the main publication and the supplementary materials were reviewed. Extracted parameters included whether the study explicitly mentioned the use of coded healthcare data, details of dataset construction and linkage, pre-specification of coding schemes, and the coding system(s) utilized. Discrepancies were resolved through consensus discussion or adjudication by a third reviewer. The manually extracted dataset characterized the quality and completeness of reporting practices, and was used to develop the NLP model. Following this, a separate set of 420 studies were randomly selected for manual annotation by two human reviewers to determine whether each study explicitly mentioned the use of coded healthcare data or not, with the aim of improving the accuracy of the NLP model. Discrepancies in annotation were resolved through independent adjudication by a third reviewer.
Model synthesis
For the NLP approach, a text classification pipeline^4–6^ was developed to classify documents as to whether they explicitly reported use of healthcare coding in their methodology. The dataset was further split into a training set and a test set (see Supplementary material online, Table S4). The training set was used to develop a rule-based sentence-matching system, composed of 24 regular expression patterns, to identify mentions of healthcare coding. These were added to a set of explicit patterns that matched particular codes for heart failure, such as the International Classification of Diseases (ICD-10) code ‘I50.0’, which were queried from the Health Data Research (HDR) UK Phenotype Library. The entire training set was then evaluated for matches to any of these 323 codes. These codes were used as the basis for feature vectors, which were used to train the model. The manually annotated set of 420 studies were used to enhance the model. The Stanford CoreNLP^7^ was employed to identify mentions of healthcare coding using this system.
To complete evaluation of whether articles explicitly mentioned healthcare coding, a machine learning classification approach was used. The purpose of this was to further resolve ambiguity for documents that matched one of the rules, by creating a classifier to learn which matched rules, or relations between matched rules, indicated actual mentions of healthcare coding, rather than incidental or erroneous mentions. For each document, a vector was created consisting of the Term Frequency—Inverse Document Frequency (TF-IDF) value (to assess the relative importance of a term in each document in the collection of studies) for each of the matched instances of vocabulary patterns across the training set. A stochastic gradient descent classifier was then employed to reinforce the training set; this was trained using the manually marked documents in the training set, a 5-cross-fold grid search for optimization of hyperparameters, and with Synthetic Minority Oversampling Technique (SMOTE) data augmentation.
Outcomes
The primary outcome was the proportion of heart failure studies that utilized coded healthcare data to define disease or ascertain outcomes. The secondary outcomes included assessment of study characteristics, dataset construction, data linkage and coding schemes, the lists used to define HF, and how clearly and unambiguously the studies reported their use of coded healthcare data. Process outcomes included performance evaluation of the NLP model vs. manual human extraction, including disagreement between the human operators used to evaluate inter-annotator agreement. It was not feasible or necessary to assess the risk of bias for each individual study as this review was focused on study methodology rather than results.
Statistical analysis
Descriptive statistics were generated to summarize and compare relevant HF study characteristics. Logistic regression was employed to develop a multivariable model predicting the explicit mention of HF coding. A two-tailed P-value <0.05 was used to denote statistical significance. Predictors in the model included journal, citation count, and publication year, all retrieved from the CrossRef database on 9 January 2023. Model discrimination was assessed using the concordance statistic (C-statistic), and calibration was evaluated using a calibration plot. Point biserial correlation was used to examine the relationship between the numeric publication year and the outcome. Publication year was also included in the model as a categorical factor to allow for the possibility of capturing non-linear relationships. The analysis was conducted using R and the following packages: Caret, forestplot, pROC, broom, readr, and dplyr. Python, with the habanero library, was utilized to access CrossRef records.
Results
A total of 4289 unique studies matched the search criteria, were published in the top 25 journals by impact factor, and had full text and XML availability (Figure 1).
*Study flow diagram. Flow chart of the search results and study inclusions. † The search description for heart failure that was used to identify relevant studies can be found in Supplementary material online, Table S2. ‡ Impact factor rating was in accordance with Clarivate Analytics 2019 categories ‘Cardiac & Cardiovascular Systems’ and ‘Medicine, General & Internal’. 10 articles excluded as not based on human participants. HF = Heart failure; ML = Machine learning; NLP = Natural language processing; XML = Extensible Markup Language.
Transparency and quality of reporting
From the 170 random studies that underwent manual data extraction and evaluation by human operators, 118 (69.4%) were observational studies and 33 (19.4%) were randomized controlled trials. The remaining 19 studies (11.2%) included genetic association, validation, and methodology-focused research. There was broad geographical distribution, with the commonest region being Europe (74 studies, 43.5%), and clinical research or registries the most common source of healthcare data; Table 1. Evaluation of the article text by human reviewers identified 40 studies (23.5%) that had used coded healthcare data. These studies were a mix of primary and secondary care, were mostly large (32 studies with >1000 participants, 80.0%) and typically used versions of the ICD coding system; Table 2. 21/40 studies (52.5%) did not provide clear details on dataset construction or linkage, and 22/40 studies (55.0%) did not have pre-specified or pre-published coding lists. 6/40 studies (15.0%) did not explicitly mention that the research had used coded data in some element of the study, despite evidence of this in the main or Supplementary material. Including the additional manually annotated studies, a total of 119/590 research articles (20.2%) were found to explicitly mention the use of coded healthcare data (see Supplementary material online, Table S4).
Scalable machine-learning assessment
Following training and optimization of the model, 3689 unique studies were evaluated by the NLP algorithm, which classified 909 studies (24.6%) as reporting the use of coded healthcare data. Using the precision metric to adjust for the model's precision and based on the manual ‘ground truth’ data, the point estimate of the number of studies predicted by the NLP model for explicitly mentioning the use of coded healthcare data in the wider dataset was 782 (95% CI 761–802), or 21.2% of studies (95% CI 20.6–21.7%). There was no correlation between publication year and the predicted reporting of coded healthcare data usage (correlation coefficient −0.05; P = 0.21), with the proportion of studies explicitly reporting coded data remaining stable between 2015 and 2020; Figure 2. There was no correlation between citation count and the predicted reporting of coded data use (correlation coefficient −0.13; P = 0.12).
Use of healthcare data coding by year. Pie charts showing the proportions of studies explicitly mentioning the use of coding stratified by year of publication as per the natural language processing model prediction.
Performance of the NLP model
The area under the receiver operating characteristic curve on the test set for the NLP model was 0.97; Figure 3. The weighted average precision was 0.95 and recall 0.95, with the F1 score indicating accuracy of 0.96 (see Supplementary material online, Table S5). The inter-assessor agreement (Cohen's kappa coefficient) was 0.79. The average human-to-machine agreement was 0.78. Introducing a third human adjudicator improved the reliability overall, with an average assessor-to-adjudicator agreement of 0.90 and the human-to-machine agreement rising to 0.87 (Table 3).
Performance of natural language processing model. Receiver operating characteristic curve (A) and precision-recall curve (B) for the natural language processing model. ROC = Receiver operating characteristic; NLP = Natural language processing; F1 score = harmonic mean of the precision and recall (max = 1).
Discussion
This study evaluated the transparency of reporting practices related coded healthcare data use in heart failure research, and explored whether NLP could be used to support scalable assessment and tracking of changes in such practices over time. We demonstrate that the reporting of coded healthcare data use is often incomplete or unclear, with fewer than half of the studies describing how datasets were constructed, linked or which coding schemes were used. The NLP machine learning approach confirmed that around one-fifth of contemporary research studies on the topic of heart failure are already using coded healthcare data. This is likely to be an underestimate, as the manual human data extraction identified a number of studies that failed to explicitly mention their use of structured health data sources to define diseases or outcomes. Regardless of the true proportion, our findings highlight the need for more transparency and improvements in research methods, so that clinicians, policymakers and the public can better understand and integrate results, and improve implementation of evidence-based care.
Modern-day EHR systems are gradually becoming the norm, both across developed and developing countries.^8,9^ They have the potential to unlock new insights for observational research and clinical trials,^10,11^ including better representation of the true population at-risk. However, there are considerable challenges in data quality, timeliness and linkage that remain fragmented within and across different healthcare systems.^12^ The CODE-EHR framework was specifically developed as a set of principles and guidelines to enhance the use of structured, routine healthcare data in clinical research.^2^ CODE-EHR was developed by a broad range of stakeholders (regulators, academics, clinicians, patients, payers, journals and industry) and aims for all research using EHR systems to be high quality, transparent and reproducible. The framework uses a set of minimum and preferred standards to systematically embed appropriate dataset construction, data quality, disease and outcome definitions, analysis and governance into the design and execution of such studies.
The human-derived extraction in this study underscores the importance of these data standards. A number of studies failed to mention they had used coded healthcare data, instead inferring this or relegating detail to supplementary documentation. Even in those studies that explicitly acknowledged their use of healthcare data, only a minority adequately discussed data provenance or provided detailed code lists to enable validation. The manual data extraction performed was a labour-intensive process that would not be applicable across a larger volume of studies, hence we developed a more scalable approach using machine learning. Although the depth of understanding is more limited with the NLP method (in this case, distilled to a binary question on reported use of coded healthcare data), it does provide a scalable solution to review published literature en-mass. It also presents an opportunity to address the issue that manually curated reviews include few eligible articles relative to the initial search strategy. Our use of NLP aligns with the broader trend in automation of systematic reviews, where machine learning and NLP have been increasingly used to expedite various steps in the review process, including study searches, screening and data extraction.^13^ This study presents a vanguard application of NLP to enhance systematic reviews through content analysis, extending its use beyond published roles such as extracting the diagnosis and severity of disease,^14^ or supporting clinical quality improvement through abstract screening.^15,16^
The NLP model demonstrated a robust ability to classify documents with high performance, albeit using partitions of the same dataset. Precision and recall metrics were particularly noteworthy for the ‘False’ label, indicating a high accuracy in identifying studies that did not explicitly mention healthcare coding. The model also achieved respectable precision and recall for the ‘True’ label (studies that did report use of coded healthcare data), with slightly lower performance reflecting the inherent complexity of accurately capturing all instances of coded data usage, given the varied ways such usage can be reported in the literature. Although we tend to consider human data extraction as the ‘gold-standard’, there is of course variability across reviewers and challenges in achieving consensus. Inter-reviewer (human-to-human) agreement was substantial, with an average Cohen’s kappa of 0.79, rising to 0.90 after adjudication. This was comparable to inter-reviewer reliability demonstrated in a meta-analysis of 45 studies.^17^ NLP-to-human agreement averaged 0.87 post-adjudication, suggesting high model concordance with human annotation and aligning closely with rates observed in recent published work using large language models.^18^
Limitations
For feasibility reasons, this study only included articles from a selection of journals. By including the top 25 journals by impact factor, we were able to limit the number of articles where XML were not available that could have biased the NLP model. We also included a very broad range of terms for heart failure, using this condition as an exemplar for cardiovascular disease. Further research would be needed to understand if the findings apply to lower impact journals and other medical conditions. The relatively small size of the training dataset necessitated iteration using the additional human-annotated random study set. As with any model, performance metrics can usually be improved with a more extensive training dataset.^19^ The NLP model performance was internally validated, resulting in high precision and recall metrics, but not externally tested which may limit generalizability. A technical limitation of the approach was that the classifier was built solely on the vector of matching mentions of manually developed patterns (or instances in the text where certain patterns relating to heart failure coding appear). This excludes the potential benefits of vectorizing additional context, such as by creating full sentence or whole document embeddings. Finally, while precision remained very high on the test dataset, there was some reduction in recall, which indicates use of additional terms to explicitly refer to heart failure coding that were not considered in the original set of rule-based patterns. A wider consideration of document content may have bridged this gap in recall. Preliminary explorations using full content embeddings did not yield better results, possibly due to the small training set size. Moving forward, it may be beneficial to explore other advanced machine learning techniques, such as transformer-based models,^13^ to better capture the context around mentions of coded data and leverage richer contextual embeddings that might lead to improved performance. Generative large language models are also developing at a rapid pace.
Conclusion
One-fifth of contemporary research articles on heart failure report using coded healthcare data, highlighting the critical need for standardized and transparent approaches within clinical research studies based on healthcare records. This study demonstrates a scalable, automated approach to assess transparency in the use of coded healthcare data, with the aim of strengthening reporting standards and clarity in modern research.
Lead author biography
Dr Asgher Champsi is a cardiologist in training and PhD fellow supported by the NIHR Birmingham Biomedical Research Centre. His research focuses on leveraging big data and novel analytic techniques to improve the care of patients with cardiovascular multimorbidity. He is passionate about health data innovation, pragmatic clinical research, addressing health inequalities and improving research participation among underrepresented populations.
Authors’ contributions
The manual data extraction was conducted independently by all authors. The analysis was conducted by K.T.S., under the direction of D.K. The manuscript was drafted by A.C., K.T.S., and D.K., with all other authors editing the manuscript for intellectual content. D.K. and G.G. provided supervision and were responsible for the decision to submit the manuscript.
Asgher Champsi (MBChB (Data curation [equal]; Formal analysis [supporting]; Writing—original draft [lead]; Writing—review & editing [equal])), Karin T. Slater (PhD (Formal analysis [lead]; Methodology [equal]; Software [lead]; Writing—original draft [supporting])), Simrat Gill (MBChB PhD (Data curation [equal]; Writing—review & editing [equal])), Tomasz Dyszynski (MD (Data curation [equal]; Writing—review & editing [equal])), Megan Schröder (PhD (Data curation [equal]; Formal analysis [supporting]; Writing—review & editing [equal])), Kiliana Suzart-Woischnik (MD MPH (Data curation [equal]; Writing—review & editing [equal])), Benoit Tyl (MD (Data curation [equal]; Writing—review & editing [equal])), Guillaume Allée (PhD (Data curation [equal]; Writing—review & editing [equal])), Alfonso Sartorius (MD (Data curation [equal]; Writing—review & editing [equal])), R. Thomas Lumbers (MBChB PhD (Data curation [equal]; Writing—review & editing [equal])), Folkert W Asselbergs {MD PhD [Writing—review & editing (equal)]}, Diederick E. Grobbee (MD PhD (Conceptualization [supporting]; Writing—review & editing [equal])), Georgios Gkoutos (PhD (Conceptualization [supporting]; Data curation [supporting]; Writing—review & editing [supporting])), and Dipak Kotecha (MBChB PhD (Conceptualization [lead]; Data curation [equal]; Methodology [equal]; Supervision [lead]; Writing—original draft [equal]; Writing—review & editing [equal]))
Supplementary Material
ztaf123_Supplementary_Data
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Studer R, Sartini C, Suzart-Woischnik K, Agrawal R, Natani H, Gill SK, et al Identification and mapping real-world data sources for heart failure, acute coronary syndrome, and atrial fibrillation. Cardiology 2021;147:98–106.34781301 10.1159/000520674 PMC 8985014 · doi ↗ · pubmed ↗
- 2Kotecha D, Asselbergs FW, Achenbach S, Anker SD, Atar D, Baigent C, et al CODE-EHR best practice framework for the use of structured electronic healthcare records in clinical research. Bmj 2022;378:e 069048.36562446 10.1136/bmj-2021-069048 PMC 9403753 · doi ↗ · pubmed ↗
- 3Champsi A, Slater K, Gill S, Dyszynski T, Molnar M, Suzart-Woischnik K, et al Transparency in the use of coded healthcare data for published studies in heart failure. EU Open Res Repository 2024.
- 4Slater LT, Bradlow W, Desai T, Aziz A, Evison F, Ball S, et al Making Words Count with Computerised Identification of Hypertrophic Cardiomyopathy Patients. med Rxiv, 10.1101/2021.04.13.21255353, 15 April 2021, preprint:not peer reviewed. · doi ↗
- 5Slater LT, Bradlow W, Hoehndorf R, Motti DF, Ball S, Gkoutos GV. Komenti: A semantic text mining framework. bio Rxiv, 10.1101/2020.08.04.233049, 4 August 2020, preprint:not peer reviewed. · doi ↗
- 6Slater LT, Bradlow W, Motti DFA, Hoehndorf R, Ball S, Gkoutos GV. A fast, accurate, and generalisable heuristic-based negation detection algorithm for clinical text. Comput Biol Med 2021;130:104216.33484944 10.1016/j.compbiomed.2021.104216 PMC 7910278 · doi ↗ · pubmed ↗
- 7Manning C, Surdeanu M, Bauer J, Finkel J, Bethard S, Mc Closky D. The Stanford Core NLP natural language processing toolkit, In: Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Baltimore, Maryland: Association for Computational Linguistics; 2014. p 55–60.
- 8Jiang JX, Qi K, Bai G, Schulman K. Pre-pandemic assessment: a decade of progress in electronic health record adoption among U.S. Hospitals. Health Aff Sch 2023;1:qxad 056.38756982 10.1093/haschl/qxad 056PMC 10986221 · doi ↗ · pubmed ↗