Machine learning-based online prediction of nocturnal hypoglycemia in elderly patients with type 2 diabetes
Yuntong Liu, Chenhua Guo, Xinyu Li, Shen Li, Jiajun Huang, Liang Zhao, Yan Zhu, Xuhan Liu, Bing Wang, Rui Lin, Jingshi Wang, Zhengnan Gao, Jing Gao, Yingshu Liu

TL;DR
A machine learning model was developed to predict nighttime low blood sugar in elderly type 2 diabetes patients, using easily accessible clinical data.
Contribution
A novel ensemble machine learning model (RF-ET-KNN) was developed and validated for predicting nocturnal hypoglycemia in elderly T2D patients.
Findings
The RF-ET-KNN model achieved an AUROC of 0.947 and sensitivity of 0.929 in predicting nocturnal hypoglycemia.
Daytime lowest blood glucose, fasting blood glucose, and daytime hypoglycemia events were identified as significant risk factors for nocturnal hypoglycemia.
The model uses 11 clinically accessible features and is available as an online risk calculator.
Abstract
Nocturnal hypoglycemia (NH) is a common adverse event in elderly patients with type 2 diabetes (T2D). This study aims to develop a clinically applicable model for predicting the risk of NH in elderly patients with T2D. This retrospective cohort study, conducted from May 2018 to June 2024, analyzed 1,128 elderly T2D patients undergoing continuous glucose monitoring, with an independent validation involving 100 outpatients. Clinical characteristics were collected, and feature engineering was performed to select a manageable set of clinically accessible features. An ensemble model was developed using multiple base models and a stacking approach. The best-performing model was deployed as an online risk calculator. Of the development set, 288 (25.5%) experienced NH, while 40 (40%) of the independent validation cohort experienced NH. The final ensemble model, “RF-ET-KNN”, combined random…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
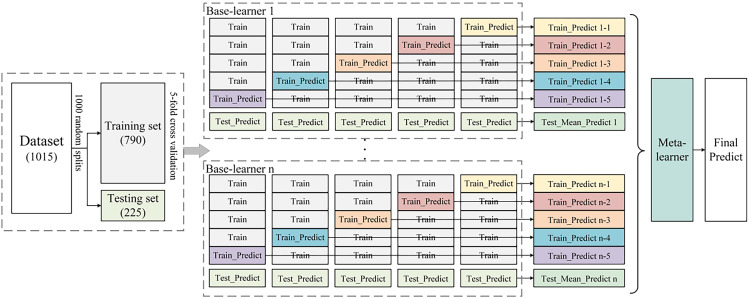 Figure 1
Figure 1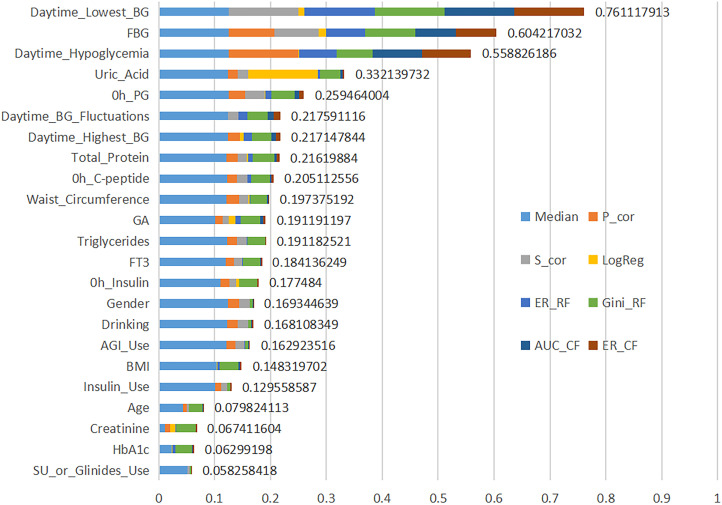 Figure 2
Figure 2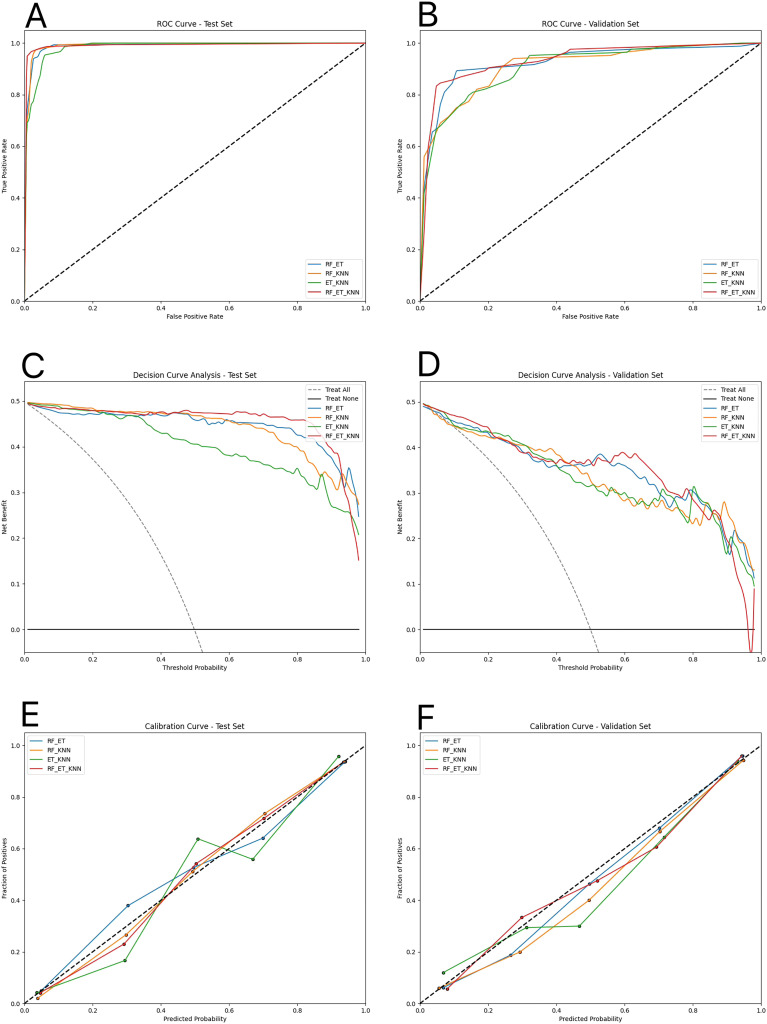 Figure 3
Figure 3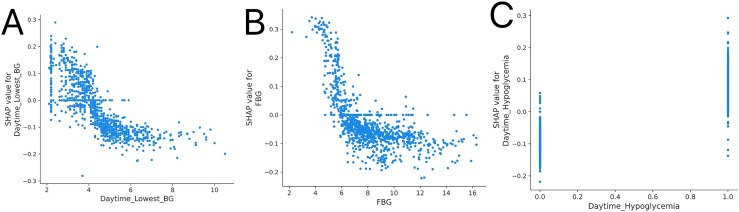 Figure 4
Figure 4| Performance Metric | RF-ET | RF-KNN | ET-KNN | RF-ET-KNN | LR | Lasso |
|---|---|---|---|---|---|---|
| Maximum AUROC | 0.957 | 0.960 | 0.955 | 0.961 | 0.915 | 0.913 |
| Average AUROC | 0.918 | 0.921 | 0.913 | 0.926 | 0.855 | 0.855 |
| Maximum Accuracy | 0.894 | 0.908 | 0.884 | 0.901 | 0.848 | 0.842 |
| Average Accuracy | 0.832 | 0.836 | 0.822 | 0.840 | 0.770 | 0.765 |
| Maximum Sensitivity | 0.934 | 0.941 | 0.934 | 0.940 | 0.895 | 0.888 |
| Average Sensitivity | 0.842 | 0.849 | 0.847 | 0.853 | 0.778 | 0.768 |
| Maximum Specificity | 0.921 | 0.921 | 0.901 | 0.914 | 0.861 | 0.861 |
| Average Specificity | 0.821 | 0.822 | 0.798 | 0.826 | 0.763 | 0.761 |
| Maximum F1 Score | 0.897 | 0.907 | 0.889 | 0.904 | 0.855 | 0.849 |
| Average F1 Score | 0.833 | 0.838 | 0.826 | 0.842 | 0.772 | 0.765 |
| Maximum AUPRC | 0.956 | 0.962 | 0.952 | 0.962 | 0.916 | 0.915 |
| Average AUPRC | 0.921 | 0.926 | 0.915 | 0.929 | 0.844 | 0.844 |
| Maximum PPV | 0.910 | 0.912 | 0.891 | 0.905 | 0.847 | 0.846 |
| Average PPV | 0.826 | 0.828 | 0.808 | 0.832 | 0.767 | 0.763 |
| Maximum NPV | 0.921 | 0.927 | 0.925 | 0.936 | 0.883 | 0.876 |
| Average NPV | 0.839 | 0.845 | 0.840 | 0.850 | 0.775 | 0.767 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDiabetes Management and Research · Hyperglycemia and glycemic control in critically ill and hospitalized patients · Mobile Health and mHealth Applications
Background
1
With an aging population, the prevalence of diabetes among the elderly is rising. In Western countries, more than 20% of individuals over the age of 65 have diabetes (1, 2). In China, the average prevalence among those aged 60 and older is also above 20% (3). Nocturnal hypoglycemia (NH) is a severe complication in elderly patients with type 2 diabetes (T2D), with its prevalence ranging from 39% to 45% (4, 5). In elderly patients with T2D, the threshold for experiencing hypoglycemic symptoms is lower compared to normal blood glucose levels, which may more easily lead to cognitive dysfunction (6). Consequently, symptoms of NH are frequently obscured and challenging for clinicians to detect. NH can impact multiple organs including the heart, nervous system, and kidneys (7–10); and in severe cases, may lead to bradyarrhythmias, cardiac arrest, and even death (7, 11, 12). Therefore, accurate prediction and mitigation of NH episodes are essential. Continuous glucose monitoring (CGM) offers precise and all-day glucose tracking, facilitating more accurate assessment of nocturnal asymptomatic hypoglycemia.
Recent advancements in machine learning technology have facilitated the application of these techniques in hypoglycemia prediction research, where it has shown promising predictive capabilities. Despite the scarcity of studies focusing on NH in elderly patients with T2D, two notable studies employing multivariate logistic regression (LR) models have emerged (13, 14). In one such study, data derived from CGM showed that daytime mean absolute glucose and pre-midnight mean glucose were the most reliable predictors of NH, achieving a prediction accuracy of 0.756, with a sensitivity of 84% and a specificity of 62.1% (4). These studies, however, did not utilize machine learning approaches and were not translated into clinically applicable models.
Although LR models have played an important role in hypoglycemia prediction, recent advances in deep learning methods have shown substantial improvements in predicting hypoglycemic events. Compared to traditional logistic regression, deep learning methods are capable of handling more complex data features, such as time-series data and higher-dimensional inputs. They offer stronger nonlinear modeling capabilities, higher accuracy, greater stability, and better generalization, while exhibiting a lower risk of overfitting. Consequently, machine learning models often demonstrate superior predictive performance in practical applications. A previous study developed a LSTM model for mild and severe hypoglycemia prediction using a large data set of 619 patients with diabetes from China and the United States (15). The selected features in this study included sex, age, type of diabetes, hemoglobin A1c (HbA1c) levels, and CGM data. Although the LSTM model achieved an AUROC ranging from 0.93 to 0.97 in the validation set, it lacked a clinically applicable implementation. Currently, there are no studies based on machine learning methods to predict NH in elderly patients with T2D. The novelty of this study lies in the combination of machine learning methods and the use of clinically interpretable features, addressing the limitations of traditional approaches in handling complex data and translating these models into clinical applications.
We aimed to develop a novel ensemble learning prediction model that integrates multiple base learners and a meta-learner to accurately assess the risk of NH in elderly patients with T2D. The model utilizes extensive clinical data and CGM indices, including daytime blood glucose levels, to predict nighttime glucose risk. Additionally, we created an online calculator for clinicians to support accurate clinical assessments and treatment decisions, mitigating associated complications of NH.
Materials and methods
2
Study subjects
2.1
This study analyzed data from 2,455 patients with T2D treated at the Department of Endocrinology and underwent continuous glucose monitoring (CGM), Central Hospital of Dalian University of Technology, between May 2018 and June 2024. Eligible participants were aged ≥ 65 years, diagnosed with T2D based on the 1999 WHO criteria. To address discrepancies between dynamic and actual glucose levels, CGM data from 5 AM to 7 AM was compared with fasting plasma glucose (FPG) concentrations: inclusion criteria required that patients with dynamic glucose ≥ 3.9 mmol/L had to have a fluctuation range of ≤ 20%, while those with dynamic glucose < 3.9 mmol/L required a range of ± 0.83 mmol/L. Exclusion criteria were severe liver or kidney dysfunction and a psychiatric history. Ultimately, 1,128 patients were included in the analysis. For independent validation, 112 elderly outpatient participants with T2D were recruited to wear CGM devices from November 2024 to January 2025, of whom 100 were ultimately included in the validation analysis. Among these 100 participants, 40 (40%) experienced nocturnal hypoglycemia (NH). The study was conducted in accordance with the Declaration of Helsinki and received approval from the Ethics Committee of the Central Hospital of Dalian University of Technology. Informed consent was obtained from outpatient participants, while it was waived for the retrospective inpatient data due to the study’s retrospective nature.
Data collection
2.2
Data were collected via the hospital’s electronic medical record system, encompassing antidiabetic medication categories and personal information (Age, height, weight, body mass index [BMI], blood pressure, waist circumference [WC], etc.), biochemical tests (liver function, renal function, lipid profile, FPG, HbA1c, glycated serum albumin, thyroid function, etc.), and assessments of pancreatic function (venous plasma glucose [PG], insulin, and C-peptide measured during a standardized meal test at 0, 0.5, and 2 hours), along with medication usage records. Additionally, dynamic glucose data were recorded every 15 minutes using Abbott FreeStyle Libre CGM system.
Variable definition
2.3
The primary outcome variable, NH, was defined as a continuous dynamic glucose level below 3.9 mmol/L for more than 15 minutes during the night (21:00 to 06:00 the following day) (16). In addition to the original variables, five new variables were designed to facilitate a more detailed analysis of hypoglycemia in type 2 diabetes patients: (1) Daytime hypoglycemia: This was defined as at least one instance when dynamic glucose data fell below 3.9 mmol/L during daytime hours (06:00 to 21:00); (2) Daytime highest blood glucose (BG): This recorded the highest glucose level of the day if nocturnal hypoglycemia occurred. If nocturnal hypoglycemia did not occur, it calculated the average of the highest glucose levels each day throughout the study period; (3) Daytime lowest BG: This captured the lowest glucose level of the day when NH was present. If NH was absent, it computed the average of the daily lowest glucose levels during the study period; (4) Glucose fluctuation range: This represented the difference between the highest and lowest daytime glucose levels; (5) Fasting blood glucose (FBG): This was measured as the glucose level recorded from 06:00:00 to 06:14:59 using dynamic glucose data.
The Machine learning models are trained to predict a binary label which is equal to 1 if the patient experienced NH and to 0 otherwise.
Model construction
2.4
Data preprocessing
2.4.1
Given the initially low glucose levels at the onset of monitoring and the frequent adjustments in treatment plans, the dynamic glucose records from the first three days of each patient’s data were excluded to enhance the quality of the research analysis. For clinical data with missing entries, missing patterns were investigated, and missing values were imputed using joint modeling inference and multiple imputation techniques. Additionally, collinearity analysis was conducted to identify and exclude features with high correlations to ensure the integrity of the statistical findings.
Dataset partitioning
2.4.2
The dataset was randomly divided into training, testing, and validation sets in a 7:2:1 ratio. The training and testing sets were split 1,000 times for model training and performance evaluation, while the validation set was used to verify model performance. An independent validation set comprising 100 participants was also employed to further evaluate the generalizability of the model.
Feature engineering
2.4.3
Multi-stage feature selection, which comprises mixed feature selection (MFS) and ensemble feature selection (EFS), was designed to select a subset of meaningful, relevant and clinically accessible features for improving the performance of the machine-learning model. The model of MFS is shown in Supplementary Figure 1. MFS employed a variety of techniques including forward sequential selection, backward sequential search, Backout, and random sequential search. We evaluated the performance using the extreme gradient boosting (XGBoost) model through cross-validation (CV). The EFS method incorporated eight algorithms—based on median values, Pearson’s product moment correlation test (P_cor), Spearman’s rank correlation test (S_cor), beta-values of LR, error-rate-based variable importance measure (ER_RF), Gini-index-based variable importance measure (Gini_RF), area under the curve-based variable importance measure (AUC_CF), and error-rate-based variable importance measure for cross-fold validation (ER_CF).
Construction of ensemble learning prediction model
2.4.4
The ensemble learning prediction model was constructed using a stacking approach, which combines the outputs of multiple base learners to improve prediction accuracy and robustness. Base learners, selected from models including random forest (RF), gradient boosting decision tree (GBDT), extremely randomized trees (ET), K nearest neighbor (KNN), XGBoost, and SVM were trained on the dataset. The three highest-performing models were selected as base learners. A meta-learner, chosen from the best-performing models, integrated their predictions to generate the final output. The optimal combination of base learners and meta-learner constituted the final ensemble model, as shown in Figure 1.
Ensemble learning prediction model. The dataset (N = 1015) is randomly split into a training set (N = 790) and a testing set (N = 225) through 1000 iterations. Within the training set, 5-fold cross-validation is performed to train multiple base-learners (1 to n). Each base-learner is fitted on the 4 parts of the training set and predictions are made for the remaining part (represented as “Train_Predict”). The base-learner also generates predictions on testing set (represented as “Test_Predict”) and the mean predictions from the cross-validation folds for each base-learner are aggregated (represented as “Test_Mean Predict”). The meta-learner uses intermediate predictions (composed of “Train_Predict” and “Test_Mean Predict”) built by multiple base-learners as input to make a final prediction.
Model parameters were adjusted in the training set, and performance evaluation metrics such as area under the receiver operating characteristic curve (AUROC), accuracy, sensitivity, specificity, F1 Score (F1), area under the precision recall curve (AUPRC), negative predictive value (NPV), and positive predictive value (PPV) were used for evaluation on the testing set. The hyperparameters were tuned through the grid search strategy to obtain the best classification results. This ensemble learning model was ultimately presented in the form of an online calculator.
Model evaluation
2.4.5
The performance of the ensemble learning prediction model was evaluated on both the testing and validation sets by plotting the receiver operating characteristic (ROC) curve. Clinical decision analysis (DCA) was utilized to assess the clinical benefits, measuring the actual efficacy of different models based on decision costs and benefits. Calibration curves were employed to compare the predicted probabilities of the models with the actual observed outcomes, evaluating prediction accuracy. Additionally, Shapley Additive Explanations (SHAP) dependence values were used to illustrate the relationship between each feature in the prediction model and the outcome.
Statistical analyses and model configuration
2.5
For continuous variables, normality was assessed using the Kolmogorov-Smirnov test. Variables following a normal distribution were expressed as mean ± standard deviation, and group comparisons were performed using the t-test. For variables that deviated from a normal distribution, the median and interquartile range were used for description, with the Mann-Whitney U test applied for group comparisons. Categorical variables were described using frequencies and percentages, with intergroup comparisons performed via the chi-square test. All statistical tests were carried out using R version 4.0.0 and Python 3.6.13. The machine learning algorithms were implemented using Python 3.8 along with libraries such as “sklearn.ensemble”, “sklearn.model_selection”, and “sklearn.metrics” for model development and evaluation.
Results
3
Data preprocessing results
3.1
The pattern of missing data was illustrated in Supplementary Figure 2, where each column represented a specific missing pattern. The number at the top of each column indicated the number of patients with that specific pattern, while the number at the bottom indicated the number of missing features. The right side of the row represented the name of the feature, and the left side showed the number of patients with missing data for those features. The feature collinearity correlation matrix heatmap was depicted in Supplementary Figure 3, where color variations in each cell represented the magnitude of the Pearson correlation coefficients between variables. Following collinearity analysis, and considering the rates of missing data and the ease of clinical application, eight features (weight, height, glucose, insulin, and C-peptide measurements at 0.5 and 2 hours) were excluded. Concurrently, five new features were introduced, culminating in a final selection of 43 features for the model.
Baseline characteristics
3.2
The baseline characteristics of the study population are shown in Supplementary Table 1, including a total of 1,128 elderly patients with type 2 diabetes, of which 288 (25.5%) were in the NH group. The NH group had a higher proportion of Man, Daytime_Hypoglycemia, Daytime_BG_Fluctuations, while exhibiting lower levels of AGI_Use, Triglycerides, Uric Acid, FBG, Total_Protein, free triiodothyronine (FT3), 0h_PG, 0h_C-peptide, 0h_Insulin, Daytime_Highest_BG, Daytime_Lowest_BG compared to the non-NH group (P < 0.05).
Feature engineering experiments and analysis
3.3
MFS method
3.3.1
Following mixed feature selection, the optimal combination of features was identified, comprising: Daytime_Lowest_BG, FBG, Daytime_Hypoglycemia, Uric_Acid, 0h_PG, Daytime_BG_Fluctuations, Daytime_Highest_BG, Total Protein, 0h_C-peptide, WC, GA, Triglycerides, FT3, 0h_Insulin, Gender, Drinking, AGI_Use, BMI, Insulin_Use, Age, Creatinine, HbA1c, and SU_or_Glinides_Use.
EFS method
3.3.2
The EFS scores for the features, identified through MFS and the analysis of previously reported risk factors as well as baseline data, were calculated, as shown in Figure 2. Based on the EFS results and clinical accessibility, eleven features were ultimately selected for inclusion in the model study: Daytime_Lowest_BG, FBG, Daytime_Hypoglycemia, Daytime_Highest_BG, WC, Gender, Drinking, AGI_Use, BMI, Insulin_Use and Age.
Variables ranking based on EFS score. The y-axis shows the 23 variables ordered by importance value. The x-axis shows the cumulative importance values, calculated via an ensemble of feature selection methods including Median, Pearson’s product moment correlation test (P_cor), Spearman’s rank correlation test (S_cor), beta-values of Logistic regression (LogReg), error-rate-based variable importance measure (ER_RF), Gini-index-based variable importance measure (Gini_RF), area under the curve-based variable importance measure (AUC_CF), and error-rate-based variable importance measure for cross-fold validation (ER_CF). BG, blood glucose; FBG, fasting blood glucose; PG, plasma glucose; GA, glycated albumin; FT3, free triiodothyronine; AGI, alpha-glucosidase inhibitor; BMI, body mass index; HbA1c, hemoglobin A1c; SU, sulfonylurea.
Selection of base learners and meta-learner
3.4
The selected features were entered into six foundational models, and the maximum and average values of various model evaluation metrics were calculated from 1,000 random splits of the dataset, as shown in Supplementary Table 2. The final candidate base learners included RF (average AUROC: 0.886), ET (average AUROC: 0.905), and KNN (average AUROC: 0.877). Among these, ET, which achieved the highest AUROC, was selected as the meta-learner.
Selection of ensemble learning prediction models
3.5
We developed four distinct ensemble learning prediction models: “RF-ET” which combines RF and Extra Trees; “RF-KNN” which pairs RF with KNN; “ET-KNN” which integrates Extra Trees and KNN; and “RF-ET-KNN” which utilizes RF, Extra Trees, and KNN as base learners. In all four models, Extra Trees functioned as the meta-learner. As shown in Table 1, the four proposed ensemble learning models outperformed traditional regression analysis methods (LR and Lasso) across all performance metrics. The “RF-ET-KNN” model achieved an average AUROC of 0.926. Predictions with probabilities below 0.5 were classified as non-occurrence of NH, and those equal to or above 0.5 as occurrence of NH.
The evaluation results of the four ensemble models on the internal and independent validation set were presented in Supplementary Table 3 and Supplementary Table 4. The final selected model, “RF-ET-KNN” outperformed the other models across most metrics, demonstrating superior predictive performance.
As shown in Supplementary Table 4, on the independent validation set, the model achieved an AUROC of 0.874, sensitivity of 0.800, and specificity of 0.782, confirming its robustness and generalizability.
Online calculator
3.6
In this study, an online calculator was developed to serve as an interface for clinicians utilizing the model. The “RF-ET-KNN” model was selected for integration into the calculator. During use, clinicians are required to input the patient’s Daytime_lowest_BG, FBG, Daytime_Hypoglycemia, Daytime_highest_BG, BMI, WC, drinking, AGI_use, Insulin_Use, Age, and Gender. The model processed these inputs in the background and displayed the results on the webpage, as illustrated at http://122.51.219.102:8000/.
Evaluation of the prediction model
3.7
ROC curve
3.7.1
(Figures 3A, B showed that the “RF-ET-KNN” ensemble learning prediction model achieved a high true positive rate and a low false positive rate, demonstrating its robust classification performance.
Performance evaluation of four ensemble learning models. (A, B) ROC curves of the four models on the test and validation sets, respectively, showing their discrimination performance. (C, D) Decision curve analysis (DCA) curves on the test and validation sets, respectively, illustrating the clinical net benefit across various threshold probabilities. (E, F) Calibration curves on the test and validation sets, respectively, demonstrating the agreement between predicted and observed outcomes. RF, random forest; ET, extremely randomized trees; KNN, K nearest neighbor.
DCA curve
3.7.2
The DCA illustrated the clinical benefit of each model at various thresholds; a higher curve indicated greater clinical utility. (Figures 3C, D) showed that the “RF-ET-KNN” ensemble learning prediction model consistently outperformed other models across the 0.5-0.8 threshold range.
Calibration curve
3.7.3
The calibration curve compared the model’s predicted probabilities (x-axis) with the actual proportion of positive cases (y-axis), with the diagonal line representing ideal calibration. (Figures 3E, F) showed that the “RF-ET-KNN” ensemble learning prediction model exhibited better calibration, aligning closely with the ideal diagonal line.
SHAP dependence
3.7.4
(Figures 4A, B) illustrated that Daytime_lowest_BG and FBG were negatively correlated with the occurrence of NH, whereas Daytime_Hypoglycemia events in (Figure 4C) were positively correlated. NH occurrence decreased when Daytime_lowest_BG exceeded 4.5 mmol/L or FBG exceeded 6.5 mmol/L. The absence of Daytime_Hypoglycemia served as a protective factor against the occurrence of NH.
SHAP dependence plots for key predictors associated with NH. (A) SHAP dependence plot for daytime lowest BG, (B) SHAP dependence plot for FBG, and (C) SHAP dependence plot for daytime hypoglycemia, highlighting their relationships with NH. SHAP, Shapley additive explanations; Daytime lowest BG, daytime lowest blood glucose; FBG, fasting blood glucose; NH, nocturnal hypoglycemia.
Discussion
4
Since NH in elderly patients with T2D is often asymptomatic and easily overlooked, early identification and intervention are of critical importance. Li et al. applied LR, SVM, RF, and LSTM networks to predict future NH events from CGM data in a large cohort of 1,921 patients with diabetes (17). Their study further revealed that combining mean sensor glucose with glucose gradient improved the prediction of NH events, achieving good predictive performance. However, the prediction of NH in their study was based on static analysis and lacked a clinically applicable implementation. In contrast, our study constructed an ensemble model combining RF, ET, and KNN algorithms, integrating CGM data with easily accessible clinical features. Furthermore, we developed a web-based calculator to facilitate clinical application and assist clinicians in decision-making (18). Our work aimed to establish a more accurate and practical model for predicting NH in elderly patients with T2D. The model achieved an average AUROC of 0.947 and sensitivity of 0.929 on the internal validation set, outperforming traditional LR models without CGM (AUROC 0.7–0.75) in predicting NH among elderly T2D patients (13, 14). This finding suggests that the selected data features and the constructed model exhibits superior predictive performance and generalization capability.
The final model is presented as an online calculator for clinical use, providing a foundation for clinical decision-making. In clinical practice, the online calculator can be easily applied during routine visits. Clinicians can simply enter several common clinical variables and daytime glucose measurements to obtain an estimated risk of NH. This provides an early warning that helps to identify high-risk elderly patients with T2D and supports timely adjustment of treatment strategies. Compared with existing tools, few models specifically predict NH in elderly T2D patients. These models are all based on LR and generally show only moderate predictive performance (AUROC 0.7–0.75) (14). Moreover, none have been translated into clinically applicable tools. Our calculator addresses this critical gap by providing a practical and user-friendly solution for clinical implementation. However, certain challenges remain, including the occurrence of false positives and false negatives. The model demonstrated good sensitivity (0.929), which minimizes the likelihood of missing patients at elevated risk for NH. This enables clinicians to initiate timely interventions, thereby reducing adverse outcomes and improving patient safety.
According to the EFS analysis, the three most important features were Daytime_lowest_BG, FBG, and Daytime_Hypoglycemia. The results from the SHAP model indicated that the occurrence of NH decreased when Daytime_lowest_BG exceeded 4.5 mmol/L or when FBG exceeded 6.5 mmol/L. Furthermore, the absence of Daytime_Hypoglycemia was identified as a protective factor against the occurrence of NH.
Over 90% of diabetes cases in the elderly are classified as T2D. The incidence of hypoglycemia in older adults is higher than in younger individuals due to decreased autonomic reflex regulation, slower drug metabolism, reduced treatment adherence, and unstable dietary intake (6, 19). These mechanisms clarify how decreased FBG contributes to lower daytime glucose levels and why Daytime_Hypoglycemia events represent significant risk factors for NH in elderly T2D patients. Firstly, excessive use of insulin or insulin secretagogues can result in absolute insulin excess, while increased nighttime insulin sensitivity may lead to relative insulin excess, both contributing to lowered blood glucose levels. Secondly, excess insulin inhibits alpha cells, reducing glucagon’s response to hypoglycemia, which in turn decreases glucagon secretion and exacerbates blood glucose decline (14, 20, 21). Additionally, recurrent hypoglycemia can impair or eliminate the glucose counter-regulatory mechanism, resulting in decreased secretion of glucose-elevating hormones (such as glucagon and epinephrine) and reduced hepatic glucose production (22–24). This creates a vicious cycle of recurrent hypoglycemia (25, 26). Therefore, addressing these factors is crucial for the prevention and management of hypoglycemic events in older diabetes patients.
The findings of this study align with existing research on risk factors for hypoglycemia. Kanazawa et al. identified FBG, Age, and Insulin_Use as independent risk factors for clinically significant nighttime hypoglycemia in elderly patients with T2D through LR analysis, with FBG being the most significant predictor (13). Similarly, Fang et al. established FBG as a valid predictive indicator for NH in elderly male T2D patients using LR (14). Another study employing LR to predict NH in T2D patients found that Daytime_Hypoglycemia events were also significant predictive factors (4). Notably, we are the first to identify Daytime_lowest_BG levels as an important risk factor for NH in elderly T2D patients. Furthermore, Zale et al.’s research, which utilized random forest methods to predict hypoglycemia in hospitalized patients, corroborates our findings by indicating that the lowest blood glucose level within 24 hours was a significant predictor of hypoglycemia (27).
Several additional features were identified for analysis, including anthropometric indicators (BMI and WC), lifestyle factors (Drinking), demographic characteristics (Age and Gender), and medical interventions (Insulin_Use and AGI_Use). Lower BMI and WC have been associated with an increased risk of hypoglycemia (28–30), likely reflecting poor nutritional status and reduced glycogen stores (31). Underweight patients may also exhibit decreased insulin secretion, requiring higher doses of hypoglycemic medications and increasing NH events (32). Drinking has been linked to hypoglycemic episodes in T2D patients (28, 29), as alcohol inhibits hepatic glycogenolysis and gluconeogenesis, reducing blood glucose production. Furthermore, drinking often correlates with unhealthy lifestyle behaviors, such as irregular eating and lack of exercise, which further contribute to hypoglycemia risk (33). Our findings also align with research demonstrating that hypoglycemia risk increases with age in elderly T2D patients, potentially due to age-related declines in counter-regulatory responses and hepatic glucose production (13, 34). Additionally, similar to this study found that male gender may increase the risk of NH in elderly patients with type T2D (35). Insulin, with its potent glucose-lowering effects, has been consistently associated with hypoglycemic episodes in T2D patients, further supporting our results (13, 36–38). AGI, a glucose-lowering drug, delays carbohydrate absorption by inhibiting α-glucosidase, which helps control blood glucose and, when used alone, does not increase the risk of hypoglycemia (39, 40). The previous study reported no cases of hypoglycemia in 93 elderly patients with T2D treated with AGI (41).
Limitations of the study
4.1
Firstly, our study was a single-center investigation and has not yet been externally validated in other populations. Future research should validate the model in diverse populations across various countries and regions to better evaluate its generalization. Secondly, this study did not account for multiple factors such as diet, physical activity, and medication adherence, which could potentially influence NH. However, considering that nighttime food intake and physical activity is typically minimal, the direct impact of dietary carbohydrate intake on nocturnal blood glucose fluctuations is likely limited, although not entirely negligible. Future studies should consider incorporating these variables into the model to improve prediction accuracy and to better understand their contribution to the risk of NH.
Conclusion
5
This study developed a well-performing and generalizable ensemble learning model based on “RF-ET-KNN” utilizing CGM data and clinical indicators to identify 11 clinically accessible risk factors. The model was further implemented as an online calculator for clinical use.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Saelee R Hora IA Pavkov ME Imperatore G Chen Y Benoit SR . Diabetes prevalence and incidence inequality trends among U.S. Adults, 2008-2021. Am J Prev Med. (2023) 65:973–82. doi: 10.1016/j.amepre.2023.07.009, PMID: 37467866 PMC 10792096 · doi ↗ · pubmed ↗
- 2Magliano DJ Boyko EJ . IDF diabetes atlas. Jama. (2022) 326:2498–2506.
- 3Wang L Peng W Zhao Z Zhang M Shi Z Song Z . Prevalence and treatment of diabetes in China, 2013-2018. Jama. (2021) 326:2498–506. doi: 10.1001/jama.2021.22208, PMID: 34962526 PMC 8715349 · doi ↗ · pubmed ↗
- 4Klimontov VV Myakina NE . Glucose variability indices predict the episodes of nocturnal hypoglycemia in elderly type 2 diabetic patients treated with insulin. Diabetes Metab syndrome. (2017) 11:119–24. doi: 10.1016/j.dsx.2016.08.023, PMID: 27569727 · doi ↗ · pubmed ↗
- 5Ishikawa T Koshizaka M Maezawa Y Takemoto M Tokuyama Y Saito T . Continuous glucose monitoring reveals hypoglycemia risk in elderly patients with type 2 diabetes mellitus. J Diabetes Invest. (2018) 9:69–74. doi: 10.1111/jdi.12676, PMID: 28397367 PMC 5754529 · doi ↗ · pubmed ↗
- 6Bellary S Kyrou I Brown JE Bailey CJ . Type 2 diabetes mellitus in older adults: clinical considerations and management. Nat Rev Endocrinology. (2021) 17:534–48. doi: 10.1038/s 41574-021-00512-2, PMID: 34172940 · doi ↗ · pubmed ↗
- 7Andersen A Jørgensen PG Knop FK Vilsbøll T . Hypoglycaemia and cardiac arrhythmias in diabetes. Ther Adv Endocrinol Metab. (2020) 11:2042018820911803. doi: 10.1177/2042018820911803, PMID: 32489579 PMC 7238305 · doi ↗ · pubmed ↗
- 8Yun JS Park YM Han K Kim HW Cha SA Ahn YB . Severe hypoglycemia and the risk of end stage renal disease in type 2 diabetes. Sci Rep. (2021) 11:4305. doi: 10.1038/s 41598-021-82838-5, PMID: 33619302 PMC 7900096 · doi ↗ · pubmed ↗