Automatic forward model parameterization with Bayesian inference of conformational populations
Robert M. Raddi, Tim Marshall, Vincent A. Voelz

TL;DR
The paper introduces new methods to improve computational models by optimizing parameters using Bayesian inference, enhancing agreement between simulations and experimental data.
Contribution
The study introduces two novel methods for optimizing forward model parameters using Bayesian inference and variational minimization.
Findings
Treating forward model parameters as nuisance parameters improves Bayesian inference accuracy.
Variational minimization of the BICePs score optimizes parameters for better model validation.
The approach successfully refines Karplus relation parameters for J-coupling constants in human ubiquitin.
Abstract
To quantify how well theoretical predictions of structural ensembles agree with experimental measurements, we depend on the accuracy of forward models (FMs). These models are computational frameworks that generate observable quantities from molecular configurations based on empirical relationships linking specific molecular properties to experimental measurements. Bayesian Inference of Conformational Populations (BICePs) is a reweighting algorithm that reconciles simulated ensembles with ensemble-averaged experimental observations, even when such observations are sparse and/or noisy. This is achieved by sampling the posterior distribution of conformational populations under experimental restraints as well as sampling the posterior distribution of uncertainties due to random and systematic error. In this study, we enhance the algorithm for the refinement of empirical FM parameters. We…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
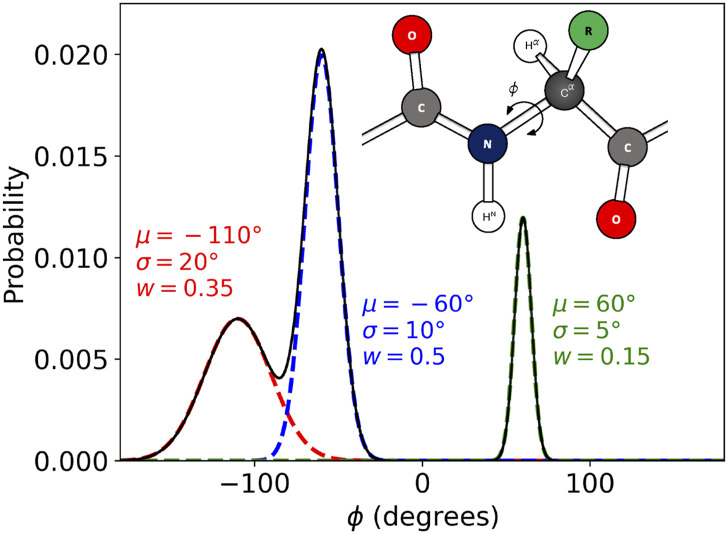 FIG. 1
FIG. 1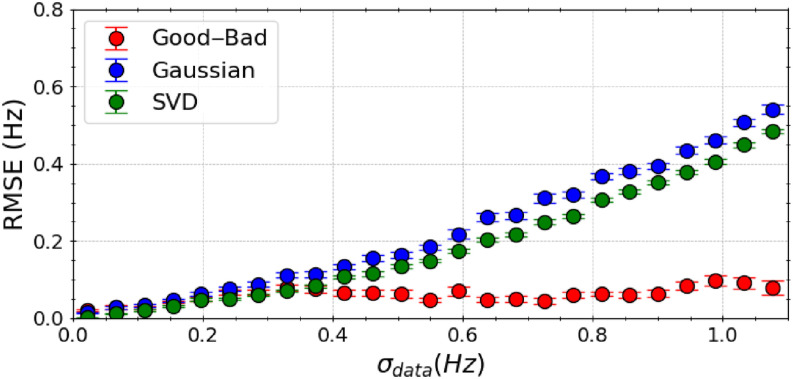 FIG. 2
FIG. 2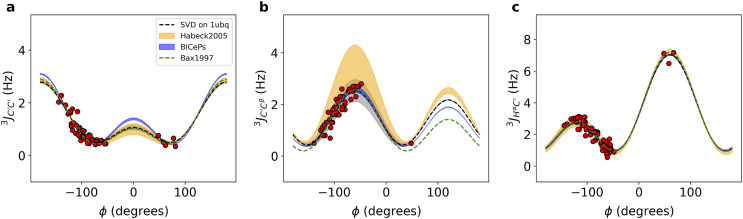 FIG. 3
FIG. 3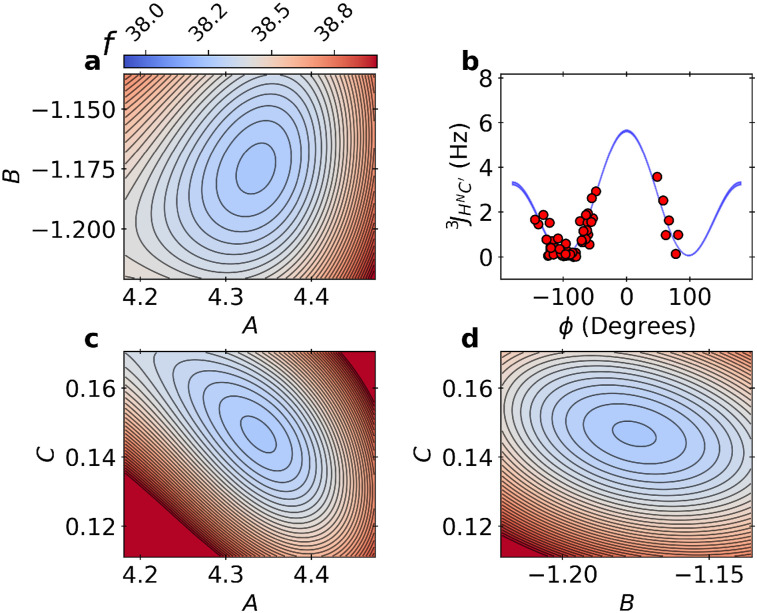 FIG. 4
FIG. 4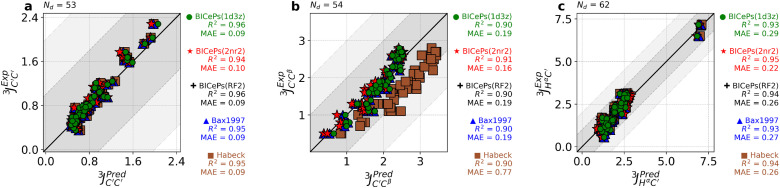 FIG. 5
FIG. 5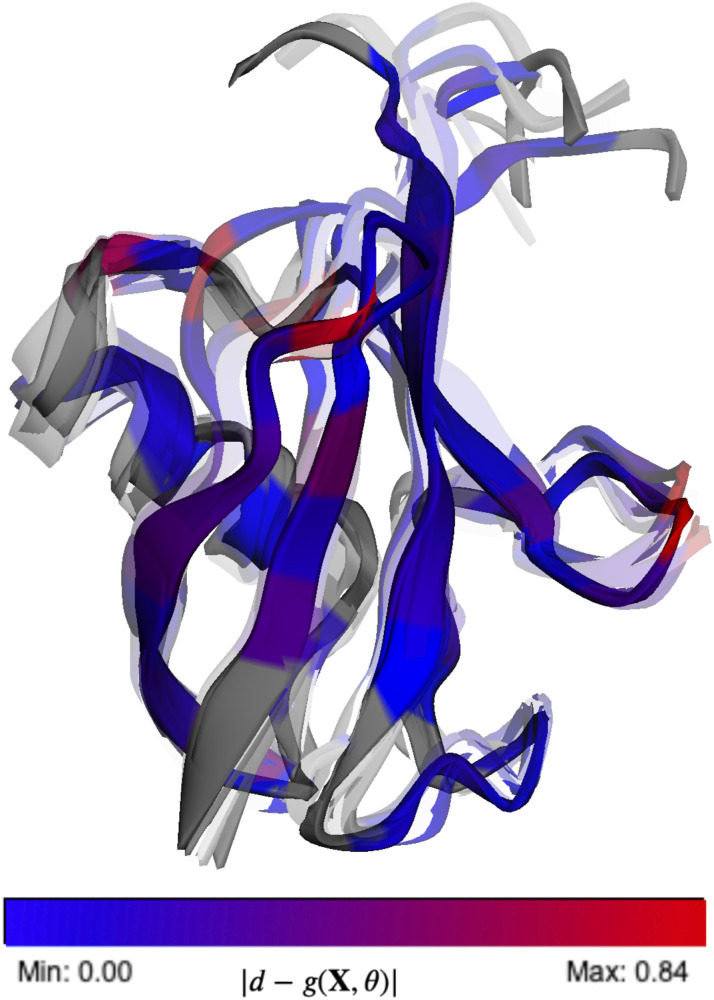 FIG. 6
FIG. 6| A (Hz) | B (Hz) | C (Hz) | |||
|---|---|---|---|---|---|
|
| 1 | 0 | 1.71 ± 0.02 | −0.85 ± 0.01 | 0.54 ± 0.00 |
| 2 | 0 | 1.30 ± 0.03 | −0.91 ± 0.01 | 0.62 ± 0.01 | |
| 3 | 0 | 1.62 ± 0.03 | −0.87 ± 0.01 | 0.63 ± 0.01 | |
|
| 1 | 60 | 1.83 ± 0.04 | 0.34 ± 0.05 | 0.41 ± 0.02 |
| 2 | 60 | 2.20 ± 0.04 | 0.34 ± 0.04 | 0.04 ± 0.02 | |
| 3 | 60 | 1.81 ± 0.04 | 0.38 ± 0.04 | 0.31 ± 0.02 | |
|
| 1 | 120 | 3.64 ± 0.02 | −2.14 ± 0.02 | 1.27 ± 0.02 |
| 2 | 120 | 4.10 ± 0.03 | −2.00 ± 0.02 | 0.95 ± 0.02 | |
| 3 | 120 | 3.78 ± 0.02 | −2.12 ± 0.02 | 1.21 ± 0.02 | |
|
| 1 | 180 | 4.33 ± 0.04 | −1.17 ± 0.01 | 0.14 ± 0.01 |
| 2 | 180 | 4.60 ± 0.12 | −0.57 ± 0.03 | −0.10 ± 0.01 | |
| 3 | 180 | 4.57 ± 0.09 | −1.20 ± 0.03 | 0.13 ± 0.01 | |
|
| 1 | 60 | 2.72 ± 0.03 | −0.35 ± 0.03 | 0.12 ± 0.01 |
| 2 | 60 | 3.00 ± 0.04 | −0.26 ± 0.03 | −0.28 ± 0.02 | |
| 3 | 60 | 2.52 ± 0.03 | −0.03 ± 0.02 | −0.09 ± 0.02 | |
|
| 1 | −60 | 7.11 ± 0.05 | −1.38 ± 0.03 | 1.43 ± 0.04 |
| 2 | −60 | 7.50 ± 0.07 | −1.50 ± 0.02 | 1.50 ± 0.06 | |
| 3 | −60 | 6.97 ± 0.07 | −1.49 ± 0.04 | 1.63 ± 0.05 |
| Parameters |
|
|
|
|---|---|---|---|
| Bax 1997 | 61.12 ± 0.08 | 132.49 ± 0.09 | 99.27 ± 1.91 |
| Habeck 2005 | 135.66 ± 0.08 | 199.32 ± 0.24 | 165.64 ± 0.47 |
| SVD(1D3Z) | 44.76 ± 0.66 | 147.44 ± 0.70 | 120.63 ± 0.21 |
| BICePs(1D3Z) | 141.69 ± 0.16 | 105.00 ± 0.74 | |
| BICePs(2NR2) | 118.42 ± 0.14 | ||
| BICePs(RF2) | 68.07 ± 0.60 | 129.42 ± 0.15 | 88.04 ± 0.21 |
- —National Institutes of Health https://doi.org/10.13039/100000002
- —National Science Foundation https://doi.org/10.13039/100000001
- —US Army Research Laboratory https://doi.org/10.13039/100019923
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsProtein Structure and Dynamics · Enzyme Structure and Function · Computational Drug Discovery Methods
INTRODUCTION
I.
In the field of molecular modeling and dynamics, the accuracy of theoretical predictions is crucial. The quantitative agreement between theory and experiment is typically characterized through the use of accurate forward models (FMs)—computational frameworks that predict observable quantities from molecular configurations. These models often depend on empirical relationships that link specific molecular properties to experimental measurements.
Model validation and refinement of structural ensembles against nuclear magnetic resonance (NMR) observables critically depends on reliable forward models (FMs) that have been robustly parameterized to reduce error. In refining these FMs, it is important to consider random and systematic errors inherent to the experimental data, which in turn contribute to overall uncertainty of integrative models. It is usually challenging to obtain complete knowledge of such errors; instead, such errors typically need to be inferred from the data.
A further challenge is presented by missing or insufficient examples of known structures that can be used to train forward models. For NMR observables that depend on backbone ϕ-angles, such as J-coupling constants, the reference data from x-ray crystallography may be missing or dynamically averaged, creating large uncertainties in the correct ϕ-angles. Numerous approaches have been developed to address some of these challenges.1–4 Some algorithms rely heavily on x-ray crystal structure data; others have many hyperparameters that need to be determined.
To address these challenges, we extend the Bayesian Inference of Conformational Populations (BICePs) algorithm5,6 to refine FM parameters. BICePs is a reweighting algorithm to refine structural ensembles against sparse and/or noisy experimental observables, which has been used in many previous applications.7–10 BICePs infer all possible sources of error by sampling the posterior distribution of these parameters directly from the data through Markov chain Monte Carlo (MCMC) sampling. BICePs also compute a free energy-like quantity called the BICePs score that can be used for model selection and model parameterization.6,11,12
Recently, BICePs were enhanced with a replica-averaging forward model, making it a maximum-entropy (MaxEnt) reweighting method and unique in that no adjustable regularization parameters are required to balance experimental information with the prior.6 With this new approach, the BICePs score becomes a powerful objective function to parameterize optimal models. Here, we show that the BICePs score, which reflects the total evidence for a model, can be used for variational optimization of FM parameters. The BICePs score contains a form of inherent regularization and is particularly powerful when used with specialized likelihood functions that allow for the automatic detection and down-weighting of the importance of experimental observables subject to systematic error.6
Beyond structural biology, Bayesian methods are widely used in survival analysis to model censored and heterogeneous discrete data. Recent work by Akhtar and colleagues shows that flexible priors and robust loss functions enable accurate parameter estimation and outlier resistance in such settings.13,14 These developments highlight the versatility of Bayesian inference for complex, noisy datasets and provide additional examples of analogous strategies for handling heterogeneity and outliers in our domain.
To effectively refine FM parameters, we use BICePs to sample over the entire posterior distribution of FM parameters, enabling simultaneous ensemble reweighting and parameter refinement. In addition, we show that by variational minimization of the BICePs score, we obtain the same result and show that the two approaches are equivalent, with each method requiring particular considerations. We first demonstrate our method’s effectiveness using a toy model and then apply it to optimize six distinct sets of Karplus parameters for the human protein ubiquitin. As a proof-of-concept for more complex models, we also train a neural network to learn J-coupling constants from dihedral angles using the BICePs’ score as a loss function. We then discuss how this idea could be applied to neural networks for chemical shift prediction.15–18 Of course, our framework naturally extends to other empirical forward models with tunable parameters—for example, hydrogen–deuterium exchange (HDX) models, with adjustable hydrogen-bonding and burial weights, or paramagentic relaxation enhancement (PRE) models with system-specific correlation times and scaling factors. These examples illustrate the generality and flexibility of our approach for refining a wide range of forward models to improve the agreement between simulations and experiment.
THEORY
II.
In this section, we develop two different theoretical approaches to optimize forward models. In the first method, we include forward model parameters in the posterior and sample the full posterior distribution of all parameters. In the second approach, we optimize the forward model by minimizing the BICePs score, a free energy-like quantity that can be used for variational optimization. While the two methods are theoretically equivalent (see the supplementary material for a short proof of this), each has practical advantages and disadvantages.
Forward model optimization by posterior sampling of forward model parameters
A.
BICePs uses a Bayesian statistical framework, inspired by Inferential Structure Determination (ISD),19 to model the posterior distribution p(X, σ), for conformational states, X, and nuisance parameters, σ, which characterize the extent of uncertainty in the experimental observables D,
Here, p(D|X, σ) is a likelihood function that uses a forward model to enforce the experimental restraints, p(X) is a prior distribution of conformational populations from some theoretical model, and p(σ) ∼ σ^−1^ is a non-informative Jeffrey’s prior.
For a specific forward model g(X, θ) with a set of FM parameters θ = (θ1, θ2, …, θm), where m is the number of parameters, we can additionally include the parameters in the posterior,
Replica-averaging: when BICePs is used with a replica-averaged forward model, it becomes a MaxEnt reweighting method in the limit of large numbers of replicas.20–25 Consider a set of N replicas, X = {Xr}, where Xr is the conformational state being sampled by replica r. To compare the sampled replicas with ensemble-averaged experimental observables, we define a replica-averaged forward model . This quantity is an estimator of the true ensemble average, with an error due to finite sampling for the observable j estimated using the standard error of the mean (SEM):20,25 . Thus, decreases as the square root of the number of replicas.
For a single forward model with parameters θ, the joint posterior distribution for all parameters is
where X is a set of N conformation replicas. In many cases, we wish to optimize several forward models at once. For example, there are unique sets of Karplus parameters in the forward models for vicinal J-coupling constant observables , , and . If there are K different forward models θ^(1)^, θ^(2)^, …, θ^(K)^, each with their own set of parameters and error distributions, we can describe their full joint posterior distribution as
where Dk represents the experimental observables predicted by the k^th^ forward model, θ^(k)^ represents the parameters for the k^th^ FM, and , describing the total error for the kth observable. The total error originates from both finite samplings through the standard error of the mean and uncertainty in the experimental measurements, known as a Bayesian uncertainty parameter . The prior distribution of uncertainties p(σk) is treated as a non-informative Jeffrey’s prior for each collection of observables, and the posterior of FM parameters p(θ|D) is recovered by marginalization over all X and σ,
Gradients speed up convergence: In our methodology, Markov chain Monte Carlo (MCMC) is used to sample the posterior with acceptances following the Metropolis–Hastings criterion. Our algorithm can be used with or without gradients. However, significantly faster convergence, especially in higher dimensions, is achieved through an integration of stochastic gradient descent approach. Our gradient descent approach allows for informed updates to the FM parameters, incorporating stochastic noise to facilitate the escape from local minima and enhance exploration of the parameter space.
The update mechanism is succinctly encapsulated in the following equation:
where θtrial and θold denote the trial parameters and previous parameters, respectively. The learning rate is denoted by lrate; ∇u signifies the calculated gradient of BICePs energy function u = −ln p(X, σ, θ|D) with respect to the parameters θ; and η scales the noise drawn from a standard normal distribution .
This parameter update strategy is designed to satisfy the Metropolis–Hastings criterion, ensuring each step in the parameter space not only moves toward minimizing the energy of the forward model but also adheres to the probabilistic acceptance of potentially non-optimal moves to avoid local optima traps. Ergodic sampling is ensured by “turning off” the gradient after burn-in. The sampling procedure involves (1) acquiring derivatives of the FM parameters, (2) perturbing these parameters based on the derived information, (3) predicting observables using perturbed FM parameters and computing the total energy, and (4) assessing the new energy against the previous one to determine acceptance based on the Metropolis–Hastings criterion. This ensures a thorough and effective search of the parameter space, taking advantage of both the landscape topology and stochastic elements to guide the exploration.
The Good-and-Bad model accounts for systematic error due to outlier measurements. Recent work has developed sophisticated likelihood models for BICePs, designed to detect outliers that are robust in the presence of systematic error.6 Raddi et al. developed two likelihood models for this purpose: the Student’s model and the Good-and-Bad model. In related work using BICePs to perform automated force field optimization, we used Student’s model.12 Here, in this work, we use the Good-and-Bad model, primarily because the derivatives are less complicated than those of Student’s model.
The Good-and-Bad likelihood model6 assumes that the level of noise is mostly uniform, except for a few erratic measurements. This limits the number of uncertainty parameters that need to be sampled, while still capturing outliers. Consider a model in which the uncertainties σj for particular observables j are distributed with respect to some typical uncertainty σ^B^ according to a conditional probability p(σj|σ^B^). We derive a posterior for the parameters of the kth FM having a single uncertainty parameter σ^B^ by marginalizing over all σj,
where . Under the Good–Bad model, we say that the “good” data consist of observables normally distributed about their true values with effective variance , while the “bad” data are subject to systematic error, leading to a larger effective variance, , where φ ≥ 1.
By this assignment, p(σj|σ0) from Eq. (7) becomes
where 0 ≤ ω < 1 describes the fraction of “bad” observables. Since the value of ω is unknown, it is treated as a nuisance parameter and marginalized over its range. The resulting posterior is
where H is the Heaviside-step function. After marginalization, we are left with the Bayesian uncertainty parameter, , and an additional parameter, φ. Both parameters are sampled in the posterior. When φ = 1, the model reverts to a Gaussian likelihood model. When considering the full posterior, this extra nuisance parameter is given a non-informative Jeffrey’s prior, p(φ) ∼ φ^−1^.
For a single set of FM parameters (for simplicity), the BICePs energy function, u = −log p(X, σ0, φ, θ^(k)^|D), the negative logarithm of the posterior in its full form is given by
When φ = 1, this energy function is the same result we would get if we used a Gaussian likelihood function,
The first derivative of Eq. (10) with respect to the ith FM parameter in the parameter set θ^(k)^ is
where and . Both represent the reciprocal of Gaussian likelihoods, where and denote inverse-weighted forms of normal distributions with variances and , respectively.
When φ = 1, the gradient becomes
Second derivatives of the BICePs energy function and the BICePs score are useful for descent and uncertainty quantification using other forward models. We refrain from writing out the second derivative here, but the derivation is straightforward. For the forward models, we consider in the following (Karplus relations) all have second derivatives that go to zero. For more general cases, see the supplementary material, Appendix A for more details. The energy of the Good–Bad likelihood model and its first and second derivatives are shown in Fig. S1.
Forward model optimization by variational minimization of the BICePs score
B.
As we show in Sec. III and Sec. IV, treating the forward model parameters as nuisance parameters and sampling them as part of the full posterior is an efficient strategy to refine FM parameters. However, in the limit of a very large number of FM parameters, the dimensionality of the posterior may become unwieldy and may suffer from the “curse of dimensionality.”
As an alternative strategy, we consider optimization of forward model parameters using variational minimization of the BICePs score, an approach that we have used to perform automated force field optimization.12 In this approach, the FM parameters are no longer part of the joint posterior density. Instead, the posterior is conditioned on the set of FM parameters, θ, that is, Eq. (2) becomes
In this view, ensemble refinement is performed with a static set of FM parameters for each BICePs calculation. The BICePs score then enables the selection of the optimal model parameterized by θ.
BICePs evaluate model quality by calculating a free energy-like quantity called the BICePs score. For a forward model with parameters θ, the BICePs score f(θ) is computed as the negative logarithm of a Bayes factor comparing the total evidence of a given model against a well-defined reference, marginalizing over all uncertainty,
where
is the evidence for FM parameters θ, Z0 is the evidence for a suitable reference state, and u is the unchanged BICePs’ energy function Eq. (10). To construct the reference state, we consider a series of likelihoods pξ(D, θ|X, σ) ∼ [p(D|X,σ)]^ξ^ parameterized by ξ ∈ [0, 1] and set the reference state as the thermodynamic ensemble corresponding to ξ = 0. The BICePs score is then calculated as the free energy of “turning on” experimental restraints (ξ = 0 → 1).
It should be noted that in other applications of BICePs,6,12 the reference state for the BICePs score is defined using the λ = 0 state for a series of priors pλ(X) ∼ [p(X)]^λ^ and the BICePs score is computed as the free energy of (λ = 0 → 1) and (ξ = 0 → 1) transformations. Here, since we are only interested in evaluating and/or parameterizing the likelihood functions, we set p(X) to be uniform.
To optimize forward model parameters, the BICePs score is used as an objective function that is estimated given a candidate value of θ. Based on the estimate (and possibly other previous estimates), new candidates for θ are iteratively proposed and accepted or rejected, with the goal of finding the values θ* that minimize the BICePs score.
For this purpose, gradient-based searches are very helpful. Conveniently, the derivative of the BICePs score f(θ) with respect to the FM parameters reduces to the Boltzmann-averaged values of the gradient ∂u/∂θ,
In our results in the following, we use the first-order optimization method L-BFGS-B,26 which only requires first derivatives. For more complex forward models, second-order methods may be needed. The Hessian matrix (of second partial derivatives of the BICePs score with respect to FM parameters) can be used for uncertainty estimation when f(θ) is convex. Assuming this is true, we estimate uncertainties in the FM model parameters using covariances obtained through inversion of the Hessian. Conceptually, this means that the estimated uncertainties in the best-fit values represent the widths of the basins in the BICePs score landscape. For non-convex problems, this can sometimes lead to an under-estimation of uncertainty depending upon the curvature of the basins of the local minima in the BICePs score landscape.
Calculation of the BICePs score (a free energy difference) and its derivatives (expectation values of energy derivatives) is performed using the multistate Bennett acceptance ratio (MBAR) free energy estimator27 by sampling at several intermediates ξ = 0 → 1, which enables accurate estimates of all quantities. The accuracy of the BICePs score depends on converged sampling and sufficient thermodynamic overlap of intermediates (ξ = 0 → 1) in the BICePs computation. To ensure strong overlap, we optimize the ξ-values by spacing ensembles equidistantly in thermodynamic length,28,29 employing a strategy akin to the “thermodynamic trailblazing” method proposed by Rizzi.30 This optimization is performed using an algorithm we have developed called pylambdaopt.31
RESULTS
III.
A toy model to test the performance of forward model optimization
A.
To investigate the performance of BICePs in optimizing forward models, we introduce a simplified, yet physical, toy model. This model is designed to mimic the complexity of protein backbone structures by generating ϕ-angles from a multi-modal distribution, thereby emulating configurations characteristic of different secondary structural elements (Fig. 1). This distribution encompasses three distinct modes, each characterized by a mean (μ), standard deviation (σ), and weight (w): beta sheets (μ = −110°, σ = 20°, and w = 0.35), right-handed helices (μ = −60°, σ = 10°, and w = 0.5), and left-handed helices (μ = 60°, σ = 5°, and w = 0.15). These parameters were chosen to accurately reflect the structural variability found in proteins. Angles ϕi were sampled from the multi-modal distribution,
The sampled ϕi were then used to calculate synthetic ensemble-averaged experimental J-coupling constants, ^3^J(ϕ), using the Karplus relation,
with the coefficients set to their chosen true values: (A* = 6.51, B* = -1.76, and C* = 1.6). The synthetic J-coupling constant observables were calculated using the ensemble-average, as ∑i^3^J(ϕi)p(ϕi).
Toy model for measuring the performance of forward model optimization. The ϕ-angles for each conformational state is pulled from a multi-modal distribution and corresponding energies. (a) This multi-modal distribution of ϕ-angles was intended to represent configurations with different secondary structure elements having three distinct modes described by the mean (μ), standard deviation (σ), and weight (w): beta sheets (μ = −110°, σ = 20°, and w = 0.35), right-handed helices (μ = −60°, σ = 10°, and w = 0.5), and left-handed helices (μ = 60°, σ = 5°, and w = 0.15). (b) Cartoon representation of the backbone torsion angle, ϕ.
Including forward model parameters in the BICePs posterior is a robust method to optimize Karplus parameters in the presence of experimental errors
B.
Using the toy model described above, we next perform tests to examine whether including forward model parameters in the BICePs posterior can be used to find the optimal Karplus parameters starting from an initial reference forward model with parameters (A0, B0, C0). Through these tests, we evaluate the precision of the results and how robust the algorithm is in the presence of noise.
To evaluate the robustness of our algorithm in the presence of experimental inaccuracies, we introduced random and systematic errors of varying magnitudes (σdata) into the synthetic experimental scalar couplings. The performance of our Good–Bad likelihood model, a Gaussian likelihood model, and singular value decomposition (SVD) was compared under these conditions.
SVD calculations: Parameters of many reference Karplus relations were previously determined using a singular value determination approach.32 To test this approach against our BICePs method, we derived Karplus parameters θ = {A, B, C} using a weighted singular value decomposition (SVD) fitting approach to optimally fit the J-coupling values as a function of dihedral angles. For each observation j across Nd measurements, the matrix M was constructed with rows for each ϕ angle,
where p(X) represents the true populations for state X and ϕ0 is the phase shift of −60°.
SVD was applied to decompose the matrix as M = UΣV^T^, and Karplus coefficients were derived using
where ɛ = 1 × 10^−6^ is a small regularization term added to the diagonal of Σ to ensure stability of the pseudo-inverse and J^exp^ represents the vector of experimental J-coupling values. This method ensures robust estimation of θ under ideal experimental conditions, given the true conformational populations. In practice, the true populations are not known a priori. The uncertainty in SVD coefficients was determined through 1000 iterations of fitting, each omitting 10% of the data points chosen at random.
Typical uncertainties in NMR frequency measurements range from 0.1 to 1.0 Hz, primarily influenced by magnetic field strength, instrument quality, sample conditions, and the specifics of the pulse sequence used. In these experiments, 100 conformational states and 60 synthetic experimental scalar couplings were used. We introduced systematic error by shifting the experimental ^3^J values by +2.0 to +4.0 Hz for up to 20% of the data points. BICePs calculations were performed by averaging FM parameters over three chains of MCMC starting from different initial parameters ({A = 9, B = −1, C = 1}, {A = 4, B = 0, C = 3}, {A = 0, B = 0, C = 0}). Regardless of different starting parameters, posterior sampling universally converges to “true” optimal FM parameters. In these calculations, we used 32 BICePs replicas and burned 10k steps, followed by 50k steps of MCMC sampling.
We evaluated model performance by the root-mean-square error (RMSE) between the true J-coupling values with parameters {A* = 6.51, B* = −1.76, C* = 1.6} and the J-coupling values using predicted Karplus coefficients for all 60 synthetic measurements, performed over 1k independent trials of random generations of toy model data. Average RMSE results, computed over 100 BICePs calculations, highlight the algorithm’s robustness and its ability to accurately predict FM parameters even in the presence of data perturbations. Error bars in our results represent the standard deviation across these calculations, providing a comprehensive measure of the algorithm’s reliability under various experimental accuracies.
Our findings indicate that the Good–Bad likelihood model (red) exhibits superior insensitivity to experimental errors compared to a traditional Gaussian likelihood model (blue) and SVD (green) approaches (Fig. 2). Predictions from SVD and the Gaussian likelihood model become notably less dependable when the experimental data contain errors, especially when σdata exceeds 0.5 Hz. On average, error in predictions (RMSE) from the Good–Bad model does not exceed 0.1 Hz over the full range of σdata.
Comparative analysis in the performance of the Good–Bad likelihood model (red), a Gaussian likelihood model (blue), and singular value decomposition (SVD) using the “true” ϕ angles with synthetic experimental data. Here, we induced random and systematic errors of varying magnitudes (σdata) to the experimental scalar couplings. Model performance was measured by computing RMSE (Hz) between the “true” scalar couplings and the couplings generated from the Karplus relations, with predicted Karplus coefficients over 1500 random perturbations to the experimental data, and represents the average of 100 BICePs calculations. The error bars represent the standard deviation. Predictions from SVD and the Gaussian likelihood model become notably less dependable when data incorporate errors, especially when σdata exceeds 0.5 Hz.
An example of a single trial of forward model parameter refinement using the toy model is shown in the supplementary material Fig. S2), where BICePs predict Karplus coefficients by posterior sampling over FM parameters. Both BICePs and SVD methods successfully reproduce the “true” Karplus curve. However, BICePs can accurately identify the error present in the data (σdata = 0.471 Hz), as indicated in the marginal posterior of uncertainty p(σJ). The BICeP-predicted maximum a posteriori uncertainty was found to be σJ = 0.272 with a variance scaling parameter of φJ = 1.98. The marginal posterior distributions of FM parameters for the Good–Bad model were {A = 6.6 ± 0.04, B = −1.8 ± 0.02, C = 1.5 ± 0.03}, and for SVD, {A = 6.11 ± 0.06, B = −1.63 ± 0.04, C = 1.80 ± 0.04}.
In addition to the Good–Bad model, we refined parameters using the Student’s model ({A = 6.8 ± 0.03, B = −1.9 ± 0.03, C = 1.4 ± 0.03}) to demonstrate that the Student’s model yields similar performance (supplementary material, Fig. S3). The computed Gelman–Rubin statistic33 for these calculations was found to be for each of the marginal posterior distributions of Karplus coefficients, which demonstrates that our chains converge to the same parameter location with similar variance.
Furthermore, we assessed model performance across varying qualities of prior structural ensembles (supplementary material, Fig. S4). By introducing varying levels of prior error σprior (measured in degrees) through perturbations to the “true” ϕ angles, even in the presence of random and systematic error, we observed strong correlation between the BICePs score and the quality of the structural ensemble, with a coefficient of determination R^2^ of 0.99. For these calculations, we employed the Good–Bad model, utilizing 32 replicas, and conducted 1000 random perturbations to the ϕ angles with errors up to σprior = 4° and perturbations to the experimental data σdata = 0.68 ± 0.24 Hz.
The comprehensive evaluation of our algorithm with this toy model underscores its efficacy in accurately determining FM parameters, reflecting scenarios commonly encountered in real-world applications. The robust performance of the algorithm, even in the face of random and systematic errors, can be attributed to BICePs’ sophisticated error-handling within its likelihood models. This approach also ensures predicted FM parameters derived from sub-optimal structural ensembles remain reliable. In addition, our findings reveal a strong correlation between the BICePs score and the quality of the structural ensemble, demonstrating an immense utility in this context.
Variational minimization of the BICePs score to optimize FM parameters and comparison with posterior sampling
C.
Next, we performed variational minimization of the BICePs score to determine optimal FM parameters for our toy model (see the supplementary material, Fig. S2) and compared the results to the posterior sampling approach under the same conditions.
Variational minimization was performed using the Good–Bad model with four replicas (for reduced computational cost), where each evaluation of the objective function consisted of running 10 000 MCMC steps. Optimal parameters were determined to be {A = 6.31 ± 0.02, B = −1.69 ± 0.03, C = 1.69 ± 0.01}, averaged over three independent runs with very low variance between runs (supplementary material, Fig. S6). Regardless of different starting parameters ({A = 9, B = −1, C = 1}, {A = 4, B = 0, C = 3}, {A = 0, B = 0, C = 0}), variational minimization converges to “true” optimal FM parameters. This analysis demonstrated that both the joint posterior sampling approach and variational minimization show nearly equivalent performance when applied to this model.
As a method for forward model optimization, variational minimization of the BICePs score has advantages and disadvantages. This method is particularly advantageous for handling many FM parameters, offering a potential solution to the curse of dimensionality faced by basic Monte Carlo Markov chain (MCMC) methods. In addition, it is easier for users to adapt different forward models and performs exceptionally well in convex landscapes. When landscapes are non-convex, however, the inverse Hessian may not provide a comprehensive view of the parameter space’s uncertainty; instead, uncertainty estimation could be computed using the variance across multiple BICePs runs starting from different initial parameters. The variational minimization approach also requires careful consideration of disperse starting parameters to ensure global minimization.
The posterior sampling method, which involves sampling the joint posterior distribution of forward model (FM) parameters, has several advantages. One significant benefit is that the posterior distribution provides a direct estimate of the uncertainties of the parameters and their covariance. Compared to variational minimization, this method generally has a faster runtime and is particularly effective in handling non-convex landscapes, allowing for robust parameter estimation even in complex scenarios. However, it is not without drawbacks. As the number of FM parameters increases, the posterior sampling method may encounter the curse of dimensionality, which makes it computationally challenging to explore the parameter space efficiently.
In summary, while both approaches are valuable tools for parameter estimation in parameter and ensemble refinement, each has its strengths and weaknesses. The choice between these methods should be guided by the specific characteristics of the problem at hand, such as the landscape’s convexity and the number of parameters involved.
Determination of optimal Karplus coefficients for ubiquitin
D.
As an application of our algorithm, we applied BICePs to human ubiquitin to predict Karplus coefficients for six sets of scalar coupling constants: , , , , , and . To test the robustness of our algorithm, we conducted a comprehensive evaluation using three different structural ensembles as priors, each derived from distinct computational approaches: (1) 10 conformations from the NMR-refined structural ensemble, 1D3Z,34 (2) 144 conformations from NMR-restrained simulations, 2NR2,35 and (3) 25 conformations from the RosettaFold2 (RF2) algorithm.36 Further details about these ubiquitin structural ensembles are given in the supplementary material.
We validated the forward model parameters derived from each prior using the BICePs score, R^2^, and mean absolute errors (MAE) for forward model predictions. As priors for these validation calculations, we used three independent structural ensembles: 1D3Z and 2NR2 (described above) and a 500-state conformational ensemble derived from a millisecond-long simulation of ubiquitin using CHARMM22*.37 Further details about the CHARMM22* ensemble are given in the supplementary material.
To refine the forward model (FM) parameters, we employed full joint posterior distribution sampling. This method was chosen to navigate the non-convex parameter space efficiently, given its relatively low dimensionality (18 FM parameters). Estimates of FM parameters were made by averaging the BICePs results over four Markov chain Monte Carlo (MCMC) sampling runs, each starting from distinct initial parameters: {A = 9, B = −1, C = 1}, {A = 4, B = 0, C = 3}, {A = 0, B = 0, C = 0}, and {A = 6, B = −1, C = 0}. Flexible residues were excluded from the calculations, consistent with previous studies.2,3 As a result, a total of 346 J-couplings were used in these refinements. We used the Good–Bad model with 32 BICePs replicas, discarding the first 50k steps as burn-in, followed by 50k steps for MCMC sampling. Unlike the parameters derived from 1D3Z and RF2, the Karplus coefficients obtained by using the 2NR2 ensemble required a burn-in of 100k steps to appropriately converge due to a larger number of conformational states. The six sets of refined Karplus coefficients resulting from the 1D3Z, 2NR2, and RF2 ensembles are presented in Table I.
Figure 3 compares the Karplus curves derived from BICePs using the 1D3Z ensemble with previously published parameters obtained from NMR refinements, showing subtle differences. Both the marginal posterior distributions of the FM parameters and the Karplus curves for each scalar coupling demonstrate significant congruence with the historical NMR refinement results.3,34 For all six types of J-coupling, see the supplementary material, Fig. S7.
Karplus curves with BICePs-refined Karplus coefficients using the 1d3z ensemble for (a)–(c) JC′C′3, JC′Cβ3, and JHαC′3. For comparison, SVD on 1ubq using experimental scalar coupling constants with ϕ-angles derived from the x-ray structure (black dashed line) and the red dots corresponding to the fitted data points are shown. In addition, parameterizations from Bax et al. (green) and parameterization from Habeck et al. (yellow) were overlaid for comparison. The thickness of the line corresponds to the uncertainty.
The predicted parameters have large similarities across structural ensembles. BICePs-predicted coefficients using the 1D3Z ensemble (supplementary material, Fig. S8) and predicted coefficients using the RF2 ensemble (supplementary material, Fig. S9) are found to strongly overlap. Furthermore, traces of the FM parameters over time confirm that the sampling converges (supplementary material, Fig. S10).
A key advantage of BICePs is its ability to sample the posterior densities of forward model uncertainties, p(σ) (supplementary material, Fig. S11). For certain sets of J-coupling constants (e.g., and ), the marginal posterior distribution of the variance scaling parameter p(φ) has a sampled mean slightly larger than 1.0, indicating that the functional form of the likelihood opted for long tails to account for a few outlier data points deviating from the mean.
The BICePs free energy landscape for Karplus parameters: In Fig. 4, we show the free energy landscape, which is also equivalent to the BICePs score landscape fξ=0→1. The Karplus relation for was found to overlap strongly with the results obtained by SVD when using ϕ angles from the x-ray crystal structure (supplementary material, Fig. S7). The red data points are shown using the experimental J-couplings with ϕ angles derived from x-ray crystal pose 1UBQ.38 The joint BICePs score landscape for the six sets of parameters is too complex to visualize. Instead, we constructed a smooth 2-D landscape for each pair of parameters within a set of scalar couplings by training a Gaussian process on the BICePs energy trace using a radial basis function (RBF) kernel with an additive white noise to account for observational uncertainty. The characteristic length scale was bounded within [0.1, 10.0]; the signal variance was set to 1.0; and the noise variance was set to 10^−5^. The landscape matches the computed BICePs scores and shows minima in the correct locations. All BICePs score landscapes for each of the six sets of Karplus coefficients are illustrated in the supplementary material, Fig. S12.
Landscapes of the BICePs score with respect to the predicted Karplus coefficients for JHNC′3. Panels (a), (c), and (d) illustrate the energy landscape f for pairs of Karplus coefficients when using the 1D3Z structural ensemble during refinement. Panel (b) shows the Karplus model using parameters with the lowest BICePs score, with red circles showing the experimental J-coupling values and corresponding ϕ angles from the x-ray crystal structure of ubiquitin (1UBQ).
To demonstrate the transferability across different generative models and validate our parameters, we evaluated the accuracy of the back-calculated scalar couplings using the different sets of Karplus coefficients. In Fig. 5, we illustrate how the various sets of parameters derived from different techniques and different structural ensembles exhibit similar performance metrics. Interestingly, on applying BICePs-refined Karplus parameters to an ensemble generated by a molecular dynamics simulation (CHARMM22*),37 some parameter sets are revealed to be more transferable than others. The mean absolute error (MAE) and coefficient of determination (R^2^) for all six types of scalar couplings across different structural ensembles are shown in the supplementary material, Figs. S13–S15. On average, the BICeP-refined parameters derived from the 2NR2 ensemble [BICePs(2NR2)] give the lowest MAE between experiment and predictions for the CHARMM22* simulated ensemble, closely followed by BICePs(RF2) parameters, whereas Habeck 2005 has the highest MAE due to known difficulties with . A visualization of the BICePs-reweighted 2NR2 structural ensemble using BICePs(2NR2) parameters is shown in Fig. 6, with higher transparency representing lower populations. Residues are colored by the magnitude of the replica-averaged data deviation from the experiment in , where the color is normalized from blue (lowest deviation) to red (highest deviation).
Validation of BICeP-predicted Karplus coefficients perform similarly to Bax 1997 and achieve minor improvements over Habeck 2005 for scalar coupling predictions for the simulated ensemble of CHARMM22. Each panel for (a) JHαC′3, (b) JC′Cβ3, and (c) JC′C′3 shows strong correlations between predictions and experiment. Karplus coefficients derived from BICePs using the 2NR2 ensemble gives the best performance for CHARMM22*. For the remaining sets of J-coupling, please see the supplementary material, Fig. S15.*
Visualization of the 2NR2 conformational ensemble after joint conformational populations and Karplus parameter optimization using BICePs. Structures (144 in total) with higher transparency have lower populations. Residues are colored by the magnitude of the deviation between the replica-averaged forward model observations g(X, θ) and the experimental JC′C′3 data d, where the color is normalized from blue (lowest deviation) to red (highest deviation).
To quantify which parameters produce the best predictions for ubiquitin, we compute BICePs scores, fξ=0→1 for each of the structural ensembles. This score directly relates to the quality of FM parameters and their predictive accuracy at reproducing experimental scalar couplings, integrating over all sources of error. Lower BICeP scores indicate better agreement with experiment. BICeP scores were computed using 11 intermediate ξ-values ranging between 0 and 1, which were optimized using pylambdaopt.31 The results are shown in Table II. Each row in Table II corresponds to BICeP scores using all six sets of Karplus coefficients used on different structural ensembles. The lowest score is shown in bold [Note that the BICePs score is an extensive quantity that grows linearly with the number of replicas. For this reason, our results report the reduced BICePs score, f(θ)/Nr].
The leftmost column in Table II corresponds to the parameters, where BICePs(1D3Z) are the parameters in Table I (set 1), which used the 1D3Z ensemble to obtain Karplus coefficients. BICeP score columns, e.g., corresponds to BICeP scores evaluated for the 1D3Z ensemble. That is, the superscript corresponds to the structural ensemble used as a validation step. The reported BICePs scores were averaged over five independent rounds of validation each. BICeP calculations were burned for 1k MCMC steps, followed by 50k steps of production-run MCMC sampling.
The BICePs score, (Table II), is equivalent (within error) with the most probable landscape basin f = 38.15 ± 0.19 from sampling the energy landscape, computed as an average across four chains; an example for one chain is shown in Fig. 4. This is additional evidence of the algorithm’s reliability and corroborates that the results from variational minimization of the BICePs score and full joint posterior sampling are equivalent.
For both the 2NR2 and CHARMM22* structural ensembles, Bax 1997, BICePs(RF2) and BICePs(1D3Z) parameters give very similar BICePs scores, which suggests robust accuracy of FM parameters in reproducing experimental scalar couplings and the transferability of FM parameters across different prior structural ensembles. For the CHARMM22* simulated ensemble, the BICePs(2NR2) parameters give the lowest BICePs score. A partial explanation for this is that the structural ensemble 2NR2 deposited in the Protein Data Bank was generated using the CHARMM22 force field with additional experimental restraints during simulation.35
We obtained Karplus parameters using SVD with uniform populations across the 1D3Z ensemble (Table S1), denoted SVD(1D3Z). As shown in Table II, these parameters perform well for 1D3Z itself but generalize poorly to other ensembles, giving higher scores for 2NR2 and CHARMM22*. The MAE results in Table S2 show a similar trend: while SVD(1D3Z) predictions are competitive within 1D3Z, they are consistently worse than BICePs(1D3Z) for 2NR2 and CHARMM22*. This highlights a key limitation of SVD with uniform populations—without proper treatment of ensemble populations, the parameters risk overfitting to the training ensemble and lose transferability. By contrast, BICePs jointly optimize both parameters and populations, yielding lower errors across ensembles and more robust performance.
It is difficult to say which of the model parameters are the best for ubiquitin, so we compare the top four: BICePs(RF2), Bax 1997, BICePs(1D3Z), and BICePs(2NR2). The BICePs(2NR2) parameters are objectively better at predicting J-couplings from structures of ubiquitin generated from simulations using the CHARMM22* force field. In general, when looking across structural ensembles, the lowest BICePs scores come from the 1D3Z structural ensemble except for BICePs parameters derived from the 2NR2 ensemble [BICePs(2NR2)]. This confirms that the 1D3Z structural ensemble gives the strongest agreement with experimental NMR observations. However, our BICePs(RF2) parameters have the best transferability across structural ensembles and have lower BICePs scores compared to Bax 1997 parameters. In a separate study, we evaluated the performance of the BICePs(RF2) parameters (denoted as “Raddi 2024” in Ref. 39) in predicting couplings for a set of non-natural and cyclic β-hairpin peptides.39 Our results show that these parameters yield consistently lower prediction errors compared to the Bax 200740 and Kessler 198841 parameter sets. Based on all evidence, we recommend the BICePs(RF2) parameters for downstream applications, such as structural refinement and validation. Nonetheless, users should carefully assess accuracy for their specific system, as additional refinement may still be required.
DISCUSSION
IV.
Ensembles from deep generative models such as RosettaFold2 can be used for parameter refinement
A.
The booming field of machine learning and artificial intelligence is transforming the field of biomolecular modeling at a swift pace. Recent advancements in generative models, such as Alpha-Fold,42 Rosetta-Fold,36 and others, have heralded a new era in the accurate prediction of structural ensembles. Leveraging the predictive power of these models as structural priors is expected to help refine ensemble predictions when integrated with similar algorithms to BICePs.43 Here, we have demonstrated that structural ensembles generated from RosettaFold2 (RF2) can be reweighted to better align with experimental measurements, while simultaneously refining Karplus parameters. Validation of these parameters by the BICePs score and other statistics demonstrates improved accuracy across a variety of structural ensembles of ubiquitin.
Automatic determination of unknown errors
B.
Our method provides a notable advantage by automatically estimating all potential error sources throughout the ensemble refinement process. This estimation is facilitated through the analysis of posterior distributions, which are instrumental in deriving accurate error assessments for the Karplus coefficients. Consequently, this negates the need for cross-validation techniques commonly used in other approaches.1,44
In previous work, we have shown how the BICePs score is a better metric model validation than the traditional χ^2^ test.6 Unlike χ^2^, which presupposes a fixed and known error, BICePs dynamically learn the complete posterior distribution of all uncertainty parameters, providing a measure of model quality that integrates over all sources of error. Our work here supports this premise.
Comparison of joint posterior sampling and variational minimization for FM parameterization
C.
Two strategies can be used for forward model parameter optimization in BICePs: joint posterior sampling and variational minimization. Joint posterior sampling, which we recommend is efficient with modern gradient-based samplers, such as Hamiltonian Monte Carlo (HMC), provides direct estimates of parameter uncertainties and covariances, and is fast in practice (50 000 steps in 15 s on a MacBook M1 Pro). Variational minimization of the BICePs score can be advantageous when handling many parameters and is straightforward to adapt for different forward models, especially in convex landscapes, but it requires repeated free energy calculations via MBAR at each epoch, resulting in longer runtimes, and its uncertainty estimates are less reliable in non-convex landscapes. Over all, posterior sampling is faster and more robust, while variational minimization may be preferable for very high-dimensional, convex problems.
Bayesian ranking of Karplus-type relations
D.
Although here we optimize Karplus relations with a standard functional form, many possible relations can be used to accommodate the diverse characteristics of molecular structures, from rigid to flexible.45 The BICePs algorithm can determine coefficients and their uncertainties for any functional form, including those with additional parameters. Although we do pursue this aim in our current work, it is straightforward to use Bayesian model selection to objectively rank empirical models based on their BICePs scores, while automatically accounting for model complexity, thus providing a balance of model accuracy and parsimony.
Application to non-natural and cyclic peptides for fine-tuning folding landscapes
E.
Our framework for forward model optimization has recently been successfully applied to a challenging test case involving a diverse set of non-natural and cyclic β-hairpin peptides.39 In that study, we used BICePs’ forward model optimization approach to refine Karplus parameters for predictions directly against experimental NMR data. With an improved Karplus relation, BICePs reshaped the folding landscapes to better agree with NMR data, enabling more accurate predictions of folding stability for each peptide. This work highlights the resolution enhancement gained by the improved forward model predictions and population reweighting using BICePs, enabling the detection of subtle changes in folding stability—such as those introduced by a sidechain hydrogen- or halogen-bonding group, which alters stability by no more than 2 kJ/mol—offering a reliable pathway for designing foldable non-natural and cyclic peptides.
The BICePs score can be used as a loss function to train neural networks and other differentiable forward models
F.
A central challenge in physical sciences is integrating domain knowledge with data-driven models. Traditional machine learning often lacks physical consistency or interpretability, while purely physics-based models may miss subtle experimental trends. One way to bridge this gap is to use the BICePs score—a free energy-based Bayesian loss—to train machine learning forward models using ensemble-averaged experimental data. This allows one to parameterize neural networks or other differentiable models in a physically grounded, uncertainty-aware fashion. In this way, BICePs provides a general-purpose learning framework for constructing interpretable, probabilistically justified forward models for complex observables. This capability may be especially valuable in contexts where observables are too complex to be modeled analytically—such as in chemical shift prediction or other nonlinear structure–observable relationships.15,46,47
To demonstrate the viability of using BICePs for neural network training, we constructed a toy model for J-coupling prediction. In this model, the backbone dihedral angle ϕ was the sole input variable. To appropriately encode the periodicity of angular data, each ϕ-angle was embedded into two dimensions via a sine–cosine transformation,
This representation ensures continuity across the periodic boundary at ±π and provides a smooth input feature space for learning.
A fully connected feedforward neural network was constructed using this 2D input, consisting of one hidden layer with 200 neurons and Gaussian Error Linear Unit (GELU) activation functions. The final output was a scalar prediction corresponding to the J-coupling value. To ensure stable training dynamics compatible with GELU, the weights were initialized using LeCun normal initialization.48
The network was trained using Adaptive Moment Estimation (ADAM) optimization for 2000 epochs with a learning rate of 10^−3^, using the Good–Bad likelihood model with the BICePs score as the loss function. The toy dataset consisted of five conformational states, each with 60 synthetic J-coupling observables using the Karplus relation J(ϕ) = A cos^2^(ϕ) + B cos(ϕ) + C, with ground truth coefficients A = 6.51, B = −1.76, and C = 1.60. Our training dataset consisted of 300 ϕ-angles as NN inputs.
First, we test the performance without adding random or systematic noise to the synthetic experimental J-coupling observables. Figure S16(a) in the supplementary material shows the convergence behavior of the BICePs’ score across five independent training runs, where a plateau is reached around step 1500. Figure S16(b) in the supplementary material shows the Karplus curves predicted by the five trained networks, along with their mean and standard deviation (blue curve). For comparison, we also include the result of singular value decomposition (SVD) applied directly to the Karplus form under the assumption that backbone ϕ angles are known precisely, as would be the case with a high-resolution crystal structure. The parameters from SVD were determined to be A = 6.47 ± 0.002, B = −1.75 ± 0.001, and C = 1.62 ± 0.001. Our framework yields comparable predictive performance, where the predictive accuracy of J-couplings for the SVD approach achieved an RMSE of 0.01 ± 0.001 Hz, while the BICePs-trained neural network reached an RMSE of 0.04 ± 0.01 Hz.
Next, we evaluate the performance when adding random or systematic noise to the synthetic experimental J-coupling observables (σdata = 0.79 Hz). Figures S17(a) and (b) in the supplementary material shows the convergence behavior of the BICePs score and gradient norm across five independent training runs, where convergence begins around 1000 epochs. The BICePs score was determined to be fξ=0→1 = 62.29 nats. Figure S17(c) in the supplementary material shows the Karplus curves predicted by the five trained networks, along with their mean and standard deviation (blue curve). Comparison against SVD illustrates that BICePs, when used to train neural networks from conformational ensembles alone, recovers predictive performance comparable with analytical fitting based on ground-truth dihedral angles, even in the presence of random and systematic errors. When comparing predictive accuracy of J-couplings, the SVD approach achieved an RMSE of 0.24 ± 0.03 Hz, while the BICePs-trained neural network reached an RMSE of 0.21 ± 0.01 Hz, demonstrating that our framework yields improved predictive performance. For completeness, we also used BICePs to optimize the parameters of the Karplus relation in this example, obtaining A = 6.6 ± 0.05, B = −1.7 ± 0.023, and C = 1.7 ± 0.037, which resulted in the lowest RMSE of 0.17 ± 0.0001 Hz. This outcome is expected since the “true” values were originally generated using the Karplus relation. By contrast, the neural network achieves remarkably low error without being constrained to any functional form, highlighting its flexibility and strong predictive capability.
Convergence of the BICePs’ score is typically accompanied by a reduction in the posterior uncertainty parameter, σ, which sharpens the likelihood landscape and amplifies gradients with respect to model parameters. In particular, the derivative of the BICePs’ score with respect to a parameter θ contains a term proportional to 1/σ^2^ [see Eqs. (12) and (13)], meaning that as σ → 0, the sensitivity of the loss to prediction errors increases.
During training of the NN-based forward model, the posterior sampling of σ plays a critical role in regularization. If σ were held fixed during training, the model would be limited in its ability to adjust the sharpness of the likelihood surface and could fail to reach an optimal fit to the data. By treating σ as a nuisance parameter and marginalizing over it within the BICePs framework, the model adaptively tunes the effective strength of the loss function, yielding an implicit form of regularization. This dynamic adjustment helps stabilize training and ensures neural network parameters are optimized in a manner consistent with both the experimental data and the underlying physical ensemble.
Despite these advantages, neural networks trained on limited or biased datasets can still face overfitting risks. Several mitigation strategies can be incorporated within the BICePs training framework: (1) data augmentation via additional synthetic observables or sampling of underrepresented dihedral regions, (2) regularization through dropout layers to discourage over-parameterization, and (3) physically informed constraints on network architecture or inputs, such as torsional symmetries—as we did for J-coupling or local environment descriptors for chemical shifts. These strategies, combined with the adaptive regularization provided by marginalizing over σ, further safeguard against overfitting and improve model generalizability.
While this toy model serves as a useful proof-of-concept, the broader applicability of our framework is in modeling more complex observables such as NMR chemical shifts. These observables are typically nonlinear and high-dimensional functions of atomic coordinates, making them difficult to model analytically. In contrast, neural networks trained using BICePs can serve as flexible surrogates for such forward models. Importantly, this framework supports the simultaneous training of multiple neural networks, each targeting a distinct observable—for example, one network may predict couplings, another couplings, and others may be used for predicting chemical shifts. In the case of backbone chemical shift prediction, a separate neural network is generally constructed for each nucleus type (e.g., Cβ, ^1^Hα, and ^1^HN), enabling specialized learning tailored to the distinct structural dependencies of each observable. All networks can be trained jointly using a shared conformational ensemble, with BICePs enforcing consistency with the corresponding experimental data.
Models have limited predictive reliability in regions lacking sufficient training data. A central advantage of our framework lies in its ability to incorporate physically relevant information through the choice of input features or explicit regularization. In our example, using the toy model system, we employed the backbone dihedral angle ϕ as the sole input feature (projected to the unit circle to maintain periodicity). However, neural network inputs can encompass a broader range of features for complex observables such as chemical shifts, including quantum calculations, partial charges, descriptors of local atomic environments, interatomic distances, hydrogen bonding patterns, solvent accessibility, or torsional strain energies. These diverse features encode crucial structural and electronic contexts and can be precomputed from molecular simulations or quantum calculations before training.
We did not impose physical constraints or priors when training our model to predict J-coupling constants. Users might explicitly incorporate such physical priors or constraints through architectural designs, regularization terms, or physically informed input features, especially critical when dealing with sparse or unevenly distributed training data. For instance, in our experiments, neural networks employing Rectified Linear Unit (ReLU) activations struggled to accurately predict J-couplings at backbone dihedral angles greater than +90°. In contrast, GELU activations provided smoother and more reliable extrapolation in these underrepresented regions. Thus, choosing suitable activation functions and rich input features improves predictive accuracy across the conformational landscape.
Relation to mixture-based outlier models and multi-level outlier severity
G.
Our outlier-aware Good-and-Bad likelihood model uses a two-component mixture M = 2 of variances. One of the components serves to reduce the influence of data affected by systematic error, while the other component functions to preserve the influence of “good” data. A natural extension of the Good–Bad model replaces a single “bad” mode with multiple levels of outlier severity.
In reliability and survival analysis, censored finite-mixture models help separate heterogeneous data while accounting for censoring. For example, Akhtar and Alharthi49 apply a censored two-component mixture of geometric distributions under a Bayesian framework, illustrating how finite mixtures capture central trends while disregarding extreme values. Although distinct from our context, it illustrates the broader principle that finite mixtures model structured heterogeneity rather than ad hoc data exclusion.
For a natural extension to our Good–Bad model, we assign p(σj|σ0) from Eq. (7) to be a multi-severity Good–Bad prior
where ωm ≥ 0 are mixture weights with and the severity inflators satisfy φ1 ≡ 1 < φ2 < ⋯ < φM. Thus, φm scales the typical uncertainty σ0 to represent increasingly severe outliers (mild → severe). The standard two-component Good–Bad model is recovered at M = 2.
Inserting Eq. (23) into the integrand of Eq. (7) gives, for each observable j,
i.e., each observation is evaluated under a finite Gaussian scale mixture with the Heaviside factor enforcing the σ^SEM^ lower bound.
If we integrate out the mixing weights ωm as in our two-component case, a uniform Dirichlet prior that is flat on the simplex ωm ≥ 0, ∑mωm = 1 implies by symmetry, leading to
Practically, this multi-severity formulation leaves a single Bayesian uncertainty parameter and introduces M − 1 free severity parameters φm (with φ1 = 1 fixed) to be inferred in the posterior. This extends the single-severity Good–Bad model used in our framework (where only a single φ is sampled alongside ) and provides finer control over how aggressively outliers are down-weighted.
CONCLUSION
V.
In the quest for accurate forward model predictions, specifically for J-coupling, researchers often navigate the vast literature seeking Karplus parameters that align with their specific systems, occasionally settling for less-than-ideal solutions. Our work demonstrates that BICePs can be used as a robust tool for determining forward model (FM) parameters by sampling over the full posterior distribution of their values and uncertainties.
We used a toy model of protein dihedral angles to demonstrate that posterior sampling and variational minimization of the BICePs score are valid and robust approaches for FM parameter refinement. Using structural ensembles and experimental data for ubiquitin, we applied BICePs with posterior sampling to optimize six different sets of Karplus coefficients using different types of J-coupling measurements, while effectively addressing both random and systematic errors.
From these results, one can see how BICePs can be applied more generally to optimize a wide variety of forward models, including those represented by neural networks. By treating the BICePs score as a physically grounded loss function, our framework enables the training of data-driven forward models that are consistent with ensemble-averaged experimental observables and incorporate principled uncertainty quantification. These advances not only contribute to the refinement of molecular simulations but also provide a scalable and extensible machine learning approach for physical sciences, with applications in structural dynamics, model validation, and the construction of predictive, interpretable models across a broad spectrum of data regimes.
SUPPLEMENTARY MATERIAL
The supplementary material includes appendices describing second derivatives of the BICePs score and the equivalence of joint posterior sampling and variational minimization; a supplementary methods section describing more details about structural ensembles and posterior sampling; supplementary material, Figs. S1–S17.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1T. Fröhlking, M. Bernetti, and G. Bussi, “Simultaneous refinement of molecular dynamics ensembles and forward models using experimental data,” J. Chem. Phys. 158, 214120 (2023).10.1063/5.015116337272569 · doi ↗ · pubmed ↗
- 2A. C. Wang and A. Bax, “Determination of the backbone dihedral angles ϕ in human ubiquitin from reparametrized empirical Karplus equations,” J. Am. Chem. Soc. 118, 2483–2494 (1996).10.1021/ja 9535524 · doi ↗
- 3M. Habeck, W. Rieping, and M. Nilges, “Bayesian estimation of Karplus parameters and torsion angles from three-bond scalar couplings constants,” J. Magn. Reson. 177, 160–165 (2005).10.1016/j.jmr.2005.06.01616085438 · doi ↗ · pubmed ↗
- 4J. M. Schmidt, M. Blümel, F. Löhr, and H. Rüterjans, “Self-consistent 3J coupling analysis for the joint calibration of Karplus coefficients and evaluation of torsion angles,” J. Biomol. NMR 14, 1–12 (1999).10.1023/a:100834530394221136331 · doi ↗ · pubmed ↗
- 5V. A. Voelz, Y. Ge, and R. M. Raddi, “Reconciling simulations and experiments with BI Ce Ps: A review,” Front. Mol. Biosci. 8, 661520 (2021).10.3389/fmolb.2021.66152034046431 PMC 8144449 · doi ↗ · pubmed ↗
- 6R. M. Raddi, T. Marshall, Y. Ge, and V. A. Voelz, “Model selection using replica averaging with Bayesian inference of conformational populations,” J. Chem. Theory Comput. 21, 5880 (2025).10.1021/acs.jctc.5c 0004440456681 · doi ↗ · pubmed ↗
- 7V. A. Voelz and G. Zhou, “Bayesian inference of conformational state populations from computational models and sparse experimental observables,” J. Comput. Chem. 35, 2215–2224 (2014).10.1002/jcc.2373825250719 · doi ↗ · pubmed ↗
- 8H. Wan, Y. Ge, A. Razavi, and V. A. Voelz, “Reconciling simulated ensembles of apomyoglobin with experimental hydrogen/deuterium exchange data using Bayesian inference and multiensemble Markov state models,” J. Chem. Theory Comput. 16, 1333–1348 (2020).10.1021/acs.jctc.9b 0124031917926 · doi ↗ · pubmed ↗