Combination of partial least square structural equation modeling scheme of principal component analysis with importance performance analysis
Bambang Widjanarko Otok, Zulfani Alfasanah, Diaz Fitra Aksioma

TL;DR
This paper introduces a new method combining PCA and PLS-SEM with IPA to better understand and prioritize factors affecting child malnutrition in East Java.
Contribution
A novel PCA-based weighting scheme for PLS-SEM integrated with IPA for indicator prioritization.
Findings
Socio-economic conditions most strongly influence food security, parenting, and health–environment services.
Exclusive breastfeeding is identified as a priority for intervention through IPA.
The method improves PLS estimation stability and provides actionable policy insights.
Abstract
•PCA is used in the inner weighting scheme of the PLS model to obtain latent variable scores.•PLS-IPA explains the influence between latent variables and indicators while mapping indicators based on importance and performance. PCA is used in the inner weighting scheme of the PLS model to obtain latent variable scores. PLS-IPA explains the influence between latent variables and indicators while mapping indicators based on importance and performance. Structural Equation Modeling (SEM) is widely used to assess causal relationships among latent variables, yet its strict assumptions often limit empirical applications. Partial Least Squares SEM (PLS-SEM) offers greater flexibility, but the choice of weighting scheme remains a methodological challenge. This study introduces a PCA-based weighting scheme to improve the stability and accuracy of PLS estimation. Importance-Performance Analysis…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
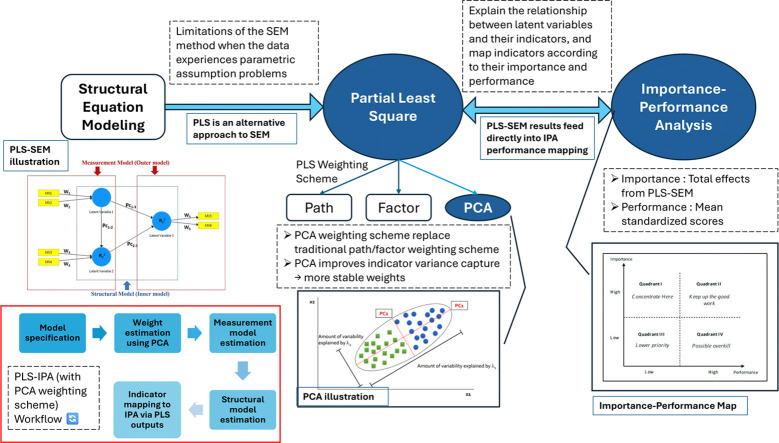 Figure 1
Figure 1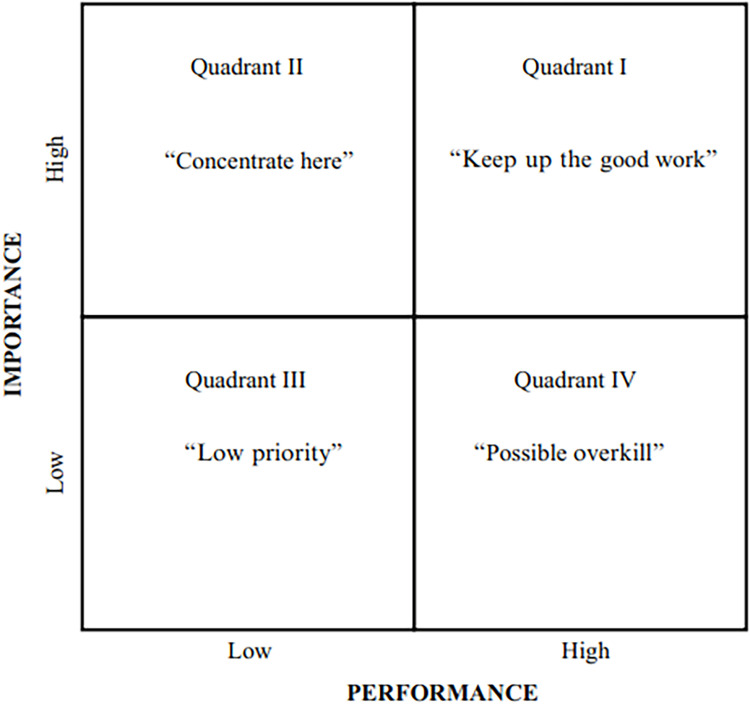 Figure 2
Figure 2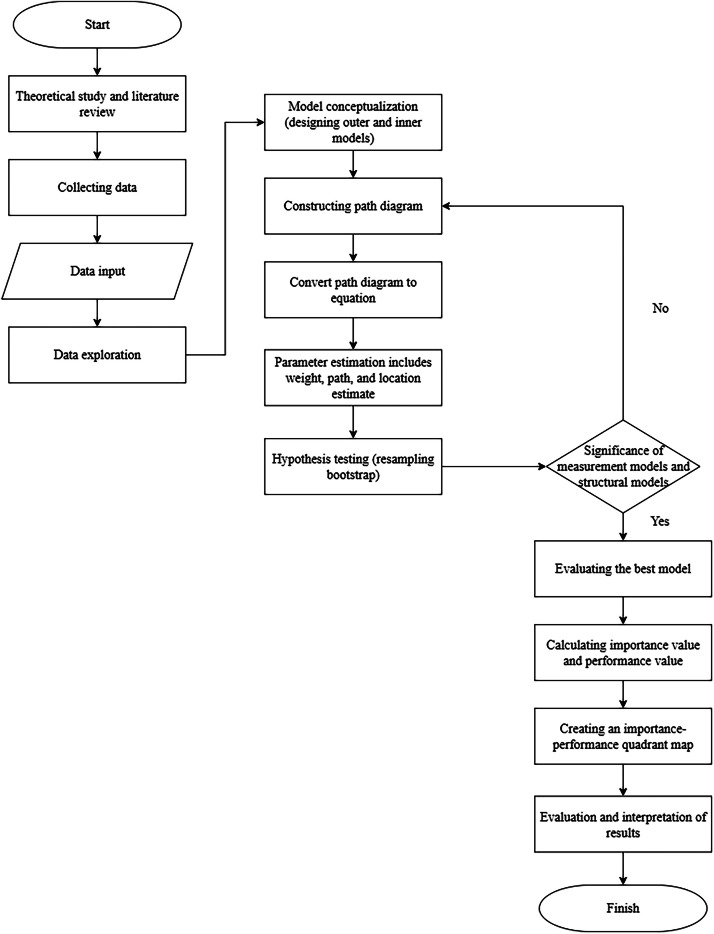 Figure 3
Figure 3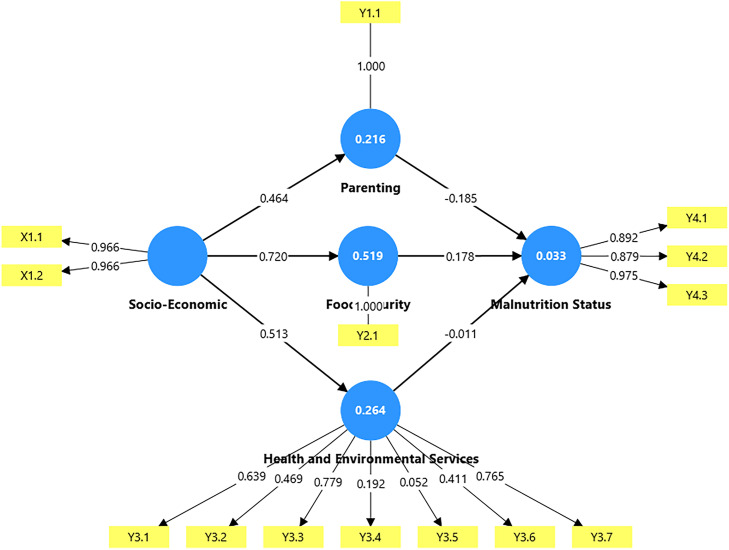 Figure 4
Figure 4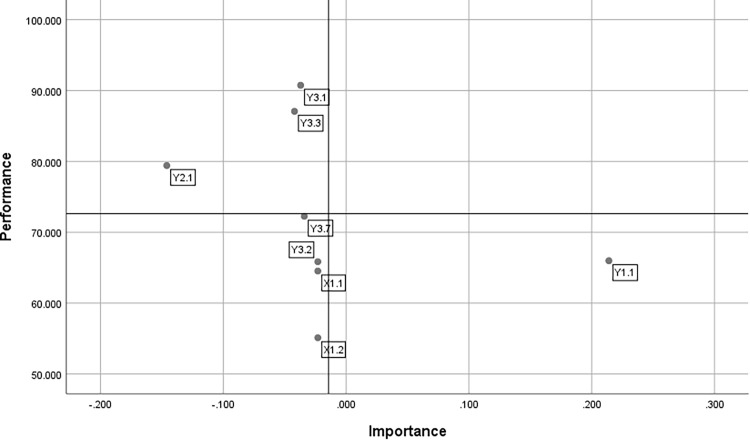 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPsychometric Methodologies and Testing · Child Nutrition and Water Access · Statistical Methods in Epidemiology
Specifications table Subject areaMathematics and StatisticsMore specific subject areaStatistics; Multivariat Data Analysis; Structural Equation ModelingName of your methodPartial Least Square – Importance Performance AnalysisName and reference of original methodB. W. Otok, Purhadi, R. Sriningsih, and D. S. Dila, “Segmentation of toddler nutritional status using REBUS and FIMIX partial least square in Southeast Sulawesi,” MethodsX, vol. 12, p. 102515, 2024, doi: 10.1016/j.mex.2023.102515.Resource availabilitySmartPLS, RStudio
Background
Structural Equation Modeling is a multivariate statistical method that integrates regression analysis, factor analysis, and path analysis to model complex relationships between variables. Despite its widespread use, conventional SEM has methodological limitations, particularly the assumptions of multivariate normality, independence of observations, and the need for relatively large sample sizes. In empirical research, data often do not meet these requirements, especially when sample sizes are limited or data distributions are non-normal [1].
As an alternative, Partial Least Squares Structural Equation Modeling was developed to address these limitations. PLS-SEM operates without the assumption of a normal distribution, can be used on various data scales, works with small sample sizes, and is suitable for exploratory research and initial theory development. Based on a composite approach, PLS-SEM allows for the estimation of causal relationships between latent variables, even when the model being analyzed is complex [2].
In the PLS-SEM algorithm, there are three commonly used weighting schemes: path, centroid, and factor. Each scheme has distinct characteristics, including causal orientation, sensitivity to correlations between latent variables, and requirements for specific data conditions [3]. This study integrates Principal Component Analysis into PLS-SEM as a scheme for selecting inner model weights. PCA reduces data dimensionality by extracting principal components, thus making the weight estimation process more structured and focused on components with the greatest contribution to data variance. This method aims to transform a set of correlated variables into a new set of uncorrelated variables, referred to as principal components [4].
Furthermore, various PLS-SEM extensions have been developed to expand the analysis capabilities. Previous studies still tend to use standard PLS path modeling, while advanced approaches such as FIMIX-PLS, PLS-POS, CTA-PLS, moderator analysis, and multigroup analysis have not been widely utilized [5]. One development in this research is Partial Least Squares Importance-Performance Analysis, which combines the dimensions of importance and performance to map construct and indicator priorities. IPA is an approach used to evaluate the quality of a system based on its level of importance and performance achievement. IPA is flexible because it can be used on various types of data, both qualitative and quantitative, and can be integrated with other analysis techniques to strengthen interpretations [6].
Several previous studies support this research. Hock et al. (2010) used PLS and IPA to evaluate visitor satisfaction factors at a multifunctional stadium [7]. Hauff et al. (2024) combined IPA, PLS, and Necessary Condition Analysis in an integrative analytical framework [8]. In the health sector, Lee et al. (2021) applied IPA to examine adolescents' health perceptions during the COVID-19 pandemic [9], Lefrandt et al. (2016) combined SEM and IPA to evaluate pedestrian satisfaction on pedestrian paths in Manado City [10]. In health and environmental contexts, IPA has also been used to identify priority intervention factors and examine the distribution of resource [6].
However, studies specifically combining the PLS-SEM PCA scheme with IPA are still limited. Therefore, this study aims to fill this gap by examining the application of the combined PLS-SEM PCA scheme with IPA in a relevant empirical context.
Method details
Partial least squares structural equation modeling
PLS-SEM is a flexible technique for analyzing latent variables represented by multiple observed indicators. Unlike covariance-based SEM, which relies on a covariance-oriented framework, PLS-SEM employs a variance-based approach. This makes it particularly advantageous when dealing with data limitations such as small sample sizes, categorical or non-interval scales, missing values, non-normal distributions, or multicollinearity. One of its main benefits is its ability to handle all types of measurement scales (nominal, ordinal, interval, and ratio) with relatively relaxed statistical assumptions. Unlike covariance-based SEM, PLS-SEM does not require strict conditions such as multivariate normality, rigid measurement specifications, or large sample sizes. This makes it highly effective for addressing multicollinearity and especially suitable for exploratory research [2].
The structural model specifies theoretical relationships among latent variables, can be written as Eq. (1).
where η and ξ represent endogenous and exogenous latent variables, respectively. Path coefficients in matrices B and Γ quantify direct and indirect effects between latent variables. The measurement model defines how latent variables relate to their observed indicators, either reflectively or formatively [11].
In reflective models, indicators mirror their latent variable, as represented by Eqs. (2) and (3).
In these equations, and represent the loading matrices connecting latent variables with their indicators, while and are the measurement error terms for endogenous and exogenous indicators, respectively. The parameters p and q indicate the number of indicators for endogenous and exogenous latent variables, whereas m and n denote the number of latent variables [11].
Since both structural and measurement models are defined conceptually, the scores of latent variables are not directly observed. To obtain these scores, outer weights must be estimated. A major strength of PLS-SEM is that it allows latent variable scores to be computed as linear combinations of their observed indicators. These scores are derived using iterative weight estimation procedures in the PLS algorithm, as represented in Eqs. (4) and (5), where and are the weights used to estimate the latent variables and , respectively [12].
The main aim of PLS-SEM is to predict and explain the variance in endogenous latent variables by estimating a system of hypothesized relationships, similar to the principle used in Ordinary Least Squares (OLS) regression [13]. Parameter estimation in PLS-SEM proceeds through a two-stage algorithm. In the first stage, the model iteratively estimates outer weights and latent variable scores. It starts with an outside approximation—computing latent scores as linear combinations of their indicators—then updates these scores through inside approximation using inner weights derived from one of three schemes: path, centroid, or factor weighting. The process repeats until convergence, indicated when the change in outer weights between iterations falls below a set threshold (typically 10⁻⁵). Once convergence is achieved, the final latent variable scores are used to estimate the relationships among latent variables. The second stage applies Ordinary Least Squares regression to obtain path coefficients for the structural model and loadings for the measurement model, thus allowing simultaneous evaluation of both models without strict data assumptions [14]
- •Bootstrap Method in PLS
Since PLS-SEM does not require the data to follow a multivariate normal distribution, conventional parametric significance tests for path coefficients, loadings, and outer weights cannot be applied. Instead, PLS utilizes a nonparametric resampling technique to assess the significance of its model parameters [13]. The bootstrap method, first proposed by Efron (1979), is a nonparametric inference approach designed to overcome issues tied to normality assumptions. It serves to estimate parameters of an unknown population distribution, measure sampling variability, and calculate standard errors. In general, the approach is carried out on a data sample from a population with an unknown distribution function, namely F, to estimate the parameter [15].
Within the PLS context, bootstrapping entails taking samples with replacement from the original dataset to produce pseudo-samples that preserve the characteristics of the original data. This repeated resampling allows for the calculation of standard errors, which are then used to evaluate the reliability and significance of estimates in both the measurement and structural models. The bootstrap standard error for an estimator θ ^ is defined as the standard deviation of the B bootstrap replications, as shown in Eq. (6).
where is the number of resampling sets of size n with replacement, and is the original data statistic calculated from repeated samples b . is defined as a plug-in estimate of as a substitute for the unknown distribution of F and is defined as [16].
The procedure for estimating standard errors using the bootstrap method involves several steps carried out sequentially. First, B independent bootstrap samples of size n are generated by drawing observations with replacement from the original dataset X. Next, the model parameters are estimated for each of these B bootstrap samples, resulting in B replications of the parameter estimates. Finally, the standard error for each parameter is calculated based on the variability observed across these B replications, following the formula described earlier [15].
In the measurement model, bootstrapping makes it possible to test whether factor loadings significantly differ from zero. The bootstrap-derived standard errors are then used to perform a t-test, as expressed in Eq. (7), where is the estimated value of and is the standard error for [13].
Likewise, in the structural model, the same principle applies for testing hypotheses related to path coefficients (β and γ). Their t-statistics are calculated following Eqs. (8) and (9). As the name suggests, the test statistic follows a t-distribution with degrees of freedom (df) of the number of observations minus 1 (n – 1). The t-distribution is approximated by a normal (Gaussian) distribution for observations greater than 30. In bootstrapping, the number of observations often exceeds the threshold (>1000 bootstrap samples). Therefore, when the t-test statistic value exceeds the critical limit of 1.96, it can be assumed that the loading factor or path coefficient value is significantly different from zero at the 5 % significance level ( ; two-tailed test) [13].
- •PLS Model Evaluation
Model evaluation in PLS is conducted using a nonparametric, predictive approach. The evaluation process includes assessing both the measurement model and the structural model [17].
- a)Structural Model
Evaluation of the measurement model with reflective indicators consists of validity and reliability.
- Validity
A latent variable is declared valid if it meets convergent and discriminant validity. Convergent validity indicates the extent to which indicators reflecting a latent variable are positively correlated. This is evaluated through factor loadings (ideal > 0.7, tolerance > 0.5) and Average Variance Extracted (AVE > 0.5), indicating that the indicator is able to explain at least 50 % of the latent variable's variance. The calculation refers to Eq. (10), where indicates the i^th^ component loading of the indicator and [18].
Discriminant validity ensures that indicators can differentiate one latent variable from another. Evaluation is performed by examining cross-loadings (an indicator must be higher on its own latent variable than on other latent variables) and the Fornell-Larcker Criterion (the square root of a construct's AVE must be greater than its correlation with other latent variables) [18].
- Reliability
Reliability is used to assess the internal consistency of a latent variable. Two commonly used measures are Cronbach's alpha and composite reliability, with composite reliability considered more accurate. Cronbach's alpha tends to provide a lower limit value because it assumes all indicators have the same weight (or equivalence), while composite reliability does not make this assumption and is therefore more accurate in measuring latent variable reliability. This method only applies to latent variables with reflective indicators. Composite reliability values range from 0 to 1, and a latent variable is considered reliable if its value is above 0.7. Composite reliability is formulated in Eq. (11), where indicates the i^th^ component loading of the indicator and [19].
- a)Measurement Model
- Coefficient of Determination
One of the statistical indicators in evaluating a structural model is the coefficient of determination (R²). This measure indicates the proportion of variation in the endogenous latent variable that can be explained by the exogenous latent variable. An R² value of 0.19 indicates a weak influence, 0.33 indicates a moderate influence, and 0.67 reflects a strong influence. The R² calculation can be done as shown in Eq. (12) [19].
- Goodness of Fit Index
Goodness of Fit (GoF) is a single measure used to assess the overall performance of a model, namely a combination of the measurement model and the structural model. The GoF value is calculated from the multiplication of the average AVE by the average R², as shown in Eq. (13) [20].
- Q^2^ Predictive Relevance
Q^2^ predictive relevance is used to test the predictive ability of the model. If the Q² value is close to 1, then the structural model is considered to fit the data and has good predictive relevance. The calculation formula is shown in Eq. (14) [20].
Principal component analysis
PCA is a multivariate statistical technique designed to reduce the dimensionality of a dataset while preserving its most essential information. PCA transforms a set of correlated observed variables into a new set of orthogonal and uncorrelated components, known as principal components, which are linear combinations of the original indicators. These components are ordered according to the amount of variance explained, with the first principal component capturing the maximum possible variance in the data [4]. Within the PLS-SEM framework, PCA serves as one of the available weighting schemes, alongside the factor and path weighting schemes. Integrating PCA into the PLS-SEM algorithm enhances analytical efficiency by reducing indicator dimensionality and producing uncorrelated composite scores. The primary advantage of the PCA weighting scheme lies in its ability to extract the maximum variance from indicators into the latent variable scores. In contrast to the path and centroid schemes, which depend on structural model relationships, the PCA scheme prioritizes variance maximization through the first principal component, enabling more efficient and information-rich latent variable estimation [21].
Mathematically, PCA in the context of PLS-SEM seeks linear combinations of indicator variables to form latent scores. The latent score can be obtained through a linear transformation:
where is the indicator data matrix and is the weight vector chosen so that the variance of is maximized:
with the normalization constraint:
In PCA implementation, the weight vector is obtained as an eigenvector of the covariance matrix :
where is an eigenvalue indicating the amount of variance explained by that principal component. The proportion of variance represented by each eigenvector can be calculated by dividing the eigenvalue corresponding to that eigenvector by the sum of all eigenvalues. The first weight obtained from the eigenvector with the largest eigenvalue will be used to form the first latent score, which is then used in the inner regression of the PLS-SEM model. This approach ensures that the formed components capture maximum information from the indicator variables while eliminating redundancy due to correlation between indicators [21].
The following schematic outlines the sequential stages of the PLS algorithm while explicitly illustrating how Principal Component Analysis (PCA) is incorporated into the initialization and refinement of the weighting scheme.
Step 1–8: Preprocessing and Structural Mapping
- 1.Initialize an empty list structure for storing outputs.
- 2.Identify the total number of indicators.
- 3.Identify the total number of latent variables.
- 4.Identify the number of observations.
- 5.Standardize the raw dataset to generate a standardized data matrix.
- 6.Map each indicator to its corresponding latent variable.
- 7.Specify the type of outer measurement model (reflective or formative).
- 8.Convert standardized matrices into list formats for model computation.
Step 9: PCA-Based Weight Extraction
For each latent variable:
- •Extract the associated standardized indicator block.
- •Perform Principal Component Analysis (PCA) on the block.
- •Extract the loading vector of the first principal component (PC1).
- •Normalize the loading vector such that the sum of absolute values equals one.
- •Treat this normalized vector as the final weight vector for the latent variable.
Step 10–12: Latent Variable Score Construction and Outer Weight Calculation
-
Compute the latent variable score for each latent variable.
-
Compute outer weights (reflective or formative) using the PCA-based latent variable score.
-
Apply outside approximation as required by the measurement model.
Step 13–16: Structural and Measurement Model Estimation
-
Identify exogenous latent variables.
-
Assemble a matrix of exogenous latent variable scores.
-
Estimate path coefficients using ordinary least squares (OLS).
-
Compute outer loadings.
Step 17: Estimation of Location Parameters
- Compute the location parameters , , , and to adjust the latent variable score positions.
These corrections ensure comparability across latent variables and align the results with PLS-IPA requirements.
The application of the PCA scheme in PLS-SEM offers several significant advantages over conventional weighting schemes. First, PCA can handle multicollinearity issues by transforming correlated variables into orthogonal components. Second, the focus on variance maximization allows for optimal information extraction from the dataset. Third, the numerical stability achieved by PCA provides more consistent convergence in the PLS-SEM algorithm, especially in situations with high data complexity [22].
Importance-Performance analysis
The Importance-Performance Analysis (IPA) method is an approach to assessing service quality based on the level of importance and customer satisfaction. IPA analysis uses a quadrant diagram with two main dimensions: importance on the vertical axis and satisfaction on the horizontal axis. The intersection of the two axes is determined by the average importance and satisfaction values. Through this mapping, service providers can identify attributes that need to be maintained or improved to optimize customer satisfaction [10].
IPA has been widely applied in various fields, such as marketing and management, and customer satisfaction studies, as it helps organizations set strategic priorities. In IPA, factors are mapped into four quadrants as seen in Fig. 1. The first quadrant (Keep Up the Good Work) includes factors with high importance and performance, which should be maintained as organizational strengths. The second quadrant (Concentrate Here) contains important factors with low performance, and therefore should be prioritized for improvement. The third quadrant (Low Priority) contains factors with low importance and performance, which do not require significant attention unless their relevance increases in the future. Meanwhile, the fourth quadrant (Possible Overkill) indicates factors with high performance but low importance, and therefore resource allocation for this aspect should be reviewed [23].Fig. 1IPA Base Map.Fig 1
PLS-IPA
Partial Least Squares is a composite-based structural equation modeling approach in which a latent variable is represented as a weighted combination of its indicators [14]. This method allows the calculation of a composite score, often interpreted as a performance value, representing respondents' assessments of a particular attribute or latent variable. For example, if respondents indicate maximum satisfaction with a latent variable, this is reflected in a performance score of 100 % [24]. The basic characteristics of PLS-SEM were then utilized in the development of standardized performance indices. Based on this principle, subsequent studies combined performance scores from PLS-SEM with importance measures derived from weights in structural and measurement models. The resulting integration gave rise to the Partial Least Squares-Importance Performance Analysis (PLS-IPA) method. In PLS-IPA, importance scores are plotted on the horizontal axis, while performance scores are displayed on the vertical axis. This mapping visualizes the strategic position of the latent variable relative to the intended outcome variable. To assess importance, PLS-IPA generally uses total effects in structural models, which include both direct and indirect influences between latent variables. This method provides a comprehensive overview of the extent to which antecedent latent variables influence the target outcome. Latent variables with high total effects but low performance are prioritized for improvement, as their improvement has the potential to have a significant impact [8,25].
The performance aspect itself is represented by the average score for each latent variable. This score can be calculated using either standardized or unstandardized data. However, standardized scores (z-transformed) are less useful because they always have a mean of zero and a standard deviation of one. Conversely, unstandardized scores are preferred because they remain on the original measurement scale, making them easier to interpret in practice. Challenges arise when the scales between indicators differ; for this, rescaling is performed to a range of 0–100, where 0 indicates the lowest performance and 100 the highest performance (Eq. (15)). This rescaling can use theoretical or empirical minimum and maximum values, so that results between latent variables can be compared equally [26].
Scaled latent variable scores are calculated as a linear combination of rescaled indicators with adjusted external weights. These weights are obtained by transforming standardized weights into unstandardized weights, then normalizing them to total one in each measurement model. The final result is a performance score ranging from 0 to 100, which is then combined with the importance score to construct an importance-performance map [26].
The importance values are obtained from the total effects of the indicators on the target latent variable, which are calculated by multiplying the rescaled outer weights of the indicators belonging to a predecessor latent variable with the unstandardized total effect of that latent variable on the target latent variable. In this sense, importance reflects the extent to which an indicator, through its associated latent variable, contributes to explaining the target latent variable. Conversely, the performance values are derived from the mean values of the rescaled data of each indicator, thereby representing the actual level of achievement of the indicators on a standardized scale. By integrating both importance and performance values across all indicators, an importance-performance map can be constructed. This analytical tool provides a systematic framework for identifying indicators that exert a substantial influence on the target latent variable but exhibit relatively low performance, thus offering critical insights for prioritizing managerial actions, resource allocation, or policy interventions [27].
In PLS-IPA, latent variables are placed into four quadrants based on the combination of their importance and performance. latent variables with high importance and high performance should be maintained, while latent variables with importance but low performance should be prioritized for improvement. Latent variables with low importance and performance require minimal attention, while latent variables with high performance but low importance may indicate overallocation of resources. Thus, PLS-IPA serves as a strategic tool that helps decision-makers accurately identify priority areas for intervention to optimize organizational outcomes [26].
The research methodology that has been described follows a sequential process outlined through the stages depicted in the flow diagram in Fig. 2.Fig. 2. Research Flowchart.Fig 2
To enhance the reproducibility of the proposed methodological approach, this study outlines a concise workflow for conducting PLS-IPA using SmartPLS 4. The procedure begins with specifying the structural and measurement models, ensuring that all latent constructs and indicators are appropriately defined. After data preparation and validation, the analysis proceeds to the IPMA module, which augments traditional PLS-SEM results by jointly evaluating construct importance and performance. Within the IPMA settings, the weighting scheme in the PLS setup is configured to PCA (Principal Component Analysis). This choice replaces conventional path or factor weighting procedures by generating latent variable scores based on the principal components of their indicators. Other parameters—such as standardized results and default initial weights—are retained to maintain comparability across replications. These settings operationalize the methodological contribution of integrating PCA-based weights into the PLS framework.
The IPMA estimation is then executed by selecting Start calculation, prompting SmartPLS to compute both importance values (total effects on the target construct) and performance scores (latent variable means scaled from 0 to 100). The resulting report includes tabular and graphical outputs that help identify indicators or constructs with high importance but low performance, supporting targeted policy recommendations. To further strengthen reproducibility, researchers are encouraged to document the exact software version used, preserve the SmartPLS project file, and provide supplementary materials such as pseudocode or workflow summaries. Such documentation is particularly beneficial for users unfamiliar with PCA-based weighting schemes and ensures that the proposed PCA-enhanced PLS-IPA procedure can be implemented consistently across future studies [22].
Method validation
Data collection
This study uses secondary data sourced from the 2022 East Java Health Profile, the 2022 East Java Education Statistics, the 2022 Food Security Index Book, and several publications from Badan Pusat Statistik (BPS) in 2022. The data represent conditions in 2022 with the analysis unit covering 38 districts/cities in East Java Province. The study focused on five latent variables, namely socioeconomic status, food security, childcare practices, health and environmental services, and child malnutrition status. Each latent variable is measured through a number ofindicators compiled based on the conceptual framework and references from previous studies [[28], [29], [30], [31], [32], [33]]. Details of the latent variables and their indicators are shown in Table 1.Table 1. Research variable.Table 1. Latent VariableIndicatorSocio-EconomicX_1.1_Per capita expenditureX_1.2_Average years if schoolingX_1.3_Percentage of poor populationParentingY_1.1_Proportion of infants exclusively breastfedFood SecurityY_2.1_Food security index scoreHealth and Environmental ServicesY_3.1_Proportion of toddlers receiving vitamin AY_3.2_Proportion of pregnant women receiving iron tabletsY_3.3_Proportion of toddlers fully immunizedY_3.4_Proportion of neonatal visits for infantsY_3.5_Percentage of households with access to safe drinking waterY_3.6_Percentage of households with access to proper sanitationY_3.7_Coverage of antenatal care for pregnant womenMalnutrition StatusY_4.1_Prevalence of stuntingY_4.2_Prevalence of wastingY_4.3_Prevalence of underweight
Parameter estimation
The parameter estimation in the PLS-SEM modeling in this study used the PCA scheme. The PCA scheme was chosen because it can generate latent variable scores based on linear combinations of its indicators, thus capturing the greatest variance in the data. The PCA scheme also supports the research objective of identifying relationships between latent variables in the model of malnutrition in toddlers in East Java.
Parameter estimation was performed using the least squares method to obtain the parameter coefficients for the measurement model and the parameter coefficients for the structural model. The parameter coefficients for the measurement model are as follows. a. Exogenous Latent Variable Indicators
b. Endogenous Latent Variable Indicators
The coefficient values of the structural model parameters are as follows:
These values are then entered into the equation so that the equation for each PLS scheme is as follows:
The results of the parameter estimation obtained can also be seen in Fig. 3.Fig. 3. Research path diagram and parameter estimation.Fig 3
Model evaluation
- •Measurement Model Evaluation
As a first step, a measurement model evaluation was conducted to identify valid and reliable indicators for each latent variable. This process included testing the validity and reliability of the indicators in relation to their respective latent variables. Indicator validity was assessed through the factor loading value, which represents the level of correlation between the indicator and the latent variable it measures.
Validity evaluation was conducted by observing the loading factor value for each indicator. Indicators were declared valid if they had a loading factor > 0.5, while indicators with a loading factor < 0.5 were deemed invalid and therefore needed to be eliminated because they were unable to adequately represent the latent variable. Based on Table 2, several indicators had loading factors < 0.5: the proportion of pregnant women receiving iron supplements (Y_3.2_), the proportion of neonatal visits for infants (Y_3.4_), the percentage of households with access to safe drinking water (Y_3.5_), and the percentage of households with proper sanitation (Y_3.6_). Meanwhile, other indicators with loading factors > 0.5 were declared valid in reflecting the latent variables being measured. Table 2 shows that per capita expenditure and average years of schooling contributed equally to shaping the socioeconomic latent variable. In the health and environmental services latent variable, the proportion of toddlers receiving complete basic immunizations was recorded as the indicator with the largest contribution. Meanwhile, in the malnutrition status latent variable, the most dominant indicator was the prevalence of underweight.Table 2. Evaluation of convergent validity with loading factor values.Table 2. Latent VariableIndicatorLoadingsInformationSocio-EconomicX_1.1_0.966ValidX_1.2_0.966ValidParentingY_1.1_1.000ValidFood SecurityY_2.1_1.000ValidHealth and Environmental ServicesY_3.1_0.639ValidY_3.2_0.469Not validY_3.3_0.779ValidY_3.4_0.192Not validY_3.5_0.052Not validY_3.6_0.411Not validY_3.7_0.765ValidMalnutrition StatusY_4.1_0.892ValidY_4.2_0.879ValidY_4.3_0.975Valid
The convergent validity test was also continued by assessing the Average Variance Extracted (AVE). If the AVE value is > 0.5, the indicator is able to explain the variance of the latent variable well. The AVE values for each latent variable can be seen in Table 3.Table 3. Evaluation of convergent validity with AVE.Table 3. Latent VariableAVEInformationSocio-Economic0933ValidParenting1000ValidFood Security1000ValidHealth and Environmental Services0290Not validMalnutrition Status0840Valid
Based on Table 3, it is known that the latent variables for health service facilities and the environment do not meet the convergence criteria. This finding is consistent with the results of previous tests based on factor loading values, which indicated that there were still invalid indicators within the latent variable.
Indicator validity was also tested using cross loading, which is used to assess discriminant validity. Cross loading indicates the level of correlation between an indicator and its original latent variable and other latent variables. Discriminant validity is considered good if the indicator's cross-loading value with the original latent variable is higher than its correlation with other latent variables. The cross loading values for the indicators are shown in Table 4.Table 4. Evaluation of discriminant validity with cross loading values.Table 4. Latent VariableIndicatorLatent VariableSocio-EconomicParentingFood SecurityHealth and Environmental ServicesMalnutrition StatusSocio-EconomicX_1.1_0.9660.4380.6390.490−0.020X_1.2_0.9660.4590.7520.5020.036ParentingY_1.1_0.4641.0000.4990.401−0.101Food SecurityY_2.1_0.7200.4991.0000.4980.081Health and Environmental ServicesY_3.1_0.1700.4550.1790.6390.059Y_3.2_0.3240.3360.3910.4690.114Y_3.3_0.1770.3120.2980.7790.132Y_3.4_−0.069−0.160**−0.2660.192−0.179Y_3.5_0.2760.1270.1730.0520.195Y_3.6_0.5900.2000.5570.411−0.188Y_3.7_0.5220.0850.3820.765**−0.112Malnutrition StatusY_4.1_−0.101−0.174−0.032−0.1520.892Y_4.2_0.099−0.0370.1210.1350.879Y_4.3_0.024−0.0670.1280.0270.975
Table 4 shows that most indicators have higher cross-loading values for their latent variables compared to other latent variables, so it can be concluded that the measurement model has met discriminant validity well. However, there are still indicators with lower cross-loading values for their latent variables, namely the Proportion of neonatal visits to infants (Y_3.4_), the Percentage of households with access to clean drinking water (Y_3.5_), and the Percentage of households with proper sanitation (Y_3.6_). This finding confirms that both indicators are not valid in representing the measured latent variables.
Another method used to assess discriminant validity is the Fornell-Larcker criterion, which is the square root of the AVE value. A latent variable is said to have good discriminant validity if the square root of the AVE value is higher than the correlation between other latent variables. The results of testing using the Fornell-Larcker criterion are shown in Table 5. Based on Table 5, it can be seen that the Fornell-Larcker values for all latent variables are greater on the diagonal. This indicates that all indicators used have met validity requirements.Table 5. Evaluation of discriminant validity with the Fornell-Larcker Criterion.Table 5. Socio-EconomicParentingFood SecurityHealth and Environmental ServicesMalnutrition StatusSocio-Economic0.9660.4640.7200.5130.008Parenting0.4641.0000.4990.401−0.101Food Security0.7200.4991.0000.4980.081Health and Environmental Services0.5130.4010.4980.5380.004Malnutrition Status0.008−0.1010.0810.0040.916
Next, reliability testing was conducted to ensure the latent variables' internal consistency in measuring the latent variables. This reliability evaluation used composite reliability values as a measure. A latent variable is considered reliable if its composite reliability value exceeds 0.70. A summary of the composite reliability calculations for each latent variable is presented in Table 6.Table 6. Reliability evaluation with composite reliability.Table 6. Latent VariableComposite ReliabilitySocio-Economic0.965Parenting1.000Food Security1.000Health and Environmental Services0.687Malnutrition Status0.940
The reliability evaluation results in Table 6 are consistent with the validity test results, which indicate that the latent variables for health services and the environment do not meet the criteria. Meanwhile, the other latent variables have met reliability standards.
- •Structural Model Evaluation
After the measurement model evaluation stage is complete, the next step is to evaluate the structural model to assess the relationships between latent variables. This process is carried out by reviewing the coefficient of determination (R²), Q-square predictive relevance, and goodness of fit (GOF) values. The R² values for each endogenous latent variable in the model of malnutrition status among toddlers in East Java are shown in Table 7.Table 7. Model determination coefficient value.Table 7. Endogenous Latent VariableR²CriteriaParenting0.216WeakFood Security0.519ModerateHealth and Environmental Services0.264WeakMalnutrition Status0.033Weak
The R² value for the latent variable parenting patterns was 0.216, indicating that socioeconomic variables explained 21.6 % of the variation in parenting patterns, while the remaining 78.4 % was influenced by factors outside the model. The latent variable food security had an R² value of 0.519, meaning that 51.9 % of the variation was influenced by socioeconomic variables, while the remaining 48.1 % was influenced by external factors outside the model. For the latent variable health and environmental services, the R² value was 0.264, meaning that 26.4 % of the variation was explained by socioeconomic variables, while the remaining 73.6 % was influenced by other factors. Meanwhile, for the latent variable malnutrition status, food security, parenting patterns, and health and environmental services explained 3.3 % of the variation, with the remainder explained by factors outside the model.
The Q² value for predictive relevance was obtained through the following calculation.
The Q² value obtained indicates that the structural model has good predictive ability.
The overall model fit test was then performed by calculating the Goodness of Fit (GoF) value. The GoF value ranges from 0 to 1, with categories of 0.10 (low), 0.25 (moderate), and 0.36 (good). The GoF value calculation is shown below.
The calculation results show that the GoF value is 0.418, so it can be concluded that the model built is appropriate (fit) and has good ability to explain the data.
Hypothesis testing
After evaluating and estimating the measurement and structural models, hypothesis testing is conducted based on the parameter estimation results of the measurement and structural models using t-test statistics. Hypothesis testing is used to demonstrate the level of significance of each parameter of each indicator in both the measurement and structural models. For the measurement model, the proposed hypothesis can be formulated as follows:
(loading factor is not significant in measuring the latent variable)
(loading factor is significant in measuring the latent variable)
In this section, i represents the indicator index, with i = 1, 2, …, p, where p indicates the total number of indicators. The significance of the measurement model parameters was evaluated using bootstrap resampling with the number of replications B = 2000 resamplings. The test statistic used was the t-test statistic according to Eq. (7). The decision to reject if the calculated t value > or p-value < α . The significance level used was α of 5 % and t-table = 1.96. Table 8 displays the t-statistics values in the measurement model hypothesis testing.Table 8. Measurement model testing results with resampling bootstrap.Table 8. Latent VariableIndicatorLoading FactorT-StatisticsP-valueInformationSocio-EconomicX_1.1_0.966116.7630.000Valid, significantX_1.2_0.966116.7630.000Valid, significantParentingY_1.1_1.000Food SecurityY_2.1_1.000Health and Environmental ServicesY_3.1_0.6393.2840.001Valid, significantY_3.2_0.4692.0270.043Valid, significantY_3.3_0.7794.9790.000Valid, significantY_3.4_0.1920.6670.505Not valid, not significantY_3.5_0.0520.1610.872Not valid, not significantY_3.6_0.4111.4250.154Not valid, not significantY_3.7_0.7654.5690.000Valid, significantMalnutrition StatusY_4.1_0.89225.8700.000Valid, significantY_4.2_0.87919.0140.000Valid, significantY_4.3_0.975130.7180.000Valid, significant
Based on Table 8, hypothesis testing using the bootstrap resampling method supports the results of the validity and reliability evaluation, where there were still insignificant indicators in the latent variables of health and environmental services. In accordance with methodological guidelines, these invalid indicators, such as Y_3.4_, Y_3.5_, and Y_3.6_, were removed from the measurement model to enhance model robustness and improve the accuracy of construct measurement. Eliminating indicators with weak psychometric properties strengthens convergent validity, reduces measurement error, and yields more stable structural path estimates. By removing these indicators, the refined measurement model provides a more coherent and reliable representation of the latent variables [34]. Therefore, in the subsequent PLS-IPA analysis, only indicators that are both valid and statistically significant were included, ensuring that the importance-performance mapping is based on robust measurement properties and yields meaningful managerial or policy insights. Moreover, the reduction of the measurement model enhances the interpretability of the results by concentrating the analysis on indicators that genuinely represent the underlying construct. This refinement ensures that the subsequent policy recommendations derived from the PLS-IPA are more targeted, credible, and aligned with the most diagnostically relevant aspects of health and environmental services. The hypotheses tested in the structural model are formulated as follows.
- The effect of socio-economic on parenting.
- The effect of socio-economic on food security.
- The effect of socio-economic on health and environmental services.
- The effect of parenting on malnutrition status.
- The effect of food security on malnutrition status.
- The effect of health and environmental services on malnutrition status.
The significance of the structural model parameters was evaluated using bootstrap resampling with the number of replications B = 2000 resamplings. The test statistic used was the t-test statistic according to (8), (9). The decision to reject if the calculated t value > or p-value < α . The significance level used was α of 5 % and t-table = 1.96. Table 9 displays the t-statistics values in testing the structural model hypothesis.Table 9. Structural model testing results with resampling bootstrap.Table 9. PathCoefficientT-StatisticsP-valueSocio-Economic → Parenting 0.4643.9630.000Socio-Economic → Food Security 0.72010.6410.000Socio-Economic → Health and Environmental Services 0.5132.1030.036Parenting → Malnutrition Status −0.1850.8510.395Food Security → Malnutrition Status 0.1780.7710.441Health and Environmental Services → Malnutrition Status −0.0110.0530.958
Table 9 shows that food security, parenting patterns, and health and environmental services do not significantly influence cases of malnutrition among toddlers in East Java. The variables that do significantly influence food security are socioeconomic factors, parenting patterns, and health and environmental services.
PLS-IPA analysis results
After conducting the analysis using PLS-SEM, the indicators with significant influence were mapped in IPA. Fig. 4 is a map of the PLS-IPA results.Fig. 4PLS-IPA Map.Fig 4
Based on Fig. 4, the following things can be interpreted.
- •Top Priorities for Improvement
In the high importance but low performance quadrant, the indicator for the proportion of infants receiving exclusive breastfeeding (Y_1.1_) is found. This indicates that this indicator is considered important, but its performance remains low. Therefore, this indicator is a top priority for improvement through more targeted policy or program interventions to ensure optimal contribution.
- •Low Priority
In the low importance and low performance quadrant, there are indicators such as per capita expenditure (X_1.1_), average years of schooling (X_1.2_), the proportion of pregnant women receiving iron tablets (Y_3.2_), and coverage of health services for pregnant women (Y_3.7_). These indicators have a low level of importance and their performance is also still weak. Therefore, these indicators are low priority and do not need to be a primary focus in the short term, although they still need to be considered in the long-term strategy.
- •Excessive Potential
In the low-importance but high-performance quadrant, there are indicators such as food affordability score (Y_2.1_), proportion of children receiving vitamin A (Y_3.1_), and proportion of children receiving complete basic immunizations (Y_3.3_). These indicators demonstrate good performance, but their importance is relatively low. Therefore, there is potential for overallocation of resources to these indicators, necessitating re-evaluation to shift focus to more important indicators.
Based on the PLS-IPA results, several key findings can be interpreted in a structured manner. First, from the structural model, the path coefficients between latent variables show different patterns of influence: the Socio-Economic latent variable has a strong influence on Food Security ( = 0.720) and a moderate influence on Parenting ( = 0.464) and Health and Environmental Services ( = 0.513). The influence of Parenting on Malnutrition Status is negative and relatively small ( = −0.185), while the influence of Food Security on Malnutrition Status is positive and relatively small ( = 0.178), and the influence of Health and Environmental Services on Malnutrition Status is almost zero ( = −0.011). The loading values in the measurement model also indicate the quality of the indicators: several indicators, such as X_1.1_ and X_1.2_, have very high loadings (≈0.966), as does indicator for the Malnutrition Status latent variable, which demonstrates measurement consistency (≈0.879–0.975). It should be noted that the (+/−) signs on the coefficients should be interpreted according to the scale and direction of the variable coding; for example, a negative sign for the Parenting → Malnutrition Status relationship indicates an inverse relationship according to the variable definition in this study. The combination of PLS results with IPA mapping enhances interpretation: IPA provides important information about the importance of each indicator to the target latent variable, along with its performance on the rescaled scale. In the resulting IPA map, indicator Y_1.1_ (proportion of infants receiving exclusive breastfeeding) is located in the high priority quadrant (high importance, low performance). This indicates that although Y_1.1_ significantly contributes to the target latent variable, its current achievement is low—making it a candidate for priority intervention. Conversely, indicators such as X_1.1_ (per capita expenditure), X_1.2_ (average years of schooling), Y_3.2_ (proportion of pregnant women receiving iron tablets), and Y_3.7_ (maternal health service coverage) fall into the low-performance and low-importance quadrant; these indicators are categorized as low priority for immediate action, although they will continue to be monitored in the long-term strategy. On the other hand, indicators that show excessive potential—that is, high performance but low importance (e.g., Y_2.1_ food affordability score, Y_3.1_ vitamin A coverage, Y_3.3_ complete immunization coverage)—suggest the potential for overallocation of resources to areas that are less decisive in their impact on malnutrition status; these results recommend reallocating or reassessing resource priorities toward indicators with greater importance but lower performance (e.g., Y_1.1_).
The use of the Combination of Partial Least Squares Structural Equation Modeling (PLS-SEM) method — Scheme of Principal Component Analysis (PCA) — with Importance–Performance Analysis (IPA) provides a comprehensive analytical framework. PLS-SEM estimates the structural relationships between latent variables and measurement quality, while IPA maps the total contribution of indicators (importance) and their actual achievements (performance), facilitating policy prioritization. The application of the PCA scheme in the context of SEM-PLS is an iterative method for extracting principal components one by one without having to calculate the full covariance matrix. Its advantages include computational efficiency on large datasets, the ability to handle non-normally distributed data, and ease of integration with weight-based PLS estimation procedures. In SEM-PLS practice, PCA is used to latent variable composite scores or higher-order latent variables, then these weights are incorporated into the measurement and structural models to obtain consistent parameter estimates. The application of PLS-IPA enhances the analytical capabilities of research: in addition to assessing the direction and magnitude of influence between latent variables (through path coefficients), this method allows mapping of the most decisive but underperforming indicators so that policy recommendations can be more targeted and effective. By combining quantitative evidence from PLS (the magnitude and sign of coefficients, and the reliability of indicators through loading) and the results of IPA mapping (prioritization of actions based on importance vs. performance), program planners or policymakers gain dual insights—namely, where interventions will have the greatest impact and what needs to be improved first.
Limitations
This study has several limitations. First, the analysis uses only aggregate data from 2022, making it cross-sectional and unable to capture the dynamics of change over time. Second, the data used are sourced from publications by the Central Bureau of Statistics, so their quality and completeness depend on the design and implementation of the official survey. Third, although the conceptual framework refers to the UNICEF 2020 model, this study only covers indirect and underlying causal factors, while direct causal factors such as dietary intake and infectious diseases could not be analyzed due to data limitations. Fourth, the PLS-SEM approach used is exploratory, so the relationships between variables represent associations rather than definitive causal relationships. Fifth, the integration of Importance–Performance Analysis (IPA) does provide a strategic overview, but it does not fully reflect contextual factors such as culture, local policies, and social dynamics that influence children's nutritional status.
Ethics statements
The data used in this research are secondary data collected from official publications of East Java Province in 2022. The data are publicly available upon request from Badan Pusat Statistik (BPS), Indonesia.
Supplementary material and/or additional information [Optional]
None
CRediT authorship contribution statement
Bambang Widjanarko Otok: Conceptualization, Methodology, Validation, Supervision, Writing – review & editing. Zulfani Alfasanah: Validation, Visualization, Conceptualization, Methodology, Writing – original draft. Diaz Fitra Aksioma: Writing – review & editing.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sarwono J.Pengertian dasar structural equation modeling (SEM)J. Ilm. Manaj. Bisnis Ukrida.103201098528
- 2Otok B.W.Purhadi R.Sriningsih Dila D.S.Segmentation of toddler nutritional status using REBUS and FIMIX partial least square in Southeast Sulawesi Methods X 12Jun. 202410251510.1016/j.mex.2023.102515 PMC 1080566038268516 · doi ↗ · pubmed ↗
- 3Cepeda-Carrion G.Cegarra-Navarro J.-G.Cillo V.Tips to use partial least squares structural equation modelling (PLS-SEM) in knowledge management J. Knowl. Manag.23120196789
- 4Jolliffe I.T.Cadima J.Principal component analysis: a review and recent developments Philos. Trans. R. Soc. A: Math. Phys. Eng. Sci.374206520162015020210.1098/rsta.2015.0202 PMC 479240926953178 · doi ↗ · pubmed ↗
- 5Sarstedt M.Hair J.F.Pick M.Liengaard B.D.Radomir L.Ringle C.M.Progress in partial least squares structural equation modeling use in marketing research in the last decade Psychol Mark.395202210351064
- 6Matzler K.Bailom F.Hinterhuber H.H.Renzl B.Pichler J.The asymmetric relationship between attribute-level performance and overall customer satisfaction: a reconsideration of the importance–performance analysis Ind. Mark. Manag.3342004271277
- 7Hock C.Ringle C.M.Sarstedt M.Management of multi-purpose stadiums: importance and performance measurement of service interfaces Int. J. Serv. Technol. Manag.142/3201018810.1504/IJSTM.2010.034327 · doi ↗
- 8Hauff S.Richter N.F.Sarstedt M.Ringle C.M.Importance and performance in PLS-SEM and NCA: introducing the combined importance-performance map analysis (c IPMA)J. Retail. Consum. Serv.78May 202410372310.1016/j.jretconser.2024.103723 · doi ↗