Machine learning for predicting clinical outcomes of hospitalised children: a systematic review of applications in low- and middle-income countries
William Nkhono, Eva van Lieshout, Job Calis, Violet Naanyu, Mark Hoogendoorn, Kamija S. Phiri, María Villalobos-Quesada

TL;DR
This review explores how machine learning is used to predict outcomes for hospitalized children in low- and middle-income countries, highlighting its potential and challenges.
Contribution
The study systematically reviews ML applications for hospitalized children in LMICs, identifying trends and barriers to clinical adoption.
Findings
Most studies focused on mortality prediction using patient files and ensemble methods.
The median AUROC of ML models was 0.81, indicating strong predictive performance.
High-quality data and alignment with local clinical needs are critical for successful implementation.
Abstract
Machine Learning (ML) can contribute to reducing child mortality and morbidity in low- and middle-income countries (LMICs), yet its development and clinical adoption remain unclear. This systematic review provides an overview of ML for hospitalised children in LMICs. In June 2025, searches in five scientific databases and one scholarly search engine identified 26 eligible peer-reviewed studies using ML on hospitalised children under 18. Studies using only conventional statistics and perinatal data were excluded. Study quality and bias were assessed using PROBAST + AI. Descriptive statistics were used for data analysis. PRISMA reporting guideline was followed. These studies were conducted in Asia (58%) and Sub-Saharan Africa (38%), mostly retrospective (62%), and predominantly used patient files (62%). The median sample size was 1291. Prognostic models dominated (69%), primarily…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
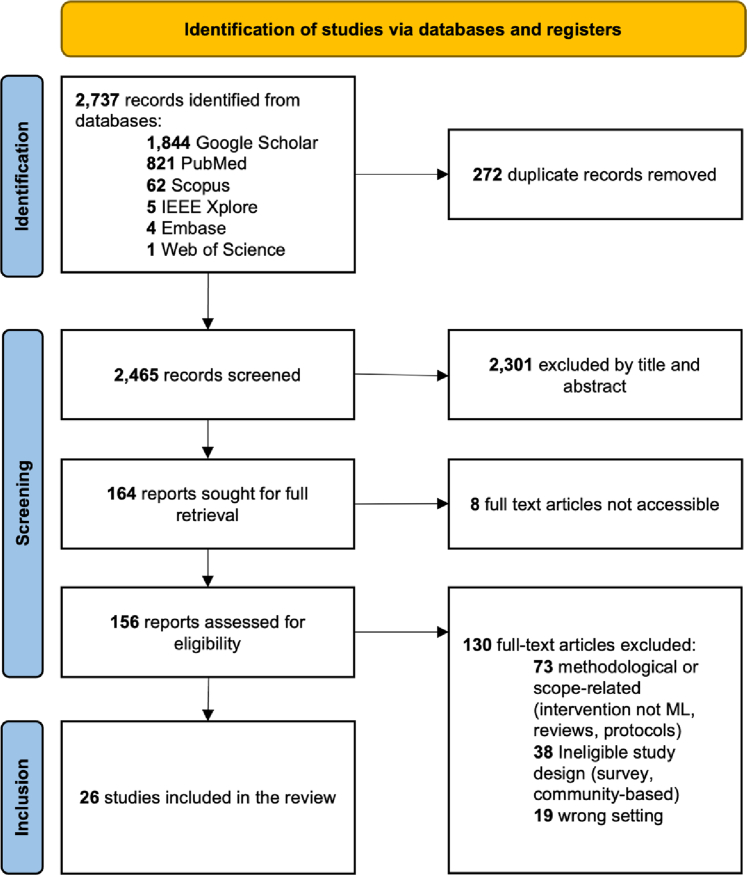 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Machine Learning in Healthcare · Advanced Causal Inference Techniques
Research in contextEvidence before this studyStudies of ML algorithms for health and healthcare have been increasing in high-income countries (HICs) and low- and middle-income countries (LMICs). However, the biggest proportion of scientific publications still comes from HICs. The development and final clinical adoption of ML in LMICs face challenges hard to overcome, such as a lack of digital infrastructure, high-quality data, skilled personnel, and a data-driven culture. Nevertheless, researchers in LMICs are making valuable contributions to the field. We searched Google Scholar, PubMed, Embase, Scopus, Web of Science and IEEE Xplore for scientific literature from database inception in October 2024 to June 2025, for papers published with no language restrictions, using the terms related to Machine Learning (ML), hospitalisation and children, with a focus on studies that apply ML to solve challenges specific to LMICs and their populations, aiming to improve access and the provision of high-quality care. Our search yielded 2737 reports.One challenge of LMICs that cannot remain unsolved is the high rate of child mortality and morbidity. Children constitute a vulnerable population whose needs should be prioritised and this is necessary to achieve the desired universal health coverage.Added value of this studyThis study makes visible the efforts to develop and use ML for paediatric in-hospital care in LMICs. It offers a critical overview of the ML tools being developed and their characteristics, providing the opportunity to understand the global landscape of these tools, and helping to identify key areas necessary to prioritise to accelerate the clinical application of ML.Implications of all the available evidenceAlthough ML holds immense potential to transform the care of hospitalised children in LMICs and models show promising predictive power according to their stage of development, ML tools still have to transition efficiently to the bedside. The readiness level of the included studies was comparable to HIC. However, the limitation of resources in LMIC, such as the lack of pre-existing data-related infrastructures, poses additional barriers to transition to clinical applications. Investing in digital infrastructure for providing care, and research and innovation in LMICs is necessary. As models become more mature, ensuring the ML's clinical relevance and building adequate evidence to determine the value of ML models in clinical practice becomes more pressing. Ethical and legal considerations such as data privacy, algorithmic bias and transparency must remain central to ML.
Introduction
More than five million children under the age of five died globally in 2020 from preventable causes, with over 80% of these deaths occurring in low- and middle-income countries (LMICs) in sub-Saharan Africa (SSA) and southern Asia.1 For children in these regions, and in LMICs in general, access to high-quality healthcare, including in-hospital care,2 remains a challenge due to limitations in timely diagnosis and effective treatment, and the acutely scarce infrastructure and medical staff.3
Machine learning (ML),4 a subdomain of artificial intelligence (AI), focuses on algorithms capable of learning from experience to improve performance at specific tasks without being explicitly programmed.5 This technique is a promising data-driven approach that can address challenges in LMICs and improve access to high-quality care.6 For instance, by leveraging available data, ML has the potential to enhance diagnostic time and accuracy where specialist expertise is scarce, for example, detecting birth asphyxia from infant cries,7 or identifying diabetic retinopathy.8 In oncology, ML has been applied to optimise the allocation of available tests and treatments where resources are limited.9 Additionally, ML has been proposed as a (partial) solution to mitigate workforce shortages, either by translating expert knowledge to local staff (for example, via smartphone-based applications), or supporting task-shifting (where non-specialists perform tasks typically reserved for specialists).10^,^11 Overall, these applications can support clinical decision-making, improving in turn, patient outcomes.12 In the case of infectious disease management, ML has been used to model and predict the occurrence of diseases such as dengue,13 thereby aiding resource allocation and preparedness within healthcare systems. Such applications can have particularly impactful effects in LMICs where the burden of preventable deaths remains high.11^,^14
Scientific research on ML is dominated by studies on populations in high-income countries (HIC).15 However, the perceived potential of ML is triggering advances in LMICs. The number of publications from LMICs on ML is rising, including applications in hospital settings.15 However, translating this research into routine clinical practice remains limited, similar to what is observed in HICs.12 Potential challenges observed in HICs, such as data scarcity, data quality, and concerns about transparency, explainability, bias, and negative effects on the work floor,5 may overlap with those in LMICs. However, challenges in LMICs are yet to be comprehensively studied.
Although ML could contribute to addressing specific challenges in LMICs, there is currently no overview of how the ML field is advancing in this setting. Additionally, comprehensive and systematic studies about potential barriers and facilitators in the development and implementation of ML models in routine clinical practice are missing. This systematic review contributes to filling that gap by providing a systematic overview of the current ML approaches used for hospitalised children to improve healthcare outcomes in low-resource settings (LRS) within LMICs.
Methods
Search strategy and selection criteria
We addressed the following research question: What ML approaches have been applied to improve health outcomes for hospitalised children in LRS within LMICs, and which barriers and facilitators have been reported for their development and implementation in clinical practice?
We focused on ML approaches developed for hospitalised children in LRS and within LMICs as defined by the World Bank.16^,^17 We defined LRS in the healthcare domain, as a setting characterised by limited access and availability to medication, equipment, supplies, devices, underdeveloped infrastructure and limited trained personnel.18
Two researchers (W.N., E.L.) systematically searched Google Scholar, PubMed, Embase, Scopus, Web of Science and IEEE Xplore for scientific literature in June 2025, without applying any date restrictions. A free-text search was carried out, based on the following string: (“artificial intelligence” OR “machine learning”) (“hospitalised” OR “admission” OR “clinical outcome”) (child∗ OR infant OR paediatric) (“low resource setting” OR “low middle-income countries”).
Studies that met the following inclusion criteria were included: (1) the study developed, tested, or applied ML techniques, (2) the study population was hospitalised children under 18 in LMICs, and (3) publications were peer-reviewed full-text original research. Studies were excluded if they exclusively employed conventional statistics. In order to distinguish ML models from conventional statistics models, we adopted the definition proposed by van Boven et al., where ML is defined as a data-driven approach, without manual selection of features and/or inclusion of more complex models such as neural networks.19 Additionally, studies were excluded when focused solely on perinatal data.20 We did not restrict the inclusion to any particular study design, language or timeframe. However, searches were carried out exclusively in English. In cases where a study developed multiple models, we reported the best-performing model.
Identified articles were exported to Rayyan AI,21 where duplicates were automatically identified and manually verified. Titles, abstracts and full texts were reviewed independently by W.N. and E.L., and discrepancies were resolved through discussion with a third reviewer (J.C). To ensure accuracy and validity, all extracted data were subsequently verified by M.V. Any remaining clinical questions were addressed to J.C., and ML questions towards M.H. The recommendations outlined in the Preferred Reporting Items for Systematic Reviews and Meta-analyses (PRISMA) were followed.22 The review was not registered in PROSPERO.
Study risk of bias assessment
We evaluated the quality, risk of bias and applicability of each study using PROBAST + AI framework, a tool designed for healthcare prediction models, whether based on regression or AI techniques.23 The assessment was carried out W.N and J.C verified a proportion of the studies. Any discrepancies or unsure studies flagged by W.N were resolved via discussion within the research team.
Data analysis
Included studies were characterised according to (1) authors, (2) title, (3) year of publication, (4) region of the study population, (5) study design, (6) sample size, (7) clinical application, (8) outcome, (9) data source and (10) type of data as defined by Annis et al.24
ML approaches were characterised according to (1) type of ML approach,25 (2) performance metrics, and (3) clinical readiness level (RL).4 The clinical RL classification was specifically developed for ML applications in intensive care, and is applicable to other hospital care settings. It comprises the following levels: (RL1) identification of the clinical problem, (RL2) proposal of model/solution, (RL3-4) model prototyping and development, (RL5) model validation, (RL6) real-time model testing, (RL7) workflow implementation, (RL8) clinical outcome evaluation, and (RL9) model integration in clinical practice.
Barriers and facilitators were categorised based on an adaptation of the themes reported by Ahmed et al., 202326: (1) data-related such as quality, acquisition and incomplete datasets, (2) computing and physical infrastructure such as servers, software, buildings, data collection machines or sensors, (3) human such as stakeholders, skills, training, (4) ethical and legal such as compliance and data privacy and (5) implementation such as clinical relevance, transparency, explainability or user acceptance.
Due to the heterogeneity of the included studies regarding clinical settings, types of data and endpoints, a meta-analysis was not feasible. Data were analysed using descriptive statistics.
Ethics statement
No formal ethical approval and informed consent were required for this review, as it involved secondary analysis of publicly available data and did not involve the collection of new data from human participants.
Role of the funding source
This project is part of the EDCTP2 programme (grant number RIA2020I-3294 IMPALA)27 supported by the European Union. The funder played no role in study design, data collection, data analysis, data interpretation, or manuscript writing.
Results
Our search identified 2737 studies, and 272 duplicates were removed. After screening titles and abstracts, 164 articles remained for full-text screening, of which 156 could be retrieved. Finally, 26 studies, published between 2017 and 2024, met the inclusion criteria (Fig. 1).Fig. 1. Study selection of evidence using Preferred Reporting Items for Systematic Reviews and Meta-Analyses for systematic review guidelines (PRISMA) flow diagram.22
Out of the 26 studies, fifteen (58%) were conducted in Asia,28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42 ten (38%) in Sub-Saharan Africa (SSA)43, 44, 45, 46, 47, 48, 49, 50, 51, 52 and one (4%) in both Asia and SSA.53 Sixteen (62%) were retrospective studies,29^,^31^,^32^,^34, 35, 36, 37, 38, 39^,^41, 42, 43^,^46^,^48^,^49^,^52 eight (31%) were prospective,28^,^30^,^33^,^44^,^45^,^47^,^50^,^53 and two (8%) used both retrospective and prospective designs40^,^51 (Table 1).Table 1. Characteristics of included studies.First authorTitleYearRegionStudy designSample sizeClinical applicationOutcomeData sourceType of dataMingApplied machine learning for the risk-stratification and clinical decision support of hospitalised patients with dengue in Vietnam2022AsiaRetros4131DiagDengue shock syndromeSpecialised research databasePatient demographics, Patient clinical observation, Laboratory dataTranA simple nomogram to predict dengue shock syndrome2024AsiaRetros4522DiagDengue shock syndromePatient filesPatient demographics, Patient clinical observationTunthanathipComparison of intracranial injury predictability between machine learning algorithms and the nomogram in paediatric traumatic brain injury2021SSARetros & pros964DiagIntracranial injuryPatient filesPatient demographics, Patient health-related behaviours and social history, Patient clinical observation, Radiology imagingBabenkoAbility of Procalcitonin and C-Reactive Protein for Discriminating between Bacterial and Enteroviral Meningitis in Children Using Decision Tree2021AsiaPros269DiagMeningitisPatient filesPatient demographics, Patient clinical observation, Laboratory dataHwangMachine learning-based prediction of critical illness in children visiting the emergency department2022AsiaRetros2,621,710ProgCritical illnessPatient filesPatient demographics, Patient health-related behaviours and social history, Patient clinical observation, Healthcare costs and expendituresLeePrediction of hospitalisation using artificial intelligence for urgent patients in the emergency department2021AsiaRetros282,971ProgHospitalisationPatient filesPatient demographics, Patient clinical observationDasDevelopment of machine learning models predicting mortality using routinely collected observational health data from 0 to 59 months old children admitted to an intensive care unit in Bangladesh: critical role of biochemistry and haematology data2024AsiaRetros3505ProgMortalityPatient filesPatient demographics, Patient clinical observation, Laboratory dataCHAIN networkCharacterising paediatric mortality during and after acute illness in SSA and South Asia: a secondary analysis of the CHAIN cohort using a machine learning approach2023SSA and AsiaPros3101ProgMortalityPatient filesPatient demographics, Patient health-related behaviours and social history, Patient clinical observationGeniscaConstructing, validating, and updating machine learning models to predict survival in children with Ebola Virus Disease Constructing, validating, and updating machine learning models to predict survival in children with Ebola Virus Disease2022SSARetros579ProgMortalityPatient filesPatient demographics, Patient health-related behaviours and social history, Patient clinical observation, Laboratory dataHsuMachine learning approaches to predict in-hospital mortality among neonates with clinically suspected sepsis in the neonatal intensive care unit2021AsiaRetros1095ProgMortalityPatient filesPatient demographics, Patient clinical observation, Laboratory dataKovacsDeveloping practical clinical tools for predicting neonatal mortality at a neonatal intensive care unit in Tanzania2021SSAPros165ProgMortalitySpecialised research databasePatient demographics, Patient health-related behaviours and social history, Patient clinical observationKwizeraA Machine Learning Based Triage Tool for Children with Acute Infection in a Low Resource Setting2019SSAPros1579ProgMortalitySpecialised research databasePatient demographics, Patient health-related behaviours and social history, Patient clinical observationPienaarAn Artificial Neural Network Model for Paediatric Mortality Prediction in Two Tertiary Paediatric Intensive Care Units in South Africa. A Development Study2022SSARetros2089ProgMortalitySpecialised research databasePatient demographics, Patient clinical observation, Laboratory dataPienaarDevelopment of artificial neural network models for paediatric critical illness in South Africa2022SSAPros765ProgMortalitySpecialised research databasePatient demographics, Patient clinical observationDomíngez-RodríguezMachine learning outperformed logistic regression classification even with limited sample size: A model to predict paediatric HIV mortality and clinical progression to AIDS2022SSAPros100ProgMortalitySpecialised research databasePatient demographics, Patient clinical observation, Laboratory dataSheikhtaheriPrediction of neonatal deaths in NICUs: development and validation of machine learning models2021AsiaRetros & Pros1762ProgMortalitySpecialised research databasePatient demographics, Patient clinical observationTutiAn exploration of mortality risk factors in non-severe pneumonia in children using clinical data from Kenya2017SSARetros10,687ProgMortalitySpecialised research databasePatient demographics, Patient clinical observationLinMachine learning models to evaluate mortality in paediatric patients with pneumonia in the intensive care unit2024AsiaRetros1231ProgMortalityPatient filesPatient demographics, Patient clinical observation, Laboratory dataRobiNeonatal Disease Prediction Using Machine Learning Techniques2023SSARetros2298ProgSepsis, birth asphyxia, necrotising enterocolitis, and respiratory distress syndromePatient filesPatient demographics, Patient clinical observation, Laboratory data, Radiology imagingRahimiA Preliminary Investigation into Use of Admission-Recorded Photoplethysmograms for Predicting Hospital Mortality in Children with Confirmed or Suspected Infection in Resource-Poor Settings2023SSARetros6533ProgMortalityPatient filesPatient demographics, Patient clinical observation, Laboratory dataLiuA novel combined nomogram for predicting severe acute lower respiratory tract infection in children hospitalised for RSV infection during the post-COVID-19 period.2024AsiaRetros1351ProgSevere acute lower respiratory tract infectionPatient filesPatient demographics, Patient clinical observation, Laboratory dataGarbernA novel digital health approach to improving global paediatric sepsis care in Bangladesh using wearable technology and machine learning2022AsiaPros100ProgSepsisSpecialised research databasePatient demographics, Patient clinical observation, Laboratory data, Radiology ImagingKanwalDiagnosis of Community-Acquired pneumonia in children using photoplethysmography and Machine learning-based classifier2024AsiaPros67DiagCommunity-Acquired PneumoniaSpecialised research databasePatient demographics, Patient clinical observation, Laboratory dataOonsivilaiUsing machine learning to guide targeted and locally-tailored empiric antibiotic prescribing in a children's hospital in Cambodia2018AsiaRetros243TheragAntibiotic susceptibilityPatient filesPatient demographics, Patient health-related behaviours and social history, Patient clinical observationXueMachine learning for screening and predicting the risk of anti-MDA5 antibody in juvenile dermatomyositis children2022AsiaRetros152TheragScreening anti-MDA5 antibodiesPatient filesPatient demographics, Patient clinical observation, Laboratory dataKashefPrediction of Cranial Radiotherapy Treatment in Paediatric Acute Lymphoblastic Leukaemia Patients Using Machine Learning: A Case Study at MAHAK Hospital2020AsiaRetros241TheragCranial radiotherapyPatient filesPatient demographics, Patient clinical observation, Laboratory dataDiag, Diagnostic; Prog, Prognostic; Pros, Prospective; Retros, Retrospective; Therag, Theragnostic; SSA, Sub-Saharan Africa.Studies were ordered by clinical application and outcome.
The median sample size was 1291 patients (IQR 250–3155). Eight studies (31%) had a sample size between 60 and 500 patients,28^,^30^,^33^,^34^,^39^,^42^,^44^,^50 three (12%) 501–1000 patients,43^,^47^,^51 eleven (42%) 1001–5000 patients29^,^31^,^36, 37, 38^,^40^,^41^,^45^,^46^,^49^,^53 and four (15%) more than 500032^,^35^,^48^,^52 (Table 1).
Prognostic clinical applications dominated, reported in eighteen studies (69%).29, 30, 31, 32^,^35, 36, 37^,^40^,^43, 44, 45, 46, 47, 48, 49, 50^,^52^,^53 Among these, thirteen studies (72%) mainly focused on mortality, mortality-associated risk factors and survival. The remaining prognostic applications focused on hospitalisation,35 sepsis, birth asphyxia, necrotising enterocolitis, and respiratory distress syndrome,30^,^49 critical illness,32 and severe acute lower respiratory tract infection.37 Diagnostic and theragnostic ML models were less common. Five diagnostic models (19%) aimed to diagnose meningitis,28 intracranial injury,51 community acquired pneumonia33 and dengue shock syndrome.38^,^41 Three theragnostic models (12%) developed predictions for screening anti-MDA5 antibodies in dermatomyositis patients,42 guided antibiotic prescription39 and predicted if Acute Lymphoblastic Leukaemia patients needed cranial radiotherapy.34
Types of data were categorised according to the framework by Annis et al.24 Patient demographics and clinical observations were the most frequently used data types reported in all 26 studies (100%). Laboratory data were used in thirteen studies (50%),28, 29, 30, 31^,^34^,^36, 37, 38^,^42^,^43^,^46^,^49^,^50 health-related behaviours and social history were used in seven studies (27%),32^,^39^,^43, 44, 45^,^51^,^53 radiographic data in three studies (12%)30^,^49^,^51 and healthcare cost and expenditure data in one study (4%).32
Data sources were categorised as patient files or specialised research databases. Patient files were defined as records generated and maintained for routine patient care and used primarily for clinical purposes such as diagnosis, treatment, monitoring, and communication among healthcare providers. This included structured paper case report forms that were digitised. Patient files were used in sixteen studies (62%).28^,^29^,^31^,^32^,^34, 35, 36, 37^,^39^,^41, 42, 43^,^48^,^49^,^51^,^53 Specialised research databases, a combination of routine care and research data, contain data extracted from patient files and often incorporate additional data elements not routinely collected in clinical practice. These databases, sometimes built using tools like REDCap, were employed in ten studies (38%).30^,^33^,^38^,^40^,^44, 45, 46, 47^,^50^,^52
Ensemble methods were the most commonly used ML approach reported in thirteen studies (50%).29^,^32^,^34^,^36^,^39^,^42^,^43^,^45^,^48, 49, 50, 51^,^53 Within this category, Random Forest, reported in eight studies (62%), was the most used ML technique, followed by Stacking models in two studies (15%),34^,^49 XGBoost in two studies (15%)36^,^53 and Elastic Net Model in one study (8%).43 The second most frequent ML approach was Neural Networks, used in six studies (23%),31^,^35^,^38^,^40^,^46^,^47 this category included five studies (83%) that applied Artificial Neural Networks (ANN) and one (17%) that applied Deep Neural Networks (DNN).31 The third category was learning linear models, used in five studies (19%), specifically Partial Least Squares – Discriminant Analysis (PLS-DA),52 LASSO regression,37 logistic regression,41 Ridge regression30 and Generalised Linear Models (GLMs).44 Classification regression tree methods (4%), specifically Fast and Frugal Trees28 and Instance-based learning (4%) with a weighted K-nearest neighbour,33 were used in one study each.
The performance evaluation metrics reported in the studies showed promising results, with various metrics used to assess effectiveness (Table 2). Twenty-two studies (85%) reported more than one metric. The area under the receiver operating characteristic (AUROC) was reported in twenty-three studies (88%) and was the most common metric, with a median value of 0.81 (IQR 0.78–0.83), indicating good discriminative ability.29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47^,^50, 51, 52, 53 Among these, thirteen studies (57%) focused on predicting mortality, achieving AUROC values ranging from 0.73 to 0.92. AUROC values above 0.80 suggest potential clinical feasibility.Table 2. Performance of ML models, readiness level and barriers, and facilitators.First authorML approachaMetricsRL 1–9bBarriersFacilitatorsML categoryaML techniqueAUROCSpecSensAcc (%)F1AUPRCBabenkoClassification and Regression TreeFast and Frugal Trees0.961.0098RL3-4DataImplementationGeniscaEnsemble MethodsElastic Net Model0.77RL5Data, HumanImplementationDomíngez-RodríguezEnsemble MethodsRandom Forest0.730.7883RL3-4ImplementationHumanKwizeraEnsemble MethodsRandom Forest0.7981RL3-4Data, HumanData, Computing, Human, ImplementationOonsivilaiEnsemble MethodsRandom Forest0.80RL3-4ComputingImplementationTunthanathipEnsemble MethodsRandom Forest0.800.340.9579RL6Data, ImplementationHuman, ImplementationDasEnsemble MethodsRandom Forest0.85RL3-4DataData, ComputingXueEnsemble MethodsRandom Forest0.97RL3-4Computing, ImplementationImplementationHwangEnsemble MethodsRandom Forest0.990.64RL3-4Data, ImplementationDataKashefEnsemble MethodsStacking model (Gradient Boosting Machine, Distributed Random Forest)0.8790RL3-4Data, ComputingComputing, ImplementationRobiEnsemble MethodsStacking model (Support Vector Machine, Random Forest, XGBoost)0.970.97970.97RL3-4ComputingImplementationLinEnsemble MethodsXGBoost0.800.710.71690.190.15RL3-4Data, ImplementationImplementationCHAIN networkEnsemble MethodsXGBoost0.830.880.66RL3-4Computing, HumanComputing, HumanKovacsLearning linear modelsGeneralised Linear Models0.760.680.76RL3-4Data, ComputingImplementationLiuLearning linear modelsLASSO regression0.820.760.78RL5DataComputing, Human, ImplementationTranLearning Linear ModelsLogistic Regression0.850.840.7182RL3-4ImplementationData, ImplementationTutiLearning linear modelsPartial Least Squares - Discriminant Analysis0.76RL3-4Human, Ethical and LegalData, ComputingLeeNeural NetworksArtificial Neural Network0.800.780.67RL3-4Data, Human, ImplementationData, ImplementationMingNeural NetworksArtificial Neural Network0.830.880.66RL5Data, ImplementationComputing, ImplementationPienaarNeural NetworksArtificial Neural Network0.890.60RL3-4Data, Computing, ImplementationComputing, HumanSheikhtaheriNeural NetworksArtificial Neural Network0.920.830.86860.91RL6DataImplementationPienaarNeural NetworksArtificial Neural Network0.840.64RL3-4ImplementationData, human, ImplementationHsuNeural NetworksDeep Neural Network0.920.830.97960.77RL3-4ImplementationComputing, ImplementationGarbernLearning linear modelsRidge regression0.860.750.83760.53RL3-4Data, Computing, ImplementationData, Computing, Human and ImplementationKanwalInstance-based learningWeighted K-nearest Neighbour0.750.690.80RL3-4DataImplementationRahimiEnsemble MethodsRandom Forest0.710.95RL3-4Data, ImplementationData, Computing, Human, ImplementationStudies were ordered according to ML category.Acc, Accuracy; AUPRC, Area Under the Precision-Recall Curve; AUROC, Area Under the Receiver Operating Characteristic Curve; F1, F1 Score; Sens, Sensitivity; Spec, Specificity.aML category according to ACM's computing classification system (CCS)[19].bClinical Readiness Level (RL) [20]: RL1 identification of the clinical problem, RL2 proposal of model/solution. RL3-4 model prototyping and development, RL5 model validation, RL6 real-time model testing, RL7 workflow implementation, RL8 clinical outcome evaluation, RL9 model integration in clinical practice.
Other metrics, such as specificity and sensitivity, were reported in fifteen studies (65%)28^,^30^,^31^,^33^,^35, 36, 37, 38^,^40^,^41^,^44^,^48^,^49^,^51^,^53 and one study (4%) reported sensitivity only.50 Specificity ranged from 0.34 to 0.97 and sensitivity from 0.66 to 1.00. Accuracy was reported in eleven studies (42%),28^,^30^,^31^,^34^,^36^,^40^,^41^,^45^,^49, 50, 51 from 69% to 98%. Five studies (19%)30^,^31^,^36^,^40^,^49 reported the F1 score ranging from 0.19 to 0.97. Four studies (15%) included the area under the precision–recall curve (AUPRC), ranging from 0.15 to 0.64.32^,^36^,^46^,^47 The significance of these metrics varies greatly depending on the specific study design, disease, clinical context, and the potential penalties of prediction errors. The variability of the included studies makes it impossible to establish universal acceptable performance thresholds or to directly compare metrics across studies that involve different populations, outcomes, and designs. However, the metrics reported are important as an indication of the models' performance and predictive capabilities. Reporting multiple relevant metrics demonstrates a thorough approach to evaluation.
Models' clinical readiness level (RL) ranged from RL3 to RL6 (Table 2). Twenty-one models (81%) were at RL3-4 (model prototyping and development).28, 29, 30, 31, 32, 33, 34, 35, 36^,^39^,^41^,^42^,^44, 45, 46, 47, 48, 49, 50^,^52^,^53 These studies showed the potential of ML models to predict or assist clinical decisions or to be further optimised and validated on characterised datasets.4 Three models (12%) were at RL5 (model validation).37^,^38^,^43 These studies focused on testing and evaluating the ML models using realistic datasets other than the original training and testing population to ensure their generalisability and reliability.4 Two models (8%) were at RL6 (real-time model testing). Sheikhtaheri et al. used an Ensemble approach40 for predicting neonatal intensive care unit (NICU) deaths, and Tunthanathip used a Neural Network approach51 to predict intracranial injury. These studies evaluated model performance in real-time and integrated the models into the electronic health record or hospital system in one or more clinical settings, but there was no implementation into the clinical workflow, e.g. prospective observational studies comparing model performance in standard of care.4 There were no models beyond RL6.
All studies reported barriers and facilitators influencing the development and implementation of ML models in healthcare. These were categorised as (1) data-related, (2) computing and physical infrastructure, (3) human, (4) ethical and legal, and (5) implementation.26
Data barriers that hindered model development and potentially compromised the models' reliability were reported in seventeen studies (65%).28, 29, 30^,^32, 33, 34, 35, 36, 37, 38^,^40^,^43, 44, 45^,^47^,^48^,^51 These included difficulties with data quality, class imbalance, small sample size, and completeness. Conversely, existing infrastructure for paperless hospitals, electronic databases, generation of prospective data, large datasets, and relatively complete datasets acted as facilitators in nine studies (34%).29^,^30^,^32^,^35^,^41^,^45^,^46^,^48^,^52
Implementation barriers were reported in thirteen studies (50%),30, 31, 32^,^35^,^36^,^38^,^41^,^42^,^46, 47, 48^,^50^,^51 including the lack of external validation, generalisability, or insufficient evidence of cost-effectiveness. Facilitators of implementation were mentioned in twenty studies (77%),28^,^30^,^31^,^33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46^,^48^,^49^,^51 including the use of SHapley Additive exPlanations (SHAP) method for explaining model output, use of simple models with simple predictors or models with high discriminatory ability.
Technological barriers related to physical infrastructure and hardware capabilities were reported in eight studies (31%),30^,^34^,^39^,^42^,^44^,^47^,^49^,^53 such as using paper-based files, and lack of electronic health records and digital data infrastructure. In contrast, the availability of advanced open-source software (e.g. Python, R, REDCap), existing infrastructure for paperless hospitals and potential of smartphone apps acted as facilitators in eleven studies (42%).29, 30, 31^,^34^,^37^,^38^,^45^,^47^,^48^,^52^,^53
Human barriers, including challenges related to user acceptance of prediction models, were present in five studies (19%).35^,^43^,^45^,^52^,^53 These included limited skills to interpret risk scores, indicating a need for training, as well as lack of model explainability (e.g. of black box models) and the associated negative impact on trust. Facilitators were identified in nine studies (35%),30^,^37^,^45, 46, 47, 48^,^50^,^51^,^53 such as multidisciplinary collaborations and the acceptance of models due to their perceived clinical relevance.
All studies had ethical and legal approval from an ethics board. One study (4%)52 reported reluctance to adopt international guidelines on pneumonia in SSA acted as a barrier. Other studies did not report legal or ethical barriers and facilitators.
The PROBAST + AI assessment (see Supplementary Appendix) indicated low concerns regarding the applicability of the included ML models, and most of them showed good performance. However, methodological rigour is a concern. The models' quality and generalisability was limited by small sample sizes, retrospective study designs, heterogeneous data sources, and selection bias. Risk of bias during evaluation highlighted a high concern due to the absence of a formal calibration assessment and net benefit reported in 6 studies (23%).37^,^38^,^42^,^43^,^46^,^47 Most models showed a strong discrimination AUC of 0.80 (IQR 0.78–0.83), but a few reported complementary performance metrics such as positive predictive value (PPV), limiting assessment of false positive rates. The limited evaluation metrics limited clinical applicability.
Discussion
This review is, to our knowledge, the first to collate ML models for hospitalised children in LMICs. We found a limited number of studies (n = 26) from SSA and Asia. Studies were published after 2017, although no publication date criteria were implemented. The field is developing prognostic clinical applications, predicting mortality, using mainly ensemble methods and achieving good discriminatory ability. Most studies used retrospective data, consistent with their stage of development, as most models were at clinical RL3-4. Facilitators for developing and implementing ML models included: data and technology (e.g. access to digital data, infrastructure, and software), implementation (e.g. use of available explainability methods, simple predictors, and acceptable performance), human aspects (e.g. multidisciplinary teams and model's clinical relevance) and ethical and legal (e.g. reluctance to adopt new WHO pneumonia classification). Key barriers included data and technology (e.g. availability of high-quality data and infrastructure), implementation (e.g. lack of external validation, generalisability, and cost-effectiveness evidence), and human aspects (e.g. insufficient skills, limited explainability and lack of trust).
The use of ML to predict mortality and critical-care related outcomes in LRS responds to the clinical need for early recognition of patients at risk, providing healthcare personnel with the opportunity to intervene earlier and more efficiently, and save human lives.54 If successful, an ML approach can potentially facilitate efficient distribution of resources, both human and material. The value of ML compared to conventional statistics remains a topic of discussion, with evidence suggesting that ML models tend to perform better in “large N, small p” settings,55 including mortality prediction.56^,^57 They have also shown advantages in highly innovative fields with large, complex datasets such as omics, radiodiagnostics, drug development and personalised treatment.58 However, this highly innovative scenario may not match the reality in LMICs. ML approaches should tested and empirical evidence about their superiority over conventional statistics should be provided.
We also showed that researchers in LMICs are tackling other clinical needs with diagnostic and theragnostic models in fields such as trauma, cancer, vector-borne diseases, antibiotic sensitivity, leukaemia treatment, and rare diseases. These efforts can contribute in the future to addressing broader healthcare issues in LMICs,59 e.g. by compensating for a lack of infrastructure such as diagnostic facilities or specialised staff, such as radiologists60^,^61 and can contribute towards personalised medicine.62
This study also showed a clear preference for ensemble methods, a popular method in general.63 Ensemble methods are relatively simple and offer high interpretability, making them suitable for health applications. They require less computing power and have a low demand for smaller datasets than deep learning techniques, making them easier to develop, in the LRS of LMICs.11 The prominence of ensemble methods aligns with the use of other simpler yet effective ML techniques such as PLS-DA, LASSO, logistic regressions, and GLMs; methods also applied in the included studies. The focus on simple, interpretable models that healthcare providers can understand builds trust and increases adoption.64 However, deep learning techniques have their advantages. They can perform very well with complex data like medical images, yet we showed that this application is still limited, presumably because of the limited digital radiological data.11 This may change, as it has been observed in upper-middle-income countries.63
Many of the reported models are proof of concept tools at an RL3-4. Only 12% of studies have performed external validation, a critical step for assessing generalisability and robustness. This supports the reported gap between research and clinical use.4^,^5 Nevertheless, from a performance perspective, the models can be considered promising, showing, for example, reasonable AUROC (median 0.81, IQR 0.78–0.83). Consistent with the low clinical RL of the included studies, nearly two-thirds used retrospective data.59 Retrospective studies have lower risks and costs, and are easier to conduct compared to prospective studies. While retrospective studies serve as a valuable foundation,61 prospective studies are crucial for model clinical validation across various clinical settings.65 Prospective data collection, creating robust databases and improving data quality will lead to clinically useful ML applications.66 The slow shift to prospective data collection and validation delays the readiness of these models for real-world clinical use.59 To transition to more advanced clinical RLs, models need to address methodological shortcomings (such as small sample sizes, retrospective study design, heterogeneous data sources, and selection bias), and associated risks of bias and limited reporting of evaluation metrics. Additionally, the application of ML to address needs in LMIC should also raise the more fundamental question of whether ML is the right approach. Addressing, for example, the question of whether ML can objectively outperform traditional methods in the task at hand.
To facilitate the transition into higher RLs, and therefore ML's adoption in clinical practice, attention needs to be paid to LMICs' challenges. While HICs often encounter hurdles related to ethical and regulatory compliance, leading to slower integration into complex workflows,67 LMICs face more fundamental obstacles.68 Our results showed that data, implementation, and technological aspects were the main challenges in LMICs. Not that these challenges are absent in HIC,69^,^70 but they are acute in LMICs. Aiming at increasing the availability of high-quality data and the local necessary infrastructures (data and technical aspects) will only be successful if we invest in acquiring the necessary computer skills and AI literacy of researchers and end users (human aspects). Aspects such as user acceptability, integration into workflows, and economic sustainability can be expected to become more tangible the more advanced the RL. Facing clinical implementation will raise ethical questions and challenges, which will increase awareness for future ML applications.71 Although perceiving the development in the field of ML in such a linear way can help to simplify a complex situation, plenty of evidence in HIC indicates that failing to consider users (views, preference and needs) and ethical and legal aspects from the inception of ML application, will hinder its successful clinical application.54^,^72^,^73 Our results suggest that leveraging existing resources (material and human), prioritising clinically relevant, actionable and interpretable ML, and fostering collaboration can maximise the impact of ML in settings with limited resources.65
LMICs are advancing in the AI field, developing regulations and best practices, and conceptualising concepts such as trustworthy AI.74 As found in our study, regulatory uncertainty is a problem for developers, and working toward clear national and regional strategies can be part of the solution. These strategies should address technical, human, ethical, and legal aspects comprehensively.75 Our research shows that AI and ML development in LMIC is happening, albeit on a smaller scale than in HIC and it is addressing locally relevant needs. The 26 studies in our review, which focused on hospitalised children, show ML models with an acceptable performance for their stage or development, directly contradicting the idea that AI in LMICs is a “chimera”.68 In Table 3, we offer general recommendations based on the findings of this study.Table 3. General recommendations for developing ML for Clinical adoption in LMIC.Recommendation focusActionable steps and rationale1. Think and design aheadMap barriers and facilitators early in the ML development process for clinical use and apply them to draft a development plan.2. Focus on data availability and qualityAddress data and technological aspects immediately, such as investing in digital data collection and server capacity to improve data quality, and developing datasets for model development. This will help generate more and higher-quality data, reduce bias (or the risk of it), and improve model quality and generalisability.3. Keep the clinical application and end user in mindAdvancing towards clinical adoption will depend on effectively incorporating users' perspectives into the design, development, validation, and implementation of ML models. Invest early in characterising user needs, acceptability, workflow integration, and economic sustainability.4. Focus on clinical implementationPrioritise addressing major LMIC health challenges as they will have the greatest impact. Report all necessary performance metrics, including those that are clinically relevant. Evaluate ML applications for clinical relevance and actionability, and prioritise implementation only when and where ML can provide improvements in patient care.5. Keep it simple and explainableMatch ML methods to clinical needs and available resources. Use simple, interpretable models when explainability is required, as this would increase clinical uptake. Invest in making outputs explainable and actionable to end users, reserving complex techniques for cases where they bring clear added value.6. Leapfrog while learning from HICsAnticipate ethical and regulatory challenges as ML approaches clinical use. Design ML systems with compliance in mind and contribute proactively to best practices and regulations. Do not forget to build on the experiences of others, including in HICs.7. Increase visibility and equitable collaborationEstablish equitable international networks (among LMICs, or between LMICs and HICs) to develop, validate, and share models and resources. Consider how your current research can contribute to lasting data infrastructures and local and regional AI strategies. If developers are based in non-English-speaking LMICs, consider publishing in both the local language and English to ensure international visibility.8. Empower policy and governance actorsPolicy-makers, regulatory bodies, ethics committees, funding agencies, and international organisations such as the WHO should prepare a facilitating environment for developing and integrating ML into healthcare in a safe, responsible, and effective way.AI, Artificial Intelligence; LMIC, Low- and Middle-Income Country; HIC, High-Income Country; ML, Machine Learning; WHO, World Health Organisation.
To interpret this study, it is necessary to consider its limitations. We identified a limited number of studies; however, this is in line with previous work,66 highlighting a technology and knowledge gap.76 It is possible that ML tools for our specific clinical scope were not published in scientific literature, as it has been reported before,77 or not captured due to the English-language-based search strategy. Furthermore, our focus on hospitalised patients excluded ML studies with other health applications and could have emphasised mortality as an outcome. Including other populations might have yielded different results. We need to acknowledge that we could not control for publication bias. Lastly, the lack of studies from regions other than SSA and Asia shows the need for future research to assess the state of ML development in other parts of the world. We should not assume a lack of ML development in other regions, based solely on the absence of published data found in this review.
Our systematic analysis of the ML models for predicting clinical outcomes for hospitalised children in LMICs showed that, regardless of the challenges, Asian and African regions are contributing to the field of ML and to addressing healthcare challenges in these LRS. LMICs must prioritise technological development, including data infrastructure, capacity building, regulation, and policy. This is needed to achieve AI's full potential. This review contributes to amplifying the presence of LMICs in the field of ML, and offers an overview of barriers and facilitators of ML development that can inform funders, policymakers, researchers, and healthcare.
Contributors
WN, JC, MH, KP and MV conceived the idea for this review. WN designed and wrote the review protocol with critical input from EL, JC, MH, KP, and MV. WN and EL developed the search strategy and conducted the searches in all databases. WN and EL independently screened all references and determined eligibility. JC oversaw and adjudicated the study selection process. WN extracted the data and EL and MV verified the data. WN drafted the first version of the manuscript. EL, JC, MH, KP, VN and MV drafted and revised the manuscript. All authors critically reviewed and approved the content of the manuscript. All authors had full access to all the data in the study and had final responsibility for the decision to submit for publication.
Data sharing statement
The datasets generated from this review are available within the paper and Supplementary Materials. Details of any process, data or analysis are available from the corresponding author upon request.
Declaration of interests
All other authors declare no competing interests.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Child mortality (under 5 years)[cited 2024 Sept 12]. Available from:https://www.who.int/news-room/fact-sheets/detail/levels-and-trends-in-child-under-5-mortality-in-2020
- 2Kruk M.E.Gage A.D.Joseph N.T.Danaei G.García-SaisóS.Salomon J.A.Mortality due to low-quality health systems in the universal health coverage era: a systematic analysis of amenable deaths in 137 countries Lancet 392101602018220322123019539810.1016/S 0140-6736(18)31668-4PMC 6238021 · doi ↗ · pubmed ↗
- 3Rahmani A.M.Yousefpoor E.Yousefpoor M.S.Machine Learning (ML) in medicine: review, applications, and challenges Mathematics 920212970
- 4Fleuren L.M.Thoral P.Shillan D.Machine learning in intensive care medicine: ready for take-off? On behalf of the right data right now collaborators right data right now collaborators Available from:10.1016/0094-576532399747 · doi ↗ · pubmed ↗
- 5van de Sande D.van Genderen M.E.Huiskens J.Gommers D.van Bommel J.Moving from bytes to bedside: a systematic review on the use of artificial intelligence in the intensive care unit Intensive Care Med 4720217507603408906410.1007/s 00134-021-06446-7PMC 8178026 · doi ↗ · pubmed ↗
- 6Ezugwu A.E.Oyelade O.N.Ikotun A.M.Agushaka J.O.Ho Y.S.Machine learning research trends in Africa: a 30 years overview with bibliometric analysis review Arch Comput Methods Eng 30720234177420710.1007/s 11831-023-09930-z PMC 1014858537359741 · doi ↗ · pubmed ↗
- 7Onu C.C.Lebensold J.Hamilton W.L.Precup D.Neural transfer learning for cry-based diagnosis of perinatal asphyxia 201930533057[cited 2025 Oct 8] Available from:https://www.isca-archive.org/interspeech_2019/onu 19_interspeech.html
- 8Bellemo V.Lim Z.W.Lim G.Artificial intelligence using deep learning to screen for referable and vision-threatening diabetic retinopathy in Africa: a clinical validation study Lancet Digit Health 112019 e 35e 443332323910.1016/S 2589-7500(19)30004-4 · doi ↗ · pubmed ↗