A benchmark of text embedding models for semantic harmonization of Alzheimer's disease cohorts
Tim Adams, Yasamin Salimi, Mehmet Can Ay, Diego Valderrama, Marc Jacobs, Holger Fröhlich

TL;DR
This paper introduces a new benchmark to evaluate text embedding models for harmonizing Alzheimer's disease cohort metadata, showing that domain-specific models perform better than general-purpose ones.
Contribution
A novel benchmark and open-source tools for evaluating text embeddings in Alzheimer's data harmonization.
Findings
Domain-specific models outperformed general-purpose models in clinical data harmonization.
Formatting guidelines for metadata were proposed to improve harmonization processes.
An open-source library and leaderboard were introduced to support future benchmarking.
Abstract
Harmonizing diverse healthcare datasets is a challenging task due to inconsistent naming conventions. Manual harmonization is time- and resource-intensive, limiting scalability for multi-cohort Alzheimer's Disease research. Large Language Models, or specifically text-embedding models, offer a promising solution, but their rapid development necessitates continuous, domain-specific benchmarking, especially since general established benchmarks lack clinical data harmonization use cases. To evaluate how different text-embedding models perform for the harmonization of clinical variables. We created a novel benchmark to assess how well different Language Model embeddings can be used to harmonize cohort study metadata with an in-house Common Data Model that includes cohort-to-cohort mappings for a wide range of Alzheimer’s Disease cohorts. We evaluated five different state-of-the-art text…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
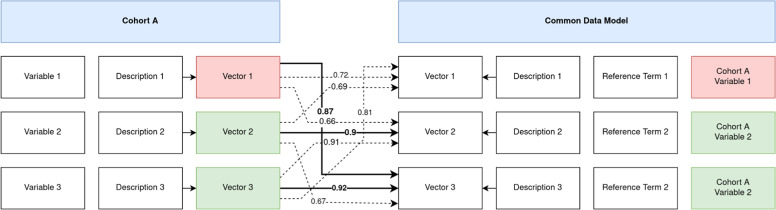 Figure 1
Figure 1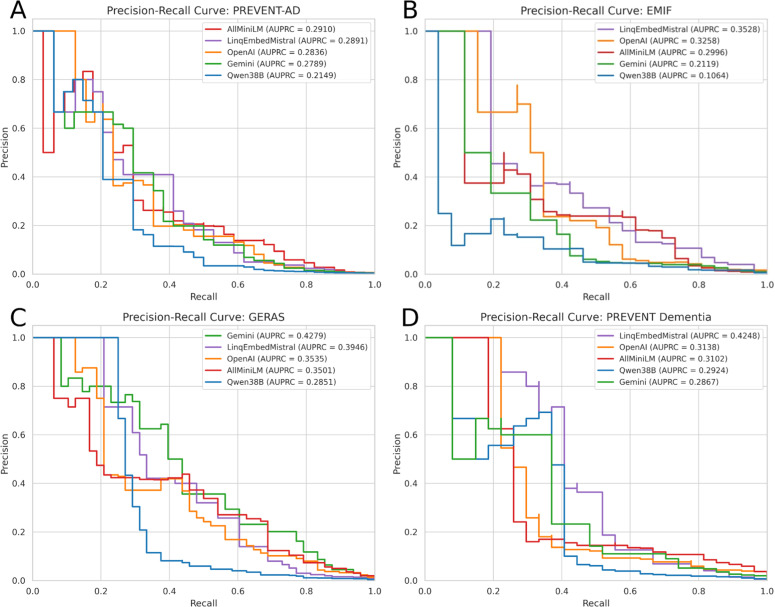 Figure 2
Figure 2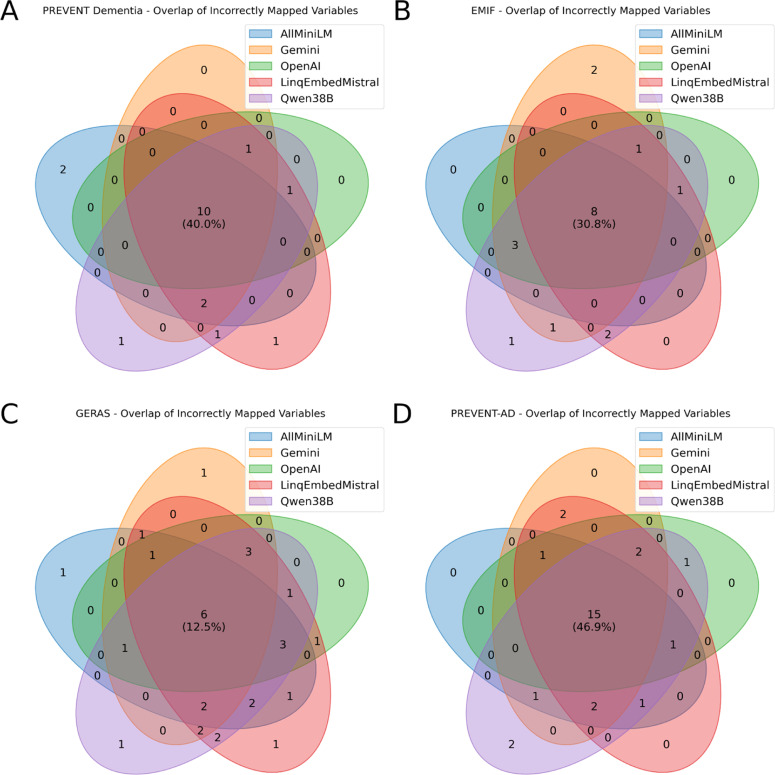 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Healthcare · Biomedical Text Mining and Ontologies · Genomics and Rare Diseases