MViT: A vision transformer with fractal path reordering and dynamic positional encoding
Bomin Liu, Linjun He, Yan Zhu, Anil Yaman, Anil Yaman, Anil Yaman, Anil Yaman

TL;DR
MViT is a new Vision Transformer that improves spatial coherence and structural adaptability using fractal path reordering and dynamic positional encoding.
Contribution
The novel use of a recursive Moore curve and fractal-based components to enhance spatial continuity and structural modeling in Vision Transformers.
Findings
MViT improves classification accuracy by 0.52% on CIFAR-100 and 0.31% on ImageNet-21k compared to ViT-B/16.
The model achieves better PSNR and SSIM scores, indicating improved structural representation.
MViT shows robustness to rotation and maintains performance across different Transformer backbones and tasks.
Abstract
Vision Transformers have demonstrated remarkable performance in image classification and structural modeling; however, fixed patch partitioning and static positional encoding often disrupt spatial continuity, thereby limiting their ability to represent rotated structures and irregular boundary regions. To address these limitations, we propose the Moore-curve Vision Transformer (MViT), a Vision Transformer (ViT) framework based on a recursive Moore curve. The proposed framework comprises three key components. First, a multi-order fractal mapping is employed to optimize patch reordering and enhance the spatial coherence of the token sequence. Second, a 7×7 dynamic partitioning template together with a boundary compensation algorithm jointly optimizes dense structural representation and resolution adaptability. Third, a period-aware positional encoding module integrates fractal periodic…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1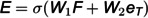 Figure 2
Figure 2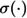 Figure 3
Figure 3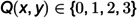 Figure 4
Figure 4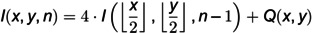 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9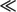 Figure 10
Figure 10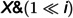 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13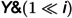 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16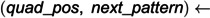 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19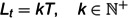 Figure 20
Figure 20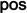 Figure 21
Figure 21 Figure 22
Figure 22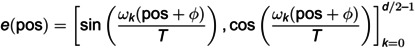 Figure 23
Figure 23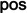 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34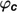 Figure 35
Figure 35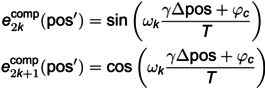 Figure 36
Figure 36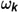 Figure 37
Figure 37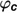 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40 Figure 41
Figure 41 Figure 42
Figure 42 Figure 43
Figure 43 Figure 44
Figure 44 Figure 45
Figure 45 Figure 46
Figure 46 Figure 47
Figure 47 Figure 48
Figure 48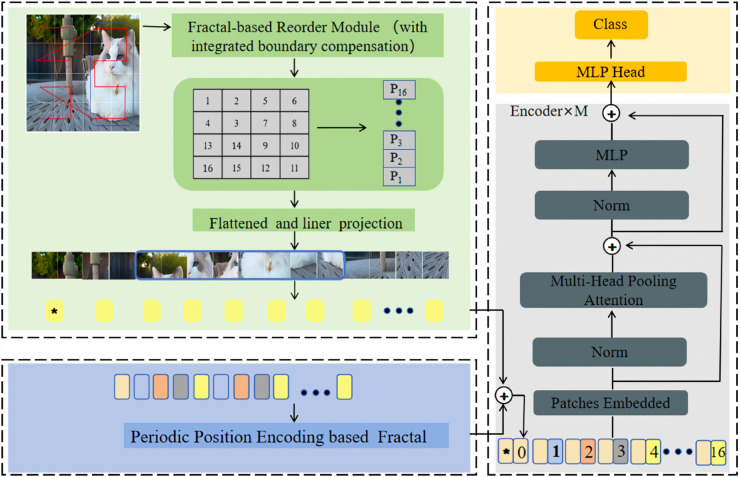 Figure 49
Figure 49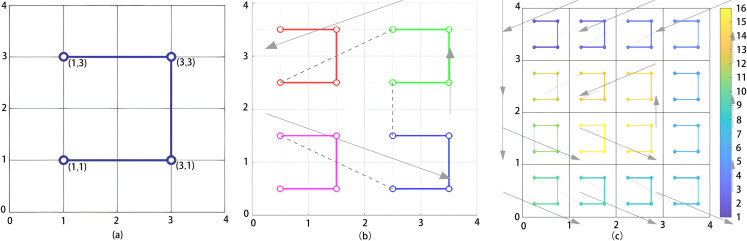 Figure 50
Figure 50Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Vision and Imaging · Face Recognition and Perception · Advanced Optical Imaging Technologies