Type I error control and interim monitoring for co-primary hypotheses involving a subgroup in the Outpatient Treatment with Anti-Coronavirus Immunoglobulin (OTAC) trial
Jiayi Hu, Abdel G. Babiker, Cavan S. Reilly, Jason V. Baker, Lianne K. Siegel

TL;DR
This paper introduces a statistical method to efficiently control type I error in clinical trials with co-primary hypotheses involving subgroups, using the OTAC trial as a case study.
Contribution
A novel method for type I error control that incorporates estimated correlations between test statistics in subgroup analyses.
Findings
The method controls type I error at the desired rate while improving power.
It reduces the expected sample size compared to the Bonferroni correction.
Simulation studies validated the method's performance in fixed and group-sequential scenarios.
Abstract
The recent growth of immunoglobulin-based therapies has motivated clinical trials testing primary endpoints both in the overall cohort and in subgroups of patients, such as in patients without specific antibodies at baseline. Multiple testing methods in clinical trials often ignore the natural correlation between test statistics in such contexts, resulting in overly conservative type I error control. The Outpatient Treatment with Anti-Coronavirus Immunoglobulin (OTAC) trial, is an ongoing Phase III trial evaluating the effect of a single infusion of anti-COVID-19 hyperimmune intravenous immunoglobulin (hIVIG), in outpatient adults with recently diagnosed SARS-CoV-2 infection, in both the overall cohort and in the subgroup of participants who had not received monoclonal antibodies or antiviral treatments. We present the method used to control the type I error at a predetermined rate…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
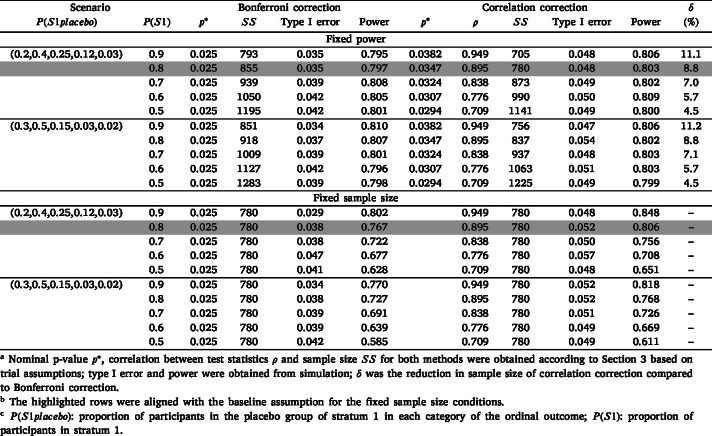 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods in Clinical Trials · Clinical Laboratory Practices and Quality Control · SARS-CoV-2 detection and testing
Introduction
1
This article describes the statistical approach of controlling the type I error rate in the Outpatient Treatment with Anti-Coronavirus Immunoglobulin (OTAC) trial, testing the treatment effect of anti-COVID-19 hyperimmune intravenous immunoglobulin (hIVIG) in both the overall population and a subgroup of the population in the primary analysis. Specifically, we consider two co-primary hypotheses comparing hIVIG versus placebo in the overall outpatient population and a nested subgroup expected to have a larger treatment effect. The practical challenge is to control the family-wise type I error rate for these correlated tests, while allowing for interim monitoring.
Immunoglobulin-based therapy includes the use of monoclonal antibodies, which were widely used during the COVID-19 pandemic, [1], [2], [3], [4], [5], [6], [7], [8], immunoglobulin replacement therapy [1], [9], [10], and immune checkpoint inhibitors [11], [12], among other treatments; this has become a common treatment in infectious diseases [1], [3], [4], auto-immune diseases [5], [12], transplantation [6], [7], [8], and several rheumatic diseases [2], [10], and its applications are still being explored [13], [14]. In the context of immunoglobulin-based therapy, evidence suggests that the treatment effect may be more pronounced among participants who lack pre-existing antibodies [15], [16] or do not use other antivirals. Therefore, clinical trial designs have prioritized testing the treatment effect in such subgroups in addition to the entire cohort.
The OTAC trial (clinicaltrials.gov identifier: NCT04910269), a phase III, multi-center, double-blind, randomized, placebo-controlled trial, is testing the safety and efficacy of a single infusion of anti-coronavirus hIVIG versus placebo among adult outpatients with recently diagnosed coronavirus 2 (SARS-CoV-2). The trial has two strata, distinguished by whether participants are receiving or plan to receive direct-acting antivirals (DAAs) or other available anti-SARS-CoV-2 agents recommended for use as part of standard of care (SOC). Stratum 1 includes participants not planning to receive these agents, and is hypothesized to have a larger treatment effect compared to stratum 2 due to the absence of other antiviral interventions. The primary efficacy outcome will be evaluated both in the overall population and specifically within stratum 1.
This leads to the need to control type I error in the presence of multiple correlated tests, as stratum 1 is a subset of the overall population. The TICO and RECOVERY studies provide two high-profile examples of other monoclonal antibody trials testing co-primary hypotheses of the treatment effect in the full cohort and in a subgroup. The tixagevimab–cilgavimab trial under the TICO master protocol [1], [17], [18], [19], [20], tested the treatment effect in the full cohort and in patients seronegative for anti-SARS-CoV-2 neutralizing antibodies at baseline using Holm’s method [21]. The lower of the two p-values was first compared to 0.025, corresponding to a Bonferroni correction. If significant, then the other -value was compared to 0.05. Here, power is limited by the threshold of 0.025 for the lower -value, which does not incorporate the correlation between tests. The RECOVERY trial [22] used a fixed-sequence method [23] to test the monoclonal antibody combination of casirivimab and imdevimab on hospitalized patients with COVID-19 in both the overall population and also in baseline seronegative subgroup. The treatment was first tested among seronegative participants, and if significant at the 0.05-level, tested in the overall cohort, requiring this order of tests to be pre-specified. Other methods have also been used for controlling the type I error rate in clinical trials with multiple tests, including the Bonferroni correction [21], Benjamini–Hochberg procedure [24], prospective alpha allocation scheme (PAAS) [25], and gate-keeping strategy [26]. However, none of the methods above leverage the correlation between tests.
Several methods have been proposed to address multiple testing in clinical trials when accounting for correlated tests. Dunnett’s test [27] compares multiple groups against the same control while accounting for the correlation between tests. Bretz and Maurer proposed a graphical approach for lowering the nominal -value based on the correlation between tests [28] including within group sequential designs [29]; its extension [30] allows for the consideration of correlations between outcomes in a fixed design; Anderson et al. [31], [32] extend the framework further to a group sequential design. However, this work primarily focuses on theoretical frameworks and does not directly address that the correlation between tests is unknown at the outset of the trial and must be estimated using the observed data; this is counter-intuitive as the nominal -value must be determined by the observed data and presents specific challenges for interim monitoring. Joo et al. [33], who illustrate the use of prospective alpha allocation in the context of the COAG trial where the correlation is unknown, incorporate the correlation between tests but do not consider interim monitoring. Sinha et al. [34] developed an adaptive enrichment group sequential design for two binary co-primary endpoints, where the subgroups are disjoint. Chen et al. [35] introduced a complete-correlation framework for group sequential trials with nested biomarker subpopulations and temporal consideration, but their method calculated the alpha spending over time at the trial design stage and did not consider recalibrating the nominal critical values when the actual correlations differed from those originally assumed.
Bayesian approaches to multiple testing and subgroup evaluation can also account for dependence across hypotheses through hierarchical modeling and decision-theoretic rules [36], [37], [38], but these methods do not typically provide the strict control of the type I error rate required for confirmatory regulatory trials such as OTAC.
In this case study, we describe the statistical details of controlling type I error in the OTAC trial by lowering the nominal -value used for each test based on the estimated correlation, which has a closed form. We simulate the operating characteristics under scenarios where the correlation between tests is estimated from the observed data at the end of the trial, with particular consideration given to interim monitoring and the consequences of the correlation differing from value assumed at the design stage. Section 2 describes the sample size assumptions used when designing the OTAC trial. We describe the methods for controlling type I error in Section 3 and illustrate the application in Section 4. Simulation methods, results with and without interim analyses are presented in Section 5. A discussion of the simulation findings, limitations, and future directions is given in Section 6.
Motivating example - OTAC
2
The primary outcome of the OTAC trial is a 5-category ordinal outcome assessing the participant’s clinical status 7 days after the infusion of hIVIG or placebo, with a value of 5 being the most severe, and 1 being the least severe. The treatment effect of hIVIG is evaluated both for all randomized participants and for only those in stratum 1.
Several key assumptions were made at the beginning of the OTAC trial when determining the sample size:
- •1:1 allocation ratio of treatment to control in both strata.
- •80% of participants enrolled in stratum 1, and the proportions of participants in each ordinal outcome category (from 1 to 5) in the stratum 1 placebo group are assumed to be .
- •An odds ratio ( ) greater than 1 indicates “better” outcomes. The placebo group in stratum 2 has a common of 1.72 relative to the placebo group in stratum 1. Under the alternative hypotheses, the summary s comparing treatment against placebo are 1.5 for stratum 1 and 1.2 for stratum 2.
Methods
3
Type I error rate control with a single analysis
3.1
Correlation between maximum likelihood estimates
3.1.1
Let denote the treatment effect in the overall population, and denote the treatment effect in stratum , . Then let and denote the asymptotically unbiased maximum likelihood estimators for and , and let and denote the corresponding variances of and . Thus, the s are independent and normally distributed with and for . is asymptotically the weighted average of the s, with weights proportional to the precision of each estimator [39]. It can also be shown that this applies to partial likelihood estimates as well.
Thus, the covariance between and is as follows:
and the correlation between and is then given by: (4)
Nominal P-value
3.1.2
Let and denote the null hypotheses that the treatment effect equals 0 overall and in stratum , respectively, . Here, denotes the number of strata included in the co-primary testing set. In the OTAC trial, for example, we pre-specified strata and included strata (Stratum 1) in the co-primary hypothesis. Let be the type I error rate; we assume that type I error is spent equally between tests, and thus the nominal p-values for all tests will be the same, denoted by . The critical values are denoted by for all tests, where . denotes the observed Z-score for the test for the overall population, for the test in the th stratum, where and . The following calculation is based on a two-sided test, and the corresponding nominal p-values for a one-sided test can be obtained by doubling the nominal -value obtained for a two-sided test so that the critical value becomes . (5)
Thus, we want an appropriate to control the overall type I error rate at a pre-specified level (e.g. 0.05). Under the null hypothesis, follows a multivariate normal distribution with the mean equal to (0, …,0) and variance–covariance matrix as follows:
The nominal -value is chosen so that the family-wise type I error equals , i.e., is the largest value satisfying (6)
This probability can be evaluated by integrating the -dimensional multivariate normal distribution with the following limits
Because Eq. (6) does not admit a closed-form solution for the two-sided nominal level , we determine numerically. For example, with two co-primary tests, as in the OTAC trial, we search over candidate values on a fine grid (step size 0.0001). For each candidate , we set and compute the joint probability of rejecting at least one null hypothesis under using the corresponding bivariate normal distribution. We then choose the largest such that this joint probability does not exceed the prespecified family-wise type I error . In practice, the true standard deviations are unknown, especially at the beginning of the trial; thus, we use the observed standard errors of the treatment effect estimates at the end of the trial to determine .
Interim monitoring
3.2
Suppose for each hypothesis test, we have planned analyses (i.e. interim analyses); the is first designated at the beginning of the trial to be the theoretical type I error rate for each hypothesis test obtained from the assumptions made during the trial design. At analysis , let denote the information fraction; denote the corresponding amount of type I error spent, i.e. ; denote the critical value; denote the observed interim z-score.
Suppose we want to adjust the critical value based on the current data in the analysis time, . If , the new will be calculated from the observed standard errors for the test statistics, and the amount of type I error to spend by time will be consequently obtained using a pre-specified alpha spending function. If , the updated critical value should be adjusted to satisfy: (7)
where is calculated based on the observed data at time point from Eq. (6). Given a pre-specified spending function , a new spending function based on can be derived according to [40]: (8)
where is the information time at the previous look.
The based on the full trial data will be no smaller than 0.05 divided by the number of tests , which corresponds to a Bonferroni correction assuming independence between the tests; thus, as long as no more than in type I error is spent in the first interim analyses, the alpha spending function for the co-primary tests based on the estimated correlation can be adjusted only at the final look without spending more than the pre-specified type I error. In the context of a Lan-DeMets O’Brien Fleming-like spending boundary, a small portion of the type I error is allocated to the first interim analyses, conserving most type I error for the final analysis and maintaining the power of the hypothesis test. In this case, the benefit of adjusting the alpha spending functions before the final analysis is uncertain due to minor differences in the earlier ones. Fig. 1 panels a and b illustrate this point by showing an example of interim stopping boundaries on the z-scale and the cumulative alpha spent when adjusting the alpha spending function during the trial compared to only at the end. We assumed that there were two hypothesis tests and three interim analyses at . When correcting the alpha spending functions at each analysis (solid line), we used a per-test two-sided nominal level of to calculate the four boundaries and alpha spent at each analysis time. In contrast, when correcting the alpha spending functions only at the final analysis (dashed line), we constructed a worst-case example of overestimating the correlation: the first three interim boundaries are set using as if the co-primary tests were perfectly correlated and required no multiplicity adjustment, and only the final boundary is re-calibrated so that the overall per-test nominal level is based on the observed correlation. The two plots showed little difference between the boundaries as well as the alpha to be spent at each test.
However, other types of boundaries may spend more type I error earlier in the trial, resulting in a greater impact of waiting until the final analysis to correct the . For example, when using Pocock boundaries, the type I error is equally spent across all analyses. The inherent uncertainty in key parameters when designing the trial may cause over-spending of the type I error prior to the final analysis, especially when is large. Fig. 1 panels c and d show an example of overspending when using a Pocock-type alpha spending function. When using a level of 0.05 to calculate the first three interim analyses, the alpha spent was already above 0.035 for three interim analyses, leaving no alpha to be spent at the final analysis. In these circumstances, one may consider using the observed data to adjust the alpha spending functions at each interim analysis and reducing the number of early planned interim analyses.Fig. 1. Interim monitoring boundaries and cumulative alpha spending correcting at each analysis (solid line) versus correcting only at the final analysis (dashed line) for O’Brien Fleming-like alpha spending function (a–b) and Pocock-type alpha spending function (c–d) for a two strata design.Fig. 1
Application to the OTAC trial
4
This section presents the steps of applying the correlation correction to the OTAC trial based on the original assumptions described in Section 2.
To obtain initial estimates of the standard errors for both test statistics, we calculated the proportion of participants in each ordinal category by treatment group and stratum using the assumptions. The results are presented in Table 1. We then constructed an exemplary dataset with 20 rows representing each combination of the 5 ordinal categories, 2 strata, and 2 treatments, with a column showing the expected proportion of patients in each category. A proportional odds model was fit in each stratum, respectively. For each stratum, we first obtained the model-based variance of the treatment effect under an effective sample size of 1 by using the observed proportions in each outcome category; this yielded a standardized standard error corresponding to , which we then rescaled to the actual stratum sample size. Supplementary Table S3 shows the sample construction of exemplary dataset for the OTAC Trial. The correlation between two test statistics was then derived from Eq. (4).
The mean and variance–covariance matrix for the bivariate normal distribution of the two test statistics under the null hypothesis was derived as described in Section 3.1.1. We iterated through values for from 0.025 to 0.05 in increments of 0.0001 to obtain the probability of rejecting either null hypothesis given both are true . The maximum that maintained an overall type I error rate below 0.05 was 0.0347; this was specified as our nominal -value at the beginning of the trial. The nominal -value will be recalculated at the end of the actual trial using the observed data. Proceeding with the nominal -value of 0.0347, we identified the smallest sample size that yielded a power of more than 80% under the alternative hypotheses to be 780 participants. After accounting for loss to follow-up, the total sample size was inflated to 820.Table 1. Assumed distribution of ordinal outcomes for different treatment groups and strata in the OTAC trial.Table 1. Stratum 1Stratum 2OrdinalProportionOrdinalProportionPlacebo10.2010.3020.4020.4230.2530.1940.1240.0850.0350.02Treatment10.2710.3420.4220.4230.2030.1740.0940.0650.0250.01
Simulation
5
Simulation methods
5.1
We simulated trials with two strata, evaluating co-primary hypotheses for the full cohort and for Stratum 1. The two null hypotheses, denoted by and , state no treatment effect for the full cohort and stratum 1, respectively. We consider the trial a “success” if either of the null hypothesis is rejected and define the type I error as the rate at which either null hypothesis is rejected given that both are true, using two-sided tests.
We compared the proposed correlation correction with Bonferroni correction in terms of the type I error rate, power, and expected sample size ( ) (when applicable) under various conditions. We used a Bonferroni correction as the benchmark, rather than Holm’s method or a gatekeeping approach to evaluate our approach for the following reasons. Although Holm’s method is commonly used, it yields identical results to Bonferroni in terms of power and type I error rate for this scenario, since the family-wise error rate depends solely on the minimum -value compared with the overall type I error rate divided by the number of tests. Gate-keeping procedures were not considered because they require a predefined hierarchical ordering of hypotheses, which conflicts with our objective of concurrently evaluating endpoints of equal clinical priority.
The proportion of patients in stratum 1 was varied from 0.9 to 0.5. For the distribution of ordinal outcome in the stratum 1 placebo group, , we examined two sets of proportions for each category: , and ; the first set of proportions is aligned with our hypotheses in the OTAC trial, the second set is the scenario when we observe fewer severe outcomes. Among these 10 conditions, the one aligned with the sample size assumptions in the OTAC trial with a sample size of 780 estimated to maintain 80% power and a type I error rate of 0.05 was used as the “fixed” sample size to assess the potential effect of deviations from the original assumption without interim analysis; this sample size was then inflated to 792 due to three planned interim analyses. In all cases, we set the summary odds ratio ( ) to be 1.72 comparing outcomes in the placebo group in stratum 2 to the placebo group in stratum 1 under the null hypothesis; the s for the treatments in stratum 1 and stratum 2 compared to placebo were set to be 1.5 and 1.2, respectively, under the alternative hypothesis.
In the first set of simulations, we evaluated the type I error rate control of the proposed method without interim analyses across various sample size assumptions. Data were first generated with the sample size and the nominal -value estimated to maintain a type I error rate of 0.05 and power of 0.8 under each scenario. The correlation of the two test statistics, the nominal -value, and the sample size were estimated based on the trial assumptions. The “actual” type I error rate and power were estimated from the simulation. We also compared the necessary sample size to maintain a power of 0.8 between the proposed approach and when using Bonferroni correction. We then fixed the sample size of 780 and simulated the type I error rate and power under deviations from these sample size assumptions. The nominal -value for the Bonferroni correction was set at 0.025 and was determined for the correlation correction based on the observed standard errors for each simulation iteration.
A second set of simulations was then carried out with 3 interim analyses at , and 75% of enrollment. We first fixed the power, varied the sample size as in the first part, and obtained the with interim monitoring through simulation. The boundaries for each interim analysis were obtained from a Lan-Demets O’Brien Fleming-like alpha spending function using the nominal -value determined based on the assumptions used to calculate the sample size. In the final analysis, we adjusted the alpha spending functions using the nominal -value estimated from the full data. However, because the data were generated in accordance with the sample size assumptions, we would not expect large differences between the assumed and estimated correlation between the test statistics at the end of the trial and thus for adjustment of the boundaries to meaningfully impact the results. We then fixed the sample size to simulate the type I error rate and power with both methods under different deviations from the sample size assumptions. We compared the results by only adjusting the alpha spending functions at the final analysis (using the nominal -value for the assumed scenario to calculate the first three boundaries), and adjusting at each analysis using the nominal -value obtained from the current simulated data. Similar simulations for a time-to-event outcome are detailed in the Supplementary Material.
All simulations were carried out using R version 4.3.1. Proportional odds regression models were carried out to evaluate the treatment effect using the “MASS” package [41]; the nominal -value was obtained using the “mvtnorm” package [42]; boundaries for interim analyses were obtained using the “gsDesign” package [43]. Each scenario included 10,000 iterations.
Simulation results
5.2
Without interim monitoring
5.2.1
Table 2 presents simulation results for the ordinal outcome scenarios without interim analysis. As the proportion of patients in each stratum became more balanced, the correlation decreased and the required sample size under the correlation correction increased. When was assumed to be , as the decreased from 0.9 to 0.5, the estimated correlation between the two test statistics decreased from 0.949 to 0.709. The sample size needed to maintain the same power for both methods correspondingly increased from 705 to 1141. The Bonferroni correction was underpowered compared to correlation correction and had a type I error rate lower than the specified rate of 0.05. The correlation correction method thus required a significantly smaller sample size to achieve an 80% power compared to the Bonferroni correction, especially in situations with larger correlations. As shown in the last column of Table 2, when was 90%, the correlation correction saved 11.1% of sample size compared to Bonferroni correction, and 4.5% when was 50%. When was assumed to be , we observed similar patterns, though a larger sample size was necessary to achieve the same power and type I error.
When fixing the sample size and , power was greater when the correlation between test statistics was higher. Though power differed from the targeted 80% when the sample size assumptions did not hold, the correlation correction method consistently controlled the type I error at approximately 0.05. Compared to the Bonferroni correction, the correlation correction provided greater power in all circumstances, with the difference in power for the two methods ranging from 0.023 to 0.046, and showed a larger difference when the correlation between test statistics was higher. Similar results were found for the time-to-event outcome (Supplementary Tables S1 & S2).
Table 2. Simulation results without interim analysis for ordinal outcome.Table 2
With interim monitoring
5.2.2
Table 3 presents the simulation results for ordinal outcomes with three interim analyses.
When adding three interim analyses, the expected sample size ( ) under the alternative hypothesis was reduced compared to the planned sample size due to the early termination of trials, with the when using the correlation correction being smaller compared to the Bonferroni correction. Taking the conditions where was for example, the reduction in for the correlation correction method compared to the Bonferroni correction ranged from 11.7% when was 90% to 4.8% when was 50%.Table 3. Simulation results with interim analysis for ordinal outcome.Table 3
We also hypothesized that the power and would differ when adjusting the interim monitoring boundaries only at the final analysis compared to adjusting at each analysis to account for differences in the nominal -value approximated at the beginning of the trial and the value ultimately used based on the observed data. This was because the first three boundaries were determined based on a nominal -value of 0.0347 (the nominal -value aligned with the original sample size assumptions) when only adjusting at the final analysis. We assumed that when only adjusting the boundaries at the final analysis, if the pre-specified correlation was larger than the true correlation, more type I error would be spent in the first three interim analyses than intended, leaving less type I error for the final analysis.
We observed that adjusting the boundaries only at the final analysis resulted in a slightly smaller when the assumed correlation was larger than the true correlation, and slightly larger when the assumed correlation was smaller than the true correlation. No clear trend with respect to power was observed. For all sets of simulations, we observed similar trends for the time-to-event outcome.
Discussion
6
In the OTAC trial, type I error for the co-primary tests of the treatment effect in the overall population and in stratum 1 will be controlled by lowering the nominal -value based on the estimated correlation between the two tests. We assessed type I error and power using this method by simulating the results for both an ordinal and time-to-event outcome under varying scenarios, both without and with interim analyses. The performance of the proposed correlation correction is robust to deviations from sample size assumptions, consistently maintaining a desired type I error rate of approximately 0.05 under all simulation settings even when the sample size was inadequate to maintain the specified power. As expected, this also reduces the required sample size compared to a Bonferroni correction, especially when the correlation between two test statistics is large.
The correlation between tests is similar among different treatment effects and baseline conditions given the same proportion of patients in important subgroups. Correcting the alpha spending functions for the co-primary tests based on the estimated correlation at each interim analysis reduces the when the correlation between tests is higher than initially anticipated (i.e. more participants in stratum 1) by allowing more type I error to be spent earlier, but leaving less for the final analysis. When the correlation is lower than anticipated, correcting the alpha spending functions at each analysis results in a slightly larger compared to correcting the alpha spending functions only at the final analysis. This is because less type I error is allocated to interim analyses once the nominal -value is adjusted. This trend was demonstrated in Section 5.2.2 through the simulations with a fixed total sample size.
While in all cases we divided the type I error equally for each hypothesis, it is straightforward to allocate more or less type I error rate for some of the hypothesis tests by adjusting the critical values in Eq. (6). In this paper, we did not specifically discuss the methods for correcting the boundaries in conjunction with a sample size re-estimation; this could be an important topic for future work. The method described also has some additional limitations. First, this assumes that the test statistics follow a multivariate normal distribution and thus may not be applicable to all primary outcomes or analyses when the sample size is too small to rely on asymptotic theory. Second, when the correlation was smaller than 0.7 (e.g. when was less than 50% in the ordinal outcome scenarios), the reduction in necessary sample size was less than 5% compared to the Bonferroni method. In cases where the correlation between test statistics is low, there may be minimal benefit over the Bonferroni correction.
Although our simulations focused on an O’Brien–Fleming-like spending function, the proposed correlation correction can be applied with other spending functions such as those resembling a Pocock boundary. Because a Pocock boundary allocates more type I error at earlier looks, mis-specification of the correlation can lead to more pronounced early overspending. In such settings, updating the nominal -value at each interim analysis rather than relying solely on a final-analysis adjustment is expected to be particularly important to preserve type I error control. By contrast, with an O’Brien–Fleming–like spending function that spends very little early, updating the correlation-adjusted alpha function only at the final look typically has a negligible impact on power while maintaining type I error control.
From a design perspective, our proposed method is most useful when there are only a few co-primary strata (e.g., the overall population plus one pre-specified subgroup). Adding more disjoint strata splits the sample and weakens correlations between test statistics, reducing the efficiency gain over a Bonferroni correction.
In the OTAC protocol, demonstration of efficacy in either the overall population or in Stratum 1 was specified as a stopping criterion for further enrollment. Because Stratum 1 was expected to constitute approximately 80% of participants and the co-primary hypotheses are defined for Stratum 1 and for the overall cohort, stopping only in Stratum 1 while continuing enrollment in Stratum 2 would effectively reveal that the overall effect is likely favorable, creating substantial risk of operational unblinding and complicating interpretation of any subsequent data. For this reason, we do not recommend designs that stop a single stratum while continuing others once efficacy has been declared. In alternative designs with multiple subgroups of interest, one could in principle allow enrollment to continue in the remaining subgroup(s) after rejecting the null hypothesis in a given subgroup, but the same concerns about partial unblinding and interpretability remain. If such a strategy were nevertheless adopted, the post-rejection monitoring problem would simply involve a reduced set of primary hypotheses, and our proposed method could be applied by updating at each subsequent analysis, (1) the joint correlation structure for the remaining test statistics and (2) the corresponding alpha-spending function.
In summary, the correlation correction method controlled the type I error at the desired rate under all simulation scenarios. It also provides the most benefit in sample size reduction compared to Bonferroni correction when the correlation between the test statistics is large (up to 12% in our simulation setting when was 90%). This robust approach provides a feasible method for controlling the type I error rate and leveraging the correlation between multiple tests to increase power. This case study can serve as a useful reference for future studies involving similar endpoint structures, especially when subgroup inference is of clinical or regulatory importance.
CRediT authorship contribution statement
Jiayi Hu: Writing – review & editing, Writing – original draft, Software, Methodology, Conceptualization. Abdel G. Babiker: Writing – review & editing, Project administration, Methodology, Conceptualization. Cavan S. Reilly: Writing – review & editing, Project administration, Methodology, Funding acquisition, Conceptualization. Jason V. Baker: Writing – review & editing, Project administration. Lianne K. Siegel: Writing – review & editing, Writing – original draft, Supervision, Software, Project administration, Methodology, Conceptualization.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Holland T.L.Ginde A.A.Paredes R.Murray T.A.Engen N.Grandits G.Tixagevimab–cilgavimab for treatment of patients hospitalised with COVID-19: a randomised, double-blind, phase 3 trial Lancet Respir. Med.1020229729843581707210.1016/S 2213-2600(22)00215-6PMC 9270059 · doi ↗ · pubmed ↗
- 2Bayry J.Lacroix-Desmazes S.Kazatchkine M.D.Kaveri S.V.Monoclonal antibody and intravenous immunoglobulin therapy for rheumatic diseases: rationale and mechanisms of action Nat. Clin. Pr. Rheumatol.3200726227210.1038/ncprheum 048117471245 · doi ↗ · pubmed ↗
- 3Stadler E.Burgess M.T.Schlub T.E.Khan S.R.Chai K.L.Mc Quilten Z.K.Monoclonal antibody levels and protection from COVID-19Nat. Commun.144545202310.1038/s 41467-023-40204-1PMC 1038250237507368 · doi ↗ · pubmed ↗
- 4Yamasoba D.Kosugi Y.Kimura I.Fujita S.Uriu K.Ito J.Neutralisation sensitivity of SARS-Co V-2 omicron subvariants to therapeutic monoclonal antibodies Lancet Infect. Dis.2220229429433569007510.1016/S 1473-3099(22)00365-6PMC 9179126 · doi ↗ · pubmed ↗
- 5Briani C.Visentin A.Therapeutic monoclonal antibody therapies in chronic autoimmune demyelinating neuropathies Neurotherapeutics 1920228748843534907910.1007/s 13311-022-01222-x PMC 9294114 · doi ↗ · pubmed ↗
- 6Hill P.Cross N.B.Barnett A.N.R.Palmer S.C.Webster A.C.Polyclonal and monoclonal antibodies for induction therapy in kidney transplant recipients Cochrane Database Syst. Rev.12017 CD 00475910.1002/14651858.CD 004759.pub 2PMC 646476628073178 · doi ↗ · pubmed ↗
- 7Mc Ginley L.M.Chen K.S.Mason S.N.Rigan D.M.Kwentus J.F.Hayes J.M.Monoclonal antibody-mediated immunosuppression enables long-term survival of transplanted human neural stem cells in mouse brain Clin. Transl. Med.122022 e 104610.1002/ctm 2.1046 PMC 947105936101963 · doi ↗ · pubmed ↗
- 8Oriol A.Abril L.Ibarra G.First-line treatment of multiple myeloma in both transplant and non-transplant candidates Expert. Rev. Anticancer. Ther.2320236856983719428310.1080/14737140.2023.2213891 · doi ↗ · pubmed ↗