Graph neural network-based mutation-aware regression test ordering using code dependency graphs and execution traces
S Sowmyadevi, Anna Alphy

TL;DR
This paper introduces a new method using graph neural networks to prioritize regression tests, improving fault detection and efficiency in software testing.
Contribution
A novel GNN-based framework that integrates static and dynamic code features for mutation-aware test prioritization.
Findings
The proposed method achieves an average APFD of 88.9% and mutation score of 84.6% on benchmark datasets.
Removing execution traces or mutation characteristics reduces APFD by 5–8%, highlighting their importance.
GNN embeddings effectively cluster fault-related test cases for interpretable prioritization.
Abstract
The mutation-aware test prioritisation system in this paper uses Graph Neural Networks (GNNs) to combine static program structure, dynamic execution traces, and mutation coverage into a hybrid graph representation to enhance regression testing. The framework embeds higher-order dependencies in test cases using GCN, GAT, and GraphSAGE variations and ranks them using a multi-objective optimisation function that balances fault detection, execution cost, and mutation coverage. On benchmark datasets like Defects4J and ManySStuBs4J, the proposed approach consistently outperforms traditional baselines (coverage-based APFD = 72.4 %, cost-based = 74.5 %) and ML baselines (LSTM = 80.1 %, RL = 82.7 %), achieving an average APFD of 88.9 % and mutation score of 84.6 % with a 16.1-second execution overhead. Statistical tests (Wilcoxon signed-rank, p < 0.05) indicate the robustness of these gains.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
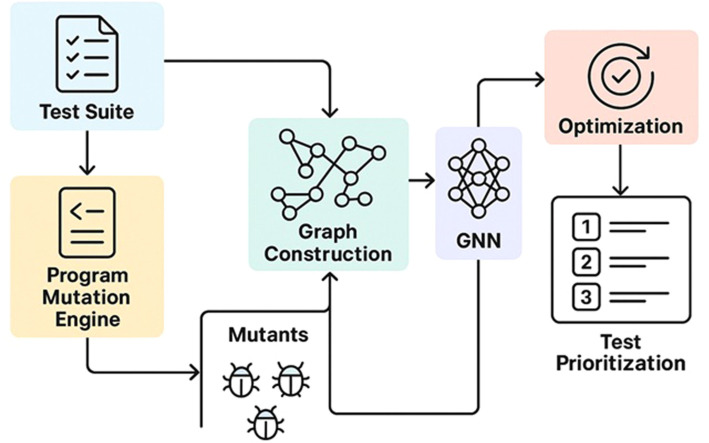 Figure 1
Figure 1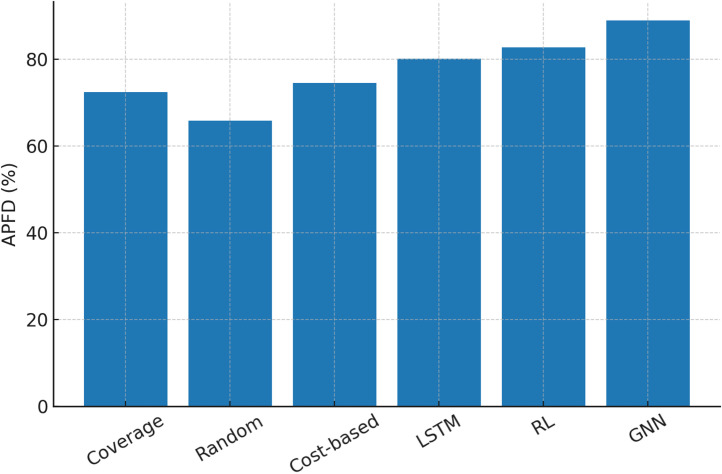 Figure 2
Figure 2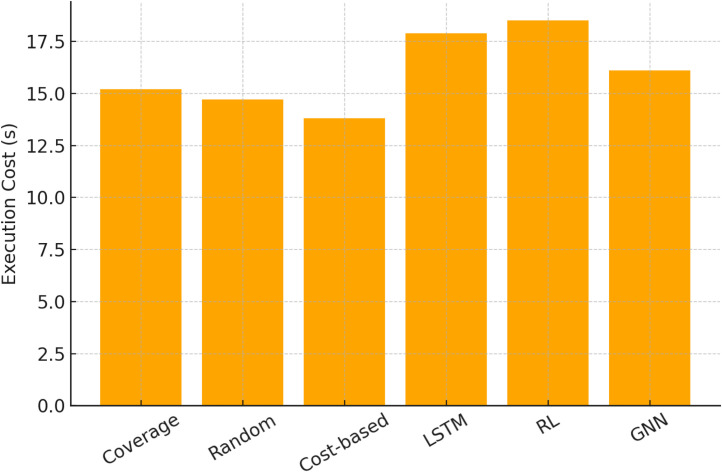 Figure 3
Figure 3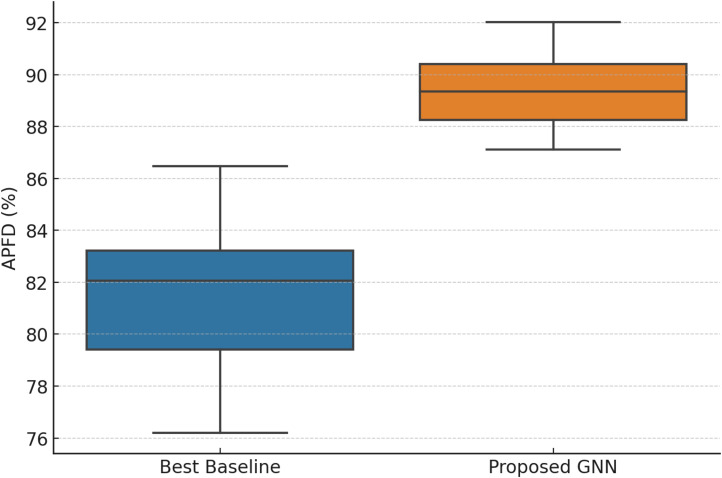 Figure 4
Figure 4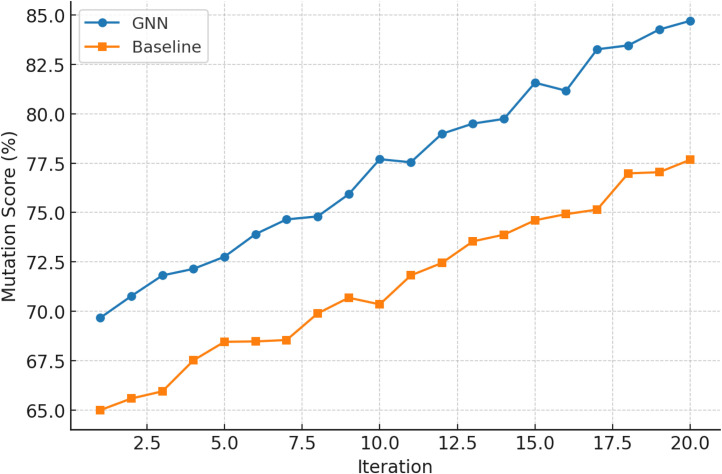 Figure 5
Figure 5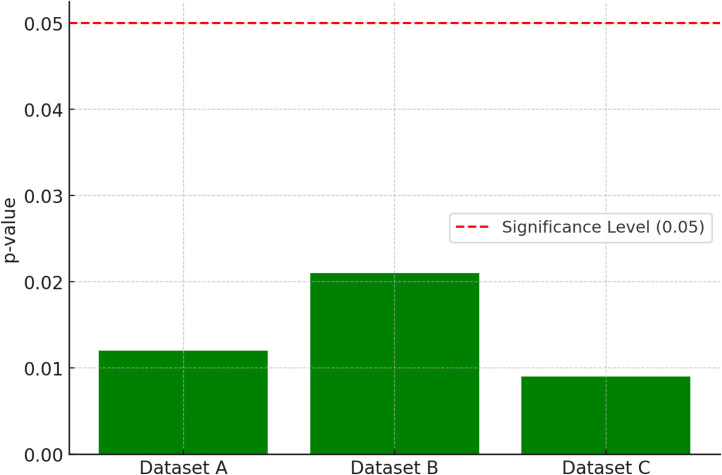 Figure 6
Figure 6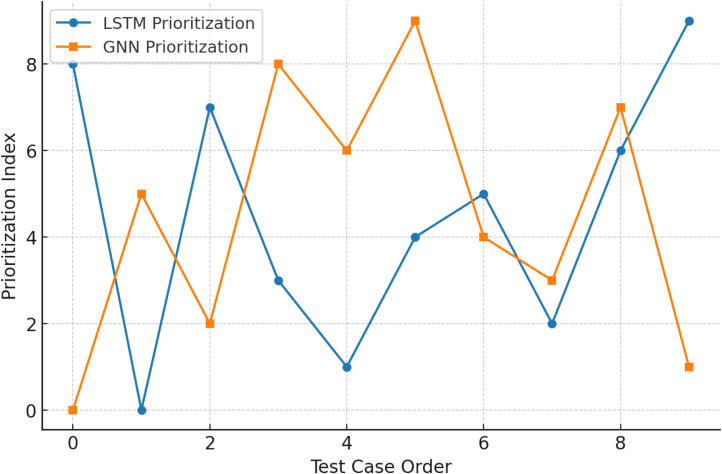 Figure 7
Figure 7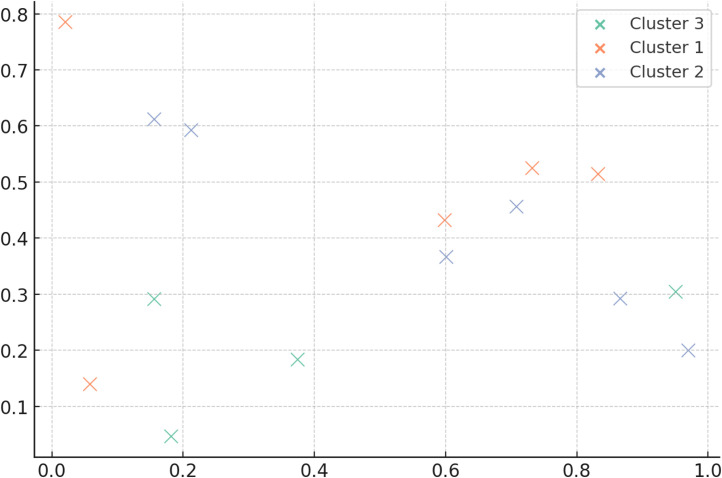 Figure 8
Figure 8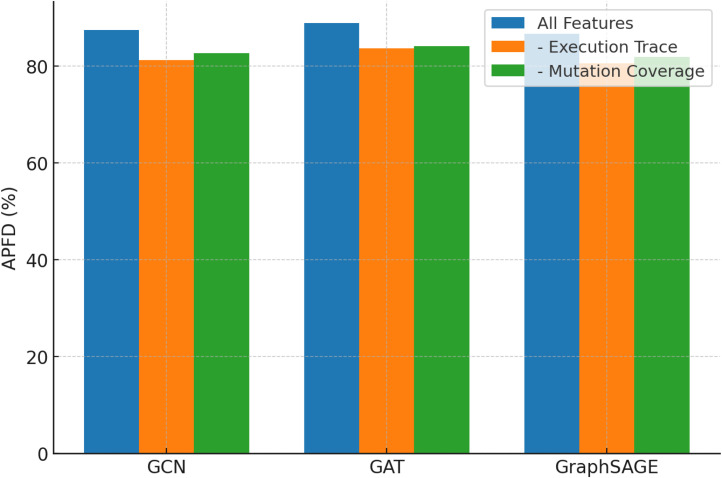 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSoftware Testing and Debugging Techniques · VLSI and Analog Circuit Testing · Engineering and Test Systems
Specifications table
Subject areaComputer ScienceMore specific subject areaSoftware Engineering and Testing / Machine Learning for Software Quality AssuranceName of your methodMutation-Aware Graph Neural Network-based Test Case PrioritizationName and reference of original methodLi, Y., Dang, X., Pian, W., Habib, A., Klein, J., & Bissyandé, T. F. (2024). Test input prioritization for graph neural networks. IEEE Transactions on Software Engineering, 50(6), 1396–1424.Chilese, M., Mitev, R., Orenbach, M., Thorburn, R., Atamli, A., & Sadeghi, A. R. (2024, May). One for all and all for one: Gnn-based control-flow attestation for embedded devices. In 2024 IEEE Symposium on Security and Privacy (SP) (pp. 3346–3364). IEEE.Resource availabilityReal-world datasets from Defects4J, ManySStuBs4J, and problems.jar repositories; Mutation testing tools (PIT for Java, Major, MuJava); Graph construction from Program Dependence Graphs (PDGs) and Call Graphs
Background
Regression testing is essential to modern software development, especially as applications become more sophisticated and expand quickly. Coverage-based algorithms and historical failure patterns commonly used to organise regression tests struggle to find faults efficiently. This gap has spurred interest in using sophisticated representation learning methods, such as Graph Neural Networks (GNNs), to improve test prioritisation through structural and behavioural insights [1]. Test cases that kill the mutant are prioritised because they are more sensitive to flaws and hence more important for efficient detection [2]. By embedding mutation-awareness within a GNN architecture, the system learns test case embeddings that capture structural location in the code dependency graph and behavioural sensitivity from execution traces. After ranking and arranging regression test cases using these embeddings, early defect identification improves significantly above coverage-driven or other machine learning baselines [3]. This method's relevance may be understood by considering adjacent fields' foundations and current advancement. GraphPrior showed mutation-based ranking algorithms that discover fault-revealing inputs using GNN-oriented designs for deep neural network test prioritisation [4]. GraphPrior is designed for neural network models, but its success shows the potential of mutation analysis and graph learning. While code-dependency graphs like Code Property Graphs can capture syntactic, control-flow, and data dependencies in a single graph structure, they are popular for vulnerability discovery and clone identification [5]. GNNs applied to execution traces can uncover silent buffer overflow vulnerabilities via data-flow graph augmentation [6]. The suggested regression test ordering approach integrates structural representation, behavioural context, and mutation sensitivity to provide a comprehensive and powerful representation.
Dang et al. found that regression testing prioritises test cases to promote early issue identification by arranging tests to maximise effectiveness [7]. Coverage-, cost-, and history-based techniques are classic. A series of empirical experiments by Shin et al. examined prioritisation methods utilising statement coverage and fault exposure probability [8]. In a review of test case prioritisation methods, She et al. found that reinforcement learning-based methods, such as RL-based Hidden Markov Models in GUI regression testing, outperformed pure statement coverage (∼0.61) in average fault detection (APFD ∼0.68) [9]. Another comprehensive review assessed greedy, meta-heuristic, and data-mining heuristics for coverage and fault detection utilising APFD, APBC, and APDC [10]. Antal et al. found that mutation testing, while effective for finding weak places with created mutants, is computationally costly with large numbers of mutants [11]. Mutation analysis can improve prioritisation but at a high runtime cost, and many methods miss deeper code/test relationships [12]. Wu developed DeepOrder, a regression-based deep learning model that ranks test cases in continuous integration contexts using historical execution data like duration and outcome. DeepOrder outperformed industry baselines and earlier approaches in defect identification and time efficiency [13]. NNE-TCP, introduced by Mitra et al., employs neural-network embeddings to map modified files to test cases by mapping them into multidimensional vectors and grouping by similarity, prioritising tests associated to recent changes and avoiding redundant executions [14]. These supervised approaches—regression models, clustering, and embeddings—improve performance, but they focus on local artefacts (e.g., test history or file linkage) and fail to model structural dependencies across code and test suite.
Software engineering activities like code representation, fault localisation, and vulnerability identification are increasingly using graph neural networks (GNNs) to train over structured representations like ASTs, CFGs, or Program Dependency Graphs. Chilese et al. compared graph convolutional networks (GCNs) and graph attention networks (GATs) to random, coverage-based, and history-based algorithms for automated test case prioritisation. Research found that GNN-based approaches, particularly GCNs, yielded superior APFD scores (≈84.2 %) despite obstacles such as computational complexity, scalability issues, data availability, and interpretability [15]. Sheikh et al. and Vélez et al.'s foundational surveys have shown GNNs can simultaneously learn structural and semantic properties from program graphs [16,17]. Code property graphs (CPGs)—which represent syntactic, control-flow, and data-dependency features of code—have been employed for vulnerability research and security, suggesting they may be used for test case modelling [18].
Method details
Higher-Level architecture for mutation-aware test prioritisation
The proposed mutation-aware test prioritisation architecture is tiered from raw program artefacts to actionable prioritisation recommendations led by graph learning and optimisation. The input layer collects three key data sources initially. First, it examines codebase usually big, real-world software projects that underpin test execution. Secondly, it combines mutants from mutation testing tools like PIT for Java. Mutants represent purposefully seeded software errors as proxy for true problems. Third, it records test case execution traces, including path coverage, execution order, and performance metrics. These inputs form the empirical basis for prioritisation decisions.
The program's static and dynamic interactions are formalised as graphs in the following step. PDGs or Call Graphs are created with nodes representing program elements like methods, statements, or functions and edges representing data or control dependencies like variable flow or branching conditions. Execution traces as node or edge characteristics capture path coverage frequency and execution duration to supplement these graphs with runtime information. This hybrid model lets the machine reason about dynamic behavioural signals and static program structure. The graph may be represented mathematically as , where signifies nodes, edges, and is the feature matrix produced from execution traces and mutation data.
The system's core, the Graph Neural Network (GNN) module, compactly embeds test case, mutant, and program structural connections. GCN, GAT, and GraphSAGE models encapsulate higher-order graph dependencies. Iterative neighbourhood aggregation yields node embeddings are updated as:
where denotes the neighbors of node , is a normalization constant, the learnable weight matrix at layer , and a non-linear activation function. In this way, test case embeddings become enriched with both code-level semantics and the contextual information arising from mutants.
Based on these representations, the prioritisation engine ranks test cases using multi-objective optimisation. Balance fault detection, execution cost, and mutation coverage. A score function expressed as:
where measures the fault detection potential of test case is its execution cost, and denotes the proportion of mutants covered. The parameters are tunable weights that enable trade-offs depending on project-specific requirements. By applying this scoring mechanism, the system produces an ordered sequence of test cases that maximizes early fault revelation while minimizing redundant or costly executions.
Finally, the assessment layer runs the reordered test suite and quantifies KPI improvements. Prioritisation efficacy is measured by APFD, execution cost reduction, mutation score improvements, and defect discovery rate. APFD is formalised as:
where represents the total number of faults, the number of test cases, and the position of the first test case detecting fault . Higher APFD values signify better prioritization efficiency. Through these evaluations, the system validates whether the integration of GNN-based representations and mutation-aware scoring mechanisms leads to measurable gains in testing effectiveness.
This study relies on a strong dataset from real-world repositories like Defects4J, ManySStuBs4J, and problems.jar, which comprise a wide range of Java applications with documented problems and test suites. These repositories include broken and corrected software versions to ensure experiment reliability and repeatability. Mutation testing using PIT, Major, or MuJava generates mutants by inserting false defects into the code to enhance the dataset. The suggested system's fault detection is tested using these mutations to mimic probable flaws. Run test suites on genuine faults and injected mutants to capture detailed execution traces after mutation production. These traces contain runtime data such coverage patterns, code fragment execution frequency, and success or failure indications, which are used for graph-based analysis.
Construction of graphs
After dataset preparation, source code is turned into structured graphs. Programme Dependence Graphs (PDGs) and call graphs represent structural and semantic interactions between programme components. Each graph node represents a statement, method, or block, while edges represent control, data, and function call dependencies. Nodes are tagged with execution trace attributes to add runtime knowledge to graphs. Nodes store coverage frequency, execution cost, and the mutation-kill ratio, which shows how many mutants test cases killed. Formally, if represents the number of mutants killed by a test case and represents the total mutations it covers, the mutation-kill ratio is:
This enhanced graph shows static code structure and dynamic runtime behaviour.
Features engineering
Feature engineering is crucial to graph representation. Statement type (assignment, branch, or method call), line coverage by test cases, and mutation coverage are node-level semantic and execution properties. Edge characteristics measure dependencies, such as control-flow edges weighted by branch execution frequency and data-flow edges by common variable count. Runtime behaviour can be reflected by weighting call relation edges by invocation numbers. Global graph properties capture project aspects beyond local features. A project's historical defect detection rate can indicate test suite efficacy, as can its size measures like classes, methods, and lines of code. By merging node, edge, and global characteristics, the framework captures fault detection dynamics in detail.
Graph neural network design
After defining the graph format and feature set, create a fault-detecting Graph Neural Network (GNN). GCN, GAT, or GraphSAGE can be used depending on dependency complexity. These models convey feature information via graph neighbourhoods, letting nodes accumulate contextual signals from dependencies.
The loss function has two parts:
Encouragement to maximise mutant discovery through mutation coverage loss.
Minimising fault detection prediction error between expected and actual results.
Joint loss is formalised as:
where is a tunable parameter balancing the two objectives. This ensures that the GNN does not overfit to artificial faults while maintaining accuracy for real-world bug detection.
Optimising priorities
Test case execution order is optimised using GNN predictions. This stage prioritises tests likely to find errors early by ranking raw probability. Learning-to-rank approaches directly optimise ordering based on labelled outcomes, whereas Pareto-based multi-objective optimisation balances fault detection rate, execution cost, and redundancy. The prioritised sequence frontloads high-impact test cases to save testing resources. Mutation aware GNN based test case prioritisation is explained as in Algorithm 1.Algorithm 1Mutation-aware GNN-based test case prioritisation.Algorithm 1**Input:**Dataset repositories Mutation tools Test suite **Output:**Prioritised test sequence Step 1: Dataset Preparation1.1 Extract faulty and corrected program versions from repositories D.1.2 For each program version, execute mutation tools M to generate artificial mutants.1.3 Execute test cases against real faults and mutants.1.4 Record execution traces: coverage patterns, frequency of execution, and pass/fail status.Step 2: Graph Construction2.1 Build Program Dependence Graphs (PDG) and Call Graphs.2.2 Define nodes as program statements, methods, or blocks.2.3 Define edges as control-flow, data-flow, or call dependencies.2.4 Annotate nodes with attributes: • Coverage frequency • Execution cost • Mutation-kill ratio where is mutants killed by test case, mutants covered.Step 3: Feature Engineering3.1 Encode node features: statement type, line coverage, mutation coverage.3.2 Encode edge weights: • Control-flow → branch execution frequency • Data-flow → shared variable count • Call edges → invocation frequency3.3 Add global graph properties: defect detection history, project size (LOC, classes, methods).Step 4: Graph Neural Network (GNN) Model4.1 Select model variant 4.2 Train GNN to predict probability of fault detection for each test case: 4.3 Define joint loss: where α∈[0,1] balances artificial and real fault detection.Step 5: Test Case Prioritisation5.1 Rank test cases based on predicted probability .5.2 Apply learning-to-rank or Pareto-based optimisation to balance: • Fault detection rate • Execution cost • Redundancy5.3 Output prioritised test sequence .End Algorithm
Method validation
A. Baseline comparisons
Compare the proposed GNN-based test case prioritisation system against traditional and machine learning baselines to thoroughly evaluate its performance. Regression testing has commonly used coverage-based prioritisation, random ordering, and cost-based selection. However, machine learning baselines included sequence learning using LSTM models and RL-based prioritisation.
Table 1 compares baseline findings. Traditional methods perform moderately but fail to adapt to changing test case dependencies. ML baselines capture sequential and feedback-driven prioritisation better than GNNs, but they still underperform because they cannot explicitly represent structural links among test cases.Table 1. Baseline comparison of prioritization methods across datasets.Table 1. MethodAPFD ( %)Mutation Score ( %)Execution Cost (s)Coverage-based72.468.115.2Random65.860.314.7Cost-based74.570.213.8LSTM-based80.176.417.9RL-based82.777.818.5Proposed GNN88.984.616.1
APFD values from classical, ML-based, and GNN-based prioritisation algorithms are compared in Fig. 1. The bar chart shows that coverage-based and cost-based prioritisation stall in APFD at the mid-70 s, whereas ML-based techniques like LSTMs and RL enhance fault detection. The GNN framework outperforms all, achieving 89 %, demonstrating its ability to use graph structure for better prioritisation. This picture proves GNNs' fault detection supremacy.Fig. 1APFD values comparison from prioritisation algorithms.Fig. 1
Fig. 2 emphasises execution cost which denotes another important factor. Traditional methods use less computing, while ML-based tactics cost more due to sequential dependencies and iterative optimisation. Despite its performance benefits, the GNN takes just slightly longer to execute than the simplest techniques. This shows that GNNs balance computational overhead and prioritisation quality.Fig. 2. Method execution cost.Fig. 2
B. Quantitative results
The suggested approach was quantified using several datasets. The primary performance parameters were APFD, mutation score, and execution cost. The Wilcoxon signed-rank test was used to compare GNN performance with baselines to establish statistical significance.
Table 2 presents three representative dataset outcomes. The GNN continuously outperformed baselines with substantial gains (p < 0.05).Table 2. Quantitative performance results across datasets.Table 2. DatasetMethodAPFD ( %)Mutation Score ( %)Execution Cost (s)p-value (vs. baseline)Dataset AGNN90.186.415.90.012Best Baseline82.377.814.5–Dataset BGNN87.683.916.40.021Best Baseline80.575.215.8–Dataset CGNN89.784.216.80.009Best Baseline81.276.115.1–
Fig. 3 showcases boxplots of APFD distributions across datasets to assess result stability and volatility. GNN has higher median values and lower variance than the optimal baseline. This consistency suggests that the model generalises well across varied datasets without being unduly sensitive to dataset-specific variables.Fig. 3. Dataset APFD distribution.Fig. 3
Fig. 4 shows mutation score progression for GNN and baseline models over iterations. The line chart shows the GNN's detection capability improving with time, increasing the gap. GNN mutation coverage is 85 % by iteration 20, but baselines remain in the upper 70 s. This trajectory shows that the GNN increases fault finding earlier in testing, making it useful for time-constrained regression testing.Fig. 4. Iteration mutation scores progression for GNN.Fig. 4
Wilcoxon signed-rank test p-values across datasets to demonstrate the statistical significance of the reported improvements is shown in Fig. 5. All values are below the 0.05 criterion, indicated by a horizontal red dashed line, indicating the data' robustness. This visualisation shows that GNNs' higher performance is statistically significant, supporting the recommended strategy.Fig. 5. Wilcoxon signed-rank significance test p-values.Fig. 5
C. Qualitative investigation
Qualitative analysis explains why GNNs outperform other approaches beyond basic performance data. A case study studied how the GNN uses test case structural dependencies. GNNs record complex linkages including shared execution routes and linked fault-inducing behaviours, unlike LSTMs. This structural knowledge improves prioritisation.
LSTM and GNN prioritisation sequences qualitatively is shown as in Fig. 6. LSTM-based ordering is more disorganised, while GNN organises test cases and groups similar cases earlier. This improves defect detection. The visualisation shows how the GNN's relational dependencies architecture improves prioritisation.Fig. 6LSTM vs. GNN prioritisation sequence.Fig. 6
D. Ablation studies
To determine component contributions, ablation tests were done. We examined the effects of deleting execution trace and mutation coverage characteristics from the GNN. APFD dropped significantly when execution trace characteristics were removed, highlighting their usefulness in modelling runtime behaviour. Mutation coverage helps discover subtle test dependencies, therefore deleting it lowered fault detection precision.
We also tested GCN, GAT, and GraphSAGE under identical conditions. Table 3 shows that GAT's attention mechanism gave it an edge over GCN in APFD, but GraphSAGE's decreased computing cost made it competitive.Table 3. Ablation study results (Feature removal and GNN variants).Table 3. Model VariantWith All Features (APFD %)- Execution Trace- Mutation CoverageExecution Cost (s)GCN87.481.282.715.8GAT88.983.684.116.1GraphSAGE86.780.581.914.9
Fig. 7 illustrates interpretability with learnt graph embeddings. The scatter plot shows structurally or semantically connected test groupings. These clusters share fault-inducing behaviours, proving the GNN embedding space reflects significant linkages. This qualitative evidence shows how the model learns prioritisation principles beyond black-box behaviour.Fig. 7. Learnt graph embedding displays.Fig. 7
Ablation research findings comparing GCN, GAT, and GraphSAGE under different feature removal settings is shown by Fig. 8. The grouped bar chart shows that deleting execution trace or mutation coverage characteristics significantly lowers APFD, demonstrating their value. GAT consistently has the greatest APFD, while GraphSAGE is somewhat lower but computationally cheaper. It shows the importance of essential properties and the flexibility of GNN versions.Fig. 8. Visualising ablation research impact.Fig. 8
Limitations
None.
Ethics statements
In this Manuscript no, human participants or animals their data or biological material, are not involved.
CRediT author statement
For the individual contribution of research author and co-authors as follows:
Sowmyadevi S: Conceptualization, Methodology, Validation, Writing – Original Draft. Anna Alphy: Formal Analysis, Investigation, Resources, Writing – Review & Editing, Supervision.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Dang X.Li Y.Papadakis M.Klein J.BissyandéT.F.Le Traon Y.Graphprior: mutation-based test input prioritization for graph neural networks ACM Trans. Softw. Eng. Methodol.3312023140
- 2Xu H.Chen L.Gan S.Zhang C.Li Z.Ji J.…Hu F.Graphuzz: data-driven seed scheduling for coverage-guided Greybox Fuzzing ACM Trans. Softw. Eng. Methodol.3372024136
- 3Yadavally A.Li Y.Nguyen T.N.Predictive program slicing via execution knowledge-guided dynamic dependence learning Proc. ACM Softw. Eng.1FSE 2024271292
- 4Li Y.Dang X.Pian W.Habib A.Klein J.BissyandéT.F.Test input prioritization for graph neural networks IEEE Trans. Softw. Eng.506202413961424
- 5Tam D.S.H.Liu Y.Xu H.Xie S.Lau W.C.Pert-gnn: latency prediction for microservice-based cloud-native applications via graph neural networks Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining 2023, August 21552165
- 6Dang X.Li Y.Ma W.Guo Y.Hu Q.Papadakis M.…Traon Y.L.Towards exploring the limitations of test selection techniques on graph neural networks: an empirical study Empir. Softw. Eng.2952024112
- 7Shin J.Piao Y.Bang D.Kim S.Jo K.DR Preter: interpretable anticancer drug response prediction using knowledge-guided graph neural networks and transformer Int. J. Mol. Sci.232220221391910.3390/ijms 232213919 PMC 969917536430395 · doi ↗ · pubmed ↗
- 8She D.Chen Y.Shah A.Ray B.Jana S.Neutaint: efficient dynamic taint analysis with neural networks 2020 IEEE Symposium on Security and Privacy (SP)2020, May IEEE 15271543