A multivariate correlated poisson generalized inverse gaussian regression model for dependent count data: Estimation and testing procedures
Yusrianti Hanike, Purhadi, Achmad Choiruddin

TL;DR
This paper introduces a new statistical model for analyzing multivariate count data with correlation and overdispersion, improving accuracy in public health applications.
Contribution
The novel MCPGIGR model integrates random effects and log-link functions for flexible and robust analysis of dependent count data.
Findings
MCPGIGR outperforms Multivariate Poisson Regression in model fit for maternal and neonatal mortality data.
Simulation studies confirm the consistency and performance of the proposed Maximum Likelihood Estimation and testing procedures.
Abstract
Regression modeling for multivariate count data often struggles with assumption of overdispersion and correlation among response variables. To address these issues, this study proposes a new model called Multivariate Correlated Poisson Generalized Inverse Gaussian Regression (MCPGIGR), which integrates random effects through common shock variables and allows for flexible mean structures via a log-link function. This research develops a Maximum Likelihood Estimation (MLE) and Maximum Likelihood Ratio Tests (MLRT) to evaluate both simultaneous and partial significance of predictors. We conduct simulation studies to assess the consistency and performance of the proposed estimators. Furthermore, in an application to maternal and neonatal mortality across 38 districts/cities in East Java (Indonesia), MCPGIGR substantially improves model fit relative to a Multivariate Poisson Regression (MPR)…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
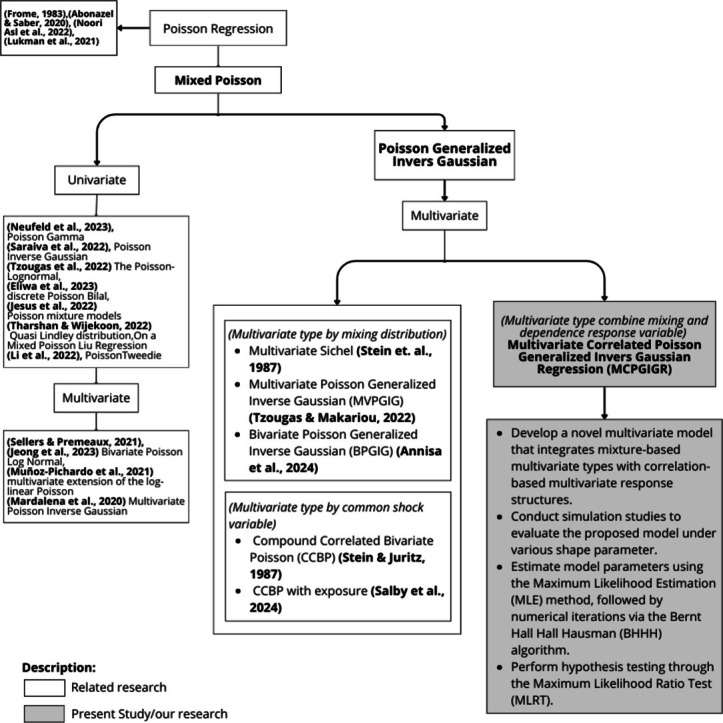 Figure 1
Figure 1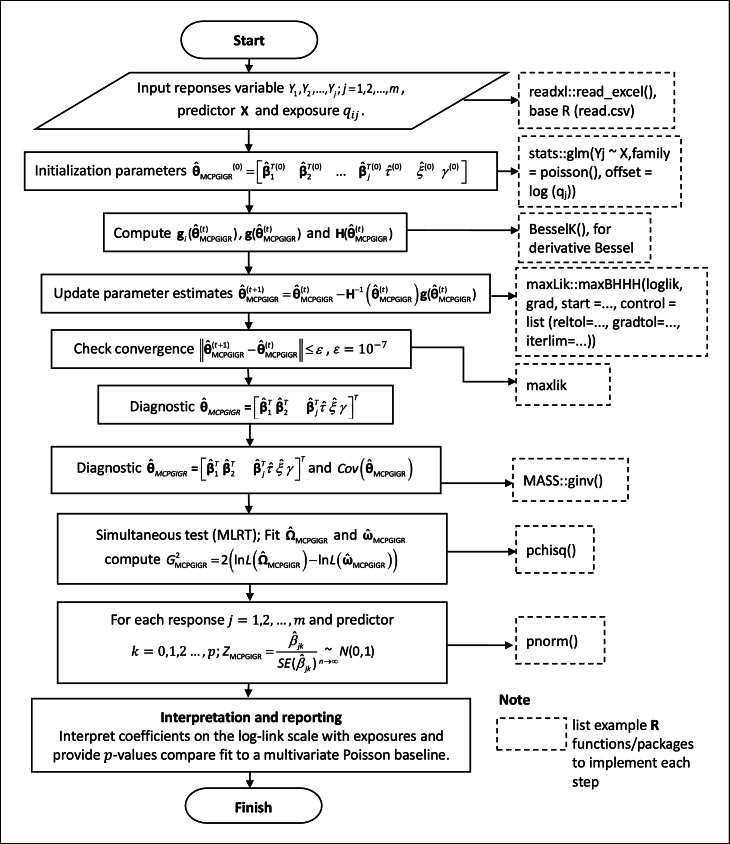 Figure 2
Figure 2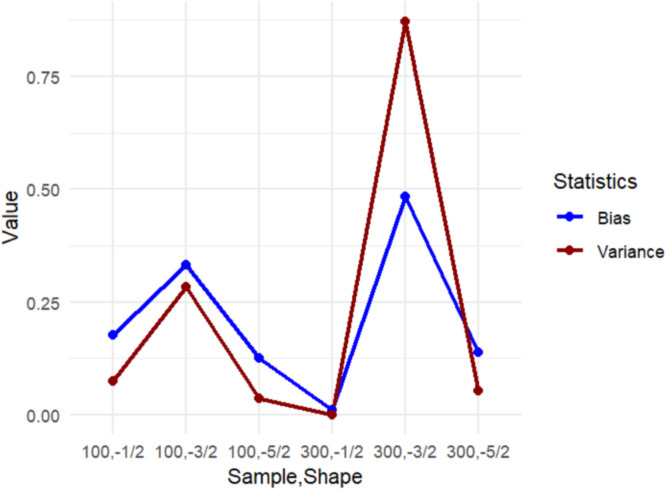 Figure 3
Figure 3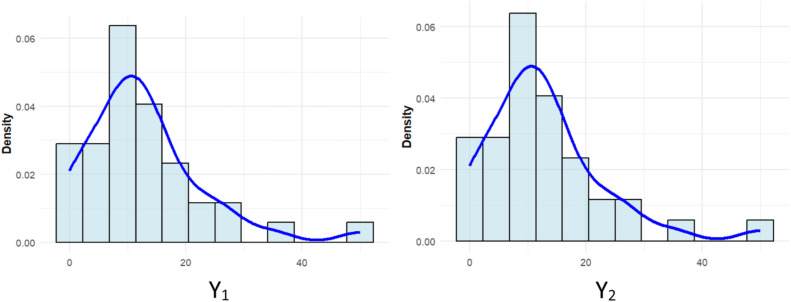 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Bayesian Inference · Bayesian Methods and Mixture Models · Statistical Distribution Estimation and Applications
Specifications table
Subject areaMathematics and StatisticsMore specific subject areaStatistics; Multivariate Analysis; Count Data; Maximum LikelihoodName of your methodMultivariate Correlated Poisson Generalized Inverse Gaussian Regression (MCPGIGR)Name and reference of original methodStein, G. Z., & Juritz, J. M. (1987). Bivariate compound Poisson distributions. Communications in Statistics - Theory and Methods, 16(12), 3591–3607. https://doi.org/10.1080/03610928708829593Resource availabilityMaternal and neonatal mortality data used in this study were obtained from the Health Profile of East Java Province 2023, published by the East Java Provincial Health Office. The dataset includes annual health indicators for all districts/municipalities in East Java. The full report can be accessed at the official website of the East Java Provincial Health Office:https://dinkes.jatimprov.go.id/index.php?r=site/file_list&id_file=10&id_berita=8Direct download link to the document:https://dinkes.jatimprov.go.id/userfile/dokumen/PROFIL%20KESEHATAN%20PROVINSI%20JAWA%20TIMUR%20TAHUN%202023.pdf
Background
Poisson regression is a workhorse for count data and has been applied in many disciplines, such as traffic accidents [1,2], maternal and infant mortality [[3], [4], [5]], and the spread of infectious diseases [6,7]. In practice, however, two features frequently violate the standard Poisson assumptions: overdispersion and dependence across outcomes. Many modern applications also involve multiple, potentially correlated counts, which calls for multivariate modeling rather than separate univariate fits.
Several strategies have been developed to induce dependence in multivariate Poisson models. A classical construction uses a common-shock component: in the bivariate case, , where , and are independent Poisson random variables [8,9]. In this perspective, the rate of the latent Poisson random variable , referred to as the common shock variable, dictates the strength of correlation between the two variables. Broader reviews of multivariate Poisson formulations are provided by [10]. The application of copulas for modeling multivariate discrete data has also been explored extensively by researchers such as [11,12]. Copulas offer flexibility but present complexities in discrete contexts. Mixed models for counts are popular [[13], [14], [15]], yet capturing cross-margin dependence typically requires careful distributional choices and may remain limited in flexibility. Therefore, it is crucial to consider the development of more flexible distributions, such as the mixed Poisson, which can provide a more adaptive and representative solution for phenomena that exhibit unobserved heterogeneity [16,17].
In this study, we build on the mixed-Poisson framework with a Poisson Generalized Inverse Gaussian (PGIG) mixing distribution and extend it to a multivariate correlated regression model, termed Multivariate Correlated Poisson Generalized Inverse Gaussian Regression (MCPGIGR). Dependence is induced through the common-shock mechanism, while GIG mixing on the Poisson rate accommodates overdispersion and yields a flexible dependence structure. The mean specification retains the interpretable log link with exposure, which is standard in applied count regression For half-integer [18,19].
Parameters are estimated by maximum likelihood (MLE) using the BHHH algorithm (Berndt–Hall–Hall–Hausman), which relies on per-observation score vectors [20,21]. We conduct maximum likelihood ratio test (MLRT) for simultaneous parameter testing and Wald Z test for partial testing. To aid accessibility, we present derivations in the main text and compile the detailed steps linking the pmf to the log-likelihood and score, including the Bessel identities in Appendix A.
Contributions of this paper are to (i) formulate MCPGIGR model, a correlated multivariate count regression with exposures and likelihood-based testing; (ii) derive estimation procedure with efficient BHHH estimation; (iii) demonstrate performance through simulations and an application to maternal and neonatal mortality in East Java, where MCPGIGR improves fit over a multivariate Poisson baseline.
This article is organized as follows: Section 2 introduces the distribution, the MCPGIGR regression specification, and the parameter estimation and testing procedures; Section 3 presents the simulations and the East Java application and concludes with brief implementation notes; Appendix A provides detailed derivations.
Methodological details
Parameter estimation and hypothesis testing for MCPGIGR begin with formulation of the multivariate Poisson and GIG, which mixes a multivariate Poisson distribution with a GIG random effect to induce dependence and handle overdispersion. Building on this distribution, we specify the MCPGIG regression with a log link and involve exposure variable. Parameters are estimated by MLE using the BHHH algorithm, and statistical tests are derived using MLRT for joint-parameter test and Wald -test for individual test. Detailed derivations are presented in Appendix A.
Multivariate poisson distribution
The Poisson distribution is a standard model for count data and may be viewed as a limiting form of the Binomial distribution. Typical settings involve rare events observed over a fixed interval (time/area) and independent trials [22]. Let be a Poisson random variable with parameter and exposure . Its probability mass function (pmf) [22]:
with . In regression applications, represents the expected number of events per unit exposure; scales the population at risk or observation time [14].
A multivariate Poisson model specifies a joint distribution for two or more Poisson responses that may be correlated. A classical construction is the variate reduction (common-shock) approach [[23], [24], [25]]. Let be mutually independent random variables, each following a Poisson distribution with respective parameters , where is defined as exposure variable.
Define new random variables as follows:
the joint pmf of the Multivariate Poisson distribution (see Appendix A.1), and can be expressed as:
with . The mean and variance of each random variable , are respectively, given by: . These expressions showed that the correlation among components arises entirely from the shared component .
Multivariate correlated poisson generalized inverse gaussian distribution
The MCPGIG is model is a mixed Multivariate Poisson which includes correlated response variables. The response variables, , assuming their means and variances are identical. The conditional variance can be greater than the conditional mean resulting from positive contagion and unobserved heterogeneity. An error term is added to ,
thus, represent the means for each response variable now, where [14,26]. The characteristics of the mixed Poisson distribution rely on the specific distribution of the random variable . In this study, follows a GIG distribution. Therefore, follows a mixed Poisson distribution based on (4), (3), probability density function (pdf) of GIG is provided in [27]. In probability theory and statistics, the distribution is a three-parameter continuous probability distribution with a pdf [18] as follows:
where , is the third kind modified Bessel function o [28]. Here, the parameter regulates the tail behavior and controls the Poisson–GIG mixing variance, while reflects the scale component that interacts with the latent mixing variable. The parameter represents the dispersion level of the GIG random effect, influencing the variability propagated into the mixed Poisson rates. These parameters jointly determine the degree of overdispersion and the flexibility of the MCPGIG distribution. The result of MCPGIG distribution (see Appendix A.2) based on the integral table by [29] as mentioned in [30], can be stated on:
with where . Eq. (6) is obtained by integrating the MP pmf in Eq. (3) with respect to the GIG mixing density in Eq. (5). Specifically, the MCPGIG pmf follows from the mixing identity (see Appendix A.2 in equation (A.2.2)) where is the Poisson component with mixed rate and is the GIG density. The mean and variance of , .
The MCPGIGR, if response variable where and then the MCPGIGR model can be stated as follows:
with is an exposure variable, defined as the weight of the observation for the i th and j-th units. Let , be the vector of predictor variables with a dimension of for the i th observation, and , be a vector of regression coefficients associated with the j-th response variable.
The MCPGIGR model combines induced correlation (via a common-shock component) with GIG mixing on the Poisson rate, thereby accommodating both overdispersion and cross response dependence. The mean structure retains the interpretable log link, while additional variability is captured through the GIG parameters.
Parameter estimation of mcpgigr model
The MLE method is employed for parameter estimation. This estimation method aims to determine the parameter values that yield the greatest probability for generating the observed data. This estimation method can be used when the pmf is known. The requirement for the MLE estimation method is that the samples are independent. The likelihood function of the MCPGIGR regression model is formed based on the MCPGIG distribution.
In the MCPGIGR regression framework, the modified Bessel function of the third kind appears naturally in the likelihood formulation. Its derivatives are computed using the standard identity . For numerical convenience, the estimation procedure also employs the Bessel ratio , which simplifies several expressions in the score function. Certain tractable forms arise when the shape parameter takes half-integer values (e.g., ), as discussed in [28]. The regression model
when the MCPGIG distribution is specified with , the regression model The parameters to be estimated are . Then, the log-likelihood function of the MCPGIG distribution that obtained is as follows:
The natural logarithm of the likelihood function in Eq. (9) is obtained by applying the logarithmic transformation of regression model in (8) to the pmf in Eq. (6) and summing it over all observations. Differentiating this log-likelihood with respect to the model parameters yields the corresponding first-order derivatives (see Appendix A.3). The first part of the log-likelihood arises from the Multivariate Poisson component, while the second part is contributed by the GIG mixing mechanism. Differentiating the log-likelihood with respect to the parameters under this specification yields the corresponding first derivatives.
The first-order derivatives of the log-likelihood (see Appendix A.4), do not yield closed-form solutions when set to zero, thus requiring an iterative procedure for parameter estimation. In this study, the BHHH algorithm is employed because it allows the Hessian matrix to be approximated without computing the second derivatives of the MCPGIGR likelihood [31,32]. The method relies solely on the gradient vector and the outer-product-of-gradients approximation of the Hessian, which enhances numerical stability for complex likelihood structures. The algorithm begins with an initial parameter vector and iteratively updates the estimates to maximize the likelihood function. Therefore, the BHHH method is employed utilizing the algorithm outlined in Table 1.Table 1BHHH iteration procedure.Table 1. StepProcedureDescription1Initialize parameter valuesSet the initial parameter vector . The initial value of the parameter is determined through separate MPR. The initial values for the overdispersion parameter and are obtained by covariance and averaging the response variable observed overdispersion based on the variance of MCPGIGR [33].2Compute gradient vectorEvaluate the gradient vector, where each elements represents the first derivative of the log-likelihood function served in Appendix A.4.3Compute Hessian matrixConstruct the observed information matrix: 4Update parameter estimatesUpdate parameter values that iteration starts from t = 0 : , where is the parameter vector in the -th iteration.5Check convergenceRepeat step (2–4) for . The iteration will stop whe , where 6CovarianceGet . The values of is obtained from the main diagonal elements of the covariance matrix of the equation .
The BHHH method utilizes the outer product of the individual gradients (score vectors) to approximate the Hessian matrix in each iteration, which enhances numerical stability and computational efficiency. The BHHH algorithm updates parameters using the outer product of individual score vectors, thereby obviating the need to compute the exact Hessian. In practice, only per-observation scores are required; a line search is employed to ensure ascent, and convergence is checked using standard criteria. Asymptotic standard errors are obtained from the inverse of the accumulated outer-product-of-gradients matrix.
Hypothesis testing procedures for the mcpgigr model
We use MLRT for simultaneous hypotheses and Wald tests for partial (coefficient-wise) inference.
Simultaneous Tests. The significance of the regression parameters and the following hypothesis are determined through simultaneous hypothesis testing.:
.
Let denote the full parameter vector and the restricted parameter under the null hypothesis. Following this, the log-likelihood function for the full model is constructed based on the MCPGIG distribution. This log-likelihood formulation corresponds to the equation provided in Eq. (10) of the model specification section.
where . Similarly, a log-likelihood function is derived for the parameter set under the null hypothesis, which may include fewer or constrained parameters depending on the hypothesis tested provided in Eq. (11) .
with and . To proceed with the likelihood ratio test, the maximum values of the log-likelihood function under both the full and restricted models are computed. These are denoted respectively as and Both estimations are obtained through MLE using the BHHH iterative algorithm as outlined in Table 1. The resulting estimates, and , represent the maximum likelihood estimators of the parameter vectors under the full model and under the null hypothesis, respectively. The estimators for the parameters under , is further, the odds ratio is determined as follows: . This equation is equivalent to: , with
The Eq. (12) continues determine the asymptotic distribution of the test statistic . Then where is the number of degree freedom such as the number parameters in vector . The rejection region for the null hypothesis , based on the quantiles of the distribution with degrees of freedom.
Partial tests. If the simultaneous hypothesis test rejects H_0_, then testing continues with a partial test to determine which predictor variables individually influence the response variable. The hypothesis for the partial test is as follows:
The asymptotic normality of the MLE is not derived in detail here but follows from the general asymptotic theory of MLE under standard regularity conditions [34]. The test statistic is the statistic asymptotically standard normal. Thus, The test statistic used is:
The rejection region for is when the where α is the significance level. imultaneous hypotheses are evaluated using a likelihood-ratio test (comparing the unrestricted and restricted models), whereas individual predictor effects are assessed with Wald Z-statistics based on the asymptotic MLE variance (from the outer product of gradients or the observed Hessian). Together, these procedures provide a coherent testing framework for multivariate responses.
Implementation note
As an implementation note following the workflow in Fig. 1, the entire procedure can be replicated in R, in this research was using R 4.3.3 version, using the following core packages: maxLik for BHHH/OPG optimization; base stats functions—most notably glm() to initialize Poisson models with offset = log(q), together with pnorm(), pchisq(), qchisq(),and besselK(); MASS for matrix inversion (to obtain covariance); and readxl for importing .xlsx files. For numerical stability with extreme Bessel arguments or high-precision arithmetic, Bessel (robust evaluation of the modified Bessel function). For benchmarking against alternative count models or a baseline, COUNT, gamlss, and MixedPoisson are useful.Fig. 1. Workflow for the MCPGIGR application.Fig 1
In practice, the BHHH-based MLE routine is sensitive to the choice of starting values, particularly for the GIG shape and scale parameters. We recommend initializing the Poisson components via glm() and obtaining initial GIG parameters using simple method-of-moments heuristics, while monitoring convergence through changes in the log-likelihood and the gradient norm. Each BHHH iteration requires a full pass over the data to compute the log-likelihood and score, so the computational cost scales approximately linearly with the number of observations and parameters. For datasets of similar size to our empirical application (tens of areas and a few hundred observations), convergence is typically achieved within a reasonable time on a standard desktop machine, whereas larger and higher-dimensional multivariate count datasets will naturally entail longer runtimes. In such settings, users may benefit from employing compiled code for Bessel function evaluations, parallelizing score computations, or using stable implementations such as lgamma()-based factorial calculations to keep computation manageable.
Empirical results
We present two complementary pieces of evidence: a simulation study (Sections 3.1–3.2) and an applied case study (Section 3.3). The simulation is tailored to MCPGIGR and evaluates whether the proposed model and its MLE estimation procedure perform well in finite samples under controlled conditions. We vary sample size and the half-integer shape parameter , generate data from the MCPGIG distribution with known coefficients, and assess estimator bias/variance, and model fit (AICc). We then apply MCPGIGR to maternal and neonatal mortality data from East Java (2023), interpret the effects under the log-link with exposures, and compare goodness-of-fit against a multivariate Poisson baseline.
Simulation design
To assess whether the proposed model performs well under the developed estimation procedure, we conduct a simulation tailored to the MCPGIGR framework in a trivariate response setting with three predictors. The simulation compares MPR and MCPGIGR with three different options of shape parameter , i.e., value. To simulate data, it is necessary to generate synthetic datasets that reflect the relationship between predictor and response variables, with the response following the MP and MCPGIG distribution. The simulation procedure consists of the following steps:
Simulation result
In this section, we present the results of a simulation study conducted to evaluate the performance of the MCPGIGR model. Parameter estimation was performed using the MLE procedure, followed by the BHHH algorithm as outlined in Table 1. The estimation results include a comparison between the true parameter values and the average estimated values obtained from the simulation, as presented inTable 3. This table displays the estimates for each parameter under different configurations of the shape parameter and across varying sample sizes.Table 2. Simulation design for MCPGIGR (predictors, shape γ, sample sizes, replications).Table 2. Steps1. Define the true values of the regression parameters and .2. Generate predictor ; set replicated 500 times.3. Set dispersion/scale : and , see [33]4. Simulate response variable data from the Multivariate Poisson and MCPGIG, see Eqs. (3) and (6).5. Estimate parameters via MPR and MCPGIGR (BHHH).6. Compute , (see in Table 2 step 6) and Akaike Information Criterion , of the estimated parameters to assess estimator performance, with is the maximized likelihood function evaluated at the estimated parameters , , is number of predictor parameters in the model, is sample size .7. Summarize results; compare across .Table 3. True parameters and average estimates across replications for MCPGIGR.Table 3. ParameterTrueSampel/Shape −5.000−5.261−6.225−5.257−5.029−7.424−5.453 −0.050−0.049−0.048−0.037−0.049−0.051−0.048 0.4000.3960.3940.4270.4000.4000.401 1.0000.7270.2650.5670.9751.3690.571 0.0700.0640.0530.0610.0690.0450.061 0.0500.0560.0620.0570.0500.0740.056 0.5000.2690.2350.5830.5040.5440.562 1.0000.3610.6070.8310.9740.0200.848
Further insights are provided by Fig. 2, which illustrates the mean absolute bias and variance across scenarios corresponding to those reported in Table 3. The graphical representation summarizes the differences in bias and variance across various shape parameter configurations. Based on the results presented in Table 3 and Fig. 2, it is clear that the MCPGIGR model demonstrates relatively accurate parameter estimates, particularly when sample sizes are larger (i.e., ). This finding suggests that parameter estimates become more stable and consistent with an increase in sample size. The variance tend to decrease with a larger sample size, indicating an improvement in the model's precision and accuracy.Fig. 2. Mean absolute bias and variance of estimators by shape parameter and sample size.Fig 2
In terms of estimator performance, the simulation results show that the MCPGIGR estimates exhibit small bias for moderate to large sample sizes, with bias approaching zero as increases, indicating consistency of the MLE under different shape parameters . The variance of the estimators decreases systematically with larger sample sizes, reflecting improved stability of the BHHH updates. Across the three shape settings , and , the model remains numerically stable, although heavier-tailed cases (e.g., ) produce slightly larger variability for small samples. No convergence failures were observed, and the log-likelihood increased monotonically across iterations. These diagnostics collectively confirm that the MCPGIGR estimators perform reliably and are robust across different distributional configurations.
Additionally, the simulation involved the calculation of the Corrected Akaike Information Criterion (AICc) for the three shape parameter configurations, with a sample size of . The AICc values were derived from the likelihood function in Eq. (8), obtained through the MCPGIGR modeling process, and the results are presented in Table 4.Table 4AICc comparison for MPR and MCPGIGR.Table 4. ModelShapeAICc (n = 300)MPR-2378.63MCPGIGR 1924.60 2280.80 2234.50
The comparison of AICc values between MCPGIGR and the MPR model (Table 4) further indicates that MCPGIGR yields a lower AICc, suggesting that it provides a better model fit compared to the baseline model. This result supports the use of MCPGIGR as a more flexible and accurate model for handling overdispersed data with response dependencies. Several studies have compared families of mixed Poisson models. The research [35] show that the shape choice serves as a strong analytical baseline. Nevertheless, in an empirical application to the Local Government Property Insurance Fund (LGPIF) data, the specification with achieves superior model fit relative to more conventional mixed Poisson formulations lacking the additional flexibility of the GIG family. In a related direction, [36] analyze a Bivariate Poisson Generalized Inverse Gaussian (BPGIG) model and demonstrate its effectiveness in addressing overdispersion in bivariate count data. Overall, these simulation results demonstrate that the proposed estimation procedure for the MCPGIGR model provides accurate and reliable parameter estimates, even under varying parameter settings, thereby ensuring its applicability for empirical studies.
Application
As an illustrative case study, the MCPGIGR model was applied to maternal and neonatal mortality data from East Java Province in 2023, covering 38 districts/cities and two response variables. N Maternal mortality (Y_1_) is defined as the death of a woman during pregnancy or within 42 days of pregnancy termination from causes related to pregnancy or its management [37]. The mean maternal mortality rate was 12.97 with a coefficient of variation (CV) of 78.86 %. Neonatal mortality (Y_2_), defined as the death of an infant within the first 28 days of life, had a mean of 89.53 and a CV of 73.74 %. The high CV values indicate substantial overdispersion, motivating the use of the MCPGIG distribution with the shape parameter fixed at . All R scripts, data files, and a fully reproducible HTML report for the MCPGIGR analysis are publicly available at the following links:
• GitHub repository: https://github.com/yusriantihanike/MCPGIGR_Method
• RPubs report: http://rpubs.com/yusriantihanike/1371097
These resources provide the complete reproducible workflow for the empirical analysis, including data preprocessing, model specification, estimation routines, diagnostic procedures, and output tables. The model components and estimation steps can be rerun directly using the provided scripts.
Six predictors were included in the analysis: Percentage of Tablet Consumption for Pregnant Women (X_1_), Percentage of Managed Obstetric Complications (X_2_), Percentage of Family planning participants (X_3_), the percentage of Antenatal care visits (X_4_), Percentage of healthcare professionals (X_5_), and Percentage of proper sanitation (X_6_). Exposure was defined as the number of pregnant women for maternal mortality (Y_1_) and the number of live births for neonatal mortality (Y_2_) in each district/city. Table 5, Table 6 summarize the descriptive statistics for both the predictors and responses.Table 5. Summary of predictor variables.Table 5. VariableMean (Standard Deviation)Percentage of Tablet Consumption for Pregnant Women (X_1_)81.65 (14.76)Percentage of Managed Obstetric Complications (X_2_)20.59 (4.40)Percentage of Family planning participants (X_3_)59.88 (16.59)Percentage of Antenatal care visits (X_4_)78.04 (11.10)Percentage of healthcare professionals (X_5_)20.44 (15.10)Percentage of proper sanitation (X_6_)92.35 (7.99)Source. Health Profile East Java, 2023.Table 6. Summary statistics for maternal and neonatal mortality (responses).Table 6. VariableMeanVarianceCoefficient of VariationMinMaxMaternal Mortality Rate (Y_1_)12.97104.6778.86050Neonatal Mortality Rate (Y_2_)89.534358.6373.745287Source. Health Profile East Java, 2023.
Before estimation, the suitability of the MCPGIG distribution was assessed using Crockett’s test [38]. The test statistic was 0.0786 with a p-value of 0.693, indicating no evidence against the MCPGIG assumption at the 5 % significance level. Histograms of the two response variables are presented in Fig. 3.Fig. 3. Histograms of maternal (Y₁) and neonatal (Y₂) mortality across districts/cities.Fig 3
Initial values for parameter estimation are provided in Table 7. . Regression coefficients were initialized using standard Poisson regression to obtain stable starting values for the mean structure. The scale parameter was set to 1, while the dispersion parameter was initialized at 0.5448 based on the relative excess variance across both responses [33].Table 7. Initial parameter values for MCPGIGR estimation.Table 7. ParameterResponse Y_1_−7.2905−0.00350.02670.0036−0.0103−0.02880.0103Y_2_−4.05170.0026−0.01490.0025−0.02870.00710.0098
Table 8 presents the parameter estimation results for the MCPGIGR model with two responses and six predictors. For maternal mortality, antenatal care (X₄) and healthcare professionals (X₅) were significant predictors, consistent with their roles in early detection and timely management of pregnancy complications. For neonatal mortality, all six predictors were statistically significant, indicating that maternal nutrition, complication management, antenatal visits, family planning, healthcare availability, and sanitation jointly contribute to neonatal survival. The model of MCPGIGR stated by :
Table 8MCPGIGR parameter estimates, SE, Z-statistics, and p-values.Table 8. ParameterY_1_EstimateSEZp-Value −4.92120.0165−297.94190.0000* −0.00340.0020−1.67510.0938 0.00640.00321.96010.0499 0.00030.00090.40140.6880 −0.01680.0025−6.59170.0000* −0.01210.0031−3.80090.0001* 0.00120.00280.45240.6509ParameterY_2_EstimateSEZ****p-Value −4.27430.0335−127.39820.0000* 0.00440.00104.10630.0000* −0.01660.0022−7.50590.0000* 0.00390.00049.44280.0000* −0.03110.0010−29.94360.0000* 0.01080.000911.19260.0000* 0.01570.001410.82880.0000*⁎Significant at = 5 %.
The likelihood ratio test statistic was conducted to evaluate the overall significance of the model. The test statistic was 336.7596, which exceeded the chi-square critical value of 21.026 (df = 12, α = 0.05), leading to rejection of the null hypothesis and confirming that the predictors jointly influence the response variables. The estimated dispersion parameters were = 1.2975 (SE = 0.0153) and = 0.04845 (SE = 0.0083). In the empirical application, the MCPGIGR model provides a substantially improved fit compared with the baseline multivariate Poisson specification, as evidenced by an approximate 19 % reduction in AICc. Beyond this improvement in information criteria, additional diagnostics indicate that the model successfully captures both marginal overdispersion and cross-response dependence, as reflected in the mixing parameters and , which are significantly. The estimation procedure also exhibits strong numerical stability: the BHHH algorithm converges in fewer than 30 iterations, and the outer-product-of-gradients matrix remains positive definite throughout the optimization process. Taken together, these findings demonstrate that MCPGIGR offers a more flexible and empirically appropriate representation of the maternal and neonatal mortality data than the standard multivariate Poisson model.
These findings are consistent with prior studies emphasizing the importance of healthcare access, maternal education, sanitation, and clinical care in reducing maternal and neonatal mortality in Indonesia [39,40]. Previous work highlights that proximity to healthcare facilities, the quality of primary health services, family planning programs, and maternal care practices significantly influence mortality outcomes. Similarly, studies on neonatal outcomes underscore the roles of antenatal care, skilled health personnel, and maternal health conditions in determining neonatal survival. The MCPGIGR model aligns with these observations and provides a more flexible multivariate framework for jointly modeling maternal and neonatal mortality.
Although this article focuses on maternal and neonatal mortality in East Java, the MCPGIGR framework can be applied to a wide range of multivariate count-data problems. In insurance and actuarial science, the model can be used to analyze joint claim counts of different claim types [41], particularly when both overdispersion and dependence across claim types are present. In transportation and traffic safety, the model can accommodate correlated counts of different crash types while simultaneously capturing marginal overdispersion and common-shock dependence induced by shared risk factors [42]. More broadly, any setting involving overdispersed and correlated count responses observed on the same statistical units (such as regions, hospitals, road segments, or customers) stands to benefit from this modeling framework.
Ethics statements
This study utilizes secondary data obtained from publicly available publications of the East Java Provincial Health Profile. No human subjects were directly involved in the research, and no individual-level or personally identifiable information was used. The dataset is available upon reasonable request to the corresponding author.
Limitations
-
The construction of hypothesis testing procedures (e.g., likelihood ratio test and Wald test) in this study relies on asymptotic theory under standard regularity conditions. A complete theoretical derivation tailored to the MCPGIGR framework is not provided, and the results are primarily based on general asymptotic properties of MLE.
-
The choice of predictor variables was made by considering both the theoretical framework and the availability of data. Consequently, potentially relevant covariates not included in the dataset could not be incorporated into the model.
Related research article
Mardalena, S., Purhadi, P., Purnomo, J.D.T., Prastyo, D.D. (2020), Parameter estimation and hypothesis testing of multivariate Poisson inverse Gaussian regression, https://www.mdpi.com/2073–8994/12/10/1738.
For a published article
none
CRediT authorship contribution statement
Yusrianti Hanike: Conceptualization, Methodology, Software, Writing – original draft, Visualization. Purhadi: Conceptualization, Methodology, Writing – review & editing, Validation, Supervision. Achmad Choiruddin: Conceptualization, Methodology, Writing – review & editing, Validation, Supervision.
Declaration of competing interest
The authors declare that they have no known financial interests or personal relationships that could have appeared to influence the work reported in this article.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hasanah A.Choiruddin A.Prastyo D.D.On the modeling of traffic accident risk in Nganjuk Regency by Poisson point process on a linear network AIP Conf. Proc.263920225000710.1063/5.0112861 · doi ↗
- 2Mohammed J.M.Spatial regression analysis using poisson regression: applications in studying traffic accidents Eur. J. Appl. Sci. Eng. Technol.3202526827510.59324/ejaset.2025.3(3).18 · doi ↗
- 3Endale F.Negassa B.Teshome T.Shewaye A.Mengesha B.Liben E.Wake S.K.Antenatal care service utilization disparities between urban and rural communities in Ethiopia: a negative binomial poisson regression of 2019 Ethiopian Demography Health Survey P Lo S One 192024 e 030025710.1371/journal.pone.0300257 PMC 1093924238483971 · doi ↗ · pubmed ↗
- 4Mwebesa E.Nakafeero M.Guwatudde D.Tumwesigye N.M.Application of a modified Poisson model in identifying factors associated with prevalence of pregnancy termination among women aged 15 –49 years in Uganda Afr. Health Sci.22202210010710.4314/ahs.v 22i 3.1236910357 PMC 9993252 · doi ↗ · pubmed ↗
- 5Adesina O.A.Oguntola T.O.Ogundunmade T.P.Akinlade Y.O.Ogunsanya A.S.Regression analysis of the factors responsible for live birth and maternal mortality in Oyo State Nigeria. Mod. Econ. Manag.12022710.53964/mem.2022007 · doi ↗
- 6Al-Manji A.Al Wahaibi A.Al-Azri M.Chan M.F.Predicting mosquito-borne disease outbreaks using poisson and negative binomial models: a comparative study J. Infect. Public Health.18202510290610.1016/j.jiph.2025.10290640753686 · doi ↗ · pubmed ↗
- 7Choiruddin A.Hannanu F.F.Mateu J.Fitriyanah V.COVID-19 transmission risk in Surabaya and Sidoarjo: an inhomogeneous marked Poisson point process approach Stoch. Environ. Res. Risk Assess.3720232271228210.1007/s 00477-023-02393-536815869 PMC 9919753 · doi ↗ · pubmed ↗
- 8Campbell J.T.The poisson correlation function Proc. Edinburgh Math. Soc.41934182610.1017/S 0013091500024135 · doi ↗