Reconciled multiplicative relational two-stage network data envelopment analysis
M. Burak Erturan

TL;DR
This paper introduces a new method for evaluating efficiency in two-stage systems that avoids prioritizing any stage and ensures unique results.
Contribution
The novel RMR model uses data reconciliation to fairly assess efficiency without bias or non-unique solutions.
Findings
The RMR model provides unique efficiency values for all processes simultaneously.
It solves the non-uniqueness problem in relational two-stage DEA models.
The model is useful when no decision-making units are preferred over others.
Abstract
Relational two-stage network DEA (data envelopment analysis) is an approach for two-stage systems, where all input, output and the intermediate products have same weights regardless of which process they are related. One of the main approaches to relational model is the multiplicative relational approach where main process efficiency is the product of two sub-process efficiencies. A shortcoming of the relational model is that the solution of the sub-process efficiencies may not be unique. Researchers have developed some models to overcome this problem, like prioritizing one sub-process to the other or assessing the sub-process efficiencies first and then the main process efficiency. In this study, a novel methodology is presented for a fairer efficiency assessment, where none of the processes is prioritized.•Reconciled Multiplicative Relational (RMR) model presented in this study uses…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
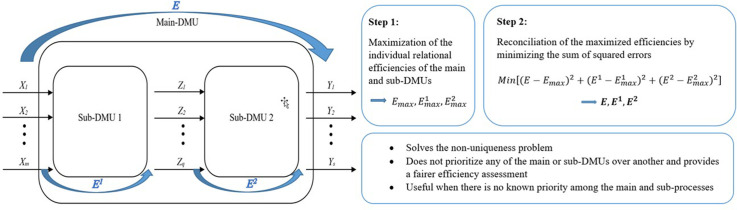 Figure 1
Figure 1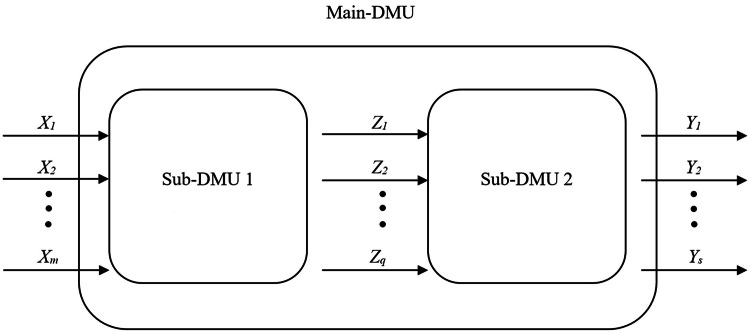 Figure 2
Figure 2 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEfficiency Analysis Using DEA · Environmental Impact and Sustainability · Water Quality Monitoring and Analysis
Specifications table Subject areaMathematics and StatisticsMore specific subject areaNetwork Data Envelopment AnalysisName of your methodReconciled Multiplicative Relational Two-Stage Network Data Envelopment AnalysisName and reference of original methodMultiplicative Relational Two-Stage Network DEAC. Kao, S.N. Hwang, Efficiency decomposition in two-stage data envelopment analysis: An application to non-life insurance companies in Taiwan, Eur. J. Oper. Res. 185 (2008) 418–429. https://doi.org/10.1016/j.ejor.2006.11.041Resource availabilityData is presented within the study
Background
The multiplicative relational (MR) two-stage network data envelopment analysis (NDEA) model presented in [1], assumes the main decision-making unit (DMU) efficiency is the product of two sub-stage efficiencies. The weights of the intermediate products are the same for both the first and the second stages. A shortcoming of the multiplicative relational model is that the decomposition of the main-process efficiency to the sub-process efficiencies may be not unique [1]. There are different approaches to solve this problem. Kao and Hwang [1] proposed a solution with a post-optimization process by prioritizing one stage to the other. First, the main-process efficiency is maximized, and then the preferred stage efficiency is maximized by keeping the main-process efficiency constant at its maximum. Liu [2] proposed a method to combine these two stages in one-step. Zhou et al. [3] uses a Nash bargaining game model to determine an efficiency decomposition for the sub-processes while keeping the main-process efficiency unchanged. The model proposed in [4] determines the main and sub-process efficiencies by using DMU-specific degree of priorities. In the compositional model of An et al. [5], first the individual non-relational (independent) efficiencies of sub-processes are determined. Next, the ratio of independent efficiency scores of the sub-processes are found, and then the decomposition of the overall efficiency is done using this ratio. Lu and Cheng [6] proposed two alternative secondary goals: maximizing the total efficiencies of sub-processes and maximizing the individual sub-efficiencies simultaneously.
In this study, a novel reconciled multiplicative relational (RMR) two-stage network data envelopment analysis is presented that uses data reconciliation method for efficiency assessment. Data reconciliation is a process usually employed in experimental sciences or industry, where measured variable values are not met with the theoretic specific consistencies. Noised or biased measuring instruments or disturbances of different nature usually affect the measurements. Therefore, the measured values may not be consistent with related physical laws. In such cases, measured values are adjusted such that sum of squared errors (differences between measured and reconciled final values) are minimized and adjusted values become consistent with related physics laws [7,8].
Proposed model consists of two main steps. In the first step, maximum individual efficiencies of main and sub-processes are determined within the relational constraints. These values are maximum possible individual efficiencies of DMUs within the relational production possibility set. In the second step, a data reconciliation process is employed such that all relational (multiplicative) model constraints are satisfied and the reconciled efficiency values are as close as possible to their maximum values found in the first step. The main difference of the proposed model from others is that this model does not prioritize main-DMU or sub-DMUs, but treat them as equally important variables. Therefore, a fairer efficiency assessment is achieved. Different models in the literature give the user/manager the opportunity to determine the efficiencies according to his/her preferences. Presented model is more suitable for the situations where there is no preference towards the importance of main or sub-processes, or no previous information about that matter.
Presented RMR model differs from the previous models with its ability to solve the non-uniqueness problem with fairer assessment of the efficiencies. All previous models prioritize the main-DMU efficiency over the sub-DMU efficiencies. It means that, maximum possible value of the main-DMU efficiency is found first, and does not change during the process. The non-uniqueness problem occurs during the efficiency assessment of sub-DMUs, because mostly there is no unique assessment of those efficiencies. Models in [1,2] and [4] solves the problem by adding another prioritization between sub-DMUs, which is pre-determined by the user/manager. In [5], sub-DMU efficiencies are determined according to the ratio of their independent efficiencies, while in [3] the assessment is done by a bargaining game between sub-DMUs. In the model of [6], stage efficiencies and their sum is maximized simultaneously. Presented RMR model is different from aforementioned models such that none of the main or sub-DMUs has priority over another. Unlike other models, main-DMU efficiency can be change during the reconciliation process and there is no non-uniqueness problem of efficiency assessment.
Method details
Multiplicative relational (MR) two-stage network DEA
In the study of Kao and Hwang [1], the multiplicative relational two-stage system is proposed. In Fig. 1, a two-stage production system is demonstrated. The main process of kth DMU uses m inputs X_ik_ (i = 1,2,…,m) to produce s outputs Y_rk_ (r = 1,2,…,s). In addition, there are q intermediate products Z_pk_ (p = 1,2,…,q), which are the outputs of the first stage and the inputs of the second one. Therefore, the linear program in Model (1) can determine the efficiency of main-process of kth DMU among n compared processes.
where, ε is a small non-Archimedean number.Fig. 1. Representation of a two-stage production system.Fig 1
The weights and therefore the weighted values of the intermediate products (w_p_, Z_pj_) are same for stages 1 and 2. After finding the optimal weight values u_r_, v_i_, and *w_p_, main (E_k_) and sub-process (E_k_^1^, E_k_^2^) efficiencies can be found as:
Therefore, the efficiency assessment is multiplicative as E_k_ = E_k_^1^ x E_k_^2^. On the other hand, the decomposition of E_k_^1^ and E_k_^2^ might not be unique, and one solution for this problem is maximizing one of the sub-DMU efficiencies while keeping the main-DMU efficiency at its maximum found in model (1). If the efficiency of stage 1 (E_k_^1^) is desired to be maximized, then the problem could be formulated as model (3) with the main process efficiency value E_k_ calculated from Model (1).
After the first stage efficiency (E_k_^1^=E_k,max_^1^) is calculated, E_k_^2^ is determined from E_k_^2^ = E_k,_max / E_k,max_^1^.
Reconciled multiplicative relational (RMR) two-stage network DEA
The non-uniqueness problem in multiplicative relational two-stage network DEA model has led researchers to develop various and mostly two-step models. Aforementioned multiplicative relational models [[1], [2], [3], [4], [5], [6]] solve the non-uniqueness problem but prioritizes main or sub-efficiencies over others. For example, in the original model [1] the main DMU efficiency is maximized first, then keeping that value constant one of the sub-DMU efficiency is maximized. These models are useful when main or sub-DMUs have differences in importance. On the other hand, there might be situations where there is not any known priorities among main or sub-DMUs, and a fairer efficiency assessment model needed.
In this study, reconciled relational multiplicative two-stage network DEA model is presented. The efficiency assessment of the model is based on data reconciliation process used especially in experimental sciences. Data reconciliation is applied when measured variables are not consistent with related physics laws. In such cases, measured values are updated (reconciled) such that the sum of squared changes of variables are minimized while maintaining the consistencies according to related physics laws.
The model presented consists of two steps. In the first step, individual maximum efficiency values of main (E_k,_max) and sub-DMUs (E_k,max_^1^, E_k,max_^2^) are found considering the relational constraints. Thus, the following linear programs (4–6) are solved separately:
E_k,_max, E_k,max_^1^, E_k,max_^2^ are found by solving models (4–6). The values found usually do not maintain the multiplicative consistency of E_k,_max = E_k,max_^1^ x E_k,max_^2^. Note that, in the original method [1], only the efficiency of main-DMU is maximized (model 1), which is exactly the same of model (4). Different from the original MR method, in RMR methodology stage 1 and stage 2 efficiencies are also maximized (models 5–6) separately.
In the second step of RMR method, a data reconciliation process is applied using the maximum efficiency values of DMUs found in (4–6). If the reconciled final values of the efficiencies are E_k_, E_k_^1^ and E_k_^2^, then the optimization problem is:
Note that model (7) is a quadratic programming problem with linear constraints, and the variables are final reconciled main and sub-DMU efficiency values (E_k_, E_k_^1^ and E_k_^2^). Therefore, the quadratic objective in (7) may require nonlinear solvers, and the software used should be selected accordingly. In this study, the applications in “method validation” are performed by MS Excel Solver add-in with GRG Nonlinear engine, efficiently.
A representation of proposed model for kth process is presented as a pseudocode in Fig. 2. Therefore, the two-step process of the RMR model can be written as: Inputs → Step 1: solve models (4)-(6) → Step 2: solve reconciliation model (7) → OutputsFig. 2A pseudocode representation of reconciled multiplicative relational model.Fig 2
Uniqueness of the efficiency assessment
A fundamental principle of DEA is that the efficiency is strictly positive [9,10]. As zero efficiency would imply an infinite return to scale or complete irrelevance of all inputs and outputs [11], a small positive non-Archimedean number (ε) is used as a lower bound for model weights. This infinitesimal number ensures that no input or output factor is entirely disregarded by assigning a zero multiplier, and prevents DMU from not just zero efficiency, but also the weak efficiency problem [12,13]. The weak efficiency problem occurs when a DMU is efficient (E = 1) and positioned on the efficiency frontier, but it is possible to reduce at least one input or increase at least one output without affecting other inputs or outputs. Which means that, while the efficiency of DMU lies on the efficient frontier, it is not operating at its full potential, as some inputs could still be decreased or outputs increased [14]. The appropriate value of the non-Archimedean number is important. Because, too high values can lead infeasible models while too low ones might fail to adequately distinguish between efficient and weakly efficient units. While, various studies have sought to establish practical bounds and methods for determining an appropriate ε value, most researchers often set to 10^–6^ or 10^–7^ practically [9,15]. Therefore, by using a non-Archimedean number in the model (stated in model 1), all main and sub-DMUs are strictly positive.
As stated earlier, the main problem with conventional multiplicative relational two-stage NDEA model is the non-uniqueness of the efficiency assessment. Method presented in this paper can be checked for the uniqueness of the solution. The optimization model (7) proposed could be written in terms of efficiency values. The objective function is:
where,
E_k,max_^1^, E_k,max_^2^, E_k,_max, E_k,min_^1^, E_k,min_^2^, and E_k,_min are relational maximum and minimum efficiency values. E_k,_max, E_k,max_^1^ and E_k,max_^2^ are already found in models (4–6), whereas E_k,_min, E_k,min_^1^ and E_k,min_^2^ can be found similarly by minimization.
If a function’s Hessian matrix’s leading principal minors are positive on the related domain, this function is called definite positive. A definite positive function is strictly convex, which means it has only one global minima. Therefore, minimization of a strictly convex function results with a unique solution of the aforementioned global minima within its domain [16,17]. The Hessian matrix (H) and its leading principle minors can be checked for the function in model (8). The Hessian matrix is:
Then, the leading principle minors are,
Since E_k_^2^>0,
Furthermore, for the second principle minor (D_2_), while E_k_^1^>0, E_k_^1^ x E_k_^2^≤ E_k,max_≤1,
Therefore,
Hence, the Hessian matrix’s (H) leading principle minors (D_1_, D_2_) are positive, the objective function is strictly convex and our proposed model has a unique solution.
Efficiency considerations
The main purposes of applying data envelopment analysis are identifying the efficient (E = 1) and inefficient (0 < E < 1) nodes and ranking them according to their efficiency values. If the kth main process is efficient according to conventional MR model of [1], hence the equation E_k_ = E_k_^1^= E_k_^2^=1 is satisfied. Then, it is also efficient according to reconciled relational model since the efficiency values are at their maximum and multiplicatively-consistent. In that circumstance, the reconciliation step is unnecessary and gives the same result even it is applied. On the other hand, any efficient sub-DMU (E_k_^1^=1 or E_k_^2^=1) according to classical MR model, or after the first step (E_k,max_^1^=1 or E_k,max_^2^=1) of RMR model; it is not necessarily efficient after the second step.
Method validation
Taiwanese non-life insurance companies
In the study of Kao and Hwang [1] the relational model presented is applied to 24 Taiwanese non-life insurance companies. This dataset has been one of the benchmark datasets for two-stage network DEA efficiency analysis. Several researchers use this dataset for application and comparison purposes, such as [[18], [19], [20], [21]]. Similarly, in this study the dataset of 24 Taiwanese non-life insurance companies [1] is used for application of the proposed methodology and compared with independent [22] and relational multiplicative model with sub-stage prioritizing [1].
The non-life insurance industry provides services to generate profit. However, the profit is not earned just from insurance, but also from investment. Non-life insurance industry uses the insurance premiums as capital for investment. The main process of non-life insurance companies can be divided into two as marketing and investment processes [1]. In the first sub-process, inputs are operation and insurance expenses, where the outputs are direct written and reinsurance premiums. In this stage, direct written premiums and reinsurance premiums are received from clients and other insurance companies respectively. In the second stage, the inputs are direct written and reinsurance premiums while underwriting and investment profits are the outputs. The second sub-process is the investment stage, where premiums are invested in a portfolio to earn profit [1].
Dataset presented in Table 1 consists of 24 non-life insurance companies in Taiwan and the values are the averages of the years 2001 and 2002. Inputs and outputs used are as follows [1]: Operation expenses (X1) are the salaries of the employees and various costs incurred in daily operation. Insurance expenses (X2) are the expenses of agencies, brokers etc.; and others associated with marketing. Underwriting profit (Y1) is the profit from the insurance business, while investment profit (Y2) is the profit from the investment portfolio. Direct written premiums (Z1) are the premiums received from clients, while reinsurance premiums (Z2) are received from ceding companies.Table 1. Dataset for 24 Taiwanese non-life insurance companies [1].Table 1CompanyX1X2Z1Z2Y1Y2****Taiwan Fire1178,744.0673,512.07451,757.0856,735.0984,143.0681,687.0Chung Kuo1381,822.01352,755.010,020,274.01812,894.01228,502.0834,754.0TaiPing1177,494.0592,790.04776,548.0560,244.0293,613.0658,428.0China Mariners601,320.0594,259.03174,851.0371,863.0248,709.0177,331.0Fubon6699,063.03531,614.037,392,862.01753,794.07851,229.03925,272.0Zurich2627,707.0668,363.09747,908.0952,326.01713,598.0415,058.0Taian1942,833.01443,100.010,685,457.0643,412.02239,593.0439,039.0Ming Tai3789,001.01873,530.017,267,266.01134,600.03899,530.0622,868.0Central1567,746.0950,432.011,473,162.0546,337.01043,778.0264,098.0The First1303,249.01298,470.08210,389.0504,528.01697,941.0554,806.0Kuo Hua1962,448.0672,414.07222,378.0643,178.01486,014.018,259.0Union2592,790.0650,952.09434,406.01118,489.01574,191.0909,295.0Shingkong2609,941.01368,802.013,921,464.0811,343.03609,236.0223,047.0South China1396,002.0988,888.07396,396.0465,509.01401,200.0332,283.0Cathay Century2184,944.0651,063.010,422,297.0749,893.03355,197.0555,482.0Allianz President1211,716.0415,071.05606,013.0402,881.0854,054.0197,947.0Newa1453,797.01085,019.07695,461.0342,489.03144,484.0371,984.0AIU757,515.0547,997.03631,484.0995,620.0692,731.0163,927.0North America159,422.0182,338.01141,951.0483,291.0519,121.046,857.0Federal145,442.053,518.0316,829.0131,920.0355,624.026,537.0Royal & Sunalliance84,171.026,224.0225,888.040,542.051,950.06491.0Aisa15,993.010,502.052,063.014,574.082,141.04181.0AXA54,693.028,408.0245,910.049,864.00.118,980.0Mitsui Sumitomo163,297.0235,094.0476,419.0644,816.0142,370.016,976.0Mean1544,214.6828,963.17832,893.0667,964.31602,872.9477,732.8Note: Units in NT$ thousands.
Efficiencies of 24 non-life insurance companies are analysed by proposed reconciled multiplicative relational (RMR) model. In Table 2 the efficiency values after the first and the second steps are presented. Maximum relational efficiency values of the DMUs found in the first step, and the final efficiencies after the reconciliation step is presented.Table 2. Efficiency scores of RMR model after the first and the second steps.Table 2Step 1Step 2CompanyE_max_E^1^maxE^2^maxEE^1^*E^2^Taiwan Fire0.6990.9930.7130.6990.9920.705Chung Kuo0.6250.9980.6260.6250.9980.626TaiPing0.6900.6901.0000.6900.6901.000China Mariners0.3040.7240.4320.3040.7240.420Fubon0.7670.8381.000**0.7570.799**0.947Zurich0.3900.9640.406**0.3890.961**0.405Taian0.2770.7520.5380.277**0.6710.412Ming Tai0.2750.7260.5110.275**0.6630.415Central0.2231.0000.2920.223**0.9900.225The First0.4660.8620.674**0.4570.835**0.547Kuo Hua0.1640.7410.327**0.1580.685**0.231Union0.7601.0000.7600.7601.0000.760Shingkong0.2080.8110.543**0.2070.681**0.304South China0.2890.7250.5180.289**0.6700.431Cathay Century0.6141.0000.705**0.6060.972**0.624Allianz President0.3200.9070.3850.320**0.8860.362Newa0.3600.7231.000**0.3300.481**0.686AIU0.2590.7940.374**0.2580.781**0.330North America0.4111.0000.4160.4111000**0.411Federal0.5470.9330.901**0.5350.816**0.656Royal & Sunalliance0.2010.7510.280**0.1990.742**0.268Aisa0.5900.5901.0000.5900.5901.000AXA0.4200.8500.560**0.4180.832**0.502Mitsui Sumitomo0.1351.0000.335**0.094*0.9420.099
In Table 2, it can be seen that three companies’ maximum relational efficiencies of all DMUs found in step 1 are already multiplicatively-consistent and do not change in the reconciliation step. Taiping, Union and Aisa are such companies. On the other hand, other companies’ at least one DMU efficiency is changed in reconciliation step. All three DMU efficiencies (including main and sub-DMU efficiencies) of Fubon, Zurich, The First, Kuo Hua, Shingkong, Cathay Century, Newa, AIU, Federal, Royal & Sunalliance, AXA and Mitsui Sumitomo are reconciled and changed in the second step.
Results of the proposed model are compared with the independent model in [22], and the multiplicative relational (MR) model presented in [1]. The independent model omits the interconnections between main and sub-DMUs. Hence, it assumes that there are three different and independent DMUs, and each DMU’s efficiency is optimized independently with simple CRS (Constant returns to scale) model presented in [23]. Multiplicative relational model is the same model presented in [1], which prioritized the second sub-DMU over the first one. In Table 3, the resulting efficiency values of independent, MR and RMR models are presented.Table 3. Efficiency scores of independent, MR and RMR models for main process (E), first stage (E^1^) and second stage (E^2^).Table 3CompanyIndependentMR****RMREE^1^****E^2^EE^1^****E^2^EE^1^*E^2^Taiwan Fire0.9840.9930.7130.6990.9930.7040.6990.9920.705Chung Kuo1.0000.9980.6260.6250.9980.6260.6250.9980.626TaiPing0.9880.6901.0000.6900.6901.0000.6900.6901.000China Mariners0.4880.7240.4320.3040.7240.4200.3040.7240.420**Fubon1.0000.8381.0000.7670.8310.9230.7570.7990.947Zurich0.5940.9640.4060.3900.9610.4060.3890.9610.405Taian0.4700.7520.5380.2770.6710.4120.2770.6710.412Ming Tai0.4150.7260.5110.2750.6630.4150.2750.6630.415Central0.3271.0000.2920.2231.0000.2230.2230.9900.225The First0.7810.8620.6740.4660.8620.5410.4570.8350.547Kuo Hua0.2830.7410.3270.1640.6470.2530.1580.6850.231**Union1.0001.0000.7600.7601.0000.7600.7601.0000.760Shingkong0.3530.8110.5430.2080.6720.3090.2070.6810.304South China0.4700.7250.5180.2890.6700.4310.2890.6700.431Cathay Century0.9791.0000.7050.6141.0000.6140.6060.9720.624Allianz President0.4720.9070.3850.3200.8860.3620.3200.8860.362Newa0.6350.7231.0000.3600.6280.5740.3300.4810.686AIU0.4270.7940.3740.2590.7940.3260.2580.7810.330North America0.8221.0000.4160.4111.0000.4110.4111.0000.411Federal0.9350.9330.9010.5470.9330.5860.5350.8160.656Royal & Sunalliance0.3330.7510.2800.2010.7320.2740.1990.7420.268**Aisa1.0000.5901.0000.5900.5901.0000.5900.590**1.000*AXA0.5990.8510.5600.4200.8430.4990.4180.8320.502Mitsui Sumitomo0.2571.0000.3350.1350.4290.3140.0940.9420.099
According to independent model, 4 main processes (Chung Kuo, Fubon, Union and Aisa) are efficient, whereas to MR and RMR models there is not any efficient main process. Independent model indicates that the first stages of 5 companies (Central, Union, Cathay Century, North America and Mitsui Sumitomo) are efficient. However, MR model results show that only four of them is efficient (leaving Mitsui Sumitomo out). According to proposed RMR model, the first stages of Union and North America are efficient. Similar results are found for the efficiency of the second stages. Independent model favors 4 companies’ second stages as efficient (TaiPing, Fubon, Newa and Aisa). According to RM model only two of them (TaiPing and Aisa) are efficient, which is the same as RMR model. It can be seen that, MR model has fewer efficient nodes than independent model, while RMR model has less than MR has.
In Table 4, the rank scores of the companies for overall (R) and sub-processes (R^1^, R^2^) are presented. If there are >1 efficient node, the rank values of those nodes are calculated as in [1]. For n efficient DMU, rank value of each of them is: .Table 4. Efficiency ranking scores of independent, MR and RMR models for main process (R), first stage (R^1^) and second stage (R^2^).Table 4CompanyIndependentMR****RMRRR^1^****R^2^*RR*^1^****R^2^R**R^1^****R^2^****Taiwan Fire677365345Chung Kuo2.5610556538TaiPing5232.54161.54171.5China Mariners142116151513151613Fubon2.5132.511232133Zurich138181271712717Taian161613171815172015Ming Tai191915182014182214Central22323202.52420523The First101199101091010Kuo Hua231822232123231822Union2.53622.5411.54Shingkong201412211721211920South China162014161912162112Cathay Century73862.57669Allianz President1510191491814918Newa11222.51322913246AIU181520191319191419North America9317112.516111.516Federal8958888127Royal & Sunalliance211724221422221521Aisa2.5242.57231.57231.5AXA121211101111101111Mitsui Sumitomo**2432124242024824
To be able to compare the rankings, Spearman’s rank correlation coefficient (ρ) is used. In Table 5 rank correlations of main and sub-DMUs between compared models are presented. The ranking of the overall efficiencies (R) with reconciled and relational model is almost identical, except for the first and the second ranks. Difference is the reconciliation process of the Fubon. After the reconciliation, main process efficiency decreases from 0.767 to 0.757, which changes Fubon’s ranking to second. On the other hand, ranking values of independent model is more diverse than relational and reconciled models. For example, first stage ranking of Mitsui Sumitomo is 20 according to conventional MR model, and increases to number 8 with RMR model. This situation is not unexpected since its maximum relational efficiency value is 1 according to first step of RMR model.Table 5. Spearman’s rank correlation coefficient (ρ) values between models.Table 5Main-DMUSub-DMU 1Sub-DMU 2ModelsInd.MRRMRInd.MRRMRInd.MRRMR****Ind.1.0000.9720.9721.0000.7490.9151.0000.9170.940MR1.0000.9991.0000.8541.0000.983RMR1.0001.0001.000
The tabulated critical value of Spearman’s rank correlation coefficient for n = 24 and α=0.05 (α is the level of significance) is 0.344 [24]. Therefore, all three model rankings are highly correlated. There is a very high rank correlation of 0.999 between proposed and MR model, while a lesser correlation of 0.972 between independent and other two models. These results show that proposed model gives close results to relational model than independent model on the main process efficiency side. However, sub-DMU efficiency rankings show different characteristics. For the first stage efficiency rankings, reconciled model is closer to independent model with a rank correlation coefficient of 0.915, which is distinctly higher than the correlation of 0.854 between MR and RMR model. Conversely, reconciled model rankings are closer to relational model for second stage efficiencies with a very high value of 0.983, while rank correlation between independent and RMR model is 0.940. The rank correlation scores found show that, the direction of the ranks determined by the proposed model is the same with other two models and the proposed model is an equally valid model with compared to two other models [6,18].
Chinese bank branches
In this section, proposed RMR model is applied to determine the efficiency decompositions of 10 bank branches of China Construction Bank (CCB) in Anhui province, PR China. The dataset is for year 2004, and used in several studies for efficiency analysis [3,6,25]. The process of bank branches is modelled as a two-stage system. In the first stage, the inputs are number of employees (X1), fixed assets (X2), and expenses (X3); where the outputs are credit (Z1) and interbank loans (Z2). In the second stage, the outputs from the first stage (Z1 and Z2) are used as inputs to generate two outputs, as loan (Y1) and profit (Y2). Dataset is presented in Table 6.Table 6. Dataset for 10 bank branches of Chinese Construction Bank [3].Table 6Bank Branch****X1 (10^3^)****X2 (10^8^ ¥)****X3 (10^8^ ¥)****Z1 (10^8^ ¥)****Z2 (10^8^ ¥)****Y1 (10^8^ ¥)****Y2 (10^8^ ¥)****Maanshan0.5260.4780.38549.9175.46134.9900.843Anqing0.7131.2360.55537.4954.08320.6010.486Huangshan0.4430.4460.34220.9850.6908.6330.129Fuyang0.6381.2480.45745.0511.7249.2350.302Suzhou0.5750.7050.40438.1622.24912.0170.314Chuzhou0.4320.6450.40130.1682.33513.8130.377Luan0.5100.7240.37126.5391.3425.0960.145Chizhou0.3220.3360.23316.1240.4895.9800.093Chaohu0.4230.6680.34722.1851.1779.2350.200Bozhou0.2560.3420.15913.4360.4062.5330.006Mean0.4840.6830.36530.0061.99612.2130.290
Efficiencies of 10 bank branches are calculated with the proposed RMR model. In Table 7, the efficiency values after the first and the second steps of the proposed model are presented.Table 7. Efficiency scores of RMR model after the first and the second steps.Table 7Step 1Step 2Bank BranchE_max_E^1^maxE^2^maxEE^1^****E^2^*Maanshan1.0001.0001.0001.0001.0001.000Anqing0.4340.5530.7850.4340.5530.785Huangshan0.2930.4991.0000.2930.3120.938Fuyang0.3010.7590.9700.301**0.3830.787Suzhou0.3550.7290.8340.355**0.5260.675Chuzhou0.5450.7361.0000.545**0.5990.910Luan0.1790.5520.6320.179**0.3630.493Chizhou0.2820.5331.0000.282**0.3050.923Chaohu0.3280.5531.0000.324**0.3740.867Bozhou0.1750.6500.4980.175**0.546*0.320
It can be seen from Table 7 that, Maanshan and Anqing branches’ maximum efficiency values are already multiplicatively-consistent, and do not change in the second step. On the other hand, all other companies’ sub-DMU efficiencies are changed and reduced after the reconciliation process. Main DMU efficiencies stay the same except Chaohu branch, which is reconciled in the second step to a lesser value. Compared efficiency results of the proposed, independent and MR models are presented in Table 8. Note that, MR model is the same model presented in [1], which prioritized the second sub-DMU over the first one.Table 8. Efficiency scores of independent, MR and RMR models for main process (E), first stage (E^1^) and second stage (E^2^).Table 8Bank BranchIndependentMR****RMREE^1^****E^2^EE^1^E^2^EE^1^****E^2^*****Maanshan1.0001.0001.0001.000**1.0001.000**1.0001.000**1.000*Anqing0.4340.5540.7860.4340.5530.7860.4340.5530.785Huangshan0.2930.4991.0000.2930.2931.0000.2930.3120.938Fuyang0.3010.7590.9700.3010.3210.9390.3010.3830.787Suzhou0.3550.7290.8330.3550.4300.8250.3550.5260.675Chuzhou0.5450.7361.0000.5450.5451.0000.5450.5990.910Luan0.1790.5520.6320.1790.2880.6210.1790.3630.493Chizhou0.2820.5331.0000.2820.3050.9230.2820.3050.923Chaohu0.3280.5531.0000.3280.3850.8540.3240.3740.867Bozhou0.1750.6500.4980.1750.3720.4700.1750.5460.320
All three models compared favour only Maanshan branch’s main DMU as efficient. Similarly, only Maanshan branch first-stage is efficient according to all models. Independent model assesses second-stages of 5 branches as efficient (Maanshan, Huangshan, Chuzhou, Chizhou and Chaohu), while according to MR model only 3 of them (Maanshan, Huangshan and Chuzhou) is efficient. However, proposed RMR model discriminatively selects only one second-stage (Maanshan) as an efficient process. Results show that, MR model has fewer or equal number of efficient nodes than independent model, while RMR model has less than or equal to which MR has. The rank scores of the bank branches are presented in Table 9 for overall (R) and sub-processes (R^1^, R^2^). Also in Table 10, rank correlations of the main and sub-DMUs between compared models are presented.Table 9. Efficiency ranking scores of independent, MR and RMR models for main process (R), first stage (R^1^) and second stage (R^2^).Table 9CompanyIndependentMR****RMRRR^1^****R^2^*RR*^1^R^2^R**R^1^R^2^Maanshan113112111Anqing368328337Huangshan7101792792Fuyang626674666Suzhou447447458Chuzhou234232224Luan9899109989Chizhou8928858103Chaohu575556575Bozhou105101061010410Table 10Spearman’s rank correlation coefficient (ρ) values between models.Table 10Main-DMUSub-DMU 1Sub-DMU 2ModelsInd.MRRMRInd.MRRMRInd.MRRMRInd.1.0001.0001.0001.0000.6850.8181.0000.8770.952MR1.0001.0001.0000.8791.0000.902RMR**1.0001.0001.000
The rankings of the overall efficiencies (R) of all compared models are the same. However, there are differences in the sub-stage rankings. RMR model ranking is closer to MR ranking in the first sub-stage, while is closer to independent model in the second sub-stage. The tabulated critical value of Spearman’s rank correlation coefficient for n = 10 and α=0.05 is 0.552 [13]. All three model rankings are highly correlated in all main and sub-stages. Proposed RMR model ranking is more correlated to MR model in the first sub-stage with ρ = 0.879, and independent model in the second sub-stage with ρ = 0.952. Obtained results show that the direction of the ranks of the proposed model is the same with other two models and proposed RMR model is a valid model as two other compared models.
Considering the results of the applications of both Taiwanese non-life insurance companies and Chinese bank branches, it can be said that some results are varies and dataset specific. In the previous application with Taiwanese non-life insurance companies’ dataset, the proposed RMR model results are closer to conventional MR model than the independent model in Main-DMU and Sub-DMU 2. Conversely, in the second example with Chinese bank branches, RMR model rankings are closer to MR model in Sub-DMU 1. On the other hand, all three models’ results have the same direction of rankings and highly close for both applications.
Limitations
Presented model does not prioritize any DMU over another, and aims a fairer efficiency assessment. Therefore, if the main-DMU or any sub-DMU has more importance than others do, presented model is not suitable to use. Additionally, proposed RMR model consists more optimization model (3 linear and 1 quadratic) than the original model [1] (2 linear). Depending on the software used, this may result less computational efficiency, which might be significant in large-scale datasets [26]. Finally, presented RMR model is possible only under the CRS model assumption as the original relational model [1,27]. Expanding the model assumption to variable returns to scale (VRS) might be another area of a future study.
Ethics statements
The method used in the study did not involve any human or animal subjects.
CRediT author statement
M. Burak Erturan: Conceptualization, Methodology, Validation, Formal analysis, Writing – Original Draft, Writing – Review & Editing Visualization.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kao C.Hwang S.N.Efficiency decomposition in two-stage data envelopment analysis: an application to non-life insurance companies in Taiwan Eur. J. Oper. Res.185200841842910.1016/j.ejor.2006.11.041 · doi ↗
- 2Liu S.T.A note on efficiency decomposition in two-stage data envelopment analysis Eur. J. Oper. Res.212201160660810.1016/j.ejor.2011.03.001 · doi ↗
- 3Zhou Z.Sun L.Yang W.Liu W.Ma C.A bargaining game model for efficiency decomposition in the centralized model of two-stage systems Comput. Ind. Eng.64201310310810.1016/j.cie.2012.09.014 · doi ↗
- 4Fang L.Stage efficiency evaluation in a two-stage network data envelopment analysis model with weight priority Omega 97202010208110.1016/j.omega.2019.06.007 · doi ↗
- 5An Q.Meng F.Ang S.Chen X.A new approach for fair efficiency decomposition in two-stage structure system Oper. Res. Int. J.18201825727210.1007/s 12351-016-0262-9 · doi ↗
- 6Lu C.Cheng H.Alternative secondary goals in multiplicative two-stage data envelopment analysis Math. Probl. Eng.20212021993179610.1155/2021/9931796 · doi ↗
- 7Miao Y.Su H.Gang R.Chu J.Industrial processes: data reconciliation and gross error detection Meas. Control.42-7200920921510.1177/002029400904200704 · doi ↗
- 8Fuente M.J.Gutierrez G.Gomez E.Sarabia D.de Prada C.Gross error management in data reconciliation IFAC–Papers On Line 48-8201562362810.1016/j.ifacol.2015.09.037 · doi ↗