Resume data extract and job recruitment Chatbot features for AI-based resume screening & analytics
Kar Weng Chong, Kok Why Ng, Yong Hong Fu

TL;DR
This paper presents an AI-based recruitment system combining resume screening and a chatbot to improve hiring efficiency and candidate experience.
Contribution
A novel integrated AI recruitment system with resume screening and chatbot features for enhanced hiring processes.
Findings
The resume screening AI effectively parses and evaluates resumes using document processing and language models.
The chatbot improves accessibility and interaction during recruitment with speech-to-text and FAQ automation.
The system is designed to be scalable and efficient for diverse hiring needs.
Abstract
AI technologies are changing the field of manpower recruitment since they make it much more efficient, accurate, and scalable than conventional approaches. The project builds an AI recruitment system that is combined to have two main elements of an integrated AI recruitment system including a Resume Screening AI and a Job Recruitment Chatbot, which have the goal of improving the process in hiring as well as making the experience of the candidates better in the process. The Resume Screening AI uses a mixed approach incorporating both classical document processing, and capabilities of advanced language models. The unstructured data of raw resumes are mined and normalized into standard forms to allow evaluation and ranking of the candidates in an organized and systematic manner according to the position’s requirements. The Job Recruitment Chatbot entails a programmed chat system of…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4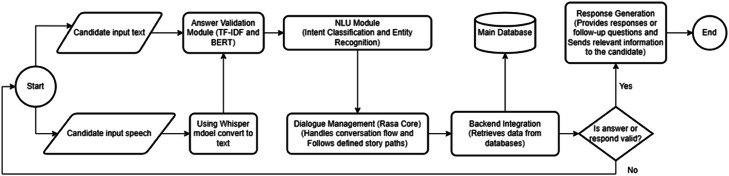 Figure 5
Figure 5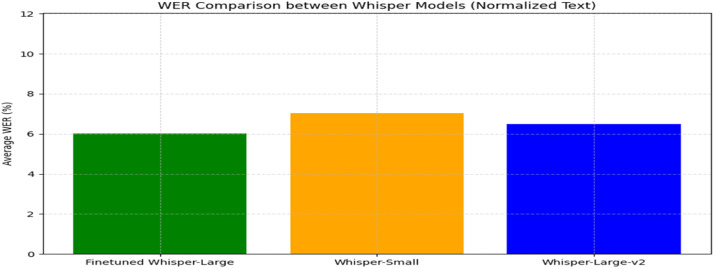 Figure 6
Figure 6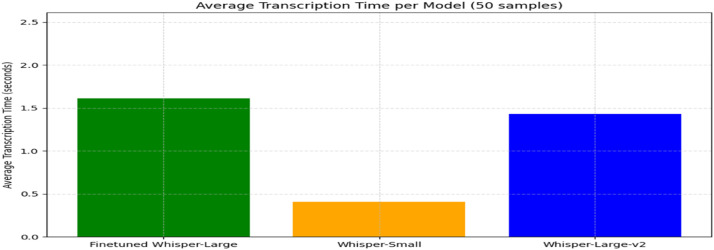 Figure 7
Figure 7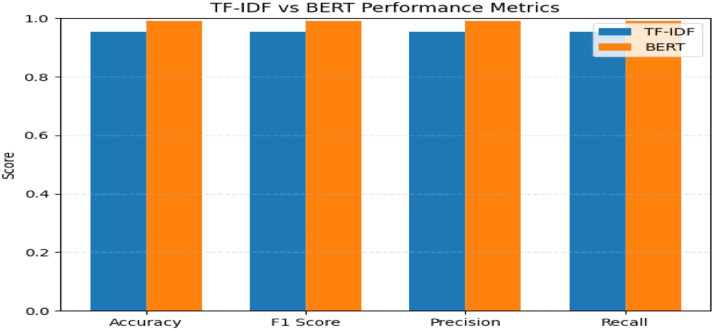 Figure 8
Figure 8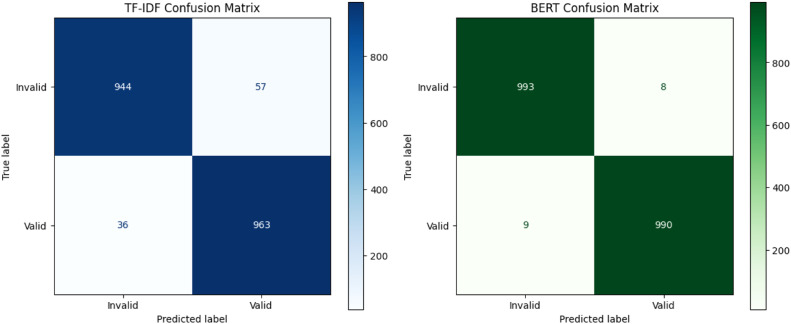 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAI in Service Interactions · Artificial Intelligence in Healthcare and Education · Expert finding and Q&A systems
Methods
Such an integrated system proves to have immense capability in minimizing manual work load and accuracy of a decision and the general efficacy in the recruitment process of an organization at different scales.
Specifications table
Subject areaComputer ScienceMore specific subject areaData ScienceName of your methodFine-Tune Whisper-Large, TF-IDF and BERT for Question-and-Answer ValidatorName and reference of original methodFine-Tune Whisper-Large, Fine-Tune BERTResource availabilityhttps://www.openslr.org/12
Background
The global digital transformation has seen artificial intelligence (AI) transform many industries like recruitment and analytics. Nevertheless, several issues remain in the way of divine process in the resume screening and recruitment [1].
Moreover, Manual resume Data Extraction is still a time problematic, error prone task. To fill position during the recruitment process there is a big volume of resumes to be filtered, identified and analyzed to candidates’ qualification, skills and experience. This typically delays and is inaccurate, so the ones that are critical information that identify the best candidates may go missing [2].
In addition, interaction modes in job recruitment chatbots are severely limited and hinder inclusivity and user experience. Existing chatbots mostly enable text-based interaction, and candidates who are physically impaired, or have limited language proficiency, may be disadvantaged. Adding a speech to text (STT) function can greatly boost accessibility and comfort which can make a much wider field of candidates using it without a hitch [3].
Accuracy of STT technology poses another challenge. Transcription errors during interaction with a chatbot occur when incoming messages have variations in accents, dialects, speech speeds and background noise, reducing reliability of the chatbot. Consider that it's particularly important that these aren't inaccurate in recruitment cases where the precise answers of candidates are essential so they can judge fairly and effectively [4,5].
Addressing these challenges would enable the efficiency, accessibility, and accuracy of AI based recruitment solutions, making the way organizations screen candidates and make hires [6].
Method details
System architecture overview
The AI-powered hiring system consists of four interconnected modules: (1) Resume Extraction (Gemini 1.5 Flash) [7], (2) Speech-to-Text (Whisper-Large) [[8], [9], [10]], (3) Q&A Validation (TF-IDF and BERT) [11,12], and (4) Chat Interface (RASA) [[13], [14], [15], [16]]. Each module functions independently while supporting the overall process.
Resume data extraction module
- • Text Extraction Process
The resume pipeline starts with ingesting resumes (PDF, DOC, DOCX) and extracting raw text using OCR and parsing libraries, handling both structured and unstructured formats [17].
- •Gemini 1.5 Flash Integration
After text extraction, a standardized prompt is generated for the Gemini 1.5 Flash model to extract key resume details (e.g., personal info, education, experience) in JSON format for further processing [7].
- •Data Validation and Error Handling
JSON files are parsed and validated for format and completeness. Errors triggers retry routines or flag resumes for human review, while valid data is stored in the system database with appropriate metadata [[17], [18], [19]].
Speech-to-Text processing module
- • Dataset Preparation and Audio Input Processing
Whisper-Large was fine-tuned on LibriSpeech train-clean-100 and dev-clean sets, split 90:10 for ∼10,000 training and 1000 test samples. Audio was resampled to 16 kHz, with average durations of 12.9 s (train) and 6.6 s (test). Data was imported using parse_librispeech(), ensuring consistency and temporal variation for effective training [[21], [22], [23]].
- •Whisper-Large Model Architecture and Configuration
The system uses OpenAI’s Whisper-Large model with 24 encoder and decoder layers, fine-tuned for speech-to-text. It includes WhisperFeatureExtractor, WhisperTokenizer, and WhisperProcessor for processing speech and text in a sequence-to-sequence pipeline [8,20] (Fig. 1).
- •Training Configuration and Fine-tuning Process Fig. 1. Flowchart of Gemini 1.5 flash model.Fig. 1
Fine-tuning used Seq2SeqTrainingArguments with batch size 16, learning rate 1e-5, fp16 precision, gradient checkpointing, and 500-step warmup. Training ran for 1000 steps with WER-based evaluation every 500 steps. Padding was handled by a custom collator to preserve attention masks. Losses showed stable training without overfitting [20,24] (Fig. 2, Table 1).Fig. 2. Flowchart fine-tune whisper-large model.Fig. 2. Table 1Training and validation loss for each step.Table 1. StepTraining LossValidation Loss5000.0086000.11251810000.0064000.111875
Question-Answer validation system
- • Dataset Development and Characteristics
A custom 10,000-sample dataset was created for Q&A validation, covering 10 interview questions with ∼1000 diverse responses each. Each entry includes a question, answer, and binary validity label, with a balanced split of 5000 valid and 5000 invalid samples.
- •Data Preprocessing and Preparation
Data preprocessing included cleaning, binary label normalization, and stratified 80:20 train-test splitting. TF-IDF used [SEP]-joined Q&A pairs, while BERT used bert-base-uncased tokenizer with 128-token truncation, padding, and attention masking.
- •Dual-Model Implementation and Training
TF-IDF Baseline Model: The baseline used TF-IDF with unigrams/bigrams, stopword removal, and min document frequency of 2. A logistic regression classifier with balanced class weights (liblinear solver) was trained for interpretable comparison [25,27,28].
BERT Fine-Tuning Architecture: The BERT model used bert-base-uncased with fp16 mixed precision, batch size 8, and a 2e-5 learning rate. Training was memory-efficient and evaluated per epoch, with the best model selected based on F1-score [11,26,29].
- •Training Results and Performance Monitoring
BERT fine-tuning showed steady improvement over 4000 steps, with training loss dropping from 0.1635 to 0.0031 and evaluation loss from 0.0973 to 0.0443. The final model was selected based on optimal F1-score, indicating effective learning without overfitting (Fig. 3).Fig. 3. Flowchart of TF-IDF and BERT for Q&A validator.Fig. 3
RASA conversational interface
- • Multi-Modal Input Processing
The RASA chatbot supports both text and speech inputs. Speech is transcribed by Whisper before being processed by the NLU pipeline [14].
- •Natural Language Understanding (NLU)
The NLU module uses trained models to classify intents and extract entities from recruitment-specific conversations, identifying queries on jobs, interviews, and personal details [30,31].
- •Dialogue Management
RASA Core manages dialogue flow and context, following predefined paths while adapting to unexpected inputs and follow-up questions [32].
- •Backend Integration and Data Retrieval
The chatbot connects to the main database to access candidate and job data, enabling real-time, consistent, and dynamic responses across modules [30].
- •Response Generation and Validation
Before responding, the system validates answers using trained models. Valid responses are delivered via the chatbot, while invalid ones prompt clarifications or escalate to human recruiters (Table 2).Table 2. Training Loss and Eval loss for fine-tuning BERT model.Table 2. StepTraining LossEval Loss10000.16350.097320000.03720.075230000.01680.055140000.00310.0443
System integration and workflow
The four modules work together: resume extraction populates the database, speech-to-text enables voice input, validation ensures response quality, and the RASA chatbot handles interaction. Error handling at each stage ensures system reliability and smooth user experience (Fig. 4).Fig. 4. Flowchart of RASA Chatbot.Fig. 4
Method validation
Speech recognition model performance
Speech recognition performance was evaluated using three Whisper variants on the LibriSpeech/dev-clean dataset, focusing on Word Error Rate (WER) and average transcription time to assess accuracy and efficiency.
- •Model Comparison Results
The fine-tuned Whisper-Large model achieved the best WER at 6.03 %, outperforming Whisper-Large-v2 (6.48 %) and Whisper-Small (7.02 %). This 0.45 % improvement highlights the effectiveness of domain-specific fine-tuning.
- •Computational Efficiency Analysis
Transcription time analysis showed a trade-off between speed and model size. Whisper-Small was fastest (0.41s/sample), while fine-tuned Whisper-Large was slower (1.61s/sample). Whisper-Large-v2 balanced both (1.43s/sample), highlighting the need to weigh accuracy against processing speed for real-time use (Fig. 5).Fig. 5. Word error rate comparison between whisper model bar chart.Fig. 5
Question-answer validation system performance
To validate the accuracy of automated Q&A system, this project implemented and compared two distinct approaches: TF-IDF with Logistic Regression and Fine-tuned BERT, evaluated on a binary classification task (valid/invalid responses) (Fig. 6).
- •Classification Performance Metrics Fig. 6. Average transcription time per model bar chart.Fig. 6
Both models performed strongly across all metrics. TF-IDF + Logistic Regression achieved 95.35 % accuracy, while fine-tuned BERT reached 99.15 %. Matching precision, recall, and F1-scores indicate balanced, unbiased classification performance.
- •Confusion Matrix Analysis
Confusion matrix analysis confirmed both models’ reliability. TF-IDF achieved strong results with 944 invalid and 963 valid correct classifications, while BERT outperformed with only 8 false positives and 9 false negatives, indicating near-perfect discrimination on 2000 samples (Fig. 7).
- •Model Selection Rationale Fig. 7TF-IDF vs BERT performance metrics bar chart.Fig. 7
Between the two models, the fine-tuned BERT achieved higher accuracy (99.15 % vs. 95.35 %) and more balanced error distribution, making it the preferred option for deployment. Its 3.8 % accuracy gain justifies the added computational cost through improved reliability in validation tasks (Fig. 8).Fig. 8. Confusion matrix for TF-IDF and BERT model heatmap.Fig. 8
Validation framework reliability
The hybrid model registered improved performance with 93.97 % accuracy in speech recognition and 99.15 % accuracy in Q&A validation. These results validate the efficiency and operational applicability of the introduced methodology in computerized interview analysis under accuracy constraints within computationally affordable capabilities (Table 3, Table 4).Table 3. Summary table for whisper-large model result.Table 3. ModelDatasetWord Error Rate (WER)Avg Transcription TimeFine-Tune Whisper-LargeLibriSpeech/dev-clean6.03 %1.61 sWhisper-Large-v2LibriSpeech/dev-clean6.48 %0.41 sWhisper-SmallLibriSpeech/dev-clean7.02 %1.43 sTable 4Summary table for Q&A validator model.Table 4. MetricTF-IDF + Logistic RegressionFine-Tuned BERTAccuracy0.95350.9915F1 Score0.95350.9915Precision0.95370.9915Recall0.95350.9915
Limitations
There were system development bottlenecks. Whisper-Large training was a computationally demanding exercise, something even laptops with mediocre capability could not handle—leading to constant crashes, long training time, and space limitation. Monitoring and optimization were needed on an ongoing basis here. Creating an evenly weighted, real-world Q&A set of 10,000 samples took time, had to be populated manually to be linguistically dense and consistent. Finetuning Whisper also involved mass-scale hyperparameter tuning via trial and error to reduce Word Error Rate (WER). Integration of the custom answer validation model into Rasa architecture was also technologically demanding, particularly real-time inference synchronization with dialogue flow, latency control, and consistent validation for multi-turn conversation.
Related research article
None
For a published article
None
Ethics statements
The report does not involve human participants or data from social media platforms.
CRediT author statement
Chong Kar Weng: Research, Conceptualization, Methodology, Implementation, Writing – original draft, Writing – review & editing
Dr. Ng Kok Why: Writing – review & editing, Supervision
Fu Yong Hong: Writing – review & editing
Supplementary material and/or additional information [OPTIONAL]
None
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Gan, C., Zhang, Q., & Mori, T. (2024, January 16). Application of LLM Agents in Recruitment: A novel Framework For Resume Screening. ar Xiv.org. https://arxiv.org/abs/2401.08315.
- 2Blessing M.AI-Powered Resume Screening: Benefits and Challenges 2025, February 5Research Gatehttps://www.researchgate.net/publication/388688179_AI-Powered_Resume_Screening_Benefits_and_Challenges
- 3Hirai A.Kovalyova A.Speech-to-text applications’ Accuracy in English Language learners’ Speech Transcription 2024 https://scholarspace.manoa.hawaii.edu/items/693fc 7a 9-b 98c-4191-a 1e 3-b 5e 5b 7e 884d 8
- 4Gyulyustan Hasan Hristov H.Stavrev S.Enkov Svetoslav Measuring and analysis of speech-to-text accuracy of some automatic speech recognition services in dynamic environment conditions AIP Conf. Proc.202410.1063/5.0196448 · doi ↗
- 5Kuhn K.Kersken V.Reuter B.Egger N.Zimmermann G.Measuring the accuracy of automatic speech recognition solutions ACM Trans. Access. Comput.164202312310.1145/3636513 · doi ↗
- 6Li, S., Li, K., & Lu, H. (2023, July 13). National Origin Discrimination in Deep-Learning-Powered Automated Resume Screening. ar Xiv.org. https://arxiv.org/abs/2307.08624.
- 7Zimbres R.Multimodality With Gemini-1.5-Flash: Technical Details and Use Cases 2024, November 23Mediumhttps://medium.com/google-cloud/multimodality-with-gemini-1-5-flash-technical-details-and-use-cases-84e 8440625 b 6
- 8Radford, A., Kim, J.W., Xu, T., Brockman, G., Mc Leavey, C., & Sutskever, I. (2022, December 6). Robust Speech Recognition Via Large-Scale Weak Supervision. ar Xiv.org. https://arxiv.org/abs/2212.04356.