A robust modeling framework to investigate transmissible diseases: COVID-19 in Chile as a case study
Oscar Rojas-Díaz, Patricio Cumsille, Carlos Conca

TL;DR
This paper introduces a flexible and robust modeling framework for predicting transmissible diseases, using Chile's COVID-19 data as a case study.
Contribution
The framework automatically selects stable initial parameters and adapts to include variables like ICU admissions and time-varying transmission rates.
Findings
The framework successfully calibrated epidemiological curves across all Chilean regions during different pandemic waves.
It accurately estimated the effective reproductive number at the national level.
The model's adaptability and robustness improve calibration accuracy for diverse datasets and diseases.
Abstract
In the face of the challenges posed by pandemics like COVID-19, the need for accurate mathematical models and methods to predict the impact of outbreaks on public health in real-time is paramount. This research aims to develop a robust, adaptable, and general framework for investigating the dynamics of any transmissible disease. The primary objective of this work is to achieve robust parameter optimization for a general modeling framework, a capability crucial for effectively applying it to reconstruct and predict epidemiological curves for any transmissible disease. The main novelty of this work is that our general modeling framework automatically selects a suitable initial parameter vector under general conditions that standard initialization heuristics do not necessarily satisfy, thereby endowing the parameter estimation method with stability and the ability to calibrate any…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
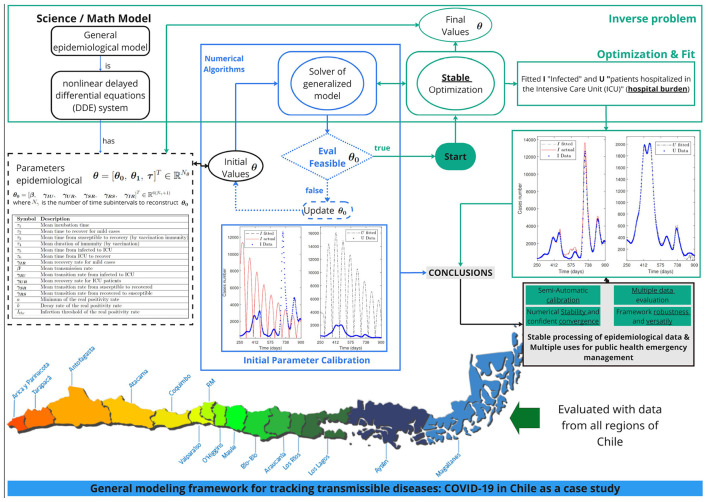 Figure 1
Figure 1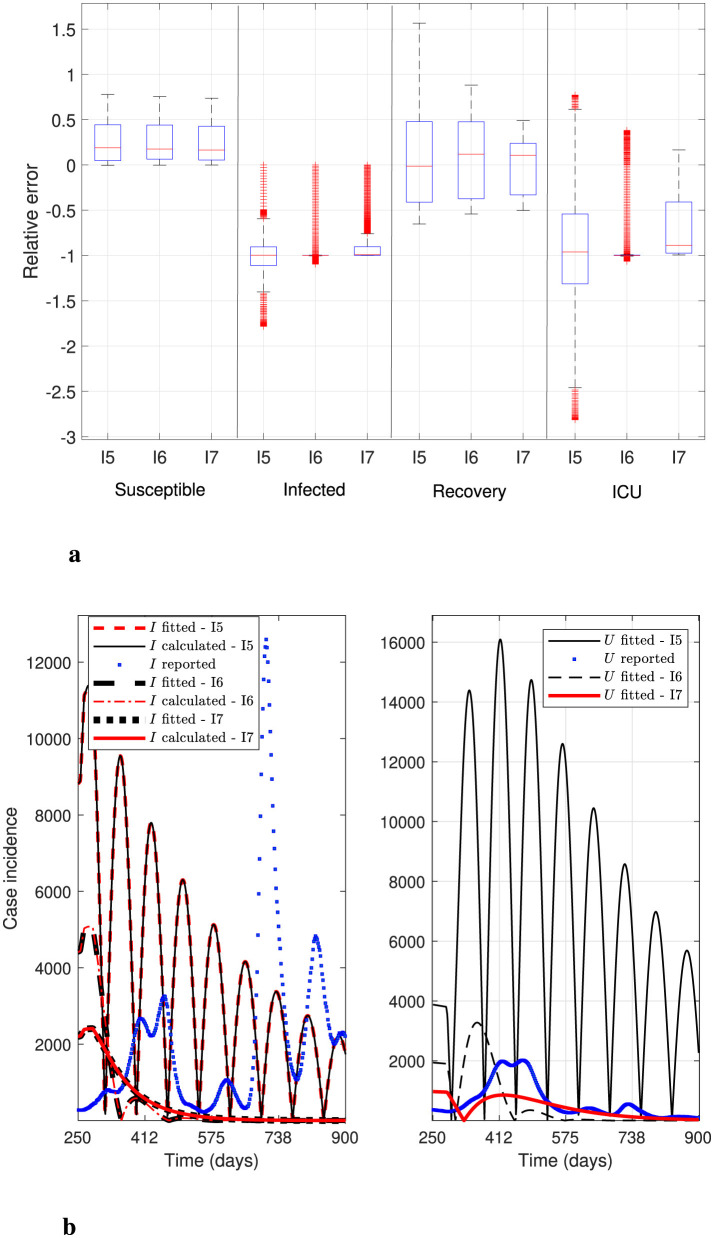 Figure 2
Figure 2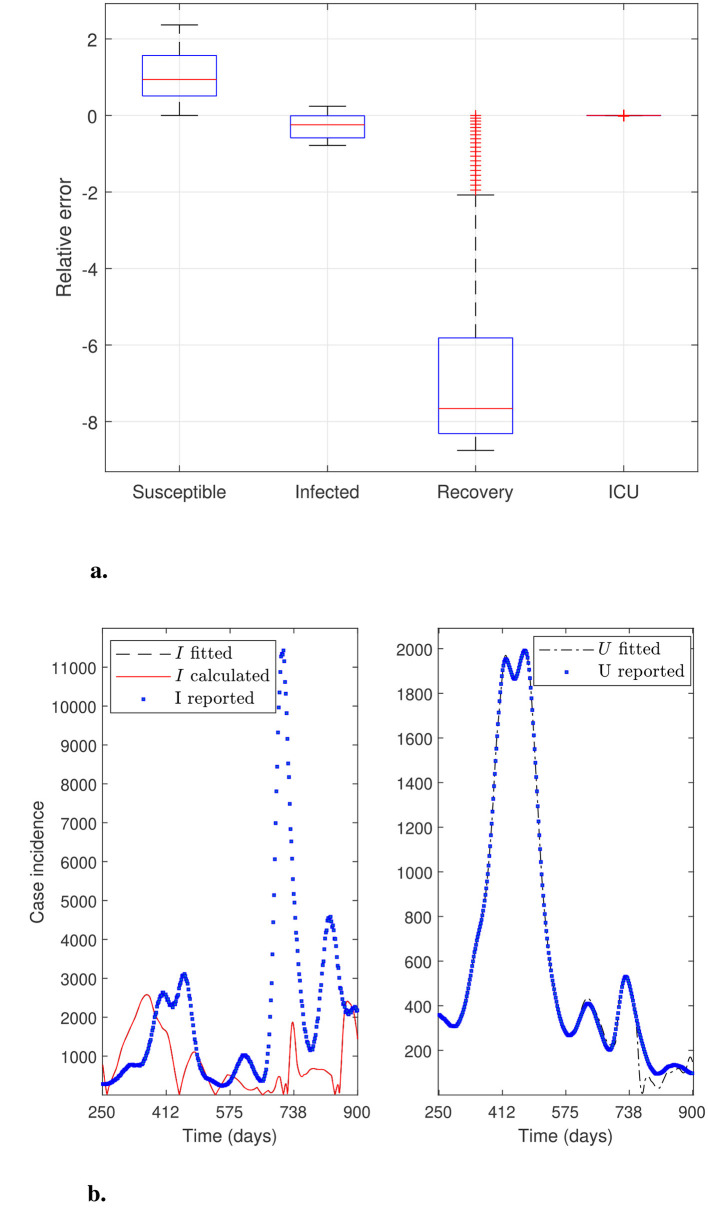 Figure 3
Figure 3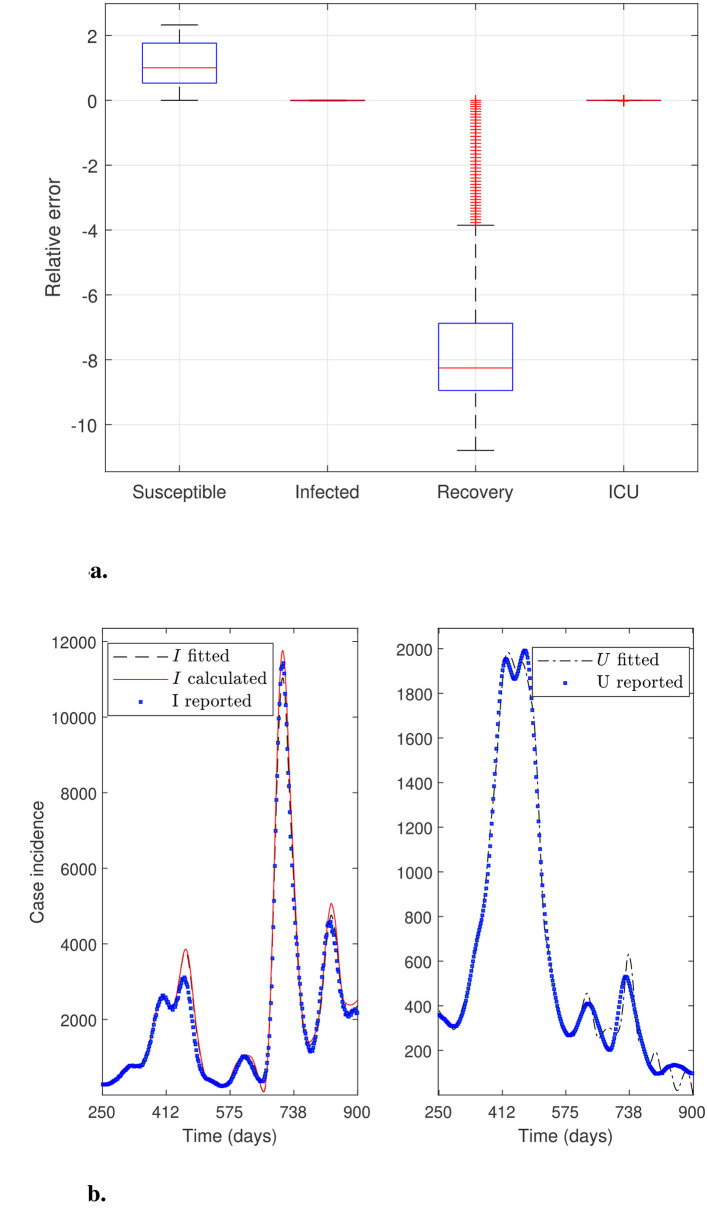 Figure 4
Figure 4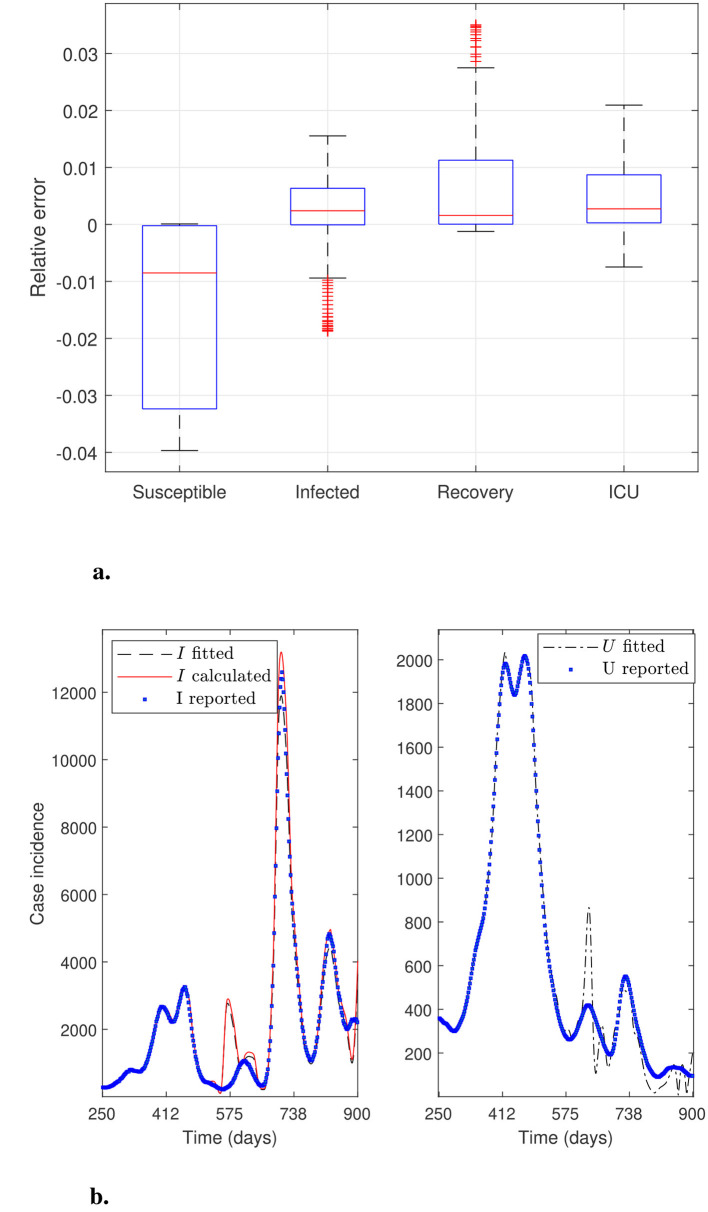 Figure 5
Figure 5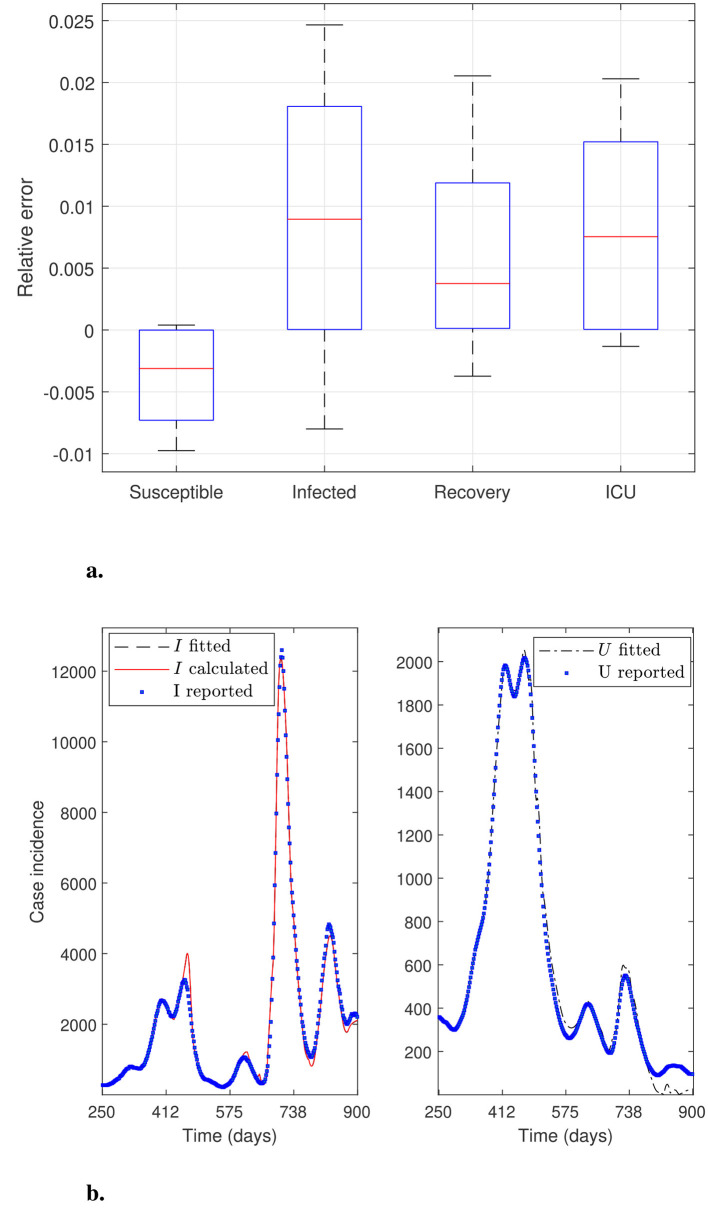 Figure 6
Figure 6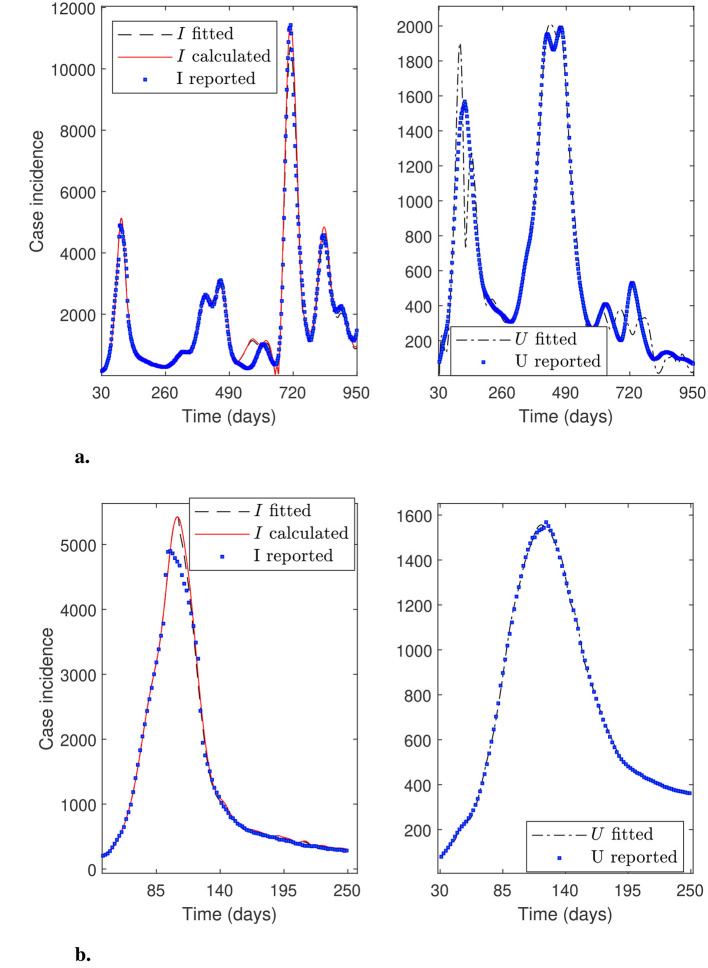 Figure 7
Figure 7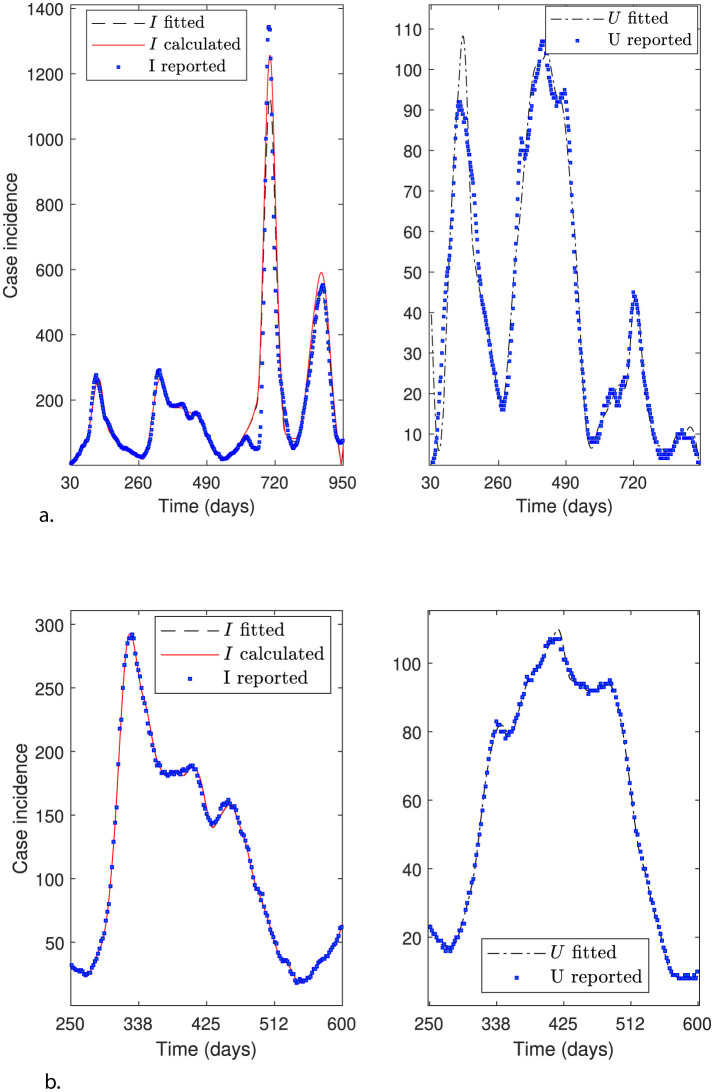 Figure 8
Figure 8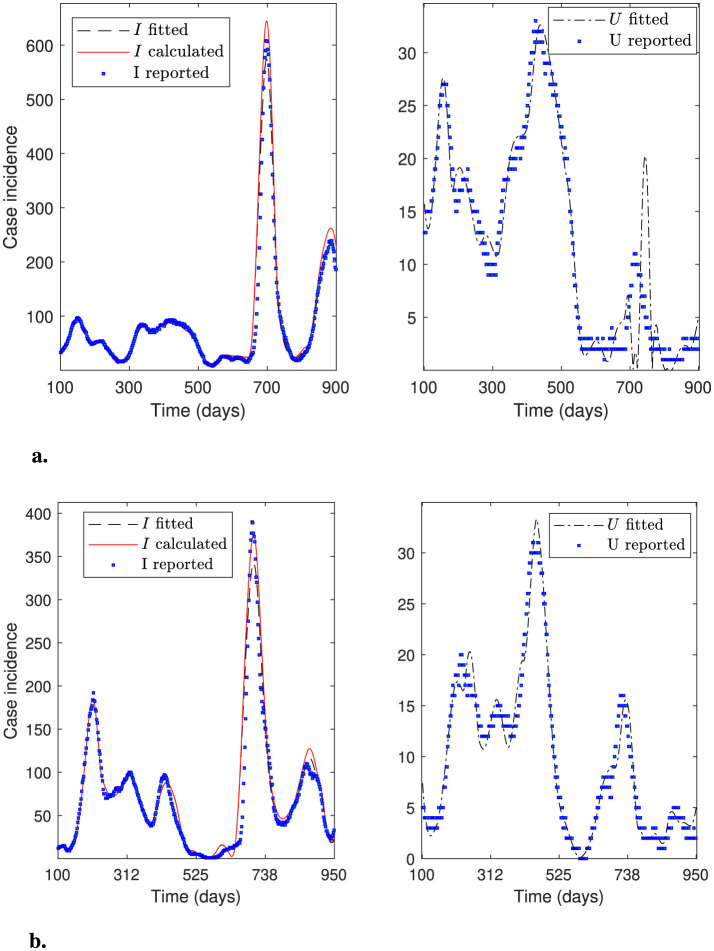 Figure 9
Figure 9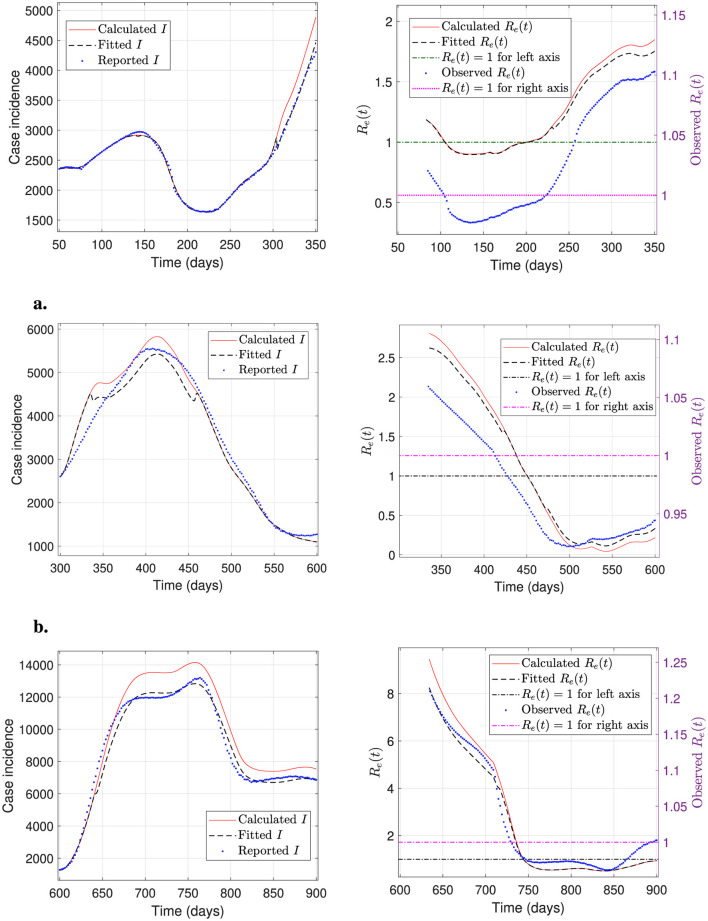 Figure 10
Figure 10|
|
|
|
|
|---|---|---|---|
| τ1 | Mean incubation time | days | 1–14 |
| τ2 | Mean time to recover for mild cases | days | 1–21 |
| τ3 | Mean time from susceptible to recovery (by vaccination immunity) | days | 1–14 |
| τ4 | Mean duration of immunity | days | 1–240 |
| τ5 | Mean time from infected to ICU | days | 14–56 |
| τ6 | Mean time from ICU to recover | days | 21–42 |
|
| Mean transition rate from susceptible to recovered (immunity rate) | days−1 | |
|
| Mean transmission rate | days−1 | |
|
| Mean recovery rate for mild cases | days−1 | |
|
| Mean transition rate from recovered to susceptible (immunity decay rate) | days−1 | |
|
| Mean transition rate from infected to ICU | days−1 | |
|
| Mean recovery rate for ICU patients | days−1 | |
|
| Minimum fraction of detected infections | – | |
|
| Steepness parameter of the fraction of detected infections | inhabitants−1 | |
|
| Threshold of detected infections | inhabitants |
|
| |||
|---|---|---|---|
|
|
|
|
|
| Mean time | 1.5 sec | 0.05 sec | 6.1 sec |
| Mean latency | 1.0 sec | 0.1 sec | 4.2 sec |
| Iters | 4 | 3 | 7 |
|
| |||
| Iters 1-4 | NaNs | - | - |
| Iters 5-7 ( | - | [5.36 | - |
| Iters 5-7 ( | - | [5.97 | - |
| Iters 5-7 ( | - | [1.81 | - |
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
| Arica ( | 2.51 | 3.01 | 2.83 | 1.32 | 4.20 | 2.68 | 100–900 | North |
| Tarapacá | 7.18 | 4.62 | 5.24 | 8.12 | 1.06 | 5.34 | 100–900 | North |
| Antofagasta ( | 8.75 | 3.09 | 2.39 | 3.47 | 2.73 | 2.40 | 250–600 | North |
| Antofagasta ( | 5.83 | 1.52 | 1.05 | 2.76 | 5.56 | 3.24 | 30–950 | North |
| Atacama | 8.11 | 1.30 | 1.95 | 8.27 | 8.95 | 3.31 | 100–900 | North |
| Coquimbo | 1.57 | 1.99 | 2.59 | 9.77 | 1.01 | 2.60 | 100–900 | North |
| Valparaiso | 1.31 | 2.54 | 1.96 | 2.74 | 4.18 | 1.12 | 250–950 | Center |
| Metropolitan ( | 2.47 | 1.43 | 3.52 | 3.14 | 4.58 | 1.35 | 30–950 | Center |
| Metropolitan ( | 2.30 | 1.61 | 2.18 | 5.06 | 3.75 | 1.02 | 30–250 | Center |
| O'Higgins | 8.37 | 5.71 | 2.24 | 9.05 | 7.44 | 3.15 | 100–900 | Center |
| Maule | 2.86 | 7.56 | 1.17 | 3.67 | 4.47 | 6.70 | 100–900 | Center |
| Ñuble | 2.86 | 3.24 | 2.98 | 1.88 | 4.97 | 2.92 | 100–900 | Center |
| Biobío | 1.76 | 3.83 | 9.84 | 2.97 | 8.37 | 2.79 | 100–900 | South |
| Araucania | 7.47 | 4.96 | 4.78 | 6.68 | 4.91 | 8.38 | 100–950 | South |
| Los Ríos | 6.52 | 4.53 | 4.58 | 3.84 | 1.54 | 3.50 | 100–900 | South |
| Los Lagos | 2.81 | 1.86 | 3.94 | 2.55 | 1.13 | 1.28 | 100–900 | South |
| Aysén | 1.62 | 5.12 | 9.16 | 1.56 | 1.26 | 2.72 | 100–900 | South |
| Magallanes ( | 2.28 | 2.52 | 2.85 | 8.28 | 4.56 | 2.26 | 100–950 | South |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCOVID-19 epidemiological studies · Zoonotic diseases and public health · COVID-19 and Mental Health
Introduction
1
The present article aims to achieve robust parameter optimization, understood as the ability to accurately calibrate any dataset under general conditions by developing suitable modeling frameworks. To the best of our knowledge, this crucial aspect has not been addressed in the literature, and it is key to effectively reconstructing and predicting epidemiological curves for any transmissible disease. Given the limitations in managing a pandemic like COVID-19 (1), this aspect is desirable for forecasting an outbreak's impact on the public health system in real time, providing scientific evidence to help inform policymakers' decisions.
Our primary objective is to endow a previously developed general modeling framework with the strength described above. Our framework employs a hybrid approach that combines mathematical modeling with a practical identifiability approach (2). The first involves suitable compartmental epidemiological modeling, whereas the second relies primarily on parameter optimization for model calibration. We conceived it by generalizing and refining previous modeling and numerical methods introduced by Cumsille et al. (3). We applied it to accurately track and predict the number of patients hospitalized in the intensive care unit (ICU) and to assess COVID-19 vaccination in Chile (4).
The main novelty of our work lies in parameter initialization that satisfies general conditions solely dependent on the parameter space, which is tied to the epidemiology of the studied transmissible disease. As a result, our framework is robust since it can successfully calibrate any dataset and reproduce the national effective reproduction number, as substantiated by fitting COVID-19 incidence curves across all of Chile's regions, with varied mobility levels, geographic locations, and population sizes during the pandemic. We remark that this ability is not trivial and, indeed, we required intensive numerical experiments to achieve it since it has no direct or unique implementation. The main difficulty is that parameter identification is an ill-posed inverse problem, as its solution lacks stability and uniqueness with respect to parameter values (5). In particular, modeling errors and measurement noise can be amplified considerably (6), leading to numerical instability, yielding poor data calibration. It is worth noting that, in the current work, the leading cause of instability lies in the evaluation of the modeling solution rather than in the optimization of the objective function. Thus, we focus on providing stability to the model solver, which, in turn, implies stability for the optimization solver, thereby avoiding the need to resort to, e.g., Tikhonov regularization.
The literature on COVID-19 modeling is vast. Thus, we only examine a few papers that are important for their applications and similarities with the present work. For example, Zhenzhen et al. (7) studied a model with “long memory” to describe the multi-wave peaks in the COVID-19 dynamics, where “long memory” enables the prediction of peaks using nonlocal terms, allowing one to include an arbitrary long history of the disease. Indeed, the authors obtain a model with time delays for a particular nonlocal term. Also, the authors modeled vaccination as an impulsive term that reduces susceptibility.
Moreover, Ghosh et al. (8) derived a model with a time delay, where the last term represents the disease duration, i.e., the average time it takes for infected individuals to recover or die. Also, (9) investigated a SEIR-type model with time delay and vaccination control. Also, they simulated vaccination as a control that decreases susceptibility, similar to the generalization we use in the present work. Finally, our current work builds upon the model developed by (3), which shares common elements with some of the works cited here. Indeed, in the cited reference, we introduce the same time delay that models the average time to recover or die. In addition, we could interpret our previous model as incorporating a long-memory effect, in the sense that it allows reproducing multi-wave peaks depending on parameter values, as we showed.
Finally, according to Moore et al. (10), vaccination protects in four ways: against infection, against symptoms, against severe disease, and against onward transmission. However, even accounting for some of the vaccine's protective mechanisms, the model can become very complex, making it difficult to estimate parameters reliably. Therefore, our present work maintains model simplicity, which is critical for a practical identifiability approach. Even so, it remains a challenge to do so in real time, as required to anticipate epidemiological scenarios and predict hospital load on the healthcare system, as was the case during the first year of the pandemic (before vaccination). In this regard, we assume that vaccination protects against infection by diminishing susceptibility, as reported in the cited literature, which entails adding several meaningful parameters associated with vaccination.
We organize this article as follows. Section 2 describes the general modeling framework, comprising a robust parameter optimization. Section 3 describes the errors, robustness measures, and the effective reproduction number. In Section 4, we present results from the general modeling framework on its performance, modeling evaluation stability, adaptability, and robustness, i.e., its calibration accuracy under general conditions. In Section 5, we analyze the results to demonstrate that our general modeling framework is stable, adaptable, and robust. Finally, in Section 6, we present conclusions and outline future directions.
General modeling framework
2
This section provides a summary of the general modeling framework, which comprises the general epidemiological modeling described in Section 2.1 and a practical identifiability approach that enables modeling parameter calibration for data of any transmissible disease, as explained in Section 2.2. Finally, in Section 2.3, we present the general percentage decrease technique, a component of the practical identifiability approach, that enables robust parameter optimization.
General epidemiological modeling
2.1
In previous works (3, 4), we developed epidemiological models containing long-memory terms that yield accurate multi-wave reproduction peaks for suitable parameter values. General epidemiological modeling developed by Cumsille et al. (4) partly consists of the following nonlinear delayed differential equations (DDE) system:
The variables of the nonlinear DDE system given by Equation 1 are S, I, and R, which describe the susceptible, infected, and recovered individuals, and U, which accounts for the sum of the patients hospitalized in the ICU plus the dead confirmed by the transmissible disease, respectively. We consider a piecewise reconstruction of time-varying parameters α(t), β(t), γ(t), δ(t), η(t), and κ(t) (see Table 1). General epidemiological modeling has Nθ: = 6Nθ_0_+9 parameters collected in the vector defined by Equation 2, where Nθ_0_ is the number of time subintervals equally spaced to interpolate parameters θ0, defined by Equation 2a, which reconstruct transmission rate and transition rates previously mentioned. In modeling calibration, we used Nθ_0_ = 20 time subintervals to describe the transmission rate and transition rates; thus, we estimated Nθ = 129 parameters for each dataset, which presented a computational challenge, as we had to develop efficient programming, which we made accessible to the scientific community in (11). It is worth noting that this high number of parameters applies only to θ0 since the rates are calculated by pieces to map the entire pandemic, accounting for temporal variability across different periods/waves. In θ1 defined by Equation 2b, parameters a and k describe the minimum and the steepness parameter of f(t) given by Equation 3, and Ithr is the threshold of detected infections such that Equation 4 holds. Parameter f(t) is the fraction of detected and fitted infections by modeling since the reported infections Ir(t) are underestimated (3). Thus, If(t) = f(t)I(t) are the new cases of modeled infections detected in day t. τ are constant time delays that represent meaningful epidemiological parameters that vary in the ranges provided in Table 1, which for COVID-19 were obtained from the references (4, 12). The initial values for vector τ are , which correspond to the mean for τ_i_ for i = 1, 2 in the COVID-19 case (13), while the other initial values are the midpoint of the ranges in Table 1. The details of the model given by equations in System 1, If(t) = f(t)I(t), and Equation 3, and parameter optimization are described in depth by Cumsille et al. (4). Table 1 defines the parameters of general epidemiological modeling, collected in the vector θ as given by the equations in System 2.
Practical identifiability approach
2.2
To carry out the practical identifiability approach, which relies primarily on parameter optimization for model calibration, we must solve the following parameter estimation problem: Given a (processed) dataset accounting for a specific transmissible disease dynamics, compute a parameter vector θ such that general epidemiological modeling fits data by least-squares. The dataset is the time observations where are the observations of variable If(tj), corresponding to the case incidence confirmed by RT-PCR tests for the i-dataset in day tj, and are the observations of variable U(tj), corresponding to the patients hospitalized in the ICU plus the dead confirmed by the disease for the i-dataset in day tj, N^i^ is the i-dataset size, and N is the total number of studied datasets. In this work, we study N = 16 datasets that cover the entire Chilean territory. We remark that, throughout this article, we omit the dependence on i for simplicity. To solve the parameter estimation problem, we must estimate a vector , given by System 2, minimizing the cost function (Equation 5).
The cost function defined in Equation 5 corresponds to the sum of squares of the differences between the data and the model relative to the model. Variables If and U are the solution of general epidemiological modeling given by equations in System 1, If(t) = f(t)I(t), and Equation 3 at (tj, θ) for j = 1, ⋯ , N^i^, for a particular parameter vector given by equations in System 2. In Equation 5, we introduce a parameter 0 ≤ ε ≤ tol to avoid division by zero and chosen as ε = 0 when If(tj, θ)>0 and U(tj, θ) for all j, where tol = 1.0e−6. Another alternative to stabilize the computation of relative residuals is to add 1 to each datapoint in the target dataset, ensuring that the numerical modeling solution is always greater than 0, thereby allowing us to set ε = 0 and obtain a calibration as good as that for the original dataset. To optimize SS(θ) (Equation 5) for the i-dataset, for all i = 1, …, N, we apply the lsqnonlin MATLAB solver that minimizes the sum of squares by the well-known Trust-Region-Interior-Reflective (TIR) Algorithm (14).
The modeling parameters θ1 given by Equation 2b depend on each dataset. As we are searching for an overall numerical method that makes robust parameter optimization for every dataset under general conditions, one can initialize θ1 strategically by defining Ithr between the minimum and maximum of the reported case incidence Ir computed among all studied datasets (4). We define the modeling parameters τ given by Equation 2c within reasonable bounds from an epidemiological viewpoint. Used vector τ values are given in Table 1 according to references (4, 12) for COVID-19.
General percentage decrease technique
2.3
Based on epidemiological considerations and our numerical experience, we generalized and improved the percentage decrease technique to select initial modeling parameters as a fraction of the upper bounds of the parameter space, endowing the practical identifiability approach with robust parameter optimization. To the best of our knowledge, this crucial aspect has not been addressed in the literature, and it is key to extending our general modeling framework to effectively reconstruct and predict epidemiological curves for any transmissible disease. The extension of our technique is implemented in Algorithm 1 for initial parameter selection, which is crucial for optimizing the cost function SS(θ) defined by Equation 5 suitably. The technique focuses on initializing modeling parameters θ0 as a fraction of the upper bound UB_θ0_ for the parameter vector θ0 as a guide for computation. In processing each dataset, the fraction value is iterated until Algorithm 1 meets the following stopping conditions: (i) the computed cumulative incidence If(tj, θ) is less than the observed cumulative incidence Ir(tj) over tj for j = 1, …, N^i^, and (ii) the computed incidence is greater or equal to 0 for all tj, j = 1, …, N^i^. Mathematically, we can formulate conditions (i) and (ii) by Equations 6a and 6b, respectively.
We remark that condition (Equation 6a) means that the area under the observed curve (tj, Ir(tj)) is greater than the area under the modeled curve (tj, If(tj, θ)) since both sums in Equation 6a are approximations for the integral over the calibration period taking Δt = 1 day. The iterative procedure we devised to determine the fraction values (Algorithm 1) effectively works independently of each dataset, as confirmed by extensive numerical experiments. This study required intensive numerical simulations, as our approach is complex and lacks a direct, unique implementation. The main difficulty is that parameter identification is an ill-posed inverse problem, as its solution lacks specific stability properties, leading to non-uniqueness in parameter optimization (5). In particular, modeling errors and measurement noise can be amplified considerably (6), possibly leading to numerical instability and divergence of the optimization solver that, in our numerical experience, occurs when implementing a careless parameter optimization technique. Algorithm 1 is a controlled-parameter initialization technique that reinitializes only θ0 to avoid instabilities in the dde23 MATLAB solver (15) when evaluating numerical solutions to the DDE system (System 1). In contrast, other initialization heuristics, such as random ones, may produce instabilities in the dde23 solver, which, in our numerical experience, are mainly due to the solver's sensitivity to changes in derivatives, especially near critical points.
Algorithm 1General percentage decrease technique.
Methods
3
In this section, we describe the methods to demonstrate the stability, adaptability, and robustness of our general modeling framework. Figure 1 presents a conceptual scheme for robust parameter optimization that incorporates the general percentage decrease technique (Algorithm 1) for parameter initialization.
Graphical abstract. The plot depicts a conceptual scheme, the main results, and the conclusions of the general modeling framework. It consists of general epidemiological modeling (GEM) and robust parameter optimization with suitable initial parameter selection. We applied our framework to calibrate COVID-19 datasets across all regions of Chile. It consistently calibrates case incidence for infections and ICU admissions, enabling assessment of the hospital burden on the public health system. In conclusion, our framework is adaptable, robust, and stable, enabling the stable processing of epidemiological data for multiple uses in public health emergency management.
Measurement of the error and robustness of the optimization
3.1
To demonstrate the performance of the general modeling framework, we present our results by plotting the relative error distributions of the general epidemiological modeling calculation for various modeling variables and their corresponding observed data. We calculate the errors relative to data defined by Equation 7:
where X stands for every modeling variable, X = S, If, R, U, and Xr denotes the corresponding observed data, Xr = Sr, Ir, Rr, Ur. Again, a small parameter ε>0 is chosen to avoid division by zero if required, which is also valid for the RMSE defined by Equation 9. In addition, we will show in tables, which display quantitative metrics of performance, the mean relative error defined as the average of the absolute value of the relative errors in the respective time interval defined by Equation 8:
where RE_X(tj_, θ) is defined in Equation 7.
We also plot the case incidence fitted If, calculated I, and reported Ir (denoted as “I fitted”, “I calculated”, and “I reported” in legends at left panels of figures). In addition, we plot the fitted variable U and the reported Ur, which represent the sum of patients in the ICU and those confirmed dead by COVID-19 (denoted as “U fitted” and “U reported” in the legends of the right panels of the figures).
The specific robustness metrics that we display are the sum of squares' approximate optimal value evaluated in the numerical approximation to a suitable minimum, , the root mean squared error (RMSE) for If and U defined by Equation 9 for X = If and X = U, the norm of step defined as the distance between and the parameter vector computed in the previous iteration, the mean relative error for If and U, and , defined by Equation 8, the calibration period, and the geographic location for every dataset; see Figure 1 for reference.
Estimation of the effective reproduction number
3.2
In addition to demonstrating calibration performance for COVID-19 datasets of all regions of Chile, we compute and plot the effective reproduction number Re(t) using the incidence curve at a national level.
From Equation 1b, we note that I′(t)>0 if and only if
Also, factorizing Equation 1b by γ(t)I(t−τ_2_)+η(t)I(t−τ_5_), we arrive at the “calculated” effective reproductive number:
In addition, we compute the “fitted” effective reproductive number:
We note that the analogy between Re(t) and (Re)f(t) is the same as for I(t) and If(t) = f(t)I(t), where If(t) is the “fitted” case incidence, whereas I(t) is the “calculated” case incidence, which is unknown since it models the reported and unreported incidence case.
In our numerical calculation of Re(t), we preferred formula 10 for stability, where we approximate the derivative I′(t) by the classical second-order centered finite-difference formula. In our numerical results, we plot the “modeled” effective reproductive number Re(t) calculated by Equation 10, the “fitted” effective reproductive number (Re)f(t) calculated by Equation 11, and the “observed” effective reproductive number calculated by using the reported case incidence Ir(t) by Equation 12:
assuming that the average time to recover for mild cases is 14 days (4), and to be admitted to the ICU due to COVID-19 is 35 days (the midpoint of the range for τ_5_; see Table 1), respectively.
Data, hardware, and software
3.3
The datasets used in this research are available in (11) and correspond to the observed case, [Ir(tj), Ur(tj)], for all regions of Chile, geographic locations (North, Center, and South), population sizes, and distinct periods/waves of the COVID-19 pandemic. Before parameter initialization and optimization for modeling calibration, we processed the datasets by cleaning, smoothing, and interpolation (4). We selected different periods of the COVID-19 pandemic to test the robustness of our general modeling framework, focusing on its ability to calibrate the entire pandemic and its various waves. The precise periods in days for the selected datasets are 30–950, 100–900, or 100–950 (almost the whole pandemic), 30–250 (first wave), 250–950 (all the pandemic except for the first wave), 250–600 (good part of the pandemic except for the first wave). We do not include graphs for all experiments to avoid overextending the presentation. We note that day 1 corresponds to March 3, 2020, the date the COVID-19 pandemic began, when the Health Ministry reported the first confirmed case in Chile.
The hardware used is a data science workstation equipped with an Intel Core i9-14900K processor, 32 logical cores, and 128 GB of RAM. The software used for development and experimentation is MATLAB R2024a©. The options we chose for the lsqnonlin solver are function tolerance 1.0e − 12, the maximum number of function evaluations 40, 000, optimality tolerance 1.0e−12, and step tolerance 1.0e−10. We also used the parallel computing MATLAB toolbox to leverage the workstations' multi-core processors.
Results
4
This section presents the results obtained from the general modeling framework. We will demonstrate that our framework, which sheds light on the understanding of epidemiological curves (4), can calibrate datasets corresponding to the entire territory of Chile. Figure 1 summarizes the main results and conclusions obtained by applying the general modeling framework for all datasets corresponding to COVID-19 cases observed across all regions of Chile, with varying mobility levels, geographic locations, and population sizes, during the pandemic's duration.
This section is organized as follows. First, we quantify the performance of the general percentage-decrease technique and determine whether it endows the practical identifiability approach with numerical stability. Second, we optimize different objective functions to determine whether our general modeling framework can better calibrate the trend of the observed epidemiological curves by incorporating additional modeling variables and parameters into the parameter estimation problem. Finally, we quantify the performance of the general modeling framework to demonstrate that it can robustly optimize parameters under general conditions ensured by the general percentage decrease technique.
General modeling framework numerical stability
4.1
Algorithm 1 selects suitable initial modeling parameters for stable numerical parameter optimization, as demonstrated below. In effect, to test stability, we used COVID-19 case incidence in the Metropolitan Region (RM in Figure 1). Table 2 quantifies the computational cost and the mean relative error (MRE) as defined in Equation 8 over the period from 250 to 900 days (excluding the first wave), calculated using the general percentage decrease technique. Note that we are not calibrating general epidemiological modeling, but rather testing the stability of Algorithm 1 before parameter optimization.
In terms of computational cost, Table 2 shows the mean time, latency1, and iterations that take Algorithm 1 to meet the stopping criteria described by conditions (i) and (ii) given by Equations 6 for the 751 datapoints in the period 250-900 days for RM.
Figure 2 below shows the general percentage decrease technique results in iterations 5, 6, and 7 (marked as I5, I6, and I7 in Figure 2). Specifically, it plots the curves generated by Algorithm 1 to test stability before applying the optimization solver. It depicts box-and-whisker plots of relative error distributions for the different modeling variables and their corresponding data, as defined by Equation 7 (top panel). It also depicts the case incidence If and I evaluated at θ^(0)^ in iterations 5-7, and the reported case incidence Ir (denoted as “If fitted”, “I calculated”, and “I reported” in the legend of the bottom-left panel of the figure). In addition, it plots the sum of patients in the ICU plus those confirmed dead by COVID-19, i.e., the variable U, calculated at θ^(0)^ in iterations 5-7, and Ur reported (denoted as “U fitted” and “U reported” in the legend in the bottom-right panel of the figure).
General percentage decrease technique results: iterations 5–7. Results correspond to the daily case incidence evaluated in the parameters obtained by running parameter initialization Algorithm 1. (a) shows the relative error distribution for all modeling variables, and (b) depicts incidence curves for variables If, I, and U in the RM of Chile. Algorithm 1 determines the initial parameter vector at iteration 7, when the I, If, and U curves stabilize, enabling robust parameter optimization.
General modeling framework adaptability
4.2
This section aims to solve modified parameter estimation problems with alternative objective functions to demonstrate whether the general modeling framework can effectively adjust the curve for variable U. This is relevant because the trend in ICU hospitalizations is the most appropriate indicator of an infectious disease's impact on the public health system. In addition, evaluating the general modeling framework's adaptability is relevant when considering the inclusion of other modeling variables, provided associated data are available. We obtain alternative objective functions by adding or dropping modeling variables and their corresponding data to the sum of squares defined in Equation 5. Furthermore, we use Nθ_0_ = 40 time subintervals to reconstruct the time-varying parameters and assess whether fitting accuracy increases (Nθ = 249 parameters to estimate). Figures 3–6 illustrate the effectiveness of the general modeling framework in achieving accurate calibration using only variable U up to the four variables S, If, R, and U, respectively. For instance, the results plotted in Figure 3 consider only the residuals of variable U in the sum of squares in Equation 5. Figure 4 considers If and U, and so on.
General modeling framework calibration using only variable U. Results correspond to the daily case incidence fitted by minimizing the objective function defined by Equation 5, keeping only the relative residuals for variable U. (a) depicts the relative error distribution of all modeling variables, and (b) incidence curves in the RM of Chile for variables I, If, and U. Calibration for the variables I and If (not fitted) is poor, whereas that for the fitted variable U is outstanding.
General modeling framework calibration using variables If and U. Results correspond to the daily case incidence fitted by minimizing the objective function defined by Equation 5. (a) depicts the relative error distribution of all modeling variables, and (b) incidence curves in the RM of Chile for variables I, If, and U. Calibration for fitted variables If and U is relatively good, except for a spurious peak around day 500 for If and I, and little oscillations for variable U near the end of the third wave.
General modeling framework calibration using variables If, R, and U. Results correspond to the daily case incidence fitted by minimizing the objective function defined by Equation 5, adding the relative residuals for variable R. (a) depicts the relative error distribution of all modeling variables, and (b) incidence curves in the RM of Chile for variables I, If, and U. Calibration is relatively good, except for a spurious peak for If and I around day 575, and a few oscillations for the fitted variable U near the end of the third wave.
General modeling framework calibration using all modeling variables. Results correspond to the daily case incidence fitted by minimizing the objective function defined by Equation 5, adding the relative residuals for variables R and S. (a) depicts the relative error distribution of all modeling variables, and (b) incidence curves in the RM of Chile for variables I, If, and U. Calibration is outstanding.
From Figure 6, we observe that using the four modeling variables, we achieve the best calibration (Figure 6b), and a median close to 0 and narrow boxes for relative error distributions (Figure 6a).
General modeling framework robustness
4.3
This section presents numerical experiments that demonstrate the robustness of the general modeling framework. When we select initial parameters using the general percentage decrease technique, the optimization solver consistently calibrates all datasets tested in this research. We obtained all the calibration results considering Nθ_0_ = 20 subintervals to reconstruct the time-varying parameters (Nθ = 129 parameters) and 30-day moving average to smooth the datasets. Table 3 presents quantitative metrics to verify the robustness of the general modeling framework applied to datasets from all of Chile, as explained in Sections 3.1 and 3.3, respectively. In addition, Figures 7–9 plot the case incidence fitted If, calculated I, and reported Ir (denoted as “I fitted”, “I calculated”, and “I reported” in legends at left panels of figures). In addition, they plot the patients in the ICU, plus those dead confirmed by COVID-19, fitted U and reported Ur (denoted as “U fitted” and “U reported” in the legends of the right panels of the figures).
Fitted incidence curves for the Metropolitan región (RM, Central Chile in Figure 1). Results correspond to the daily case incidence. (a) shows a relatively good daily case incidence, calibrated for the almost entire pandemic, even though If and I peak spuriously near day 600. The fitted ICU-stay shows oscillations around the peak in the first wave and throughout the third wave. (b) shows an outstanding daily case incidence calibrated for the first wave.
Fitted incidence curves for the Antofagasta region (Northern Chile in Figure 1). Results correspond to the daily case incidence. (a) shows a relatively good daily case incidence calibrated for the almost entire pandemic, even though variables I and If peak higher near day 600. The fitted ICU-stay shows oscillations near the end of the third wave. (b) depicts an excellent daily case incidence calibrated for the second wave.
Fitted incidence curves for the Arica and Magallanes regions (far north and south of Chile in Figure 1). Results correspond to the daily case incidence. (a) depicts daily incidence curves calculated and fitted for the Arica and Parinacota region, and (b) for the Magallanes and the Antártica region for the almost entire pandemic. The two calibrations are relatively good, given the challenge of fitting the low daily case incidence reported in these remote, sparsely populated regions of Chile.
In addition to the calibration performance demonstrated by our general modeling framework, we estimate the effective reproduction number from the national incidence curve. We show the results in Figure 10 for different periods/waves of the pandemic.
Incidence curves and effective reproductive number at a national level. The plots depict daily case incidence calculated, fitted, and reported, and the corresponding effective reproductive number Re(t), calculated, fitted, and observed over different periods/waves of the pandemic. The results show excellent agreement between the incidence curves and Re(t), and between the calculated and observed Re(t). (a) Period 50–350 (first wave). (b) Period 300–600 (second wave). (c) Period 600–900 (third wave).
Discussion
5
This section analyses the results obtained in the preceding section. First, we demonstrate that by employing the general percentage decrease technique to select initial parameters, the dde23 MATLAB solver enables stable evaluation of general epidemiological modeling. Second, we analyze alternative objective functions for parameter estimation, including modeling variables S and R (in addition to I and U), to demonstrate the adaptability of our framework. In fact, the general modeling framework is adaptable, as it can calibrate part or all of the model variables using partial or complete datasets collected in (11). Finally, we verify the robustness of the general modeling framework by demonstrating that it can calibrate any dataset under general conditions, independent of the data, as outlined in Algorithm 1.
General modeling framework is numerically stable
5.1
Table 2 shows that the calculation stabilizes after the fifth iteration of Algorithm 1, in which it exceeds the computational capacity and incurs the highest computational cost, leading to overflow. In addition, in iterations 6 and 7, it reaches stability and the stopping criteria (i) and (ii) in Equations 6a and 6b, respectively. In effect, it returns initial parameter values so that the corresponding computed curve If(t) satisfies the devised general conditions.
Figure 2b (I5) illustrates “highly oscillating” curves for variables If, I, and U, where variable U has the highest mean relative error (Table 2, Iter 5), and whose distribution has the most prolonged whisker, numerous outliers, and a long box. Conversely, in I6 and I7, the mean relative error for U is the smallest (marked in bold in Table 2), and the corresponding computed curves are significantly more stable than in I5. Note that Figure 2b in I7 depicts the initial curves for variables If, I, and U used in the optimization solver's first iteration.
In summary, the general percentage decrease technique provides stability to the general modeling framework, ensuring that NaNs are no longer present in calculations during iterations performed by the objective function evaluation and the optimization solver.
General modeling framework is adaptable
5.2
Figure 3 shows excellent calibration of the general modeling framework for variable U using only Ur data, dropping the residuals for variable If from the sum of squares defined by Equation 5. The precision of this calibration is unmistakable in the corresponding relative error distribution depicted in Figure 3a, which shows a very narrow box, no whiskers, and a median close to zero. However, the framework does not fit variable If effectively without using the Ir data, as shown in Figure 3b. Relative error distribution for If in Figure 3a extends from −1 to 0.5 approx., underscoring the role of the Ir data besides the Ur data in the framework's robustness.
Figure 4 depicts calibration of the general modeling framework using variables If and U to minimize the original sum of squares in Equation 5. Figure 4b shows a good calibration, except for a spurious peak before day 575 for the fitted If curve. This anomaly would indicate poor counting for the incidence Ir of COVID-19 cases in the first wave, despite both variables' relative errors being very close to zero, as shown in Figure 4a. This discussion highlights the crucial need to count Ir data reliably for accurate parameter estimation.
Figure 5 depicts calibration of the general modeling framework using variables If, R, and U. It considers the relative residuals already included for variables If and U, and adds those for variable R to the sum of squares given in Equation 5. Figure 5b shows a better calibration than Figure 4b for variables If and U. At the same time, their corresponding relative error distributions exhibit narrow boxes around a median close to 0 (relative error's median less than 1% for both variables and overall a relative error less than 2%), as depicted in Figure 5a. This finding suggests that fitting variable R may be suitable if the corresponding data were available and accurately counted by the health authorities, which was not the case during the first three months of the COVID-19 pandemic in Chile. It is important to note that the least narrow box is for variable R, although it was not counted during the first three months of the pandemic. It is worth noting that as we add more descriptive variables to the objective function and increase the number of subintervals (Nθ_0_ = 40), the overfitting becomes more evident (Figure 6b). However, given the real-world scenario, where we have data on infection incidence and ICU admissions, our framework can accurately fit both variables adaptively using the available data.
In summary, our general modeling framework can accurately and adaptively fit the peaks and trends of observed curves, which is particularly relevant for monitoring and informed government decision-making during health emergencies caused by transmissible diseases. In addition, our results suggest that it is crucial to include the reported incidence curve with a reliable count to achieve the highest accuracy. Regarding the addition of other modeling variables, such as S and R, we highlight that even if the corresponding data were unavailable, it would still be possible to use them to anticipate epidemiological scenarios, like those of the COVID-19 pandemic, by using synthetic data to inform the general modeling framework (4, 16).
General modeling framework is robust
5.3
From Table 3, we observe more appreciable step sizes for Antofagasta, Arica, and Magallanes datasets, which correspond to the regions of Chile with the fewest populations. In this regard, the approximate solution obtained by our general modeling framework is not necessarily the “best optimal solution”. In theory, the optimization solver could eventually iterate more times to obtain a better solution, thereby decreasing the step size. However, the relevance of our framework lies in the fact that it calibrates the observed curves and their general trends, as we demonstrated in Table 3 and Figures 7–9, which could contribute to anticipating an epidemiological outbreak and aiding policymakers in public health decision-making.
A general observation from Table 3, is that is greater than the for both calibrated variables X = If and X = U. This finding aligns with the fact that is computed with the residuals relative to the model variables, whose sum of squares we minimized (see Equation 5), whereas considers the residuals relative to the observed variables. In addition, this finding aligns with the differences between the calibrated and observed corresponding curves in terms of peaks and eventual numerical oscillations, as shown in Figures 7–9, which we discuss in detail below.
Figure 7a shows an overall good calibration for variable If, whereas it is moderately good for variable U. The and for variables X = If and X = U in Table 3 corroborate this finding (Metropolitan, period 100–900). Figure 7b shows an outstanding calibration for variables If and U, even though there was poor data counting in the first wave. By “poor data counting”, we mean the fact that the infected were consistently underestimated, particularly during the first wave, when the health system was not well prepared to conduct accurate follow-up; see (4, section 2.2.4). The and for variables X = If and X = U in Table 3 (Metropolitan, period 30-250) corroborate this finding. In addition, the and is only around 1%, which agrees with the almost perfect calibration for U, as shown in Figure 7b. In the first case (Figure 7a), the oscillations in the fitted curve for U cause a higher .
Figure 8b shows a good calibration for variable If and outstanding for variable U. The and for variables X = If and X = U in Table 3 corroborate this finding (Antofagasta, period 250-600). The is the least, which agrees with the almost perfect fitting for variable U. Figure 8a shows a good calibration for variables If and U, including the first wave in the Antofagasta Region. The and for variables X = If and X = U in Table 3 corroborate this finding (Antofagasta, period 100-900). However, the is higher for both variables X = If and X = U for Antofagasta Region in the period 30–950 than in the period 250-600, which excludes the first wave. This agrees with a higher peak for If near day 600 and U near day 700. By excluding the first wave (Figure 8b), the result is better due to the poor data counting during that period, as mentioned before.
Figure 9 shows results from regions in the far north (Figure 9a) and far south (Figure 9b) of Chile, where the distribution of U is very similar despite their geographical distance. The far north of Chile (Arica and Parinacota Region) exhibits the highest average relative error due to the low number of ICU admissions compared to the reported incidence. In some cases, only one patient per day was admitted to the ICU, whereas the model's estimate was three, implying a relative error of up to 200%. In contrast, Figure 9b shows an outstanding calibration for variables If and U in the Magallanes and Antártica Region. and for variables X = If and X = U in Table 3 corroborate this finding (Magallanes, period 100–950). The fitting is better for the variable U, which aligns with a lesser . Remarkably, the calibration of the Arica and Magallanes dataset presented an additional challenge due to the small magnitude of the data and the smallest population size.
Finally, from Figures 10a–c, we observe an excellent agreement between the observed and calculated effective reproductive numbers (right panels). In addition, these numbers are in accordance with the respective incidence curves (left panels), i.e., when the incidence increases (resp., decreases) Re(t)>1 (resp., Re(t) < 1).
In summary, our general modeling framework captures trends observed in epidemiological curves across all regions of Chile, with varying population sizes and distinct periods/waves of the COVID-19 pandemic, including the effective reproductive number at the national level, further validating the results. Therefore, it can robustly optimize parameters to assess any COVID-19 dataset under general conditions, as determined by the initial parameter selection using the general percentage decrease technique and our careful implementation of the optimization solver.
Conclusions
6
Our research provides a robust modeling framework that accurately calibrates epidemiological curves under general conditions, independent of the target dataset. Also, the framework's calibration is adaptable to available data and reproducible using the code and datasets available in (11).
In the future, we plan to address the following research. First, we must expand the predictive capabilities of our framework. In this sense, in our previous work (4), we successfully predicted trends for the observed COVID-19 curves in the Metropolitan region of Chile using a parametric bootstrapping technique, as devised by (17). Second, a natural step is to apply our framework to other transmissible diseases, thereby further expanding its applicability. Third, another natural step is to compare our framework with other modeling approaches, using our unique overall numerical algorithm. Fourth, we would like to investigate the stability and calibration capabilities of our framework, which poses a challenge to investigating the model's output stability as a function of parameters. This last is a relevant aspect to achieve robust parameter optimization that remains open in general. In this sense, we aim to generate synthetic epidemiological curves using artificial neural networks that map all COVID-19 datasets in Chile, thereby strengthening parameter optimization (16). We can also apply synthetic data generation to expand the framework's predictive capabilities, rather than using a parametric bootstrapping technique, which has a high computational cost (4). Finally, we would like to test a hybrid optimization methodology to address parameter identifiability, as proposed by (18), which combines simulated annealing with nonlinear least-squares techniques.
In conclusion, our research represents a significant first step in establishing a robust modeling framework to investigate the dynamics of any transmissible disease. Our findings not only provide a solid foundation for future studies but also have the potential to inform the development of effective disease control strategies, thereby advancing public health.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Lewis TG Ferrante P Mannai WIA. Lessons and Policy Consequences of Mathematical Modelling in Relation to Ongoing Pandemics. Boston: Lausanne: Frontiers Media SA. (2023).10.3389/fpubh.2023.1281493 PMC 1059344137876717 · doi ↗ · pubmed ↗
- 2Cumsille P Coronel A Conca C Qui ninao C Escudero C. Proposal of a hybrid approach for tumor progression and tumor-induced angiogenesis. Theoret Biol Med Model. (2015) 12:13. doi: 10.1186/s 12976-015-0009-y 26133367 PMC 4509478 · doi ↗ · pubmed ↗
- 3Cumsille P Rojas-Díaz O de Espanés PM Verdugo-Hernáández P. Forecasting COVID-19 Chile' second outbreak by a generalized SIR model with constant time delays and a fitted positivity rate. Math Comput Simul. (2022) 193:1–18. doi: 10.1016/j.matcom.2021.09.01634608351 PMC 8480140 · doi ↗ · pubmed ↗
- 4Cumsille P Rojas-Díaz O Conca C. A general modeling framework for quantitative tracking, accurate prediction of ICU, and assessing vaccination of COVID-19 in Chile. Front Public Health. (2023) 11:1111641. doi: 10.3389/fpubh.2023.111164137064668 PMC 10102609 · doi ↗ · pubmed ↗
- 5Cumsille P Godoy M Gerdtzen ZP Conca C. Parameter estimation and mathematical modeling for the quantitative description of therapy failure due to drug resistance in gastrointestinal stromal tumor metastasis to the liver. P Lo S ONE. (2019) 14:1–27. doi: 10.1371/journal.pone.021733231145737 PMC 6542538 · doi ↗ · pubmed ↗
- 6Müller S Lu J Kügler P Engl H. Parameter Identification in Systems Biology: Solving Ill-Posed Inverse Problems Using Regularization. Linz: Johann Radon Institute for Computational and Applied Mathematics (RICAM); Austrian Academy of Sciences (ÖAW) (2008).
- 7Zhenzhen L Yongguang Y Yang Quan C Guojian R Conghui X Shuhui W. Stability analysis of a nonlocal SIHRDP epidemic model with memory effects. Nonlinear Dyn. (2022) 109:121–41. doi: 10.1007/s 11071-022-07286-w 35221527 PMC 8864462 · doi ↗ · pubmed ↗
- 8Ghosh S Volpert V Banerjee M. An epidemic model with time delay determined by the disease duration. Mathematics. (2022) 10:2561. doi: 10.3390/math 10152561 · doi ↗