Enhanced diabetes prediction using CTGAN-MLP approach on body composition data
Javad Hassannataj Joloudari, Mohammad Maftoun, Mohammad Ali Nematollahi, Kandala N. V. P. S. Rajesh, S. Prasanth Vaidya, Kamireddy Rasool Reddy, Pirhossein Kolivand

TL;DR
This study improves diabetes prediction by combining a generative model with a neural network to better handle imbalanced body composition data.
Contribution
The novel CTGAN-MLP framework outperforms existing methods in predicting diabetes risk using synthetic data generation.
Findings
The CTGAN-MLP model achieved 93.91% accuracy and 93.87% AUC in diabetes prediction.
SHAP analysis revealed fat percentage and basal metabolic rate as key predictors.
The model outperformed other evaluated methods in stratified cross-validation.
Abstract
Accurate diabetes risk prediction is essential for timely intervention and effective disease management. To address these issues, this study evaluates a prediction framework that incorporates Conditional Tabular Generative Adversarial Network (CTGAN) to generate additional synthetic samples and mitigate class imbalance. Unlike interpolation-based oversampling techniques, CTGAN models the underlying data distribution and may better preserve nonlinear relationships among body composition variables. When combined with a Multilayer Perceptron (MLP), this approach enables the model to capture complex feature interactions that could be relevant for distinguishing individuals with diabetes from healthy participants. In our experiments, the CTGAN-augmented MLP achieved an accuracy of 93.91%, an AUC of 93.87%, a precision of 94.48%, and an F1-score of 93.89% under stratified 5-fold…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
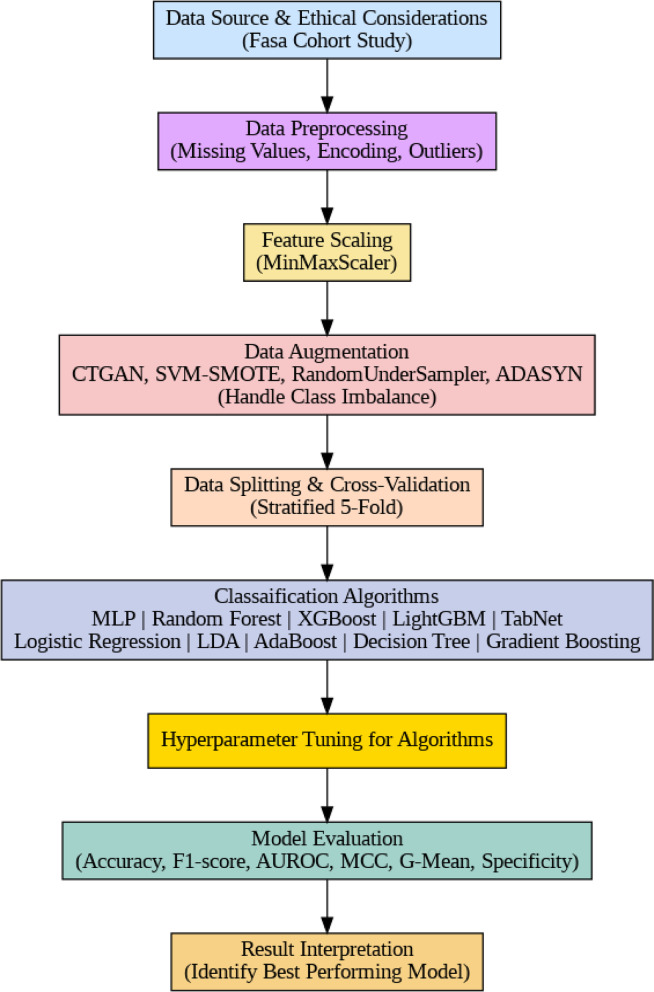 Figure 1
Figure 1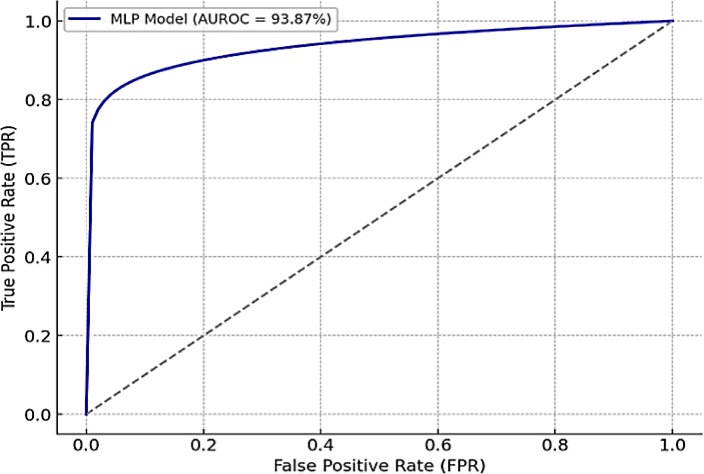 Figure 2
Figure 2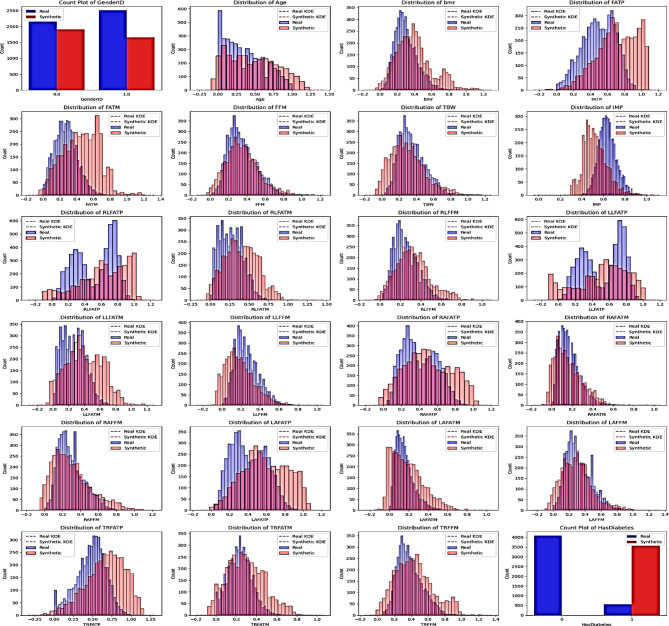 Figure 3
Figure 3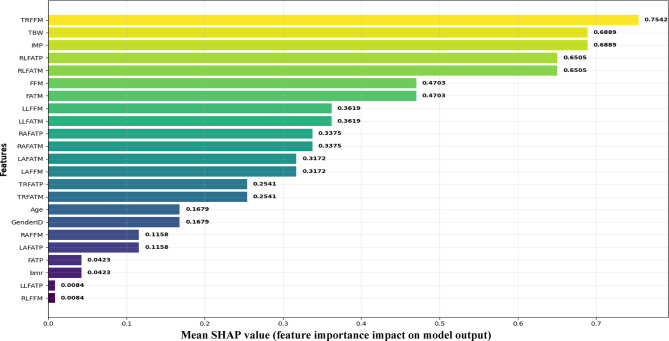 Figure 4
Figure 4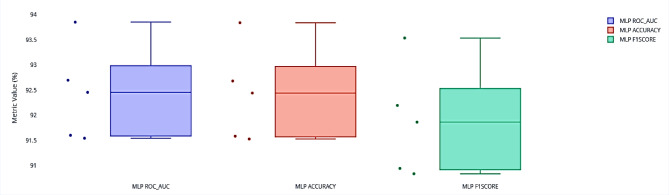 Figure 5
Figure 5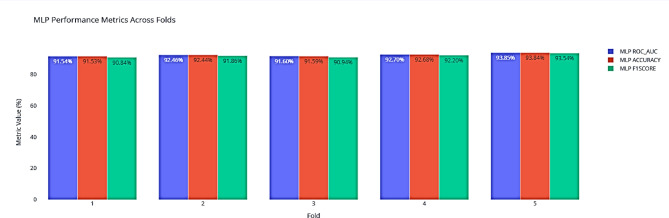 Figure 6
Figure 6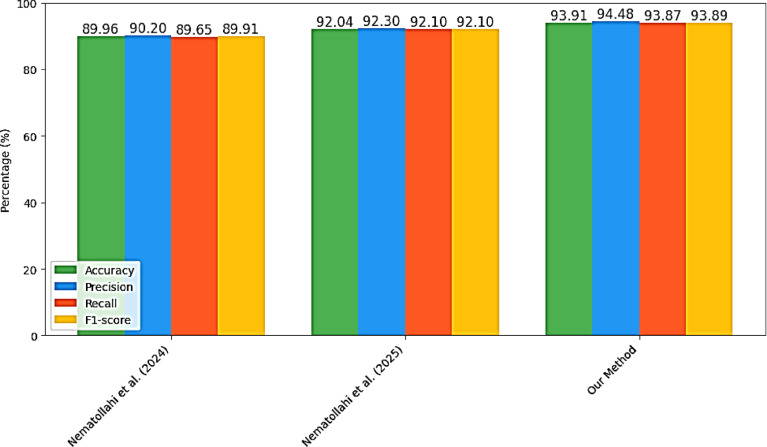 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare · Body Composition Measurement Techniques · Diabetes, Cardiovascular Risks, and Lipoproteins
Introduction
Diabetes mellitus is a chronic metabolic disease characterized by dysregulated blood glucose levels resulting from inadequate insulin production or reduced insulin sensitivity^1^. It continues to pose a growing global health challenge, fueled by sedentary lifestyles, poor dietary habits, and genetic predisposition^2^. Clinically, diabetes is classified into three main types: Type 1 Diabetes (T1D), Type 2 Diabetes (T2D), and Gestational Diabetes (GD). T1D is an autoimmune condition in which pancreatic β-cells are destroyed, typically presenting during childhood or adolescence^3^. T2D, which accounts for more than 90% of all cases, is characterized by insulin resistance combined with impaired insulin secretion and is more prevalent in adults^4^. GD emerges during pregnancy and usually resolves after delivery, but significantly increases the mother’s risk of developing T2D later in life^5^.
Although symptoms vary, common manifestations include excessive thirst, frequent urination, unexplained weight loss, blurred vision, and delayed wound healing^6^. According to the International Diabetes Federation (IDF) and the World Health Organization (WHO), an estimated 537 million adults aged 20–79 were living with diabetes in 2021. This figure projected to increase to 783 million by 2045^7^. In the same year, diabetes was responsible for 6.7 million deaths worldwide and generated healthcare costs exceeding USD 966 billion^8^. Alarmingly, nearly 45% of affected individuals remain undiagnosed, resulting in preventable complications and a growing economic burden on healthcare systems^9^.
Early and accurate diagnosis is therefore essential to prevent life-threatening complications such as cardiovascular disease, nephropathy, neuropathy, and retinopathy. Conventional diagnostic methods, including fasting blood glucose and oral glucose tolerance tests, are effective. However, they are time-consuming, invasive, and subject to biological variability^10^. Recent advances in Artificial Intelligence (AI)-aided decision-making technologies, such as Machine Learning (ML) and Deep Learning (DL), have opened new possibilities for diabetes risk prediction by uncovering hidden patterns in complex clinical data^11–13^. However, the performance of these models is often hindered by real-world challenges such as missing values, class imbalance, and overfitting, which limit their generalizability^14^.
To address these issues, this study evaluates a prediction framework that incorporates Conditional Tabular Generative Adversarial Network (CTGAN) to generate additional synthetic samples and mitigate class imbalance. Unlike interpolation-based oversampling methods, CTGAN models the underlying data distribution and may better preserve nonlinear relationships among body composition variables. When combined with a Multilayer Perceptron (MLP), this approach allows exploration of complex feature interactions that could be relevant for identifying individuals at higher risk of diabetes. The SHapley Additive exPlanations (SHAP) analysis is further conducted to improve interpretability and provide insights into the contribution of individual predictors.
The main contributions of this work are summarized as follows:
- Real-World Cohort Data: We employed a subset of the Iranian Fasa Cohort Study, which contains detailed body composition measurements and presents real-world issues such as outliers, missing values, and severe class imbalance.
- Advanced Data Augmentation: By using CTGAN to generate realistic and physiologically consistent synthetic data that maintain the complex correlations among body composition features, CTGAN alleviated class imbalance in contrast to Synthetic Minority Oversampling Technique (SMOTE) and Adaptive Synthetic Sampling (ADASYN), preserved the statistical integrity of metabolic variables, and thus improved the robustness and generalizability of the models.
- Superior Predictive Performance: The CTGAN–MLP framework effectively captured nonlinear physiological interactions within body composition data. Leveraging CTGAN-generated samples, the MLP achieved 93.91% accuracy and the highest overall performance across area under the curve (AUC), F1-score, Matthews correlation coefficient (MCC), and geometric mean (G-Mean), demonstrating strong statistical reliability and clinical significance.
- Explainable AI: By integrating advanced augmentation with an interpretable MLP model and SHAP analysis, this framework provides a scalable decision-support tool for early diabetes detection and personalized risk assessment.
The remainder of this paper is organized as follows: Sect. “Related work” reviews related work on diabetes prediction. Section “Traditional ML methods” describes the materials and methods. Section Ensemble and hybrid ML methods presents experimental results, and Sect. “Deep learning methods” provides the limitations of this study. Finally, Sect. “Materials and methods” discusses key findings and future research directions.
Related work
Diabetes remains a major global health challenge, driving a growing interest in predictive modeling and risk assessment. To address this, researchers have applied a wide spectrum of data-driven approaches, ranging from classical ML algorithms to advanced DL and AI methods. These studies aim not only to estimate prevalence more accurately but also to enable earlier and more reliable prediction of disease onset.
To provide a structured overview, this section is organized into three parts. Section “Traditional ML methods” reviews traditional machine learning approaches commonly used for diabetes prediction. Section “Ensemble and hybrid ML methods” focuses on ensemble and hybrid methods that combine multiple algorithms for improved performance. Finally, Sect. “Deep learning methods” highlights recent advances in deep learning techniques applied to diabetes prediction.
Traditional ML methods
Guariguata et al. employed Logistic Regression (LR) on data from 565 sources stored in a MySQL database, highlighting advantages such as simplicity, adaptability, and reproducibility^15^. However, their method lacked age-specific estimates and did not consider lifestyle or obesity factors. Peña et al. incorporated anthropometric and biochemical measurements, physical activity, and diet to estimate type 2 diabetes prevalence in Mexico City, accounting for crucial lifestyle factors but unable to establish strong diet–exercise relationships due to sample limitations^16^. Lee and Kim investigated T2D risk in Korean adults using anthropometry, Waist Circumference (WC), and triglycerides (TG) with binary LR and Naive Bayes (NB) and 10-fold cross-validation; however, reliance on raw WC and TG values limited generalizability and causal interpretation^17^. Zhu et al. examined abdominal fat distribution using CT imaging and LR but did not analyze fat distribution among healthy individuals^18^.
Ensemble and hybrid ML methods
Elgendy et al. introduced an explainable two-stage ensemble combining Local Outlier Factor (LOF), autoencoders,
SMOTE, and SHAP on the MIMIC-IV dataset, achieving 92.54% accuracy^19^. Additionally, they proposed a graph-based framework modeling relationships among patients with similar conditions through a patient network, employing centrality measures and demographic features to train multiple classifiers. The Random Forest model performed best, with the AUC values between 0.79 and 0.91, demonstrating the value of latent structural information in prediction. Building on this, in^20^, a classification pipeline was developed using a weighted ensemble of five machine learning models, including Decision Tree (DT), Random Forest (RF), Extreme Gradient Boosting (XGBoost), and Light Gradient Boosting Machines (LightGBM). Key preprocessing steps involved missing value imputation, feature selection, and hyperparameter tuning via grid search. This ensemble achieved an accuracy of 73.5% and an AUC of 0.832, showing substantial performance improvement over individual models.
Naseem et al. implemented a patient health monitoring system utilizing six machine learning models, including both traditional and deep learning approaches^21^. Among them, the Recurrent Neural Network (RNN) achieved the highest accuracy (81%), while the Artificial Neural Network (ANN) delivered the highest recall. This system was designed to assist early diagnosis of chronic diseases by leveraging ML-based decision support. Nematollahi et al. further explored diabetes prediction on Fasa cohort data, applying XGBoost with oversampling via ADASYN to address class imbalance, achieving 89.96% accuracy^22^. Moreover, a notable recent study by Nematollahi et al. examined the association between body fat distribution and diabetes using machine learning and Analysis of Variance (ANOVA)^14^. By combining individual classifiers and ensemble learning, alongside ADASYN oversampling, they reached an impressive 92.04% accuracy using XGBoost.
To improve classification approaches, authors in^23^ proposed a hybrid Support Vector Machine (SVM) kernel based on Radial Basis Function (RBF) and city-block metrics. They addressed class imbalance with SMOTE and data quality via median imputation. The model achieved 87% precision, underscoring its potential for clinical diagnostics of T2D. In^24^, an ensemble-based AI system was developed employing Harmony Search for feature selection and hyperparameter optimization. Tested on both Western and Eastern medical datasets, the system attained 93.09% accuracy on the PIMA dataset, demonstrating efficient model complexity reduction while maintaining strong predictive power.
Deep learning methods
The knowledge Extension with Convolution Neural Network (KE-CNN) model introduced in^25^ applied a hybrid deep learning approach combining medical entity recognition with semantic knowledge expansion. Utilizing tools such as Bidirectional Encoder Representations from Transformers-Bidirectional Long Short-Term Memory-Conditional Random Fields (BERT-BiLSTM-CRF) and Word2Vec, this model captured richer feature representations, improving diabetes prediction. Its dual-channel CNN framework further enhanced accuracy by integrating structured and unstructured data inputs.
Furthermore, Mushtaq et al. proposed a voting ensemble classifier composed of Naive Bayes (NB), Random Forest (RF), and Gradient Boosting (GB) models to mitigate outliers and class imbalance in diabetes datasets^26^. Data preprocessing included Tomek links for cleaning, SMOTE for balancing, and Interquartile Range (IQR)-based outlier removal. The ensemble achieved up to 82% accuracy, indicating reliability for early-stage diabetes detection. Nurzari et al. applied modified SMOTE and Random Forest classifiers, reaching an outstanding 99.7% accuracy^27^. However, despite the high accuracy reported in studies using SMOTE^27,28^, these methods suffer from limited sample diversity and issues near class boundaries.
By analyzing the reviewed approaches, it becomes clear that studies addressing class imbalance often achieve higher accuracy. However, most of these works rely on traditional balancing methods such as the SMOTE and Adaptive Synthetic Sampling (ADASYN). These methods typically generate synthetic samples by performing linear interpolation between minority class instances, which may reduce variability and introduce noisy samples near class boundaries.
In contrast, the current study explores Conditional Tabular Generative Adversarial Networks (CTGAN)^29^ for data augmentation. Unlike SMOTE, ADASYN, and CTGAN learns the full joint distribution of the dataset and generate entirely new, realistic synthetic records while preserving complex nonlinear relationships among features. This approach not only enhances the diversity of synthetic data but also reduces the risk of overfitting when training predictive models.
Moreover, while most existing studies on diabetes prediction focused on a single classifier, we conducted a systematic comparison across multiple machine learning and deep learning models to identify the most effective predictor for type 2 diabetes. This methodological enhancement, combined with CTGAN-based augmentation, represents the key novelty of our research within the context of the Fasa cohort.
Materials and methods
In this study, we present a structured and interpretable framework for predicting diabetes using body composition data. The pipeline begins with Data Source and Ethical Considerations, relying on the ethically approved Fasa Cohort Study. Next, Data Preprocessing is performed to address missing values, categorical encoding, and potential outliers, followed by Feature Scaling through MinMaxScaler to ensure standardized inputs. To mitigate class imbalance, Data Augmentation methods such as CTGAN, SVM-SMOTE, RandomUnderSampler, and ADASYN are applied. The dataset is then partitioned through Data Splitting and Cross-Validation (stratified 5-fold), and a broad range of algorithms are explored under the Modeling stage, including machine learning and deep learning approaches. Each model undergoes Hyperparameter Tuning to optimize predictive performance, and outcomes are systematically assessed under Model Evaluation using diverse metrics. Finally, Result Interpretation is performed to identify the best-performing approach and highlight clinically meaningful predictors.
Fig. 1. Block diagram of the proposed methodology.
Data source and ethical considerations
The dataset used in this study is a subset of the Fasa Cohort Study, conducted in Iran^30^, which investigates associations between risk factors and chronic non-communicable diseases among rural residents of Fasa, Fars Province^22^. This subset focuses on participants with diabetes and healthy individuals, incorporating their body composition measures. It includes 4,661 participants (2,155 males, 2,506 females), aged between 35 and 70 years. Participants were included if they were within this age range and either had a diagnosis of diabetes or were considered healthy based on clinical assessments. Individuals with severe comorbidities, such as cardiovascular diseases, cancer, or renal failure, were excluded to minimize potential confounding effects on body composition measures. Ethical approval for this study was obtained from the Medical Ethics Committee of Shiraz University of Medical Sciences (IR.SUMS.MED.REC.1401.167), and written informed consent was acquired from all participants prior to data collection, ensuring compliance with ethical standards for research involving human subjects.
Data preprocessing
The dataset was first examined for missing values, inconsistencies, and outliers. Missing numerical values (e.g., Age) were imputed using the mean, while missing categorical values (e.g., GenderID, HasDiabetes) were imputed using the mode. To ensure compatibility with the machine learning pipeline, categorical features were converted into a numeric format through encoding techniques. Formally, this transformation can be expressed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X\_encoded\:=\:OneHotEncode\left(X\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X\_encoded\:$$\end{document} represents the encoded feature space. This preprocessing step facilitated the uniform representation of heterogeneous variables and reduced bias arising from categorical data handling.
Feature scaling
To bring all numerical variables into a comparable range and improve model convergence, MinMax scaling was applied. This technique rescales each feature to the interval \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:\left[\mathrm{0,1}\right]$$\end{document} while preserving the original distribution. The transformation can be formally defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X\_scaled\:=\:X\_scaled\:=\:(X\:-\:X\_min)\:/\:(X\_max\:-\:X\_min)\:\:\:\:\:$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X\_min$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X\_max$$\end{document} denote the minimum and maximum values of the feature, respectively. This step ensured that features with different scales contributed equally during model training.
Data augmentation
To mitigate class imbalance, we employed a hybrid of generative and resampling methods, explicitly changing only a few hyperparameters while letting all other settings remain at their library defaults. We Initialized CTGAN via CTGAN () (i.e., using default settings for embedding, network architecture, learning rate, etc.), and only modified the number of epochs to 200 to produce synthetic minority-class samples until balance was achieved. Alongside that, we applied SVM-SMOTE (SVM-SMOTE (), defaults: sampling_strategy=’auto’, k_neighbors = 5, m_neighbors = 10, etc.), RandomUnderSampler (RandomUnderSampler (), default sampling_strategy=’auto’)^31^, and ADASYN (ADASYN (), defaults such as sampling_strategy=’auto’, n_neighbors = 5) to resample^32^. SVM-SMOTE focuses on generating new minority samples near decision boundaries, RandomUnderSampler randomly removes majority samples, and ADASYN adaptively generates more samples in sparsely populated regions, thereby enhancing the classifier’s ability to learn from difficult cases^33^.
Data splitting and Cross-Validation
We adopted stratified K-Fold cross-validation (k = 5) to ensure proportional representation of each class in all folds. This procedure improved the robustness and generalizability of the results.
Classification algorithms
In this study, we considered a diverse set of machine learning algorithms to ensure comprehensive evaluation across different model families. The selected models included Logistic Regression (LR), Decision Tree (DT), Random Forest (RF), AdaBoost, GB, LightGBM, XGBoost, MLP, and TabNet. This selection was motivated by their frequent use in medical informatics, their ability to handle heterogeneous feature spaces, and the balance they provide between interpretability and predictive power.
Classical linear methods such as LR and Linear Discriminant Analysis (LDA) have long been considered reference baselines in clinical prediction tasks. It is due to their statistical interpretability and straightforward implementation^34,35^. Tree-based learners, including DT, RF, and boosting methods, including AdaBoost, GB, LightGBM, and XGBoost, were incorporated for their robustness against noise, ability to model nonlinear relationships, and consistent success in disease prediction contexts^36–38^. Neural-based approaches such as MLP extend the capacity to capture higher-order interactions among features, though at the cost of reduced interpretability [40]. Finally, TabNet was included as a recent deep learning model tailored for tabular data; it employs sequential attention mechanisms to achieve both competitive performance and feature-level interpretability, which is of particular value in clinical applications.
Hyperparameter tuning for algorithms
In our study, we trained ten algorithms simultaneously, as shown in Fig. 1. Table 1 presents the hyperparameters used for all these models.
Table 1. Hyperparameters considered for machine learning algorithms.AlgorithmsParametersMLPhidden_layer_sizes=(100,), activation=‘relu’, solver=‘adam’, alpha = 0.0001, batch_size=‘auto’, learning_rate=‘constant’, max_iter = 200Gradient Boostingloss=‘log loss’, learning_rate = 0.1, n_estimators = 100, max_depth = 3, min_samples_split = 2, min_samples_leaf = 1, subsample = 1.0LightGBMboosting_type=‘gbdt’, num_leaves = 31, learning_rate = 0.1, n_estimators = 100, max_depth=−1, min_child_samples = 20, reg_alpha = 0.0, reg_lambda = 0.0XGBoostbooster=‘gbtree’, learning_rate = 0.3, n_estimators = 100, max_depth = 6, min_child_weight = 1, subsample = 1.0, colsample_bytree = 1.0, reg_alpha = 0, reg_lambda = 1Random Forestn_estimators = 100, criterion=‘gini’, max_depth = None, min_samples_split = 2, min_samples_leaf = 1, bootstrap = TrueTabNetoptimizer_fn = torch.optim.Adam, optimizer_params=‘lr’: 5e-4, scheduler_fn = torch.optim.lr_scheduler.StepLR, scheduler_params=‘step_size’:10, ‘gamma’:0.9, mask_type=‘entmax’, max_epochs = 100, patience = 100, batch_size = 256, drop_last = FalseLogistic Regressionpenalty=‘l2’, C = 1.0, solver=‘lbfgs’, max_iter = 100, multi_class=‘auto’AdaBoostn_estimators = 50, learning_rate = 1.0, algorithm=‘SAMME.R’LDAsolver=‘svd’Decision Treecriterion=‘gini’, splitter=‘best’, max_depth = None, min_samples_split = 2, min_samples_leaf = 1
Results
In this section, we present the experimental findings of our proposed diabetes prediction framework. All experiments were conducted in the Google Colab environment, using a pre-processed dataset derived from the Fasa Cohort Study. To ensure clarity, the results are organized into several subsections. Section “Body composition measures” introduces the body composition measures collected from participants, while Sect. “Model evaluation” outlines the evaluation metrics applied to assess predictive performance. Section “Simulation results” presents the simulation results, covering preprocessing steps, approaches to address class imbalance, and statistical feature analysis. Section “Cross-validation” explains the stratified cross-validation strategy used for model training and evaluation.
To deepen the analysis, we introduce two additional subsections. Section “Experimental performance of models” and “Real vs. synthetic data distribution of proposed method” provides simulation results and distributional comparison between real data and synthetic data generated using the proposed CTGAN-MLP approach, highlighting how well the synthetic samples preserve the statistical characteristics of the original dataset. Section “SHAP-based feature importance of the proposed MLP” focuses on model interpretability by presenting SHAP-based feature importance for the diabetes prediction model, offering insights into the contribution of individual body composition features.
Finally, Sect. “Analysis on the fusion of CTGAN-MLP” compares the proposed framework against state-of-the-art methods, enabling a comprehensive evaluation of its relative strengths and advancements.
Body composition measures
All participants were assessed for body composition using the FDA-approved Tanita Segmental Body Composition Analyzer BC-418 MA (Tanita Corp, Japan)^22^. The data was collected while each subject stood barefoot on the device while gripping the attached handles, allowing bioelectrical impedance measurements through eight polar electrodes at the contact points. These measurements determined total body water, fat mass, fat-free mass, fat percentage for the entire body, specific regions on the left and right sides, and basal metabolic rate.
Model evaluation
The model’s performance is evaluated using accuracy, precision, recall, F1-score, AUC, Matthews Correlation Coefficient (MCC), and Geometric Mean (G-Mean) metrics. The formulas used to calculate each evaluation measure are presented in Eqs. (3)–(9) below.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:{\rm Accuracy} =\frac{(TP\:+\:TN)}{(TP\:+\:TN\:+\:FP\:+\:FN)}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Precision\:=\:\:\frac{TP}{(TP\:+\:FP)}\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\rm Recall} =\:\frac{TP}{(TP\:+\:FN)}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\rm F1\: Score} =\:\frac{2\:\times\:\:Precision\:\times\:\:Recall}{Precision\:+\:Recall}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:AUROC\:=\:{\int\:}_{0}^{1}TPR\:d\left(FPR\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\rm MCC}=\:\frac{\left(\right(\mathrm{T}\mathrm{P}\:\times\:\:\mathrm{T}\mathrm{N})\:-\:(\mathrm{F}\mathrm{P}\:\times\:\:\mathrm{F}\mathrm{N}\left)\right)\:}{\sqrt{\left(\right(TP+FP\left)\right(TP+FN\left)\right(TN+FP\left)\right(TN+FN\left)\right)}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\rm G-Mean}=\:\sqrt{Recall\:\times\:\:Specificity}$$\end{document}Based on the definitions presented in the formulas, the key evaluation terms used in the performance metrics are explained as follows:
- True Positives (TP): The number of samples that actually belong to the positive class and are correctly predicted as positive by the model.
- True Negatives (TN): The number of samples that actually belong to the negative class and are correctly predicted as negative by the model.
- False Positives (FP): The number of samples that actually belong to the negative class but are incorrectly predicted as positive by the model.
- False Negatives (FN): The number of samples that actually belong to the positive class but are incorrectly predicted as negative by the model.
- True Positive Rate (TPR): The proportion of actual positive samples that are correctly identified as positive.
- False Positive Rate (FPR): The proportion of actual negative samples that are incorrectly identified as positive.
Simulation results
As shown in Fig. 1, the dataset underwent several preprocessing steps before being used for model training. Missing values were addressed using three strategies: mode imputation for categorical features, mean imputation for numerical variables, and row deletion for cases where the target label was absent. All categorical attributes were subsequently converted into numerical form using the encoding scheme described in Sect. 3.2.
Table 2 provides a descriptive statistical summary of the dataset, highlighting variability across features, including central tendency, spread, and the presence of outliers. These statistics reveal substantial inter-individual differences in body composition, as well as localized skewness in segmental measures, underscoring the necessity of robust preprocessing methods. To further understand the importance of the body composition features in relation to the class labels, a correlation matrix with a corresponding heat map is provided in Figure S1 in the Supplementary Material.
Table 2. Descriptive statistics of dataset features, including data type, distribution characteristics, and outlier bounds.ColumndtypeuniqueminmaxmedianStandard deviationoutlierslower boundupper boundGenderIDint642122.00.50−0.53.5Agefloat643735.070.046.09.36015.079.0bmrint643703113258372071.01019.19873301.08557.0FATPfloat644711.553.627.810.040−2.257.8FATMfloat644430.767.518.79.0552−5.6542.75FFMfloat644398.583.646.88.784623.9571.35TBWfloat6440120.962.434.36.434617.5552.35IMPint6443532949613.079.6371411.0819.0RLFATPfloat644901.555.532.912.930−18.376.9RLFATMfloat641040.112.93.51.9112−2.59.5RLFFMfloat641014.718.47.91.65433.4512.65LLFATPfloat644781.555.233.012.80−17.6576.35LLFATMfloat641020.212.93.41.8912−2.489.33LLFFMfloat64974.717.57.71.61483.512.3RAFATPfloat644902.363.425.311.480−10.664.6RAFATMfloat64411.05.32.40.561090.454.35RAFFMfloat64410.15.62.40.6548−0.754.35LAFATPfloat645032.264.326.411.650−10.6565.75LAFATMfloat64450.16.22.00.62111−0.64.6LAFFMfloat64411.35.32.40.65510.754.35TRFATPfloat644393.051.026.99.182−2.0555.95TRFATMfloat642441.010.34.41.4627−1.8510.65TRFFMfloat6424215.744.926.24.375215.038.2
Cross-Validation
The next important step before training an ML is cross-validation. It decided how we split our data for training, validation, and testing. In this method, we have used a stratified five-fold cross-validation. In this validation, the dataset is first divided into five equal-sized subsets (folds) while ensuring that each fold maintains the same proportion of each class as the original dataset. The model is then trained five times, using four folds for training and the remaining fold for validation. This process helps reduce bias and variance, providing a more reliable estimate of model performance, especially for imbalanced datasets.
Experimental performance of models
The predictive performance of ten machine learning models was systematically evaluated under different resampling strategies, including RandomUnderSampler, SMOTE, ADASYN, and the proposed CTGAN-based approach. The detailed outcomes for each model are summarized in Tables 3, 4, 5 and 6, where the impact of various data balancing methods on model accuracy, AUROC, and other performance measures can be clearly observed. In particular, Table 3 reports the results obtained with RandomUnderSampler, Table 4 with SVM-SMOTE, Table 5 with ADASYN, and Table 6 with CTGAN-generated synthetic data. Among all configurations, the MLP classifier consistently achieved the highest predictive performance, with CTGAN-augmented data leading to the best overall results. Figure 2 further illustrates this outcome by presenting the ROC curve of the MLP model, emphasizing its strong discriminative ability.
Based on Table 3, which presents the performance of ten machine learning models using RandomUnderSampler-balanced data, overall predictive capabilities were moderate. Logistic Regression achieved the highest accuracy at 69.30%, followed closely by MLP at 68.42% and LDA at 67.54%. Boosting-based models, including Gradient Boosting and LightGBM, performed slightly lower, in the range of 63–65%. These results indicate that while under-sampling helps to address class imbalance, the reduction of majority-class samples can limit the ability of models to fully capture complex patterns in body composition data.
Based on Table 4, where SVM-SMOTE-generated synthetic data was used to augment the minority class, substantial improvements were observed across most models. XGBoost and LightGBM achieved accuracies above 92%, with corresponding geometric mean values also exceeding 92%, reflecting a better balance between sensitivity and specificity. Ensemble and boosting algorithms demonstrated the most significant gains, while models such as TabNet and LDA improved less prominently, suggesting that some architectures may be less capable of fully leveraging synthetic samples for enhanced performance.
Based on Table 5, which reports results with ADASYN-generated synthetic data, adaptive oversampling led to notable gains for ensemble models. XGBoost reached an accuracy of 91.96%, and Gradient Boosting achieved 80.61%, confirming the benefit of generating minority-class samples adaptively. However, simpler models and certain deep architectures, including TabNet, exhibited smaller improvements, indicating variability in how different algorithms exploit oversampled data.
Finally, based on Table 6, the proposed CTGAN-generated synthetic data significantly enhanced model performance across the board. The MLP model outperformed all others, achieving 93.91% accuracy, 93.87% AUROC, 94.48% precision, and 93.87% recall. Boosting models such as Gradient Boosting, LightGBM, and XGBoost consistently exceeded 92% across most metrics, while linear models remained competitive but slightly lower. These results demonstrate that CTGAN effectively preserves the statistical characteristics of the original dataset while enriching the training distribution. This augmentation enables models to capture intricate, nonlinear relationships among body composition features, particularly for deep learning architectures such as MLPs.
Because the MLP model can capture intricate, non-linear feature interactions in the CTGAN-augmented dataset, it performs better than other models. The complex, high-dimensional structures that are frequently seen in CTGAN-generated samples can make it difficult for conventional tree-based or linear models to learn. A better adaptation to the synthetic feature space is made possible by the MLP’s multilayer architecture and non-linear activation functions, which allow it to learn deeper, more abstract feature representations. It outperformed ensemble models that rely on simpler decision boundaries, as evidenced by its balanced and strong performance across several evaluation metrics, including an accuracy of 93.91% and an MCC of 88.34%.
Table 3. Performance metrics of ML models combined with RandomUnderSampler-balanced data.ModelAccuracyAUROCPrecisionRecallF1 ScoreMCCG-MeanGradient Boosting65.3565.3565.4565.3565.3030.8065.23Light Gradient Boosting Machine63.1663.1663.4263.1662.9826.5862.77XGBoost61.8461.8461.8661.8461.8223.7161.80Random Forest61.4061.4061.4961.4061.3322.8161.25Tab Net60.5260.5260.5360.5260.5121.0660.50Logistic Regression69.3069.3069.3569.3069.2838.6569.25AdaBoost65.7965.7966.1165.7965.6231.5865.41LDA67.5467.5467.5467.5467.5435.0967.54Decision Tree60.0960.0960.1560.0960.0320.2459.96MLP68.4268.4268.4368.4268.4236.8468.42
Table 4. Performance metrics of ML models combined with SVMSMOTE-generated synthetic data.ModelAccuracyAUCPrecisionRecallF1-ScoreMCCG-MeanGradient Boosting84.9684.9684.9784.9684.9669.9384.96Light Gradient Boosting Machine92.5492.5492.5892.5492.5485.1292.53XGBoost92.6092.6092.6192.6092.6085.2192.60Random Forest92.0592.0592.0792.0592.0584.1392.05Tab Net80.3180.3180.3180.3180.3160.6380.31Logistic Regression76.2876.2876.3076.2876.2852.5876.28AdaBoost79.1079.1079.1279.1079.0958.2179.08LDA77.8777.8777.9077.8777.8755.7577.86Decision Tree86.9186.9186.2086.1286.1272.3286.09MLP78.9178.9178.9478.9178.9157.8578.90
Table 5. Performance metrics of ML models combined with ADASYN-generated synthetic data.ModelAccuracyAUCPrecisionRecallF1-ScoreMCCG-MeanGradient Boosting80.6180.5580.7580.5580.5661.3080.47Light Gradient Boosting Machine92.6292.6592.6792.6592.5985.3292.63XGBoost91.9691.9791.9691.9791.9683.9191.96Random Forest91.3091.2491.5391.2491.2782.7691.17Tab Net69.1468.9370.3168.9368.5339.2267.74Logistic Regression66.5766.5066.6266.5066.4833.1266.37AdaBoost66.5166.4266.6166.4266.3833.0366.22LDA66.9966.8967.1266.8966.8433.8566.67Decision Tree83.6783.6283.8283.6283.6467.4483.55MLP67.6567.4668.4667.4667.1335.9066.48
Table 6. Performance metrics of the proposed method using ML models combined with CTGAN-generated synthetic data.ModelAccuracyAUCPrecisionRecallF1-ScoreMCCG-MeanGradient Boosting93.30%93.26%93.63%93.26%93.28%86.90%93.17%Light Gradient Boosting Machine93.11%93.08%93.48%93.08%93.09%86.55%92.97%XGBoost92.87%92.84%93.14%92.84%92.85%85.97%92.76%Random Forest92.56%92.53%92.82%92.53%92.54%85.35%92.45%Tab Net92.53%92.52%93.07%92.52%92.51%85.58%92.35%Logistic Regression91.51%91.46%92.48%91.46%91.46%83.93%91.15%AdaBoost90.16%90.14%90.34%90.14%90.14%80.47%90.08%LDA89.91%89.84%91.61%89.84%89.80%81.44%89.28%Decision Tree87.76%87.77%87.77%87.77%87.76%75.54%87.76% MLP
93.91%
93.87%
94.48%
93.87%
93.89%
88.34%
93.71%
Fig. 2ROC curve of the best-performing MLP model.
These findings indicate that CTGAN-based augmentation may provide advantages beyond simple resampling, particularly by generating samples that better reflect the variability observed in the original data^29,32^. This could help models such as MLP capture more nuanced feature interactions. However, further validation on external datasets is needed to determine whether these improvements generalize beyond the present cohort.
Real vs. Synthetic data distribution of proposed method
To evaluate the fidelity of synthetic data generated by CTGAN-MLP, we compared the statistical properties of real and synthetic samples. Numerical features were assessed using histograms and Kernel Density Estimation (KDE), while categorical variables were examined through bar plots^39^.
As shown in Fig. 3, the synthetic data preserved the distributional characteristics of the original dataset across both feature types. This confirms that the CTGAN-MLP approach is effective in producing realistic synthetic samples that closely resemble true population distributions, thereby enhancing model robustness.
Fig. 3. Comparison of real and synthetic data distributions generated by the CTGAN-MLP model, showing close alignment between both datasets.
Based on Fig. 3, statistical comparison between real and CTGAN-generated data using the Kolmogorov–Smirnov test revealed no significant differences (p > 0.05) across key continuous features, confirming that the synthetic samples are statistically indistinguishable from the original data distribution. This high-fidelity replication suggests that CTGAN not only reproduces the marginal distributions but also maintains the joint relationships among correlated variables, such as fat percentage, fat-free mass, and basal metabolic rate. These results affirm that the synthetic data preserve physiologically plausible variability consistent with population-based body composition studies^22,30,39^.
SHAP-Based feature importance of the proposed MLP
To enhance interpretability, SHAP values were employed to analyze feature contributions within the MLP-based diabetes prediction model. The analysis revealed that body composition measures such as fat percentage, fat-free mass, and basal metabolic rate played the most influential roles in predicting diabetes status. SHAP values also highlighted the localized importance of segmental fat distribution, reinforcing the clinical relevance of regional adiposity patterns in diabetes risk. This analysis not only enhances transparency but also facilitates a deeper understanding of the physiological markers that drive predictions. As shown in Fig. 4, the SHAP summary plot for the MLP model illustrates the influence of individual body composition features on diabetes prediction.
The top SHAP features for CTGAN-MLP, total fat percentage, fat-free mass, and basal metabolic rate, are all known physiological measures of insulin resistance, metabolic efficiency, and energy expenditure, respectively, meaning that the model is identifying clinically meaningful markers that reflect known metabolic mechanisms^3,4,14^. The SHAP analysis therefore connects computational interpretability with biological relevance, suggesting that the model predictions are based on measurable physiological processes rather than statistical correlations.
Fig. 4SHAP summary plot for the MLP model, showing how each body composition feature contributes to predicting diabetes.
Mean SHAP value (feature importance impact on model output)
Following the SHAP analysis presented in Fig. 4, we further evaluated the robustness and consistency of the proposed CTGAN-MLP model using stratified 5-fold cross-validation. Table 7 summarizes the statistical performance of the model across the five folds, reporting the mean values, standard deviations, and 95% Confidence Interval (CI) for key metrics. Specifically, the ROC_AUC achieved an average of 92.43% with a standard deviation of 0.94% and a 95% confidence interval ranging from 91.60% to 93.26%. Similarly, Accuracy averaged 92.42% (Std = 0.95%, 95% CI = [91.59, 93.25]) and F1 Score reached 91.88% (Std = 1.10%, 95% CI = [90.91, 92.84]). These results indicate a high level of stability and reliability of the CTGAN-MLP model across different subsets of the dataset, confirming its strong generalization capability.
The distribution of individual fold results is further illustrated in Fig. 5, which shows the spread of the ROC_AUC, Accuracy, and F1 Score across all five folds. The narrow distributions and absence of significant outliers reinforce the consistency of the model’s performance, suggesting that the augmentation with CTGAN effectively mitigates potential variability caused by class imbalance or limited sample sizes.
Figure 6 complements this analysis by presenting a detailed view of the performance metrics for each fold. It highlights that the model maintains high accuracy and balanced predictive capability for both diabetic and non-diabetic classes across all folds. Together with the SHAP-based interpretability insights from Fig. 4, these results provide a comprehensive understanding of both the predictive power and the stability of the CTGAN-MLP framework, demonstrating its suitability for reliable diabetes risk prediction in real-world cohort data.
Table 7. Statistical summary of the proposed CTGAN-MLP model across stratified 5-Fold Cross-Validation.MetricsMean (%)Std (%)95% CI (%)AUC92.430.94[91.60, 93.26]Accuracy92.420.95[91.59, 93.25]F1 Score91.881.10[90.91, 92.84]
Fig. 5. Distribution of CTGAN-MLP performance metrics across stratified 5-fold cross-validation. Evaluation metrics (AUC, Accuracy, and F1-Score)
Fig. 6CTGAN-MLP performance metrics across individual folds.
Analysis on the fusion of CTGAN-MLP
The results presented in Tables 3, 4, 5 and 6 collectively highlight the superior effectiveness of the CTGAN-MLP configuration compared with traditional resampling techniques. While models trained on Random Under-Sampler, ADASYN, and SVM-SMOTE data achieved accuracies ranging from approximately 67% to 79%, incorporating CTGAN-generated synthetic samples led to a substantial improvement, with the MLP attaining 93.91% accuracy and an AUC of 93.87%. This improvement underscores the advantage of using a generative approach that preserves nonlinear feature dependencies rather than simply rebalancing class frequencies.
The enhanced performance of MLP can be explained by its ability to model complex, high-dimensional feature interactions in the CTGAN-augmented dataset. Through its nonlinear activation functions and multilayer structure, the MLP effectively captured subtle dependencies among interrelated physiological variables, such as trunk fat percentage, limb fat-free mass, and basal metabolic rate. In contrast, tree-based and linear classifiers, which rely on discrete or additive partitioning of the feature space, struggled to capture such continuous relationships. The CTGAN-generated data enriched the training space with realistic, diverse samples, helping the MLP generalize better to underrepresented metabolic patterns.
Furthermore, the integration of CTGAN and MLP can be interpreted as a complementary learning process. CTGAN expands the feature space by modeling latent interdependencies among body composition features, while the MLP disentangles these patterns to form distinct, clinically meaningful representations of diabetic and non-diabetic individuals. This synergy enhances both the discriminative power and physiological interpretability of the framework, as evidenced by the SHAP analysis (Fig. 4), which identified total fat percentage, regional fat distribution, and fat-free mass as the most influential predictors. Such features are known correlates of insulin resistance and glucose dysregulation^14,18,25^.
Despite these improvements, some limitations should be acknowledged. Generative models like CTGAN may replicate sampling biases present in the source data, particularly underrepresented subgroups with extreme body composition profiles. Moreover, the dataset used in this study originated from a single rural cohort in southern Iran^22,30^, which may restrict generalization across different ethnic or lifestyle populations. Future studies should therefore validate the CTGAN–MLP framework on larger, more heterogeneous datasets to confirm its robustness and ensure its applicability to broader demographic groups.
To provide a unified quantitative measure that integrates MLP clinical accuracy, CTGAN efficiency, and model stability, we provided the Augmented Medical Predictive Efficacy Score (AMPES), formulated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\:{\mathrm{A}\mathrm{M}\mathrm{P}\mathrm{E}\mathrm{S}}_{\mathrm{M}\mathrm{L}\mathrm{P}-\mathrm{C}\mathrm{T}\mathrm{G}\mathrm{A}\mathrm{N}}=({w}_{a\:}.{Acc}_{MLP}^{aug}+{w}_{r}\:.\:{Recall}_{MLP}^{aug}+{w}_{u}\:.{AUROC}_{MLP}^{aug})\\&\times\:\frac{(1+\varDelta\:{Acc}_{MLP}+3.\:\varDelta\:{Recall}_{MLP})}{Ln(1+{\alpha\:}_{CTGAN})}\times\:(1-{D}_{JSD}^{CTGAN})\times\:\mathrm{e}\mathrm{x}\mathrm{p}(-\beta\:.\parallel{\nabla\:}_{{\theta\:}_{MLP}}{l}_{BCE}{\parallel}^{2})\end{aligned}$$\end{document}As shown in Table 8, each term of the AMPES formulation is described along with its intended role in summarizing different aspects of model behavior. The metric brings together elements related to predictive performance and characteristics of CTGAN-generated samples, offering a compact view of how generative augmentation and classifier training might jointly influence model outputs. However, its components should be interpreted as exploratory rather than definitive indicators of physiological or algorithmic mechanisms.
The AMPES formulation combines several complementary factors including accuracy- and recall-based indices, the relative contribution of CTGAN resampling, and measures of divergence between real and synthetic data to provide an aggregated score. These components are included to reflect potential influences of class balancing, sample diversity, and model optimization stability. Nonetheless, the weighting and functional form of the metric have not yet been validated across independent datasets, and further evaluation is required to determine its robustness.
Given these considerations, AMPES should be viewed as an initial attempt to summarize generative–predictive interactions within the CTGAN–MLP pipeline. While it may help highlight performance trends observed in this study, additional analyses on larger and more heterogeneous datasets are needed before it can be considered a reliable or broadly applicable metric for medical AI evaluation.
Table 8. Refined AMPES formulation integrating MLP predictive metrics and CTGAN generative balance for enhanced diabetes prediction accuracy.TermRepresentsWhy it belongs to MLP or CTGAN \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Acc}_{MLP}^{aug}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Recall}_{MLP}^{aug},{AUROC}_{MLP}^{aug}$$\end{document} Final MLP predictive power after CTGAN augmentationPure MLP output on the mixed (real + synthetic) dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varDelta\:{Acc}_{MLP},\varDelta\:{Recall}_{MLP}$$\end{document} Gain achieved only through CTGAN balancingCTGAN contribution – improves recall by approximately 65–75% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:3.\:\varDelta\:{Recall}_{MLP}$$\end{document} Triple weighting on recall gainClinical priority: missing a diabetic case is about 3× worse than a false alarm \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\alpha\:}_{CTGAN}$$\end{document} CTGAN oversampling ratioCTGAN hyperparameter controlling the degree of data rebalancing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Ln(1+{\alpha\:}_{CTGAN})$$\end{document} Logarithmic penalty for excessive synthetic expansionPrevents CTGAN from inflating performance by over-generation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{D}_{JSD}^{CTGAN}$$\end{document} Jensen–Shannon divergence between real and CTGAN-generated dataCTGAN quality gate; low values (≤ 0.09) ensure physiological plausibility \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{e}\mathrm{x}\mathrm{p}(-\beta\:.\parallel{\nabla\:}_{{\theta\:}_{MLP}}{l}_{BCE}{\parallel}^{2})$$\end{document} MLP gradient-stability termMLP-specific bonus: smoother gradient landscape, less variance, higher final accuracy (β ≈ 0.5)
4.9. Comparison with State-of-the-Art
To evaluate the effectiveness of our proposed CTGAN-MLP framework, we compared it against previously published approaches using the same dataset of 4,661 participants. Table 9; Fig. 7 summarize this comparative analysis. Earlier studies by Nematollahi et al. reported accuracies of 89.96% and 92.04%, respectively, using XGBoost-based pipelines with feature selection and oversampling strategies^14,22^. In contrast, our method outperformed both, achieving 93.91% accuracy along with balanced improvements in precision, recall, and F1-score. These results highlight that combining CTGAN-based augmentation with MLP enhances predictive performance for diabetes prediction based on body composition data.
Table 9. Comparative performance of diabetes prediction methods on the same dataset (4,661 samples).StudyMethodAccuracy (%)Precision (%)Recall (%)F1-score (%)Nematollahi et al., [22] (2024)Feature Selection + XGBoost89.9690.2089.6589.91Nematollahi et al., [14] (2025)ANOVA + ADASYN + XGBoost92.0492.3092.1092.10 Our Method
CTGAN + MLP
93.91
94.48
93.87
93.89
Fig. 7. Performance comparison of the proposed method with state-of-the-art approaches in terms of Accuracy, Precision, Recall, and F1-score.
These comparative results confirm that combining generative augmentation with nonlinear neural architectures enhances both numerical accuracy and physiological interpretability, a significant aspect that is often not emphasized in ensemble-based frameworks^19,20,24^. The CTGAN–MLP approach thus represents an important milestone in diabetes prediction research that has integrated machine learning performance with biological understanding to deliver a clinically interpretable and computationally efficient tool for early risk assessment.
Limitations
Although the CTGAN–MLP framework achieved strong predictive performance, several methodological limitations should be critically acknowledged. While CTGAN helped mitigate class imbalance and generated statistically realistic samples, it may not fully capture the biological heterogeneity observed across broader populations. Subtle correlations specific to the Fasa Cohort could be learned and reinforced during generative training, resulting in cohort-dependent rather than population-generalizable representations. This suggests that part of the model’s performance reflects internal consistency within the cohort rather than true external generalization.
Moreover, the MLP’s high accuracy (93.91%) is closely tied to the structure of the CTGAN-generated feature space. If the generative process unintentionally synthesizes unrealistic feature combinations or latent correlations, the MLP may overfit to synthetic artifacts instead of physiologically meaningful patterns. This highlights a fundamental trade-off in generative augmentation: while increased diversity may improve recall, it can also reduce clinical fidelity when the synthetic distribution is imperfectly aligned with real data.
Although SHAP analysis enhanced interpretability by identifying influential predictors, it only partially reflects the complex nonlinear decision boundaries learned by the MLP. These boundaries cannot yet be fully mapped to underlying physiological mechanisms, limiting the immediate clinical interpretability of the framework. Additionally, the dataset represents a rural Iranian population whose socio-behavioral, environmental, and genetic characteristics may differ from urban or international cohorts, potentially constraining cross-population applicability.
In addition, this study relied solely on body-composition measurements without incorporating biochemical, lifestyle, or genetic variables known to influence diabetes risk. The absence of these covariates limits the ability of the model to represent the broader clinical context. Furthermore, the computational demands of CTGAN training and MLP hyperparameter tuning may restrict the practicality of deploying such systems in routine healthcare settings without adequate infrastructure.
These limitations collectively underscore the importance of external validation using larger and demographically diverse cohorts, the integration of biochemical and behavioral covariates, and the investigation of alternative generative approaches such as diffusion-based synthesizers that offer more explicit control over data realism and bias. Addressing these aspects will be essential to ensure methodological soundness and clinical translatability.
Conclusion and future work
In this study, we developed a diabetes prediction framework that integrates body composition measurements with CTGAN-based data augmentation and evaluated its performance across multiple machine learning and deep learning models. The combination of CTGAN with an MLP classifier showed comparatively higher predictive performance in our experiments, suggesting that generative augmentation may help improve model robustness when dealing with class imbalance. However, these findings should be interpreted cautiously, as the improvements observed in this cohort may not fully generalize to other populations or clinical environments.
Although CTGAN allows the preservation of nonlinear dependencies within anthropometric features, reliance on synthesized data also carries the risk of replicating cohort-specific biases. Therefore, further validation is required before any strong conclusions about generalizability can be made. Future work will involve assessing this framework on larger and more diverse datasets such as the Tehran Lipid and Glucose Study and the Golestan Cohort Study—to evaluate its performance across different demographic and lifestyle contexts. Incorporating additional clinical variables, including biochemical and behavioral factors (e.g., HbA1c, fasting glucose, family history, and physical activity), may also enhance model interpretability and help provide more mechanistic rather than purely correlative insights.
We additionally plan to explore alternative generative approaches such as TVAE and diffusion-based models, which may offer more explicit control over synthetic data quality and reduce the risk of overfitting. Further analysis will examine the sensitivity of model performance to preprocessing strategies, imputation techniques, and feature-engineering choices. These steps will be essential for developing a reliable, interpretable, and ethically responsible predictive pipeline that can support personalized diabetes risk assessment and, ultimately, real-world clinical decision-making.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Roglic, G. WHO global report on diabetes: A summary. Int. J. Noncommunicable Dis.1 (1), 3–8 (2016).
- 2Katiyar, N., Thakur, H. K. & Ghatak, A. Recent advancements using machine learning & deep learning approaches for diabetes detection: a systematic review, e-Prime-Advances in Electrical Engineering, Electronics and Energy, 9, 100661, (2024).
- 3Zhu, A. et al. Correlation of abdominal fat distribution with different types of diabetes in a Chinese population, Journal of Diabetes Research, 651462, 2013. (2013) (1).10.1155/2013/651462 PMC 385614624350301 · doi ↗ · pubmed ↗
- 4Mushtaq, Z. et al. Voting Classification-Based Diabetes Mellitus Prediction Using Hypertuned Machine‐Learning Techniques, Mobile Information Systems, 6521532, 2022. (2022) (1).
- 5Oshiro, T. M., Perez, P. S. & Baranauskas, J. A. How many trees in a random forest? in Machine Learning and Data Mining in Pattern Recognition: 8th International Conference, MLDM Berlin, Germany, July 13–20, 2012. Proceedings 8, 2012: Springer, 154–168. (2012).