From CNNs to SAM: A Survey of Deep Learning Techniques for Liver Tumor Segmentation in CT Images
NEMAN ABDOLI, YOUKABED SADRI, PATRIK GILLEY, KE ZHANG, YONG CHEN, YUCHEN QIU

TL;DR
This paper reviews deep learning techniques for segmenting liver tumors in CT images, comparing methods and highlighting challenges and trends in the field.
Contribution
A comprehensive survey of over 100 papers on deep learning for liver tumor segmentation, analyzing methodological choices and trends.
Findings
Deep learning models outperform traditional methods in liver tumor segmentation but face challenges due to tumor variability and image inconsistencies.
Current approaches show promise but are limited by issues such as indistinct tumor boundaries and computational demands.
The survey identifies key trends and methodological choices that influence segmentation accuracy and efficiency.
Abstract
Accurate liver tumor segmentation is a critical component of clinical assessment, forming the basis for treatment planning, therapy response monitoring, prognostic assessment, and the delivery of precision medicine. However, in real-world clinical practice, this task remains particularly challenging. The intrinsic diversity of liver tumors —manifested in variations of shape, texture, size, and location—combined with the similarity of neighboring organs, indistinct tumor boundaries, and inconsistencies in image acquisition conditions, makes accurate liver lesion segmentation particularly difficult. In clinical practice, traditional segmentation methods are often used due to their interpretability and lower computational requirements. These approaches are labor-intensive and time-consuming, especially when dealing with 3D medical images, making them impractical for large-scale or…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
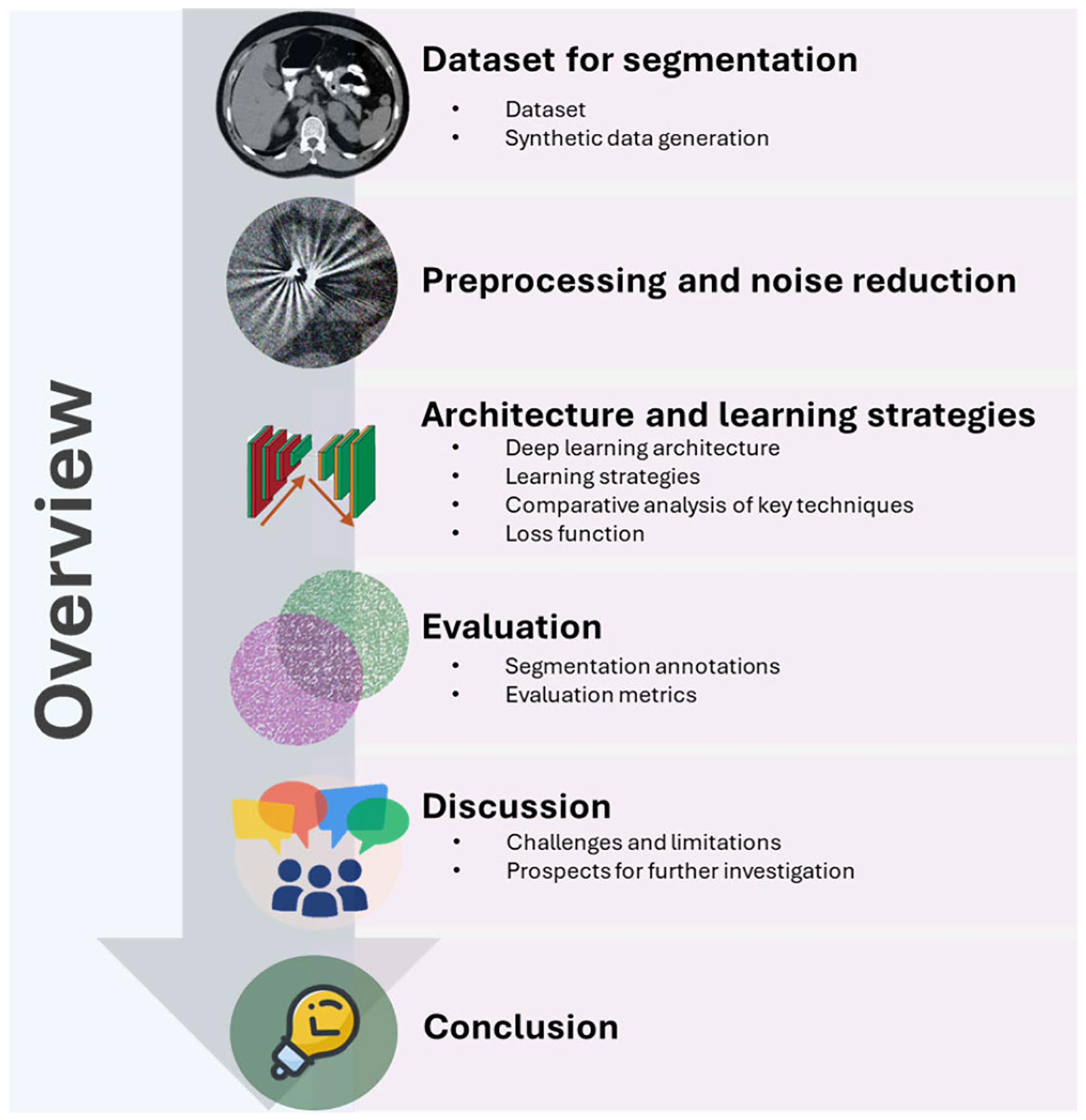 Figure 1
Figure 1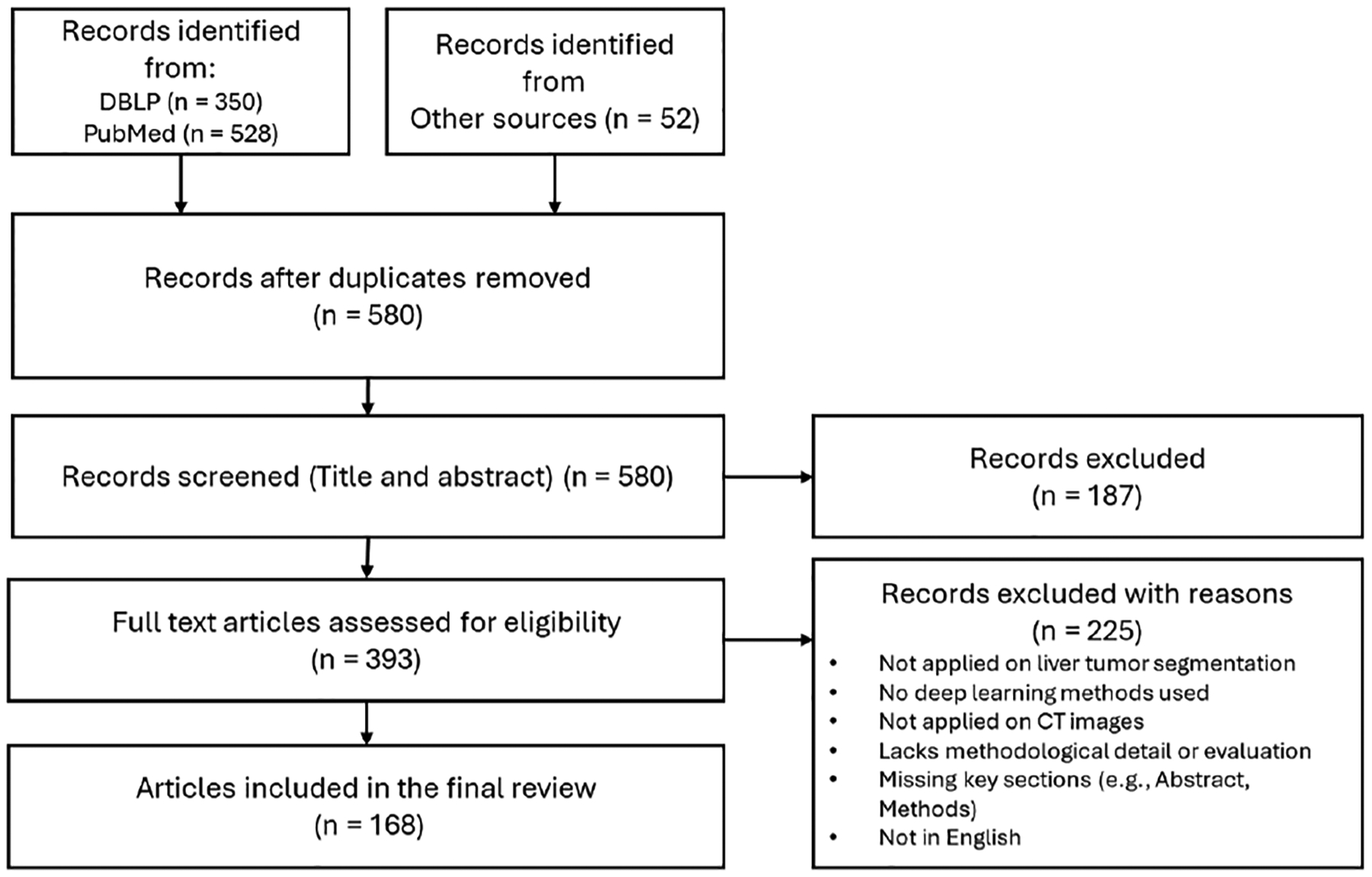 Figure 2
Figure 2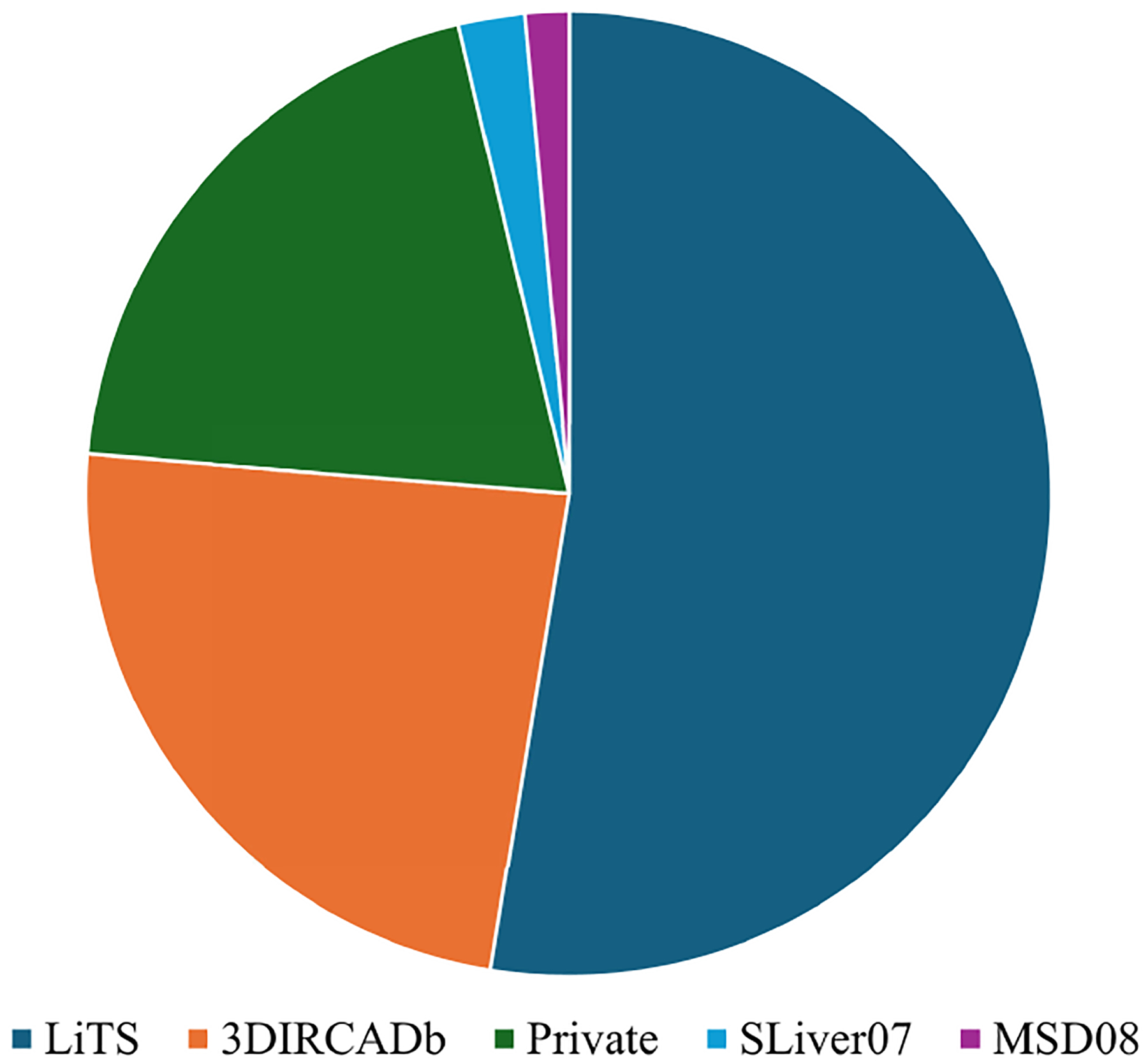 Figure 3
Figure 3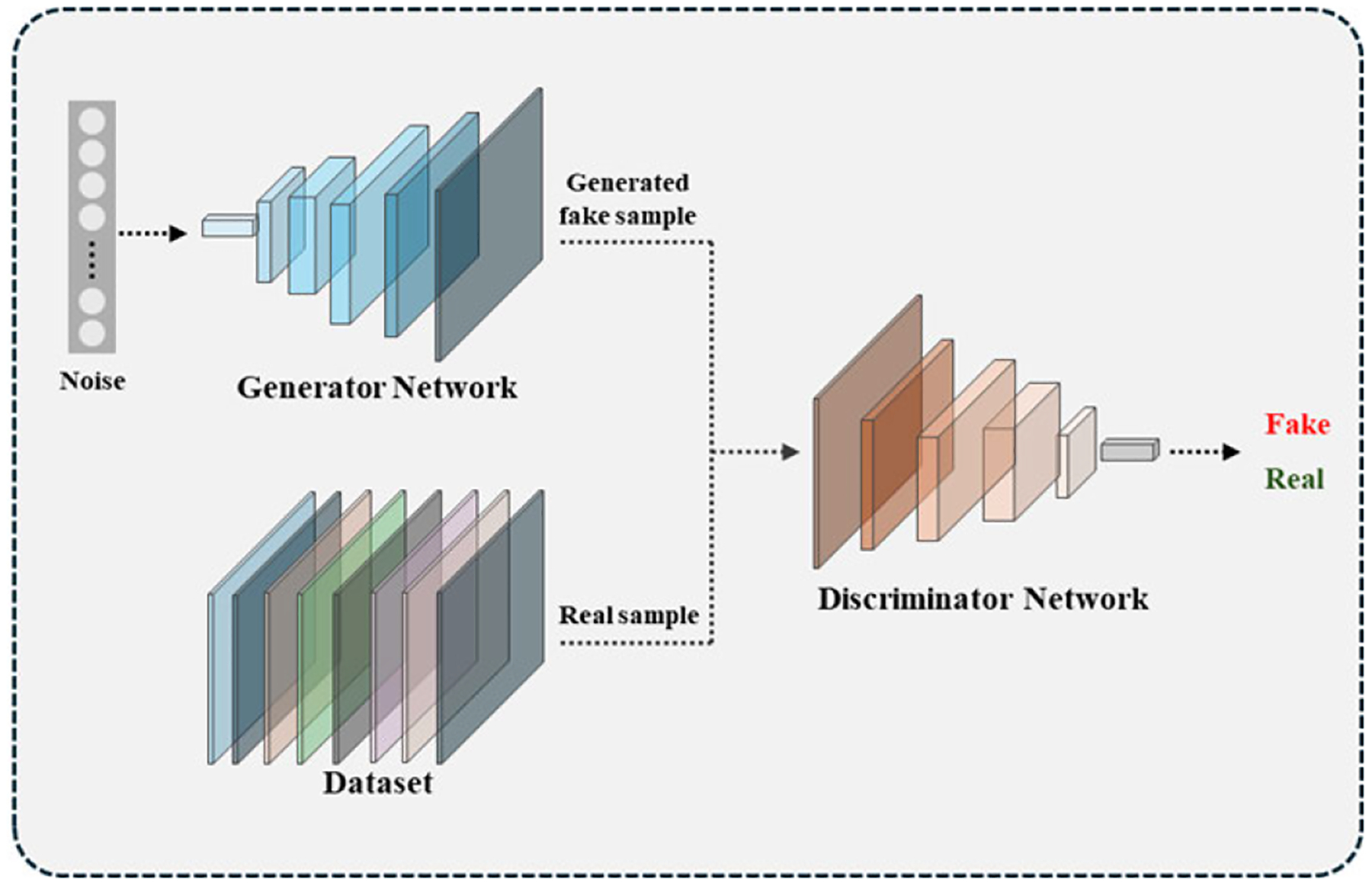 Figure 4
Figure 4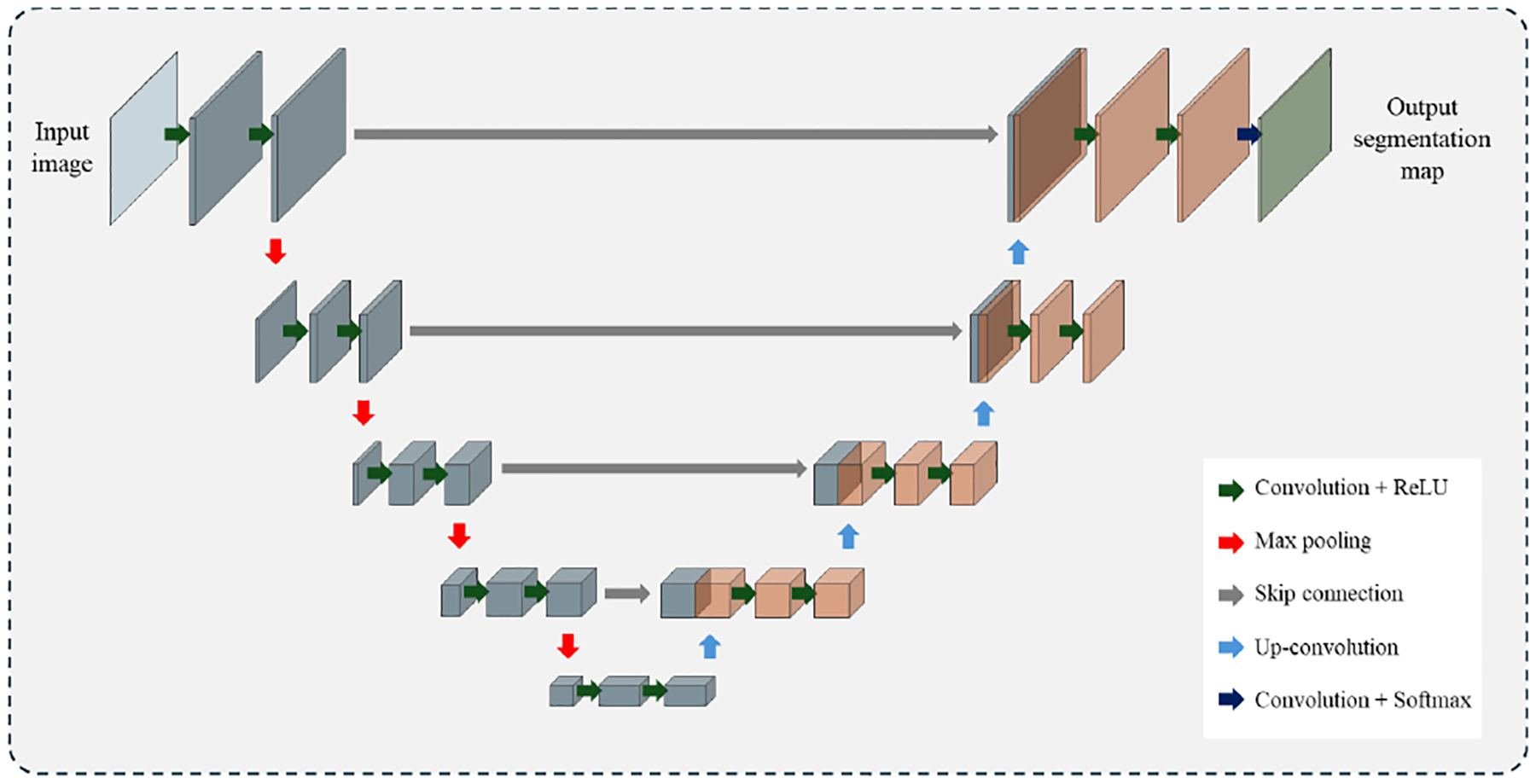 Figure 5
Figure 5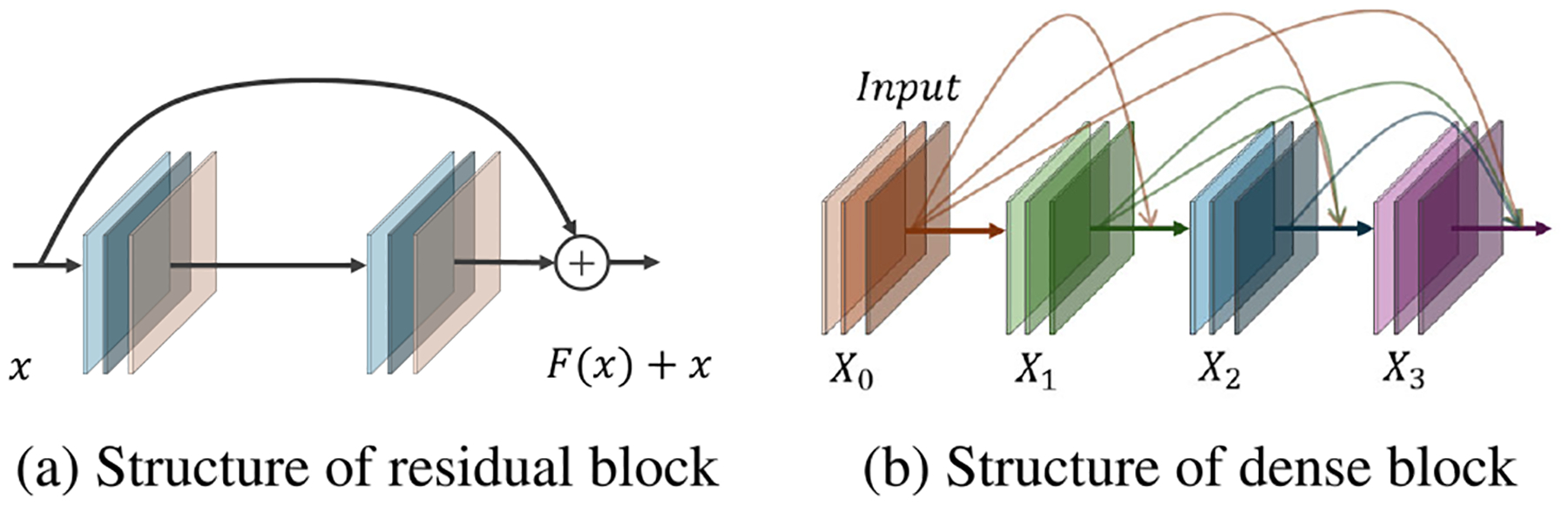 Figure 6
Figure 6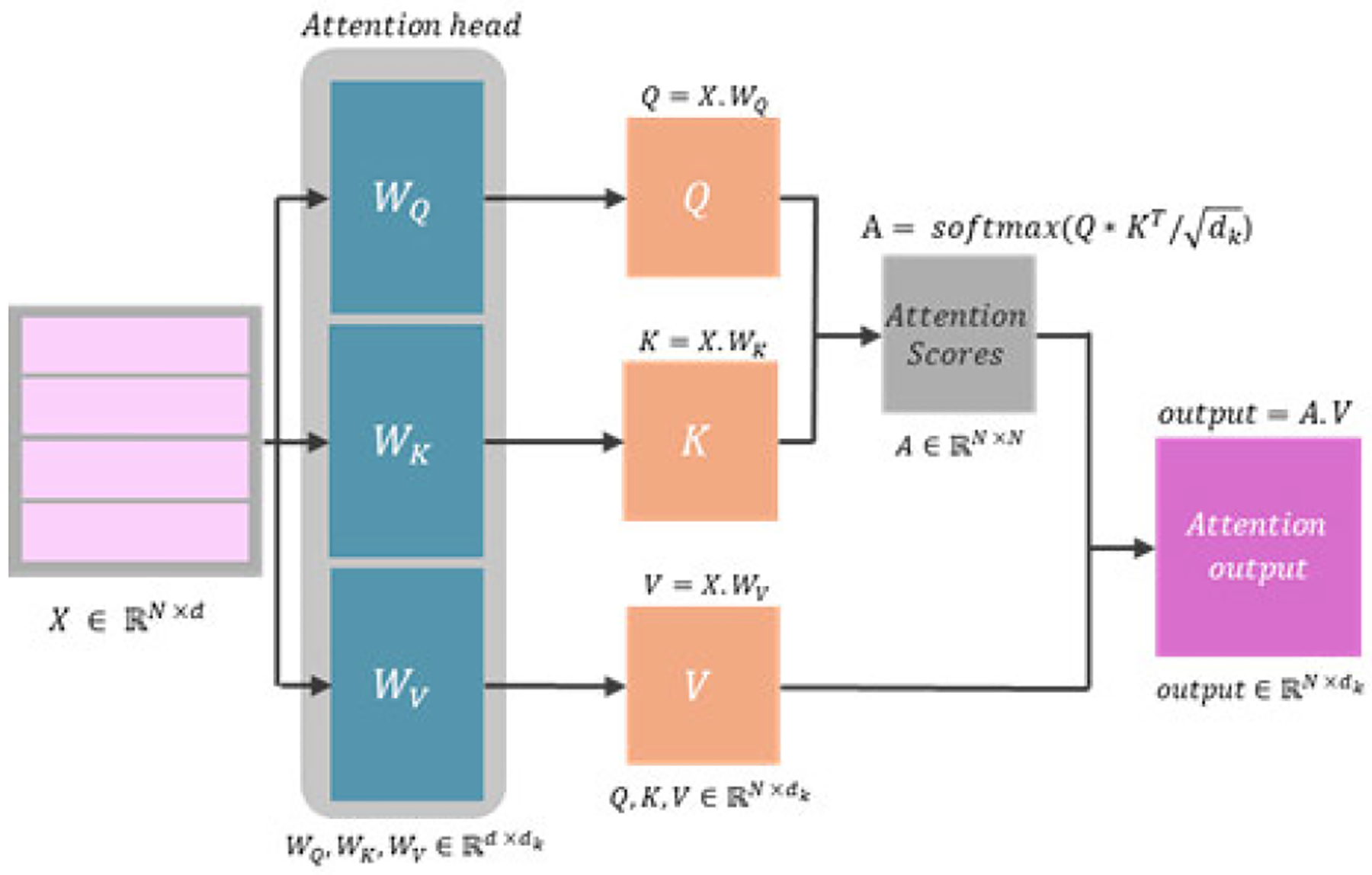 Figure 7
Figure 7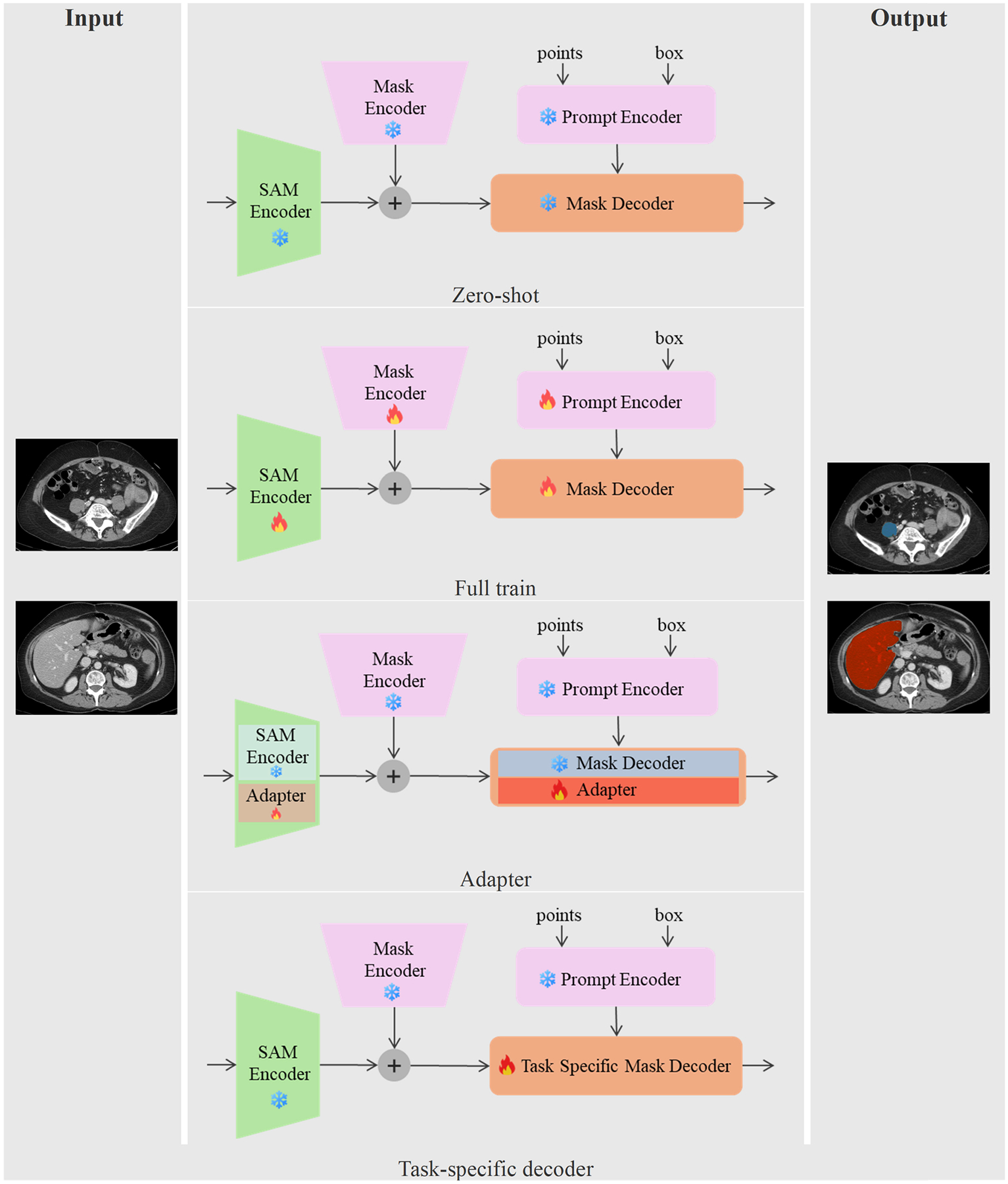 Figure 8
Figure 8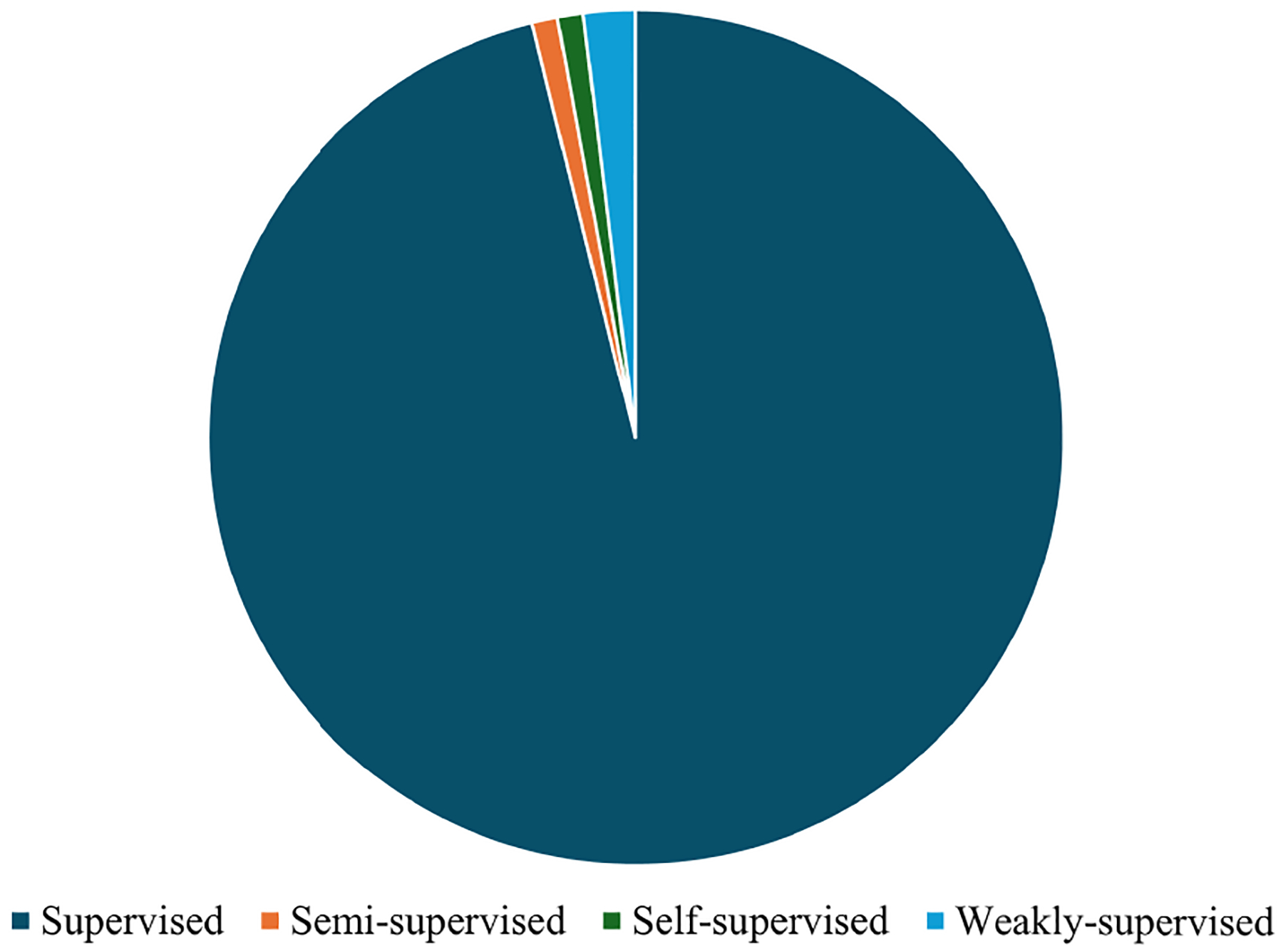 Figure 9
Figure 9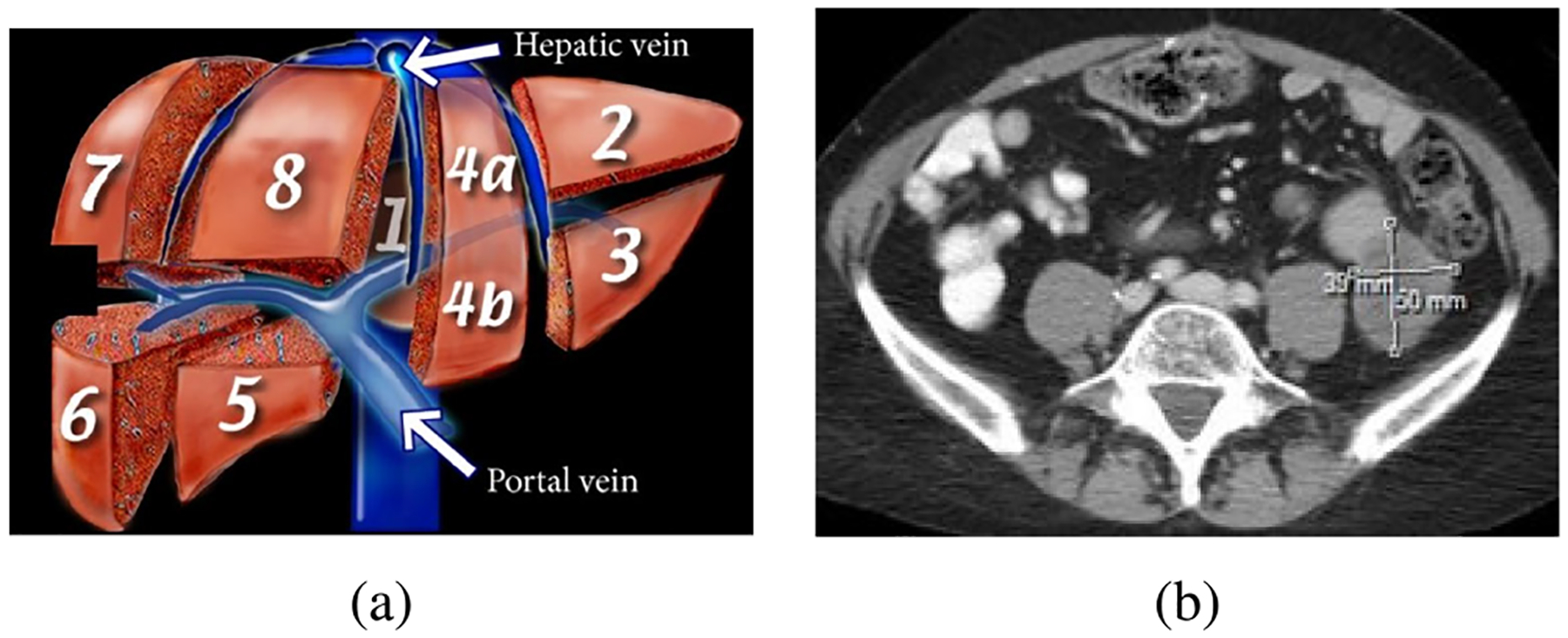 Figure 10
Figure 10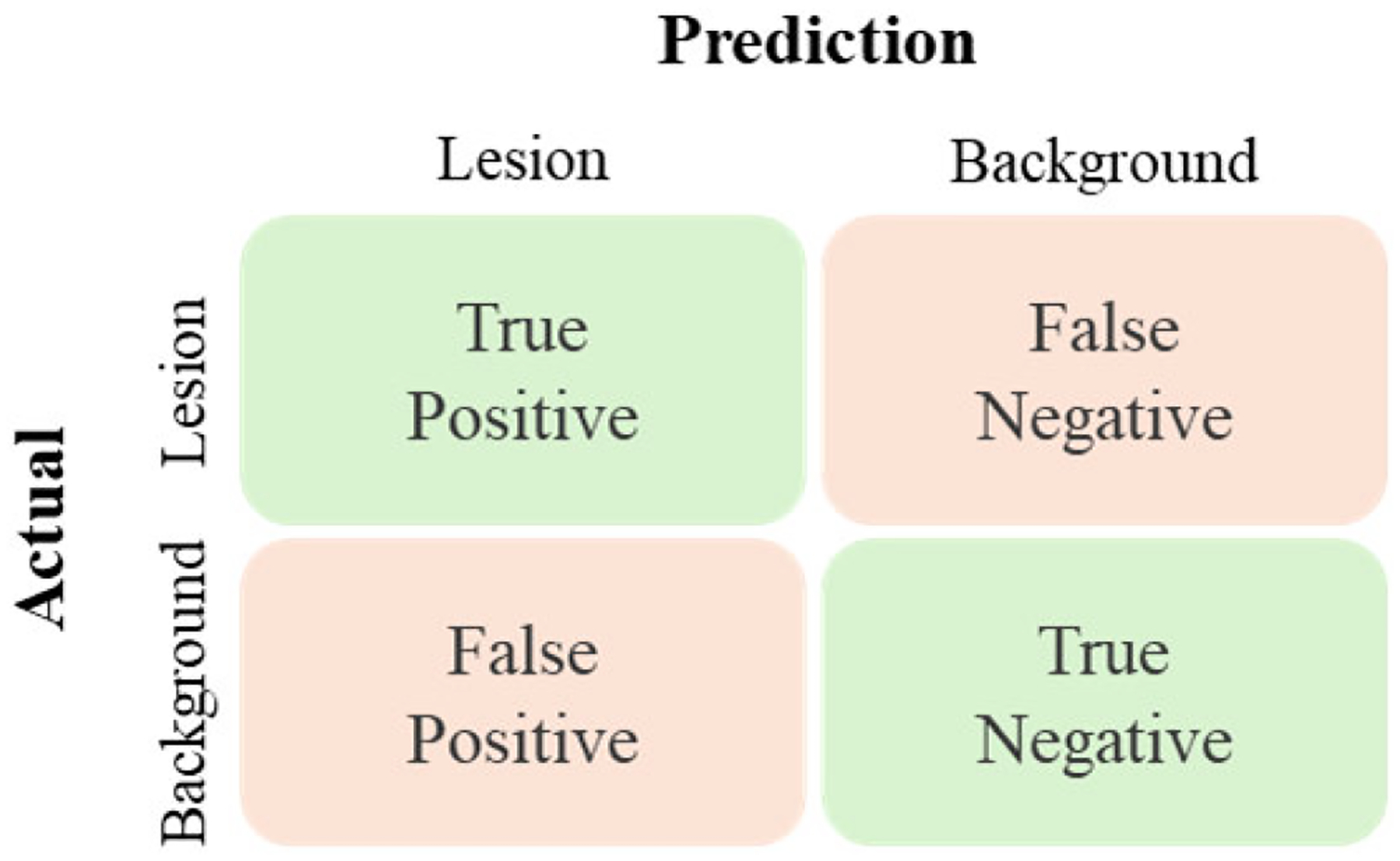 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Medical Image Segmentation Techniques · Brain Tumor Detection and Classification
INTRODUCTION
I.
Liver cancer is a highly lethal disease for both men and women in the United States. It is estimated that 30,090 cancer-related deaths nationwide will occur in 2025 [1]. Medical imaging is one of the critical tools used to assist oncologists in the diagnosis and treatment of liver cancer patients [2]. Various imaging modalities, including computed tomography (CT), contrast-enhanced CT, magnetic resonance imaging (MRI), positron emission tomography (PET), and ultrasound, are commonly used for liver cancer diagnosis [3]. CT remains the primary diagnostic tool due to its affordability, widespread availability, and fast image acquisition speed [4], [5], [6], [7]. In clinical practice, precise tumor segmentation is essential. It supports treatment response evaluation using RECIST, with assessments relying on accurate measurements of the longest tumor diameter to determine whether therapy should be continued, adjusted, or discontinued [8]. Accurate segmentation is also critical for surgical resection planning and for delivering radiation therapy, ensuring that doses are directed to the tumor while sparing adjacent healthy tissues [9], [10]. Prior studies have demonstrated that excessive radiation to surrounding liver tissue increases the risk of radiation-induced liver disease and recurrence in those areas [11], [12]. Moreover, numerous investigations have shown that changes in tumor size and volume are strongly associated with improved survival outcomes in liver cancer patients [13], [14], [15], [16]. However, achieving precise segmentation remains challenging due to the heterogeneity of liver tumors—characterized by irregularities in density, shape, and unclear tumor boundaries [17], [18], [19]. Despite advancements, liver tumor segmentation still faces significant challenges and requires continual improvement through advanced techniques and clinical experience [20].
Manual CT image segmentation is a labor-intensive and time-consuming task, as radiologists must visually inspect numerous slices and delineate tumor regions [21]. To address this limitation, various semi-automatic and automatic segmentation methods have been developed to reduce clinicians’ workload and improve segmentation accuracy [22], [23], [24], [25]. However, these methods still require time and substantial user expertise [26].
With the emergence of deep learning (DL), researchers quickly began to explore its potential to address challenges in medical image segmentation, with the first application involving convolutional neural networks (CNNs) in microscopy images [27]. Compared to traditional segmentation methods, DL-based approaches offer superior accuracy and faster processing times [28], [29].
This review explores state-of-the-art DL approaches for liver tumor segmentation in CT images. It provides a comprehensive overview of advancements in the field, highlighting key contributions, existing limitations, and ongoing challenges. The review is organized as follows: Section II introduces available datasets and synthetic data generation methods. Section III discusses various DL-based network architectures, learning strategies, and loss functions designed for liver lesion segmentation. Section IV presents segmentation evaluation techniques and metrics. Section V examines current limitations in DL-based liver lesion segmentation and outlines future research directions. Figure 1 provides a visual overview of the survey’s structure, and frequently used abbreviations are summarized in Table 1.
SEARCH STRATEGY
We conducted a systematic literature search in DBLP and PubMed to identify relevant studies published between 2014 and 2025. The search included peer-reviewed journal articles, conference proceedings, and non-peer-reviewed preprints. Only studies published in English were considered. DBLP and PubMed were selected as the primary databases because they support advanced search queries across both engineering and clinical domains. A summary of the search strategy is presented in Figure 2.
The search query used for DBLP was: ”(Liver | Hepatic) (Tumor | Cancer | Lesion | Pathology | Carcinoma | Neoplasm | Metastasis | Malignancy) (segment* | delineat* | extract* | localiz*)”. For PubMed, the following query was used to restrict results to relevant titles: ”((liver[Title] OR hepatic[Title]) AND (tumor*[Title] OR cancer[Title] OR lesion*[Title] OR pathology[Title] OR carcinoma[Title] OR neoplasm*[Title] OR metastas*[Title] OR malignancy[Title])) AND (segment*[Title])”. In addition to the database results, we included 52 additional studies from other sources. These included key general-purpose or foundation segmentation models. Although these were not originally developed for liver lesion segmentation, they were either applied to liver CT datasets or frequently referenced as comparative models in the literature.
After removing duplicates, 580 unique records remained. We then screened the titles and abstracts of these studies to assess their relevance. During this phase, we applied our inclusion and exclusion criteria to filter out unrelated or insufficiently detailed studies. A total of 187 records were excluded at this step for reasons such as lack of focus on liver tumor segmentation, absence of deep learning methods, or use of imaging modalities other than CT.
The remaining 393 articles were retrieved for full-text review. At this stage, we again applied the same eligibility criteria to confirm inclusion. Studies were eligible if they: (1) were published in English, (2) focused on liver tumor segmentation, (3) used deep learning models for automatic segmentation, (4) applied segmentation techniques to CT images, and (5) presented either a novel methodology, comparative analysis, or a significant improvement over prior approaches. We also required that full-text articles provide sufficient methodological detail and include essential sections such as the abstract and methods. Based on these criteria, 225 full-text articles were excluded. Ultimately, 168 studies met all eligibility requirements and were included in the final review. These comprised both liver-specific segmentation models and more general segmentation frameworks applied within the context of liver imaging.
DATASET FOR SEGMENTATION
II.
Deep learning-based medical image segmentation models require large, well-labeled datasets for effective training [30]. However, acquiring such datasets is challenging due to privacy restrictions, high annotation costs, and a lack of standardization [31], [32]. In the case of liver tumor segmentation, the limited availability of public datasets further hinders model development [33].
DATASETS
A.
Publicly available datasets are essential for liver tumor segmentation research. To support this need, several datasets have been introduced, sourced from medical imaging competitions and academic institutions. In liver tumor segmentation studies, it is common to segment the liver first before identifying tumor regions [34]. As a result, datasets can be classified into two categories: (1) general liver segmentation datasets, which contain liver images without specific tumor annotations, and (2) liver tumor segmentation datasets, which provide detailed tumor annotations. Table 2 summarizes the key specifications of these publicly available datasets. Figure 3 illustrates the frequency of dataset usage in the literature reviewed in this paper.
General liver segmentation datasets provide CT or MRI images of the liver but do not include specific tumor annotations. The SLiver07 dataset [35], introduced during the MICCAI 2007 conference, was one of the first challenges dedicated to automated liver segmentation, featuring 30 contrast-enhanced CT scans. The CLEF 2015 dataset was developed as part of a liver CT benchmark, providing 60 CT volumes for structured reporting rather than segmentation tasks. The BTCV multi-atlas labeling challenge [36], hosted by MICCAI, was designed to extend segmentation beyond the skull vault to include abdominal regions such as the liver, kidneys, gallbladder, esophagus, and stomach, with 50 venous-phase contrast-enhanced CT scans specifically for liver segmentation. The VISCERAL dataset [37], developed in collaboration with the IEEE international symposium on biomedical imaging (ISBI), contains 120 whole-body MRI and CT scans, made available on Microsoft Azure for automated anatomy localization and segmentation. More recently, the CHAOS challenge [38] introduced 40 CT volumes and 120 MRI volumes for healthy abdominal organ segmentation, with liver annotations included.
Although these datasets contribute significantly to liver segmentation research, they do not include well-defined patient cohorts with lesions or provide comprehensive segmentation of both the liver and its tumors. To address this, more specialized datasets with detailed liver tumor annotations have been developed. The LTSC08 dataset [39], was introduced during MICCAI 2008 and contains 30 CT scans specifically focused on liver tumor segmentation. Another notable dataset, MIDAS-LT, was part of the MIDAS initiative funded by the national library of medicine (NLM) in the USA under the imaging methods assessment and reporting (IMAR) project. MIDAS-LT consists of four CT scans annotated by up to three radiologists for liver tumor segmentation, although it does not include a liver mask. The 3D-IRCADb dataset [40], compiled by the IRCAD institute in France, includes 22 anonymized venous-phase CE-CT scans, with tumor annotations available in a subset of the cases. This dataset is divided into two parts: 3D-IRCADb01, which includes 15 cases with hepatic tumors, and 3D-IRCADb02, which consists of two additional CT scans with segmentation of other abdominal organs. The cancer genome atlas liver hepatocellular carcinoma (TCGA-LIHC) dataset [41] is part of a larger initiative linking cancer phenotypes to genotypes using clinical images from the cancer genome atlas (TCGA). This dataset includes 1,688 multi-modal images from 97 subjects, with 75 CT scans specifically focused on the liver.
Challenges designed for liver tumor segmentation have further contributed to the development of benchmark datasets. The liver tumor segmentation (LiTS) challenge [33], held at both ISBI and MICCAI in 2017, provided ground-truth labels for both liver and tumor segmentation. This challenge aimed to automate tumor detection in CT volumes and estimate tumor burden, in addition to standard liver segmentation. The medical segmentation decathlon (MSD) challenge at MICCAI 2018 further emphasized model generalization across ten different biomedical segmentation tasks, including liver segmentation [42]. Two tasks within this challenge, MSDC-T3 and MSDC-T8, are particularly relevant to liver tumor segmentation. MSDC-T3 is closely related to the LiTS dataset, while MSDC-T8 consists of 443 portal venous-phase CE-CT scans with segmentation annotations for tumors and vessels. The Barts CRL dataset [43] provides contrast-enhanced staging CT scans from colorectal cancer patients across three London hospitals annotated for liver metastases segmentation and classification of benign versus malignant lesions.
These datasets collectively provide a strong foundation for training and evaluating liver tumor segmentation models, addressing the need for both general liver segmentation and tumor-specific annotation. However, limitations such as small dataset size, annotation variability, and limited generalization to unseen clinical data remain significant challenges in developing robust deep learning-based segmentation methods [32]. Low generalizability suggests that the model may be overfitted to the training data [44]. To mitigate this and improve model performance, more specialized methods have been adopted in liver tumor segmentation [45].
SYNTHETIC DATA GENERATION
B.
Synthetic data generation has emerged as a promising solution to alleviate the data scarcity and the constraints of patient privacy. This is a popular method to enhance model training and improve generalization [46]. In this review, we categorize the explored augmentation methods into three classes: simple manipulations, synthetic image generation through deep learning methods, and artificial image synthesis using heuristic approaches.
BASIC IMAGE MANIPULATIONS
Traditional data augmentation techniques involve simple image transformations, including cropping, mirroring, translation (shifting), scaling, rotation, adding random or zero-mean Gaussian noise, random region erasing, affine or elastic deformations, intensity adjustments, sharpening, blurring, and edge enhancement [44]. Typically, a combination of these transformations is applied to reduce overfitting, such as reflection, translation, scaling, and rotation [47], [48].
The test-time augmentation approach applies transformations during inference, creating an ensemble effect that enhances the robustness of predictions [44], [49]. Techniques such as affine, pixel-level, or elastic transformations are used to better estimate uncertainty during inference [50]. While traditional augmentation methods help improve model performance by introducing variation, they remain limited in their ability to generate entirely new training samples with diverse tumor characteristics [44], [51].
DEEP LEARNING-BASED SYNTHETIC DATA GENERATION
Deep learning-based augmentation methods offer a more generalizable framework by generating entirely new and diverse training samples [52]. Key techniques include adversarial training, generative adversarial networks (GANs), and diffusion models.
Adversarial training enhances model robustness by leveraging networks with opposing objectives. One network generates perturbed images to mislead a competing classifier which exposes model vulnerabilities and improves feature extraction [53], [54]. This approach helps models learn invariant features, making them more resilient to variations. In liver tumor segmentation, adversarial densely connected networks (ADCNs) have improved accuracy by optimizing both cross-entropy (CE) and adversarial losses. A discriminator network is used to refine segmentation by comparing deep fully convolutional network (DC-FCN) outputs with ground truth labels [55].
GANs, first introduced by Goodfellow et al. [56], are widely used in medical image analysis to generate realistic synthetic data [57]. A typical GAN consists of a generator, which creates artificial samples, and a discriminator, which distinguishes the real from the fake data. The overall architecture of a typical GAN is illustrated in Figure 4. These models have been successfully applied to liver segmentation [58], [59], [60], liver tumor segmentation [61], [62], and liver lesion classification [63]. In one study, separate GAN models were used for each lesion class to synthesize 2D liver lesion Regions of Interest (ROIs) [64]. Another study introduced a GAN for free-form 3D lesion synthesis in CT images, allowing users to define the region, shape, and size of the tumor using a mask [65]. A similar study employed a GAN-based liver lesion synthesis network to generate lesion textures, where the shape, size, and rotation of the synthetic lesions were controlled using a method based on principal component analysis (PCA) [66]. Synthetic images often lack realistic lesion details, which can negatively impact AI model performance on real CT images. To address this issue, researchers trained GANs using gray-level co-occurrence matrix (GLCM) features. By focusing on liver parenchyma and tumor regions, this approach emphasized texture, shape, and grayscale attributes, resulting in more realistic synthetic liver tumor CT images [67].
Diffusion models offer a promising alternative to GANs for medical image synthesis, addressing challenges such as mode collapse and training instability [68]. These models generate high-quality, diverse synthetic images through a two-step process: forward diffusion (adding noise), and reverse diffusion (removing it to reconstruct the original input) [69]. Diffusion probabilistic models have found successful applications in various domains, including image generation tasks [69], [70]. For instance, DiffTumor [71] introduced a diffusion-based framework designed to generate realistic tumors that generalizes across different organs. Leveraging diffusion models for synthetic liver tumor generation provides a promising avenue for enhancing segmentation accuracy [72].
HEURISTIC-BASED SYNTHETIC DATA GENERATION
Deep learning-based generative models still require pixel-wise tumor masks to learn pathological patterns from annotated tumor areas [57]. However, obtaining accurate annotations is challenging, and these models are prone to both inter-annotator and intra-annotator variability, even when provided by medical experts [73]. To reduce the cost and effort of manual annotation, researchers have explored heuristic methods for generating synthetic tumors as an alternative. Realistic tumor synthesis requires careful consideration of factors such as shape, intensity, size, location, and texture. For instance, in a study [74], liver and brain tumors were synthesized for pre-training, enabling the model to adapt to tumor segmentation within the same organ under low-annotation conditions. By integrating artificial anomalies into normal organ images, shape and texture were effectively captured. Another investigation [75] examined the impact of using handcrafted tumors for training deep learning models for liver tumor segmentation. The findings indicated that incorporating synthetic tumor data into training improved segmentation performance, demonstrating its potential as a viable augmentation technique. However, early heuristic methods did not account for spatial awareness, occasionally resulting in synthetic tumors overlapping with vascular structures. To address this, Hu et al. [76] proposed a strategy for synthesizing realistic liver tumors of varying sizes based on clinical knowledge. Evaluating the generalizability of these methods across tumors in different organs remains an intriguing direction for future research. Overall, the discussed methods vary in complexity and realism. Table 3 consolidates these approaches, highlighting their relative strengths and weaknesses.
PREPROCESSING AND NOISE REDUCTION
III.
Preprocessing of CT images is a crucial step before training deep learning models, as it enhances quality and ensures consistency across datasets. CT scans inherently suffer from low contrast and multiple noise types introduced during image acquisition and reconstruction. These include additive Gaussian noise (random pixel fluctuations), quantum noise (graininess from limited X-ray photons), impulse or salt-and-pepper noise (isolated extreme values), speckle noise, and structured artifacts such as streaks, ring or blockiness [77], [78]. Such distortions obscure fine anatomical details and textures, complicating segmentation tasks for deep learning models that depend on clear boundaries.
To address these challenges, preprocessing pipelines commonly integrate denoising alongside standard steps such as HU adjustments, intensity normalization, and resampling. Traditional denoising techniques include spatial-domain filters (median, bilateral, non-local means) and transform-domain approaches [79]. For instance, in liver segmentation studies, 7×7×7 median and bilateral filters have been applied to suppress noise [80], while more advanced approaches like anisotropic diffusion and adaptive likelihood estimation have shown promise in improving contrast between tumors and surrounding tissue [81].
In recent years, DL-based preprocessing has become increasingly effective at suppressing CT noise while preserving anatomical structures [82]. CNNs [83], GANs [84], deep residual networks [85], and transformers [86] have been applied to low-dose CT denoising. For example, DnCNN-SR improved liver margin segmentation [87], and RED-CNN or MAP-NN significantly improved liver vessel segmentation accuracy with nnU-Net [88]. However, while these approaches reduce noise more effectively than traditional filters, they may also over-smooth fine structures or introduce artificial features, underscoring the need for careful validation in clinical applications.
ARCHITECTURE AND LEARNING STRATEGIES
IV.
DEEP LEARNING ARCHITECTURE
A.
CNN AND FCN
CNNs were introduced to overcome the limitations of traditional machine learning (ML) methods by enabling automatic feature extraction through convolutional operations. They learn spatial hierarchies of features, improving performance in medical image segmentation, including liver tumor segmentation [89]. Several studies have demonstrated the effectiveness of CNNs in liver tumor segmentation. For instance, Li et al. [17] employed a patch-based CNN approach to segment liver tumors, assessing the impact of different patch sizes on 2D CT images. They found that a 17×17 patch size effectively focused on tumor regions, outperforming traditional ML methods such as AdaBoost, Random Forest, and support vector machines (SVMs). Another study [90] proposed a three-step approach to segment the liver coarsely and finely before isolating tumors using CNNs. Similarly, [91] implemented a 3D patch-based CNN for fine liver segmentation following an initial coarse segmentation. In another study [92], researchers combined 2D CNNs with patient-specific 3D CNNs to further enhance segmentation of follow-up CT scans. Additionally, a two-path CNN using original, normalized, and texture-encoded images was developed to optimize patch sizes for more effective segmentation [93]. Despite their effectiveness, CNNs struggle to capture long-range dependencies, maintain structural integrity, and efficiently handle pixel- or voxel-level loss computation, especially for large anatomical structures [94].
Fully convolutional networks (FCNs) extend CNN-based segmentation by replacing fully connected layers with convolutional layers. This reduces the number of parameters and enables the model to process entire images at once, improving contextual understanding [24]. The first application of FCNs for semantic segmentation showed promising results [95], leading to their adoption in liver tumor segmentation. Several studies have since employed FCNs in liver tumor segmentation. For example, one study [96] combined a 2D FCN with 3D deformable model optimization [97], based on local cumulative spectral histograms and non-negative matrix factorization (NMF), to improve segmentation accuracy. Another study used multi-phase CT data (arterial, portal venous, delayed) within a multi-channel FCN (MC-FCN) to fuse phase-specific high-level features [98]. One approach implemented 3D convolutions in an FCN architecture for coarse-to-fine liver segmentation, effectively masking non-liver tissues and initializing a level-set method to refine tumor boundaries [99]. This method also enhanced edge detection by incorporating a fuzzy c-means (FCM) probabilistic mask. To address the complexity of 3D convolutions, a lightweight hybrid 2D/3D model employed separable factorization to reduce the number of parameters while maintaining high performance [100]. Cascaded frameworks have also been explored. A two-stage FCN was used to first identify the liver as a ROI, then segment lesions within that region [101]. Sequential FCNs combined with conditional random fields (CRFs) have also been proposed to improve segmentation quality [102], [103]. Comparative studies have confirmed the superiority of FCNs over patch-based CNNs in liver segmentation and metastasis detection, highlighting their ability to leverage full-image context [104]. However, traditional FCNs suffer from a loss of spatial detail due to pooling operations, resulting in imprecise or blurred segmentation maps [105]. Introducing connections between early and late convolutional layers can help recover fine spatial details and improve overall segmentation precision [98].
U-NET AND ITS VARIANTS
The U-Net architecture, initially developed for 2D electron microscopy image segmentation, has gained significant popularity in medical image research due to its effectiveness in semantic segmentation tasks [106]. It features a U-shaped symmetric encoder-decoder structure composed of convolutional and up-convolutional layers, as illustrated in Figure 5. Skip connections between corresponding encoder and decoder blocks help preserve low-level information that may be lost during pooling operations [106]. Numerous studies have investigated both the original U-Net and its modified architectures to improve liver tumor segmentation performance [48], [107], [108], [109], [110], [111], [112], [113], [114], [115]. For example, SegNet [116], a U-Net variant, replaces full feature maps in skip connections with max-pooling indices to improve efficiency while retaining essential spatial information. A modified version of SegNet was fine-tuned for liver segmentation, using a K-Means algorithm to isolate tumors within the segmented liver [51]. Various adaptations of SegNet-based models have also improved segmentation accuracy in liver tumor detection [117], [118]. CompNet, a notable U-Net variant, employs dual pathways to extract features from both the target tissue and the complementary background [119]. Based on this architecture, [120] proposed a framework for liver and lesion segmentation in CT images: liver regions were first segmented slice by slice using a 2D CompNet, the slices were then stacked into a 3D volume, and lesion detection was performed using a combination of a 2D CompNet for large lesions and a 3D CompNet for smaller ones.
To address the continuity of 3D medical images, V-Net extended U-Net into 3D. However, its relatively shallow architecture—with only a single max-pooling layer following initial convolutions—limited its capacity for multi-scale analysis [121]. This shortcoming was addressed by 3D U-Net, introduced by Çiçek et al., which has since become a widely adopted architecture for volumetric medical image segmentation [122]. Further improvements were proposed in [123], where a single 3D U-Net was trained using a three-stage curriculum learning strategy: starting with full 3D volumes, progressing to 3D tumor patches, and finally combining tumor-specific features with global context.
Given the high computational demands of 3D models, several studies have explored complexity reduction techniques, such as processing only tumor-containing slices (2.5D) or employing hybrid 2D/3D architectures. For example, UV-Net combines a 3D V-Net encoder with a 2D U-Net decoder to balance accuracy and efficiency [124], [125], [126]. Additionally, lightweight U-Net variants have emerged, utilizing depthwise separable convolutions to reduce computational overhead while preserving performance [127], [128]. The nnU-Net framework, which dynamically configures CT slice arrangements based on varying spatial adjacency, has also demonstrated enhanced segmentation precision [125].
RESIDUAL NETWORKS (RESNET) AND THEIR EXTENSIONS
Residual networks, introduced in ResNet, enhance feature propagation and mitigate vanishing gradient issues, making them particularly valuable for deep medical image segmentation tasks [129]. Numerous studies have incorporated ResNet blocks into U-Net architectures to improve segmentation accuracy [123], [127], [130], [131], [132]. Some approaches embedded residual blocks in both the encoder and decoder stages alongside conventional convolutional layers [133]. One notable method employed pretrained ResNet50 blocks (trained on ImageNet) within the encoder, combined with feature-fusion skip connections to merge multi-scale features, thereby enhancing segmentation performance [134].
Building upon this, a cascaded U-ResNet model was proposed in [135] to simultaneously segment the liver and lesions. This architecture utilized intra-network skip connections, allowing the lesion segmentation network to refine its outputs using features extracted from liver segmentation.
Beyond standard ResNet blocks, residual connections have been extended to fractal-like structures to capture and integrate multi-scale contextual information for deep semantic segmentation. Fractal residual networks, extensively studied in liver tumor segmentation [136], [137], [138], have demonstrated robust performance. Specifically, studies in [137] and [138] reported that these networks significantly improved tumor candidate classification following initial segmentation, enabling effective handling of complex tumor morphologies.
DENSE NETWORKS (DENSENET) AND THEIR EXTENSIONS
Dense blocks, originally introduced in DenseNet [139], enhance feature propagation, gradient flow, and parameter efficiency by establishing direct connections between all layers within a network stage. Each layer in a dense block receives input from all preceding layers and passes its own feature maps forward, reducing redundancy and improving segmentation performance. Figure 6a and Figure 6b illustrate the differences between a residual block and a dense block, highlighting how dense connections promote efficient feature reuse.
To leverage these advantages in medical imaging, UNet++ [140] introduced dense skip connections to reduce the semantic gap between encoder and decoder features, thereby improving segmentation accuracy. Further utilizing dense connectivity, Kaluva et al. [123] employed dense blocks in both the encoder and decoder of a U-Net trained on CT axial slices at three different HU levels, demonstrating enhanced liver tumor segmentation performance.
Similarly, the bottleneck supervised U-Net (BS U-Net) [141] incorporated dense connections in the bottleneck layer, refining feature representations and boosting segmentation accuracy. To further optimize dense connections, H-DenseUNet proposed a two-stage hybrid approach that combined 2D DenseUNet for intra-slice feature extraction with 3D DenseUNet for volumetric feature aggregation. This design improved segmentation consistency across slices, addressing challenges associated with volumetric medical imaging [142].
While deeper networks generally improve segmentation accuracy, they also increase computational costs [128]. To address this, one study optimized a U-Net-like structure by replacing pooling layers with strided convolutions and employing depthwise separable convolutions within dense blocks. This significantly reduced the number of learnable parameters while preserving segmentation performance [143].
MULTI-SCALE FEATURE FUSION TECHNIQUES
Deep learning-based liver tumor segmentation often employs multi-scale feature fusion schemes to improve segmentation accuracy by combining information from different spatial levels. These methods enhance performance by capturing contextual information from objects of varying sizes, reusing spatial details across network layers, and enabling deeper layers to learn more complex representations [144]. In encoder-decoder architectures, multi-scale features are typically extracted after pooling operations and fused across layers to boost liver tumor segmentation accuracy [20], [55], [134], [145], [146], [147].
Several strategies have been proposed to optimize multi-scale feature fusion. For instance, [147] introduced a multitask network that leveraged multi-scale features from both encoder and decoder stages to enhance liver lesion mask prediction and classification. Another approach utilized dense connections to propagate features across multiple scales, improving the segmentation of tumors with complex spatial structures. A study by [55] developed a segmentation framework that integrated dense feature fusion within an adversarial training setting and incorporated dilated convolutions to expand the intra-slice receptive field, thus enhancing robustness.
To further improve multi-scale learning, some models apply parallel convolutions with varying kernel sizes (e.g., 3×3, 5×5, 7×7) to effectively capture features of tumors at different scales [19], [148], [149], [150], [151]. High-resolution networks (HRNet) [149] maintain multi-resolution feature representations throughout the network, ensuring consistent segmentation performance across varying tumor sizes. Another approach, RIS-UNet [152], employs Residual–Inception–SE (RIS) blocks that integrate residual connections, parallel convolutions at multiple scales to enhance multi-scale feature fusion and improve liver tumor segmentation performance. Additionally, dilated (atrous) convolutions are widely used to increase the receptive field without significantly increasing computational cost, enabling the capture of broader spatial dependencies [153].
Atrous spatial pyramid pooling (ASPP), introduced in DeepLab, is a widely used technique that enhances segmentation by combining multiple dilation rates with global average pooling [154]. Several studies have incorporated ASPP into liver tumor segmentation frameworks [155], [156], [157], [158], [159]. For example, the TDS-U-Net network [160] integrated ASPP in the bridge section to capture multi-scale contextual features, and further extended its use to the decoder’s transition and output layers to enrich multi-scale representation. Similarly, Ma et al. [158] proposed a modified U-Net incorporating a cascaded adaptive feature extraction unit with multi-head attention blocks and ASPP modules to refine segmentation precision. Another study [159] fused ASPP features with boundary information at each layer, enabling the model to better focus on tumor structures and fine anatomical details. In addition, a comparative evaluation of U-Net, U Net++, and DeepLabV3+ on liver tumor CT datasets showed that U-Net remains robust, while newer architectures such as DeepLabV3+ can further boost performance [161].
ATTENTION MECHANISMS
To tailor deep learning models specifically to the liver region in CT images and to limit the influence of irrelevant information, several approaches have been employed [162]. For example, one strategy uses both the CT image and a liver mask generated by a separate liver segmentation model to restrict the analysis to the liver region [102], [120]. Another approach uses liver and tumor bounding box masks as inputs to a multi-encoder-decoder architecture, thereby focusing on task-relevant features by isolating the regions of interest [163]. Attention mechanisms [164] further enhance this process by adaptively assigning weights to different regions in an image, enabling the network to focus on areas critical to the task while disregarding irrelevant ones. These mechanisms have demonstrated significant effectiveness in medical image segmentation and are widely adopted in recent research [134], [162].
Spatial attention (SA) methods refine feature selection by assigning importance scores to different regions based on mean and max pooling operations [165]. This technique enhances segmentation accuracy by prioritizing tumor-specific regions while reducing background influence [166], [167], [168]. For instance, one study used a spatial attention mechanism to merge low-level spatial information and high-level semantic information, improving fusion efficiency in liver tumor segmentation [166]. Attention gates (AGs) build on this by combining input features with a coarse-scale gate signal to generate spatial attention weight maps. Several studies have utilized AGs to improve segmentation performance [159], [160], [169], [170], [171]. Attention U-Net [172], for instance, incorporates AGs into skip connections, suppressing irrelevant features in liver and tumor segmentation tasks. Another method includes residual attention mechanisms (RA-UNet), which use a trunk branch to retain original feature information and a soft mask branch to selectively enhance or suppress specific features [168].
Unlike spatial attention, channel attention (CA) mechanisms focus on reweighting feature channels to emphasize relevant attributes of liver tumors [165]. One study incorporated CA within a novel skip connection strategy in U-Net architectures for CT liver image segmentation [173]. This approach intentionally excluded spatial attention to preserve spatial continuity, mitigate overfitting, and maintain model simplicity. Squeeze-and-excitation (SE) modules [174] exemplify this approach by applying global average pooling (GAP) to recalibrate channel weights, improving sensitivity to liver tumor-relevant features [136], [175], [176]. Studies incorporating SE modules in Res-UNet architectures [110], [134] and densely connected networks [136] have demonstrated improved segmentation accuracy by refining both low-level and high-level feature representations. MS-UNet [177] incorporates the SE module to enhance channel-wise feature recalibration and improve the network’s ability to describe high-level features. Additionally, HfRU-Net [178] modified skip pathways using SE modules and employed an ASPP module in the bottleneck to enhance segmentation performance while reducing computational complexity.
Some architectures combine spatial and channel attention to further enhance feature refinement in liver tumor segmentation [148], [179], [180]. For instance, a study [145] proposed an approach that refines spatial and channel features by highlighting the difference between the encoder and decoder through a subtractive operation. The convolutional block attention module (CBAM) [181] combines channel and spatial attention to achieve comprehensive feature refinement, inheriting the strengths of both mechanisms for medical image classification and segmentation. Researchers also introduced a context-guidance (CG) branch and a boundary-learning (BL) branch to enhance contextual feature extraction and boundary detection for tumors [155]. To improve boundary representation, CBAMs were integrated into their model. A multi-attention network (MANet) was proposed to enhance liver tumor segmentation by integrating four attention mechanisms: skip connection AGs, channel attention, spatial attention, and CBAM [34]. The skip connection attention gates capture crucial shallow features from the encoder, which are concatenated with semantically rich features from the decoder. Additionally, they incorporated both GAP and global max pooling for channel attention, demonstrating improved inter-channel relationships compared to conventional methods. Building on these hybrid attention strategies, the multi-scale feature fusion attention network (MFA-Net) leveraged a U-Net architecture and incorporated modified versions of SE and GAP modules to implement channel and spatial attention, addressing the lack of spatial awareness in FCNs [176].
While spatial and channel attention mechanisms enhance feature refinement in static images, medical imaging often involves sequential data, such as dynamic scans or time-series inputs. In such cases, temporal attention is used for temporal relation modeling [162], making it particularly useful for enhancing inter-slice consistency [182], processing multi-frame sequences or videos, such as those used in clinical settings [183], [184].
SELF-ATTENTION AND TRANSFORMERS
Self-attention mechanisms capture long-range dependencies by computing pairwise relationships across all elements of the input, integrating both spatial and channel information [162], [164]. This mechanism is illustrated in Figure 7. Unlike conventional attention mechanisms, which primarily focus on local relationships—whether within a single slice (intra-slice) or between adjacent slices (inter-slice)—self-attention considers pairwise relationships across all input elements. Axial attention [185] and criss-cross attention [186] were introduced to improve computational efficiency by focusing on axial or cross-pattern relationships, thereby enhancing segmentation performance. Criss-cross attention has been successfully applied in the bottleneck of a U-Net-like architecture with dense blocks, improving feature propagation and segmentation precision [187]. A similar approach employed axial attention in a comparable context [185], demonstrating its ability to capture long-range dependencies with reduced computational complexity. Additionally, a study [149] utilized criss-cross attention to model long-range relationships between feature pairs in the same row and column of multi-scale encoder feature maps, significantly reducing the computational cost of traditional self-attention.
Building on these techniques, multi-head self-attention (MHSA) has been widely used in medical image segmentation. MHSA allows the model to capture a broader variety of relationships and patterns by employing multiple attention heads operating on different subspaces of the feature representations [188]. One study integrated MHSA and a series of dense connections in the bottleneck of a Res-UNet architecture to enhance the extraction and reuse of relevant features [158]. Another study applied MHSA in the spatial encoder of an XFuse network, which combines spatial and frequency features to improve liver tumor segmentation [189]. Inspired by MHSA, researchers developed a double-branched encoder with multi-axis aggregation Hadamard attention (MAHA) and group multi-head cross-attention aggregation to fuse information from both the Fourier domain and spatial features [190].
Attention mechanisms have also been applied to enhance multi-scale feature fusion by dynamically selecting the most relevant features across different scales, minimizing computational overhead, and improving segmentation accuracy across varying spatial resolutions [19], [134], [149], [157]. For instance, DPC-Net [19] integrates a pyramid structure with spatial and channel attention modules in the encoder, enabling the extraction of multi-level features and improving segmentation of tumors with diverse sizes, shapes, and locations. This network leverages attention mechanisms to exploit semantic and spatial correlations among pyramid features for more effective liver tumor segmentation. Similarly, [191] proposed T-MPEDNet, a Transformer-aware multiscale progressive encoder–decoder network that integrates feature recalibration and contextual attention to capture long-range dependencies. By refining multi-scale features and boundaries, it improves segmentation of small and indistinct liver tumors while achieving state-of-the-art performance on public datasets.
The breakthrough multi-head self-attention mechanism—originally introduced in transformer architectures for natural language processing (NLP) [164]—was quickly adopted in computer vision tasks, leading to the development of the Vision Transformer (ViT) [192]. In liver tumor segmentation, transformers have gained attention for their capability to model global relationships between image patches across various positions in encoder-decoder frameworks. Wang et al. proposed ACF-TransUNet [173], which integrates a transformer block into the bottleneck of a U-Net architecture and includes channel attention modules in skip connections to improve segmentation accuracy. Similarly, the attention connect network (AC-Net) [185] combines a transformer block in the bottleneck with axial attention in skip connections to enhance efficiency. Another hybrid model combined transformers and CNNs, placing a transformer module in the fourth skip connection to capture global context [193]. Kang et al. [159] proposed a dual-encoder pathway network that uses an attentional feature fusion block to integrate global semantic features from a transformer-based encoder with local features from a CNN-based encoder. More recent approaches have further advanced this trend.
Other innovative approaches have also emerged. One model used a multiple feature extractor and a fusion module to integrate semantic features from transformers, spatial features from CNNs, and edge-enhanced features [175]. Another employed a dynamic hierarchical transformer network based on the 3D U-Net architecture, introducing an edge aggregation block (EAB) to better capture fine-grained edge details [194]. In a separate study [195], a 3D transformer structure was adopted for multi-phase tumor segmentation. This model used a generative adversarial strategy to provide domain-adaptive features and minimize the feature gap across CT phases.
While transformers apply global self-attention by computing relationships among image patches, this results in quadratic computational complexity. To address this issue, Vaswani et al. [196] introduced shifted window-based local self-attention, which reduces complexity to linear levels while enabling cross-window connections through shifting. Building on this idea, a novel network—SWTR-UNet—was developed, integrating SWIN transformer blocks with ResNet blocks [197]. Similarly, [198] utilized Swin-neighborhood fusion transformer blocks (SFTB), which combine Swin transformer and neighborhood attention transformer modules. The Swin blocks capture global contextual information via shifted windows, and the added neighborhood attention (NA) operates at a per-pixel level within local neighborhoods (e.g., 3×3), enabling finer local context modeling. This fusion allows SFTB to jointly capture both global and local contextual information more effectively than Swin blocks alone. While transformers rely on computationally expensive self-attention, recent studies have proposed token-based multilayer perceptron (MLP) blocks as lightweight alternatives. For example, a modified tokenized MLP U-shaped network incorporated spatial-shift MLP blocks to enhance inter-token information flow, attention gates in skip connections to suppress irrelevant features, and a multiscale attention module for improved boundary delineation. This model achieved competitive performance on the LiTS dataset using limited number of parameters, highlighting its efficiency for real-time clinical tasks while maintaining high segmentation accuracy [199].
VISION-LANGUAGE MODELS (VLMS) AND FOUNDATION MODELS
In recent years, foundation models have transformed AI technologies and reshaped our understanding across various domains [200]. Among these, large language models (LLMs) [201], characterized by their scale and complexity [200], have facilitated the development of models pretrained on both visual and linguistic data, leading to the emergence of vision-language models (VLMs) [202]. VLMs, such as contrastive language–image pre-training (CLIP) [203] and large-scale image and noisy-text embedding (ALIGN) [204], have significantly integrated textual supervision into vision models, garnering notable attention in medical imaging applications.
One of the most prominent foundation models in image segmentation is the segment anything model (SAM) [205], originally designed for natural image segmentation. SAM operates as a prompt-based segmentation framework, supporting both sparse prompts (e.g., points, boxes, text) and dense prompts (e.g., masks), and has demonstrated strong performance in interactive segmentation tasks [206]. In medical image segmentation, SAM’s zero-shot performance has been explored in several studies. However, its effectiveness is often limited when segmenting complex medical structures [207], [208], [209]. These limitations largely arise from the dominance of natural images in SAM’s training dataset and its lack of domain-specific medical knowledge, leading to suboptimal performance in clinical applications [207].
For instance, a study on liver tumor segmentation found that SAM’s accuracy was unsatisfactory with a limited number of prompts. However, its performance improved with more expert intervention and additional prompts [210], [211]. To address such limitations, several strategies have been developed to improve SAM’s effectiveness in the medical domain [212]. One common approach is fine-tuning SAM on task-specific medical images [213], [214]. For example, MedSAM [21] retrained SAM’s image encoder using 1.57 million image-mask pairs from 11 modalities and over 30 cancer types, while keeping the prompt encoder frozen and using only bounding box prompts. Nevertheless, full-scale fine-tuning for medical applications remains computationally expensive and data-intensive [206], [209].
To mitigate this, some studies have proposed retaining the frozen SAM encoder while replacing its decoder with task-specific alternatives optimized for medical image segmentation [215], [216]. While this preserves SAM’s pretrained visual knowledge, the results remain highly prompt-dependent, particularly when handling multi-modal medical images where domain shifts from natural images affect performance [217], [218]. Another efficient method integrates adapter modules within the SAM encoder, allowing for parameter-efficient fine-tuning and improved adaptability to medical tasks [206], [219], [220], [221]. For instance, SAMed [221] enhances medical image segmentation by incorporating low-rank adaptation (LoRA) modules into the pretrained SAM image encoder.
Despite these advancements, limited research has focused specifically on applying VLMs to liver tumor segmentation. A study by Chen et al. [222] proposed a three-stage semi-supervised framework that generates pseudo-labels, which are subsequently used as prompts to fine-tune the Med-SA model for liver tumor segmentation. Various strategies for adapting SAM to medical image segmentation are illustrated in Figure 8.
One major limitation of SAM in 3D medical image segmentation is its slice-by-slice processing of axial CT images, which ignores inter-slice spatial continuity. This limitation prevents the model from fully capturing 3D spatial relationships needed for accurate segmentation. To overcome this, researchers have explored SAM2, which applies video tracking techniques for zero-shot 3D segmentation [223], [224]. However, SAM2 has shown poor performance on CT images due to the lack of domain-specific training [225].
An alternative direction involves integrating 3D adapters into SAM, maintaining most of its pretrained parameters frozen while enriching deep features with spatial and depth information. These parameter-efficient finetuning approaches have shown promise in improving segmentation accuracy in medical imaging [226], [227], [228], [229], [230], [231]. A notable development in this field is Med-SA, which extends SAM’s capabilities to 3D medical image segmentation using trainable adapter layers [232].
Beyond architectural modifications, leveraging SAM’s predictions as prior knowledge has become a prominent trend in medical image segmentation [222], [233], [234]. For instance, [233] demonstrated that integrating SAM-generated pseudo-labels into U-Net-based segmentation models achieved performance comparable to fully supervised models.
Due to the limited availability of public datasets [33] and challenges in acquiring high-quality annotated medical images [235], new learning strategies have been developed to improve segmentation with reduced reliance on annotations [236]. While supervised learning remains widely used for liver tumor segmentation (as shown in Figure 9) [237], it typically requires large amounts of labeled data, which may be impractical in many clinical settings [238]. To overcome these constraints, recent studies have explored novel learning paradigms that make better use of available data and improve generalizability. These include knowledge transfer, which leverages pretrained models and external datasets, and data-efficient learning, which aims to maintain strong performance with minimal annotated data [236]. A summary of key representative papers, including the segmentation methods employed, their evaluation performance on benchmark datasets, and the advantages and weaknesses of each method, is presented in Table 4.
LEARNING STRATEGIES
B.
KNOWLEDGE TRANSFER METHODS
In medical image segmentation, prior knowledge from external datasets is often leveraged to enhance model performance. Transfer learning, for instance, involves finetuning pre-trained models on large datasets for specific downstream tasks and has been shown to improve liver lesion segmentation [29], [51], [98], [104]. In one study [185], a network was first pre-trained on the LiTS dataset and then fine-tuned on a larger private liver tumor dataset to further enhance segmentation accuracy. Some studies have adapted the VGG-16 as a transfer learning framework to improve liver tumor segmentation on small CT datasets [29], [104]. Defeudis et al. [239] compared liver lesion segmentation performance with and without transfer learning, highlighting its advantages.
Beyond transfer learning, other knowledge transfer techniques such as zero-shot, one-shot, and few-shot learning allow models to learn effectively from minimal labeled examples, thereby extending deep learning’s capabilities to smaller datasets [240], [241], [242], [243]. These strategies are particularly valuable in scenarios where annotated liver tumor datasets are limited, enabling models to generalize to new tasks with minimal supervision.
DATA-EFFICIENT LEARNING METHODS
To minimize annotation burdens and enhance learning efficiency, various strategies have been developed [244], including active learning [245], semi-supervised learning [246], self-supervised learning [247], and weakly supervised learning [248].
Active learning optimizes the annotation process by selecting the most informative samples for manual labeling, thereby reducing the total number of labeled instances required for effective model training. A study comparing active learning strategies across MSD datasets showed that both random sampling and strided sampling serve as strong baselines, offering insights into their respective strengths and limitations [249].
Semi-supervised learning combines a small amount of labeled data with large volumes of unlabeled data, often using pseudo-labeling techniques to generate training annotations. For instance, dynamic thresholding and uncertainty rectification have been applied to create reliable pseudo-labels, improving liver tumor segmentation accuracy [189], [250]. Another study refined pseudo-labels using labeled data to enhance model robustness during training [251].
Self-supervised learning (SSL) further reduces the need for manual annotation by using unlabeled raw data to learn meaningful visual representations. One approach blends artificial tumors into normal organs and refines predictions through self-training [252]. Additionally, synthetic-to-real test-time training (SR-TTT) [73] utilizes SSL by incorporating two auxiliary networks—a generator and a reconstruction network—alongside the main segmentation model. These auxiliary networks help the model adapt to real-world data during inference by generating synthetic samples and reconstructing inputs, thereby improving segmentation performance.
Weakly supervised learning, on the other hand, trains models using noisy, partial, or imprecise labels such as image-level labels [253] or sparse annotations (e.g., bounding boxes, scribbles) [74], [145], [254], [255], [256], [257]. For example, [258] employed image-level labels to train an object presence classifier, and used a reinforcement learning–optimized policy to guide a sliding window across the 3D image volume. The classifier outputs were accumulated to construct a voxel-level probability map, which was subsequently converted into a tumor segmentation mask. In other study, Sun et al. [163] employed a teacher-student framework that utilized both a pixel-annotated (strong) dataset and a bounding box-annotated (weak) dataset. Similarly, DeepRecS [155] segmented tumor regions using response evaluation criteria in solid tumors (RECIST) measurements [259]. Additionally, Couinaud segment annotations [260], commonly used by radiologists, have been leveraged to enhance liver tumor segmentation [74]. Several studies have used weak labels to segment lesions [254], [255], [257], with one specifically focusing on liver tumor segmentation [256].
These data-efficient learning strategies help address annotation challenges while enhancing segmentation performance in liver tumor analysis. Figure 10a and Figure 10b depict the Couinaud segments and RECIST marks, respectively.
COMPARATIVE ANALYSIS OF KEY TECHNIQUES
C.
Initial deep learning models (e.g., [90], [91], [101]) eliminated the need for hand-crafted features by automatically learning local spatial dependencies. Although they performed reasonably well on small objects, they often failed to preserve structural integrity and produced imprecise segmentation maps. Architectures with shortcut connections and deeper layers, such as H-Dense U-Net [142] and the modified SegNet proposed in [115], improved feature reuse, enabled richer representations, and allowed relatively fast training; however, they still struggled to capture global context and often lacked boundary precision. Reference [155] incorporated multi-scale feature fusion, which enhanced boundary delineation by leveraging global context, though at the expense of increased architectural complexity and the risk of including irrelevant features. Lightweight designs [100], [143], further reduced the number of parameters and training time but generally sacrificed robustness when applied to heterogeneous tumors. More recent efforts have integrated attention mechanisms to focus on clinically relevant regions and features. For example, [182] introduced HANS-Net, which combines hyperbolic convolutions with adaptive temporal attention and a synaptic plasticity module. These components enhance hierarchical feature representation, enforce inter-slice consistency, and improve robustness, leading to more accurate liver and tumor segmentation, albeit with higher architectural complexity. A comparative summary of these categorized approaches is provided in Table 5.
LOSS FUNCTION
D.
A liver tumor segmentation model maps an input image to a segmentation mask , which can be formalized as:
where is a binary mask indicating the tumor region [106]. DL models adjust a large set of parameters during the training process to maximize the likelihood of the predicted mask and the ground-truth mask . The optimal set of parameters is obtained by maximizing the log-likelihood over the training set [32]:
where denotes the total number of training samples. To achieve optimal segmentation, the loss between the predicted mask and the ground-truth mask must be minimized:
Choosing an appropriate loss function is critical when training DL models. An effective loss function should be differentiable, handle class imbalance, be robust to outliers, and align with the task objectives [262]. In liver tumor segmentation research, various loss functions have been widely adopted to enhance segmentation accuracy and overall model performance [45], [237], [263].
STANDARD LOSS FUNCTIONS IN TUMOR SEGMENTATION
CROSS ENTROPY (CE) LOSS
a:
Semantic segmentation is often considered as a pixel-wise classification problem. In this context, minimizing the negative log-likelihoods of pixel-wise predictions is achieved by minimizing the CE loss [264].
where denotes the set of all pixels in image , and is the predicted probability for pixel .
In liver tumor segmentation research, each pixel is typically classified as either part of a tumor or background. Binary cross-entropy (BCE) loss is widely used for this binary classification task [136]. However, due to the significant class imbalance between tumor regions and background, weighted cross-entropy (WCE) loss has been proposed to address this issue [265]. WCE applies pixel-wise or class-wise weighting schemes to assign greater importance to tumor pixels during training. For instance, some studies [47], [101] have applied foreground-background pixel weights to mitigate the effects of class imbalance.
DICE LOSS
b:
Dice loss is derived from the Dice similarity coefficient (DSC), which is a widely used statistical measure for evaluating segmentation accuracy [121]. It measures the overlap between predicted segmentation and ground-truth mask:
where is the number of images. and is a small constant that prevents the denominator from dropping to zero.
INTERSECTION OVER UNION LOSS
c:
The intersection over union (IoU) or Jaccard index, also known as the Jaccard similarity coefficient, measures the similarity between the predicted and ground truth masks [266]. The IoU loss function is formulated as:
The IoU loss function is effective for handling segmentation errors, particularly in cases where small regions like liver lesions are more likely to be misclassified.
TVERSKY LOSS
d:
The Tversky loss, inspired by the Tversky index [267], is a generalized form of the Jaccard Index that allows for asymmetric weighting of false positives and false negatives. It is specifically designed to address class imbalance in segmentation tasks by adjusting the penalty applied to each type of error.
where and are parameters that control the balance between false positives and false negatives. Typically, higher values of penalize false negatives more, which is beneficial when tumor regions are small compared to the background [268].
FOCAL LOSS
e:
Focal loss is a modified version of cross-entropy loss, designed to focus learning on hard-to-classify pixels by down-weighting well-classified examples [269]. This scaling mechanism reduces the impact of easy examples during training, enabling the model to prioritize learning from challenging examples more efficiently.
Here, is a balancing factor that adjusts the contribution of minority and majority classes in the data. is a focusing parameter that controls the emphasis on hard-to-classify examples. Higher values of reduce the impact of easy examples, allowing the model to concentrate on difficult cases. Focal loss is particularly useful in medical image segmentation, where small tumors are often underrepresented in training data [270].
COMBINED LOSS FUNCTIONS FOR ENHANCED SEGMENTATION
To improve the accuracy of liver tumor segmentation, mitigate class imbalance in CT images, and enhance model generalization, hybrid loss functions—which combine multiple loss types—are widely employed in recent research [271]. By integrating complementary loss functions, models can leverage the strengths of each while compensating for their individual limitations.
One of the most common combinations in liver tumor segmentation is Dice loss with BCE. While Dice loss captures the overall segmentation quality by focusing on region-level overlap, BCE ensures pixel-wise classification precision, leading to a more stable and effective optimization process [159]. Several studies have combined these two into a single BCE + Dice hybrid loss, resulting in improved segmentation accuracy and training stability [100], [125], [159].
To further address the prevalent imbalance between foreground and background samples, [173] proposed integrating cross-entropy loss, Dice loss, and Focal Tversky loss. Another study adopted a two-stage loss strategy—employing BCE during early training for faster convergence, followed by Tversky loss to focus on hard negative samples, thereby reducing misclassification of background regions [272].
In another approach, a dual supervision scheme was introduced by combining Dice loss with Euclidean loss, ensuring both spatial consistency and pixel-wise accuracy in liver tumor segmentation [141]. Additionally, shape-aware losses such as boundary loss, first proposed by Kervadec et al. [273], have been effectively combined with Dice loss to improve sensitivity to tumor boundaries and fine details [195]. Similarly, Han et al. [124] proposed a composite loss function—Dice+CE+contour loss—to enhance tumor edge detection and segmentation precision.
Beyond standard hybrid loss formulations, deep supervision has emerged as an effective strategy for further refining segmentation performance. Unlike conventional methods that apply a loss function only at the final layer, deep supervision introduces auxiliary loss terms at intermediate layers, encouraging the model to learn meaningful hierarchical representations [274]. For instance, a cascaded segmentation network, CDS-Net, applied deep supervision to guide liver lesion segmentation within a single deep network architecture [275].
Another powerful technique is adversarial training, which introduces a discriminator to evaluate the realism of predicted segmentation masks. This additional supervision encourages the segmentation network to produce more realistic and coherent results [276]:
where balances pixel-wise loss and adversarial loss . Adversarial loss typically uses BCE to push predictions closer to ground truth distributions [277].
MULTI-OBJECTIVE LOSS FUNCTIONS
Deep learning models for liver tumor segmentation have increasingly been extended to multi-task learning frameworks, where segmentation is performed alongside additional tasks such as lesion classification or boundary detection. These methods leverage shared feature representations to reduce false positives and improve overall efficiency.
Cascaded networks typically segment the liver first, followed by tumor segmentation, applying separate loss functions at each step [138], [218], [278]. However, cascade frameworks are not end-to-end; they require longer training times and introduce the risk of error propagation from liver segmentation to tumor segmentation [111].
To address this limitation, researchers have explored end-to-end joint segmentation models, where a single network simultaneously segments both the liver and liver tumors [111], [160], [197]. One such approach employed a dual U-Net architecture, with two parallel branches handling liver and tumor segmentation independently within the same network. This study found that similarity-based loss functions outperformed WCE loss [135].
Several studies have further expanded this approach by integrating segmentation and classification tasks within a unified model. For example, Y-Net [110] combined weighted cross-entropy for segmentation with categorical cross-entropy for classification, improving both segmentation accuracy and lesion categorization. Similarly, [167] used a joint loss function to simultaneously perform liver tumor segmentation and classification, while [147] extended this by incorporating detection, segmentation, and classification into a single pipeline. This model leveraged a weighted loss function combining cross-entropy loss and Dice loss for pixel-wise segmentation, BCE for patient-level classification, and L2 consistency loss to align lesion- and patient-level predictions.
Another promising direction involves boundary-aware segmentation models, which explicitly integrate edge detection into the segmentation task. Given the challenges posed by blurry tumor boundaries, a study by [279] introduced a three-channel model wherein separate channels were designed to learn liver segmentation, tumor segmentation, and edge prediction. This method improved segmentation accuracy, particularly near the boundaries.
Traditional models often treat segmentation and classification as independent tasks, leading to redundant computation due to separate feature extraction processes. This separation can reduce classification accuracy since segmentation-derived features are not fully utilized, and may lead to suboptimal feature representations, where classification models do not benefit from segmentation-guided learning. In contrast, multi-task learning frameworks provide a more unified approach by integrating segmentation and classification, allowing for shared feature representations that improve overall model performance and enhance feature learning [156].
EVALUATION
V.
SEGMENTATION ANNOTATIONS
A.
Accurate annotations are essential for evaluating deep learning-based liver tumor segmentation models, yet obtaining high-quality ground truth is both costly and challenging. Expert-annotated datasets enable model training, with annotation methods ranging from semi-automatic techniques, where experts refine software-generated borders, to manual segmentation, in which lesions are traced using tools like ITK-SNAP [280], a widely used open-source annotation software. While manual annotation is commonly used and generally reliable, it is time-consuming and requires expert-level training [237], [281].
Annotation noise—resulting from data uncertainties and inter-observer variability—can significantly impact segmentation performance [282]. Variability among annotators, or even within the same expert over time, introduces inconsistencies. Metrics such as the Dice similarity coefficient (DSC) and Cohen’s Kappa [283] are commonly used to quantify inter-annotator agreement, providing a quantitative measure of annotation reliability. Due to the high cost of annotation, many datasets rely on a single annotator; however, multi-expert annotations, such as those in the LiTS17 dataset, often implement consensus mechanisms to resolve discrepancies [32].
Strategies for ground truth consolidation include bitwise operations [284], majority voting [285], shape averaging [286], [287], and statistical methods such as STAPLE [288] and SIMPLE [289], which weigh annotations based on annotator expertise. For example, the LiTS17 dataset was manually segmented by a radiologist with over three years of oncologic imaging experience, reviewed by three independent readers, and finalized by the most senior expert [33]. Such multi-expert validation enhances dataset reliability and ultimately improves the performance of segmentation models.
EVALUATION METRICS
B.
Several metrics are widely used to evaluate the performance of medical image segmentation algorithms, particularly in liver tumor segmentation research [290]. These metrics quantitatively assess the agreement between predicted segmentations and ground truth annotations. Liver tumor segmentation can be framed as a classification problem, where the positive class represents the tumor lesion and the negative class represents the background, as illustrated in Figure 11.
For this classification task, a confusion matrix [291] is used, where TP, FN, FP, and TN represent true positives, false negatives, false positives, and true negatives, respectively. In addition to confusion matrix-based metrics, distance-based evaluation metrics are also employed to capture the spatial accuracy of the segmentation results. Table 6 provides a summary of key evaluation metrics commonly reported in the literature.
DISCUSSION
VI.
CHALLENGES AND LIMITATIONS
A.
While CT remains the most widely used modality for liver tumor segmentation due to its availability, high spatial resolution, and quantitative HU values, it has notable disadvantages compared with other modalities. MRI offers superior soft-tissue contrast and multiparametric imaging sequences, which improve delineation of small lesions, but it is more expensive, slower, and less accessible in routine practice. Notably, 4D MRI has been shown to yield fewer artifacts and more accurate motion assessment than 4D CT, thereby reducing uncertainty in target delineation for radiotherapy [292]. Ultrasound, particularly contrast-enhanced ultrasound (CEUS), offers portability, cost-effectiveness, real-time imaging, and higher temporal and in-plane spatial resolution than CT or MRI, with the added benefit of being radiation-free and associated with lower risk of adverse reactions. Nevertheless, CEUS is constrained by operator dependence, limited penetration in certain patients, lack of multiplanar capability, and reduced reproducibility [293]. Recent studies suggest that combining CT with CEUS or MRI can leverage the complementary strengths of these modalities—CT for structural and quantitative information, CEUS/MRI for functional or contrast sensitivity— to improve segmentation accuracy [45]. However, multi-modal approaches introduce additional challenges, including registration, increased computational cost, and harmonization across imaging protocols [45].
In liver tumor segmentation, data diversity and quality are critical for developing effective DL models [33]. A major limitation in this field is the scarcity of benchmark datasets with expert pixel-level annotations, which are essential for accurate tumor identification [45]. While traditional image augmentation techniques attempt to address this limitation by generating new data, they typically provide only minor modifications to existing samples, offering limited enhancement in data diversity [76]. Consequently, augmented data often retains the same underlying distribution, providing minimal variation and limited additional insight for the model.
Generative approaches, such as GAN-based synthesis, offer a more advanced solution. However, they are computationally intensive, require large amounts of real data for training, may be sensitive to inconsistent tumor masks and depend heavily on precise pixel-wise tumor masks [57], [65]. Similarly, heuristic methods struggle to accurately replicate complex tumor characteristics—such as shape, location, and texture—that are essential for capturing the detailed pathology of liver tumors [235]. As a result, achieving high-quality, diverse data for liver tumor synthesis remains a major challenge, limiting further improvements in segmentation accuracy.
The lack of diverse, annotated datasets can result in poor model generalizability, increased risk of overfitting, and domain shift issues when synthetic data is used for training [235]. Table 2 illustrates the scarcity of publicly available datasets with comprehensive annotations. These challenges highlight the importance of developing effective strategies to preserve the utility of synthetic data in enhancing model performance. While supervised learning continues to dominate training paradigms in DL-based segmentation (as shown in Figure 9) [294], alternative approaches— such as semi-supervised, self-supervised, weakly supervised, and unsupervised learning—remain underexplored and may provide promising avenues to address data limitations [236], [294].
The continued success of DL in medical image analysis depends significantly on appropriate learning paradigms (e.g., supervised vs. unsupervised) and the evolution of network architectures [295]. Architectural advancements—from basic CNNs to specialized models like U-Net—have played a pivotal role in improving segmentation performance [296]. Attention mechanisms and transformer-based architectures further enhanced global context modeling and introduced valuable inductive biases, boosting segmentation accuracy for complex medical images [173]. However, larger models capable of analyzing high-dimensional medical images often demand significant computational resources, posing accessibility barriers for researchers without high-end hardware [297]. This trade-off between performance and resource efficiency emphasizes the importance of optimizing both model architecture and computational cost.
Additionally, a recurring limitation in the literature is the lack of transparency regarding code, hyperparameter settings, and implementation details, which hampers reproducibility [298]. Promoting open sharing of models, code, and training settings can significantly contribute to community-wide progress and amplify scientific impact.
Beyond algorithmic performance, liver tumor segmentation carries important clinical implications. Accurate delineation of tumors enables precise estimation of tumor burden, which informs surgical planning and eligibility for liver transplantation [113]. In radiation oncology, reliable segmentation ensures accurate targeting of lesions while minimizing exposure to surrounding healthy tissue [12]. Segmentation results are also essential for monitoring treatment response under RECIST criteria and can support prognostic modeling by quantifying tumor morphology and heterogeneity [14]. Despite these benefits, clinical adoption remains limited, highlighting the need for models that are reproducible, stable, and generalizable across centers, as well as seamlessly integrated into existing clinical workflows. Privacy concerns surrounding patient data storage and inter-institutional sharing require robust solutions and regulatory frameworks that ensure security and compliance. Furthermore, developing standardized protocols for secure data exchange between medical institutions will be essential for multi-center validation and deployment. Another critical direction is the simplification of annotation processes, which remain a major bottleneck in training and validating segmentation models. Tools that streamline annotation and support radiologists more efficiently will facilitate smoother integration into clinical practice and encourage widespread adoption.
In summary, overcoming the challenges and limitations of deep learning techniques for liver segmentation is essential for their effective adoption in clinical settings. Key areas of focus should include managing data scarcity by utilizing more accessible datasets, enhancing the robustness of DL approaches, improving interpretability, refining uncertainty estimation, and considering ethical implications. These efforts will be essential for advancing and responsibly implementing deep learning models in liver segmentation.
PROSPECTS FOR FURTHER INVESTIGATION
B.
Deep learning has revolutionized medical image segmentation, particularly in the challenging domain of liver tumor analysis [299]. While numerous studies have demonstrated its effectiveness [296], several promising avenues remain underexplored.
First, leveraging state-of-the-art image generation techniques could significantly enhance segmentation performance [64]. The success of deep learning models largely depends on the availability of large, diverse, and accurately annotated datasets [76]. However, publicly available liver tumor datasets often suffer from limitations in terms of size, heterogeneity, and representativeness [33]. This underscores the importance of exploring advanced generative methods, which have the potential to substantially improve segmentation outcomes [64], [65]. In particular, diffusion probabilistic models represent a compelling direction for generating realistic synthetic data, thereby augmenting training datasets and improving model generalizability [300].
Second, integrating expert knowledge with deep features holds great promise for advancing segmentation accuracy [69]. Radiologists possess valuable domain-specific insights, enabling precise manual segmentation. However, this process is both time-consuming and subject to inter-observer variability [235], [288]. A hybrid approach—one that combines deep learning-derived features with handcrafted features reflecting anatomical priors (e.g., shape, texture, appearance)—could improve not only segmentation accuracy but also model interpretability [301]. Although some research has begun to explore this integration [302], further studies are needed to fully realize its potential.
Third, the automation of annotation using information from radiologists’ reports is an emerging area of interest. These reports—whether in free-text form or structured formats like the liver imaging reporting and data system (LI-RADS)—contain rich semantic information that could guide model training [303]. Previous work has investigated using Couinaud segment annotations and RECIST markers as weak supervision sources for segmentation [74], [155]. However, automatically converting narrative reports into accurate annotations using NLP remains a significant challenge [304].
Finally, leveraging existing medical images and annotations across multiple organs to improve the generalizability of models for liver tumor segmentation has recently emerged as a promising direction that warrants greater attention and has the potential to transform the field [305]. development of foundation models such as SAM and CLIP offers exciting opportunities for interactive, general-purpose medical image segmentation guided by natural language supervision [200], [203], [205]. When combined with large language models (LLMs), these systems could bridge the gap between image and text understanding, enabling more intuitive and flexible interactions with medical data.
In summary, future research in liver tumor segmentation should prioritize the development of more diverse and representative datasets [52], [76], the integration of expert-driven and deep features [301], the use of advanced generative models such as diffusion methods [68], the automation of annotation via NLP techniques [304], and the application of foundation models and large language models to bridge visual and textual data [200]. These advancements will play a crucial role in enhancing both the accuracy and clinical applicability of deep learning-based segmentation systems.
CONCLUSION
VII.
Medical image analysis heavily relies on segmentation—a fundamental task for identifying anatomical structures and pathological regions of interest. In this study, we conducted a comprehensive survey of DL architectures applied to liver tumor segmentation in CT images. Our investigation spans from early DL models to recent advances, highlighting the architectural evolution over time.
CNNs have emerged as the dominant architecture for both liver and liver tumor segmentation in 3D medical images. A common strategy adopted by researchers involves a two-step process: initially segmenting the liver, followed by tumor segmentation within the liver region defined as the ROI. While recent DL architectures have significantly improved tumor segmentation accuracy, further refinement is needed for practical clinical deployment.
Although automatic liver segmentation techniques have achieved performance levels comparable to human experts, liver tumor segmentation continues to pose major challenges. One of the primary obstacles is the limited availability of publicly accessible datasets with comprehensive tumor annotations. Broader access to such datasets would support the development and evaluation of more robust 3D DL architectures tailored for volumetric medical imaging. Moreover, insights derived from models trained on these datasets could inform the design of computer-aided detection (CAD) systems, enabling automated tumor identification with minimal human intervention.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Siegel RL, Kratzer TB, Giaquinto AN, Sung H, and Jemal A, “Cancer statistics,” CA, Cancer J. Clinicians, vol. 75, no. 1, pp. 10–45, Jan. 2025.
- 2Chou R, Cuevas C, Fu R, Devine B, Wasson N, Ginsburg A, Zakher B, Pappas M, Graham E, and Sullivan SD, “The diagnostic value of serum Glypican-3 in the diagnosis of hepatocellular carcinoma: A systematic review and meta-analysis,” Int. J. Health Med. Res, vol. 2, no. 10, pp. 697–711, Sep. 2015.
- 3Fass L, “Imaging and cancer: A review,” Mol. Oncol, vol. 2, no. 2, pp. 115–152, 2008.19383333 10.1016/j.molonc.2008.04.001PMC 5527766 · doi ↗ · pubmed ↗
- 4Fox SH, Tanenbaum L, Ackelsberg SM, He H, Hsieh J, and Hu H, “Future directions in CT technology,” Neuroimaging Clinics North Amer, vol. 8, no. 3, pp. 497–513, 1998.
- 5Yeh BM, Fitz Gerald PF, Edic PM, Lambert JW, Colborn RE, Marino ME, Evans PM, Roberts JC, Wang ZJ, Wong MJ, and Bonitatibus PJ, “Opportunities for new CT contrast agents to maximize the diagnostic potential of emerging spectral CT technologies,” Adv. Drug Del. Rev, vol. 113, pp. 201–222, Apr. 2017.
- 6Stoker J, “Magnetic resonance imaging and the acute abdomen,” Brit. J. Surgery, vol. 95, no. 10, pp. 1193–1194, Sep. 2008.
- 7Rashidian N, Alseidi A, and Kirks RC, “Cancers metastatic to the liver,” Surgical Clinics North Amer, vol. 100, no. 3, pp. 551–563, Jun. 2020.
- 8Schwartz LH, Litière S, de Vries E, Ford R, Gwyther S, Mandrekar S, Shankar L, Bogaerts J, Chen A, Dancey J, Hayes W, Hodi FS, Hoekstra OS, Huang EP, Lin N, Liu Y, Therasse P, Wolchok JD, and Seymour L, “RECIST 1.1—Update and clarification: From the RECIST committee,” Eur. J. Cancer, vol. 62, pp. 132–137, Jul. 2016.27189322 10.1016/j.ejca.2016.03.081PMC 5737828 · doi ↗ · pubmed ↗