Delayformer: Spatiotemporal Transformation for Predicting High‐Dimensional Dynamics
Zijian Wang, Peng Tao, Luonan Chen

TL;DR
Delayformer is a new framework that uses a shared Vision Transformer to predict dynamics in high-dimensional systems by converting variables into delay-embedded states.
Contribution
Introduces Delayformer with a novel multivariate spatiotemporal transformation for high-dimensional time-series prediction.
Findings
Delayformer outperforms state-of-the-art methods on synthetic and real-world datasets.
The framework demonstrates cross-domain forecasting capabilities and broad applicability.
Uses delay embedding theory and Transformer architecture to handle nonlinear interactions.
Abstract
Predicting time series is of great importance in various scientific and engineering fields. However, in the context of limited and noisy data, accurately predicting the dynamics of all variables in a high‐dimensional system is a challenging task due to their nonlinearity and complex interactions. This study introduces the Delayformer framework for simultaneously predicting the dynamics of all variables by developing a novel multivariate spatiotemporal information (mvSTI) transformation that makes each observed variable into a delay‐embedded state (vector) and further cross‐learns those states from different variables. From a dynamical systems viewpoint, Delayformer predicts system states rather than individual variables, thus theoretically and computationally overcoming such nonlinearity and cross‐interaction problems. Specifically, it first utilizes a single shared Visual Transformer…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
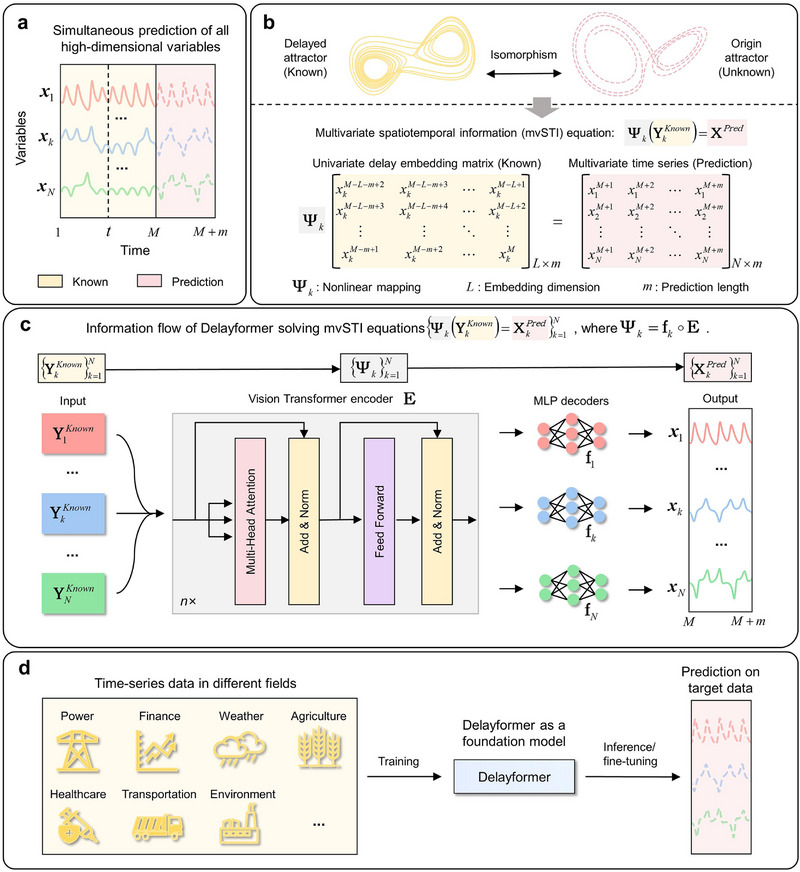 Figure 1
Figure 1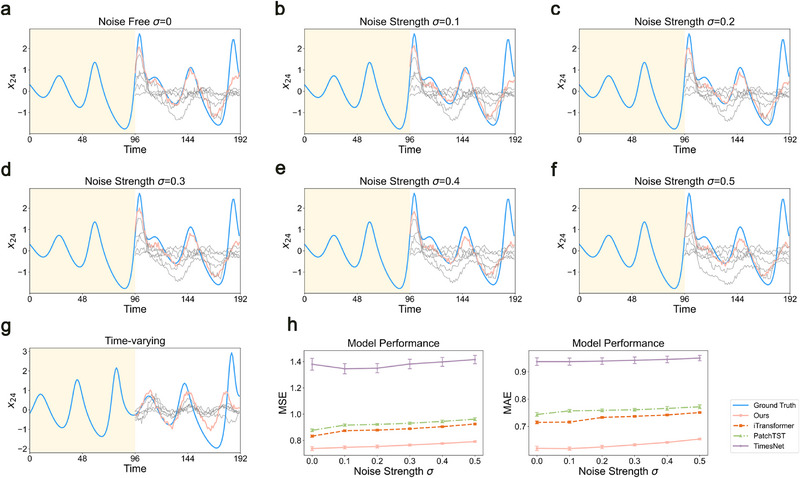 Figure 2
Figure 2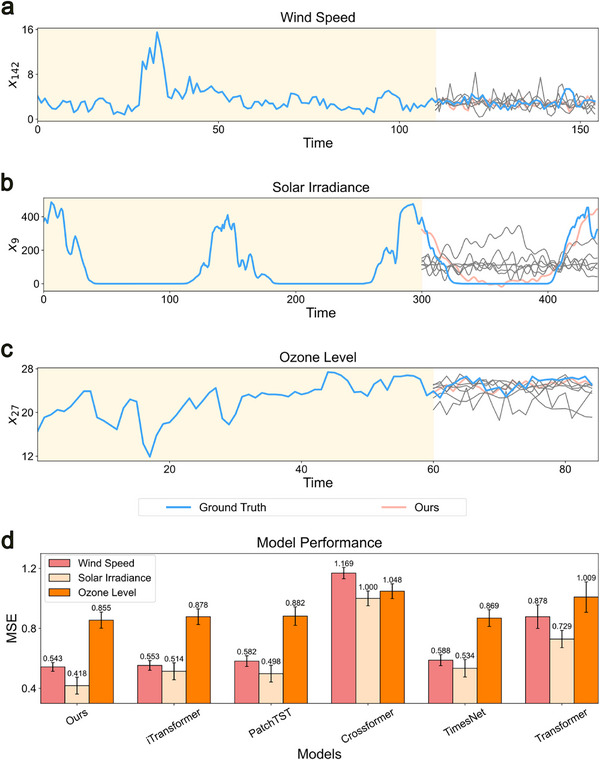 Figure 3
Figure 3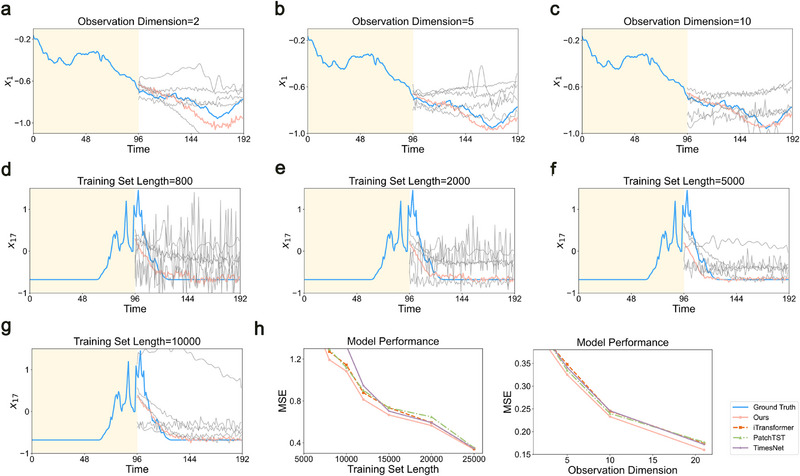 Figure 4
Figure 4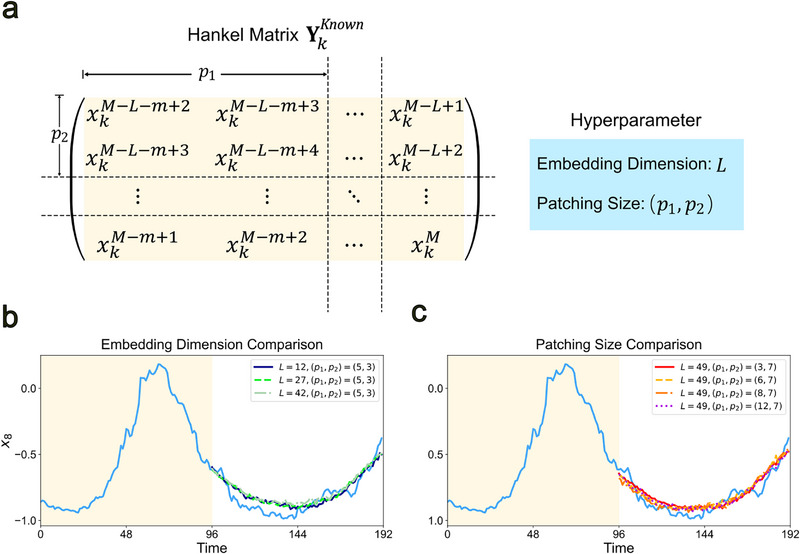 Figure 5
Figure 5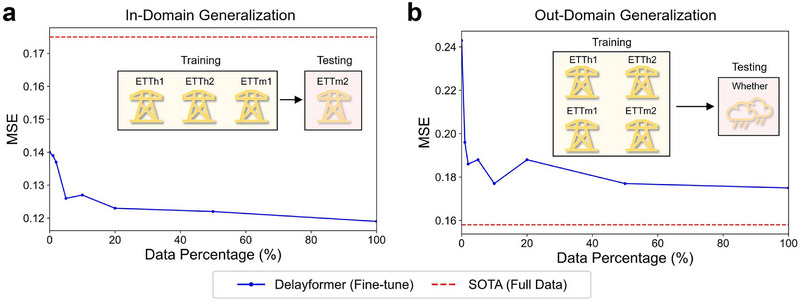 Figure 6
Figure 6| Models | Ours | iTransformer | Rlinear | PatchTST | Crossformer | TiDE | TimesNet | Dlinear | SCINet | FEDformer | Stationary | Autoformer | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | |
| ETTh1 | 96 | 0.379 | 0.400 | 0.386 | 0.405 | 0.386 | 0.395 | 0.414 | 0.419 | 0.423 | 0.448 | 0.479 | 0.464 | 0.384 | 0.402 | 0.386 | 0.400 | 0.654 | 0.599 | 0.376 | 0.419 | 0.513 | 0.491 | 0.449 | 0.459 |
| 192 | 0.428 | 0.434 | 0.441 | 0.436 | 0.437 | 0.424 | 0.460 | 0.445 | 0.471 | 0.474 | 0.525 | 0.492 | 0.436 | 0.429 | 0.437 | 0.432 | 0.719 | 0.631 | 0.420 | 0.448 | 0.534 | 0.504 | 0.500 | 0.482 | |
| 336 | 0.476 | 0.451 | 0.487 | 0.458 | 0.479 | 0.446 | 0.501 | 0.466 | 0.570 | 0.546 | 0.565 | 0.515 | 0.491 | 0.469 | 0.481 | 0.459 | 0.778 | 0.659 | 0.459 | 0.465 | 0.588 | 0.535 | 0.521 | 0.496 | |
| 720 | 0.468 | 0.465 | 0.503 | 0.491 | 0.481 | 0.470 | 0.500 | 0.488 | 0.653 | 0.621 | 0.594 | 0.558 | 0.521 | 0.500 | 0.519 | 0.516 | 0.836 | 0.699 | 0.506 | 0.507 | 0.643 | 0.616 | 0.514 | 0.512 | |
| Avg | 0.438 | 0.438 | 0.454 | 0.447 | 0.446 | 0.434 | 0.469 | 0.454 | 0.529 | 0.522 | 0.541 | 0.507 | 0.458 | 0.450 | 0.456 | 0.452 | 0.747 | 0.647 | 0.440 | 0.460 | 0.570 | 0.537 | 0.496 | 0.487 | |
| ETTh2 | 96 | 0.290 | 0.338 | 0.297 | 0.349 | 0.288 | 0.338 | 0.302 | 0.348 | 0.745 | 0.584 | 0.400 | 0.440 | 0.340 | 0.374 | 0.333 | 0.387 | 0.707 | 0.621 | 0.358 | 0.397 | 0.476 | 0.458 | 0.346 | 0.388 |
| 192 | 0.369 | 0.391 | 0.380 | 0.400 | 0.374 | 0.390 | 0.388 | 0.400 | 0.877 | 0.656 | 0.528 | 0.509 | 0.402 | 0.414 | 0.477 | 0.476 | 0.860 | 0.689 | 0.429 | 0.439 | 0.512 | 0.493 | 0.456 | 0.452 | |
| 336 | 0.423 | 0.427 | 0.428 | 0.432 | 0.415 | 0.426 | 0.426 | 0.433 | 1.043 | 0.731 | 0.643 | 0.571 | 0.452 | 0.452 | 0.594 | 0.541 | 1.000 | 0.744 | 0.496 | 0.487 | 0.552 | 0.551 | 0.482 | 0.486 | |
| 720 | 0.427 | 0.441 | 0.427 | 0.445 | 0.420 | 0.440 | 0.431 | 0.446 | 1.104 | 0.763 | 0.874 | 0.679 | 0.462 | 0.468 | 0.831 | 0.657 | 1.249 | 0.838 | 0.463 | 0.474 | 0.562 | 0.560 | 0.515 | 0.511 | |
| Avg | 0.377 | 0.399 | 0.383 | 0.407 | 0.374 | 0.398 | 0.387 | 0.407 | 0.942 | 0.684 | 0.611 | 0.550 | 0.414 | 0.427 | 0.559 | 0.515 | 0.954 | 0.723 | 0.437 | 0.449 | 0.526 | 0.516 | 0.450 | 0.459 | |
| ETTm1 | 96 | 0.320 | 0.362 | 0.334 | 0.368 | 0.355 | 0.376 | 0.329 | 0.367 | 0.404 | 0.426 | 0.364 | 0.387 | 0.338 | 0.375 | 0.345 | 0.372 | 0.418 | 0.438 | 0.379 | 0.419 | 0.386 | 0.398 | 0.505 | 0.475 |
| 192 | 0.356 | 0.382 | 0.377 | 0.391 | 0.391 | 0.392 | 0.367 | 0.385 | 0.450 | 0.451 | 0.398 | 0.404 | 0.374 | 0.387 | 0.380 | 0.389 | 0.439 | 0.450 | 0.426 | 0.441 | 0.459 | 0.444 | 0.553 | 0.496 | |
| 336 | 0.388 | 0.406 | 0.426 | 0.420 | 0.424 | 0.415 | 0.399 | 0.410 | 0.532 | 0.515 | 0.428 | 0.425 | 0.410 | 0.411 | 0.413 | 0.413 | 0.490 | 0.485 | 0.445 | 0.459 | 0.495 | 0.464 | 0.621 | 0.537 | |
| 720 | 0.445 | 0.440 | 0.491 | 0.459 | 0.487 | 0.450 | 0.454 | 0.439 | 0.666 | 0.589 | 0.487 | 0.461 | 0.478 | 0.450 | 0.474 | 0.453 | 0.595 | 0.550 | 0.543 | 0.490 | 0.585 | 0.516 | 0.671 | 0.561 | |
| Avg | 0.377 | 0.398 | 0.407 | 0.410 | 0.414 | 0.407 | 0.387 | 0.400 | 0.513 | 0.496 | 0.419 | 0.419 | 0.400 | 0.406 | 0.403 | 0.407 | 0.485 | 0.481 | 0.448 | 0.452 | 0.481 | 0.456 | 0.588 | 0.517 | |
| ETTm2 | 96 | 0.175 | 0.260 | 0.180 | 0.264 | 0.182 | 0.265 | 0.175 | 0.259 | 0.287 | 0.366 | 0.207 | 0.305 | 0.187 | 0.267 | 0.193 | 0.292 | 0.286 | 0.377 | 0.203 | 0.287 | 0.192 | 0.274 | 0.255 | 0.339 |
| 192 | 0.245 | 0.308 | 0.250 | 0.309 | 0.246 | 0.304 | 0.241 | 0.302 | 0.414 | 0.492 | 0.290 | 0.364 | 0.249 | 0.309 | 0.284 | 0.362 | 0.399 | 0.445 | 0.269 | 0.328 | 0.280 | 0.339 | 0.281 | 0.340 | |
| 336 | 0.304 | 0.344 | 0.311 | 0.348 | 0.307 | 0.342 | 0.305 | 0.343 | 0.597 | 0.542 | 0.377 | 0.422 | 0.321 | 0.351 | 0.369 | 0.427 | 0.637 | 0.591 | 0.325 | 0.366 | 0.334 | 0.361 | 0.339 | 0.372 | |
| 720 | 0.401 | 0.400 | 0.412 | 0.407 | 0.407 | 0.398 | 0.402 | 0.400 | 1.730 | 1.042 | 0.558 | 0.524 | 0.408 | 0.403 | 0.554 | 0.522 | 0.960 | 0.735 | 0.421 | 0.415 | 0.417 | 0.413 | 0.433 | 0.432 | |
| Avg | 0.281 | 0.328 | 0.288 | 0.332 | 0.286 | 0.327 | 0.281 | 0.326 | 0.757 | 0.610 | 0.358 | 0.404 | 0.291 | 0.333 | 0.350 | 0.401 | 0.571 | 0.537 | 0.305 | 0.349 | 0.306 | 0.347 | 0.327 | 0.371 | |
| Weather | 96 | 0.160 | 0.210 | 0.174 | 0.214 | 0.192 | 0.232 | 0.177 | 0.218 | 0.158 | 0.230 | 0.202 | 0.261 | 0.172 | 0.220 | 0.196 | 0.255 | 0.221 | 0.306 | 0.217 | 0.296 | 0.173 | 0.223 | 0.266 | 0.336 |
| 192 | 0.208 | 0.252 | 0.221 | 0.254 | 0.240 | 0.271 | 0.225 | 0.259 | 0.206 | 0.277 | 0.242 | 0.298 | 0.219 | 0.261 | 0.237 | 0.296 | 0.261 | 0.340 | 0.276 | 0.336 | 0.245 | 0.285 | 0.307 | 0.367 | |
| 336 | 0.265 | 0.293 | 0.278 | 0.296 | 0.292 | 0.307 | 0.278 | 0.297 | 0.272 | 0.335 | 0.287 | 0.335 | 0.280 | 0.306 | 0.283 | 0.335 | 0.309 | 0.378 | 0.339 | 0.380 | 0.321 | 0.338 | 0.359 | 0.395 | |
| 720 | 0.346 | 0.346 | 0.358 | 0.349 | 0.364 | 0.353 | 0.354 | 0.348 | 0.398 | 0.418 | 0.351 | 0.386 | 0.365 | 0.359 | 0.345 | 0.381 | 0.377 | 0.427 | 0.403 | 0.428 | 0.414 | 0.410 | 0.419 | 0.428 | |
| Avg | 0.245 | 0.275 | 0.258 | 0.279 | 0.272 | 0.291 | 0.259 | 0.281 | 0.259 | 0.315 | 0.271 | 0.320 | 0.259 | 0.287 | 0.265 | 0.317 | 0.292 | 0.363 | 0.309 | 0.360 | 0.288 | 0.314 | 0.338 | 0.382 | |
| Solar‐Energy | 96 | 0.213 | 0.271 | 0.203 | 0.237 | 0.322 | 0.339 | 0.234 | 0.286 | 0.310 | 0.331 | 0.312 | 0.399 | 0.250 | 0.292 | 0.290 | 0.378 | 0.237 | 0.344 | 0.242 | 0.342 | 0.215 | 0.249 | 0.884 | 0.711 |
| 192 | 0.246 | 0.295 | 0.233 | 0.261 | 0.359 | 0.356 | 0.267 | 0.310 | 0.734 | 0.725 | 0.339 | 0.416 | 0.296 | 0.318 | 0.320 | 0.398 | 0.280 | 0.380 | 0.285 | 0.380 | 0.254 | 0.272 | 0.834 | 0.692 | |
| 336 | 0.266 | 0.304 | 0.248 | 0.273 | 0.397 | 0.369 | 0.290 | 0.315 | 0.750 | 0.735 | 0.368 | 0.430 | 0.319 | 0.330 | 0.353 | 0.415 | 0.304 | 0.389 | 0.282 | 0.376 | 0.290 | 0.296 | 0.941 | 0.723 | |
| 720 | 0.267 | 0.309 | 0.249 | 0.275 | 0.397 | 0.356 | 0.289 | 0.317 | 0.769 | 0.765 | 0.370 | 0.425 | 0.338 | 0.337 | 0.356 | 0.413 | 0.308 | 0.388 | 0.357 | 0.427 | 0.285 | 0.295 | 0.882 | 0.717 | |
| Avg | 0.248 | 0.295 | 0.233 | 0.262 | 0.369 | 0.356 | 0.270 | 0.307 | 0.641 | 0.639 | 0.347 | 0.417 | 0.301 | 0.319 | 0.330 | 0.401 | 0.282 | 0.375 | 0.291 | 0.381 | 0.261 | 0.381 | 0.885 | 0.711 | |
| Electricity | 96 | 0.158 | 0.260 | 0.148 | 0.240 | 0.201 | 0.281 | 0.195 | 0.285 | 0.219 | 0.314 | 0.237 | 0.329 | 0.168 | 0.272 | 0.197 | 0.282 | 0.247 | 0.345 | 0.193 | 0.308 | 0.169 | 0.273 | 0.201 | 0.317 |
| 192 | 0.172 | 0.271 | 0.162 | 0.253 | 0.201 | 0.283 | 0.199 | 0.289 | 0.231 | 0.322 | 0.236 | 0.330 | 0.184 | 0.289 | 0.196 | 0.285 | 0.257 | 0.355 | 0.201 | 0.315 | 0.182 | 0.286 | 0.222 | 0.334 | |
| 336 | 0.191 | 0.289 | 0.178 | 0.269 | 0.215 | 0.298 | 0.215 | 0.305 | 0.246 | 0.337 | 0.249 | 0.344 | 0.198 | 0.300 | 0.209 | 0.301 | 0.269 | 0.369 | 0.214 | 0.329 | 0.200 | 0.304 | 0.231 | 0.338 | |
| 720 | 0.230 | 0.323 | 0.225 | 0.317 | 0.257 | 0.331 | 0.256 | 0.337 | 0.280 | 0.363 | 0.284 | 0.373 | 0.220 | 0.320 | 0.245 | 0.333 | 0.299 | 0.390 | 0.246 | 0.355 | 0.222 | 0.321 | 0.254 | 0.361 | |
| Avg | 0.188 | 0.286 | 0.178 | 0.270 | 0.219 | 0.298 | 0.216 | 0.304 | 0.244 | 0.334 | 0.251 | 0.344 | 0.192 | 0.295 | 0.212 | 0.300 | 0.268 | 0.365 | 0.214 | 0.327 | 0.193 | 0.296 | 0.227 | 0.338 | |
| Traffic | 96 | 0.504 | 0.316 | 0.395 | 0.268 | 0.649 | 0.389 | 0.544 | 0.359 | 0.522 | 0.290 | 0.805 | 0.493 | 0.593 | 0.321 | 0.650 | 0.396 | 0.788 | 0.499 | 0.587 | 0.366 | 0.612 | 0.338 | 0.613 | 0.388 |
| 192 | 0.513 | 0.319 | 0.417 | 0.276 | 0.601 | 0.366 | 0.540 | 0.354 | 0.530 | 0.293 | 0.756 | 0.474 | 0.617 | 0.336 | 0.598 | 0.370 | 0.789 | 0.505 | 0.604 | 0.373 | 0.613 | 0.340 | 0.616 | 0.382 | |
| 336 | 0.510 | 0.309 | 0.433 | 0.283 | 0.609 | 0.369 | 0.551 | 0.358 | 0.558 | 0.305 | 0.762 | 0.477 | 0.629 | 0.336 | 0.605 | 0.373 | 0.797 | 0.508 | 0.621 | 0.383 | 0.618 | 0.328 | 0.622 | 0.337 | |
| 720 | 0.547 | 0.332 | 0.467 | 0.302 | 0.647 | 0.387 | 0.586 | 0.375 | 0.589 | 0.328 | 0.719 | 0.449 | 0.640 | 0.350 | 0.645 | 0.394 | 0.841 | 0.523 | 0.626 | 0.382 | 0.653 | 0.355 | 0.660 | 0.408 | |
| Avg | 0.519 | 0.319 | 0.428 | 0.282 | 0.626 | 0.378 | 0.555 | 0.362 | 0.550 | 0.304 | 0.760 | 0.473 | 0.620 | 0.336 | 0.625 | 0.383 | 0.804 | 0.509 | 0.610 | 0.376 | 0.624 | 0.340 | 0.628 | 0.379 | |
| 1st+2nd | 39 | 35 | 16 | 20 | 6 | 14 | 10 | 10 | 3 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | |
- —Natural Science Foundation of China10.13039/501100001809
- —National Key R&D Program of China10.13039/501100012166
- —Zhejiang Province Vanguard Goose‐Leading Initiative
- —Hangzhou Institute for advanced study of UCAS
- —Moonshot Research and Development Program10.13039/501100020963
- —Science and Technology Commission of Shanghai Municipality10.13039/501100003399
- —Lingang Laboratory
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTime Series Analysis and Forecasting · Neural Networks and Reservoir Computing · Machine Fault Diagnosis Techniques
Introduction
1
Time‐series data, which comprises sequences of values or observations obtained over successive periods, is ubiquitous across diverse domains, such as meteorology (temperature,^[^ 1 ^]^ precipitation,^[^ 2 ^]^ typhoon movement^[^ 3 ^]^), finance (stock prices,^[^ 4 ^]^ economic indicators^[^ 5 ^]^), healthcare (heart rate,^[^ 6 ^]^ patient monitoring^[^ 7 ^]^), epidemic outbreak prediction,^[^ 8 ^]^ and industry (instrument detection,^[^ 9 ^]^ electricity allocation^[^ 10 ^]^). Modeling time‐series data for real‐world systems remains a significant challenge^[^ 11, 12 ^]^ despite its widespread applications, with numerous mathematical and computational approaches developed over the years. Among these, time‐series forecasting (TSF) stands out as particularly critical.
In early studies, statistical analysis and machine learning approaches such as autoregressive (AR) models,^[^ 13 ^]^ seasonal autoregressive integrated moving average with exogenous variables (SARIMAX),^[^ 14, 15 ^]^ and support vector machines (SVM)^[^ 16 ^]^ were commonly employed. More recently, deep learning has shown remarkable performance in natural language processing (NLP),^[^ 17 ^]^ computer vision (CV),^[^ 18 ^]^ and time‐series forecasting,^[^ 19 ^]^ attributed to its strong representation capability. In the realm of TSF, methods based on recurrent neural networks (RNNs),^[^ 20 ^]^ temporal convolutional networks (TCNs),^[^ 21 ^]^ linear models,^[^ 22 ^]^ and Transformers^[^ 23 ^]^ have emerged as mainstream approaches. Notably, despite the challenges posed by linear models,^[^ 22, 24 ^]^ the emergence of models like PatchTST,^[^ 25 ^]^ Crossformer,^[^ 26 ^]^ and iTransformer^[^ 27 ^]^ indicates the high development potential of Transformer‐based models. These models highlight the importance of incorporating patching and channel‐independence in Transformers for TSF.^[^ 28, 29 ^]^ However, they still face challenges in learning from limited and noisy training samples, especially in high‐dimensional and short‐term forecasting scenarios, because they tend to overlook the dynamic properties of the underlying system. Additionally, Transformers often rely on heuristic methods to handle interactions between different variables and are less effective in embedding temporal information.^[^ 30 ^]^
Dynamical system theory, which treats time‐series data as observations of a system state, different from statistical theory, offers a wide range of analytical tools, including phase space reconstruction,^[^ 31 ^]^ Lyapunov exponents,^[^ 32 ^]^ attractors,^[^ 33 ^]^ bifurcation theory,^[^ 34 ^]^ differential equation models,^[^ 35 ^]^ and time‐delay embedding techniques.^[^ 36 ^]^ Delay embedding theory suggests that the information in the phase space (or feature space in machine learning) of a system is often redundant.^[^ 37 ^]^ The fractal dimension of attractors in high‐dimensional nonlinear systems tends not to be large and is actually rather low even with many variables.^[^ 38 ^]^ Moreover, according to the delay embedding theory, the topology of a dynamical system can generally be reconstructed from the delay embedding of any observed variable. Classical results such as the Whitney Embedding Theorem and Takens' theorem established that the state space of a dynamic system can be faithfully recovered from time‐delayed observations of a single variable. These foundations were further generalized in the seminal works by Sauer et al.^[^ 39 ^]^ and Hunt et al.,^[^ 40 ^]^ which extends the theory from smooth manifolds to fractal attractors and infinite‐dimensional Banach spaces. These allow one to transform the spatial information (the interactions between variables) of high‐dimensional data into the temporal dynamics of a single variable, a process known as spatiotemporal information (STI) transformation, thus immediately leading to the prediction of this variable. Many methods have been developed based on STI for this purpose. Ma et al.^[^ 41 ^]^ introduced a randomly distributed embedding (RDE) framework for one‐step‐ahead prediction by constructing multiple STI maps separately. Subsequently, multilayer neural networks,^[^ 42 ^]^ reservoir computing,^[^ 43 ^]^ Transformer,^[^ 44 ^]^ multitask Gaussian process regression^,[^ 45 ^]^ and temporal convolutional networks^[^ 43, 46 ^]^ have been applied to enhance the prediction accuracy and/or computational efficiency. Recently, Wu et al.^[^ 47 ^]^ proposed a feature‐and‐reconstructed manifold mapping approach that combines feature embedding and delay embedding for forecasting all components in complex systems. Recent works have further extended STI‐based methods to real‐world forecasting tasks, such as earthquake early warning,^[^ 48 ^]^ general time‐series forecasting,^[^ 49 ^]^ efficient neural architectures,^[^ 50 ^]^ and critical transition detection.^[^ 51 ^]^ However, the mappings between the feature embedding and multiple delay embeddings are solved independently, which ignores their interactions or consistent information, further complicating hyperparameter tuning as optimal settings often vary across different variables, especially in heterogeneous systems. Moreover, STI‐based methods are typically tested on short time‐series data, and their prediction performance on long time‐series data remains unclear. In other words, accurately and simultaneously forecasting multiple variables for both short and long time series remains a challenge due to their complex interactions and nonlinearity (Figure 1a).
*Overview of Delayformer. a) Delayformer simultaneously predicts states or all variables (t=M+1,,…,M+m) in a high‐dimensional system based only on the observed data (t=1,,…,m). b) In this work, we design the mvSTI equation Ψk(YkKnown)=XPred based on the delayed embedding theorem, which converts the embedded states or known temporal (YkKnown={Ykt}t=M−L−m+2M−L+1) information of any variable xk into original states or the unknown future spatial information (XPred={Xt}t=M+1M+m) of all variables, thus predicting the states or all variables simultaneously. c) To solve mvSTI equation, Delayformer treats the delay‐embedded Hankel matrix of the k‐th variable YkKnwon as an image, which is then divided into a number of patches and fed into a shared ViT encoder E for all k=1,…,N, thus achieving the cross‐learning of high‐dimensional variables with the consideration of both global and local interactions. The encoded common representations Z
t for different variables are decoded to {XkPred}k=1N by distinct linear layers {fk}k=1N. (d) Delayformer can be trained as a time‐series foundation model.*
In order to accurately make multi‐step predictions for all variables simultaneously, we propose the Delayformer method, which actually predicts the states rather than individual variables from the observed high‐dimensional data, by exploiting the advantages of both Transformer‐based and STI‐based methods. Specifically, Delayformer first designs a multivariate STI (mvSTI) equation, which transforms each observed variable into a delay‐embedded state (vector) and then solves the mapping of states between the original system and the delay‐embedded system across different variables with the mvSTI equation by leveraging the powerful representational capability of the Transformer. From a dynamical systems viewpoint, Delayformer predicts the states rather than individual variables, thus theoretically and computationally overcoming those nonlinearity and cross‐interaction problems. Finally, Delayformer employs distinct linear decoders for predicting states, i.e., equivalently predicting all original variables in parallelly. Compared to existing Transformer‐based methods, Delayformer has a solid theoretical foundation based on dynamical system theory, which endows it with superior predictive performance in high‐dimensional short‐term forecasting scenarios. In contrast to existing STI methods, it treats the delay‐embedded Hankel matrix as a 2D image, where the global and local structures of the Hankel matrix respectively correspond to the long‐range and short‐range dependencies of the image. To simultaneously consider both the global and local structural properties, we adopted the architecture of Vision Transformer (ViT^[^ 52 ^]^) to extract common dynamical representations of delay‐embedded states rather than original variables in the system, followed by distinct decoders to predict next states or, equivalently, all individual variables concurrently. Due to fully exploiting the advantages of both Transformers and STI methods, Delayformer not only surpasses state‐of‐the‐art (SOTA) methods in both long‐term and short‐term tasks but also demonstrates robustness to noise and hyperparameters. Finally, we tested a cross‐domain forecasting task, which demonstrated that Delayformer is able to exceed the best result in cross‐domain predictions and zero‐shot predictions, thus confirming the potential of Delayformer as a foundational model for time‐series prediction.
Results
2
Framework of Delayformer
2.1
Spatiotemporal Information (STI) Equation to Convert Original States to Future Embedded States Based on the Observed Time‐Series
2.1.1
In multi‐variable forecast tasks, let Xt=(x1t,x2t,…,xNt)T represent the N‐dimensional time‐series data or the original state at time t where t=1,2,…,M, and T stands for a transpose. Then, one can construct a corresponding delayed vector Ykt=(xkt,xkt+1,…,xkt+L−1)T for the k‐th variable with L > 0 as the embedding dimension. According to the delay embedding theory, Ykt can be viewed as an embedded state although it is formed only by the k‐th variable of the original state X ^ t ^, and thus the original state X ^ t ^ can generally be topologically reconstructed from the delayed embedded state Ykt if L > 2d > 0 where d is the box‐counting dimension of the system. The STI equation illustrates that a spatial vector‐sequence (XKnown={Xt}t=M−m+1M) and a temporal vector‐sequence (YkMix={Ykt}t=M−m+1M) can be converted into one another (as shown in Figure S1a, Supporting Information and Experimental Section) and can be written as:
or;
where Φ _ k _ is a nonlinear differentiable function and M > m. Once Φ _ k _ is determined, then one can predict the (L − 1) unknown future values xkM+1,xkM+2,…,xkM+L−1. Clearly, Equation (1) or (2) of the original STI is to transform a sequence of the original states to the corresponding sequence of the embedded states by Φ _ k _, thus predicting (L − 1) steps of a single target variable xkt. The accuracy of prediction is dependent on the method used to solve the mapping function Φ _ k _ based on the observed time‐series X ^ t ^ with t=1,2,…,.
Multivariate STI (mvSTI) Equation to Convert Embedded States to Future Original States Based on the Observed Time‐Series
2.1.2
To make multi‐step predictions for all variables simultaneously, we design a multivariate STI (mvSTI, Figure 1b) equation, which converts the known temporal vector‐sequence (YkKnown={Ykt}t=M−L−m+2M−L+1) into the future spatial vector‐sequence (XPred={Xt}t=M+1M+m), that is
or;
where Ψ _ k _ is also a nonlinear differentiable function. Once Ψ k is determined, one can predict m steps of all N variables simultaneously. We can derive the mvSTI equation, Equation (3) or (4) based on the delay embedding theorem. Clearly, in contrast to Equation (1) or (2) of the original STI, Equation (3) or (4) of the mvSTI is to transform a sequence of the embedded states to the corresponding sequence of the original states by Ψ _ k _, thus predicting m steps of all variables X ^ t ^ simultaneously. Note that Equation (4) is able to predict all original variables X ^ t ^ with t=M+1,,…,M+m from only one observed variable xkt with t=M−L−m+2,,…,M, which implies that we can make a reliable/accurate prediction of X ^ t ^ if using every k=1,2,…,N, i.e., exploring all available high‐dimensional information. This is also a major feature of this method.
Solving mvSTI Equation by Delayformer
2.1.3
The predictive performance by straightforwardly using the mvSTI equation with only one variable xkt is dependent on the information content of this specific k and its mapping Ψ _ k _, which ignores the information and interaction of other observed variables. Here, we propose Delayformer (Figure 1c) to address these issues by exploiting the information contents and their interactions of all observed variables. Letting E be an encoder or function across all variables X ^ t ^, and Z ^ t ^ be the latent vector/matrix, then we have the following expression based on Equation (3):
where ^○^ denotes the function composition operation. Clearly, if we use such a single encoder E to cross‐learn information of all observed variables with k=1,…,N, we can obtain a reliable representation Z ^ t ^ of X ^ t ^ due to the consideration of all interactions and nonlinearity. Thus, with the decoder D = (E)^−1^ from Z ^ t ^ of Equation (5), we can reconstruct X^t for t=M−L−m+2,M−L−m+1,…,M as:
In this work, we use a linear decoder f _ k _ for predicting each variable xk from Equation (5), i.e., Y^kM, thus Ψ _ k _ = f _ k _ ^○^ E or the prediction can also be expressed as follows:
For efficiently training an encoder, patching has been demonstrated to be powerful for Transformer‐based methods. As shown in Figure S1b (Supporting Information), to better embed the temporal information in Delayformer, the delay‐embedded Hankel matrix of the k‐th variable YkKnwon is treated as an image. Then the matrix/image is divided into a number of patches, which are fed into a ViT encoder E, thus considering both global and local interactions during the training process. Note that the encoder E is shared among all variables, thus enabling it to cross‐learn the intrinsic common representation of the dynamical system. Furthermore, since different variables correspond to different mappings {Ψk}k=1N, the encoded common representations Z ^ t ^ for different variables are decoded to {XkPred}k=1N by distinct linear layers {fk}k=1N. The mapping Ψ _ k _ = f _ k _ ^○^ E can be learned through supervised training and generalized to unseen time series.
Delayformer adopts a shared encoder with independent linear decoders design. The shared encoder captures universal temporal dynamics across channels, aligning with recent state‐of‐the‐art channel‐independent forecasting models (e.g., PatchTST^[^ 25 ^]^). Independent decoders then project the shared representation to each channel, accommodating heterogeneity in scale, units, and dynamics. To validate this design choice, we compared three architectures: i) shared encoder + shared decoder, ii) shared encoder + independent decoders (Delayformer). As shown in Note S5 and Table S5 (Supporting Information), our design consistently achieved superior performance on heterogeneous datasets, while maintaining efficiency and scalability.
Performance on Lorenz Systems
2.2
To validate the model performance and the fundamental mechanism of Delayformer, we first compared it with the latest competitive TSF models with Transformer backbones (iTransformer,^[^ 27 ^]^ PatchTST^,[^ 25 ^]^ and Crossformer^[^ 26 ^]^), TCN backbones (TimesNet^[^ 53 ^]^), and linear backbones (DLinear^[^ 22 ^]^) on 30D coupled Lorenz systems under various noise and parameter conditions.
where X(t)=(x1t,x2t,…,x30t)T and h(·) is the nonlinear function set of the Lorenz system. * θ *(t) and * b *(t) represent the parameter and noise vector, respectively. A detailed description of the system is provided in the Methods section.
Time Invariant and Noise‐Free Situation
2.2.1
In the time‐invariant and noise‐free scenario, the parameter * θ *(t) remains constant over time and the noise vector * b *(t) is set to 0. We generated 5000 time points for the experiments, with 70% used for training (3500 points) and the remaining 30% split evenly for validation (500 points) and testing (1000 points). Following the current standard TSF pipeline, 96 known time points are used to predict the future unknown 96 time points (see Note S8, Supporting Information for varying input lengths and prediction horizons). To ensure consistency in the validation environment, we set all hyperparameters in the same way (see Methods). Two metrics, mean squared error (MSE) and mean absolute error (MAE), were used to evaluate overall performance and sensitivity to outliers on the test set. Figure 2a compares the prediction results for a randomly selected variable (x24t, average result is shown in Figure 2h). The prediction of Delayformer closely matches the ground truth during multiple fluctuations within a single input sliding window, outperforming other baseline methods.
Validation of Delayformer on synthetic data. Time‐series data from a 30D coupled Lorenz system were generated under varying noise strengths and parametric conditions. Delayformer and other baselines were tested on these data. The training set, validation set, and test set sizes were 3500, 500, and 1500, respectively, for the following conditions: a–g) Future state predictions (blank regions) for a sliding window of input data (shaded region) in the test set, where the blue curve represents the ground truth; the red curve represents the prediction of Delayformer; and the gray curves represent baseline models (see Figures S2–S5, Supporting Information for detailed results). (a) Noise‐free condition. (b–f) Conditions with additive Gaussian noise, mean value of 0, and noise strength σ = 0.1, 0.2, 0.3, 0.4, 0.5. (g) Time‐varying condition, where the Lorenz system's parameters change over time. h) Comparison of MSE and MAE for Delayformer and other baselines on the test set under different noise strengths on six identical experiments with different random number seeds, and the error bar represents the standard deviation of each condition.
Time‐Invariant and Additive Noise Situation
2.2.2
When additive Gaussian noise b(t)∼N(0,σ2) was introduced, Delayformer and five other baselines were applied to the same Lorenz system under varying noise strengths σ (increasing from 0.1 to 0.5). Figure 2b–f demonstrate that Delayformer effectively and consistently captures the dynamical trends and robustly anticipates future states. Moreover, although the performance of all methods decreases as the noise increases, Delayformer achieved the lowest MSE and MAE among the tested methods under different noise strengths (Figure 2h).
Time‐Varying and Noise‐Free Situation
2.2.3
When the parameter vector * θ *(t) varies over time (i.e., a time‐varying system), the system state becomes closely related to recent short‐term statuses. In this scenario, Delayformer effectively learns recent short‐term information and still predicts the future states with high accuracy (MSE = 0.745 and MAE = 0.623), outperforming other baseline methods (Figure 2g).
Performance on Real‐World Short‐Term Datasets
2.3
Previous STI‐based methods, e.g., ALM42 and ARNN43, have been tested on high‐dimensional short‐term datasets. Transformer‐based methods usually perform poorly on these datasets due to short time series or short‐term samples. To demonstrate that Delayformer can effectively handle those datasets, we compared its performance with other Transformer‐based methods (i.e., iTransformer, PatchTST, Crossformer, TimesNet, DLinear, and Transformer) on three real‐world meteorological datasets. Detailed descriptions of these datasets can be found in Note S2 (Supporting Information).
- Wind speed dataset: This 155D dataset was collected from 155 sampling sites in Wakkanai, Japan, by the Japan Meteorological Agency. Using the same settings as ARNN, 110 known time points were used to train Delayformer and other baseline models to predict 45 steps ahead. As shown in Figure 3a,d, the predictions of Delayformer are more accurate than those of other methods.
- Solar irradiance dataset: This 155D dataset was also collected from 155 sampling sites in Wakkanai, Japan. A total of 300 known time points were used for training, with Delayformer and baseline models predicting 140 steps ahead. As illustrated in Figure 3b,d, Delayformer outperformed the other models, yielding more precise predictions.
- Ground ozone‐level dataset: This 72D dataset was collected every hour in the Houston, Galveston, and Brazoria areas from 1998 to 2004. A total of 60 known time points were used for training, with Delayformer and baseline models predicting 25 steps ahead. Figure 3c,d display the superior performance of Delayformer in predicting ground ozone levels.
Predictions using Delayformer on three meteorological datasets. We applied Delayformer to three meteorological datasets with limited training data. Each figure exhibits predictions of future states (blank region) based on the training data (shadow region), where the blue curve represents the ground truth, the red curve represents the prediction of Delayformer, and the gray curves represent the baselines (see Figures S6–S10, Supporting Information for detailed results). a) Predictions on the wind speed dataset (155 dimensions). The number of known data points is 110, and the predicted unknown data points are 45. b) Predictions on the solar irradiance dataset (155 dimensions). The number of known data points is 300, and the predicted unknown data points are 140. c) Predictions on the ground ozone‐level dataset (72 dimensions). The number of known data points is 160, and the predicted unknown data points are 25. d) Comparison of the MSE values on the three datasets for Delayformer and baseline models on six identical experiments with different random number seeds, and the error bar represents the standard error of each condition.
The results across these datasets demonstrate the ability of Delayformer to handle complex, high‐dimensional data with limited training samples, a common scenario in real‐world applications.
Performance on Long‐Term Forecasting Benchmarks
2.4
Previous STI‐based methods have not been tested on long‐term datasets. Here, to further evaluate the performance of Delayformer on general long‐term forecasting, we conducted the experiments on eight benchmarks, including ETTh1,^[^ 23 ^]^ ETTh2,^[^ 23 ^]^ ETTm1,^[^ 23 ^]^ ETTm2,^[^ 23 ^]^ weather,^[^ 54 ^]^ solar‐energy,^[^ 55 ^]^ electricity^,[^ 54 ^]^ and traffic.^[^ 54 ^]^ Detailed descriptions of the datasets can be found in Note S1 (Supporting Information).
We selected influential Transformer‐based models: iTransformer,^[^ 27 ^]^ PatchTST,^[^ 25 ^]^ Crossformer,^[^ 26 ^]^ FEDformer,^[^ 56 ^]^ Stationary^[^ 57 ^]^ and Autoformer,^[^ 54 ^]^ TCN‐based models: SCINet^[^ 54 ^]^ and TimesNet^[^ 53 ^]^ and linear models: RLinear,^[^ 24 ^]^ DLinear^[^ 22 ^]^ and TiDE^[^ 58 ^]^ as our baselines. In the implementation of the baselines, we referred to the Time‐Series‐Library (https://github.com/thuml/Time‐Series‐Library), setting the input sequence length for our model and baselines to 96 (see Note S7, Table S7, and Figure S16, Supporting Information for other input lengths). As shown in Table 1, Delayformer achieved top‐two performances in all benchmarks, demonstrating its superior capability and robustness in long‐term forecasting tasks.
Performance of Delayformer with Limited Data
2.5
Limited Training Set Size
2.5.1
Although the effectiveness of Delayformer on both short and long‐term datasets has been validated, the relationship between its performance and the size of the training set remains unknown. We began by evaluating the impact of training set size on the weather dataset. Unlike typical benchmarks, we fixed the validation and test set sizes at 1000 and 20000 points, respectively, and varied the training set sizes from 800 to 10 000 points. Despite the wide range in training set sizes, Delayformer consistently outperformed baseline models.
- Small training set (800 and 2000 points): Under extremely small training set conditions, baseline models struggled to predict the future states accurately, often failing to capture the underlying dynamics of the time series (Figure 4d,e). In contrast, Delayformer demonstrated remarkable robustness, providing reliable forecasts even with limited data.
- Moderate and large training set (5000 and 10 000 points): With a more substantial training set, the performance of baseline models improved, but Delayformer maintained its superior predictive accuracy (Figure 4f,g).
- The MSE across different training set sizes further confirmed the robustness of Delayformer, consistently achieving lower MSE compared to other models (Figure 4h).
Performance of Delayformer under varying training set sizes and observation dimensions. a–c) Predictions of future states with different numbers of observed variables: (a) 2 variables, (b) 5 variables, (c) 10 variables. The shaded region represents one sliding window of input data, with the blue curve indicating the ground truth, the red curve showing Delayformer predictions, and the gray curves depicting baseline model predictions in the blank region (see Figures S11–S15, Supporting Information for different baselines). d–g) Predictions of future states (unshaded region) using different training set sizes: (d) 800 points, (e) 2000 points, (f) 5000 points (g) 10000 points. Again, the shaded region represents one sliding window of input data, with the blue curve indicating the ground truth, the red curve showing Delayformer predictions, and the gray curves depicting baseline model predictions in the blank region. h) Mean Squared Error (MSE) on the test set for Delayformer and baseline models is shown across varying training set sizes (left) and observed variables (right). Delayformer consistently exhibits lower MSE, underscoring its robustness and significant performance gains over baseline models, particularly under data‐scarce conditions.
Limited Observation Dimension
2.5.2
In practice, the absence of certain observed variables is common, especially in situations where only a subset of potential predictors is available. To test the ability of Delayformer to handle such scenarios, we trained the model using only the first 2, 5, and 10 variables from the dataset to predict the first variable x 1 for the same input sequence in the test set.
- Few Observations (2 variables): Even with only two observed variables, Delayformer managed to extract sufficient information to predict future states effectively, outperforming the baselines (Figure 4a).
- Increasing Observations (5 and 10 variables): As the number of observed variables increased, the predictions of Delayformer became more accurate, further distancing itself from the baseline models (Figure 4b,c).
The overall MSE for different observation dimensions demonstrated the capability of Delayformer to handle limited observations without significant loss of accuracy, further solidifying its robustness in practical, data‐constrained environments (Figure 4h).
Hyperparameters of Delayformer
2.6
In Delayformer, Hankel matrices are generated by embedding one input sliding window with length W = L + m − 1 into L dimensions, which are then sliced into patches with patching size (p 1, p 2) (Figure 5a). We conducted experiments to test the sensitivity of Delayformer to these hyperparameters (L, p 1, p 2) and found that the results were relatively consistent (Note S3, Supporting Information).
Additional hyperparameters of Delayformer. a) Delayformer introduces hyperparameters embedding dimension m and patching size (p 1,p 2). b) Prediction of Delayformer trained with L = 12, 27, 42, with a fixed patching size of (p 1,p 2) = (5, 3). The blue curve represents the ground truth, and other curves represent the predictions. c) Prediction of the Delayformer trained with (p 1,p 2) = (3, 7), (6, 7), (8, 7), (12, 7) with a fixed embedding dimension of L = 49. Again, the blue curve and other curves represent the ground truth and the predictions, respectively.
The embedding dimension L represents the number of states in the reconstruction space. While established methods^[^ 41 ^]^ provide rules for determining L, but in our tests, it was often calculated as an extreme value. Therefore, we set L as a value between 1 and the input sequence length, choosing a value that was neither too large nor too small based on empirical experience. We tested m values of 12, 27, and 42 on the weather dataset (corresponding to the task in Table 1) with a fixed patching size (p 1, p 2) = (5, 3). The input sequence length and output sequence length were both set to 96. The predictions (Figure 5b) and metrics (Table S2, Supporting Information) indicate that the results were similar across these cases.
The patching size (p 1, p 2) determines the size of the Hankel matrix slices, representing the fine‐grain size sensing range of the Hankel matrices. (p 1,p 2) must satisfy the condition that m is divisible by p 1 and L is divisible by p 2. We tested different (p 1, p 2) values on the weather dataset with L = 49 fixed and compared four cases: (p 1,p 2) = (3, 7), (6, 7), (8, 7) and (12, 7). The input sequence length and output sequence length were both set to 96. The predictions (Figure 5c) and metrics (Table S3, Supporting Information) indicate that the results were again similar across these cases.
Potential of Delayformer as a Time‐Series Foundation Model
2.7
Delayformer presents an efficient approach to constructing input tokens and cross‐learning all observed variables on multi‐domain tasks from time‐series sequences, thereby enabling its scalability for large‐scale model training (Figure 1d). Due to space constraints, we provide two cases to illustrate the potential of Delayformer as a time‐series foundation model. In contrast to prior experiments, we expanded the network depth to 10 encoder layers, aligning it with current large‐scale time‐series models.^[^ 59, 60 ^]^ For the TSF task, we evaluated the domain generalization capabilities of Delayformer on unseen datasets, both within the same domain and across different domains from the training data. To ensure comparability with Table 1, we set both the input and output sequence lengths to 96. Further details regarding hyperparameters and training are provided in Note S4 (Supporting Information).
Case 1. In‐domain generalization: To demonstrate in‐domain generalization, we selected four datasets from the energy domain: ETTh1, ETTh2, ETTm1 for training, and ETTm2 for testing. We first assessed the zero‐shot performance of the pretrained Delayformer, which achieved MSE and MAE values of 0.139 and 0.254, respectively. As shown in Table 1, these values are lower than the current SOTA, indicating strong in‐domain generalization. Additionally, we fine‐tuned the pretrained Delayformer using various proportions of available training samples from the unseen dataset (Figure 6a). Notably, only 5% of the available training data was sufficient for the large Delayformer to achieve significantly improved performance (MSE 0.139 → 0.126, Table S4, Supporting Information), demonstrating its few‐shot learning capabilities and ability to capture intrinsic patterns within the same domain.
Performance of large Delayformer fine‐tuned on the pretrained model. MSE is shown for two cases, each utilizing different fine‐tuning data ratios applied to the pretrained Delayformer. The blue line denotes the fine‐tuned Delayformer, while the red line represents SOTA model trained with the complete set of training samples. a) In‐domain generalization: Training is conducted on ETTh1, ETTh2, and ETTm1 from the energy domain, with ETTm2 from the same domain as the unseen testing dataset. b) Out‐of‐domain generalization: Training encompasses ETTh1, ETTh2, ETTm1, and ETTm2 from the energy domain, with unseen testing performed on a dataset from the weather domain, a distinct natural domain.
Case 2. Out‐of‐domain generalization: To evaluate out‐of‐domain generalization, we trained Delayformer on four energy domain datasets (ETTh1, ETTh2, ETTm1, ETTm2) and tested it on a weather dataset from a different domain. The zero‐shot forecasting performance resulted in MSE and MAE values of 0.243 and 0.282, respectively, which are comparable to current small models as shown in Table 1. These results are competitive with those of current exclusively trained small models, even though the weather dataset is outside the domain of the training data. Fine‐tuning with various proportions of available training samples (Figure 6b) revealed that only 2% of the training samples were necessary for the large Delayformer to further improve its performance (MSE 0.243 → 0.186, Table S4, Supporting Information). This highlights its few‐shot learning capabilities and ability to transfer knowledge across domains.
In conclusion, Delayformer exhibits promising scalability to match the size of current large‐scale time‐series models while maintaining impressive generalization capabilities. This suggests its potential for development as a foundational model for time‐series.
Discussion
3
In this work, we proposed the Delayformer method, which is to accurately predict high‐dimensional time‐series by overcoming the limitations of the existing methods for handling limited and noisy data.^[^ 42, 43, 47 ^]^ Specifically, this study introduces the Delayformer framework for simultaneously predicting the dynamics of all variables by developing a novel multivariate spatiotemporal information (mvSTI) transformation. This transformation converts each observed variable into a delay‐embedded state/vector and cross‐learns these states from different variables. From a dynamical systems viewpoint, Delayformer predicts system states rather than individual variables, thus theoretically and computationally overcoming issues related to nonlinearity and cross‐interactions. Computationally, Delayformer first transforms each observed variable into a delay‐embedded state (vector) by a mvSTI equation, and then solves the mapping of states between the original system and the delay‐embedded system across different variables with the mvSTI equation, thus leading to the robust prediction due to the cross‐learning of all variables on the same shared encoder with the consideration of both global and local interactions. By leveraging the theoretical foundations of delay embedding theory and the representational capabilities of Transformers, Delayformer outperforms current state‐of‐the‐art methods in forecasting tasks on both synthetic and real‐world datasets. Furthermore, the potential of Delayformer as a foundational time‐series model is demonstrated through cross‐domain forecasting tasks, highlighting its broad applicability across various scenarios.
From a computational viewpoint, Delayformer treats the Hankel matrix obtained from time‐delayed embedding as a 2D image and extracts the dynamical representations of all variables using a shared ViT encoder, thus overcoming the lack of temporal encoding capability of current Transformer‐based methods. Notably, compared to ViT, convolutional neural networks are limited by their local receptive fields and thus less effective at capturing long‐range dynamics (Note S6 and Table S6, Supporting Information). Moreover, since the dimension of the shared encoder is relatively large, the representation (Zk) can be treated as the projections in the Koopman space. Koopman theory^[^ 61 ^]^ suggests that the evolution of a system can be represented by a linear operator in the Koopman space. Therefore, the forecast of the system can be implemented by a linear combination of the observation functions in Koopman space. Finally, traditional STI‐based methods (e.g., ARNN^[^ 43 ^]^) to high‐dimensional, real‐world data is that they often require a laborious, per‐variable tuning process, because the prediction model for each variable is solved independently. Delayformer overcomes this exact inefficiency by employing a single set of core hyperparameters (Table S8, Supporting Information).
Due to its full utilization of the strengths of both Transformers and STI methods, our experimental results demonstrate that Delayformer consistently outperforms existing models across a variety of benchmarks, including synthetic and real‐world datasets. Furthermore, Delayformer exhibits robustness in scenarios with limited data and varying noise levels, making it a versatile tool for real‐world applications. Finally, the introduction of hyperparameters for the embedding dimension and patching size offers additional flexibility, enabling Delayformer to be adapted to various backbones, such as decoder‐only Transformers and TCNs,^[^ 21 ^]^ and is potential as a foundational time‐series model. Thus, Delayformer provides a new approach that effectively combines deep learning with dynamical system theory, representing a significant advancement in the field of TSF.
Although Delayformer has achieved excellent prediction results on a range of benchmark datasets, it still has room for continued optimization. First, the construction of the Hankel matrix relies on two parameters, the embedding dimension and the time delay of the phase space reconstruction,^[^ 62 ^]^ and debugging these parameters on very large‐scale datasets may impose an additional computational burden. Second, while ViT is a representative architecture used in Delayformer, it is not the SOTA architecture in the field of computer vision. More advanced model can be adopted, e.g., Convolutions Vision Transformer,^[^ 63 ^]^ to further improve the prediction performance of Delayformer. Finally, although we have validated the potential of Delayformer as a large model for time‐series in a cross‐domain prediction task, it has not yet been trained on a sufficiently large time‐series dataset, e.g. TimesFM^[^ 64 ^]^ and Moment,^[^ 65 ^]^ which will be the focus of our future work.
In summary, by leveraging the rich theoretical framework of nonlinear dynamics and the powerful representation capability of the Transformer model, Delayformer opens a new avenue for enhancing the accuracy and robustness of time‐series forecasting, thus will benefit many real‐world applications.
Experimental Section
4
The Coupled Lorenz System
The 30D Lorenz system contains 10 3D subsystems, and the n‐th (n=1,2,…10) subsystem is described as:
σ, ρ, β are the parameters of the Lorenz system, and we set them as σ = 10, ρ = 28, β = 8/3 under time‐invariant system. z _ n − 1_ in the third equation indicates the influence from the (n − 1)‐th system on the n‐th system. γ controls the interaction level between each subsystem and was set to be 0.1 constantly in the two datasets. In the time‐varying Lorenz system, σ changes as the time course: σ(t)=10+0.2×t10. The initial values are *x_n_ *(0) = −0.1 + 0.003 × n, *y_n_ *(0) = −0.097 + 0.003 × n, *z_n_ *(0) = −0.094 + 0.003 × n.
Delay‐Embedding Theorem and STI Transformation
For a general discrete‐time N‐dimensional dynamical system with evolution function ϕ:RN→RN, the dynamics can be written as:
where Xt=(x1t,x2t,…,xNt)T (T stands a transpose) represents the N‐dimensional observation vector/state at time point t, sampled at equally time intervals from the system. The Takens’ embedding theorem is stated as:
If M⊆RN is an attractor with the box‐counting dimension d, for a smooth diffeomorphism ϕ:M→M and a smooth function h:M→R, the mapping Φϕ,h:M→RL is an embedding when L > 2d, that is:
where symbol “∘” represents the function composition operation.
While Takens' theorem provides the foundational basis for reconstructing dynamics on smooth manifolds, many real‐world systems, especially the high‐dimensional complex systems we study, exhibit attractors that are fractal sets rather than smooth manifolds. Therefore, the theoretical validity of our work is more rigorously guaranteed by the generalized embedding theorems proposed by Sauer et al. and Hunt et al. Specifically, the Fractal Whitney Prevalence Embedding Theorem, as detailed in their seminal work “Embedology”,^[^ 39 ^]^ and grounded in the concept of “Prevalence”,^[^ 40 ^]^ extends the embedding theory from smooth manifolds to fractal sets. These theorems prove that for an attractor with a box‐counting dimension d, an embedding of the attractor can be achieved from the delay coordinates of a single generic observable as long as the embedding dimension L > 2d. Our Delayformer framework, which processes data from such complex systems, is built upon this solid mathematical foundation, justifying the reconstruction of the entire system state from the delay‐embedded Hankel matrix of a single variable.
Letting Φ _ϕ,h _ = Φ _ k _ for short and h(X ^ t ^) to be any target variable xkt, i.e., h(Xt)=xkt, then we have the primary STI equation:
One can also derive its conjugate form as Ψk(Ykt)=Φk−1(Xt)=Xt since the embedding is a one‐to‐one mapping, satisfying Φ _ k _○Ψ _ k _ = id and id represents the identity function.
As theoretically derived from the delay‐embedding theory, the STI equation can transform the spatial information of high‐dimensional data (XKnown={Xt}t=M−L−m+2M−L+1) to the temporal information (YkMix={Ykt}t=M−m+1M) of any target variable. However, to predict all variables, the mappings {Ψk}k=1N in STI equation are usually independently solved one by one, which is extremely inefficient for high‐dimensional data in designing specific models and setting hyperparameters. To address this issue, we design the mvSTI equation:
which converts the known temporal (YkKnown={Ykt}t=M−L−m+2M−L+1) information of any variable into the future spatial (XPred={Xt}t=M+1M+m) information of all variables. Clearly, in contrast to (1) or (2) of the original STI, (3) or (11) of the mvSTI is to transform a sequence of the embedded states to the corresponding sequence of the original states by Ψ _ k _, thus predicting m steps of all variables X ^ t ^ simultaneously.
Channel‐Independence
Delayformer adopts a channel‐independence (CI) strategy during training, which treats each channel (or variable) of the time‐series data independently while using identical parameters for the model across channels in deep learning backbones. CI was first introduced in TSF models, demonstrating its effectiveness. Practically, CI calculates the total loss of all channels while training. Although CI exhibits low robustness on unseen variables, Delayformer enhances this approach by employing time‐delay embeddings rather than the raw time‐series data, thereby overcoming the robustness limitations typically associated with CI. Furthermore, the embedding vectors of each variate YkKnwon for k=1,2,…,n can reconstruct the system independently, which are topologically conjugated. Then the function E is thus uniformly applied to represent YkKnwon as Z=E(YkKnwon) for different k across different channels, consistent with CI.
Patching for Hankel Matrixes
Dynamical system theory illustrates that a state of the system X ^ t ^ is primarily influenced by its proximate states. As it shown in Figure 5a, Delayformer splits Hankel matrices into pieces of p 1 × p 2 as patches inspired by Vision Transformer (ViT). Like images, Hankel matrices are locally close in properties, and thus, these patches contain the local information of Hankel matrices. Since the elements of Hankel matrices are symmetric along the diagonal, p 1 and p 2 are set to be different value to confirm Delayformer can capture the features of the reconstructed systems in different fine grain sizes. Practically, the time‐series for each variable with window length W = L + m − 1, {xkt}t=1W, is embedded into a Hankel matrix in the shape of L × (W − L + 1). This matrix is then sliced into L×W−L+1p1p2 patches, which are subsequently flattened into tokens for downstream processing. For reasons of operability, the patch number and patch dimension should be balanced to save memory while computing. In most experiments in this paper, the input length is 96, and we made embedding dimension (L) 49 or 27 in most cases. When L = 49, the patch shape (p 1, p 2) was often (6, 7) and (24, 7); when L = 27, (p 1, p 2) was often set to be (5, 3). The detail setting for L and (p 1, p 2) is shown in Table S1 (Supporting Information).
Constructing Transformer Encoder
Denoting the patches of Hankel matrices {YkKnown}k=1N as {Pk}k=1N, where each component *P_k_
- contains p=L×W−m+1p1p2 patches. With the analogy to ViT, Delayformer leverages a common transformer encoder (Vanilla Transformer) to represent the patches. The patches are projected to tokens on transformer dimension D through a linear layer after flattening, and then added a sinusoidal position encoding, i.e., the first hidden state of k‐th variable:
There are n Transformer encoder blocks to calculate the correlations and representations of variate tokens. Each Transformer encoder block covers two steps, one multi‐head self‐attention (MSA) layer and one feed‐forward (FF) layer, i.e.:
The encoding representation of k‐th variable Zk is the output of the last transformer encoder block Hkn.
Predicting Future States and Training One Delayformer
In typical TSF tasks, datasets are commonly divided into segments using sliding windows, a method that aligns well with the framework presented herein. For a dataset with batch size B, the input data size of one batch is B × W × N, where the input sliding window has a length W and encompasses N variables. Each of these N variables are embedded into L dimensions individually, resulting in a transformation of the batch to B × (W − L + 1) × L × N after applying Hankelization. The resulting Hankel matrices are then treated as images, subsequently patched and flattened into tokens, yielding a shape of B×L×(W−L+1)p1×p2×p1p2×N. Following the structural framework established in the previous section, the tokens are first projected into D dimensions, and positional encoding is added, transforming the hidden state shape of the tokens to B×L×(W−L+1)p1×p2×D×N. Each variable's tokens are then processed through n Transformer encoder blocks independently, utilizing shared parameters across variables. Ultimately, N bilinear layer decoders, {fk}k=1N, are employed for all variables to project the Transformer encoder representation {Zk}k=1N into the prediction X^pred within the feature space RN for a prediction length L.
In this study, we employed MSE loss to quantify the discrepancy between predicted and true values. The loss computation follows CI strategy, where the predictions of each variable are aggregated to formulate the objective function:
Adam optimizer was utilized for the model optimization. More training details shown in the Results section can be found in Note S1 (Supporting Information).
Conflict of Interest
The authors declare no conflict of interest.
Author Contributions
Z.W. and P.T. contributed equally to this work. Z.W. and P.T. conceived the idea. Z.W. and P.T. designed the research. Z.W. performed the research. All authors analyzed the data and wrote the paper.
Supporting information
Supporting Information
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1L. Chen , X. Zhong , H. Li , J. Wu , B. Lu , D. Chen , S.‐P. Xie , L. Wu , Q. Chao , C. Lin , Nat. Commun. 2024, 15, 6425.39080287 10.1038/s 41467-024-50714-1PMC 11289088 · doi ↗ · pubmed ↗
- 2B. S. Orlove , J. C. Chiang , M. A. Cane , Nature 2000, 403, 68.10638752 10.1038/47456 · doi ↗ · pubmed ↗
- 3L.‐C. Chang , F.‐J. Chang , S.‐N. Yang , F.‐H. Tsai , T.‐H. Chang , E. E. Herricks , Nat. Commun. 2020, 11, 1983.32332746 10.1038/s 41467-020-15734-7PMC 7181664 · doi ↗ · pubmed ↗
- 4S. Selvin , R. Vinayakumar , E. Gopalakrishnan , V. K. Menon , K. Soman , presented at 2017 Int. Conf. on Advances in Computing, Communications and Informatics (ICACCI) , Udupi, India 2017.
- 5A. Sözen , E. Arcaklioglu , Energy policy 2007, 35, 4981.
- 6M. T. La Rovere , J. T. Bigger , F. I. Marcus , A. Mortara , P. J. Schwartz , Lancet 1998, 351, 478.9482439 10.1016/s 0140-6736(97)11144-8 · doi ↗ · pubmed ↗
- 7P. N. Ramkumar , H. S. Haeberle , M. R. Bloomfield , J. L. Schaffer , A. F. Kamath , B. M. Patterson , V. E. Krebs , J. Arthroplasty 2019, 34, 2204.31280916 10.1016/j.arth.2019.06.018 · doi ↗ · pubmed ↗
- 8Y. Gao , G.‐Y. Cai , W. Fang , H.‐Y. Li , S.‐Y. Wang , L. Chen , Y. Yu , D. Liu , S. Xu , P.‐F. Cui , Nat. Commun. 2020, 11, 5033.33024092 10.1038/s 41467-020-18684-2PMC 7538910 · doi ↗ · pubmed ↗