A novel deep transformer based CvT model for sign language recognition in visual communication
Jing Hao, Hezhe Pan

TL;DR
This paper introduces a new deep learning model for sign language recognition that outperforms existing methods using a combination of convolutional and transformer techniques.
Contribution
The novel contribution is a CvT model that integrates hierarchical convolutional tokenization with transformer attention for improved sign language recognition.
Findings
The proposed CvT model achieves 99% accuracy on a sign language digits dataset.
The model outperforms traditional CNN and BeIT transformer models in classification performance.
The model improves generalization and reduces misclassifications across training, validation, and test sets.
Abstract
Sign language serves as a crucial mode of communication for the deaf and hard-of-hearing communities, enabling effective interaction in daily life. With the growing advancements in Artificial Intelligence (AI) and computer vision, there has been a significant shift toward automating SLR, making communication more accessible and inclusive. Traditional AI-based approaches, such as rule-based and statistical models, struggle to handle complex hand gestures, varying lighting conditions, and occlusions. Deep learning-based methods, particularly Convolutional Neural Networks (CNNs), have improved recognition capabilities, but they often fail to capture intricate spatial and temporal dependencies that are essential for accurate classification. To address these limitations, vision transformers (ViTs) have emerged as a breakthrough technology, offering superior feature extraction through…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
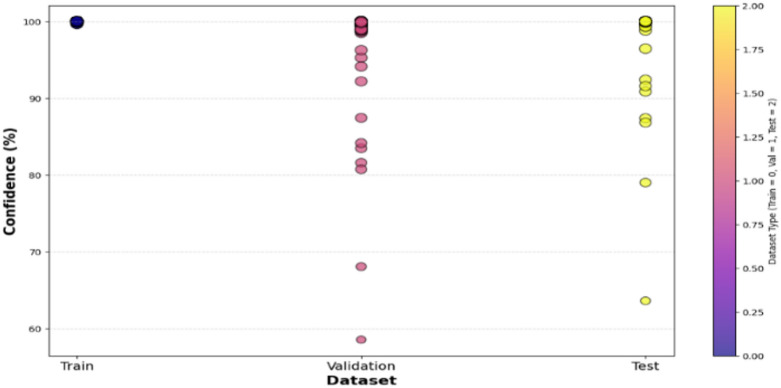 Figure 10
Figure 10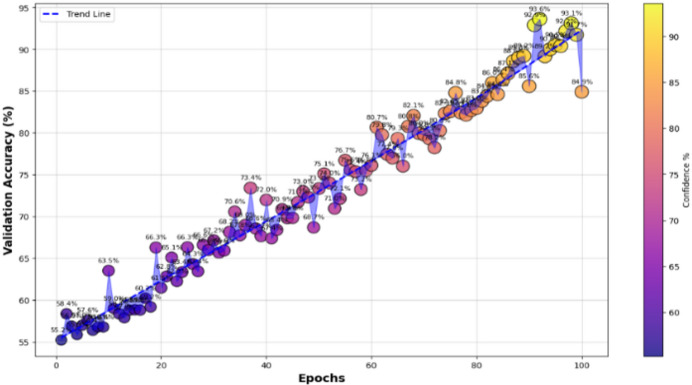 Figure 11
Figure 11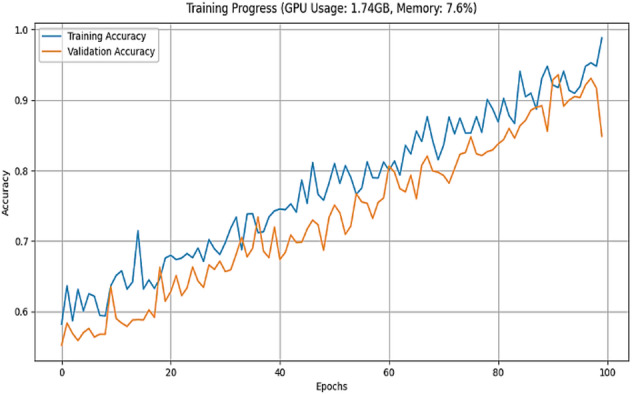 Figure 12
Figure 12 Figure 13
Figure 13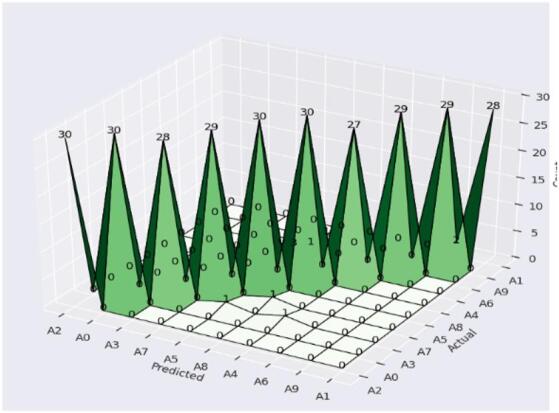 Figure 14
Figure 14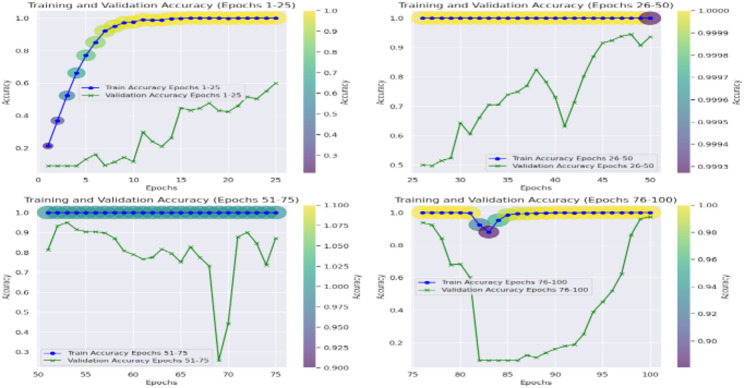 Figure 15
Figure 15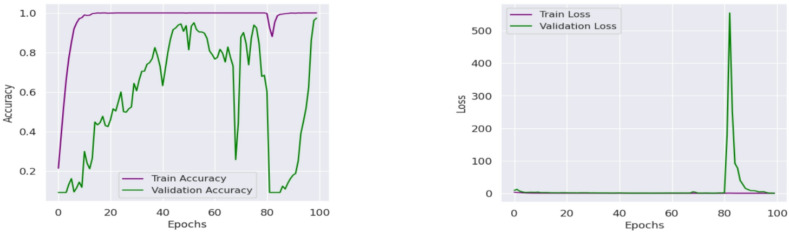 Figure 16
Figure 16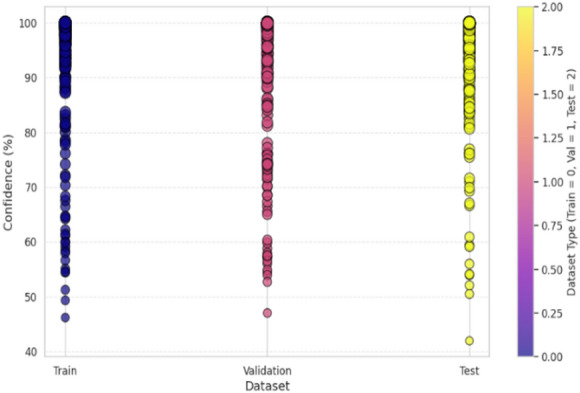 Figure 17
Figure 17 Figure 18
Figure 18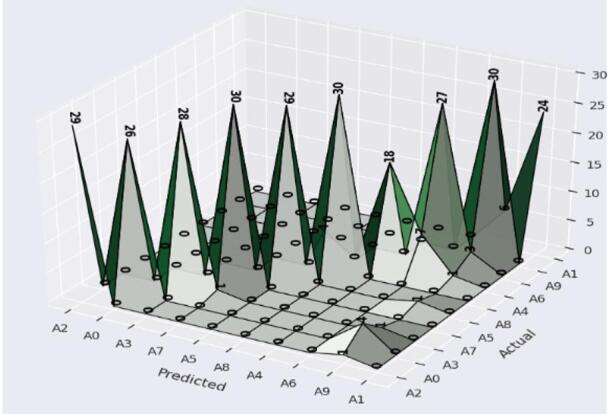 Figure 19
Figure 19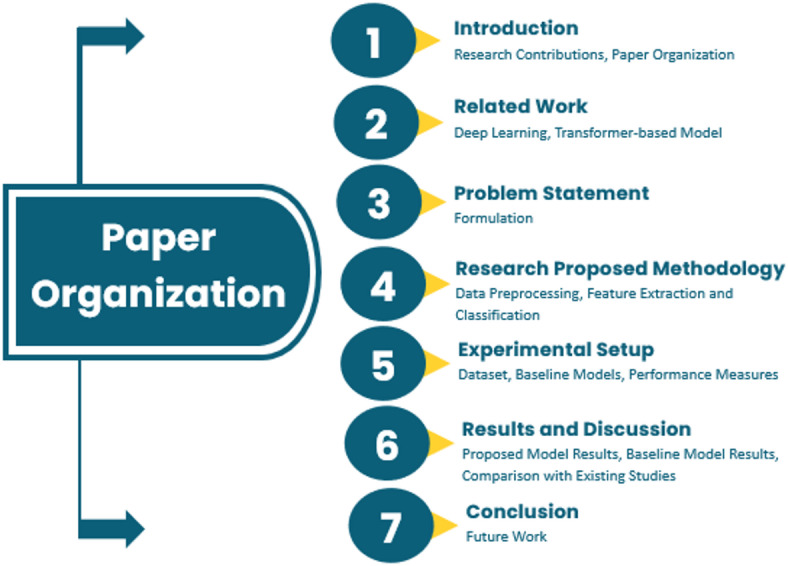 Figure 1
Figure 1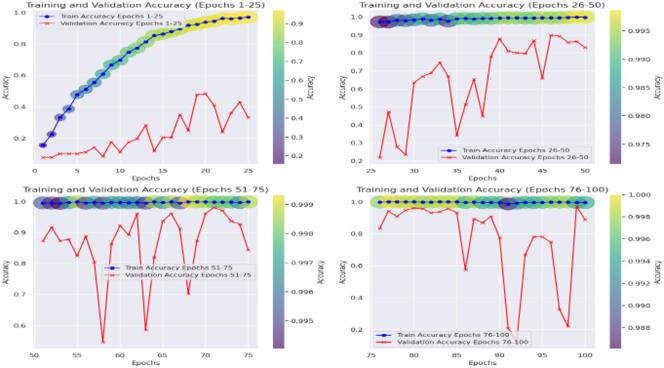 Figure 20
Figure 20 Figure 21
Figure 21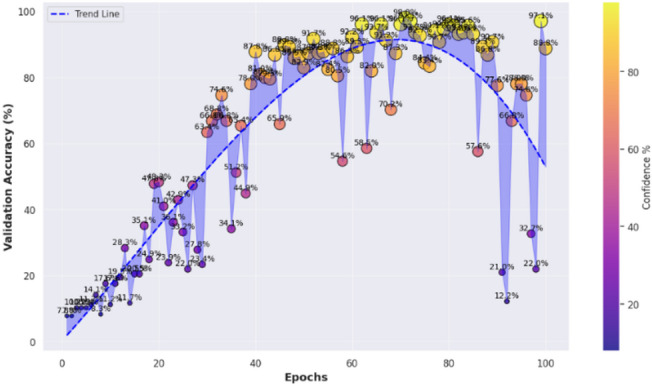 Figure 22
Figure 22 Figure 23
Figure 23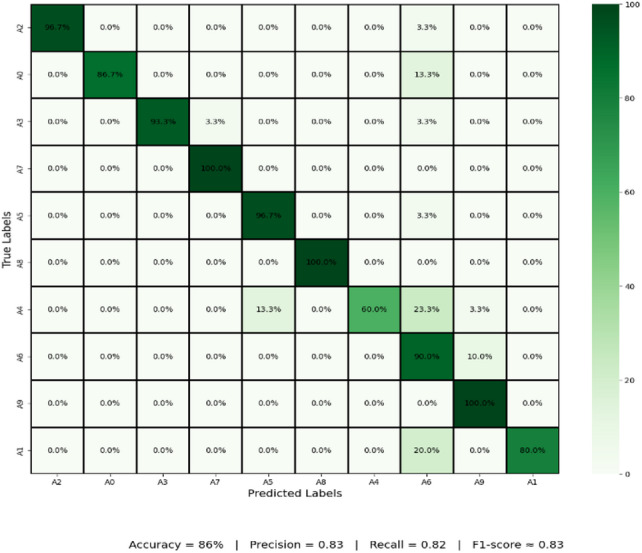 Figure 24
Figure 24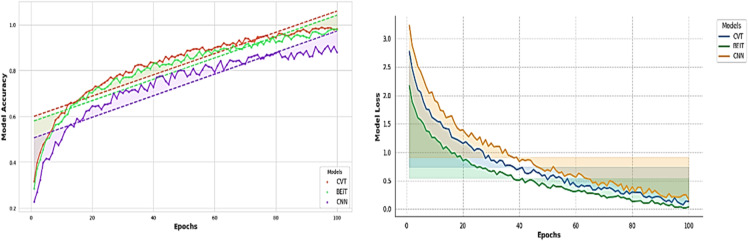 Figure 25
Figure 25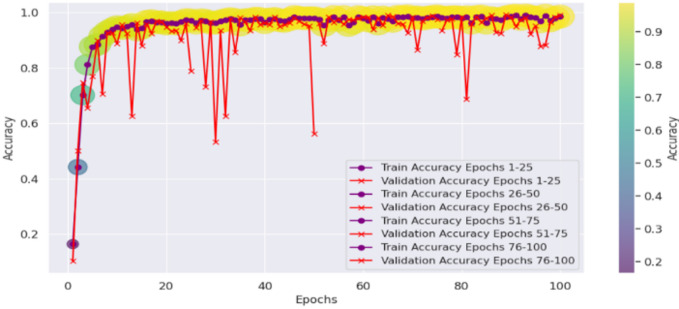 Figure 26
Figure 26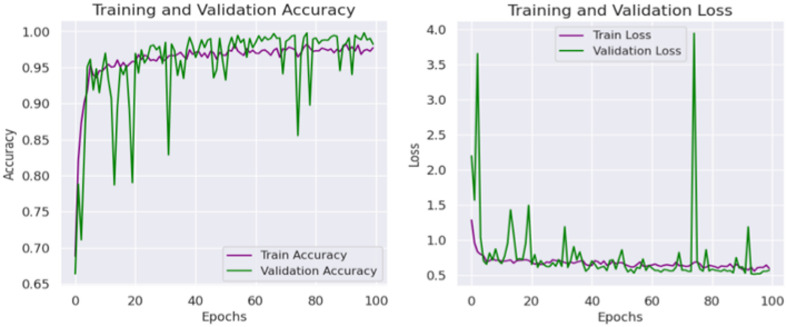 Figure 27
Figure 27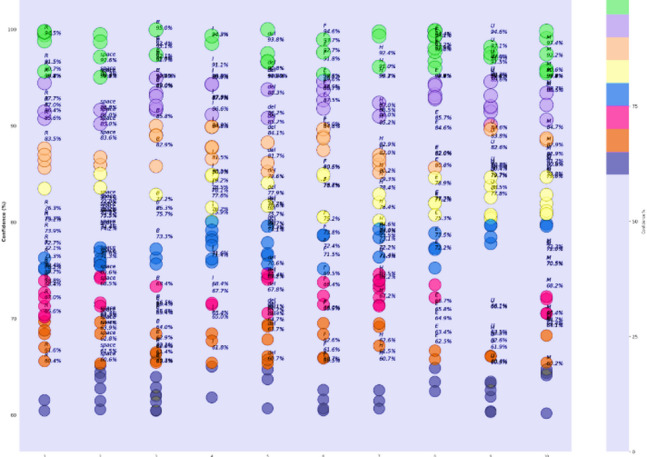 Figure 28
Figure 28 Figure 29
Figure 29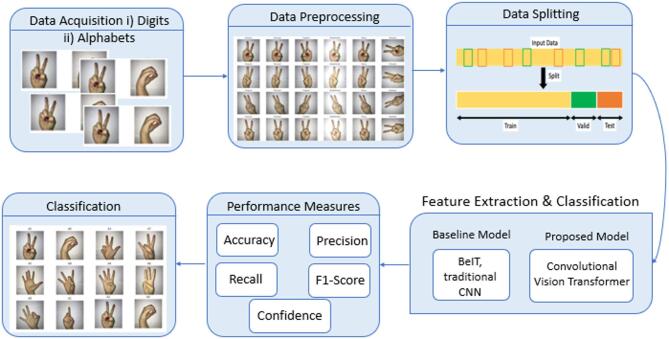 Figure 2
Figure 2 Figure 30
Figure 30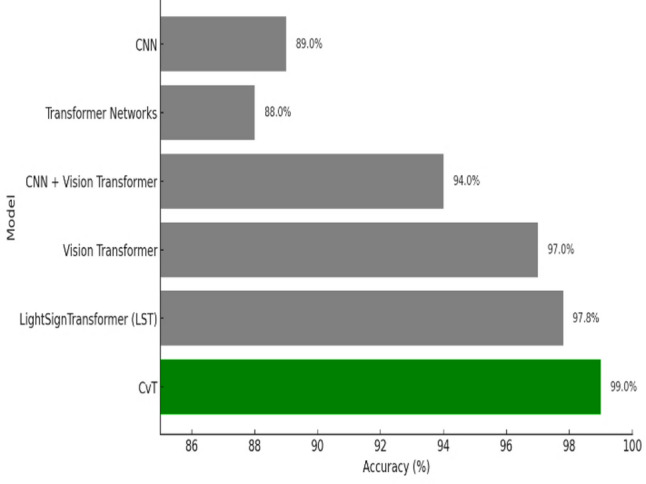 Figure 31
Figure 31 Figure 3
Figure 3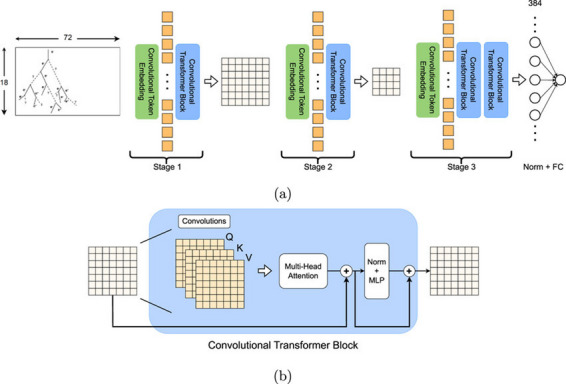 Figure 4
Figure 4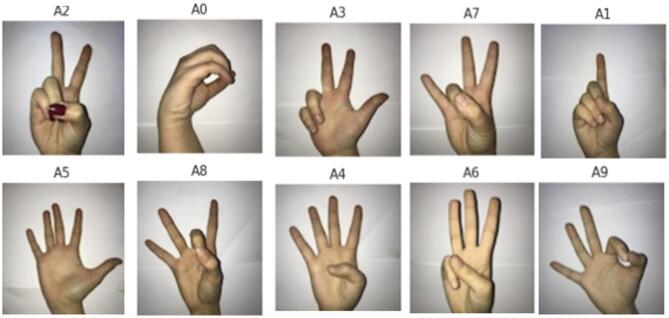 Figure 5
Figure 5 Figure 6
Figure 6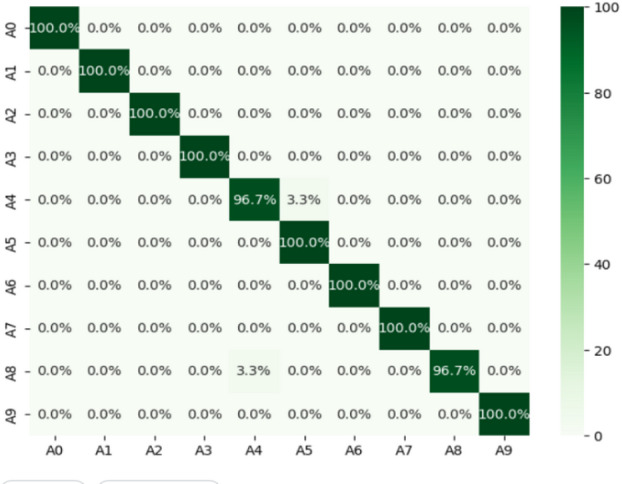 Figure 7
Figure 7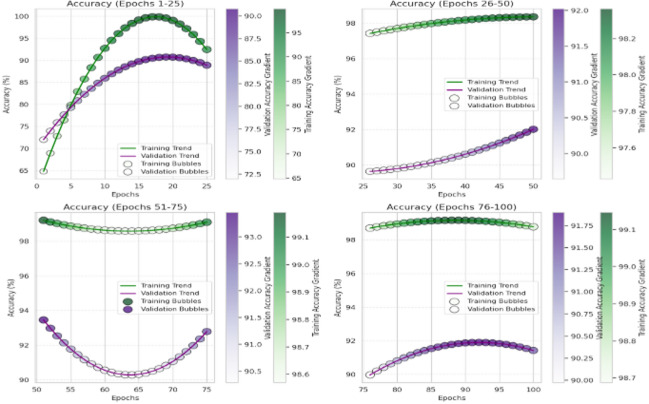 Figure 8
Figure 8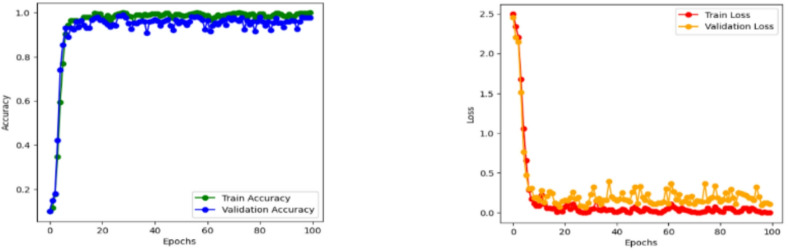 Figure 9
Figure 9 Figure 32
Figure 32Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHand Gesture Recognition Systems · Hearing Impairment and Communication · Interactive and Immersive Displays