Can registry-based auxiliary variables improve handling of missing outcome data in mental health trials? Evidence from a registry-linked randomized study
Amanda Iselin Olesen Andersen, Marit Knapstad, Otto Robert Frans Smith

TL;DR
This study explores whether linking mental health trial data with administrative registries improves handling of missing data, finding limited added value in treatment effect estimates.
Contribution
The paper evaluates the practical value of registry-linked auxiliary variables in reducing bias from missing data in mental health trials.
Findings
Registry variables showed weak associations with missingness and symptom levels.
Including registry data in multiple imputation did not change estimated treatment effects.
Baseline financial assistance was strongly linked to nonresponse at 12 months.
Abstract
Missing outcome data are a pervasive challenge in randomized controlled trials (RCTs) of mental health interventions, potentially biasing effect estimates. Linking survey data with administrative registries offers new opportunities to include auxiliary variables in multiple imputation (MI), but evidence of their added value remains scarce. We used data from the Norwegian RCT of Prompt Mental Health Care (PMHC; N = 681) which assessed self-report outcomes of depression (PHQ-9) and anxiety (GAD-7) at 6 and 12 months. Registry linkage provided information on prescriptions, consultations, sick leave, and benefits (N = 651). We examined whether registry variables were associated with missingness and assessed their correlations with depression and anxiety symptom levels. Further, we compared estimated treatment effects through a linear regression model with treatment group as a predictor…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
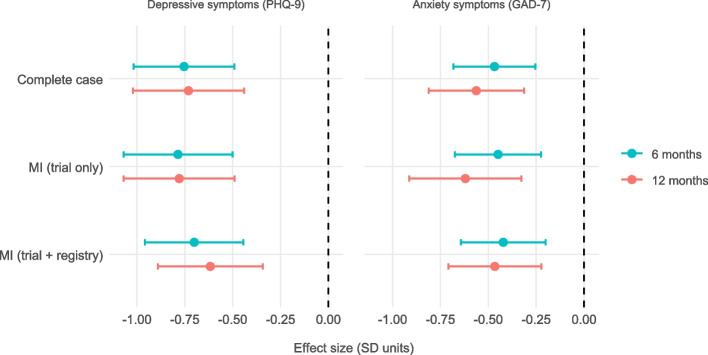 Figure 1
Figure 1- —http://dx.doi.org/10.13039/501100005416Norges Forskningsråd
- —Norwegian Institute of Public Health (FHI)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Bayesian Inference · Advanced Causal Inference Techniques · Meta-analysis and systematic reviews
Background
Missing outcome data are a major threat to the validity of randomized trials and longitudinal studies, regardless of research design. This problem is particularly common when outcomes are collected through surveys or questionnaires, where nonresponse and attrition are widespread. When outcomes such as symptom measures are unavailable for a substantial proportion of participants, effect estimates can become biased, and generalizability is compromised if not adequately addressed [1–4]. This risk is especially acute when missingness is related to unmeasured participant characteristics or directly to the unobserved outcomes themselves [5–7].
One way to reduce bias under a missing-at-random (MAR) assumption is to incorporate auxiliary variables; that is, variables included in the imputation model (but not in the final analysis) which help capture relationships between observed data, missingness, and the incomplete outcomes [5, 8, 9]. Including variables that predict missingness can improve the plausibility of the MAR assumption, but their impact on estimates depends on whether they are also associated with the incomplete outcomes. Variables that predict missingness but are uncorrelated with the outcomes add little, because they do not inform what the missing values would have been, and in some settings may even exacerbate bias [10–12]. By contrast, variables related to both missingness and the outcomes can substantially reduce bias and increase precision [4, 5, 13]. Simulation studies indicate that associations weaker than about r = 0.30–0.40 have limited influence on effect estimates, although weaker predictors may still contribute incrementally when included alongside stronger ones [13, 14]. Accordingly, an inclusive strategy is often recommended, since auxiliary variables are generally unlikely to be detrimental to imputation models and may increase robustness [8, 15, 16]. This is particularly true when auxiliaries are well measured and the outcome is the main incomplete variable [17], though exceptions exist, for example, when auxiliary variables act as colliders [10, 11]. Moreover, even in situations where missingness depends partly on the unobserved values themselves (MNAR), incorporating strong predictors of the outcomes can help to attenuate bias by capturing systematic differences between responders and non-responders [8]. Selection of auxiliary variables should therefore be purposeful and informed by their relevance to both the outcome and the mechanisms leading to missingness.
In longitudinal studies, it is often difficult to identify strong auxiliary variables beyond prior measures of the outcome, since participants are typically completely missing at a given follow-up. Administrative registry data represent a potentially powerful source in this context. These data are routinely collected for entire populations, less prone to recall bias, and available regardless of survey participation [18–20]. Importantly, they may also enrich outcome measurement by capturing information relevant to the outcomes at hand. For example, registries often provide indicators such as healthcare use, prescriptions, and welfare benefits, which may offer indirect insights into mental health status and functioning relevant for studies of mental health.
So far, very few studies have examined the potential of administrative registry data for handling missing outcome data. Population-based surveys have linked registry data to assess selection bias, showing that compared with respondents, non-respondents tend to have poorer health, higher subsequent mortality, and are more likely to have a lower socioeconomic position or precarious employment [21–23]. Nordic registry-linked studies similarly report higher rates of disability pension among non-respondents, often involving mental or musculoskeletal diagnoses [24, 25], while long-term sick leave does not necessarily differ consistently by response status [25, 26]. Some cohort and registry-based studies have explored their use in imputation models, with modest gains in representativeness or precision [27, 28]. Although registry-based RCTs increasingly use registry data for participant identification and clinical endpoints [29, 30], to our knowledge, no randomized controlled trial has tested whether registry-based variables can improve the imputation of self-reported mental health outcomes and reduce potential bias in effect estimates.
In this article, we examine whether registry-based variables can serve as effective auxiliary variables in handling missing outcome data from a randomized controlled trial of Prompt Mental Health Care (PMHC), a Norwegian early intervention program for depression and anxiety. Specifically, we assess the extent to which registry-based variables are associated with the missingness of mental health outcomes, their associations with the outcomes themselves, and whether including them in multiple imputation models changes effect estimates.
Methods
Trial design and participants
This is a secondary analysis of a published randomized controlled trial evaluating PMHC compared to treatment as usual (TAU) at 6 and 12 months [31, 32]. The trial was reported according to the CONSORT statement and is registered at ClinicalTrials.gov (NCT03238872). No changes to the design were made after trial commencement. A thorough description of the trial design is provided in the primary evaluation publication [31]. In total, 681 adults with mild to moderate symptoms of anxiety and/or depression were randomized (70:30 ratio; PMHC n = 463, TAU n = 218). Outcomes were assessed at 6 months (63% response in PMHC, 46% in TAU) and 12 months (54% in PMHC, 43% in TAU).
Self-reported outcomes
The primary outcomes were symptoms of depression and anxiety, assessed using the Patient Health Questionnaire-9 (PHQ-9) and Generalized Anxiety Disorder-7 (GAD-7), respectively. Both instruments were administered via self-report at baseline, 6 months, and 12 months. The PHQ-9 consists of nine items assessing how often participants experienced core symptoms of depression (e.g., “little interest or pleasure in doing things,” “feeling down, depressed, or hopeless”) over the past 2 weeks [33, 34]. Responses are rated on a four-point scale from 0 (“not at all”) to 3 (“nearly every day”), yielding a sum score from 0 to 27. The GAD-7 uses the same format and response scale to assess seven symptoms of anxiety (e.g., “feeling nervous, anxious or on edge,” “not being able to stop or control worrying”), with total scores ranging from 0 to 21 [33, 35]. Both instruments have shown good psychometric properties, with Cronbach’s alpha of 0.80 (PHQ-9) and 0.83 (GAD-7) in the current sample [31].
Demographic variables included self-reported gender (female/male), age (in years), and education level (primary/lower secondary, upper secondary, or higher education).
Linked register data
Nationally linked administrative register data were obtained for 651 participants (96% of the total sample). These data were retrieved from the Norwegian Prescription Database (NorPD), the Norwegian Control and Payment of Health Reimbursements Database (KUHR), and the FD-Trygd database (based on data from the Norwegian Labour and Welfare Administration, NAV). Data were constructed for the three time windows aligned with the survey assessments, around baseline, 6 months, and 12 months, enabling time-specific and future auxiliary variables to be included in imputation models.
The register data included:
- Sick leave and social benefits (FD-Trygd): number of sick leave days, receipt of sickness benefits, work assessment allowance, disability pension, and financial assistance (means-tested social welfare support).
- Medication use (NorPD): dispensed prescriptions for antidepressants, anxiolytics, and sedatives within 90 days before or after each follow-up point.
- Healthcare utilization (KUHR): general consultations and mental health–related consultations within 30 days of each survey assessment.
These indicators were chosen to reflect underlying health status, functional impairment, and socioeconomic context, factors that are theoretically linked to both mental health outcomes and the likelihood of missing data. For example, the receipt of work assessment allowance and disability pension are indicators of functional impairment, shown to correlate with depressive symptoms and lower survey participation, particularly when related to mental disorders [24, 25]. Prescription data is also suggested to serve as a proxy for mental health diagnoses and treatment intensity, particularly in populations with known depression or anxiety diagnoses [36]. In addition, consultation data from healthcare registers capture patterns of healthcare utilization, including mental health–related services, which may reflect symptom severity. Thus, all register-based variables were judged conceptually relevant for use as auxiliary variables in imputation.
Although some register indicators (e.g., 12-month data) were temporally located after some of the outcomes of interest (e.g., at 6 months), they were still considered as potential auxiliary variables in imputation models. Including such future data in imputation models is supported in the context of longitudinal studies, where strongly correlated variables can help improve prediction accuracy and reduce bias [37–39].
Variables associated with missingness and outcome
Separate unadjusted analyses were conducted for each predictor. Specifically, we ran individual logistic regressions for missing outcome data at 6 and 12 months, with odds ratios and p-values used to evaluate strength and significance. In addition, we estimated Pearson correlation coefficients between registry-based variables and PHQ-9 and GAD-7 scores at 6 and 12 months, using pairwise complete cases. Because these analyses were exploratory and aimed at describing patterns rather than testing specific hypotheses, no corrections for multiple comparisons were applied. Together, these analyses provided an overview of the empirical relevance of the registry-based variables.
Handling of missing data and multiple imputation models
We compared three analytic strategies for handling missing outcome data: (1) complete case analysis (listwise deletion); (2) multiple imputation (MI) with trial data only, including self-reported outcomes (PHQ-9, GAD-7), treatment group, and demographics (gender, age, and education); and (3) MI including both trial data and all available register-based auxiliary variables.
We applied a liberal selection strategy for auxiliary variables, retaining all register-based variables judged conceptually relevant, regardless of statistical significance or effect size. While some authors recommend including only variables with strong associations with either the missingness indicator or the incomplete outcome variable (typically r ≥ 0.40–0.50) to optimize efficiency and reduce noise [8, 13, 40], others have shown that even weaker associations may improve imputation accuracy, especially in the presence of high levels of missingness [8, 14–16]. A liberal approach is consistent with recommendations to increase the plausibility of the MAR assumption by incorporating diverse sources of information [8] and with findings that inclusive approaches tend to perform better in improving missing data procedures in realistic settings [15]. To reduce the risk of overfitting and model instability, the number of auxiliary variables remained within the recommended limit of fewer than one-third of complete cases [41].
MI was performed using Multiple Imputation by Chained Equations (MICE), implemented in the mice package (version 3.17.0) in R [39]. MICE is a flexible approach that supports variable-specific imputation models, allows the inclusion of auxiliary variables not used in the analysis model, and generates complete datasets suitable for downstream analyses. MI was run separately for each outcome (PHQ-9 at 6 and 12 months, and GAD-7 at 6 and 12 months), resulting in four imputation models. For each model, 100 imputed datasets were generated. Predictive Mean Matching (PMM) was used for continuous variables to preserve realistic distributions and prevent implausible values [42]. The plausibility of imputed values was confirmed by density plots showing broadly similar distributions of observed and imputed data for all outcomes and time points.
Estimating treatment effects
Treatment effects on PHQ-9 and GAD-7 scores at 6- and 12-month follow-up were estimated using linear regression models run separately for each outcome and time point, with treatment group (PMHC versus TAU) as a predictor. Models were estimated within each of the 100 imputed datasets and pooled using Rubin’s rules [43] to obtain combined effect estimates and confidence intervals. Results across MI strategies were compared to evaluate whether including register-based auxiliary variables affected the magnitude or precision of estimated treatment effects. Standardized treatment effects were calculated by dividing the treatment coefficient by the baseline standard deviation of the corresponding outcome variable, to allow comparability across strategies and outcomes.
All analyses were conducted using R version 4.4.0 [44] and RStudio version 2024.12.1 [45].
Results
Variables associated with missingness
In unadjusted logistic regression models (Table 1), several trial- and registry-based variables showed associations with missing outcome data at 6 and 12 months. Among the trial variables, higher baseline PHQ-9 scores were modestly associated with increased odds of missingness at both follow-up points (OR = 1.07, p < 0.001; OR = 1.05, p = 0.005). Baseline GAD-7 scores showed a somewhat similar pattern but were not statistically significantly associated with attrition. Higher age and education level were protective factors, with education showing a moderate association, especially at 12 months (OR = 0.63, p < 0.001). Female gender was weakly protective at 6 months only (OR = 0.70, p = 0.033). Table 1. Odds ratios for missing outcomes by time point (N = 651)Variable****Time pointMissing at 6 monthsMissing at 12 monthsORpORp**Trial variables AgeBaseline0.976 < 0.0010.972< 0.001* Education levelBaseline0.7230.0080.634< 0.001* GenderBaseline0.7000.0330.8700.405 GAD-7 scoreBaseline1.0330.0941.0330.0886 months--1.0390.15912 months1.1260.001**-- PHQ-9 scoreBaseline1.067 < 0.0011.0520.0056 months--1.0260.21312 months1.0960.001**--Registry variables Any consultationBaseline1.0250.1661.0100.5566 months1.0210.2021.0170.30712 months1.0270.1291.0240.195 Any prescriptionBaseline0.9990.9760.9990.9706 months1.0260.5740.9820.69712 months0.9590.3410.9310.102 Disability pensionBaseline0.5400.2090.8320.6786 months0.5400.2090.8320.67812 months0.5550.1970.6470.302 Mental health consultationBaseline1.0700.0811.0860.0416 months1.0410.2611.0690.08012 months1.0740.0691.0180.625 On sick leaveBaseline1.0510.7691.1290.4736 months0.7680.2281.0850.70212 months1.6030.1011.1230.688 Sick leave daysBaseline1.0010.6921.0000.9246 months0.9990.4521.0010.59612 months1.0020.3281.0010.642 Financial assistanceBaseline1.3840.57710.4300.0256 months2.5270.1003.4540.05912 months1.7330.4163.2680.142 Work assessment allowanceBaseline0.6690.2041.0000.9996 months0.8270.4631.0670.79612 months0.8770.5481.0390.857All odds ratios are derived from separate unadjusted logistic regression models, each including one predictor at a time**p *< 0.05, **p < 0.01, ***p < 0.001
For registry-based variables, most indicators showed weak or inconsistent associations. For example, receipt of financial assistance around baseline was strongly associated with increased missingness at 12 months (e.g., OR = 10.43, p = 0.025), but not at 6 months (OR = 1.38, p = 0.577). Similarly, mental health consultations around baseline were statistically significantly associated with missingness at 12 months (OR = 1.09, p = 0.041), but not at 6 months. Other registry-based indicators, including prescriptions and sick leave, did not show meaningful associations with attrition.
Group-level description for registry-based variables is provided in the Appendix (Table A1), and indicates very similar distributions across PMHC and TAU, with only small and inconsistent differences observed.
Variables associated with depression and anxiety outcomes
Correlational analyses (see Tables 2 and 3) identified several variables that were moderately to strongly associated with depression (PHQ-9) and anxiety (GAD-7) symptoms at both 6 and 12 months. Among the trial variables, baseline symptom scores (PHQ-9 and GAD-7) were moderately associated with later symptoms (e.g., r = 0.32 for PHQ-9 at 6 months;* r* = 0.26 for PHQ-9 at 12 months; both* p* < 0.001). The strongest correlations, however, were observed for concurrent symptom scores (e.g., PHQ-9 at 6 months with GAD-7 at 6 months: r = 0.73, p < 0.001; PHQ-9 at 12 months with GAD-7 at 12 months: r = 0.77, p < 0.001). In addition, higher baseline education level and female gender were weakly associated with lower symptom scores at 6 and 12 months for PHQ-9, while only education level was statistically significant at 12 months for GAD-7. Table 2. Variables associated with symptoms of depression (N = 651)PHQ-9 at 6 monthsPHQ-9 at 12 months**VariableTime pointrprp**Trial variables AgeBaseline0.0440.396−0.0360.526 Education levelBaseline−0.1350.009**−0.1680.003** GenderBaseline−0.1040.044*−0.1680.003** GAD-7 scoreBaseline0.1180.0220.0870.1246 months0.725< 0.0010.509< 0.00112 months0.526< 0.0010.772< 0.001* PHQ-9 scoreBaseline0.317< 0.0010.261< 0.0016 months--0.677< 0.00112 months0.677< 0.001--Registry-variables Any consultationBaseline0.0030.953−0.0260.6536 months0.1640.0010.0780.16912 months0.1450.0050.202< 0.001*** Any prescriptionBaseline0.0550.2910.0160.7836 months0.1520.0030.1390.01412 months0.232< 0.0010.224< 0.001*** Disability pensionBaseline−0.0530.3050.0300.6006 months−0.0530.3050.0300.60012 months−0.0590.2530.0240.670 Mental health consultationBaseline0.0970.059−0.0490.3846 months0.319< 0.0010.1220.03112 months0.282< 0.0010.434< 0.001** On sick leaveBaseline0.0070.893−0.1000.0786 months0.184< 0.0010.0540.34312 months0.0290.5730.1760.002 Sick leave daysBaseline0.0920.075−0.0390.4976 months0.187< 0.0010.0630.26412 months0.0560.2820.1420.012* Financial assistanceBaseline0.0740.1500.202< 0.0016 months0.1450.0050.248< 0.00112 months0.0290.5740.0570.312 Work assessment allowanceBaseline0.0980.058−0.0090.8766 months0.1530.0030.0780.16712 months0.224< 0.0010.1610.004Correlations represent separate unadjusted analyses between each predictor and the outcomep < 0.05, p *< 0.01, ****p *< 0.001Table 3Variables associated with symptoms of anxiety (N = 651)GAD-7 at 6 monthsGAD-7 at 12 monthsVariableTime pointrprpTrial variables* AgeBaseline−0.0700.176−0.0890.120 Education levelBaseline−0.0630.224−0.1280.024* GenderBaseline−0.0550.287−0.1110.052 GAD-7 scoreBaseline0.357< 0.0010.261< 0.0016 months--0.583< 0.00112 months0.583< 0.001-- PHQ-9 scoreBaseline0.178< 0.0010.1170.0396 months0.725< 0.0010.526< 0.00112 months0.509< 0.0010.772< 0.001Registry-variables Any consultationBaseline−0.0060.906−0.0680.2356 months0.1470.0040.0980.08512 months0.0820.1110.0970.089 Any prescriptionBaseline−0.0320.530−0.0900.1126 months0.0460.3740.0330.56512 months0.1280.0130.1080.058 Disability pensionBaseline−0.0190.720−0.0310.5896 months−0.0190.720−0.0310.58912 months−0.0370.478−0.0410.477 Mental health consultationBaseline0.0950.066−0.0840.1416 months0.277< 0.0010.1270.02512 months0.257< 0.0010.373< 0.001*** On sick leaveBaseline0.0330.522−0.1130.0466 months0.1550.003**0.0350.54112 months0.0190.7200.1200.035 Sick leave daysBaseline0.0370.474−0.0710.2146 months0.193< 0.0010.0330.56612 months0.0760.1410.1300.022 Financial assistanceBaseline0.0430.4100.1730.0026 months0.0530.3070.201< 0.00112 months−0.0340.5110.0950.094 Work assessment allowanceBaseline0.0240.643−0.0060.9136 months0.0980.0580.0630.26912 months0.1630.0020.0980.085Correlations represent separate unadjusted analyses between each predictor and the outcome**p < 0.05, ***p *< 0.01, ***p < 0.001
Among the registry-based variables, concurrent indicators of mental health consultations and prescription use (at 6 and 12 months) showed the most consistent associations with higher depression and anxiety symptoms. For example, mental health consultation at 12 months was moderately correlated with PHQ-9 symptoms at the same time point (r = 0.43, p < 0.001) and with GAD-7 (r = 0.37, p < 0.001). Prescription use around 12 months showed a moderate association with depressive symptoms (r = 0.23, p < 0.001) but a weaker association with anxiety (r = 0.14, p = 0.022). Other registry indicators, such as sick leave days, financial assistance, and work assessment allowance, were occasionally associated with symptom severity at some time points, but most of these correlations were weak and inconsistent. In contrast, disability pension and most baseline registry indicators were generally unrelated to symptoms of depression and anxiety.
Estimated treatment effects across missing data strategies
To examine whether including register-based auxiliary variables improves the handling of missing outcomes data and influences treatment effect estimates, we compared three analytic strategies: (1) complete case analysis, (2) MI using trial data only, and (3) MI including all registry-based auxiliary variables. Table 4 and Fig. 1 present estimated treatment effects of PMHC compared to TAU on PHQ-9 and GAD-7 scores at 6- and 12-month follow-up across the strategies. Table 4. Estimated treatment effects on PHQ-9 and GAD-7 scores using different missing data strategies*OutcomeTime pointModelTreatment effect (b)SEStandardized effect95% CIPHQ-96 monthsComplete case−3.3610.597−0.754[−1.017, −0.492]MI (trial only)−3.5000.646−0.786[−1.07, −0.501]MI (trial + registry)−3.1240.586−0.701[−0.959, −0.444]12 monthsComplete case−3.2570.660−0.731[−1.021, −0.441]MI (trial only)−3.4720.659−0.779[−1.069, −0.49]MI (trial + registry)−2.7490.623−0.617[−0.891, −0.343]GAD-76 monthsComplete case−1.9480.453−0.468[−0.682, −0.255]MI (trial only)−1.8690.478−0.449[−0.675, −0.224]MI (trial + registry)−1.7550.468−0.422[−0.643, −0.201]12 monthsComplete case−2.3400.529−0.563[−0.812, −0.313]MI (trial only)−2.5780.622−0.620[−0.913, −0.327]MI (trial + registry)−1.9390.517−0.466[−0.709, −0.223]*Note that the effect estimates presented here differ from those in our 2020 article [31]. In the present study, we included all participants who met caseness at baseline, defined as PHQ ≥ 10 and/or GAD ≥ 8. By contrast, in the 2020 article we reported effect estimates separately for participants who met caseness for depression (PHQ-9 ≥ 10) and for those who met caseness for anxiety (GAD ≥ 8). Additional, less central, differences are that the current analysis was restricted to participants with valid registry data, excluded the 3-month follow-up, and used a different analytic model (MI + linear regression vs. MLR + piecewise latent growth)Fig. 1. Standardized treatment effects of PMHC on PHQ-9 and GAD-7 at 6 and 12 months, estimated using three different strategies for handling missing outcome data. Points represent estimated effects with 95% confidence intervals. Negative values indicate lower symptom burden in the intervention group. MI = multiple imputations; registry = registry-based auxiliary variables
For all outcomes and time points, the estimated effects consistently favored the PMHC group over TAU. Standardized effect sizes ranged from − 0.42 to − 0.79 SD, indicating small to moderate effects in favor of PMHC (i.e., relatively greater reductions in symptoms in the intervention group). Estimates were broadly similar across analytic strategies: complete case and trial-only MI models yielded slightly larger effect estimates, while inclusion of registry-based auxiliary variables produced somewhat more conservative effects (about 0.03–0.16 SD; 6–25% smaller in absolute values, with attenuation a bit more pronounced at 12 months than 6 months). Similarly, standard errors and confidence intervals were largely comparable across analytic strategies, with moderate reductions when registry-based auxiliary variables were included (SE reductions of 2–17% relative to trial-only MI). Overall, the inclusion of registry-based auxiliary variables had a limited impact on the estimated treatment effects or their precision, and the direction and magnitude of effects were robust across all missing-data approaches.
Discussion
This study examined whether including registry-based auxiliary variables in MI models for missing outcomes would influence treatment effect estimates in a randomized trial of PMHC. The intervention showed benefits for both depression and anxiety outcomes at 6 and 12 months, and the pattern of results was robust regardless of how missing data were handled. Including registry-based auxiliary variables in imputation might support more plausible assumptions about missing data mechanisms and reduce potential bias; in this study, however, adding these variables made only modest changes to the estimated treatment effects compared with complete case and trial-only MI models. These differences were small enough that they are unlikely to alter the practical interpretation of the intervention’s effectiveness, suggesting that the main conclusions remained unchanged. At the same time, the inclusion of registry-based auxiliary variables yielded modest but meaningful gains in precision, with standard errors reduced by up to 17% for some outcomes. Such improvements are non-trivial from an experimental precision perspective. The findings are also valuable in showing when additional data sources do not materially alter conclusions, potentially because missing data may have introduced minimal bias in this particular trial. Taken together, these results may help to refine methodological recommendations, avoid unnecessary model complexity, and direct future efforts towards contexts where such data are more likely to add value.
Our approach aligns with general recommendations to include relevant auxiliary variables in MI to improve the plausibility of the MAR assumption [5, 8, 9]. Prior work has shown that incorporating external data can improve outcome estimation [27, 46] or inform differences between participants and non-participants [21]. However, the added value of auxiliary variables might be context-dependent and rely on their predictive strength and complementarity with existing data. A UK cohort study similarly found that administrative data added little value to imputation models [28]. Notably, while their imputation model already included rich and highly predictive survey-based variables, the available factors in our study, both demographic and register-based, were only modestly associated with both symptom outcomes and missingness.
Several factors may help explain the limited utility of registry-based auxiliary variables in our analyses. Most indicators, such as medication use, sick leave, and healthcare consultations, showed only weak associations with both symptom severity and follow-up attrition. One likely reason is that registry data and self-reported symptoms capture different aspects of mental health: administrative indicators primarily reflect service use or eligibility for benefits, whereas symptom scales assess current subjective distress. Individual variability in help-seeking behavior, the timing of service contact, and day-to-day symptom fluctuations may further reduce alignment between the two. Additionally, several registry variables were relevant only for a minority of participants, reducing their statistical contribution. The trial’s eligibility criteria, reflecting the intervention’s target group, may have constrained the explanatory potential of registry indicators. Because the PMHC trial included only individuals with mild to moderate symptoms, excluding more severe or complex cases, the range of both outcomes and auxiliary variables was restricted. This restriction likely reduced statistical variability at the group level, attenuating the observed associations with symptom levels and dropout risk. Taken together, these considerations highlight that the usefulness of registry-based auxiliary variables depends not only on their availability, but also on their conceptual relevance, population characteristics, and explanatory power in relation to both outcomes and mechanisms of missingness. Viewed this way, these domains also point to practical criteria that may help determine when auxiliary variables are likely to meaningfully strengthen imputation models in other studies.
Registry-based auxiliary variables may be particularly valuable in studies with higher attrition, greater heterogeneity in symptom severity, or, perhaps most important, outcomes more directly aligned with administrative domains (e.g., healthcare use, medication adherence, employment). A promising direction for future work is the systematic collection of short patient-reported outcome measures (PROMs) across primary care services, which could then be made available in registries. Such data would likely correlate more strongly with questionnaire-based outcomes used in trials and thereby enhance the ability to handle missing data and evaluate intervention effects in real-world settings. Evidence from reviews and implementation studies underscores both the potential and the challenges of such integration [47, 48]. Thus, the limited added value observed here should not be taken to imply that registry data are unhelpful in other trials, especially where survey predictors are sparse or attrition is higher.
We adopted an inclusive MI strategy that also allowed time-window variables measured after some outcomes (e.g., 12-month registry indicators when imputing 6-month outcomes) as auxiliary information. While the inclusion of “future” variables in imputation can be debated, using strongly correlated post-outcome auxiliaries can improve imputations without changing the analysis model’s interpretation. Importantly, results were highly consistent across strategies, suggesting this decision did not materially affect conclusions. However, even with extensive auxiliary information, the risk of a missing-not-at-random (MNAR) mechanism cannot be excluded. MNAR may arise either because missingness depends on predictors that were not observed, or because it depends directly on the unobserved outcome values themselves. If non-responders differ from responders in ways not captured by either trial or registry data, some uncertainty will persist in the estimated treatment effects. For instance, participants with high symptom burden might avoid follow-up surveys without showing increased service use, leaving them unobserved in both data sources. Auxiliary variables can help strengthen analytic transparency and increase the plausibility of the MAR assumption, but they cannot eliminate the possibility of bias. The robustness of estimates across strategies in this study should therefore not be taken as evidence that all sources of bias were addressed. Still, missing data mechanisms remain partially untestable. Ultimately, the most effective way to minimize uncertainty in outcome estimation is to ensure high response rates and complete follow-up. Registry data can be a valuable supplement in some studies but cannot replace high-quality outcome data collected directly from participants.
Strengths and limitations
A key strength of this study is the integration of detailed trial information with highly relevant nationally linked registry data for most of the randomized participants, regardless of survey response status. This enabled a rare and rigorous evaluation of whether administrative data can meaningfully contribute to the handling of missing outcome data in a randomized trial context. The pragmatic design and real-world setting increase the relevance of findings, particularly in mental health research where missing data are common and auxiliary information may be especially valuable. To our knowledge, this is one of the first studies to empirically test this approach in the field of mental health. Furthermore, the analytic strategy was transparent, applying an inclusive approach to auxiliary variable selection that was theoretically grounded and consistent with methodological recommendations. This strengthens the credibility and reproducibility of results while also illustrating the potential and limitations of registry data as auxiliary information in MI.
Nonetheless, several limitations should be noted. All imputations were conducted on the full sample, combining the intervention and control groups. While this ensured sufficient power and stable estimates, it assumes that symptom development and dropout mechanisms operate similarly across groups. However, it is possible that different factors influenced follow-up participation or symptom change in the two conditions in opposite directions. For example, symptom improvement might explain dropout in the intervention group, while ongoing distress or disengagement could drive non-response in the control group. If such group-specific mechanisms exist, pooling the data could obscure important differences and limit the precision of the imputed estimates. Although the treatment group was included in the imputation model, future studies may benefit from stratified imputations. Lastly, generalizability may be limited to settings with similar registry infrastructures, such as the Nordic countries, where linkage is feasible and coverage is high or with different patterns of missingness and follow-up. In other contexts, with less robust administrative systems or different help-seeking patterns, the utility of registry-based auxiliary variables may differ.
Conclusion
In this PMHC trial, incorporating registry-based auxiliary variables into multiple imputation models had limited impact on treatment effect estimates or their precision. The direction and magnitude of effects were consistent across analytic strategies, supporting the use of both conventional and more inclusive MI approaches in mental health trials. Nonetheless, registry data remains a promising resource for improving the handling of missing data, particularly in studies where such data are more strongly related to missingness or outcomes, or where trial data are less complete or less predictive. However, efforts to maximize response rates at follow-up should remain the primary strategy for addressing missing outcome data.
Supplementary Information
Supplementary Material 1: Table A1. Descriptives for linked register data.Supplementary Material 2: Consort.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Collins LM, Schafer JL, Kam CM. A comparison of inclusive and restrictive strategies in modern missing data procedures. Psychol Methods. 2001;6(4):330–51. 10.1037/1082-989X.6.4.330.11778676 · pubmed ↗
- 2Mainzer RM, Nguyen CD, Carlin JB, Moreno-Betancur M, White IR, Lee KJ. A comparison of strategies for selecting auxiliary variables for multiple imputation. Biom J. 2024;66(1):e 2200291. 10.1002/bimj.202200291.10.1002/bimj.202200291 PMC 761572738285405 · doi ↗ · pubmed ↗
- 3Nilsen TS, Knapstad M, Skogen JC, Aarø LE, Vedaa Ø. Non-response bias in the Norwegian Counties Public Health Survey: Insights from linkage to register data. Scand J Public Health. 2025;1–8. 10.1177/14034948251360674.10.1177/1403494825136067440770836 · doi ↗ · pubmed ↗
- 4R Core Team. R: A Language and Environment for Statistical Computing. Vienna (Austria): R Foundation for Statistical Computing; 2024. Available from: https://www.r-project.org/.
- 5Posit team. R Studio: Integrated Development Environment for R. Boston (MA): Posit Software, PBC; 2025. Available from: https://posit.co/.