Prompt-to-Pill: Multi-Agent Drug Discovery and Clinical Simulation Pipeline
Ivana Vichentijevikj, Kostadin Mishev, Monika Simjanoska Misheva

TL;DR
This paper introduces a modular AI framework for drug discovery and clinical simulation, demonstrating a full pipeline from molecule generation to virtual patient recruitment.
Contribution
A novel multi-agent LLM-based system for end-to-end drug discovery and clinical trial simulation is proposed and implemented.
Findings
The Prompt-to-Pill framework successfully simulated drug discovery and clinical trial phases for the DPP4 target.
Integration of generative and predictive LLMs enabled molecule creation, ADMET evaluation, and virtual patient screening.
The system demonstrated the feasibility of using AI to streamline drug development workflows in silico.
Abstract
This study presents a proof-of-concept, comprehensive, modular framework for AI-driven drug discovery (DD) and clinical trial simulation, spanning from target identification to virtual patient recruitment. Synthesized from a systematic analysis of 51 large language model (LLM)-based systems, the proposed Prompt-to-Pill architecture and corresponding implementation leverages a multi-agent system (MAS) divided into DD, preclinical and clinical phases, coordinated by a central Orchestrator. Each phase comprises specialized LLM for molecular generation, toxicity screening, docking, trial design, and patient matching. To demonstrate the full pipeline in practice, the well-characterized target Dipeptidyl Peptidase 4 (DPP4) was selected as a representative use case. The process begins with generative molecule creation and proceeds through ADMET (Absorption, Distribution, Metabolism, Excretion,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
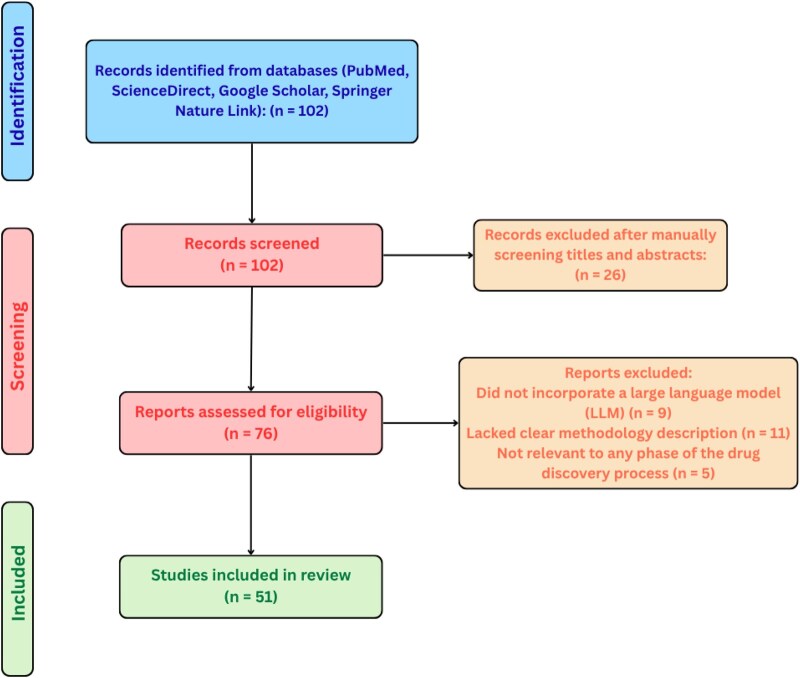 Figure 1
Figure 1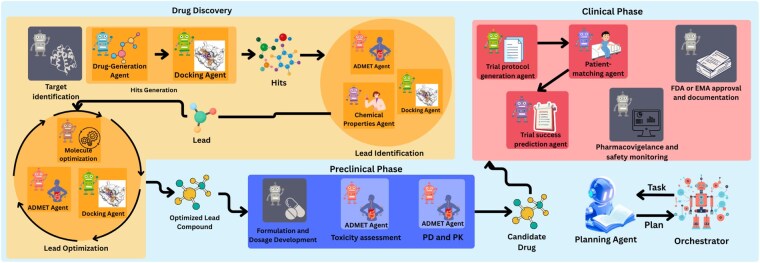 Figure 2
Figure 2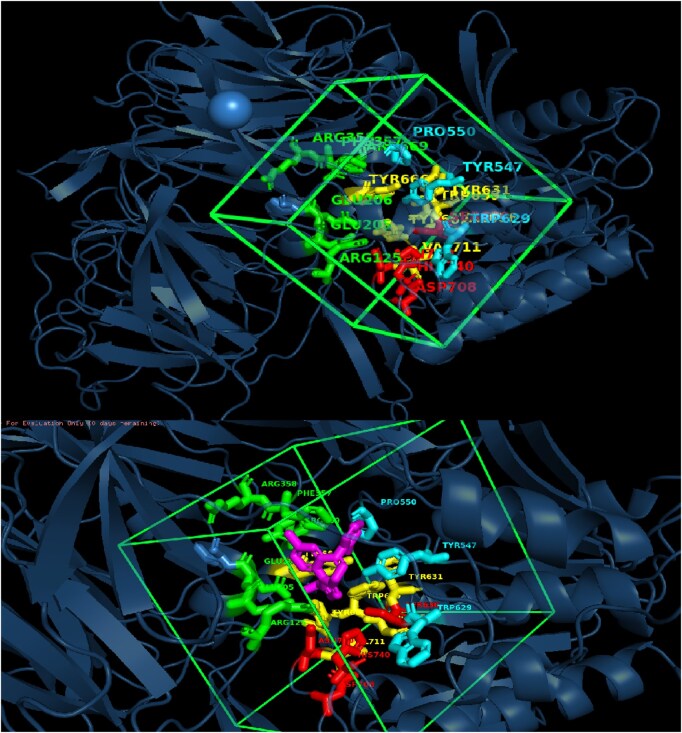 Figure 3
Figure 3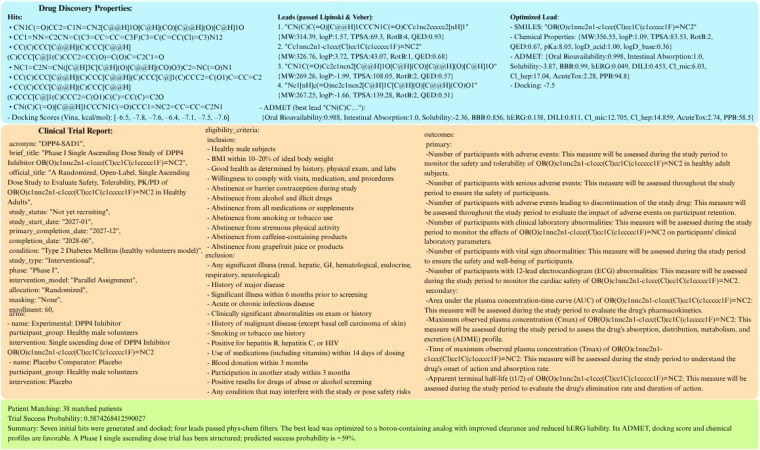 Figure 4
Figure 4| Category | Preclinical/DD | Clinical | ||||
|---|---|---|---|---|---|---|
| Yes | No | N/A | Yes | No | N/A | |
| GitHub/HF link | 20 | 12 | – | 9 | 10 | – |
| Input examples | 17 | 2 | 1 | 6 | 2 | 1 |
| Output examples | 6 | 13 | 1 | 1 | 7 | 1 |
| RAG usage | 3 | 29 | – | 6 | 13 | – |
| Citation | Agent | Dataset/Task | Metric(s) | Value(s) | Type |
|---|---|---|---|---|---|
|
| Molecule Generation (Druggen) | – | Validity, Novelty, Diversity | 99.9%, 41.88%, 60.32% | Generation |
|
| Property Prediction (ChemFM) | Drug Oral Bioavailability | ROC-AUC | 0.715 | Classification |
| BBB | ROC-AUC | 0.908 | Classification | ||
| Drug Half-Life Duration | Spearman | 0.551 | Regression | ||
| Drug Mutagenicity | ROC-AUC | 0.854 | Classification | ||
| Clearance Hepatocyte | Spearman | 0.495 | Regression | ||
| Clearance Microsome | Spearman | 0.611 | Regression | ||
| DILI | ROC-AUC | 0.920 | Classification | ||
| hERG Channel Blockage | ROC-AUC | 0.848 | Classification | ||
| Drug Acute Toxicity | MAE | 0.541 | Regression | ||
| PPBR | MAE | 7.505 | Regression | ||
| P-glycoprotein Inhibition | ROC-AUC | 0.931 | Classification | ||
| Drug Aqueous Solubility | MAE | 0.725 | Regression | ||
| VDss | Spearman | 0.662 | Regression | ||
| CYP2C9 Inhibition | PRC-AUC | 0.788 | Classification | ||
| CYP3A4 Inhibition | PRC-AUC | 0.878 | Classification | ||
| CYP2C9 Substrate | PRC-AUC | 0.414 | Classification | ||
| CYP2D6 Inhibition | PRC-AUC | 0.704 | Classification | ||
| CYP2D6 Substrate | PRC-AUC | 0.739 | Classification | ||
| Human IA | ROC-AUC | 0.984 | Classification | ||
| CYP3A4 Substrate | ROC-AUC | 0.654 | Classification | ||
| Drug Permeability | MAE | 0.322 | Regression | ||
|
| Trial Outcome Prediction(Meditab) | Phase I Trials | AUROC, PRAUC | 0.699, 0.726 | Classification |
| Phase II Trials | AUROC, PRAUC | 0.706, 0.733 | Classification | ||
| Phase III Trials | AUROC, PRAUC | 0.734, 0.881 | Classification | ||
|
| Molecule Optimization (DrugAssist) | – | Solubility, BBBP, All, Valid rate, Similarity | 0.74, 0.80, 0.62, 0.98, 0.69 | Generation |
|
| PatientMatching (Panacea) | SIGIR | BACC, F1, R, P | 0.43, 0.57, 0.52, 0.66 | Classification |
| TREC 2021 | BACC, F1, R, P | 0.47, 0.58, 0.54, 0.69 | Classification | ||
| TrialDesign (Panacea) | Criteria | BLEU, ROUGE, CR | 0.24, 0.44, 0.68 | Generation | |
| Arms | BLEU, ROUGE, CR | 0.28, 0.50, 0.61 | Generation | ||
| Outcome | BLEU, ROUGE, CR | 0.31, 0.51, 0.55 | Generation |
- —European Union under the Horizon Europe programme
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComputational Drug Discovery Methods · Machine Learning in Healthcare · Artificial Intelligence in Healthcare and Education
1 Introduction
The ability of large language model (LLMs) to learn from massive datasets and adapt to diverse inputs provides unprecedented capabilities that surpass traditional methods. Their use accelerates decision-making and reduces experimental costs across the development pipeline (Oniani et al. 2024), as evidenced by applications ranging from generating novel molecular structures (Li et al. 2023, Sheikholeslami et al. 2025) to predicting pharmacokinetics and toxicity (Liu et al. 2024, Cai et al. 2025), simulating clinical trials (Xu et al. 2025), and optimizing patient-trial matching (Lin et al. 2024, Datta et al. 2025).
The integration of LLMs into drug development pipelines has gained notable traction, especially across preclinical phases.
Gao et al. proposed a domain-guided multi-agent system (MAS) for reliable drug-target interaction (DTI) prediction, using a debate-based ensemble of LLMs. The framework partitions the DTI task into protein sequence understanding, drug structure analysis, and binding inference, handled by dedicated agents. Evaluation was conducted on the BindingDB dataset, showing improvements in both accuracy and prediction consistency compared to single-LLM baselines. The system integrates GPT-4o, LLaMA-3, and GLM-4-Plus (Gao et al. 2024).
Lee et al. developed CLADD, a retrieval-augmented MAS addressing multiple DD tasks. CLADD includes specialized teams for molecular annotation, knowledge graph querying, and prediction synthesis. Evaluations spanned property-specific captioning (BBBP, SIDER, ClinTox, BACE), target identification (DrugBank, KIBA), and toxicity classification. All agents were instantiated with GPT-4o-mini, showcasing the utility of general-purpose models when combined with structured Retrieval-augmented generation (RAG) mechanisms (Lee et al. 2025).
Song et al. presented PharmaSwarm, a hypothesis-driven agent swarm for therapeutic target and compound identification. The architecture orchestrates three specialized agents (Terrain2Drug, Market2Drug, Paper2Drug) and a central evaluator, all integrated via a shared memory and tool-augmented validation layer. Case studies included idiopathic pulmonary fibrosis and triple-negative breast cancer, combining omics analysis, literature mining, and market signals. Agents were powered by GPT-4, Gemini 2.5, and TxGemma (Song et al. 2025).
Yang et al. proposed DrugMCTS, a novel multi-agent drug repurposing system that incorporates Monte Carlo Tree Search (MCTS) with structured agent workflows. Using Qwen2.5-7B-Instruct for all agents, the system conducts iterative reasoning across molecule retrieval, analysis, filtering, and protein matching. The framework was benchmarked on DrugBank and KIBA, achieving up to 55.34% recall. A case study involving Equol and CXCR3 showed successful prediction of interaction, supported by AutoDock Vina simulations with a binding score of kcal/mol (Yang et al. 2025).
Inoue et al. introduced DrugAgent, an explainable multi-agent reasoning system for drug repurposing. Their architecture coordinates agents handling knowledge graph queries, machine learning scoring, and biomedical literature summarization. Evaluation on a kinase inhibitor dataset revealed strong interpretability and modularity. Detailed ablation studies confirmed that each agent contributes distinctly to the performance. The system employed GPT-4o, o3-mini, and GPT-4o-mini, and the full pipeline is available open-source (Inoue et al. 2025). Among the surveyed systems, only DrugAgent provides a publicly accessible implementation (https://anonymous.4open.science/r/DrugAgent-B2EA).
None of the described MASs engages with clinical trial simulation, real-world evidence (RWE), or electronic health records (EHRs), thereby limiting their applicability to the preclinical stage of drug development.
This paper introduces Prompt-to-Pill, a unified multi-agent framework build on a systematic analysis of 51 LLM-based studies published between 2022 and 2025. The architecture integrates specialized LLM agents for molecule generation, docking, property prediction, trial construction, patient matching, and outcome forecasting through a central Orchestrator. Unlike prior frameworks confined to molecule-level reasoning, Prompt-to-Pill provides a proof-of-concept prototype from molecular ideation to virtual trial execution, demonstrating how modular LLM agents can operate synergistically within a closed-loop DD and development ecosystem. A complete implementation of the pipeline is available at GitHub (https://github.com/ChatMED/Prompt-to-Pill).
2 Methods
The systematic review was conducted in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. The PRISMA framework was employed to ensure transparency, methodological rigor, and reproducibility in identifying, screening, and synthesizing eligible studies. A structured multi-stage review process was followed, encompassing database search, eligibility screening, full-text assessment, and data extraction. The complete selection workflow is detailed in the accompanying PRISMA flow diagram depicted in Fig. 1.
PRISMA-based selection process.
2.1 Information sources and search strategy
A structured and comprehensive literature search was conducted to identify and evaluate LLM-based approaches applied in drug design and discovery. The search was conducted between 1 May and 15 June 2025, across PubMed, ScienceDirect, Google Scholar, and Springer Nature Link. The search covered the publication period 2022–5.
Search queries with predefined Boolean combinations captured studies across all DD stages. Representative search strings included: “large language models” AND (“target identification” OR “binding site prediction”), “large language models” AND (“molecule generation” OR “de novo molecule generation”), “large language models” AND (“clinical trial design” OR “eligibility criteria extraction” OR “trial outcome prediction”), “retrieval-augmented generation” AND (“drug discovery” OR “clinical trials”), “large language models” AND (“patient recruitment” OR “clinical trial matching”). These terms were selected to align with a conceptual pipeline spanning DD, preclinical and clinical phases of pharmaceutical development.
2.2 Study selection process
Two reviewers independently screened the titles and abstracts of all retrieved records. Full-text reviews were then performed to assess eligibility based on the predefined inclusion and exclusion criteria.
The inclusion criteria were defined as follows: open-source studies written in English; publications or preprints published between 2022 and 2025; research incorporating LLMs for drug development tasks with clearly defined input–output structure, functional purpose, and workflow integration potential; and studies relevant to at least one stage of the DD or clinical trial process.
The exclusion criteria were: articles not written in English; studies lacking a clear methodological or architectural description; studies that are not publicly accessible; and research not directly applicable to any stage of drug development.
The PRISMA flow diagram in Fig. 1 details the number of records identified, screened, excluded (with reasons), and finally taken into consideration for building the Prompt-to-Pill pipeline.
2.3 Data extraction and synthesis
For each included study, detailed metadata were manually extracted into structured tables, one for preclinical models and DD and another for clinical applications. Metadata fields were designed to support both technical evaluation and contextual information from each source as follows:
Bibliographic: Authors, Year, Title, DOI. Technical: Base model (e.g. GPT-4, BioGPT), Task Type, RAG usage, Evaluation Metrics, Datasets. Reproducibility: GitHub/Hugging Face links, Input/Output examples. Contextual: Task Narrative, Clinical Trial Phase (I–IV), Abstract Summary.
Extracted data were then synthesized by stage as needed for the drug development pipeline. Studies were profiled and compared across multiple dimensions including application scope, base architecture, task type, and dataset diversity. The complete metadata tables containing all reviewed studies are provided in the section Data Availability. This structured comparison informed the construction of the Prompt-to-Pill multi-agent framework introduced later in the paper.
3 Methodology
3.1 Prompt-to-pill architecture foundation
The systematic review of 51 studies (2022–5) shows a sharp growth in research, peaking in 2024 (14 preclinical/DD, 8 clinical), with 17 in 2025, and fewer in 2022 (4) and 2023 (8).
Preclinical/DD studies mainly used generative LLMs such as LLaMA and GPT-2 for creative molecular tasks on open datasets (TDC, DrugBank). Models like DrugGen (Sheikholeslami et al. 2025) and DrugGPT (Li et al. 2023) generate SMILES from protein sequences, 3D structures, or text, while others introduce spatial constraints [3DSMILES-GPT (Wang et al. 2025b)] or RNA design [GenerRNA (Zhao et al. 2024)]. DrugAssist (Ye et al. 2023) extends this process with prompt-based molecule optimization, refining compounds to improve pharmacological properties. LLMs also support ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) prediction, synthesis feasibility, and reactivity analysis (Chaves et al. 2024, Cai et al. 2025, Wang et al. 2025a), as well as biological interaction modeling and drug repurposing (Edwards et al. 2023, Beasley et al. 2025, Li et al. 2025, Schmitt et al. 2025).
Clinical studies, in contrast, rely on discriminative or hybrid models such as GPT-4 and BioBERT, often trained on structured data (e.g. ClinicalTrials.gov). About half of the 19 clinical papers propose cross-phase models addressing patient selection, outcome prediction, and document generation. LLMs assist in patient-trial matching (Lin et al. 2024, Datta et al. 2025), trial simulation (Reinisch et al. 2024, Wang et al. 2024, Xu et al. 2025), and pharmacovigilance through tools like AskFDALabel and DAEDRA (von Csefalvay 2024, Wu et al. 2025), occasionally enhanced with RAG pipelines for context-aware text generation (Markey et al. 2025, Painter et al. 2025).
RAG methods showed limited adoption despite their potential for complex reasoning tasks. As shown in Table 1, most studies provided input examples but fewer included output data or reproducible code, underscoring the need for transparency and standardized evaluation.
This analysis informed the design of the proposed Prompt-to-Pill architecture, implemented using the AutoGen (Wu et al. 2023) framework for scalable multi-agent AI systems. Each agent is adapted from rigorously evaluated domain models, with key performance metrics summarized in Table 2.
The datasets listed in Table 2 implicitly define the applicability domains (ADs) of the models integrated into the pipeline. For example, ChemFM’s ADME and toxicity predictors are trained on specific benchmarking collections of drug-like compounds, while Panacea and MediTab operate within the disease areas and trial structures represented in CT.gov, SIGIR, and TREC. Because Prompt-to-Pill connects these components sequentially, the effective AD of the full system corresponds to the intersection of all model-specific ADs.
3.2 The Prompt-to-Pill multi-agent pipeline
Constructed from the models identified and reviewed in this study, a comprehensive AI-driven pipeline for DD and clinical trial simulation is presented in Fig. 2, structured into three main phases: DD Agents, Preclinical Agents and Clinical Agents, coordinated by a central Orchestrator, assisted by a Planning Agent. The workflow is task-driven, dynamically selecting the appropriate agent and its tools according to the requirements of the given task.
Prompt-to-pill multi-agent architecture.
In our scenario, we demonstrate this process by focusing on the development of drug candidates for the DPP4 protein target (UniProt ID: P27487). For this drug development task, the pipeline begins with Drug Discovery Agents. Here we have three subgroups of agents: Hits Generation, Leads Identification, and Lead Optimization.
The workflow begins with Hits Generation, where the Drug-Generation Agent, based on the DrugGen framework (Sheikholeslami et al. 2025), produces a set of candidate SMILES sequences. Then the generated SMILES are docked against the target with Docking Agent. The Docking Agent is responsible for evaluating the binding affinity of generated molecules against the target protein. Retrieves the target structure from the Protein Data Bank (Berman et al. 2000) or defaults to AlphaFold models (Jumper et al. 2021) when no experimental structure is available. Candidate SMILES from the Drug-Generation Agent are converted into 3D conformations using RDKit (https://www.rdkit.org). Binding pockets are predicted with P2Rank (Krivák and Hoksza 2018) (P2Rank success rates: 72.0% Top-n, 78.3% Top-(n+2) on COACH420; 68.6% Top-n, 74.0% Top-(n+2) on HOLO4K), and the highest-ranked pocket defines the docking box, whose coordinates are extracted from the P2Rank output and expanded with a fixed padding margin. With receptor and ligand prepared, AutoDock Vina (v1.1.2) performs docking within the predicted pocket, generating 20 poses ranked by affinity. Using this approach, we achieved RMSD lower than 2 Å in 86.59% of cases and a mean RMSD of 1.16 Å on the Astex dataset. The docking setup and visualization, including binding sites, grid box, and ligand, are shown in Fig. 3.
Docking visualization of DPP4 (PDB ID: 2QT9) showing the predicted binding pocket (green grid box; center = 37.87, 49.09, 36.58; edge = 25.02 Å) and the docked ligand (magenta; SMILES: OB(O)c1nnc2n1-c1ccc(Cl)cc1C(c1ccccc1F)=NC2). Pocket side chains are shown as colored sticks (colors for visual separation only) and correspond to validated binding residues ARG125, GLU205, GLU206, TYR547, TYR631, SER630, HIS740, and ASN710 (Mathur et al. 2023).
Following the generation and docking of hits, the workflow progresses to the Lead Identification stage. The Chemical Properties Agent calculates key physicochemical descriptors (molecular weight, logP, TPSA, hydrogen bond donors and acceptors, rotatable bonds, QED, etc.) using RDkit driven tools. Molecules are filtered according to Lipinski’s Rule of Five (HBD 5, HBA 10, MW 500, logP 5) (Lipinski et al. 2001) and Veber’s rules (RotB 10, TPSA 140 Å) (Veber et al. 2002), ensuring that only drug-like compounds advance. In parallel, the ADMET Properties Agent, using ChemFM (Cai et al. 2025) framework, is also invoked at this stage to provide an early assessment of ADMET. Properties that this agent can predict are presented in 2. Compound that show the most favorable docking, pass physicochemical filters, and exhibit acceptable ADMET predictions are prioritized as lead.
Next is Lead Optimizations stage. This stage focuses on optimizing the chosen molecule to enhance its pharmacological profile while preserving strong binding affinity to the DPP4 target. The Molecule Optimization Agent, based on DrugAssist (Ye et al. 2023), iteratively modifies the structure to enhance bioavailability, solubility, and safety. Each optimized variant is re-evaluated by the ADMET Properties Agent and Docking Agent, and this loop continues until optimal properties are achieved.
The optimized compound with properties serve entry point into the Preclinical Phase, where the optimized candidate undergoes systematic pharmacokinetic and toxicity profiling using ADMET Agent’s tools. Once these evaluations are completed, the workflow is shifted into the Clinical Phase for trial simulation.
In the Clinical Phase, the Trial Generation Agent constructs a trial protocol tailored to the compound and disease driven by Panacea model for criteria, arms and outcomes prediction. This protocol is parsed into structured data and passed to the Patient-Matching Agent, which also employs the Panacea model (Lin et al. 2024) to evaluate patient EHR descriptions and identify candidates who meet the trial’s inclusion and exclusion criteria. The agent returns number of matched patients in the final report, and a set of matched patient IDs. These identifiers are saved to a file and the total number of matched patients is computed and included in the final trial report. Subsequently, the Trial Outcome Prediction Agent uses MediTab (Wang et al. 2024) to estimate the probability that the proposed trial will succeed, given its protocol structure. In line with the original MediTab formulation (Wang et al. 2024), this module operates on trial-level metadata and text and learns patterns from historical ClinicalTrials.gov and HINT benchmarks.
Finally, the matched patient data, drug properties, and trial design are provided to the Orchestrator, which aggregates all outputs into a structured report.
The input and output format for the Dipeptidyl peptidase 4 (DPP4) target are shown in Fig. 4.
Prompt-to-Pill’s I/O example for Task: “Simulate drug development for DPP4 (P27487) with patients on/path/to/patients.xml”. “Trial Success Probability” correspond to MediTab’s predicted likelihood of clinical trial success based on protocol text and structured trial metadata (e.g. phase, condition, enrollment, arms, outcomes), and do not represent estimates of the underlying drug’s biological efficacy.
4 Limitations and future work
Prompt-to-Pill is designed as a research-oriented, hypothesis-generation framework intended for use exclusively by trained professionals such as bioinformaticians, medicinal chemists, pharmacologists, and clinicians. The system is not intended for clinical or regulatory decision-making. Instead, its outputs serve as exploratory insights that must be experimentally or clinically validated before any real-world application. The framework aims to support early ideation, academic research, and computational prototyping. While the proposed Prompt-to-Pill pipeline offers a structured, automated approach to drug discovery and clinical simulation, several limitations remain.
First, as shown in Fig. 2, some agents remain conceptual placeholders (highlighted in grey), like Target Identification Agent, the Formulation and Dosage Development Agent, FDA or EMA approval and documentation and the Pharmacovigilance and Safety Monitoring Agent. Although we identified related approaches in the literature, most lack accessible implementations or compatible I/O interfaces, preventing integration. Bridging this gap remains a key direction for future work.
Second, the Orchestrator is currently implemented using OpenAI’s o4-mini model, which has been shown to perform strongly in medical reasoning and biomedical tasks Arora et al. (2025). However, in the trial generation phase, its role is used to producing structured protocol fields such as: study documents, brief summary, acronym, brief title, official title, study status, study start date, primary completion date, completion date, condition, study type, phase, intervention model, allocation, masking, and enrollment. While useful for structuring and simulating trial protocols, these outputs cannot substitute for expert-driven trial design.
Third, each component model operates within the applicability domain (AD) of its training data, and the pipeline therefore inherits the intersection of all ADs. Predictions involving molecules, trial structures, or patient populations far from these distributions should be interpreted as exploratory, not definitive.
This study also presents only a single-target case (DPP-4, P27487), demonstrating feasibility but not generalizability. Future work will extend the framework to multiple targets and diseases for broader validation.
Future work will focus on completing missing agents, enlarging the AD of existing components, and performing multi-disease, multi-target validation studies.
5 Discussion
While LLMs have opened transformative opportunities in drug discovery and clinical research, realizing their full potential requires addressing key challenges in transparency, evaluation consistency, and reproducibility.
A key limitation is the limited reasoning ability of current models. In biomedical contexts, correctness alone is insufficient—decisions must be grounded in clear, interpretable reasoning that experts can verify. To address this, several recent models have introduced mechanisms to make reasoning more explicit. These include retrieval-augmented generation (Feng et al. 2025, Wang et al. 2025a, Xu et al. 2025), instruction-tuned multitask learning (Liu et al. 2024, Ma et al. 2024), and multi-hop rationale generation (Wang et al. 2023, Feng et al. 2025). Such approaches represent important progress toward interpretability. However, without standardized frameworks to assess reasoning quality or consistency, trust in LLM-driven biomedical insights remains limited.
Another major challenge in LLM-based DD is the inconsistency in evaluation protocols across model types. Generative models are assessed using metrics like validity, docking scores, or QED (Zhao et al. 2024, Sheikholeslami et al. 2025, Wang et al. 2025b), while discriminative models report AUROC or F1 scores (Liu et al. 2024, Ma et al. 2024, Wang et al. 2025a), yet differ in datasets and thresholds. Knowledge-retrieval and reasoning systems often rely on qualitative outputs without standardized measures (Wang et al. 2023, Feng et al. 2025). This fragmentation hinders comparability and progress. To address this, the field urgently needs task-specific, model-type-sensitive benchmarks.
Reproducibility and transparency also remain persistent issues. Many studies lack public access to code, models, or I/O examples, and when repositories exist, documentation is often incomplete. This fragmentation limits cumulative progress and undermines trust.
These models are the future of drug development, but there is still much work to be done. The path forward requires not only better models, but better systems around the models. This includes standardized evaluations, transparent documentation, expert-guided development, and thoughtful regulation. Only by meeting these unmet needs can we ensure that LLMs evolve from experimental tools to trusted agents in the future of biomedical discovery.
6 Ethical and regulatory considerations
As highlighted in recent discussions on responsible biomedical AI deployment (Tang et al. 2025), LLM-based systems in safety-critical domains such as clinical trial design raise central concerns around transparency, explainability, bias mitigation, and the risk of over-reliance on unvalidated outputs. The European Union’s Artificial Intelligence Act (2024) explicitly designates healthcare AI as “high-risk” (Recital 58; Annex III), requiring safeguards such as traceability, human oversight, and fundamental rights impact assessments. The authors have recently published their work on AI Act compliance within the MyHealth@EU framework (Simjanoska Misheva et al. 2025), demonstrating strong ethical responsibility in advancing AI use within sensitive healthcare environments. Their tutorial addresses the dual-compliance challenge of embedding AI Act safeguards (transparency, provenance, robustness) while meeting MyHealth@EU interoperability requirements, showing how AI metadata can be integrated into HL7 (Health Level Seven) CDA (Clinical Document Architecture) and FHIR (Fast Healthcare Interoperability Resources) messages without disrupting existing standards. The goal is not to bypass current guidelines but to ease clinicians’ workload, strengthen trust in AI-assisted decisions, and ensure that compliance and safety are engineered into systems from the outset. In this context, the present pipeline is strictly positioned as a research prototype and decision-support artifact, never as an automated tool for patient eligibility or therapeutic approval. By embedding governance mechanisms early and framing the work as proof-of-concept exploration, the approach contributes to the broader dialogue on trustworthy AI in DD while acknowledging the rigorous benchmarking, reproducibility, and expert oversight still required before clinical translation.
7 Conclusion
To illustrate practical integration, the Prompt-to-Pill multi-agent framework was proposed, uniting specialized LLM agents to automate decision-making across preclinical and clinical stages. This architecture showcases how coordinated LLM workflows can collaborate, iterate, and self-correct within a modular design. Crucially, the successful implementation of this architecture served simultaneously as a “limitation demonstrator,” significantly highlighting the applicability domain limitations and systemic challenges that must be overcome, thereby establishing a rigorous foundation upon which reliable hypothesis generation can be built.
Looking ahead, the progress of LLM-driven drug development will depend not only on more capable models but on robust evaluation protocols, transparent sharing, and clear regulatory standards. Addressing these challenges will allow LLMs not just to accelerate, but to redefine the future of drug development.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Arora RK, Wei J, Soskin Hicks R et al. Health Bench: evaluating large language models towards improved human health. ar Xiv, https://arxiv.org/abs/2505.08775, 2025, preprint: not peer reviewed.
- 2Beasley J-MT, Schatz K, Ding E et al. TARRAGON: therapeutic target applicability ranking and retrieval-augmented generation over networks. bio Rxiv. 10.1101/2025.04.19.649662, 2025, preprint: not peer reviewed. · doi ↗
- 3Berman HM , Westbrook J, Feng Z et al The protein data bank. Nucleic Acids Res 2000;28:235–42. 10.1093/nar/28.1.23510592235 PMC 102472 · doi ↗ · pubmed ↗
- 4Cai F, Zacour K, Zhu T et al. Chem FM as a scaling law guided foundation model pre-trained on informative chemicals. Commun Chem 2025. 10.1038/s 42004-025-01793-8 · doi ↗
- 5Chaves JMZ, Wang E, Tu T et al. Tx-LLM: a large language model for therapeutics. ar Xiv, https://arxiv.org/abs/2406.06316, 2024, preprint: not peer reviewed.
- 6Datta S , Lee K, Huang L-C et al Patient 2trial: from patient to participant in clinical trials using large language models. Inform Med Unlocked 2025;53:101615. 10.1016/j.imu.2025.101615. · doi ↗
- 7Edwards C, Naik A, Khot T et al. Syner GPT: in-context learning for personalized drug synergy prediction and drug design. bio Rxiv, 10.1101/2023.07.06.547759, 2023, preprint: not peer reviewed. · doi ↗
- 8Feng Y , Wang J, He R et al A retrieval-augmented knowledge mining method with deep thinking LL Ms for biomedical research and clinical support. Giga Science 2025;14:giaf 109. 10.1093/gigascience/giaf 10940971592 PMC 12448786 · doi ↗ · pubmed ↗