Structure preserving t-SNE of matrix framed data
Soohyun Ahn, Johan Lim, Wei Jiang, Sungim Lee, Xinlei Wang

TL;DR
The paper introduces Matrix t-SNE, a new visualization method that preserves row and column structures in matrix-framed data, outperforming traditional t-SNE.
Contribution
The novel Matrix t-SNE algorithm extends t-SNE to handle matrix-framed data while preserving row and column group structures.
Findings
Matrix t-SNE provides better separation of data elements based on row and column group structures.
The method was successfully applied to exergame, gene expression, and temperature datasets.
Results show improved visualization compared to classical t-SNE for matrix-framed data.
Abstract
Across various fields, we can align data elements into a matrix frame with both row and column indices, forming what we refer to as matrix-framed data. These elements can take various forms, such as scalars, vectors, time series, matrices, or arrays. Existing data visualization methods aim to represent data elements of different groups without considering the underlying two-dimensional structure present in matrix-framed data. To address this limitation, we introduce a novel visualization method called Matrix t-SNE, designed to effectively embed matrix elements into a low-dimensional Euclidean space while preserving both row-wise and column-wise group structures. Our approach extends the classical t-SNE algorithm to accommodate matrix-framed data, providing a detailed algorithmic framework for embedding such data into low-dimensional representations. To demonstrate the effectiveness of…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
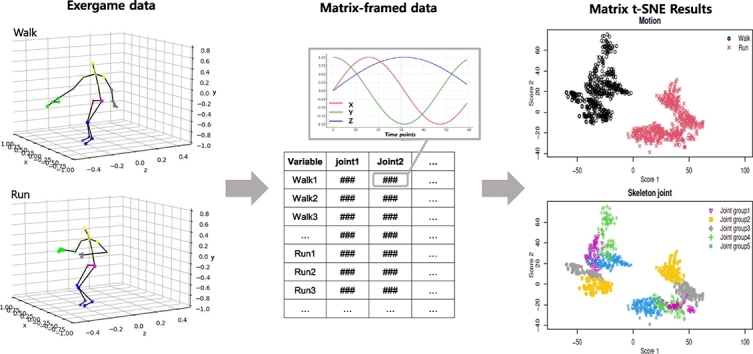 Figure 1
Figure 1 Figure 2
Figure 2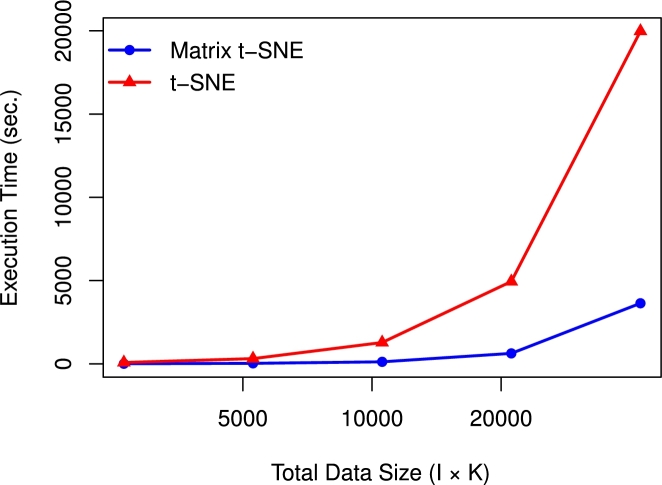 Figure 3
Figure 3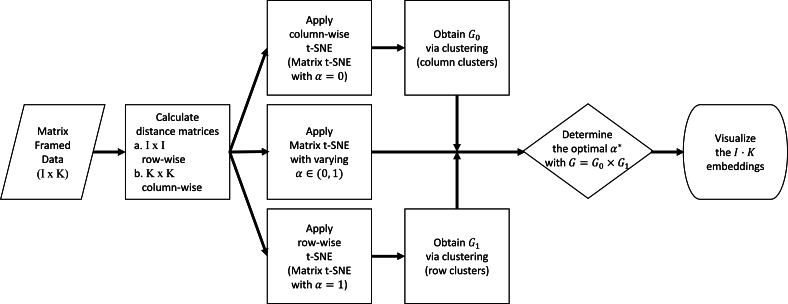 Figure 4
Figure 4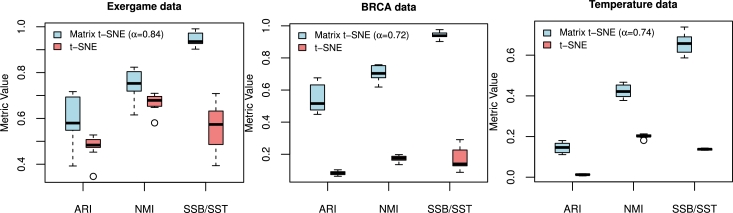 Figure 5
Figure 5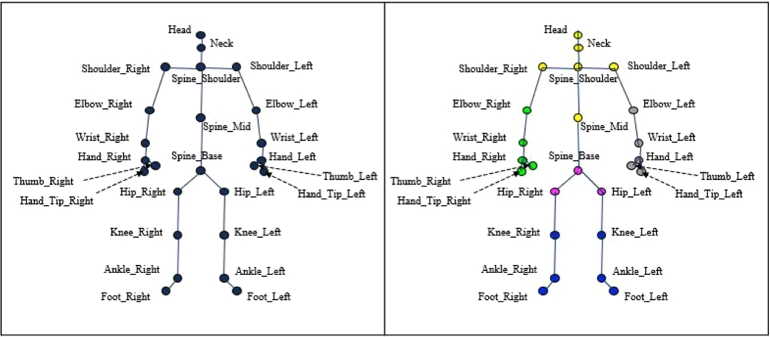 Figure 6
Figure 6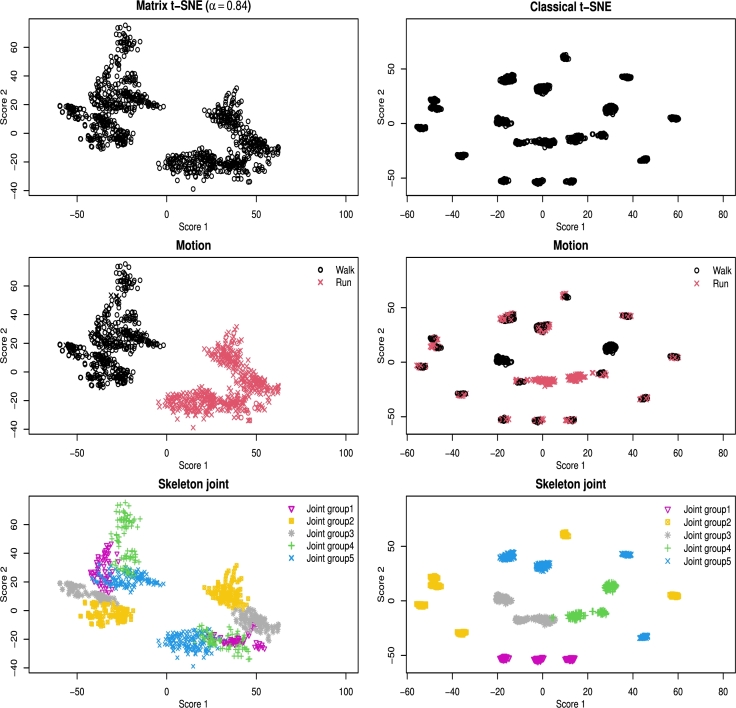 Figure 7
Figure 7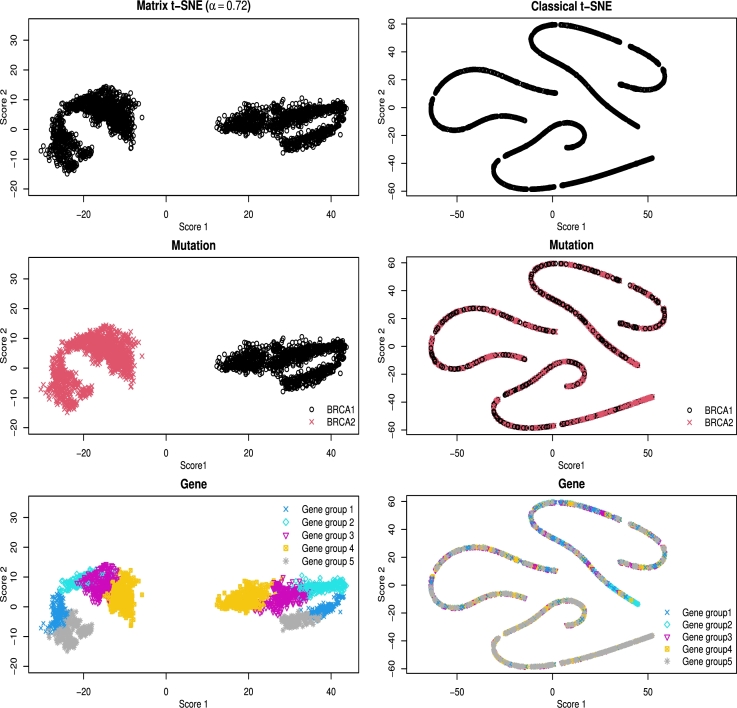 Figure 8
Figure 8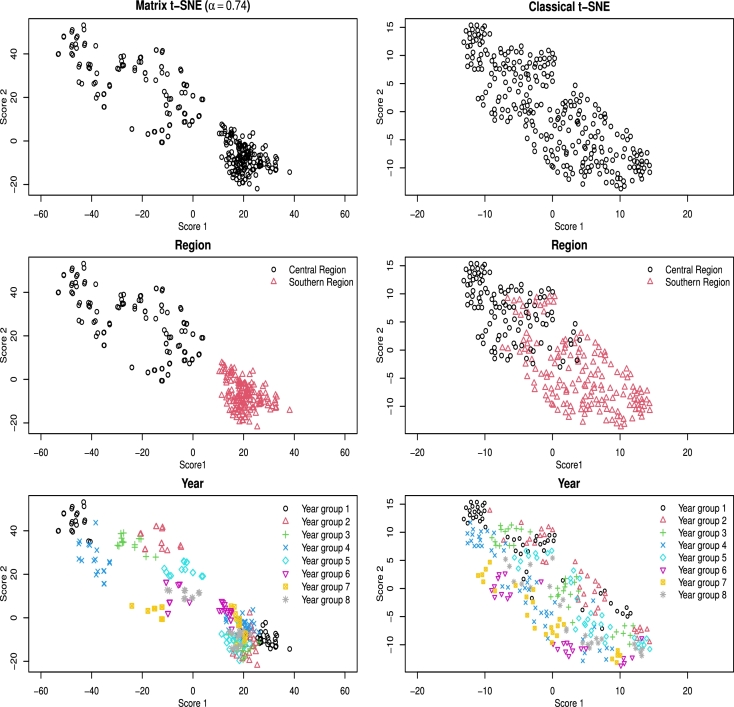 Figure 9
Figure 9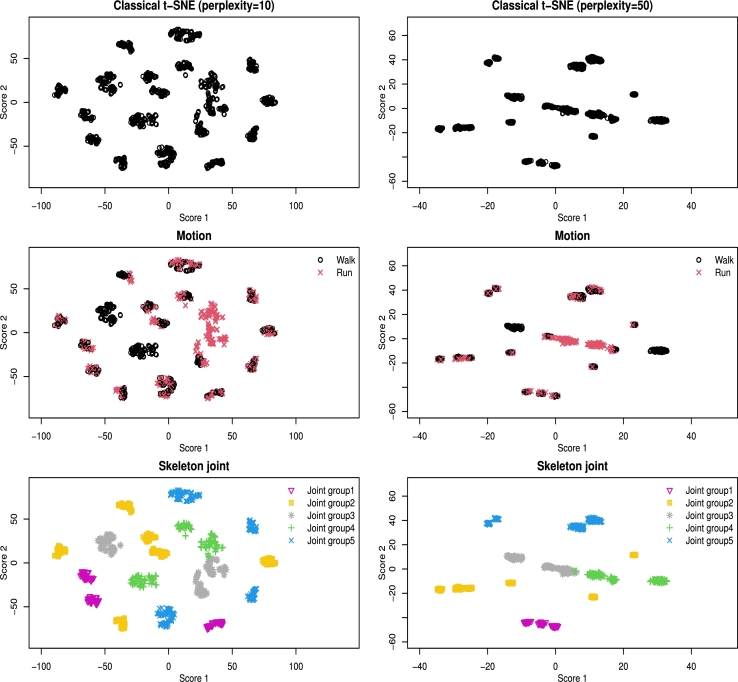 Figure 10
Figure 10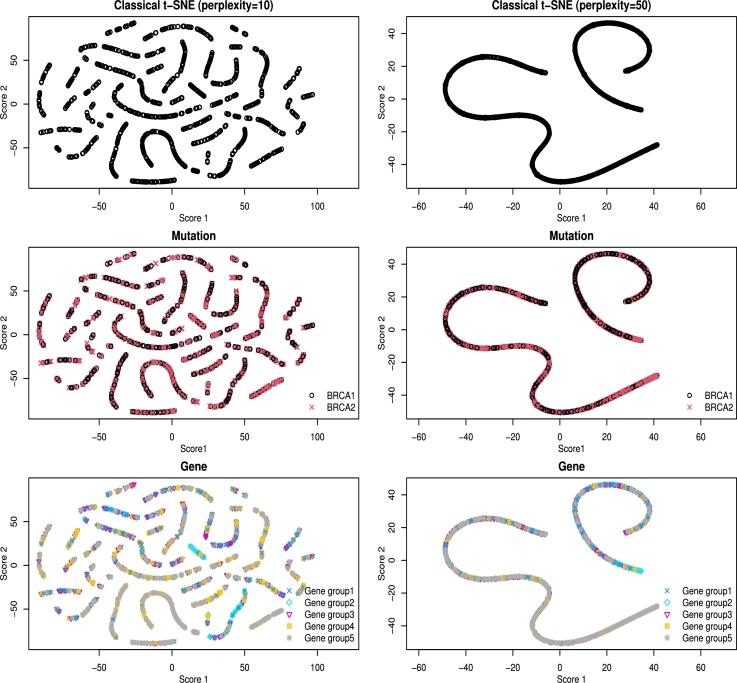 Figure 11
Figure 11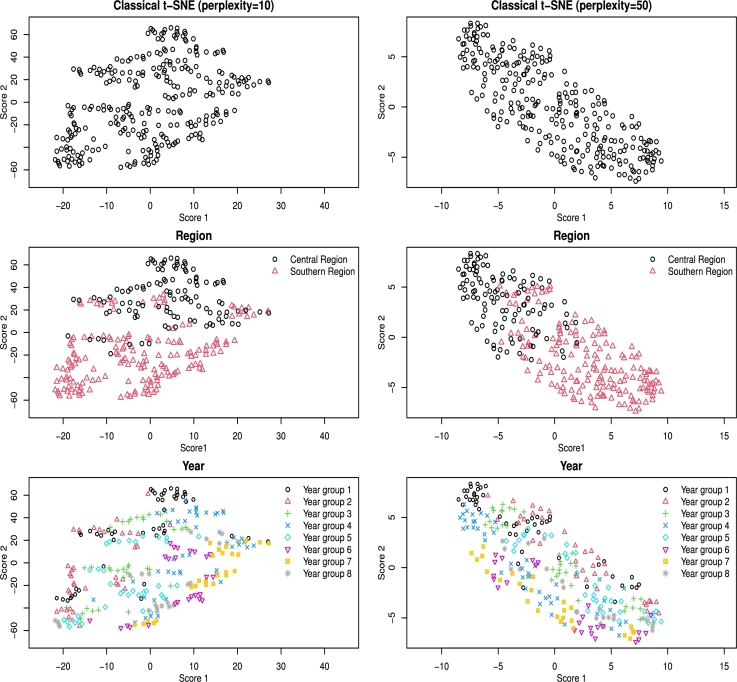 Figure 12
Figure 12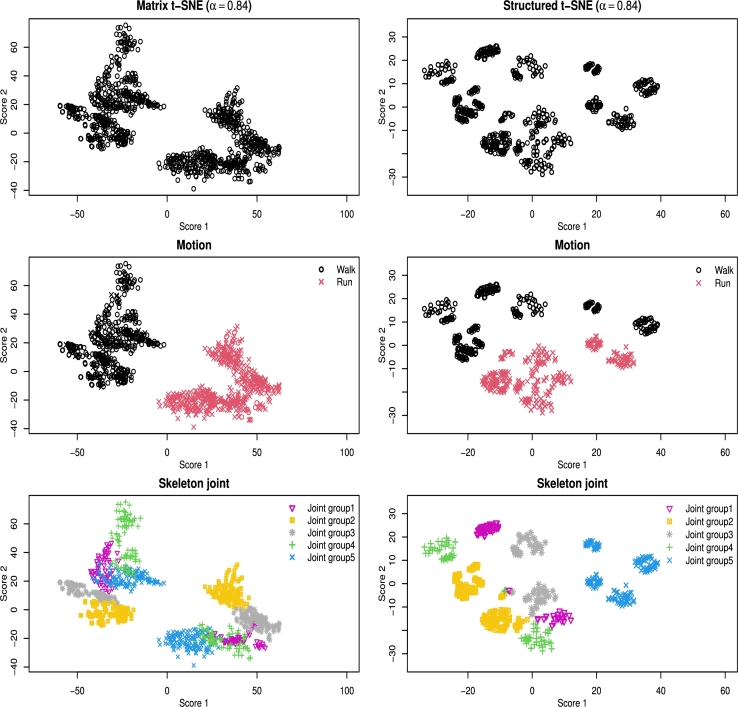 Figure 13
Figure 13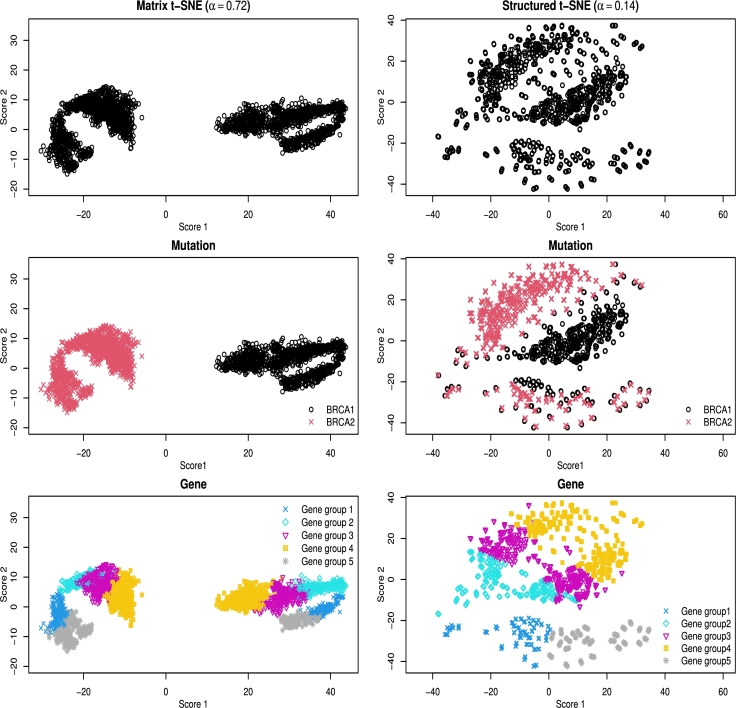 Figure 14
Figure 14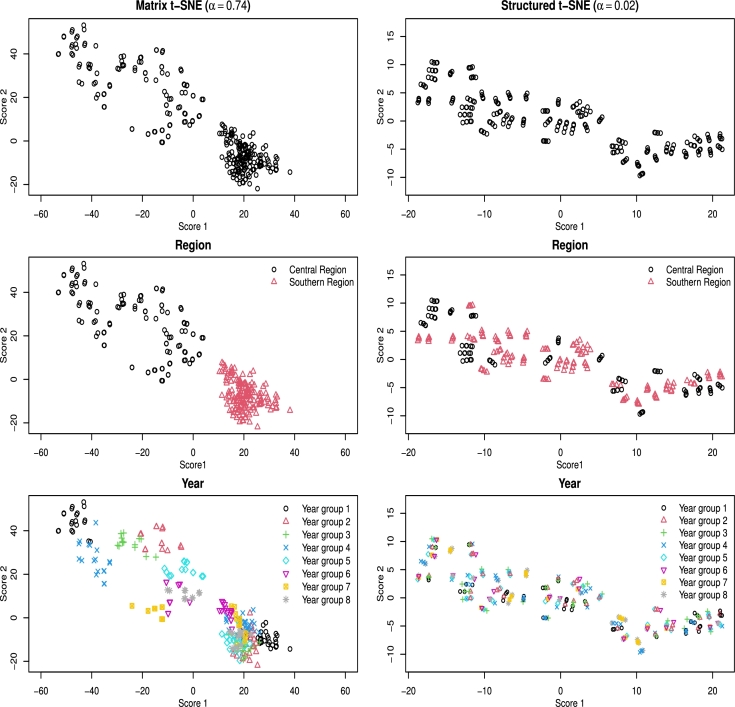 Figure 15
Figure 15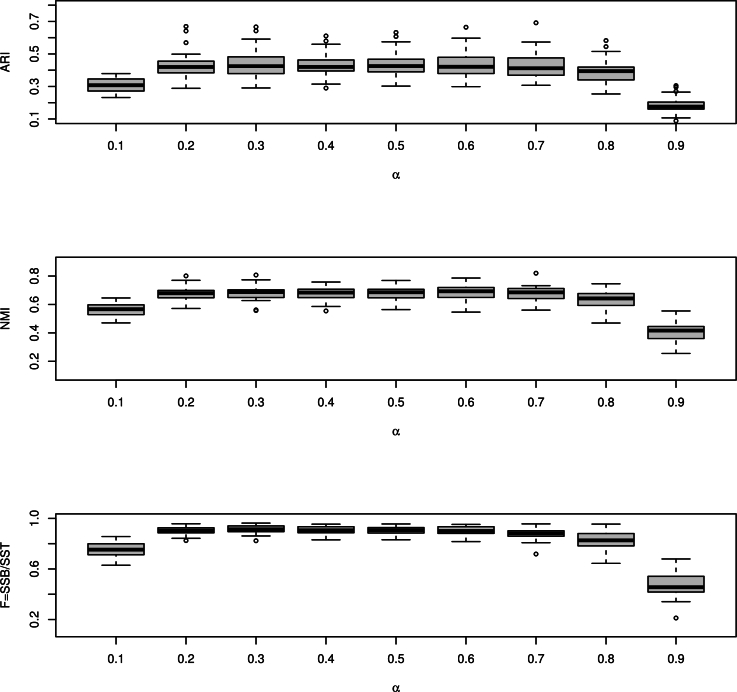 Figure 16
Figure 16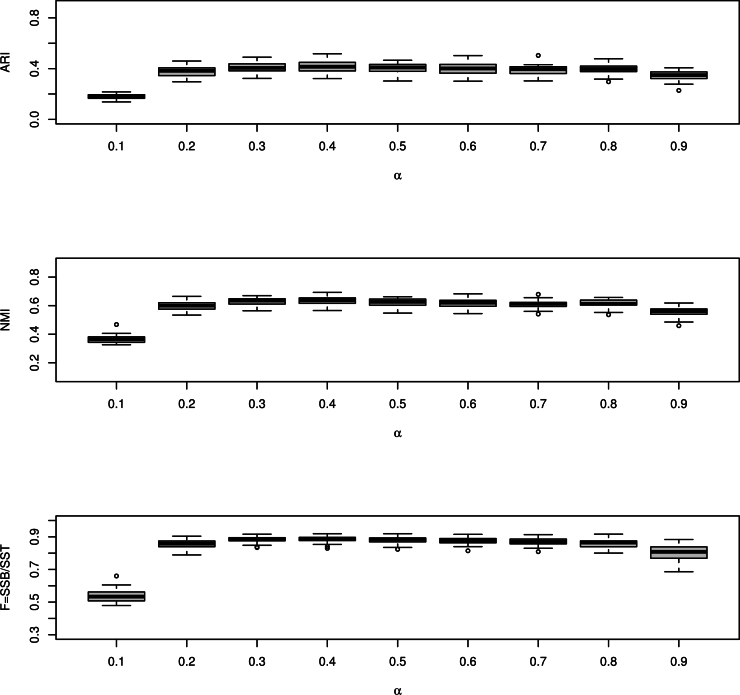 Figure 17
Figure 17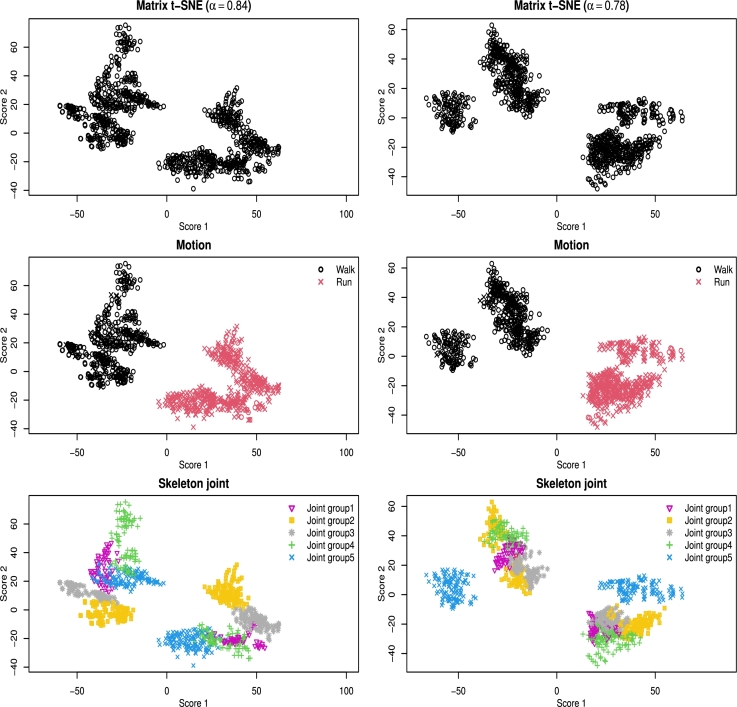 Figure 18
Figure 18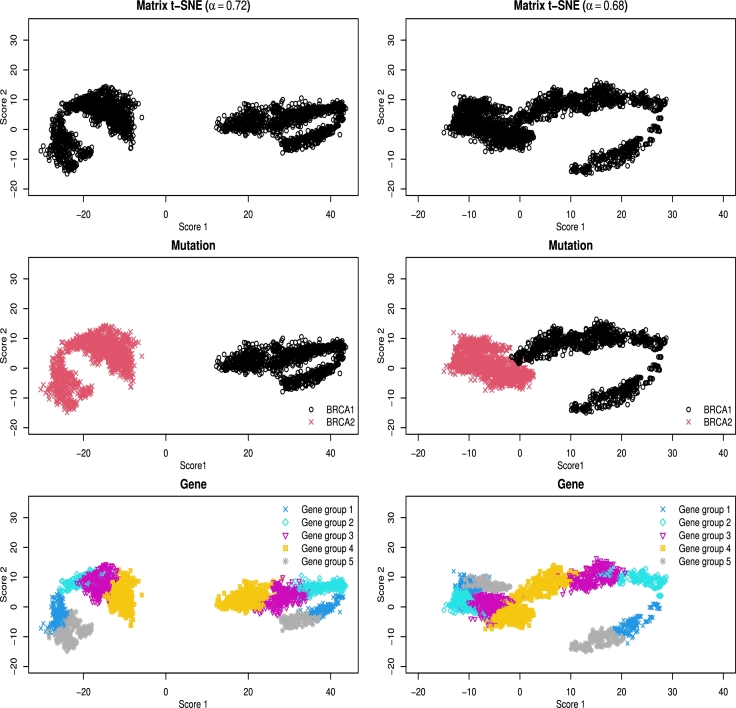 Figure 19
Figure 19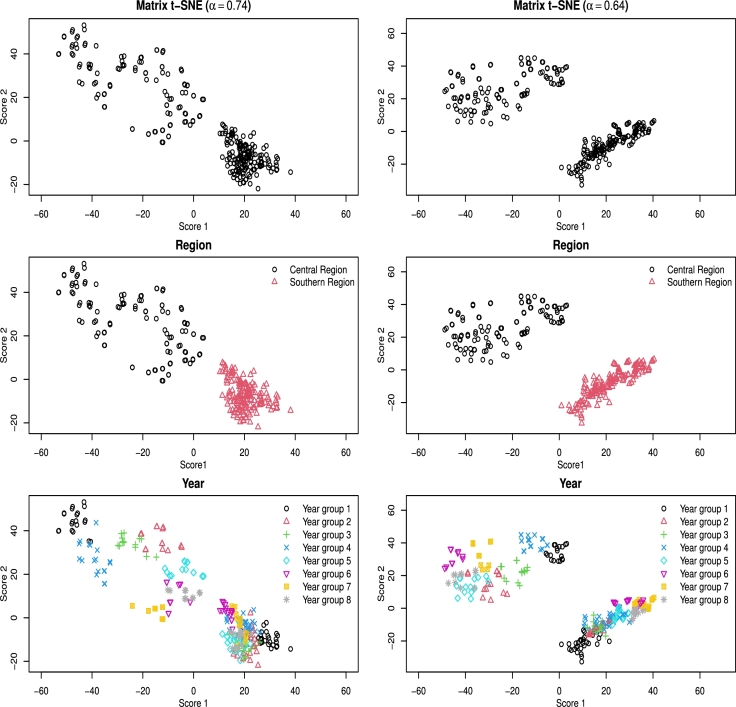 Figure 20
Figure 20Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGene expression and cancer classification · Face and Expression Recognition · Neural Networks and Applications
Introduction
1
Across various fields, we can effectively organize data elements into a matrix frame, featuring both row and column indices. For instance, in public health research, Park et al. [1] demonstrated the utility of structuring longitudinal blood pressure data as matrices, where rows correspond to systolic and diastolic measurements, and columns represent distinct time points. Similarly, in genomics studies, Madeira and Oliveira [2] analyzed gene expression data that were structured as matrices, with genes represented by rows and conditions or time points represented by columns. Furthermore, in the realm of economics, Tsay [3] organized employment statistics across multiple states into a matrix frame, with state information listed along the rows and employment-related variables along the columns.
We refer to this type of data with elements aligning into a matrix frame as matrix-framed data, which retains a two-dimensional structure that preserves the structural information of the individual elements. Within this type of data, the elements can take various forms, such as scalars, vectors, matrices, or (multivariate) time series. Furthermore, these matrix-framed data sets are characterized by two indexing indicators, which define the respective rows and columns. It is essential to note that not all structured datasets with a matrix representation benefit from preserving row-wise and column-wise group structures. In some cases, the structural information does not inherently exist, making it unnecessary to retain such relationships. For instance, image datasets like MNIST can be represented as matrices of pixels, but they typically do not possess inherent row-wise or column-wise dependencies that require preservation.
To illustrate the importance of preserving matrix structures in certain applications, we examine three matrix-framed datasets that exhibit underlying structural relationships: exergame data (Section 3.1), gene expression data (Section 3.2), and temperature data (Section 3.3). In the exergame dataset, the row index corresponds to individual IDs and the column index stands for joints, where the individuals are grouped by activities (e.g., walking or running) and the joints are grouped by locations. In the gene expression dataset, the row index again represents individual IDs and the column index represents genes, where the individuals are grouped by breast cancer mutation types (either 1 or 2), and the genes are grouped based on similarities. In the temperature dataset, the rows corresponds to different regions, while the columns represent years, capturing both spatial and temporal structures of temperature variations. The regional grouping reflects geographic similarities, whereas the temporal grouping allows for trend analysis across different periods.
In high-dimensional data analysis, data visualization plays a crucial preliminary role, with a rich history of development. To facilitate effective visualization, dimensionality reduction techniques are commonly employed. Linear methods such as principal components analysis (PCA; Hotelling [4]) and multidimensional scaling (MDS; Torgerson [5]) have been widely used. Moreover, several non-linear approaches have been developed to preserve the distances in the original high-dimensional space. These include stochastic neighbor embedding (SNE; Hinton and Roweis [6]), t-distributed SNE (t-SNE; Van Der Maaten and Hinton [7]), and uniform manifold approximation and projection (UMAP; McInnes et al. [8]).
Among various dimensionality reduction techniques, t-SNE stands out for its ability to capture local patterns by utilizing conditional probabilities to project high-dimensional data onto a lower-dimensional space. Notably, this study highlights the specific advantages of t-SNE in capturing complex local relationship within data, as demonstrated through numerous applications discussed in previous research by Amir et al. [9], Kobak and Berens [10], and Wang et al. [11]. On the computational side, Van Der Maaten [12] improved t-SNE's efficiency by using tree-based algorithms to approximate gradients, while Chan et al. [13] developed an optimized GPU implementation called t-SNE-CUDA for handling large-scale data visualization tasks.
In addition to its original formulation, several variations and extensions of t-SNE have been developed in the literature. For instance, Van Der Maaten [14] proposed a parametric version of t-SNE to learn parametric mapping. Gisbrecht et al. [15] and Gisbrecht et al. [16] proposed to represent the new observations by a linear combination of the low-dimensional representations and to use outcome information through a Fisher metric for a supervised version, respectively. More recently, Cheng et al. [17] introduced St-SNE, a novel supervised dimension reduction method preserving similarities in both feature and outcome spaces. Similarly, Meng et al. [18] introduced class-constrained t-SNE, which preserves similarities in both feature and class probability spaces. These approaches adopt a convex combination of multiple cost functions to accommodate multiple similarity measures. In these methods, each cost function is derived from t-SNE applied to a single similarity matrix and their combination enables the preservation of diverse structural relationships.
In this paper, we focus on developing a novel method namely Matrix t-SNE, specifically for visualizing high-dimensional matrix-framed data. Our goal is to find low-dimensional representations of elements in matrix-framed data that preserve both row-wise and column-wise group structures. For illustration, let us consider the task of reducing the dimensionality of an matrix for visualization purpose. This can be achieved by flattening the matrix into a -dimensional vector, where each element is labeled by a row index and column index . To achieve our goal of preserving both group structures, we define the distance between two elements and using both the row-wise distance and the column-wise distance . Our approach involves finding a lower-dimensional representation of these p elements . There are two possible approaches to achieve this goal: (i) applying the classical t-SNE with a convex combination of row-wise and column-wise distances and (ii) optimizing a convex combination of two independent cost functions for the row-wise and column-wise structures, as inspired by Cheng et al. [17] and Meng et al. [18]. In this paper, we adopt the second approach (ii) to better preserve both row-wise and column-wise neighborhood structures by incorporating separate perplexities that account for the scale differences and variability of rows and columns. While the first approach is simpler than the second one by adopting a single perplexity, it is sensitive to scale differences between rows and columns. In contrast, the second approach accommodates these differences naturally, enabling a more balanced preservation of local neighborhoods in both row-wise and column-wise structures. For comparison, we also present the results of the first approach (i) in Appendix C.
Moreover, we can also view Matrix t-SNE as a projection into a low-dimensional space for enhanced biclustering of data elements. Biclustering is a statistical procedure that clusters the rows and columns of a matrix simultaneously, yielding groups where subsets of rows exhibit similar behavior across subsets of columns (or vice versa). For example, in bioinformatics, we can use biclustering to examine the dependencies between conditions (samples) and genes and identify condition-indicative genes. Traditional clustering methods might not be suitable for such cases, as genes may only exhibit similarity within specific conditions or vice versa. Biclustering encompasses various structural patterns, including exclusive row and column biclusters, and checkerboard structure. In exclusive row and column biclusters, every row and every column are assigned exclusively to one bicluster (Lazzeroni and Owen [19]). Checkerboard structures allow rows and columns to belong to more than one bicluster (Klug et al. [20]). Variations of these structures have been explored by researchers such as Tibshirani et al. [21] and Wang et al. [22]. However, Matrix t-SNE differs fundamentally from standard biclustering in its primary goal. While traditional biclustering aims to group elements into distinct biclusters, the main objective of Matrix t-SNE is dimension reduction to obtain a low-dimensional representation of high-dimensional data. This distinction enables Matrix t-SNE to provide a more comprehensive understanding of complex relationships within the data by preserving the structure and patterns in the original data.
The remainder of the paper is organized as follows. In Section 2, we introduce a novel t-SNE variant specifically designed for matrix-framed data and provide an algorithm to compute Matrix t-SNE. In Section 3, we demonstrate the effectiveness of our new method by applying it to three real data examples: visualization of skeleton joints and motion types using exergame data, visualization of mutation types and genes using breast cancer data, and visualization of regions and years using temperature data. Additionally, we provide a comparative analysis between Matrix t-SNE with the classical t-SNE with unstructured distance, highlighting the distinctions and advantages of our approach. Finally, in Section 4, we conclude the paper by summarizing its main findings and discussing potential avenues for further extension and exploration.
Method
2
Data and notation
2.1
Let us consider a matrix-framed dataset X consisting of I rows and K columns, where each element represents the -th element of X, represents the i-th row, and represents the k-th column for , . Here, we emphasize that the elements are not restricted to scalars; they can represent arbitrary forms such as scalars, vectors, or matrices. For example, in the gene expression dataset discussed in Section 3, each element represents a scalar value, whereas in the exergame dataset, each corresponds to a three-dimensional (3D) trajectory of a joint.
We introduce Matrix t-SNE, a novel t-distributed stochastic neighborhood embedding method specifically designed for matrix-framed data. By embedding the matrix-framed data into a new space, Matrix t-SNE aims to better capture and represent the structure inherent in the matrix. Typically, we embed the data into a lower-dimensional, and without loss of generality, assume a two-dimensional space. The resulting embedded data is denoted by , where . While embedding into a two-dimensional space may not constitute strict dimensionality reduction in cases like the gene expression dataset, it provides a more suitable embedding that better captures the matrix structure.
Matrix t-distributed stochastic neighborhood embedding
2.2
Matrix t-SNE minimizes the Kullback-Leibler divergence (7) between the joint probabilities in the high-dimensional space, and , and their respective counterparts in the low-dimensional space, and , for and . The superscripts ‘r’ and ‘c’ indicate the row-wise and column-wise embeddings, respectively. The pairwise similarity between subjects (rows) in the high-dimensional space is defined as
where
denotes the distance between rows i and j in the high-dimensional space, and the variance is chosen such that the conditional distribution achieves the desired perplexity , as explained in Van Der Maaten and Hinton [7]. Note that the calculation of distance is selected depending on the structures of elements. For instance, Van Der Maaten and Hinton [7] considered the Euclidean distance for scalar elements. In Section 3, for 3D trajectory elements in the exergame data, we consider the multi-dimensional dynamic time warping (DTW) distance (Shokoohi-Yetka et al. [23]) (i.e., ). For the breast cancer data, we use the Euclidean distance for scalar elements (i.e., ). Lastly, for the temperature data, we use the Wasserstein (WS) distance (Irpino and Verde [24] and Kang et al. [25]) for histogram elements (i.e., ). The row-wise perplexity captures the local neighborhood structure of rows in the high-dimensional space. Here, we use to represent the conditional probability across all data points, given the data point . We define the corresponding pairwise similarities in the low-dimensional space as
where denotes the Euclidean distance between the two embeddings and in , as defined in Section 2.1.
Similarly, we define the pairwise similarities between variables (columns) in the high-dimensional space as
where
and the variance is determined by finding the value that yields a conditional probability for a given perplexity . This column-wise perplexity reflects the local neighborhood structure of columns in the high-dimensional space. The corresponding pairwise similarity in the low-dimensional space is defined as
Then we minimize a convex combination of the row-wise and column-wise cost functions, which are defined as the sum of corresponding KL divergences between and , and between and , respectively. We define each column (or row)-wise KL divergence by the distances between column (or row) vectors, and each distance is calculated as the sum of element-wise distances across rows (or columns). The combined cost function is
where we set and the weight . However, the column (or row)-wise KL divergence is not simply the sum of element-wise KL divergences. Therefore, this combined cost function of Matrix t-SNE cannot be expressed as the sum of separable element-wise KL divergences, ensuring that both row-wise and column-wise relationships are preserved in the low-dimensional embedding and effectively capturing the joint structure of matrix-framed data.
In short, Matrix t-SNE extends the classical t-SNE to matrix-framed data. As in the classical t-SNE, our method derives joint probability distributions in the high-dimensional space, computes their corresponding probabilities in the low-dimensional representation, and minimizes the KL divergence between these two distributions. However, a crucial distinction exists between Matrix t-SNE and the classical t-SNE. In particular, the KL divergence formulation is modified to incorporate a convex combination of row-wise and column-wise KL divergences, each following the classical t-SNE formulation but applied separately to row-wise and column-wise distances. This innovative design enables both structural relationships inherent in the matrix-framed data to be preserved in the embedding space, thereby providing a more comprehensive representation of the underlying patterns.
The cost function (7) is minimized by a gradient descent approach, in which the gradient of the cost function is given by
We provide a detailed derivation of the gradient in Appendix A.
As in Van Der Maaten and Hinton [7], we update the gradient with a momentum term and summarize the Matrix t-SNE algorithm in Algorithm 1. We use the same optimization parameters as in Van Der Maaten and Hinton [7]: iteration ; momentum for and for ; initial learning rate . Since and correspond to the original t-SNE, we use equal initial scores across columns for fixed i when and across rows for fixed k when , respectively. For , we initialize using a standard Gaussian distribution. To account for the distinct neighborhood structures of rows and columns, Matrix t-SNE incorporates two independently defined perplexity parameters, and . These parameters adapt to the local distance distributions of rows and columns, respectively. By normalizing pairwise similarities into probabilities, these perplexities achieve scale invariance while preserving row-wise and column-wise group structures.Algorithm 1Matrix t-SNE algorithm.Algorithm 1
Selection of weight α
2.3
The minimization of the KL divergence (7) yields data points, which are achieved through the simultaneous embedding of rows and columns. The weight α leverages the importance of row-wise and column-wise variations in separating the data points. In particular, the special cases and correspond to applying t-SNE to the column vectors and row vectors, respectively. In practice, the choice of the weight α should balance both column and row structures of the matrix data. Here we adopt the following procedure for selecting α.
Let and represent the number of clusters in the embeddings obtained from column-wise ( ) and row-wise ( ) t-SNE, respectively. In our implementation, we define these quantities as
where and represent the sum of squares between clusters and the total sum of squares for g clusters under a given α, respectively. Although we employed K-means clustering to determine and in this article, alternative clustering methods could also be used for this purpose. We then define the true clusters as the combination of marginal clusters from separate column-wise and row-wise embeddings. Consequently, the total number of clusters is set as for Matrix t-SNE. Given these G clusters, we define the optimal weight as
This approach naturally aligns with the goal of Matrix t-SNE to simultaneously preserve both marginal structures, ensuring that the overall variability of the matrix-framed data is best explained. While our primary selection metric is the SSB/SST ratio, alternative clustering metrics such as Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI) may also be employed for selecting .
Examples and applications
3
To illustrate Matrix t-SNE, we apply it to three real datasets, the exergame data, the breast cancer data, and temperature data. We compare the results with the classical t-SNE, which creates low-dimensional embeddings of elements using unstructured distance (without consideration of row-wise or column-wise structure). For this comparison, we computed unstructured pairwise distances directly from the high-dimensional data using a suitable distance metric . For instance, we used DTW distance for the exergame data, Euclidean distance for the breast cancer data, and Wasserstein distance in temperature data.
The computational complexity of Matrix t-SNE is , whereas for the classical t-SNE with unstructured distance, it is . As matrix data size increases, both Matrix t-SNE and t-SNE become slower, but t-SNE becomes significantly slower compared to Matrix t-SNE. For instance, when , Matrix t-SNE has cubic complexity , whereas t-SNE scales with the fourth power , making Matrix t-SNE significantly more efficient for large matrix data. For the exergame dataset ( ), Matrix t-SNE completed in 1.09 seconds, while t-SNE took 11.03 seconds. For the breast cancer dataset ( ), Matrix t-SNE completed in 6.08 seconds, compared to 81.01 seconds for t-SNE. For the temperature dataset ( ), Matrix t-SNE completed in 0.41 seconds, while t-SNE took 0.88 seconds.
To further investigate the computational complexity and scalability for larger-scale datasets, we conducted a sensitivity analysis using the breast cancer dataset. Specifically, we increased the number of genes (K) while keeping the number of subjects (I) fixed by bootstrapping the genes (column vectors), and recorded the execution time in seconds for both Matrix t-SNE and the classical t-SNE. We increased K exponentially, resulting in matrix sizes of , and . Consequently, the total number of embedded data points reached , and 42240. The results are presented in Fig. 1 and show that Matrix t-SNE can be done in substantially lower computation time compared to t-SNE as the dataset size increases. This finding demonstrates that Matrix t-SNE can handle larger structured datasets efficiently, making it computationally feasible for large-scale applications. All analyses were performed on a PC with an Intel(R) Xeon(R) W-2145 CPU @ 3.70GHz and 64GB of memory.Fig. 1. Execution time (in seconds) for different data sizes using the breast cancer dataset for the fixed I = 15 and varying K.Fig. 1
Through these examples, we aim to visualize the data points based on different attributes including motion types and joint skeletons for the exergame data, mutation types and genes for the breast cancer data, and regions and years for temperature data. With the optimal weight derived based on Section 2.3, we find the representation that captures both the column-wise and row-wise structures underlying the data. The process of applying Matrix t-SNE is depicted in Fig. 2. Additionally, we demonstrate how Matrix t-SNE provides a more comprehensive representation of matrix-framed data compared to the classical t-SNE with unstructured distance. To quantitatively assess the robustness and stability of Matrix t-SNE, we compared its performance with t-SNE by computing three performance metrics-ARI, NMI, and SSB/SST-to evaluate clustering quality and embedding separability using the combined clusters defined from the marginal embeddings, as described in Section 2.3. The experiments were conducted using the selected weight , which was set to 0.84, 0.72, and 0.74 for the exergame, breast cancer, and temperature datasets, respectively. We evaluated each method over 10 perturbed maps generated from different random initializations. The results, summarized as boxplots in Fig. 3, indicate that Matrix t-SNE consistently outperforms t-SNE across all datasets and evaluation metrics. This demonstrates its effectiveness in preserving meaningful structures in the embedded space.Fig. 2. Flowchart of the Matrix t-SNE.Fig. 2. Fig. 3Boxplots of quantitative performance comparisons across three metrics (ARI, NMI, SSB/SST) for Matrix t-SNE and t-SNE at the selected α, chosen based on SSB/SST for each dataset.Fig. 3
When the group memberships are already known for each feature (row or column), we skip the K-means clustering for or 1 and directly use the known groups to define and , as outlined in Section 2.3. For instance, in our exergame data example, we utilize both joint and motion groups which are already known. In contrast, for the breast cancer data, we use the known mutation information (BRCA1 and BRCA2) but employ K-means clustering to identify gene groups through from the genes' embeddings. Notably, on these examples, even though the group memberships for rows or columns are already known, we applied the process outlined in the flowchart to identify these memberships, and the resulting groupings are closely match the actual memberships.
For Matrix t-SNE, we set two perplexity values based on recommendations from the R package Rtsne. Specifically, the perplexity for row-wise t-SNE ( ) and column-wise t-SNE ( ) were chosen as the smaller of one-third of the sample size or the default value of 30. To preserve the marginal structures in both row and column spaces, Matrix t-SNE directly adopts these values for corresponding perplexities, and , respectively. For the classical t-SNE with unstructured distance, we similarly used the default perplexity value of 30, and the results using various perplexity values are provided in Fig. B.8, Fig. B.10 in Appendix B.
Exergame data
3.1
We apply Matrix t-SNE to the exergame data collected from a physical activity study conducted by Kim et al. [26] investigating the effects of exercise type and gameplay mode. This dataset consists of skeleton joint sequence data captured by the Microsoft Kinect V2 sensor. Microsoft Kinect is a sophisticated sensor that localizes human body parts and produces moving 3D skeletons for action recognition. The dataset comprises 3D coordinate for 25 joints, continuously provided at 30 frames per second. Fig. 4 shows the 25 joints. The camera's center point is set as the origin , with the x-axis representing left and right movements, the y-axis up and down movements, and the z-axis front and back depths.Fig. 425 Skeletons by Microsoft Kinect v2 (left) and 5 clusters of skeletons (right).Fig. 4
A total of 20 participants performed walking and running motions for 3 minutes each motion while playing a Nintendo Switch game, resulting in 5400 frames ( sec. ×30 frames/sec.) of observed skeleton coordinates per motion. For each motion, 60 frame-length joint information was extracted from the data observed for 2 seconds. In detail, the point where the left foot is closest to the ground was set as the starting point so that there were no overlapping frames for each motion. Then, 60 frames from each starting point generated a sequence, resulting in approximately 70 sequences for each subject's motion. After preprocessing (i.e., averaging the sequences on each subject's motion), we obtained 60 frame-length 3D coordinates for 25 joints for each participant's motion. Readers can refer to Kim et al. [26] for detailed information on the data and preprocessing steps.
To apply Matrix t-SNE to this exergame data, we extend the notations as follows: we denote the -th element where for and is the k-th skeleton joint's 3D coordinate of i-th subject at the t-th frame (time) for , , and . Thus, each -th element is a three-dimensional vector measured across times (i.e., multivariate longitudinal data). In other words, the size of the matrix data is where each entry is a three-dimensional vector across 60 time points. Accordingly, we consider the multi-dimensional DTW distance (Shokoohi-Yetka et al. [23]) in the probabilities and . To be specific, in (2), the distance between skeleton joint sequences of the i-th and j-th subjects is given by
Similarly, in (5), the distance between motions of the k-th and l-th skeleton joints is given by
The pairwise DTW distances between sequences were computed using the dtw package in R with the default alignment setting (window.type=”none”), which allows full flexibility in sequence alignment.
To find a low-dimensional representation of the data points, we first identify the column-wise structure (the clusters of skeleton joints) and the row-wise structure (the clusters of motions) by applying the original t-SNE which corresponds to Matrix t-SNE with and , respectively. As a result, we identified and , which matched the actual memberships, and set . For this selected G, we determined the optimal weight using (9) as . The subjects were clustered based on their motions, and the skeleton joints were grouped into five subgroups according to their anatomical locations. These group memberships are indicated by different colors in Fig. 4, Fig. 5, which display the results obtained using Matrix t-SNE. In addition, an alternative analysis using alternative clustering metrics ARI and NMI resulted in a slightly different optimal weight of . The corresponding embedding visualizations are provided in Appendix D and show minimal differences from those obtained with , indicating the stability of the embeddings across different metric-based selections of α.Fig. 5. Visualization of exergame data (40 × 25) by Matrix t-SNE at a selected weight (α^⁎^ = 0.84) and the classical t-SNE with unstructured distance. Top panels: embeddings without color differentiation; middle panels: colored by motion type; bottom panels: colored by skeleton joint group.Fig. 5
The left three panels in Fig. 5 illustrate the embeddings generated by Matrix t-SNE at the optimal weight . Two additional figures are presented: one colored by motion type (middle) and another by skeleton joint group (bottom). The middle panel shows a clear separation of data points based on the two motions, while the bottom panel shows how the joint groups are clustered within each motion type. These figures effectively visualize both column-wise and row-wise structures. Specifically, the joints are well separated in the walking motion but partially overlap in the running motion. This indicates that the nested structures differ depending on the motion type.
In contrast, the classical t-SNE with unstructured pairwise DTW distance is applied directly to the 3D trajectory elements without considering row and column structures. The right three panels in Fig. 5 show the resulting embeddings, with data points colored by motion type (middle) and skeleton joint group (bottom). The bottom panel shows the given embedding separates finely the skeleton joint group than the marginal row-wise embedding. However, it visualizes well different skeleton joint groups. The middle panel shows the embedding colored by motion types, where two motion types are not differentiated clearly. This result is because the variability of the distances among different skeleton joints is smaller than that between motions, and thus, the local neighbors in this case more easily preserves the group structure of the skeleton joints than the motions.
Breast cancer data
3.2
Next, we consider the breast cancer dataset from a gene expression study of BRCA tumors in 22 beast cancer patients as reported in [27]. The breast cancers are associated with three types of mutations: BRCA1, BRCA2, and Sporadic mutations. Seven patients have the BRCA1 mutation, eight patients have the BRCA2 mutation, and the remaining seven patients have the sporadic type. For each patient, 3226 genes are observed, resulting in a matrix data. To illustrate the new method, we selected the most significant 176 genes that could discriminate breast cancers with BRCA1 mutation from those with BRCA2 mutation, resulting in a matrix. The selected 176 genes are listed in the supplementary material of [27]. Note that we used the Euclidean distance in the probabilities and . The data had been preprocessed through log transformation and normalization.
Using row-wise t-SNE, the data points are separated clearly groups, corresponding to the two actual mutation types. Using column-wise t-SNE, we identified that the genes clustered into groups. Therefore, we set and determined the optimal weight using (9). The Matrix t-SNE embeddings are shown in Fig. 6. An alternative analysis with ARI and NMI yielded a similar optimal weight , confirming the stability of embeddings (see Appendix D).Fig. 6. Visualization of breast cancer data (15 × 176) by Matrix t-SNE at a selected weight (α^⁎^ = 0.72) and the classical t-SNE with unstructured distance. Top panels: embeddings without color differentiation; middle panels: colored by mutation type; bottom panels: colored by gene group.Fig. 6
The left three panels in Fig. 6 illustrate the embeddings generated by Matrix t-SNE at the optimal weight . The middle panel is colored by mutation type and the bottom panel is colored by gene cluster. The middle panel shows a clear separation of data points based on the two mutation types, while the bottom panel illustrates how the gene groups are clustered within each mutation type. These figures effectively visualize both column-wise and row-wise structures. Specifically, the gene groups are well separated in both BRCA1 and BRCA2 mutations, although the BRCA2 genes are more densely clustered. This indicates that the nested structures are similar depending on the mutation type.
In contrast, the right three panels in Fig. 6 display the results from the classical t-SNE with unstructured distance. The resulting embeddings show a tangled structure, lacking clear separation of both mutation types (middle) and gene groups (bottom). Due to the scalar nature of the elements in this matrix, the distances between elements are simply Euclidean distances between points, leading to the formation of three elongated bands based solely on straight-line distances: near zero, medium, and long. These bands do not reflect any meaningful structural relationships. The gene clusters and mutation types are less apparent, highlighting the limitation of the classical t-SNE with unstructured distance in simultaneously preserving the underlying structures of genes and mutations, which Matrix t-SNE effectively captures.
Temperature data
3.3
To further assess the versatility of Matrix t-SNE, we examine a climate dataset that captures temperature variations across different regional and temporal units in Korea. The dataset contains daily average temperature records collected over a 55-year period, from January 1, 1969, to December 31, 2023, across five key regions: Seoul, Busan, Daegu, Gwangju, and Daejeon. We obtain the data from the Open MET Data Portal of the Korea Meteorological Administration (https://data.kma.go.kr/cmmn/main.do).
For each region and year, we summarize the daily temperature observations as a histogram, representing the distribution of temperatures over 365 days. Thus, the -th element of the matrix is a histogram-valued entry. The dataset is structured as a matrix, where each row corresponds to a region, each column represents a year, and each element is a histogram. To measure dissimilarities between elements, we use the Wasserstein distance (Irpino and Verde [24] and Kang et al. [25]), which is well-suited for comparing histogram-valued data, in the probabilities and .
We employed row-wise t-SNE, which revealed two regional groups : Group 1 (Central Region), which includes Seoul and Daejeon, and Group 2 (Southern Region), which consists of Busan, Daegu, and Gwangju. Conversely, using column-wise t-SNE, we identified distinct temporal clusters, which represent different climate patterns across historical periods. The specific year groupings are summarized in Table 1. Overall, the temporal clusters can be broadly categorized into two groups: Group 1-4 (pre-2000 dominant) and Group 5-8 (post-2000 dominant), reflecting the general increase in temperature around the year 2000. Notably, certain years before 2000 that exhibited higher temperatures - such as 1989, 1990, 1994, 1997, 1998, and 1999 - were grouped with post-2000 clusters (Group 5-8). Conversely, some post-2000 years that experienced relatively lower temperatures - including 2000, 2001, 2003, 2005, 2010, 2011, 2012, and 2013 - were classified with the earlier period clusters (Group 1-4). This pattern suggests that temperature variations played a key role in the clustering process, rather than a strict chronological separation. This temporal clustering effectively captures long-term climate trends and structural shifts in temperature distributions.Table 1. Identified temporal clusters using column-wise t-SNE. Each temporal group represents a distinct climate pattern across historical periods.Table 1. Temporal GroupYearsYear group 11969, 1970, 1971, 1973, 1974, 1976, 1980, 1981, 1984, 1986Year group 21972, 1979, 1987, 1989, 1991, 1992, 1993, 2003Year group 31975, 1982, 1983, 1985, 1995, 1996, 2000Year group 41977, 1978, 1985, 2001, 2005, 2010, 2011, 2012, 2013Year group 51989, 1997, 1999, 2002, 2006, 2007, 2020Year group 61990, 1998, 2004, 2021, 2023Year group 71994, 2016, 2017, 2018, 2022Year group 82008, 2009, 2014, 2015, 2019
To determine the optimal weight , we set and obtained an optimal value of using (9). The Matrix t-SNE embeddings are shown in Fig. 7. The left three panels in Fig. 7 illustrate the embeddings generated by Matrix t-SNE at the optimal weight . The middle panel colors data points by regional groups, while the bottom panel highlights the clustering of years within each region. These visualizations effectively capture both row-wise (regional) and column-wise (temporal) structures. Notably, the temporal clusters are well-separated for Seoul and Daejeon (central region) but less distinct for Busan, Daegu, and Gwangju (southern region), suggesting that temperature variation patterns differ between these spatial groups. An alternative analysis with ARI and NMI yielded a similar optimal weight , confirming the stability of embeddings (see Appendix D).Fig. 7. Visualization of temperature data (5 × 55) by Matrix t-SNE at a selected weight (α^⁎^ = 0.84) and the classical t-SNE with unstructured distance. Top panels: embeddings without color differentiation; middle panels: colored by regional group; bottom panels: colored by temporal group.Fig. 7
In contrast, the right three panels in Fig. 7 display the results from the classical t-SNE using unstructured pairwise Wasserstein distance, with data points colored by regional group (middle) and temporal group (bottom). The middle panel shows that the regional groups are more finely separated than in the marginal column-wise embedding. However, the temporal clusters in the bottom panel are not differentiated. This suggests that while the classical t-SNE effectively captures regional variations, it struggles to differentiate temporal patterns due to the variability of distances among different regions being smaller than those among years. Consequently, local neighborhoods in this case tend to preserve regional structures rather than temporal structures.
Conclusion
4
In this paper, we propose a novel t-SNE procedure, named Matrix t-SNE, designed to visualize matrix data while preserving the inherent grouping patterns along both rows and columns. The workflow of Matrix t-SNE is depicted in Fig. 2. To demonstrate its effectiveness, we apply Matrix t-SNE to three real-world datasets, exergame data, breast cancer gene expression data, and temperature data. In addition, we compare it with the classical t-SNE with unstructured distance that disregards row and column structures in the data. Our results show that Matrix t-SNE maintains structural coherence in the embedded space while achieving comparable or improved computational efficiency relative to the classical t-SNE. Moreover, quantitative comparisons using clustering metrics (ARI, NMI, and SSB/SST) demonstrate that Matrix t-SNE consistently captures marginal structures more effectively across all datasets considered.
One notable feature of our Matrix t-SNE is its ability to preserve the nested dichotomy of the data. From the examples presented, we find that Matrix t-SNE maintains a hierarchical structure, where columns (or rows) form larger clusters and rows (or columns) form smaller clusters within these larger clusters. For instance, in the exergame data, the (smaller) clusters of joints are nested within the (larger) clusters of subjects (motions). Similarly, in the breast cancer data, gene clusters are nested within patient clusters (mutations). In contrast, the classical t-SNE with unstructured distance potentially tends to lose the inherent row-column structure (or either one of them) of the original matrix.
Matrix t-SNE effectively preserves both row-wise and column-wise structures regardless of scale differences. However, it has limitations. First, defining marginal structures such as , , and combined clusters is necessary to determine the optimal weight α. In this paper, we use K-means clustering for this purpose, constructing true clusters via the cross-product of marginal clusters. While K-means is computationally efficient and widely used, it assumes spherical clusters and may introduce bias when clusters are non-spherical or overlapping. Exploring alternative clustering methods, such as hierarchical clustering or density-based clustering, could capture more complex structures. This remains an open question for future research. Second, our current study does not include explicit experiments under conditions of noisy data and overlapping clusters. Similar to the classical t-SNE, Matrix t-SNE incorporates data-specific distance metrics (e.g., DTW, Wasserstein) as marginal distance metrics, which may provide greater robustness under conditions of noisy data and overlapping clusters. Therefore, we expect the selection of appropriate distance can mitigate the effects of noise and overlapping clusters. This also warrants further investigation.
Beyond the datasets analyzed in this study, Matrix t-SNE can be applied to various structured datasets where preserving both row-wise and column-wise dependencies is essential. For example, in electrogastrography (EGG) data, rows represent individuals or disease types, while columns correspond to frequency bands. Similarly, in longitudinal health data, such as blood pressure measurements over time, rows represent measurement types, and columns represent time points. These examples illustrate the versatility of Matrix t-SNE as a visualization tool for structured matrix-framed data across various domains.
Code availability
The R code to fit Matrix t-SNE and example code for the breast cancer data are available at https://github.com/shahn63/Matrix-t-SNE. The repository includes a README file that provides detailed descriptions of all included files, their usage, example code, and step-by-step instructions on loading the necessary scripts and running Matrix t-SNE.
CRediT authorship contribution statement
Soohyun Ahn: Writing – review & editing, Writing – original draft, Software, Methodology, Formal analysis. Johan Lim: Writing – review & editing, Writing – original draft, Methodology, Conceptualization. Wei Jiang: Writing – review & editing. Sungim Lee: Writing – review & editing, Visualization, Investigation. Xinlei Wang: Writing – review & editing, Supervision, Project administration.
Declaration of Competing Interest
No conflict of interest is declared for this submission.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Park S.Lim J.Choi H.Kwak M.Clustering of longitudinal interval-valued data via mixture distribution under covariance separability J Appl Stat 4720191739175610.1080/02664763.2019.169279535707136 PMC 9042104 · doi ↗ · pubmed ↗
- 2Madeira S.C.Oliveira A.L.Biclustering algorithms for biological data analysis: a survey IEEE/ACM Trans Comput Biol Bioinform 112004244510.1109/TCBB.2004.217048406 · doi ↗ · pubmed ↗
- 3Tsay R.S.Matrix-variate time series analysis: a brief review and some new developments Int Stat Rev 92202424626210.1111/insr.12558 · doi ↗
- 4Hotelling H.Analysis of a complex of statistical variables into principal components J Educ Psychol 241993417441
- 5Torgerson W.S.Multidimensional scaling: I. Theory and method Psychometrika 17195240141910.1007/BF 02288916 · doi ↗
- 6Hinton G.E.Roweis S.T.Stochastic neighbor embedding Adv Neural Inf Process Syst 152002833840 Cambridge, MA, USA. The MIT Press
- 7Van Der Maaten L.Hinton G.E.Visualizing data using t-SNEJ Mach Learn Res 9200825792605
- 8Mc Innes L.Healy J.Saul N.Großberger L.UMAP: uniform manifold approximation and projection J Open Source Softw 329201886110.21105/joss.00861 · doi ↗