Hybrid real-synthetic dataset framework for robotic hazard detection in industrial environments
Amr Khamis, Heba A. Shaban, Heba A. Fayed, Moustafa H. Aly

TL;DR
This paper presents RoboFusion, a framework combining real and synthetic data to improve hazard detection in industrial environments using robotic systems.
Contribution
RoboFusion introduces a novel hybrid dataset generation pipeline to address data scarcity and imbalance in industrial hazard detection.
Findings
RoboFusion collected one million multi-modal sensor records over 180 days in an industrial testbed.
Synthetic data augmentation improved hazard F1 scores significantly for models like Random Forest and SVM.
The framework supports cross-domain gains and enhances AI resilience for industrial safety.
Abstract
The increasing complexity of industrial environments requires the development of real-time hazard detection and environmental monitoring using intelligent robotic systems. This paper introduces RoboFusion, an integrated framework that combines Autonomous Mobile Robots (AMRs), fixed sensing nodes, and a novel hybrid dataset generation pipeline for data-driven industrial safety. Deployed in a functioning industrial testbed, RoboFusion collected real-time telemetry over 180 days using four sensor suites: two fixed units and two additional units mounted on Near-Field Communication (NFC) guided AMRs, each equipped with 12 sensors sampling at one-minute intervals. This deployment yielded approximately one million multi-modal sensor records, including temperature, humidity, gas concentrations, air quality, and pressure. Data streams were processed onboard using ESP32 microcontrollers, and they…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
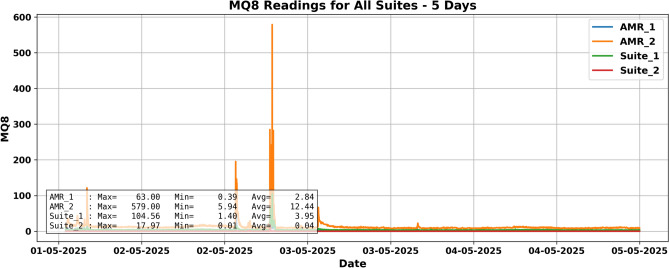 Figure 10
Figure 10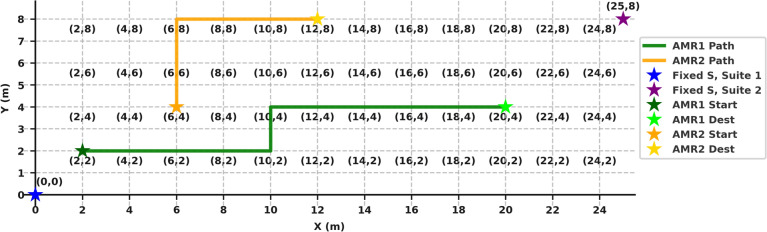 Figure 11
Figure 11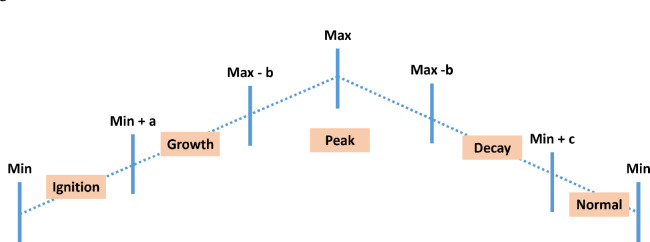 Figure 12
Figure 12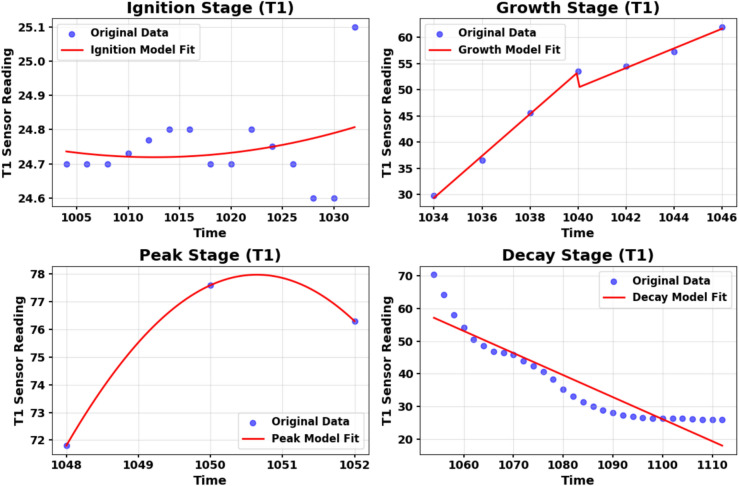 Figure 13
Figure 13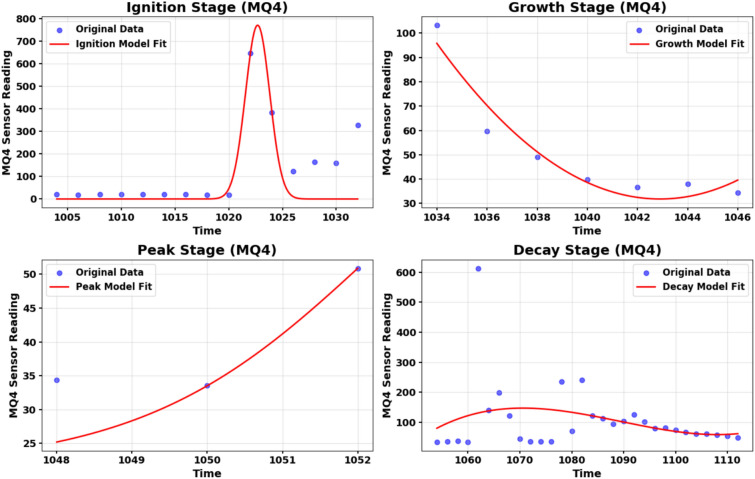 Figure 14
Figure 14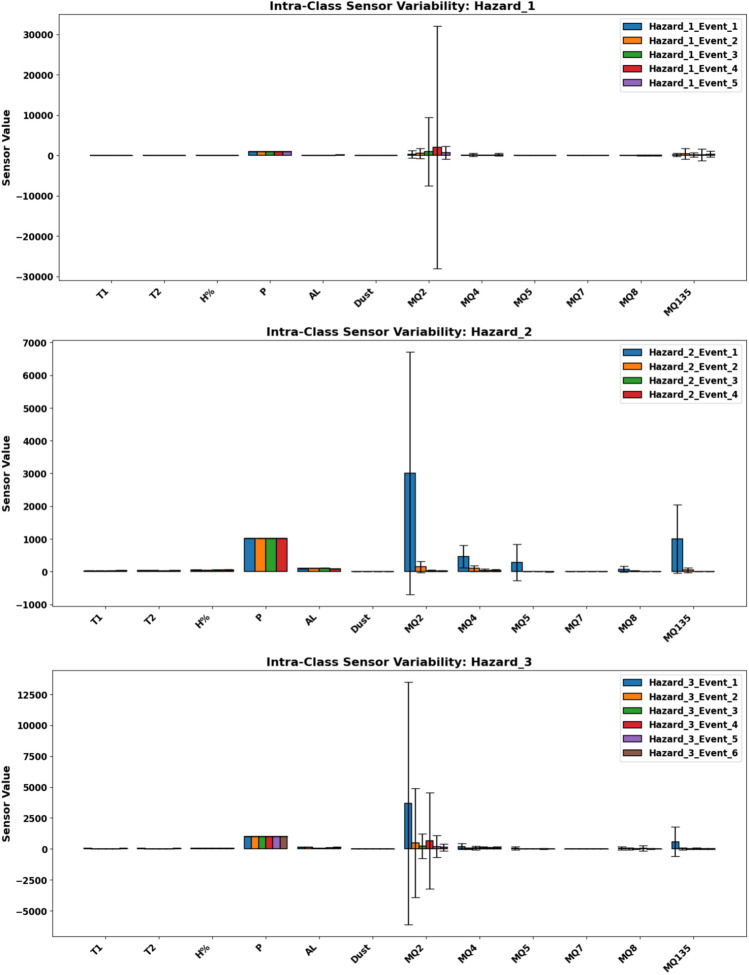 Figure 15
Figure 15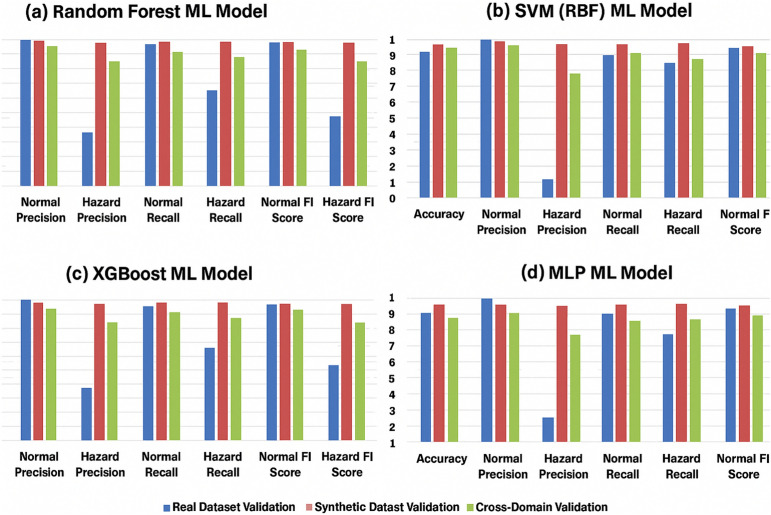 Figure 16
Figure 16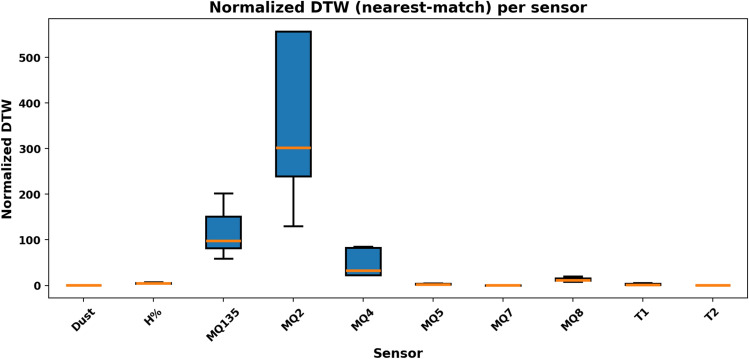 Figure 17
Figure 17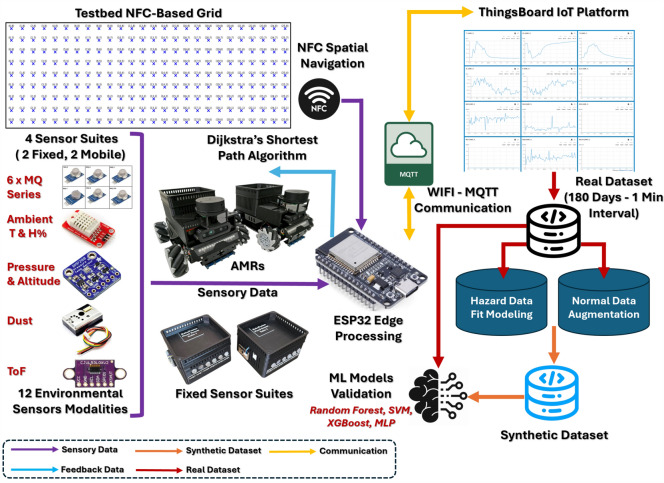 Figure 1
Figure 1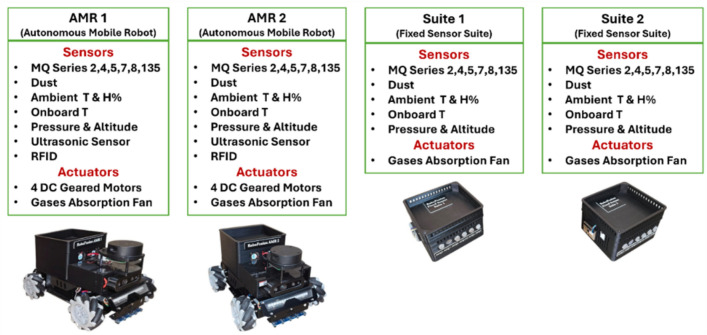 Figure 2
Figure 2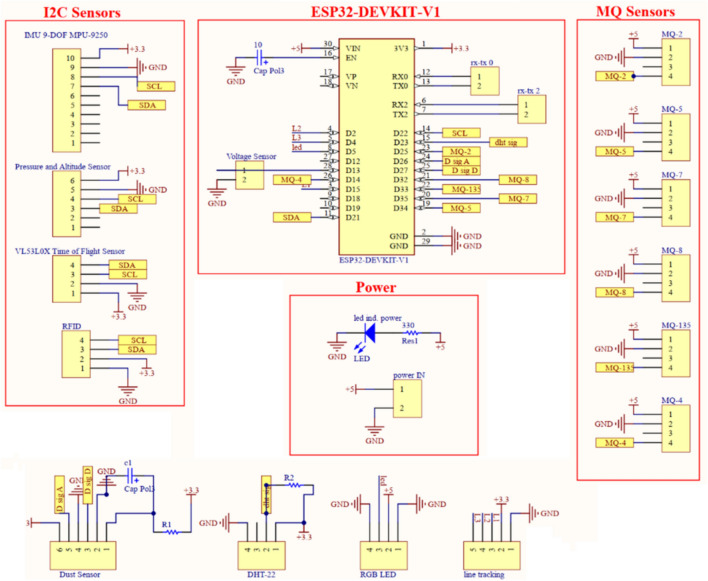 Figure 3
Figure 3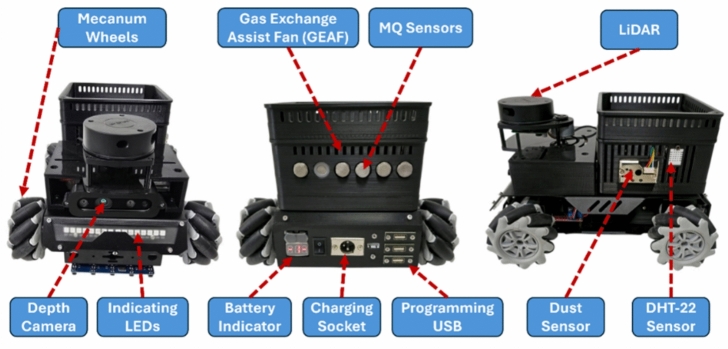 Figure 4
Figure 4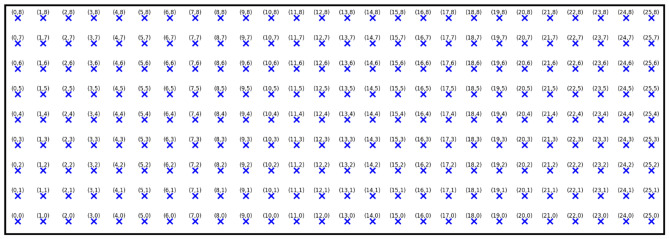 Figure 5
Figure 5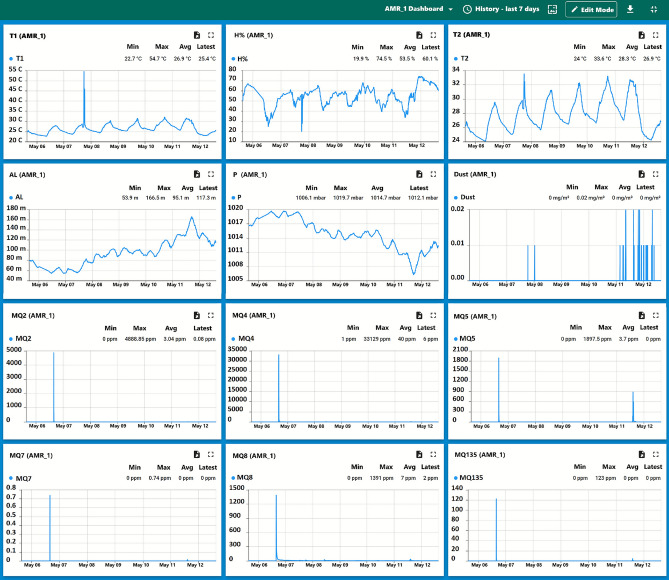 Figure 6
Figure 6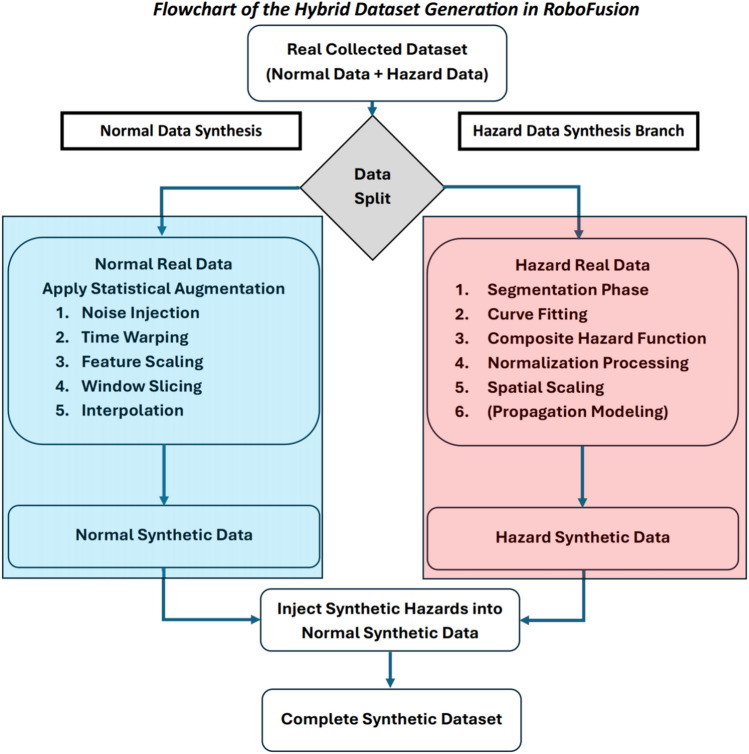 Figure 7
Figure 7 Figure 8
Figure 8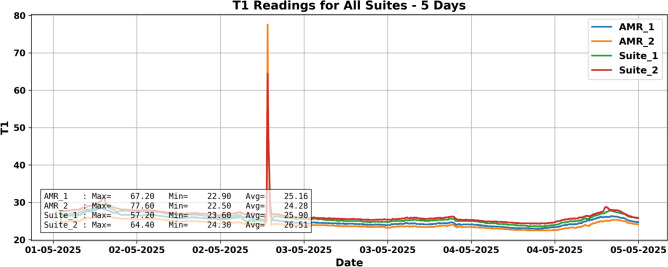 Figure 9
Figure 9- —Arab Academy for Science, Technology & Maritime Transport (AAST)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAnomaly Detection Techniques and Applications · Air Quality Monitoring and Forecasting · Fault Detection and Control Systems
Introduction
Modern industrial environments are becoming increasingly complex, demanding advanced, real-time solutions to enhance operational efficiency, situational awareness, and safety. In response, industries are adopting Autonomous Mobile Robots (AMRs), which represent a significant evolution from traditional Automated Guided Vehicles (AGVs) that rely on static paths and complex infrastructure. AMRs can autonomously navigate, execute logistics tasks, and collect telemetry data, and they serve as key enablers of Industry 4.0 in smart manufacturing systems^1^.
The capabilities of AMRs have grown substantially with the integration of multi-sensor systems, Internet of Things (IoT) communication protocols, and Artificial Intelligence (AI) driven analytics. These systems can detect critical environmental anomalies such as gas leaks, temperature spikes, fire hazards, and airborne pollutants^2^. However, the reliability of AI-based hazard detection in industrial contexts is often limited by the scarcity of high-quality datasets, particularly those capturing rare and unpredictable hazard scenarios. Simulating hazardous events in real industrial facilities is constrained by safety, ethical, and regulatory concerns. Furthermore, environmental variability across time and space creates a need for datasets that are both statistically robust and operationally diverse^3^. Conventional hazard detection systems, which typically rely on fixed sensor networks, lack the mobility and adaptability required for effective deployment in large industrial spaces. This limitation leads to biased learning models, higher false negatives, and poor generalization when the system encounters unseen anomalies^4^.
Internet of Robotic Things (IoRT) enables robotic systems to sense, interpret, and respond in real time. In RoboFusion this is achieved through embedded edge computing on ESP32 microcontrollers and through Message Queuing Telemetry Transport (MQTT) protocol based communication, which together provide low-latency real-time data processing onboard the AMRs^5^. This design minimizes reliance on cloud services, reduces latency^6,7^, and supports predictive modeling to enhance system resilience and reduce operational downtime^8^.
While the hardware platform in RoboFusion, which features a vision-free Near-Field Communication (NFC) guided ESP32 based dual-AMR system and four sensor suites, two mobile and two fixed, is essential for comprehensive real data collection, the core novelty of RoboFusion lies in its synthetic dataset generation framework. RoboFusion introduces a dual-pipeline approach that transforms real, multi-modal, multi-location sensor data into a comprehensive synthetic dataset that mirrors real-world behavior.
Specifically, RoboFusion addresses the critical scarcity of hazard data by:
- Collecting real-world data (180 days at a one-minute sampling rate) from AMRs and fixed sensor suites, covering both normal operations and rare hazard events, and using this as the foundational dataset.
- Augmenting real normal data to generate synthetic normal data via noise injection, time warping, and feature scaling, thereby reflecting the natural variability of industrial processes.
- Generating synthetic hazard data through a multi-phase modeling process that fits mathematical functions to real hazard events (covering the ignition, growth, peak, and decay stages), simulates spatial propagation, and produces diverse, location-aware hazard scenarios. RoboFusion distinguishes itself from prior works by:
- Integrating multi-modal data from 12 distinct sensors across four sensor suites (two mobile AMRs and two fixed stations) within a real industrial facility.
- Generating the first hybrid dataset that combines real and synthetic data for industrial hazard detection, validated across multiple machine learning models.
- Providing a scalable, reproducible, and open-access dataset that supports research in AI-driven robotics, environmental monitoring, and industrial safety. The remainder of this paper is organized as follows: Section "Background and related work" reviews background and related work. Section “System architecture” outlines the system architecture. Section “Methods” details the RoboFusion methodology. Section “Results” presents results and validation. Section “Discussion” discusses findings, and Section “Conclusions” concludes with future directions.
Background and related work
Autonomous and guided mobile robots in industrial sensing
Recent studies on Autonomous Mobile Robots (AMRs) and Automated Guided Vehicles (AGVs) for industrial automation^5–16^ have explored Light Detection and Ranging (LiDAR) and Inertial Measurement Unit (IMU) based navigation, Reinforcement Learning (RL), and Convolutional Neural Network (CNN) driven obstacle avoidance. However, these approaches typically require high computational power, dense training data, and centralized control architectures. In contrast, RoboFusion employs a lightweight Near Field Communication (NFC) guided navigation system combined with decentralized edge processing, which enables reliable real-time operation in an industrial testbed.
While simulation-based RL approaches for AMR navigation were demonstrated in^9^ and Long Short-Term Memory (LSTM) based obstacle avoidance was proposed in^7^, these techniques faced high data requirements. Similarly, CNN driven vision systems^10^ were limited in low-light environments. Earlier AGV frameworks^11–15^ rely on centralized or semi-centralized control and communication improvement strategies, whereas RoboFusion operates fully on embedded controllers with both mobile and fixed sensing nodes to achieve distributed, low-latency decision-making.
Unlike anomaly detection systems that rely solely on internal telemetry such as motor current or velocity^16^, RoboFusion captures the environmental context, a capability that enables synthetic hazard generation to expand model robustness under realistic industrial safety conditions.
Internet of Robotic Things (IoRT)
The Internet of Robotic Things (IoRT) extends the Internet of Things (IoT) paradigm by integrating robotic systems with cloud and edge analytics for adaptive and connected automation^17–27^. IoRT applications span multiple domains, including secure robotic healthcare frameworks^17^, industrial manufacturing^18,19^, and predictive maintenance^20–22^. Although these systems have advanced connectivity, they often face latency and heterogeneity challenges. Vision based IoRT systems using Simultaneous Localization and Mapping (SLAM)^23,24^ improved perception and autonomous mapping, although they remain computationally expensive.
RoboFusion instead achieves IoRT functionality through embedded microcontrollers and lightweight Message Queuing Telemetry Transport (MQTT) protocols, providing low-latency and bidirectional communication between mobile robots, fixed sensing nodes, and cloud dashboards. While theoretical IoRT architectures were explored in^25–27^, RoboFusion demonstrates a fully implemented and hardware integrated deployment validated in a real industrial facility, which bridges the gap between conceptual models and operational systems.
Sensor fusion and synthetic datasets
Sensor fusion remains central to robotic perception and localization, traditionally combining LiDAR, IMU, and odometry data^28,29^. RoboFusion, however, collects twelve heterogeneous sensory inputs, including temperature, humidity, pressure, air quality, and multiple gas concentrations, to form high-dimensional hazard profiles. Although no explicit fusion algorithm is applied, the framework’s multi-modal data architecture enables downstream machine learning for anomaly and hazard detection.
Data augmentation for robust sensing and modeling under noise has been studied in^30–34^, including smartphone based telemetry^31^, time series augmentation^32,33^, and domain adaptation^34^. Building upon these foundations, RoboFusion introduces a dual-pipeline synthetic data generation framework that augments normal operating data and simulates hazard events through phase segmentation, curve fitting, normalization, and spatial scaling. The resulting hybrid real and synthetic dataset provides balanced class representation and greater diversity for AI based hazard prediction, capabilities that were not previously demonstrated in industrial robotics datasets.
Environmental and gas hazard monitoring
Indoor environmental and air quality monitoring has been widely studied across diverse contexts, including urban comfort modeling^35–38^, thermal environments^39–42^, and large-scale building datasets^43–49^. However, these studies primarily rely on fixed sensors and lack mobile data collection. RoboFusion contributes the first combined real and synthetic industrial dataset for Egypt, covering both Mediterranean and desert climatic conditions and integrating mobile and fixed sensing modalities for continuous environmental coverage. Further, large-scale air quality datasets and pollutant tracking efforts^50–54^, Heating, Ventilation, and Air Conditioning (HVAC) adaptation systems^55–57^, and simulation-based datasets^57,58^ provide valuable context but lack the dynamic, multi-robot sensing found in RoboFusion. IoT-enabled monitoring platforms for industrial and domestic use^59–61^ demonstrate data integration capabilities, though without mobile sensing for real-time hazard localization.
Gas hazard detection research has employed LiDAR-based mapping^62^, threshold triggers^63^, and Receding Horizon Control (RHC) for gas leak mitigation^64^, while swarm-based detection with nano quadcopters was proposed in^65^. Other studies explored Robot Operating System (ROS)-based frameworks^66^, optical spectroscopy for gas leak sensing^66^, and digital-twin-based predictive maintenance^67,68^. Unlike these simulation-oriented systems, RoboFusion fuses real-world sensor data with structured synthetic generation, enabling machine-learning–ready hazard prediction under realistic conditions. Finally, by combining low-cost sensors, edge computation, and modular mobile platforms, RoboFusion achieves scalable, cost-efficient environmental monitoring and hazard detection. A comparative analysis of all related environmental datasets, sensing domains, and machine learning applications is provided in Supplementary Appendix B (Tables B1 and B2).
System architecture
RoboFusion is a decentralized robotic sensing platform designed to collect high-resolution, multi-modal environmental data from industrial facilities. Its core architecture enables both real-time hazard detection and the generation of a hybrid dataset that combines real-world observations with synthetic scenarios for machine learning applications.
The system consists of four sensor suites, two are mounted on Autonomous Mobile Robots ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {AMR}_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {AMR}_2$$\end{document} ) and two fixed sensor suites ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {Suite}_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {Suite}_2$$\end{document} ), equipped with identical sensor arrays deployed at strategic locations within a 9 m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 26 m industrial testbed at the Industry Service Complex (ISC) of Arab Academy for Science, Technology and Maritime Transport (AASTMT) main campus, Alexandria, Egypt. The testbed is segmented into 200 one-square-meter zones, each marked by an NFC tag (Type A, 13.56 MHz) adhered to the floor. These tags act as static beacons for AMR localization, enabling a grid-based navigation strategy. The overall system block diagram is illustrated in Fig. 1.Fig. 1RoboFusion system end to end block diagram.
Sensor suites
Each sensor suite integrates a 12-sensor array designed for multi-modal environmental monitoring, including both physical and chemical measurements. As shown in Table 1, each suite comprises four domains: (1) Ambient sensing is handled by the DHT-22 for ambient temperature (T1) and humidity (H%), (2) Onboard telemetry is measured by the BMP280 sensor, which provides pressure (P), altitude (AL), and onboard temperature (T2), (3) Particulate matter concentration is detected using the GP2Y1010AU0F optical dust sensor, and (4) Gas detection is performed using six analog MQ sensors (MQ2, MQ4, MQ5, MQ7, MQ8, MQ135) capable of sensing a range of hazardous gases (e.g., LPG, methane, CO, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {H}_2$$\end{document} , VOCs) and measured in parts per million (ppm).
To ensure consistent air sampling across sensor surfaces, particularly in areas of low circulation, each suite includes a Gas Exchange Assist Fan (GEAF), which is a 5,Volts Direct Current (VDC) axial fan operating at 4000,Revolutions Per Minute (RPM). This active airflow system enhances the accuracy and stability of gas concentration sensor readings. The BMP280 sensor is intentionally placed near the ESP32 board to serve as a thermal reference that distinguishes environmental heating from microcontroller-induced heat, while the DHT-22 provides external thermal measurements. The layout of the four sensor suites is shown in Fig. 2, and their internal schematic diagram is represented in Fig. 3.Table 1. Sensor suites composition.DomainSensorMeasurandInterfaceUse CaseAmbientDHT-22Ambient temperature (T1), humidity (H%)Digital (single-wire)General indoor ventilation monitoringTelemetry (Onboard)BMP280Pressure (P), altitude (AL), onboard temperature (T2)I^2^CFire-risk detection (pressure drop), gas-dispersion estimationParticulate MatterGP2Y1010AU0FDust concentration (ppm)AnalogSmoke, dust and particulate detectionGas DetectionMQ2, MQ4, MQ5, MQ7, MQ8, MQ135Gas concentrations (ppm): LPG, methane, CO, H_2_, VOCs, etc.AnalogFire hazards, gas leaks and chemical-anomaly detection
Fig. 2. Sensor suites composition overview. Fig. 3. Hardware schematic of the RoboFusion sensing module (created by the authors using Altium Designer).
Autonomous Mobile Robots (\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\hbox {AMR}_1$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\hbox {AMR}_2$$\end{document})
The AMRs serve as mobile sensor platforms capable of navigating autonomously across the testbed environment along either predefined or dynamically generated patrol routes. As shown in Fig. 4, each AMR is constructed on a custom-designed omnidirectional chassis measuring 285 mm \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 250 mm and fitted with four 60 mm Mecanum wheels. This wheel configuration allows the robot to maneuver in any direction without changing orientation, a feature that enables precise navigation in the grid-constrained layout of the testbed. Each AMR is actuated by four GM37-520 DC gear motors (12 V, 152 RPM, 7 kg \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\cdot$$\end{document} cm torque), each equipped with Hall-effect encoders providing 11 pulses per revolution (PPR). The encoder signals are processed using interrupt-driven counters on the ESP32, which estimates rotational speed and computes linear displacement using wheel diameter and gear ratios.
Position tracking is achieved using a hybrid localization strategy. At each grid intersection, an NFC reader attached to the robot detects passive tags embedded in the floor. These tags correspond to unique cell identifiers (C00 to C199), mapped to (x, y) coordinates via an onboard lookup table where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x = [0-8]$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y = [0-25]$$\end{document} . Between tags, dead-reckoning is applied using encoder feedback to maintain positional continuity. The grid layout and tag positions are illustrated in Fig. 5.
Navigation follows a rule-based logic with fallback mechanisms. A custom implementation of Dijkstra’s Shortest Path Algorithm computes optimal routes based on Euclidean distance between Cells. During traversal, the robot validates cell transitions through combined encoder data and tag recognition.
To avoid collisions, each AMR is equipped with three VL53L0X Time-of-Flight (ToF) sensors mounted at the front and sides, with a maximum range of 200 cm and an obstacle threshold of 3 cm. The chassis is fabricated from lightweight aluminum alloy with vibration damping and a low center of gravity, supporting a payload capacity of up to 25 kg. Each robot is powered by an 11.1 V, 2200 mAh Lithium-ion (Li-ion) battery pack, offering approximately 2 hours of operation under combined sensing and mobility workloads.Fig. 4AMRs front and back views – main components.Fig. 5. Testbed grid configuration.
Embedded firmware and data flow
The ESP32 firmware manages all sensing, localization, data processing, and wireless communication. Analog gas sensor readings are converted into parts per million (ppm) values using manufacturer-provided sensitivity curves from datasheets and empirical calibration performed during lab-based gas exposure experiments. Digital sensors are interfaced through designated General-Purpose Input/Output (GPIO) or Inter-Integrated Circuit (I^2^C) lines. For example, the DHT-22 sensor operates on GPIO4 with a 10 k \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega$$\end{document} pull-up resistor, while the BMP280 communicates via I^2^C using GPIO21 (Serial Data (SDA)) and GPIO22 (Serial Clock (SCL)).
The adopted sampling rate of one reading per minute was selected after testing higher rates (2 s and 10 s), which produced denser data without additional informative variation. This rate therefore offered a practical balance between temporal resolution and system stability during the 180-day deployment. Nevertheless, the RoboFusion framework remains fully programmable, allowing adaptive or higher-frequency sampling when required by specific test conditions.
The firmware acquires sensor data at each sampling interval, performs NFC-based zone identification, applies calibration functions, and formats telemetry into structured JavaScript Object Notation (JSON) messages. These packets include suite ID, coordinates, sensor readings, and a timestamp generated from the ESP32 system clock. If Wi-Fi connectivity is lost, data is cached in flash memory and retransmitted once the connection is restored. The telemetry schema and communication logic are designed to be modular, allowing additional sensor suites or AMRs to be added without modifying existing infrastructure.
Communication and cloud integration
All sensor suites transmit their telemetry via the MQTT protocol to the ThingsBoard Cloud platform. Each suite publishes a unique topic (for example, telemetry/AMR1 or telemetry/Suite2), and messages are formatted in JSON to maintain compatibility with cloud based analytics tools. MQTT communication occurs over port 1883 with Wi-Fi Protected Access 2 using a Pre Shared Key (WPA2 PSK) secured Wireless Fidelity (Wi-Fi) connection. Static Internet Protocol (IP) addressing ensures deterministic routing and device identification.
ThingsBoard platform supports real-time dashboards as shown in Fig. 6, rule-based alerts, device telemetry, and remote procedure calls (RPCs). Telemetry can be exported using the built-in utilities in Comma-Separated Values (CSV)/Excel formats, each containing 15 fields: Date, Time, T1, H%, P, AL, T2, Dust, MQ2, MQ4, MQ5, MQ7, MQ8, MQ135, and Condition.Fig. 6. Dashboard Sample for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {AMR}_1$$\end{document} displaying the reading of 12 sensors array.
Summary and design rationale
The RoboFusion system is tailored to operate under realistic industrial conditions, where infrastructure may be limited and operational safety is critical. NFC based localization eliminates the need for power intensive visual navigation. Modular firmware and a decentralized architecture ensure resilience and scalability. Preprocessing steps, including analog calibration, zone tagging, and fault handling, are managed locally at the edge, which reduces latency and minimizes dependency on cloud services. By combining autonomous mobile sensing, robust embedded processing, and scalable cloud integration, RoboFusion provides a reliable platform for real-time industrial monitoring and hybrid dataset creation. Its use of low-cost hardware and communication protocols ensures accessibility for research groups aiming to replicate or extend the system.
Additional implementation-level details related to the firmware architecture and system deployment are provided in Appendix C. In particular, the end-to-end sensing, communication, and cloud integration pipeline is illustrated in Supplementary Figure C1.
Methods
The RoboFusion framework follows a structured and reproducible methodology designed to generate hybrid environmental datasets for training AI based hazard detection models in industrial robotic environments. The primary aim is to simulate both normal and hazard operational scenarios that can arise in dynamic industrial settings. This framework enables learning algorithms to generalize effectively, especially when deployed on autonomous robotic platforms.
At the core of this methodology is a hybrid sensing system that combines real sensor data, collected from the four sensor suites, with a dual synthetic data generation pipeline. This architecture as shown in Fig. 7, addresses a fundamental limitation in industrial robotics research, which is the scarcity of high fidelity hazard data due to the rarity, unpredictability, and safety risks associated with such events.Fig. 7. Overview of the RoboFusion dataset generation pipeline, including real-world data acquisition, synthetic normal and hazard data creation, and hazard injection.
The methodology comprises three main phases:
- Real-world data acquisition, performed over a 180-day deployment across the four distributed sensor suites.
- Synthetic data generation, using independent branches for normal condition augmentation and hazard condition modeling.
- Hybrid dataset assembly, in which generated synthetic hazards are injected into dense synthetic normal data at semantically meaningful intervals and spatial positions, forming a continuous, labeled time series for machine learning applications. This process yields a robust dataset that not only captures the complex dynamics of industrial hazards but also enables mobile robotic platforms to be trained under diverse environmental conditions.
Real dataset collection
Environmental sensing data was collected and transmitted wirelessly via Wi-Fi to a central router, then forwarded to the ThingsBoard IoT platform. Each suite was registered as a separate IoT device with unique tokens. The real dataset pipeline in RoboFusion begins with exporting environmental telemetry data from the ThingsBoard cloud platform, where each of the four sensor suites generates 12 separate CSV files corresponding to individual sensor channels.
This results in 48 timestamped files containing raw sensor readings. These files are then merged using a Python script into a unified dataset by aligning records through a common timestamp key and adding a new column namely “Suite_ID” to distinguish the origin of each reading.
Following this, interpolation is applied to compensate for data losses caused by network interruptions, ensuring temporal continuity in the dataset. The interpolated dataset is subsequently used to generate a set of 12 time-series plots each corresponding to one sensor modality where sensor outputs from all four suites are color-coded and displayed together to allow for comparative analysis across space and time.
This streamlined data pipeline, shown in Fig. 8 transforms raw telemetry into a structured, complete, and interpretable real-world dataset. The complete schema of the real dataset is illustrated in Table 2.Fig. 8. Workflow of RoboFusion real dataset processing: From telemetry export on the ThingsBoard platform to dataset consolidation, interpolation, and multi-suite visualization.Table 2. Real dataset schema.DateTimeSuite_IDT1T2H%PALDustMQ2MQ4MQ5MQ7MQ8MQ135ConditionSchema (column names) only; values omitted for brevity.
The testbed hosted 15 controlled real hazard events of three types, (1) five fire events (labeled as Hazard_1), (2) four high-temperature fluctuations events (labeled as Hazard_2), and (3) six gas leaks events (labeled as Hazard_3). Each event lasted between 30–120 minutes, yielding labeled sequences for supervised learning. Each hazard scenario was carefully carried out under safe, controlled conditions, following AASTMT safety guidelines. Trained staff supervised the experiments, and risk assessments were completed beforehand. During data collection, all necessary precautions like wearing wearing Personal Protective Equipment (PPE), keeping safe distances, and having fire extinguishers on hand were strictly followed.
For instance, in a five-day test, a “fire event” on May 4, 2025, triggered notable sensor responses. T1 readings exceeded 43 °C in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {Suite}_2$$\end{document} , while AMRs registered earlier temperature rises due to mobility as shown in Fig. 9, Gas sensors MQ8 as shown in Fig. 10 and MQ4 detected hydrogen, validating spatial synchrony and sensor fusion potential.
Prior to synthetic generation, this real dataset served as the foundational baseline for the hybrid framework explained in the next section, informing both the statistical modeling of normal conditions and the temporal dynamics of hazard scenarios.Fig. 9T1 readings across all sensor suites over 5 days. A sharp spike on May 4 indicates a simulated alcohol-based fire, with Suite2 recording the highest peak and AMRs detecting the rise earlier.Fig. 10. Hydrogen sensor readings during the same period. AMR2 shows a strong hydrogen peak ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 758 ppm) on May 4, aligned with the fire event, confirming detection of combustion gases.
Basic descriptive statistics for the collected real dataset are provided in Supplementary Appendix E. Table E1 reports overall sensor statistics (count, mean, median, standard deviation, variance, min, max, range, skewness, kurtosis) computed across the combined 12-day normal baseline and five Hazard_1 events as a real dataset sample, while Table E2 shows the same statistics computed separately for each sensor suite. These statistics were used to validate and parameterize the synthetic-augmentation methods so that generated signals reproduce the observed central tendency and dispersion without producing unrealistic extremes.
Synthetic dataset generation
Due to the limited number of real hazard events and the inherent risks of reproducing them in physical industrial settings, the RoboFusion framework incorporates a dual-branch synthetic data generation pipeline. This extension aims to produce consistent synthetic signals, ensuring the availability of balanced, diverse training data suitable for evaluating AI-driven robotic hazard detection systems.
The synthetic pipeline consists of two parallel branches: (1) One for augmenting normal environmental conditions, (2) another for simulating realistic hazard progression patterns. These branches operate independently on the preprocessed real dataset to ensure isolation of statistical properties.
Each synthetic record is mapped onto the grid-based testbed environment, enabling it to be associated with specific spatial zones and AMR traversal paths. This design reflects real-world deployments in robotics, where sensing and environmental interaction are both location-aware and time-dependent.
Synthetic normal dataset generation
The industrial testbed is divided into a virtual grid of 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 1 m zones as illustrated in Fig. 11. AMRs were programmed to systematically traverse this layout using a relaxed Dijkstra algorithm, allowing efficient coverage of all spatial cells without excessive redundancy.Fig. 11. Testbed environment modeled as a grid with two fixed sensor suites and two AMRs.
Fixed sensor suites are located at coordinates (0, 0) and (25, 8) as strategic locations within the testbed. They are positioned at the entrance and exit of the testbed to capture both incoming and outgoing ambient conditions. These areas coincide with zones of frequent material-handling activity and the presence of heat-generating equipment, which together represent the most likely sources of thermal and gas hazards. Placing the suites at these points also maximizes sensing coverage across the monitored area by providing complementary views of the environment’s inflow and outflow dynamics. While this layout proved optimal for our testbed, other industrial environments may define “strategic” sensor locations differently, depending on their spatial layout, airflow behavior, and dominant hazard types.
To replicate realistic fluctuations observed during non-hazardous operations (Normal Condition), five statistical augmentation techniques were employed. Each technique was carefully parameterized and validated to ensure it preserved the core structure of the original data from all the 12 sensors while introducing controlled variability. These techniques are summarized in Table 3.Table 3. Augmentation Techniques with Configurable Parameters Description.TechniqueParameterWhen to UseNoise InjectionNoise Level (%)Simulates low-frequency sensor drift or noiseTime WarpingTime Distortion (%)Models timing irregularities caused by environmental variabilityFeature ScalingScaling Factor (%)Represents amplitude fluctuations from calibration or seasonal changesWindow SlicingWindow SizeCreates additional overlapping time windows for sequence expansionInterpolationPolynomial DegreeSmooths transition or fill short data gaps using curve fitting
Following augmentation, statistical similarity was quantitatively assessed using (1) Pearson correlation coefficient^69^ as shown in Supplementary Appendix D Equation D1, (2) Kullback–Leibler divergence^70^ as shown in Supplementary Appendix D Equation D2, and (3) Basic statistics (mean, standard deviation, range). These metrics ensured that the augmented data did not introduce synthetic artifacts that could bias downstream learning models.
Although Table 4 presents evaluation metrics for the MQ4 gas sensor as a representative example, it is important to note that all augmentation techniques are systematically applied across the entire sensor array comprising 12 sensor channels per suite. The user may select one of the five augmentation methods independently, depending on the nature of the learning task or the desired variation (e.g., temporal jitter, drift simulation, or partial data loss).
Alternatively, the techniques can be executed sequentially in a pipeline, referred here as “merged augmentation”, where each method enhances a distinct aspect of the signal. In our example, the merged approach following the sequence (Smart Noise Injection \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Time Warping \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Feature Scaling) consistently produced the broadest signal range and most realistic variability without compromising evaluation metrics. These findings establish it as a robust configuration for generating synthetic normal-condition data in mobile robotic sensing applications.
This branch of the pipeline enables scenario diversity across time and space, crucial for training robust robotic perception systems capable of operating under various nominal conditions.Table 4. Evaluation metrics between original and augmented MQ4 data for AMR_.MethodMinMaxMeanSTDRangeCorrelation****KL_DivergenceNoise Injection103.18184.40150.994.4881.221.00.0Window Slicing103.19163.38151.065.2660.190.718.1Time Warping103.19184.36150.994.4881.171.00.0Interpolation103.19184.36150.994.4881.171.00.0Feature Scaling98.03175.14143.444.2677.111.00.0Merged Augmentation98.01175.11143.444.2677.101.00.0
Synthetic hazard dataset generation
While normal environmental conditions can be reliably augmented using statistical methods, real hazard events remain scarce, inconsistent, and risky to reproduce on a scale. To overcome this, the RoboFusion framework incorporates a structured synthetic modeling process that replicates the temporal dynamics of real hazard events across multiple hazard types. This synthetic hazard generation process enables the safe creation of high-fidelity signals to support robust learning in autonomous robotic systems deployed in industrial environments.
Unlike traditional sensor datasets which either simulate hazards using simple noise profiles or exclude them entirely, RoboFusion uniquely models real hazard dynamics using signal segmentation, function fitting, and spatial propagation. To the best of our knowledge, this is the first dataset-generation framework that synthesizes environmental hazards in both the temporal and spatial domains for industrial mobile robotics.
The methodology is designed to be generalizable across the three major hazard types observed in the dataset. Each hazard type exhibits a unique temporal and spatial signature, typically dominated by a leading sensor - the one most responsive to that hazard among the 12 sensors in each suite. For fire and high temperature events (Hazard_1 and Hazard_2), the leading sensor is T1, which records sharp rises in ambient temperature. For gas leakage events (Hazard_3), the most sensitive sensor is selected dynamically from the MQ family (MQ4, MQ5, MQ7, MQ8, or MQ135), depending on the gas type and dispersion pattern. The segmentation, fitting, and modeling steps are applied using this leading sensor as the primary reference.
Segmentation
Each real hazard event is segmented into four temporal segments based on the pattern observed in the leading sensor:
- Ignition: Initial deviation from baseline
- Growth: Rapid escalation in signal amplitude
- Peak: Sustained high-intensity phase
- Decay: Gradual return to ambient baseline Phase boundaries shown in Fig. 12 are identified using slope analysis of the leading sensor’s time series, leveraging the first derivative to detect inflection points (a, b, and c). Thresholds are determined empirically for each hazard type to ensure consistent segmentation.Fig. 12. Temporal segmentation of a fire hazard event using the T1 temperature sensor.
Curve fitting
Each segment is modeled independently using a group of candidate regression functions including polynomial (up to degree 4), Gaussian, and exponential fits. Grid search is used to tune parameters for non-linear models. Candidate fitting functions are summarized in Supplementary Appendix D Table D1 for hazard_1 and T1 is the Leading Sensor in Suite_1. The best-fitting function per segment is selected based on two criteria: minimum root mean square error (RMSE) and maximum coefficient of determination ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^2$$\end{document} ).
This process is repeated for all sensors within the four sensor suites, beginning with the leading sensor. An example of the fit models selected for T1 and MQ4 are shown in Figs. 13 and 14, respectively. The fitting coefficients for each model are stored per stage (ignition, growth, peak, decay) and used in the next synthesizing phase.
Composite hazard
Once the optimal models are identified for each of the four segments, they are combined to form a piecewise composite hazard function that represents each sensor in hazard condition. This function reconstructs the full synthetic signal in the time domain, as expressed in Supplementary Appendix D Equation D3.Fig. 13. Fit models for T1 sensor with coefficients and evaluation metrics in hazard condition.Fig. 14. Fit models for MQ4 sensor with coefficients and evaluation metrics in hazard condition.
Normalization process
To ensure signal realism and consistency with the real dataset’s scale, the composite synthetic signal is normalized to match the real amplitude ranges of the respective sensors. This scaling is achieved through linear normalization as shown in Supplementary Appendix D Equation D4.
Spatial scaling (Propagation modeling)
In real hazard scenarios, signal strength naturally decreases with increasing distance from the hazard origin. To replicate this behavior, the synthetic hazard signal is adjusted using a logistic attenuation function applied over the Euclidean distance to the source zone. This spatial modulation ensures that AMRs perceive hazard intensity in a realistic manner that depends on their proximity and traversal path. The resulting spatially varying intensity is computed using Supplementary Appendix D Equation D5^71^.
The temporal evolution of the hazard intensity follows a logistic growth model, as defined in Supplementary Appendix D Equation D6^72^. The parameters of this model are tuned using Bayesian optimization to produce realistic propagation curves that match the desired hazard behavior, whether fast, gradual, or delayed.
By combining segmented curve fitting, amplitude normalization, and spatial scaling, the synthetic hazard generation process provides flexible control over hazard dynamics. From a single real hazard event, the framework can generate limitless variations of the same hazard with different speeds, shapes, and intensities. These outcomes are governed by tunable parameters such as segment curvature, normalization range, and attenuation slope. This parameterized control enables the simulation of realistic and diverse hazard behaviors, directly contributing to improved generalization of ML models by exposing them to a broader distribution of hazard manifestations during training.
The final step involves injecting the modeled hazard signals into the dense synthetic normal dataset generated earlier. Each injection occurs at a randomly selected timestamp and zone location to simulate diverse scenarios. Multiple synthetic hazards can be injected into a single sequence to model temporal overlaps or spatially distributed events across space.
This method enables the same hazard event to be rendered at different zones, durations, and intensities, creating diverse training scenarios for autonomous mobile robots.
A representative row from the generated synthetic dataset is shown in Table 5. It maintains the same schema and labeling strategy as the real dataset, including suite ID, timestamp, spatial location, and all 15 sensor readings.Table 5. Synthetic normal dataset schema.DateTimeSuite_IDLocationT1T2H%PALDustMQ2MQ4MQ5MQ7MQ8MQ135ConditionSchema (column names) only; values omitted for brevity.
Summary
RoboFusion generates synthetic environmental datasets for hazard prediction by combining real sensor measurements from AMRs and fixed sensor nodes deployed across a mapped facility. The collected data are first labeled as normal or hazardous, and each hazard event is decomposed into four universal phases, namely Ignition, Growth, Peak, and Decay, which capture the typical temporal evolution of physical hazards. For every hazard type, the most sensitive (leading) sensor is identified and used to model how the event unfolds. Synthetic data are then produced through two pipelines: one that augments normal condition data to create natural variability, and another that models hazard phases using fitted temporal curves and spatial propagation functions. This structure enables RoboFusion to generate realistic and controllable datasets for training hazard prediction models.
Results
This section presents a comprehensive validation of the RoboFusion framework using a range of ML models applied to both real and synthetic datasets. The objective is to evaluate how effectively these models can detect hazardous environmental conditions under varying data availability scenarios and training constraints. To ensure broad coverage, four classifiers were selected, namely Random Forest (RF), Support Vector Machine (SVM with RBF kernel), Extreme Gradient Boosting (XGBoost), and a shallow Multi Layer Perceptron (MLP), which together represent tree based, kernel based, ensemble, and neural architectures. All models were trained and evaluated as binary classifiers (Normal, Hazard) using precision, recall, and F1 score as the primary performance metrics.
Three main data-domain scenarios were examined (S1, S2, and S3), summarized in Table 6. Each scenario differs in the type of data used for training and testing, and collectively they evaluate baseline real data, synthetic-only, and cross-domain performance.Table 6. Overview of the three main data-domain scenarios used for model evaluation, showing training–testing data types and corresponding result tables.Scenario IDTraining dataTesting dataPurposeResults tableS1Real datasetReal datasetEvaluate baseline model performance using only real dataTable 9S2Synthetic datasetSynthetic datasetAssess consistency and learning behavior using purely synthetic dataTable 10S3Synthetic datasetReal datasetEvaluate transferability of synthetic-trained models to real hazardsTable 11
Real dataset evaluation (S1)
A real-world dataset was collected over 180 days, comprising \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 1,036,800 samples from the four sensor suites. Fifteen hazard events were recorded and labeled, covering three distinct hazard types: Hazard_1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Fire (5 events), Hazard_2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} High temperature fluctuations (4 events), Hazard_3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Gas leakage (6 events). Each hazard spanned 30 to 120 minutes, enabling robust yet limited supervised training.
Table 7 summarizes the number of samples collected during the 180-day deployment, categorized into normal data and three hazard classes. As shown, normal conditions account for over 99.6% of all samples, while hazard events collectively represent less than 0.5%. This extreme imbalance reflects the natural scarcity of real hazards in controlled industrial settings and underscores the importance of synthetic augmentation to ensure adequate representation for supervised learning models.Table 7. Summary of collected samples across normal and hazard conditions during the 180-day deployment.Data typeDuration/no. of eventsNo. of samplesPercentage (%)**Normal Data180 Days1,036,80099.61%Hazard_15 Events1,6840.16%Hazard_24 Events1,0320.10%Hazard_36 Events1,3480.13%Total–**1,040,864100%
Within Scenario S1, four test cases (T1 to T4) were designed to explore how different real data configurations, such as temporal splits, reduced hazard density, and unseen hazard events, affect classifier performance. These test cases, summarized in Table 8, correspond to the first row presented in Scenario S1 in Table 6.Table 8. Definition of the four test cases (T1–T4) under Scenario S1 (Real \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Real).Test caseDescriptionClassifierTrainingTesting****PurposeT1Baseline (70%–30% temporal split on full dataset)RF180 days180 days (reuse)Establish baseline performance on real data.T2Leave-One-Hazard-Out (LOHO) validationRF180 days45 days (reuse)Assess generalization to unseen hazard events.T3Reduced-data experimentRF50 days12 days (non-overlapping)Evaluate model performance with limited real-data availability.T4Reduced-data experimentXGBoost50 days12 days (non-overlapping)Compare classifier robustness under the same reduced-data condition.
Table 8 summarizes the four test configurations (T1–T4) designed under Scenario S1 (Real \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Real) to examine the influence of data partitioning, hazard exposure, and data availability on model robustness. The baseline test case (T1) adopts a conventional 70–30% temporal split to establish reference performance on the full real dataset. The Leave-One-Hazard-Out validation (T2) evaluates model generalization to unseen hazard events. Reduced-data experiments (T3 and T4) simulate constrained data conditions using shorter, non-overlapping periods, with T3 employing Random Forest and T4 using XGBoost to compare algorithmic resilience under identical data scarcity. Together, these configurations systematically test temporal, structural, and model-level generalization within purely real-world data scenarios.Table 9. Hazard classification performance under real-world constraints.Test case IDHazard_1 F1Hazard_2 F1Hazard_3 F1Macro F1****ConclusionT10.980.980.980.99Perfect scores; overfitting.T20.000.000.000.25Total failure of unseen hazards.T30.600.940.060.65Improved generalization.T40.390.430.100.48XGBoost underperforms RF.
The results shown in Table 9 indicate that even with 180 days of real-world data, generalization fails unless hazards are duplicated or densely represented. The most striking failure is in T2, where the RF model trained on all available hazards except one instance (LOHO) per hazard type completely failed to detect the unseen events (F1 = 0.00 for Hazard_1 and Hazard_2). This highlights a critical gap: real data alone is not sufficiently diverse to support ML model generalization to new but semantically similar hazards.
To understand why real-world hazard classification underperforms, we analyzed intra-class sensor variability within each hazard class across all 15 hazards events. For each event, we calculated the mean and standard deviation of all sensor readings:
- Hazard_1 showed moderate consistency across gas and thermal sensors, although signal magnitudes varied between locations.
- Hazard_2 exhibited broader fluctuations, particularly in MQ135 and MQ2, indicating sensitivity to local airflow and ambient dynamics.
- Hazard_3 was the most inconsistent, with wide differences in response shape and peak amplitude caused by variations in dispersion conditions and source proximity. Fig. 15. Intra-class variability across hazard types — Mean ± standard deviation.
This intra-class variability prevents the formation of stable sensor space patterns; without consistent features across events of the same hazard type, supervised models struggle to learn reliable decision boundaries. This explains the observed class wise differences in model detectability, especially the reduced accuracy for gas leak events, and underscores the importance of synthetic data in enhancing per class consistency.
These results, visually illustrated in Fig. 15, confirm that limited and internally diverse real hazard data provide weak support for generalizable ML, thereby highlighting the value of the hybrid synthetic-augmentation strategy proposed in RoboFusion.
Synthetic dataset evaluation (S2)
To address the scarcity and inconsistency of real hazards, the RoboFusion framework generated a synthetic dataset containing 360 days of normal operations and 100 staged hazard sequences with varied onset, magnitude, and duration (These synthetic data sizes can be extended to limitless sizes). Models trained and tested on this synthetic dataset showed consistently high performance as shown in Table 10.Table 10. Synthetic dataset evaluation (Train on Synthetic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Test on Synthetic).ModelAccuracyNormal precisionHazard precisionNormal recallHazard recallNormal F1****Hazard F1RF0.980.980.970.990.990.980.98SVM (RBF)0.960.960.950.970.970.960.96XGBoost0.970.970.960.980.980.970.97MLP0.950.950.940.950.950.950.94
Cross-domain validation (S3)
To test generalization, we trained models only on synthetic data and evaluated them on real hazard events. Despite the domain shift, synthetic-trained models substantially outperformed real-only models in recall and F1 score for all hazard types as shown in Table 11.Table 11. Cross-domain validation (Train on Synthetic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Test on Real).ModelAccuracyNormal precisionHazard precisionNormal recallHazard recallNormal F1****Hazard F1RF0.920.930.830.910.870.920.85SVM (RBF)0.900.920.750.890.840.910.79XGBoost0.910.920.810.900.860.910.83MLP0.850.870.690.840.780.850.73
This performance recovery demonstrates that synthetic hazards, when modeled across diverse parameters, help models generalize even to unseen real world events. Figure 16 compares the performance of the four machine learning models across real, synthetic, and cross domain validation scenarios. Each subplot illustrates key classification metrics versus each ML model.Fig. 16. Model performance across real, synthetic, and cross-domain validation scenarios. (a) RF; (b) SVM (RBF); (c) XGBoost; (d) MLP.
To further examine the statistical robustness of the reported results, a 5-fold stratified cross-validation (CV) procedure was employed following standard machine-learning evaluation practices.
In this protocol, the dataset is randomly partitioned into five equally sized subsets (folds) while preserving the proportion of normal and hazard samples within each split. During each iteration, four folds are used for training and one for testing; this process repeats five times such that each sample appears exactly once in a test fold. The reported values correspond to the mean ± standard deviation (SD) of precision, recall, and F1-score across folds. This approach quantifies the stability and reproducibility of model performance under resampling, ensuring that the reported metrics are not artifacts of a single train–test configuration.
To complement the single-run experiments reported above and address the reviewer’s concern regarding statistical validation, three validation scenarios were examined:
- Real \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Real (5-fold CV): The real dataset was evaluated under stratified 5-fold cross-validation. The low standard deviations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma \approx 0.001$$\end{document} –0.005) indicate consistent classifier behavior across folds despite class imbalance.
- Synthetic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Synthetic (5-fold CV): The synthetic dataset was validated using the same CV protocol to confirm internal coherence. Both Random Forest and XGBoost achieved near-perfect separability (F1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx$$\end{document} 0.99, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma < 0.003$$\end{document} ), confirming the dataset’s structural consistency.
- Synthetic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Real (single cross-domain evaluation): Models trained on the full synthetic dataset were tested once on the complete real dataset to measure domain transferability. This setup intentionally avoids cross-validation to maintain domain independence. These results align with those of the original cross-domain experiment (Table 11), confirming that the synthetic data preserve real-world statistical characteristics. The consolidated outcomes are summarized in Table 12, combining intra-domain and cross-domain validations in a unified format.Table 12. Consolidated cross-validation and cross-domain results (Scenarios 1–3).Scenario/ModelPrecision (mean ± SD)Recall (mean ± SD)F1-score (mean ± SD)**S1 – Real ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} Real (5-fold CV)Random Forest0.501 ± 0.0020.518 ± 0.0030.362 ± 0.005XGBoost0.500 ± 0.0010.491 ± 0.0020.300 ± 0.004S2 – Synthetic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} **Synthetic (5-fold CV)Random Forest0.987 ± 0.0020.986 ± 0.0030.987 ± 0.002XGBoost0.991 ± 0.0010.992 ± 0.0010.992 ± 0.001S3 – Synthetic ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow$$\end{document} **Real (single evaluation)**Random Forest0.5010.5180.362XGBoost0.5000.4910.300SVM (RBF)0.4940.3870.292MLP0.4860.2530.286
Table 12 presents the consolidated results of the three validation scenarios. Scenarios 1 and 2 report 5-fold cross-validation outcomes (mean ± SD), whereas Scenario 3 represents a single cross-domain evaluation in which models trained on synthetic data are tested on real data. The low fold variance observed in Scenarios 1 and 2 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma \approx 0.001$$\end{document} –0.005) confirms the stability and reproducibility of model performance, while the consistency observed in Scenario 3 verifies the alignment between synthetic and real domains.
These validation experiments demonstrate that the RoboFusion framework produces reproducible results under resampling and maintains stable performance when transferring from synthetic to real environments, thereby reinforcing the statistical credibility of the reported findings.
Quantitative similarity between real and synthetic signals
To quantitatively assess how closely the synthetic dataset reproduces the temporal dynamics of the real sensor data, three complementary similarity metrics were applied between each real–synthetic signal pair: Dynamic Time Warping (DTW), Fréchet distance, and Energy distance. Each metric captures a distinct aspect of realism:
- DTW measures temporal alignment between two sequences that may differ in timing or duration, identifying how well the synthetic signal follows the time-evolving shape of the real signal.
- Fréchet distance quantifies the overall geometric similarity between curves, being sensitive to both amplitude and shape.
- Energy distance compares statistical distributions, indicating whether the synthetic signals share the same overall value distribution as the real data. The analysis was performed for all twelve sensors using five real Hazard1 (fire) events and twelve synthetic counterparts generated by the RoboFusion framework. Results are summarized in Table 13 and visualized in Fig. 17.Fig. 17. Normalized Dynamic Time Warping (DTW) similarity between real and synthetic signals across all sensors.
Sensors primarily responsive to thermal and particulate phenomena (T1, T2, Dust, H%, P, AL) show very low normalized DTW values ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx$$\end{document} 0.8–2.5) and Energy Distances < 1.6, confirming that the synthetic generator effectively captures the real fire dynamics. Gas sensors (MQ2, MQ4, MQ135) exhibit higher distances because they play a minor role in fire events and remain close to baseline; thus, their apparent mismatch is physically expected. These sensors become dominant in Hazard3 (Gas Leak) scenarios.Table 13. Quantitative similarity metrics (DTW, Fréchet, and Energy distances) between real and synthetic Hazard1 signals across all sensors.SensorDTW (Mean)Normalized DTWFréchet distanceEnergy distanceT1435.80.887.341.11T2497.30.919.271.42H%2231.45.0035.011.30P912.62.0415.521.25AL1201.92.4516.091.46Dust510.30.946.821.64MQ2223216.7512.90117150.835.90MQ420055.449.361424.786.12MQ518243.841.021210.675.35MQ76841.214.23372.553.48MQ89324.419.57587.413.91MQ13552529.4118.527634.264.68
Discussion
The evaluation of the RoboFusion framework across real, synthetic, and cross domain validation scenarios reveals critical insights into the limitations of real world datasets for hazard detection and the transformative potential of synthetic datasets.
The 180 day real dataset, which included fifteen controlled hazard events, provided a valuable testbed for exploring model performance under realistic operational conditions. However, even when models were trained on nearly all available real hazard data, with just one event withheld for each hazard type, the results showed complete failure to generalize. Specifically, in the LOHO scenario, F1 scores dropped to zero for both fire and high temperature hazards, which exposed a significant weakness in relying solely on real data. These findings confirm that hazard diversity in real datasets is simply too limited to support robust machine learning generalization.
Further analysis of intra-class sensor behavior revealed substantial variability in how different hazard instances express themselves across sensing modalities. In some cases, the same hazard type led to different sensor peaks, durations, or rates of change depending on spatial location, environmental dynamics, or sensor position. This inconsistency prevents models from learning stable, repeatable decision boundaries. Even increasing the density of hazard events only partially recovered performance, and often for a subset of hazard classes.
By contrast, the synthetic dataset generated by RoboFusion offers consistent and structured hazard representations while maintaining statistical variability. Synthetic hazards are constructed using stage-wise curve fitting, distance-based spatial modeling, and tunable intensity dynamics. These design elements enable the generation of hundreds of hazard profiles with controlled diversity, creating training conditions that support generalized learning.
Cross domain experiments further underscore this point. Models trained exclusively on synthetic data achieved hazard F1 scores up to 0.85 when tested on real world events, far outperforming models trained only on real data. This performance gap reinforces the idea that the bottleneck in hazard detection is not the classifier architecture, but the scarcity and inconsistency of labeled hazard data.
In safety-critical environments, where real hazards are rare, dangerous, and often non-reproducible, the RoboFusion framework enables scalable and transferable AI-based hazard detection. Rather than replacing real data, synthetic augmentation fills in the statistical and semantic gaps that real datasets cannot cover. Future work will extend the hazard types modeled, explore domain adaptation techniques, and validate performance across varied industrial layouts to further enhance the robustness and adaptability of the framework.
While RoboFusion successfully integrates real and synthetic data to reproduce realistic environmental dynamics, some of the current validation was limited to the Hazard_1 (fire) event class and a single-site deployment. Future work will extend the framework to encompass additional hazard types such as high temperature fluctuations (Hazard_2) and gas leaks (Hazard_3), incorporate domain-adaptation metrics (e.g., MMD and t-SNE) for cross-domain evaluation, and validate the system across multiple industrial layouts to enhance robustness and generalization.
Unlike purely data-driven generators such as SMOTE and TimeGAN, which focus on statistical or latent-space interpolation, RoboFusion blends empirical signal dynamics with analytically modeled hazard evolution. This hybrid strategy preserves physical interpretability while maintaining statistical diversity, avoiding mode collapse and unrealistic correlations often observed in fully generative methods.
Conclusions
This paper introduced RoboFusion, an integrated robotic framework that enables real-time environmental sensing and synthetic hazard modeling within industrial environments. By combining AMRs with fixed sensor suites, NFC-based localization, and embedded edge computing, RoboFusion offers a practical and low-cost solution for mobile robotic monitoring in structured facilities.
A key innovation of this work is the hybrid dataset generation pipeline, which merges real telemetry from mobile and static suites with synthetic hazard simulations. The synthetic generation strategy models realistic multi-phase hazard dynamics and spatial propagation, offering a scalable and reproducible method to expose robotic systems to rare safety-critical events without physical risk.
Experimental results demonstrated that machine-learning models trained on synthetic data significantly outperform models trained on real data alone, particularly in detecting underrepresented hazard events. In cross-domain validation, synthetic-trained models preserved generalization, with hazard F1-scores reaching 0.85 (Random Forest) and 0.79 (SVM). This highlights the utility of synthetic datasets for pre-training or augmenting robotic perception systems.
As a whole, RoboFusion serves as both a robotic platform and a data generation tool for advancing intelligent sensing in hazardous environments. Its modular architecture, open-access dataset, and deployable in real-world industrial conditions make it valuable for researchers in robotics, AI, and smart manufacturing.
Future work will focus on integrating RoboFusion with adaptive robot control policies, online learning, and transfer learning across different industrial environments. We also plan to explore domain adaptation techniques that allow models trained on synthetic hazards to adapt quickly to new facilities, even when limited real data is available. Expanding real-world hazard recordings and applying the framework to additional robotic platforms will help validate RoboFusion’s generalizability and impact across a wider range of conditions.
Supplementary Information
Supplementary Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wang, R., Veloso, M. & Seshan, S. Active sensing data collection with autonomous mobile robots. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2583–2586 (Stockholm, Sweden, 2016).
- 2Abdulrazzq, R. A., Sajid, N. M. & Hasan, M. S. Artificial intelligence-driven predictive maintenance in iot systems. South Fla. J. Dev. 5, 45669, 10.46932/sfjdv 5n 12-030 (2024).
- 3Polvara, R. et al. A next-best-smell approach for remote gas detection with a mobile robot, 10.48550/ar Xiv.1801.06819 (2018). ar Xiv:1801.06819.
- 4Azar, A. T., Sardar, M. Z., Ahmed, S., Hassanien, A. E. & Kamal, N. A. Autonomous robot navigation and exploration using deep reinforcement learning with gazebo and ros. In Lecture Notes on Data Engineering and Communications Technologies 184, 287–299. 10.1007/978-3-031-43247-7_26 (Springer, Cham, Switzerland) (2023).
- 5Ellithy, K., Salah, M., Fahim, I. S. & Shalaby, R. Agv and industry 4.0 in warehouses: a comprehensive analysis of existing literature and an innovative framework for flexible automation. The Int. J. Adv. Manuf. Technol. 10.1007/s 00170-024-14127-0 (2024).
- 6Maoudj, A. & Christensen, A. L. Decentralized multi-agent path finding in warehouse environments for fleets of mobile robots with limited communication range. In Social Robotics, vol. 14425, (ed. Kheddar, A.) 109–120, 10.1007/978-3-031-20176-9_9 (Springer, Cham, Switzerland, 2024).
- 7Samigulin, T. I. et al. Development of a mobile robot platform for smart warehouse management system. Her. Kazakh-British Tech. Univ. 21, 28–41, 10.55452/1998-6688-2024-21-2-28-41 (2024).
- 8Li, P. Machinery and logistics: Development trends and prospects of automated warehouse technology. In Proceedings of the 6th International Conference on Computer and Data Science (CDS), 10.54254/2755-2721/65/20240472 (Xiamen, China, 2024).