A stochastic approach to k-nearest neighbors search using a fixed radius method
Brahian Cano Urrego, Alexander Alsup, Jeffrey A. Thompson, Devin C. Koestler

TL;DR
This paper introduces a faster way to find the k-nearest neighbors in large datasets by using a stochastic method that reduces computation time without losing accuracy.
Contribution
A novel stochastic kNN search method is proposed that uses a fixed radius and probabilistic assumptions to reduce computational burden.
Findings
The proposed method outperforms the Brute-force approach in large datasets.
A 27.57-fold improvement in total elapsed time was observed on an Alzheimer’s disease dataset.
The method maintains accuracy while significantly reducing computational load.
Abstract
This study aims to optimize the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}\end{document}-nearest neighbors search (kNN search) by reducing the computational burden of the well-known Brute-force method while providing the same solution. While there exist rule-based approaches for reducing the computational burden of the kNN search, methods that use the stochastic patterns inherent to the data are lacking. Our method leverages data structures and probabilistic assumptions to enhance the scalability of the search. By focusing on the Training set where our neighbors reside, we define a sample space that limits the \documentclass[12pt]{minimal}…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
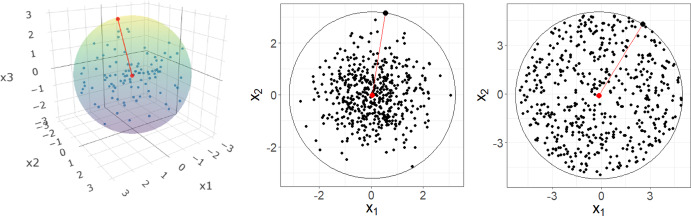 Figure 1
Figure 1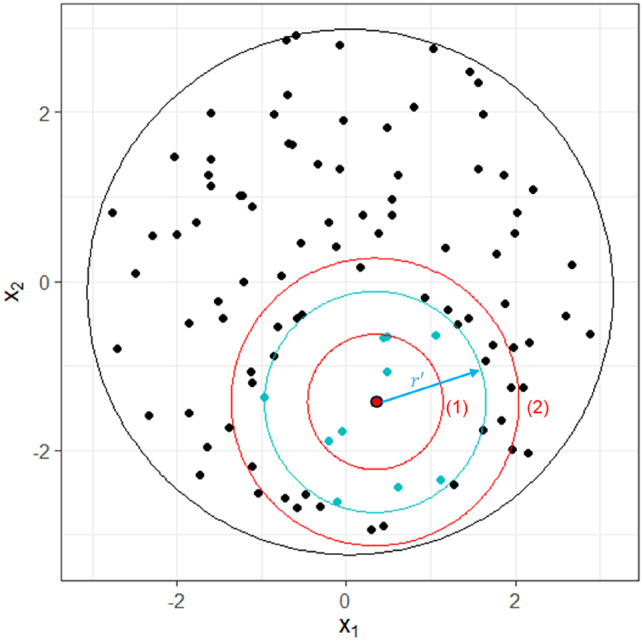 Figure 2
Figure 2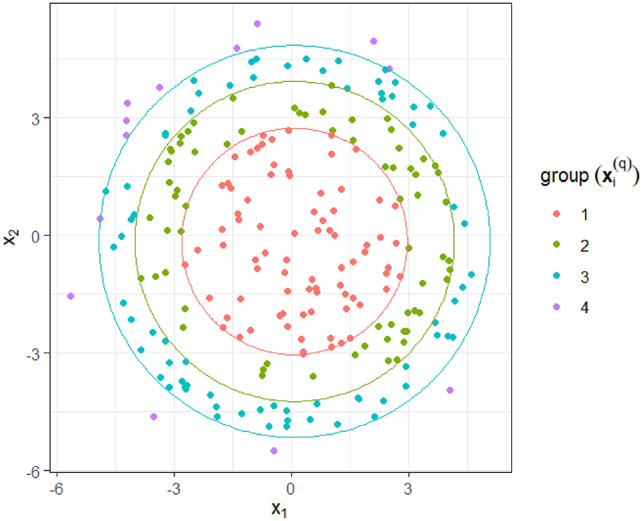 Figure 3
Figure 3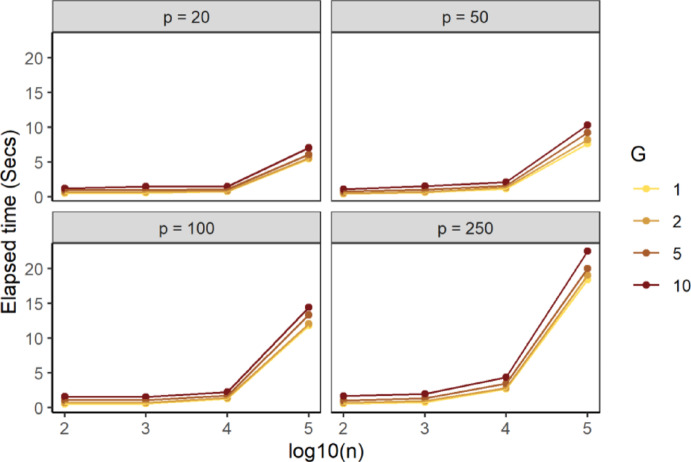 Figure 4
Figure 4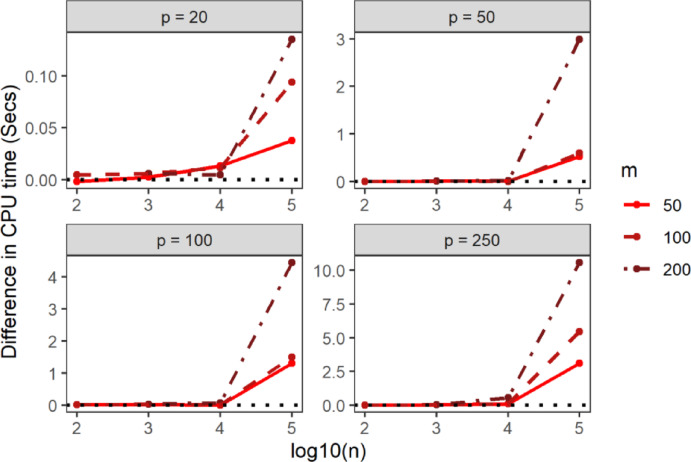 Figure 5
Figure 5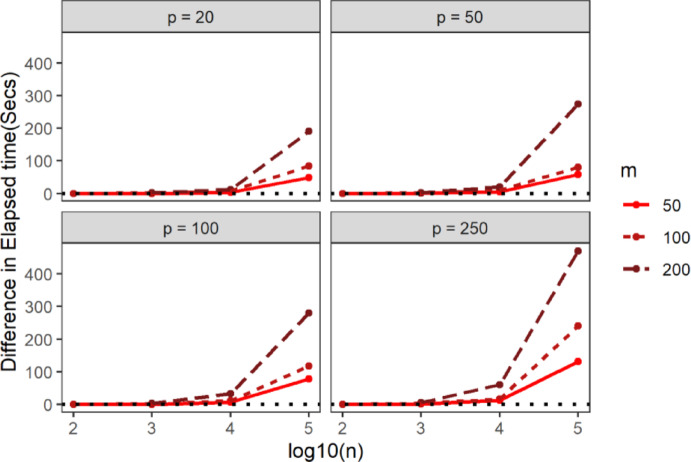 Figure 6
Figure 6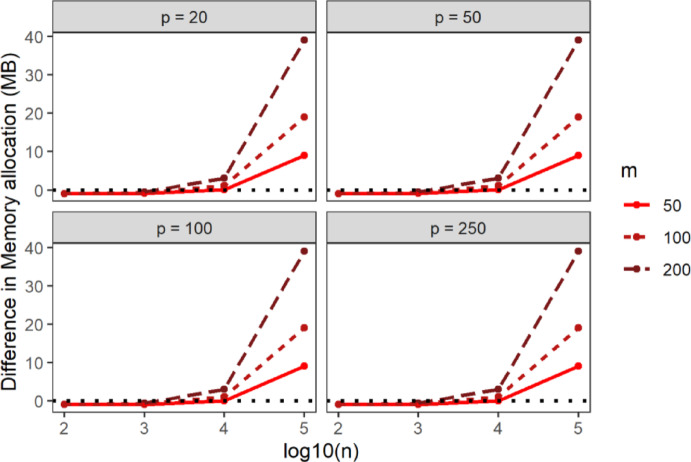 Figure 7
Figure 7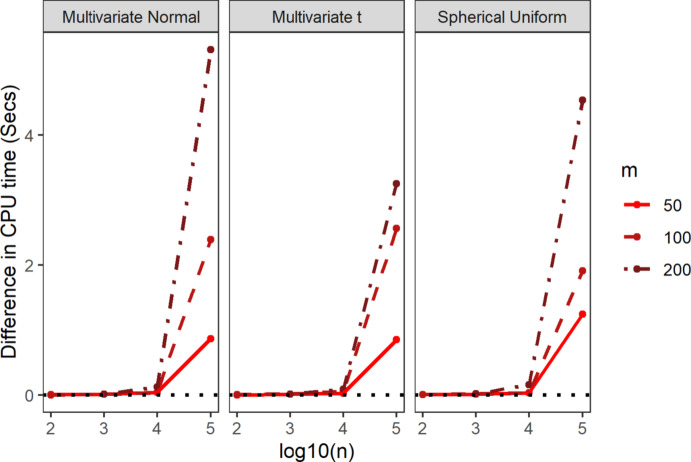 Figure 8
Figure 8- —http://dx.doi.org/10.13039/100000009Foundation for the National Institutes of Health
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image and Video Retrieval Techniques · Advanced Clustering Algorithms Research · Medical Image Segmentation Techniques
Introduction
The field of machine learning has garnered significant interest in recent years. This surge in attention is primarily due to the promise and potential of machine learning to advance and accelerate research discoveries across a broad spectrum of research areas. Supervised learning is a branch of machine learning that involves the identification of response-specific patterns in a data set with the goal of predicting or classifying future observations for which the response is unknown. Examples of supervised machine learning methods abound and include well-known methods such as: Decision Trees, Support Vector Machines, Neural Networks, and Random Forests. Among the suite of existing supervised machine learning methodologies, one of the simplest and most intuitive is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors (kNN) (Fix and Hodges 1985). The kNN algorithm is a non-parametric method that uses the proximity or similarity between a query point and observations in the Training set to make classifications or predictions. It has been extensively applied across various scientific fields and adapted to address the nuances of different study designs and data types. For example, Hou et al. optimized the kNN classification by creating a KD-tree structure that includes labels of all training observations (Hou et al. 2018). Dong et al. proposed a kNN weighted imputation method to address block-missing data arising in the field of trans-omics (Dong et al. 2019). Recently, Jena et al. used a kNN filtering-based algorithm for an e-learning recommendation system (Jena et al. 2023). In addition, Kaplan et al., found kNN to be the best performing method to classify brain tumors based on magnetic resonance imaging (Kaplan et al. 2020). Despite its widespread applications and advantages, kNN suffers from computational inefficiencies, especially in the case of high-dimensionality. Importantly, this inefficiency becomes pronounced with large sample sizes in either the Query set (the set of observations for which a classification is desired) or the Training set.
Several methods have been proposed to address the computational challenges intrinsic to kNN. These methods aim to optimize the kNN search by reducing the computational burden while providing the same or an approximate solution. Specific example of such methods include: linear search (Fix and Hodges 1985), approximate nearest neighbor (Aria et al. 1998), dimensionality reduction techniques (Gates 1972; Hart 1968), and principal axis (McNames 2001). Each of these methods have specific strengths and limitations. For example, approximate nearest neighbor algorithms sacrifice exactitude for speed, while dimensionality reduction techniques might not always preserve the essential structure of the data. Despite these advancements, there remain opportunities for improvement as existing solutions do not fully address the scalability issues of kNN search, particularly in the case of extremely large datasets. Additionally, there is a need for methods that can efficiently manage high-dimensional data without significant loss of information. Furthermore, mainstream approaches rely on deterministic data structures, highlighting the potential of stochastic-based alternatives as a promising direction for research.
In this paper, we propose an approach to address the computational inefficiencies of kNN search. Our method uses a stochastic approach to the kNN search problem using a fixed-radius search (STNNfr) by leveraging data structures and probabilistic assumptions to enhance the scalability of the kNN search. By leveraging the kNN search definition, we define a sample space that limits the kNN search to a smaller space. For each observation in the Query set, a fixed radius search is used where the radius is stochastically linked to the desired number of neighbors. Consequently, we require only a fraction of the Training set to find the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors for a given observation in the Query set. This results in a more efficient solution for large-scale, high-dimensional data as we demonstrate both theoretically and empirically.
In what follows, we first formally introduce the kNN search problem and its most well-known algorithm, the Brute-force method. This is followed by a description of our approach, STNNfr, which seeks to address the computational shortcomings of the Brute-force method. We next describe the rationale behind our simulation scenarios and the metrics used to benchmark the approaches being compared. A computational comparison of our approach and the Brute-force method is carried out, providing an opportunity to offer guidance into hyper-parameter tuning. We finish by summarizing important insights from this work, along with a discussion of the limitations of our study and avenues for future work.
Methods
We first review the Brute-force approach (i.e., linear search) to the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbor search in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} -dimensions. As a means toward introducing this approach, we follow the notation of James et al. (James et al. 2013):
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{X}}^{\left(q\right)}$$\end{document} : Query set containing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} observations (e.g., observations for which a prediction or classification is desired).
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\boldsymbol{X}$$\end{document} : Training set. Contains the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} observations from which the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors are derived.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{N}_{i}$$\end{document} : Set of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors belonging to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\boldsymbol{X}$$\end{document} for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} -th observation in the Query set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{x}}_{i}^{\left(q\right)}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i=1,\dots\:,m$$\end{document} based on some measure of distance or proximity.
In the standard formulation of kNN, the distance between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{x}}_{i}^{\left(q\right)},\:i=1,\dots\:,m\:$$\end{document} and all observations in the Training set is first calculated, which we define as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{d}}_{i}^{\left(q\right)}=\left[{d}_{i1}^{\left(q\right)},\:{d}_{i2}^{\left(q\right)},\dots\:,\:{d}_{in}^{\left(q\right)}\right]$$\end{document} . Next, distances are sorted in ascending order to create the order statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{i\left(1\right)}^{\left(q\right)},{d}_{i\left(2\right)}^{\left(q\right)},\dots\:,\:{d}_{i\left(n\right)}^{\left(q\right)}$$\end{document} . Finally, the set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{N}_{i}$$\end{document} is constructed to contain the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} observations in the Training set with smallest distance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{N}_{i}=\left\{j|\:{d}_{ij}^{\left(q\right)}\in\:\:\left\{{d}_{i\left(1\right)}^{\left(q\right)},{d}_{i\left(2\right)}^{\left(q\right)},\dots\:,{d}_{i\left(k\right)}^{\left(q\right)}\right\}\right\}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k\le\:n$$\end{document} . This process is repeated for each of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} observations in the Query set, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{X}}^{\left(q\right)}$$\end{document} .
Although the Brute-force method provides exact and reliable solutions, the computational complexity of this algorithm is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:O\left(nm\right)$$\end{document} , which is not optimal. For instance, when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} is small relative to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} , say 5, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} is, for example 1000, there will be 995 observations in the Training set that will not be used for the ultimate classification or prediction of a specific query point. To curb the computational burden associated with Brute-force \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbor search, we present a stochastic approach that uses a radius-based method with complexity no more than \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:O\left(m\left({n}^{1-\frac{1}{p}}+k\right)\right)$$\end{document} .
Stochastic kNN search based on fixed-radius search (STNNfr)
Since the search for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors of a given observation in the Query set occurs only in the Training set, we define a sample space of the Training set that limits it to a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} -dimensional hypersphere that contains all observations in the Training set (Fig. 1). Subsequently, a fixed-radius search is performed for each observation in the Query set where the radius of a given point has a stochastic relationship to the desired number of neighbors. As a result, we expect to find the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors for a given observation using only a fraction of the full Training set. To illustrate our approach, first define:
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{x}}_{\stackrel{-}{j}}=\stackrel{-}{\boldsymbol{x}}=\left[{\stackrel{-}{x}}_{1},{\stackrel{-}{x}}_{2},\dots\:,{\stackrel{-}{x}}_{p}\right]^{\prime\:}$$\end{document} as the centroid of Training set and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{-}{j}$$\end{document} represents its index.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{d}}_{\stackrel{-}{j}}=\left[{d}_{1\stackrel{-}{j}},{d}_{2\stackrel{-}{j}},\dots\:,{d}_{n\stackrel{-}{j}}\right]^{\prime\:}$$\end{document} is a vector of distances between each of the Training set observations and the overall centroid of the Training set, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \:d_{{j\mathop j\limits^{ - } }} = \left\| {x_{j} - \bar{x}_{j} } \right\| = \left\| {x_{j} - \bar{x}} \right\|\:\:for\:j = 1,\: \ldots \:,\:n $$\end{document} in the case of the Euclidean distance metric.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:r=\mathrm{max}\left(\left\{{d}_{1\stackrel{-}{j}},{d}_{2\stackrel{-}{j}},\dots\:,{d}_{n\stackrel{-}{j}}\right\}\right)\:\:$$\end{document} as the maximum distance calculated between all observations in the Training set to the centroid of the Training set.
Next, we create a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} -dimensional hypersphere \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:S$$\end{document} of radius \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:r$$\end{document} centered at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{-}{\boldsymbol{x}}$$\end{document} such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:S$$\end{document} contains all the observations in the Training set (Fig. 1). In doing so, the kNN search is reduced to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:S\:\subseteq\:{\mathbb{R}}^{p}$$\end{document} . An advantage of this framework is that we know that by construction, no neighbors can be found outside \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:S$$\end{document} .
To find the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{x}}_{i}^{\left(q\right)}$$\end{document} , create \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} -dimensional hypersphere \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{S}_{i}$$\end{document} with unknown radius \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{i}$$\end{document} , centered at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{x}}_{i}^{\left(q\right)}$$\end{document} .
Fig. 1. Visual representation of the construction of the Training set sample space for STNNfr. Left panel shows a 3-dimensional spherical uniform distribution, middle panel shows a 2-dimensional standard normal distribution, right panel shows a 2-dimensional uniform circular distribution
The novelty here is to solve for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{i}$$\end{document} such that at least \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors fall inside the hypersphere \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{S}_{i}$$\end{document} . In order to do this, assume that the Training data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\boldsymbol{X}$$\end{document} originates from a spherical uniform distribution, with probability distribution function, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:g\left(\boldsymbol{x}|r,\boldsymbol{z}\right)=\frac{1}{\mathrm{v}\mathrm{o}\mathrm{l}\mathrm{u}\mathrm{m}\mathrm{e}\left(S\right)}=\frac{1}{{\pi\:}^{\frac{p}{2}}\:\frac{{\mathrm{r}}^{p}}{{\Gamma\:}\left(\frac{p}{2}+1\right)}}$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \:\left\{ {x:\left\| {x - z} \right\| \le \:r} \right\} $$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\Gamma\:}\left(a\right)$$\end{document} is the Gamma function and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\boldsymbol{z}$$\end{document} is the centroid of the hypersphere. We refer interested readers to (Sun and Chen 2008) for further details regarding the spherical uniform distribution. Next, we seek to find an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{i}$$\end{document} such that:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P\left( {S_{i} \:} \right) = \tau \:,\:\:\mathrm{where}\:S_{i} = \left\{ {x:\left\| {x - x_{i}^{{\left( q \right)}} } \right\| \le \:r_{i} } \right\} $$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:\in\:\left(\mathrm{0,1}\right]$$\end{document} is a pre-specified probability threshold and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{x}}_{i}^{\left(q\right)}$$\end{document} is the centroid of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{S}_{i}$$\end{document} . For example, finding \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{i}$$\end{document} such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P\left({S}_{i}\:\right)=\tau\:=0.1$$\end{document} would imply that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{S}_{i}$$\end{document} contains 10% of the observation in the Training set in probability; this would be the case if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} is set to 10 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k\:=\:10$$\end{document} ) and the Training set contains 100 observations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n\:=\:100$$\end{document} ).
By the definition of our sample space and assumption that the Training set follows a spherical uniform distribution, we have:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P\left( {S_{i} \:} \right) = P(S_{i} \: \cap \:S) = \frac{{volume(S_{i} \: \cap \:S)\:}}{{volume\left( S \right)}} $$\end{document}In the above expression, volume \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm{(}{S}_{i}\:{\cap}\:S\mathrm{)}$$\end{document} can be calculated using existing derivations and adapted formulas for calculating the intersection of two \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} -dimensional hyper-spheres (Li 2010; User 2013). This enables us to proceed with the following:
Define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{i\stackrel{-}{j}}^{\left(q\right)}=\Vert\:{\boldsymbol{x}}_{i}^{\left(q\right)}-\stackrel{-}{\boldsymbol{x}}\Vert\:$$\end{document} and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \:volume\left( {S_{i} \: \cap \:S} \right) = \left\{ {\begin{array}{*{20}c} {\:if\:\:d_{{i\mathop j\limits^{ - } }}^{{\left( q \right)}} \ge \:r_{i} + r\:,\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:0\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:} \\ {\:if\:\:d_{{i\mathop j\limits^{ - } }}^{{\left( q \right)}} \le \:\:\:\left| {r_{i} - r} \right|,\:\:\:\:\:\:\:\pi \:^{{\frac{p}{2}}} \:\frac{{\min \left( {r_{i} \:,r} \right)^{p} }}{{\Gamma \:\left( {\frac{p}{2} + 1} \right)}}\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:} \\ {\:else,\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:V_{p}^{{cap}} \left( {r,c_{1} } \right) + V_{p}^{{cap}} (r_{i} ,c_{2} )} \\ \end{array} } \right. $$\end{document}where,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{c}_{1}=\frac{{{d}_{i\stackrel{-}{j}}^{\left(q\right)}}^{2}+{r}^{2}-{r}_{i}^{2}}{2{d}_{i\stackrel{-}{j}}^{\left(q\right)}},\:{\:\:\:\:\:\:\:\:\:\:\:\:c}_{2}=\frac{{{d}_{i\stackrel{-}{j}}^{\left(q\right)}}^{2}-{r}^{2}+{r}_{i}^{2}}{2{d}_{i\stackrel{-}{j}}^{\left(q\right)}}$$\end{document}and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{V}_{p}^{cap}\left(r^{\prime\:},a\right)=\left\{\begin{array}{c}if\:a\ge\:0,\:\:\:\:\frac{{\pi\:}^{\frac{p}{2}}}{2}\:\frac{{{r}^{{\prime\:}}}^{p}}{{\Gamma\:}\left(\frac{p}{2}+1\right)}{I}_{1-{a}^{2}/{{r}^{{\prime\:}}}^{2}}\left(\frac{p+1}{2},\frac{1}{2}\right)\:\\\:if\:a<0,\:\:{\pi\:}^{\frac{p}{2}}\frac{{{r}^{{\prime\:}}}^{p}}{{\Gamma\:}\left(\frac{p}{2}+1\right)}-{V}_{p}^{cap}\left({r}^{{\prime\:}},-a\right)\end{array}\right.$$\end{document}.
such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{I}_{1-\alpha\:}\left(b,c\right)\:$$\end{document} is the regularized incomplete beta function. Next, we numerically find the value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{i}$$\end{document} . Defining \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f\left({r}_{i}\right|r,p,{d}_{i\stackrel{-}{j}}^{\left(q\right)},\tau\:)=P\left({S}_{i}\:\right)-\tau\:$$\end{document} , it suffices to find the roots of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f\left( {r_{i} |r,p,d_{{i\mathop j\limits^{ - } }}^{{\left( q \right)}} ,\tau \:} \right) = 0 \Leftrightarrow P\left( {S_{i} \:} \right) - \tau \: = 0 \Leftrightarrow\:\frac{{volume(S_{i} \:\cap\:S)}}{{volume(S)}} - \tau \: \Leftrightarrow \frac{{volume(S_{i} \:\cap\:S)}}{{\pi \:^{{\frac{p}{2}}} \:\frac{{r^{p} }}{{\Gamma \:\left( {\frac{p}{2} + 1} \right)}}}} - \tau \: = 0 $$\end{document}Once \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{i}$$\end{document} is obtained, we use a fixed-radius search algorithm. In our case, we use a KD-tree based algorithm (Bentley 1975), in which we partition the data using the Training set. Note that the partition only needs to be created once. Subsequently, we submit a query of radius \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{i}$$\end{document} and if less than \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors are found, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} is increased. We repeat the above steps until \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{k}^{{\prime\:}}$$\end{document} neighbors have been found, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k\le\:{k}^{{\prime\:}}\le\:n$$\end{document} .
Lastly, we compute the sorted distances to create the order statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{i\left(1\right)},{d}_{i\left(2\right)},\dots\:,\:{d}_{i\left({k}^{{\prime\:}}\right)}$$\end{document} , and construct \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{N}_{i}$$\end{document} to consist of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} observations in the Training set with smallest distance. Specifically:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{N}_{i}=\left\{j|\:{d}_{ij}\in\:\:\left\{{d}_{i\left(1\right)},{d}_{i\left(2\right)},\dots\:,{d}_{i\left(k\right)}\right\}\right\}$$\end{document}.
It is worth mentioning that every query point has its own unknown hypersphere that contains the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors, where its radius \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:r^{\prime\:}$$\end{document} is equal to the distance between the query point and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -th nearest neighbor (Fig. 2, blue circle/dots). This hypersphere has an unknown probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau^{\prime\:}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{0<\tau\:}^{{\prime\:}}\le\:1$$\end{document} . To guarantee that our method captures the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors, we require a hypersphere whose volume is equal to or greater than unknown hypersphere (Fig. 2, red circle \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left(2\right)$$\end{document} ). Since we sweep \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} from some initial value up to 1.0, this approach will eventually create a hypersphere that contains the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors.
Fig. 2. Example of the iterative process to find the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors. For a query point (red dot) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:r{\prime\:}$$\end{document} is the radius of the unknown hypersphere (blue circle) determined by the k-th nearest neighbor. The algorithm iterates twice (red (1) and red (2)) and stops once a circle bigger than the unknown circle (blue circle) is found. This circle (red circle \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left(2\right)$$\end{document} ) will contain the k-nearest neighbors
Optimization based on ring groups
One caveat of our approach concerns the apparent need to solve Eq. (1) as many times as there are observations in the Query set. However, further inspection of Eq. (1) reveals that it does not depend on the actual coordinates of the observations in the Query set but rather: (1) their distance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{i\stackrel{-}{j}}^{\left(q\right)}$$\end{document} to the overall centroid of the Training set, (2) the radius \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:r$$\end{document} , (3) the desired threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} , and (4) the number of dimensions/features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} . Thus, for fixed values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:r,\:\tau\:,\:\mathrm{a}\mathrm{n}\mathrm{d}\:p$$\end{document} , observations in the Query set with the same distance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{i\stackrel{-}{j}}^{\left(q\right)}={d}_{{i}^{{\prime\:}}\stackrel{-}{j}}^{\left(q\right)},\:\:i\ne\:{i}^{{\prime\:}}$$\end{document} , would result in the same \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{i}$$\end{document} . Consequently, we propose reducing the number of equations by grouping the observations in the Query set homogeneously in terms of their distance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{i\stackrel{-}{j}}^{\left(q\right)}$$\end{document} . Let us define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} as the number of ring groups such that:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \:group\left( {x_{i}^{{\left( q \right)}} } \right) = \left\{ {\begin{array}{*{20}c} {1,\:\:\:\:\:\:\:\:if\:\:\delta \:_{0} = 0 \le \:d_{{i\mathop j\limits^{ - } }}^{{\left( q \right)}} \le \:\delta \:_{1} \:\:\:\:\:\:\:\:} \\ {\:2,\:\:\:\:\:\:\:\:if\:\:\:\delta \:_{1} < d_{{i\mathop j\limits^{ - } }}^{{\left( q \right)}} \le \:\delta \:_{2} \:\:\:\:\:\:\:\:\:\:\:\:\:\:\:} \\ {\: \vdots } \\ {\:G,\:\:\:\:\:\:\:if\:\:\:\delta \:_{{G - 1}} < d_{{i\mathop j\limits^{ - } }}^{{\left( q \right)}} \le \:\delta \:_{G} \:\:\:\:\:\:\:\:\:} \\ {\:G + 1,\:\:\:if\:\:\:d_{{i\mathop j\limits^{ - } }}^{{\left( q \right)}}> \delta \:_{G} = r\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:} \\ \end{array} } \right. $$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\delta\:}_{g}$$\end{document} is the radius of a sub-hypersphere with centroid \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{S}_{\stackrel{-}{j}}$$\end{document} having probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:g/G$$\end{document} . More specifically:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \:P\left( {S_{{\mathop j\limits^{ - } }} } \right) = \frac{g}{G}\: \Leftrightarrow \:P\left( {S_{{\mathop j\limits^{ - } }} \cap \:S} \right) = \frac{{volume(S_{{\mathop j\limits^{ - } }} \: \cap \:S)}}{{volume(S)}} = \frac{g}{G}\: \Leftrightarrow \:\frac{{volume(S_{{\mathop j\limits^{ - } }} )}}{{volume(S)}} = \frac{g}{G}\: $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\iff\:\frac{{\pi\:}^{\frac{p}{2}}\:\frac{{{\delta\:}_{g}}^{p}}{{\Gamma\:}\left(\frac{p}{2}+1\right)}}{{\pi\:}^{\frac{p}{2}}\:\frac{{\mathrm{r}}^{p}}{{\Gamma\:}\left(\frac{p}{2}+1\right)}}=\frac{g}{G}\iff\:\frac{{{\delta\:}_{g}}^{p}}{{\mathrm{r}}^{p}}=\frac{g}{G}\:\iff\:\:\:{\delta\:}_{g}=r\:\:\sqrt[p]{\frac{g}{G}}\:,\:\:\:g=1,\:\dots\:,\:G.$$\end{document}This grouping is exemplified in (Fig. 3).
Fig. 3A 2-Dimensional representation of the ring grouping where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=3$$\end{document}
Once each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{x}}_{i}^{\left(q\right)}$$\end{document} has been classified, we proceed to establish a common equation to determine the fixed radius search of all observations belonging to the group, solving numerically \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f\left({r}_{i,g}|r,p,{d}_{i\stackrel{-}{j}}^{\left(q\right)}={\delta\:}_{g},\tau\:\right),\:\mathrm{f}\mathrm{o}\mathrm{r}\:g=1,\dots\:,G$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{i,g}$$\end{document} is the new radius for all the observations in Query set that belong to group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:g$$\end{document} . Note, the main difference when solving this equation is that we use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{i\stackrel{-}{j}}^{\left(q\right)}={\delta\:}_{g}$$\end{document} , which is the outer part of the ring. This reduces the number of equations from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G<m$$\end{document} . This variant of our search algorithm has a computational complexity of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:O\left(m\left({n}^{1-\frac{1}{p}}+k\right)\right)$$\end{document} . Finally, we follow the same steps outlined Sect. 2.1, with the exception that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{r}_{i}\:$$\end{document} is replaced by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:{r}_{i,g}$$\end{document} , for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i=1,\:\dots\:,\:m.$$\end{document} The full pipeline of the proposed STNNfr algorithm is summarized in Table 1. Taken together, we note that for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n\ge\:1$$\end{document} we have that:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:O\left(\:{mn}^{1-\frac{1}{p}}+mk\right)=O\left(m\left({n}^{1-\frac{1}{p}}+k\right)\right)\le\:O\left(m\left({n}^{1-\frac{1}{p}}+n\right)\right)<O\left(m\left(n+n\right)\right)=$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:O\left(m\left(2n\right)\right)=O\left(mn\right)\Rightarrow\:O\left(\:{mn}^{1-\frac{1}{p}}+mk\right)<O\left(mn\right)$$\end{document}Thus, the proposed STNNfr algorithm is theoretically more efficient than the Brute-force kNN search method.
Table 1. Pipeline and complexity of stochastic kNN fixed radius search (STNNfr)StepComputational Cost1.Calculate the centroid of the training set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} 2.Distances from training points to centroid \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} 3.Defining the rings groups \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} 4.Assigning groups to the query set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} 5.Solving \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G\times\:t$$\end{document} numerical equations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G\times\:\:t\times\:\mathrm{O}\left(1\right)$$\end{document} 6.Create searching structure (KD-tree) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:pnlog\left(n\right)$$\end{document} 7.Iterative radius search \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m\times\:t\times\:\left({n}^{1-\frac{1}{p}}+k\right)$$\end{document} 8.Return Neighbors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{mlog}\left({k}^{{\prime\:}}\right),\:{k}^{{\prime\:}}=c\times\:\:n$$\end{document} Worst case \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\to\:m\mathrm{log}\left(n\right)$$\end{document} Total complexity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:O\left(\:{mn}^{1-\frac{1}{p}}+mk\right)$$\end{document}
Simulation study
Even though the complexity of STNNfr has been derived theoretically and shown to be superior to the Brute-force method (Eq. 2), for two algorithms with identical complexity, one can be faster than the other due to simplifications associated with Big O notation. On the other hand, algorithms are not only evaluated based on their speed but also their memory consumption. For these reason, the goals of our simulation study were two-fold: (1) compare the computational time, total elapsed time, and the memory consumption of STNNfr relative to the standard Brute-force search method across different simulated different sets and (2) shed light on the selection/specification of the hyper parameter, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} .
For our simulation studies, we generated data for both the Query and Training sets from: a multivariate standard normal distribution; a multivariate t-distribution with 10 degrees of freedom and an identity covariance matrix; and a spherical uniform distribution with a radius of 1.0. The purpose of generating data from a multivariate normal and t-distribution was to assess the performance of STNNfr when the distributional assumptions of the Training set observations are violated. The choice of 10 degrees of freedom for multivariate t-distribution is motivated by the desire to generate a more scattered set data and heavier density around the outer parts of the sphere. We considered samples sizes of 100, 1000, 10,000, and 100,000 for the Training set and samples sizes of 50, 100, and 200, in the Query set, with the additional constraint that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m\le\:n$$\end{document} . The number of features/dimensions, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} , assumed four values: 20, 50, 100, and 250. The number of nearest neighbors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} was proportional to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} : \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:1,\:0.16n,\:0.33n,\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:0.5n$$\end{document} , rounded to nearest whole number. The number of ring groups \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} was set to: 1, 2, 5, and 10. Each combination of parameter settings was replicated a total of 25 times to account for random variation.
In an effort to minimize the number of iterations needed by STNNfr with respect to set of prespecified thresholds \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\: T=\left({\tau\:}^{\left(1\right)},\dots\:,\:{\tau\:}^{\left(t\right)}\right)$$\end{document} , we started the search with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\tau\:}^{\left(1\right)}\:$$\end{document} equal to proportion of nearest neighbors with respect to the Training set sample size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k/n$$\end{document} . We considered ten values in total, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t=10$$\end{document} , which ranged from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k/n\:$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:1,$$\end{document} evenly spaced. We preserved this structure for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T$$\end{document} across all simulation scenarios. Thus, under the worst-case scenario, the algorithm would iterate a total of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t=10$$\end{document} times. Moreover, for the sake of simplicity and without loss of generality we used the well-known and widely used Euclidean distance to calculate proximity/similarity between observations.
For each combination of parameters, we report: (1) the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors of all observations in the Query set; (2) the CPU and elapsed time averaged across the 25 replications; (3), the memory allocation averaged across the 25 replications; and (4) specific to STNNfr, the average number of iterations required for the algorithm averaged across the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} observations in the Query set and averaged again across the 25 replications.
Due to the computational complexity of the simulations considered, simulations were conducted on the University of Kansas High-Performance Computing (HPC) cluster. The R statistical programming language (https://cran.r-project.org/) was used to carry out the simulations (R Core Team 2023). The implementation of the Brute-force method was based on the algorithm described in Sect. 2.1. In contrast to loops (e.g., for loops, while loops, etc.), we used vectorized functions to improve the efficiency of our implementation. The implementation of STNNfr included functions from MASS (Venables and Ripley 2002) and dbscan R packages (Hahsler et al. 2019). CPU and elapsed were calculated using the system.time() function in R, and memory allocation was calculated using the mem_change() function from pryr R package (Wickham 2023).
The R code implementing the methods and simulations is available on the following GitHub repository: bencuben/2025_STNNfr: Code and material for the manuscript.
Results
Simulation results
For all simulation scenarios considered and for each replication, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} observations in the Query set were exactly the same for both the Brute-force method and STNNfr, and in the same order. This observation serves to demonstrate the consistency in results between STNNfr and the standard, Brute-force search method.
STNNfr can be considered as a branch and bound algorithm, where we divide the problem into several iterations. Our expectation is that by selecting a “good set” of hyperparameters, the average number of iterations are as close to 1 as possible. Our simulation results confirmed that regardless of the parameter settings, the number of iterations required until convergency was, on average, equal to 1.
As shown in Fig. 4, smaller values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} result in a smaller elapsed time, suggesting that an overall radius for all observations could be a suitable strategy. Although larger values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} were not considered in the simulation, we expect that elapsed time would increase as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} increases. This aligns with the rationale in Sect. 2.2, where the algorithm was simplified by solving fewer numerical equations instead of having to solve numerical equations for each observation in the Query set ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=m$$\end{document} ). It is worth mentioning that the selection of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} does not have any impact on the accuracy of the kNN search; it only impacts the running time.
Fig. 4. Average elapsed time of STNNfr within the same simulation scenario as a function of the Training set sample size in log10 scale (x-axis), number of ring groups (color), the dimension of the feature-space (panels). Data were generated from the spherical uniform distribution
Next, to benchmark STNNfr’s computational efficiency against the Brute-force method, we compared the difference in CPU time, elapsed time, and memory allocation under identical simulation parameters and setting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=1$$\end{document} . In Figs. 5, 6 and 7, values above 0 indicate better performance for STNNfr. Generally, as the number of dimensions, Training set sample size, or Query set sample size increased, the average CPU time, elapsed time, and memory allocation difference between STNNfr and Brute-force increased. While STNNfr performed slightly worse for small dimensions ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n=100,\:\:p=20,\:50$$\end{document} ), it demonstrated significant improvements in high-dimensional cases. Specifically, Fig. 6 highlights an average of an ~ 500-second improvement in elapsed time when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n=100,\:000,\:\:p=250,\:m=200$$\end{document} . These findings align with our theoretical derivation in Eq. (2), confirming STNNfr’s reduced computational complexity.
Fig. 5. Average difference in CPU time (y-axis) of the Brute-force and STNNfr methods (Brute-force minus STNNfr) within same simulation scenario as a function of the Training set sample size on the log10 scale (x-axis), Query set sample size (color), the dimension of the feature-space (panels). Data were generated from a spherical uniform distribution with the number of ring groups assumed to be one, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=1$$\end{document}
Fig. 6. Average difference in elapsed time (y-axis) between the Brute-force method and STNNfr (Brute-force minus STNNfr) within same simulation scenario as a function of the Training set sample size on the log10 scale (x-axis), Query set sample size (color), and the dimension of the feature-space (panels). Data were generated from a spherical uniform distribution with the number of ring groups assumed to be one, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=1$$\end{document}
Fig. 7. Average difference in memory allocation (y-axis) between the Brute-force method and STNNfr (Brute-force minus STNNfr) within same simulation scenario as a function of the Training set sample size on the log10 scale (x-axis), Query set sample size (color), and the dimension of the feature-space (panels). Data were generated from a spherical uniform distribution with the number of ring groups assumed to be one, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=1$$\end{document}
Lastly, to evaluate the performance of STNNfr under distributional violation, data were generated from both a multivariate normal and multivariate t-distribution (df = 10). Figure 8 (Appendix) presents the average difference in CPU time between the Brute-force method and STNNfr as a function of the Training and Query set sample sizes when data are generated from a spherical uniform, multivariate normal, and multivariate t-distribution. The results in Fig. 8 demonstrate that irrespective of the distribution used to generate the data, STNNfr consistently outperforms Brute-force method in high-dimensional settings. Notably, while STNNfr exhibits a general advantage across distributions relative to the Brute-force method, its performance gains are slightly less pronounced under the multivariate t-distribution.
Application for alzheimer’s disease dataset
To further benchmark STNNfr to the Brute-force approach, we considered the dataset Diagnosis AlzheimeR WIth haNdwriting (DARWIN) (Cilia et al. 2022) available at: DARWIN - UCI Machine Learning Repository. DARWIN includes data collected on 88 Alzheimer’s patients and 85 healthy participants. Each study participant was assigned 25 tasks that assessed the participant’s capability to perform in four different categories: graphics, copy, memory, and dictation. For each task, 18 different metrics were recorded from a tablet equipped with a pen that allowed the researchers to track the space-coordinates of the pen at every moment. As a result, 450 features were collected.
Since the number of patients was relatively small, we generated synthetic observations from healthy participants and Alzheimer’s patients. We first estimated the mean vectors and variance-covariance matrices for both groups. Assuming normal distributions, we then sampled 50,000 synthetic observations from each population using their respective mean vectors and variance-covariance matrices. Next, data was split into Training and Query sets using 90/10 allocation while maintaining a consistent ratio of healthy to Alzheimer’s patients. This resulted in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n=90000,\:m=10000,\:\:p=450$$\end{document} . For the sake of numerical stability and tackling the effect of the scale in measurements, the Training set was preprocessed by normalizing it (subtracting the mean and dividing by the standard deviation) and the same preprocessing for the Query set was used. Finally, for the kNN search we set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k=15$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=1$$\end{document} .
The Brute-Force method obtained a CPU time of 179 s, an elapsed time of 49,329 s and a memory usage of 8.65 MB. In comparison, STNNfr achieved a CPU time of 20 s (8.95-fold improvement in efficiency); an elapsed time of 1,789 s (27.57-fold improvement in efficiency); and a memory usage of 8.98 MB (3.67% larger memory consumption). These results confirm the insights from simulations and theoretical calculations, demonstrating that STNNfr is much faster than the Brute-force method, with the trade-off of slightly increased memory usage in high-dimensional situations.
Discussion
In this paper we introduced a novel method to find the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors based on a stochastic approach to fixed-radius search, providing an alternative strategy to the kNN search problem. This problem is of high relevance for scientific and applied fields, where challenges of classification, regression, and unsupervised clustering of “big-data” require computational efficiency (e.g., health claims data, EHR, national repositories, etc.). Our primary aim was to compare the computational efficiency of STNNfr and the well-known Brute-force method. As reported, STNNfr consistently matched the Brute-force method in identifying the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors for all scenarios and replications, demonstrating its reliability and consistency in the solutions arrived at via the Brute-force method. STNNfr averaged 1 iteration irrespective of the parameter settings. For the scenarios considered, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=1$$\end{document} provided the best performance across the simulations. In practice, there might be cases in which a different selection of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} would be optimal; nevertheless, the only consequence of mis specifying \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G$$\end{document} is an increase in convergence time. Computational efficiency benchmarks in both our simulation study and computational complexity calculations showed STNNfr to outperform the Brute-force method, especially for high-dimensional situations. Specifically, the application in the DARWIN data set revealed a 23-fold improvement in in elapsed time. However, for small dimensions, STNNfr was slightly slower compared to the Brute-force method, indicating areas for coding-based improvement.
Despite the noted contributions of our method and its performance relative to the Brute-force approach, no study is free from limitations. Our simulation study evaluated STNNfr against the Brute-force method, that, although it is not widely used in practice, serves as a fundamental benchmark for kNN search due to its exhaustive nature and neutrality. It imposes no partitioning or distribution assumptions, ensuring a fair evaluation of efficiency gains achieved by STNNfr. Consequently, future comparisons against more commonly used methods, such as KD-tree and Ball-tree, present an opportunity to further contextualize STNNfr’s effectiveness.
Distributional assumptions must be carefully evaluated when imposed. While our findings indicate that STNNfr exhibits robustness to distributional violations, there may be applications where such violations pose challenges. The choice of a spherical uniform distribution was motivated by the need to establish a worst-case scenario, in which all training points are evenly dispersed.
Another potential limitation of our study is that we fixed our simulations to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m\le\:n$$\end{document} to limit the amount of memory needed to conduct our simulation study and since we believe that in many applications, the size of the Query set tends to be smaller than the Training set. Nevertheless, based on the results presented we expect that STNNfr would still outperform the Brute-force method when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m>n$$\end{document} . It is also important to note that to enable a fair comparison between STNNfr and the Brute-force method, we used our own coded version of the Brute-force method since several of the existing implementations are coded in the general purpose programming language, C++ (ISO/IEC 14882:2023, 2023). By coding the Brute-force method in R we sought to avoid a situation where differences between the two approaches were driven by the level where functions are running by standardizing their coding language. There are some current inefficiencies in the coded STNNfr algorithm that are opportunities for future work. These include redundant computation and memory optimization. Lastly, the current implementation of the STNNfr is based on KD-tree, however other more efficient alternatives could be explored such as fixed-radius NN search based on sorting (SNN) (Chen and Güttel 2024).
Additional future work includes: expanding the simulation scenarios where needed; implementation of some parts of our algorithm in C++; inclusion of competitors coded in C++, like KD-tree, Ball-tree, and Brute-force. We also plan to analyze the impact of data transformations on our algorithm’s performance and results, along with expanding to different assumed distributions for the Training and Query set beyond the multivariate standard normal, the multivariate t, and spherical uniform distributions that were considered herein. Future work should also be directed toward innovating a more methodical approach to define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T$$\end{document} , and alternatives to define the initial value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} in the STNNfr algorithm. We also plan to analyze the performance of STNNfr using different distance metrics other than Euclidean distance, however, we expect STNNfr to exhibit superior performance as compared to the Brute-force method on the basis of our theoretical calculations of its complexity and the invariance of our calculations relative to the chosen distance metric.
In conclusion, we introduced a new method to find the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} -nearest neighbors based on a stochastic approach to fixed radius search (STNNfr). To our knowledge, STNNfr is the first method to address the kNN search problem from a stochastic perspective. We compared the computational efficiency of STNNfr to the well-known Brute-force method using both simulations studies and theoretical computational complexity calculations. Our results demonstrate favorable performance of STNNfr, especially for large Training and Query sample sizes. We see STNNfr having an impact in areas such as biomedicine, economics, and social sciences, by helping to reduce the computational burden of finding similar/proximal observations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hou W, Li D, Xu C, Zhang H, Li T (2018) An advanced k nearest neighbor classification algorithm based on KD-tree. In 2018 IEEE international conference of safety produce informatization (IICSPI), 902–905: IEEE
- 2Jena KK, Bhoi SK, Malik TK et al (2023) E-Learning Course Recommender System Using Collaborative Filtering Models. Electronics 12