Lessons learned from implementing FAIRification workflows in diabetes research in Germany
Esther Thea Inau, Angela Dedié, Ivona Anastasova, Renate Schick, Brigitte Fröhlich, Michael Roden, Andreas L. Birkenfeld, Martin Hrabě de Angelis, Martin Preusse, Dagmar Waltemath, Atinkut Alamirrew Zeleke

TL;DR
This study compares two FAIRification workflows for diabetes research data in Germany and finds that domain-specific adjustments improve efficiency but not FAIRness scores.
Contribution
The study provides a comparative analysis of FAIRification workflows and identifies key requirements for FAIRifying core health data.
Findings
Both generic and domain-specific FAIRification workflows required similar resources and achieved the same FAIRness rating.
Domain-specific adaptations improve efficiency but do not necessarily increase FAIRness scores for core data sets.
Early planning of FAIR data strategies is emphasized for effective implementation.
Abstract
The FAIR principles guide data stewardship towards maximizing the value of scientific data while offering a high level of flexibility to accommodate differences in standards and scientific practices. Research communities have developed and implemented domain-specific workflows to make their data FAIR. This work compares the implementation of two externally developed structured FAIRification workflows—a generic workflow and a domain-specific workflow— using the example of metadata captured in diabetes research in Germany and applying the FAIR data maturity model developed by the Research Data Alliance. Interestingly, the implementation of both workflows required similar resources and led us to achieve the same FAIRness rating. We therefore conclude that the adaptations made in the FAIRification workflow for health research data improve efficiency but do not necessarily lead to higher…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
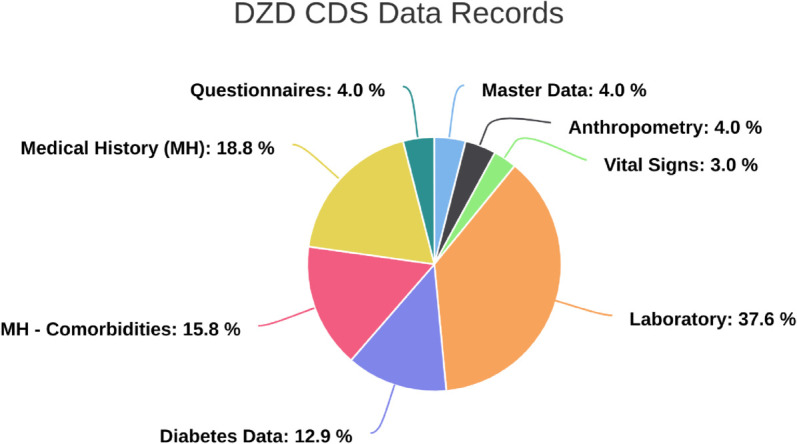 Fig 1
Fig 1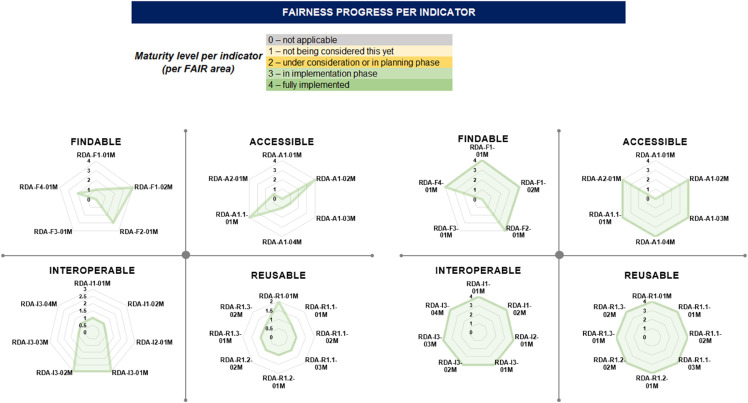 Fig 2
Fig 2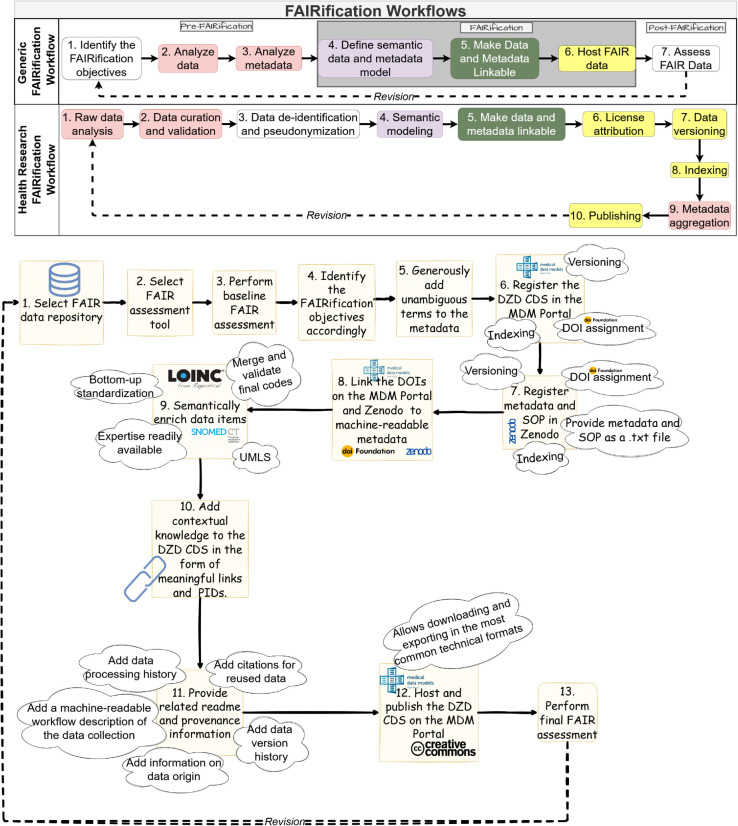 Fig 3
Fig 3- —NFDI4Health
- —Deutsches Zentrum für Diabetesforschung
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsResearch Data Management Practices · Scientific Computing and Data Management · Cell Image Analysis Techniques
Introduction
The FAIR principles guide data stewardship towards improved findability, accessibility, interoperability, and reusability (FAIRness) of research objects [1,2]. These principles systematically usher research data management (RDM) towards maximizing the value of scientific data and reproducibility of research findings [3]. FAIR RDM strengthens data sharing among heterogeneous data silos and enables collaborative research [4–8].
FAIRification is described as the process of making research objects FAIR [9]. It has been implemented in different sectors of biomedical research from computational biology where the results have helped to improve the quality of modelling pipelines [10] to clinical epidemiology where the results have enabled the combination of metadata on epidemiological studies in Germany [11].
FAIRification typically starts with a FAIR assessment in which a tool is used to determine how FAIR the research object is using a structured assessment [12,13]. The results of this assessment are used to inform measures that ought to be taken for the research object to become FAIRer. After these measures have been applied, a second assessment is conducted to determine their impact. A higher FAIR score is often the expected outcome of FAIRification [6,12,14]. The FAIRification journey, which is often embarked on to fulfil requirements set by funders or research institutions, has been described as intensive [5,6]. Therefore, work has been done to prescribe simpler steps to improve FAIRness [12,15]. In this context, FAIRification workflows promise to provide the needed guidance on how to implement the FAIR data principles in a practical and gradual manner [6,16,17].
The Research Data Alliance (RDA) has collected maturity indicators and determined evaluation levels that together serve as the assessment criteria for FAIRness [14]. This common set of assessment criteria has been used in FAIR assessments across different scientific communities and has also shown to be useful for other tasks such as the calibration of reporting guidelines for machine learning models in health research [18–22]. The RDA further incorporated these assessment criteria into the FAIR Data Maturity Model (FDMM), which enables comprehensive manual FAIR assessment and guides FAIRification [19,23]. The FDMM evaluates both data and metadata compliance with each FAIR data principle through one or more indicators [19]. Each indicator is associated with (often domain-dependent) impact levels described as essential, important, or useful [14]. Communities have developed standardised FAIRification templates and workflows for their respective research domains [2,5,24–27]. For example, Jacobsen et al. developed a generic FAIRification workflow that has been instructive for the FAIRification of electronically captured data on vascular anomalies and COVID-19 [16,28–30]. To accommodate differences in contexts and scientific practices, Sinaci et al. proposed a FAIRification workflow which applies restrictions considerate of the technical, ethical and legal requirements specific to health research data [17]. This workflow has shown promise in improving health research management outcomes in terms of time and costs [4].
The German Center for Diabetes Research (known locally as Deutsches Zentrum für Diabetesforschung - DZD) is a federal government and state-funded national association that brings together experts to conduct translational research across the full spectrum of diabetes and metabolism [31]. In 2021 the DZD established a minimum data set known as the DZD CORE DATA SET (CDS), which is geared toward research projects in the fields of diabetes and metabolism research [32]. The DZD CDS enables the harmonization of data items, labels, definitions, and documentation across all the DZD clinical studies, which further enables data comparability between related studies. Insights gained from our earlier retrospective FAIRification efforts informed the decision to implement structured, established FAIRification workflows in the FAIRification of the DZD CDS [12,33]. The enhanced data sharing that has been facilitated by the FAIRification of the DZD CDS is expected to contribute to its increased uptake among relevant stakeholders within the DZD and the wider diabetes research community [12]. The objective of this work is to explore the retrospective implementation of a generic [16] and a domain-specific [17] FAIRification workflow using the DZD CDS as a case study. While previous work detailed the FAIRification of the DZD CDS [12], the novelty of the present work lies in its use of established FAIR infrastructure to uniquely compare the implementation of these two externally developed FAIRification workflows in the DZD CDS. This work further distills a set of minimum requirements for successful FAIRification, derived from the practical insights gained through this comparative implementation. Stakeholders considering the implementation of FAIRification workflows may use the experiences and results obtained from this work to inform the development of FAIRification standard operating procedures (SOPs) for their research domains.
Methods
Data set
The DZD CDS is a mandatory component for the design of all upcoming DZD clinical studies and it has been implemented in various DZD studies since its conception [34–36]. It also includes the common CDS that was established among the German Centers for Health Research (Deutsche Zentren der Gesundheitsforschung) [37]. It contains 147 data items that have been selected by a group of medical experts and categorized into eight modules. It also contains optional modules relevant for special studies as shown in the following Fig 1.
DZD CDS data records (base set).Included modules: master data (contains patient information), anthropometry (contains patients’ height, weight, waist & hip circumference, as well as the techniques used to obtain these measurements), vital signs (contains blood pressure and heart rate), laboratory (contains selected laboratory blood, plasma, serum and urine tests), diabetes data (contains date and type of diabetes diagnosis as well as treatment offered), medical history (contains a record of a patient’s health background and the occurrence of disease events), medical history- comorbidities (indicates the presence of co-existing diseases with reference to the diagnosis) and questionnaires (contains the Baecke Index for sports, leisure, work and the total score) [12].
Analysis setup
A structured comparison was performed by retrospectively implementing the generic FAIRification workflow and the FAIRification workflow for health research in the context of the DZD CDS [16,17]. The decision to employ the FDMM as an evaluation instrument for this work was arrived at after a series of tools were tried, tested and eliminated for various reasons such as poor interpretation of the FAIR data principles, poor FAIRness assessment methods, and poor user friendliness [38]. We also considered the success reported by other researchers who used this tool for their own FAIR assessments [14,39–42]. The FDMM allowed us to discard the data indicators and instead focus on the metadata indicators (26 out of 41 indicators) as is necessary for the FAIR assessment of a CDS. Two data curators (ETI and AD) collaboratively assessed the DZD CDS FAIRness based on the publicly available guidance provided for this tool [19]. The curators assessed the DZD CDS FAIRness in three iterations for surety. Prior to this effort, the clinical relevance of data items and their alignment with study design requirements was validated by the stakeholder clinicians and study designers. In our assessment of the CDS we only used the FDMM metadata indicators shown in S1 Table (supporting information).
Selection of FAIRification workflows
The results of our previous scoping review of FAIRification workflows [5] led us to select the workflows developed by Jacobsen et al. and Sinaci et al. for the FAIRification of the DZD CDS [16,17]. Both workflows have already been successfully implemented in various health research settings [4,28,29].
Selection of a FAIR metadata repository
We included a structured selection process for a FAIR metadata repository in our FAIRification process prior to the implementation of the workflows. More specifically, we embarked on a search for a FAIR repository in which we would house the DZD CDS as part of the FAIRification. The Swiss National Science Foundation (SNSF) released a checklist for the selection of FAIR repositories [43].
Using the criteria from the SNSF checklist, we evaluated the Medical Data Models (MDM) Portal against the SNSF checklist for FAIR repositories [44,45]. Table 1 shows the results of this evaluation.
Table 1: Adherence of the German Portal for Medical Data Models (MDM Portal) to the SNSF’s Criteria for FAIR Repositories [43].
Based on the results of this evaluation, we identified the MDM Portal as a FAIR repository employable in the FAIRification of the DZD CDS.
Results
Implementation of FAIRification workflows
1. Generic FAIRification workflow
The generic FAIRification workflow developed by Jacobsen et al. consists of 7 steps which are categorised into the pre-FAIRification phase, the FAIRification phase and the post-FAIRification phase [16].
Identifying the FAIRification objectives: We conducted a baseline FAIR assessment on the DZD CDS and then considered the results of this assessment (shown in Fig 2), along with the DZD CDS context, stakeholders’ priorities and the desired scientific value of the data to formulate the objectives of the DZD CDS FAIRification as follows:
Findability: To improve the searchability and findability of the DZD CDS items for users and across future DZD CDS versionsAccessibility: To maintain the DZD CDS items in a manner that allows for them to be accessed under well-defined access conditionsInteroperability: To annotate the DZD CDS items with biomedical ontologies, data standards, terminologies and a structured format so as to facilitate interoperability and automatic extraction of relevant data items across different future DZD CDS versionsReusability: To represent the data in a concise manner that allows for reuse of the data collected across all the different future DZD CDS versions
The diagram on the left illustrates the results of the baseline DZD CDS FAIR assessment while the diagram on the right illustrates the results of the final DZD CDS FAIR assessment.The indicator maturity levels are defined in the legend above the radar charts. This legend is used to indicate the FAIRness progress per indicator [12].
Analysis of the data and metadata: The data fields, types, and values were characterized. The data elements and data fields were extracted and the curated data was validated by the clinical data experts. We identified missing metadata with regard to temporal and spatial factors as well as contact persons, keywords and information on the target group.
Defining the semantic data and metadata model: We used the version of the DZD CDS provided by the MDM Portal which offers a bottom-up standardization process that facilitates the semantic enrichment of all the data items with codes from LOINC, SNOMED CT and UMLS [45,48,49]. All previous versions of the DZD CDS are listed under https://medical-data-models.org/46011.
Making data and metadata linkable: Contextual knowledge (persistent IDs and references to other data sets/publications) was added to the dataset in the form of meaningful links. The metadata and SOP were registered and hosted in Zenodo and the related Zenodo link was also added to the dataset [34,50].
Hosting FAIR data: The DZD CDS has been hosted on the MDM Portal for purposes of making it a community resource available for human and machine consumption. Hosting the DZD CDS on the MDM Portal allows downloading and exporting the file in most common technical formats. Hosting the CDS on the MDM Portal also required us to assign it a licence that stipulates its reuse. In all DZD multicentred clinical trials, the direct identifying data (IDAT) are handled spatially and organisationally separated from the medical data (MDAT) to comply with legal, organisational and technical requirements regarding data protection [51]. For this reason the IDAT is not part of the CDS. This, along with the fact that the DZD CDS does not contain personal data, influenced the decision to choose an open machine-readable licence (the Creative Commons BY-NC-SA 4.0) [52]. Hosting the DZD CDS on the MDM Portal also led to data versioning and indexing.
Assessing FAIR data: Finally, we determined if the defined objectives have been achieved and conducted a final FAIR assessment. The final FAIR assessment results of the DZD CDS are shown in Fig 2.
S2 Table (supporting information) illustrates the implementation of the generic FAIRification workflow in the DZD CDS and the decisions made in adapting it to this context.
FAIR assessments
We assessed the FAIRness of the DZD CDS before (left diagram) and after (right diagram) application of the FAIRification workflows using the FDMM. The results are shown in the following Fig 2.
We observe that all FAIR indicators recorded significant improvement after the implementation of the FAIRification workflows. The implementation of both workflows led us to achieve the same FAIRness score. The DZD CDS contains neither patient identification data nor sensitive data. For this reason, the RDA-A1-01M and RDA-F3-01M indicators (defined in S1 Table, supporting information) were not applicable [14].
2. Domain-specific FAIRification workflow
The FAIRification workflow specific to health research developed by Sinaci et al. consists of 10 steps [17].
Analysing the data and metadata: The implementation of this workflow began with raw (meta)data analysis similar to the one performed in the implementation of the generic FAIRification workflow.
Curating and validating the data: This step was performed as already indicated in the implementation of the generic FAIRification workflow.
De-identifying and pseudonymising data: We skipped the pseudonymization and de-identification step of this workflow because the DZD CDS does not contain any sensitive patient data.
Semantic modelling: This step was performed as already indicated in the step that calls for "defining of the semantic data and metadata model" in the generic FAIRification workflow.
Making data and metadata linkable: The data was then enriched by adding contextual knowledge in the form of meaningful links as performed in the implementation of the generic workflow.
Attributing a licence, data versioning and indexing: These steps were already performed in the implementation of the generic workflow when the DZD CDS was registered in the MDM Portal. The same was done for the metadata and SOP in Zenodo where they were registered as shown in the implementation of the generic workflow [50].
Aggregating the metadata: The metadata was then aggregated, leading to the provision of the DZD CDS readme file and provenance information that contains the data origin, citations for reused data, description of the data collection, data processing history and version history.
Publishing: The DZD CDS was then published in the MDM Portal for consumption by the audience.
S3 Table (supporting information) illustrates the implementation of the health research FAIRification workflow in the DZD CDS and the decisions made in adapting it to this context.
Similarities in workflows
The following Fig 3 illustrates the steps taken in both FAIRification workflows and the principles achieved by implementing each step. The steps with similar colours are representative of the steps we found to be similar in our implementation. The bottom sketch shows our implementation of these workflows in the FAIRification of the DZD CDS.
Comparison of generic and domain-specific worklows: The upper lane shows the generic workflow (Jacobsen et al.) and the lower lane shows the steps specific to the health research workflow (Sinaci et al.) [16,17].The sketch at the bottom shows our implementation of these workflows in the FAIRification of the DZD CDS.
Notably, information about licensing options is more distinct in the health research workflow than in the generic FAIRification workflow. Although the generic FAIRification workflow does not explicitly indicate licensing as a FAIRification step, we still licensed the CDS in our implementation of this workflow because hosting it on the MDM Portal required us to do so. Hosting the DZD CDS on the MDM Portal also simultaneously led to its versioning and indexing.
Minimum requirements for successful FAIRification of core data sets in health research
This work has shown that regardless of the selected FAIRification workflow, there are some bare minimums that should be present for successful metadata FAIRification of core data sets in health research. They include:
A thorough understanding of the processes by which the metadata is defined, adapted, and expanded: The data analysis step helps to understand the project capabilities and resources. This step is also useful in developing an understanding the processes by which the dataset is defined, adapted, and expanded. It also helps to identify the data characteristics that should be improved based on the defined FAIRification goal. The capabilities that a FAIR data management environment should exhibit to enable and support the realization of a FAIR dataset can also be determined, including data access, data hosting, ontology services and data sharing. Finally, the findings of the raw data analysis play a critical role in determining the FAIR assessment tool and requirements needed to achieve the desired FAIRification outcome.Collaborative development of standards: A cultural shift is required to enable the implementation and co-development of standards for metadata, centrally managed and organized [23,53]. This cultural change needs to be broadly accepted in order to implement continuous FAIR RDM throughout the data lifecycle [27,53].Collaborative data stewardship: A shift away from the culture of individualised data ownership towards one of collaborative data stewardship is necessary for efficient data sharing that facilitates impactful research [54,55]. Consultations and training for data publication pipelines should be offered to ensure sustainably operated FAIR infrastructures.An investment of resources: A significant investment of time, money and domain knowledge is necessary to implement the described FAIRification steps [23,56]. No significant difference in personnel requirement was observed in the implementation of both workflows. Customised incentives are important to encourage stakeholders to engage in data sharing beyond their moral obligations, especially if tangible motivators for this remain limited [55].
Discussion
The comprehensive approach including initial FAIR assessments, FAIRification activities, post-FAIRification adjustments, and being intentional about implementing FAIR-enabling infrastructure can significantly improve the FAIRness of health data sets, as demonstrated in this work using the example of the DZD CDS. The application and comparison of two common FAIRification workflows underscores both the adaptability and domain-specific nuances of such processes. The domain-agnosticism of the generic workflow provides a flexible framework applicable to diverse datasets. Conversely, the health-specific workflow addresses the vital additions that are necessary to safeguard the integrity of health research data.
The inclusion of metadata aggregation and systematic data versioning in the health-specific workflow emphasizes the importance of robust data management practices to address the complexities of health research data. Domain-specific requirements shape FAIRification, balancing technical interoperability with adherence to contextual and legal constraints. Thereby, tailored health FAIRification workflows enhance the applicability of the FAIR principles and showcase how FAIRification efforts can be extended in other contexts, ensuring flexibility and precision.
The implementation of structured FAIRification workflows significantly improved the FAIRness of the DZD CDS. Previous FAIRification efforts, guided by experience rather than structured workflows, required extended timelines due to multiple consultations and iterative revisions [12,57]. Contrarily, the two workflows applied in this work were straightforward to implement, with the FDMM proving instrumental. The FDMM facilitated both binary and scaled approaches to FAIR assessment, enabling objective evaluations with minimal reliance on personal judgement while allowing for progress measurement towards FAIRer scores. Baseline and final FAIR assessments, though not explicitly included in the FAIRificaton workflow for health research, were invaluable in evaluating improvements and demonstrating the impact of FAIRification efforts [13,42]. Interestingly, the implementation of both workflows led us to achieve the same FAIRness rating and required similar resources for implementation. However, adapting these workflows to specific objectives and contexts may improve cost and time efficiency, particularly when applied to real-world medical data.
De-identification and pseudonymization are measures implemented to preserve the data privacy rights of the subjects and is performed based on the purpose for which the dataset has been developed [58,59]. Unlike the generic FAIRification workflow, the FAIRification workflow for health research includes pseudonymization and de-identification as a distinct FAIRification step. This indicates the workflow’s consideration of the heightened sensitivity of health research data, especially in the wake of the implementation of the General Data Protection Regulation in the European Union [60,61]. Skipping this step in the implementation of the FAIRification workflow for health research did not adversely affect the final results of the final FAIR assessment. This may indicate that de-identification and pseudonymization of health research data does not directly contribute to data FAIRness. Pseudonymization and de-identification processes have been described as slow and cumbersome and would likely increase the effort required in the FAIRification of DZD CDS-related clinical research datasets that contain patient information [58,62–65]. Other components unique to the health-specific workflow—such as metadata aggregation and structured licensing—contributed to improved procedural efficiency but had no discernible impact on the FDMM score. We therefore deduce that the adaptations made in the FAIRification workflow for health research data are useful to improve efficiency but do not necessarily lead to higher FAIRness scores when applied to core data sets. We were able to incorporate all the other metadata indicators without modifying them.
Goal-oriented and flexible implementation
While the health research FAIRification workflow does not explicitly include goal setting, defining the objectives has shown to be a critical component of FAIRification [6,59]. In this context, collaboratively setting objectives helped to ensure that the objectives are inclusive of the perspectives of the various pertinent stakeholders and served as a means to justify the expenditure of resources in the FAIRification exercise. The business interest that is expected to evolve as the number of exports from the MDM Portal increases also served as a factor that encouraged collaboration among the stakeholders. There are also previous success stories that served as reference points [66–72]. The objectives also served as the basis for feedback on the effectiveness of individual FAIRification tasks. This feedback can be used to determine the overall success of the process and set a clear endpoint for this FAIRification iteration. Jacobsen et al. indicated that the generic FAIRification workflow steps need not follow a strict sequence [73]. This flexibility allowed us to start the DZD CDS FAIRification by selecting FAIR infrastructure, evaluating the baseline FAIRness and identifying the FAIRification objectives accordingly (step 1). We then proceeded to enrich the metadata as informed by our metadata analysis (steps 2 and 3) and then registered the DZD CDS in the MDM portal (step 6). The related metadata and SOP were registered in Zenodo. After this, we semantically annotated the data items since the MDM Portal provided codes and we were able to discern these codes (Step 4). The data stewards ensured the choice of terminologies aligned with international standards in real-world clinical practice. Accordingly, LOINC and SNOMED CT concepts were included in addition to UMLS codes. The semantic enrichment of DZD CDS raw data items also required retrospective reconciliation of terminology preferences between the data curators at the DZD and the German Centers for Health Research. As a result, all numeric parameters were annotated using LOINC codes. Several collaborative sessions regarding the choice of standard concepts between data curators at the DZD but also with the German Centers for Health Research ensured semantic accuracy while preserving domain usability. However, establishing a common understanding of the parameters presented a substantial clerical burden [49,74]. Once this process was complete, subsequent workflow implementation (shown in Fig 3) required comparatively less time and effort.
FAIR infrastructure
Registering the DZD CDS in the MDM Portal alongside metadata and SOPs in Zenodo enabled simultaneous completion of multiple workflow steps as shown in Fig 3. This approach streamlined the process and demonstrated the importance of selecting FAIR infrastructure prior to the onset of a FAIRification journey. Jacobsen et al. have highlighted that the generic FAIRification workflow specifically targets the implementation of principles F1, F2, R1, R1.1, R1.2 and R1.3 [1,73]. In our context these principles target the corresponding metadata sub principles as defined by the RDA (see S1 Table, supporting information). Depositing the metadata and SOPs in Zenodo also led to the fulfillment of the corresponding F3 and F4 metadata principles (defined in S1 Table, supporting information). Registering the DZD CDS in the MDM Portal led to the fulfillment of the "accessibility" metadata sub-principles. The DZD CDS can now be downloaded and exported in most common technical formats and provides UMLS codes for semantic enrichment, which further enables the implementation of an ontology matching service for querying FAIR data [12,75]. Qualified references are available in the form of links to the comprehensive metadata and SOP in Zenodo, which further fulfils the "interoperability" sub-principles. An interesting finding in the implementation of the generic workflow is that key FAIRification measures were already implemented while we were still in the pre-FAIRification phase. These include addition of rich explicit metadata, licensing, versioning, DOI assignment, as well as registration and indexing of the metadata and SOPs. This raises the question, "when does FAIRification actually begin?"
Expected impact of a FAIRer DZD CDS
FAIRification has increasingly become an important part of the DZD RDM priorities and this has necessiated FAIR data sharing of the DZD CDS. The FAIRer DZD CDS has been made available to the community on the MDM portal and supports data sharing among DZD sites [76]. FAIRification of the DZD CDS aligns with the DZD’s commitment to comprehensive data stewardship [12], enhanced data sharing and data analysis across DZD sites [12,57]. A machine-actionable framework to describe and structure the CDS has been established and the DZD CDS is better interoperable [49,77]. The expected return on the investment of the efforts made to provide machine-actionable, heterogenous data is that there are now wider possibilities for data integration and larger-scale analyses. Expanding access via alternative authentication and authorisation procedures could further enhance utility for non-MDM portal users.
The transferable lessons derived from this work include the importance of dedicated multidisciplinary collaboration that fosters mutual understanding, the clear definition of stakeholder roles, rigorous version control and documentation throughout the FAIRification process, the early and deliberate selection of appropriate FAIR infrastructure, as well as the anticipation of resource demands and justification of the effort by articulating the expected return on investment. However, this work only addresses a single CDS. We did not have any particular domain-specific requirements that influenced the FAIRification process therefore we cannot comment on any domain-specific challenges. We expect, however, that such challenges may occur in the context of real-world data related to the DZD CDS.
Is the FAIRification journey of medical research data worthwhile?
FAIRification of medical research data is essential for evidence-informed decisions and has proven beneficial for datasets such as the DZD CDS, which has garnered significant interest (725 views and 379 downloads as of November 2024) [5,78,79]. Enhanced reusability increases the value of the CDS, provides a basis for profitable reuse in other contexts, and may eliminate the need for a new data collection process. The improved reusability of the data set over an extended period of time may further result in the development of new therapeutic regimens by the secondary data user and increased business value for the DZD.
Interoperability, supported by standardized technical formats and metadata, supports integration with heterogeneous datasets, broadening research opportunities, and simplifying cross-evaluation [80]. Since all current DZD clinical studies launched in 2021 and later use the same CDS, the data pool is enlarged and the possibility of cross-evaluation is simplified [12]. Novel research based on integrated and analyzed heterogenous data is anticipated once the FAIRified DZD CDS is connected to routine data from data integration centers [81,82]. In addition, the semantic enrichment of the DZD CDS supports seamless interoperability with patient-generated health data and routine electronic health records. This enhanced interoperability is anticipated to support more inclusive and diverse study designs, and to accelerate the generation of evidence for improved therapeutic strategies in diabetes care. Taken together, these efforts improve discoverability and readiness for artificial intelligence, contributing to greater visibility and impact of the DZD CDS.
The key resources required for the implementation of both FAIRification workflows included funding, incentives and expertise for the metadata curation and enrichment. The DZD CDS FAIRification required numerous consultations and iterative meetings between data owners and FAIR experts to make key decisions, which contributed to a significant time investment that spanned several months. The quantified investment amount that should be made in running FAIRification cycles in a manner that keeps it beneficial to stakeholders remains open to discussion. We recommend that this discussion should include the stakeholders of other clinical core data sets such as the one developed by the German Medical Informatics Initiative and the French CDS for geriatric oncology studies [33,83,84].
Conclusion
In this work, we compared the implementation of two FAIRification workflows for the core data set applied to German diabetes studies. We also identified minimums that will help to reduce efforts and costs for FAIRification, when applied. We recommend that more FAIRification workflows that take into account the nature of domain-specific data should be developed for other scientific domains that have embraced FAIRification as a necessary journey. Although this work focused on the DZD CDS, we hypothesize that the identified lessons and minimum requirements are applicable to the FAIRification of core datasets of other clinical domains.
Retrospective data FAIRification is a cumbersome task regardless of the FAIRification workflow implemented. For this reason, we resonate with current recommendations that encourage scientists and data owners to design their scientific projects in a way that takes into account the FAIRification of prospective data right from the infancy stage and continuously improves FAIRness throughout the lifecycle of the project [23,85]. One aspect of these preparatory steps is the thoughtful collection of appropriate FAIRification infrastructure as early as possible [38].
However, this is a multi-stakeholder engagement and different stakeholders may have different preferences with regard to the FAIRification process. For example, the funders may deem it more cost-effective to FAIRify data all in one cycle as opposed to gradually and iteratively while other participant stakeholders may have different preferences on the order in which the FAIRification steps should be implemented. The implementation of both FAIRification workflows in the DZD CDS would not have been possible without the tremendous involvement of the data owners, data stewards and the pertinent stakeholders. We therefore recognise the importance of harmonizing the stakeholders’ perspectives and expectations.
Templates for FAIR data management plans (DMPs) continue to be developed as funders and policy makers continue to require DMPs to be prospectively FAIR inclusive [5,26,43,86]. It remains to be seen how these prospective FAIR DMPs can be integrated into retrospective FAIR workflows. It may also be necessary to develop FAIRification workflows for prospective implementation specific to the health research data domain. It also remains to be explored what the resultant differences would be to the FAIRification workflows if the respective steps were implemented prospectively.
Quite a lot of work has already been done to automate the semantic enrichment of health data [22,87–90]. It would be interesting to further research how automated semantic enrichment can be incorporated into FAIR workflows, how many more of the steps in the FAIR workflows can be automated, and what would be the consequent changes, if any, to the workflows once the steps are automated. In 2019 the European Commission estimated the cost of not having FAIR research data in the European research economy at € 10.2 billion [91]. Another interesting area of research would be to determine how much time and resources have been saved by FAIRifying the DZD CDS. It remains to be seen which steps will be iterated or eliminated in subsequent FAIRification cycles as the priorities of this FAIRification journey evolve and new insights are obtained.
Supporting information
S1 TableFDMM metadata indicators.S1 Table illustrates the RDA FDMM metadata indicators that we employed in the FAIRness assessment of the DZD CDS [14].(TEX)
S2 TableImplementation of the generic FAIRification workflow.S2 Table illustrates the implementation of the generic FAIRification workflow in the DZD CDS and the decisions made to adapt it to this context [16].(TEX)
S3 TableImplementation of the health research FAIRification workflow.S3 Table illustrates the implementation of the health research FAIRification workflow in the DZD CDS and the decisions made in adapting it to this context [17].(TEX)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wilkinson MD, Dumontier M, Aalbersberg IJJ, Appleton G, Axton M, Baak A, et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data. 2016;3:160018. doi: 10.1038/sdata.2016.18 26978244 PMC 4792175 · doi ↗ · pubmed ↗
- 2Wilkinson SR, Eisenhauer G, Kapadia AJ, Knight K, Logan J, Widener P, et al. F*** workflows: when parts of FAIR are missing. In: 2022 IEEE 18th International Conference on e-Science (e-Science). 2022. p. 507–12. 10.1109/escience 55777.2022.00090 · doi ↗
- 3Alharbi E, Gadiya Y, Henderson D, Zaliani A, Delfin-Rossaro A, Cambon-Thomsen A, et al. Selection of data sets for FAI Rification in drug discovery and development: which, why, and how?. Drug Discov Today. 2022;27(8):2080–5. doi: 10.1016/j.drudis.2022.05.010 35595012 PMC 9236643 · doi ↗ · pubmed ↗
- 4Martínez-García A, Alvarez-Romero C, Román-Villarán E, Bernabeu-Wittel M, Luis Parra-Calderón C. FAIR principles to improve the impact on health research management outcomes. Heliyon. 2023;9(5):e 15733. doi: 10.1016/j.heliyon.2023.e 15733 37205991 PMC 10189186 · doi ↗ · pubmed ↗
- 5Inau ET, Sack J, Waltemath D, Zeleke AA. Initiatives, concepts, and implementation practices of the findable, accessible, interoperable, and reusable data principles in health data stewardship: scoping review. J Med Internet Res. 2023;25:e 45013. doi: 10.2196/45013 37639292 PMC 10495848 · doi ↗ · pubmed ↗
- 6Welter D, Juty N, Rocca-Serra P, Xu F, Henderson D, Gu W, et al. FAIR in action - a flexible framework to guide FAI Rification. Sci Data. 2023;10(1):291. doi: 10.1038/s 41597-023-02167-2 37208349 PMC 10199076 · doi ↗ · pubmed ↗
- 7Batista DO, Leiva Mederos AA, Peralta González MJ. FAI Rification: a necessary practice for research data management. Advanced Notes in Information Science. Pro-Metrics. 2024. 10.47909/978-9916-9974-5-1.92 · doi ↗
- 8Waithira N, Mukaka M, Kestelyn E, Chotthanawathit K, Thi Phuong DN, Thanh HN, et al. Data sharing and reuse in clinical research: are we there yet? A cross-sectional study on progress, challenges and opportunities in LMI Cs. PLOS Glob Public Health. 2024;4(11):e 0003392. doi: 10.1371/journal.pgph.0003392 39565766 PMC 11578489 · doi ↗ · pubmed ↗